hadoop入门学习资料大全
Hadoop 初步学习文档
Hadoop初步学习文档1 Hadoop简介Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。
它支持在商品硬件构建的大型集群上运行的应用程序。
Hadoop是根据Google 公司发表的MapReduce和Google文件系统的论文自行实现而成。
1.1Hadoop基本构成Hadoop是一个能够对大量数据进行分布式处理的软件框架, Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
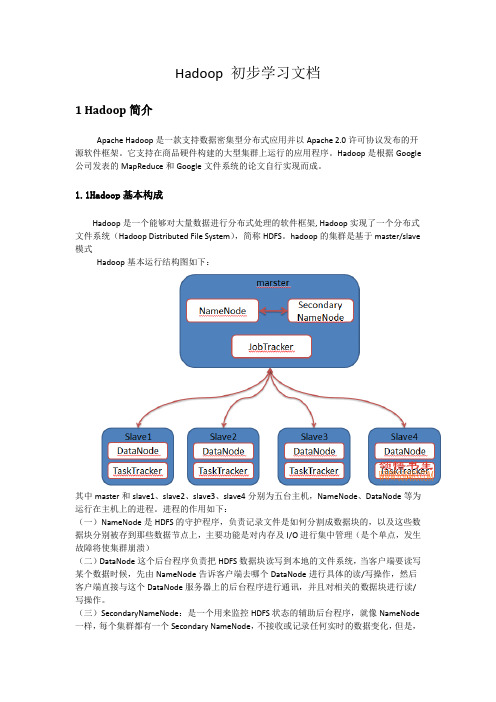
hadoop的集群是基于master/slave 模式Hadoop基本运行结构图如下:其中master和slave1、slave2、slave3、slave4分别为五台主机,NameNode、DataNode等为运行在主机上的进程。
进程的作用如下:(一)NameNode是HDFS的守护程序,负责记录文件是如何分割成数据块的,以及这些数据块分别被存到那些数据节点上,主要功能是对内存及I/O进行集中管理(是个单点,发生故障将使集群崩溃)(二)DataNode这个后台程序负责把HDFS数据块读写到本地的文件系统,当客户端要读写某个数据时候,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后客户端直接与这个DataNode服务器上的后台程序进行通讯,并且对相关的数据块进行读/写操作。
(三)SecondaryNameNode:是一个用来监控HDFS状态的辅助后台程序,就像NameNode 一样,每个集群都有一个Secondary NameNode,不接收或记录任何实时的数据变化,但是,他会与NameNode进行通信,以便定期的保存HDFS元数据的快照,如果Name发生问题,SecondaryNameNode可以及时的作为备用NameNode。
(四)JobTracker:用来连接应用程序与Hadoop,用户代码提交到集群以后,由JobTracker 决定那个文件将被处理,并且为不同的task分配节点,同时,他还监控所有运行的task一旦某个task失败了JobTacker就会自动重新开启task。
大数据hadoop基础

大数据hadoop基础目前人工智能和大数据火热,使用的场景也越来越广,日常开发中前端同学也逐渐接触了更多与大数据相关的开发需求。
因此对大数据知识也有必要进行一些学习理解。
基础概念大数据的本质一、数据的存储:分布式文件系统(分布式存储)二、数据的计算:分部署计算基础知识学习大数据需要具备Java知识基础及Linux知识基础学习路线(1)Java基础和Linux基础(2)Hadoop的学习:体系结构、原理、编程第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)第二阶段:数据分析引擎-> Hive、Pig数据采集引擎-> Sqoop、Flume第三阶段:HUE:Web管理工具ZooKeeper:实现Hadoop的HA Oozie:工作流引擎(3)Spark的学习第一阶段:Scala编程语言第二阶段:Spark Core -> 基于内存、数据的计算第三阶段:Spark SQL -> 类似于mysql 的sql语句第四阶段:Spark Streaming ->进行流式计算:比如:自来水厂(4)Apache Storm 类似:Spark Streaming ->进行流式计算NoSQL:Redis基于内存的数据库HDFS分布式文件系统解决以下问题:•硬盘不够大:多几块硬盘,理论上可以无限大•数据不够安全:冗余度,hdfs默认冗余为3 ,用水平复制提高效率,传输按照数据库为单位:Hadoop1.x 64M,Hadoop2.x 128MMapReduce基础编程模型:把一个大任务拆分成小任务,再进行汇总•MR任务:Job = Map + ReduceMap的输出是Reduce的输入、MR的输入和输出都是在HDFSMapReduce数据流程分析:•Map的输出是Reduce的输入,Reduce的输入是Map的集合HBase什么是BigTable? 把所有的数据保存到一张表中,采用冗余---> 好处:提高效率•因为有了bigtable的思想:NoSQL:HBase数据库•HBase基于Hadoop的HDFS的•描述HBase的表结构核心思想是:利用空间换效率。
Hadoop基础知识培训

存储+计算(HDFS2+Yarn)
集中存储和计算的主要瓶颈
Oracle IBM
EMC存储
scale-up(纵向扩展)
➢计算能力和机器数量成正比 ➢IO能力和机器数量成非正比
多,Intel,Cloudera,hortonworks,MapR • 硬件基于X86服务器,价格低,厂商多 • 可以自行维护,降低维护成本 • 在互联网有大规模成功案例(BAT)
总 结
• Hadoop平台在构建数据云(DAAS)平台有天 然的架构和成本的优势
成本投资估算:从存储要求计算所需硬件及系统软件资源(5000万用户 为例)
往HDFS中写入文件
• 首要的目标当然是数 据快速的并行处理。 为了实现这个目标, 我们需要竟可能多的 机器同时工作。
• Cient会和名称节点达 成协议(通常是TCP 协议)然后得到将要 拷贝数据的3个数据节 点列表。然后Client将 会把每块数据直接写 入数据节点中(通常 是TCP 协议)。名称 节点只负责提供数据 的位置和数据在族群 中的去处(文件系统 元数据)。
• 第二个和第三个数据 节点运输在同一个机 架中,这样他们之间 的传输就获得了高带 宽和低延时。只到这 个数据块被成功的写 入3个节点中,下一 个就才会开始。
• 如果名称节点死亡, 二级名称节点保留的 文件可用于恢复名称 节点。
• 每个数据节点既扮演者数据存储的角色又 冲当与他们主节点通信的守护进程。守护 进程隶属于Job Tracker,数据节点归属于 名称节点。
hadoop 三大部件基础知识

hadoop 三大部件基础知识Hadoop是一个分布式计算框架,由三个主要部件组成:Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)、Hadoop MapReduce和Hadoop YARN(Yet Another Resource Negotiator)。
HDFS是Hadoop的文件系统,它被设计为能够容纳大规模数据集,并且能够在廉价硬件上高效运行。
HDFS将数据划分为多个块,并将这些块分布在集群的不同节点上,以实现数据的可靠存储和高效读写。
HDFS还提供了高容错性和高可伸缩性,通过数据冗余和自动数据备份来保证数据的安全性。
MapReduce是Hadoop的计算模型,它能够并行地处理大规模数据集。
MapReduce将任务分为两个主要阶段:Map阶段和Reduce阶段。
在Map阶段,数据被划分为多个小任务,并由集群中的不同节点并行处理。
在Reduce阶段,Map阶段的结果被整合和汇总。
MapReduce模型的优势在于能够充分利用大规模集群的计算能力,从而加速数据处理过程。
YARN是Hadoop的资源管理系统,它负责集群资源的调度和管理。
YARN将集群的计算资源划分为多个容器,每个容器都有一定的计算能力和内存资源。
YARN可以根据任务的需求,动态地分配和管理集群资源,以提高系统的利用率和性能。
YARN的灵活性和可扩展性使得Hadoop能够更好地适应不同类型的工作负载。
通过使用HDFS、MapReduce和YARN,Hadoop能够处理大规模的数据,并提供高效的分布式计算能力。
它已经被广泛应用于各个领域,包括搜索引擎、社交网络分析、数据挖掘等。
Hadoop的三大部件相互协作,共同构建了一个强大的分布式计算平台,为大数据处理提供了可靠和高效的解决方案。
无论是处理海量数据还是提供实时分析,Hadoop都是一个不可或缺的工具。
hadoop复习

算数据和计算任务
1.3 Hadoop 集群的启动过程
首先启动 hdfs start-dfs.sh
然后启动 yarn start-yarn.sh
最后启动 mr-jobhistory-daemo.sh start historyserver
1.4 Hadoop 启动成功的标志。
在 hadoop1 上 jps
Jps
DataNode
NameNode
在 hadoop2 上 jps
Jps
DataNode
ResourceManager
NodeManager
在 hadoop3 上 jpsLeabharlann JpsDataNode
JobHistoryServer
NodeManager
SecondaryNameNode
1.5 Master/Slave 架构的概念
MapReduce
1.7 HDFS 的存储原理、DataNode 与 NameNode 的概念
Hdfs 中最基本的存储单位就是数据块,DFS 上的文件被划分为块大小的多个分块,作为
Hadoop大数据处理入门指南

Hadoop大数据处理入门指南第一章:大数据概述1.1 什么是大数据大数据指的是数据量庞大、种类多样、处理速度快的数据集合。
随着互联网的普及和信息化的发展,大数据愈发普遍,这些数据包括来自社交媒体、传感器、日志文件等多个来源。
1.2 大数据的挑战大数据的处理面临着四个主要挑战,即数据量庞大、数据多样性、数据处理速度和数据价值挖掘。
第二章:Hadoop概述2.1 Hadoop的定义Hadoop是一个开源的分布式计算框架,能够处理大规模数据集,提供了可靠性、可扩展性和分布式计算的特性。
2.2 Hadoop的架构Hadoop的架构由HDFS(分布式文件系统)和MapReduce(分布式计算框架)组成。
HDFS用于存储和管理大数据集,MapReduce用于处理和分析这些数据。
第三章:Hadoop生态系统3.1 Hadoop生态系统简介Hadoop生态系统由多个组件组成,包括Hive、HBase、Pig、Spark等工具和技术,用于进一步扩展Hadoop的功能和应用范围。
3.2 HiveHive是一个基于Hadoop的数据仓库工具,可以用SQL语言查询和分析大数据集。
它提供了类似于关系数据库的功能,简化了大数据处理的复杂性。
3.3 HBaseHBase是一个分布式、可扩展且高性能的数据库,用于存储和查询海量结构化数据。
它具有快速随机读写功能,适用于需要实时访问大数据集的应用。
3.4 PigPig是一个用于大数据分析的平台,它提供了一种类似于脚本的语言Pig Latin来处理结构化和半结构化数据。
3.5 SparkSpark是一个快速、通用的集群计算系统,用于大规模数据处理。
它支持多种编程语言,并提供了高级API,以便于进行复杂数据分析和机器学习算法。
第四章:Hadoop的安装与配置4.1 下载与安装在本节中,将介绍如何从官方网站下载Hadoop,并进行详细的安装说明。
4.2 配置Hadoop集群探讨如何配置Hadoop集群,包括修改配置文件,设置环境变量和网络连接等。
Hadoop大数据处理简易教程

Hadoop大数据处理简易教程第一章:Hadoop概述Hadoop是一个开源的、可扩展的大数据处理框架,它的设计思想是将大规模数据分成多个块,之后分布式存储和处理这些块。
Hadoop解决了传统数据处理方法在处理大规模数据时遇到的瓶颈和性能问题。
本章将介绍Hadoop框架的基本概念和组件。
第二章:Hadoop核心组件Hadoop由两个核心组件组成,分别是Hadoop分布式文件系统(HDFS)和Hadoop MapReduce。
本章将详细介绍这两个组件的功能和工作原理,并给出相关的示例代码。
第三章:Hadoop生态系统Hadoop生态系统包括了一系列与Hadoop相关的工具和项目,如Hive、Pig、HBase等。
本章将依次介绍这些工具和项目,并解释它们在大数据处理中的作用和优势。
第四章:Hadoop集群部署搭建Hadoop集群是进行大数据处理的关键步骤。
本章将介绍Hadoop集群的搭建和配置,包括如何选择适合的硬件和操作系统、设置网络和安全参数等。
第五章:Hadoop作业调度和监控在一个大规模的Hadoop集群中,作业调度和监控是非常重要的,可以有效提高集群的利用率和性能。
本章将介绍如何使用Hadoop的作业调度和监控工具,如YARN和Hadoop Job Tracker。
第六章:Hadoop性能优化Hadoop的性能优化是提高大数据处理效率的关键。
本章将介绍一些常用的Hadoop性能优化技巧,如数据分区、压缩和并行执行等,并给出相应的实例和案例。
第七章:Hadoop问题排查与故障处理在使用Hadoop进行大数据处理的过程中,难免会遇到一些问题和故障。
本章将介绍常见的Hadoop问题和故障,并给出解决方案和排查方法,帮助读者快速定位和解决问题。
第八章:Hadoop应用实践Hadoop已经在各行各业得到了广泛应用,本章将介绍一些Hadoop在实际场景中的应用案例,如日志分析、推荐系统和图像处理等,以帮助读者更好地理解和运用Hadoop进行大数据处理。
Hadoop大数据分析入门教程

Hadoop大数据分析入门教程第一章理解大数据分析的重要性随着信息技术的快速发展和互联网应用的广泛普及,大量的数据被不断产生和积累。
这些数据以前所未有的速度和规模增长,其中蕴含着宝贵的信息和洞察力,可以帮助企业做出更准确的决策和预测未来的趋势。
然而,由于数据量庞大、种类繁多以及处理和分析难度大的特点,如何高效地处理和分析这些大数据成为了亟待解决的问题。
第二章 Hadoop简介及其核心组件Hadoop是一个开源的分布式计算框架,被广泛应用于大数据分析领域。
Hadoop的核心组件包括Hadoop分布式文件系统(Hadoop Distributed File System, HDFS)和Hadoop分布式计算框架(Hadoop MapReduce)。
HDFS具有高度容错性和可靠性的特点,适合存储海量的数据。
而MapReduce则是一种基于分布式计算的编程模型,可以并行处理、分析和计算海量数据。
第三章 Hadoop生态系统除了HDFS和MapReduce,Hadoop还有一些其他重要的组件,构成了完整的Hadoop生态系统。
例如,Hadoop YARN(Yet Another Resource Negotiator)是一个资源管理器,负责协调和调度集群上的计算任务。
Hadoop Hive是一个基于SQL的数据仓库工具,提供了类似于关系数据库的查询语言,可以方便地进行数据查询和分析。
此外,还有Hadoop HBase、Hadoop Pig等组件,提供了更丰富的功能和更高层次的抽象。
第四章如何搭建Hadoop集群要使用Hadoop进行大数据分析,首先需要搭建一个Hadoop集群。
一个Hadoop集群由一个主节点(Master)和多个从节点(Slave)组成,它们相互协作完成数据存储和计算任务。
搭建Hadoop集群可以采用几种不同的方式,比如本地模式、伪分布式模式和完全分布式模式。
这些模式的不同在于节点的数量和部署方式,根据实际情况选择适合的模式。
hadoop复习资料大全

hadoop复习资料大全Hadoop复习资料大全在当今信息爆炸的时代,数据已经成为了一种宝贵的资源。
然而,要处理和分析海量的数据并从中获取有用的信息是一项复杂而困难的任务。
这就是为什么Hadoop这样的大数据处理框架变得如此重要和流行的原因之一。
作为一个开源的分布式系统,Hadoop提供了一种可靠和高效地处理大规模数据的方法。
对于那些希望深入了解和掌握Hadoop的人来说,复习资料是必不可少的。
一、Hadoop的基础知识要理解Hadoop的工作原理和基本概念,首先需要掌握一些基础知识。
这包括Hadoop的核心组件,如Hadoop分布式文件系统(HDFS)和MapReduce。
此外,还需要了解Hadoop的架构,包括主节点(NameNode)和从节点(DataNode)之间的交互方式。
二、Hadoop生态系统除了核心组件外,Hadoop还有一个庞大而丰富的生态系统。
这个生态系统包括各种工具和技术,用于处理和分析大规模数据。
其中一些工具包括Hive、Pig、HBase和Sqoop等。
每个工具都有其独特的功能和用途,掌握它们可以帮助我们更好地利用Hadoop的能力。
三、Hadoop的安装和配置要使用Hadoop,首先需要将其安装和配置在自己的机器上。
这可能是一个有些复杂的过程,因为Hadoop有很多配置选项和参数需要设置。
因此,掌握正确的安装和配置过程是非常重要的。
有很多在线教程和指南可以帮助你完成这个过程,你可以找到一些详细的步骤和说明。
四、Hadoop的性能调优一旦你安装和配置好了Hadoop,接下来就是优化它的性能。
Hadoop的性能调优是一个复杂的过程,需要细致的分析和调整。
这包括调整Hadoop的配置参数,优化数据存储和访问方式,以及使用适当的算法和技术来处理数据。
了解这些技巧和技术可以帮助你更好地利用Hadoop的潜力。
五、Hadoop的安全性和故障恢复在处理大规模数据时,安全性和故障恢复是非常重要的考虑因素。
hadoop相关知识

hadoop相关知识Hadoop相关知识Hadoop是一种开源的分布式计算系统,它能够高效地处理大规模数据集。
它的核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce计算模型。
本文将介绍Hadoop的基本概念、架构和应用。
一、Hadoop的基本概念1. Hadoop分布式文件系统(HDFS)HDFS是Hadoop的核心组件之一,它是一个分布式文件系统,用于存储大规模数据集。
HDFS将数据分割成多个块,并将这些块存储在多个计算机节点上,以实现数据的高可靠性和高可扩展性。
2. MapReduce计算模型MapReduce是Hadoop的另一个核心组件,它是一种并行计算模型,用于处理大规模数据集。
MapReduce将计算任务分解为两个阶段:Map阶段和Reduce阶段。
在Map阶段,将输入数据划分为多个独立的片段,并分配给不同的计算节点进行处理。
在Reduce阶段,将Map阶段的输出进行汇总和整合,得到最终的计算结果。
二、Hadoop的架构Hadoop的架构主要由以下几个组件组成:1. Hadoop集群Hadoop集群是由多个计算机节点组成的,每个节点都运行着Hadoop的各个组件。
集群中的一个节点被指定为主节点(称为NameNode),负责管理HDFS的元数据信息。
其他节点被指定为工作节点(称为DataNode),负责存储和处理数据。
2. Hadoop分布式文件系统(HDFS)HDFS是Hadoop的核心组件之一,它负责存储大规模数据集。
HDFS 将数据分割成多个块,并将这些块存储在不同的DataNode上。
HDFS 还提供了高可靠性和高可扩展性的特性,能够处理大规模数据集的存储需求。
3. MapReduce计算模型MapReduce是Hadoop的另一个核心组件,它负责处理大规模数据集的计算任务。
MapReduce将计算任务分解为两个阶段:Map阶段和Reduce阶段。
在Map阶段,将输入数据划分为多个独立的片段,并分配给不同的计算节点进行处理。
hadoop大数据开发基础笔记

Hadoop大数据开发基础笔记一、概述随着互联网和信息技术的迅猛发展,大数据技术已成为当前热门的领域之一。
Hadoop作为大数据处理领域的重要工具,对于开发者来说是必须掌握的技能之一。
本文将从Hadoop的概念、架构、组件以及基本操作等方面进行系统的介绍和总结,帮助读者快速掌握Hadoop大数据开发的基础知识。
二、Hadoop概述1. Hadoop的概念Hadoop是一个开源的分布式存储和计算评台,最初是由Apache基金会开发的。
它能够处理海量数据,并提供高性能的分布式数据存储和处理能力。
Hadoop的核心是HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算框架),它们共同构成了Hadoop评台的基础架构。
2. Hadoop的特点Hadoop具有高可靠性、高可扩展性和高效能处理大规模数据的能力。
它支持海量数据的存储和处理,并且能够快速地处理数据,从而为用户提供快速的数据分析和挖掘能力。
三、Hadoop架构1. Hadoop的架构组成Hadoop的架构分为HDFS和MapReduce两部分。
其中,HDFS负责数据的存储和管理,而MapReduce负责数据的计算和处理。
另外,Hadoop还包括了YARN(资源调度和管理),这是最新版本中引入的资源管理框架,它为Hadoop提供了更好的资源管理和任务处理能力。
2. Hadoop的工作流程Hadoop的工作流程包括数据的存储、计算和结果的输出等基本步骤。
数据被分割成小的块并存储在HDFS中,然后MapReduce框架将数据分发给不同的计算节点进行处理,最后将处理结果输出到HDFS中。
四、Hadoop组件1. HDFSHDFS是Hadoop分布式文件系统的简称,它是Hadoop的核心组成部分之一。
HDFS采用主从架构,包括一个NameNode节点和多个DataNode节点。
NameNode负责管理文件系统的命名空间和数据块的映射信息,而DataNode负责实际的数据存储。
云计算-Hadoop基础知识

云计算-Hadoop基础知识hadoop是什么?(1)Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。
用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
(2)Hadoop就是一个分布式计算的解决方案.hadoop能做什么?hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似的协同过滤的推荐效果。
淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。
(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)下面举例说明:设想一下这样的应用场景. 我有一个100M 的数据库备份的sql 文件.我现在想在不导入到数据库的情况下直接用grep操作通过正则过滤出我想要的内容。
例如:某个表中含有相同关键字的记录那么有几种方式,一种是直接用linux的命令 grep 还有一种就是通过编程来读取文件,然后对每行数据进行正则匹配得到结果好了现在是100M 的数据库备份.上述两种方法都可以轻松应对.那么如果是1G , 1T 甚至 1PB 的数据呢 ,上面2种方法还能行得通吗?答案是不能.毕竟单台服务器的性能总有其上限.那么对于这种超大数据文件怎么得到我们想要的结果呢?有种方法就是分布式计算, 分布式计算的核心就在于利用分布式算法把运行在单台机器上的程序扩展到多台机器上并行运行.从而使数据处理能力成倍增加.但是这种分布式计算一般对编程人员要求很高,而且对服务器也有要求.导致了成本变得非常高.Haddop 就是为了解决这个问题诞生的.Haddop 可以很轻易的把很多linux的廉价pc 组成分布式结点,然后编程人员也不需要知道分布式算法之类,只需要根据mapreduce的规则定义好接口方法,剩下的就交给Haddop. 它会自动把相关的计算分布到各个结点上去,然后得出结果.例如上述的例子: Hadoop 要做的事首先把 1PB的数据文件导入到 HDFS中, 然后编程人员定义好 map和reduce, 也就是把文件的行定义为key,每行的内容定义为value , 然后进行正则匹配,匹配成功则把结果通过reduce聚合起来返回.Hadoop 就会把这个程序分布到N 个结点去并行的操作.这也就是所谓的大数据云计算了.如果还是不懂的话再举个简单的例子比如1亿个 1 相加得出计算结果, 我们很轻易知道结果是 1亿.但是计算机不知道.那么单台计算机处理的方式做一个一亿次的循环每次结果+1那么分布式的处理方式则变成我用 1万台计算机,每个计算机只需要计算 1万个 1 相加然后再有一台计算机把 1万台计算机得到的结果再相加从而得到最后的结果.理论上讲, 计算速度就提高了 1万倍. 当然上面可能是一个不恰当的例子.但所谓分布式,大数据,云计算大抵也就是这么回事了.hadoop能为我司做什么?零数据基础,零数据平台,一切起点都是0。
使用Hadoop进行大数据处理的基础知识

使用Hadoop进行大数据处理的基础知识一、大数据处理概述大数据处理是指通过利用各种相关技术和工具,对海量数据进行分析、处理和挖掘,并从中提取有价值的信息和洞察力。
随着互联网和移动设备的普及,人们每天产生的数据量呈爆炸式增长,这些建立在大规模分布式计算和存储基础上的大数据处理技术应运而生。
二、Hadoop的简介Hadoop是一个基于Java的开源框架,用于处理大规模数据集的分布式计算和存储。
它采用了分布式文件系统(Hadoop Distributed File System,简称HDFS)和分布式计算模型(MapReduce),能够高效地存储和处理PB级以上的数据。
1. Hadoop Distributed File System(HDFS)HDFS是Hadoop的核心组成部分之一,它是一个可靠、高容错性和高扩展性的分布式文件系统。
HDFS将大文件切分为多个数据块,并在集群中的多个节点上存储这些数据块的多个副本,以提供数据的冗余备份和高可用性。
2. MapReduce计算模型MapReduce是Hadoop的另一个核心组件,它是一种用于处理大规模数据集的分布式计算模型。
MapReduce将计算过程分为两个阶段:Map阶段和Reduce阶段。
在Map阶段,将输入数据切分为若干个独立的子问题,并在集群的多个节点上进行并行计算。
在Reduce阶段,将Map阶段的输出结果进行合并和聚合,最终得到最终结果。
三、Hadoop生态系统Hadoop生态系统是由与Hadoop相关的各种工具和项目组成的。
这些工具和项目提供了对数据处理、存储和分析的更多功能和选项。
1. Hadoop StreamingHadoop Streaming是一个用于在Hadoop集群上运行任意编程语言的工具。
它通过标准输入和输出来实现与MapReduce的集成,使得用户可以使用自己熟悉的编程语言进行大数据处理。
2. HiveHive是一个数据仓库基础设施,它在Hadoop上提供了一个类似于传统关系型数据库的查询和分析环境。
快速上手使用Hadoop进行大数据处理

快速上手使用Hadoop进行大数据处理第一章:Hadoop简介Hadoop是一个开源的大数据处理框架,它由Apache基金会进行开发和维护。
Hadoop的目标是提供一种可靠、可伸缩、可扩展的分布式计算解决方案,适用于处理大规模数据集。
1.1 Hadoop的主要组件Hadoop由四个核心组件组成,分别是Hadoop分布式文件系统(HDFS)、Hadoop YARN、Hadoop MapReduce和Hadoop Common。
1.1.1 Hadoop分布式文件系统(HDFS)HDFS是Hadoop的文件系统,它是一个可靠的、具有高容错性的分布式文件系统。
HDFS将大文件切分为多个数据块,并分布式存储在多个节点上,从而实现了数据的高可靠性和高可用性。
1.1.2 Hadoop YARNHadoop YARN(Yet Another Resource Negotiator)是Hadoop的资源管理系统,它负责集群资源的分配和任务调度。
YARN将集群的计算资源划分为多个容器,每个容器运行一个任务。
1.1.3 Hadoop MapReduceHadoop MapReduce是Hadoop的计算模型和编程框架,它用于处理分布式计算任务。
MapReduce将大规模的计算任务分解成多个小的子任务,并在集群中并行运行。
1.1.4 Hadoop CommonHadoop Common是Hadoop的公共库,它为其他Hadoop组件提供了基础功能和工具。
第二章:安装和配置Hadoop2.1 下载Hadoop在使用Hadoop之前,首先需要从官方网站上下载Hadoop的最新版本。
下载完成后,解压缩文件到本地目录。
2.2 配置Hadoop环境变量在配置Hadoop之前,需要设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
将这些环境变量添加到系统的path中,以便能够在命令行中直接访问到Hadoop的可执行文件。
Hadoop基础入门指南

Hadoop基础入门指南Hadoop是一个基于Java的开源分布式计算平台,能够处理大规模数据存储和处理任务。
它是处理大数据的一种解决方案,被广泛应用于各种领域,例如金融、医疗、社交媒体等。
本文将介绍Hadoop的基础知识,帮助初学者快速入门。
一、Hadoop的三大模块Hadoop有三个核心模块,分别是HDFS(Hadoop分布式文件系统)、MapReduce、和YARN。
1. HDFS(Hadoop分布式文件系统)HDFS是Hadoop的存储模块,它可以存储大量的数据,并在多台机器之间进行分布式存储和数据备份。
HDFS将文件切割成固定大小的块,并复制多份副本,存储在不同的服务器上。
如果某个服务器宕机,数据仍然可以从其他服务器中获取,保障数据的安全。
2. MapReduceMapReduce是Hadoop的计算模块,它可以对存储在HDFS上的大量数据进行分布式处理。
MapReduce模型将大数据集划分成小数据块,并行处理这些小数据块,最后将结果归并。
MapReduce模型包含两个阶段:Map阶段和Reduce阶段。
Map阶段:将输入的大数据集划分成小数据块,并将每个数据块分配给不同的Map任务处理。
每个Map任务对数据块进行处理,并生成键值对,输出给Reduce任务。
Reduce阶段:对每个键值对进行归并排序,并将具有相同键的一组值传递给Reduce任务,进行汇总和计算。
3. YARNYARN是Hadoop的资源管理器,它负责分配和管理Hadoop集群中的计算资源。
YARN包含两个关键组件:ResourceManager和NodeManager。
ResourceManager:管理整个集群的资源,包括内存、CPU等。
NodeManager:运行在每个计算节点上,负责监控本地计算资源使用情况,并与ResourceManager通信以请求或释放资源。
二、Hadoop的安装与配置在开始使用Hadoop之前,需要进行安装和配置。
Hadoop大数据技术基础与应用 第1章 Hadoop技术概述

2.Hadoop是什么
Hadoop是由一系列软件库组成的框架。这些软件库各自负责Hadoop的一部分 功能,其中最主要的是HDFS、MapReduce和YARN。HDFS负责大数据的存储、 MapReduce负责大数据的计算、YARN负责集群资源的调度。
Mahout
Flume
Sqoop
4.Hadoop发展历程
• 第三阶段
✓ Hadoop商业发行版时代(2011-2020) ✓ 商业发行版、CDH、HDP等等,云本,云原生商业版如火如荼
4.Hadoop报导过的Expedia也在其中。
2.Hadoop的应用领域
• 诈骗检测 这个领域普通用户接触得比较少,一般只有金融服务或者政府机构会用到。利用Hadoop来存
储所有的客户交易数据,包括一些非结构化的数据,能够帮助机构发现客户的异常活动, 预防欺诈行为。
• 医疗保健 医疗行业也会用到Hadoop,像IBM的Watson就会使用Hadoop集群作为其服务的基础,包括语
✓ 国产化开源发行版时代(2021开始) ✓ USDP ✓ 标准的发行版纷纷收费,国产化开源发行版势在必行
5.Hadoop名字起源
Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者, Doug Cutting解释Hadoop的得名:“这个名字是我孩子给一个棕黄色的大象 玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义, 并且不会被用于别处。小孩子恰恰是这方面的高手。”
✓ 后Hadoop时代(2008-2014) ✓ Hadoop、HBase、Hive、Pig、Sqoop等百花齐放,眼花缭乱 ✓ 各个组件层出不穷,相互之间的兼容性管理混乱,虽然选择性多,但是很乱
hadoop基础知识

hadoop基础知识Hadoop基础知识Hadoop是一个开源的分布式计算框架,用于处理大规模数据和执行并行计算任务。
它由Apache基金会开发和维护,具有高可靠性、高扩展性和高容错性等优点。
本文将介绍Hadoop的基础知识,包括Hadoop的概述、核心组件以及其在大数据处理中的应用。
一、Hadoop概述Hadoop的核心目标是通过并行处理大规模数据集,将计算任务分布在多个计算节点上,从而实现更快速、高效的数据处理。
它采用了分布式文件系统(Hadoop Distributed File System,简称HDFS)和分布式计算框架(MapReduce)来实现大规模数据的存储和处理。
Hadoop的分布式文件系统(HDFS)将大规模数据集分散存储在多个计算节点上,这些节点可以是廉价的商用计算机。
HDFS将数据划分成多个数据块,并将这些数据块复制到不同的计算节点上,以实现数据的冗余备份和容错性。
Hadoop的分布式计算框架(MapReduce)是一种用于处理大规模数据的编程模型。
它将计算任务分割成多个子任务,并将这些子任务分布在不同的计算节点上并行执行。
MapReduce框架将输入数据分成多个输入分片,并通过Map函数将每个分片映射成一系列键值对。
然后,通过Reduce函数对这些键值对进行合并和聚合,最后生成最二、Hadoop核心组件1. Hadoop Common:提供了Hadoop的基本工具和库,包括文件系统和输入输出操作等。
2. HDFS:Hadoop的分布式文件系统,用于存储大规模数据集。
3. YARN:Hadoop的资源管理器,用于管理集群上的计算资源并调度任务。
4. MapReduce:Hadoop的分布式计算框架,用于并行处理大规模数据。
5. Hadoop EcoSystem:Hadoop生态系统包括了许多与Hadoop相关的开源项目,如Hive、HBase、Spark等,用于扩展Hadoop的功能和应用范围。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop是一个分布式系统基础架构,由Apache基金会开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。
而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
搜索了一些WatchStor存储论坛关于hadoop入门的一些资料分享给大家希望对大家有帮助
jackrabbit封装hadoop的设计与实现
/thread-60444-1-1.html
用Hadoop进行分布式数据处理
/thread-60447-1-1.html
Hadoop源代码eclipse编译教程
/thread-60448-1-2.html
Hadoop技术讲解
/thread-60449-1-2.html
Hadoop权威指南(原版)
/thread-60450-1-2.html
Hadoop源代码分析完整版
/thread-60451-1-2.html
基于Hadoop的Map_Reduce框架研究报告
/thread-60452-1-2.html
Hadoop任务调度
/thread-60453-1-2.html
Hadoop使用常见问题以及解决方法
/thread-60454-1-2.html HBase:权威指南
/thread-60455-1-2.html
CentOS下Hadoop-0.20.2集群配置文档
/thread-60457-1-2.html
[Hadoop实战].(Hadoop.in.Action)m.文字版/thread-60458-1-2.html
基于Hadoop_平台的数据分析方案的设计应用
/thread-60459-1-2.html
基于单机的Hadoop伪分布式运行模拟实现即其分析过程(完整版) /thread-60460-1-2.html
精通Hadoop
/thread-60462-1-2.html
MongoDB高级查询
/thread-60463-1-1.html
Hadoop分布式文件系统:架构和设计
/thread-60465-1-1.html
Eclipse Hadoop环境配置
/thread-60466-1-1.html
Hadoop集群配置
/thread-60467-1-1.html
MapReduce&Hadoop技术、原理及应用
/thread-60469-1-1.html
使用Hadoop构建云计算平台
/thread-60471-1-1.html
实战Hadoop——开启通向云计算的捷径
/thread-60473-1-1.html
Hadoop云计算技术介绍
/thread-60474-1-1.html
hadoop源码分析-mapreduce部分
/thread-60475-1-1.html
Hbase_分析报告白皮书
/thread-60476-1-1.html
Hadoop in Action
/thread-60477-1-1.html
Hadoop Map/Reduce教程
/thread-60478-1-1.html
Hadoop+Ubuntu学习笔记
/thread-60479-1-1.html
hadoop-0.20_程式设计
/thread-60480-1-1.html
Hadoop FAQ
/thread-60481-1-1.html。