南昌大学《编译原理》实验报告(用Java编写)
编译原理 实验报告

编译原理实验报告编译原理实验报告引言编译原理是计算机科学中的重要课程,它研究的是如何将高级语言程序转化为机器语言程序的过程。
在本次实验中,我们学习了编译原理的基本概念和技术,并通过实践来加深对这些概念和技术的理解。
本报告将对我们在实验中遇到的问题、解决方案以及实验结果进行总结和分析。
实验目的本次实验的主要目的是设计并实现一个简单的编译器,能够将类C语言的源代码翻译成目标代码。
通过这个实验,我们可以更好地理解编译器的工作原理,掌握编译器设计的基本方法和技术。
实验过程在实验中,我们首先对给定的类C语言的语法进行了分析,并根据语法规则设计了相应的语法分析器。
然后,我们使用了自顶向下的递归下降分析法来实现语法分析器。
在实现语法分析器的过程中,我们遇到了一些问题,例如如何处理语法规则中的左递归、如何处理语法规则中的优先级和结合性等。
通过仔细研究相关的文献和资料,我们成功地解决了这些问题,并完成了语法分析器的设计和实现。
接下来,我们对语法分析器进行了测试,并对测试结果进行了分析。
通过测试,我们发现语法分析器在处理简单的源代码时能够正确地识别出语法错误,并给出相应的错误提示。
然而,在处理复杂的源代码时,语法分析器可能会出现一些错误,例如无法正确地处理嵌套的语法结构、无法正确地处理运算符的优先级和结合性等。
为了解决这些问题,我们对语法分析器进行了改进,并进行了多次测试,最终得到了令人满意的结果。
实验结果通过本次实验,我们成功地设计并实现了一个简单的编译器,能够将类C语言的源代码翻译成目标代码。
在实验中,我们对编译器的工作原理有了更深入的了解,掌握了编译器设计的基本方法和技术。
同时,我们也发现了一些问题,并通过不断地改进和测试,最终得到了令人满意的结果。
结论编译原理是一门重要的计算机科学课程,它研究的是如何将高级语言程序转化为机器语言程序的过程。
通过本次实验,我们对编译原理的基本概念和技术有了更深入的了解,并通过实践来加深了对这些概念和技术的理解。
编译原理实验报告

编译原理实验报告一、实验目的和要求本次实验旨在对PL_0语言进行功能扩充,添加新的语法特性,进一步提高编译器的功能和实用性。
具体要求如下:1.扩展PL_0语言的语法规则,添加新的语法特性;2.实现对新语法的词法分析和语法分析功能;3.对扩展语法规则进行语义分析,并生成中间代码;4.验证扩展功能的正确性。
二、实验内容1.扩展语法规则本次实验选择扩展PL_0语言的语句部分,添加新的控制语句,switch语句。
其语法规则如下:<switch_stmt> -> SWITCH <expression> CASE <case_list><default_stmt> ENDSWITCH<case_list> -> <case_stmt> , <case_stmt> <case_list><case_stmt> -> CASE <constant> : <statement><default_stmt> -> DEFAULT : <statement> ,ε2.词法分析和语法分析根据扩展的语法规则,需要对新的关键字和符号进行词法分析,识别出符号类型和记号类型。
然后进行语法分析,建立语法树。
3.语义分析在语义分析阶段,首先对switch语句的表达式进行求值,判断其类型是否为整型。
然后对case语句和default语句中的常量进行求值,判断是否与表达式的值相等。
最后将语句部分生成中间代码。
4.中间代码生成根据语法树和语义分析的结果,生成对应的中间代码。
例如,生成switch语句的跳转表,根据表达式的值选择相应的跳转目标。
5.验证功能的正确性设计一些测试用例,验证新语法的正确性和扩展功能的实用性。
三、实验步骤与结果1.扩展语法规则,更新PL_0语法分析器的词法规则和语法规则。
编译原理实验报告

编译原理实验报告一、实验概述本次实验旨在设计并实现一个简单的词法分析器,即实现编译器的第一个阶段,词法分析。
词法分析器将一段源程序代码作为输入,将其划分为一个个的词法单元,并将其作为输出。
二、实验过程1.设计词法规则根据编程语言的规范和所需实现的功能,设计词法规则,以明确规定如何将源程序代码分解为一系列的词法单元。
2.实现词法分析器采用合适的编程语言,根据所设计的词法规则,实现词法分析器。
词法分析器的主要任务是读入源程序代码,并将其根据词法规则进行分解,生成对应的词法单元。
3.测试词法分析器设计测试用例,用于检验词法分析器的正确性和性能。
测试用例应包含各种情况下的源程序代码。
4.分析和修正错误根据测试过程中发现的问题,分析产生错误的原因,并进行修正。
重复测试和修正的过程,直到词法分析器能够正确处理所有测试用例。
三、实验结果我们设计了一个简单的词法分析器,并进行了测试。
测试用例涵盖了各种情况下的源程序代码,包括正确的代码和错误的代码。
经过测试,词法分析器能够正确处理所有的测试用例。
词法分析器将源程序代码分解为一系列的词法单元,每个词法单元包含了单词的种类和对应的值。
通过对词法单元的分析,可以进一步进行语法分析和语义分析,从而完成编译过程。
四、实验总结通过本次实验,我深入了解了编译原理的词法分析阶段。
词法分析是编译器的第一个重要阶段,它将源程序代码分解为一个个的词法单元,为后续的语法分析和语义分析提供基础。
在实现词法分析器的过程中,我学会了如何根据词法规则设计词法分析器的算法,并使用编程语言实现词法分析器。
通过测试和修正,我掌握了调试和错误修复的技巧。
本次实验的经验对我今后的编程工作有很大帮助。
编译原理是计算机科学与技术专业的核心课程之一,通过实践能够更好地理解和掌握其中的概念和技术。
我相信通过进一步的学习和实践,我能够在编译原理领域取得更大的成果。
编译原理实验报告

编译原理实验报告编译原理实验报告一、实验目的1. 了解编译器的基本原理和工作过程;2. 掌握编译器设计和实现的基本方法和技巧;3. 通过设计和实现一个简单的编译器,加深对编程语言和计算机系统的理解和认识。
二、实验原理编译器是将高级语言程序翻译成机器语言程序的一种软件工具。
它由编译程序、汇编程序、链接程序等几个阶段组成。
本次实验主要涉及到的是编译程序的设计和实现。
编译程序的基本原理是将高级语言程序转换为中间代码,再将中间代码转换为目标代码。
整个过程可以分为词法分析、语法分析、语义分析、代码生成和代码优化几个阶段。
三、实验内容本次实验的设计目标是实现一个简单的四则运算表达式的编译器。
1. 词法分析根据规定的语法规则,编写正则表达式将输入的字符串进行词法分析,将输入的四则运算表达式划分成若干个单词(Token),例如:运算符、操作数等。
2. 语法分析根据定义的语法规则,编写语法分析程序,将词法分析得到的Token序列还原成语法结构,构建抽象语法树(AST)。
3. 语义分析对AST进行遍历,进行语义分析,判断表达式是否符合语法规则,检查语义错误并给出相应的提示。
4. 代码生成根据AST生成目标代码,目标代码可以是汇编代码或者机器码。
四、实验过程和结果1. 首先,根据输入的表达式,进行词法分析。
根据所定义的正则表达式,将输入的字符串划分成Token序列。
例如:输入表达式“2+3”,经过词法分析得到的Token序列为["2", "+", "3"]。
2. 然后,根据语法规则,进行语法分析。
根据输入的Token序列,构建抽象语法树。
3. 接着,对抽象语法树进行语义分析。
检查表达式是否符合语法规则,给出相应的提示。
4. 最后,根据抽象语法树生成目标代码。
根据目标代码的要求,生成汇编代码或者机器码。
五、实验总结通过本次实验,我对编译器的工作原理有了更深入的认识,掌握了编译器设计和实现的基本方法和技巧。
南昌大学java实验报告4

南昌大学实验报告学生姓名:学号:专业班级:网络工程091实验类型:□验证□综合□设计□创新实验日期:2012.5.18 实验成绩:实验四简单的万年历一、实验目的学习使用布局类。
二、实验任务编写一个应用程序,有一个窗口,该窗口为BorderLayout布局。
窗口的中心添加一个Panel容器:pCenter,pCenterd的布局是7行7列的GridLayout布局,pCenter中放置49个标签,用来显示日历。
窗口的北面添加一个Panel容器pNorth,其布局是FlowLayout布局,pNorth放置两个按钮:nextMonth和previousMonth,单击nextMonth按钮,可以显示当前月的下一月的日历;单击previousMonth按钮可以显示当前月的上一月的日历。
窗口的南面添加一个Panel容器pSouth,起布局是FlowLayout,pSouth中放置一个标签用来显示一些信息。
三、实验内容编译并运行程序,查看结果。
程序如下:CalendarFRame.javapackage calendar;import java.awt.BorderLayout;import java.awt.Button;import java.awt.GridLayout;import bel;import java.awt.Panel;import java.awt.ScrollPane;import java.awt.event.ActionEvent;import java.awt.event.ActionListener;import javax.swing.JFrame;public class CalendarFrame extends JFrame implements ActionListener { Label labelDay[]=new Label[42];Button titleName[]=new Button[7];String name[]={"日","一","二","三", "四","五","六"};Button nextMonth,previousMonth;int year=2012,month=5;CalendarBean calendar;Label showMessage=new Label("",Label.CENTER);public CalendarFrame(){Panel pCenter=new Panel();pCenter.setLayout(new GridLayout(7,7));//将pCenter的布局设置为7行7列的GridLayout 布局。
编译原理实验报告

《编译原理》实验报告软件131 陈万全132852一、需求分析通过对一个常用高级程序设计语言的简单语言子集编译系统中词法分析、语法分析、语义处理模块的设计、开发,掌握实际编译系统的核心结构、工作流程及其实现技术,获得分析、设计、实现编译程序等方面的实际操作能力,增强设计、编写和调试程序的能力。
通过开源编译器分析、编译过程可视化等扩展实验,促进学生增强复杂系统分析、设计和实现能力,鼓励学生创新意识和能力。
1、词法分析程序设计与实现假定一种高级程序设计语言中的单词主要包括五个关键字begin、end、if、then、else;标识符;无符号常数;六种关系运算符;一个赋值符和四个算术运算符,试构造能识别这些单词的词法分析程序。
输入:由符合和不符合所规定的单词类别结构的各类单词组成的源程序文件。
输出:把所识别出的每一单词均按形如(CLASS,VALUE)的二元式形式输出,并将结果放到某个文件中。
对于标识符和无符号常数,CLASS字段为相应的类别码的助记符;VALUE字段则是该标识符、常数的具体值;对于关键字和运算符,采用一词一类的编码形式,仅需在二元式的CLASS字段上放置相应单词的类别码的助记符,VALUE字段则为“空”。
2、语法分析程序设计与实现选择对各种常见高级程序设计语言都较为通用的语法结构——算术表达式的一个简化子集——作为分析对象,根据如下描述其语法结构的BNF定义G2[<算术表达式>],任选一种学过的语法分析方法,针对运算对象为无符号常数和变量的四则运算,设计并实现一个语法分析程序。
G2[<算术表达式>]:<算术表达式> → <项> | <算术表达式>+<项> | <算术表达式>-<项><项> → <因式> | <项>*<因式> | <项>/<因式><因式> → <运算对象> | (<算术表达式>)若将语法范畴<算术表达式>、<项>、<因式>和<运算对象>分别用E、T、F和i 代表,则G2可写成:G2[E]:E → T | E+T | E-T T → F | T*F | T/F F → i | (E)输入:由实验一输出的单词串,例如:UCON,PL,UCON,MU,ID ······输出:若输入源程序中的符号串是给定文法的句子,则输出“RIGHT”,并且给出每一步分析过程;若不是句子,即输入串有错误,则输出“ERROR”,并且显示分析至此所得的中间结果,如分析栈、符号栈中的信息等,以及必要的出错说明信息。
南昌大学编译原理实验报告二

南昌⼤学编译原理实验报告⼆南昌⼤学实验报告⼆实验类型:□验证□综合■设计□创新实验⽇期:2013.5 实验成绩:⼀、实验⽬的通过设计、编制、调试⼀个典型的语法分析程序,实现对词法分析程序所提供的单词序列进⾏语法检查和结构分析,进⼀步掌握常⽤的语法分析中递归下降分析⽅法。
⼆、实验内容设计⼀个⽂法的递归下降分析程序,判断特定表达式的正确性。
三、实验要求1、给出⽂法如下:G[E]E->T|E+T;T->F|T*F;F->i|(E);2、根据该⽂法构造相应的LL(1)⽂法及LL(1)分析表,并为该⽂法设计预测分析程序,利⽤C语⾔或C++语⾔实现;3、利⽤预测分析程序完成下列功能:1)⼿⼯将测试的表达式写⼊⽂本⽂件,每个表达式写⼀⾏,⽤“;”表⽰结束;2)读⼊⽂本⽂件中的表达式;3)调⽤实验⼀中的词法分析程序搜索单词;4)把单词送⼊预测分析程序,判断表达式是否正确(是否是给出⽂法的语⾔),若错误,应给出错误信息;5)完成上述功能,有余⼒的同学可以进⼀步完成通过程序实现对⾮LL(1)⽂法到LL(1)⽂法的⾃动转换。
四、实验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境五、实验步骤1、分析⽂法,将给出的⽂法转化为LL(1)⽂法;2、学习预测分析程序的结构,设计合理的预测分析程序;3、编写测试程序,包括表达式的读⼊和结果的输出;4、测试程序运⾏效果,测试数据可以参考下列给出的数据。
六、测试数据输⼊数据:编辑⼀个⽂本⽂⽂件expression.txt,在⽂件中输⼊如下内容:正确结果:(1)10;输出:正确(2)1+2;输出:正确(3)(1+2)*3+(5+6*7);输出:正确(4)((1+2)*3+4输出:错误(5)1+2+3+(*4+5)输出:错误(6)(a+b)*(c+d)输出:正确(7)((ab3+de4)**5)+1输出:错误实验代码:以下分别⽤递归下降和预测分析两种⽅法进⾏编程递归下降:#includeusing namespace std;char t[100];char s[100];int i, SIGN,j;void E();void E1();void E2();void T();void T1();void F();bool F1(char k);int main(){cout<<"请输⼊⼀个语句,以#号结束语句(直接输⼊#号推出)"< while( 1 ){cin>>t;E2();SIGN = 0;i=0;if( s[0] == '#')return 0;E();if(s[i]=='#')cout<<"正确语句!"<cout<<"请输⼊⼀个语句,以#号结束语句"<}return 1;}void E(){if(SIGN==0){T();E1();}}void E1(){if(SIGN==0){if(s[i]=='+'){++i;T();E1();}else if(s[i]!='#'&&s[i]!=')'){cout<<"语句有误!"<SIGN=1;}}}void T(){if(SIGN==0){F();T1();}}void T1(){if(SIGN==0){if(s[i]=='*'){++i;F();T1();}else if(s[i]!='#'&&s[i]!=')'&&s[i]!='+') {cout<<"语句有误!"<SIGN=1;}}}void F(){if(SIGN==0){if(s[i]=='('){++i;E();if(s[i]==')')++i;else if(s[i]== '#'){cout<<"语句有误!"< SIGN=1;++i;}}else if(s[i]=='i')++i;else{cout<<"语句有误!"< SIGN=1;}}}void E2(){i=0;j=0;while(t[j]!='#'){if(F1(t[j])){j++;while(F1(t[j])){j++;}s[i++]='i';}else s[i++]=t[j++];}s[i]='#';}bool F1(char k){if(k>='0'&&k<='9')return true;else if(k>='a'&&k<='z')return true;else return false;}实验截图:预测分析:#includeusing namespace std;char VT[6]={'i','(',')','*','+','#',}; int ob[5][6]={ {1,0,0,1,0,0},{0,1,0,0,2,2},{1,0,0,1,0,0},{0,2,1,0,2,2},{2,0,0,1,0,0}};int p(char c){switch(c){case'E':return 0;break;case'B':return 1;break;case'T':return 2;break;case'C':return 3;break;case'F':return 4;break;case'i':return 0;break;case'+':return 1;break;case'*':return 2;break;case'(':return 3;break;case')':return 4;break;case'#':return 5;break;default:return 6;break;}}bool V(char c){int i;for(i=0;i<6;i++){if(c==VT[i])return 1;}return 0;}class LL1{private:char s[100];int j;public:LL1(){s[0]='#';s[1]='E';j=1;}char g(){return s[j];}int gc(){return j;}void show(){cout<void cj(){j--;}void change(int i){if(s[j]=='E'&&i==1){s[j++]='B';s[j]='T';}else if(s[j]=='B'&&i==1){s[j++]='B';s[j++]='T';s[j]='+';} else if(s[j]=='B'&&i==2){j--;}else if(s[j]=='T'&&i==1){s[j++]='C';s[j]='F';}else if(s[j]=='C'&&i==1){s[j++]='C';s[j++]='F';s[j]='*';} else if(s[j]=='C'&&i==2){j--;}else if(s[j]=='F'&&i==1){s[j++]=')';s[j++]='E';s[j]='(';} else if(s[j]=='F'&&i==2){s[j]='i';}else cout<<"推导出错"<}};void main(){FILE *t;char in[30];char a,c;cout<<"请输⼊源⽂件名(包括路径和后缀名):";for(;;){cin>>in;if((t=fopen(in,"r"))!=NULL) break;else cout<<"⽂件路径错误!请输⼊源⽂件名(包括路径和后缀名):"; } while((a=getc(t))!=EOF){LL1 S;cout<<"原式"<if(p(a)==6){a='i';c=a;}while(1){if(V(S.g())){if(S.g()=='#'&&a=='#'){a=getc(t);break;}else if(S.g()==a){S.cj();while(1){c=a;a=getc(t);cout<if(a==';'){a='#';}if(p(a)==6){a='i';}if(c!='i'||a!='i')break;}continue;}else {if(a=='#')break;while(a!=';'){a=getc(t);cout<break;}}else if(ob[p(S.g())][p(a)]>0){S.change(ob[p(S.g())][p(a)]);continue;}else {if(a=='#')break;while(a!=';'){a=getc(t);cout<break;}}if(S.gc()==0){cout<<"符合LL(1)⽂法"< else {a=getc(t);cout<<"不符合LL(1)⽂法"< system("pause");}实验截图:。
编译原理实验报告

编译方法实验报告实验1:扫描器的设计一、实验目的熟悉并实现一个扫描器(词法分析程序)。
二、实验要求(1) 设计扫描器的有限自动机(识别器);(2) 设计翻译、生成Token的算法(翻译器);(3) 编写代码并上机调试运行通过。
·输入——源程序文件或源程序字符串;·输出——相应的Token序列;关键字表和界符表;符号表和常数表;三、实验步骤流程:初始化;打开用户源程序文件;while (文件未结束){ 读入一行到w[i],i=0;do //处理一行,每次处理一个单词{ 滤空格,直到第一个非空的w[i];i--;s=1; //处理一个单词开始while (s!=0)//拼单词并生成相应Token{act(s); //执行q sif (s>=11 && s<=14)//一个单词处理结束break;i++; //getchar()s=find(s, w[i]);}if (s==0)词法错误;}while (w[i]!=换行符);}关闭用户源程序文件;生成Token文件;输出关键字表;输出Token序列;输出符号表;输出常数表;有限自动机的状态转换图: ed d d+|- -1/+/-+① d ② . ③ d ④ e ⑤ ⑥ d ⑦ d --1/+/-l/d -1/+/--1l ⑧ --1b ⑨ b ⑩ --1--1-其中:d 为数字,l 为字母,b 为界符,-1代表其它符号(如在状态8处遇到了非字母或数字的其它符号,会变换到状态12)。
关键字表和界符表:Program; Begin: End( Var) While, Do:= Repeat+ Until- For* To/ If> Then>= Else==< <=四、 主要数据结构①状态转换矩阵:int aut[10][7]={ 2, 0, 0, 0, 8, 9, 15,2, 3, 5,11, 0, 0, 11,4, 0, 0, 0, 0, 0, 0,4, 0, 5,11, 0, 0, 11,7, 0, 0, 6, 0, 0, 0,7, 0, 0, 0, 0, 0, 0,7, 0, 0,11, 0, 0, 11,8, 0, 0, 0, 8, 0, 12,0, 0, 0, 0, 0, 10, 14,0, 0, 0, 0, 0, 0, 13};12 11 13 14 15②关键字表:char keywords[30][12]={“program”,”begin”,”end”,”var”,”while”,”do”,”repeat”,”until”,”for”,”to”,”if”,”then”,”else”,“;”, ”:”, ”(“, ”)”, ”,”, ”:=”, ”+”, ”-“, ”*”, ”/”,”>”, ”>=”, ”==”, “<”, “<=”};③符号表:char ID[50][12]; //表中存有源程序中的标识符④常数表:float C[20];⑤其它变量:struct token{ int code;int value}; //Token结构struct token tok[100]; //Token数组int s; //当前状态int n,p,m,e,t; //尾数值,指数值,小数位数,指数符号,类型float num; //常数值char w[50]; //源程序缓冲区int i; //源程序指针,当前字符为w[i]char strTOKEN[12]; //当前已经识别出的单词五、实验核心代码int main(int argc, char* argv[]){FILE *fp;int s; //当前状态 *有限自动机中的状态fp=fopen("exa.txt","r");while (!feof(fp)){fgets(w,50,fp);i=0;//*处理一行do{printf("%c ",w[i]); //测试显示每个token的首字母//*处理一个tokenwhile (w[i]==' ') //滤空格i++;if (w[i]>='a' && w[i]<='z') //判定单词类别*是字母(关键字或标识符){ptr=col2; num_map=2;}else if (w[i]>='0' && w[i]<='9') //*是数字(常量的开头){ptr=col1; num_map=4;}else if (strchr(col3[0].str,w[i])==NULL) //*其他字符算为非法字符{printf("非法字符%c\n",w[i]);i++;continue;}else //界符{ptr=col3; num_map=1;}i--; //*向后退一个字符s=1; //开始处理一个单词while (s!=0){act(s);if (s>=11 && s<=14) //*判断是否是终止状态 *是终止状态,则形成一个tokenbreak;i++; //getchar() *读取下一个字符s=find(s,w[i]); //状态转换}if (s==0){strTOKEN[i_str]='\0';printf("词法错误:%s\n",strTOKEN);}}while (w[i]!=10);}printf("关键字表:"); //输出结果for (i=0;i<30;i++)printf("%s ",keywords[i]);printf("\n");printf("Token序列:");for (i=0;i<num_token;i++)printf("(%d,%d)",tok[i].code,tok[i].value);printf("\n");printf("符号表:");for (i=0;i<num_ID;i++)printf("%s ",ID[i]);printf("\n");printf("常数表:");for (i=0;i<num_C;i++)printf("%d ",C[i]);printf("\n");fclose(fp);printf("Hello World!\n");return 0;}//*状态转换后,达到新的状态之后,记录的变化void act(int s){int code;switch (s){case 1:n=0;m=0;p=0;t=0;e=1;num=0;i_str=0;strTOKEN[i_str]='\0'; //其它变量初始化break;case 2:n=10*n+w[i]-48;break;case 3:t=1;break;case 4:n=10*n+w[i]-48; m++;break;case 5:t=1;break;case 6:if (w[i]=='-') e=-1;break;case 7:p=10*p+w[i]-48;break;case 8:strTOKEN[i_str++]=w[i]; //将ch中的符号拼接到strTOKEN的尾部;break;case 9:strTOKEN[i_str++]=w[i]; //将ch中的符号拼接到strTOKEN的尾部;break;case 10:strTOKEN[i_str++]=w[i]; //将ch中的符号拼接到strTOKEN的尾部;break;case 11:num=n*pow(10,e*p-m); //计算常数值tok[i_token].code=2; tok[i_token++].value=InsertConst(num); //生成常数Tokennum_token++;break;case 12:strTOKEN[i_str]='\0';code=Reserve(strTOKEN); //查关键字表if (code){ tok[i_token].code=code; tok[i_token++].value=0; } //生成关键字Token else{ tok[i_token].code=1;tok[i_token++].value=InsertID(strTOKEN); } //生成标识符Token num_token++;break;case 13:strTOKEN[i_str]='\0';code=Reserve(strTOKEN); //查界符表if (code){ tok[i_token].code=code; tok[i_token++].value=0; } //生成界符Token else{strTOKEN[strlen(strTOKEN)-1]='\0'; //单界符i--;code=Reserve(strTOKEN); //查界符表tok[i_token].code=code; tok[i_token++].value=0; //生成界符Token }num_token++;break;case 14:strTOKEN[i_str]='\0';code=Reserve(strTOKEN); //查界符表tok[i_token].code=code; tok[i_token++].value=0; //生成界符Token num_token++;break;}}//*状态转换int find(int s,char ch){int i,col=7;struct map *p;p=ptr;for (i=0;i<num_map;i++)if (strchr((p+i)->str,ch)){col=(p+i)->col;break;}return aut[s][col];}//*向常量表中插入常量int InsertConst(double num){int i;for (i=0;i<num_C;i++)if (num==C[i])return i;C[i]= (int)num;num_C++;return i;}int Reserve(char *str){int i;for (i=0;i<num_key;i++)if (!strcmp(keywords[i],str))return (i+3);return 0;}//*向符号表中插入新的符号int InsertID(char *str){int i;for (i=0;i<num_ID;i++)if (!strcmp(ID[i],str)) //*符号已经存在,则返回地址return i;strcpy(ID[i],str);num_ID++;return i;}六、实验结果实验思考题:1.扫描器的任务是什么?答:词法分析程序又称扫描器,任务有:(1) 识别单词——从用户的源程序中把单词分离出来;(2) 翻译单词——把单词转换成机内表示,便于后续处理。
南昌大学编译原理实验报告一

南昌⼤学编译原理实验报告⼀⼤学实验报告⼀实验类型:□验证□综合■设计□创新实验⽇期:2013.4 实验成绩:词法分析程序设计⼀、实验⽬的掌握计算机语⾔的词法分析程序的开发⽅法。
⼆、实验容编制⼀个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。
三、实验要求1、根据状态图,设计词法分析函数int scan( ),完成以下功能:1)从⽂本⽂件中读⼊测试源代码,根据状态转换图,分析出⼀个单词,2)以⼆元式形式输出单词<单词种类,单词属性>其中单词种类⽤整数表⽰:0:标识符1:⼗进制整数2:⼋进制整数3:⼗六进制整数运算符和界符,关键字采⽤⼀字⼀符,不编码其中单词属性表⽰如下:标识符,整数由于采⽤⼀类⼀符,属性⽤单词表⽰运算符和界符,关键字采⽤⼀字⼀符,属性为空2、编写测试程序,反复调⽤函数scan( ),输出单词种别和属性。
四、实验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境五、实验步骤编辑⼀个⽂本⽂件program.txt,在⽂件中输⼊如下容:正确结果:【实验代码】#include#includeusing namespace std;#define MAX 5char ch =' ';string key[5]={"if","then","else","while","do"};int Iskey(string c){ //关键字判断int i;for(i=0;iif(key[i].compare(c)==0) return 1;}return 0;}int IsLetter(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1; else return 0;}int IsLetter1(char c) { //判断是否为a~f字母if(((c<='f')&&(c>='a'))||((c<='F')&&(c>='A'))) return 1; else return 0;}int IsDigit(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}void scan(FILE *fpin){string arr="";while((ch=fgetc(fpin))!=EOF){arr="";if(ch==' '||ch=='\t'||ch=='\n'){}else if(IsLetter(ch)||ch=='_'){arr=arr+ch;ch=fgetc(fpin);while(IsLetter(ch)||IsDigit(ch)){if((ch<='Z')&&(ch>='A')) ch=ch+32; arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);if (Iskey(arr)){cout<else cout<}else if(IsDigit(ch)){int flag=0;if(ch=='0'){arr=arr+ch;ch=fgetc(fpin);if(ch>='0'&&ch<='7'){while(ch>='0'&&ch<='7'){flag=1;arr=arr+ch;ch=fgetc(fpin);}}else if(ch=='x'||ch=='X'){flag=2;arr=arr+ch;ch=fgetc(fpin);while(IsDigit(ch)||IsLetter1(ch)) {arr=arr+ch;ch=fgetc(fpin);}}else if(ch==' '||ch==','||ch==';' ){ cout<}fseek(fpin,-1L,SEEK_CUR); if(flag==1) cout<else if(flag==2) cout<}else{arr=arr+ch;ch=fgetc(fpin);while(IsDigit(ch)){arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR); cout<}}else switch(ch){case'+':case'-' :case'*' :case'=' :case'/' :cout<case'(' :case')' :case'[' :case']' :case';' :case'.' :case',' :case'{' :case'}' :cout<case':' :{ch=fgetc(fpin);if(ch=='=') cout<<":="<<"\t$运算符"<else {cout<<"::"<<"\t$界符"<fseek(fpin,-1L,SEEK_CUR);}}break;case'>' :{ch=fgetc(fpin);if(ch=='=') cout<<">="<<"\t$运算符"<if(ch=='>')cout<<">>"<<"\t$输⼊控制符"< else {cout<<">"<<"\t$运算符"<fseek(fpin,-1L,SEEK_CUR);}}break;case'<' :{ch=fgetc(fpin);if(ch=='=')cout<<"<="<<"\t$运算符"<else if(ch=='<')cout<<"<<"<<"\t$输出控制符"< else if(ch=='>') cout<<"<>"<<"\t$运算符"< else{cout<<"<"<<"\t$运算符"<fseek(fpin,-1L,SEEK_CUR);}}break;default : cout<}}}void main(){char in_fn[30];FILE * fpin;cout<<"请输⼊源⽂件名(包括路径和后缀名):";for(;;){cin>>in_fn;if((fpin=fopen(in_fn,"r"))!=NULL) break;else cout<<"⽂件路径错误!请输⼊源⽂件名(包括路径和后缀名):"; }cout<<"\n********************分析如下*********************"<scan(fpin);system("pause");fclose(fpin);}【实验截图】。
编译原理实验报告
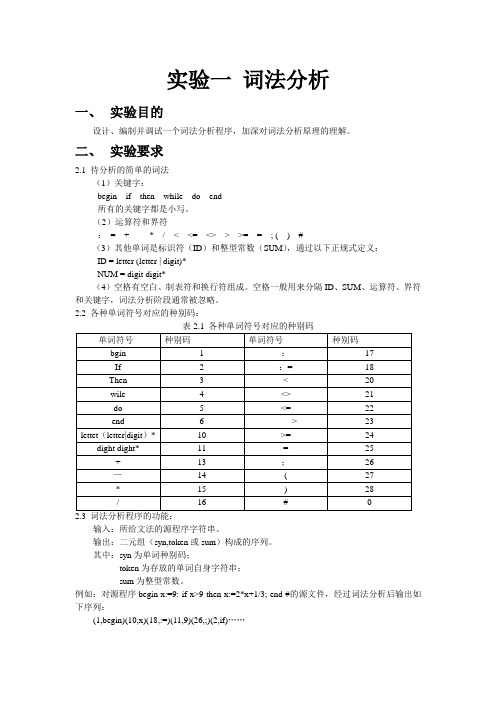
实验一词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:表2.1 各种单词符号对应的种别码单词符号种别码单词符号种别码bgin 1 :17If 2 := 18Then 3 < 20wile 4 <> 21do 5 <= 22end 6 > 23lettet(letter|digit)* 10 >= 24 dight dight* 11 = 25 + 13 ;26—14 ( 27* 15 ) 28/ 16 # 02.3 词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
编译原理实验报告

编译原理实验报告一、实验目的编译原理是计算机科学中的重要课程,旨在让学生了解编译器的基本工作原理以及相关技术。
本次实验旨在通过设计和实现一个简单的编译器,来进一步加深对编译原理的理解,并掌握实际应用的能力。
二、实验环境本次实验使用了Java编程语言及相关工具。
在开始实验前,我们需要安装Java JDK并配置好运行环境。
三、实验内容及步骤1. 词法分析词法分析是编译器的第一步,它将源代码分割成一系列词法单元。
我们首先实现一个词法分析器,它能够将输入的源代码按照语法规则进行切割,并识别出关键字、标识符、数字、运算符等。
2. 语法分析语法分析是编译器的第二步,它将词法分析得到的词法单元序列转化为语法树。
我们使用自顶向下的LL(1)语法分析算法,根据文法规则递归地构建语法树。
3. 语义分析语义分析是编译器的第三步,它对语法树进行检查和转换。
我们主要进行类型检查、语法错误检查等。
如果源代码存在语义错误,编译器应该能够提供相应的错误提示。
4. 代码生成代码生成是编译器的最后一步,它将经过词法分析、语法分析和语义分析的源代码翻译为目标代码。
在本次实验中,我们将目标代码生成为Java字节码。
5. 测试与优化完成以上步骤后,我们需要对编译器进行测试,并进行优化。
通过多个测试用例的执行,我们可以验证编译器的正确性和性能。
四、实验心得通过完成这个编译器的实验,我收获了很多。
首先,我对编译原理的知识有了更深入的理解。
在实验过程中,我深入学习了词法分析、语法分析、语义分析和代码生成等关键技术,对编译器的工作原理有了更系统的了解。
其次,我提高了编程能力。
实现一个完整的编译器需要处理复杂的数据结构和算法,这对我的编程能力是一个很好的挑战。
通过实验,我学会了合理地组织代码,优化算法,并注意到细节对程序性能的影响。
最后,我锻炼了解决问题的能力。
在实验过程中,我遇到了很多困难和挑战,但我不断地调试和改进代码,最终成功地实现了编译器。
编译原理实验报告

编译原理实验报告一、实验目的本次实验的目的是了解编译原理的基本知识,并运用所学知识实现一个简单的词法分析器。
二、实验内容1.设计一个词法分析器,能够识别并输出源程序中的关键字、标识符、常数和运算符等。
2.设计并实现一个词法分析器的算法。
3.对编写的词法分析器进行测试。
三、实验过程1.设计词法分析器的算法在设计词法分析器的时候,需要先了解源程序的基本构成,了解关键字、标识符、常数和运算符等的特点,以及它们在源程序中的表示形式。
然后,根据这些特点,设计一个适合的算法来进行词法分析。
2.实现词法分析器根据设计好的算法,在编程语言中实现词法分析器。
在实现过程中,需要根据不同的词法单元,设计相应的正则表达式来进行匹配和识别。
3.测试词法分析器编写几个简单的测试用例,对词法分析器进行测试。
检查输出结果是否正确,并根据实际情况对词法分析器进行调试和优化。
四、实验结果经过测试,词法分析器能够正确识别并输出源程序中的关键字、标识符、常数和运算符等。
测试用例的输出结果与预期结果一致。
五、实验总结通过本次实验,我学习了编译原理的基本知识,掌握了词法分析器的设计和实现方法。
在实验过程中,我遇到了一些困难和问题,但通过仔细思考和查阅文献资料,最终成功地完成了实验任务。
这次实验不仅帮助我巩固了所学知识,还提高了我的编程能力和解决问题的能力。
通过实践,我深刻体会到了编译原理在软件开发中的重要性和作用,并对将来的学习和工作有了更好的规划和方向。
通过本次实验,我对编译原理的相关知识有了更深入的理解和掌握,对词法分析器的设计和实现方法有了更加清晰的认识。
同时,我还学会了如何进行实验报告的撰写,提高了我的文档写作能力。
通过本次实验,我不仅实现了实验的目标,还提高了自己的综合素质和能力。
南昌大学编译原理实验--语法分析(含代码)

南昌大学实验报告学生姓名:学号:专业班级:实验类型:□验证□综合□√设计□创新实验日期:实验成绩:]实验二语法分析程序的设计(1)一、实验目的通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析中预测分析方法。
二、实验内容设计一个文法的预测分析程序,判断特定表达式的正确性。
三、实验要求1、给出文法如下:G[E]E->T|E+T;T->F|T*F;F->i|(E);2、根据该文法构造相应的LL(1)文法及LL(1)分析表,并为该文法设计预测分析程序,利用C语言或C++语言或Java语言实现;3、利用预测分析程序完成下列功能:1)手工将测试的表达式写入文本文件,每个表达式写一行,用“;”表示结束;2)读入文本文件中的表达式;3)调用实验一中的词法分析程序搜索单词;4)把单词送入预测分析程序,判断表达式是否正确(是否是给出文法的语言),若错误,应给出错误信息;5)完成上述功能,有余力的同学可以进一步完成通过程序实现对非LL(1)文法到LL(1)文法的自动转换(见实验二附加资料1)。
四、实验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境五、实验步骤1、分析文法,将给出的文法转化为LL(1)文法;2、学习预测分析程序的结构,设计合理的预测分析程序;3、编写测试程序,包括表达式的读入和结果的输出;4、测试程序运行效果,测试数据可以参考下列给出的数据。
六、测试数据输入数据:编辑一个文本文文件expression.txt,在文件中输入如下内容:正确结果:(1)10;输出:正确(2)1+2;输出:正确(3)(1+2)*3+(5+6*7);输出:正确(4)((1+2)*3+4输出:错误(5)1+2+3+(*4+5)输出:错误(6)(a+b)*(c+d)输出:正确(7)((ab3+de4)**5)+1输出:错误七、实验报告要求实验报告应包括以下几个部分:1、给定文法的LL(1)形式;2、预测分析程序的算法和结构;3、程序运行流程;4、程序的测试结果和问题;5、实验总结。
编译原理上机实验报告

编译原理上机实验报告一、实验目的本次实验旨在通过实践的方式理解和掌握编译原理中的一些重要概念和技术,包括词法分析、语法分析和语义分析等。
通过实验的操作,了解和体验编译器的工作过程,深入理解编译原理的相关理论知识。
二、实验环境本次实验使用了Java语言作为编程语言,使用Eclipse作为开发环境,实验所需的相关工具和库已经提前配置完成。
三、实验内容本次实验主要分为三个部分,分别是词法分析、语法分析和语义分析。
1.词法分析词法分析是编译器的第一个阶段,也是最基础的阶段。
在本次实验中,我们首先需要实现一个词法分析器,该分析器可以将源代码分割成一个个的词法单元,将其存储到一个词法单元表中。
我们首先需要定义一些词法单元的模式,比如关键字、标识符、常量等。
然后,我们使用正则表达式和有限自动机的思想来实现一个可以识别各种模式的词法分析器。
2.语法分析语法分析是编译器的第二个阶段,其目的是将词法单元表中的内容按照语法规则进行分析,生成一个语法树。
在本次实验中,我们需要实现一个递归下降的语法分析器。
我们首先需要定义一些语法规则,然后根据这些规则逐条实现相应的语法分析函数。
最终,我们可以通过递归调用这些函数,将源代码转换成语法树的形式。
3.语义分析语义分析是编译器的第三个阶段,其目的是对语法树进行进一步的检查和处理。
在本次实验中,我们需要实现一个简单的语义分析器。
我们可以在语法分析的基础上,增加一些语义规则,然后对生成的语法树进行检查。
比如,我们可以检查变量的定义和使用是否一致,是否存在未定义的变量等。
最终,我们可以通过语义分析器发现和纠正一些潜在的错误。
四、实验总结通过本次实验,我深入学习了编译原理的相关知识,并通过实践中加深了对这些知识的理解和掌握。
实验中,我了解到了词法分析、语法分析和语义分析在编译器设计中的重要性,也学会了如何使用相关工具和技术来实现这些功能。
通过实验,我发现编译原理是一门非常有趣且实用的课程,它既涉及到理论知识,又需要实践操作。
编译原理实验报告

实验一词法分析一、实验目的通过设计、编写和调试词法分析程序,了解词法分析程序的作用,组成结构,不同种类单词的识别方法,掌握由单词的词法规则出发,画出识别单词的状态转换图,然后在用程序实现词法分析程序设计方法。
二、词法规则1、注释用{和}括起来。
注释体中不能有{。
注释可以出现在任何记号的后面。
2、记号间的空格可有可无,但关键字前后必须有空格、换行、程序的开头或者结尾的原点。
3、标识符的记号id 与以字母开头的字母数字串相匹配:Letter->[a-zA-Z]Digit->[0-9]Id->letter (letter | digit)*4、记号num与无符号整数相匹配:Digits->digit digit*Optional_fraction -> . Digits | ɛOptional_exponent->(E(+ | - | ɛ ) digits) | ɛNum ->digits optional_fraction optional_exponent5、关键字要被保留且在文法中以黑体出现6、关系运算符(relop)指:=、<、<>、<=、>=、>7、Addop: + 、 - 、or8、Mulop:*、/ 、div、mod、and9、Assignop: :=三、词法分析程序详细设计及判别状态图1、无符号数(可带小数和指数)的状态转换图:2、标识符/关键字的状态转换图:字母或数程序详细设计:四、开发环境本程序在Microsoft Visual C++ 6.0环境中编写,无特殊编译要求。
五、函数清单void LexcialAnalysis(FILE *fp);//词法分析主函数int JudgeFirstLetter(char ch);//判断单词的第一个字符int IsDigit(char ch);//判断是否为数字int IsLetter(char ch);//判断是否为字母int IsSpecialPunc(char ch);//判断是否为特殊标点void RecogDigit(char StrLine[]);//用状态图识别无符号数字void RecogIdentifier(char strLine[]);//用状态图识别标识符void RecogPunc(char strLine[]);//识别特殊标点int IsKeyWord(string str);//判断标识符是否为关键字void error();//出错处理六、测试程序program example(input, output);{comments goes here!}var x, y: integer;function gcd(a, b: integer): integer;beginif b =1.2e3 then gcd := aelse gcd := gcd(b, a mod b)end;beginread(x, y);write(gcd(x, y));end.七、运行效果八、实验总结通过这次编译器词法分析程序的编写,我更好地了解了词法分析的作用及工作原理,讲课本中的知识融入到程序编写过程中,理论结合了实际。
编译原理教程实验报告

一、实验目的本次实验旨在使学生通过编译原理的学习,了解编译程序的设计原理及实现技术,掌握编译程序的各个阶段,并能将所学知识应用于实际编程中。
二、实验内容1. 词法分析2. 语法分析3. 语义分析4. 中间代码生成5. 代码优化6. 目标代码生成三、实验步骤1. 词法分析(1)设计词法分析器,识别输入源代码中的各种词法单元;(2)使用C语言实现词法分析器,并进行测试。
2. 语法分析(1)根据文法规则设计语法分析器,识别输入源代码的语法结构;(2)使用C语言实现语法分析器,并进行测试。
3. 语义分析(1)设计语义分析器,检查语法分析后的语法树,确保语义正确;(2)使用C语言实现语义分析器,并进行测试。
4. 中间代码生成(1)设计中间代码生成器,将语义分析后的语法树转换为中间代码;(2)使用C语言实现中间代码生成器,并进行测试。
5. 代码优化(1)设计代码优化器,对中间代码进行优化,提高程序性能;(2)使用C语言实现代码优化器,并进行测试。
6. 目标代码生成(1)设计目标代码生成器,将优化后的中间代码转换为特定目标机的汇编语言;(2)使用C语言实现目标代码生成器,并进行测试。
四、实验结果与分析1. 词法分析实验结果:成功识别输入源代码中的各种词法单元,包括标识符、关键字、运算符、常量等。
2. 语法分析实验结果:成功识别输入源代码的语法结构,包括表达式、语句、程序等。
3. 语义分析实验结果:成功检查语法分析后的语法树,确保语义正确。
4. 中间代码生成实验结果:成功将语义分析后的语法树转换为中间代码,为后续优化和目标代码生成提供基础。
5. 代码优化实验结果:成功对中间代码进行优化,提高程序性能。
6. 目标代码生成实验结果:成功将优化后的中间代码转换为特定目标机的汇编语言,为程序在目标机上运行做准备。
五、实验心得1. 编译原理是一门理论与实践相结合的课程,通过本次实验,我对编译程序的设计原理及实现技术有了更深入的了解。
南昌大学Java实验报告

南昌大学实验报告学生姓名:学号:专业班级:实训类型:□验证□综合□设计□创新实验日期:2017.11.1 实验成绩:一、实验项目名称Java开发环境搭建和Java语言基础二、实验的评分标准实验分为A~F,A为最高,F最低。
F:在规定时间内没有完成所有的实验,而且没有及时提交实验报告,或者实验过程中出现了抄袭复制他人实验代码。
D:能完成实验,但是实验结果出现严重错误,不能体现对教学内容的理解。
C:能基本完成实验,实验结果基本正确。
但是实验内容有较少的错误,提交的实验代码质量一般。
B:能较好的完成实验,实验报告条理清楚,实验代码结构清晰,代码质量较高,及时更正试验中出现的错误,并对运行中一些异常错误进行分析,解释错误产生的原因。
A:能较好的完成实验,实验代码质量高,实验报告完成度高,能在实验完成的基础上,根据个人的理解增加实验的新功能,具有一定的创新能力。
三、实验目的和要求1.掌握Java的基础知识2.掌握和运用Java的控制语句和数组3.使用Eclipse平台开发Java应用四、实验内容1.HelloWorld的应用程序和Applet程序。
A.javap工具解析HelloWord字节码的类B.javap反汇编HelloWorld字节码C.修改代码,使之成为应用程序和Applet小程序两种程序的“入口”不同,一个是main()函数,一个是init()函数,所以直接添加代码即可,运行时,根据IDE的run功能,选择相应的程序执行即可。
第一个和最后一个分别是Applet程序和Application程序D.写文档注释,生成文件一些效果截图2.打印日历程序3.枚举类统计Java成绩非法输入程序会报错退出正确结果自学了一下javafx,写了个简陋的UI。
(要配合控制台输入数据,有待改进)4.四连子游戏继续自学了一下javafx,给这个游戏包装了一个UI。
本题和老师理解的要求可能有出入,游戏规则有点差别,但是底层逻辑是差不多的,于是我还是按照自己的想法写了下去,希望老师理解。
编译原理 词法分析实验报告 java版

while(k!=(char)System.in.read())
System.out.println("请输入y");
c.analyser();
System.out.println(" ");
////System.out.println("\n类型单词符号");
// System.out.println("0标识符");
if(s.indexOf("*/")!=-1){s=s.substring(stIndexOf("*/"),s.length());s=s.replaceAll("\t"," ");
s=s.replaceAll("\n"," ");
s=s.toLowerCase();
bw1.write(s);
else{stringCompiler=stringCompiler+((Character)o).charValue()+" ";}}publicstaticvoidmain(String[] args)throwsException {System.out.println("*****************************************************");
e.printStackTrace();
returnfalse;}finally{}}
voidanalyser(){
try{
BufferedReader br =newBufferedReader(newFileReader(result1));BufferedWriter bw =newBufferedWriter(newFileWriter(result));String a = br.readLine();
编 译 原 理实验报告

编译原理实验报告《编译原理》实验报告学号:1441901105姓名:谢卉实验一词法分析设计实验学时:4实验类型:综合实验要求:必修一、实验目的通过本实验的编程实践,使学生了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,使学生对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。
二、实验内容用VC++/VB/JAVA语言实现对C语言子集的源程序进行词法分析。
通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。
以下是实现词法分析设计的主要工作:(1)从源程序文件中读入字符。
(2)统计行数和列数用于错误单词的定位。
(3)删除空格类字符,包括回车、制表符空格。
(4)按拼写单词,并用(内码,属性)二元式表示。
(属性值——token的机内表示)(5)如果发现错误则报告出错(6)根据需要是否填写标识符表供以后各阶段使用。
单词的基本分类:◆关键字:由程序语言定义的具有固定意义的标识符。
也称为保留字例如if、for、while、printf ;单词种别码为1。
◆标识符:用以表示各种名字,如变量名、数组名、函数名;◆常数:任何数值常数。
如125, 1,0.5,3.1416;◆运算符:+、-、*、/;◆关系运算符:<、<=、= 、>、>=、<>;◆分界符:;、,、(、)、[、];三、词法分析实验设计思想及算法1、主程序设计考虑:◆程序的说明部分为各种表格和变量安排空间。
在具体实现时,将各类单词设计成结构和长度均相同的形式,较短的关键字后面补空。
k数组------关键字表,每个数组元素存放一个关键字(事先构造好关键字表)。
s 数组------存放分界符表(可事先构造好分界符表)。
为了简单起见,分界符、算术运算符和关系运算符都放在s表中(编程时,应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
System.out.println("<"+char1[i]+",->") ;
elseif(char1[i]=='<')
System.out.println("<"+char1[i]+",->") ;
elseif(char1[i]=='(')
System.out.println("<"+char1[i]+",->") ;
return1;
else
return0;
}
publicintisdigit(charchar2){
if(char2>='0'&&char2<='9')
return1;
else
return0;
}
publicintreverse(StringBuffer st){
String str=st.toString();
num++;
}
elseif(this.isdigit(char1[i])==1){
while(i<char1.length&&(this.isdigit(char1[i])==1||this.isletter(char1[i])==1)){
st[num].append(char1[i]);
i++;
}
0:标识符
1:十进制整数
2:八进制整数
3:十六进制整数
运算符和界符,关键字采用一字一符,不编码
其中单词属性表示如下:
标识符,整数由于采用一类一符,属性用单词表示
运算符和界符,关键字采用一字一符,属性为空
3、编写测试程序,反复调用函数scan( ),输出单词种别和属性。
四、主要仪器设备及耗材
PC微机
DOS操作系统或Windows操作系统
StringBuffer st[]=newStringBuffer[20];
intnum=0;
for(inti=0;i<char1.length;i++){
st[num]=newStringBuffer();
if(this.isletter(char1[i])==1){
while(i<char1.length&&(this.isletter(char1[i])==1||this.isdigit(char1[i])==1)){
4、写测试程序,包括表达式的读入和结果的输出;
5、程序运行效果,测试数据可以参考下列给出的数据。
六、实验数据及处理结果
输入数据:
编辑一个文本文文件expression.txt,在文件中输入如下内容:
正确结果:
(1)10;
输出:正确
(2)1+2;
输出:正确
(3)(1+2)*3+(5+6*7);
输出:正确
四、主要仪器设备及耗材
PC微机
DOS操作系统或Windows操作系统
Turbo C程序集成环境或Visual C++程序集成环境或Java
五、实验步骤
设计一个文法的算法优先分析程序,判断特定表达式的正确性。
1、分析文法中终结符号的优先关系;
2、存放优先关系或构造优先函数;
3、利用算符优先分析的算法编写分析程序;
System.out.print("Error:"+e);
System.exit(1);
}
}
}
classPerhang{
Stringkeys[]={"if","then","else","while","do"};
publicintisletter(charchar2){
if((char2>='a'&&char2<='z')||(char2>='A'&&char2<='Z'))
输入数据:编辑一个文本文件program.txt,在文件中输入如下内容:
正确结果:
Java源程序代码如下:
packageex_1;
importjava.io.BufferedReader;
importjava.io.FileReader;
importjava.io.IOException;
publicclassIdentity {
2、程序设计中哪些环节影响词法分析的效率?如何提高效率?
答:整个程序都由状态转换图而来。由递归方法实现的状态转换图,影响了整个词法分析器的分析效率,可以考虑使用栈来非递归的实现词法分析。
心得体会:
1、先利用FileReader读文件,再利用BufferedReader把数据放入缓冲区中
2、判断第一个字符,若是关键字或标识符,若是数字,则可能是十进制数或八进制数或十六进制数
intnum=0;
for(intj=0;j<keys.length;j++){
if(keys[j].compareTo(str)==0)
num++;}
if(num==0)
return0;
else
return1;
}
publicintdigitsort(String s){
if(s.charAt(0)=='0'){
1、给出算符优先分析算法如下:
k:=1; S[k]:=‘#’;
REPEAT
把下一个输入符号读进a中;
IF S[k]∈VTTHEN j:=k ELSE j:=k-1;
WHILE S[j] a DO
BEGIN
REPEAT
Q:=S[j];
IF S[j-1]∈VTTHEN j:=j-1 ELSE j:=j-2
System.out.println("<2,"+st[num]+">") ;//八进制
}
else{
st[num].delete(0, 2);
System.out.println("<3,"+st[num]+">") ;//十六进制
}
num++;
}
elseif(char1[i]=='+')
System.out.println("<"+char1[i]+",->") ;
}
}
}
将program.txt文件放在指定路径下,并运行上面的Java源程序,可以得到如下所示的结果截图。
七、思考讨论题或体会或对改进实验的建议
思考题:
1、词法分析能否采用空格来区分单词?
答:不能,在词法分析中,处理不光有标识符还有连接符,而连接符和其他的标识符是可以连在一起出现的。如果用空格来区分单词的话,就会使连接符和标识符无法区分。
1、根据以下的正规式,编制正规文法,画出状态图;
标识符<字母>(<字母>|<数字字符>)*
十进制整数0 |((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*)
八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)*
十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*
实验
一、
语法分析程序的设计
二
通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析中算法优先分析方法。
三
1、给出文法如下:
G[E]
E->T|E+T;
T->F|T*F;
F->i(E);
可以构造算符优先表如下:
+
*
(
)
i
+
*
(
)
i
2、计算机中表示上述优先关系,优先关系的机内存放方式有两种1)直接存放,2)为优先关系建立优先函数,这里由学生自己选择一种方式;
elseif(char1[i]=='-')
System.out.println("<"+char1[i]+",->") ;
elseif(char1[i]=='*')
System.out.println("<"+char1[i]+",->") ;
elseif(char1[i]=='/')
System.out.println("<"+char1[i]+",->") ;
Turbo C程序集成环境或Visual C++程序集成环境或Java
五、实验步骤
1、根据正规式,画出状态转换图;
2、根据状态图,设计词法分析算法;
3、采用C或C++语言,设计函数scan( ),实现该算法;