第二章 一维极小化方法-牛顿法
一维牛顿法

一维牛顿法也称为一维牛顿-拉夫逊方法,是一种迭代的优化算法,用于求解一维非线性函数的极值点。
这种方法通过利用函数的二阶导数信息来逼近极值点,并在每次迭代中更新搜索方向,以快速收敛到最优解。
一维牛顿法的具体步骤如下:
初始化:选择初始点x0,并设定迭代终止条件,如迭代次数或函数值的收敛阈值。
计算一阶和二阶导数:计算函数f(x)在当前点xk处的一阶导数f'(xk)和二阶导数f''(xk)。
更新搜索方向和步长:根据二阶导数的信息,计算搜索方向dk和步长αk。
更新当前点:计算新的点xk+1 = xk + αk * dk。
判断终止条件:检查是否满足终止条件,如果满足则停止迭代,否则返回步骤2。
例如,对于函数f ( x ) = x 3 −2 sin ( x ) f(x) = x^3 - 2\sin(x)f(x)=x3−2sin(x),在A AA点处对函数f ( x ) f(x)f(x)展开,得到近似的二次函数φ( x ) \varphi(x)φ(x),φ( x ) \varphi(x)φ(x)的最小值在B BB点处取得,高斯牛顿法的下一步迭代点即为与B BB点横坐标相等的C CC点。
如此,只需数次,迭代能够达到很高的精度,可见牛顿法收敛速度快。
拟牛顿法算法步骤

拟牛顿法算法步骤拟牛顿法(Quasi-Newton Method)是一种用于无约束优化问题的迭代算法。
它的主要思想是利用得到的函数值和梯度信息近似估计目标函数的Hessian矩阵,并利用这个估计值来进行迭代优化。
拟牛顿法的算法步骤如下:1.初始化参数:选择初始点$x_0$作为迭代起点,设定迭代停止准则和迭代次数上限。
2. 计算目标函数的梯度:计算当前点$x_k$处的梯度向量$g_k=\nabla f(x_k)$。
3. 计算方向:使用估计的Hessian矩阵$B_k$和负梯度$g_k$来计算方向$d_k=-B_k g_k$。
4. 一维:通过线方法(如Armijo准则、Wolfe准则等)选择一个合适的步长$\alpha_k$,使得函数在方向上有明显的下降。
5. 更新参数:根据步长$\alpha_k$更新参数$x_{k+1}=x_k+\alpha_k d_k$。
6. 计算目标函数的梯度差:计算新点$x_{k+1}$处的梯度向量$g_{k+1}=\nabla f(x_{k+1})$。
7. 更新Hessian矩阵估计:根据梯度差$g_{k+1}-g_k$和参数差$\Delta x_k=x_{k+1}-x_k$,利用拟牛顿公式来更新Hessian矩阵估计$B_{k+1}=B_k+\Delta B_k$。
8.更新迭代次数:将迭代次数$k$加一:$k=k+1$。
9.判断终止:如果满足终止准则(如梯度范数小于给定阈值、目标函数值的变化小于给定阈值等),则停止迭代;否则,返回步骤310.输出结果:输出找到的近似最优解$x^*$作为优化问题的解。
拟牛顿法有许多不同的变体,最经典和最常用的是DFP算法(Davidon-Fletcher-Powell Algorithm)和BFGS算法(Broyden-Fletcher-Goldfarb-Shanno Algorithm)。
这两种算法都是基于拟牛顿公式来更新Hessian矩阵估计的,但具体的公式和更新规则略有不同,因此会产生不同的数值性能。
目标函数的几种极值求解方法

目标函数极值求解的几种方法题目:()()2221122min -+-x x,取初始点()()Tx 3,11=,分别用最速下降法,牛顿法,共轭梯度法编程实现。
一维搜索法:迭代下降算法大都具有一个共同点,这就是得到点()k x 后需要按某种规则确定一个方向()k d ,再从()k x 出发,沿方向()k d 在直线(或射线)上求目标函数的极小点,从而得到()k x 的后继点()1+k x ,重复以上做法,直至求得问题的解,这里所谓求目标函数在直线上的极小点,称为一维搜索。
一维搜索的方法很多,归纳起来大体可以分为两类,一类是试探法:采用这类方法,需要按某种方式找试探点,通过一系列的试探点来确定极小点。
另一类是函数逼近法或插值法:这类方法是用某种较简单的曲线逼近本来的函数曲线,通过求逼近函数的极小点来估计目标函数的极小点。
本文采用的是第一类试探法中的黄金分割法。
原理书上有详细叙述,在这里介绍一下实现过程:⑴ 置初始区间[11,b a ]及精度要求L>0,计算试探点1λ和1μ,计算函数值()1λf 和()1μf ,计算公式是:()1111382.0a b a -+=λ,()1111618.0a b a -+=μ。
令k=1。
⑵ 若L a b k k <-则停止计算。
否则,当()K f λ>()k f μ时,转步骤⑶;当()K f λ≤()k f μ时,转步骤⑷ 。
⑶ 置k k a λ=+1,k k b b =+1,k k μλ=+1,()1111618.0++++-+=k k k k a b a μ,计算函数值()1+k f μ,转⑸。
⑷ 置k k a a =+1,k k b μ=+1,k k μμ=+1,()1111382.0++++-+=k k k k a b a λ,计算函数值()1+k f λ,转⑸。
⑸ 置k=k+1返回步骤 ⑵。
1. 最速下降法实现原理描述:在求目标函数极小值问题时,总希望从一点出发,选择一个目标函数值下降最快的方向,以利于尽快达到极小点,正是基于这样一种愿望提出的最速下降法,并且经过一系列理论推导研究可知,负梯度方向为最速下降方向。
最优化理论方法——牛顿法
牛顿法牛顿法作为求解非线性方程的一种经典的迭代方法,它的收敛速度快,有内在函数可以直接使用。
结合着matlab 可以对其进行应用,求解方程。
牛顿迭代法(Newton ’s method )又称为牛顿-拉夫逊方法(Newton-Raphson method ),它是牛顿在17世纪提出的一种在实数域和复数域上近似求解方程的方法,其基本思想是利用目标函数的二次Taylor 展开,并将其极小化。
牛顿法使用函数()f x 的泰勒级数的前面几项来寻找方程()0f x =的根。
牛顿法是求方程根的重要方法之一,其最大优点是在方程()0f x =的单根附近具有平方收敛,而且该法还可以用来求方程的重根、复根,此时非线性收敛,但是可通过一些方法变成线性收敛。
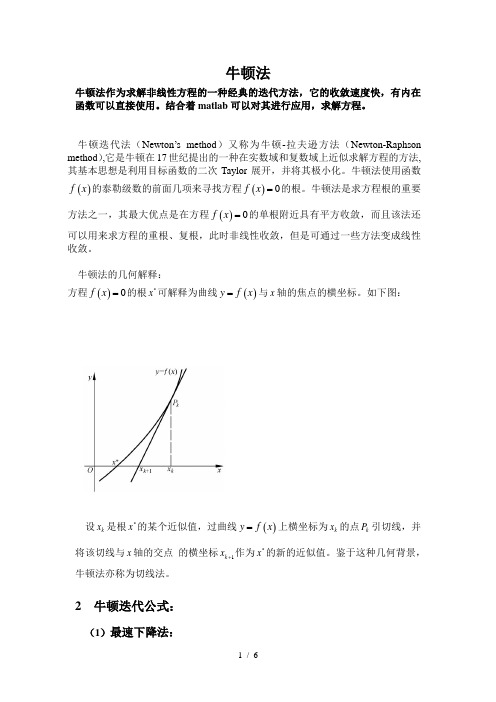
牛顿法的几何解释:方程()0f x =的根*x 可解释为曲线()y f x =与x 轴的焦点的横坐标。
如下图:设k x 是根*x 的某个近似值,过曲线()y f x =上横坐标为k x 的点k P 引切线,并将该切线与x 轴的交点 的横坐标1k x +作为*x 的新的近似值。
鉴于这种几何背景,牛顿法亦称为切线法。
2 牛顿迭代公式:(1)最速下降法:以负梯度方向作为极小化算法的下降方向,也称为梯度法。
设函数()f x 在k x 附近连续可微,且()0k k g f x =∇≠。
由泰勒展开式: ()()()()()Tk k k k fx f x x x f x x x ο=+-∇+- (*)可知,若记为k k x x d α-=,则满足0Tk k d g <的方向k d 是下降方向。
当α取定后,Tk k d g 的值越小,即T kk d g -的值越大,函数下降的越快。
由Cauchy-Schwartz 不等式:T k k kk d g d g ≤,故当且仅当k k d g =-时,Tk k d g 最小,从而称k g -是最速下降方向。
最速下降法的迭代格式为: 1k k k k x x g α+=-。
第二章一维搜素解析

不存在极值点
当x x0时,f x 0,当x x0时,f x 0,则x0为极小值
当x x0时,f x 0,当x x0时,f x 0,则x0为极大值
又 f x lim f x f x0
xx0 0
x x0
0,极小值
一维函数极值条件: f x0 0,且f x 0,极大值
0,非极值
(1) 如 果 f1
f
,
2
则
留
下
的
区
间
为[a,x2
]
(2) 如 果 f1
f
,
2
则
留
下
的
区
间
为[ x1,b]
(3) 如 果 f1
f
,
2
则
留
下
的
区
间
为[ x1,x2
]
a) f a1 f b1
b) f a1 f b1
迭代
迭代是重复反馈过程的活动,
其目的通常是为了逼近所需目标或结果。
每一次对过程的重复称为一次“迭代”,
B. 当 f1> f2 时,极小点必在[x1, b]中,则
x1 a, x2 x1, f2 f1, x2 a 0.618(b a), f2 f (x2 )
(4)判断是否满足精度要求。若新区间已缩短至预 定精度要求,即 b a ,则转第5)步;否则 转第3)步,进行下一次迭代计算。
迭代
• %求第十个斐波那契数
• a0=0
• a1=1
• for i=2:10
•
a2=a0+a1
•
a0=a1;a1=a2;
• end
•
• %求不大于100的最大斐波那契数
数学中的最优化方法

数学中的最优化方法数学是一门综合性强、应用广泛的学科,其中最优化方法是数学的一个重要分支。
最优化方法被广泛应用于各个领域,如经济学、物理学、计算机科学等等。
本文将从理论和应用两个角度探讨数学中的最优化方法。
一、最优化的基本概念最优化是在给定约束条件下,寻找使某个目标函数取得最大(或最小)值的问题。
在数学中,最优化可以分为无约束最优化和有约束最优化两种情况。
1. 无约束最优化无约束最优化是指在没有限制条件的情况下,寻找使目标函数取得最大(或最小)值的问题。
常见的无约束最优化方法包括一维搜索、牛顿法和梯度下降法等。
一维搜索方法主要用于寻找一元函数的极值点,通过逐步缩小搜索区间来逼近极值点。
牛顿法是一种迭代方法,通过利用函数的局部线性化近似来逐步逼近极值点。
梯度下降法则是利用函数的梯度信息来确定搜索方向,并根据梯度的反方向进行迭代,直至达到最优解。
2. 有约束最优化有约束最优化是指在存在限制条件的情况下,寻找使目标函数取得最大(或最小)值的问题。
在解决有约束最优化问题时,借助拉格朗日乘子法可以将问题转化为无约束最优化问题,进而使用相应的无约束最优化方法求解。
二、最优化方法的应用最优化方法在各个领域中都有广泛的应用。
以下将以几个典型的应用领域为例加以说明。
1. 经济学中的最优化在经济学中,最优化方法被广泛应用于经济决策、资源配置和生产计划等问题的求解。
例如,在生产计划中,可以使用线性规划方法来优化资源分配,使得总成本最小或总利润最大。
2. 物理学中的最优化最优化方法在物理学中也是常见的工具。
例如,在力学中,可以利用最大势能原理求解运动物体的最优路径;在电磁学中,可以使用变分法来求解电磁场的最优配置;在量子力学中,可以利用变分法来求解基态能量。
3. 计算机科学中的最优化在计算机科学中,最优化方法被广泛应用于图像处理、机器学习和数据挖掘等领域。
例如,在图像处理中,可以使用最小割算法来求解图像分割问题;在机器学习中,可以使用梯度下降法来求解模型参数的最优值。
牛顿迭代法(Newton‘s Method)

牛顿迭代法(Newton’s Method)又称为牛顿-拉夫逊(拉弗森)方法(Newton-Raphson Method),它是牛顿在17世纪提出的一种在实数域和复数域上近似求解方程的方法。
与一阶方法相比,二阶方法使用二阶导数改进了优化,其中最广泛使用的二阶方法是牛顿法。
考虑无约束最优化问题:其中 \theta^{\ast} 为目标函数的极小点,假设 f\left( \theta \right) 具有二阶连续偏导数,若第 k 次迭代值为 \theta^{k} ,则可将f\left( \theta \right)在\theta^{k}近进行二阶泰勒展开:这里,g_{k}=x^{\left( \theta^{k} \right)}=∇f\left( \theta^{k} \right)是f\left( \theta \right) 的梯度向量在点 \theta^{k}的值, H\left( \theta^{k} \right) 是 f\left( \theta \right) 的Hessian矩阵:在点 \theta^{\left( k \right)}的值。
函数 f\left( \theta \right) 有极值的必要条件是在极值点处一阶导数为0,即梯度向量为0,特别是当H\left( \theta\right) 是正定矩阵时,函数 f\left( \theta \right) 的极值为极小值。
牛顿法利用极小点的必要条件:这就是牛顿迭代法。
迭代过程可参考下图:在深度学习中,目标函数的表面通常非凸(有很多特征),如鞍点。
因此使用牛顿法是有问题的。
如果Hessian矩阵的特征值并不都是正的,例如,靠近鞍点处,牛顿法实际上会导致更新朝错误的方向移动。
这种情况可以通过正则化Hessian矩阵来避免。
常用的正则化策略包括在Hessian矩阵对角线上增加常数α 。
正则化更新变为:这个正则化策略用于牛顿法的近似,例如Levenberg-Marquardt算,只要Hessian矩阵的负特征值仍然相对接近零,效果就会很好。
第二章 一维极小化方法

2. 若 bk a k , 停止, 且
bk a k . 否则, 2 当 f ( k ) f ( k ) 时,转 3;当 f ( k ) f ( k ) 时,转 4. x
bk 1 bk ,
3. 令 a k 1 k ,
k 1 k ,
k 1 a k 1 0.618(bk 1 a k 1 ), 计算 f ( k 1 ), 令 k : k 1, 转 2。
b) 令一阶导函数为零,解得驻点
c) 根据驻点处的二阶导函数的符号,判断驻点是否为极小点
一. 一维优化问题
古典微分法的局限性
情况1:目标函数复杂,令导函数为零时得不到解析解(例2-1,2-2)
情况2:目标函数写不出明显的表达式(例2-3)
实际化工问题中,有许多属于以上两种情况,因此必须寻求其他方法进 行求解,而借助于计算机进行的数值计算方法则能够完成这一任务
要求其满足以下两个条 件:
1. bk λk μk ak β 1 α
(1)
ak
k
uk
bk
2. 每次迭代区间长度缩短 比率相同,即
bk 1 ak 1 α(bk ak ) 另 有 : k λk /αk μk αk μk /1 α 即 ,β/α α/1
由式( )与(2)可得: 1
[ a k 1 , bk 1 ] [ a k , uk ]。
在第 k 1 次迭代时选取 k 1 , uk 1 , 则由(4)有 uk 1 a k 1 (bk 1 a k 1 )
ak 2 (bk ak )
如果令 2 1 , uk 1 k ,因此 uk 1 不必重新计算 。 则
牛顿法

如前面所提到的,最速下降法在最初几步迭代中函数值下降很快外,总的说来下降的并不快,且愈接近极值点下降的愈慢。
因此,应寻找使目标函数下降更快的方法。
牛顿法就是一种收敛很快的方法,其基本思路是利用二次曲线来逐点近似原目标函数,以二次曲线的极小值点来近似原目标函数的极小值点并逐渐逼近改点。
一维目标函数()f x 在()k x 点逼近用的二次曲线(即泰勒二次多项式)为()()()()()()21()()()()()()2k k k k k k x f x f x x x f x x x ϕ'''=+-+- 此二次函数的极小点可由()()0k xϕ'=求得。
对于n 维问题,n 为目标函数()f X 在()k X 点逼近用的二次曲线为:()()()()()2()()1()()().[][].().[]2k k k k k T k k X f x f X X X X X f X X X ϕ⎡⎤=+∇-+-∇-⎣⎦令式中的Hessian 2()()()()k k f XH X ∇=,则上式可改写为:()()()()()()()1()()().[][].().[]2()k k k k k T k k X f x f X X X X X H X X X f X ϕ⎡⎤=+∇-+--⎣⎦≈当()0X ϕ∇=时可求得二次曲线()X ϕ的极值点,且当且仅当改点处的Hessian 矩阵为正定时有极小值点。
由上式得:()()()()()()[]k k k X f X H X X X ϕ∇=∇+-令()0X ϕ∇=,则()()()()()[]0k k k f X H X X X ∇+-=若()()k H X为可逆矩阵,将上式等号两边左乘1()()k H X -⎡⎤⎣⎦,则得1()()()()()[]0k k k n H X f X I X X -⎡⎤∇+-=⎣⎦整理后得1()()()()()k k k X X H X f X -⎡⎤=-∇⎣⎦当目标函数()f X 是二次函数时,牛顿法变得极为简单、有效,这时()()k H X 是一个常数矩阵,式()()()()()()()1()()().[][].().[]2()k k k k k T k k X f x f X X X X X H X X X f X ϕ⎡⎤=+∇-+--⎣⎦≈变成精确表达式,而利用式1()()()()()k k k X XH X f X -⎡⎤=-∇⎣⎦作一次迭代计算所得的X 就是最优点*X 。
凸优化之无约束优化(一维搜索方法:二分法、牛顿法、割线法)

凸优化之⽆约束优化(⼀维搜索⽅法:⼆分法、⽜顿法、割线法)1、⼆分法(⼀阶导)⼆分法是利⽤⽬标函数的⼀阶导数来连续压缩区间的⽅法,因此这⾥除了要求 f 在 [a0,b0] 为单峰函数外,还要去 f(x) 连续可微。
(1)确定初始区间的中点 x(0)=(a0+b0)/2 。
然后计算 f(x) 在 x(0) 处的⼀阶导数 f'(x(0)),如果 f'(x(0)) >0 , 说明极⼩点位于 x(0)的左侧,也就是所,极⼩点所在的区间压缩为[a0,x(0)];反之,如果 f'(x(0)) <0,说明极⼩点位于x(0)的右侧,极⼩点所在的区间压缩为[x(0),b0];如果f'(x(0)) = 0,说明就是函数 f(x) 的极⼩点。
(2)根据新的区间构造x(1),以此来推,直到f'(x(k)) = 0,停⽌。
可见经过N步迭代之后,整个区间的总压缩⽐为(1/2)N,这⽐黄⾦分割法和斐波那契数列法的总压缩⽐要⼩。
1 #ifndef _BINARYSECTION_H_2#define _BINARYSECTION_H_34 typedef float (* PtrOneVarFunc)(float x);5void BinarySectionMethod(float a, float b, PtrOneVarFunc fi, float epsilon);67#endif1 #include<iostream>2 #include<cmath>3 #include "BinarySection.h"45using namespace std;67void BinarySectionMethod(float a, float b, PtrOneVarFunc tangent, float epsilon)8 {9float a0,b0,middle;10int k;11 k = 1;12 a0 = a;13 b0 = b;14 middle = ( a0 + b0 )/2;1516while( abs(tangent(middle)) - epsilon > 0 )17 {18 #ifdef _DEBUG19 cout<<k++<<"th iteration:x="<<middle<<",f'("<<middle<<")="<<tangent(middle)<<endl;20#endif2122if( tangent(middle) > 0)23 {24 b0 = middle;25 }26else27 {28 a0 = middle;29 }30 middle =( a0+b0)/2;31 }3233 cout<<k<<"th iteration:x="<<middle<<",f'("<<middle<<")="<<tangent(middle)<<endl;34 }1 #include<iostream>2 #include "BinarySection.h"345float TangentFunctionofOneVariable(float x)6 {7return14*x-5;//7*x*x-5*x+2;8 }910int main()11 {12 BinarySectionMethod(-50, 50, TangentFunctionofOneVariable, 0.001);13return0;14 }1th iteration:x=0,f'(0)=-52th iteration:x=25,f'(25)=3453th iteration:x=12.5,f'(12.5)=1704th iteration:x=6.25,f'(6.25)=82.55th iteration:x=3.125,f'(3.125)=38.756th iteration:x=1.5625,f'(1.5625)=16.8757th iteration:x=0.78125,f'(0.78125)=5.93758th iteration:x=0.390625,f'(0.390625)=0.468759th iteration:x=0.195312,f'(0.195312)=-2.2656210th iteration:x=0.292969,f'(0.292969)=-0.89843811th iteration:x=0.341797,f'(0.341797)=-0.21484412th iteration:x=0.366211,f'(0.366211)=0.12695313th iteration:x=0.354004,f'(0.354004)=-0.043945314th iteration:x=0.360107,f'(0.360107)=0.041503915th iteration:x=0.357056,f'(0.357056)=-0.001220716th iteration:x=0.358582,f'(0.358582)=0.020141617th iteration:x=0.357819,f'(0.357819)=0.0094604518th iteration:x=0.357437,f'(0.357437)=0.0041198719th iteration:x=0.357246,f'(0.357246)=0.0014495820th iteration:x=0.357151,f'(0.357151)=0.0001144412、⽜顿法(⼆阶导)前提:f 在 [a0,b0] 为单峰函数,且[a0,b0] 在极⼩点附近,不能离的太远否则可能⽆法收敛。
拟牛顿法

•主页•专栏作家•量化基础理论•软件使用经验•量化软件•资源导航•资料下载•量化论坛搜索搜索用户登录用户名:*密码:*登录•创建新帐号•重设密码首页拟牛顿法及相关讨论星期三, 2009-06-17 00:24 —satchel1979使用导数的最优化算法中,拟牛顿法是目前为止最为行之有效的一种算法,具有收敛速度快、算法稳定性强、编写程序容易等优点。
在现今的大型计算程序中有着广泛的应用。
本文试图介绍拟牛顿法的基础理论和若干进展。
牛顿法(Newton Method)牛顿法的基本思想是在极小点附近通过对目标函数做二阶Taylor展开,进而找到的极小点的估计值[1]。
一维情况下,也即令函数为则其导数满足因此(1)将作为极小点的一个进一步的估计值。
重复上述过程,可以产生一系列的极小点估值集合。
一定条件下,这个极小点序列收敛于的极值点。
将上述讨论扩展到维空间,类似的,对于维函数有其中和分别是目标函数的的一阶和二阶导数,表现为维向量和矩阵,而后者又称为目标函数在处的Hesse矩阵。
设可逆,则可得与方程(1)类似的迭代公式:(2)这就是原始牛顿法的迭代公式。
原始牛顿法虽然具有二次终止性(即用于二次凸函数时,经有限次迭代必达极小点),但是要求初始点需要尽量靠近极小点,否则有可能不收敛。
因此人们又提出了阻尼牛顿法[1]。
这种方法在算法形式上等同于所有流行的优化方法,即确定搜索方向,再沿此方向进行一维搜索,找出该方向上的极小点,然后在该点处重新确定搜索方向,重复上述过程,直至函数梯度小于预设判据。
具体步骤列为算法1。
算法1:(1) 给定初始点,设定收敛判据,.(2) 计算和.(3) 若< ,则停止迭代,否则确定搜索方向.(4) 从出发,沿做一维搜索,令.(5) 设,转步骤(2).在一定程度上,阻尼牛顿法具有更强的稳定性。
拟牛顿法(Quasi-Newton Method)如同上一节指出,牛顿法虽然收敛速度快,但是计算过程中需要计算目标函数的二阶偏导数,难度较大。
简化牛顿法与牛顿下山法的比较

简化牛顿法与牛顿下山法的比较1.引言1.1 概述牛顿法和牛顿下山法都是用于求解方程根或最优化问题的常用数值计算方法。
牛顿法是一种迭代方法,通过使用函数的一阶和二阶导数来找到函数的零点或最小值。
而牛顿下山法则是对牛顿法的改进,在每次迭代时引入一个步长参数,以便更快地接近最优解。
在牛顿法中,我们首先需要给定一个初始猜测值,然后通过使用函数的一阶导数和二阶导数来更新猜测值,直到找到函数的零点或最小值。
牛顿法的优点在于其收敛速度较快,在适当的初始化条件下,通常能够快速找到解。
然而,牛顿法也存在局限性,例如可能出现迭代过程发散的情况,并且在某些情况下需要计算复杂的二阶导数。
与之相比,牛顿下山法在牛顿法的基础上引入了步长参数。
通过在每次迭代时选择合适的步长,可以更快地接近最优解。
牛顿下山法的优点在于其对初值的选择较为不敏感,即使初始猜测值较远离最优解,也能够通过适当的步长控制方法逐渐逼近最优解。
然而,牛顿下山法也存在局限性,例如可能会陷入局部最小值而无法找到全局最小值。
综上所述,牛顿法和牛顿下山法都是求解方程根或最优化问题的常用方法。
牛顿法适用于已知初始猜测值较接近最优解的情况,而牛顿下山法适用于对初始猜测值较不确定的情况。
根据具体的问题要求和初始条件,可以选择合适的方法来进行数值计算。
1.2文章结构文章结构是指文章的框架和组织方式,用于展示文章中各个部分之间的逻辑关系。
本文旨在比较简化牛顿法和牛顿下山法,因此文章的结构应该清晰地展示这两种方法的差异和优劣,同时对它们进行详细的介绍和分析。
下面是文章1.2部分的内容:1.2 文章结构在本文中,我们将按照以下结构来比较简化牛顿法和牛顿下山法:1.2.1 算法原理:- 简化牛顿法的算法原理:该部分将详细介绍简化牛顿法的基本思想和计算步骤,包括如何利用一阶导数和二阶导数进行迭代优化。
- 牛顿下山法的算法原理:这部分将详细介绍牛顿下山法的基本原理,包括如何结合简化牛顿法和线性搜索,在每次迭代中选择合适的下降方向。
极大化和极小化函数的方法

极大化和极小化函数的方法极大化和极小化函数的方法主要是指将函数最终达到极大值或极小值的计算过程。
一般来说可以采用梯度下降法(gradient descent)、牛顿法(Newton's Method)、拉格朗日法(Lagrange Multipliers)、或者其他的优化方法来实现极大化和极小化函数的目标。
梯度下降法是一种基于步长搜索的独立变量函数最小化法,它通过使用梯度指示器对对函数进行逐步迭代来搜索最小点。
每一次迭代,它会考虑在梯度方向上的升降来选择下次迭代的位置,并按照梯度的大小来改变迭代的步长大小。
当梯度的值接近于零时,会收敛到最优值。
弊端是当函数处于非凸空间时,求解出的结果会受到起始点的影响,可能得到的答案不是最优的。
牛顿法是用于求解非线性函数极值的方法,它使用x在函数f(x)附近的一阶导数和二阶导数来确定跳跃位置。
它最大的优点是可以在收敛速度上快于梯度下降法,并且可以从任何一点开始,例如局部极值。
然而,这种方法也有一些局限性,牛顿法不适合处理多维空间,它只能处理单元素函数,并且当函数极值有许多个点时,牛顿法可能会陷入局部极小值点而不是全局极小值点。
拉格朗日法是一种在极大化和极小化函数时常见的优化方法。
它结合了梯度下降法和牛顿法,可以发现函数极值的极小点。
它的基本思想是,对于给定的对偶变量Λ,把原始函数改写成一个新的函数F,然后根据牛顿法或梯度下降法求解F的极值。
这种方法能够从不同的角度考虑最优化问题,避免陷入局部极小值。
另外,还有一些其他的优化方法,可以用来求解极大化和极小化函数的极值,比如:Simulated Annealing Algorithm(模拟退火算法), Genetic Algorithm(遗传算法), Particle Swarm Optimization(粒子群优化)等。
所有这些方法都旨在找出函数最优解,不同优化算法有一定的适用范围,在不同场景下,需要选择合适的优化方法,以达到最优解。
牛顿法二阶矩阵为正定矩阵-概述说明以及解释

牛顿法二阶矩阵为正定矩阵-概述说明以及解释1. 引言1.1 概述牛顿法是一种经典的数值优化方法,广泛应用于求解非线性方程、最优化问题等数学领域。
其基本思想是通过不断迭代逼近函数的最优解。
在牛顿法中,二阶矩阵的正定性是一个重要的条件,它影响着算法的稳定性、迭代速度以及收敛性。
二阶矩阵是指一个矩阵的维度为2×2,可以表示为:A = [a11 a12a21 a22]正定矩阵是指所有特征值均为正的矩阵。
对于二阶矩阵来说,它是正定矩阵的条件是主对角线元素a11和a22大于0,并且行列式a11*a22 - a12*a21大于0。
牛顿法中,二阶矩阵为正定矩阵的意义不容忽视。
首先,算法的稳定性得到了保证。
正定矩阵保证了牛顿法每次迭代都能够朝着极小值点的方向前进,避免了出现震荡、发散等问题。
其次,正定矩阵的存在保证了牛顿法的收敛性。
正定矩阵可以保证牛顿法的收敛速度比其他方法更快,能够更快地逼近最优解。
最后,正定矩阵的存在也影响了牛顿法的迭代速度。
正定矩阵可以提供更精确的方向信息,使得牛顿法能够更快地寻找到最优解。
综上所述,牛顿法中二阶矩阵为正定矩阵是非常重要的。
它保证了算法的稳定性、收敛性和迭代速度,为牛顿法的应用奠定了基础。
在实际问题中,我们需要对二阶矩阵的正定性进行判断,以确保牛顿法能够有效地求解问题。
对于二阶矩阵的正定性的重视,也引发了对于正定矩阵性质的深入研究和应用的重要性。
文章结构部分的内容可以如下所示:1.2 文章结构本文将以牛顿法二阶矩阵为正定矩阵为主题,从引言、正文和结论三个部分来展开。
具体结构如下:引言部分将对文章的主题进行概述,介绍牛顿法的基本原理和应用领域,并指出本文的目的。
正文部分将分为三个主要章节,分别为牛顿法简介、二阶矩阵与正定矩阵以及牛顿法中二阶矩阵为正定矩阵的意义。
其中,通过对牛顿法的原理、应用领域以及优缺点的介绍,读者可以对牛顿法有一个全面的了解。
然后,通过对二阶矩阵和正定矩阵的定义以及二阶矩阵为正定矩阵的条件进行讲解,读者可以掌握相关概念和定理。
拟牛顿法
•主页•专栏作家•量化基础理论•软件使用经验•量化软件•资源导航•资料下载•量化论坛搜索搜索用户登录用户名:*密码:*登录•创建新帐号•重设密码首页拟牛顿法及相关讨论星期三, 2009-06-17 00:24 —satchel1979使用导数的最优化算法中,拟牛顿法是目前为止最为行之有效的一种算法,具有收敛速度快、算法稳定性强、编写程序容易等优点。
在现今的大型计算程序中有着广泛的应用。
本文试图介绍拟牛顿法的基础理论和若干进展。
牛顿法(Newton Method)牛顿法的基本思想是在极小点附近通过对目标函数做二阶Taylor展开,进而找到的极小点的估计值[1]。
一维情况下,也即令函数为则其导数满足因此(1)将作为极小点的一个进一步的估计值。
重复上述过程,可以产生一系列的极小点估值集合。
一定条件下,这个极小点序列收敛于的极值点。
将上述讨论扩展到维空间,类似的,对于维函数有其中和分别是目标函数的的一阶和二阶导数,表现为维向量和矩阵,而后者又称为目标函数在处的Hesse矩阵。
设可逆,则可得与方程(1)类似的迭代公式:(2)这就是原始牛顿法的迭代公式。
原始牛顿法虽然具有二次终止性(即用于二次凸函数时,经有限次迭代必达极小点),但是要求初始点需要尽量靠近极小点,否则有可能不收敛。
因此人们又提出了阻尼牛顿法[1]。
这种方法在算法形式上等同于所有流行的优化方法,即确定搜索方向,再沿此方向进行一维搜索,找出该方向上的极小点,然后在该点处重新确定搜索方向,重复上述过程,直至函数梯度小于预设判据。
具体步骤列为算法1。
算法1:(1) 给定初始点,设定收敛判据,.(2) 计算和.(3) 若< ,则停止迭代,否则确定搜索方向.(4) 从出发,沿做一维搜索,令.(5) 设,转步骤(2).在一定程度上,阻尼牛顿法具有更强的稳定性。
拟牛顿法(Quasi-Newton Method)如同上一节指出,牛顿法虽然收敛速度快,但是计算过程中需要计算目标函数的二阶偏导数,难度较大。
python牛顿法求解二元二次方程的极小值点

一、概述本文将介绍如何利用Python的牛顿法求解二元二次方程的极小值点。
牛顿法是一种数值优化方法,通过不断逼近函数的极小值点来求解最优解。
二元二次方程是数学中常见的函数形式,通过牛顿法求解其极小值点可以帮助我们优化问题,找到最佳的解决方案。
二、二元二次方程及其极小值点二元二次方程的一般形式为:f(x, y) = ax^2 + by^2 + cxy + dx + ey + f其中,a、b、c、d、e、f为系数,x、y为变量。
二元二次方程的极小值点即为函数f(x, y)取得最小值的点。
通过求解极小值点,我们可以找到函数的最优解,从而解决实际问题或优化算法。
三、牛顿法求解二元二次方程的极小值点牛顿法是一种迭代求解极值点的方法,其迭代公式为:x(k+1) = x(k) - H^(-1) * ∇f(x(k))其中,x(k)为第k次迭代的值,H为函数f的Hessian矩阵,∇f为函数f的梯度向量。
牛顿法通过不断更新变量的值,逼近函数的极小值点。
四、利用Python实现牛顿法求解二元二次方程的极小值点下面我们将通过Python代码实现牛顿法求解二元二次方程的极小值点。
我们定义二元二次函数的系数,然后编写牛顿法的迭代过程,最终求得函数的极小值点。
1. 定义二元二次函数我们首先需要定义二元二次函数f(x, y)及其梯度和Hessian矩阵。
假设我们要求解的二元二次函数为:f(x, y) = 2x^2 + 3y^2 + 4xy + 5x + 6y + 7我们可以使用SymPy库来对函数进行符号运算,求取梯度和Hessian矩阵。
2. 实现牛顿法接下来,我们编写Python代码实现牛顿法的迭代过程。
我们需要计算函数的梯度和Hessian矩阵,并根据迭代公式进行更新,直至收敛到极小值点。
3. 求解极小值点我们利用实现的牛顿法算法,对定义的二元二次函数进行求解,得到函数的极小值点。
五、实例演示下面我们通过一个具体的实例来演示如何利用Python的牛顿法求解二元二次方程的极小值点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(2) 初始点的选取困难,甚至无法实施。 ) 初始点的选取困难,甚至无法实施。
(3)
−1 G k 的存在性和计算量问题
。
问题一: 问题一: 如何使得 f ( x k + 1 ) < f ( x k ) ?
法中, 在 Newton 法中,有
− x k +1 = x k − G k 1 g k = x k + d k
而
t k = 1。
3. 算法步骤
step 1. 给定初始点 x 0,精度 ε > 0 , k := 0
step2. 计算g k = ∇f ( x k )和G k = ∇ 2 f ( x k )
− 可逆时, 当 G k 可逆时, x k + 1 = x k − G k 1 g k 。
step3. 由方程组∇Q( x ) = g k + G k ( x − x k ) = 0 解出x k +1
− H k ≈ Gk1
↔
− 如何保证 H k > 0和 H k ≈ G k 1 ?
如何确定 ∆ H k ?
拟 Newton 条件
− 拟 Newton 条件 ↔ H k ≈ G k 1
分析: − 需满足的条件, G 分析: k 1 需满足的条件,并利用 此条件确定 H k 。
记 g ( x ) = ∇ f ( x ), g k = ∇ f ( x k ) G k = ∇ f 2 ( x k ), 则因为
f ( x ) ≈ f ( x k +1 ) + ∇f ( x k +1 )T ( x − x k +1 )
1 + ( x − x k +1 )T ∇ 2 f ( x K +1 )( x − x k +1 ) 2
g ( x ) ≈ g ( x k + 1 ) + ∇ 2 f ( x k + 1 )( x − x k + 1 )
T − − 当Gk > 0 时, ∇f ( x k )T d k = −∇f ( x k )T Gk 1 gk = − gk Gk 1 gk < 0 , 有
∴ 当Gk > 0 时, k 是下降方向。 d 是下降方向。
如果对 Newton 法稍作修正: 法稍作修正: x
k +1
= x + tk d
k
k
令
∇Q(x) = gk +Gk(x − x ) = 0
k
正定, 若 Hesse 矩阵 G k 正定,即 G k > 0,
− 则 G k 1 > 0,此时有
− x k +1 = x k − G k 1 g k
这就是 Newton 迭代公式 。
比较迭代公式
− d k = −G k 1 g k ,
x k +1 = x k + t k d k , 有
step4. 若 || ∇f ( x
k +1
) ||< ε , 停止, = x 停止, x
*
k +1
;
令 否则, k := k + 1 , 转step 4 。
4. 算法特点
收敛速度快,为二阶收敛。 初始点要选在初始点附近。
5. 存在缺点及修正
(1) f ( x k +1 ) < f ( x k ) ?
一、Newton 法
1. 问题
min f ( x )
x∈R n ∈ n
f ( x )是R 上二次连续可微函数 即f ( x ) ∈ C ( R )
2 n
2. 算法思想
x → x →L→ x → x
0 1 k k +1
→L
为了由 x 产生x
k
k +1
,用二次函数 Q( x )近似f ( x )。
f ( x) ≈ Q( x) = f ( xk ) + ∇f ( xk )T ( x − xk ) + 1 k T 2 k k + ( x − x ) ∇ f ( x )(x − x ) 2 1 k T k k T k = f ( x ) + gk ⋅ ( x − x ) + ( x − x ) Gk ( x − x ) 2 其中 g k = ∇f ( x k )T , G k = ∇ 2 f ( x k )。
xT I x
法为变尺度算法。 称 Newton 法为变尺度算法。
3.
附加某些条件使得: 如何对 H k 附加某些条件使得: (1)迭代公式具有下降性 质 (2) H k 的计算量要小 (3)收敛速度要快↔源自↔Hk > 0
H k +1 = H k + ∆H k ( ∆H k = H k +1 − H k )
t k : f ( x k + t k d k ) = min f ( x k + t d k )
则有: 则有: f ( x k + 1 ) < f ( x k ) 。
问题二: 如何克服缺点( 问题二: 如何克服缺点( 2)和( 3) ?
二、拟 Newton 算法
1.
k +1 k −1 k
( 变尺度法 )
k
迭代公式: 先考虑 Newton 迭代公式: x = x − G ∇f ( x )
迭代公式中, 在 Newton 迭代公式中,如果我们 用
− 则有: 正定矩阵 H k 替代 G k 1,则有:
x k +1 = x k − H k ∇ f ( x k )
2.
考虑更一般的形式: 考虑更一般的形式: x k +1 = x k − t k H k ∇ f ( x k )
Step 1 . 给定初始点 x 0 ,正定矩阵 H 0 , 精度 ε > 0, k := 0
step 3. 令 x k + 1 = x k + t k d k , 其中 t k : f ( x k + t k d k ) = min f ( x k + t d k )。
x k +1 = x k − t k H k ∇f ( x k ) H k ≡ I时 ⇒ 梯度法 最速下降方向 d k = −∇ f ( x k ) , 度量为 x =
− H k = G k 1时 ⇒ Newton 法 − 最速下降方向 d k = − G k 1∇ f ( x k ), 度量为 x = − xT Gk 1 x
g k ≈ g k +1 + G k +1 ( x k − x k +1 )
−1 G k +1 ( g k +1 − g k ) = x k +1 − x k ,
这样我们想到
记 y k = g k + 1 − g k , s k = x k + 1 − x k , 则有
4、拟 Newton 算法
( 变尺度法 )的一般步骤; 的一般步骤;