java 基础知识之hadoop源码阅读必备(一)
Hadoop源代码分析_之hadoop配置及启动(1)-----classpath与配置文件
* strings. If no such property is specified, then <code>null</code> * is returned. Values are whitespace or comma delimted. */ public String[] getStrings(String name) {
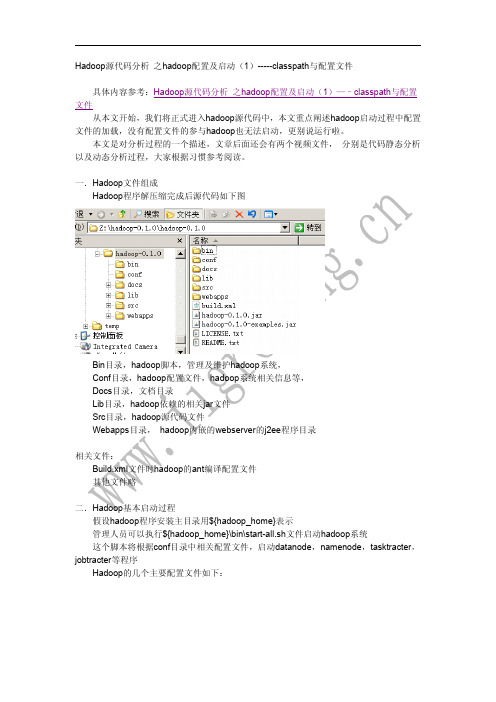
我们打开hadoop的源代码项目(eclipse的java项目)
如下图,我们打开如上目录及java源代码文件
双击左侧 main函数的节点, 然后右面显示相关源代码, 然后在 “runAndWait(new Configuration());”函数调用处,右击鼠标,弹出相关对话框,选择“open Declaration” 选项, 可以直接使用快捷方式 F3按键,可以快速到达相关源代码处 代码如下: private static void runAndWait(Configuration conf) throws IOException {
String valueString = get(name); // 重点语句,负责初始化相关代码,我们需要跟踪进入相 关代码
if (valueString == null) return null;
StringTokenizer tokenizer = new StringTokenizer (valueString,", \t\n\r\f"); List values = new ArrayList(); while (tokenizer.hasMoreTokens()) {
一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)

⼀起学Hadoop——使⽤IDEA编写第⼀个MapReduce程序(Java和Python)上⼀篇我们学习了MapReduce的原理,今天我们使⽤代码来加深对MapReduce原理的理解。
wordcount是Hadoop⼊门的经典例⼦,我们也不能免俗,也使⽤这个例⼦作为学习Hadoop的第⼀个程序。
本⽂将介绍使⽤java和python编写第⼀个MapReduce程序。
本⽂使⽤Idea2018开发⼯具开发第⼀个Hadoop程序。
使⽤的编程语⾔是Java。
打开idea,新建⼀个⼯程,如下图所⽰:在弹出新建⼯程的界⾯选择Java,接着选择SDK,⼀般默认即可,点击“Next”按钮,如下图:在弹出的选择创建项⽬的模板页⾯,不做任何操作,直接点击“Next”按钮。
输⼊项⽬名称,点击Finish,就完成了创建新项⽬的⼯作,我们的项⽬名称为:WordCount。
如下图所⽰:添加依赖jar包,和Eclipse⼀样,要给项⽬添加相关依赖包,否则会出错。
点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所⽰:依次点击Modules和Dependencies,然后选择“+”的符号,如下图所⽰:选择hadoop的包,我⽤得是hadoop2.6.1。
把下⾯的依赖包都加⼊到⼯程中,否则会出现某个类找不到的错误。
(1)”/usr/local/hadoop/share/hadoop/common”⽬录下的hadoop-common-2.6.1.jar和haoop-nfs-2.6.1.jar;(2)/usr/local/hadoop/share/hadoop/common/lib”⽬录下的所有JAR包;(3)“/usr/local/hadoop/share/hadoop/hdfs”⽬录下的haoop-hdfs-2.6.1.jar和haoop-hdfs-nfs-2.7.1.jar;(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”⽬录下的所有JAR包。
hadoop源码编译

hadoop源码编译Hadoop是目前最流行的分布式计算框架之一,广泛应用于大数据领域。
为了更好地理解Hadoop的内部运行机制,我们有时需要对其源码进行深入研究和编译。
下面就来一步步讲解如何编译Hadoop源码。
一、环境准备在开始编译Hadoop源码之前,需要安装一些必备的软件和环境。
首先要确保已经安装了Java JDK和Maven,其中Java JDK的版本应该至少是1.7或1.8,而Maven则需要3.0以上的版本。
其次需要安装SSH,这是Hadoop用于节点之间通信和管理的必备组件。
最后需要下载Hadoop源码压缩包,解压到本地文件夹。
二、修改配置文件在进行编译过程之前,还需要修改一些Hadoop的配置文件。
具体来说,需要先修改pom.xml文件中的Hadoop版本号,确保与本地安装的版本一致。
然后需要修改hadoop-common-project/hadoop-common/src/main/conf/hadoop-metrics2.properties文件中的hostname值,确保与你当前的主机名一致。
三、编译源码当所有环境准备工作完成后,就可以开始编译Hadoop源码了。
首先需要在hadoop源码文件夹下运行以下命令,生成configure脚本:$ ./bootstrap.sh接着需要执行configure命令,生成Makefile:$ ./configure这个命令会检查编译环境,并根据环境配置参数。
最后,你需要执行make命令来编译Hadoop源码:$ mvn package -Pdist,native -DskipTests -Dtar以上命令会编译生成Hadoop发布版本,并将所有生成的二进制文件打成一个.tar包。
编译过程需要一定的时间,具体取决于你的电脑性能和网络速度。
四、启动HadoopHadoop源码编译完成之后,就可以启动它了。
首先需要将生成的.tar包解压到一个文件夹中:$ tar xf hadoop-x.x.x.tar.gz然后使用以下命令添加环境变量:$ export HADOOP_HOME=/path/to/hadoop-x.x.x$ export PATH=$PATH:$HADOOP_HOME/bin至此,Hadoop就已经编译成功并且可以在本地运行了。
hadoop原理及组件

hadoop原理及组件Hadoop是一个开源的分布式计算框架,旨在处理大规模数据集。
它提供了一个可靠、高效和可扩展的基础设施,用于存储、处理和分析数据。
本篇文章将详细介绍Hadoop的原理以及其核心组件。
一、Hadoop原理Hadoop的核心原理包括数据分布式存储、数据切分、数据复制和数据计算等。
首先,Hadoop使用HDFS(分布式文件系统)进行数据存储,支持大规模数据的存储和读取。
其次,Hadoop采用了MapReduce 模型对数据进行分布式计算,通过将数据切分为小块进行处理,从而实现高效的计算。
此外,Hadoop还提供了Hive、HBase等组件,以支持数据查询和分析等功能。
二、Hadoop核心组件1.HDFS(Hadoop分布式文件系统)HDFS是Hadoop的核心组件之一,用于存储和读取大规模数据。
它支持多节点集群,能够提供高可用性和数据可靠性。
在HDFS中,数据被分成块并存储在多个节点上,提高了数据的可靠性和可用性。
2.MapReduceMapReduce是Hadoop的另一个核心组件,用于处理大规模数据集。
它采用分而治之的策略,将数据集切分为小块,并分配给集群中的多个节点进行处理。
Map阶段将数据集分解为键值对,Reduce阶段则对键值对进行聚合和处理。
通过MapReduce模型,Hadoop能够实现高效的分布式计算。
3.YARN(资源调度器)YARN是Hadoop的另一个核心组件,用于管理和调度集群资源。
它提供了一个统一的资源管理框架,能够支持多种应用类型(如MapReduce、Spark等)。
YARN通过将资源分配和管理与应用程序解耦,实现了资源的灵活性和可扩展性。
4.HBaseHBase是Hadoop中的一个列式存储系统,用于大规模结构化数据的存储和分析。
它采用分布式架构,支持高并发读写和低延迟查询。
HBase与HDFS紧密集成,能够快速检索和分析大规模数据集。
5.Pig和HivePig和Hive是Hadoop生态系统中的两个重要组件,分别用于数据管道化和数据仓库的构建和管理。
Hadoop源代码eclipse编译教程

源代码eclipse编译教程一见/hadoopor@1.下载Hadoop源代码Hadoop各成员源代码下载地址:/repos/asf/hadoop,请使用SVN 下载,在SVN浏览器中将trunk目录下的源代码check-out出来即可:请注意只check-out出SVN上的trunk目录下的内容,如:/repos/asf/hadoop/common/trunk,而不是/repos/asf/hadoop/common,原因是/repos/asf/hadoop/common目录下包括了很多非源代码文件,并且很庞大,会导致需要很长的check-out时间。
建议组织成如下图所示的目录结构,以保持本地的目录结构和SVN上的目录结构一致:2.准备编译环境2.1.Hadoop代码版本本教程所采用的Hadoop是北京时间2009-8-26日上午下载的源代码,和hadoop-0.19.x 版本的差异可能较大。
2.2.联网编译Hadoop会依赖很多第三方库,但编译工具Ant会自动从网上下载缺少的库,所以必须保证机器能够访问Internet。
2.3.java编译Hadoop要求使用1.6或更新的JDK,可以从:/javase/downloads/index.jsp上下载JDK。
安装好之后,请设置好JAVA_HOME环境变量,如下图所示:2.4.Ant和Cygwin需要使用Ant工具来编译Hadoop,而Ant需要使用到Cygwin提供的一些工具,如sed 等,可以从:/ivy/download.cgi下载Ant,从/下载Cygwin(Cygwin的安装,请参考《在Windows上安装Hadoop教程》一文)。
安装好之后,需要将Ant和Cygwin的bin目录加入到环境变量PATH中,如下图所示:在安装Cygwin时,建议将SVN安装上,因为在Ant编译过程中会通过SVN下载些文件,但这个不是必须的,下载不成功时,并未见出错,编译仍然可以成功。
Hadoop基础入门指南

Hadoop基础入门指南Hadoop是一个基于Java的开源分布式计算平台,能够处理大规模数据存储和处理任务。
它是处理大数据的一种解决方案,被广泛应用于各种领域,例如金融、医疗、社交媒体等。
本文将介绍Hadoop的基础知识,帮助初学者快速入门。
一、Hadoop的三大模块Hadoop有三个核心模块,分别是HDFS(Hadoop分布式文件系统)、MapReduce、和YARN。
1. HDFS(Hadoop分布式文件系统)HDFS是Hadoop的存储模块,它可以存储大量的数据,并在多台机器之间进行分布式存储和数据备份。
HDFS将文件切割成固定大小的块,并复制多份副本,存储在不同的服务器上。
如果某个服务器宕机,数据仍然可以从其他服务器中获取,保障数据的安全。
2. MapReduceMapReduce是Hadoop的计算模块,它可以对存储在HDFS上的大量数据进行分布式处理。
MapReduce模型将大数据集划分成小数据块,并行处理这些小数据块,最后将结果归并。
MapReduce模型包含两个阶段:Map阶段和Reduce阶段。
Map阶段:将输入的大数据集划分成小数据块,并将每个数据块分配给不同的Map任务处理。
每个Map任务对数据块进行处理,并生成键值对,输出给Reduce任务。
Reduce阶段:对每个键值对进行归并排序,并将具有相同键的一组值传递给Reduce任务,进行汇总和计算。
3. YARNYARN是Hadoop的资源管理器,它负责分配和管理Hadoop集群中的计算资源。
YARN包含两个关键组件:ResourceManager和NodeManager。
ResourceManager:管理整个集群的资源,包括内存、CPU等。
NodeManager:运行在每个计算节点上,负责监控本地计算资源使用情况,并与ResourceManager通信以请求或释放资源。
二、Hadoop的安装与配置在开始使用Hadoop之前,需要进行安装和配置。
Hadoop源码分析

Hadoop源代码分析于泓烈 200921060171一、引言一个分布式系统基础架构,有Apache基金会开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。
而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
下面列举hadoop主要的一些特点:(1)扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
(2)成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。
这些服务器群总计可达数千个节点。
(3)高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
(4)可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
二、NameNode和DataNode介绍一个典型的HDFS系统包括一个NameNode和多个DataNode。
NameNode维护名字空间;而DataNode存储数据块。
DataNode负责存储数据,一个数据块在多个DataNode中有备份;而一个DataNode对于一个块最多只包含一个备份。
所以我们可以简单地认为DataNode上存了数据块ID和数据块内容,以及他们的映射关系。
hadoop源码_hdfs启动流程_1_NameNode

hadoop源码_hdfs启动流程_1_NameNode执⾏start-dfs.sh脚本后,集群是如何启动的?本⽂阅读并注释了start-dfs脚本,以及namenode和datanode的启动主要流程流程源码。
阅读源码前准备源码获取拉取Apache Hadoop官⽅源码⽤idea打开...切换到想看的版本...这⾥⽤的最新版本3.3.1阅读⽬标本篇的阅读⽬标是搞明⽩hadoop中的start-dfs.sh启动脚本执⾏后都做了什么,hadoop中的NameNode,DataNode启动过程等⼤致流程,不会细追细节。
start-dfs.sh ⼲了什么hdfs集群的启动命令为:start-dfs.sh, 脚本的位置在下图中:![image-脚本中⼤致分位两块内容,第⼀部分是调⽤hdfs-config.sh脚本配置hdfs以及hadoop的参数以及环境等,第⼆部分是启动datanode、namenode以及secondary namenode等等。
我们的重点是看第⼆部分的启动流程。
hdfs-config 简述start-dfs.sh中启动hdfs-config.sh的代码如下:# let's locate libexec...if [[ -n "${HADOOP_HOME}" ]]; thenHADOOP_DEFAULT_LIBEXEC_DIR="${HADOOP_HOME}/libexec"elseHADOOP_DEFAULT_LIBEXEC_DIR="${bin}/../libexec"fiHADOOP_LIBEXEC_DIR="${HADOOP_LIBEXEC_DIR:-$HADOOP_DEFAULT_LIBEXEC_DIR}"# shellcheck disable=SC2034HADOOP_NEW_CONFIG=trueif [[ -f "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh" ]]; then. "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh"elseecho "ERROR: Cannot execute ${HADOOP_LIBEXEC_DIR}/hdfs-config.sh." 2>&1exit 1fi在hdfs-config.sh脚本中会尝试启动hdfs-evn.sh脚本(如果存在)之后会检查以及设置HDFS的各种参数,例如:# turn on the defaultsexport HDFS_AUDIT_LOGGER=${HDFS_AUDIT_LOGGER:-INFO,NullAppender}export HDFS_NAMENODE_OPTS=${HDFS_NAMENODE_OPTS:-"-Dhadoop.security.logger=INFO,RFAS"}export HDFS_SECONDARYNAMENODE_OPTS=${HDFS_SECONDARYNAMENODE_OPTS:-"-Dhadoop.security.logger=INFO,RFAS"}export HDFS_DATANODE_OPTS=${HDFS_DATANODE_OPTS:-"-Dhadoop.security.logger=ERROR,RFAS"}export HDFS_PORTMAP_OPTS=${HDFS_PORTMAP_OPTS:-"-Xmx512m"}# depending upon what is being used to start Java, these may need to be# set empty. (thus no colon)export HDFS_DATANODE_SECURE_EXTRA_OPTS=${HDFS_DATANODE_SECURE_EXTRA_OPTS-"-jvm server"}export HDFS_NFS3_SECURE_EXTRA_OPTS=${HDFS_NFS3_SECURE_EXTRA_OPTS-"-jvm server"}再之后会启动hadoop-config.sh脚本:# shellcheck source=./hadoop-common-project/hadoop-common/src/main/bin/hadoop-config.shif [[ -n "${HADOOP_COMMON_HOME}" ]] &&[[ -e "${HADOOP_COMMON_HOME}/libexec/hadoop-config.sh" ]]; then. "${HADOOP_COMMON_HOME}/libexec/hadoop-config.sh"elif [[ -e "${HADOOP_LIBEXEC_DIR}/hadoop-config.sh" ]]; then. "${HADOOP_LIBEXEC_DIR}/hadoop-config.sh"elif [ -e "${HADOOP_HOME}/libexec/hadoop-config.sh" ]; then. "${HADOOP_HOME}/libexec/hadoop-config.sh"elseecho "ERROR: Hadoop common not found." 2>&1exit 1fihadoop-config.sh是最基本的、公⽤的环境变量配置脚本,会再调⽤etc/hadoop/hadoop-env.sh脚本。
基础学习hoop编程篇完整版

基础学习h o o p编程篇集团标准化办公室:[VV986T-J682P28-JP266L8-68PNN]编程需要哪些基础编程需要注意哪些问题3.如何创建mapreduce程序及其包含几部分4.如何远程连接eclipse,可能会遇到什么问题5.如何编译hadoop源码阅读此篇文章,需要些基础下面两篇文章如果看过的话,看这篇不成问题,此篇讲hadoop编程篇。
hadoop,hadoop是一个Java框架,同时也是编程的一次革命,使得传统开发运行程序由单台客户端(单台电脑)转换为可以由多个客户端运行(多台机器)运行,使得任务得以分解,这大大提高了效率。
hadoop既然是一个Java框架,因为我们必须要懂Java,网上有大量的资料,所以学习Java不是件难事。
但是学到什么程度,可能是我们零基础同学所关心的。
语言很多情况下都是相通的,如果你是学生,还处于打基础的阶段,那么难度对于你来说还是不小的。
1.初学者要求必须有理论基础,并且能够完成一个小项目,最起码能够完成几个小例子,例如图书馆里等。
初学者基本的要求:(1)懂什么是对象、接口、继续、多态(2)必须熟悉Java语法(3)掌握一定的常用包(4)会使用maven下载代码(5)会使用eclipse,包括里面的快捷键,如何打开项目传统程序员,因为具有丰富的编程经验,因此只要能够掌握开发工具:(1)会使用maven下载代码(2)会使用eclipse,包括里面的快捷键,如何打开项目(3)简单熟悉Java语法上面的只是基础,如果想开发hadoop,还需要懂得下面内容(1)会编译hadoop(2)会使用hadoop-eclipse-plugin插件,远程连接集群(3)会运行hadoop程序。
上面列出大概的内容,下面我们具体说一些需要学习的内容。
无论是传统开发人员还是学生,零基础下面都是需要掌握的:我们就需要进入开发了。
开发零基础,该如何,咱们提供了相关的内容分别介绍下面文章这一篇我们使用什么开发工具,甚至考虑使用什么操作系统。
Hadoop大数据技术基础与应用 第1章 Hadoop技术概述

2.Hadoop是什么
Hadoop是由一系列软件库组成的框架。这些软件库各自负责Hadoop的一部分 功能,其中最主要的是HDFS、MapReduce和YARN。HDFS负责大数据的存储、 MapReduce负责大数据的计算、YARN负责集群资源的调度。
Mahout
Flume
Sqoop
4.Hadoop发展历程
• 第三阶段
✓ Hadoop商业发行版时代(2011-2020) ✓ 商业发行版、CDH、HDP等等,云本,云原生商业版如火如荼
4.Hadoop报导过的Expedia也在其中。
2.Hadoop的应用领域
• 诈骗检测 这个领域普通用户接触得比较少,一般只有金融服务或者政府机构会用到。利用Hadoop来存
储所有的客户交易数据,包括一些非结构化的数据,能够帮助机构发现客户的异常活动, 预防欺诈行为。
• 医疗保健 医疗行业也会用到Hadoop,像IBM的Watson就会使用Hadoop集群作为其服务的基础,包括语
✓ 国产化开源发行版时代(2021开始) ✓ USDP ✓ 标准的发行版纷纷收费,国产化开源发行版势在必行
5.Hadoop名字起源
Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者, Doug Cutting解释Hadoop的得名:“这个名字是我孩子给一个棕黄色的大象 玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义, 并且不会被用于别处。小孩子恰恰是这方面的高手。”
✓ 后Hadoop时代(2008-2014) ✓ Hadoop、HBase、Hive、Pig、Sqoop等百花齐放,眼花缭乱 ✓ 各个组件层出不穷,相互之间的兼容性管理混乱,虽然选择性多,但是很乱
hadoop基础知识

hadoop基础知识Hadoop基础知识Hadoop是一个开源的分布式计算框架,用于处理大规模数据和执行并行计算任务。
它由Apache基金会开发和维护,具有高可靠性、高扩展性和高容错性等优点。
本文将介绍Hadoop的基础知识,包括Hadoop的概述、核心组件以及其在大数据处理中的应用。
一、Hadoop概述Hadoop的核心目标是通过并行处理大规模数据集,将计算任务分布在多个计算节点上,从而实现更快速、高效的数据处理。
它采用了分布式文件系统(Hadoop Distributed File System,简称HDFS)和分布式计算框架(MapReduce)来实现大规模数据的存储和处理。
Hadoop的分布式文件系统(HDFS)将大规模数据集分散存储在多个计算节点上,这些节点可以是廉价的商用计算机。
HDFS将数据划分成多个数据块,并将这些数据块复制到不同的计算节点上,以实现数据的冗余备份和容错性。
Hadoop的分布式计算框架(MapReduce)是一种用于处理大规模数据的编程模型。
它将计算任务分割成多个子任务,并将这些子任务分布在不同的计算节点上并行执行。
MapReduce框架将输入数据分成多个输入分片,并通过Map函数将每个分片映射成一系列键值对。
然后,通过Reduce函数对这些键值对进行合并和聚合,最后生成最二、Hadoop核心组件1. Hadoop Common:提供了Hadoop的基本工具和库,包括文件系统和输入输出操作等。
2. HDFS:Hadoop的分布式文件系统,用于存储大规模数据集。
3. YARN:Hadoop的资源管理器,用于管理集群上的计算资源并调度任务。
4. MapReduce:Hadoop的分布式计算框架,用于并行处理大规模数据。
5. Hadoop EcoSystem:Hadoop生态系统包括了许多与Hadoop相关的开源项目,如Hive、HBase、Spark等,用于扩展Hadoop的功能和应用范围。
java基础知识之hadoop源码阅读必备(一)

java基础知识之hadoop源码阅读必备(一)java 程序员你真的懂java吗?一起来看下hadoop中的如何去使用java的大数据是目前IT技术中最火热的话题,也是未来的行业方向,越来越多的人参与到大数据的学习行列中。
从最基础的伪分布式环境搭建,再到分布式环境搭建,再进入代码的编写工作。
这时候码农和大牛的分界点已经出现了,所谓的码农就是你让我做什么我就做什么,我只负责实现,不管原理,也不想知道原理。
大牛就开始不听的问自己why?why?why?于是乎,很自然的去看源码了。
然而像hadoop这样的源码N多人参与了修改和完善,看起来非常的吃力。
然后不管如何大牛就是大牛,再硬的骨头也要啃。
目前做大数据的80%都是从WEB开发转变过来的,什么spring mvc框架、SSH框架非常熟悉,其实不管你做了多少年的WEB开发,你很少接触到hadoop中java代码编写的风格,有些人根本就看不懂什么意思。
下面我来介绍下hadoop源码怎么看。
hadoop体现的是分布式框架,因此所有的通信都基于RPC来操作,关于RPC的操作后续再介绍。
hadoop源码怎么看系列分多个阶段介绍,下面重点介绍下JA V A基础知识。
一、多线程编程在hadoop源码中,我们能看到大量的类似这样的代码return executor.submit(new Callable() {@Overridepublic String call() throws Exception {//方法类}下面简单介绍下java的多线程编程启动一个线程可以使用下列几种方式1、创建一个Runnable,来调度,返回结果为空。
ExecutorService executor =Executors.newFixedThreadPool(5);executor.submit(new Runnable() {@Overridepublic void run() {System.out.println("runnable1 running.");}});这种方式启动一个线程后,在后台运行,不用等到结果,因为也不会返回结果2、创建一个Callable,来调度,有返回结果Future future1 = executor.submit(new Callable() {@Overridepublic String call() throws Exception {// TODO Auto-generated method stub//具体执行一些内部操作return "返回结果了!";}});System.out.println("task1: " + future1.get());这种启动方式一直等到call的方法体执行完毕后,并返回结果了才继续执行下面的代码二、内部类实现hadoop中同样能看到大量这样形式的代码status = ugi.doAs(new PrivilegedExceptionAction() {public JobStatus run() throws IOException, InterruptedException,ClassNotFoundException {return submitter.submitJobInternal(Job.this, cluster);}});这是一个典型的内部类实现,PrivilegedExceptionAction是一个接口,里面有一个run方法需要实现,程序调用的时候,会执行里面的submitter.submitJobInternal方法体为了方便大家理解,我写了一个模拟程序来演示先定义一个接口类public interface TransactionAction {void execute() throws Exception;}再定义一些模板方法,参数对象是一个接口来处理相关业务public class TemplateAction {public void transactionProcess(TransactionAction action, ActionEvent event){System.out.println("lock");try {action.execute();} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}System.out.println("unlock");}}调用过程public void doSome(){TemplateAction t=new TemplateAction();//public void transactionProcess(TransactionAction action, ActionEvent event)event2 =new ActionEvent ();event2.setMsg("内部类");final DoAction doaction=new DoAction();t.transactionProcess(new TransactionAction() {@Overridepublic void execute() throws Exception {// TODO Auto-generated method stubdoaction.sayWhatEvent(event2);}}, new ActionEvent());}运行结果如下:locksay:内部类unlock上面的内部类执行过程很明确,到底execute何时执行不是由dosome来设定,而是由TemplateAction中的transactionProcess 来确定三、枚举类型枚举类型比较容易理解,例如在我们习惯定义一些常量,static int ACTION_TYPE=0; //0表示初始,1表示启动,2表示运行中3表示停止程序中我们这样判断if(ACTION_TYPE==1){doSomeThing()}例如:// TODO Auto-generated method stubJobState state = JobState.DEFINE;if(state==JobState.RUNNING){System.out.println("运行状态");}else{System.out.println("初始状态");}if(jobType==0){System.out.println("初始状态"); }else if(jobType==1){ System.out.println("启动状态"); }。
Hadoop源代码分析完整版

Hadoop源代码分析(一)关键字: 分布式云计算Google的核心竞争技术是它的计算平台。
Google的大牛们用了下面5篇文章,介绍了它们的计算设施。
GoogleCluster:Chubby:GFS:BigTable:MapReduce:很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是:Chubby-->ZooKeeperGFS-->HDFSBigTable-->HBaseMapReduce-->Hadoop目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。
HDFS作为一个分布式文件系统,是所有这些项目的基础。
分析好HDFS,有利于了解其他系统。
由于Hadoop的HDFS和MapReduce 是同一个项目,我们就把他们放在一块,进行分析。
下图是MapReduce整个项目的顶层包图和他们的依赖关系。
Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统,该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。
这就造成了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。
功能的相互引用,造成了蜘蛛网型的依赖关系。
一个典型的例子就是包conf,conf用于读取系统配置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。
Hadoop的关键部分集中于图中蓝色部分,这也是我们考察的重点。
Hadoop源代码分析(二)下面给出了Hadoop的包的功能分析。
Package Dependencestool提供一些命令行工具,如DistCp,archivemapreduce Hadoop的Map/Reduce实现filecache提供HDFS文件的本地缓存,用于加快Map/Reduce的数据访问速度fs文件系统的抽象,可以理解为支持多种文件系统实现的统一文件访问接口hdfs HDFS,Hadoop的分布式文件系统实现ipc一个简单的IPC的实现,依赖于io提供的编解码功能参考:表示层。
hadoop源码阅读

hadoop源码阅读1、hadoop源码下载2、我们看⼀下hadoop源码中提供的⼀个程序WordCount1/**2 * Licensed to the Apache Software Foundation (ASF) under one3 * or more contributor license agreements. See the NOTICE file4 * distributed with this work for additional information5 * regarding copyright ownership. The ASF licenses this file6 * to you under the Apache License, Version 2.0 (the7 * "License"); you may not use this file except in compliance8 * with the License. You may obtain a copy of the License at9 *10 * /licenses/LICENSE-2.011 *12 * Unless required by applicable law or agreed to in writing, software13 * distributed under the License is distributed on an "AS IS" BASIS,14 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.15 * See the License for the specific language governing permissions and16 * limitations under the License.17*/18package org.apache.hadoop.examples;1920import java.io.IOException;21import java.util.StringTokenizer;2223import org.apache.hadoop.conf.Configuration;24import org.apache.hadoop.fs.Path;25import org.apache.hadoop.io.IntWritable;26import org.apache.hadoop.io.Text;27import org.apache.hadoop.mapreduce.Job;28import org.apache.hadoop.mapreduce.Mapper;29import org.apache.hadoop.mapreduce.Reducer;30import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;31import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;32import org.apache.hadoop.util.GenericOptionsParser;3334public class WordCount {3536// Mapper<Object,Text,Text,IntWritable>37// Object是输⼊的key的类型38// Text是输⼊的value的类型39// Text是输出的key的类型40// IntWritable是输出的value的类型41public static class TokenizerMapper42extends Mapper<Object, Text, Text, IntWritable>{4344private final static IntWritable one = new IntWritable(1);45private Text word = new Text();4647public void map(Object key, Text value, Context context48 ) throws IOException, InterruptedException {49 StringTokenizer itr = new StringTokenizer(value.toString());50while (itr.hasMoreTokens()) {51 word.set(itr.nextToken());52 context.write(word, one);53 }54 }55 }5657public static class IntSumReducer58extends Reducer<Text,IntWritable,Text,IntWritable> {59private IntWritable result = new IntWritable();6061public void reduce(Text key, Iterable<IntWritable> values,62 Context context63 ) throws IOException, InterruptedException {64int sum = 0;65for (IntWritable val : values) {66 sum += val.get();67 }68 result.set(sum);69 context.write(key, result);70 }71 }7273public static void main(String[] args) throws Exception {74 Configuration conf = new Configuration();75 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();76if (otherArgs.length < 2) {77 System.err.println("Usage: wordcount <in> [<in>...] <out>");78 System.exit(2);79 }80 Job job = Job.getInstance(conf, "word count");81 job.setJarByClass(WordCount.class);82 job.setMapperClass(TokenizerMapper.class);83 job.setCombinerClass(IntSumReducer.class);84 job.setReducerClass(IntSumReducer.class);85 job.setOutputKeyClass(Text.class);86 job.setOutputValueClass(IntWritable.class);87for (int i = 0; i < otherArgs.length - 1; ++i) {88 FileInputFormat.addInputPath(job, new Path(otherArgs[i]));89 }90 FileOutputFormat.setOutputPath(job,91new Path(otherArgs[otherArgs.length - 1]));92 System.exit(job.waitForCompletion(true) ? 0 : 1);93 }94 }Map()阶段其中的42-55⾏,MapReduce程序需要继承org.apache.hadoop.mapreduce.Mapper 这个类,并在这个类中的继承类中⾃定义实现Map()⽅法其中 org.apache.hadoop.mapreduce.Mapper 要求的参数有四个(keyIn、valueIn、keyOut、valueOut),即Map()任务的输⼊和输出都是< key,value >对的形式源代码此处各个参数的意义是:1. Object:输⼊< key, value >对的 key 值,此处为⽂本数据的起始位置的偏移量。
hadoop.源码阅读总结

hadoop.源码阅读总结CommonIPC/RPC Server⼤概流程基于NIO,Listener关注OP_ACCEPT事件,当有客户端连接过来,Accept后,从readers中选取⼀个Reader将客户端C hannel注册到Reader中的NIO selector,并新建⼀个Connection对象关联客户端Channel,Reader关注OP_READ事件. 客户端建⽴连接后,⾸先发送的是ConnnectionHeader包含协议名,⽤户组信息,验证⽅法,Connection会根据以上信息进⾏校验.之后将是先读取4位的长度代表这次请求的数据的长度,然后⼀直等待事件触发读取够长度,将读取的数据解码为调⽤id和param,新建⼀个Call对象(关联Connection)放⼊call队列中,handlers中的Handler会将Call中call Quene中取⾛,Call中的param实际为Invocation对象,包含调⽤⽅法名,参数名,参数类型,由这些信息使⽤Java反射A PI调⽤Server的instance对象,获取返回值,组织返回数据,写⼊Call的response属性中,马上调⽤responder的doRes pond⽅法,将Call加⼊到Connection的responseQuene中,如果responseQuene长度等于1做⼀次NIO写操作,如果不能⼀次性能够将数据写完,将客户端channel注册到responder关注写事件OP_WRITE,下⼀次继续写,如果长度不为1证明该channel已经注册到了responder了直接加⼊队列,由responder线程后续处理.NOTE:客户端关闭流后出发⼀次读操作,返回为-1,Server关闭连接CurCall与获取客户端IPHandler获取⼀个Call后,会将Server的curCall(ThreadLocal类型)设置为当前的Call,调⽤Instance⽅法实际是在H andler线程中,在Instance的⽅法内就可以使⽤Server提供的⽅法来获取客户端IPPing在上述过程中如果读取的4位长度为-1代表是客户端PING操作清理空闲连接如果⼀定时间ipc.client.connection.maxidletime没有读取到数据并且当前连接现有Call数⽬为0,则视为空闲连接,Listener会在每次接受完新连接之后进⾏⼀次清理,最多清理ipc.client.kill.max个连接,如果出现OutOfMemoryError则强制清理全部空闲连接D ATA N ODE,T ASK T RACTOR设置的⼼跳时间需⼩于空闲时间.清理长时间未发送到客户端的响应注册到responder的Call如果长时间没有发送到客户端,每隔⼀段时间会清理掉涉及参数ipc.server.handler.queue.sizecallQuene队列⼤⼩,随集群增⼤⽽增⼤,ipc.server.max.response.size如果返回的结果序列化后⼤⼩⼤于这个值,重置缓冲区ByteArrayOutputStream释放内存.ipc.server.read.threadpool.sizereaders个数ipc.server.tcpnodelayTCP优化参数N AGLE'S ALGORITHMhandlerCounthandler个数,由构造参数指定,在DN,TT中配置SOCKET S END B UFFER S IZEsocket设置ipc.server.listen.queue.sizesocket设置socket.bind(address, BACKLOG)ipc.client.idlethreshold总连接数超过多少后,开始清理空闲连接ipc.client.kill.max⼀次最多清理多少个空闲连接IPC/RPC ClientClient代理模式,调⽤RPC.getProxy实际上返回的⼀个代理对象,当调⽤⽅法的时候实际调⽤的是Invoker, Invoker 将协议,调⽤的⽅法名,参数,参数类型封装成Invocation对象经过client发送到server,并读取返回流,根据流中的id,判断是服务器返回的是那次调⽤的结果.Connection线程负责读取Server返回值,在读取的过程中,调⽤Client的线程会wait直到Connection获取到返回值.读取时候如果超时(ipc.ping.interval)就发送⼀次ping,如果没有出现IOException就继续读取,Conneciton可以根据标识(地址,⽤户组信息,协议)共⽤.IPC/RPC AuthingHDFSName协议ClientProtocol:客户端调⽤协议,涉及⽂件操作,DFS管理,升级(DFSAdmin)DatanodeProtocol:DN与NN通讯协议,注册,BlockReport,⼼跳,升级NamenodeProtocol: SN和NN通讯协议,通知NN使⽤新的fsimage和editRefreshAuthorizationPolicyProtocol, RefreshUserMappingsProtocolFSNamesystem数据结构LightWeightGSetGset 类似Set但提供get⽅法,主要⽤于存储BlockInfo,根据Block找到BlockInfo其中⼀个实现LightWeightGSet,利⽤数组存储元素,⽤链表解决冲突问题,类似HashMap但是没有ReHash操作BlocksMap初始化LightWeightGSet时候,会根据JVM内存将数组的⼤⼩初始为最⼤能占⽤的内存数(4194304 -Xmx10 24M)加上⾼效的hash映射算法, LightWeightGSet在BlockInfo数量⽐较⼩的时候get性能逼近数组.BlockInfo继承Block,没有重写hashCode和equals⽅法,在Block中equals⽅法只要求传⼊的对象是Block实例并且b lockId相等,就认为两个对象相等,故存储BlockInfo时候分配的在数组中的Index和Get时候由Block的hashCode定位是⼀致的. BlockMapsBlockMaps负责管理Block以及Block相关的元数据Block 有3个long型的属性blockId(随机⽣成)numBytes(块⼤⼩),generationStampBlockInfo继承Block添加了2个属性,实现了⽤户LightWeightGSet的LinkedElement接⼝inode:引⽤⽂件Inodetriplets:3Xreplication的数组,即replication 个组,每组有3个元素,第⼀个指向DatanodeDescriptor,代表在这个DN 上有⼀个Block,第⼆个和第三个分别代表DN上的上⼀个blockInfo和下⼀个blockInfoDatanodeDescriptor有⼀个属性blockList指向⼀个BlockInfo,因为每个BlockInfo中的triplets中有⼀组记录着对应的D N上的上⼀个,下⼀个BlockInfo,所以从这个⾓度来看BlockInfo是⼀个双向链表.新建⽂件打开输⼊流后,写⼊,会在namenode中分配BlockInfo,当Block写⼊到分配的DN后,DN在发送⼼跳时候会将新接受到的块报告给NN,此时NN在将triplets可⽤的组关联到DN(DD).(例⼦前提假设:新建的集群没有⽂件,操作是在DN1上,此时很⼤可能性每次分配块的时候都会⾸选本地DN1,bkl_* *实际为随机数)namenode中分配BlockInfo 并加⼊Gset中,blk_1,0-64M,此时DN1的blockList为nullDN1向NN报告接收了新的Block blk_1 ,NN从blocksMap中根据Block blk_1找到BlockInfo blockInfo1 将triplets 的可⽤组(==null)的第⼀位关联到DN1(DatanodeDescriptor1),将DN1的blockList指向blockInfo1此时blockList指向的是blockInfo1NN分配blockInfo2,DN1向NN报告接受到了信的Block blk_2,NN找到blockInfo2后1,将triplets的可⽤组(==null)的第⼀位关联到DN1(DatanodeDescriptor1)2,将第三位指向blockList即blockInfo1,2,将blockInfo1的对应DN1的组的第⼆位指向blockInfo24,将DN1的blockList指向blockInfo1升级LoadBalance磁盘占⽤,还是分布策略可能出现⼀个DN上两个相同的Block么. MapReduce命令⾏运⾏bin/hadoop jar jarFile [mainClass] args...设置JVM启动参数,将lib,conf等加⼊classpath,启动JVM运⾏RunJarRunJar阶段:1,设定MainClass如果jar设置了Manifest,则作为MainClass否则取第⼆个参数2,在临时⽬录(hadoop.tmp.dir)中建⽴临时⽬录(File.createTempFile("hadoop-unjar", "", tmpDir)),并注册钩⼦JVM 退出时候删除.3,将Jar解压到建⽴的临时⽬录中4,将⽬录hadoop-unjar38923742,⽬录hadoop-unjar38923742/class, ⽬录hadoop-unjar38923742/lib中的每个⽂件作为URLClassLoader参数,构造⼀个classLoader.5,将当前线程的上下⽂ClassLoader设置为classLoader6,以上5步都是为mainClass启动做准备,最后应⽤反射启动mainClass,将args作为参数MainClassbin/hadoop jar -libjars testlib.jar -archives test.tgz -files file.txt inputjar argsjob.setXXX均将KV设置到了Conf实例中(传值,例如将-file指定的⽂件设定到Conf中,在submit中获取,从本地复制到hdfs)在Job.submit⽅法中会向hdfs写⼊以下信息⽬录:hdfs://${mapreduce.jobtracker.staging.root.dir}/${user}/.staging/${jobId}/hdfs://tmp/hadoop/mapred/staging/${user}/.staging/${jobId}/⽬录下⽂件:job.split ->(Split信息)由writeSplits⽅法写⼊job.splitmetainfo ->( Split信息元数据,版本,个数,索引)由writeSplits⽅法写⼊job.xml ->conf对象job.jar ->inputjarfiles/ ->参数-files 逗号分割,交给(DistributedCache管理)archives/ ->参数-archives 逗号分割, 交给(DistributedCache管理)libjars/ ->参数-libjars 逗号分割, 交给(DistributedCache管理)split,splitmetainfo(FileSplit)设计⽬的job.splitmetainfo中保存有Split的在那⼏个机器上有副本,JT读取这个⽂件⽤,⽤来分配Task使Task能够读取本地磁盘⽂件.job.split保存具体的Split,不保存位置信息,因为TT不需要(hdfs决定)JT调度CapacityTaskScheduler,TTTT启动时候,启动线程mapLauncher(⽤于启动MapTask),reduceLauncher(⽤于启动ReduceTask), taskCleanupThrea d(⽤于清理Task或者Job),TT 通过⼼跳从JT获得HeartbeatResponse,包含TaskTrackerAction,具体有5种操作LAUNCH_TASK启动任务,将LaunchTaskAction中包装的Task与Conf对象和TaskLauncher组合成TaskInProgres,然后添加到mapL auncher或者reduceLauncher中的队列中.TaskLauncher构造参数numSlots代表当前TaskTractor能同时执⾏多少个Task,由参数mapred.tasktracker.map.tasks.maximum, mapred.tasktracker.reduce.tasks.maximum设定,slot意思为: 槽,位置将TaskTractor的资源抽象化,⼀般情况下⼀个task占⽤⼀个slot,如果有对资源需求⼤的Task也可以通过参数来控制(调度器CapacityTaskScheduler设置,未开放给User?) TaskLauncher根据剩余空闲的槽位(numFreeSlots)和队列情况,来从队列中取出Task来运⾏(synchronized, wait, n otify). KILL_TASK杀死任务KILL_JOB杀死和Job相关的任务,放⼊tasksToCleanup队列中REINIT_TRACKER重新启动TTCOMMIT_TASK提交任务(1, speculative execution 2,need commit file?) OutputCommitterREINIT_TRACKER 重启TT,startNewTask新的JVM(不是TT的JVM,错误处理,GC)执⾏Child.class,通过main参数argsMap过程MapTask中会根据jobConf记录的hdfs上的job.split⽂件以及JT分配的splitIndex获取InputSplit,根据jobConf的配置新建Map和InputFormat,由InputFormat获取RecordReader来读取inputSplit,⽣成原始original_key, original_value 交给Mapper.map⽅法处理⽣成gen_key,gen_value,根据partitioner⽣成partition,成对的(gen_key,gen_value, partition)会先放⼊⼀个缓冲区,如图,这个缓冲区分为3级索引(排序kvoffset,复制效率)等这个缓冲区到达⼀定阀值之后,并不是缓冲区慢之后,SplitThread会标记当前前后界,对界内数据进⾏排序(现根据partition在根据kv),并写⼊到磁盘⽂件中(split.x.out)并记录各个partition段的位置,部分存到内存部分存到磁盘,在这个过程中,map仍然继续进⾏,如果缓冲区满之后,map线程暂时wait,到SplitThread完毕.当输⼊读取完毕,随之的SplitThread也结束后,磁盘中中间⽂件为split.1.out -> split.n.out ,索引部分存在内存⾥⾯,超过1024*1024个,作为索引⽂件spill.n.out.index(避免内存不够⽤).然后通过合并排序将分段的⽂件(split.x.n)合并排序成⼀个⽂件file.out,file.out.index记录partition信息.(详细见MergeQueue)这样在Reduce过程中,通过http请求TT其中需要的partition段(参数reduce),TT根据file.out.index记录的索引信息将file.out的partition段,⽣成http响应.如果有CombinerSortAndSpillkvoffset达到临界点softRecordLimit,例如100个,设定80个为临界点.Kvbuffer达到临界点softBufferLimit,例如100M,当80M为临界点.⽬的是为了不让map过程停⽌浪费时间,但由于IO map可能会慢⼀点(进⼀步多磁盘负载).io.sort.mb配置的是图中kvoffset,kvindices,kvbuffer占⽤的空间总⼤⼩Mb.上述参数都可以通过conf.setXXX来配置,根据特定job的特点来设定.来减少Spill次数,同时避免内存溢出. Reduce过程JobInProgress初始化mapred.reduce.tasks个ReduceTask ⽤参数partition区别.然后JT在⼼跳过程中,将ReduceTask分给TT执⾏.ReduceTask有SHUFFLE, SORT, REDUCE三个阶段SHUFFLE这⼀阶段是ReduceTask初始化阶段,新建了N(参数控制)个下载线程,来获取Map的输出,TaskTracker中有⼀个线程会不断的从JT中获取在本TT运⾏的ReudceTask(s)的JOB的Map完成事件. ReduceTask不断从TT中获取Job的Map完成事件,然后将事件中的Map输出位置交给下载线程来获取.下载的时候,从HTTP响应头获取⽂件的⼤⼩,决定是放在内存中还是写⼊磁盘.在内存中的数据,满⾜⼀定条件会在后台将内存中的数据Merger写⼊硬盘,在硬盘中的数据,满⾜⼀定条件(数⽬超过了2 * ioSortFactor - 1)会在后台做Merger.所有的Map输出下载完毕,并且后台Merger线程也结束后,进⼊SORT 阶段.SORT这个阶段还是Merger,将内存和硬盘中的数据,做合并排序(ioSortFactor),使能够⾼效率的输出key ,values.然后进⼊REDEUCE 阶段.REDUCE这⼀阶段只要是将上述产⽣的key value通过ReduceContext转化成key values(ValueIterable),传递给reduce,最后通过输出配置,将reduce的输出写⼊HDFS(part-r-00000,1,2…),或者其他.MergeQueueMR 优化1,控制好每个Map的输⼊和输出,尽量使Map处理存在本地的Block,⼀个InputSpilt不要太⼤,最好使产⽣的输出能控制在io.sort.mb之内,这样能够减少从内存将输出数据写到磁盘的磁盘的个数. 根据任务将io.sort.mb设置合理,尽量能容纳单个Map全部输出.2, 多磁盘负载,MR中⼤量的临时输出⽂件会放在这个下mapred.local.dir = /hd1/mr, /hd2/mr, /hd3/mr hd*为挂载的不同磁盘.LocalDirAllocator从以上多个⽬录中分配每次创建⽂件的⽬录,降低IO负载.(其他SSD)HDFS中逗号分隔的⽬录(dfs.data.dir, /doc/6513913901.html.dir, /doc/6513913901.html.edits.dir)是为了冗余.3,Map输出压缩,减少⽹络传输.4,Reduce阶段,将各个map的输出下载到本地,由于各个Map输出可能有⼤有⼩,合适的可以放到内存中,(mapred.job.reduce.total.mem.bytes, mapred.job.shuffle.input.buffer.percent),减少N个下载线程写磁盘.5,设置Java运⾏内存偏⼤,GC回收算法. UseConcMarkSweepGC.6,频外⼼跳mapreduce.tasktracker.outofband.heartbeat,会加重JT负担.预想优化Reduce负载较重(收集N个map输出,执⾏统计⼯作),可以通过指定⾼配置机器,⽹络节离中⼼交换机近.做Merger的时候[k,vvv,k,vv]最后源码基于hadoop-0.20.203.0,粗糙整理,不断完善中,正误⾃辩,如有疑问交流或指正错误,可发邮件nice2mu@/doc/6513913901.html。
Hadoop核心源码剖析系列(一)

Hadoop核⼼源码剖析系列(⼀)第⼀时间获取好内容关于⼀门技术源码的解读是很令⼈头疼的⼀件事情,很多⼩伙伴都不知道从何⼊⼿,作为⼀名程序猿,我也是这样经历过来的,在没⼈指导的情况下不断碰壁,那种想⼊⽽不得的感觉相当难受,希望通过这篇⽂章能帮从何⼊⼿通过《Hadoop之HDFS架构演进之路》这篇⽂章我们能了解到HDFS的核⼼组成就是NameNode和DataNode,开始剖析源码之前,我们要先理解HDFS的本质,HDFS是⼀个分布式⽂件系统,那么就意味着核⼼功能看到下⾯的图⽚,想必⼤家应该都很熟悉,那么进程中的NameNode和DataNode是怎么产⽣的呢?对于⼀个百万级别代码⾏数的技术框架的源码阅读和剖析其实是很难的,尤其是在不清楚源码架构设计的情况下显得更加难以下⼿,我们只能通过能看到的东西⼀步⼀步去剖析,对于分布式框架,⾸先我们要了解它底Hadoop各个节点之间和客户端之间的通信是基于RPC协议,RPC(Remote Procedure Call Protocol)即远程调⽤协议。
不同进程的⽅法调⽤,本质上就是客户端调⽤服务端的⽅法,⽅法的执⾏在服务端。
⼀个RPC的实现主要包含三个部分,客户端、服务端和⽹络协议接⼝,见下图。
⼿动实现Hadoop RPC在pom.xml引⼊依赖:<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.0</version> </dependency></dependencies>定义通信协议接⼝:/** * ⽹络协议 */public interface Protocol { //定义版本号,可⾃定义 long versionID=123456789L; void hello(String msg); void add(int num); }定义服务端实现类:package RPC;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.ipc.RPC;import org.apache.hadoop.ipc.Server;import java.io.IOException;/** * RPC 服务端 */public class NameNodeRPCServer implements Protocol { public static void main(定义客户端类:··· package RPC;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.ipc.RPC;import java.io.IOException;import .InetSocketAddress;/** * RPC 客户端 */public class Client { public static void main(String[] args) throws IOException {启动NameNodeRPCServer,到服务器控制台执⾏jps,你会发现多了⼀个NameNodeRPCServer进程,所以不管是NameNode还是DataNode,其实都是⼀个RPC进程,于是我们可以从NameNode和DataNode这两⾛进NameNode在这⾥我们选择⼀个企业中⽤得⽐较多且稳定的hadoop版本来进⾏展开,这⾥选定hadoop 2.7.3 版本,跟⼤家分享⼀种⾼效阅读源码的⽅法——场景驱动,⽐如说你想了解组件启动的过程,写数据或者读数据的过程剖析⼀个类,⾸先看类的注释说明,其次找 main() ⽅法,结合流程图阅读。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
java 程序员你真的懂java吗?
一起来看下hadoop中的如何去使用java的
大数据是目前IT技术中最火热的话题,也是未来的行业方向,越来越多的人参与到大数据的学习行列中。
从最基础的伪分布式环境搭建,再到分布式环境搭建,再进入代码的编写工作。
这时候码农和大牛的分界点已经出现了,所谓的码农就是你让我做什么我就做什么,我只负责实现,不管原理,也不想知道原理。
大牛就开始不听的问自己why?why?why?于是乎,很自然的去看源码了。
然而像hadoop这样的源码N多人参与了修改和完善,看起来非常的吃力。
然后不管如何大牛就是大牛,再硬的骨头也要啃。
目前做大数据的80%都是从WEB开发转变过来的,什么spring mvc框架、SSH框架非常熟悉,其实不管你做了多少年的WEB开发,你很少接触到hadoop中java代码编写的风格,有些人根本就看不懂什么意思。
下面我来介绍下hadoop源码怎么看。
hadoop体现的是分布式框架,因此所有的通信都基于RPC来操作,关于RPC的操作后续再介绍。
hadoop源码怎么看系列分多个阶段介绍,下面重点介绍下JA V A基础知识。
一、多线程编程
在hadoop源码中,我们能看到大量的类似这样的代码
return executor.submit(new Callable<String>() {
@Override
public String call() throws Exception {
//方法类
}
下面简单介绍下java的多线程编程
启动一个线程可以使用下列几种方式
1、创建一个Runnable,来调度,返回结果为空。
ExecutorService executor = Executors.newFixedThreadPool(5);
executor.submit(new Runnable() {
@Override
public void run() {
System.out.println("runnable1 running.");
}
});
这种方式启动一个线程后,在后台运行,不用等到结果,因为也不会返回结果
2、创建一个Callable,来调度,有返回结果
Future<String> future1 = executor.submit(new Callable<String>() {
@Override
public String call() throws Exception {
// TODO Auto-generated method stub
//具体执行一些内部操作
return "返回结果了!";
}
});
System.out.println("task1: " + future1.get());
这种启动方式一直等到call的方法体执行完毕后,并返回结果了才继续执行下面的代码二、内部类实现
hadoop中同样能看到大量这样形式的代码
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
这是一个典型的内部类实现,PrivilegedExceptionAction是一个接口,里面有一个run方法需要实现,程序调用的时候,会执行里面的submitter.submitJobInternal方法体
为了方便大家理解,我写了一个模拟程序来演示
先定义一个接口类
public interface TransactionAction {
void execute() throws Exception;
}
再定义一些模板方法,参数对象是一个接口来处理相关业务
public class TemplateAction {
public void transactionProcess(TransactionAction action, ActionEvent event){
System.out.println("lock");
try {
action.execute();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("unlock");
}
}
调用过程
public void doSome(){
TemplateAction t=new TemplateAction();
//public void transactionProcess(TransactionAction action, ActionEvent event)
event2 =new ActionEvent ();
event2.setMsg("内部类");
final DoAction doaction=new DoAction();
t.transactionProcess(new TransactionAction() {
@Override
public void execute() throws Exception {
// TODO Auto-generated method stub
doaction.sayWhatEvent(event2);
}
}, new ActionEvent());
}
运行结果如下:
lock
say:内部类
unlock
上面的内部类执行过程很明确,到底execute何时执行不是由dosome来设定,而是由TemplateAction中的transactionProcess来确定
三、枚举类型
枚举类型比较容易理解,例如在我们习惯定义一些常量,
static int ACTION_TYPE=0; //0表示初始,1表示启动,2表示运行中3表示停止
程序中我们这样判断
if(ACTION_TYPE==1){
doSomeThing()
}
例如:
// TODO Auto-generated method stub
JobState state = JobState.DEFINE;
if(state==JobState.RUNNING){
System.out.println("运行状态");
}else{
System.out.println("初始状态");
}
if(jobType==0){
System.out.println("初始状态");
}else if(jobType==1){
System.out.println("启动状态");
}。