项目8 MapReduce实例
mapreduce例子

MapReduce 是一种用于分布式计算的编程模型,可以并行处理大规模数据集。
它采用两个主要的操作:Map 和Reduce,Map 特定计算数据集上的每个元素,而Reduce 对所有Map 输出进行聚合。
MapReduce 执行流程通常分为以下几个步骤:1. 输入分片(Input Splits):将待处理的输入数据切分成多个分片,这些分片可以并发地处理。
2. Map 阶段(Map Phase):由多个Mapper 并行执行,将输入数据切分成键值对,再对每个键值对执行指定的操作,输出中间结果。
3. 中间合并(Intermediate Combining):对Map 输出的中间结果进行本地合并,以减少数据传输和存储的成本。
4. 分区(Partitioning):将中间结果派发到不同的Reducer 上进行处理。
5. Reduce 阶段(Reduce Phase):由多个Reducer 并行执行,对同一分区中的中间结果进行归约操作,输出最终结果。
6. 输出(Output):将Reduce 输出的结果存储在指定位置。
下面是一个简单的MapReduce 示例,用于计算文本中每个单词的出现次数:1. 输入数据:一段文本文件。
2. Map 阶段:将文本分成多行并行处理,对于每一行文本,将单词作为键,出现次数作为值,输出中间结果。
3. 中间合并阶段:对Map 的输出结果进行本地合并,即在每个Map 节点的本地计算中,将相同的键值对合并,以减少数据传输和存储数量。
4. 分区阶段:将中间结果根据键的哈希值分配给不同的Reducer 节点进行处理。
5. Reduce 阶段:每个Reducer 节点对自己的所有输入进行聚合,输出键值对,键是单词,值是该单词在文本中出现的总次数。
6. 输出阶段:将最终结果输出到文件系统中。
通过这个示例,可以看出MapReduce 的基本流程和应用场景。
它可以方便地处理大规模数据集,加速计算速度,实现数据分析和挖掘等应用。
第4章大数据技术教程-MapReduce

第四章分布式计算框架MapReduce4.1初识MapReduceMapReduce是一种面向大规模数据并行处理的编程模型,也一种并行分布式计算框架。
在Hadoop流行之前,分布式框架虽然也有,但是实现比较复杂,基本都是大公司的专利,小公司没有能力和人力来实现分布式系统的开发。
Hadoop的出现,使用MapReduce框架让分布式编程变得简单。
如名称所示,MapReduce主要由两个处理阶段:Map阶段和Reduce 阶段,每个阶段都以键值对作为输入和输出,键值对类型可由用户定义。
程序员只需要实现Map和Reduce两个函数,便可实现分布式计算,而其余的部分,如分布式实现、资源协调、内部通信等,都是由平台底层实现,无需开发者关心。
基于Hadoop开发项目相对简单,小公司也可以轻松的开发分布式处理软件。
4.1.1 MapReduce基本过程MapReduce是一种编程模型,用户在这个模型框架下编写自己的Map函数和Reduce函数来实现分布式数据处理。
MapReduce程序的执行过程主要就是调用Map函数和Reduce函数,Hadoop把MapReduce程序的执行过程分为Map和Reduce两个大的阶段,如果细分可以为Map、Shuffle(洗牌)、Reduce三个阶段。
Map含义是映射,将要操作的每个元素映射成一对键和值,Reduce含义是归约,将要操作的元素按键做合并计算,Shuffle在第三节详细介绍。
下面以一个比较简单的示例,形象直观介绍一下Map、Reduce阶段是如何执行的。
有一组图形,包含三角形、圆形、正方形三种形状图形,要计算每种形状图形的个数,见下图4-1。
图:4-1 map/reduce计算不同形状的过程在Map阶段,将每个图形映射成形状(键Key)和数量(值Value),每个形状图形的数量值是“1”;Shuffle阶段的Combine(合并),相同的形状做归类;在Reduce阶段,对相同形状的值做求和计算。
Chapter7-厦门大学-林子雨-大数据技术原理与应用-第七章-MapReduce

图7-1 MapReduce工作流程
《大数据技术原理与应用》
厦门大学计算机科学系
林子雨
Hale Waihona Puke ziyulin@7.2.2MapReduce各个执行阶段
节点1
从分布式文件系统中加载文件
节点2
从分布式文件系统中加载文件
InputFormat 文件 文件 Split Split Split Split
7.3.1WordCount程序任务
表7-2 WordCount程序任务 WordCount
一个包含大量单词的文本文件 文件中每个单词及其出现次数(频数),并按照单词 字母顺序排序,每个单词和其频数占一行,单词和频 数之间有间隔
程序 输入 输出
表7-3 一个WordCount的输入和输出实例 输入 Hello World Hello Hadoop Hello MapReduce 输出 Hadoop 1 Hello 3 MapReduce 1 World 1
输入的中间结果<k2,List(v2)>中的 List(v2)表示是一批属于同一个k2的 value
Reduce
<k2,List(v2)>
<k3,v3>
《大数据技术原理与应用》
厦门大学计算机科学系
林子雨
ziyulin@
7.2 MapReduce工作流程
• 7.2.1 • 7.2.2 • 7.2.3 工作流程概述 MapReduce各个执行阶段 Shuffle过程详解
1.“Hello World Bye World”
Map
2.“Hello Hadoop Bye Hadoop”
Map
3.“Bye Hadoop Hello Hadoop”
7.1mapreduce的工作机制任务流程执行步骤

7.1mapreduce的⼯作机制任务流程执⾏步骤1.1 Mapreduce任务流程Mapreduce是⼤量数据并发处理的编程模型,主要包括下⾯五个实体,客户端将作业⽂件复制到分布式⽂件系统,向资源管理器提交mapreduce作业,资源管理器向节点管理器分配容器资源,节点管理器启动application Master,application master启动另外⼀个节点管理器,向资源管理器申请容器资源,⽤来运⾏作业任务。
客户端提交mapreduce作业资源管理器管理分配资源节点管理器启动、管理、监视集群中的container容器⼯作Application Master每个程序对应⼀个AM,负责程序的任务调度,本⾝也是运⾏在NM的Container中分布式⽂件系统存储作业⽂件mapreduce流程图mapreduce的⼯作流程(1)客户端调⽤Job实例的Submit()或者waitForCompletion()⽅法提交作业;(2)客户端向ResourceManage请求分配⼀个Application ID,客户端会对程序的输出路径进⾏检查,如果没有问题,进⾏作业输⼊分⽚的计算。
(3)将作业运⾏所需要的资源拷贝到HDFS中,包括jar包、配置⽂件和计算出来的输⼊分⽚信息等;(4)调⽤ResourceManage的submitApplication⽅法将作业提交到ResourceManage;(5) ResourceManage收到submitApplication⽅法的调⽤之后会命令⼀个NM启动⼀个Container,.在该NodeManage的Container上启动管理该作业的ApplicationMaster进程;(6) .AM对作业进⾏初始化操作,并将会接收作业的处理和完成情况报告;(7) AM从HDFS中获得输⼊数据的分⽚信息;根据分⽚信息确定要启动的map任务数,reduce任务数则根据mapreduce.job.reduces属性或者Job实例的setNumReduceTasks⽅法来决定。
mongotemplate mapreduce用法

MongoTemplate是Spring Data MongoDB提供的一个工具类,它封装了对MongoDB的常见操作,如查询、更新、删除等。
而MapReduce是MongoDB提供的一种数据处理方法,它可以对大规模数据集进行分布式计算和处理。
在MongoDB中,使用MongoTemplate来执行MapReduce操作可以很方便地实现对数据的复杂处理和分析。
1. MongoTemplate简介MongoTemplate是Spring Data MongoDB中的核心类之一,它提供了对MongoDB的许多操作方法,包括保存数据、查询数据、更新数据、删除数据等。
通过MongoTemplate,我们可以方便地与MongoDB进行交互,而不需要编写繁琐的原生MongoDB操作语句。
2. MapReduce基本原理MapReduce是一种分布式数据处理模型,它分为两个阶段:Map阶段和Reduce阶段。
在Map阶段,数据会被拆分并进行初步处理,生成键值对;在Reduce阶段,相同键的值会被合并并进行进一步的处理,得到最终的结果。
MapReduce可以很好地应用于大规模数据的处理和分析,可以显著提高处理效率。
3. 在Spring Data MongoDB中使用MapReduce在Spring Data MongoDB中,通过MongoTemplate来执行MapReduce操作是很简单的。
我们需要定义一个Map函数和一个Reduce函数,分别对数据进行初步处理和最终处理。
通过MongoTemplate的mapReduce方法,传入Map函数、Reduce函数以及其他参数,即可执行MapReduce操作。
4. 使用MapReduce进行数据分析MapReduce不仅可以帮助我们处理大规模数据,还可以帮助我们进行数据分析。
通过MapReduce,我们可以对数据进行聚合、统计、分组等操作,得到更深层次的数据分析结果。
mapreduce简单例子

mapreduce简单例子
1. 嘿,你知道吗?就像把一堆杂乱的拼图碎片整理清楚一样,MapReduce 可以用来统计一个大文档里某个单词出现的次数呢!比如说统计《哈利·波特》里“魔法”这个词出现了多少次。
2. 哇塞,想象一下把一个巨大的任务拆分给很多小能手去做,这就是MapReduce 呀!像计算一个庞大的数据库中不同类别数据的数量,这多厉害呀!
3. 嘿呀,MapReduce 就像是一支高效的团队!比如统计一个城市里各种宠物的数量,能快速又准确地得出结果。
4. 哎呀呀,用 MapReduce 来处理大量的数据,这简直就像是一群勤劳的小蜜蜂在共同完成一项大工程!比如分析一个月的网络流量数据。
5. 你瞧,MapReduce 能轻松搞定复杂的任务,这不就跟我们一起合作打扫一间大房子一样嘛!像处理海量的图片数据。
6. 哇哦,MapReduce 真的好神奇!可以像变魔术一样把一个巨大的计算任务变得简单。
例如统计全国人口的年龄分布。
7. 嘿嘿,它就像是一个神奇的魔法棒!用 MapReduce 来计算一个大型工厂里各种产品的产量,是不是超简单。
8. 哎呀,MapReduce 真是太有用啦!就好像有无数双手帮我们一起做事一样。
举个例子,分析一个大型网站的用户行为数据。
9. 总之啊,MapReduce 真的是数据处理的一把好手,能搞定很多看似不可能的任务,就像一个超级英雄!它能在各种场景大显身手,帮助我们更高效地处理数据呀!。
mapreduce 统计首字母次数 案例

一、背景介绍近年来,随着互联网和大数据技术的迅速发展,大数据分析已经成为各行各业不可或缺的一部分。
而在大数据处理中,MapReduce作为一种经典的并行计算框架,被广泛应用于数据处理和分析任务中。
在实际应用中,经常会遇到需要对大规模数据进行统计分析的需求,比如统计单词、字母出现的频次等。
本文将以统计中文文章中每个词的首字母的出现次数为例,介绍MapReduce在统计任务中的应用。
二、MapReduce介绍MapReduce是一种用于处理大规模数据的编程模型,由Google在2004年提出,并在2006年发表了论文。
它的核心思想是将数据处理任务分解成Map和Reduce两个阶段,使得分布式计算变得简单和高效。
在MapReduce模型中,Map阶段负责对输入数据进行处理和过滤,并生成中间的键值对数据;Reduce阶段则负责对中间数据进行汇总和统计,生成最终的输出数据。
三、统计首字母次数的MapReduce实现在统计中文文章中每个词的首字母的出现次数的案例中,我们可以利用MapReduce模型来实现。
对于输入的中文文章,我们需要对每个词进行分词处理,并提取每个词的首字母;在Map阶段,我们将每个首字母作为键,将出现的频次作为值,生成中间的键值对;在Reduce 阶段,我们对相同首字母的频次进行累加,得到最终的统计结果。
接下来,我们将详细介绍Map和Reduce两个阶段的具体实现。
四、Map阶段:1. 数据输入:将中文文章作为输入数据,以行为单位读取并进行分词处理,得到每个词和其对应的首字母。
2. Map函数:对于每个词,提取其首字母作为键,将出现的频次设为1,生成中间的键值对数据。
3. 数据输出:将生成的中间数据按照键值对的形式输出。
五、Reduce阶段:1. 数据输入:接收Map阶段输出的中间数据,以键为单位进行分组。
2. Reduce函数:对于每个键值对数据,将相同键的频次进行累加,得到每个首字母的总频次。
实验3-MapReduce编程初级实践
实验3 MapReduce编程初级实践1.实验目的1.通过实验掌握基本的MapReduce编程方法;2.掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
2.实验平台已经配置完成的Hadoop伪分布式环境。
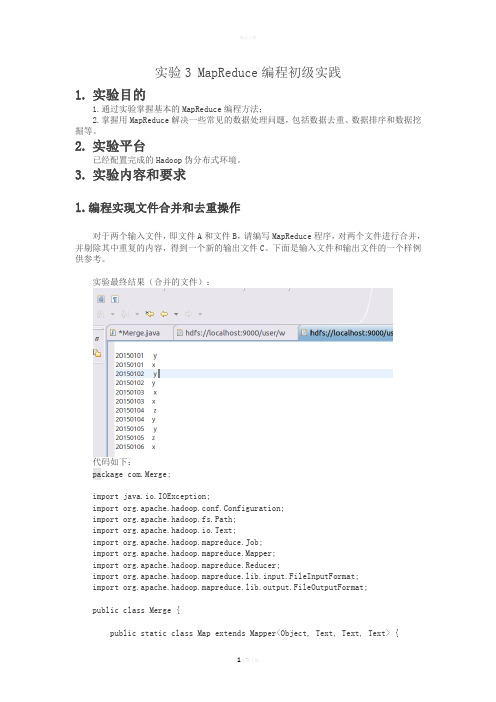
3.实验内容和要求1.编程实现文件合并和去重操作对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。
下面是输入文件和输出文件的一个样例供参考。
实验最终结果(合并的文件):代码如下:package com.Merge;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class Merge {public static class Map extends Mapper<Object, Text, Text, Text> {private static Text text = new Text();public void map(Object key, Text value, Context context)throws IOException, InterruptedException {text = value;context.write(text, new Text(""));}}public static class Reduce extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {context.write(key, new Text(""));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");String[] otherArgs = new String[] { "input", "output" };if (otherArgs.length != 2) {System.err.println("Usage: Merge and duplicate removal <in><out>");System.exit(2);}Job job = Job.getInstance(conf, "Merge and duplicate removal");job.setJarByClass(Merge.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}2. 编写程序实现对输入文件的排序现在有多个输入文件,每个文件中的每行内容均为一个整数。
实验6:Mapreduce实例——WordCount

实验6:Mapreduce实例——WordCount实验⽬的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会⾃⼰编写WordCount程序进⾏词频统计实验原理MapReduce采⽤的是“分⽽治之”的思想,把对⼤规模数据集的操作,分发给⼀个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
简单来说,MapReduce就是”任务的分解与结果的汇总“。
1.MapReduce的⼯作原理在分布式计算中,MapReduce框架负责处理了并⾏编程⾥分布式存储、⼯作调度,负载均衡、容错处理以及⽹络通信等复杂问题,现在我们把处理过程⾼度抽象为Map与Reduce两个部分来进⾏阐述,其中Map部分负责把任务分解成多个⼦任务,Reduce部分负责把分解后多个⼦任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map⽅法。
通过在map⽅法中添加两句把key值和value值输出到控制台的代码,可以发现map⽅法中输⼊的value值存储的是⽂本⽂件中的⼀⾏(以回车符为⾏结束标记),⽽输⼊的key值存储的是该⾏的⾸字母相对于⽂本⽂件的⾸地址的偏移量。
然后⽤StringTokenizer类将每⼀⾏拆分成为⼀个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map⽅法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce⽅法。
Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输⼊到reduce⽅法中,reduce⽅法只要遍历values并求和,即可得到某个单词的总次数。
mapreduce应用案例

mapreduce应用案例MapReduce是一种用于处理大规模数据集的编程模型和处理框架,主要用于并行化和分布式计算。
以下是一些MapReduce的应用案例:1. Word Count(词频统计):这是MapReduce最简单的应用之一。
通过将文本数据划分为若干块,然后对每个块进行词频统计,最后将结果合并以得到整体文本的词频分布。
2. Log分析:大规模服务器日志的分析是一个常见的应用场景。
通过Map阶段将日志按照关键信息分割,然后Reduce阶段对相同关键信息的数据进行汇总和分析,例如计算访问频率、错误率等。
3. PageRank算法:用于搜索引擎的排名算法,通过MapReduce来实现。
Map阶段负责解析页面和构建图,Reduce阶段迭代计算每个页面的PageRank值。
4. 倒排索引(Inverted Index):用于搜索引擎的索引构建。
Map阶段将文档中的词语映射到文档ID,Reduce阶段将词语和对应的文档ID列表进行合并。
5. 数据清洗和预处理:处理原始数据,例如清理缺失值、格式转换等。
MapReduce可以分布式地处理大规模数据,加速数据清洗和准备工作。
6. 机器学习:在大规模数据集上进行机器学习模型的训练。
Map阶段用于数据分割和特征提取,Reduce阶段用于参数更新和模型融合。
7. 社交网络分析:在社交网络数据中寻找关键人物、社群检测等。
MapReduce可以有效地处理这些数据,找到网络中的关键节点和结构。
8. 图像处理:大规模图像数据集的处理,例如图像特征提取、相似度计算等。
MapReduce 可以并行处理多个图像任务。
9. 实时数据分析:结合实时处理框架,如Apache Kafka和Apache Flink,可以在流数据上实现实时的MapReduce分析,用于监控和实时决策。
这些案例展示了MapReduce在不同领域的广泛应用,能够处理大规模数据并提供分布式计算的能力。
Mapreduce实例——排序

Mapreduce实例——排序原理Map、Reduce任务中Shuffle和排序的过程图如下:流程分析:1.Map端:(1)每个输⼊分⽚会让⼀个map任务来处理,默认情况下,以HDFS的⼀个块的⼤⼩(默认为64M)为⼀个分⽚,当然我们也可以设置块的⼤⼩。
map输出的结果会暂且放在⼀个环形内存缓冲区中(该缓冲区的⼤⼩默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区⼤⼩的80%,由io.sort.spill.percent属性控制),会在本地⽂件系统中创建⼀个溢出⽂件,将该缓冲区中的数据写⼊这个⽂件。
(2)在写⼊磁盘之前,线程⾸先根据reduce任务的数⽬将数据划分为相同数⽬的分区,也就是⼀个reduce任务对应⼀个分区的数据。
这样做是为了避免有些reduce任务分配到⼤量数据,⽽有些reduce任务却分到很少数据,甚⾄没有分到数据的尴尬局⾯。
其实分区就是对数据进⾏hash的过程。
然后对每个分区中的数据进⾏排序,如果此时设置了Combiner,将排序后的结果进⾏Combia操作,这样做的⽬的是让尽可能少的数据写⼊到磁盘。
(3)当map任务输出最后⼀个记录时,可能会有很多的溢出⽂件,这时需要将这些⽂件合并。
合并的过程中会不断地进⾏排序和combia操作,⽬的有两个:①尽量减少每次写⼊磁盘的数据量。
②尽量减少下⼀复制阶段⽹络传输的数据量。
最后合并成了⼀个已分区且已排序的⽂件。
为了减少⽹络传输的数据量,这⾥可以将数据压缩,只要将press.map.out设置为true就可以了。
(4)将分区中的数据拷贝给相对应的reduce任务。
有⼈可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务⼀直和其⽗TaskTracker保持联系,⽽TaskTracker⼜⼀直和JobTracker保持⼼跳。
所以JobTracker中保存了整个集群中的宏观信息。
只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
MapReduce 中文版论文

Google MapReduce中文版译者: alexMapReduce是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。
用户首先创建一个Map函数处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然后再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值。
现实世界中有很多满足上述处理模型的例子,本论文将详细描述这个模型。
MapReduce架构的程序能够在大量的普通配置的计算机上实现并行化处理。
这个系统在运行时只关心:如何分割输入数据,在大量计算机组成的集群上的调度,集群中计算机的错误处理,管理集群中计算机之间必要的通信。
采用MapReduce架构可以使那些没有并行计算和分布式处理系统开发经验的程序员有效利用分布式系统的丰富资源。
我们的MapReduce实现运行在规模可以灵活调整的由普通机器组成的集群上:一个典型的MapReduce 计算往往由几千台机器组成、处理以TB计算的数据。
程序员发现这个系统非常好用:已经实现了数以百计的MapReduce程序,在Google的集群上,每天都有1000多个MapReduce程序在执行。
在过去的5年里,包括本文作者在内的Google的很多程序员,为了处理海量的原始数据,已经实现了数以百计的、专用的计算方法。
这些计算方法用来处理大量的原始数据,比如,文档抓取(类似网络爬虫的程序)、Web请求日志等等;也为了计算处理各种类型的衍生数据,比如倒排索引、Web文档的图结构的各种表示形势、每台主机上网络爬虫抓取的页面数量的汇总、每天被请求的最多的查询的集合等等。
大多数这样的数据处理运算在概念上很容易理解。
然而由于输入的数据量巨大,因此要想在可接受的时间内完成运算,只有将这些计算分布在成百上千的主机上。
如何处理并行计算、如何分发数据、如何处理错误?所有这些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处理。
实验二 Hadoop环境下MapReduce并行编程

实验二Hadoop环境下MapReduce并行编程一. 实验目的1.学习MapReduce编程模型,理解MapReduce的编程思想。
会用MapReduce框架编写简单的并行程序。
2.熟悉使用eclipse编写、调试和运行MapReduce并行程序。
二. 实验内容1.登录Openstack云平台,进入搭建好Hadoop的虚拟机,按照实验指导说明,在终端启动hadoop、启动eclipse。
2.用MapReduce编程思想,修改hadoop自带的例子程序WordCount,实现如下功能:统计给定文件data.dat中出现频率最多的三个单词,并输出这三个单词和出现的次数。
(注:这里不区分字母大小写,如he与He当做是同一个单词计数)三. 实验指导1.进入虚拟机,打开终端,切换为root用户,命令使用:su root输入密码2.进入hadoop安装目录,本实验中hadoop安装目录为:/usr/local/hadoop-2.6.0/,使用ls命令查看该目录中的文件:3.所有与hadoop启动/关闭有关的脚本位于sbin目录下,所以继续进入sbin目录。
其中,hadoop2.X版本的启动命令主要用到start-dfs.sh和start-yarn.sh。
关闭hadoop主要用到stop-dfs.sh和stop-yarn.sh。
执行start-dfs.sh,然后使用jps命令查看启动项,保证NameNode和DataNode 已启动,否则启动出错:执行start-yarn.sh,jps查看时,保证以下6个启动项已启动:4.打开eclipse,在右上角进入Map/Reduce模式,建立eclispe-hadoop连接5.连接成功后,能够在(1)这个文件夹下再创建文件夹(创建后需refresh)6.建立wordcount项目,如下步骤:7.next,项目名任意(如wordcount),finish。
将WordCount.java文件复制到wordcount项目下src文件中,双击打开。
MapReduce技术详解

MapReduce技术详解1.什么是MapReduce?MapReduce 是由Google公司的Jeffrey Dean 和 Sanjay Ghemawat 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。
MapReduce实现了两个功能。
Map把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集。
而Reduce是把从两个或更多个Map中,通过多个线程,进程或者独立系统并行执行处理的结果集进行分类和归纳。
Map() 和 Reduce() 两个函数可能会并行运行,即使不是在同一的系统的同一时刻。
Google 用MapReduce来索引每个抓取过来的Web页面。
它取代了2004开始试探的最初索引算法,它已经证明在处理大量和非结构化数据集时更有效。
用不同程序设计语言实现了多个MapReduce,包括 Java, C++, Python, Perl, Ruby和C, 其它语言。
在某些范例里,如Lisp或者Python, Map() 和Reduce()已经集成到语言自身的结构里面。
通常,这些函数可能会如下定义:List2 map(Functor1, List1);Object reduce(Functor2, List2);Map()函数把大数据集进行分解操作到两个或更多的小“桶”。
而一个“桶”则是包含松散定义的逻辑记录或者文本行的集合。
每个线程,处理器或者系统在独立的“桶”上执行Map()函数,去计算基于每个逻辑记录处理的一系列中间值。
合并的结果值就会如同是单个Map()函数在单个“桶”上完全一致。
Map()函数的通常形式是:map(function, list) {foreach element in list {v = function(element)intermediateResult.add(v)}} // mapReduce()函数把从内存,磁盘或者网络介质提取过来的一个或多个中间结果列表,对列表中的每个元素逐一执行一个函数。
大数据mapreduce课程设计

大数据mapreduce课程设计一、教学目标本课程旨在让学生掌握大数据处理技术中的MapReduce编程模型,理解其核心概念和基本原理,培养学生运用MapReduce解决实际问题的能力。
具体目标如下:1.知识目标:(1)了解MapReduce的起源、发展及其在大数据处理领域的应用;(2)掌握MapReduce的基本概念,包括Map、Shuffle、Reduce等阶段;(3)理解MapReduce的数据抽象、编程模型以及编程接口;(4)熟悉Hadoop生态系统中相关组件,如HDFS、YARN等。
2.技能目标:(1)能够运用MapReduce编程模型解决简单的数据处理问题;(2)熟练使用Hadoop框架进行MapReduce程序的开发和部署;(3)掌握MapReduce程序的调试和优化方法。
3.情感态度价值观目标:(1)培养学生对大数据处理技术的兴趣,认识其在现代社会的重要性;(2)培养学生团队合作精神,提高解决实际问题的能力;(3)培养学生创新意识,激发学生持续学习的动力。
二、教学内容本课程的教学内容主要包括以下几个部分:1.MapReduce概述:介绍MapReduce的起源、发展及其在大数据处理领域的应用。
2.MapReduce基本概念:讲解MapReduce的核心概念,包括Map、Shuffle、Reduce等阶段。
3.MapReduce编程模型:详述MapReduce的数据抽象、编程模型以及编程接口。
4.Hadoop生态系统:介绍Hadoop生态系统中相关组件,如HDFS、YARN等。
5.MapReduce实例分析:分析实际应用中的MapReduce实例,让学生掌握运用MapReduce解决问题的方法。
6.MapReduce程序开发与调试:讲解如何使用Hadoop框架进行MapReduce程序的开发和部署,以及程序的调试和优化方法。
三、教学方法本课程采用多种教学方法,以激发学生的学习兴趣和主动性:1.讲授法:讲解MapReduce的基本概念、原理和编程模型;2.案例分析法:分析实际应用中的MapReduce实例,让学生学会运用MapReduce解决问题;3.实验法:让学生动手编写和调试MapReduce程序,提高实际操作能力;4.讨论法:学生分组讨论,培养团队合作精神和创新意识。
大数据技术原理与应用 第七章 MapReduce分析

7.3.2 MapReduce各个执行阶段
节点1
从分布式文件系统中加载文件
节点2
从分布式文件系统中加载文件
InputFormat 文件 文件 Split Split Split Split
InputFormat 文件 Split Split 文件
输入 <key,value>
RR Map
RR Map
Reduce <k2,List(v2)> <k3,v3> 如:<“a”,<1,1,1>> <“a”,3>
7.2 MapReduce的体系结构
MapReduce体系结构主要由四个部分组成,分别是: Client、JobTracker、TaskTracker以及Task
Client
Client
Client
7.4.2 WordCount设计思路
首先,需要检查WordCount程序任务是否可 以采用MapReduce来实现 其次,确定MapReduce程序的设计思路 最后,确定MapReduce程序的执行过程
7.4.3
一个WordCount执行过程的实例
Map输入 Map输出 <Hello,1> <World,1> <Bye,1> <World,1> <Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1> <Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
函数 Map 输入 <k1,v1> 如:
<行号,”a b c”>
实验五 MapReduce实验

实验五MapReduce实验:单词计数5.1 实验目的基于MapReduce思想,编写WordCount程序。
5.2 实验要求1.理解MapReduce编程思想;2.会编写MapReduce版本WordCount;3.会执行该程序;4.自行分析执行过程。
5.3 实验原理MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。
适用范围:数据量大,但是数据种类小可以放入内存。
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
理解MapReduce和Yarn:在新版Hadoop中,Yarn作为一个资源管理调度框架,是Hadoop下MapReduce程序运行的生存环境。
其实MapRuduce除了可以运行Yarn 框架下,也可以运行在诸如Mesos,Corona之类的调度框架上,使用不同的调度框架,需要针对Hadoop做不同的适配。
一个完成的MapReduce程序在Yarn中执行过程如下:(1)ResourcManager JobClient向ResourcManager提交一个job。
(2)ResourcManager向Scheduler请求一个供MRAppMaster运行的container,然后启动它。
(3)MRAppMaster启动起来后向ResourcManager注册。
(4)ResourcManagerJobClient向ResourcManager获取到MRAppMaster相关的信息,然后直接与MRAppMaster进行通信。
(5)MRAppMaster算splits并为所有的map构造资源请求。
(6)MRAppMaster做一些必要的MR OutputCommitter的准备工作。
(7)MRAppMaster向RM(Scheduler)发起资源请求,得到一组供map/reduce task 运行的container,然后与NodeManager一起对每一个container执行一些必要的任务,包括资源本地化等。
Java实现MapReduceWordcount案例

Java实现MapReduceWordcount案例先改pom.xml:<project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.mcq</groupId><artifactId>mr-1101</artifactId><version>0.0.1-SNAPSHOT</version><dependencies><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.2</version></dependency></dependencies></project>在resources⽂件夹下添加⽂件 log4j.properties:log4j.rootLogger=INFO, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderyout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%d %p [%c] - %m%nlog4j.appender.logfile=org.apache.log4j.FileAppenderlog4j.appender.logfile.File=target/spring.logyout=org.apache.log4j.PatternLayoutyout.ConversionPattern=%d %p [%c] - %m%nWordcountDriver.java:package com.mcq;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordcountDriver{public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {System.out.println("hello");Configuration conf=new Configuration();//1.获取Job对象Job job=Job.getInstance(conf);//2.设置jar存储位置job.setJarByClass(WordcountDriver.class);//3.关联Map和Reduce类job.setMapperClass(WordcountMapper.class);job.setReducerClass(WordcountReducer.class);//4.设置Mapper阶段输出数据的key和value类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//5.设置最终输出的key和value类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//6.设置输⼊路径和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));//7.提交Job// job.submit();job.waitForCompletion(true);// boolean res=job.waitForCompletion(true);//true表⽰打印结果// System.exit(res?0:1);}}WordcountMapper.java:package com.mcq;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;//map阶段//KEYIN:输⼊数据的key(偏移量,⽐如第⼀⾏是0~19,第⼆⾏是20~25),必须是LongWritable//VALUEIN:输⼊数据的value(⽐如⽂本内容是字符串,那就填Text)//KEYOUT:输出数据的key类型//VALUEOUT:输出数据的值类型public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{IntWritable v=new IntWritable(1);Text k = new Text();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {// TODO Auto-generated method stub//1.获取⼀⾏String line=value.toString();//2.切割单词String[] words=line.split(" ");//3.循环写出for(String word:words) {k.set(word);context.write(k, v);}}}WordcountReducer.java:package com.mcq;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;//KEYIN、VALUEIN:map阶段输出的key和value类型public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{IntWritable v=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {// TODO Auto-generated method stubint sum=0;for(IntWritable value:values) {sum+=value.get();}v.set(sum);context.write(key, v);}}在run configuration⾥加上参数e:/mrtest/in.txt e:/mrtest/out.txt在集群上运⾏:⽤maven打成jar包,需要添加⼀些打包依赖:<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin </artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>com.mcq.WordcountDriver</mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>注意上⾯mainClass⾥要填驱动类的主类名,可以点击类名右键copy qualified name。
Mapreduce实例——去重

Mapreduce实例——去重"数据去重"主要是为了掌握和利⽤并⾏化思想来对数据进⾏有意义的筛选。
统计⼤数据集上的数据种类个数、从⽹站⽇志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
MaprReduce去重流程如下图所⽰:数据去重的最终⽬标是让原始数据中出现次数超过⼀次的数据在输出⽂件中只出现⼀次。
在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后交给reduce。
我们⾃然⽽然会想到将同⼀个数据的所有记录都交给⼀台reduce机器,⽆论这个数据出现多少次,只要在最终结果中输出⼀次就可以了。
具体就是reduce的输⼊应该以数据作为key,⽽对value-list则没有要求(可以设置为空)。
当reduce接收到⼀个<key,value-list>时就直接将输⼊的key复制到输出的key中,并将value设置成空值,然后输出<key,value>。
实验环境Linux Ubuntu 14.04jdk-7u75-linux-x64hadoop-2.6.0-cdh5.4.5hadoop-2.6.0-eclipse-cdh5.4.5.jareclipse-java-juno-SR2-linux-gtk-x86_64实验内容现有⼀个某电商⽹站的数据⽂件,名为buyer_favorite1,记录了⽤户收藏的商品以及收藏的⽇期,⽂件buyer_favorite1中包含(⽤户id,商品id,收藏⽇期)三个字段,数据内容以"\t"分割,由于数据很⼤,所以为了⽅便统计我们只截取它的⼀部分数据,内容如下:1. ⽤户id 商品id 收藏⽇期2. 10181 1000481 2010-04-04 16:54:313. 20001 1001597 2010-04-07 15:07:524. 20001 1001560 2010-04-07 15:08:275. 20042 1001368 2010-04-08 08:20:306. 20067 1002061 2010-04-08 16:45:337. 20056 1003289 2010-04-12 10:50:558. 20056 1003290 2010-04-12 11:57:359. 20056 1003292 2010-04-12 12:05:2910. 20054 1002420 2010-04-14 15:24:1211. 20055 1001679 2010-04-14 19:46:0412. 20054 1010675 2010-04-14 15:23:5313. 20054 1002429 2010-04-14 17:52:4514. 20076 1002427 2010-04-14 19:35:3915. 20054 1003326 2010-04-20 12:54:4416. 20056 1002420 2010-04-15 11:24:4917. 20064 1002422 2010-04-15 11:35:5418. 20056 1003066 2010-04-15 11:43:0119. 20056 1003055 2010-04-15 11:43:0620. 20056 1010183 2010-04-15 11:45:2421. 20056 1002422 2010-04-15 11:45:4922. 20056 1003100 2010-04-15 11:45:5423. 20056 1003094 2010-04-15 11:45:5724. 20056 1003064 2010-04-15 11:46:0425. 20056 1010178 2010-04-15 16:15:2026. 20076 1003101 2010-04-15 16:37:2727. 20076 1003103 2010-04-15 16:37:0528. 20076 1003100 2010-04-15 16:37:1829. 20076 1003066 2010-04-15 16:37:3130. 20054 1003103 2010-04-15 16:40:1431. 20054 1003100 2010-04-15 16:40:16要求⽤Java编写MapReduce程序,根据商品id进⾏去重,统计⽤户收藏商品中都有哪些商品被收藏。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
运行结果如下所示:
This is map results: <This 1> <is 1> <map 1> <reduce 1> <swvtc 1> <map 1> <swvtc 1> <shanwei 1> <shanwei 1> <reduce 1> This is reduce results: <This 1> <is 1> <map 2> <reduce 2> <swvtc 2> <shanwei 2>
步骤10:输入类名后,打开代码编辑窗口。
输入代码,代码如下所示:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser;
8.2.2实训目的
1、掌握Eclipse工具的安装;
2、掌握Eclipse插件的使用;
3、掌握Eclipse开发基本应用程序。
8.2.3实训步骤
步骤1:1)下载Eclipse软件包。下载地址如下:
/eclipse/technology/epp/downloads/release/kepler/ SR2/eclipse-java-kepler-SR2-linux-gtk-x86_64.tar.gz 2)解压到/usr/local目录下。操作命令如下: [root@node1 ~]# cd /usr/local [root@node1 local]# tar xzvf /root/eclipse-java-kepler-SR2linux-gtk-x86_64.tar.gz
8.2实训二 安装Eclipse开发工具
8.2.1实训内容
Eclipse 是一个开放源代码的、基于Java的可扩展 开发平台。就其本身而言,它只是一个框架和一组 服务,用于通过插件组件构建开发环境。使用 Eclipse工具便于我们开发hadoop应用软件。本实训 主要完成Eclipse工具的安装和使用。
步骤3:运行Eclipse。操作命令如下: [root@node1 ~]# /usr/local/eclipse/eclipse & 执行命令后打开对话框,输入工作目录。
步骤4:单击“OK”后,进入工作界面。
步骤5:单击菜单栏的“Window—>Open
Perspective—>Other…”菜单项,显示“Open perspective”窗口。
8.1.2实训目的
1、了解Map/Reduce的工作流程;
2、掌握Map/Reduce的单节点编程和运行。
8.1.3实训步骤
步骤1:编写代码。如下所示: [root@node1 ~]$vi mapreduce.c 输入以下编写代码: /*文件名:mapreduce.c*/ #include <stdio.h> #include <string.h> #include <stdlib.h> #define BUF_SIZE 2048 int my_map(char *buffer,char (*mapbuffer)[100]); int my_reduce(char (*mapbuffer)[100],char (*reducebuffer)[100],int *count,int num);
// map函数,输入参数为字符串指针buffer,map后的结果通过
mapbuffer参数传出 // 函数返回值为字符串中单词个数 int my_map(char *buffer,char (*mapbuffer)[100]) { char *p; int num=0; if(p=strtok(buffer," ")) { strcpy(mapbuffer[num],p); num++; } else return num; while(p=strtok(NULL," ")) { strcpy(mapbuffer[num],p); num++; } return num; }
步骤6:单击“Add External JARs…”,把目录 “/home/hadoop/share/hadoop/common”、 “/home/hadoop/share/hadoop/mapreduce”、 “/home/hadoop/share/hadoop/hdfs”、 “/home/hadoop/share/hadoop/common/lib/commons-cli”和 “/home/hadoop/share/hadoop/yarn”下的jar包添加到库中。
// reduce函数,输入参数为字符串map后的结果mapbuffer和单词个数num // reduce结果通过reducebuffer和count参数传出 // 函数返回值为reduce的结果个数 int my_reduce(char (*mapbuffer)[100],char (*reducebuffer)[100],int *count,int num) { int i,j; int flag[BUF_SIZE]={0}; char tmp[100]; int countnum=0; for(i=0;i<num;i++) { if(flag[i]==0) { strcpy(tmp,mapbuffer[i]); flag[i]=1; strcpy(reducebuffer[countnum],mapbuffer[i]); count[countnum]=1; for(j=0;j<num;j++) { if(memcmp(tmp,mapbuffer[j],strlen(tmp))==0&&(strlen(tmp)==strlen(mapbuffer[j]))&&(flag[j]==0)) count[countnum]++; flag[j]=1; } } countnum++; } } return countnum; }
8.3.2实训目的
1、掌握新建Map/Reduce项目的方法和步骤;
2、掌握Map/Reduce项目的编译打包;
3、掌握Map/Reduce项目的提交运行。
8.3.3实训步骤
步骤1:运行eclipse,选择菜单栏的“File—New—
Other…”菜单项。
步骤2:选择“Map/Reduce Project”。
{
步骤2:编译代码。如下所示:
[root@node1 ~]$ cc -o mapreduce mapreduce.c 步骤3:运行程序,输入字符串,如下所示: [root@node1 ~]# ./mapreduce This is map reduce swvtc map swvtc shanwei shanwei reduce
步骤2:安装hadoop插件,hadoop插件的下载地址如
下: https:///winghc/hadoop2x-eclipseplugin/archive/master.zip,解压出hadoop-eclipse-plugin2.6.0.jar后,放在Eclipse下的plugin目录下。操作命令 如下: [root@node1 ~]# cd /usr/local/eclipse/plugins/ [root@node1 plugins]# mv /root/hadoop-eclipse-plugin2.6.0.jar .
public class WordCount { //继承mapper接口,设置map的输入类型为<Object,Text> //输出类型为<Text,IntWritable> public static class Map extends Mapper<Object,Text,Text,IntWritable>{ //one表示单词出现一次 private static IntWritable one = new IntWritable(1); //word存储切下的单词 private Text word = new Text(); public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ //对输入的行切词 StringTokenizer st = new StringTokenizer(value.toString());//以默认的分隔符将value切分 while(st.hasMoreTokens()){ word.set(st.nextToken());//切下的单词存入word context.write(word, one); //将word为key,one为value写入磁盘 } } }