Tutorial_2
Stata_Tutorial2

STATA Tutorial 2Professor ErdinçPlease follow the directions once you locate the Stata software in yourcomputer. Room 114 (Business Lab) has computers with Stata software1.Wald TestWald Test is used to test the joint significance of a subset of coefficients, namely. Take for example the two variables from the example above, baths and bedrms. These two variables are individually insignificant based on t-tests with very high p values. But before dropping them together, we may want to test the joint significance of them using Wald test.Run in Stata:test bedrms bathsThe command test bedrms baths tests whether baths and bedrms are insignificant jointly. Since the null says they are, and F-stat’s p-value=0.6375, then we cannot reject the null. DROP both baths and bedrms from the regression equation. They don’t belong to the model.MODEL Areg price sqft bedrms bathsSource SS df MS Number ofobs 14F (3, 10) 16.99Model 85114.94 3. 28371.6473 Prob > F 0.0003Residual 16700.07 10.1670.00687 R-squared 0.836Adj R-squared 0.7868Total 101815 13 7831.9239 Root MSE 40.866 price Coef. Std. Err. t P>t [95% Conf. Interval]sqft 0.1548 .03194044.85 0.001 0.083632 0.225968bedrms -27.02933 -0.443 -81.8126 38.6375821.5875 0.80 baths-12.1928 43.25 -0.280.784 -108.56 84.17425_cons 129.0616 88.30326 1.460.175 -67.6903 325.8136( 1) bedrms = 0 ( 2) baths = 0F( 2, 10) = 0.47 Prob > F = 0.6375Special Wald TestThis is an F-test for the significance of all variables in the model, i.e. sqft, bedrms and baths . Hence, the null states betas of all variables in the model are set equal to zero.Null 0H : 0sqft bedrms baths βββ===Alternative A H : At least some are non zero.Run in Stata this command:test bedrms baths sqft( 1) bedrms = 0 ( 2) baths = 0 ( 3) sqft = 0F( 3, 10) = 16.99 Prob > F = 0.0003Notice that F-test p-value is 0.0003, which is lower than 1% of α. Hence, we can reject the null and at least some variables in this trio is significant. This variable is SQFT! (based on the t-test).RESTRICTED MODELMODEL B reg price sqftSourceSSdf MSNumber of obs14F( 1, 12) 54.86 Model 83541.4429 1 83541.4429 Prob > F 0 Residual 18273.5678 12 1522.79731 R-squared 0.8205Adj R-squared 0.8056 Total 101815.011 13 7831.9239 Root MSE 39.023 price Coef. Std. Err. t P>t [95% Conf. Interval]sqft 0.1387503 .01873297.41 0 0.0979349 0.179566cons 52.3509 37.285491.40 0.186 -28.88719 133.5892. OLS RegressionRegress yvar xvarlist Regress the dependent variable yvar on the independent variables xvarlist.Regress yvar xvarlist, vce(robust) Regress, but this time compute robust (Eicker-Huber-White)standard errors. We are always using the vce(robust) optionbecause we want consistent (i. e,, asymptotically unbiased) results, but we do not want to have to assume homoskedasticity and normality of the random error terms. So, remember always to specify the vce(robust) option after estimation commands. The“vce” stands for variance-covariance estimates (of the estimated model parameters).Regress yvar xvarlist, vce(robust) level(#) Regress with robust standard errors, and this time change the confidence interval to #% (e.g. use 99 for a 99% confidence interval).Improved Robust Standard Errors in Finite SamplesFor robust standard errors, an apparent improvement is possible. Davidson and MacKinnon*report two variance-covariance estimation methods that seem, at least in their Monte Carlo simulations, to converge more quickly, as sample size n increases, to the correct variance covariance estimates. Thus their methods seem to be better, although they require more computational time. Stata by default makes Davidson and MacKinnon’s recommended simple degrees of freedom correction by multiplying the estimated variance matrix by n/(n-K). However, we should learn about an alternative in which the squared residuals are rescaled. To use this formula, specify “vce(hc2)” instead of “vce(robust)”. An alternative is “vce(hc3)” instead of “vce(robust)”.Weighted Least SquaresWe learn about (variance-) weighted least squares. If you know (to within a constant multiple) the variances of the error terms for all observations, this yields more efficient estimates (OLS with robust standard errors works properly using asymptotic methods but is not the most efficient estimator). Suppose you have, stored in a variable sdvar, a reasonable estimate of the standard deviation of the error term for each observation. Then weighted least squares can be performed as follows:Run in Stata:vwls yvar xvarlist, sd(sdvar)3. Post-Estimation CommandsCommands described here work after OLS regression. They sometimes work after other estimation commands, depending on the command.Fitted Values, Residuals, and Related Plotspredict yhatvar After a regression, create a new variable, having the name you enter here, that contains for each observation its fitted value ˆyi .predict rvar, residuals After a regression, create a new variable, having the name you enter here, that contains for each observation its residual ˆ ui .scatter y yhat x Plot variables named y and yhat versus x.scatter resids x It is wise to plot your residuals versus each of your x-variables. Such “residual plots” may reveal a systematic relationship that your analysis has ignored. It is also wise to plot your residuals versus the fitted values of y, again to check for a possible nonlinearity that your analysis has ignored.rvfplot Plot the residuals versus the fitted values of y.rvpplot Plot the residuals versus a “predictor” (x-variable).Confidence Intervals and Hypothesis TestsFor a single coefficient in your statistical model, the confidence interval is already reported in the table of regression results, along with a 2-sided t-test for whether the true coefficient is zero. However, you may need to carry out F-tests, as well as compute confidence intervals and t-tests for “linear combinations” of coefficients in the model.Here are example commands. Note that when a variable name is used in this subsection, it really refers to the coefficient (the βk) in front of that variable in the model equation. Run in Stata:lincom logpl+logpk+logpf Compute the estimated sum of three model coefficients, which are the coefficients in front of the variables named logpl, logpk, and logpf. Along with this estimated sum, carry out a t-test with the null hypothesis being that the linear combination equals zero, and compute a confidence interval.lincom 2*logpl+1*logpk-1*logpf Like the above, but now the formula is a different linear combination of regression coefficients.lincom 2*logpl+1*logpk-1*logpf, level(#) As above, but this time change the confidence interval to #% (e.g. use 99 for a 99% confidence interval).test logpl+logpk+logpf==1 Test the null hypothesis that the sum of the coefficients of variables logpl, logpk, and logpf, totals to 1. This only makes sense after a regression involving variables with these names. This is an F-test.test (logq2==logq1) (logq3==logq1) (logq4==logq1) (logq5==logq1) Test the null hypothesis that four equations are all true simultaneously: the coefficient oflogq2 equals the coefficient of logq1, the coefficient of logq3 equals the coefficient of logq1, the coefficient of logq4 equals the coefficient of logq1, and the coefficient oflogq5 equals the coefficient of logq1; i.e., they are all equal to each other. This is an F-test.test x3 x4 x5 Test the null hypothesis that the coefficient of x3 equals 0 and the coefficient of x4 equals 0 and the coefficient of x5 equals 0. This is an F-test. Nonlinear Hypothesis TestsAfter estimating a model, you could do something like the following:testnl _b[popdensity]*_b[landarea] = 3000 Test a nonlinear hypothesis. Note that coefficients must be specified using _b, whereas the linear “test” command lets you omit the _b[].testnl (_b[mpg] = 1/_b[weight]) (_b[trunk] = 1/_b[length]) For multi-equation tests you can put parentheses around each equation (or use multiple equality signs in the same equation)Computing Estimated Expected Values for the Dependent Variabledi _b[xvarname] Display the value of an estimated coefficient after a regression. Use the variable name “_cons” for the estimated constant term. Of course there’s no need just to display these numbers, but the good thing is that you can use them in formula. See the next example.di _b[_cons] + _b[age]*25 + _b[female]*1 After a regression of y on age and female (but no other independent variables), compute the estimated value of y for a 25-year-old female. See also the predict command mentioned above. Also Stata’s “adjust” command provides a powerful tool to display predicted values when the x-variables taken on various values (but for your own understanding, do the calculation by hand a few times before you try using adjust).Displaying Adjusted 2R and Other Estimation Resultsdisplay e(r2_a) After a regression, the adjusted R-squared, 2R , can be looked up as “e(r2_a)”. (Stata does not report the adjusted 2R when you do regression with robust standard errors, because robust standard errors are used when the variance (conditional on your right-hand-side variables) is thought to differ between observations, and this would alter the standard interpretation of the adjusted2R statistic. Nonetheless, people often report the adjusted 2R in this situation anyway. It may still be a useful indicator, and often the (conditional) variance is still reasonably close to constant across observations, so that it can be thought of as an approximation to the adjusted 2R statistic that would occur if the (conditional) variance were constant.)ereturn list Display all results saved from the most recent model you estimated, including the adjusted 2R and other items. Items that are matrices are not displayed; you can see them with the command “matrix list r(matrixname)”.Plotting Any Mathematical Functiontwoway function y=exp(-x/6)*sin(x), range(0 12.57) Plot a function graphically, for any function (of a single variable x) that you specify. A command like this maybe useful when you want to examine how a polynomial in one regressor (which here must be called x) affects the dependent variable in a regression, without specifying values for other variables.Influence StatisticsInfluence statistics give you a sense of how much your estimates are sensitive to particular observations in the data. This may be particularly important if there might be errors in the data. After running a regression, you can compute how much different theestimated coefficient of any given variable would be if any particular observation were dropped from the data. To do so for one variable, for all observations, use this command: predict newvarname, dfbeta(varname) Computes the influence statistic (“DFBETA”) for varname: how much the estimated coefficient of varname would change if each observation were excluded from the data. The change divided by the standard error of varname, for each observation i, is stored in the ith observation of the newly created variable newvarname. Then you might use “summarize newvarname, detail” to find out the largest values by which the estimates would change (relative to the standard error of the estimate). If these are large (say close to 1 or more), then you might be alarmed that one or more observations may completely change your results, so you had better make sure those results are valid or else use a more robust estimation technique (such as “robust regression,” which is not related to robust standard errors, or “quantile regression,” both available in Stata). If you want to compute influence statistics for many or all regressors, Stata’s “dfbeta” command lets you do so in one step. Functional Form TestIt is sometimes important to ensure that you have the right functional form for variables in your regression equation. Sometimes you don’t want to be perfect, you just want to summarize roughly how some independent variables affect the dependent variable. But sometimes, e.g., if you want to control fully for the effects of an independent variable, it can be important to get the functional form right (e.g., by adding polynomials and interactions to the model). To check whether the functional form is reasonable and consider alternative forms, it helps to plot the residuals versus the fitted values and versus the predictors. Another approach is to formally test the null hypothesis that the patterns in the residuals cannot be explained by powers of the fitted values. One such formal test is the Ramsey RESET test:estat ovtest Ramsey’s (1969) regression equation specification error test. Heteroskedasticity TestsAfter running a regression, you can carry out White’s test for heteroskedasticity using the command:estat imtest, whiteNote, however, that there are many other heteroskedasticity tests that may be more appropriate. Stata’s imtest command also carries out other tests, and the commands hettest and szroeter carry out different tests for heteroskedasticity.The Breusch-Pagan Lagrange multiplier test, which assumes normally distributed errors, can be carried out after running a regression, by using the command:estat hettest, normalOther tests that do not require normally distributed errors include:estat hettest, iid (Heteroskedasticity test – Koenker’s (1981)’s score test, assumes iid errors.)estat hettest, fstat (Heteroskedasticity test – Wooldridge’s (2006) F-test, assumes iid errors.)estat szroeter, rhs mtest(bonf) (Heteroskedasticity test – Szroeter (1978) rank test for null hypothesis that variance of error term is unrelated to each variable.)estat imtest ( Heteroskedasticity test – Cameron and Trivedi (1990), also includes tests for higher-order moments of residuals (skewness and kurtosis).Serial Correlation TestsTo carry out these tests in Stata, you must first “tsset” your data. For a Breusch-Godfrey test where, say, p = 3, do your regression and then use Stata’s “estat bgodfrey” command: estat bgodfrey, lags(1 2 3) Heteroskedasticity tests including White test.Other tests for serial correlation are available. For example, the Durbin-Watson d-statistic is available using Stata’s “estat dwatson” command. However the Durbin-Watson statistic assumes there is no endogeneity even under the alternative hypothesis, an assumption which is typically violated if there is serial correlation, so you really should use the Breusch-Godfrey test instead (or use Durbin’s alternative test, “estat durbinalt”).4.LM (Lagrange multiplier) Test on Non-linearities and Model Specification/ Likelihood Ratio TestRun in Stata:Step 1 : reg y x1 x2x3(Run in Stata the dependable variable with the independablevariables)Step 2: estimates store a1Step 3: Gen X2sq= X2∧2 ( To generate the square of the variable X2)Step 4: reg Y x1 x2x3x2sq ( Now run the regression including the new variableX2)Step 5: estimates store a 2Step 6: lrtest a 1 a 2Step 7: Reject H 0 if : a.Fstat > F* b.P-value< α。
Tutorial2Algebra...

Algebraic formulations sound hard. But they are not so hard. However, they do take a while to get used to.
In this tutorial, we will explain algebraic formulations with some examples. Algebraic
min
500 x1 + 200 x2 + 250 x3 + 125 x4
s.t. 50,000 x1 + 25,000 x2 + 20,000 x3 + 15,000 x4 ≥ 1,500,000 0 ≤ x1 ≤ 20; 00 ≤≤ xxj2≤≤ d1j 5fo; r j0= ≤1 txo34≤. 10; 0 ≤ x4 ≤ 15
0 ≤ xj ≤ dj for j = 1 to 4.
11
Replacing the number of variables.
Minimize subject to
Next Finally, we use n to
represent the number of variables.
Is dj decision variable?
It looks like dj is a variable, but it isn’t. It’s called a “parameter” and it means that there is an associated value stored for it somewhere, perhaps in a spreadsheet, perhaps
3
致用英语听力教程2

致用英语听力教程2English Listening Tutorial 2Hello, and welcome to English Listening Tutorial 2. In this tutorial, we will focus on developing your listening skills further to help you become more confident in understanding spoken English.1. Listening to Conversations: Conversations are an essential part of everyday life, and understanding them is crucial for effective communication. Practice listening to various conversations on different topics. Start with simple ones and gradually move on to more complex dialogs. Pay attention to the speaker's tone, rhythm, and intonation to grasp the intended meaning.2. Listening to Audio Recordings: Listening to audio recordings helps improve your listening comprehension as they simulate real-life situations. Engage in activities such as listening to podcasts, audiobooks, news broadcasts, or documentaries. Try to focus on the main ideas and important details while taking notes if necessary.3. Listening to Music: Listening to English songs can be an enjoyable way to enhance your listening skills. Choose songs with clear vocals and try to understand the lyrics. Sing along if you feel comfortable, as it helps improve your pronunciation and intonation as well.4. Dictation Exercises: Dictation exercises are an excellent way to enhance your listening and writing skills simultaneously. Find audio recordings or videos with transcripts and listen carefully.Write down what you hear and then compare it with the actual transcript to identify your mistakes. This exercise will also help you improve your spelling and vocabulary.5. Watching Movies/TV Shows: Watching movies or TV shows in English with subtitles can significantly improve your listening abilities. Start with English subtitles and gradually switch to the subtitles in your native language. Focus on understanding the dialogues and try to follow the plot without relying too much on the subtitles.6. Engaging in Conversations: Initiate conversations with native English speakers or practice with language exchange partners. Engaging in real-life conversations will expose you to different accents, vocabulary, and speech patterns. This practice will help train your ears to understand various English speakers and improve your overall comprehension.7. Taking Listening Tests: Practice taking listening comprehension tests to assess your progress. Online platforms and language learning websites offer various listening exercises designed to test your ability to understand spoken English. Regularly taking these tests will help you recognize your strengths and weaknesses and allow you to focus on areas that need improvement. Remember, improving listening skills takes time and consistent practice. Be patient with yourself and keep challenging yourself to listen to a variety of materials in different contexts. Stay motivated and have fun while exploring new ways to improve your English listening abilities.That concludes English Listening Tutorial 2. Stay tuned for our next tutorial, where we will discuss effective strategies to enhance your speaking skills.。
新编简明英语语言学教程第2版学习指南答案

新编简明英语语言学教程第2版学习指南答案Study Guide for New Concise English Linguistics Tutorial 2nd Edition AnswersIntroductionThe New Concise English Linguistics Tutorial 2nd Edition is a comprehensive guide to the study of the English language. This study guide provides answers to the exercises and questions found in the textbook, helping students to better understand the concepts and theories discussed in each chapter.Chapter 1: Introduction to Linguistics1.1 What is Linguistics?Linguistics is the scientific study of language and its structure, including phonology, morphology, syntax, semantics, and pragmatics.1.2 What are the subfields of Linguistics?The subfields of linguistics include phonetics, phonology, morphology, syntax, semantics, and pragmatics.1.3 What is the difference between prescriptive and descriptive grammar?Prescriptive grammar is concerned with rules for what is considered "correct" language use, while descriptive grammar describes how language is actually used by speakers.Chapter 2: Phonetics and Phonology2.1 What is phonetics?Phonetics is the study of the physical properties of speech sounds, including their production, transmission, and reception.2.2 What is phonology?Phonology is the study of the sound system of a language, including the patterns and rules that govern the pronunciation of words.2.3 What is the difference between consonants and vowels?Consonants are speech sounds that are produced with some degree of obstruction in the vocal tract, while vowels are speech sounds that are produced without obstruction.Chapter 3: Morphology3.1 What is morphology?Morphology is the study of the structure of words and how words are formed from smaller units called morphemes.3.2 What are free and bound morphemes?Free morphemes can stand alone as words, while bound morphemes must be attached to other morphemes to form a complete word.3.3 What is the difference between inflectional and derivational morphemes?Inflectional morphemes modify the grammatical function of a word (e.g., tense, number), while derivational morphemes create new words or change the meaning of existing words.Chapter 4: Syntax4.1 What is syntax?Syntax is the study of the structure of sentences and how words are combined to create meaningful phrases and sentences.4.2 What is the difference between phrases and clauses?Phrases are groups of words that function as a single unit within a sentence, while clauses are larger structures that contain a subject and a predicate.4.3 What is the difference between syntax and semantics?Syntax deals with the structure of language, while semantics is concerned with the meaning of language.Chapter 5: Semantics and Pragmatics5.1 What is semantics?Semantics is the study of meaning in language, including how words and sentences convey meaning.5.2 What is pragmatics?Pragmatics is the study of how context influences the interpretation of language, including the social and cultural factors that affect communication.5.3 What are speech acts?Speech acts are actions that are performed through speech, such as making a request or giving an order.ConclusionThis study guide provides answers to the exercises and questions found in the New Concise English Linguistics Tutorial 2nd Edition, helping students to deepen their understanding of the core concepts and theories in the study of English linguistics. By using this guide, students can enhance their knowledge andskills in the field of linguistics and improve their overall comprehension of the English language.。
Tutorial2_Trade Association

Theme Park Statistics
Number of theme parks in the U.S.: 600+
Annual number of visitors to U.S. theme parks: 335 million
Percentage of Americans surveyed who visited a theme park last year: 28 percent Percentage of people whose favorite theme park ride is the roller coaster: 46 percent
Luna Park
THE TURN OF 20TH CENTURY
• 1955 Disneyland opens. • Generally considered the nation's first theme park. • Built at a cost of $17 million, Disneyland represented the largest investment for building an amusement park • The park was an instant success, drawing 3.8 million visitors to its five themed areas during its first season.
Early
• 1550 thru 1700 Pleasure Gardens begin to appear in Europe. • These were the first permanent areas set aside specifically for outdoor entertainment. • The attractions included fountains, flower gardens, bowling, games, music, dancing, staged spectacles and a few primitive amusement rides.
2CityEngine手记(Street Tutorial街道建模)

2CityEngine手记Street Tutorial本节学习道路网络和具体的道路模型如何创建。
在新建道路时会响应诸如地形和湖泊等障碍。
第二部分,在街道图中创建街道的形状,应用CGA规则,生成更具体的街景。
最后一部分是一些需要属性参数的道路生成。
Part1 创建道路网络导入教程2:Tutorial_02_Streets。
在scenes文件夹里新建一个场景File → New .. → CityEngine scene命名为"MyStreets.cej"创建一个障碍图层(Obstacle Layer)▪创建一个map layer Layer → New Map Layer▪选择Obstacle,下一步▪选择obstacles.png文件作为障碍图层▪对齐方式居中,选中保持比例按钮▪X 设为3000▪Tip: 如果在viewport窗口看不见obstacle图层,在viewport的菜单里改成。
创建一个地形图层(Terrain Layer)▪在File Navigator的maps文件夹找到文件file elevation.jpg▪把该文件拖进3D viewport▪把文件topo.png作为纹理(Texture file)▪最大高程设置为250▪对齐方式居中,选中保持比例按钮▪X 设为3000▪完成▪选中Obstacle图层把Elevation Offset设为-15 (Window →Inspector ).防止两个图层层叠。
生成街道▪不选中obstacle图层,点击Scene的空白处▪Graph → Grow Streets...▪街道数量设为1500▪在Environment Settings的Heightmap下拉框中选择terrain elevation ▪Obstaclemap下拉框中选择obstacle▪单击apply完成解决冲突生成的或者导入的道路都会有冲突,在图中是红色标识的。
商务英语阅读教程2——英译汉

商务英语阅读教程2——英译汉Business English Reading Tutorial 2 - English to Chinese TranslationOriginal English Text:Translation in Chinese:工作场所的有效沟通有效沟通对任何商业组织的成功至关重要。
它在促进积极的工作环境、增强团队合作和提高总体生产力方面起到了关键作用。
在今天快节奏的商业世界中,有效沟通技巧比以往任何时候都更重要。
有效沟通的关键之一是清晰。
必须清晰准确传达信息,以确保没有误解的空间。
这可以通过使用简单明了的语言,避免可能会让听众困惑的行话或技术术语来实现。
重要的是要意识到接收者的理解水平,并相应地调整沟通方式。
除了清晰度外,积极倾听是有效沟通的另一个关键要素。
聆听他人的想法和关切有助于建立信任和融洽关系。
它还可以提供更好的问题解决和决策能力。
积极倾听包括全神贯注地听讲者说话,保持眼神交流,并提供反馈或提问以显示兴趣和理解。
有效沟通还涉及非语言暗示,如肢体语言、面部表情和语调。
这些非言语暗示可以传递情感、意图和态度,而仅凭文字可能无法表达。
了解自己的非语言沟通并能够阅读和解释他人的非语言暗示可以极大地增强沟通效果。
在技术时代,电子沟通已成为工作场所沟通的重要组成部分。
虽然电子邮件、即时消息和视频会议提供了便利和效率,但它们不能取代面对面的互动。
在虚拟和面对面沟通之间保持平衡是确保信息有效和有意义交流的关键。
最后,反馈对于有效沟通至关重要。
建设性的反馈帮助个人了解自己的长处和弱点,使其能够提高自己的沟通技巧。
反馈应具体、及时和可操作,才能发挥作用。
它应该关注行为或行动,并避免个人批评。
总之,有效沟通对任何商业组织的成功至关重要。
它涉及到清晰度、积极倾听、非语言暗示、电子和面对面沟通的平衡以及建设性反馈。
通过发展和实践这些技能,个人可以成为更有效的沟通者,并为积极和富有成效的工作环境做出贡献。
Tutorial 2 Matlab 工作空间窗口的使用
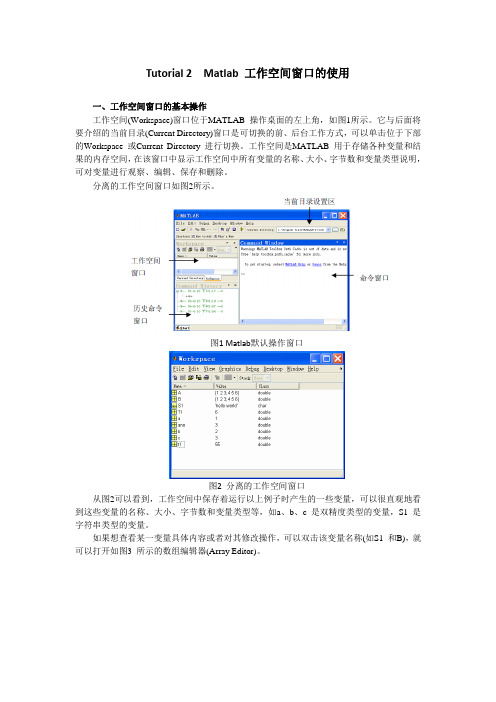
Tutorial 2 Matlab 工作空间窗口的使用一、工作空间窗口的基本操作工作空间(Workspace)窗口位于MATLAB 操作桌面的左上角,如图1所示。
它与后面将要介绍的当前目录(Current Directory)窗口是可切换的前、后台工作方式,可以单击位于下部的Workspace 或Current Directory 进行切换。
工作空间是MATLAB 用于存储各种变量和结果的内存空间,在该窗口中显示工作空间中所有变量的名称、大小、字节数和变量类型说明,可对变量进行观察、编辑、保存和删除。
分离的工作空间窗口如图2所示。
图1 Matlab默认操作窗口图2 分离的工作空间窗口从图2可以看到,工作空间中保存着运行以上例子时产生的一些变量,可以很直观地看到这些变量的名称、大小、字节数和变量类型等,如a、b、c 是双精度类型的变量,S1 是字符串类型的变量。
如果想查看某一变量具体内容或者对其修改操作,可以双击该变量名称(如S1 和B),就可以打开如图3 所示的数组编辑器(Array Editor)。
图3 数组编辑器从图3可以看到,S1 字符串的具体内容是hello world,数组B 的大小为2 行3 列,具体存放方式为1 2 34 5 6注意如果数组过大,可能无法显示,如读入一个1 400×1 200 的数组,在数组编辑器中双击该数组名称时,显示以下内容。
Cannot display variables with more than 524288 elements.这表示在数组编辑器中不能显示大于524 288 个元素的数组。
工作空间的物理本质就是计算机内存中的某一特定区域,在MATLAB 关闭时其变量的数据将丢失。
若想以后再利用这些数据,可在退出前用数据文件(.MAT)将其保存在外存中,这可以在工作空间窗口中利用菜单命令实现,也可以利用后面将介绍的相关命令在命令窗口执行实现。
二、练习1、打开Matlab主界面,找出工作空间窗口并分离。
Flotherm_8.2-Tutorial_2
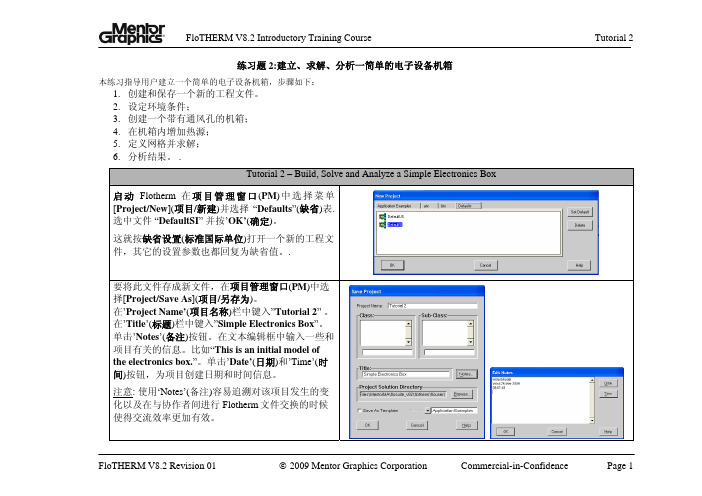
要将此文件存成新文件,在项目管理窗口(PM)中选 择[Project/Save As](项目/另存为)。 在’Project Name’(项目名称)栏中键入”Tutorial 2” 。 在’Title’(标题)栏中键入”Simple Electronics Box”。 单击’Notes’(备注)按钮。在文本编辑框中输入一些和 项目有关的信息。比如“This is an initial model of the electronics box.”。单击’Date’(日期)和’Time’(时 间)按钮,为项目创建日期和时间信息。 注意: 使用‘Notes’(备注)容易追溯对该项目发生的变 化以及在与协作者间进行 Flotherm 文件交换的时候 使得交流效率更加有效。
Tutorial 2
选中机箱(Enclosure)名称,点击名称,重命名为 “Chassis”.右键点击项目管理窗口的任意地方,退出 名称编辑(Edit Name)功能 。 您可以按此方法重命名 任何物体或组件的名称,但名称长度最多包含 32 个 字符。 选中机箱(Chassis),右击调出机箱菜单(Enclosure Menu),选择‘Construction’ 检查对话框中参数,尺寸 (dimensions)应该是 (260,250,100) mm. 保证选项 ‘Modeling Level’(建模级别)选择在 ‘Thin’(薄)。将机箱壁厚度‘Thickness’设置为 1mm。 点击‘OK’退出‘Enclosure’ (机箱)菜单
Tutorial 2
FloTHERM V8.2 Revision 01
© 2009 Mentor Graphics Corporation
Commercial-in-Confidence
AUTOPIPE Tutorial翻译2

Tutorial-2模型的建立与分析一.建立并连接段1.导入PXF文件(1)选择“File/Open/AutoPLANT(*.pxf)选项。
(2)双击“TUTOR2.pxf”文件。
(3)“General Model Options”中按下图输入(4)弹出的“Import AutoPLANT”对话框,按下图输入:之后会弹出提示对话框和一个文件,忽略并关闭。
最后模型如下图:2.将Run节点转变成Tee节点(1)点击A07,使其处于活动状态。
(2)选择“Modify/Convert Point to/Tee”,将其转化成Tee。
(3)按上图点击Tee的指示箭头,选择“Insert/Run”。
(4)“DX-Offsets”项输入32(英尺)。
3.管嘴/容器连接柔度计算(1)选择“Insert/Nozzle”。
(2)“Length”输入0.5”,“Vessel Radius”输入2,“Thickness”输入0.5。
(3)“Nozzle Flexibility Method”选择WRC 297。
(4)L1、L2分别输入2和8英尺。
(5)“Direction of vessel axis”选择Global Y。
(6)单击OK。
(7)选择“File/Save”。
4.建立一个独立的段(1)选择“Insert/Segement”。
(2)按下图输入“Segement”对话框:(3)选择OK,弹出“Pipe Properties”对话框要求输入VESSEL的参数,按下图输入:(4)单击OK后,弹出“Pressure&Temperature”对话框。
(5)“Hot allow”项输入40000,其它值不变,单击OK。
(6)选择“Insert/Anchor”,接受默认值,单击OK。
(7)选择“Insert/Run”,在“DY Offsets”项输入8英尺,关闭对话框。
(8)再次选择“Insert/Run”,在“DY Offsets”项输入2英尺,关闭对话框。
Tutorial 2

Tutorial 2 - Modes of UltrasoundMODES OF ULTRASOUNDThe principal modes of ultrasound in echocardiography are1.2-D or 2 dimensional mode2.M-mode or motion mode3.Colour flow doppler imaging4.Pulse wave doppler5.Continuous wave doppler6.Tissue doppler2DThis is the default mode that comes on when any ultrasound / echo machine is turned on. It is a 2 dimensional cross sectional view of the underlying structures and is made up of numerous B-mode (brightness mode) scan lines. This is the most intuitive of all modes to understand. The field of view is the portion of the organs or tissues that are intersected by the scanning plane. Depending on the probe used, the shape of this field could be a sector - commonly seen with Echo and abdominal ultrasound probes or rectangular or trapezoid - seen with superficial or vascular probes.Multiple images of the field or frames are generated every second on the screen, giving an illusion of movement. A frame rate of at least 20 frames per second is needed to give a realistic illusion of motion.On a grey scale, high reflectivity (bone) is white; low reflectivity (muscle) is grey and no reflection (water) is black. Deeper structures are displayed on the lower part of the screen and superficial structures on the upper part.Figure 1: An example of 2D imaging: From www.medison.ru/uzi/eho408.htmThe main uses for 2-D mode are to measure cardiac chamber dimensions, assess valvular structure & function, estimate global & segmental ventricular systolic function, and improve accuracy of interpretation of Doppler modalities.While this mode is useful to accurately represent the 2- dimensional structure of the underlying tissues, it does not resolve rapid movements well and may misrepresent 3-dimensional nature of structures.If you would like some more information about 2D, the section on 2-Dimensional imaging athttp://folk.ntnu.no/stoylen/strainrate/Ultrasound/ is very informative with excellent graphical explanations.M-modeThis represents movement of structures over time. Initially a 2-D image is acquired and a single scan line is placed along the area of interest. The M-mode will then show how the structures intersected by that line move toward or away from the probe over time.Figure 2: An example of M Mode showing movements of the mitral leaflets over time: http://www.medison.ru/uzi/eho36.htm The M-mode has good temporal resolution, so it is useful in detecting and recording rapid movements. We can also correlate and time events with ECG or respiratory pressure waveforms traced alongside the M-mode tracings. The M-mode is commonly used for measuring chamber dimensions and calculating fractional shortening and ejection fraction.Figure 3: Another example of M mode through the left ventricle showing movement of the walls over timeColour flow Doppler imaging (CFI)In this mode, the velocity and direction of blood flows are depicted in a color map superimposed on the 2-D image.It uses pulse wave Doppler signals to derive this image. This is usually done with lower frequency ultrasound waves and hence the resolution of the 2-D image deteriorates in this mode. As it takes many pulses in each scan line to derive the color image, the frame rate is reduced compared to 2-D mode. Reducing the depth and size of the color box and reducing the scanning sector width can compensate for this. Although it can be changed, by convention, blood flowing away from the probe is depicted in blue and that flowing toward the probe in red. (BART: blue away, red toward). Blood flowing perpendicular to the scanning plane will appear black. Areas of turbulent flow may be depicted in green or white.Fig 4: Schematic diagram of Colour Doppler: The mid-zone has no signalbecause the beam is perpendicular to flow. The conventional colour codes are – BART: Blue Away, Red Towards, but can be changed.Figure 5: An example of Color Flow Imaging of a mitral regurgitation jet: http://www.medison.ru/uzi/eho187.htmFigure 6: Using Colour flow to guide CWD in aortic regurgitation: http://www.medison.ru/uzi/eho189.htmColor flow imaging tells us about intra-cardiac blood flows in relation to the anatomy. Hence it is useful in visualizing and semi-quantitatively assessing regurgitant jets and other abnormal flows. It can also be used to guide the accurate placement of the cursor for pulse and continuous wave Dopplers.In addition to the poor 2D resolution, the reduced frame rate also reduces temporal resolution. Estimates of velocity and direction of blood flow are not as accurate as in Continuous wave or pulse waveDopplers.Pulse wave Doppler (PWD)This is a pulsed Doppler technique in which the Doppler signal arising from a specific position in the scanned tissue is analyzed to depict velocity and direction of flow.The transducer crystal transmits the ultrasound and receives it after a preset delay. This allows it to precisely localize the site of origin of a velocity signal. For this, a cursor or 'sample volume' is placed over the 2-D image at the region of interest.Figure 7: An example of Pulsed Wave Doppler of normal flowthrough the left ventricular outflow tractThe PWD also gives us information about the nature of flow-laminar orturbulent. In laminar flows, since most of the RBCs are traveling at the same velocity, the Doppler waveform has a thick white edge but isblack within. In turbulent flow - e.g. across a stenotic valve, there is a wide distribution of RBC velocities and the Doppler signal appears filled-in. This is known as spectral broadening.A key disadvantage with PWD is the inability to measure high velocities accurately. High velocities result in a phenomenon called'aliasing'. This causes the velocity waveform to wrap around both sides of the baseline. Direction and velocity information cannot be interpreted for an aliased waveform.Figure 8: This Pulsed Wave Doppler of mitral inflow shows an aliased mitral regurgitation waveform:.au/Videos/Echobk/CH3/Aliasing_PW.jpgAliasing usually sets in when the Doppler shift being measured exceeds one-half of the pulse repetition frequency (PRF). At usual settings, this is seen to happen above a velocity of 2m/sec.To minimize the possibility of aliasing, the following can be done:1.Shift the baseline and the scale to accommodate the maximumvelocity possible2.Reduce the depth of the sample volume, if that is possiblee a lower frequencye a high PRF mode.Steps 3 and 4 may not be possible on all machines. If the velocities are still too high, use continuous wave Doppler.PWD is used to analyze Mitral and Tricuspid inflow patterns, measure velocities of flow at the left ventricular outflow tract (LVOT) and pulmonary and hepatic venous flow patterns.Continuous Wave Doppler (CWD)In this mode, a part of the transducer is continuously transmitting and a part of the transducer is continuously receiving the Doppler signal along a single line that is placed on the 2-D image. This method gives very good resolution of high velocities, but it does not give any information about the location of the signal, which may originate anywhere along the preset line of the ultrasound beam. As it measures velocities along the entire line, there will be a range of RBC velocities and the Doppler waveform is normally filled-in in contrast to the PWD.Figure 9: An example of Continuous Wave Doppler of a mitral regurgitation jet.CWD is used to measure velocities of Tricuspid, Pulmonary, Mitral and Aortic regurgitation, and velocity of systolic flow through the aortic valve.Tissue DopplerThis mode is similar to the Pulsed Wave Doppler except that it is usedto measure velocities of tissue movement, which are much lower thanblood velocities. The cursor or sample volume is placed on the 2-Dimage over the tissue of interest and the Doppler waveforms are acquired. The machine filters out the high velocities and displays awaveform that is very similar in appearance to the PWD waveform.Figure 10: An example of Tissue Doppler through the medial mitral annulusTissue Doppler is used to measure tricuspid and mitral annulus velocities to assess RV systolic function and estimate LA pressure.Tissue Harmonic ImagingIn this modality, the transducer looks for reflected echoes at twice the frequency of that which was emitted. This results in darker cavities and brighter walls leading to better endocardial definition, better resolution even at greater depths and reduced near field clutter.It is better to leave this mode on at all times throughout the echocardiographic examination. Other modes can be used concomitantly with this.。
全新版大学进阶英语综合教程2 4单元作文

全新版大学进阶英语综合教程2 4单元作文全文共3篇示例,供读者参考篇1The Importance of Time Management in University LifeTime management is a crucial skill that every university student should master in order to succeed in their academic and personal lives. With the increasing demands of coursework, extracurricular activities, and social commitments, it can be easy for students to feel overwhelmed and fall behind. By effectively managing their time, students can reduce stress, improve their academic performance, and have a more balanced and fulfilling university experience.One of the key benefits of good time management is the ability to prioritize tasks and allocate time to each one accordingly. This involves setting goals, breaking them down into smaller, manageable tasks, and creating a schedule or to-do list to ensure that everything gets done on time. By organizing their time in this way, students can focus on what is most important and avoid getting sidetracked by less urgent tasks.Time management also allows students to make the most of their study time. By setting aside specific blocks of time for studying and revision, students can ensure that they are not only putting in the hours but also studying effectively. This may involve using techniques such as the Pomodoro method, which breaks study sessions into short, focused intervals with regular breaks in between, or creating a distraction-free study environment by turning off phones and other devices.In addition to academic success, good time management can also improve students' overall well-being. By setting aside time for self-care activities such as exercise, relaxation, and socializing, students can prevent burnout and maintain a healthy work-life balance. This is essential for mental health and can help students stay motivated and focused throughout the semester.One of the biggest challenges in managing time effectively is the temptation to procrastinate. Procrastination can be a major obstacle to productivity and can lead to last-minute cramming and poor performance on assignments. To overcome procrastination, students can use strategies such as breaking tasks into smaller, more manageable chunks, setting deadlines for each task, and rewarding themselves for completing tasks on time.Overall, good time management is essential for university students to succeed academically, maintain a healthy work-life balance, and reduce stress. By prioritizing tasks, making the most of study time, and avoiding procrastination, students can make the most of their university experience and set themselves up for success in the future.篇2New Version of College Advanced English Comprehensive Tutorial 2 Unit 4 CompositionIn today's ever-changing world, the ability to communicate effectively in English is becoming increasingly important. In this dynamic and globalized environment, mastering the English language can open up a world of opportunities in education, work, and personal growth. The new version of College Advanced English Comprehensive Tutorial 2 Unit 4 provides students with the necessary skills to navigate this complex linguistic landscape.One of the key themes in this unit is the importance of effective communication in international business. As more companies expand their operations globally, the ability to communicate clearly and professionally in English is essential.From negotiating contracts to giving presentations, the language skills taught in this unit are crucial for success in today's business world.Another important topic covered in this unit is intercultural communication. In an increasingly interconnected world, it is essential to understand and appreciate different cultures and communication styles. By learning how to navigate cultural differences and communicate effectively with people from different backgrounds, students can become more successful and empathetic global citizens.Furthermore, the new version of College Advanced English Comprehensive Tutorial 2 Unit 4 also focuses on enhancing critical thinking and analytical skills. By engaging with complex texts and challenging ideas, students can develop their ability to think critically and formulate well-informed opinions. These skills are not only valuable in academic settings but also in everyday life, helping students to make informed decisions and navigate a complex world.Overall, the new version of College Advanced English Comprehensive Tutorial 2 Unit 4 provides students with the tools they need to succeed in today's globalized world. Through a focus on effective communication, intercultural competence, andcritical thinking, students can develop the skills necessary to thrive in an increasingly interconnected and diverse society. By mastering the English language and honing these important skills, students can open up a world of opportunities and make a positive impact on the world around them.篇3Unit 4: Studying AbroadStudying abroad is a valuable experience that can enrich your academic knowledge, cultural understanding, and personal growth. In today's globalized world, more and more students are choosing to pursue their education in a foreign country. In this essay, we will discuss the benefits of studying abroad and how it can positively impact your life and future career.First and foremost, studying abroad offers a unique opportunity to immerse yourself in a new culture and language. By living in a foreign country, you will have the chance to interact with people from different backgrounds, learn about their traditions, and broaden your perspective on the world. This cultural exchange can enhance your communication skills, adaptability, and empathy towards others.Secondly, studying abroad can provide access tohigh-quality education and research opportunities that may not be available in your home country. Universities in countries like the United States, United Kingdom, and Australia are renowned for their cutting-edge research, innovative teaching methods, and diverse academic programs. By studying in one of these institutions, you can gain a competitive edge in your field of study and expand your professional network.Moreover, studying abroad can be a transformative experience that fosters personal growth and independence. Living in a foreign country challenges you to step out of your comfort zone, navigate unfamiliar situations, and develop problem-solving skills. This can build your self-confidence, resilience, and ability to thrive in diverse environments. Additionally, studying abroad can help you discover your passions, interests, and career goals by exposing you to new ideas, disciplines, and experiences.In conclusion, studying abroad is a life-changing opportunity that can broaden your horizons, enhance your skills, and shape your future. Whether you choose to study in Europe, Asia, or Latin America, the benefits of studying abroad are endless. So, if you have the chance to study abroad, seize it withopen arms and embrace the adventure that awaits you. Good luck on your academic journey!。
零起点大学英语基础教程2-UnitPPT

03
reading comprehension
reading skill
Reading for Meaning: It is essential to read the text carefully and understand the main idea, as well as the details that support it. Skills such as predicting the main idea from the title or first paragraph, and summarizing the text in your own words, are crucial.
Answer Questions
Answering comprehension questions after reading an article can help you assess your understanding. It also helps in identifying areas where you may need to improve.
Multiple choice questions can be used to test listeners' comprehension of listening materials by providing them with a choice of possible answers.
Practice with fill-in-the-blank questions
Listening materials
Authentic
materials
Materials that are similar to real-life English usage, such as podcasts, news broadcasts, and conversations between native speakers.
Tutorial_2_solutions

1.Maria can read 20 pages of economics in an hour. She can also read 50 pages of sociology inan hour. She spends 5 hours per day studying.a.Draw Maria production possibilities frontier for reading economics and sociology.b.What is Maria’s opportunity cost o f reading 100 pages of sociology?2.Suppose that there are 10 million workers in Canada and that each of these workers canproduce either 2 cars or 30 bushels of wheat in a year.a.What is the opportunity cost of producing a car in Canada? What is the opportunitycost of producing a bushel of wheat in Canada? Explain the relationship between theopportunity costs of the two goods.b.Draw Canada’s production possibilities frontier. If Canada chooses to consume 10million cars, how much wheat can it consume without trade? Label this point on theproduction possibilities frontier.c.Now suppose that the United States offers to buy 10 million cars from Canada inexchange for 20 bushels of wheat per car. If Canada continues to consume 10 millioncars, how much what does this deal allow Canada to consume? Label this point onyour diagram. Should Canada accept the deal?3.Are these statements true or false?a.It is possible for two countries to achieve gains from trade even if one of thecountries has an absolute comparative advantage in the production of all goods.b.Some people have a comparative advantage in everything they do.c.When two people decide to trade, if the trade is good for one person it cannot begood for the other person.d.Trades that make a country better off cannot harm any individual of that country.4.Suppose that all goods can be produced with fewer worker hours in Germany than in France:a.In what sense is the cost of all goods lower in Germany than in France?b.In what sense is the cost of some goods lower in France?c.If Germany and France traded with each other, would both countries be better off asa result?5.England and Scotland both produce scones and sweaters. Suppose that an English workercan produce 50 scones per hour or 1 sweater per hour. Suppose that a Scottish worker can produce 40 scones per hour or 2 sweaters per hour.a.Which country has the absolute advantage in the production of each good? Whichcountry has the comparative advantage?b.If England and Scotland decide to trade, which commodity will Scotland trade toEngland? Explain.c.If a Scottish worker could produce only 1 sweater per hour, would Scotland still gainfrom trade? Explain.1.a. See graph below. If Maria spends all five hours studying economics, she can read 100 pages, so that isthe vertical intercept of the production possibilities frontier. If she spends all five hours studying sociology, she can read 250 pages, so that is the horizontal intercept. The opportunity costs are constant, so the production possibilities frontier is a straight line.b. It takes Maria two hours to read 100 pages of sociology. In that time, she could read 40 pages ofeconomics. So the opportunity cost of 100 pages of sociology is 40 pages of economics.2.a. Because a Canadian worker can make either two cars a year or 30 bushels of wheat, the opportunity costof a car is 15 bushels of wheat. Similarly, the opportunity cost of a bushel of wheat is 1/15 of a car. The opportunity costs are the reciprocals of each other.b. See graph below. If all ten million workers produce two cars each, they produce a total of 20 million cars,which is the vertical intercept of the production possibilities frontier. If all ten million workers produce 30 bushels of wheat each, they produce a total of 300 million bushels, which is the horizontal intercept of the production possibilities frontier. Because the trade-off between cars and wheat is always the same, the production possibilities frontier is a straight line. If Canada chooses to consume ten million cars, it will need five million workers devoted to car production. That leaves five million workers to produce wheat, who will produce a total of 150 million bushels (five million workers times 30 bushels per worker). This is shown as point A in the graph.c. If the United States buys 10 million cars from Canada and Canada continues to consume10 million cars, then Canada will need to produce a total of 20 million cars. So Canadawill be producing at the vertical intercept of the production possibilities frontier. However, if Canada gets20 bushels of wheat per car, it will be able to consume 200 million bushels of wheat, along with the 10million cars. This is shown as point B in the figure. Canada should accept the deal because it gets the same number of cars and 50 million more bushels of wheat.3.a. True; two countries can achieve gains from trade even if one of the countries has an absolute advantagein the production of all goods. All that's necessary is that each country have a comparative advantage in some good.b. False; it is not true that some people have a comparative advantage in everything they do. In fact, noone can have a comparative advantage in everything. Comparative advantage reflects the opportunity cost of one good or activity in terms of another. If you have a comparative advantage in one thing, you must have a comparative disadvantage in the other thing.c. False; it is not true that if a trade is good for one person, it can't be good for the other one. Trades canand do benefit both sides especially trades based on comparative advantage. If both sides didn't benefit, trades would never occur.d. False; trade that makes the country better off can harm certain individuals in the country. For example,suppose a country has a comparative advantage in producing wheat and a comparative disadvantage in producing cars. Exporting wheat and importing cars will benefit the nation as a whole, as it will be able to consume more of all goods. However, the introduction of trade will likely be harmful to domestic autoworkers and manufacturers.4.a. The cost of all goods is lower in Germany than in France in the sense that all goods can be produced withfewer worker hours.b. The cost of any good for which France has a comparative advantage is lower in France than in Germany.Though Germany produces all goods with less labor, that labor may be more valuable in the production of some goods and services. So the cost of production, in terms of opportunity cost, will be lower in France for some goods.c. Trade between Germany and France will benefit both countries. For each good in which it has acomparative advantage, each country should produce more goods than it consumes, trading the rest to the other country. Total consumption will be higher in both countries as a result.5.a. English workers have an absolute advantage over Scottish workers in producing scones, since Englishworkers produce more scones per hour (50 vs. 40). Scottish workers have an absolute advantage over English workers in producing sweaters, since Scottish workers produce more sweaters per hour (2 vs. 1).Comparative advantage runs the same way. English workers, who have an opportunity cost of 1/50 sweater per scone (1 sweater per hour divided by 50 scones per hour), have a comparative advantage in scone production over Scottish workers, who have an opportunity cost of 1/20 sweater per scone (2 sweaters per hour divided by 40 scones per hour). Scottish workers, who have an opportunity cost of 20 scones per sweater (40 scones per hour divided by 2 sweaters per hour), have a comparative advantage in sweater production over English workers, who have an opportunity cost of 50 scones per sweater (50 scones per hour divided by 1 sweater per hour).b. If England and Scotland decide to trade, Scotland will produce sweaters and trade them for sconesproduced in England. A trade with a price between 20 and 50 scones per sweater will benefit both countries, as they'll be getting the traded good at a lower price than their opportunity cost of producing the good in their own country.c. Even if a Scottish worker produced just one sweater per hour, the countries would still gain from trade,because Scotland would still have a comparative advantage in producing sweaters. Its opportunity cost for sweaters would be higher than before (40 scones per sweater, instead of 20 scones per sweater before).But there are still gains from trade since England has a higher opportunity cost (50 scones per sweater).。
ST-nucleo_tutorial2-按键
NUCLEO教程之二:按个键编译:netlhx前一个教程,我们了解了如何使用STM32CubeMX及MDK来实现NUCLEO F072RB开发板的LED功能。
这个教程和上个教程一样,都是使用的STM32的GPIO功能。
GPIO与按键GPIO,通用输入输出接口的简称,LED使用的是GPIO的输出功能,今天介绍的按键则是使用的输入功能。
一般来说,控制外设状态用的是输出功能,读取外设状态则使用的是输入功能。
具体配置每个引脚功能,要参考用户手册并结合外设引脚功能来定。
比如读取按键状态明显是要将对应的引脚设定为输入功能,到底用的是上拉还是下拉,则要结合原理图来最后确定。
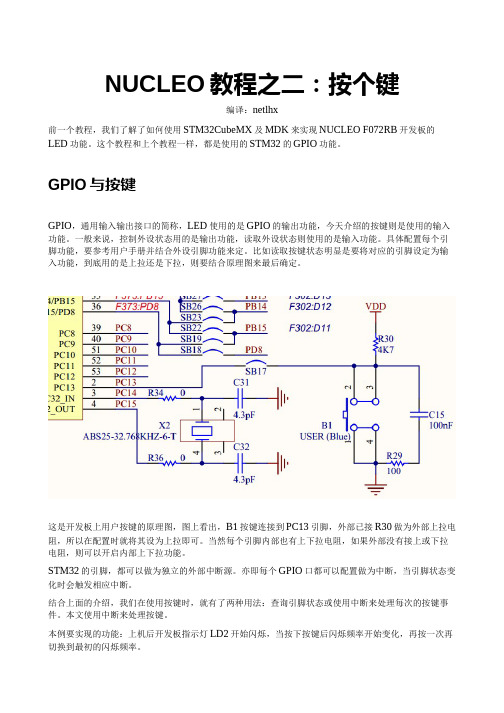
这是开发板上用户按键的原理图,图上看出,B1按键连接到PC13引脚,外部已接R30做为外部上拉电阻,所以在配置时就将其设为上拉即可。
当然每个引脚内部也有上下拉电阻,如果外部没有接上或下拉电阻,则可以开启内部上下拉功能。
STM32的引脚,都可以做为独立的外部中断源。
亦即每个GPIO口都可以配置做为中断,当引脚状态变化时会触发相应中断。
结合上面的介绍,我们在使用按键时,就有了两种用法:查询引脚状态或使用中断来处理每次的按键事件。
本文使用中断来处理按键。
本例要实现的功能:上机后开发板指示灯LD2开始闪烁,当按下按键后闪烁频率开始变化,再按一次再切换到最初的闪烁频率。
创建工程具体设置方法就不详述了,请参考教程一,点个灯。
这里只介绍相关的配置内容。
在外设及引脚配置选项卡里,做如下配置,将PC13引脚配置为外部中断功能。
接下来配置GPIO的具体参数注意看“GPIO Mode”里面选择的是上升沿触发,当然也可以选择下降沿触发。
“Pull up/Pull down”里选择的是不使用上下拉功能。
接下来就是开启外部中断功能好了,现在可以生成工程文件了。
就差在里面写功能代码了。
实现功能要实现的功能主要有两个,一个是LD2闪烁功能;另一个是按键变换闪烁频率的功能。
tutorial-2

Coot Tutorial II:More Advanced UsageCCP4School APS2009February10,2010The idea here is to use more advanced1tools of Coot.There will be less de-scription of low-level widget manipulation in this tutorial-we presume that you already have experience with that.You may well trip over issues not discussed here2.1PreambleWhen automatic building fails,typically because the resolution limit of your data is too low,then building the molecule“by hand”may be the only way to proceed. Recognizing the shape of main-chain and side-chain densities is valuable and this tutorial aims to introduce these to you.Note that this tutorial map is an easy map to build into,the sidechains are(mostly)clear.If you want a more realistic“bad”map,you can apply a resolution limit to the data read in from the MTZfile3.Using just a map and a sequence,we will attempt to generate a model.This model can then be validated and refined with Refmac for several rounds.With some experience you should be able to get an R-factor of less than20%in less than 30minutes.2Skeletonization and Baton BuildingYou can calculate the map skeleton in Coot directly:Calculate→Map Skeleton...→On.This can be used to“baton build”a map.You can turn off the coordinates and try it if you like(the Baton Building window can be found by clicking“Ca Baton Mode...”in the Other Modelling Tools dialog.I suggest you use Go To Atom and start residue2A.This allows you to build the complete A chain in the correct direction and you can directly compare it to the real structure afterward4.Once you are at residue2A,use the Display Manager to turn off the‘‘tutorial-modern.pdb’’and don’t look at it again until you have finished building,validating and refining.Remember,when you start,you are placing a CA at the baton tip and at the start you are placing atom CA1.This might seem that you are“double-backing”on yourself-which can be confusing thefirst time.So build from the N-terminus to the C(it takes about15minutes or so).There are96residues to build.1“less commonly-used”might be a better description2Feel free to shout out if you do,several others may have this same problem and we can examine the issue together.3the resolution limit widget will appear when you activate the“Expert Mode“button.4if don’t follow this instruction,you could well build a symmetry related molecule,which is per-fectly valid,of course,just that the comparison versus the correct structure will be more difficult.Note that you need at least6CA baton points for CA Zone to Mainchain to work53Key BindingsIf you look at”Paul’s Key Bindings”6in the Coot Wiki7,you will see a page of customizations.One of those customizations can help you in Baton-Building mode -and that is the“quoteleft”key binding.So,cut the bindings out of the web page,paste them into afile and then use Calculate→Run Script...to evaluate thatfile8.To check that your key-bindings are activated,Use Extensions→Key Bindings....Now,we can use quoteleft(or“backquote”,”‘”is how it might appear on the keyboard)to accept the baton position-this is much more convenient than using the“Accept”button9.4At the end of the ChainAt some stage10you will come to a point where no progress can be made,the only direction takes us into density we’ve already built into.OK,so stop:Dismiss.Now we need to turn these CA positions into mainchain.Calculate→Other Modelling T ools→CA Zone to e the Go T o Atom dialog to centre on thefirst residue of“Baton Atoms”,click it,then centre on the last residue of“Baton Atoms”and click on that.[Coot thinks for a several seconds while building a mainchain]OK,great,we have a mainchain.Let’s tidy it up:Extensions→Stepped Refine.Refine the“mainchain”molecule,watch it as it goes.Is it making mistakes?That refinement may have gone to quickly to make a note of problem areas,so use Validation→Density Fit Analysis on the“mainchain”molecule andfind areas that are marked with large spikes.“There are none”you say?Good11.Let’s move on.5Assign SequenceLet’s tell Coot that we have a sequence associated with this set of CA points.So, Extensions→Dock Sequence→Assign SequenceTurn on auto-fit of residuesSo when thefile is assigned“Assign Closest fragment”.[Coot thinks for a several seconds while assigning sidechains,then goes about mutating andfitting the residues]What’s that you say?Coot didn’t do that?Well,that’s because you mainchain model is too bad for Coot to recognize the sidechain positions.You need to review you mainchain model and make sure sure that the CBs are in density and pointing 5otherwise it silently fails-more feedback will be added in later versions.6Use Bernhard’s Key-bindings if you are using pythonized or WinCoot7you canfind a link to this from the Coot web page8“read it in”,you might say9You can do that as well,of course,but clicky-clicky pressy button is for Coot noobs,and that’s not us, right?10hopefully residue9611If that’s not what you say,you can use the refinement or other tools that we learned about in the first tutorial to improve thefit to density.in the right direction.When you have improved you model sufficiently well,Coot will apply the sequence to it using the above method.Change the Chain ID from““to“A”.6Cell and SymmetryDisplay Symmetry Atoms:Draw→Cell&Symmetry→Master Switch:Show Symmetry Atoms→Y es and OK.By zooming out and eyeballing the density,check for unassigned density.[Coot displays symmetry-related atoms in grey-by default(you may not see many symmetry related atoms,it depends on where in the unit cell you are)]7Build another moleculeNow we need to build another molecule(the NCS related copy).So using the map skeleton search around tofind a volume of density not already build(and not symmetry related to the model already built).Here’s a hint,find the a helix in the skeleton.•Using the Other Modelling Tools,place a helix over the skeleton points of the skeleton.•Improve thefit of the skeleton,taking note that the N and C terminus of the helix are well-fitted.•Associate the same sequence with the new Helix molecule•Dock sidechains on the new molecule(it should work if your helix is good)•Now compare the Helix molecule with the previously built model.Find matching start and end point on the helix and previous model.•LSQfit a copy of the previous model on top of the Helix molecule [Coot displayes a new molecule that almostfits the so-far unbuilt density.] Let’s call this new chain,chain“B”•Now clean up thefit,first do a rigid body refinement of the whole new model...•then an All Molecule stepped refine should make thefit nice.8Merge MoleculesMerge the“B”chain into the“A”chain molecule above:Calculate→Merge molecules→Append/Insert Molecule(s)[Choose the most recent mainchain molecule]into Molecule[Choose the molecule of the A chain]→Merge.9GhostsUnfortunately,there is no slick way to make Coot rebuild ghosts for this composite molecule.We need to write out the pdbfile and read it in again-inelegant.File→Save Coordinates,[Choose the molecule that does now contains both the A and B chains]→Select Filename...Pick afilename then use File→Open Coordinates...to read it in again.Check the console as you do this,Coot will tell you that there are NCS related molecules.If12it does this,we’re in business.In the following,you will need to know thefirst and last residue numbers in the“A”e the Go To Atom dialog tofind them.If ghosts appear,use:Extensions→NCS...→Copy NCS Residue ing“A”13as the Mas-ter Chain ID thenfill in thefirst and last residue numbers of the A chain.[Coot builds the B chain as an NCS copy of the A chain]10Rinse,RepeatUse NCS jumping(the’O’key)to see NCS differences.Now unmodelled blobs-like we did before.Find the ligand(3GP),merge it in.Refine using Refmac.Validate.Rebuild.11Make some pictures•Highlight active site,with ligand.Take a screenshot.•Use Raster3D to take a screenshot•Now make a Raster3D image without spheres for atoms,how do you do that?•Now give the ligand a dotted surface•Now Use Extension→Mask Map to make a map that has density only around the ligand.•Now take the residues in the active site,use Copy Fragment and merge molecule to make a single mlecule of them.Display this atom selection as an electrostatic surface12ViewsTry out the“View”system•Zoom out to see the whole molecule on the screen•Recentre and Zoom in to the active site•Play Views...12When13presumably13More ExercisesWhat does“Another Level”do?What does“Multi-chicken”do?Use the skeletonization of a map tofind a e Calculate→Other Modelling T ools to add a helix there.Try to represent the map with a higher resolution grid(use Edit→Map Parame-ters).Do you prefer that?Why?Use the EDS service to download1H4P.Can youfind anything wrong with the main-chain?If so,how can you correct it?。
新技能英语高级教程2课程介绍

新技能英语高级教程2课程介绍English Answer:New Skill English Advanced Tutorial 2。
Course Description.This course is designed to provide students with the advanced English skills necessary to communicate effectively in a variety of academic and professional settings. The course covers a wide range of topics, including:Advanced grammar and syntax.Vocabulary development.Reading comprehension.Writing skills.Listening and speaking skills.The course is taught by experienced instructors who will provide students with the support and guidance they need to succeed. Students will have the opportunity to participate in a variety of activities, including:Class discussions.Group projects.Presentations.Role-playing exercises.By the end of the course, students will be able to:Use advanced grammar and syntax correctly.Expand their vocabulary and use it effectively in writing and speaking.Comprehend complex texts.Write clear, concise, and well-organized essays and reports.Communicate effectively in spoken English.Prerequisites.Students should have a strong foundation in English grammar and vocabulary. They should also be able to read and write at a college level.Course Materials.The following materials are required for the course:Textbook: New Skill English Advanced Tutorial 2。
Tutorial_2

Identify points at which the plane intercepts the x, y, z axis. Take reciprocals of these intercepts. Clear fractions and do NOT reduce to the lowest integers. Enclose the numbers in parentheses () and a bar over negative integers.
E.g. (010) ≠ (020) See example!
Each unit cell, equivalent planes have their particular indices because of the orientation of the coordinates.
Family of planes: {110} = (110),(110),(110),(101), (101),…
Special note for directions…
For Miller Indices of directions:
Since directions are vectors, a direction and its negative are not identical!
[100] ≠ [100] Same line, opposite directions!
A direction and its multiple are identical!
[100] is the same direction as [200] ( need to reduce!) [111] is the same direction as [222], [333]!
Tutorial2

• Ia termasuk aspek seperti pengukuran, anggaran kuantiti, bearing, pembacaan peta, jaringan, ciri-ciri bentuk dan kewangan sendiri dan membuat bajet.
• Numerasi terdiri daripada pelajar dalam mengintegrasikan kemahiran seperti :
✓ Menginterpretasikan maklumat kuantitatif. ✓ Menyelesaikan pengiraan mental yang
sekolah rendah.
❖ Pelbagaikan aktiviti.
• In group of 2-3, discuss:
Why and when do we need rough estimation
What are the advantages and disadvantages of applying estimation in real life?
Bahan Manipulatif Fizikal Bahan Manipulatif Maya
❖ Bersifat konkrit di mana ❖ Tidak memerlukan
ቤተ መጻሕፍቲ ባይዱ
pelajar
boleh persediaan alat yang
menggunakan kemahiran banyak
students to acquire this proficiency?
1. Apa maksud Numerasi?
Tutorial2_5.1 chinese-Flotherm

TUTORIAL 2: 对电源机箱的抗扰性能进行建模分析
在这个教程中,利用FLOEMC 来对带有不同配置的缝隙、开孔或通风板的空机箱进行建模。
模型的激励源是幅度为1V/m 的平面波,在机箱内放置一个正方形的环天线用来监测机箱内的场并用来度量机箱的屏蔽效能。
本教程一步步地指导用户来建模并分析。
1.设置边界的尺寸和边界类型
2.建立几何模型
3.定义网格、激励源、材料和输出
4.求解并对结果进行分析
,这将创建一个和求解域相同大小的机箱。
来放大此窗口,通过点击箭头图标改变
.
…Wire
中的库图标
来打开它。
来扩大此视图,通过点“箭头”图标
a
中点击开始运行图标。
(
(
F12 )
)图标
)
窗口中点击选项板图标。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Tutorial – 1 Basic introduction to HyperWorks Student Edition.Getting started with HyperWorks, Import, Export, Open, Save, Working with panels, Rotate, Zoom, pan… etc .Tools The HyperMesh – Student Edition interface contains several areas. Each is described below.Title bar The bar across the top of the interface is the title bar. It contains the version of HyperMesh that you are running andthe name of the file you are working on.Menu Bar Located just under the title bar. Like the pull-down menus in many graphical user interface applications, these menus"drop down" a list of options when clicked. Use these options to access different areas of HyperMesh functionality.Toolbars Located around the graphics area, these buttons provide quick access to commonly-used functions, such as changingdisplay options. They can now be dragged and placed at top or side of the graphics area.Tab Area The Tab Area is so named because various specialized tools display on tabs in this area of the interface. Two suchexamples are the Model Browser and the Utility Menu .∙ The Model tab contains the Model Browser . This tool displays the contents of amodel in a hierarchical tree format. It can be used to create and edit many types ofentities, and also to organize them and control their display status.∙The Utility Menu contains four pages of tools that perform various functions,accessed via buttons at the bottom of the menu. By default, the Disp page is active;the Disp page tools control how a model is displayed in the graphics area. The otherpages available are QA/Model (element checking tools), Geom/Mesh (tools forworking with a model’s geometry as well as for creating and editing meshes), andUser (custom tools you create). The content of the Utility tab changes based upon theselected user profile. Graphics area The graphics area under the title bar is the display area for your model. You can interact with the model in three-dimensional space in real time. In addition to viewing the model, entities can be selected interactively from thegraphics area.Title BarToolbarsGraphics Area Menu barTab AreaMain MenuMain MenuPagesCommand WindowStatus BarStarting HyperMeshTo start HyperMesh on a PC, go to Start > Programs > Altair HyperWorks 11.0 Student Edition > Altair HyperWorks. Open the HyperMesh model file1.Access the Open File… dialog in one of the following ways:∙From the menu bar, choose File > Open > Model.∙From the standard toolbar, click Open Model ()2.Open the model file, bumper_cen_mid1.hm.The model file, bumper_cen_mid1.hm, is now loaded. This file contains mesh and geometry data.HyperMesh model file, bumper_cen_mid1.hm, opened in HyperMeshImport the HyperMesh model file1.Access the Import tab in one of the following ways:∙From the menu bar, choose File > Import > Model.∙From the standard toolbar, click Import ().2.From the Import tab in the tab area, click the Import HM model icon , if not already active.3.Under File selection, click the file icon () and browse to select the file, bumper_mid.hm.4.Click Import.The file, bumper_mid.hm, is now imported into the session.HyperMesh model file, bumper_mid.hm, imported on top of existing data in the HyperMesh sessionImport the IGES geometry file1.From the Import tab in the tab area, click the Geometry icon .2.In the File type: field, select IGES from the pull-down menu.3.Click the file icon () and browse to select the file, bumper_end.iges.4.Click Import.Geometry data is added to the model.IGES geometry file, bumper_end.igs, imported into the sessionImport the OptiStruct input file1.From the Import tab in the tab area, click the Import Solver Deck icon .2.In the File type: field, select OptiStruct from the pull-down menu.3.In the File field, click the folder icon and browse to bumper_end_rgd.fem.4.Click Import.This OptiStruct input file contains mesh for the bumper’s end portion. The mesh is added to the existing data in the current HyperMesh session and will be located in the same area as the geometry representing the bumper’s end.OptiStruct input file, bumper_end_rgd.fem, imported on top of data in the current HyperMesh sessionSave the HyperMesh session as a HyperMesh model file1.From the menu bar, click File >Save As > Mode.2.Enter the name, practice.hm.3.Click Save.The data currently loaded in HyperMesh is now saved in a HyperMesh binary data file of the name you entered. Export the model’s geometry data to an IGES file1.Access the Export tab in one of the following ways:a.From the menu bar, choose File > Export > Geometry.b.From the standard toolbar, click Export Geometry.2.In the Export tab, click the Export Geometry icon if not already selected.3.Set the File type: field to IGES.4.Click the folder icon in the File field, browse to the desired destination folder, and enter practice.igs.5.Click Export.All of the geometry loaded in HyperMesh (points, lines, surfaces) is now saved in an .iges file with the name you entered. Export the model’s mesh data to an OptiStruct input file1.In the Export tab, click the Export FE model icon .2.Under File selection, choose File type:OptiStruct from the pull-down menu.3.Under File selection, click the folder icon in the File field, browse to the desired destination folder, and enter practice.fem.4.Click Export.All of the finite element data loaded in HyperMesh (nodes, elements, loads, etc.) is now saved as an .fem file with the name you enteredDelete all data from the current HyperMesh session by starting a new session1.Access the New HyperMesh Model function in one of the following ways:a.From the menu bar, click File > New > Model.b.From the standard toolbar, click New Model ().2.Answer Yes to the pop-up question "Do you wish to delete the current model? (y/n)”.Controlling the DisplayRetrieve the HyperMesh model file, bumper.hm.When performing finite element modeling and analysis setup, it is important to be able to view the model from different vantage points and control the visibility of entities. You may need to rotate the model to understand the shape, zoom in to view details more closely, or hide specific parts of the model so other parts can be seen. Sometimes a shaded view is best, while other times, a wireframe view allows you work on details inside the model.HyperMesh has many functions to help you control the view, visibility, and display of entitiesManipulate the model view using the mouse controlsThe CTRL + mouse keys are used to rotate the model, change the center of rotation, zoom, fit, and pan1.Move the mouse pointer into the graphics area.2.Press the CTRL key + left mouse button and move the mouse around.The model rotates with the movement of the mouse.A small white square appears in the middle of the graphics area, indicating the center of the rotation.Release the left mouse button and press it again to rotate the model in a different direction.3.Press the CTRL key and quick-click the left mouse button anywhere on the model.The center of rotation square appears near where you clickedHyperMesh searches for one of the following conditions in the listed order and relocates the center of rotation at or near the first condition identified (if none of the conditions are met, the center of rotation is relocated to the center of the screen): ∙ A nearby node or surface vertex.∙ A nearby surface edge to project onto.∙ A nearby geometry surface or shaded element.4.Press the CTRL key + left mouse button to rotate the model and view the change in rotation behaviour.5.Press the CTRL key and quick-click the left mouse button anywhere in the graphics area, except for on the model.The center of rotation square is relocated to the center of the screen.6.Press the CTRL key + left mouse button to rotate the model and observe the change in rotation behaviour.7.Press the CTRL key + middle mouse button, move the mouse around, and then release the mouse button.A white line is drawn along the path of the mouse movement. When the mouse button is released, HyperMesh zooms in onthe portion of the model where the line was drawn. You can also simply draw a line to zoom in on a portion of the model.8.Press the CTRL key + quick-click the middle mouse button.The model is fitted to the graphics area.9.Press the CTRL key and spin the mouse wheel.The model zooms in or out depending on which direction you spin the mouse wheel.10.Move the mouse pointer to a different location in the graphics area and repeat #9.Notice the model zooms in or out from where the mouse handle is located.11.Press the CTRL key + quick-click the middle mouse button to fit the model to the graphics area.12.Press the CTRL key + right mouse button and move the mouse around.The model is panned (translated) according to the mouse movement.Control the display of components using the toolbar1.On the Visualization toolbar, click Shaded Elements and Mesh Lines, .2.Notice the shell elements now have been shaded.3.Right-click Shaded Elements and Mesh Lines, , and switch to Shaded Elements and Feature Lines, .4.Notice now the elements shading does not show any mesh lines. Only feature lines are displayed.5.Right-click Shaded Elements and Feature Lines, , to access Shaded Elements, .6.Notice now the feature lines are also removed from the display.7.Click Wireframe Elements (Skin Only),, to return to the wireframe shading mode.Control the display of entities using the Mask panel1.Click Mask to open the Mask panel.2.Go to the mask subpanel if not already there.3.With the elems selector active, select elems >> by collector.4.Select the component, mid1.5.Click select to complete the selection of components.6.From the graphics area, manually select a few elements in the center (blue) component.7.Click mask to mask the elements.The elements in the mid1 component and the elements you selected from the graphics area are no longer displayed.8.In the Model Browser, notice that the elements () for the components center and mid1 are still displayed. Their displayicons indicate that they are activated even though some or all of the elements in these components are masked (hidden).9.In the Mask panel, click unmask all, or on the Display toolbar click unmask all ().All the elements in the components, center and mid1, are visible again. Notice the elements in the other components are not displayed. This is because these components are not active in the Display panel.10.Click return to exit to the main menu.。