Prime算法纯代码自己做的绝对正确
SageMath简易入门手册

SageMath简易入门指导中国矿业大学(北京)理学院2014级创新小组编组长:孙裕道组员:孟坤,尹娟,董光林,李欢,王思高导师: 刘兰冬前言一些数学商业软件如Matlab、Maple、Mathematica需要下载到电脑上,而且这些软件在电脑中需要占用很大的内存,单说Matlab 在电脑中就会占用6.5G的内存左右,从官网下载该软件也会要下载半天,非常不方便。
互联网时代,在云端进行操作和存储事物已经成为一种趋势,SageMath软件就是顺应这种趋势的发展。
SageMath是网上免费的开源数学软件,注册一个SageMath的账号在云端就可以进行相关的操作,非常方便,所以我们创新小组决定学习SageMath.SageMath的功能强大,可以求积分,求极限,求导等一些列高等数学的运算,并且可以对一些复杂问题进行SagaMath编程求解。
我们创新小组在刘兰冬老师的指导下,系统地学习SageMath软件的相关知识,使大家对SageMath的这门语言的一些基础语法和用法有了初步的了解,可以对一些数学问题进行编程求解。
希望我们小组的这个SageMath简易入门指导可以对这门语言感兴趣的人,想学习这门语言的人有入门指导的帮助。
2014年11月1日目录1 SageMath的登陆方法 (4)1.1进入官网 (4)1.2 界面登陆 (5)1.3创建账号 (5)1.4创建工程 (6)1.5工程搜索 (7)1.6新建文件 (8)1.7新建工作簿 (8)1.8编辑界面 (9)1.9进行操作 (9)2.SageMath的基本语法 (12)2.1基本命令语 (9)2.1.1 加法 (10)2.1.2 减法 (10)2.1.3 乘法 (10)2.1.4 除法 (10)2.1.5 乘方 (10)2.1.6 开方 (10)2.2判断语句 (10)2.2.1 if语句的用法 (10)2.3循环语句 (11)2.3.1 For循环语句 (11)2.3.2 While循环语句 (11)2.4 画图 (12)2.4.1 plot语句 (12)2.4.2 show语句 (12)3.SageMath中的数学函数 (13)3.1高等数学中的Sage命令 (13)3.1.1函数表示 (13)3.1.2复合函数 (13)3.1.3微分 (14)3.1.4Talor公式 (15)3.1.6求极限 (16)3.1.8数论素数分解 (16)3.2线性方程组中常用命令 (16)3.2.1矩阵运算 (16)3.2.2逆矩阵 (17)3.2.3求解方程组 (17)4.Sage中的编程 (19)4.1插值多项式 (19)参考文献 (20)SageMath简介SageMath 是一个免费的、开源的数学软件系统,采用GPL协议。
Prime 算法设计过程演示

•}
• int count = N;
ቤተ መጻሕፍቲ ባይዱ
• cout << "此图的最短路径是:" << endl;
• while(--count)
•{
•
min = M;
•
j = 0;
•
for(i = 0; i < N; ++i)
•
{
•
if(!flag[i] && nearest[i] < min)
•
{
•
min = nearest[i];
在无向带权连通图G中,如果一个连通子树
包含所有顶点,并且连接这些顶点的边权之
和最小,那么这个连通子图就是G的最小生 成树。求最小生成树的一个常见算法是Prim 算法,该算法的基本思想是:1)设置两个 集合V和S,任意选择一个顶点作为起始顶点, 将起始顶点放入集合S,其余顶点存入集合V 中;2)然后使用贪心策略,选择一条长度 最短并且端点分别在S和V中的边(即为最小 生成树中的一条边),将这条边在V中的端 点加入到集合S中;3)循环执行第2)步直 到S中包含了所有顶点。
1
6
1 5
6
2
3
3 5
6
5
2
4
6
3
5
4
• 具体代码实现如下: • #include <iostream> • using namespace std;
• //用邻接矩阵表示无向图 • const int N = 6; //节点个数 • const int M = 100000; //M表示不可达及无穷 • //假设给出如下矩阵表示的无向图 • int matrix[N][N] = { • M,6,1,5,M,M, • 6,M,5,M,3,M, • 1,5,M,5,6,4, • 5,M,5,M,M,2, • M,3,6,M,M,6, • M,M,4,2,6,M • };
prim算法c语言

prim算法c语言什么是Prim算法?Prim算法,也叫普里姆算法,是一种用于求解最小生成树的贪心算法。
最小生成树是指在一个无向连通图中,连接所有节点且边权值之和最小的树。
Prim算法的基本思想是从一个起始节点开始,每次选择与当前已经构建好的部分形成的子图相连的、权值最小的边所连接的节点,并将该节点加入到已经构建好的部分中。
直到所有节点都被加入到已经构建好的部分中,此时得到了一棵最小生成树。
Prim算法步骤1. 选定一个起点作为已经构建好的部分。
2. 将与该起点相连且未被访问过的边加入到候选集合中。
3. 从候选集合中选择一条权值最小的边连接到未被访问过的节点,并将该节点加入到已经构建好的部分中。
4. 将新加入节点所连接且未被访问过的边加入到候选集合中。
5. 重复步骤3和步骤4,直至所有节点都被加入到已经构建好的部分中。
Prim算法C语言实现下面给出Prim算法C语言实现代码:```#include <stdio.h>#include <stdlib.h>#include <limits.h>#define MAX_VERTICES 100#define INF INT_MAXtypedef struct {int weight;int visited;} Vertex;typedef struct {int vertices[MAX_VERTICES][MAX_VERTICES]; int num_vertices;} Graph;void init_graph(Graph *graph, int num_vertices) {graph->num_vertices = num_vertices;for (int i = 0; i < num_vertices; i++) {for (int j = 0; j < num_vertices; j++) {graph->vertices[i][j] = INF;}}}void add_edge(Graph *graph, int u, int v, int weight) { graph->vertices[u][v] = weight;graph->vertices[v][u] = weight;}void prim(Graph *graph) {Vertex vertices[MAX_VERTICES];for (int i = 0; i < graph->num_vertices; i++) {vertices[i].weight = INF;vertices[i].visited = 0;}vertices[0].weight = 0;for (int i = 0; i < graph->num_vertices - 1; i++) {// 找到未访问过的权值最小的节点int min_vertex_index = -1;for (int j = 0; j < graph->num_vertices; j++) {if (!vertices[j].visited && (min_vertex_index == -1 || vertices[j].weight < vertices[min_vertex_index].weight)) { min_vertex_index = j;}}// 将该节点标记为已访问vertices[min_vertex_index].visited = 1;// 更新与该节点相连的未访问过的节点的权值for (int j = 0; j < graph->num_vertices; j++) {if (!vertices[j].visited && graph->vertices[min_vertex_index][j] < vertices[j].weight) {vertices[j].weight = graph->vertices[min_vertex_index][j];}}}// 输出最小生成树printf("Minimum Spanning Tree:\n");for (int i = 1; i < graph->num_vertices; i++) {printf("%d - %d (%d)\n", i, (i - 1), vertices[i].weight); }}int main() {Graph graph;init_graph(&graph, 6);add_edge(&graph, 0, 1, 6);add_edge(&graph, 0, 2, 1);add_edge(&graph, 0, 3, 5);add_edge(&graph, 1, 4, 3);add_edge(&graph, 2, 4, 5);add_edge(&graph, 2, 3, 5);add_edge(&graph, 2, 5, 4);add_edge(&graph, 3 ,5 ,2);prim(&graph);return EXIT_SUCCESS;}```代码解释- 定义了Vertex结构体,用于存储节点的权值和访问状态。
matlab 普里姆算法

matlab 普里姆算法普里姆算法是一种最小生成树算法,用于求解给定图的最小生成树。
该算法基于贪心策略,每次选择当前已选中的点集到未选中的顶点集中距离最近的一条边,将该边所连接的点加入到已选中的点集中。
在实现普里姆算法时,我们需要使用一个优先队列用于存储当前已选中的点集到未选中的顶点集中的边,以及每个顶点到已选中的点集中最小距离。
在每次选取最小距离的边时,我们将该边所连接的点加入到已选中的点集中,并将该点与未选中的点集中的所有点之间的距离加入到优先队列中,同时更新已选中的点集到未选中的顶点集中的最小距离。
该过程重复进行,直到所有的顶点都已经被加入到已选中点集中,最终得到的图就是原图的最小生成树。
下面是使用matlab实现普里姆算法的示例代码:function MST = prim_algorithm(graph)% graph为邻接矩阵,MST为最小生成树的邻接矩阵表示n = size(graph, 1); % 获取图中节点数key = Inf(1,n); % 存储每个顶点与已选中点集的最小距离mst = zeros(n, n); % 存储最小生成树的邻接矩阵表示visited = false(1,n); % 存储每个顶点是否已加入到已选中点集中pq = PriorityQueue(n); % 创建优先队列start = 1; % 从任意一个顶点开始寻找最小生成树key(start) = 0; % 起始点距离已选中点集的最小距离为0pq.insert(start, 0); % 将起始点加入到优先队列中while ~pq.isempty() % 当优先队列非空时进行迭代[u, cost] = pq.deleteMin(); % 选取距离已选中点集最近的边visited(u) = true; % 将选中的顶点加入到已选中点集中if u ~= start % 将当前边加入到最小生成树的邻接矩阵中mst(parent(u), u) = cost;mst(u, parent(u)) = cost;endfor v = 1:n % 更新与已选点集中每个顶点的最小距离if ~visited(v) && graph(u,v) < key(v)parent(v) = u;key(v) = graph(u,v);if pq.contains(v)pq.updatePriority(v, key(v));elsepq.insert(v, key(v));endendendendMST = mst;end该代码中借助matlab的优先队列类PriorityQueue实现了优先队列的功能,其中包括了队列插入、队列删除、队列是否为空、队列中是否包含某元素以及队列中某元素优先级的更新等方法。
c语言中prime 的用法

c语言中prime 的用法C语言中prime的用法在C语言中,prime(素数)是一个常见的概念,用于描述只能被1和自身整除的正整数。
在编程中,我们经常需要判断一个给定的数是否为素数,以及找到一定范围内的所有素数。
要判断一个数是否为素数,可以使用以下方法:1. 定义一个变量isPrime并初始化为1(表示是素数)。
2. 使用一个循环遍历2到该数的平方根(因为一个数的因子不可能超过其平方根)。
循环的条件是i从2开始递增,且isPrime为1。
3. 在循环中,如果该数能被i整除,则将isPrime设置为0,并跳出循环。
4. 最后,判断isPrime的值,如果为1,则说明该数是素数,否则不是素数。
以下是一个判断素数的示例代码:```c#include <stdio.h>#include <math.h>int isPrimeNumber(int num) {int isPrime = 1;for (int i = 2; i <= sqrt(num); i++) {if (num % i == 0) {isPrime = 0;break;}}return isPrime;}int main() {int num;printf("请输入一个正整数: ");scanf("%d", &num);if (isPrimeNumber(num)) {printf("%d是素数。
\n", num);} else {printf("%d不是素数。
\n", num);}return 0;}```通过上述代码,我们可以判断用户输入的数是否为素数。
另外,如果我们想找到一定范围内的所有素数,可以使用以下方法:1. 定义一个函数isPrimeNumber,用于判断一个数是否为素数,参考上述代码。
2. 定义一个循环从2开始遍历到指定范围内的最大值。
伪代码描述算法

伪代码描述算法算法标题:最小生成树(Prim算法)在图论中,最小生成树是指在一个连通图中找出一棵包含所有顶点且权值最小的树。
Prim算法是一种常用的解决最小生成树问题的算法。
1. 算法思想Prim算法的核心思想是以一个顶点为起点,逐步扩展生成最小生成树。
具体步骤如下:- 首先选取一个起始顶点,将其加入最小生成树的集合中。
- 然后,从与起始顶点相连的边中选择一条权值最小的边,并加入最小生成树的集合中。
- 接着,从已选取的边所连接的顶点中,选择一条权值最小的边,并加入最小生成树的集合中。
- 重复上述步骤,直到最小生成树的集合包含了所有顶点。
2. 算法实现下面通过伪代码来描述Prim算法的实现过程:```Prim(G, s):初始化集合V为图G的所有顶点初始化集合S为空,用于存放最小生成树的顶点集合初始化集合E为空,用于存放最小生成树的边集合将起始顶点s加入集合S中重复以下步骤,直到集合S包含了所有顶点:从集合V-S中选择一条连接到集合S中的顶点的权值最小的边(u, v)将顶点v加入集合S中将边(u, v)加入集合E中返回最小生成树的边集合E```3. 算法示例下面通过一个示例图来演示Prim算法的具体执行过程。
```输入:图G(V, E),其中V为顶点集合,E为边集合输出:最小生成树的边集合E1. 初始化集合V为{A, B, C, D, E, F, G, H}初始化集合S为空,用于存放最小生成树的顶点集合初始化集合E为空,用于存放最小生成树的边集合2. 将起始顶点A加入集合S中3. 重复以下步骤,直到集合S包含了所有顶点:- 从集合V-S中选择一条连接到集合S中的顶点的权值最小的边(u, v)- 将顶点v加入集合S中- 将边(u, v)加入集合E中第一次循环:- 选择边(A, B),将顶点B加入集合S中,将边(A, B)加入集合E 中第二次循环:- 选择边(B, D),将顶点D加入集合S中,将边(B, D)加入集合E 中第三次循环:- 选择边(D, C),将顶点C加入集合S中,将边(D, C)加入集合E 中第四次循环:- 选择边(C, F),将顶点F加入集合S中,将边(C, F)加入集合E 中第五次循环:- 选择边(F, E),将顶点E加入集合S中,将边(F, E)加入集合E 中第六次循环:- 选择边(E, G),将顶点G加入集合S中,将边(E, G)加入集合E中第七次循环:- 选择边(G, H),将顶点H加入集合S中,将边(G, H)加入集合E中4. 返回最小生成树的边集合E,即{(A, B), (B, D), (D, C), (C, F), (F,E), (E, G), (G, H)}```4. 算法分析- 时间复杂度:Prim算法的时间复杂度为O(|V|^2),其中|V|为顶点的数量。
普里姆算法(Prim)

普⾥姆算法(Prim)概览普⾥姆算法(Prim算法),图论中的⼀种算法,可在加权连通图(带权图)⾥搜索最⼩⽣成树。
即此算法搜索到的边(Edge)⼦集所构成的树中,不但包括了连通图⾥的所有顶点(Vertex)且其所有边的权值之和最⼩。
(注:N个顶点的图中,其最⼩⽣成树的边为N-1条,且各边之和最⼩。
树的每⼀个节点(除根节点)有且只有⼀个前驱,所以,只有N-1条边。
)该算法于1930年由捷克数学家沃伊捷赫·亚尔尼克(Vojtěch Jarník)发现;并在1957年由美国计算机科学家罗伯特·普⾥姆(Robert C. Prim)独⽴发现;1959年,艾兹格·迪科斯彻再次发现了该算法。
因此,在某些场合,普⾥姆算法⼜被称为DJP算法、亚尔尼克算法或普⾥姆-亚尔尼克算法。
定义假设G=(V, {E})是连通⽹,TE是N上最⼩⽣成树中边(Edge)的集合。
V是图G的顶点的集合,E是图G的边的集合。
算法从U={u0}(u0∈V),TE={}开始。
重复执⾏下述操作:在所有u∈U,v∈V-U的边(u, v)∈E中找⼀条代价(权值)最⼩的边(u0, v0)并⼊集合TE。
同时v0并⼊U直⾄U=V为⽌。
此时TE中必有n-1条边,则T=(V, {TE})为N的最⼩⽣成树。
由算法代码中的循环嵌套可得知此算法的时间复杂度为O(n2)。
过程简述输⼊:带权连通图(⽹)G,其顶点的集合为V,边的集合为E。
初始:U={u},u为从V中任意选取顶点,作为起始点;TE={}。
操作:重复以下操作,直到U=V,即两个集合相等。
在集合E中选取权值最⼩的边(u, v),u∈U,v∈V且v∉U。
(如果存在多条满⾜前述条件,即权值相同的边,则可任意选取其中之⼀。
)将v并⼊U,将(u, v)边加⼊TE。
输出:⽤集合U和TE来描述所得到的最⼩⽣成树如何实现如上⾯的这个图G=(V, {E}),其中V={v0, v1, v2, v3, v4, v5, v6, v7, v8},E= {(v0, v1), (v0, v5), (v1, v6), (v5, v6), (v1, v8), (v1, v2), (v2, v8), (v6, v7), (v3, v6), (v4, v5), (v4, v7), (v3, v7), (v3, v4), (v3,v8), (v2, v3)}⽤邻接矩阵来表⽰该图G,得上图右边的⼀个邻接矩阵。
hp prime 解方程组

hp prime 解方程组
要在HP Prime上解方程组,你可以使用其内置的求解器功能。
首先,进入“CAS”(计算代数系统)应用程序。
然后,选择“方程求解器”功能,这将允许你输入你的方程组并求解。
例如,如果你要解决以下方程组:
2x + 3y = 8。
4x 2y = 6。
你可以在方程求解器中输入这些方程,然后命令HP Prime求解方程组。
系统将会给出x和y的值,从而解决这个方程组。
此外,HP Prime还提供了图形界面,你可以通过图形界面输入方程组并获得解。
你也可以使用HP Prime的程序功能来编写自定义程序来解决方程组,这样可以更灵活地处理各种类型的方程组。
总之,HP Prime提供了多种方法来解决方程组,包括使用内置
的求解器功能、图形界面输入和自定义编程。
希望这些信息对你有所帮助。
Prime算法的简述

Prime算法的简述前⾯在介绍并查集时顺便提了Kruskal算法,既然已经说到了最⼩⽣成树问题,就没有道理不把Prime算法说了。
这⾥⾯先补充下Kruskal算法的⼤概意思,Kruskal算法通过把所有的边从⼩到⼤排列后,不断取权值最⼩的边加⼊最⼩⽣成树(起初可能是离散的多个树,最终连成⼀个整体),并通过并查集来舍弃形成回路的边。
Prime算法有所不同,Prime算法先将⼀个起点加⼊最⼩⽣成树,之后不断寻找与最⼩⽣成树相连的边权最⼩的边能通向的点,并将其加⼊最⼩⽣成树,是⼀种更符合⼈的主观直觉的最⼩⽣成树算法。
需要注意的是,Kruskal和Prime都仅适⽤于⽆向图。
#include <algorithm>const int MAX_V = 100;const int INF = 1000000;int cost[MAX_V][MAX_V];//图int V;bool path[MAX_V][MAX_V];//记录结果int res;bool used[MAX_V];//表⽰是否访问过int mincost[MAX_V];//表⽰到此点消耗值void Prime(){res = 0;//统计最⼩消耗for (int i = 0;i < V;++i)//初始化{used[i] = false;mincost[i] = INF;for (int j = 0;j < V;++j){path[i][j] = false;}}mincost[0] = 0;//从0点开始int prev = 0;//记录路径while (true){int visited = -1;for (int i = 0;i < V;++i){if (!used[i] && (visited == -1 || mincost[i] < mincost[visited])) visited = i;//贪婪寻找最短边}if (visited == -1) break;used[visited] = true;if (visited){path[prev][visited] = true;prev = visited;}res += mincost[visited];for (int i = 0;i < V;++i){mincost[i] = std::min(mincost[i], cost[visited][i]);}}}下⾯给出⼀组Kruskal和Prime的测试数据及结果:测试代码:void mstTest(){cin >> V;for (int i = 0;i < V;++i)for (int j = 0;j < V;++j){cin >> cost[i][j];}for (int i = 0;i < V;++i) d[i] = INF;cout << "Kruskal:" << endl;Kruskal();for (int i = 0;i < V;++i){for (int j = 0;j < V;++j){if (path[i][j]) cout << i << "" << j << endl;}}cout << res << endl;cout << endl;cout << "Prime" << endl;Prime();for (int i = 0;i < V;++i){for (int j = 0;j < V;++j){if (path[i][j]) cout << i << "" << j << endl;}}cout << res << endl;}测试结果:91000000 1 5 7 4 1000000 1000000 1000000 10000001 1000000 1000000 1000000 1000000 3 10 1000000 10000005 1000000 1000000 1000000 1000000 2 1000000 2 10000007 1000000 1000000 1000000 1000000 1000000 1 1000000 10000004 1000000 1000000 1000000 1000000 1000000 1000000 3 1000000 1000000 3 2 1000000 1000000 1000000 1000000 1000000 21000000 10 1000000 1 1000000 1000000 1000000 1000000 91000000 1000000 2 1000000 3 1000000 1000000 1000000 51000000 1000000 1000000 1000000 1000000 2 9 5 1000000Kruskal:0 10 31 52 52 73 64 75 821Prime0 11 52 73 64 35 27 88 421请按任意键继续. . .可以看到,两种算法⽣成了拥有相同最⼩消耗的两颗完全不同的最⼩⽣成树。
Prime算法

Prime算法MST(Minimum Spanning Tree,最⼩⽣成树)问题有两种通⽤的解法,Prim算法就是其中之⼀,它是从点的⽅⾯考虑构建⼀颗MST,⼤致思想是:设图G顶点集合为U,⾸先任意选择图G中的⼀点作为起始点a,将该点加⼊集合V,再从集合U-V中找到另⼀点b使得点b到V中任意⼀点的权值最⼩,此时将b点也加⼊集合V;以此类推,现在的集合V= {a,b},再从集合U-V中找到另⼀点c使得点c到V中任意⼀点的权值最⼩,此时将c点加⼊集合V,直⾄所有顶点全部被加⼊V,此时就构建出了⼀颗MST。
因为有N个顶点,所以该MST就有N-1条边,每⼀次向集合V中加⼊⼀个点,就意味着找到⼀条MST的边。
原⽂链接:https:///yeruby/article/details/38615045下⾯⽤图和代码来解释:我们⾸先定义⼀个数组:lowcost[i];我们初始将V1作为起点,那么lowcost[2] = 6,lowcost[3] = 1,lowcost[4] =5,lowcost[5] = inf,lowcost[6] = inf;(其中inf=0x7ffffff,i指的是以i为终点的路径的长度,若没有⼀步可达的路径那么就赋值为inf)我们明显可以看出,以V3为终点的路径最短那么就将V3加⼊集合V中,lowcost[2]=5,lowcost[3]=0,lowcost[4]=5,lowcost[5]=6,lowcost[6]=4,将lowcost[3]标记为0,说明V3已经加⼊到集合V中了。
同时在这⾥更新以V3为起点所能直接到达的点的最短路。
此时,因为点V6的加⼊,需要更新lowcost数组lowcost[2]=5,lowcost[3]=0,lowcost[4]=2,lowcost[5]=6,lowcost[6]=0明显看出,以V4为终点的边的权值最⼩=2此时,因为点V4的加⼊,需要更新lowcost数组:lowcost[2]=5,lowcost[3]=0,lowcost[4]=0,lowcost[5]=6,lowcost[6]=0重复执⾏直到所有点都加⼊集合V;#include <iostream>#define Max 100#define MaxCost 0x7fffffffusing namespace std;int Graph[Max][Max];void prime(int n) {int lowcost[Max];;int i, j, min1, minid, sum = 0;for (i = 2; i <= n; i++) {lowcost[i] = Graph[1][i];}mst[1] = 0;for (i = 2; i <= n; i++) {min1 = MaxCost;minid = 0;for (j = 2; j <= n; j++) {if (lowcost[j] < min1 && lowcost[j] != 0) { min1 = lowcost[j];}}sum += min1;lowcost[minid] = 0;for (j = 2; j <= n; j++) {if (Graph[minid][j] < lowcost[j]) {lowcost[j] = Graph[minid][j];}}}cout << sum;}int main() {ios::sync_with_stdio(false);int n, m;//n为顶点的个数,m为边;int i, j;cin >> n >> m;for (i = 1; i <= n; i++) {for (j = 1; j <= n; j++) {Graph[i][j] = MaxCost;}}int b, e, cost;for (i = 1; i <= m; i++) {cin >> b >> e >> cost;Graph[b][e] = cost;Graph[e][b] = cost;}prime(n);return0;}。
Prime 编程说明介绍

编程
453
程序结构
一个程序可以含有任何数量的子程序 (每个子程序可以 是一个函数或一个程序) 。子程序首先显示由名称组成 的标题,随后是括号,括号中包含一列由逗号隔开的参 数或实参。子程序主体是一系列置于 BEGIN–END; 对中 的语句。例如,一个名称为 MYPROGRAM 的简单程序的 主体看起来如下所示: EXPORT MYPROGAM() BEGIN PIXON(1,1); END;
S= 或 S\ C SJ
创建新的程序
1. 打开程序目录,并 启动一个新程序。
Sx(程序)
2. 为程序输入名称。
AA (锁定
alpha 模式) MYPROGRAM 。
3. 再按 。随后 会自动为您的程序 创建一个模板。该 模板包含一个函数 标题 (与程序 EXPORT MYPROGRAM() 同 名)以及一个括起 函数语句的 BEGIN–END; 结构对。 提示 程序名只能含有字母与数字字符及下划线字符。第一个 字符必须为字母。例如, GOOD_NAME 和 Spin2 是有效 的程序名,而 HOT STUFF (包含空格)和 2Cool! (以数字开头且包含 !)无效。
请注意,已插入 FOR_FROM_TO_DO _ 模板。您只需填写 缺少的信息。
编程
459
4. 使用光标键和键盘, 填写命令缺少的部 分。在此情况下, 使语句匹配以下项: FOR N FROM 1 TO 3 DO 5. 将光标移到 FOR 语 句下方的空白行。 6. 点击 以打开常用编程命令菜单。
重命名为选定的程序重
命名。
排序对程序列表进行排
序。 (排序选项按字母 顺序或时间顺序排序) 。
删除删除选定的程序。 清除删除所有程序。
最小生成树-prime算法

最⼩⽣成树-prime算法Prime算法的核⼼步骤是:在带权连通图中V是包含所有顶点的集合, U已经在最⼩⽣成树中的节点,从图中任意某⼀顶点v 开始,此时集合U={v},重复执⾏下述操作:在所有u∈U,w∈V-U的边(u,w)∈E中找到⼀条权值最⼩的边,将(u,w)这条边加⼊到已找到边的集合,并且将点w加⼊到集合U中,当U=V时,就找到了这颗最⼩⽣成树。
其实,算法的核⼼步骤就是:在所有u∈U,w∈V-U的边(u,w)∈E中找到⼀条权值最⼩的边。
知道了普利姆算法的核⼼步骤,下⾯我就⽤图⽰法来演⽰⼀下⼯作流程,如图:⾸先,确定起始顶点。
我以顶点A作为起始点。
根据查找法则,与点A相邻的点有点B和点H,⽐较AB与AH,我们选择点B,如下图。
并将点B加⼊到U中。
继续下⼀步,此时集合U中有{A,B}两个点,再分别以这两点为起始点,根据查找法则,找到边BC(当有多条边权值相等时,可选任意⼀条),如下图。
并将点C加⼊到U中。
继续,此时集合U中有{A,B,C}三个点,根据查找法则,我们找到了符合要求的边CI,如下图。
并将点I加⼊到U中。
继续,此时集合U中有{A,B,C,I}四个点,根绝查找法则,找到符合要求的边CF,如下图。
并将点F加⼊到集合U中。
继续,依照查找法则我们找到边FG,如下图。
并将点G加⼊到U中。
继续,依照查找法则我们找到边GH,如下图。
并将点H加⼊到U中。
继续,依照查找法则我们找到边CD,如下图。
并将点D加⼊到U中。
继续,依照查找法则我们找到边DE,如下图。
并将点E加⼊到U中。
此时,满⾜U = V,即找到了这颗最⼩⽣成树。
同样,我继续⽤POJ 2395这题为例⼦给出代码:#include <iostream>#include <string.h>using namespace std;const int MAXN = 2010;const int INF = 1 << 30;int map[MAXN][MAXN];int N, M;int lowcost[MAXN];void init(){for(size_t i = 0; i <= N; ++i)for(size_t j = 0; j <= N; ++j)map[i][j] = INF;}int prime(){for(size_t i = 1; i <= N; ++i)lowcost[i] = map[1][i];int min;bool visited[N + 1];// index begin from 1 not 0int ans = -1;memset(visited, false, sizeof(visited));lowcost[1] = 0;lowcost[1] = 0;visited[1] = true;for(size_t i = 1; i < N; ++i)//loop N - 1 times{min = INF;int k;for(size_t j = 1; j <= N; ++j)// find the minimun edge between two edge set {if(!visited[j] && min > lowcost[j]){min = lowcost[j];k = j;}}visited[k] = true;ans = ans > min ? ans : min;for(size_t j = 1; j <= N; ++j)// update the array of lowcost{if(!visited[j] && lowcost[j] > map[k][j])lowcost[j] = map[k][j];}}return ans;}int main(){while(cin >> N >> M){init();int x, y, c;for(size_t i = 0; i < M; ++i){cin >> x >> y >> c;if(map[x][y] > c)map[x][y] = c;if(map[y][x] > c)map[y][x] = c;}cout << prime() << endl;}}。
Python经典贪心算法之Prim算法案例详解
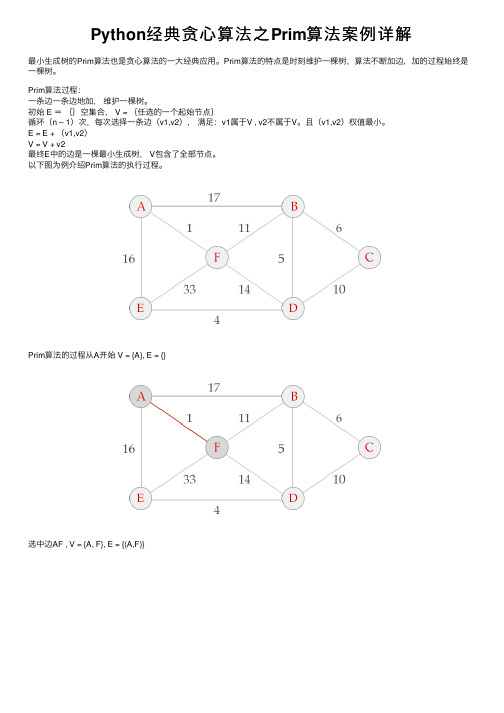
Python经典贪⼼算法之Prim算法案例详解最⼩⽣成树的Prim算法也是贪⼼算法的⼀⼤经典应⽤。
Prim算法的特点是时刻维护⼀棵树,算法不断加边,加的过程始终是⼀棵树。
Prim算法过程:⼀条边⼀条边地加,维护⼀棵树。
初始 E ={}空集合, V = {任选的⼀个起始节点}循环(n – 1)次,每次选择⼀条边(v1,v2),满⾜:v1属于V , v2不属于V。
且(v1,v2)权值最⼩。
E = E + (v1,v2)V = V + v2最终E中的边是⼀棵最⼩⽣成树, V包含了全部节点。
以下图为例介绍Prim算法的执⾏过程。
Prim算法的过程从A开始 V = {A}, E = {}选中边AF , V = {A, F}, E = {(A,F)}选中边FB, V = {A, F, B}, E = {(A,F), (F,B)}选中边BD, V = {A, B, F, D}, E = {(A,F), (F,B), (B,D)}选中边DE, V = {A, B, F, D, E}, E = {(A,F), (F,B), (B,D), (D,E)}选中边BC, V = {A, B, F, D, E, c}, E = {(A,F), (F,B), (B,D), (D,E), (B,C)}, 算法结束。
Prim算法的证明:假设Prim算法得到⼀棵树P,有⼀棵最⼩⽣成树T。
假设P和T不同,我们假设Prim算法进⾏到第(K – 1)步时选择的边都在T中,这时Prim算法的树是P', 第K步时,Prim算法选择了⼀条边e = (u, v)不在T中。
假设u在P'中,⽽v不在。
因为T是树,所以T中必然有⼀条u到v的路径,我们考虑这条路径上第⼀个点u在P'中,最后⼀个点v不在P'中,则路径上⼀定有⼀条边f = (x,y),x在P'中,⽽且y不在P'中。
我们考虑f和e的边权w(f)与w(e)的关系:若w(f) > w(e),在T中⽤e换掉f (T中加上e去掉f),得到⼀个权值和更⼩的⽣成树,与T是最⼩⽣成树⽭盾。
prime,素数的判断——c语言

}-------------------------------------------------------------//用循环来判断是否是素数
if(i*i>a) y=1; return y; } int main() { int x,y,k,i; scanf("%d %d",&x,&y);------------------------------------//读两个数 for(i=x;i<=y;i++) {
prime,素数的判断 ——c语言
输入一个数a,求他是否是素数(用函数) 程序:
#include<stdio.h> int prime(int a)-----------------------------------//定义一个prime的自定义函数 {
int i,y=0; for(i=1;i<=a;i++) {
k=Allprime(i); if(k==1)
printf("%d ",i); }----------------------------------------------------//用Allprime函数来判断a到b之间的书 return 0; }
我一定会在将来的路上继续努力,得到更多的成功,加油!O(∩_∩)O哈!0(^_^)0哈!
if(a%i!=0) y++;
}------------------------------------------//判断是不是素数 return y;----------------------------------//返回值为y } int main() { int x,i; scanf("%d",&x);---------------------------//读一个数 i=prime(x);----------------------------------------------//用prime函数来判断x if(i==2) printf("true"); else printf("false");---------------------------------------------//用值来判断x return 0; } 我又改了一道题:
最小生成树之算法记录【prime算法+Kruskal算法】【模板】

最⼩⽣成树之算法记录【prime算法+Kruskal算法】【模板】⾸先说⼀下什么是树:1、只含⼀个根节点2、任意两个节点之间只能有⼀条或者没有线相连3、任意两个节点之间都可以通过别的节点间接相连4、除了根节点没⼀个节点都只有唯⼀的⼀个⽗节点5、也有可能是空树(不含任何节点)最⼩⽣成树就是:在所有数据满⾜是⼀棵树的情况下⼀条将所有节点都连接起来且长度最短的⼀条路(因为任意两个节点之间有权值(相连的两点之间权值为⼀个具体的数,不相连的两个点之间权值为⽆穷⼤))下⾯介绍通⽤的求最⼩⽣成树的两种算法:ps:这⾥⽤的两种算法都是⽤邻接矩阵实现适合点稠密型数据或者数据较⼩的情况:(1)prime算法:/** 数组tree[]⽤来记录最⼩⽣成树的节点* 数组lowdis[]记录从起点到其余所有点的距离并不断更新* 数组map[][]记录所有数据两点之间的距离* point是所有节点的数⽬,begin是起点* mindis是最⼩⽣成树的长度*/void prime(){int i,j,min,mindis=0,next;memset(tree,0,sizeof(tree));for(i=1;i<=point;i++){lowdis[i]=map[begin][i];//⽤lowdis[]数组记录下从起点到剩下所有点的距离}tree[begin]=1;//标记起点(即最⼩⽣成树中的点)for(i=1;i<point;i++){min=INF;for(j=1;j<=point;j++){if(!tree[j]&&min>lowdis[j]){min=lowdis[j];//求出从当前起点到其余所有点的距离中最短的next=j;}}mindis+=min;//记录下整条最⼩树的长度tree[next]=1;for(j=1;j<=point;j++){if(!tree[j]&&lowdis[j]>map[next][j])lowdis[j]=map[next][j];//更新lowdis[]数组}}printf("%d\n",mindis);}kruskal算法:此算法的核⼼就是在并查集(并查集知识请看知识⼩总结记录分类中的并查集())的基础上对两点之间距离进⾏排序:find()函数⽤来查找根节点int find(int father)//查找根节点{int t;int children=father;while(father!=set[father])father=set[father];while(fa!=set[children]){t=set[children];set[children]=father;children=t;}return father;}mix函数⽤来合并两个节点,使两个节点的⽗节点相同void mix(int x,int y)//将两个点合并(即另两点根节点相同){int fx;int fy;fx=find(x);fy=find(y);if(fx!=fy)set[fx]=fy;}利⽤结构体排序:struct record{int begin;//记录两个点中的⼀个int end;//记录两个点中的⼀个int dis;//记录两点之间距离}num[MAX];bool cmp(int a,int b){return a.dis<b.dis;//对两点之间距离进⾏从⼤到⼩的排序}⽤⼀个题来实现上述两个算法:省政府“畅通⼯程”的⽬标是使全省任何两个村庄间都可以实现公路交通(但不⼀定有直接的公路相连,只要能间接通过公路可达即可)。
最大素数python代码

最大素数python代码最大素数Python代码介绍素数是指只能被1和自己整除的正整数。
在计算机科学中,找到最大的素数是一个常见的问题。
Python语言提供了一些方法来解决这个问题。
方法一:暴力枚举法暴力枚举法是最简单直接的方法,它从2开始逐个判断每个数字是否为素数。
如果是素数,则将其保存下来,直到找到最大的素数为止。
代码实现:```pythondef is_prime(num):if num < 2:return Falsefor i in range(2, int(num ** 0.5) + 1):if num % i == 0:return Falsereturn Truedef max_prime(n):for i in range(n, 1, -1):if is_prime(i):return i```方法二:埃氏筛法埃氏筛法是一种更高效的方法。
它从2开始,将所有小于等于n的正整数标记为合数(除了2本身),然后再依次判断每个数字是否为素数。
代码实现:```pythondef max_prime(n):primes = [True] * (n + 1)primes[0] = primes[1] = Falsefor i in range(2, int(n ** 0.5) + 1):for j in range(i * i, n + 1, i):primes[j] = Falsefor i in range(n, 1, -1):if primes[i]:return i```方法三:米勒-拉宾素性检验米勒-拉宾素性检验是一种更加高级的方法,它可以判断一个数是否为素数。
这个算法基于费马小定理和二次探测定理,可以在O(k log^3n)的时间复杂度内进行k次测试。
代码实现:```pythonimport randomdef is_prime(n, k=5):if n < 2:return Falsefor p in [2, 3, 5, 7, 11]:return Trueif n % p == 0:return Falser, s = 0, n - 1while s % 2 == 0:r += 1s //= 2for _ in range(k):a = random.randint(2, n - 1) x = pow(a, s, n)if x == 1 or x == n - 1:continuefor _ in range(r - 1):x = pow(x, 2, n)if x == n - 1:breakelse:return Falsereturn Truedef max_prime(n):for i in range(n, 1, -1):if is_prime(i):return i```总结以上是三种求最大素数的Python代码实现。
图的最小生成树,prime算法

图的最⼩⽣成树,prime算法算法的复杂度与节点数量有关,⽽与边⽆关。
适⽤于稠密图。
1.⾸先选出节点x,更新它与其他节点的边权值。
2.将其⾃⾝的边权值设为-1,表⽰节点已被使⽤,或者说已经加⼊了U。
3.找出相连边中最⼩权值的点v0,将它加⼊U(置为-1),并更新U中节点的所有边值。
4.重复3,直到所有节点均加⼊U。
struct CloseEdge{VerTextType adjvex; //最⼩边在u中的顶点ArcType lowcost; //最⼩边权值};int minEdge(CloseEdge* closeEdge, int m) {int min = INT_MAX;int u = -1;for(int i = 0;i < m;++i) {if(closeEdge[i].lowcost != -1 && closeEdge[i].lowcost < min) {min = closeEdge[i].lowcost;u = i;}}return u;}//G为⼆维数组,存储边void minSpanTree(vector<vector<int> > G) {int m = G.size();if(m == 0) return;//以顶点0为起点,求最⼩⽣成树int u = 0;CloseEdge closeEdge[m];memset(closeEdge,-1,sizeof(CloseEdge)*m);for(int i = 1;i<m;i++){closeEdge[i] = {u, G[u][i]};}//此时已经知道了u周围的边中的最⼩边。
closeEdge[0] = {0,-1};for(int i = 1;i<m;i++) {//v0是其最⼩边的⼀个顶点int v0 = minEdge(closeEdge, m);int u0 = closeEdge[v0].adjvex;cout<<u0<<v0<<endl;for(int j=0;j<m;++j) {//更新与v0相连的最边,选择⼩的。
素数算法——精选推荐

素数算法
看着空荡荡的博客不知道写些什么,写些以前的⼼得吧
素数算法⽐较的常⽤,这次就写它了。
这⾥我给出⾃⼰常⽤的写法
写法1:
int n=10000;
int prime[10000]; //⽤于存储素数
int num=0;
int j;
for(int i=2;i<=n;i++){
for(j=2;j<=sqrt(i);j++){ //⾥层只要循环到sqrt(i)就⾏了
if(i%j==0)
break;
}
if(j>sqrt(i))prime[num++]=i;
没有太多好讲的地⽅,就这⼏⾏,思路⾮常简单,只是把最基础的内层循环j<=n替换成了j<=sqrt[i],⼩优化了⼀下⽽已
写法2:素数筛
int num=0;
int n=10000;
int prime[10000]; //⽤于存放素数
int flag[10005]; //⽤于判断i是否为素数
memset(flag,0,sizeof(flag));
for(int i=2;i<=n;i++){
if(flag[i]==0){
prime[num++]=i;
for(int j = i+i; j<=n; j+=i)
flag[j]=1;
}
}
⾮常常⽤的⼀个算法,思路也很简单,每找到⼀个素数之后,把它的倍数筛掉(因为肯定不是素数),这样时间复杂度就被降低到了线性,所以⼜称线性素数筛法。
prime算法负边最优解

prime算法负边最优解
说到最小(大)生成树的典型算法当然是Prime和Kruskal了。
Kruskal比较好理解就不说了。
这里主要是谈一谈Prime算法。
Prime算法负边最优解的核心步骤:
在带权连通图中假设V是包含所有顶点的集合, U是已经在最小生成树中的节点的集合,从图中任意某一顶点v开始,此时集合U={v}。
重复执行下述操作:
在所有u∈U,w∈V-U的边(u,w)∈E中找到一条权值最小的边,将(u,w)这条边加入到已找到边的集合,并且将点w加入到集合U中,当U=V 时,就找到了这颗最小生成树。
这样讲可能对新人来说比较难理解。
我们可以这样想:
首先最小生成树他是一颗“树”。
树的一大核心思想就是可以把问题下移到子树上从而达到简化,细化问题的目的。
那么一颗树最小的问题就变成了他的最小子树加一条权值最小的边的问题。
那么那条最小的边是哪条呢?我们可以这样想,我们最后的目的是把所有点连成一颗树同时使树的权值和最小,那么我们根本不关心新的点会连到树的哪个点上,只要边权值小就行。
那么我们可以把已有的树(集合U)看成一个“点”,只需要不断更新这个“点”到其他边的权值,然后每次从其中选一个最小的连上就行。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
for (j = 1; j < G.VertexNum;j++) //查找权值最小的一个邻接边
if (weight[j] < min && tmpvertex[j] != 0) //找到具有最小权值的未使用边
{
min = weight[j]; //保存权值
k = j; //保存邻接点序号
return 0;
}
OutMatrix(&G);
cout << "生成最小生成树的边:" << endl;
Prim(G); //调用最小生成树函数
cout << "是否继续?" << endl;
cin >> select;
getchar();
} while (select != 'n'&&select != 'N');
}
cout << "请输入构成各边的两个顶点及权值:\n";
for (k = 0; k < G->EdgeNum; k++)
{
cout << "第" << k + 1 << "条边:";
cin >> start >> end >> weight;
for (i = 0; start != G->Vertex[i]; i++); //在已有顶点中查找起始顶点
{
int i, j, k, weight;
char start, end; //边的起点、终点
cout<<"请输入顶点信息:"<<endl;
for (i = 0; i < G->VertexNum; i++) //输入顶点
{
cout << "第" << i + 1 << "个顶点:";
cin >> G->Vertex[i];
#include<iostream>
#include<stdio.h>
using namespace std;
#define VERTEX_MAX 26 //图的最大顶点数
#define MAXVALUE 32767 //最大值
typedef struct
{
char Vertex[VERTEX_MAX]; //保存顶点信息
}
}
cout << endl << "最小生成树总权值为:" << sum;
}
int main()
{
MatrixGraph G; //定义保存邻接矩阵的图
int i, j, s, t;
char select;
do
{
cout << "请输入图的顶点数和边数:";
cin >> G.VertexNum >> G.EdgeNum; //输入顶点数和边数
{
int i, j;
for (j = 0; j < G->VertexNum; j++)
printf("\t%c", G->Vertex[j]); //第一行输出顶点信息
cout << endl;
for (i = 0; i < G->VertexNum; i++)
{
cout << G->Vertex[i];
for (i = 0; i < G.VertexNum; i++) //清空矩阵
for (j = 0; j < G.VertexNum; j++)
G.Edges[i][j] = MAXVALUE; //设置矩阵中各元素的值
CreateMatrixGraph(&G); //生成邻接矩阵的图
cout << "邻接矩阵如下:" << endl;
}
sum += min; //累加权值
printf("(%c,%c),", tmpvertex[k], G.Vertex[k]); //输出最小生成树的一条边
tmpvertex[k] = USED; //将编号为k的顶点并入U集
weight[k] = MAXVALUE; //已使用顶点的权值为最大值
char tmpvertex[VERTEX_MAX]; //临时顶点信息
for (i = 1; i < G.VertexNum; i++)
{
weight[i] = G.Edges[0][i];
if (weight[i] == MAXVALUE)
tmpvertex[i] = NOADJ; //非邻接顶点
for (j = 0; j < G->VertexNum; j++)
{
if (G->Edges[i][j] == MAXVALUE) //若权值为最大值
printf("\t00"); //无穷大,暂时用00代替
else
printf("\t%d", G->Edges[i][j]); //输出边的权值
}
else
tmpvertex[i] = G.Vertex[0]; //邻接顶点
}
tmpvertex[0] = USED; //将0号顶点并入U集
weight[0] = MAXVALUE; //设已使用顶点权值为最大值
for (i = 1; i < G.VertexNum; i++)
{
min = weight[0]; //最小权值
for (j = 0; j < G.VertexNum;j++) //重新选择最小边
if(G.Edges[k][j] < weight[j] && tmpvertex[j] != 0)
{
weight[j] = G.Edges[k][j]; //权值
tmpvertex[j] = G.Vertex[k]; //上一个顶点信息
int Edges[VERTEX_MAX][VERTEX_MAX]; //保存边的权
int isTraபைடு நூலகம்[VERTEX_MAX]; //遍历标志
int VertexNum; //顶底数量
int EdgeNum; //边数量
}MatrixGraph;
void CreateMatrixGraph(MatrixGraph *G)
for (j = 0; end != G->Vertex[j]; j++); //在已有顶点中查找终顶点
G->Edges[i][j] = weight; //对应位置保存权值
G->Edges[j][i] = weight; //在对角位置保存权值
}
}
void OutMatrix(MatrixGraph *G)
cout << endl;
}
}
#define USED 0 //已使用,加入U集合
#define NOADJ -1 //非邻接顶点
void Prim(MatrixGraph G) //最小生成树
{
int i, j, k, min, sum = 0;
int weight[VERTEX_MAX]; //权值