(完整word版)hadoop安装教程
大数据Hadoop集群安装部署文档

大数据Hadoop集群安装部署文档一、背景介绍大数据时代下,海量数据的处理和分析成为了一个重要的课题。
Hadoop是一个开源的分布式计算框架,能够高效地处理海量数据。
本文将介绍如何安装和部署Hadoop集群。
二、环境准备1.集群规模:本文以3台服务器组成一个简单的Hadoop集群。
2.操作系统:本文以Linux作为操作系统。
三、安装过程1.安装JavaHadoop是基于Java开发的,因此需要先安装Java。
可以通过以下命令安装:```sudo apt-get updatesudo apt-get install openjdk-8-jdk```2.安装Hadoop```export HADOOP_HOME=/opt/hadoopexport PATH=$PATH:$HADOOP_HOME/bin```保存文件后,执行`source ~/.bashrc`使配置生效。
3.配置Hadoop集群在Hadoop安装目录中的`etc/hadoop`目录下,有一些配置文件需要进行修改。
a.修改`hadoop-env.sh`文件该文件定义了一些环境变量。
可以找到JAVA_HOME这一行,将其指向Java的安装目录:```export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64```b.修改`core-site.xml`文件```<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>```c.修改`hdfs-site.xml`文件```<property><name>dfs.replication</name><value>3</value></property>```其中,`dfs.replication`定义了数据的副本数,这里设置为34.配置SSH免密码登录在Hadoop集群中,各个节点之间需要进行通信。
hadoop安装流程

hadoop安装流程Hadoop是一个开源的分布式计算平台,可以用于存储和处理大数据集。
在安装Hadoop之前,您需要确保您的系统满足以下要求:硬件要求:-至少2个可用的CPU核心-至少4GB的内存-至少10GB的可用存储空间-网络连接稳定软件要求:- 操作系统:Hadoop支持多种操作系统,包括Linux、Windows和Mac OS X。
- Java:Hadoop是用Java编写的,所以您需要安装Java并配置JAVA_HOME环境变量。
下面是Hadoop的安装流程:第二步:配置环境变量- HADOOP_HOME:指向Hadoop安装目录- JAVA_HOME:指向Java安装目录您可以在.bashrc或.bash_profile文件中添加以下行来设置这些环境变量:```export HADOOP_HOME=/path/to/hadoopexport JAVA_HOME=/path/to/javaexport PATH=$PATH:$HADOOP_HOME/bin```第三步:修改配置文件Hadoop的配置文件位于Hadoop安装目录的`etc/hadoop`目录下。
您需要修改以下几个核心配置文件:1. core-site.xml:```<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>```2. hdfs-site.xml:```<property><name>dfs.replication</name><value>1</value>```3. mapred-site.xml.template:```<property><name></name><value>yarn</value></property>```4. yarn-site.xml:```<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value>```第四步:格式化HDFS打开终端,进入Hadoop安装目录并执行以下命令来格式化HDFS:```hdfs namenode -format```第五步:启动Hadoop集群在终端中执行以下命令来启动Hadoop集群:```start-dfs.shstart-yarn.sh```您还可以使用以下命令检查集群是否成功启动:```jps```您应该能够看到类似以下输出:```...```至此,您已经成功地安装了Hadoop并启动了一个简单的Hadoop集群。
(完整word版)centos6下安装部署hadoop2.2

centos6下安装部署hadoop2。
2hadoop安装入门版,不带HA,注意理解,不能照抄.照抄肯定出错。
我在安装有centos7(64位)的机器上,使用hadoop2。
5版本,安装验证过,但我没有安装过hadoop2。
2,仅供参考.如果你的(虚拟机)操作系统和JVM/JDK是64位的,就直接安装hadoop 2.5版本,无需按照网上说的去重新编译hadoop,因为它的native库就是64位了;如果你的(虚拟机)操作系统和JVM/JDK是32位的,就直接安装hadoop 2。
4以及之前的版本.安装小技巧和注意事项:1. 利用虚拟机clone的技术。
2. 不要在root用户下安装hadoop,自己先事先建立一个用户。
3。
如果需要方便操作,可以把用户名添加到sudoers文件中,使用sudo命令执行需要root权限的操作。
4。
Linux里面有严格的权限管理,很多事情普通用户做不了,习惯使用windows的同学,需要改变观念。
5。
centos7与之前的版本,在很多命令上有区别,centos与ubuntu有存在很多操作上的差别。
6. Hadoop 2.5版本中的native lib库是64位的,而hadoop 2。
2版本中的native lib库是32位的。
网上教程大多数针对hadoop2。
2写的,如果你是64位的虚拟机,你直接安装Hadoop 2.5版本就行。
7. 确认虚拟机安装并启用了sshd服务后,用xshell客户端连接Linux虚拟机,不要在vmware workstation 里面操作。
用xshell可以非常方便的复制文字和命令等。
学习Hadoop安装的步骤(1)可以先参考网上的资料“虾皮博客”http://www。
/xia520pi/xia520pi/archive/2012/05/16/2503949.html安装一个hadoop 1.2 版本,熟悉一下,搞明白后,再安装hadoop 2.x版本。
hadoop 大数据环境 安装攻略

先在Bios里面把虚拟机设置为enable第一步:安装虚拟机虚拟光驱VMware-workstation-full-11.0.0-2305329.exe需要注册码的,里面有生成注册码的小软件第二步:解压CentOS65-ori.rar里面有一个txt文档,打开后为用户名:root/hadoophadoop/hadoop(加入sudoers和root组)做好的设置:jdk(JAVA_HOME=/Usr/java/jdk1.8.0_20--有错别字,应该是小写的u)hosts和network做了基本修改ip地址是dhcpmysql安装完毕(utf8编码,root/123456)iptable和selinux都关掉了hadoop用户建立了ssh密钥,root还没有ssh安装了vmwaretools,但不是特别灵敏将CentOS65-ori.rar解压缩后的文件里面的CentOS65-origin.vmx文件直接拖入虚拟机里面。
这样就打开了登陆进去,密码是hadoop第三步:右键启动一个终端输入java –version第四步在虚拟机里面有快照功能,就像是ghost一样,可以随时还原。
可以将Windows里面的文件直接拖入linux虚拟机里面的系统里。
接下来,解压这个文件,拖入到linux虚拟机里面的系统里,郁闷的是没有拖进去,这个地方有问题。
第五步新建一个虚拟机,利用那个4G多的镜像文件。
之后一顿自动的安装,另外一个系统进来了,进到虚拟机里面了,功能更多。
中间貌似出现错误了,但是等待后,继续安装,启动输入密码hh,进入了第五步这个linux系统里面有火狐狸浏览器,进入,登陆baidu,搜索jdk linux,找到合适的jdk下载下载了,安装两个大招:再次关闭防火墙,确认关闭防火墙,重启Ctrl+C 停止配置完毕后,在系统命令行下执行;source~/.bash_profile,使得环境变量配置生效。
可以在系统命令行下输入source接下来,把这个文件.bash_profile 拖入,拖到source后面。
简单梳理hadoop安装流程文字

简单梳理Hadoop安装流程
今儿个咱们来简单梳理下Hadoop的安装流程,让各位在四川的兄弟姐妹也能轻松上手。
首先,你得有个Linux系统,比如说CentOS或者Ubuntu,这点很重要。
然后在系统上整个Java环境,Hadoop 是依赖Java运行的。
把JDK下载安装好后,记得配置下环境变量,就是修改`/etc/profile`文件,把Java的安装路径加进去。
接下来,你需要在系统上整个SSH服务,Hadoop集群内部的通信要用到。
安好SSH后,记得配置下无密钥登录,省得每次登录都要输密码,多麻烦。
Hadoop的安装包可以通过官方渠道下载,也可以在网上找现成的。
下载好安装包后,解压到你的安装目录。
然后就开始配置Hadoop的环境变量,跟配置Java环境变量一样,也是在
`/etc/profile`文件里加路径。
配置Hadoop的文件是重点,都在Hadoop安装目录下的`etc/hadoop`文件夹里。
有`hadoop-env.sh`、`core-site.xml`、`hdfs-site.xml`这些文件需要修改。
比如`core-site.xml`里要设置HDFS的地址和端口,`hdfs-site.xml`里要设置临时目录这些。
最后,就可以开始格式化HDFS了,用`hdfs namenode-format`命令。
然后启动Hadoop,用`start-all.sh`脚本。
如果一
切配置正确,你就可以用`jps`命令看到Hadoop的各个进程在运行了。
这整个过程看似复杂,但只要你跟着步骤来,注意配置文件的路径和内容,相信你也能轻松搞定Hadoop的安装。
Hadoop详细安装配置过程

1.下载并安装安装sshsudo apt-get install openssh-server openssh-client3.搭建vsftpd#sudo apt-get update#sudo apt-get install vsftpd配置参考的开始、关闭和重启$sudo /etc/vsftpd start #开始$sudo /etc/vsftpd stop #关闭$sudo /etc/vsftpd restart #重启4.安装sudo chown -R hadoop:hadoop /optcp /soft/ /optsudo vi /etc/profilealias untar='tar -zxvf'sudo source /etc/profilesource /etc/profileuntar jdk*环境变量配置# vi /etc/profile●在profile文件最后加上# set java environmentexport JAVA_HOME=/opt/export CLASSPATH=.:$JAVA_HOME/lib/:$JAVA_HOME/lib/ export PATH=$JAVA_HOME/bin:$PATH配置完成后,保存退出。
●不重启,更新命令#source /etc/profile●测试是否安装成功# Java –version其他问题:出现unable to resolve host 解决方法参考开机时停在Starting sendmail 不动了的解决方案参考安装软件时出现E: Unable to locate package vsftpd 参考vi/vim 使用方法讲解参考分类: Hadoop--------------------------------------------克隆master虚拟机至node1 、node2分别修改master的主机名为master、node1的主机名为node1、node2的主机名为node2 (启动node1、node2系统默认分配递增ip,无需手动修改)分别修改/etc/hosts中的ip和主机名(包含其他节点ip和主机名)---------配置ssh免密码连入hadoop@node1:~$ ssh-keygen -t dsa -P ''-f ~/.ssh/id_dsaGenerating public/private dsa key pair.Created directory '/home/hadoop/.ssh'.Your identification has been saved in/home/hadoop/.ssh/id_dsa.Your public key has been saved in/home/hadoop/.ssh/.The key fingerprint is:SHA256:B8vBju/uc3kl/v9lrMqtltttttCcXgRkQPbVoU hadoop@node1The key's randomart image is:+---[DSA 1024]----+|....||o+.E .||. oo +||..++||o +.o ooo +||=o.. o. ooo. o.||*o....+=o .+++.+|+----[SHA256]-----+hadoop@node1:~$ cd .sshhadoop@node1:~/.ssh$ ll总用量16drwx------ 2 hadoop hadoop 4096 Jul 24 20:31 ./drwxr-xr-x 18 hadoop hadoop 4096 Jul 2420:31../-rw------- 1 hadoop hadoop 668 Jul 24 20:31 id_dsa-rw-r--r-- 1 hadoop hadoop 602 Jul 24 20:31hadoop@node1:~/.ssh$ cat >> authorized_keyshadoop@node1:~/.ssh$ ll总用量20drwx------ 2 hadoop hadoop 4096 Jul 24 20:32 ./drwxr-xr-x 18 hadoop hadoop 4096 Jul 2420:31../-rw-rw-r-- 1 hadoop hadoop 602 Jul 24 20:32 authorized_keys-rw------- 1 hadoop hadoop 668 Jul 24 20:31 id_dsa-rw-r--r-- 1 hadoop hadoop 602 Jul 24 20:31单机回环ssh免密码登录测试hadoop@node1:~/.ssh$ ssh localhostThe authenticity of host'localhost ' can't be established.ECDSA key fingerprint is SHA256:daO0dssyqt12tt9yGUauImOh6tt6A1SgxzSfSmpQqJVEiQTxas. Are you sure you want to continue connecting (yes/no) yesWarning: Permanently added 'localhost'(ECDSA)to the list of known hosts.Welcome to Ubuntu (GNU/Linux x86_64)* Documentation:packages can be updated.178 updates are security updates.New release' LTS' available.Run 'do-release-upgrade'to upgrade to it.Last login: Sun Jul 2420:21:392016from exit注销Connection to localhost closed.hadoop@node1:~/.ssh$出现以上信息说明操作成功,其他两个节点同样操作让主结点(master)能通过SSH免密码登录两个子结点(slave)hadoop@node1:~/.ssh$ scp hadoop@master:~/.ssh/./The authenticity of host'master ' can't be established.ECDSA key fingerprint is SHA256:daO0dssyqtt9yGUuImOh646A1SgxzSfatSmpQqJVEiQTxas.Are you sure you want to continue connecting (yes/no) yesWarning: Permanently added 'master,'(ECDSA)to the list of known hosts.hadoop@master's password:100%603s 00:00 hadoop@node1:~/.ssh$ cat >> authorized_keys如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,这一过程需要密码验证。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
hadoop安装步骤

hadoop安装步骤1.准备Linux环境1.0先将虚拟机的⽹络模式选为NAT1.1修改主机名 hostnamectl set-hostname server11.2修改IP 修改配置⽂件⽅式(修改的是⽹卡信息 ip a 查看⽹卡),第⼀次启动时没有ip的,需要将⽹卡配置之中 ONBOOT=yes, 然后重启⽹络vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE="eth0"BOOTPROTO="static"###HWADDR="00:0C:29:3C:BF:E7"IPV6INIT="yes"NM_CONTROLLED="yes"ONBOOT="yes"TYPE="Ethernet"UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"IPADDR="192.168.1.101"###NETMASK="255.255.255.0"###GATEWAY="192.168.1.1"###1.3修改主机名和IP的映射关系(每台机器都要有)192.168.33.101 server1192.168.33.102 server2192.168.33.103 server31.4关闭防⽕墙#查看防⽕墙状态service iptables status#关闭防⽕墙service iptables stop#查看防⽕墙开机启动状态chkconfig iptables --list#关闭防⽕墙开机启动chkconfig iptables off1.5 关闭linux服务器的图形界⾯:vi /etc/inittab1.6重启Linuxreboot2.安装JDK#创建⽂件夹mkdir /home/hadoop/app#解压tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app2.3将java添加到环境变量中(如果在 .bashrc 之中配置了java环境变量,hadoop 是不需要指定 JAVA_HOME,如果在 /etc/profile 需要指定,因为 ssh 默认不会加载 /et/profile) vim ~/.bashrc#在⽂件最后添加export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585export PATH=$PATH:$JAVA_HOME/bin#刷新配置source ~/.bashrc3.安装hadoop2.4.1(要保证以下⽂件都有读写权限)先上传hadoop的安装包到服务器上去/home/hadoop/分布式需要修改5个配置⽂件3.1配置hadoopvim hadoop-env.shexport JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585第⼆个:core-site.xml<!-- 指定HADOOP所使⽤的⽂件系统schema(URI),HDFS的⽼⼤(NameNode)的地址 --><property><name>fs.defaultFS</name><value>hdfs://server1:9000</value><!--hadoop 的默认⽤户--><property><name>er</name><value>master</value></property><!--datanode.data.dir 存储⽂件⽬录, .dir 元数据,namenode.edits.dir ⽇志⽬录三者都依赖于此⽬录--> <property><name>hadoop.tmp.dir</name><value>/opt/modules/hadoop-2.7.0/data/tmp</value></property>第三个:hdfs-site.xml<!--其他⽤户使⽤hdfs 操作⽂件,是否进⾏验证!--><property><name>dfs.permissions</name><value>false</value></property>第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)<property><name></name><value>yarn</value></property><!--⽇志页⾯的显⽰ ip:port--><property><name>mapreduce.jobhistory.address</name><value>sserver1:10020</value></property><!--运⾏ yarn 任务跳转的页⾯--><property><name>mapreduce.jobhistory.webapp.address</name><value>server1:19888</value></property>第五个:yarn-site.xml<property><name>yarn.resourcemanager.hostname</name><value>server1</value></property><!-- reducer获取数据的⽅式,⼀种辅助 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--开启⽇志聚集--><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!--⽇志存放的时间(s)--><property><name>yarn.log-aggregation.retain-seconds</name><value>100000</value></property>第六个 salves(代表着 DataNode个数, 在sbin/slaves 之中 ssh 遍历连接)server1server2server33.2将hadoop添加到环境变量vim /etc/proflieexport JAVA_HOME=/usr/java/jdk1.7.0_65export HADOOP_HOME=/master/hadoop-2.4.1export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile3.3 将 app ⽂件夹配置到其他的节点之上(节点信息与master配置信息是⼀样的)scp -r app/ hdp-node-01:/home/slave3.4 格式化namenode(是对namenode进⾏初始化)hdfs namenode -format (hadoop namenode -format)3.5启动hadoop先启动HDFSsbin/start-dfs.shsbin/start-yarn.sh3.6验证是否启动成功使⽤jps命令验证27408 NameNode28218 Jps27643 SecondaryNameNode28066 NodeManager27803 ResourceManager27512 DataNodehttp://192.168.1.101:50070 (HDFS管理界⾯)http://192.168.1.101:8088 (MR管理界⾯)4.配置ssh免登陆#⽣成ssh免登陆密钥#进⼊到我的home⽬录cd ~ssh-keygen -t rsa #四个回车#执⾏完这个命令后,会⽣成两个⽂件id_rsa(私钥)、id_rsa.pub(公钥)# master ,authorized_keys ⽂件(新⽣成)ssh-copy-id -i ~/.ssh/id_rsa.pub localhost#slave, authorized_keys ⽂件(新⽣成),此处是在 /etc/hosts 写⼊的(集群是相同的⽤户名) ssh-copy-id -i ~/.ssh/id_rsa.pub server15,注:更改⽂件夹权限更改⽂件夹权限# 切换超级权限su# 当前⽂件夹所有的⽤户与组chown -R hadoop:hadoop *。
(完整版)hadoop安装教程
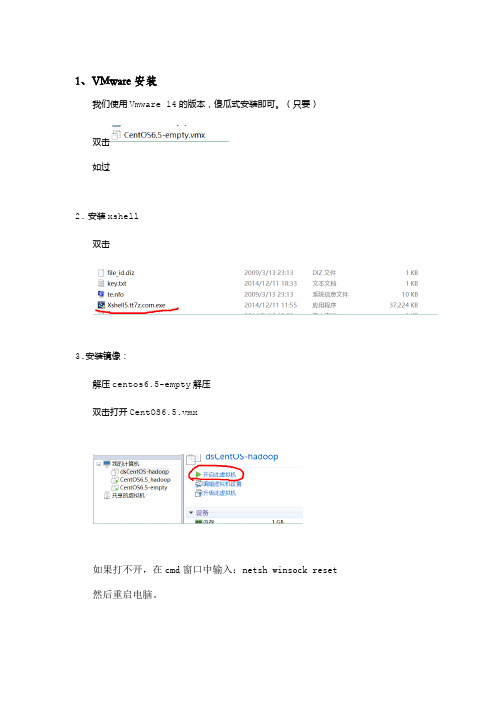
1、VMware 安装我们使用Vmware 14的版本,傻瓜式安装即可。
(只要)双击如过2.安装xshell双击3.安装镜像:解压centos6.5-empty 解压双击打开CentOS6.5.vmx如果打不开,在cmd 窗口中输入:netsh winsock reset 然后重启电脑。
进入登录界面,点击other 用户名:root密码:root然后右键open in terminal 输入ifconfig回车查看ip地址xshell打开点击链接如果有提示,则接受输入用户名:root输入密码:root4.xshell 连接虚拟机打开虚拟机,通过ifconfig 查看ip5.安装jkd1. 解压Linux版本的JDK压缩包mkdir:创建目录的命令rm -rf 目录/文件删除目录命令cd 目录进入指定目录rz可以上传本地文件到当前的linux目录中(也可以直接将安装包拖到xshell窗口)ls可以查看当前目录中的所有文件tar解压压缩包(Tab键可以自动补齐文件名)pwd可以查看当前路径文档编辑命令:vim文件编辑命令i:进入编辑状态Esc(左上角):退出编辑状态:wq保存并退出:q!不保存退出mkdir /home/software#按习惯用户自己安装的软件存放到/home/software目录下cd /home/software #进入刚刚创建的目录rz 上传jdk tar包#利用xshell的rz命令上传文件(如果rz 命令不能用,先执行yum install lrzsz -y ,需要联网)tar -xvf jdk-7u51-linux-x64.tar.gz#解压压缩包2. 配置环境变量1)vim /etc/profile2)在尾行添加#set java environmentJAVA_HOME=/home/software/jdk1.8.0_65JAVA_BIN=/home/software/jdk1.8.0_65/binPATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JAVA_HOME JAVA_BIN PATH CLASSPATHEsc退出编辑状态:wq#保存退出注意JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安装的jdk,安装完之后jdk的根目录为:/usr/java/jdk1.8.0_111,也可以通过命令:rpm -qal|grep jdk 来查看目录3)source /etc/profile使更改的配置立即生效4)java -version查看JDK版本信息。
在Windows上安装Hadoop教程

上图中的端口号 9999,可以改成其它未被占用的端口。到这里,hadoop 宣告安装完毕, 可以开始体验 hadoop 了!
9. 启动 hadoop
在 Cygwin 中, 进入 hadoop 的 bin 目录, 运行 ./start-all.sh 启动 hadoop, 在启动成功之后 , 可以执行./hadoop fs -ls /命令,查看 hadoop 的根目录,如下图所示:
在 Windows 上安装 Hadoop 教程
一见 hadoopor@
1. 安装 JDK
不建议只安装 JRE,而是建议直接安装 JDK,因为安装 JDK 时,可以同时安装 JRE。 MapReduce 程序的编写和 Hadoop 的编译都依赖于 JDK,光 JRE 是不够的。 JRE 下载地址:/zh_CN/download/manual.jsp JDK 下载地址:/javase/downloads/index.jsp,下载 Java SE 即可。
4. 安装 sshd 服务
点击桌面上的 Cygwin 图标,启动 Cygwin,执行 ssh-host-config 命令,如下图所示:
9
在 Windows 上安装 Hadoop 教程
在执行 ssh-host-config 时,当要求输入 yes/no 时,选择输入 no,如下图所示:
如果是 Cygwin 1.7 之前的版本,则 ssh-host-config 显示界面如下图所示:
至此,配置 ssh 登录成功,下面就可以开始安装 hadoop 了。
7. 下载 hadoop 安装包
hadoop 安装包下载地址: /apache-mirror/hadoop/core/hadoop-0.20.1/hadoop-0.20.1.tar.gz 当然,也可以进入 /apache-mirror/hadoop/core 下载其它的版本,不 过建议直接上 0.20 版本。
hadoop安装配置指南

Hadoop安装、配置指南一、环境1、软件版本Hadoop:hadoop-0.20.2.Hive:hive-0.5.0JDK:jdk1.6以上版本2、配置的机器:主机[服务器master]:192.168.10.121 hadoop13从机[服务器slaves]:192.168.10.68 hadoop4在本文中,在命令或二、先决条件1、配置host:打开/etc/host文件,添加如下映射192.168.10.121 hadoop13 hadoop13192.168.10.68 hadoop4 hadoop42、配置SSH自动登陆1)以ROOT用户,登陆到[服务器master]上执行,如下操作:ssh-keygen -t rsa //一路回车cd ~/.sshcat id_rsa.pub >> authorized_keysscp -r ~/.ssh [服务器slaves]:~/2)以ROOT用户,登陆到[服务器slaves]上执行,如下操作:scp -r ~/.ssh [服务器master]:~/3)测试SSH是否配置成功在主服务器中执行如下命令:ssh [服务器master]ssh 192.168.10.68成功显示结果:Last login: Thu Aug 26 14:11:27 2010 from 在从服务器中执行如下命令:ssh [服务器slaves]ssh 192.168.10.121成功显示结果Last login: Thu Aug 26 18:23:58 2010 from 三、安装hadoop1、JDK安装,解压到/usr/local/jdk1.6.0_17,并配置/etc/profile环境export JAVA_HOME=/usr/local/jdk/jdk1.7.0export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarJDK路径:/usr/local/jdk/jdk1.7.0export JAVA_HOME=/usr/local/jdk/jdk1.7.0export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar/usr/local/jdk/jdk1.7.02、下载Hadoop 并解压到[服务器master]的/root/zwmhadoop目录下tar zxvf hadoop-0.20.2.tar.gz四、配置hadoop1.配置主机[服务器master]到zwm hadoop/hadoop-0.20.2/ hadoop 目录下,修改以下文件:1)配置conf/hadoop-env.sh文件,在文件中添加环境变量,增加以下内容:export JAVA_HOME=/usr/local/jdk1.6.0_17export HADOOP_HOME=/root/zwmhadoop/hadoop-0.20.2/2)配置conf/core-site.xml文件,增加以下内容<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>hdfs://192.168.10.121:9000</value>//你的namenode的配置,机器名加端口<description>The nam e of the default file system. Either the literal string "local" o r a host:port for DFS.</description></property></configuration>3)配置conf/hdfs-site.xml文件,增加以下内容<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.t m p.dir</name><value>/root/zwmhadoop/t m p</value>//Hadoop的默认临时路径,这个最好配置,然后在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的t mp目录即可。
HADOOP安装

Hadoop是Apache下的一个项目,由HDFS、MapReduce、Hbase、Hive和ZooKeeper等成员组成,其中HDFS和MapReduce是两个最重要的成员。
HDFS是Google GFS的开源版本,一个高度容错的分布式文件系统,它能够提供高吞吐量的数据访问,适合存储海量的大文件,其原理如下图所示:采用Master/Slave结构。
NameNode维护集群内的元数据,对外提供创建、打开、删除和重命名文件或目录的功能。
DataNode存储数据,并提负责处理数据的读写请求。
DataNode 定期向NameNode上报心跳,NameNode通过响应心跳来控制DataNode。
InfoWord将MapReduce评为2009年十大新兴技术的冠军。
MapReduce是大规模数据计算的利器,Map和Reduce是它的主要思想,来源于函数式编程语言,它的原理如下图所示:Map负责将数据打散,Reduce负责对数据进行集聚,用户只需要实现Map和Reduce 两个接口,即可完成TB级数据的计算,常见的应用包括:日志分析和数据挖掘等数据分析应用。
另外,还可用于科学数据计算,入圆周率PI的计算等。
Hadoop MapReduce的实现也采用了Master/Slave结构。
Master叫做JobTracker,而Slave 叫做TaskTracker。
用户提交的计算叫做Job,每一个Job会被划分成若干个Tasks。
JobTracker负责Job和Tasks的调度,而TaskTracker负责执行Tasks。
在Linux下搭建Hadoop集群,要先熟悉Linux的基本概念和操作,如cd、ls、tar、cat、ssh、sudo、scp等操作。
养成搜索意识很重要,遇到问题借用Google、百度等,或者论坛,推荐Hadoop技术论坛。
Ubuntu和redhat等版本的Linux在操作命令上有不同点,但安装Hadoop的流程一样。
(完整版)Hadoop安装教程_伪分布式配置_CentOS6.4_Hadoop2.6.0

Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0都能顺利在CentOS 中安装并运行Hadoop。
环境本教程使用CentOS 6.4 32位作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS)。
如果用的是Ubuntu 系统,请查看相应的Ubuntu安装Hadoop教程。
本教程基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1, Hadoop 2.4.1等。
Hadoop版本Hadoop 有两个主要版本,Hadoop 1.x.y 和Hadoop 2.x.y 系列,比较老的教材上用的可能是0.20 这样的版本。
Hadoop 2.x 版本在不断更新,本教程均可适用。
如果需安装0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。
新版是兼容旧版的,书上旧版本的代码应该能够正常运行(我自己没验证,欢迎验证反馈)。
装好了CentOS 系统之后,在安装Hadoop 前还需要做一些必备工作。
创建hadoop用户如果你安装CentOS 的时候不是用的“hadoop” 用户,那么需要增加一个名为hadoop 的用户。
首先点击左上角的“应用程序” -> “系统工具” -> “终端”,首先在终端中输入su,按回车,输入root 密码以root 用户登录,接着执行命令创建新用户hadoop:如下图所示,这条命令创建了可以登陆的hadoop 用户,并使用/bin/bash 作为shell。
CentOS创建hadoop用户接着使用如下命令修改密码,按提示输入两次密码,可简单的设为“hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):可为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:如下图,找到root ALL=(ALL) ALL这行(应该在第98行,可以先按一下键盘上的ESC键,然后输入:98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:为hadoop增加sudo权限添加上一行内容后,先按一下键盘上的ESC键,然后输入:wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
Hadoop安装配置超详细步骤

Hadoop安装配置超详细步骤Hadoop的安装1、实现linux的ssh无密码验证配置.2、修改linux的机器名,并配置/etc/hosts3、在linux下安装jdk,并配好环境变量4、在windows下载hadoop 1.0.1,并修改hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,masters,slaves文件的配置5、创建一个给hadoop备份的文件。
6、把hadoop的bin加入到环境变量7、修改部分运行文件的权限8、格式化hadoop,启动hadoop注意:这个顺序并不是一个写死的顺序,就得按照这个来。
如果你知道原理,可以打乱顺序来操作,比如1、2、3,先哪个后哪个,都没问题,但是有些步骤还是得依靠一些操作完成了才能进行,新手建议按照顺序来。
一、实现linux的ssh无密码验证配置(1)配置理由和原理Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,(datanode向namenode传递心跳信息可能也是使用SSH协议,这是我认为的,还没有做深入了解)。
大概意思是,namenode 和datanode之间发命令是靠ssh来发的,发命令肯定是在运行的时候发,发的时候肯定不希望发一次就弹出个框说:有一台机器连接我,让他连吗。
所以就要求后台namenode和datanode 无障碍的进行通信。
以namenode到datanode为例子:namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。
当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。
hadoop安装指南(非常详细,包成功)

➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
Hadoop完全分布式详细安装过程
Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
Hadoop及hive 集群配置安装文档

Hadoop 及hive 集群配置安装文档安装说明:1)首先我们统一一下定义,在这里所提到的Hadoop是指Hadoop Common,主要提供DFS(分布式文件存储)与Map/Reduce的核心功能。
2)Hadoop在windows下还未经过很好的测试,所以目前只能在linux,unix环境下安装。
3)为了避免出现权限方面的问题,请使用root用户登录安装。
4)要使用hive必须先安装Hadoop环境,所以我们的安装步骤以Hadoop为先。
5)首先登录进入master机,然后再进入slave机,两者的对hadoop安装配置顺序是一致的。
对于hive的安装与相关配置只在master机器上。
6)本文档中使用了jdk1.6,rsync3.0,hadoop-0.20.2,hive-0.6.0的tar包,要想安装Hadoop 请从相关网站下载。
机器情况:机器型号:HP Praliant DL380服务器* 2机器IP:10.17.36.34 (master机)10.17.36.33(slave机)操作系统:Red Hat Enterprise 5.5(linux)HADOOP环境:hapoop-0.20.2HIVE环境:hive-0.6.0-bin准备工作:准备安装Hadoop集群之前我们得先检验系统是否安装了如下的必备软件:ssh、rsync 和Jdk1.6(因为Hadoop需要使用到Jdk中的编译工具,所以一般不直接使用Jre)。
SSH:一般在安装系统后已经存在,可以用rpm –qa openssh-server检查是否已经安装。
如未安装可以在系统光盘寻找openssh-server-4.3p2-16.el5.i386.rpm安装。
rsync:rsync-3.0.8pre1.tarJDK:这里的JDK版本至少是1.5,本次实验的版本是1.6开始安装:第一步:安装JDK1.6LINUX下安装JDK1.6.doc第二步:安装HADOOP环境安装文件:hadoop-0.20.2.tar.gz下面是在linux平台下安装Hadoop的过程:这里注意最后一步,最好把HADOOP_HOME写入/etc/profile中然后注销,重新用root用户登录:vi /etc/profile在profile末尾写入以下两行export HADOOP_HOME=/opt/hadoop/hadoop-0.20.2export HADOOP_HOME第三步:配置SSH如果事先不存在authorized_keys,先要执行命令:touch ~/.ssh/authorized_keys经过以上步骤,我们的无密码访问就配置好了,可以通过如下命令进行验证:第四步:配置Hadoop相关文件对$HADOOP_HOME/src文件下的core-site.xml,hdfs-site.xml, mapred-site.xml进行如下的配置:(红色字体为添加部分)Core-site.xml代码:<configuration><property><!-- 用于dfs命令模块中指定默认的文件系统协议--><name></name><value>hdfs://10.17.36.34:9000</va lue></property></configuration>Hdfs-site.xml代码:<configuration><property><!-- DFS中存储文件命名空间信息的目录--><name>.dir</name><value>/opt/hadoop/data/.dir</value> </property><property><!-- DFS中存储文件数据的目录--><name>dfs.data.dir</name><value>/opt/hadoop/data/dfs.data.dir</value> </property><property><!-- 是否对DFS中的文件进行权限控制(测试中一般用false)--><name>dfs.permissions</name><value>false</value></property></configuration>Mapred-site.xml代码:<configuration><property><!-- 用来作JobTracker的节点的(一般与NameNode 保持一致) --><name>mapred.job.tracker</name><value>10.18.36.33:9001</value></property><property><!-- map/reduce的系统目录(使用的HDFS的路径)--><name>mapred.system.dir</name><value>/system/mapred.system.dir</value></property><property><!-- map/reduce的临时目录(可使用“,”隔开,设置多重路径来分摊磁盘IO)--><name>mapred.local.dir</name><value>/opt/hadoop/data/mapred.local.dir< /value></property></configuration>主从配置:在$HADOOP_HOME/conf目录中存在masters和slaves这两个文件,用来做Hadoop的主从配置。
Hadoop分布式详细安装步骤

Hadoop分布式详细安装步骤版本:0.20.2准备工作:由于Hadoop要求所有主机上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
二台机器上是这样的:都有一个coole的帐户,主目录是/home/coole两台机器(内存应在512以上,否则可能会出现计算极度缓慢的情况):一台机器名:master IP:211.87.239.181一台机器名:slave IP:211.87.239.182每台都建coole用户如果是ubuntu,为了便于用coole帐号修改系统设置和访问系统文件,推荐把coole也设为sudoers(有root 权限的用户),具体做法是用已有的sudoer登录系统,执行sudo visudo –f /etc/sudoers,并在此文件中添加以下一行:mapred ALL=(ALL) ALL一、更改主机名:1、修改/etc/sysconfig/networkNETWORKING=yesHOSTNAME=yourname (在这修改hostname,把yourname换成你想用的名字)NISDOMAIN=修改后机器211.87.239.181中/etc/sysconfig/network文件内容为:NETWORKING=yesHOSTNAME=master修改后机器211.87.239.182中/etc/sysconfig/network文件内容为:NETWORKING=yesHOSTNAME=slave2、最后在终端下执行:# hostname ***** (*****为修改后的hostname,即你想用的名字)例如#hostname master特别提示:各处修改的名字要保持一致,否则会出现问题。
3、修改每台机器的/etc/hosts,保证每台机器间都可以通过机器名解析配置etc/hosts文件,以root 身份打开/etc/hosts文件。
Master/slave做同样修改。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、VMware安装我们使用Vmware 14的版本,傻瓜式安装即可。
(只要)双击如过2.安装xshell双击3.安装镜像:解压centos6.5-empty解压双击打开CentOS6.5.vmx如果打不开,在cmd窗口中输入:netsh winsock reset 然后重启电脑。
进入登录界面,点击other用户名:root密码:root然后右键open in terminal输入ifconfig 回车查看ip地址打开xshell点击链接如果有提示,则接受输入用户名:root输入密码:root4.xshell连接虚拟机打开虚拟机,通过ifconfig查看ip5.安装jkd1.解压Linux版本的JDK压缩包mkdir:创建目录的命令rm -rf 目录/文件删除目录命令cd 目录进入指定目录rz 可以上传本地文件到当前的linux目录中(也可以直接将安装包拖到xshell窗口)ls 可以查看当前目录中的所有文件tar 解压压缩包(Tab键可以自动补齐文件名)pwd 可以查看当前路径文档编辑命令:vim 文件编辑命令i:进入编辑状态Esc(左上角):退出编辑状态:wq 保存并退出:q! 不保存退出mkdir /home/software #按习惯用户自己安装的软件存放到/home/software目录下cd /home/software #进入刚刚创建的目录rz 上传jdk tar包 #利用xshell的rz命令上传文件(如果rz命令不能用,先执行yum install lrzsz -y ,需要联网)tar -xvf jdk-7u51-linux-x64.tar.gz #解压压缩包2.配置环境变量1)vim /etc/profile2)在尾行添加#set java environmentJAVA_HOME=/home/software/jdk1.8.0_65JAVA_BIN=/home/software/jdk1.8.0_65/binPATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JAVA_HOME JAVA_BIN PATH CLASSPATHEsc 退出编辑状态:wq #保存退出注意JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安装的jdk,安装完之后jdk的根目录为:/usr/java/jdk1.8.0_111,也可以通过命令:rpm -qal|grep jdk 来查看目录3)source /etc/profile使更改的配置立即生效4)java -version查看JDK版本信息。
如显示版本号则证明成功。
6.安装hadoop1. 安装配置jdk、关闭防火墙service iptables stop执行该命令可以关闭防火墙,但是如果虚拟机重启的话,防火墙会重新开启。
chkconfig iptables off执行该命令可以永久关闭防火墙。
两个命令配合使用2. 修改主机名vim /etc/sysconfig/network以后的Hadoop会有多台主机,因此需要根据主机名来区分这些系统。
注意:主机名里不能有下滑线,或者特殊字符#$,不然会找不到主机,从而导致无法启动。
这种方式更改主机名需要重启才能永久生效,因为主机名属于内核参数。
如果不想重启,可以执行:hostname hadoop01。
但是这种更改是临时的,重启后会恢复原主机名。
所以可以结合使用。
先修改配置文件,然后执行:hostname hadoop01 。
可以达到不重启或重启都是主机名都是同一个的目的3. 配置hosts文件vim /etc/hosts修改hosts文件,以后用到IP连接的地方就可以直接使用hadoop01代替IP地址了。
4. 配置免密码登录ssh-keygen这里只需要回车,无需输入。
ssh-copy-id root@hadoop01想从这台机器免密登录哪个机器,就把公钥文件发送到哪个机器上。
5. 安装配置jdk(省略)6. 上传和解压hadoop安装包过程省略,解压路径为:要记着这个路径,后面的配置要用到。
bin目录:命令脚本etc/hadoop:存放hadoop的配置文件lib目录:hadoop运行的依赖jar包sbin目录:启动和关闭hadoop等命令都在这里libexec目录:存放的也是hadoop命令,但一般不常用最常用的就是bin和etc目录7. 在hadoop根目录下创建tmp目录mkdir tmp 存放Hadoop运行时产生的文件目录8. 配置hadoop-env.sh文件cd etc/hadoopvim hadoop-env.sh修改JAVA_HOME路径和HADOOP_CONF_DIR 路径,注意路径一定要写对,里面原始的获取系统路径的方式不起作用。
(修改两个地方)export JAVA_HOME=/home/software/jdk1.8.0_65:wq 退出source hadoop-env.sh 让配置立即生效9. 修改core-site.xmlvim core-site.xml 在<configuration></configuration>标签中添加如下代码<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/software/hadoop-2.7.1/tmp</value> </property></configuration><!--第一个property参数用来指定hdfs的老大,namenode的地址--><!--第二个property参数用来指定hadoop运行时产生文件的存放目录-->10. 修改 hdfs-site .xmlvim hdfs-site.xml 在<configuration></configuration>标签中添加如下代码<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property></configuration><!--第一个property参数指定hdfs保存数据副本的数量,包括自己,默认值是3。
如果是伪分布模式,此值是1 --><!--第二个property参数设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件 -->11. 修改 mapred-site.xmlcp mapred-site.xml.template mapred-site.xml拷贝模板文件并重命名vim mapred-site.xml 在<configuration></configuration>标签中添加如下代码<configuration><property><name></name><value>yarn</value></property></configuration><!--property参数指定mapreduce运行在yarn上 -->yarn是Hadoop的资源协调工具。
12. 修改yarn-site.xmlvim yarn-site.xml 在<configuration></configuration>标签中添加如下代码<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration><!--第一个property参数用来指定yarn的老大resoucemanager的地址 --><!--第二个property参数用来指定NodeManager获取数据的方式 -->13. 配置slaves文件vim slaveshadoop0114. 配置hadoop的环境变量vim /etc/profile 修改配置文件,使hadoop命令可以在任何目录下执行,下面是修改后的代码JAVA_HOME=/home/software/jdk1.8.0_111HADOOP_HOME=/home/software/hadoop-2.7.1JAVA_BIN=/home/software/jdk1.8.0_111/binPATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/s bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/to ols.jarexport JAVA_HOME JAVA_BIN PATH CLASSPATH HADOOP_HOME 加粗的地方都是需要修改的地方,注意PATH多个参数值之间用冒号隔开,所有的参数都在$PATH之前source /etc/profile使配置文件生效15. 格式化namenodehadoop namenode -format中间如果提示是否需要重新格式化,则根据自己的需求输入即可。