dwbasics (Data WH)
浅析数据库(DB)、操作数据存储(ODS)和数据仓库(DW)的区别与联系

浅析数据库(DB)、操作数据存储(ODS)和数据仓库(D W)的区别与联系文章背景:相信大部分刚接触上面三个概念的同学,都多多少少会有些迷惑,现在我就给大家简单分析下这三者的关系,希望大家对这三者的概念理解有所帮助吧。
本文主要从下面两类关系来叙述上面三者的关系:1. 数据库(DB)和数据仓库(DW)的区别与联系2. 操作数据存储(ODS)和数据仓库(DW)的区别与联系数据库与数据仓库的区别与联系数据库与数据仓库基础概念:数据库:传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
数据仓库:数据仓库系统的主要应用主要是OLAP(On-Line Analytical Proces sing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP和OLAP概念补充:数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction proc essing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
举一个具体的例子:(转自知乎作者:陈诚),个人觉得例子描述的很清晰举个最常见的例子,拿电商行业来说好了。
基本每家电商公司都会经历,从只需要业务数据库到要数据仓库的阶段。
第一阶段,电商早期启动非常容易,入行门槛低。
找个外包团队,做了一个可以下单的网页前端+ 几台服务器+ 一个MySQL,就能开门迎客了。
这好比手工作坊时期。
第二阶段,流量来了,客户和订单都多起来了,普通查询已经有压力了,这个时候就需要升级架构变成多台服务器和多个业务数据库(量大+分库分表),这个阶段的业务数字和指标还可以勉强从业务数据库里查询。
DW总体工具介绍(经典)

DW总体工具介绍(转)数据仓库项目是以关系数据库为依托,以数据仓库理论为指导、以OLAP 为多层次多视角分析,以ETL工具进行数据集成、整合、清洗、加载转换,以前端工具进行前端报表展现浏览,以反复叠代验证为生命周期的综合处理过程。
最终目标是为了达到整合企业信息,把数据转换成信息、知识,提供决策支持。
数据仓库不是一门纯粹的技术,如果从Oracle、SQLServer等专业数据库的角度去学习,就有失偏颇了。
数据仓库应该是一种体系结构,它的核心是在于对于数据的整合,通过抽丝剥茧把企业原始数据进行集成、归类、分析,从而提供了企业决策分析需要的KPI。
数据库和数据仓库从物理设计角度应该是一致的,都是基于传统的关系数据库理论,而且这两者有融合的趋势。
SQLServer,Sybase,DB2,Oracle都是传统的关系数据库,同时只要经过认真的数据模型设计或者参数设置也可以变成很好的数据仓库实体;与此同时数据仓库也在基于自身的特点不断地进行发展演变,例如SybaseIQ、Terradata就是完全的数据仓库,用它来设计OL TP系统显然是存在各种问题的。
OLAP也逐渐被融合到数据库和数据仓库产品中来,例如微软的Analysis Se rvice 和 DB2的OLAP Server,通过自身提供的专用接口可以加快多维数据的转换处理。
当然象Essbase这样纯粹的OLAP也是非常优秀的产品,实际上80%以上的大型OLAP都是采用Essbase的。
说到ETL,一般市场上最重要最全面的还是Informatica,但是关系数据库厂商通过自身的吸取和发展得以改进后,仍旧在不断蚕食这一市场,最常见的是与SQLServer搭配的SSIS和Oracle的OWB。
报表工具呢,还是原来的几个专业工具厂商,Hyperion,BO,Congos,Brio,当然价格也不菲,如果想用便宜的还是请选用微软的ReportService吧。
《DW基础教程》课件

ETL是指将数据从源系统抽取(Extract)、转换 (Transform)并加载(Load)到数据仓库中的 过程。
Transform的操作
Transform操作包括数据清洗、转换和整合,使 数据适应数据仓库的要求。
Extract的操作
Extract操作包括读取源系统的数据、验证数据的 完整性和一致性等。
章节四:DW的设计
DW的数据仓库设计
数据仓库的设计包括定义维度和事实表、确定数据仓库的模式和粒度。
维度和事实表的设计
维度表用于描述业务维度,事实表用于存储业务指标,两者之间通过关联关系建立连接。
关联关系的建立
在DW中,可以通过定义和维护外键关系来建立维度表和事实表的关联关系。
章节五:DW的ETL
章节三:DW的数据源
数据的概念
数据是指记录事实和描述属 性的信息,可以分为结构化 数据、半结构化数据和非结 构化数据。
数据源的类型
数据源包括关系型数据库、 文件系统、Web服务、传感 器数据等,用于提供数据仓 库的输入。
创建数据源
在DW中,可以通过配置连接 参数、选择数据源类型和指 定数据源位置来创建数据源。
子查询
子查询是指嵌套在其他查询中的查询语句,用 于在查询中使用查询结果。
章节七:DW的应用实例
薪酬管理系统
薪酬管理系统利用数据仓库分析员工薪酬情况,为企业的薪酬决策提供支持。
客户关系管理系统
客户关系管理系统利用数据仓库分析客户的购买行为和需求,为企业的营销策略提供指导。
营销分析系统
营销分析系统利用数据仓库分析市场趋势、产品销售和竞争对手,为企业的营销决策提供支 持。
DW的安装
学习和使用DW前,需要安装适合的DW软件,如Oracle Data Warehouse或Microsoft SQL Server。
dw知识点总结

dw知识点总结DW概念Data Warehousing是指从多个数据源中提取、转换和加载数据,并将其存储在一个集中的数据库或存储器中的过程。
DW主要用于支持企业决策制定,通过提供一致的、集成的和易于访问的数据来支持数据分析和报告。
主要特点包括:·集成:将来自不同数据源的数据合并,以便进行分析。
·非易失性:存储的数据通常是只读的,不会被修改或删除。
·主题导向:将数据以主题为中心进行组织,而不是按照应用程序或功能。
·时间性:数据存储会追踪时间变化,使用户能够进行历史数据分析。
DW架构DW架构包括数据提取、清洗、转换和加载(ETL),存储和元数据管理等组件。
常见的DW架构包括:企业数据仓库(EDW)、数据集市和操作数据存储(ODS)。
EDW是一个主要的DW系统,用于整合企业级数据,并支持高级分析和报告。
数据集市是一个专门的DW系统,提供特定主题的数据。
ODS是一个用于操作和实时决策支持的数据存储。
这些组件共同构成了一个完整的DW系统。
数据模型数据模型是DW的核心,它描述了数据在DW系统中的组织方式。
常见的数据模型包括:·星型模式:使用一个中心的事实表,连接到多个维度表。
·雪花模式:在星型模式的基础上,维度表进一步规范化,形成多层结构。
·灵活的模式:使用多个事实表和维度表,构建更复杂的关联结构。
ETL过程ETL过程包括三个主要步骤:数据提取、数据转换和数据加载。
数据提取是从不同数据源中获取数据,数据清洗和转换是对数据进行清理、处理和规范化,数据加载是将处理过的数据加载到DW系统中。
ETL工具是用于支持ETL过程的软件,如Informatica、SSIS和DataStage等。
数据分析数据分析是DW的一个主要应用场景,包括查询和报表、数据挖掘和预测分析等。
通过数据分析,企业能够发现潜在的商业机会、识别趋势和模式,并做出更明智的决策。
常用的数据分析工具包括Tableau、QlikView、Power BI和MicroStrategy等。
GWBASIC使用手册

第1章 BASIC语言的特点及运行环境 (1)1.1 BASIC语官的发展与版本简介 (1)1.2 GWBASIC语言的特点 (1)1.3 GWBASIC的运行环境 (1)1.4 GWBASIC的启动 (2)1.5 BASIC的使用方式 (2)1.5.1 直接方式 (3)1.5.2 间接方式 (3)1.5.3 BASIC的退出 (3)第2章 BASIC的词法规则 (4)2.1 BASIC字符集 (4)2.2 BASIC保留字 (4)2.3 BASIC常数 (6)2.3.1 数值常数 (6)2.3.2 字符常数 (7)2.3.3 逻辑常数 (7)2.4 变量 (7)2.4.1 变量的类型 (7)2.4.2 变量的命名规则 (7)2.4.3 变量类型的说明 (7)2.5 下标变量 (8)2.5.1 数组 (8)2.5.2 下标变量 (9)2.5.3 下标变量的有关规定 (10)2.6 BASIC函数 (10)2.6.1 内部函数 (10)2.6.2 自定义函数 (15)2.7 运算符与表达式 (16)2.7.1 算术表达式 (16)2.7.2 关系表达式 (17)2.7.3 逻辑表达式 (17)2.7.4 复合逻辑表达式的运算顺序 (19)2.7.5 字符串表达式 (19)第3章 BASIC的程序结构 (21)3.1 BASIC语句和命令 (21)3.1.1 BASIC语句 (21)3.1.2 BASIC命令 (21)3.2 BASIC程序结构 (22)第4章 BASIC输入和输出 (23)4.1 输入数据的语句 (23)4.1.1 LET语句 (23)4.1.2 INPUT语句 (23)4.1.3 READ语句 (24)4.1.4 DATA语句 (24)4.1.5 RESTORE语句 (25)4.1.6 LINE INPUT语句 (25)4.1.7 SWAP语句 (26)4.2 输出语句 (26)4.2.1 PRINT语句 (26)4.2.2 PRINT USING语句 (27)4.2.3 LPRINT语句 (28)4.2.4 LPRINT USING语句 (28)4.3 输入、输出的辅助函数及变量 (29)4.3.1 TAB函数 (29)4.3.2 SPC函数 (29)4.3.3 LPOS函数 (29)4.3.4 INPUT$函数 (29)4.3.5 INKEY$变量 (30)4.4 提供系统日期和时间的语句和变量 (30)4.4.1 TIME$语句 (30)4.4.2 TIME$变量 (30)4.4.3 DATE$语句 (30)4.4.4 DATE$变量 (31)第5章 控制语句 (32)5.1 无条件控制转移语句 (32)5.1.1 GOTO语句 (32)5.1.2 GOSUB语句 (32)5.2 有条件转移语句 (33)5.2.1 IF语句 (33)5.2.2 ON n GOTO语句 (34)5.2.3 ON n GOSUB语句 (34)5.2.4 ON ERROR GOTO语句及相关变量 (34)5.2.5 ON KEY(n)GOSUB语句 (36)5.2.6 ON PLAY(n) GOSUB语句 (36)5.2.7 ON TIMER(n) GOSUB语句 (37)5.2.8 ON COM(n) GOSUB语句 (37)5.2.9 光笔控制语句与函数 (38)5.2.10 游戏杆操作的控制语句及函数 (38)5.3 循环控制 (39)5.3.1 FOR...NEXT语句 (39)5.3.2 WHILE...WEND语句. (41)第6章 数据文件及操作 (42)6.1 BASIC数据文件的有关概念 (42)6.1.1 数据文件的命名规则 (42)6.1.2 数据文件的分类 (43)6.2 顺序数据文件的建立和输入、输出 (43)6.2.1 顺序数据文件的打开和关闭 (43)6.2.2 顺序文件的输入和输出 (44)6.3 随机文件的建立和输入、输出 (46)6.3.1 随机文件的打开和关闭 (46)6.3.2 类型转换函数 (47)6.3.3 随机文件的输出有关语句 (48)6.3.4 随机文件的输入语句及转换函数 (48)第7章 BASIC绘图 (50)7.1 绘图环境的设置 (50)7.1.1 彩色图形显示器的工作模式 (50)7.1.2 显示器工作模式的选择语句 (51)7.1.3 绘图环境设置的其他语句 (53)7.2 绘图语句及相关函数 (54)7.2.1 画点、擦点语句 (54)7.2.2 画线语句 (55)7.2.3 画圆、圆弧及填充语句 (57)7.3 窗口与视口设置 (58)7.3.1 WINDOW语句 (58)7.3.2 VIEW语句 (59)7.4 动画设计语句及函数 (59)7.4.1 字符动画函数和变量 (59)7.4.2 图形模式下的动画设计语句和函数 (60)7.5 DXY-880A绘图仪BASIC命令 (61)7.5.1 DXY-880A绘图仪的联机方式 (61)7.5.2 DXY绘图命令 (62)第8章 GWBASIC的特殊语句及函数 (67)8.1 BASIC通信 (67)8.1.1 通信文件的打开与关闭 (67)8.1.2 通信文件的输入与输出 (68)8.2 机器级语句及函数 (68)8.2.1 机器级基本语句及函数 (68)8.2.2 机器语言子程序的调用 (71)8.3 其他语句 (71)8.3.1 CHAIN语句 (71)8.3.2 COMMON语句 (72)第9章 BASIC命令与键盘操作 (73)9.1 编辑命令 (73)9.1.1 AUTO命令 (73)9.1.2 RENUM命令 (73)9.1.3 DELETE命令 (73)9.1.4 EDIT命令 (74)9.1.5 LIST命令 (74)9.1.6 LLIST命令 (74)9.1.7 NEW命令 (74)9.2 文件的管理与操作命令 、 (75)9.2.1 FILES命令 (75)9.2.2 LOAD命令 (75)9.2.3 SAVE命令 (75)9.2.4 BSAVE命令 (75)9.2.5 BLOAD命令 (76)9.2.6 KILL命令 (76)9.2.7 NAME命令 (76)9.2.8 MERGE命令 (76)9.2.9 目录管理命令 (77)9.3 程序的执行命令 (77)9.3.1 RUN命令 (77)9.3.2 CLEAR命令 (78)9.3.3 RESET命令 (78)9.3.4 SYSTEM命令 (78)9.3.5 程序追踪命令 (78)9.3.6 CONT命令 (79)9.4 BASIC屏幕编辑键 (79)9.5 BASIC功能键的定义及使用 (80)9.5.1 命令功能键的定义及使用 (80)9.5.2 语句功能键 (80)第10章 编译BASIC (82)10.1 编译BASIC的构成 (82)10.2 编译BASIC的使用 (82)10.2.1 源程序编译 (82)10.2.2 目标程序的连接 (84)10.2.3 程序的执行 (84)10.3 编译BASIC与解释BASIC的主要区别 (84)10.3.1 操作命令的区别 (84)10.3.2 说明语句的区别 (85)附录A GWBASIC命令、语句和函数索引 (86)附录B ASCII字符代码表 (92)附录C GWBASIC错误信息 (97)附录D GWBASIC专用键 (103)第1章 BASIC语言的特点及运行环境1.1 BASIC语官的发展与版本简介BASIC语言是国际上通用的计算机语言之一,各种规模的计算机系统均配有BASlC语言。
DW统计量的名词解释

DW统计量的名词解释DW统计量是一种常用的经济学和统计学中的指标,用于评估时间序列数据的自相关性。
它的全称为“Durbin-Watson统计量”,得名于经济学家 James Durbin 和Geoffrey Watson。
DW统计量是一种检验自相关性的工具,可以用于判断时间序列数据是否存在一定的自相关性,以及自相关性的程度。
在解释DW统计量之前,我们先来了解一下什么是自相关性。
自相关性是指时间序列数据中的数据点与其自身在不同时间点的相关性。
换句话说,自相关性反映了数据点之间的时间依赖关系。
例如,一组表示股票价格的时间序列数据,如果在某个时间点的价格与前一天的价格存在较高的相关性或者模式,就可以说该数据存在自相关性。
DW统计量的计算方法是基于时间序列的残差,它是观测值与预测值之间的差异。
残差的计算公式为 Yt - Yt_hat,其中 Yt 表示观测值,Yt_hat 表示基于模型的预测值。
DW统计量的计算公式为:DW = Σ(et - et-1)^2 / Σet^2其中 et 表示残差序列,et-1 表示残差序列的滞后一期值。
DW统计量的取值范围为0到4,DW=2 表示数据不存在自相关性,DW小于2表示数据存在正自相关性,DW大于2表示数据存在负自相关性。
DW越接近于0或4,自相关性越强烈;而DW越接近于2,说明数据的自相关性较弱。
DW统计量的解释有一些限制和注意事项。
首先,DW统计量只适用于线性回归模型和时间序列样本量较大的数据,对于其他类型的模型和小样本数据,DW统计量的解释可能不准确。
其次,DW统计量只能检验一阶自相关性,对于高阶自相关性的检验需要使用其他的统计检验方法或模型。
除了DW统计量,还有一些其他的统计量也可以用于时间序列数据的自相关性检验,例如Ljung-Box统计量和Breusch-Godfrey统计量等。
同时,值得注意的是,在使用DW统计量进行自相关性检验时,也需要结合其他的统计方法和技巧,例如画残差图、观察偏自相关图等。
dw代码大全

DW代码大全1. 简介本文档是关于DW(Data Warehouse)代码的详细指南,旨在帮助开发人员快速了解和使用DW代码。
DW是一种用于分析和报告的数据存储和处理技术,它能够将不同来源的数据整合起来,支持复杂的查询和分析操作。
本文档将涵盖DW的基本概念、数据准备、数据加载、数据转换等方面的内容,并提供了一些示例代码和最佳实践供读者参考。
2. DW基本概念2.1 什么是DWDW(Data Warehouse)是指一种用于存储和处理大量数据的技术,它将来自不同来源的数据整合起来,并提供了一种便于查询和分析的方式。
DW通常采用星型或雪花型的数据模型,使用ETL(Extract、Transform、Load)过程将数据从原始数据源中抽取、转换和加载到DW中。
2.2 DW的优势•高性能:DW通常具有优化的查询性能,能够对大规模数据进行快速查询和分析。
•强大的分析能力:DW提供了丰富的分析功能,能够支持复杂的查询和数据挖掘操作。
•数据整合:DW能够将来自不同来源的数据整合起来,提供一致的视图。
•历史数据存储:DW可以存储历史数据,支持时间序列分析和趋势预测等操作。
3. 数据准备在开始构建DW之前,需要进行数据准备工作,包括数据清洗、数据集成、数据转换等过程。
3.1 数据清洗数据清洗是指对原始数据进行预处理,去除重复数据、填充缺失值、处理异常值等。
常用的数据清洗技术包括数据去重、缺失值处理、异常值检测和处理等。
以下是一个用Python实现数据清洗的示例代码:import pandas as pd# 读取原始数据data = pd.read_csv('raw_data.csv')# 去重data = data.drop_duplicates()# 处理缺失值data = data.fillna(0)# 处理异常值data = data[(data['value'] >=0) & (data['value'] <=100)]3.2 数据集成数据集成是指将来自不同数据源的数据整合到一起,创建一个统一的数据视图。
dw数据仓库

粒度
第一种粒度:对数据仓库中的数据综合程
度高低的度量,它影响数据仓库中数据量 的多少,也影响所能回答问题的种类。
第二种粒度:样本数据库采样率的高低。
(采样粒度不同的样本数据库可以有相同 级别的综合级别。)
分割
将数据分散到各自的物理单元中去以便能分别独
立处理,以提高处理效率,数据分割后的数据单 元称为分片。 分割的一个例子 健康保险 生命保险 事故保险
数据库体系化环境
什么是数据库体系化环境? 四层体系化环境 数据集市
什么是数据库体系化环境
数据库体系化环境是在一个企业或组织内,
由各面向应用的OLTP数据库及各级面向 主题的数据仓库所组成的完整的数据环境, 在这个数据环境上建立和进行一个企业或 部门的从联机事务处理到企业管理决策的 所有应用。 两个组成部分:
数据仓库数据的不可更新性
数据仓库的数据主要提供企业决策分析之
用,所涉及的数据操作主要是数据查询, 一般情况不进行修改操作。
数据仓库数据的时变性
数据仓库随时间变化不断增加新的数据内容;
数据仓库随时间变化不断删去旧的数据内容;
数据仓库中含有大量的综合数据,这些数据随时
间变化不断进行重新组合。
DW的设计是从已有的DB系统出发,按照分析领域对
数据及数据之间的联系重新考察、组织DW中的主题。
系统设计方法的中心是利用数据模型有效地识别原有
的数据库中的数据和数据仓库中主题的数据的“共同 性”。
数据模型 是数据驱动设计方法的中心
操作型环境设计
数据仓库设计
DB
DB DW DB 数据模型
操作型处理应用 开发与设计
ODS的定义与特点
dw知识点总结大学

dw知识点总结大学数据仓库(Data Warehouse,DW)是用于支持管理决策的关键任务和关键业务活动的数据仓库。
DW将各种数据源中的数据整合在一起,以提供单一、一致的视图,使得企业的管理者和决策者能够更好地理解数据和作出合理的决策。
数据仓库的核心功能包括数据整合、数据分析和数据处理等。
数据仓库通常处理海量的数据,因此其设计和建设需要充分考虑数据的规模和性能等方面的问题。
另外,DW还需要支持多维分析、数据挖掘等高级数据分析功能,以满足企业管理者的多样化决策需求。
1. 数据仓库的概念和特点数据仓库是一个面向主题的、集成的、时变的、非易失性的数据集合,用于支持管理决策的过程。
它的主要特点包括:- 面向主题:DW的数据是按照特定的主题或业务过程进行组织的,以便于管理者理解和分析。
- 集成性:DW汇集了来自各个数据源的数据,经过整合和清洗后,提供了一致且准确的数据视图。
- 时变性:DW中的数据是随时间变化的,可以帮助管理者了解过去的数据、现在的数据和未来的趋势。
- 非易失性:DW中的数据是不会被修改或删除的,因此具有不变性和可靠性。
2. 数据仓库的架构数据仓库的架构通常包括数据源层、ETL层、数据存储层、数据管理层和数据使用层等几个主要组成部分。
其中:- 数据源层:包括各类数据源,如企业内部的OLTP系统、外部数据文件、数据仓库和数据湖等。
- ETL层:包括数据抽取、转换和加载等过程,以将数据从各类数据源中提取并加载到数据仓库中。
- 数据存储层:包括数据仓库和数据湖等多种数据存储方式,通常采用关系型数据库、NoSQL数据库或分布式存储等技术。
- 数据管理层:管理数据仓库的元数据、数据质量、数据安全等方面的问题。
- 数据使用层:向管理者提供各种数据分析、报表查询、数据挖掘和商业智能等功能。
3. 数据仓库的设计数据仓库的设计需要考虑多方面的问题,包括数据建模、数据抽取、ETL流程、数据存储和数据查询等方面的问题。
dw中模板的作用

dw中模板的作用
DW (Data Warehouse) 模板的作用
DW (Data Warehouse) 模板是一种在数据仓库中使用的工具,它提供了一种快速创建和管理数据仓库的方式。
它可以帮助数据仓库开发人员快速搭建数据仓库,并提供了一些常见的数据处理和分析功能。
首先,DW 模板提供了一个框架和结构,使开发人员能够更快地构建数据仓库。
它定义了一些基本的表和字段,以及它们之间的关系。
这样,开发人员就不需要从头开始构建整个数据仓库,而是可以直接基于模板进行修改和扩展。
其次,DW 模板提供了一些常见的数据处理和分析功能,使开发人员能够更轻松地进行数据处理和分析。
例如,模板中可能包含了一些常用的数据转换和清洗功能,使开发人员能够快速处理原始数据。
同时,模板还可能提供了一些常见的报表和分析功能,使开发人员能够更方便地进行数据分析和可视化。
最后,DW 模板还可以提高数据仓库的可维护性和扩展性。
由于模板定义了一些基本的结构和功能,开发人员可以更容易地理解和管理整个数据仓库。
同时,在需要扩展数据仓库时,开发人员可以基于模板进行修改和扩展,而无需从头开始构建。
综上所述,DW 模板在数据仓库开发中起到了重要的作用。
它可以快速搭建数据仓库、提供常见的数据处理和分析功能,以及提高数据仓库的可维护性和扩展性。
通过使用模板,数据仓库开发人员可以
更高效地进行工作,并为企业提供准确、可靠的数据分析和决策支持。
微机原理中关于dw的数据

微机原理中关于dw的数据dw是微机原理中的一种数据类型,表示双字(double word)类型数据,也被称为DWORD 数据类型。
双字可以存储在32位的寄存器中,占用4个字节的内存空间。
dw数据通常用于存储整数和无符号整数,取值范围为0到4,294,967,295。
dw数据可以使用汇编语言进行读取、写入和操作。
在汇编代码中,dw数据可以直接使用数据段(data segment)进行定义和初始化。
例如:data segmentnum1 dw 5 ; 定义一个双字类型数据num1,初始值为5data endsmov ax, num1 ; 将num1的值存入ax寄存器中上述代码定义了一个双字类型数据num1,并将其初始值设置为5。
然后将num1加载到ax寄存器中,对ax寄存器中的值加上10,最后将修改后的值存回到num1中。
另一个常见的使用dw数据的情况是作为指针(pointer)。
指针是指向内存中某个地址的变量,可以通过指针来获取或修改该地址处存储的数据。
在汇编语言中,指针通常使用双字类型数据来表示。
例如:mov ax, offset arr ; 获取数组arr的内存地址mov bx, [ax+2] ; 获取数组第3个元素的值上述代码定义了一个长度为5的数组arr,并将其存储在数据段中。
然后将数组的内存地址存储在ax寄存器中,并使用ax寄存器中的值来获取数组第3个元素的值。
需要注意的是,在汇编语言中,数组的下标从0开始。
除此之外,dw数据还可以用于存储和操作二进制数据和位运算。
例如:and dword ptr [eax], 0x0000FFFF ; 将eax指向地址处的低16位清零上述代码使用and指令进行位运算,将eax寄存器指向的地址处的高16位清零,只保留低16位。
综上所述,dw数据是微机原理中常用的数据类型之一,可以存储整数、无符号整数、指针等数据,常用于汇编语言中的数据定义、读写和操作,也可用于存储和处理二进制数据和位运算。
dwcc知识点总结

dwcc知识点总结DWCC的功能和优势DWCC具有诸多功能和优势,能够帮助组织高效管理数据仓库,提高数据处理效率和质量。
下面是DWCC的主要功能和优势:1. 数据仓库监控和管理:DWCC可以监控和管理数据仓库系统的运行状态,包括数据加载、数据转换、数据质量、性能等方面的监控和管理。
通过DWCC可以对数据仓库进行全面的监控和管理,及时发现和解决问题,保证数据仓库系统的稳定运行。
2. 运营监控:DWCC可以监控数据仓库系统的运营状态,包括数据加载、查询性能、数据分发等方面的监控。
可以帮助组织及时发现系统运营中的问题,并采取相应措施加以解决。
3. 数据质量监控:DWCC可以监控数据仓库中的数据质量,包括数据准确性、完整性、一致性等方面的监控。
可以帮助组织及时发现数据质量方面的问题,并及时进行数据质量的修正和改进。
4. 数据管理:DWCC提供了数据管理的功能,可以对数据仓库中的数据进行管理,包括数据的加载、转换、集成、分发等方面的管理。
可以帮助组织更加高效地管理数据仓库中的数据。
5. 历史数据管理:DWCC可以对数据仓库中的历史数据进行管理,包括历史数据的清理、归档、保留等方面的管理。
可以帮助组织更加有效地管理历史数据,提高数据仓库系统的性能和效率。
6. BI系统集成:DWCC可以与BI系统集成,实现数据仓库和BI系统的无缝集成。
可以帮助组织实现数据仓库和BI系统的高效管理和监控。
7. 自动化任务调度:DWCC可以实现数据仓库中的任务自动化调度,包括数据加载、数据转换、报表生成等任务的自动化调度。
可以帮助组织更好地管理数据仓库中的各项任务,提高数据处理效率和质量。
8. 性能优化:DWCC可以对数据仓库系统进行性能优化,包括查询性能、数据加载性能、数据处理性能等方面的优化。
可以帮助组织提高数据仓库系统的性能,提高数据处理效率和质量。
上述功能和优势使DWCC成为组织实现高效数据仓库管理和监控的重要工具,能够帮助组织更好地管理和利用数据仓库系统,提高数据处理效率和质量。
dws建设思路和实现方法

dws建设思路和实现方法DWS(Data Warehouse Service)是数据仓库领域提供的一种云服务。
它基于大数据领域的丰富经验和技术积累,为开发者提供了一个高效、稳定、易用的数据仓库解决方案。
一、DWS的建设思路1.统一数据仓库架构:DWS采用统一的数据仓库架构,确保数据在各个层级的一致性和可管理性。
通过数据分层设计,实现了数据的分层存储和查询,提高了数据处理的效率。
2.简化数据开发和运维:DWS提供了一站式的数据开发和管理平台,开发者可以通过简单的操作就能完成数据的采集、清洗、转换和存储等任务。
同时,DWS还提供了自动化的运维工具,降低了数据开发和运维的难度。
3.保障数据安全:DWS注重数据的安全性,通过多种安全措施保障数据不被泄露和篡改。
例如,DWS提供了数据加密、访问控制、审计日志等功能,确保数据的安全性和完整性。
4.高效的数据处理能力:DWS采用了先进的数据处理技术,如分布式计算、列式存储等,提高了数据处理的速度和效率。
同时,DWS还支持多种数据处理任务,如实时计算、离线计算、数据挖掘等,满足了不同业务场景的需求。
二、DWS的实现方法1.云基础设施:DWS建立在阿里云的基础设施之上,利用了阿里云的高可用、高扩展性的特点,为数据仓库提供了稳定、可靠的计算和存储资源。
2.数据采集和传输:DWS提供了数据采集和传输的工具和服务,支持多种数据源的接入和数据的实时传输。
通过这些工具和服务,开发者可以方便地将各种数据源的数据采集到DWS中。
3.数据处理和管理:DWS提供了数据处理和管理工具,支持数据的清洗、转换、加载等任务。
通过这些工具,开发者可以方便地对数据进行处理和管理,提高数据处理效率和质量。
4.数据分析和挖掘:DWS提供了数据分析和挖掘工具,支持多种数据分析方法和模型。
通过这些工具,开发者可以对数据进行深入的分析和挖掘,发现数据中的规律和价值。
5.数据安全保障:DWS注重数据的安全性保障,提供了多种安全措施和服务。
大数据平台的3个核心功能
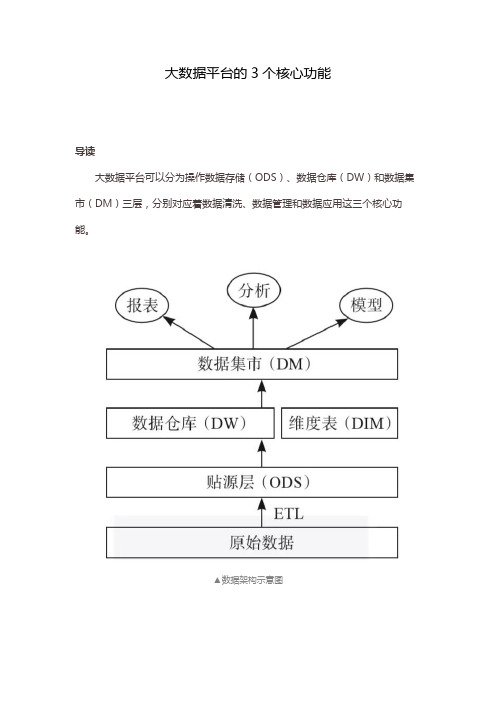
大数据平台的3个核心功能导读大数据平台可以分为操作数据存储(ODS)、数据仓库(DW)和数据集市(DM)三层,分别对应着数据清洗、数据管理和数据应用这三个核心功能。
▲数据架构示意图一、原始数据清洗操作数据存储(Operational Data Store,ODS),又被称为贴源层,是原始数据经过ETL(Extract-Transform-Load)清洗后存储的位置。
ODS通常有如下几个作用。
▪在业务系统和数据仓库之间做了隔离,将业务系统产生的原始数据备份的同时,保证了两个系统之间数据的一致性。
▪存储了业务侧的明细数据,方便后续的查询和加工以及报表的产出。
▪完成数据仓库中不能实现的一些功能,相比于DW和DM层通常使用Hive查询,ODS一般利用更底层的编程语言加工而成,可以实现一些更复杂和更高效的ETL操作。
此外,ODS层保留了大量的历史明细数据,通常约定只能增加不能修改,利用时间分区的方式进行区分。
二、数据仓库管理数据仓库(Data Warehouse,DW)是企业级数据集中汇总的位置。
DW 层最大的特点是面向主题,根据不同的主题设计表的结构和内容,这样做的好处是排除了与主题无关的冗余数据,提高了特定主题下的查询和加工效率。
另一方面,数据仓库作为连接原始数据和标签之间的中间层,必须保证数据质量,包括唯一性、权威性、准确性等。
以风控主题为例,DW层中通常会包括授信、支用、还款、催收等一系列数据,方便后期相关标签的计算。
另外,还会有一些公用的维度表被存在与DW层平行的DIM层中,这些表通常是一些城市、日期类的字典数据,贯穿多个主题数据。
三、数据标签应用整个数据平台的最上层是数据集市(Data Market,DM),也是与风控人员联系最紧密的一层。
顾名思义,数据集市就是将数据仓库中的主题数据根据不同的业务需要挑选出来,构成特定的业务场景标签。
例如想构建与客户逾期表现相关的标签,只需要将DW层中与还款相关的表抽取出来加工即可,这样不仅结构清晰,还保证了标签计算的效率。
DW中记录集的使用方法

第一步,我们先来链接网页与数据库,如下图。
第二步,我们点开绑定面板,选取“记录集(查询)”如下图。
SQL语句里select *from 数据表where 字段名=字段值order by 字段名[desc]这句,我们在基础里面已经学过了。
这里的记录集,就是对这句SQL的操作。
我们继续往下看我们点开记录集窗口旁边的“高级”,来看一下。
SQL里面语句里我们可以调用变量。
在记录集高级里面,我们可以清楚的看到,SQL语句,以及下面的变量操作框SQL语句我们已经在基础里讲过。
这里不再重复。
我们来定义一下记录集。
记录集的作用就是:利用SQL语句检索数据库中的内容。
也就是说,来读取数据库中的内容。
第三步,在网页中读取记录集的内容1.我们设置读取新闻表xinwen中所有的新闻内容,并进行降序排列我们点测试查看数据库新闻表xinwen里的数据,如下图所示我们点开绑定面板,左键摁住biaoti不放拖动到网页中我们需要的位置,如下图这样就读取出了数据库中xinwen表,满足记录集条件的第一条信息。
网页预览结果如下:因为是倒序排列,第四条新闻显示在第一条。
2.既然已经读出了一条信息,我们如何将满足记录集设置条件的所有新闻都读取出来呢?首先,我们选中网页中,要重复出现的内容。
这里,我们选中标题,如下图然后,我们点开Dreamweaver中服务器行为面板,选择“重复区域”,点开,进行设置,如下图选择记录集,这里我们选择Recordset1,设置显示条件。
设置完成,确定,保存。
然后接着点开“服务器行为”面板,选择“显示区域”,选择“如果记录集不为空则显示”。
这样设置,是因为,如果数据库中没有满足记录集筛选条件的数据,也就是说记录集为空,会产生错误。
选择记录集,这里要注意,记录集一定要选择正确,确定保存。
预览效果如下图来设置详细页面。
我们创建一个显示每条新闻详细内容的页面xiangxi.php,我们打开服务器行为面板,创建一个记录集,设置如下图上图,标注位置,可以随便写。
数据仓库ADS、DWD、DWS、ADS分层详解

数据仓库ADS、DWD、DWS、ADS分层详解一、ODS层ODS层通常包含多个数据源,包括企业内部的各种业务系统、外部的数据供应商、第三方数据服务等。
这些数据源通常具有不同的数据格式、结构、语义和质量,因此需要进行一系列的数据处理和转换,以使其能够被有效地集成到数据仓库中。
ODS层的数据处理主要包括以下几个方面:数据抽取:从各个数据源中抽取数据,包括全量抽取和增量抽取等方式。
数据清洗:对抽取到的数据进行清洗和去重,确保数据的一致性和准确性。
数据集成:将清洗后的数据进行整合和集成,以生成一个一致的、可信的、实时的数据集。
数据同步:将ODS层的数据同步到下一层,即DWD层,以供后续的数据处理和分析。
ODS层的数据模型通常是基于源系统中的数据模型进行设计,其主要目的是将不同的数据源中的数据整合到一个统一的数据集中,并尽量保证数据的质量和可用性。
ODS层的数据通常是面向业务过程和业务事件的,包含大量的原始业务数据和事件流数据,可以为企业提供实时的数据集成和分析能力。
ODS层是数据仓库架构中的第一层,主要负责数据集成和整合,将多个数据源中的数据进行清洗、整合和同步,为后续的数据仓库处理提供原始数据。
ODS层的数据模型通常是基于源系统中的数据模型进行设计,其主要目的是将不同的数据源中的数据整合到一个统一的数据集中,并尽量保证数据的质量和可用性。
二、DWD层数据仓库的DWD层(Data Warehouse Detail Layer)是整个数据仓库架构中的核心层次,也是数据仓库的基础层,它主要用于存储处理过的数据。
DWD层是对原始数据进行清洗、整合、标准化和去重等处理,将数据转化为面向主题的数据集。
在DWD层,数据会被按照主题进行建模,即按照不同的业务领域或业务流程进行分类和组织。
这种建模方法被称为主题建模,它是数据仓库架构的核心特点之一。
DWD层的主要任务是将原始数据转换成具有较高质量和较高复用性的数据集,使得数据在后续的处理和分析过程中更加容易理解和使用。
dw设计报告需求分析

dw设计报告需求分析DW设计报告需求分析一、引言数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、非易失的数据集合,用于支持管理决策。
它是一个以主题为中心的数据源集合,能够支持管理级的决策。
本报告旨在通过需求分析,明确设计数据仓库的目标、功能和特点,为后续的设计工作提供指导。
二、目标数据仓库的设计目标是为了满足企业对数据的需求,从而支持决策层进行有效的数据分析和决策。
具体目标如下:1. 提供可靠、一致、准确的数据源;2. 提供灵活、易于使用的查询和分析工具;3. 支持快速和可扩展的数据处理;4. 提供高性能和高可用性的系统。
三、功能数据仓库设计需要满足以下功能需求:1. 数据提取和清洗:从不同的数据源中提取数据,并进行清洗和转换,确保数据的一致性和准确性;2. 数据集成和整合:将多个数据源的数据整合到一个一致的数据模型中,以满足企业对数据的全面分析和决策需求;3. 数据存储和管理:设计合适的数据存储结构和管理方式,以提高数据的读写效率和存储空间的利用率;4. 数据查询和分析:提供强大的查询和分析功能,支持用户对数据的灵活查询、分组、排序、聚合、统计等操作;5. 数据安全和权限控制:确保数据的安全性和机密性,通过权限管理和用户访问控制,限制用户对数据的访问权限;6. 数据备份和恢复:设计合理的数据备份和恢复策略,以保证数据的可靠性和可用性。
四、特点数据仓库的设计具有以下几个特点:1. 面向主题:数据仓库主要关注业务主题,将不同来源的数据集成到一个一致的主题模型中,方便用户进行主题分析和决策支持。
2. 集成性:数据仓库整合了多个数据源和业务系统的数据,提供全面和一致的数据视图。
3. 相对稳定:数据仓库的数据相对稳定,只在需要时进行定期的数据更新,以提高数据一致性和查询性能。
4. 非易失性:数据仓库中的数据是非易失的,不会因为外部操作或故障而丢失。
5. 支持决策:数据仓库是为决策层提供数据支持的,具有较高的查询和分析性能,方便用户快速获取有价值的数据。
dw src参数

dw src参数DW src参数是什么?如何使用它?在软件开发领域,DW src参数是指在使用DW(Dynamic Web)技术构建Web应用程序时,用于指定数据源的参数。
通过使用DW src参数,开发人员可以从数据库、文本文件或其他数据源中获取数据,并将其用于动态生成网页内容。
DW src参数的使用方式是在DW代码中使用特定的标记来引用数据源,并将其传递给DW引擎进行处理。
在标记中,可以指定数据源的类型、连接信息以及要获取的数据字段等。
通过这种方式,开发人员可以实现灵活的数据获取和处理,从而为用户提供更加丰富和个性化的网页内容。
在实际的开发过程中,DW src参数的使用非常灵活。
对于不同的数据源类型,可以使用不同的DW src参数来进行配置。
例如,对于关系型数据库,可以使用DW src参数指定数据库的连接信息、查询语句和结果集字段;对于文本文件,可以使用DW src参数指定文件路径和读取方式等。
通过灵活配置DW src参数,开发人员可以满足不同的数据获取需求,并实现数据与页面的无缝集成。
使用DW src参数的好处是能够将数据源与页面内容进行解耦,提高开发效率和代码可维护性。
通过将数据获取和处理逻辑与页面代码分离,可以使开发人员更加专注于页面设计和交互逻辑的实现,而无需关心具体的数据源和查询细节。
同时,使用DW src参数还可以实现数据的动态更新和实时展示,提升用户体验和网站的实用性。
总结起来,DW src参数是一种在DW技术中使用的参数,用于指定数据源和查询条件,实现动态生成网页内容。
通过灵活配置DW src 参数,开发人员可以实现灵活的数据获取和处理,提高开发效率和代码可维护性。
在实际开发中,使用DW src参数可以实现数据与页面的解耦,提升用户体验和网站的实用性。
金融项目dws层宽表设计实例

金融项目dws层宽表设计实例(最新版)目录一、金融项目 DWS 层宽表设计概述二、DWS 层宽表设计的具体实例三、DWS 层宽表设计的优势与应用前景正文一、金融项目 DWS 层宽表设计概述在金融项目中,DWS(Data Warehouse System)层宽表设计是一种关键的技术手段。
DWS 层宽表设计的目标是为了更好地存储、管理和查询金融数据,以便金融机构可以更加高效地进行业务运营和决策。
本文将通过一个具体的设计实例,来介绍如何进行 DWS 层宽表设计。
二、DWS 层宽表设计的具体实例假设某金融机构需要设计一个用于存储客户信用贷款信息的 DWS 层宽表。
根据金融业务的特点和需求,该表需要包含以下字段:客户 ID、贷款金额、贷款期限、贷款利率、放款日期、还款方式、贷款状态等。
这些字段构成了表的主键和属性。
接下来,我们需要对这些属性进行层宽表设计。
具体操作如下:1.首先,将表中的每个属性都转换为一个独立的维度。
例如,客户 ID 可以转换为“客户”维度,贷款金额可以转换为“贷款金额”维度,以此类推。
2.然后,对于每个维度,根据业务需求和数据特点,选择合适的层宽表结构。
例如,对于“客户”维度,可以选择按照客户类型、客户地区、客户行业等进行层宽表设计;对于“贷款金额”维度,可以选择按照贷款金额区间进行层宽表设计。
3.最后,将各个维度的层宽表设计结果进行整合,形成一个完整的DWS 层宽表。
整合时,需要注意保持数据的一致性和完整性。
三、DWS 层宽表设计的优势与应用前景DWS 层宽表设计具有以下优势:1.提高数据查询效率:通过层宽表设计,可以大大减少查询时间和计算资源消耗,提高数据查询效率。
2.便于数据分析:层宽表设计使得数据更加结构化,便于进行数据挖掘和分析,从而为金融机构的业务决策提供有力支持。
3.适应性强:DWS 层宽表设计可以灵活适应金融业务的变化,使得金融数据管理更加灵活和高效。
随着金融业务的不断发展和金融科技的日益普及,DWS 层宽表设计在金融领域的应用前景十分广阔。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DATA WAREHOUSE CONCEPTSA fundamental concept of a data warehouse is the distinction between data and information. Data is composed of observable and recordable facts that are often found in operational or transactional systems. At Rutgers, these systems include the registrar’s data on students (widely known as the SRDB), human resource and payroll databases, course scheduling data, and data on financial aid. In a data warehouse environment, data only comes to have value to end-users when it is organized and presented as information. Information is an integrated collection of facts and is used as the basis for decision-making. For example, an academic unit needs to have diachronic information about its extent of instructional output of its different faculty members to gauge if it is becoming more or less reliant on part-time faculty.DATA WAREHOUSE DEFINITIONSThe data warehouse is that portion of an overall Architected Data Environment that serves as the single integrated source of data for processing information. The data warehouse has specific characteristics that include the following:Subject-Oriented: Information is presented according to specific subjects or areas of interest, not simply as computer files. Data is manipulated to provide information about a particular subject. For example, the SRDB is not simply made accessible to end-users, but is provided structure and organized according to the specific needs.Integrated: A single source of information for and about understanding multiple areas of interest. The data warehouse provides one-stop shopping and contains information about a variety of subjects. Thus the OIRAP data warehouse has information on students, faculty and staff, instructional workload, and student outcomes.Non-Volatile: Stable information that doesn’t change each time an operational process is executed. Information is consistent regardless of when the warehouse is accessed.Time-Variant: Containing a history of the subject, as well as current information. Historical information is an important component of a data warehouse.Accessible: The primary purpose of a data warehouse is to provide readily accessible information to end-users.Process-Oriented: It is important to view data warehousing as a process for delivery of information. The maintenance of a data warehouse is ongoing and iterative in nature.Other DefinitionsData Warehouse: A data structure that is optimized for distribution. It collects and stores integrated sets of historical data from multiple operational systems and feeds them to one or more data marts. It may also provide end-user access to support enterprise views of data.Data Mart: A data structure that is optimized for access. It is designed to facilitate end-user analysis of data. It typically supports a single, analytic application used by a distinct set of workers.Staging Area: Any data store that is designed primarily to receive data into a warehousing environment. Operational Data Store: A collection of data that addresses operational needs of various operational units. It is not a component of a data warehousing architecture, but a solution to operational needs. OLAP (On-Line Analytical Processing): A method by which multidimensional analysis occurs. Multidimensional Analysis: The ability to manipulate information by a variety of relevant categoriesor “dimensions” to facilitate analysis and understanding of the underlying data. It is also sometimes referred to as “drilling-down”, “drilling-across” and “slicing and dicing”Hypercube: A means of visually representing multidimensional data.Star Schema: A means of aggregating data based on a set of known dimensions. It stores data multidimensionally in a two dimensional Relational Database Management System (RDBMS), such as Oracle.Snowflake Schema: An extension of the star schema by means of applying additional dimensions to the dimensions of a star schema in a relational environment.Multidimensional Database: Also known as MDDB or MDDBS. A class of proprietary, non-relational database management tools that store and manage data in a multidimensional manner, as opposed to the two dimensions associated with traditional relational database management systems.OLAP Tools: A set of software products that attempt to facilitate multidimensional analysis. Can incorporate data acquisition, data access, data manipulation, or any combination thereof.COMPARISON OF DATA WAREHOUSE AND OPERATIONAL DATA HOW IS THE WAREHOUSE DIFFERENT?The data warehouse is distinctly different from the operational data used and maintained by day-to-day operational systems. Data warehousing is not simply an “access wrapper” for operational data, where data is simply “dumped” into tables for direct access. Among the differences:OPERATIONAL DATA DW DATAapplication oriented subject orienteddetailed summarized, otherwise refinedaccurate, as of the moment of access represents values over time, snapshotsserves the clerical community serves the managerial communitycan be updated is not updatedrun repetitively and nonreflectively run heuristicallyrequirements for processing understood before initial development requirements for processing not completely understood before developmentcompatible with the Software Development LifeCyclecompletely different life cycleperformance sensitive (immediate responserequired when entering a transaction)performance relaxed (immediacy not required)accessed a unit at a time (limited number of data elements for a single record) accessed a set at a time (many records of many data elements)transaction driven analysis drivencontrol of update a major concern in terms ofownershipcontrol of update no issuehigh availability relaxed availabilitymanaged in its entirety managed by subsets nonredundancy redundancy is a fact of lifestatic structure; variable contents flexible structuresmall amount of data used in a process large amount of data used in a processThe Data Warehousing Process – Part 1Determine Informational Requirements•Identify and analyze existing informational capabilities.•Identify from key users the significant business questions and key metrics that the target user.group regards as their most important requirements for information.•Decompose these metrics into their component parts with specific definitions.•Map the component parts to the informational model and systems of record.The Data Warehousing Process – Part 2Evolutionary and Iterative Development ProcessWhen you begin to develop your first data warehouse increment, the architecture is new and fresh. With the second and subsequent increments, the following is true:•Start with one subject area (or subset or superset) and one target user group.•Continue and add subject areas, user groups and informational capabilities to the architecture based on the organization’s requirements for information, not technology.•Improvements are made from what was learned from previous increments.•Improvements are made from what was learned about warehouse operation and support.•The technical environment may have changed.•Results are seen very quickly after each iteration.•The end user requirements are refined after each iteration.Data Warehousing is an evolutionary/iterative process that follows a spiral pattern •The warehouse architecture is initially developed at the start.•The first increment is developed based on the architecture.•Building the first increment causes architectural changes.•Operation of the warehouse brings architectural changes.•Each additional increment extends the warehouse.•Each new increment may cause architectural adjustments.•Continued operation may cause architectural adjustments.THE WAREHOUSE POPULATING PROCESSA data warehouse is populated through a seri es of steps that1) Remove data from the source environment (extract).2) Change the data to have desired warehouse characteristics like subject-orientation and time-variance(transform).3) Place the data into a target environment (load).This process is represented by the acronym ETL for Extract, Transform and Load.Complexity of Transformation and Integration•The extraction of data from the operational environment to the data warehouse environment requires a change in technology.•The selection of data from the operational environment may be very complex.•Data is reformatted.•Data is cleansed.•Multiple input sources of data exist.•Default values need to be supplied.•Summarization of data often needs to be done.•The input records that must be read have “exotic” or nonstandard formats.•Data format conversion must be done.•Massive volumes of input must be accounted for.•Perhaps the worst of all: Data relationships that have been built into old legacy program logic must be understood and unraveled before those files can be used as input.Data Warehouse Tools/SoftwareComponent Product used byInstitutional ResearchComponent DescriptionReporting CrystalReports Create presentation style reports with chart and graphs. Can be used to access any type of data source.Querying Access2000 Create complex ad-hoc queries against a variety of data sources using ODBC access to DW databases. Able to export to other types of formats such as text files,OLAP Crystal AnalysisProfessionalAccess data cubes for designing views to pivot, filterand aggregate facts on pre-defined dimensions forspecific subject areas such as enrollment, degreesconferred, etc.DataMining/Statistical Analysis SASStatistical Analysis using ODBC access to IR DWdatabases.Recommended System Requirements For Web AccessInternet Explorer for using OLAP web based ActiveX control Expand video to 1024 X 768 for more viewing space。