Datastage问题总结
datastage面试300题

1. What are the Environmental variables in Datastage?2. Check for Job Errors in datastage3. What are Stage V ariables, Derivations and Constants?4. What is Pipeline Parallelism?5. Debug stages in PX6. How do you remove duplicates in dataset7. What is the difference between Job Control and Job Sequence8. What is the max size of Data set stage?9. performance in sort stage10. How to develop the SCD using LOOKUP stage?12. What are the errors you expereiced with data stage13. what are the main diff between server job and parallel job in datastage14. Why you need Modify Stage?15. What is the difference between Squential Stage & Dataset Stage. When do u use them.16. memory allocation while using lookup stage17. What is Phantom error in the datastage. How to overcome this error.18. Parameter file usage in Datastage19. Explain the best approch to do a SCD type2 mapping in parallel job?20. how can we improve the performance of the job while handling huge amount of data21. HI How can we create read only jobs in Datastage.22. how to implement routines in data stage,have any one has any material for data stage23. How will you determine the sequence of jobs to load into data warehouse?24. How can we Test jobs in Datastage??25. DataStage - delete header and footer on the source sequential26. How can we implement Slowly Changing Dimensions in DataStage?.27. Differentiate Database data and Data warehouse data?28. How to run a Shell Script within the scope of a Data stage job?29. what is the difference between datastage and informatica30. Explain about job control language such as (DS_JOBS)32. What is Invocation ID?33. How to connect two stages which do not have any common columns between them?34. In SAP/R3, How do you declare and pass parameters in parallel job .35. Difference between Hashfile and Sequential File?36. How do you fix the error "OCI has fetched truncated data" in DataStage37. A batch is running and it is scheduled to run in 5 minutes. But after 10 days the time changes to 10 minutes. What type of error is this and how to fix it?38. Which partition we have to use for Aggregate Stage in parallel jobs ?39. What is the baseline to implement parition or parallel execution method in datastage job.e.g. more than 2 millions records only advised ?40. how do we create index in data satge?41. What is the flow of loading data into fact & dimensional tables?42. What is a sequential file that has single input link??43. Aggregators –What does the warning “Hash table has grown to …xyz‟ ….” mean?44. what is hashing algorithm?45. How do you load partial data after job failedsource has 10000 records, Job failed after 5000 records are loaded. This status of the job is abort , Instead of removing 5000 records from target , How can i resume the load46. What is Orchestrate options in generic stage, what are the option names. value ? Name of an Orchestrate operator to call. what are the orchestrate operators available in datastage for AIX environment.47. Type 30D hash file is GENERIC or SPECIFIC?48. Is Hashed file an Active or Passive Stage? When will be it useful?49. How do you extract job parameters from a file?50.1.What about System variables?2.How can we create Containers?3.How can we improve the performance of DataStage?4.what are the Job parameters?5.what is the difference between routine and transform and function?6.What are all the third party tools used in DataStage?7.How can we implement Lookup in DataStage Server jobs?8.How can we implement Slowly Changing Dimensions in DataStage?.9.How can we join one Oracle source and Sequential file?.10.What is iconv and oconv functions?51What are the difficulties faced in using DataStage ? or what are the constraints in using DataStage ?52. Have you ever involved in updating the DS versions like DS 5.X, if so tell us some the steps you have53. What r XML files and how do you read data from XML files and what stage to be used?54. How do you track performance statistics and enhance it?55. Types of vies in Datastage Director?There are 3 types of views in Datastage Director a) Job View - Dates of Jobs Compiled. b) Log View - Status of Job last run c) Status View - Warning Messages, Event Messages, Program Generated Messag56. What is the default cache size? How do you change the cache size if needed?Default cache size is 256 MB. We can incraese it by going into Datastage Administrator and selecting the Tunable Tab and specify the cache size over there.57. How do you pass the parameter to the job sequence if the job is running at night?58. How do you catch bad rows from OCI stage?59. what is quality stage and profile stage?60. what is the use and advantage of procedure in datastage?61. What are the important considerations while using join stage instead of lookups.62. how to implement type2 slowly changing dimenstion in datastage? give me with example?63. How to implement the type 2 Slowly Changing dimension in DataStage?64. What are Static Hash files and Dynamic Hash files?65. What is the difference between Datastage Server jobs and Datastage Parallel jobs?66. What is ' insert for update ' in datastage67. How did u connect to DB2 in your last project?Using DB2 ODBC drivers.68. How do you merge two files in DS?Either used Copy command as a Before-job subroutine if the metadata of the 2 files are same or created a job to concatenate the 2 files into one if the metadata is different.69. What is the order of execution done internally in the transformer with the stage editor having input links on the lft hand side and output links?70. How will you call external function or subroutine from datastage?71. What happens if the job fails at night?72. Types of Parallel Processing?Parallel Processing is broadly classified into 2 types. a) SMP - Symmetrical Multi Processing. b) MPP - Massive Parallel Processing.73. What is DS Administrator used for - did u use it?74. How do you do oracle 4 way inner join if there are 4 oracle input files?75. How do you pass filename as the parameter for a job?76. How do you populate source files?77. How to handle Date convertions in Datastage? Convert a mm/dd/yyyy format to yyyy-dd-mm? We use a) "Iconv" function - Internal Convertion. b) "Oconv" function - External Convertion. Function to convert mm/dd/yyyy format to yyyy-dd-mm is Oconv(Iconv(Filedname,"D/M78. How do you execute datastage job from command line prompt?Using "dsjob" command as follows. dsjob -run -jobstatus projectname jobname79. Differentiate Primary Key and Partition Key?Primary Key is a combination of unique and not null. It can be a collection of key values called as composite primary key. Partition Key is a just a part of Primary Key. There are several methods of80 How to install and configure DataStage EE on Sun Micro systems multi-processor hardware running the Solaris 9 operating system?Asked by: Kapil Jayne81. What are all the third party tools used in DataStage?82. How do you eliminate duplicate rows?83. what is the difference between routine and transform and function?84. Do you know about INTEGRITY/QUALITY stage?85. how to attach a mtr file (MapTrace) via email and the MapTrace is used to record all the execute map errors86. Is it possible to calculate a hash total for an EBCDIC file and have the hash total stored as EBCDIC using Datastage?Currently, the total is converted to ASCII, even tho the individual records are stored as EBCDIC.87. If your running 4 ways parallel and you have 10 stages on the canvas, how many processes does datastage create?88. Explain the differences between Oracle8i/9i?89. How will you pass the parameter to the job schedule if the job is running at night? What happens if one job fails in the night?90. what is an environment variable??91. how find duplicate records using transformer stage in server edition92. what is panthom error in data stage93. How can we increment the surrogate key value for every insert in to target database94. what is the use of environmental variables?95. how can we run the batch using command line?96. what is fact load?97. Explain a specific scenario where we would use range partitioning ?98. what is job commit in datastage?99. hi..Disadvantages of staging area Thanks,Jagan100. How do you configure api_dump102. Does type of partitioning change for SMP and MPP systems?103. what is the difference between RELEASE THE JOB and KILL THE JOB?104. Can you convert a snow flake schema into star schema?105. What is repository?106. What is Fact loading, how to do it?107. What is the alternative way where we can do job control??108.Where we can use these Stages Link Partetionar, Link Collector & Inter Process (OCI) Stage whether in Server Jobs or in Parallel Jobs ?And SMP is a Parallel or Server ?109. Where can you output data using the Peek Stage?110. Do u know about METASTAGE?111. In which situation,we are using RUN TIME COLUMN PROPAGA TION option?112. what is the difference between datasatge and datastage TX?113. 1 1. Difference between Hashfile and Sequential File?. What is modulus?2 2. What is iconv and oconv functions?.3 3. How can we join one Oracle source and Sequential file?.4 4. How can we implement Slowly Changing Dimensions in DataStage?.5 5. How can we implement Lookup in DataStage Server jobs?.6 6. What are all the third party tools used in DataStage?.7 7. what is the difference between routine and transform and function?.8 8. what are the Job parameters?.9 9. Plug-in?.10 10.How can we improv114. Is it possible to query a hash file? Justify your answer...115. How to enable the datastage engine?116. How I can convert Server Jobs into Parallel Jobs?117. Suppose you have table "sample" & three columns in that tablesample:Cola Colb Colc1 10 1002 20 2003 30 300Assume: cola is primary keyHow will you fetch the record with maximum cola value using data stage tool into the target system118. How to parametarise a field in a sequential file?I am using Datastage as ETL Tool,Sequential file as source.119. What is TX and what is the use of this in DataStage ? As I know TX stand for Transformer Extender, but I don't know how it will work and where we will used ?120. What is the difference betwen Merge Stage and Lookup Stage?121. Importance of Surrogate Key in Data warehousing?Surrogate Key is a Primary Key for a Dimension table. Most importance of using it is it is independent of underlying database. i.e Surrogate Key is not affected by the changes going on with a databas122. What is the difference between Symetrically parallel processing,Massively parallel processing?123.What is the diffrence between the Dynamic RDBMS Stage & Static RDBMS Stage ?124. How to run a job using command line?125. What is user activity in datastage?126. how can we improve the job performance?127. how we can create rank using datastge like in informatica128. What is the use of job controle??129. What does # indicate in environment variables?130. what are two types of hash files??131. What are different types of star schema??132. what are different types of file formats??133. What are different dimension table in your project??Plz explain me with an example?? 134. what is the difference between buildopts and subroutines ?135. how can we improve performance in aggregator stage??136. What is SQL tuning? how do you do it ?137. What is the use of tunnable??138. how to distinguish the surogate key in different dimensional tables?how can we give for different dimension tables?139. how can we load source into ODS?140. What is the difference between sequential file and a dataset? When to use the copy stage?141. how to eleminate duplicate rows in data stage?142. What is complex stage? In which situation we are using this one?143. What is the sequencer stage??144. where actually the flat files store?what is the path?145. what are the different types of lookups in datastage?146. What are the most important aspects that a beginner must consider doin his first DS project ?147. how to find errors in job sequence?148. it is possible to access the same job two users at a time in datastage?149. how to kill the job in data stage?150. how to find the process id?explain with steps?151. Why job sequence is use for? what is batches?what is the difference between job sequence and batches?152. What is Integrated & Unit testing in DataStage ?153. What is iconv and oconv functions?154. For what purpose is the Stage Variable is mainly used?155. purpose of using the key and difference between Surrogate keys and natural key156. how to read the data from XL FILES?my problem is my data file having some commas in data,but we are using delimitor is| ?how to read the data ,explain with steps?157. How can I schedule the cleaning of the file &PH& by dsjob?158. Hot Fix for ODBC Stage for AS400 V5R4 in Data Stage 7.1159. what is data stage engine?what is its purpose?160. What is the difference between Transform and Routine in DataStage?161. what is the meaning of the following..1)If an input file has an excessive number of rows and can be split-up then use standard 2)logic to run jobs in parallel3)Tuning should occur on a job-by-job basis. Use the power of DBMS.162. Why is hash file is faster than sequential file n odbc stage??163. Hello,Can both Source system(Oracle,SQLServer,...etc) and Target Data warehouse(may be oracle,SQLServer..etc) can be on windows environment or one of the system should be in UNIX/Linux environment.Thanks,Jagan164. How to write and execute routines for PX jobs in c++?165. what is a routine?166. how to distinguish the surrogate key in different dimentional tables?167. how can we generate a surrogate key in server/parallel jobs?168. what is NLS in datastage? how we use NLS in Datastage ? what advantages in that ? at thetime of installation i am not choosen that NLS option , now i want to use that options what can i do ? to reinstall that datastage or first uninstall and install once again ?169. how to read the data from XL FILES?explain with steps?170. whats the meaning of performance tunning techinque,Example??171. differentiate between pipeline and partion parallelism?172. What is the use of Hash file??insted of hash file why can we use sequential file itself?173. what is pivot stage?why are u using?what purpose that stage will be used?174. How did you handle reject data?175. Hiwhat is difference betweend ETL and ELT?176. how can we create environment variables in datasatage?177. what is the difference between static hash files n dynamic hash files?178. how can we test the jobs?179. What is the difference between reference link and straight link ?180. What are the command line functions that import and export the DS jobs?181. what is the size of the flat file?182. Whats difference betweeen operational data stage (ODS) & data warehouse?183. I have few questions1. What ar ethe various process which starts when the datastage engine starts?2. What are the changes need to be done on the database side, If I have to use dB2 stage?3. datastage engine is responsible for compilation or execution or both?184. Could anyone plz tell abt the full details of Datastage Certification.Title of Certification?Amount for Certification test?Where can v get the Tutorials available for certification?Who is Conducting the Certification Exam?Whether any training institute or person for guidens?I am very much pleased if anyone enlightwn me abt the above saidSuresh185. how to use rank&updatestratergy in datastage186. What is Ad-Hoc access? What is the difference between Managed Query and Ad-Hoc access?187. What is Runtime Column Propagation and how to use it?188. how we use the DataStage Director and its run-time engine to schedule running the solution, testing and debugging its components, and monitoring the resulting e/xecutable versions on ad hoc or scheduled basis?189. What is the difference bitween OCI stage and ODBC stage?190. Is there any difference b/n Ascential DataStage and DataStage.191. How do you remove duplicates without using remove duplicate stage?192. if we using two sources having same meta data and how to check the data in two sorces is same or nif we using two sources having same meta data and how to check the data in two sorces is same or not?and if the data is not same i want to abort the job ?how we can do this?193. If a DataStage job aborts after say 1000 records, how to continue the job from 1000th record after fixing the error?194. Can you tell me for what puorpse .dsx files are used in the datasatage195. how do u clean the datastage repository.196. give one real time situation where link partitioner stage used?197. What is environment variables?what is the use of this?198. How do you call procedures in datastage?199. How to remove duplicates in server job200. What is the exact difference betwwen Join,Merge and Lookup Stage??202. What are the new features of Datastage 7.1 from datastage 6.1203. How to run the job in command prompt in unix?204. How to know the no.of records in a sequential file before running a server job?205. Other than Round Robin, What is the algorithm used in link collecter? Also Explain How it will works?206. how to drop the index befor loading data in target and how to rebuild it in data stage?207. How can ETL excel file to Datamart?208. what is the transaction size and array size in OCI stage?how these can be used?209. what is job control?how it is developed?explain with steps?210. My requirement is like this :Here is the codification suggested: SALE_HEADER_XXXXX_YYYYMMDD.PSVSALEMy requirement is like this :Here is the codification suggested: SALE_HEADER_XXXXX_YYYYMMDD.PSVSALE_LINE_XXXXX_YYYYMMDD.PSVXXXXX = LVM sequence to ensure unicity and continuity of file exchangesCaution, there will an increment to implement.YYYYMMDD = LVM date of file creation COMPRESSION AND DELIVERY TO: SALE_HEADER_XXXXX_YYYYMMDD.ZIP AND SALE_LINE_XXXXX_YYYYMMDD.ZIPif we run that job the target file names are like this sale_header_1_20060206 & sale_line_1_20060206.If we run next time means the211. what is the purpose of exception activity in data stage 7.5?212. How to implement slowly changing dimentions in Datastage?213. What does separation option in static hash-file mean?214. how to improve the performance of hash file?215. Actually my requirement is like that :Here is the codification suggested: SALE_HEADER_XXXXX_YYYYMMActually my requirement is like that :Here is the codification suggested: SALE_HEADER_XXXXX_YYYYMMDD.PSVSALE_LINE_XXXXX_YYYYMMDD.PSVXXXXX = LVM sequence to ensure unicity and continuity of file exchangesCaution, there will an increment to implement.YYYYMMDD = LVM date of file creation COMPRESSION AND DELIVERY TO: SALE_HEADER_XXXXX_YYYYMMDD.ZIP AND SALE_LINE_XXXXX_YYYYMMDD.ZIPif we run that job the target file names are like this sale_header_1_20060206 & sale_line_1_20060206.if we run next216. How do u check for the consistency and integrity of model and repository?217. how we can call the routine in datastage job?explain with steps?218. what is job control?how can it used explain with steps?219. how to find the number of rows in a sequential file?220. If the size of the Hash file exceeds 2GB..What happens? Does it overwrite the current rows?221. where we use link partitioner in data stage job?explain with example?222 How i create datastage Engine stop start script.Actually my idea is as below.!#bin/bashdsadm - usersu - rootpassword (encript)DSHOMEBIN=/Ascential/DataStage/home/dsadm/Ascential/DataStage/DSEngine/binif check ps -ef | grep DataStage (client connection is there) { kill -9 PID (client connection) }uv -admin - stop > dev/nulluv -admin - start > dev/nullverify processcheck the connectionecho "Started properly"run it as dsadm223. can we use shared container as lookup in datastage server jobs?224. what is the meaning of instace in data stage?explain with examples?225. wht is the difference beteen validated ok and compiled in datastage.226. hi all what is auditstage,profilestage,qulaitystages in datastge please explain indetail227what is PROFILE STAGE , QUALITY STAGE,AUDIT STAGE in datastage..please expalin in detail.thanks in adv228. what are the environment variables in datastage?give some examples?229. What is difference between Merge stage and Join stage?230. Hican any one can explain what areDB2 UDB utilitiesub231. What is the difference between drs and odbc stage232. Will the data stage consider the second constraint in the transformer once the first condition is satisfied ( if the link odering is given)233. How do you do Usage analysis in datastage ?234. how can u implement slowly changed dimensions in datastage? explain?2) can u join flat file and database in datastage?how?235. How can you implement Complex Jobs in datastage236. DataStage from Staging to MDW is only running at 1 row per second! What do we do to remedy?237. what is the mean of Try to have the constraints in the 'Selection' criteria of the jobs iwhat is the mean of Try to have the constraints in the 'Selection' criteria of the jobs itself. This will eliminate the unnecessary records even getting in before joins are made?238. * What are constraints and derivation?* Explain the process of taking backup in DataStage?*What are the different types of lookups available in DataStage?239. # How does DataStage handle the user security?240. What are the Steps involved in development of a job in DataStage?241. What is a project? Specify its various components?242. What does a Config File in parallel extender consist of?Config file consists of the following. a) Number of Processes or Nodes. b) Actual Disk Storage Location.243. how to implement type2 slowly changing dimensions in data stage?explain with example?244. How much would be the size of the database in DataStage ?What is the difference between Inprocess and Interprocess ?245. Briefly describe the various client components?246. What are orabulk and bcp stages?247. What is DS Director used for - did u use it?248. what is meaning of file extender in data stage server jobs.can we run the data stage job from one job to another job that file data where it is stored and what is the file extender in ds jobs.249. What is the max capacity of Hash file in DataStage?250. what is merge and how it can be done plz explain with simple example taking 2 tables .......251. it is possible to run parallel jobs in server jobs?252. what are the enhancements made in datastage 7.5 compare with 7.0253. If I add a new environment variable in Windows, how can I access it in DataStage?254. what is OCI?255. Is it possible to move the data from oracle ware house to SAP Warehouse using withDA TASTAGE Tool.256. How can we create Containers?257. what is data set? and what is file set?258. How can I extract data from DB2 (on IBM iSeries) to the data warehouse via Datastage as the ETL tool. I mean do I first need to use ODBC to create connectivity and use an adapter for the extraction and transformation of data? Thanks so much if anybody could provide an answer.259. it is possible to call one job in another job in server jobs?260. how can we pass parameters to job by using file.261. How can we implement Lookup in DataStage Server jobs?262. what user varibale activity when it used how it used !where it is used with real example263. Did you Parameterize the job or hard-coded the values in the jobs?Always parameterized the job. Either the values are coming from Job Properties or from a …Parameter Manager‟ – a third part tool. There is no way you will hard–code some parameters in your jobs. The o264. what is hashing algorithm and explain breafly how it works?265. what happends out put of hash file is connected to transformer ..what error it throughs266. what is merge ?and how to use merge? merge is nothing but a filter conditions that have been used for filter condition267. What will you in a situation where somebody wants to send you a file and use that file as an input What will you in a situation where somebody wants to send you a file and use that file as an input or reference and then run job.268. What is the NLS equivalent to NLS oracle code American_7ASCII on Datastage NLS?269. Why do you use SQL LOADER or OCI STAGE?270. What about System variables?271. what are the differences between the data stage 7.0 and 7.5in server jobs?272. How the hash file is doing lookup in serverjobs?How is it comparing the key values?273. how to handle the rejected rows in datastage?274. how is datastage 4.0 functionally different from the enterprise edition now?? what are the exact changes?275. What is Hash file stage and what is it used for?Used for Look-ups. It is like a reference table. It is also used in-place of ODBC, OCI tables for better performance.276. What is the utility you use to schedule the jobs on a UNIX server other than using Ascential Director?Use crontab utility along with d***ecute() function along with proper parameters passed.277. How can I connect my DB2 database on AS400 to DataStage? Do I need to use ODBC 1st to open the database connectivity and then use an adapter for just connecting between the two? Thanks alot of any replies.278. what is the OCI? and how to use the ETL Tools?OCI means orabulk data which used client having bulk data its retrive time is much more ie., your used to orabulk data the divided and retrived Asked by: ramanamv279. what is difference between serverjobs & paraller jobs280. What is the difference between Datastage and Datastage TX?281. Hi!Can any one tell me how to extract data from more than 1 hetrogenious Sources.mean, example 1 sequenal file, Sybase , Oracle in a singale Job.282. How can we improve the performance of DataStage jobs?283. How good are you with your PL/SQL?On the scale of 1-10 say 8.5-9284. What are OConv () and Iconv () functions and where are they used?IConv() - Converts a string to an internal storage formatOConv() - Converts an expression to an output format.285. If data is partitioned in your job on key 1 and then you aggregate on key 2, what issues could arise?286. How can I specify a filter command for processing data while defining sequential file output data?287. There are three different types of user-created stages available for PX. What are they? Which would you use? What are the disadvantage for using each type?288. What is DS Manager used for - did u use it?289. What are Sequencers?Sequencers are job control programs that execute other jobs with preset Job parameters.290. Functionality of Link Partitioner and Link Collector?291. Containers : Usage and Types?Container is a collection of stages used for the purpose of Reusability. There are 2 types of Containers. a) Local Container: Job Specific b) Shared Container: Used in any job within a project.292. Does Enterprise Edition only add the parallel processing for better performance?Are any stages/transformations available in the enterprise edition only?293. what are validations you perform after creating jobs in designer.what r the different type of errors u faced during loading and how u solve them294. how can you do incremental load in datastage?295. how we use NLS function in Datastage? what are advantages of NLS function? where we can use that one? explain briefly?296. Dimension Modelling types along with their significanceData Modelling is Broadly classified into 2 types. a) E-R Diagrams (Entity - Relatioships). b) Dimensional Modelling.297. Did you work in UNIX environment?Yes. One of the most important requirements.298. What other ETL's you have worked with?Informatica and also DataJunction if it is present in your Resume.299. What is APT_CONFIG in datastage300. Does the BibhudataStage Oracle plug-in better than OCI plug-in coming from DataStage? What is theBibhudataStage extra functions?301. How do we do the automation of dsjobs?302. what is trouble shhoting in server jobs ? what are the diff kinds of errors encountered while。
DataStage抽取数据的问题

DataStage抽取数据的问题一、环境情况系统运行环境,服务器地址121.42.26.103(版本贵州交通云),操作系统的版本:iZ28xmwpyf3Z:/var # uname -aLinux iZ28xmwpyf3Z 3.11.10-17-default #1 SMP Mon Jun 16 15:28:13 UTC 2014 (fba7c1f) x86_64 x86_64 x86_64 GNU/LinuxiZ28xmwpyf3Z:/var # cat /etc/issueWelcome to openSUSE 13.1 "Bottle" - Kernel \r (\l).二、连接数据库的情况Oracle数据库:SQL> select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') today from dual;select count(*) from tbrd_toll_info;select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') today from dual;TODAY-------------------2014-10-27 11:19:55SQL>COUNT(*)----------88448102SQL>TODAY-------------------2014-10-27 11:20:00Mysql 数据库:--------------------------------------mysql> select now();+---------------------+| now() |+---------------------+| 2014-10-27 11:24:35 |+---------------------+1 row in set (0.00 sec)mysql> select count(*) from tbrd_toll_info;+----------+| count(*) |+----------+| 34095000 |+----------+1 row in set (2 min 4.07 sec)mysql> select now();+---------------------+| now() |+---------------------+| 2014-10-27 11:26:39 |+---------------------+1 row in set (0.00 sec)目前导入到mysql的数据库有:数据中心数据库:jtdatacenter/jtdatacenter信息资源规划成果管理系统数据库:GDC_IRP/GDC_IRPGPS数据库:gdc_gzgps/gdc_gzgps交通建设数据库:gdc_rc_dbcenter/gdc_rc_dbcenter公路数据库:gdc_rd_dbcenter/gdc_rd_dbcenter交通运输数据库:gdc_rt_dbcenter/gdc_rt_ddbcenter内网网站数据库:gdc_iw_db/gzjtxxzx_iwdb三、DataStage作业迁移的情况ODBC驱动:iZ28texom2fZ:~ # ls -l /opt/mysql_odbc/lib/-rwxrwxrwx 1 root root 7924426 Oct 19 13:51 libmyodbc5.soDataStage数据抽取作业共98个,原来的所有作业都是通过Oracle Connector组件连接Oracle数据库,现在数据库从Oracle迁移到MySQL,相应的需要把DataStage作业的Oracle Connector组件换成ODBC Connector组件,目前所有作业都已经迁移完毕,但具备测试条件(测试环境中能连接到源数据库)的作业均运行失败,以下是失败的初步原因分析:1、在把DataStage组件从Oracle换成Mysql,通过ODBC连接MySQL数据库过程中,每次需要重新导入MySQL的表结构定义,但这个操作失败了,目前无法导入MySQL的表定义,只能使用原来Oracle的表定义。
DataStage常用函数大全

DataStage常⽤函数⼤全DataStage常⽤函数⼤全DATASTAGE常⽤函数⼤全 (1)⼀、类型转换函数 (4)1.Char (4)2.DateToString (4)3.DateToDecimal (4)4.DecimalToDate (5)5.DecimalToDecimal (6)6.DecimalToDFloat (6)7.DecimalToString (7)8.DecimalToTime (8)9.DecimalToTimestamp (8)10.DFloatToDecimal (9)11.DfloatToStringNoExp (10)12.IsValidDate (10)13.IsValidTime (11)14.IsValidTimestamp (11)15.RawNumAt (11)16.RawToString (12)17.Seq (12)18.SeqAt (12)19.StringToDate (12)20.StringToDecimal (13)21.StringToRaw (13)22.StringToTime (13)23.StringToTimestamp (14)24.StringToUstring (14)25.TimestampToDate (14)26.TimestampToDecimal (14)27.TimestampToString (15)28.TimestampToTime (16)29.TimeToString (16)30.TimeToDecimal (16)/doc/5f04fb6b10661ed9ad51f38d.html tringToString (17)⼆、字符串函数 (17)32.AlNum (17)33.Alpha (17)/doc/5f04fb6b10661ed9ad51f38d.html pare (18)/doc/5f04fb6b10661ed9ad51f38d.html pareNoCase (18) /doc/5f04fb6b10661ed9ad51f38d.html pareNum (18)/doc/5f04fb6b10661ed9ad51f38d.html pareNumNoCase (19)39.Convert (19)40.Count (19)41.Dcount (19)42.DownCase (20)43.DQuote (20)44.Field (20)45.Index (20)46.Left (21)47.Len (21)48.Num (21)49.PadString (21)50.Right (21)51.Soundex (22)52.Space (22)53.SQuote (22)54.Str (22)55.StripWhiteSpace (23)56.Trim (23)57.TrimB (24)58.TrimF (24)59.TrimLeadingTrailing (24)60.UpCase (24)三、数字函数 (25)61.AsDouble (25)62.AsFloat (25)63.AsInteger (25)64.MantissaFromDecimal (26)65.MantissaFromDFloat (26)四、⽇期和时间函数 (26)66.CurrentDate (26)67.CurrentTime (27)68.CurrentTimeMS (27)69.CurrentTimestamp (27)70.CurrentTimestampMS (27)71.DateFromDaysSince (27)72.DateFromComponents (28)73.DateFromJulianDay (28)74.DateOffsetByComponents (28)76.DaysInMonth (29)77.DaysInYear (29)78.DateOffsetByDays (30)79.HoursFromTime (30)80.JulianDayFromDate (30)81.MicroSecondsFromTime (30)82.MidnightSecondsFromTime (31)83.MinutesFromTime (31)84.MonthDayFromDate (31)85.MonthFromDate (31)86.NextWeekdayFromDate (32)87.NthWeekdayFromDate (32)88.PreviousWeekdayFromDate (32)89.SecondsFromTime (32)90.SecondsSinceFromTimestamp (33)91.TimeDate (33)92.TimeFromComponents (33)93.TimeFromMidnightSeconds (33)94.TimeOffsetByComponents (34)95.TimeOffsetBySeconds (34)96.TimestampFromDateTime (34)97.TimestampFromSecondsSince (34)98.TimestampFromTimet (35)99.TimestampOffsetByComponents (35) 100.TimestampOffsetBySeconds (35)101.TimetFromTimestamp (36)102.WeekdayFromDate (36)103.YeardayFromDate (36)104.YearFromDate (36)105.YearweekFromDate (37)五、Null处理函数 (37)106.IsNotNull (37)107.IsNull (37)108.NullToEmpty (38)109.NullToZero (38)110.NullToValue (38)111.SetNull (38)⼀、类型转换函数类型转换函数⽤于更改参数的类型。
ETL的经验总结

ETL的经验总结ETL的考虑做数据仓库系统,ETL是关键的⼀环。
说⼤了,ETL是数据整合解决⽅案,说⼩了,就是倒数据的⼯具。
回忆⼀下⼯作这么些年来,处理数据迁移、转换的⼯作倒还真的不少。
但是那些⼯作基本上是⼀次性⼯作或者很⼩数据量,使⽤access、DTS或是⾃⼰编个⼩程序搞定。
可是在数据仓库系统中,ETL上升到了⼀定的理论⾼度,和原来⼩打⼩闹的⼯具使⽤不同了。
究竟什么不同,从名字上就可以看到,⼈家已经将倒数据的过程分成3个步骤,E、T、L分别代表抽取、转换和装载。
其实ETL过程就是数据流动的过程,从不同的数据源流向不同的⽬标数据。
但在数据仓库中,ETL有⼏个特点,⼀是数据同步,它不是⼀次性倒完数据就拉到,它是经常性的活动,按照固定周期运⾏的,甚⾄现在还有⼈提出了实时ETL的概念。
⼆是数据量,⼀般都是巨⼤的,值得你将数据流动的过程拆分成E、T和L。
现在有很多成熟的⼯具提供ETL功能,例如datastage、powermart等,且不说他们的好坏。
从应⽤⾓度来说,ETL的过程其实不是⾮常复杂,这些⼯具给数据仓库⼯程带来和很⼤的便利性,特别是开发的便利和维护的便利。
但另⼀⽅⾯,开发⼈员容易迷失在这些⼯具中。
举个例⼦,VB是⼀种⾮常简单的语⾔并且也是⾮常易⽤的编程⼯具,上⼿特别快,但是真正VB的⾼⼿有多少?微软设计的产品通常有个原则是"将使⽤者当作傻⽠",在这个原则下,微软的东西确实⾮常好⽤,但是对于开发者,如果你⾃⼰也将⾃⼰当作傻⽠,那就真的傻了。
ETL⼯具也是⼀样,这些⼯具为我们提供图形化界⾯,让我们将主要的精⼒放在规则上,以期提⾼开发效率。
从使⽤效果来说,确实使⽤这些⼯具能够⾮常快速地构建⼀个job来处理某个数据,不过从整体来看,并不见得他的整体效率会⾼多少。
问题主要不是出在⼯具上,⽽是在设计、开发⼈员上。
他们迷失在⼯具中,没有去探求ETL的本质。
可以说这些⼯具应⽤了这么长时间,在这么多项⽬、环境中应⽤,它必然有它成功之处,它必定体现了ETL的本质。
datastage入门教程

简介DataStage 使用了Client-Server 架构,服务器端存储所有的项目和元数据,客户端DataStage Designer 为整个ETL 过程提供了一个图形化的开发环境,用所见即所得的方式设计数据的抽取清洗转换整合和加载的过程。
Datastage 的可运行单元是Datastage Job ,用户在Designer 中对Datastage Job 的进行设计和开发。
Datastage 中的Job 分为Server Job, Parallel Job 和Mainframe Job ,其中Mainframe Job 专供大型机上用,常用到的Job 为Server Job 和Parallel Job 。
本文将介绍如何使用Server Job 和Parallel Job 进行ETL 开发。
Server Job一个Job 就是一个Datastage 的可运行单元。
Server Job 是最简单常用的Job 类型,它使用拖拽的方式将基本的设计单元-Stage 拖拽到工作区中,并通过连线的方式代表数据的流向。
通过Server Job,可以实现以下功能。
1.定义数据如何抽取2.定义数据流程3.定义数据的集合4.定义数据的转换5.定义数据的约束条件6.定义数据的聚载7.定义数据的写入Parallel JobServer Job 简单而强大,适合快速开发ETL 流程。
Parallel Job 与Server Job 的不同点在于其提供了并行机制,在支持多节点的情况下可以迅速提高数据处理效率。
Parallel Job 中包含更多的Stage 并用于不同的需求,每种Stage 使用上的限制也往往大于Server Job。
Sequence JobSequence Job 用于Job 之间的协同控制,使用图形化的方式来将多个Job 汇集在一起,并指定了Job 之间的执行顺序,逻辑关系和出错处理等。
数据源的连接DataStage 能够直接连接非常多的数据源,应用范围非常大,可连接的数据源包括:∙文本文件∙XML 文件∙企业应用程序,比如SAP 、PeopleSoft 、Siebel 、Oracle Application∙几乎所有的数据库系统,比如DB2 、Oracle 、SQL Server 、Sybase ASE/IQ 、Teradata 、Informix 以及可通过ODBC 连接的数据库等∙Web Services∙SAS 、WebSphere MQServer JobServer Job 中的Stage 综述Stage 是构成Datastage Job 的基本元素,在Server Job 中,Stage 可分为以下五种:1.General2.Database3.File4.Processing5.Real Time本节中将介绍如何使用Datastage 开发一个Server Job。
DataStage简介

DataStage简单介绍:一、DataStage的特性:DataStage是在构建数据仓库过程中进行数据清洗、数据转换的一套工具。
它的工作流程如下图所示:DataStage包括设计、开发、编译、运行及管理等整套工具。
通过运用DataStage 能够对来自一个或多个不同数据源中的数据进行析取、转换,再将结果装载到一个或多个目的库中。
通过DataStage的处理,最终用户可以得到分析和决策支持所需要的及时而准确的数据及相关信息。
DataStage支持不同种类的数据源和目的库,它既可以直接从Oracle、Sybase 等各种数据库中存取数据,也可以通过ODBC接口访问各种数据库,还支持Sequential file类型的数据源。
这一特性使得多个数据源与目标的连接变得非常简单,可以在单个任务中对多个甚至是无限个数据源和目标进行连接。
DataStage自带了超过300个的预定义库函数和转换,即便是非常复杂的数据转换也可以很轻松的完成。
它的图形化设计工具可以控制任务执行而无须任何脚本。
二、DataStage的架构:DataStage采用C/S模式工作,其结构如下:DatastageServerProjectManager Designer DirectorDataStage 支持多种平台,其Server 端可运行于以下平台:Windows 2000、Windows NT 、COMPAQ Tru64、HP-UX 、IBM AIX 、Sun Solaris ;Client 端支持以下平台:Win95、Win98、Winme 、Windows NT 、Windows 2000;三、功能介绍DataStage 的Server 端由Repository 、DataStage Server 及DataStage Package Installer 三部分组成,Client 端则由DataStage Manager 、DataStage Designer 、DataStage Driect 及DataStage Administrator 四部分组成。
DATASTAGE的介绍及基本操作

1、在‘General'页框中,设置Job监控的一些限制信息 和Director中的其他信息。
2、在‘Permission'页框中,设置并分配开发人员组的 权限 。
3、在‘Tracing' 页框中, 设置或取消服务端进行跟踪 。
? Designer提供一个数据流程的模式,轻松将设置和Job的设计有 机的组成。
? 使用Designer,可以: 1、指定数据如何抽取。
? 2、指定数据的转换规则和进行转换。
? 3、使用参考性质的LookUp到数据集市中编辑数据。
? a)例如,如果销售的记录集包括CustomerID,可以在 CustomerMaster表中使用LookUp查找到Customer的名称。
? 自定义的Routines和Transforms 也在DataStage 中 的Manager 里创建。
DataStage中的Designer
? DataStage中的Designer允许使用熟练地拖拽图标和连线的方式 来表示数据抽取、清洗、转换、整合和加载的过程,并将数据导 入数据仓库的表单之中。
? 问题二:
Datastage的Manager用来执行编译通过的Jobs。(Yes/No )
答案二:
No, Datastage的Manager是用来管理元数据的,如表单结 构,内置和自定义Routines等的,使Datastage用来管理资 源存储的。
? 问题三: Datastage 的Director用来执行编译通过的 Jobs。( Yes/No ) 答案三: Yes ,使用Director来对编译通过的 job进行验证或 者运行,也可以在 jobs运行过程中对其进行监控。
DataStage V7.5 学习总结
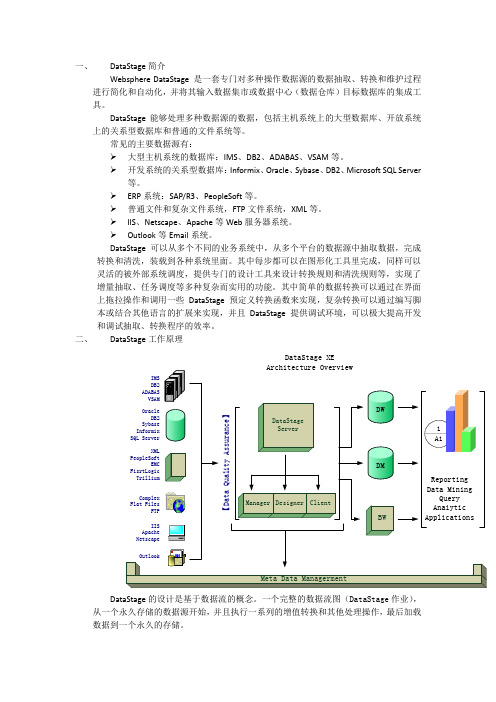
一、DataStage简介Websphere DataStage 是一套专门对多种操作数据源的数据抽取、转换和维护过程进行简化和自动化,并将其输入数据集市或数据中心(数据仓库)目标数据库的集成工具。
DataStage能够处理多种数据源的数据,包括主机系统上的大型数据库、开放系统上的关系型数据库和普通的文件系统等。
常见的主要数据源有:➢大型主机系统的数据库:IMS、DB2、ADABAS、VSAM等。
➢开发系统的关系型数据库:Informix、Oracle、Sybase、DB2、Microsoft SQL Server 等。
➢ERP系统:SAP/R3、PeopleSoft等。
➢普通文件和复杂文件系统,FTP文件系统,XML等。
➢IIS、Netscape、Apache等Web服务器系统。
➢Outlook等Email系统。
DataStage 可以从多个不同的业务系统中,从多个平台的数据源中抽取数据,完成转换和清洗,装载到各种系统里面。
其中每步都可以在图形化工具里完成,同样可以灵活的被外部系统调度,提供专门的设计工具来设计转换规则和清洗规则等,实现了增量抽取、任务调度等多种复杂而实用的功能。
其中简单的数据转换可以通过在界面上拖拉操作和调用一些DataStage 预定义转换函数来实现,复杂转换可以通过编写脚本或结合其他语言的扩展来实现,并且DataStage 提供调试环境,可以极大提高开发和调试抽取、转换程序的效率。
二、DataStage工作原理DataStage XEDataStage的设计是基于数据流的概念。
一个完整的数据流图(DataStage作业),从一个永久存储的数据源开始,并且执行一系列的增值转换和其他处理操作,最后加载数据到一个永久的存储。
数据集(Data Set)就是对通过数据流程的记录的收集。
一个数据集可以是屋里放置在磁盘上,也可以是虚拟放置在内存中。
数据在数据流中的Stage中移动使用的是虚拟的数据集,这样可以大大提高性能;分区(在后面介绍)是在Stage的属性中设置的。
datastage经验总结

目录1 如何重新启动DataStage服务器, 步骤如下: (4)2 DataStage开发经验积累: (4)2.1模板开发 (4)2.2通过S ERVER S HARED C ONTAINER在P ARALLEL J OB中添加S ERVER J OB S TAGE (4)2。
3去除不需要的字段 (4)2.4T RANSFORMER S TAGE的使用 (4)2。
5L OOK UP/JOIN 空值处理 (5)2。
6D ATA S TAGE中默认和隐式类型转换时注意的问题 (5)2。
7配置一个INPUT或OUTPUT,就VIEW DATA一下,不要等到RUN时再回头找ERROR (5)2。
8D ATA型数据是比较麻烦的 (5)2.9行列互换之H ORIZONTAL P IVOT(P IVOT S TAGE) (6)2.10行列互换之V ERTICAL P IVOT (6)2。
11O RACLE EE S TAGE在VIEW数据时出现的错误及解决方法 (8)2。
12D ATA S TAGE SAP S TAGE的使用 (9)2.13C OLUM I MPORT S TAGE的使用 (9)2.14C OLUM E XPORT S TAGE的使用 (11)2。
15G OT ERROR:C ANNOT FIND ANY PROCESS NUMBER FOR STAGES IN J OB J OBNAME解决 (12)2.16U NABLE TO CREATE RT_CONFIG NNN (13)2.17查看JOB和CLIENT的对应的后台进程 (13)2。
18强制杀死DS进程 (13)2.19查看S ERVER E NGINE的进程 (14)2。
20查看S ERVER L OCKS (14)2。
21关于UNIX系统下无法启动服务的解决办法 (15)2.22L OCKED BY OTHER USER (16)2。
DataStage解锁被锁定的JOB

DataStage解锁被锁定的JOB
经常性会有这样的情况,正在编辑某个作业的时候,突然机器断电了,或者网断了。
于是当我们再打开这个作业的时候,DS会提示作业正被另一个用户编辑,无法打开。
这种情况我们称做作业被锁住了。
这种情况下,通过重启DS服务器是可以解锁的,但只能是最后的手段。
DS本身提供了两种方法,可以用来解锁。
一是通过Director。
在Administrator中,查看相应项目的属性,切换到常规属性页,这里有一个选项,Enable job administration in Director,勾选这个选项后,Director中Job 菜单下Cleanup Resources和Clear Status File两个子菜单就可以用了。
Cleanup Resources主要有两个功能,一是查看和终止作业进程,二是查找和释放被锁定的作业。
通过这个菜单就可以解锁相应作业。
Clear Status File则用来清除作业中所有stage的状态信息。
如果前一个菜单没有解锁作业,还可以试一试这个菜单。
另一种方法是直接在Administrator中,选中被锁定的作业所在的项目后,点击Command按钮,然后在其中输入命令LIST.READU,从该命令中找到被锁定的作业,以及其对应的编号,再输入命令:UNLOCK USER “编号” ALL,其中编号是前个命令中你查询出来的。
这样子也可以解锁作业。
数据挖掘中常见问题及解决方案汇总

数据挖掘中常见问题及解决方案汇总数据挖掘作为分析大规模数据集的过程,已经被广泛应用于各个行业和领域。
然而,数据挖掘过程中可能会遇到一些常见问题,如数据质量问题、特征选择问题、过拟合问题等。
本文将围绕这些问题提供相应的解决方案。
首先,数据质量问题是数据挖掘中一个非常重要的问题,因为数据质量直接影响到最终模型的准确性和可靠性。
常见的数据质量问题包括缺失值、异常值、重复值等。
针对缺失值问题,可以考虑使用插补方法来填补缺失值,例如均值、中位数或者使用机器学习算法来预测缺失值。
对于异常值问题,可以使用统计方法或者离群点检测算法来识别和处理异常值。
对于重复值问题,可以使用去重算法来删除重复值,确保数据的唯一性。
其次,特征选择是数据挖掘中另一个常见问题。
在大规模数据集中,可能存在许多冗余或者无关的特征,这些特征会增加计算复杂度,并降低模型的准确性。
因此,需要进行特征选择以提取关键特征。
常用的特征选择方法包括过滤法、包装法和嵌入法。
过滤法通过计算特征和目标变量之间的相关性来选择特征。
包装法基于模型的性能指标进行特征选择,例如递归特征消除(Recursive Feature Elimination)和前向选择(Forward Selection)。
嵌入法是在模型训练过程中自动选择特征,例如正则化方法(如L1和L2正则化)和决策树算法。
另外,过拟合问题是数据挖掘中一个常见且严重的问题。
过拟合指的是模型在训练集上表现良好,但在测试集上表现不佳的情况。
过拟合的原因可能是模型太复杂,导致在训练集上过度拟合了噪声。
为了解决过拟合问题,可以采用以下几种方法。
首先,增大训练集的样本数量可以有效减少过拟合。
其次,可以使用正则化技术,如L1正则化和L2正则化,来控制模型的复杂度。
另外,使用交叉验证方法来评估模型的泛化能力,并选择最合适的模型。
最后,可以使用集成学习方法,如随机森林和梯度提升树,来减少过拟合。
除了上述问题外,还有一些其他常见的数据挖掘问题值得关注。
datastage学习文档

工作总结1 如何重新启动DataStage服务器, 步骤如下: (5)2 DataStage开发经验积累: (5)2.1模板开发 (5)2.2通过S ERVER S HARED C ONTAINER在P ARALLEL J OB中添加S ERVER J OB S TAGE (5)2.3去除不需要的字段 (5)2.4T RANSFORMER S TAGE的使用 (5)2.5L OOK UP/JOIN 空值处理 (6)2.6D ATA S TAGE中默认和隐式类型转换时注意的问题 (6)2.7配置一个INPUT或OUTPUT,就VIEW DATA一下,不要等到RUN时再回头找ERROR (6)2.8D ATA型数据是比较麻烦的 (6)2.9行列互换之H ORIZONTAL P IVOT(P IVOT S TAGE) (7)2.10行列互换之V ERTICAL P IVOT (7)2.11O RACLE EE S TAGE在VIEW数据时出现的错误及解决方法 (9)2.12D ATA S TAGE SAP S TAGE的使用 (10)2.13C OLUM I MPORT S TAGE的使用 (10)2.14C OLUM E XPORT S TAGE的使用 (12)2.15G OT ERROR:C ANNOT FIND ANY PROCESS NUMBER FOR STAGES IN J OB J OBNAME解决 (13)2.16U NABLE TO CREATE RT_CONFIG NNN (14)2.17查看JOB和CLIENT的对应的后台进程 (14)2.18强制杀死DS进程 (14)2.19查看S ERVER E NGINE的进程 (15)2.20查看S ERVER L OCKS (15)2.21关于UNIX系统下无法启动服务的解决办法 (16)2.22L OCKED BY OTHER USER (17)2.23DATA S TAGE J OB L OG的处理 (17)2.24一些BASIC语言中处理字符串的函数 (17)2.25BASIC程序中使用到的一些语法知识 (18)3DS中常见问题记录 (22)3.1权限管理问题 (22)3.2JOB MAY BE BEING MONITORED或者是CLEANUP问题 (22)3.3删除文件的问题 (22)3.4SEQUENCE调度出现的错误问题 (23)3.17字符集问题 (23)3.18V ERSION C ONTROL的问题 (23)3.19SEQUENCE调不起JOB的问题 (23)3.20SEQUENCE调度失败的问题 (24)3.21DS发送邮件的配置问题 (25)3.22随机错误问题 (26)3.23DS中的日期问题 (26)3.24DS连接ORACLE问题 (27)。
datastage总结

1 Satge分为被动Stage和主动Stage===被动Stage,是用来读写数据源的数据的,包括Odbc Connector、Oracle Connector、Sequential File等。
===主动Satage,是用来筛选和转换部分的Stage,包括Transformer、Aggregator、Sort等21>Sequential_File适用于一般顺序文件(定长或不定长),可识别文本文件或IBM大机ebcdic文件。
2>Annotation一般用于注释,可利用其背景颜色在job中分颜色区别不同功能块。
3>Copy StageCopy Stage可以有一个输入,多个输出,它可以在输出时改变字段的顺序,但不能改变字段类型。
4>Filter StageFilter Stage只有一个输入,可以有多个输出。
根据不同的筛选条件,可以将数据输出到不同的output link5>Funnel Stage将多个字段相同的数据文件合并为一个单独的文件输出。
6>Transformer Stage一个功能强大的stage,有一个input link,多个output link,可以将字段进行转换,也可以通过条件来指定数据输出到哪个output link.注意:Transformer Stage功能强大,但在运行过程中是以牺牲速度为代价的。
在只有简单的变换,拷贝等操作时,最好用Modify Stage,Copy Stage,Filter Stage等来替换Transformer Stage。
transformer可以实现很多功能的,cope只是其中一部分。
大数据分析常见问题解决方法总结

大数据分析常见问题解决方法总结随着互联网和信息技术的快速发展,大数据分析在各个领域中的应用变得越来越广泛。
然而,在进行大数据分析的过程中,我们经常会遇到各种各样的问题。
本文将总结一些常见的大数据分析问题,并提供一些解决方法,希望能帮助读者更好地应对这些挑战。
问题一:数据量过大,分析速度慢大数据分析的一个重要挑战是如何处理巨大的数据量。
当数据集非常庞大时,分析过程可能会非常缓慢,甚至无法进行。
为解决这个问题,我们可以采取以下方法:1. 数据预处理:在数据分析之前,我们可以先对数据进行预处理,包括数据清洗、压缩和采样等。
这样可以减小数据集的规模,提高分析速度。
2. 并行计算:使用并行计算框架(如Hadoop、Spark等)对数据进行分布式处理,将任务分解成多个子任务并行执行,极大地提高了分析速度。
3. 数据索引:为了快速检索和查询数据,可以使用数据索引技术,如建立索引表、创建倒排索引等。
问题二:数据质量问题大数据中常常存在着数据质量问题,如缺失数据、异常值、错误数据等。
这些问题会影响分析结果的准确性和可靠性。
为解决这个问题,我们可以采取以下方法:1. 数据清洗:对数据进行清洗,去除无效数据和错误数据,填补缺失值,纠正错误数据等。
可以借助数据清洗工具和算法来实现自动化的数据清洗过程。
2. 数据校验:在进行数据分析之前,我们应该对数据进行校验,确保数据的完整性和准确性。
可以使用数据校验规则和算法来进行数据校验,并对不符合规则的数据进行处理。
3. 数据采样:当数据量过大时,我们可以使用数据采样技术来降低数据质量问题的影响。
通过从整体数据集中选择部分样本进行分析,可以在一定程度上反映整个数据集的特征。
问题三:隐私保护问题在进行大数据分析的过程中,涉及到大量的个人隐私数据。
如何保护这些隐私数据,防止泄露和滥用,是一个重要的问题。
以下是一些隐私保护的方法:1. 匿名化处理:在进行数据分析之前,对个人隐私数据进行匿名化处理。
DataStage简介

Administrator(管理器):在服务器端管理 DataStage的项目和使用者权限的分配
Thank you!
DataStage用来做什么
DataStage可以从多个不同的业务系统,从多个平 台的数据源中抽取数据,完成转换和清洗,装载到其它 系统里面。其中每步都可以在图形化工具里完成,同样 可以灵活地被外部系统调度,提供专门的设计工具来设 计转换规则和清洗规则等,实现了增量抽取、任务调度 等多种复杂而实用的功能。其中简单的数据转换可以通 过在界面上拖拉操作和调用预定义转换函数来实现,复 杂转换可以通过编写代码或结合其他程序的扩展来实现 ,并且DataStage提供调试环境,可以极大提高开发和 调试抽取、转换程序的效率。
DataStage简介及工作原理
为什么要使用DataStage
数据仓库中的数据来自于多种业务数据源,这些数 据源可能来自于不同硬件平台,使用不同的操作系统, 数据模型也相差很远,因而数据以不同的方式存在于不 同的数据库中。
如何获取并向数据仓库加载这些数据量大、种类多 的数据,已成为建立数据仓库所面临的一个关键问题。
DataStage工具介绍
DataStage是基于客户机/服务器的数据集成架构, 优化数据收集,转换和巩固的过程。它提供了一套图形 化的客户工具,包括:
DataStage工具介绍
Designer(设计器):创建执行数据集成任务Job的同 时,对数据流和转换过程创建一个可视化的演示,并对 每个工程的各个单元,包括库表定义,集中的数据转换 ,元数据连接等对象进行分类和组织
业务系统数据源
SAP BW
SAP ERP (rev. R/3)
DATASTAGE常用组件的使用

DATASTAGE常用组件的使用Datastage产品开发使用指南北京先进数通信息技术有限公司商业智能应用部Datastage产品开发使用指南文档信息标题 Datastage产品开发使用指南2005-12-22 创建日期打印日期文件名 PMA-003-Datastage产品开发使用指南-V1.0.doc DI\PMA 存放目录所有者北京先进数通信息技术有限公司作者何应龙修订记录日期作者描述文档审核/审批姓名职务/职称审核批准文档分发此文档将分发至如下各人姓名职务/职称- i -Datastage产品开发使用指南目录目录 ..................................................................... (II)1. 引言 ..................................................................... .........................................................................1 2. 常用STAGE使用说明 ..................................................................... ........................................... 1 2.1. SEQUENTIAL FILE STAGE .................................................................. ........................................ 1 2.2. ANNOTATION.............................................................. .............................................................. 4 2.3. CHANGE CAPTURESTAGE .................................................................. ....................................... 5 2.4. COPY STAGE................................................................... .......................................................... 7 2.5. FILTERSTAGE .................................................................. ........................................................ 8 2.6. FUNNEL STAGE .................................................................. ....................................................... 9 2.7. TANSFORMERSTAGE .................................................................. ............................................ 10 2.8. SORTSTAGE .................................................................. ......................................................... 11 2.9. LOOKUP STAGE .................................................................. .................................................... 12 2.10. JOIN STAGE .................................................................. ........................................................ 12 2.11. MERGE STAGE .................................................................. .................................................... 14 2.12. MODIFY STAGE .................................................................. (15)DATA SETSTAGE .................................................................. ................................................ 16 2.13.2.14. FILE SETSTAGE .................................................................. .. (17)LOOKUP FILE SETSTAGE .................................................................. .................................... 19 2.15.2.16. ORACLE ENTERPRISESTAGE .................................................................. ............................... 21 2.17. AGGREGATORSTAGE .................................................................. .......................................... 22 2.18. REMOVE DUPLICATES STAGE .................................................................. .............................. 24 2.19. COMPRESSSTAGE .................................................................. .. (25)EXPAND STAGE................................................................... .................................................. 26 2.20.2.21. DIFFERENCESTAGE .................................................................. ............................................ 27 2.22. COMPARESTAGE .................................................................. ................................................ 29 2.23. SWITCH STAGE .................................................................. ................................................... 30 2.24. COLUMN IMPORTSTAGE ....................................................................................................... 31 2.25. COLUMN EXPORTSTAGE .................................................................. ..................................... 33 3. DATASTAGE ADMINISTRATOR常用配置 ..................................................................... ...... 35 3.1. 设置TIMEOUT时间...................................................................... .......................................... 35 3.2. 设置PROJECT的属性 ..................................................................... ........................................ 36 3.3. 更新DATASTAGE SERVER的LICENSE和本地CLIENT的LICENSE .............................................. 37 4. DATASTAGE MANAGER使用 ..................................................................... ........................... 37 4.1. 导入导出JOB及其它组件...................................................................... ................................ 37 4.2. 管理配置文件 ..................................................................... .................................................. 39 5. DATASTAGE DIRECTOR使用 ..................................................................... .......................... 40 5.1. 察看JOB的状态,运行已经编译好的JOB .................................................................... ......... 40 5.2. 将编译好的JOB加入计划任务 ..................................................................... ......................... 43 5.3. 监控JOB的运行情况 ..................................................................... . (44)- ii -Datastage产品开发使用指南1. 引言DataStage EE的开发主要由DataStage Designer完成。
datastage培训提纲

培训提纲1.ETL定义说明ETL过程指的是从数据源中抽取数据,然后对这些数据进行清洗、转换,最终加载到目标数据库和数据仓库中。
数据抽取:数据抽取主要是针对各个业务系统及不同网点的分散数据,充分理解数据定义后,规划需要的数据源及数据定义,制定可操作的数据源,制定增量抽取的定义。
数据转化和清洗:数据转换是真正将源数据变为目标数据的关键环节,它包括数据格式转换、数据类型转换、数据汇总计算、数据拼接等等。
但这些工作可以在不同的过程中处理视具体情况而定,比如,可以在数据抽取时转换,也可以在数据加载时转换。
数据清洗主要是针对系统的各个环节可能出现的数据二义性、重复、不完整、违反业务规则等问题,允许通过试抽取,将有问题的纪录先剔除出来,根据实际情况调整相应的清洗操作。
数据加载:数据加载主要是将经过转换和清洗的数据加载到数据仓库(或数据库)里面,即入库,操作者可以通过数据文件直接装载或直连数据库的方式来进行数据装载。
2.ETL工具的选择2.1.支持平台随着各种应用系统数据量的飞速增长和对业务可靠性等要求的不断提高,人们对数据抽取工具的要求往往是将几十、上百个GB的数据在有限的几个小时内完成抽取转换和装载工作,这种挑战势必要求抽取工具对高性能的硬件和主机提供更多支持。
因此,我们可以从数据抽取工具支持的平台,来判断它能否胜任企业的环境,目前主流的平台包括SUN Solaris、HP-UX、IBM AIX、AS/400、OS/390、Sco UNIX、Linux、Windows等。
2.2.支持数据源对数据源支持的重要性不言而喻,因此这个指标必须仔细地考量。
首先,我们需要对项目中可能会遇到的各种数据源有一个清晰的认识;其次对各种工具提供的数据源接口类型也要有深入了解,比如,针对同一种数据库,使用通用的接口(如ODBC/JDBC)还是原厂商自己的专用接口,数据抽取效率都会有很大差别,这直接影响到我们能不能在有限的时间内完成ETL任务。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译c程序的并行例程命令:
(0) 链接datastage的administrator客户端
(1)
(2)
(3)
(4)
此处可以查看到变异c程序的命令,不同的datastage版本其变异命令,不一样
如何建立全局的参数
(0)链接datastage的administrator客户端
(1)
(2)
(3)
(4)自定义参数
(5)
(6)
Load导致的暂挂问题
场景描述:
1:在运行job时,如果起初找不到源文件,那么会产生异常,大致内容“打不开该文件”2:由于没有文件,我手动创建该文件(空),再运行job,该job就处于暂挂状态,code“3”解决方法:
load from /dev/null of del terminate into schema.tablename;
Load中需要配置的选项
Datastage用户配置指南参考------------------------------Datastage用户配置指南.pdf
如何解决重复数据的清洗
8.Sort Stage
功能说明:
只能有一个输入及一个输出,按照指定的Key值进行排列。
可以选择升序还是降序,是否去除重复的数据等等。
Option具体说明:
Allow Duplicates:是否去除重复数据。
为False时,只选取一条数据,当Stable Sor t为True时,选取第一条数据。
当Sort Unility为UNIX时此选项无效。
Sort Utility:选择排序时执行应用程序,可以选择DataStage内建的命令或者Unix的Sort命令。
Output Statistics:是否输出排序统计信息到job日志。
Stable Sort:是否对数据进行二次整理。
Create Cluster Key Change Column:是否为每条记录创建一个新的字段: cluster KeyChange。
当Sort Key Mode为Don’t Sort(Previously Sorted) 或 Don’t Sort (Pre viously Grouped)时,对于第一条记录该字段被设置为1,其余的记录设置为0。
Create Key Change Column:是否为每一条记录创建一个新的字段KeyChange。