数据抽取与主题开发基础流程
数据中心逻辑架构设计
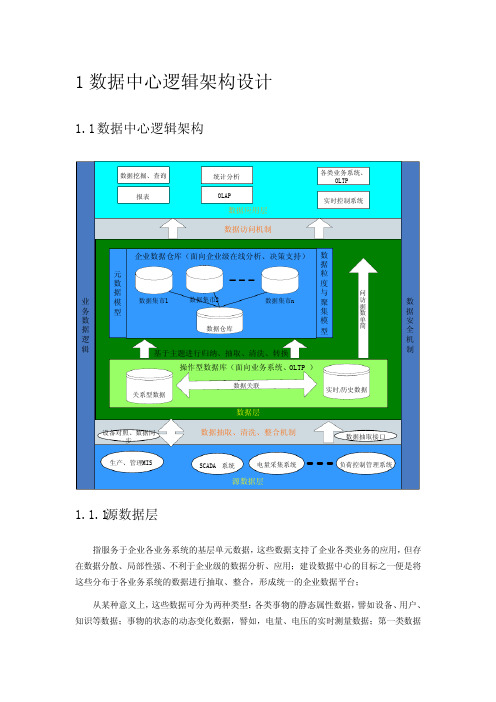
1数据中心逻辑架构设计1.1数据中心逻辑架构数据抽取、清洗、整合机制数据层企业数据仓库(面向企业级在线分析、决策支持)操作型数据库(面向业务系统、OLTP )源数据层电量采集系统负荷控制管理系统SCADA 系统数据抽取接口设备对照、数据同步生产、管理MIS关系型数据数据集市1实时/历史数据数据关联数据集市2数据集市n简单数据访问业务数据逻辑数据安全机制数据应用层报表数据挖掘、查询OLAP统计分析各类业务系统、OLTP 实时控制系统数据访问机制基于主题进行归纳、抽取、清洗、转换数据仓库元数据模型数据粒度与聚集模型1.1.1源数据层指服务于企业各业务系统的基层单元数据,这些数据支持了企业各类业务的应用,但存在数据分散、局部性强、不利于企业级的数据分析、应用;建设数据中心的目标之一便是将这些分布于各业务系统的数据进行抽取、整合,形成统一的企业数据平台;从某种意义上,这些数据可分为两种类型:各类事物的静态属性数据,譬如设备、用户、知识等数据;事物的状态的动态变化数据,譬如,电量、电压的实时测量数据;第一类数据的特点是在局部区域内是保持相对稳定的,人们更多关心的是这些数据的关联;第二类数据具有很强的“时间本性”,它们或明确或潜在的都具有“时间标签”的属性,人们更多关注的是它们在某一时刻的值。
1.1.2数据层或者说是企业数据平台、数据中心,通过对企业数据的整体规划、抽取、加工、整合,将存在于各独立系统的数据组织为一个有机的整体,使纷杂无序的数据成为企业有用信息,同时,使基于企业级的数据深层挖掘、分析成为可能;数据层负责对企业数据进行收集、加工、标准化并将之进行科学的存贮,同时,需要为上层应用提供安全、高效、方便的访问接口;如上所述,我们可以将现实世界的数据抽象为两类,基于这两类数据特征,分别采用关系型数据库譬如Oracle和实时数据库譬如eDNA进行管理,两类数据以数据的逻辑关系进行关联;为便于数据的挖掘、分析,在面向业务系统的操作型数据库上建立一组基于业务主题的数据仓库、集市,可以提高数据分析的性能;进一步讲,操作型数据面向具体业务系统、联机事务处理(OLTP)等应用,而数据仓库(Data Warehouse)、数据集市(DataMarts)为企业决策支持、联机分析处理(OLAP)等深层数据挖掘提供基础。
文本信息处理基本概念

文本信息处理基本概念文本信息处理基本概念随着信息时代的到来,文本信息处理成为了我们日常工作和学习中不可或缺的一部分。
文本信息处理涉及到对文本数据的获取、存储、分析、挖掘和应用等方面。
在本文中,我们将介绍文本信息处理的基本概念,包括文本数据的特点、文本处理的流程和常用的文本处理技术。
一、文本数据的特点文本数据是指以自然语言形式表述的信息,具有以下特点:1.非结构化:文本数据不像结构化数据那样有明确的表格和字段,而是以自由文本的形式存在。
这使得对文本数据的处理更加复杂和困难。
2.多样性:文本数据来源广泛,包括新闻、论文、社交媒体、电子邮件等。
不同领域和不同作者的文本数据会有不同的特点和风格。
3.主观性:文本数据通常包含作者的主观意见和情感倾向。
因此,对于文本数据的处理需要考虑到作者的个人喜好和情绪。
4.时效性:大部分文本数据都是实时产生的,比如社交媒体和新闻报道。
因此,对于文本数据的处理需要及时性和实时性。
二、文本处理的流程文本处理的流程通常包括数据收集、数据清洗、特征提取和应用等步骤。
1.数据收集:数据收集是指获取文本数据的过程。
常见的数据收集方法包括网络爬虫、API接口、数据库查询等。
在数据收集过程中,需要考虑数据的来源、数据的质量和数据的规模等因素。
2.数据清洗:数据清洗是指对获取到的文本数据进行预处理和过滤,以便后续的分析和挖掘。
常见的数据清洗操作包括去除重复数据、去除噪声数据、纠正拼写错误等。
数据清洗的目的是提高数据质量,减少后续分析的误差。
3.特征提取:特征提取是指从文本数据中提取出有用的特征信息。
特征可以包括词频、主题、情感倾向等。
常见的特征提取方法包括词袋模型、主题模型、情感分析等。
特征提取是后续文本分析和挖掘的基础。
4.应用:应用是指利用提取出的特征信息进行具体任务的实现。
常见的文本应用包括文本分类、文本聚类、情感分析、舆情监控等。
应用可以帮助我们更好地理解文本数据并从中获取有用的信息。
BI介绍

一、BI的定义BI是Business Intelligence的英文缩写,中文解释为商务智能,用来帮助企业更好地利用数据提高决策质量的技术集合,是从大量的数据中钻取信息与知识的过程。
简单讲就是业务、数据、数据价值应用的过程。
用图解的方式可以理解为下图:图(1)这样不难看出,传统的交易系统完成的是Business到Data的过程,而BI要做的事情是在Data的基础上,让Data产生价值,这个产生价值的过程就是Business Intelligence analyse的过程。
如何实现Business Intelligence analyse的过程,从技术角度来说,是一个复杂的技术集合,它包含ETL、DW、OLAP、DM等多环节,基本过程可用下图描述。
图(2)上图流程,简单的说就是把交易系统已经发生过的数据,通过ETL工具抽取到主题明确的数据仓库中,OLAP后生成Cube或报表,透过Portal 展现给用户,用户利用这些经过分类(Classification)、聚集(Clustering)、描述和可视化(Description and Visualization)的数据,支持业务决策。
说明:BI不能产生决策,而是利用BI过程处理后的数据来支持决策。
哪么BI 所谓的智能到底是什么呢?(理清这个概念,有助于对BI的应用。
)BI最终展现给用户的信息就是报表或图视,但它不同于传统的静态报表或图视,它颠覆了传统报表或图视的提供与阅读的方式,产生的数据集合就象玩具“魔方”一样,可以任意快速的旋转组合报表或图视,有力的保障了用户分析数据时操作的简单性、报表或图视直观性及思维的连惯性。
我想这是大家热衷于BI的根本原因。
二、BI的诞生随着IT技术的进步,传统的业务交易系统有了长足的发展,已经实现了业务信息化,每一笔业务数据都记录在数据库中,星转斗移,累积了以TB为计量单位的业务数据记录。
也许你会问:这么多数据,占用了很多存储设备,耗费存储成本,却又不经常访问,留着它有什么用处?可以给你肯定的回答,留着这些历史数据意义巨大,挖掘业务的规律、支持决策。
ETL初学入门

ETL 学习之一收藏ETL有时候显得很神秘,其实大部分项目都有用到,只要有报表展示,就是一个ETL过程。
首先,我们来了解最基本的定义:嗯,也有人将ETL简单称为数据抽取。
至少在未学习之前,领导告诉我的是,你需要做一个数据抽取的工具。
其实呢,抽取是ETL中的关键环节,顾名思义,也就将数据从不同的数据源中抓取(复制)出来。
太简单了!上面的解释无首无尾,有点象能让你吃饱的第七个烧饼,仔细一想,抽取是不可能单独存在,我们需要将与之关联的一些其它环节拿出来。
于是,得到ETL的定义:将数据抽取(Extract)、转换(Transform)、清洗(Cleansing)、装载(Load)的过程。
好的,既然到了这一个层次,我们完全会进一步展开联想,引出上面这个抽象事件的前因后果,抽取的源在哪里?装载的目的又是什么呢?抽取源:大多数情况下,可以认为是关系数据库,专业一点,就是事务处理系统(OLTP)。
当然,广义一点,可能会是其它数据库或者是文件系统。
目的地:OK,我们希望是数据仓库。
数据仓库是啥?在学习之前,它对我来说是个抽象的怪物,看过一些简单的资料之后,才了解这个怪物一点都不怪。
堆积用来分析的数据的仓库。
是了,是用来分析的,于是,它区别于OLTP中的数据存储。
然后,我们来看看为什么要ETL?在我看来,有两个原因。
一:性能将需要分析的数据从OLTP中抽离出来,使分析和事务处理不冲突。
咦?这不是数据仓库的效果吗?是了,数据仓库,大多数情况下,也就是通过ETL工具来生成地。
二:控制用户可以完全控制从OLTP中抽离出来的数据,拥有了数据,也就拥有了一切。
嗯,OLAP分析,数据挖掘等等等……。
本文来自CSDN博客,转载请标明出处:/laszloyu/archive/2009/04/13/4068111.aspxETL学习之二收藏ETL为数据仓库服务,数据仓库用于数据分析,数据分析属于BI系统的要干的事儿。
一般中/小型ERP系统都会有不成熟的BI系统,为啥叫做不成熟?因为它们或者有报表分析功能,但不具有OLAP(在线分析),或者有OLAP,但却没有数据挖掘和深度分析。
大数据数据抽取流程

大数据数据抽取流程Data extraction is a critical process in big data analysis. 大数据分析中的数据抽取是一个非常关键的步骤。
It involves retrieving data from various sources such as databases, data warehouses, and other storage systems. 它涉及从各种来源,如数据库、数据仓库和其他存储系统中检索数据。
Data extraction is essential for businesses and organizations to gain insights and make informed decisions based on the data. 数据抽取对于企业和组织来说非常重要,可以帮助他们获得洞察并基于数据做出明智的决策。
There are several steps involved in the data extraction process, including identifying data sources, designing extraction methods, and transforming the data for analysis. 数据抽取过程涉及几个步骤,包括识别数据来源、设计抽取方法以及转换数据以进行分析。
In this article, we will explore the data extraction process in big data analysis and its significance.The first step in the data extraction process is to identify the data sources. 数据抽取过程中的第一步是识别数据来源。
元数据管理规范

元数据管理规范首先对数据资源进行全面梳理,规划构建最优化的、具有差别化的、面向应用主题的、贵阳高新区数据资源中心,进而支持实现相应分析目标的数据挖掘、多维数据分析等,主要包含以下五大方面数据资源:(1)整合以高新区企业为维度的统计口径的数据,主要以一套表系统数据和火炬系统数据为主,建立高新区企业(被纳入统计的)全景视图;(2)整合部分其它国家级高新区的相关数据以及火炬计划年鉴的数据,建立国家级高新区数据资源库,用于横向比较等分析研究;(3)整合必要的外部宏观经济数据和区域经济等数据,形成高新区经济分析补充数据资源库,用于相关的分析应用;(4)整合省市部分相关部门的企业数据源,如:省(市)统计局、省(市)经信委、省(市)发改委、省科技厅、商务厅和市科技局及中关村贵阳科技园等处可以协商采集的相关数据,用于综合分析园区的经济发展态势;(5)基于精准招商需求,整合相关行业的全量企业数据,并在分析后形成招商对象企业数据库,服务高新区精准招商。
上述数据源将通过相关系统接口开发导入、数据格式转换等方式进行自动、半自动的定期加载,形成动态更新的贵阳高新区“经济气象”数据资源中心。
其次,高质量的数据是数据分析的基础,为此数据的产生、收集、清洗、存储、整合需要一套完整的数据管理体系来支撑。
数据管理体系按照数据类型可以分为元数据管理和数据质量管理。
(1)元数据管理是数据质量管理的基础和先行条件。
元数据可以简单理解为数据的标准。
确立统一的数据统计口径标准,构建全面、丰富的数据指标体系。
形成一系列面向应用的可更新的综合分析专题数据库。
通过元数据管理可以很大程度上从源头杜绝问题数据的产生。
(2)数据质量是数据分析的基础,为此需要结合具体数据质量问题,制定严密的数据质量校核方案。
为了保证数据的可靠性和可用性,在使用数据前必须要对每个准备应用的数据项做数据质量评估,并通过数据质量监控,进行问题数据追溯和问题数据处理。
数量质量校核是针对目前园区数据管理中存在的数据质量问题,例如完整性、一致性、准确性、规范性等问题,整合数据仓库、数据分析、数据挖掘、可视化展现以及工作流等多项信息技术,将结合客户的业务规则,设计并开发数据质量完整性模型、规范性模型、准确性模型、离群值模型、孤立点探测模型等,实现对业务数据的全面、专业、高效的数据质量校核与监控。
《商务数据分析基础》课程标准

《商务数据分析基础》课程标准第一部分课程性质与任务一、课程性质《商务数据分析基础》课程是高等职业院校商务数据分析与应用专业的一门专业基础课程。
对学生商务数据分析与应用职业能力的培养和职业素养的养成起着重要的支撑作用。
通过本课程的学习,使学生掌握调查方案设计、数据资料的收集、整理、分析和数据分析报告的撰写方法和思路,及运用EXCEL进行数据分析的基本方法。
该课程主要是培养学生完整数据分析的理念与运用EXCEL进行分析的能力,为学生学习和掌握《运营数据分析》、《市场数据分析》等其他专业课程提供必备的专业基础知识,也为学生从事电子商务运营与推广、客户服务等电子商务相关岗位工作打下良好的基础。
先导课程是《数据采集与处理》等课程,后续课程是《数据可视化》等课程,建议课程开设在第三学期。
二、课程任务通过企业调研和召开典型工作任务实践专家研讨会,确定了本课程的PGSD能力分析目标,根据PGSD能力分析目标确定了本课程的任务内容。
具体如下:三、课程设计理念及依据该门课程以就业为导向,以能力为本位,以职业技能为主线,以模块项目为主题,以夯实基础、适应岗位为目标,形成科学的模块化课程体系。
突出学生的主体地位,重视能力培养和素质培养,突出教育思想转变。
采用真实案例启发学生对现实问题的思考,引导学生发现问题、提出问题、分析问题、解决问题的教学方法。
对学生采用分组讨论、探究式教学方式等调动学生的自主性学习。
将课堂知识与创新创业实践紧密结合起来,培养学生在实践中运用所学知识发现问题和解决实际问题的创新能力和创业能力。
本课程在广泛听取行业企业的实践工作者的意见和建议,并在来自企业的兼职教师的参与下,从实战任务出发,并结合1+X证书制度、思政元素、职业竞赛内容需要整合而成。
以工作任务为主线优化教学设计,创新教学方法,开发工学结合特色教材,调整评价考核方法等,从而构建一个体现职业能力,适应专业发展和人才培养需要的完整的课程教学体系。
数仓设计及开发流程

数仓设计及开发流程随着企业数据规模的不断增大,数据集中存储和管理的需求变得越来越重要。
数仓作为企业数据仓库的一种,具有集成数据、支持决策分析等优点,在企业中得到广泛应用。
为了确保数仓的高效运作,必须有一个完整的设计及开发流程。
一、需求调研首先需要对企业的业务需求进行分析和调研,确定数仓所需要集成的数据内容和业务需求。
这一步需要与业务部门进行沟通,在了解企业的业务流程和数据来源后,确定数据仓库建设的目标和方向。
二、数据建模在有了业务需求的基础上,需要对数据建模进行设计。
数据建模是数仓设计的核心,包括维度模型和事实模型的建立。
维度模型主要用于描述业务过程中的业务对象,事实模型则主要用于描述业务过程中的事实数据。
在建立数据模型时,需要考虑数据的完整性、准确性和可扩展性。
三、数据抽取在数据建模完成后,需要进行数据抽取,将不同数据源中的数据抽取到数仓中。
在数据抽取时,需要选择合适的数据抽取工具,以保证数据的准确性和完整性。
同时,需要对数据进行清洗和转换,确保数据的一致性和规范性。
四、数据加载数据加载是将抽取到的数据加载到数仓中进行存储的过程。
在数据加载时,需要考虑数据的存储结构和存储方式,以及对数据进行分区和索引等优化操作,以提高数据的查询效率。
五、数据分析在数据加载完成后,需要对数据进行分析和挖掘,以支持企业的决策分析。
数据分析的过程包括数据可视化、报表分析、多维分析、数据挖掘等。
在数据分析中,需要选择合适的工具和技术,以提高数据的分析效率和精度。
六、数据维护和更新数仓建设并不是一次性的过程,需要进行长期的维护和更新。
在数据维护和更新中,需要对数仓中的数据进行定期清理和更新,以保证数据的准确性和完整性。
同时,需要对数仓的性能进行监控和调整,以满足不断增长的业务需求。
综上所述,数仓的设计及开发流程包括需求调研、数据建模、数据抽取、数据加载、数据分析、数据维护和更新等多个环节。
只有按照完整的流程进行建设和维护,才能保证数仓的高效运作和可靠性。
数据治理系列4:主数据管理实施四部曲概论

数据治理系列4:主数据管理实施四部曲概论导读:我们知道主数据项目的建设是一个循序渐进、持续优化的过程,不可一蹴而就。
个人认为主数据管理项目从咨询规划到落地实施再到初步见效需要经历四个阶段,而每个阶段都是必经阶段,每个阶段均可独立成章,所以这里是四部曲,不是四步曲。
作者:石秀峰,多年来一直从事企业数据资源规划、企业数据资产管理、数据治理,欢迎关注。
主数据项目建设从方法上,分为以下四部,简单归结为12个字:“摸家底、建体系、接数据、抓运营”!一、摸家底摸家底需要全面调研和了解企业的数据管理现状,以便做出客观切实的数据管理评估!1、数据资源普查数据资源普查的方法常用的有两种,一种是自顶向下的梳理和调研,另一种是自底向上的梳理和调研。
自顶向下的调研一般会用到IRP(信息资源规划)和BPM(业务流程管理)两个方法。
这里重点介绍一下IRP,信息资源规划(Information Resource Planning ,简称IRP),是指对所在单位信息的采集、处理、传输和使用的全面规划。
其核心是运用先进的信息工程和数据管理理论及方法,通过总体数据规划,奠定资源管理的基础,促进实现集成化的应用开发,构建信息资源网。
IRP是信息工程方法论、总体数据规划和信息资源管理标准的结合体,其实现方法可概括为:IRP = 两个阶段+ 两条主线+ 三个模型+ 一套标准,如下图所示:采用IRP方法进行数据梳理需要对职能域、业务域进行定义,并对每个职能域和业务域中的业务流程进行梳理,同时需要收集各类业务单据、用户视图,并对每个单据和用户视图进行梳理和数据元素分析。
该方法优点让企业能够对现有数据资源有个全面、系统的认识。
特别是通过对职能域之间交叉信息的梳理,使我们更加清晰地了解到企业信息的来龙去脉,有助于我们把握各类信息的源头,有效地消除“信息孤岛”和数据冗余、控制数据的唯一性和准确性,确保获取信息的有效性。
缺点是需要消耗较大的成本和周期。
BI基础知识测试以及答案

BI 基础知识测试以及答案一、填空题:每空1分,共40分1、商业智能技术(Business Intelligence),以数据仓库、在线分析(OLAP) 、数据挖掘为核心技术,同时融合了关系数据库和联机分析处理技术2、数据抽取在技术上主要涉及互连、复制、增量、转换、调度、监控以及数据安全性等方面。
3、业界主要的数据抽取工具有SSIS 、PowerCenter 、DataStage和Sagent等4、业界主要的OLAP Server有: IBM OLAP Server 、 SSAS等5、业界主要的前端工具: Cognos 、 BO 、 Brio 、BI.Office 等6、多维数据结构是OLAP的核心,其组织形式包括星型模型,雪花模型。
7、维度分类包括:普通维、雪花维、父子维8、数据仓库基本元素包括:关系型数据库、数据源、事实表、维表、索引9、多维模型设计基本元素:维度(级别、成员)、度量值(指标)、计算值、存储方式、角色权限和安全机制10、项目的具体的实施步骤:1). 项目前期准备;2). 需求分析;3).逻辑数据模型设计;4). 系统体系结构设计;5). 物理数据库设计;6). 数据转换加载ETL;7). 前端应用开发;8)、数据仓库管理(处理流程与操作) ;9)、解决方案集成(测试验收与试运行)11、数据挖掘的模式,按功能可分有两大类:预测型(Predictive)模式和描述型(Descriptive)模式。
在实际应用中,往往根据模式的实际作用细分为以下6 种:1)、分类模式2)、回归模式 3)、时间序列模式 4)、聚类模式 5)、关联模式 6)、序列模式二、问答题:共60分12、(6分)请说明BI技术体系之间是如何实现互补的?数据仓库技术:数据整合集成各系统的历史数据,建立面向主题的企业数据中心在线分析处理技术:数据分析灵活、动态、快速的多维分析、随机查询、即席报表数据挖掘技术:知识发现通过数学模型发现隐藏的、潜在的规律,以辅助决策13、(9分)请简述一下数据仓库系统的显著特征一、频繁的变化数据仓库系统在任何企业信息系统中都是最不稳定的环节,对数据仓库各个部分的调整和修改十分频繁。
BI基本概念、BIEE开发流程

一,数据仓库,BI涉及到的相关概念1.DW:即数据仓库(Data Warehouse),是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合,用于支持管理决策。
数据仓库系统是一个信息提供平台,他从业务处理系统获得数据,主要以星型模型(可以做钻取用,经常用到)和雪花模型进行数据组织,并为用户提供各种手段从数据中获取信息和知识。
2.DSS:决策支持系统(decision support system ,简称dss)是辅助决策者通过数据、模型和知识,以人机交互方式进行半结构化或非结构化决策的计算机应用系统。
它是管理信息系统(mis)向更高一级发展而产生的先进信息管理系统。
它为决策者提供分析问题、建立模型、模拟决策过程和方案的环境,调用各种信息资源和分析工具,帮助决策者提高决策水平和质量。
3.数据字典(Data dictionary):是一种用户可以访问的记录数据库和应用程序源数据的目录。
数据字典是数据库的重要组成部分。
它存放着数据库所有的相关信息,对用户来说可能只是一组只读的表。
但是对于我们来说,数据字典越完善,越详细就越有助于我们流程开发的进行,深入的业务挖掘。
数据字典内容包括:(1)数据库中所有模式对象的信息,如表,试图,索引及各表关联关系(2)分配多少空间,当前使用了多少空间等。
(3)列的缺省值(4)约束信息的完整性(5)用户的名字,用户及角色被授予的权限。
用户访问或使用的审计信息(6)其他产生的数据库信息4.元数据:元数据(Meta Data)是关于数据仓库的数据,指在数据仓库建设过程中所产生的有关数据源定义,目标定义,转换规则等相关的关键数据。
同时元数据还包含关于数据含义的商业信息,所有这些信息都应当妥善保存,并很好地管理。
为数据仓库的发展和使用提供方便。
元数据是一种二进制信息,用以对存储在公共语言运行库可移植可执行文件(PE) 文件或存储在内存中的程序进行描述。
数据库基本知识和软件开发流程

第7章 数据库基本知识和软件开发流程教学目标1. 了解数据库系统的相关概念、历史和特点(数据、数据库等概念,数据管理技术发展的三个阶段,数据库系统的特点);2. 掌握数据模型(关系模型等);3. 了解数据库管理系统(常见数据库管理系统);4. 了解软件系统开发流程(软件系统开发的六个阶段)。
7.1 数据库系统概述数据库是数据管理的最新技术,是计算机科学的重要分支。
今天,信息资源已成为各个部门的重要财富和资源。
建立一个满足各级部门信息处理要求的行之有效的信息系统也成为一个企业或组织生存和发展的重要条件。
因此,作为信息系统核心和基础的数据库技术得到越来越广泛的应用,从小型单项事务处理系统到大型信息系统,从联机事务处理到联机分析处理,从一般企业管理到计算机辅助设计与制造(CAD/CAM)、计算机集成制造系统(CIMS)、办公信息系统(OIS)、地理信息系统(GIS)等,越来越多新的应用领域采用数据库存储和处理他们的信息资源。
7.1.1数据、数据库、数据库管理系统和数据库系统1. 数据(Data)数据是数据库中存储的基本对象。
数据在大多数人头脑中的第一个反应就是数字。
其实数字只是最简单的一种数据,是数据的一种传统和狭义的理解。
广义的理解,数据的种类很多,文字、图形、图像、声音、学生的档案记录、货物的运输情况等,这些都是数据。
可以对数据做如下定义:描述事物的符号记录称为数据。
描述事物的符号可以是数字,也可以是文字、图形、图像、声音、语言等,数据有多种表现形式,它们都可以经过数字化后存入计算机。
2. 数据库(DataBase,简称DB)数据库,顾名思义,是存放数据的仓库。
只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的。
人们收集并抽取出一个应用所需要的大量数据之后,应将其保存起来以供进一步加工处理。
进一步抽取有用信息。
在科学技术飞速发展的今天,人们的视野越来越广,数据量急剧增加。
过去人们把数据存放在文件柜里,现在人们借助计算机和数据库技术科学地保存和管理大量的复杂的数据,以便能方便而充分地利用这些宝贵的信息资源。
数据开发工程师岗位面试题及答案(经典版)

数据开发工程师岗位面试题及答案1.介绍一下你的数据开发经验。
答:我有X年的数据开发经验,曾在公司ABC负责搭建数据管道,ETL流程和数据仓库的构建。
我设计了一个实时数据流,从多个数据源汇集数据,经过清洗、转换后加载到数据仓库中。
我使用了Python和ApacheSpark来实现这个过程,确保数据的高质量和可靠性。
2.请解释ETL流程是什么,为什么在数据开发中它如此重要?答:ETL代表抽取(Extract)、转换(Transform)和加载(Load),它是数据开发的核心流程。
在数据开发中,从不同数据源中抽取数据,进行必要的转换和清洗,然后将其加载到数据仓库或目标系统中。
这确保了数据的一致性、准确性和可用性,为分析和报告提供了可靠的基础。
3.你在数据抽取阶段如何处理不同数据格式?答:我会根据数据源的不同使用适当的工具和技术来处理不同数据格式。
例如,使用Python的pandas库处理结构化数据,使用Spark处理大规模数据,使用正则表达式来解析文本数据,使用JSON解析器处理JSON数据等。
4.请描述一次你在数据转换过程中遇到的复杂情况,以及你是如何解决的。
答:在一个项目中,我需要将两个不同数据源的数据进行合并,但它们的字段名和结构不同。
我首先进行了数据映射,将字段进行对应匹配,然后使用Python编写自定义转换函数,将数据转换为相同的结构。
最后,我使用Spark的DataFrameAPI执行转换操作,并在完成后进行了严格的测试和验证,确保数据的准确性。
5.在构建数据管道时,你是如何确保数据的安全性和隐私性的?答:在数据传输和存储过程中,我会使用加密协议(如SSL)来保护数据的传输安全。
另外,我会确保数据在传输和处理过程中进行脱敏和匿名化,以保护个人隐私。
我还会设置访问权限,限制只有授权人员可以访问敏感数据。
6.请解释什么是增量加载,它与全量加载的区别是什么?答:增量加载是指只将新的或变更的数据加载到数据仓库中,以减少处理时间和资源消耗。
数据分析六步法

类别
具体内容
集中趋势 反映一组数据间的一般水平
离散趋势 反映一组数据间的波动水平
决定频数 频数分布
相对频数
交叉分布
举例 平均工资 基尼系数
EXCEL操作方法
平均数(AVERAGE) 中位数(MEDIAN) 众数(MODE)
极差(MAX-MIN) 方差(VAR) 标准差(STDEV)
数据分析六步法
4
数据分析六步法
数据分析测试
(1)2、6、7、8、15、7、19中的中位数为____,众数为_____。 (2)EXCEL中,图表类型共有___种。 (3)请找到如下数字的规律,并将正确答案填到括号中:
6、10、18、34、( ) (4)请运用加减乘除和括号计算下列试题,计算结果为24,请 写出过程: 4、5、9、7 结果:_______________
清洗类别 具体内容
举例
改善/处理方法
查重 改缺
纠错
数据重复 在录入某个数据时录入两次
修改数据
空值 非逻辑错误
在收集数据环节忘记填写,或着录入环 节忘记录入
(1)补录数据 (2)删除缺失值 (3)用平均数代替
填写数据人员不小心将电话号码(性别、 (1)加强录入
年龄、)填错了,或者录入时错误
(2)电话复核
数据分析六步法
二、衍生分析
项目类别 分析方法
战略分析 投资分析 营销分析
矩阵分析法、层次分析法
时间序列法、类比法、经济评价指标 聚类分析、漏斗分析、KANO模型 AIDA模型、PSM模型
数据分析 用途
方针管理 专案管理 问题解决 日常报告
其他方面
数据分析六步法
环境分析 竞争分析
数据抽取流程

数据抽取流程
什么是数据抽取
由于数据来源广泛,使得多样性成为了大数据的重要特点之一。
大数据的数据类型复杂,也就意味着这种复杂的数据环境将给大数据的处理带来极大的挑战。
因此要想处理大数据,必须先对所需的数据源的数据进行抽取和集成,从中提取出数据的实体和关系,经过关联和聚合之后,再采用统一定义的结构来存储这些数据。
在对数据进行集成和提取时,需要对数据进行清洗,保证数据质量及可信度。
数据抽取作为数据处理的第一步,具有至关重要的作用。
数据抽取并不是一项全新的技术,在传统数据库领域此问题就已经得到了比较成熟的研究。
数据抽取指从源数据源系统中抽取出目的数据源系统所需要的
数据,也就是从数据源中抽取数据的过程。
数据源又可以简单分为结构化数据、半结构化数据和非结构化数据。
由于大数据与传统海量数据的差别主要在于海量数据一般都是
指存储在数据库中的结构化数据,而大数据面对的则是大量非结构化的业务数据,如法院公告文本、招标公告文本、采购文本中的各类有价值的项目数据、招标金额、产品规格信息等。
数据抽取通过搜索整个数据源,使用一定的标准来筛选出合乎要求的数据,并把这些数据传送到目的文件中。
打个比方,数据抽取的
整个过程就类似于当我们登陆企通查-企业大数据平台后,在平台中(相当于整个数据源)通过增加简单过滤条件“司法文书-法律诉讼-天津市-农林牧渔业”(对全数据进行筛选),得到平台根据条件筛选后呈现在右侧页面的多页结果。
数据抽取样例流程

数据抽取样例流程Data extraction is a process of collecting and retrieving specific data from various sources to be used for specific purposes. 数据抽取是从各种来源收集和检索特定数据的过程,以用于特定目的。
It involves extracting, transforming, and loading data from heterogeneous data sources such as databases, spreadsheets, and text files. 它涉及从异构数据源(如数据库、电子表格和文本文件)中提取、转换和加载数据。
Data extraction is crucial in various industries and business functions, as it enables organizations to make informed decisions based on accurate and timely data. 数据抽取在各行各业和业务功能中至关重要,因为它使组织能够根据准确和及时的数据做出明智的决策。
The first step in the data extraction process is to identify the specific data that needs to be retrieved. 数据抽取过程的第一步是确定需要检索的特定数据。
This involves understanding the business requirements and objectives for extracting the data, as well as identifying the sources where the data is located. 这涉及了解抽取数据的业务需求和目标,以及确定数据所在的来源。
数据整合方案

1.信息资源标准化数据标准化主要实现了数据格式、内容和语义的映射、转换,实现编码一致化、面向主题集成、数据聚合等功能。
通过数据交换、采集,形成的基础业务数据,通过数据整合进一步的数据ETL(数据抽取、转换、加载),按照定制的标准信息规范进行匹配映射(Match)、数据格式转换(Transform),并对重复数据进行数据清洗(Cleanse)、过滤(Filtrate)、聚合(Aggregate),最后多维加载(Load)后形成标准化数据。
采用数据同步工具和ETL工具完成数据抽取、同步等整合工作,并通过任务调度管理实现对整合工具的集中管理和执行。
数据采集时可以按信息资源平台的要求将数据标准化。
在采集抽取数据时没有按信息资源平台转换为标准数据的数据,需要按信息资源平台的要求转换成标准的数据如字典的统一。
2.数据加工管理2.1.数据抽取数据抽取是利用抽取工具,建立抽取模型,将多个数据源数据汇总到一个数据库的过程。
2.2.数据清洗由于数据来自多个业务系统,而且包含历史数据,需要按照一定的规划把数据进行清洗,整个数据清洗的对象应包括不完整的数据、错误的数据、重复的数据等三大类。
2.3.数据转换数据转换主要实现数据标准化的过程,信息资源平台的数据,来自多个业务系统,有些数据源没有按照统一的标准规范设计,因此会造成数据难以与其他数据共享。
数据转换应实现按照统一的数据标准和既定的格式转换规则,对数据的整理和格式统一。
2.4.数据装载数据装载操作效率是数据资源平台需要考虑的重要环节。
投标人应详细描述针对本项目的不同数据资源所应采用的数据装载策略。
2.5.数据标识数据标识主要为了突出数据的关键性信息,便于实时的统计和更有效的比对,进而获取符合用户业务办理相关的结果。
3.数据整合处理系统3.1.数据处理流程数据中心的构建,基础和核心的工作是需要对来自各方的数据进行充分的整合和处理,对获取的各类源数据,需要进行大量的数据梳理、分析,并作相关的数据整理工作,通过数据梳理和转换工作,把不同来源的数据基于数据标准,转换成标准化数据后,再进行入库,从而保证进入数据中心的数据质量,不产生垃圾数据,从而为数据中心的全局应用奠定基础。
数据 三步蒸馏法-概述说明以及解释

数据三步蒸馏法-概述说明以及解释1.引言1.1 概述在当今信息爆炸的时代,数据已经成为我们生活和工作中不可或缺的一部分。
数据的重要性无处不在,从个人生活到商业决策,都离不开数据的支持。
然而,随着数据规模的不断增长,如何有效地处理和利用数据成为了一个亟待解决的问题。
为了解决数据处理和利用的难题,在本文中我们将介绍一种名为“数据三步蒸馏法”的方法。
这种方法通过一系列步骤,可以帮助我们从海量的数据中提取出有用的信息和知识,为我们的决策提供有力支持。
本文的目的在于介绍数据三步蒸馏法的原理和应用,帮助读者了解如何通过这种方法更好地处理和利用数据,提高数据的价值和效益。
同时,我们也将展望未来数据蒸馏方法的发展方向,为数据领域的研究和实践提供一些思路和建议。
通过本文的阅读,相信读者们能够对数据处理和利用有更深入的认识,为自己的工作和生活带来更大的收益和成就。
1.2 文章结构文章结构部分应当包括对整篇文章的大致框架和各个部分的内容进行介绍,为读者提供方便快速了解文章主要内容的指引。
在这篇关于数据三步蒸馏法的文章中,我们会按照以下结构展开:1.引言部分将首先概述文章的主题和重要性,介绍即将探讨的内容。
随后会详细说明文章的结构和目的,为读者解释为什么应该关注数据蒸馏和三步蒸馏法。
2.正文部分将分为三个子部分:数据的重要性、三步蒸馏法介绍以及三步蒸馏法的应用。
我们将首先讨论数据在现代社会中的重要性和作用,然后详细介绍三步蒸馏法的概念、原理和操作步骤,最后展示这种方法在不同领域的实际应用和效果。
3.结论部分将对整篇文章进行总结,强调数据蒸馏的重要性和三步蒸馏法的价值。
我们还会展望未来,探讨这种方法可能带来的影响和发展方向,并提出结论和建议,引导读者进一步思考和行动。
通过这样的结构,我们希望为读者呈现出一篇系统、清晰、有逻辑性的文章,让他们能够全面了解数据三步蒸馏法的相关知识和实际应用,同时激发对数据处理和利用方式的思考和探索。
数据开发过程介绍

数据开发是指在数据工程中,从原始数据源中提取、转换、加载(ETL)数据,以满足数据分析、报告、机器学习等需求的过程。
以下是数据开发的一般过程介绍:1. **需求分析**:- 理解业务需求:首先,数据开发团队需要与业务部门合作,明确他们的需求和目标。
这有助于确定要提取和处理的数据。
2. **数据提取(Extract)**:- 数据源识别:确定数据来源,这可以包括数据库、API、日志文件、云服务等。
- 数据抽取:使用工具或脚本从数据源中提取数据,并将其转换为可用的格式。
通常,数据提取涉及到筛选、选择列、数据转换等操作。
3. **数据转换(Transform)**:- 数据清洗:处理不一致、不完整或错误的数据,例如处理缺失值、去除重复数据、处理异常值等。
- 数据转换:将数据转换为适合分析的结构,例如将日期格式标准化、进行聚合、创建派生字段等。
- 数据合并:将多个数据源的数据合并为一个一致的数据集。
4. **数据加载(Load)**:- 将转换后的数据加载到目标存储区域,如数据仓库、数据湖、数据库等。
- 数据仓库通常用于存储历史数据,而数据湖通常用于存储原始数据以及数据湖中的原始拷贝。
5. **调度和自动化**:- 使用调度工具(如Apache Airflow、Cron Job等)来自动执行数据开发任务,确保数据的定期提取、转换和加载。
- 设置监控和报警机制,以便及时发现和处理数据开发过程中的错误和异常。
6. **质量控制和测试**:- 实施数据质量控制措施,确保数据的准确性和一致性。
- 进行单元测试、集成测试和端到端测试,以验证数据开发过程的正确性。
7. **文档和元数据管理**:- 创建文档以记录数据开发过程,包括数据流程、字段定义、数据字典等。
- 管理元数据,以便跟踪数据的来源、变化和使用情况。
8. **维护和优化**:- 定期维护数据开发工作流程,确保它们仍然满足业务需求。
- 优化数据开发过程,提高效率和性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据抽取与主题开发基础流程公司内部编号:(GOOD-TMMT-MMUT-UUPTY-UUYY-DTTI-数据抽取、主题报表基础开发流程示例1数据抽取根据SG186一体化平台数据标准,相关数据抽取流程如下:为了使用户能更全面的了解数据体系的原理及应用流程。
下面我们以生产数据为例,详细演示数据的抽取的过程。
抽取模块:(中间到基础,基础到主题,基础到支撑)下面以基础表到主题表的数据抽取为例,予以详细说明。
另外,基础到支撑表的抽取与基础到主题抽取建模类似。
1.1明细表(源表)例:SC_DEV_EXAM_REP(生产设备检修基础表)表。
表结构如下:目标表T_SC_EQUIP_REPAIR(设备检修主题表)表.其表结构如下:附:T_SC_EQUIP_REPAIR(设备检修主题表)主题表数据标准。
定义宏为了移植方便,要定义宏。
应用于整个数据抽取流程。
其中定义了生产、营销的中间库、基础库、主题库的连接方式(ORACLE 9i、ORACLE 10g等数据库的连接方式)、数据库实例、用户名、密码以及数据抽取的时间戳。
(定义宏)设计Map及Process源连接选择基础表相对应的源连接、数据库别名、用户ID、密码。
最后将数据源按维度字段(在目标表(主题表)中需要分类查看的字段,其在源表(基础表中对应的字段)进行排序,以下是样例查询语句:SELECT * FROM SC_DEV_EXAM_REP WHERE TAB_YEAR = $(SOURCE_TIME_YEAR) AND TAB_MONTH = $(SOURCE_TIME_MONTH)ORDER BY TAB_YEAR,TAB_MONTH,REPAIR_TYPE,VOL_LEVEL注:这里的对源数据进行分组的依据是目标表里面的维度字段。
目标连接选择和源表相关的主题表。
选择输出模式、更新选项有四种输出模式,可以根据实际的情况选择。
定义全局变量(属性)将目标表中的维度和指标设为全局变量。
由于在源数据转化为目标数据的过程中,需要对源数据指标进行Sum或Count或百分比的计算。
其计算的结果就暂时赋给全局变量,然后又全局变量再赋给个目标值字段。
实现了源数据指标经全局变量赋给目标字段的过程。
为了便于开发、维护,全局变量的别名是依据目标字段产生的。
初始化全局变量在BeforeTransfaction事件中将需要进行计算(Sum、Count、百分比)的全局变量赋初始值0 (初始化的值一般在这里用Execute方法指定)。
将全局变量依次赋给目标字段把无值的全局变量赋给目标字段,由于全局变量是依据目标字段产生的,因此这里的赋值就便于理解以及后期的维护。
为全局变量赋值在源AfterEveryRecord事件中设置其它各维度字段的值,执行指标字段Sum 或Count以及百分比计算,也就是为全局变量赋值的过程。
可参考《农电管理主题数据》经过步骤、、、的操作,整个值传递的过程结束。
此处做清洗的操作,如源表中一些数据不合规范,或不完整,需在此处做过滤,归并,重置值等操作(具体的清洗方法需根据实际源数据的质量水平来确定)。
处理OnDataChange1事件选择数据变化监视器选择需要监视的维度字段,多个字段则用表达式来处理用&关联,为全局变量赋值提供赋值依据。
ClearMapPut Record事件。
执行向目标表里面插入数据的动作。
还原全局变量,赋初始值0.为下次赋值做准备。
处理OnError事件OnError事件resume,如果抽取工程发生错误,该时间将执行数据回滚动作。
调试运行运行映射。
直接运行或调度运行。
结果是:成功读取48条,修改4条。
源表:共48条记录目标表:共4条记录注:步骤至:完成源与目标的连接、对应。
步骤至:完成源指标经全局变量赋给目标指标的过程。
步骤:监测抽取过程是否顺利进行。
步骤 : 运行、调试。
此步骤只基于源、目标一对一的情况。
建立多个映射后可将其集中到单个或多个流程中批量执行。
2主题开发以上述主题表T_SC_EQUIP_REPAIR(设备检修主题表)为例,介绍一下主题开发的具体步骤。
其表结构如下:附:T_SC_EQUIP_REPAIR(设备检修主题表)主题的设计标准。
介绍元数据库Microstrategy 元数据是存储在关系型数据库中的一个预定义的结构。
Microstrategy定义了这个元数据的结构。
元数据和数据仓库的RDBMS不必相同。
当应用程序连接到这个元数据库时,所有的框架对象、报表对象、配置对象和项目设置信息都存储在这里。
我们在这里使用Oracle数据库来存储MSTR元数据。
准备空的RDB,并定义ODBC以ORACLE 9i为例,在ORACLE中创建一个数据库实例SG186ND。
创建2个用户:basic_data/basic_data(数据仓库用户)、mstr_user/mstr_user(元数据用户)定义一个系统ODBC,命名为SG186ND_L。
配置元数据库使用Configuration Wizard(开始/程序/Microstrategy/Configuration Wizard)第一项:下一步,选择创建元数据表,下一步选择ODBC数据源名称:SG186ND_L,输入用户名和密码。
(如果使用Access 作为元数据库,则选择在Access数据库配置资料库,在下面的文本框中输入Access文件的路径即可,系统会创建Access文件并配置ODBC。
)点击下一步。
如果有警告信息,点击关闭,再点下一步。
选择元数据脚本位置,一般情况下系统会根据元数据库类型选择出默认的脚本程序,如本例中系统会找到…..\。
点击下一步。
点击完成。
点击确定。
配置元数据库完毕!!连接项目源项目源对象处于Microstrategy对象的最高级。
一个项目源代表一个元数据库连接。
这个连接可以由两种方式实现:(1)直接或两层模式:通过知道DSN、LOGIN、口令连接到元数据库。
(2)服务器或三层模式:通过指向一个定义好的Intelligence Server连接到元数据库。
这里首先使用直接方式连接,稍后再把建设好的应用配置成三层模式,以便远程用户可以访问(通过desktop或直接在网页上访问)。
启动Microstrategy Desktop。
选择菜单工具/项目源管理器,点击添加,输入项目源名称(如Training),选择连接模式为直接,选择ODBC:SG186ND_L,点击确定(两次)。
可以看到我们刚刚创建的项目源 Training创建项目在应用中定义的MSTR对象(框架对象和用户对象等)隶属于项目。
项目在项目源下,一个项目源下可以有多个项目。
在Microstrategy Desktop中双击进入刚才定义的项目源Training (最初配置一个项目源时,MSTR会创建一个内嵌的用户,用户名是Administrator,口令为空,当进入一个项目源时,需要输入这个项目源的user/PWD。
从安全的角度考虑,进入一个新项目源后,应该修改MSTR内嵌用户Administrator的口令),选择菜单框架/创建新项目。
Desktop弹出项目创建助理:项目创建助理有4个按钮,用于创建项目和快速初始化一个项目。
在这里,首先用创建项目按钮来创建项目,其余按钮的功能在后面介绍。
点击创建项目按钮输入项目名称和描述,点击确定,在弹出的登录窗口输入用户名(Administrator)和密码(空)。
项目创建完毕后,点击确定。
在项目源下出现新建的项目。
定义数据库实例数据库实例代表与数据仓库的连接。
用于在某个项目中使用的数据仓库。
在项目源下的管理 / 数据库实例管理器中点击菜单文件/新建/数据库实例输入一个数据库实例名称,选择数据库连接类型,[输入描述]在数据库连接中点击新建,输入数据库连接名称,选择一个指向所要的数据库的本地系统ODBC数据源;在数据库登录名中点击新建输入数据库登录以及合法的登录ID和密码,点击确定选择正确的数据库登录名,点击确定选择正确的数据库连接名称,点击确定。
这样就定义了一个数据库实例,来代表物理的数据仓库。
选择数据仓库表刚才创建了一个项目(TestProject),我们要在项目中创建报表等BI应用,这些报表需要从数据仓库中的某些TABLES中选取数据。
一个项目需要哪些数据仓库表,就在仓库目录中定义。
每个项目可以配制不同的仓库目录。
将焦点放置所要控制的项目上(TestProject),选择菜单框架/仓库目录,由于现在是第一次进入仓库目录对话框,系统会弹出选择数据库实例界面:选择刚刚创建的SG186ND数据库实例,点击确定。
系统弹出仓库目录对话框。
左侧是数据仓库中可用的TABLE,右侧是选中的数据仓库表。
作为最简单项目,我们先选取6个张表:事实表T_SC_EQUIP_REPAIR,维表C_VOL_LEVEL、C_REPAIP_TYPE、CODE_MONTH、CODE_YEAR、CODE_QUARTER。
定义事实在MicroStrategy产品环境中事实是关联数据仓库中的数值和MicroStrategy报表环境的框架对象。
他们对应到数据仓库中的物理字段,并用以创建对事实数据进行运算的度量对象。
在该项目中,先定义三个事实(Fact):PLAN_NUM(计划数),FINI_PLAN_NUM (完成数),REPAIR_RATE(完成率)。
将焦点移至TestProject项目下的框架对象/事实中,选择菜单文件/新建/事实,系统载入事实编辑器,并进入到创建事实表达式界面。
先创建PLAN_NUM事实,PLAN_NUM事实存在于事实表T_SC_EQUIP_REPAIR中,在源表下拉列表中选择T_SC_EQUIP_REPAIR,把PLAN_NUM字段从可用的列拖到事实表达式中,在映射方法中选择手动,点击确定:选中T_SC_EQUIP_REPAIR表前的复选框,点击保存并新建。
确认保存的路径是框架对象/事实,输入对象名称计划数,点击保存。
再创建FINI_PLAN_NUM事实。
FINI_PLAN_NUM事实也存在于事实表T_SC_EQUIP_REPAIR中确认保存的路径是框架对象/事实,输入对象名称完成数,点击保存。
再创建REPAIR_RATE事实确认保存的路径是框架对象/事实,输入对象名称完成率,点击保存。
定义实体在Microstrategy环境中,实体——以及组成实体的元素——是业务内容的概念。
你在报表中按照实体来汇总和查看数据。
每个实体可能具有多个形式;每个形式可能从多个物理表中表示;实体间会有父子关系。
一个实体的实体形式是考察实体的一个角度。
每个实体至少有一个实体形式,通常有两个:ID描述(DESC)一些实体可能会有其它描述型形式。
比如,客户实体有客户名称形式,还有地址、Email等其它描述型形式。