Geometrically Guided Fuzzy C-means Clustering for Multivariate Image Segmentation
三维荧光二阶校正方法用于体液和细胞培养基中五味子甲素含量的快速测定

关键 词
五味子 甲素 ; 激发发射矩 阵荧光光 谱 ;自加权交替三线性 分解 法 ; 阶校正 二
0 5 . 673 文献标识码 A 文章 编 号 0 5 -70 2 1 ) 812 -7 2 1 9 ( 0 1 0 —7 00 0
中 图分 类 号
收稿 日期 : 0 O1 一0 2 1一 2. O
齄金项 目:国家 自然科学基金( 批准号 :27 5 2 ) 0 7 0 5 及教育部长江学者和创新 团队发展 划资助. 联系人简介 : 吴海龙 ,男 , 博士 ,教授 , 博士生 导师 ,主要从事化学计量学方面的研究 E-al hw @hu c m i: lu n . m
张晓华等 : 三维 荧光二阶校正方 法用 于体液和 细胞培养基 中五味子 甲素含 量的快速 测定
食 品¨ 及化妆品 等领域的直接定量分析. 本文利用该方法实现了体液和细胞培养基 中五味子 甲素 的定量分析.克服了常规荧光法选择性低和在严重 的背景干扰下无法对待测物进行定量分析等困难. 另外 , 用统计 参数 与 品质 因子 , 采 包括 灵敏 度 ( E 、 S N) 选择 性 (E ) 检测 下 限 ( O 、 测残 差平方 SL 、 L D) 预
张晓华 ,吴海龙 , 王建瑶 , 俞汝勤
( 湖南大学化学生物传感与计量学 国家重点实验室 , 长沙 4 0 8 ) 10 2 摘要 采用三维激发 发射 荧光光谱 结合 自加权交替三线性分解 ( WA L 二阶校正方法 , S T D) 对人体 液样 ( 浆 血
样及尿液样 ) 和细胞培养基样 中五味子 甲素 的含量进行 了直 接快速定 量分析.在血浆 背景 、 液背景 和细胞 尿
V0 . 2 13 21 0 1年 8月
用密度函数理论和杜比宁方程研究活性炭纤维多段充填机理

密度函数理论和杜比宁方程可以用来研究活性炭纤维在多段充填过程中的吸附行为。
密度函数理论是一种分子统计力学理论,它建立在分子统计学和热力学的基础上,用来研究一种系统中分子的分布。
杜比宁方程是一种描述分子吸附行为的方程,它可以用来计算吸附层的厚度、吸附速率和吸附能量等参数。
在研究活性炭纤维多段充填过程中,可以使用密度函数理论和杜比宁方程来研究纤维表面的分子结构和吸附行为。
通过分析密度函数和杜比宁方程的解,可以得出纤维表面的分子结构以及纤维吸附的分子的种类、数量和能量。
这些信息有助于更好地理解活性炭纤维的多段充填机理。
在研究活性炭纤维的多段充填机理时,还可以使用其他理论和方法来帮助我们更好地了解这一过程。
例如,可以使用扫描电子显微镜(SEM)和透射电子显微镜(TEM)等技术来观察纤维表面的形貌和结构。
可以使用X射线衍射(XRD)和傅里叶变换红外光谱(FTIR)等技术来确定纤维表面的化学成分和结构。
还可以使用氮气吸附(BET)和旋转氧吸附(BJH)等技术来测量纤维表面的比表面积和孔结构。
通过综合运用密度函数理论、杜比宁方程和其他理论和方法,可以更全面地了解活性炭纤维的多段充填机理,从而更好地控制和优化多段充填的过程。
在研究活性炭纤维多段充填机理时,还可以使用温度敏感性测试方法来研究充填过程中纤维表面的动力学性质。
例如,可以使用动态氧吸附(DAC)或旋转杆氧吸附(ROTA)等技术来测量温度对纤维表面吸附性能的影响。
通过对比不同温度下纤维表面的吸附性能,可以更好地了解充填过程中纤维表面的动力学性质。
此外,还可以使用分子动力学模拟方法来研究纤维表面的吸附行为。
例如,可以使用拉曼光谱或红外光谱等技术来测量纤维表面的分子吸附构型。
然后,使用分子动力学模拟方法来模拟不同分子吸附构型下的纤维表面的动力学性质,帮助我们更好地了解活性炭纤维的多段充填机理。
Identification of overlapping community structure in complex networks using fuzzy c-means clustering

Physica A 374(2007)483–490Identification of overlapping community structure in complexnetworks using fuzzy c -means clusteringShihua Zhang a,Ã,Rui-Sheng Wang b ,Xiang-Sun Zhang aa Academy of Mathematics &Systems Science,Chinese Academy of Science,Beijing 100080,Chinab School of Information,Renmin University of China,Beijing 100872,ChinaReceived 28June 2006Available online 7August 2006AbstractIdentification of (overlapping)communities/clusters in a complex network is a general problem in data mining of network data sets.In this paper,we devise a novel algorithm to identify overlapping communities in complex networks by the combination of a new modularity function based on generalizing NG’s Q function,an approximation mapping of network nodes into Euclidean space and fuzzy c -means clustering.Experimental results indicate that the new algorithm is efficient at detecting both good clusterings and the appropriate number of clusters.r 2006Elsevier B.V.All rights reserved.Keywords:Overlapping community structure;Modular function;Spectral mapping;Fuzzy c -means clustering;Complex network1.IntroductionLarge complex networks representing relationships among set of entities have been one of the focuses of interest of scientists in many fields in the recent years.Various complex network examples include social network,worldwide web network,telecommunication network and biological network.One of the key problems in the field is ‘How to describe/explain its community structure’.Generally,a community in a network is a subgraph whose nodes are densely connected within itself but sparsely connected with the rest of the network.Many studies have verified the community/modularity structure of various complex networks such as protein-protein interaction network,worldwide web network and co-author network.Clearly,the ability to detect community structure in a network has important practical applications and can help us understand the network system.Although the notion of community structure is straightforward,construction of an efficient algorithm for identification of the community structure in a complex network is highly nontrivial.A number of algorithms for detecting the communities have been developed in various fields (for a recent review see Ref.[1]and a recent comparison paper see Ref.[2]).There are two main difficulties in detecting community structure.The first is that we don’t know how many communities there are in a given network.The usual drawback in many /locate/physa0378-4371/$-see front matter r 2006Elsevier B.V.All rights reserved.doi:10.1016/j.physa.2006.07.023ÃCorresponding author.E-mail addresses:zsh@ (S.Zhang),wrs@ (R.-S.Wang),zxs@ (X.-S.Zhang).algorithms is that they cannot give a valid criterion for measuring the community structure.Secondly,it is a common case that some nodes in a network can belong to more than one community.This means the overlapping community structure in complex networks.Overlapping nodes may play a special role in a complex network system.Most known algorithms such as divisive algorithm [3–5]cannot detect them.Only a few community-detecting methods [6,7]can uncover the overlapping community structure.Taking into account the first difficulty,Newman and Girvan [8]has developed a new approach.They introduced a modularity function Q for measuring community structure.In order to write the context properly,we refer to a similar formulation in Ref.[5].In detail,given an undirected graph/network G ðV ;E ;W Þconsisting of the node set V ,the edge set E and a symmetric weight matrix W ¼½w ij n Ân ,where w ij X 0and n is the size of the network,the modularity function Q is defined asQ ðP k Þ¼X k c ¼1L ðV c ;V c ÞL ðV ;V ÞÀL ðV c ;V ÞL ðV ;V Þ 2"#,(1)where P k is a partition of the nodes into k groups and L ðV 0;V 00Þ¼P i 2V 0;j 2V 00w ði ;j Þ.The Q function measuresthe quality of a given community structure organization of a network and can be used to automatically select the optimal number of communities k according to the maximum Q value [8,5].The measure has been used for developing new detection algorithms such as Refs.[5,9,4].White and Smyth [5]showed that optimizing the Q function can be reformulated as a spectral relaxation problem and proposed two spectral clustering algorithms that seek to maximize Q .In this study,we develop an algorithm for detecting overlapping community structure.The algorithm combines the idea of modularity function Q [8],spectral relaxation [5]and fuzzy c -means clustering method[10]which is inspired by the general concept of fuzzy geometric clustering.The fuzzy clustering methods don’t employ hard assignment,while only assign a membership degree u ij to every node v i with respect to the cluster C j .2.MethodSimulation across a wide variety of simulated and real world networks showed that large Q values are correlated with better network clusterings [8].Then maximizing the Q function can obtain final ‘optimal’community structure.It is noted that in many complex networks,some nodes may belong to more than one community.The divisive algorithms based on maximizing the Q function fail to detect such case.Fig.1shows an example of a simple network which visually suggests three clusters and classifying node 5(or node 9)intoFig.1.An example of network showing Q and e Qvalues for different number k of clusters using the same spectral mapping but different cluster methods,i.e.k -means and fuzzy c -means,respectively.For the latter,it shows every node’s soft assignment and membership of final clusters with l ¼0:15.S.Zhang et al./Physica A 374(2007)483–490484two clusters at the same time may be more appropriate intuitively.So we introduce the concept of fuzzy membership degree to the network clustering problem in the following subsection.2.1.A new modular functionIf there are k communities in total,we define a corresponding n Âk ‘soft assignment’matrix U k ¼½u 1;...;u k with 0p u ic p 1for each c ¼1;...;k and P kc ¼1u ic ¼1for each i ¼1;...;n .With this we define the membership of each community as ¯V c ¼f i j u ic 4l ;i 2V g ,where l is a threshold that can convert a soft assignment into final clustering.We define a new modularity function e Q as e Q ðU k Þ¼X k c ¼1A ð¯V c ;¯V c ÞA ðV ;V ÞÀA ð¯V c ;V ÞA ðV ;V Þ 2"#,(2)where U k is a fuzzy partition of the vertices into k groups and A ð¯V c ;¯V c Þ¼P i 2¯V c ;j 2¯V c ððu ic þu jc Þ=2Þw ði ;j Þ,A ð¯V c ;V Þ¼A ð¯V c ;¯V c ÞþP i 2¯V c ;j 2V n ¯V c ððu ic þð1Àu jc ÞÞ=2Þw ði ;j Þand A ðV ;V Þ¼P i 2V ;j 2V w ði ;j Þ.This of coursecan be thought as a generalization of the Newman’s Q function.Our objective is to compute a soft assignment matrix by maximizing the new Q function with appropriate k .How could we do?2.2.Spectral mappingWhite and Smyth [5]showed that the problem of maximizing the modularity function Q can be reformulated as an eigenvector problem and devised two spectral clustering algorithms.Their algorithms are similar in spirit to a class of spectral clustering methods which map data points into Euclidean space by eigendecomposing a related matrix and then grouping them by general clustering methods such as k -means and hierarchical clustering [5,9].Given a network and its adjacent matrix A ¼ða ij Þn Ân and a diagonal matrix D ¼ðd ii Þ,d ii ¼P k a ik ,two matrices D À1=2AD À1=2and D À1A are often used.A recent modification [11]uses the top K eigenvectors of the generalized eigensystem Ax ¼tDx instead of the K eigenvectors of the two matrices mentioned above to form a matrix whose rows correspond to original data points.The authors show that after normalizing the rows using Euclidean norm,their eigenvectors are mathematically identical and emphasize that this is a numerically more stable method.Although their result is designed to cluster real-valued points[11,12],it is also appropriate for network clustering.So in this study,we compute the top k À1eigenvectors of the eigensystem to form a ðk À1Þ-dimensional embedding of the graph into Euclidean space and use ‘soft-assignment’geometric clustering on this embedding to generate a clustering U k (k is the expected number of clusters).2.3.Fuzzy c-meansHere,in order to realize our ‘soft assignment’,we introduce fuzzy c -means (FCM)clustering method [10,13]to cluster these points and maximize the e Qfunction.Fuzzy c -means is a method of clustering which allows one piece of data to belong to two or more clusters.This method (developed by Dunn in 1973[10]and improved by Bezdek in 1981[13])is frequently used in pattern recognition.It is based on minimization of the following objective functionJ m ¼Xn i ¼1X k j ¼1u m ij k x i Àc j k 2,(3)over variables u ij and c with P j u ij ¼1.m 2½1;1Þis a weight exponent controlling the degree of fuzzification.u ij is the membership degree of x i in the cluster j .x i is the i th d -dimensional measured data point.c j is the d -dimensional center of the cluster j ,and k Ãk is any norm expressing the similarity between any measured data and the center.Fuzzy partitioning is carried out through an iterative optimization of the objective function shown above,with the update of membership degree u ij and the cluster centers c j .This procedure converges to a local minimum or a saddle point of J m .S.Zhang et al./Physica A 374(2007)483–4904852.4.The flow of the algorithmGiven an upper bound K of the number of clusters and the adjacent matrix A ¼ða ij Þn Ân of a network.The detailed algorithm is stated straightforward for a given l as follows:Spectral mapping:(i)Compute the diagonal matrix D ¼ðd ii Þ,where d ii ¼P k a ik .(ii)Form the eigenvector matrix E K ¼½e 1;e 2;...;e K by computing the top K eigenvectors of thegeneralized eigensystem Ax ¼tDx .Fuzzy c -means:for each value of k ,2p k p K :(i)Form the matrix E k ¼½e 2;e 3;...;e k from the matrix E K .(ii)Normalize the rows of E k to unit length using Euclidean distance norm.(iii)Cluster the row vectors of E k using fuzzy c -means or any other fuzzy clustering method to obtain a softassignment matrix U k .Maximizing the modular function:Pick the k and the corresponding fuzzy partition U k that maximizes e QðU k Þ.In the algorithm above,we initialize FCM such that the starting centroids are chosen to be as orthogonal as possible which is suggested for k -means clustering method in Ref.[12].The initialization does not change the time complexity,and also can improve the quality of the clusterings,thus at the same time reduces the need for restarting the random initialization process.The framework of our algorithm is similar to several spectral clustering methods in previous studies[5,9,12,11].We also map data points (work nodes in our study)into Euclidean space by computing the top K eigenvectors of a generalized eigen system and then cluster the embedding using a fuzzy clustering method just as others using geometric clustering algorithm or general hierarchical clustering algorithm.Here,we emphasize two key points different from those earlier studies:We introduce a generalized modular function e Q employing fuzzy concept,which is devised for evaluating the goodness of overlapping community structure. In combination with the novel e Qfunction,we introduce fuzzy clustering method into network clustering instead of general hard clustering methods.This means that our algorithm can uncover overlapping clusters,whereas general framework:‘‘Objective function such as Q function and Normalized cut function+Spectral mapping+general geometric clustering/hierarchical clustering’’cannot achieve this.3.Experimental resultsWe have implemented the proposed algorithm by Matlab.And the fuzzy clustering toolbox [14]is used for our analysis.In order to make an intuitive comparison,we also compute the hard clustering based on the original Q -function,spectral mapping (same as we used)and k -means clustering.We illustrate the fuzzy concept and the difference of our method with traditional divisive algorithms by a simple example shown in Fig.1.Just as mentioned above,the network visually suggests three clusters.But classifying node 5(or node 9)simultaneously into two clusters may be more reasonable.We can see from Fig.1that our method did uncover the overlapping communities for this simple network,while the traditional method can only make one node belong to a single cluster.We also present the analysis of two real networks,i.e.the Zachary’s karate club network and the American college football team network for better understanding the differences between our method and traditional methods.S.Zhang et al./Physica A 374(2007)483–490486S.Zhang et al./Physica A374(2007)483–490487 3.1.Zachary’s karate clubThe famous karate club network analyzed by Zachary[15]is widely used as a test example for methods of detecting communities in complex networks[1,8,16,3,4,17,9,18,19].The network consists of34members of a karate club as nodes and78edges representing friendship between members of the club which was observed over a period of two years.Due to a disagreement between the club’s administrator and the club’s instructor, the club split into two smaller ones.The question we concern is that if we can uncover the potential behavior of the network,detect the two communities or multiple groups,and particularly identify which community a node belongs to.The network is presented in Fig.2,where the squares and the circles label the members of the two groups.The results of k-means and our analysis are illustrated in Fig.3.The k-means combined with Q function divides the network into three parts(see in Fig.3A),but we can see that some nodes in one cluster are also connected densely with another cluster such as node9and31in cluster 1densely connecting with cluster2,and node1in cluster2with cluster3.Fig.3B shows the results of our method,from which we can see that node1,9,10,31belong to two clusters at the same time.These nodes in the network link evenly with two clusters.Another thing is that the two methods both uncover three communities but not two.There is a small community included in the instructor’s faction,since the set of nodes5,6,7,11,17only connects with node1in the instructor’s faction.Note that our method also classifies node1into the small community,while k-means does not.work of American college football teamsThe second network we have investigated is the college football network which represents the game schedule of the2000season of Division I of the US college football league.The nodes in the network represent the115 teams,while the links represent613games played in the course of the year.The teams are divided into conferences of8–12teams each and generally games are more frequent between members of the same conference than between teams of different conferences.The natural community structure in the network makes it a commonly used workbench for community-detecting algorithm testing[3,5,7].Fig.4shows how the modularity Q and e Q vary with k with respect to k-means and our method,respectively. The peak for k-means is at k¼12,Q¼0:5398,while for our algorithm at k¼10,e Q¼0:4673with l¼0:10. Both methods identify ten communities which contain ten conferences almost exactly.Only teams labeled as Sunbelt are not recognized as belonging to a same community for both methods.This group is classified as well in the results of Refs.[3,19].This happens because the Sunbelt teams played nearly as many games against Western Athletic teams as they played in their own conference,and they also played quite a number of gamesagainst Mid-American team.Our method identified11nodes(teams)which belong to at least twoFig.2.Zachary’s karate club network.Square nodes and circle nodes represent the instructor’s faction and the administrator’s faction, respectively.Thisfigure is from Newman and Girvan[8].communities (see Fig.5,11red nodes).These nodes generally connect evenly with more than one community,so we cannot classify them into one specific community correctly.These nodes represent ‘fuzzy’points which cannot be classified correctly by employing current link information.Maybe such points play a ‘bridge’role in two or more communities in complex network of other types.4.Conclusion and discussionIn this paper,we present a new method to identify the community structure in complex networks with a fuzzy concept.The method combines a generalized modularity function,spectral mapping,and fuzzy clustering technique.The nodes of the network are projected into d -dimensional Euclidean space which is obtained by computing the top d nontrivial eigenvectors of the generalized eigensystem Ax ¼tDx .Then the fuzzy c -means clustering method is introduced into the d -dimensional space based on general Euclidean distance to cluster the data points.By maximizing the generalized modular function e QðU d Þfor varying d ,we obtain the appropriate number of clusters.The final soft assignment matrix determines the final clusters’membership with a designated threshold l .Fig.3.The results of both k -means and our method applied to karate club network.A:The different colors represent three different communities obtained by k -means and the right table shows values of NG’Q versus different k .B:Four red nodes represent the overlap of two adjacent communities obtained by our method and the right table shows values of new Q versus different k with l ¼0:25.3.t y 0510152000.10.20.30.40.50.6k-meansK N G ' Q 0510152000.10.20.30.40.5fuzzy c-means K N e w Q Fig.4.Q and e Qvalues versus k with respect to k -means and fuzzy c -means clustering methods for the network of American college football team.S.Zhang et al./Physica A 374(2007)483–490488Although spectral mapping has been comprehensively used before to detect communities in complex networks (even in clustering the real-valued points),we believe that our method represents a step forward in this field.A fuzzy method is introduced naturally with the generalized modular function and fuzzy c -means clustering technique.As our tests have suggested,it is very natural that some nodes should belong to more than one community.These nodes may play a special role in a complex network system.For example,in a biological network such as protein interaction network,one node (protein or gene)belonging to two functional modules may act as a bridge between them which transfers biological information or acts as multiple functional units [6].One thing should be noted is that when this method is applied to large complex networks,computational complexity is a key problem.Fortunately,some fast techniques for solving eigensystem have been developed[20]and several methods of FCM acceleration can also be found in the literature [21].For instance,if we adopt the implicitly restarted Lanczos method (IRLM)[20]to compute the K À1eigenvectors and the efficient implementation of the FCM algorithm in Ref.[21],we can have the worse-case complexity of O ðmKh þnK 2h þK 3h Þand O ðnK 2Þ,respectively,where m is the number of edges in the network and h is the number of iteration required until convergence.For large sparse networks where m $n ,and K 5n ,the algorithms will scale roughly linearly as a function of the number of nodes n .Nonetheless,the eigenvector computation is still the most computationally expensive step of the method.We expect that this new method will be employed with promising results in the detection of communities in complex networks.AcknowledgmentsThis work is partly supported by Important Research Direction Project of CAS ‘‘Some Important Problem in Bioinformatics’’,National Natural Science Foundation of China under Grant No.10471141.The authors thank Professor M.E.J.Newman for providing the data of karate club network and the college football team network.Fig.5.Fuzzy communities of American college football team network (k ¼10and e Q¼0:4673)with given l ¼0:10(best viewed in color).S.Zhang et al./Physica A 374(2007)483–490489References[1]M.E.J.Newman,Detecting community structure in networks,Eur.Phys.J.B 38(2004)321–330.[2]L.Danon,J.Duch,A.Diaz-Guilera,A.Arenas,Comparing community structure identification,J.Stat.Mech.P09008(2005).[3]M.Girvan,M.E.J.Newman,Community structure in social and biological networks,A 99(12)(2002)7821–7826.[4]J.Duch,A.Arenas,Community detection in complex networks using extremal optimization,Phys.Rev.E 72(2005)027104.[5]S.White,P.Smyth,A spectral clustering approach to finding communities in graphs,SIAM International Conference on DataMining,2005.[6]G.Palla,I.Derenyi,I.Farkas,T.Vicsek,Uncovering the overlapping community structure of complex networks in nature and society,Nature 435(2005)814–818.[7]J.Reichardt,S.Bornholdt,Detecting fuzzy community structures in complex networks with a Potts model,Phys.Rev.Lett.93(2004)218701.[8]M.E.J.Newman,M.Girvan,Finding and evaluating community structure in networks,Phys.Rev.E 69(2004)026113.[9]L.Donetti,M.A.Mun oz,Detecting network communities:a new systematic and efficient algorithm,J.Stat.Mech.P10012(2004).[10]J.C.Dunn,A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters,J.Cybernet.3(1973)32–57.[11]D.Verma,M.Meila,A comparison of spectral clustering algorithms.Technical Report,2003,UW CSE Technical Report 03-05-01.[12]A.Ng,M.Jordan,Y.Weiss,On spectral clustering:analysis and an algorithm,Adv.Neural Inf.Process.Systems 14(2002)849–856.[13]J.C.Bezdek,Pattern Recognition with Fuzzy Objective Function Algorithms,Plenum Press,New York,1981.[14]Fuzzy Clustering Toolbox-h http://www.fmt.vein.hu/softcomp/fclusttoolbox/i .[15]W.W.Zachary,An information flow model for conflict and fission in small groups,J.Anthropol.Res.33(1977)452–473.[16]M.E.J.Newman,Fast algorithm for detecting community structure in networks,Phys.Rev.E 69(2004)066133.[17]F.Radicchi,C.Castellano,F.Cecconi,V.Loreto,D.Parisi,Defining and identifying communities in networks,Proc.Natl.Acad.A 101(9)(2004)2658–2663.[18]F.Wu,B.A.Huberman,Finding communities in linear time:a physics approach,Eur.Phys.J.B 38(2004)331–338.[19]S.Fortunato,tora,M.Marchiori,A method to find community structures based on information centrality,Phys.Rev.E 70(2004)056104.[20]Z.Bai,J.Demmel,J.Dongarra,A.Ruhe,H.Vorst (Eds.),Templates for the Solution of Algebraic Eigenvalue Problems:A PracticalGuide,SIAM,Philadelphia,PA,2000.[21]J.F.Kelen,T.Hutcheson,Reducing the time complexity of the fuzzy c -means algorithm,IEEE Trans.Fuzzy Systems 10(2)(2002)263–267.S.Zhang et al./Physica A 374(2007)483–490490。
Modeling the Spatial Dynamics of Regional Land Use_The CLUE-S Model

Modeling the Spatial Dynamics of Regional Land Use:The CLUE-S ModelPETER H.VERBURG*Department of Environmental Sciences Wageningen UniversityP.O.Box376700AA Wageningen,The NetherlandsandFaculty of Geographical SciencesUtrecht UniversityP.O.Box801153508TC Utrecht,The NetherlandsWELMOED SOEPBOERA.VELDKAMPDepartment of Environmental Sciences Wageningen UniversityP.O.Box376700AA Wageningen,The NetherlandsRAMIL LIMPIADAVICTORIA ESPALDONSchool of Environmental Science and Management University of the Philippines Los Ban˜osCollege,Laguna4031,Philippines SHARIFAH S.A.MASTURADepartment of GeographyUniversiti Kebangsaan Malaysia43600BangiSelangor,MalaysiaABSTRACT/Land-use change models are important tools for integrated environmental management.Through scenario analysis they can help to identify near-future critical locations in the face of environmental change.A dynamic,spatially ex-plicit,land-use change model is presented for the regional scale:CLUE-S.The model is specifically developed for the analysis of land use in small regions(e.g.,a watershed or province)at afine spatial resolution.The model structure is based on systems theory to allow the integrated analysis of land-use change in relation to socio-economic and biophysi-cal driving factors.The model explicitly addresses the hierar-chical organization of land use systems,spatial connectivity between locations and stability.Stability is incorporated by a set of variables that define the relative elasticity of the actual land-use type to conversion.The user can specify these set-tings based on expert knowledge or survey data.Two appli-cations of the model in the Philippines and Malaysia are used to illustrate the functioning of the model and its validation.Land-use change is central to environmental man-agement through its influence on biodiversity,water and radiation budgets,trace gas emissions,carbon cy-cling,and livelihoods(Lambin and others2000a, Turner1994).Land-use planning attempts to influence the land-use change dynamics so that land-use config-urations are achieved that balance environmental and stakeholder needs.Environmental management and land-use planning therefore need information about the dynamics of land use.Models can help to understand these dynamics and project near future land-use trajectories in order to target management decisions(Schoonenboom1995).Environmental management,and land-use planning specifically,take place at different spatial and organisa-tional levels,often corresponding with either eco-re-gional or administrative units,such as the national or provincial level.The information needed and the man-agement decisions made are different for the different levels of analysis.At the national level it is often suffi-cient to identify regions that qualify as“hot-spots”of land-use change,i.e.,areas that are likely to be faced with rapid land use conversions.Once these hot-spots are identified a more detailed land use change analysis is often needed at the regional level.At the regional level,the effects of land-use change on natural resources can be determined by a combina-tion of land use change analysis and specific models to assess the impact on natural resources.Examples of this type of model are water balance models(Schulze 2000),nutrient balance models(Priess and Koning 2001,Smaling and Fresco1993)and erosion/sedimen-tation models(Schoorl and Veldkamp2000).Most of-KEY WORDS:Land-use change;Modeling;Systems approach;Sce-nario analysis;Natural resources management*Author to whom correspondence should be addressed;email:pverburg@gissrv.iend.wau.nlDOI:10.1007/s00267-002-2630-x Environmental Management Vol.30,No.3,pp.391–405©2002Springer-Verlag New York Inc.ten these models need high-resolution data for land use to appropriately simulate the processes involved.Land-Use Change ModelsThe rising awareness of the need for spatially-ex-plicit land-use models within the Land-Use and Land-Cover Change research community(LUCC;Lambin and others2000a,Turner and others1995)has led to the development of a wide range of land-use change models.Whereas most models were originally devel-oped for deforestation(reviews by Kaimowitz and An-gelsen1998,Lambin1997)more recent efforts also address other land use conversions such as urbaniza-tion and agricultural intensification(Brown and others 2000,Engelen and others1995,Hilferink and Rietveld 1999,Lambin and others2000b).Spatially explicit ap-proaches are often based on cellular automata that simulate land use change as a function of land use in the neighborhood and a set of user-specified relations with driving factors(Balzter and others1998,Candau 2000,Engelen and others1995,Wu1998).The speci-fication of the neighborhood functions and transition rules is done either based on the user’s expert knowl-edge,which can be a problematic process due to a lack of quantitative understanding,or on empirical rela-tions between land use and driving factors(e.g.,Pi-janowski and others2000,Pontius and others2000).A probability surface,based on either logistic regression or neural network analysis of historic conversions,is made for future conversions.Projections of change are based on applying a cut-off value to this probability sur-face.Although appropriate for short-term projections,if the trend in land-use change continues,this methodology is incapable of projecting changes when the demands for different land-use types change,leading to a discontinua-tion of the trends.Moreover,these models are usually capable of simulating the conversion of one land-use type only(e.g.deforestation)because they do not address competition between land-use types explicitly.The CLUE Modeling FrameworkThe Conversion of Land Use and its Effects(CLUE) modeling framework(Veldkamp and Fresco1996,Ver-burg and others1999a)was developed to simulate land-use change using empirically quantified relations be-tween land use and its driving factors in combination with dynamic modeling.In contrast to most empirical models,it is possible to simulate multiple land-use types simultaneously through the dynamic simulation of competition between land-use types.This model was developed for the national and con-tinental level,applications are available for Central America(Kok and Winograd2001),Ecuador(de Kon-ing and others1999),China(Verburg and others 2000),and Java,Indonesia(Verburg and others 1999b).For study areas with such a large extent the spatial resolution of analysis was coarse(pixel size vary-ing between7ϫ7and32ϫ32km).This is a conse-quence of the impossibility to acquire data for land use and all driving factors atfiner spatial resolutions.A coarse spatial resolution requires a different data rep-resentation than the common representation for data with afine spatial resolution.Infine resolution grid-based approaches land use is defined by the most dom-inant land-use type within the pixel.However,such a data representation would lead to large biases in the land-use distribution as some class proportions will di-minish and other will increase with scale depending on the spatial and probability distributions of the cover types(Moody and Woodcock1994).In the applications of the CLUE model at the national or continental level we have,therefore,represented land use by designating the relative cover of each land-use type in each pixel, e.g.a pixel can contain30%cultivated land,40%grass-land,and30%forest.This data representation is di-rectly related to the information contained in the cen-sus data that underlie the applications.For each administrative unit,census data denote the number of hectares devoted to different land-use types.When studying areas with a relatively small spatial ex-tent,we often base our land-use data on land-use maps or remote sensing images that denote land-use types respec-tively by homogeneous polygons or classified pixels. When converted to a raster format this results in only one, dominant,land-use type occupying one unit of analysis. The validity of this data representation depends on the patchiness of the landscape and the pixel size chosen. Most sub-national land use studies use this representation of land use with pixel sizes varying between a few meters up to about1ϫ1km.The two different data represen-tations are shown in Figure1.Because of the differences in data representation and other features that are typical for regional appli-cations,the CLUE model can not directly be applied at the regional scale.This paper describes the mod-ified modeling approach for regional applications of the model,now called CLUE-S(the Conversion of Land Use and its Effects at Small regional extent). The next section describes the theories underlying the development of the model after which it is de-scribed how these concepts are incorporated in the simulation model.The functioning of the model is illustrated for two case-studies and is followed by a general discussion.392P.H.Verburg and othersCharacteristics of Land-Use SystemsThis section lists the main concepts and theories that are prevalent for describing the dynamics of land-use change being relevant for the development of land-use change models.Land-use systems are complex and operate at the interface of multiple social and ecological systems.The similarities between land use,social,and ecological systems allow us to use concepts that have proven to be useful for studying and simulating ecological systems in our analysis of land-use change (Loucks 1977,Adger 1999,Holling and Sanderson 1996).Among those con-cepts,connectivity is important.The concept of con-nectivity acknowledges that locations that are at a cer-tain distance are related to each other (Green 1994).Connectivity can be a direct result of biophysical pro-cesses,e.g.,sedimentation in the lowlands is a direct result of erosion in the uplands,but more often it is due to the movement of species or humans through the nd degradation at a certain location will trigger farmers to clear land at a new location.Thus,changes in land use at this new location are related to the land-use conditions in the other location.In other instances more complex relations exist that are rooted in the social and economic organization of the system.The hierarchical structure of social organization causes some lower level processes to be constrained by higher level dynamics,e.g.,the establishments of a new fruit-tree plantation in an area near to the market might in fluence prices in such a way that it is no longer pro fitable for farmers to produce fruits in more distant areas.For studying this situation an-other concept from ecology,hierarchy theory,is use-ful (Allen and Starr 1982,O ’Neill and others 1986).This theory states that higher level processes con-strain lower level processes whereas the higher level processes might emerge from lower level dynamics.This makes the analysis of the land-use system at different levels of analysis necessary.Connectivity implies that we cannot understand land use at a certain location by solely studying the site characteristics of that location.The situation atneigh-Figure 1.Data representation and land-use model used for respectively case-studies with a national/continental extent and local/regional extent.Modeling Regional Land-Use Change393boring or even more distant locations can be as impor-tant as the conditions at the location itself.Land-use and land-cover change are the result of many interacting processes.Each of these processes operates over a range of scales in space and time.These processes are driven by one or more of these variables that influence the actions of the agents of land-use and cover change involved.These variables are often re-ferred to as underlying driving forces which underpin the proximate causes of land-use change,such as wood extraction or agricultural expansion(Geist and Lambin 2001).These driving factors include demographic fac-tors(e.g.,population pressure),economic factors(e.g., economic growth),technological factors,policy and institutional factors,cultural factors,and biophysical factors(Turner and others1995,Kaimowitz and An-gelsen1998).These factors influence land-use change in different ways.Some of these factors directly influ-ence the rate and quantity of land-use change,e.g.the amount of forest cleared by new incoming migrants. Other factors determine the location of land-use change,e.g.the suitability of the soils for agricultural land use.Especially the biophysical factors do pose constraints to land-use change at certain locations, leading to spatially differentiated pathways of change.It is not possible to classify all factors in groups that either influence the rate or location of land-use change.In some cases the same driving factor has both an influ-ence on the quantity of land-use change as well as on the location of land-use change.Population pressure is often an important driving factor of land-use conver-sions(Rudel and Roper1997).At the same time it is the relative population pressure that determines which land-use changes are taking place at a certain location. Intensively cultivated arable lands are commonly situ-ated at a limited distance from the villages while more extensively managed grasslands are often found at a larger distance from population concentrations,a rela-tion that can be explained by labor intensity,transport costs,and the quality of the products(Von Thu¨nen 1966).The determination of the driving factors of land use changes is often problematic and an issue of dis-cussion(Lambin and others2001).There is no unify-ing theory that includes all processes relevant to land-use change.Reviews of case studies show that it is not possible to simply relate land-use change to population growth,poverty,and infrastructure.Rather,the inter-play of several proximate as well as underlying factors drive land-use change in a synergetic way with large variations caused by location specific conditions (Lambin and others2001,Geist and Lambin2001).In regional modeling we often need to rely on poor data describing this complexity.Instead of using the under-lying driving factors it is needed to use proximate vari-ables that can represent the underlying driving factors. Especially for factors that are important in determining the location of change it is essential that the factor can be mapped quantitatively,representing its spatial vari-ation.The causality between the underlying driving factors and the(proximate)factors used in modeling (in this paper,also referred to as“driving factors”) should be certified.Other system properties that are relevant for land-use systems are stability and resilience,concepts often used to describe ecological systems and,to some extent, social systems(Adger2000,Holling1973,Levin and others1998).Resilience refers to the buffer capacity or the ability of the ecosystem or society to absorb pertur-bations,or the magnitude of disturbance that can be absorbed before a system changes its structure by changing the variables and processes that control be-havior(Holling1992).Stability and resilience are con-cepts that can also be used to describe the dynamics of land-use systems,that inherit these characteristics from both ecological and social systems.Due to stability and resilience of the system disturbances and external in-fluences will,mostly,not directly change the landscape structure(Conway1985).After a natural disaster lands might be abandoned and the population might tempo-rally migrate.However,people will in most cases return after some time and continue land-use management practices as before,recovering the land-use structure (Kok and others2002).Stability in the land-use struc-ture is also a result of the social,economic,and insti-tutional structure.Instead of a direct change in the land-use structure upon a fall in prices of a certain product,farmers will wait a few years,depending on the investments made,before they change their cropping system.These characteristics of land-use systems provide a number requirements for the modelling of land-use change that have been used in the development of the CLUE-S model,including:●Models should not analyze land use at a single scale,but rather include multiple,interconnected spatial scales because of the hierarchical organization of land-use systems.●Special attention should be given to the drivingfactors of land-use change,distinguishing drivers that determine the quantity of change from drivers of the location of change.●Sudden changes in driving factors should not di-rectly change the structure of the land-use system asa consequence of the resilience and stability of theland-use system.394P.H.Verburg and others●The model structure should allow spatial interac-tions between locations and feedbacks from higher levels of organization.Model DescriptionModel StructureThe model is sub-divided into two distinct modules,namely a non-spatial demand module and a spatially explicit allocation procedure (Figure 2).The non-spa-tial module calculates the area change for all land-use types at the aggregate level.Within the second part of the model these demands are translated into land-use changes at different locations within the study region using a raster-based system.For the land-use demand module,different alterna-tive model speci fications are possible,ranging from simple trend extrapolations to complex economic mod-els.The choice for a speci fic model is very much de-pendent on the nature of the most important land-use conversions taking place within the study area and the scenarios that need to be considered.Therefore,the demand calculations will differ between applications and scenarios and need to be decided by the user for the speci fic situation.The results from the demandmodule need to specify,on a yearly basis,the area covered by the different land-use types,which is a direct input for the allocation module.The rest of this paper focuses on the procedure to allocate these demands to land-use conversions at speci fic locations within the study area.The allocation is based upon a combination of em-pirical,spatial analysis,and dynamic modelling.Figure 3gives an overview of the procedure.The empirical analysis unravels the relations between the spatial dis-tribution of land use and a series of factors that are drivers and constraints of land use.The results of this empirical analysis are used within the model when sim-ulating the competition between land-use types for a speci fic location.In addition,a set of decision rules is speci fied by the user to restrict the conversions that can take place based on the actual land-use pattern.The different components of the procedure are now dis-cussed in more detail.Spatial AnalysisThe pattern of land use,as it can be observed from an airplane window or through remotely sensed im-ages,reveals the spatial organization of land use in relation to the underlying biophysical andsocio-eco-Figure 2.Overview of the modelingprocedure.Figure 3.Schematic represen-tation of the procedure to allo-cate changes in land use to a raster based map.Modeling Regional Land-Use Change395nomic conditions.These observations can be formal-ized by overlaying this land-use pattern with maps de-picting the variability in biophysical and socio-economic conditions.Geographical Information Systems(GIS)are used to process all spatial data and convert these into a regular grid.Apart from land use, data are gathered that represent the assumed driving forces of land use in the study area.The list of assumed driving forces is based on prevalent theories on driving factors of land-use change(Lambin and others2001, Kaimowitz and Angelsen1998,Turner and others 1993)and knowledge of the conditions in the study area.Data can originate from remote sensing(e.g., land use),secondary statistics(e.g.,population distri-bution),maps(e.g.,soil),and other sources.To allow a straightforward analysis,the data are converted into a grid based system with a cell size that depends on the resolution of the available data.This often involves the aggregation of one or more layers of thematic data,e.g. it does not make sense to use a30-m resolution if that is available for land-use data only,while the digital elevation model has a resolution of500m.Therefore, all data are aggregated to the same resolution that best represents the quality and resolution of the data.The relations between land use and its driving fac-tors are thereafter evaluated using stepwise logistic re-gression.Logistic regression is an often used method-ology in land-use change research(Geoghegan and others2001,Serneels and Lambin2001).In this study we use logistic regression to indicate the probability of a certain grid cell to be devoted to a land-use type given a set of driving factors following:LogͩP i1ϪP i ͪϭ0ϩ1X1,iϩ2X2,i......ϩn X n,iwhere P i is the probability of a grid cell for the occur-rence of the considered land-use type and the X’s are the driving factors.The stepwise procedure is used to help us select the relevant driving factors from a larger set of factors that are assumed to influence the land-use pattern.Variables that have no significant contribution to the explanation of the land-use pattern are excluded from thefinal regression equation.Where in ordinal least squares regression the R2 gives a measure of modelfit,there is no equivalent for logistic regression.Instead,the goodness offit can be evaluated with the ROC method(Pontius and Schnei-der2000,Swets1986)which evaluates the predicted probabilities by comparing them with the observed val-ues over the whole domain of predicted probabilities instead of only evaluating the percentage of correctly classified observations at afixed cut-off value.This is an appropriate methodology for our application,because we will use a wide range of probabilities within the model calculations.The influence of spatial autocorrelation on the re-gression results can be minimized by only performing the regression on a random sample of pixels at a certain minimum distance from one another.Such a selection method is adopted in order to maximize the distance between the selected pixels to attenuate the problem associated with spatial autocorrelation.For case-studies where autocorrelation has an important influence on the land-use structure it is possible to further exploit it by incorporating an autoregressive term in the regres-sion equation(Overmars and others2002).Based upon the regression results a probability map can be calculated for each land-use type.A new probabil-ity map is calculated every year with updated values for the driving factors that are projected to change in time,such as the population distribution or accessibility.Decision RulesLand-use type or location specific decision rules can be specified by the user.Location specific decision rules include the delineation of protected areas such as nature reserves.If a protected area is specified,no changes are allowed within this area.For each land-use type decision rules determine the conditions under which the land-use type is allowed to change in the next time step.These decision rules are implemented to give certain land-use types a certain resistance to change in order to generate the stability in the land-use structure that is typical for many landscapes.Three different situations can be distinguished and for each land-use type the user should specify which situation is most relevant for that land-use type:1.For some land-use types it is very unlikely that theyare converted into another land-use type after their first conversion;as soon as an agricultural area is urbanized it is not expected to return to agriculture or to be converted into forest cover.Unless a de-crease in area demand for this land-use type occurs the locations covered by this land use are no longer evaluated for potential land-use changes.If this situation is selected it also holds that if the demand for this land-use type decreases,there is no possi-bility for expansion in other areas.In other words, when this setting is applied to forest cover and deforestation needs to be allocated,it is impossible to reforest other areas at the same time.2.Other land-use types are converted more easily.Aswidden agriculture system is most likely to be con-verted into another land-use type soon after its396P.H.Verburg and othersinitial conversion.When this situation is selected for a land-use type no restrictions to change are considered in the allocation module.3.There is also a number of land-use types that oper-ate in between these two extremes.Permanent ag-riculture and plantations require an investment for their establishment.It is therefore not very likely that they will be converted very soon after into another land-use type.However,in the end,when another land-use type becomes more pro fitable,a conversion is possible.This situation is dealt with by de fining the relative elasticity for change (ELAS u )for the land-use type into any other land use type.The relative elasticity ranges between 0(similar to Situation 2)and 1(similar to Situation 1).The higher the de fined elasticity,the more dif ficult it gets to convert this land-use type.The elasticity should be de fined based on the user ’s knowledge of the situation,but can also be tuned during the calibration of the petition and Actual Allocation of Change Allocation of land-use change is made in an iterative procedure given the probability maps,the decision rules in combination with the actual land-use map,and the demand for the different land-use types (Figure 4).The following steps are followed in the calculation:1.The first step includes the determination of all grid cells that are allowed to change.Grid cells that are either part of a protected area or under a land-use type that is not allowed to change (Situation 1,above)are excluded from further calculation.2.For each grid cell i the total probability (TPROP i,u )is calculated for each of the land-use types u accord-ing to:TPROP i,u ϭP i,u ϩELAS u ϩITER u ,where ITER u is an iteration variable that is speci fic to the land use.ELAS u is the relative elasticity for change speci fied in the decision rules (Situation 3de-scribed above)and is only given a value if grid-cell i is already under land use type u in the year considered.ELAS u equals zero if all changes are allowed (Situation 2).3.A preliminary allocation is made with an equalvalue of the iteration variable (ITER u )for all land-use types by allocating the land-use type with the highest total probability for the considered grid cell.This will cause a number of grid cells to change land use.4.The total allocated area of each land use is nowcompared to the demand.For land-use types where the allocated area is smaller than the demanded area the value of the iteration variable is increased.For land-use types for which too much is allocated the value is decreased.5.Steps 2to 4are repeated as long as the demandsare not correctly allocated.When allocation equals demand the final map is saved and the calculations can continue for the next yearly timestep.Figure 5shows the development of the iteration parameter ITER u for different land-use types during asimulation.Figure 4.Representation of the iterative procedure for land-use changeallocation.Figure 5.Change in the iteration parameter (ITER u )during the simulation within one time-step.The different lines rep-resent the iteration parameter for different land-use types.The parameter is changed for all land-use types synchronously until the allocated land use equals the demand.Modeling Regional Land-Use Change397Multi-Scale CharacteristicsOne of the requirements for land-use change mod-els are multi-scale characteristics.The above described model structure incorporates different types of scale interactions.Within the iterative procedure there is a continuous interaction between macro-scale demands and local land-use suitability as determined by the re-gression equations.When the demand changes,the iterative procedure will cause the land-use types for which demand increased to have a higher competitive capacity (higher value for ITER u )to ensure enough allocation of this land-use type.Instead of only being determined by the local conditions,captured by the logistic regressions,it is also the regional demand that affects the actually allocated changes.This allows the model to “overrule ”the local suitability,it is not always the land-use type with the highest probability according to the logistic regression equation (P i,u )that the grid cell is allocated to.Apart from these two distinct levels of analysis there are also driving forces that operate over a certain dis-tance instead of being locally important.Applying a neighborhood function that is able to represent the regional in fluence of the data incorporates this type of variable.Population pressure is an example of such a variable:often the in fluence of population acts over a certain distance.Therefore,it is not the exact location of peoples houses that determines the land-use pattern.The average population density over a larger area is often a more appropriate variable.Such a population density surface can be created by a neighborhood func-tion using detailed spatial data.The data generated this way can be included in the spatial analysis as anotherindependent factor.In the application of the model in the Philippines,described hereafter,we applied a 5ϫ5focal filter to the population map to generate a map representing the general population pressure.Instead of using these variables,generated by neighborhood analysis,it is also possible to use the more advanced technique of multi-level statistics (Goldstein 1995),which enable a model to include higher-level variables in a straightforward manner within the regression equa-tion (Polsky and Easterling 2001).Application of the ModelIn this paper,two examples of applications of the model are provided to illustrate its function.TheseTable nd-use classes and driving factors evaluated for Sibuyan IslandLand-use classes Driving factors (location)Forest Altitude (m)GrasslandSlope Coconut plantation AspectRice fieldsDistance to town Others (incl.mangrove and settlements)Distance to stream Distance to road Distance to coast Distance to port Erosion vulnerability GeologyPopulation density(neighborhood 5ϫ5)Figure 6.Location of the case-study areas.398P.H.Verburg and others。
Kernelized fuzzy attribute C-means clustering algorithm

Received 30 October 2006; received in revised form 17 March 2008; accepted 18 March 2008 Available online 26 March 2008
Abstract A novel kernelized fuzzy attribute C-means clustering algorithm is proposed in this paper. Since attribute means clustering algorithm is an extension of fuzzy C-means algorithm with weighting exponent m = 2, and fuzzy attribute C-means clustering is a general type of attribute means clustering with weighting exponent m > 1, we modify the distance in fuzzy attribute C-means clustering algorithm with kernel-induced distance, and obtain kernelized fuzzy attribute C-means clustering algorithm. Kernelized fuzzy attribute C-means clustering algorithm is a natural generalization of kernelized fuzzy C-means algorithm with stable function. Experimental results on standard Iris database and tumor/normal gene chip expression data demonstrate that kernelized fuzzy attribute C-means clustering algorithm with Gaussian radial basis kernel function and Cauchy stable function is more effective and robust than fuzzy C-means, fuzzy attribute C-means clustering and kernelized fuzzy C-means as well. © 2008 Elsevier B.V. All rights reserved.
病灶定位技术的英语

病灶定位技术的英语Lesion Localization Techniques.Introduction.In the field of medicine, lesion localization techniques play a pivotal role in accurately pinpointing the exact location of diseased or abnormal tissues within the body. These techniques have evolved significantly over the years, enabling doctors to make more informed diagnoses and devise targeted treatment plans. The ability to precisely locate lesions is crucial for effective disease management and patient outcomes.Imaging Modalities for Lesion Localization.1. X-ray Imaging: X-rays are electromagnetic radiation that can pass through the body, allowing doctors to visualize internal structures. While X-rays are useful for detecting fractures and some lung diseases, they are not assensitive as other imaging modalities for lesion localization.2. Ultrasound Imaging: Ultrasound uses sound waves to create images of internal organs. It is particularly useful for lesion localization in pregnant women, as it can safely visualize the fetus. It is also commonly used in the breast and thyroid.3. Computed Tomography (CT) Scans: CT scans combine multiple X-ray images taken from different angles to create cross-sectional views of the body. This technique is highly accurate for lesion localization and can detect even small abnormalities.4. Magnetic Resonance Imaging (MRI): MRI uses strong magnets and radio waves to generate detailed images of internal structures. It is excellent for soft tissue visualization and lesion localization, particularly in the brain and joints.5. Positron Emission Tomography (PET) Scans: PET scansdetect gamma rays emitted by radiolabeled substances injected into the patient. This technique is useful for lesion localization in cancer patients, as it can show tumor activity and spread.Advanced Lesion Localization Techniques.1. Fusion Imaging: This technique combines the data from multiple imaging modalities to create a single, comprehensive image. For example, PET-CT fusion imaging combines the functional information from a PET scan with the anatomical detail from a CT scan, improving lesion localization accuracy.2. Image-guided Interventions: These procedures use real-time imaging to guide surgical or therapeutic interventions. Examples include biopsy procedures, where a needle is guided to the lesion using ultrasound or CT imaging, or radiation therapy, where high-energy beams are precisely targeted to the lesion.3. Artificial Intelligence (AI) and Machine Learning:These technologies are revolutionizing lesion localization by enabling computers to analyze vast amounts of imaging data and detect patterns that may indicate disease. AI-powered algorithms can assist doctors in identifying lesions and even predicting their behavior.Conclusion.The evolution of lesion localization techniques has been transformative in medicine, enabling doctors to diagnose and treat patients more effectively. From traditional imaging modalities to advanced fusion imaging and AI-powered analysis, these techniques are constantly evolving to improve patient outcomes. As technology continues to advance, so will our ability to pinpoint and treat lesions with precision and accuracy.。
基于弹性网和直方图相交的非负局部稀疏编码

DOI: 10. 11772 / j. issn. 1001-9081. 2018071483
基于弹性网和直方图相交的非负局部稀疏编码
*பைடு நூலகம்
万 源,张景会 ,陈治平,孟晓静
( 武汉理工大学 理学院,武汉 430070) ( * 通信作者电子邮箱 Jingzhang@ whut. edu. cn)
摘 要: 针对稀疏编码模型在字典基的选择时忽略了群效应,且欧氏距离不能有效度量特征与字典基之间距离 的问题,提出基于弹性网和直方图相交的非负局部稀疏编码方法( EH-NLSC) 。首先,在优化函数中引入弹性网模型, 消除字典基选择数目的限制,能够选择多组相关特征而排除冗余特征,提高了编码的判别性和有效性。然后,在局部 性约束中引入直方图相交,重新定义特征与字典基之间的距离,确保相似的特征可以共享其局部的基。最后采用多 类线性支持向量机进行分类。在 4 个公共数据集上的实验结果表明,与局部线性约束的编码算法( LLC) 和基于非负 弹性网的稀疏编码算法( NENSC) 相比,EH-NLSC 的分类准确率分别平均提升了 10 个百分点和 9 个百分点,充分体现 了其在图像表示和分类中的有效性。
Key words: sparse coding; elastic net model; locality; histogram intersection; image classification
0 引言
图像分类是计算机视觉领域的一个重要研究方向,广泛 应用于生物特征识别、网络图像检索和机器人视觉等领域,其 关键在于如何提取特征对图像有效表示。稀疏编码是图像特 征表示 的 有 效 方 法。考 虑 到 词 袋 ( Bag of Words,BoW) 模 型[1]和空 间 金 字 塔 匹 配 ( Spatial Pyramid Matching,SPM) 模 型[2]容易造成量化误差,Yang 等[3] 结合 SPM 模型提出利用 稀疏编 码 的 空 间 金 字 塔 的 图 像 分 类 算 法 ( Spatial Pyramid Matching using Sparse Coding,ScSPM) ,在图像的不同尺度上 进行稀疏编码,取得了较好的分类效果。在稀疏编码模型中, 由于 1 范数在字典基选择时只考虑稀疏性而忽略了群体效 应,Zou 等[4]提出一种新的正则化方法,将弹性网作为正则项 和变量选择方法。Zhang 等[5]提出判别式弹性网正则化线性
粗糙空间上基于VC维的风险泛函的界

要: 为了完善粗糙 空间上学习过程收敛速 度的界,根据粗糙 空间上的信赖 性测度的性质和传统的统计学习理
论 的 相 关 知 识 , 粗 糙 空 间上 学 习理 论 的 关 键 定理 和 学 习 过 程 一 致 收 敛 速 度 的 界 的 基 础 上 , 出 了粗 糙 空 间上 退 在 给 火 熵 、 生 长 函数 、VC维 的概 念 及 其 相 关 的性 质 , 以此 为基 础 构 建 了粗 糙 空 间 上基 于 VC维 的构 造 性 的 与 分布 无
引 言
非 概 率 测 度 空 间上 基 ຫໍສະໝຸດ 非 实 随机 样 本 的统 计
学 习理论 是传 统 的统计 学 习理论 的重 要拓 广 ,现 己 取得 系 列研 究成 果 【引 卜 ,其 中刘 杨 [] 出 了基 于粗 1给 0
H A i hu M ng , ZH A O Chunli , ZH AN G o e H ng
( . l g f a h maisa dCo u e ce c s He e ie st , o i g0 1 0 , ia 1Col eo t e t n mp t rS in e, b i e M c Un v r i Ba d n 7 0 2 Ch n ; y
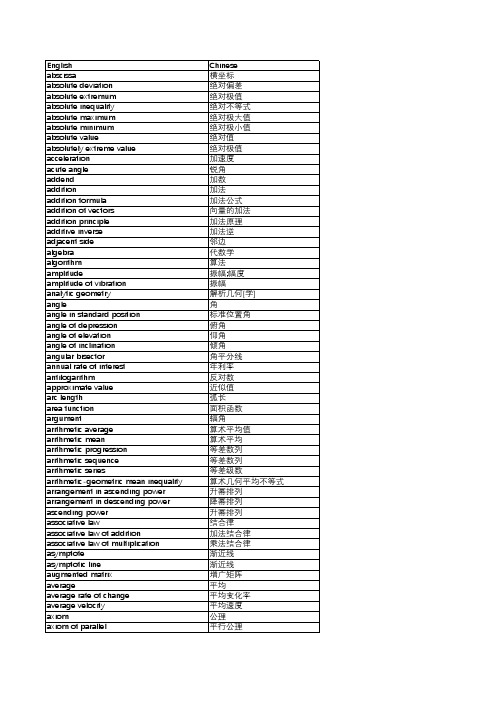
TW 142数学名词-中小学教科书名词中英对照术语
Survey of clustering data mining techniques

A Survey of Clustering Data Mining TechniquesPavel BerkhinYahoo!,Inc.pberkhin@Summary.Clustering is the division of data into groups of similar objects.It dis-regards some details in exchange for data simplifirmally,clustering can be viewed as data modeling concisely summarizing the data,and,therefore,it re-lates to many disciplines from statistics to numerical analysis.Clustering plays an important role in a broad range of applications,from information retrieval to CRM. Such applications usually deal with large datasets and many attributes.Exploration of such data is a subject of data mining.This survey concentrates on clustering algorithms from a data mining perspective.1IntroductionThe goal of this survey is to provide a comprehensive review of different clus-tering techniques in data mining.Clustering is a division of data into groups of similar objects.Each group,called a cluster,consists of objects that are similar to one another and dissimilar to objects of other groups.When repre-senting data with fewer clusters necessarily loses certainfine details(akin to lossy data compression),but achieves simplification.It represents many data objects by few clusters,and hence,it models data by its clusters.Data mod-eling puts clustering in a historical perspective rooted in mathematics,sta-tistics,and numerical analysis.From a machine learning perspective clusters correspond to hidden patterns,the search for clusters is unsupervised learn-ing,and the resulting system represents a data concept.Therefore,clustering is unsupervised learning of a hidden data concept.Data mining applications add to a general picture three complications:(a)large databases,(b)many attributes,(c)attributes of different types.This imposes on a data analysis se-vere computational requirements.Data mining applications include scientific data exploration,information retrieval,text mining,spatial databases,Web analysis,CRM,marketing,medical diagnostics,computational biology,and many others.They present real challenges to classic clustering algorithms. These challenges led to the emergence of powerful broadly applicable data2Pavel Berkhinmining clustering methods developed on the foundation of classic techniques.They are subject of this survey.1.1NotationsTo fix the context and clarify terminology,consider a dataset X consisting of data points (i.e.,objects ,instances ,cases ,patterns ,tuples ,transactions )x i =(x i 1,···,x id ),i =1:N ,in attribute space A ,where each component x il ∈A l ,l =1:d ,is a numerical or nominal categorical attribute (i.e.,feature ,variable ,dimension ,component ,field ).For a discussion of attribute data types see [106].Such point-by-attribute data format conceptually corresponds to a N ×d matrix and is used by a majority of algorithms reviewed below.However,data of other formats,such as variable length sequences and heterogeneous data,are not uncommon.The simplest subset in an attribute space is a direct Cartesian product of sub-ranges C = C l ⊂A ,C l ⊂A l ,called a segment (i.e.,cube ,cell ,region ).A unit is an elementary segment whose sub-ranges consist of a single category value,or of a small numerical bin.Describing the numbers of data points per every unit represents an extreme case of clustering,a histogram .This is a very expensive representation,and not a very revealing er driven segmentation is another commonly used practice in data exploration that utilizes expert knowledge regarding the importance of certain sub-domains.Unlike segmentation,clustering is assumed to be automatic,and so it is a machine learning technique.The ultimate goal of clustering is to assign points to a finite system of k subsets (clusters).Usually (but not always)subsets do not intersect,and their union is equal to a full dataset with the possible exception of outliersX =C 1 ··· C k C outliers ,C i C j =0,i =j.1.2Clustering Bibliography at GlanceGeneral references regarding clustering include [110],[205],[116],[131],[63],[72],[165],[119],[75],[141],[107],[91].A very good introduction to contem-porary data mining clustering techniques can be found in the textbook [106].There is a close relationship between clustering and many other fields.Clustering has always been used in statistics [10]and science [158].The clas-sic introduction into pattern recognition framework is given in [64].Typical applications include speech and character recognition.Machine learning clus-tering algorithms were applied to image segmentation and computer vision[117].For statistical approaches to pattern recognition see [56]and [85].Clus-tering can be viewed as a density estimation problem.This is the subject of traditional multivariate statistical estimation [197].Clustering is also widelyA Survey of Clustering Data Mining Techniques3 used for data compression in image processing,which is also known as vec-tor quantization[89].Datafitting in numerical analysis provides still another venue in data modeling[53].This survey’s emphasis is on clustering in data mining.Such clustering is characterized by large datasets with many attributes of different types. Though we do not even try to review particular applications,many important ideas are related to the specificfields.Clustering in data mining was brought to life by intense developments in information retrieval and text mining[52], [206],[58],spatial database applications,for example,GIS or astronomical data,[223],[189],[68],sequence and heterogeneous data analysis[43],Web applications[48],[111],[81],DNA analysis in computational biology[23],and many others.They resulted in a large amount of application-specific devel-opments,but also in some general techniques.These techniques and classic clustering algorithms that relate to them are surveyed below.1.3Plan of Further PresentationClassification of clustering algorithms is neither straightforward,nor canoni-cal.In reality,different classes of algorithms overlap.Traditionally clustering techniques are broadly divided in hierarchical and partitioning.Hierarchical clustering is further subdivided into agglomerative and divisive.The basics of hierarchical clustering include Lance-Williams formula,idea of conceptual clustering,now classic algorithms SLINK,COBWEB,as well as newer algo-rithms CURE and CHAMELEON.We survey these algorithms in the section Hierarchical Clustering.While hierarchical algorithms gradually(dis)assemble points into clusters (as crystals grow),partitioning algorithms learn clusters directly.In doing so they try to discover clusters either by iteratively relocating points between subsets,or by identifying areas heavily populated with data.Algorithms of thefirst kind are called Partitioning Relocation Clustering. They are further classified into probabilistic clustering(EM framework,al-gorithms SNOB,AUTOCLASS,MCLUST),k-medoids methods(algorithms PAM,CLARA,CLARANS,and its extension),and k-means methods(differ-ent schemes,initialization,optimization,harmonic means,extensions).Such methods concentrate on how well pointsfit into their clusters and tend to build clusters of proper convex shapes.Partitioning algorithms of the second type are surveyed in the section Density-Based Partitioning.They attempt to discover dense connected com-ponents of data,which areflexible in terms of their shape.Density-based connectivity is used in the algorithms DBSCAN,OPTICS,DBCLASD,while the algorithm DENCLUE exploits space density functions.These algorithms are less sensitive to outliers and can discover clusters of irregular shape.They usually work with low-dimensional numerical data,known as spatial data. Spatial objects could include not only points,but also geometrically extended objects(algorithm GDBSCAN).4Pavel BerkhinSome algorithms work with data indirectly by constructing summaries of data over the attribute space subsets.They perform space segmentation and then aggregate appropriate segments.We discuss them in the section Grid-Based Methods.They frequently use hierarchical agglomeration as one phase of processing.Algorithms BANG,STING,WaveCluster,and FC are discussed in this section.Grid-based methods are fast and handle outliers well.Grid-based methodology is also used as an intermediate step in many other algorithms (for example,CLIQUE,MAFIA).Categorical data is intimately connected with transactional databases.The concept of a similarity alone is not sufficient for clustering such data.The idea of categorical data co-occurrence comes to the rescue.The algorithms ROCK,SNN,and CACTUS are surveyed in the section Co-Occurrence of Categorical Data.The situation gets even more aggravated with the growth of the number of items involved.To help with this problem the effort is shifted from data clustering to pre-clustering of items or categorical attribute values. Development based on hyper-graph partitioning and the algorithm STIRR exemplify this approach.Many other clustering techniques are developed,primarily in machine learning,that either have theoretical significance,are used traditionally out-side the data mining community,or do notfit in previously outlined categories. The boundary is blurred.In the section Other Developments we discuss the emerging direction of constraint-based clustering,the important researchfield of graph partitioning,and the relationship of clustering to supervised learning, gradient descent,artificial neural networks,and evolutionary methods.Data Mining primarily works with large databases.Clustering large datasets presents scalability problems reviewed in the section Scalability and VLDB Extensions.Here we talk about algorithms like DIGNET,about BIRCH and other data squashing techniques,and about Hoffding or Chernoffbounds.Another trait of real-life data is high dimensionality.Corresponding de-velopments are surveyed in the section Clustering High Dimensional Data. The trouble comes from a decrease in metric separation when the dimension grows.One approach to dimensionality reduction uses attributes transforma-tions(DFT,PCA,wavelets).Another way to address the problem is through subspace clustering(algorithms CLIQUE,MAFIA,ENCLUS,OPTIGRID, PROCLUS,ORCLUS).Still another approach clusters attributes in groups and uses their derived proxies to cluster objects.This double clustering is known as co-clustering.Issues common to different clustering methods are overviewed in the sec-tion General Algorithmic Issues.We talk about assessment of results,de-termination of appropriate number of clusters to build,data preprocessing, proximity measures,and handling of outliers.For reader’s convenience we provide a classification of clustering algorithms closely followed by this survey:•Hierarchical MethodsA Survey of Clustering Data Mining Techniques5Agglomerative AlgorithmsDivisive Algorithms•Partitioning Relocation MethodsProbabilistic ClusteringK-medoids MethodsK-means Methods•Density-Based Partitioning MethodsDensity-Based Connectivity ClusteringDensity Functions Clustering•Grid-Based Methods•Methods Based on Co-Occurrence of Categorical Data•Other Clustering TechniquesConstraint-Based ClusteringGraph PartitioningClustering Algorithms and Supervised LearningClustering Algorithms in Machine Learning•Scalable Clustering Algorithms•Algorithms For High Dimensional DataSubspace ClusteringCo-Clustering Techniques1.4Important IssuesThe properties of clustering algorithms we are primarily concerned with in data mining include:•Type of attributes algorithm can handle•Scalability to large datasets•Ability to work with high dimensional data•Ability tofind clusters of irregular shape•Handling outliers•Time complexity(we frequently simply use the term complexity)•Data order dependency•Labeling or assignment(hard or strict vs.soft or fuzzy)•Reliance on a priori knowledge and user defined parameters •Interpretability of resultsRealistically,with every algorithm we discuss only some of these properties. The list is in no way exhaustive.For example,as appropriate,we also discuss algorithms ability to work in pre-defined memory buffer,to restart,and to provide an intermediate solution.6Pavel Berkhin2Hierarchical ClusteringHierarchical clustering builds a cluster hierarchy or a tree of clusters,also known as a dendrogram.Every cluster node contains child clusters;sibling clusters partition the points covered by their common parent.Such an ap-proach allows exploring data on different levels of granularity.Hierarchical clustering methods are categorized into agglomerative(bottom-up)and divi-sive(top-down)[116],[131].An agglomerative clustering starts with one-point (singleton)clusters and recursively merges two or more of the most similar clusters.A divisive clustering starts with a single cluster containing all data points and recursively splits the most appropriate cluster.The process contin-ues until a stopping criterion(frequently,the requested number k of clusters) is achieved.Advantages of hierarchical clustering include:•Flexibility regarding the level of granularity•Ease of handling any form of similarity or distance•Applicability to any attribute typesDisadvantages of hierarchical clustering are related to:•Vagueness of termination criteria•Most hierarchical algorithms do not revisit(intermediate)clusters once constructed.The classic approaches to hierarchical clustering are presented in the sub-section Linkage Metrics.Hierarchical clustering based on linkage metrics re-sults in clusters of proper(convex)shapes.Active contemporary efforts to build cluster systems that incorporate our intuitive concept of clusters as con-nected components of arbitrary shape,including the algorithms CURE and CHAMELEON,are surveyed in the subsection Hierarchical Clusters of Arbi-trary Shapes.Divisive techniques based on binary taxonomies are presented in the subsection Binary Divisive Partitioning.The subsection Other Devel-opments contains information related to incremental learning,model-based clustering,and cluster refinement.In hierarchical clustering our regular point-by-attribute data representa-tion frequently is of secondary importance.Instead,hierarchical clustering frequently deals with the N×N matrix of distances(dissimilarities)or sim-ilarities between training points sometimes called a connectivity matrix.So-called linkage metrics are constructed from elements of this matrix.The re-quirement of keeping a connectivity matrix in memory is unrealistic.To relax this limitation different techniques are used to sparsify(introduce zeros into) the connectivity matrix.This can be done by omitting entries smaller than a certain threshold,by using only a certain subset of data representatives,or by keeping with each point only a certain number of its nearest neighbors(for nearest neighbor chains see[177]).Notice that the way we process the original (dis)similarity matrix and construct a linkage metric reflects our a priori ideas about the data model.A Survey of Clustering Data Mining Techniques7With the(sparsified)connectivity matrix we can associate the weighted connectivity graph G(X,E)whose vertices X are data points,and edges E and their weights are defined by the connectivity matrix.This establishes a connection between hierarchical clustering and graph partitioning.One of the most striking developments in hierarchical clustering is the algorithm BIRCH.It is discussed in the section Scalable VLDB Extensions.Hierarchical clustering initializes a cluster system as a set of singleton clusters(agglomerative case)or a single cluster of all points(divisive case) and proceeds iteratively merging or splitting the most appropriate cluster(s) until the stopping criterion is achieved.The appropriateness of a cluster(s) for merging or splitting depends on the(dis)similarity of cluster(s)elements. This reflects a general presumption that clusters consist of similar points.An important example of dissimilarity between two points is the distance between them.To merge or split subsets of points rather than individual points,the dis-tance between individual points has to be generalized to the distance between subsets.Such a derived proximity measure is called a linkage metric.The type of a linkage metric significantly affects hierarchical algorithms,because it re-flects a particular concept of closeness and connectivity.Major inter-cluster linkage metrics[171],[177]include single link,average link,and complete link. The underlying dissimilarity measure(usually,distance)is computed for every pair of nodes with one node in thefirst set and another node in the second set.A specific operation such as minimum(single link),average(average link),or maximum(complete link)is applied to pair-wise dissimilarity measures:d(C1,C2)=Op{d(x,y),x∈C1,y∈C2}Early examples include the algorithm SLINK[199],which implements single link(Op=min),Voorhees’method[215],which implements average link (Op=Avr),and the algorithm CLINK[55],which implements complete link (Op=max).It is related to the problem offinding the Euclidean minimal spanning tree[224]and has O(N2)complexity.The methods using inter-cluster distances defined in terms of pairs of nodes(one in each respective cluster)are called graph methods.They do not use any cluster representation other than a set of points.This name naturally relates to the connectivity graph G(X,E)introduced above,because every data partition corresponds to a graph partition.Such methods can be augmented by so-called geometric methods in which a cluster is represented by its central point.Under the assumption of numerical attributes,the center point is defined as a centroid or an average of two cluster centroids subject to agglomeration.It results in centroid,median,and minimum variance linkage metrics.All of the above linkage metrics can be derived from the Lance-Williams updating formula[145],d(C iC j,C k)=a(i)d(C i,C k)+a(j)d(C j,C k)+b·d(C i,C j)+c|d(C i,C k)−d(C j,C k)|.8Pavel BerkhinHere a,b,c are coefficients corresponding to a particular linkage.This formula expresses a linkage metric between a union of the two clusters and the third cluster in terms of underlying nodes.The Lance-Williams formula is crucial to making the dis(similarity)computations feasible.Surveys of linkage metrics can be found in [170][54].When distance is used as a base measure,linkage metrics capture inter-cluster proximity.However,a similarity-based view that results in intra-cluster connectivity considerations is also used,for example,in the original average link agglomeration (Group-Average Method)[116].Under reasonable assumptions,such as reducibility condition (graph meth-ods satisfy this condition),linkage metrics methods suffer from O N 2 time complexity [177].Despite the unfavorable time complexity,these algorithms are widely used.As an example,the algorithm AGNES (AGlomerative NESt-ing)[131]is used in S-Plus.When the connectivity N ×N matrix is sparsified,graph methods directly dealing with the connectivity graph G can be used.In particular,hierarchical divisive MST (Minimum Spanning Tree)algorithm is based on graph parti-tioning [116].2.1Hierarchical Clusters of Arbitrary ShapesFor spatial data,linkage metrics based on Euclidean distance naturally gener-ate clusters of convex shapes.Meanwhile,visual inspection of spatial images frequently discovers clusters with curvy appearance.Guha et al.[99]introduced the hierarchical agglomerative clustering algo-rithm CURE (Clustering Using REpresentatives).This algorithm has a num-ber of novel features of general importance.It takes special steps to handle outliers and to provide labeling in assignment stage.It also uses two techniques to achieve scalability:data sampling (section 8),and data partitioning.CURE creates p partitions,so that fine granularity clusters are constructed in parti-tions first.A major feature of CURE is that it represents a cluster by a fixed number,c ,of points scattered around it.The distance between two clusters used in the agglomerative process is the minimum of distances between two scattered representatives.Therefore,CURE takes a middle approach between the graph (all-points)methods and the geometric (one centroid)methods.Single and average link closeness are replaced by representatives’aggregate closeness.Selecting representatives scattered around a cluster makes it pos-sible to cover non-spherical shapes.As before,agglomeration continues until the requested number k of clusters is achieved.CURE employs one additional trick:originally selected scattered points are shrunk to the geometric centroid of the cluster by a user-specified factor α.Shrinkage suppresses the affect of outliers;outliers happen to be located further from the cluster centroid than the other scattered representatives.CURE is capable of finding clusters of different shapes and sizes,and it is insensitive to outliers.Because CURE uses sampling,estimation of its complexity is not straightforward.For low-dimensional data authors provide a complexity estimate of O (N 2sample )definedA Survey of Clustering Data Mining Techniques9 in terms of a sample size.More exact bounds depend on input parameters: shrink factorα,number of representative points c,number of partitions p,and a sample size.Figure1(a)illustrates agglomeration in CURE.Three clusters, each with three representatives,are shown before and after the merge and shrinkage.Two closest representatives are connected.While the algorithm CURE works with numerical attributes(particularly low dimensional spatial data),the algorithm ROCK developed by the same researchers[100]targets hierarchical agglomerative clustering for categorical attributes.It is reviewed in the section Co-Occurrence of Categorical Data.The hierarchical agglomerative algorithm CHAMELEON[127]uses the connectivity graph G corresponding to the K-nearest neighbor model spar-sification of the connectivity matrix:the edges of K most similar points to any given point are preserved,the rest are pruned.CHAMELEON has two stages.In thefirst stage small tight clusters are built to ignite the second stage.This involves a graph partitioning[129].In the second stage agglomer-ative process is performed.It utilizes measures of relative inter-connectivity RI(C i,C j)and relative closeness RC(C i,C j);both are locally normalized by internal interconnectivity and closeness of clusters C i and C j.In this sense the modeling is dynamic:it depends on data locally.Normalization involves certain non-obvious graph operations[129].CHAMELEON relies heavily on graph partitioning implemented in the library HMETIS(see the section6). Agglomerative process depends on user provided thresholds.A decision to merge is made based on the combinationRI(C i,C j)·RC(C i,C j)αof local measures.The algorithm does not depend on assumptions about the data model.It has been proven tofind clusters of different shapes,densities, and sizes in2D(two-dimensional)space.It has a complexity of O(Nm+ Nlog(N)+m2log(m),where m is the number of sub-clusters built during the first initialization phase.Figure1(b)(analogous to the one in[127])clarifies the difference with CURE.It presents a choice of four clusters(a)-(d)for a merge.While CURE would merge clusters(a)and(b),CHAMELEON makes intuitively better choice of merging(c)and(d).2.2Binary Divisive PartitioningIn linguistics,information retrieval,and document clustering applications bi-nary taxonomies are very useful.Linear algebra methods,based on singular value decomposition(SVD)are used for this purpose in collaborativefilter-ing and information retrieval[26].Application of SVD to hierarchical divisive clustering of document collections resulted in the PDDP(Principal Direction Divisive Partitioning)algorithm[31].In our notations,object x is a docu-ment,l th attribute corresponds to a word(index term),and a matrix X entry x il is a measure(e.g.TF-IDF)of l-term frequency in a document x.PDDP constructs SVD decomposition of the matrix10Pavel Berkhin(a)Algorithm CURE (b)Algorithm CHAMELEONFig.1.Agglomeration in Clusters of Arbitrary Shapes(X −e ¯x ),¯x =1Ni =1:N x i ,e =(1,...,1)T .This algorithm bisects data in Euclidean space by a hyperplane that passes through data centroid orthogonal to the eigenvector with the largest singular value.A k -way split is also possible if the k largest singular values are consid-ered.Bisecting is a good way to categorize documents and it yields a binary tree.When k -means (2-means)is used for bisecting,the dividing hyperplane is orthogonal to the line connecting the two centroids.The comparative study of SVD vs.k -means approaches [191]can be used for further references.Hier-archical divisive bisecting k -means was proven [206]to be preferable to PDDP for document clustering.While PDDP or 2-means are concerned with how to split a cluster,the problem of which cluster to split is also important.Simple strategies are:(1)split each node at a given level,(2)split the cluster with highest cardinality,and,(3)split the cluster with the largest intra-cluster variance.All three strategies have problems.For a more detailed analysis of this subject and better strategies,see [192].2.3Other DevelopmentsOne of early agglomerative clustering algorithms,Ward’s method [222],is based not on linkage metric,but on an objective function used in k -means.The merger decision is viewed in terms of its effect on the objective function.The popular hierarchical clustering algorithm for categorical data COB-WEB [77]has two very important qualities.First,it utilizes incremental learn-ing.Instead of following divisive or agglomerative approaches,it dynamically builds a dendrogram by processing one data point at a time.Second,COB-WEB is an example of conceptual or model-based learning.This means that each cluster is considered as a model that can be described intrinsically,rather than as a collection of points assigned to it.COBWEB’s dendrogram is calleda classification tree.Each tree node(cluster)C is associated with the condi-tional probabilities for categorical attribute-values pairs,P r(x l=νlp|C),l=1:d,p=1:|A l|.This easily can be recognized as a C-specific Na¨ıve Bayes classifier.During the classification tree construction,every new point is descended along the tree and the tree is potentially updated(by an insert/split/merge/create op-eration).Decisions are based on the category utility[49]CU{C1,...,C k}=1j=1:kCU(C j)CU(C j)=l,p(P r(x l=νlp|C j)2−(P r(x l=νlp)2.Category utility is similar to the GINI index.It rewards clusters C j for in-creases in predictability of the categorical attribute valuesνlp.Being incre-mental,COBWEB is fast with a complexity of O(tN),though it depends non-linearly on tree characteristics packed into a constant t.There is a similar incremental hierarchical algorithm for all numerical attributes called CLAS-SIT[88].CLASSIT associates normal distributions with cluster nodes.Both algorithms can result in highly unbalanced trees.Chiu et al.[47]proposed another conceptual or model-based approach to hierarchical clustering.This development contains several different use-ful features,such as the extension of scalability preprocessing to categori-cal attributes,outliers handling,and a two-step strategy for monitoring the number of clusters including BIC(defined below).A model associated with a cluster covers both numerical and categorical attributes and constitutes a blend of Gaussian and multinomial models.Denote corresponding multivari-ate parameters byθ.With every cluster C we associate a logarithm of its (classification)likelihoodl C=x i∈Clog(p(x i|θ))The algorithm uses maximum likelihood estimates for parameterθ.The dis-tance between two clusters is defined(instead of linkage metric)as a decrease in log-likelihoodd(C1,C2)=l C1+l C2−l C1∪C2caused by merging of the two clusters under consideration.The agglomerative process continues until the stopping criterion is satisfied.As such,determina-tion of the best k is automatic.This algorithm has the commercial implemen-tation(in SPSS Clementine).The complexity of the algorithm is linear in N for the summarization phase.Traditional hierarchical clustering does not change points membership in once assigned clusters due to its greedy approach:after a merge or a split is selected it is not refined.Though COBWEB does reconsider its decisions,its。
构造地球化学找矿方法及其应用

找矿技术P rospecting technology构造地球化学找矿方法及其应用陈航华(广东省有色金属地质局九四〇队,广东 清远 511520)摘 要:在我国新发展形式下,地质矿产勘查技术不断发展创新,尤其是构造地球化学找矿方法,现已经被广泛应用。
将化学地球与构造地质理论融会贯通,应用到实际找矿工作中,理论结合实践,解决了以往矿产勘查中的种种困难,使找矿工作更加高效、准确。
本文从构造地球化学找矿工作原理着手,阐述利用构造地球化学找矿方法的发展历程和意义。
最后,对构造地球化学找矿方法的应用,以具体案例展开详细分析。
关键词:构造地球化学;找矿方法;实践应用;预测隐伏矿体中图分类号:P632 文献标识码:A 文章编号:1002-5065(2021)04-0070-2Structural geochemical prospecting method and its applicationCHEN Hang-hua(No.940 Branch of Nonferrous Metals Geological Bureau of Guangdong Province,Qingyuan 511520,China)Abstract: Under the new development form of China, the geological and mineral exploration technology has been developing and innovating, especially the tectonic geochemical prospecting method, which has been widely used. The combination of chemical earth and tectonic geology theory is applied to the actual prospecting work. The theory combined with practice solves the difficulties in the past mineral exploration, and makes the prospecting work more efficient and accurate. This paper starts with the principle of tectonic geochemical prospecting, and expounds the development process and significance of using the method of tectonic geochemical prospecting. Finally, the application of tectonic geochemical prospecting method is analyzed in detail with specific cases.Keywords: tectonic geochemistry; prospecting method; practical application; prediction of concealed ore bodies构造地球化学法是一种将地球化学和构造地质相结合的找矿新方法,同时研究地质构造组成和地质化学元素活化迁移及其运动内在规律。
《磁共振成像》杂志审稿流程和时间

coefficients. Radiology, 2011, 261(1): 182-192.[22] Dong TF, Mai H, Wei HH, et al. Gray level co-occurrence matrix basedon T2WI in differential diagnosis of benign and malignant ovarian solid tumors. Chin J Med Imaging Technol, 2018, 34(9): 1377-1380.董天发, 麦慧, 魏慧慧, 等. 基于常规T2WI灰度共生矩阵纹理参数鉴别诊断卵巢实性肿瘤良恶性. 中国医学影像技术, 2018, 34(9): 1377-1380.[23] Faschingbauer F, Beckmann MW, Goecke TW, et al. Automatic texture-based analysis in ultrasound imaging of ovarian masses. Ultraschall Med, 2013, 34(2): 145-150.[24] Aramendía-Vidaurreta V, Cabeza R, Villanueva A, et al. Ultrasoundimage discrimination between benign and malignant adnexal masses based on a neural network approach. Ultrasound Med Biol, 2016, 42(3):742-752.[25] Vargas HA, Veeraraghavan H, Micco M, et al. A novel representationof inter-site tumour heterogeneity from pre-treatment computed tomography textures classifies ovarian cancers by clinical outcome. Eur Radiol, 2017, 27(9): 3991-4001.[26] Rizzo S, Botta F, Raimondi S, et al. Radiomics of high-grade serousovarian cancer: association between quantitative CT features, residual tumour and disease progression within 12 months. Eur Radiol, 2018, 28(11): 4849-4859.[27] Pathak H, Kulkarni V. Identification of Ovarian mass through ultrasoundimages using machine learning techniques. New York: Ieee, 2015. [28] Su HF, Zhou GF, Xie CM, et al. The rise and development ofradioomics. Natl Med J Chin, 2015, 95(7): 553-556.苏会芳, 周国锋, 谢传淼, 等. 放射组学的兴起和研究进展. 中华医学杂志, 2015, 95(7): 553-556.[29] Chou QT, Duan JH, Gong GZ, et al. Research progress on radiomicsreproducibility. Chin J Radiat Oncol, 2018, 27(3): 327-330.仇清涛, 段敬豪, 巩贯忠, 等. 影像组学可重复性问题研究进展. 中华放射肿瘤学杂志, 2018, 27(3): 327-330.[30] Zhao B, Tan Y, Tsai WY, et al. Reproducibility of radiomics fordeciphering tumor phenotype with imaging. Sci Rep, 2016, 6: 23428. [31] Chen WJ, Giger ML, Bick U. A fuzzy c-means (FCM)-based approachfor computerized segmentation of breast lesions in dynamic contrast-enhanced MR images. Acad Radiol, 2006, 13(1): 63-72.[32] Velazquez ER, Aerts H, Gu YH, et al. A semiautomatic CT-basedensemble segmentation of lung tumors: Comparison with oncologists' delineations and with the surgical specimen. Radiother Oncol, 2012, 105(2): 167-173.[33] Galavis PE, Hollensen C, Jallow N, et al. Variability of texturalfeatures in FDG PET images due to different acquisition modes and reconstruction parameters. Acta Oncol, 2010, 49(7): 1012-1016.编读往来《磁共振成像》杂志审稿流程和时间《磁共振成像》杂志(Chinese Journal of Magnetic Resonance Imaging,ISSN 1674-8034,CN 11-5902/R),是由中华人民共和国国家卫生健康委员会主管、中国医院协会和首都医科大学附属北京天坛医院主办的学术期刊,创刊于2010年1月,创刊主编:美国医学科学院外籍院士戴建平教授。
脱落酸长距离运输的生物学意义和分子机制解析

脱落酸长距离运输的生物学意义和分子机制解析钦鹏,张国华,胡彬华,李仕贵*(四川农业大学水稻研究所,成都611130)摘要:【目的】水稻灌浆期高温严重影响其产量和品质,解析温度影响灌浆的分子机制,对保障水稻高产和优质意义重大。
【方法】利用水稻中一份温度敏感的灌浆缺陷突变体dg1,结合遗传、生理、生化和3H-ABA feeding 等技术方法,解析温度影响水稻灌浆的分子机制。
【结果】我们克隆了一个调控水稻籽粒灌浆的关键基因DG1。
DG1编码一个MATE 转运蛋白,该蛋白具有外排脱落酸(abscisic acid ,ABS )活性,在节和小花轴参与调控叶片到颖果的ABA 长距离运输。
高温通过诱导DG1高表达促进叶片到颖果的ABA 长距离转运,该长距离转运的ABA 诱导淀粉合成关键基因表达,从而确保高温下水稻籽粒正常灌浆。
相关研究成果以“Leaf-derived ABA regulates rice seed development via a transporter-mediated and temperature-sensitive mechanism ”为题于2021年1月发表在国际期刊Science Advances (10.1126/sciadv.abc8873)。
【结论】该成果揭示了DG1通过调控叶片到颖果ABA 长距离运输确保高温下种子正常发育的分子机制。
关键词:水稻;MATE 转运蛋白;脱落酸;长距离运输;温度响应中图分类号:S511文献标志码:A文章编号:1000-2650(2021)01-0001-03Revealing the Biological Significance and Molecular Mechanism ofAbscisic Acid Long-Distance Transport in PlantsQIN Peng ,ZHANG Guohua ,HU Binhua ,LI Shigui *(Rice Research Institute ,Sichuan Agricultural University ,Chengdu 611130,China )Abstract:【Objective 】Rice is easy to encounter to high temperature during grain filling period in sum -mer ,that seriously affects rice yield and quality.It is of great significance for ensuring high yield and good quality of rice to reveal the molecular mechanism of rice grain filling affected by temperature.【Method 】We take advantage of a rice temperature-sensitively defective grain-filling mutant ,named dg1(defective grain-filling 1)coupling with genetic ,physiological ,biochemical and 3H-ABA feeding meth -ods ,to analyze the molecular mechanism of rice grain filling affected by temperature.【Result 】We clonea key gene which regulates rice grain filling.DG1encodes a MATE transporter which has abscisic acid (ABS )efflux activity ,and regulates the leaf-to-caryopsis ABA long distance transport at node and rachilla.Higher temperature promotes the leaf-to-caryopsis ABA transport efficiency by inducing the ex -pression level of DG1.Such long-distance transported ABA ensure normal grain filling at high tempera -ture by inducing the expression of several key genes involved in starch synthesis.【Conclusion 】Publishedon Science Advances in January 2021with the title "Leaf-derived ABA regulates rice seed develop -ment via a transporter-mediated and temperature-sensitive mechanism"(10.1126/sciadv.abc8873)This result reveals the molecular mechanism that DG1ensures normal grain filling at higher temperature by第39卷第1期2021年2月收稿日期:2021-01-27基金项目:国家自然科学基金项目(31771759,31771760);科技部项目(2016ZX08001-003-005)。
基于Zernike矩和拼贴误差的布料图案检索算法

第41卷第2期贵州大学学报(自然科学版)Vol.41No.22024年 3月JournalofGuizhouUniversity(NaturalSciences)Mar.2024文章编号 1000 5269(2024)02 0053 07DOI:10.15958/j.cnki.gdxbzrb.2024.02.08基于Zernike矩和拼贴误差的布料图案检索算法张 琴 ,曹一青(莆田学院机电与信息工程学院,福建莆田351100)摘 要:为提高纺织品企业检索布料图案的效率,提出了一种基于Zernike矩和拼贴误差的布料图案检索算法(ZMCE)。
首先,通过计算选取最佳匹配时的分形参数和Zernike矩;其次,根据值域块与最佳匹配的定义域块之间的相似性度量计算拼贴误差;最后,将Zernike矩和拼贴误差作为布料图案检索的特征量进行特征提取。
实验结果表明,ZMCE算法的平均查准率、平均查全率和单张图案的检索时间分为88 6%、53 4%和0 207s,显著优于基本分形算法(BFC)、单一拼贴误差算法(SCE)和联合正交化分形参数和改进Hu不变矩算法(OFH),此外,ZMCE算法的平均查准率和查全率还优于文献[4]中的算法。
因此,ZMCE算法在纺织品行业布料图案检索方面具有良好的应用价值。
关键词:布料图案检索;拼贴误差;Zernike矩;分形编码中图分类号:TN919 8 文献标志码:A 纺织品行业中,布料图案的检索和分类依靠人工经验完成,效率较低、成本较高且准确率不高,无法满足高效准确地检索出特定布料图案的需求,因此,本文拟实现一种检索效果和效率兼具的布料花案图像检索算法。
布料图案的花纹相对繁杂,且图案拍摄过程不当可能会引起图像的角度随意和非平面结构等问题,这些问题给图像检索带来了一定的困难。
单一图像特征用于检索无法准确地描述布料图案的全部信息,导致检索准确率不高。
DING等[1]利用尺度不变特征变换(scale invariantfeaturetransform,SIFT)和高斯函数获取了畲族服装图像中的特征,并依据获得的特征对图像进行了分类,该方法可有效识别不同类别的畲族服装。
生物大分子的原位可视化和分子成像技术

生物大分子的原位可视化和分子成像技术随着科技的不断发展,生物学领域也在进行着革命性的变化,其中,原位可视化和分子成像技术的突飞猛进,引领着生物学研究的新方向。
生物大分子是构成生物体的基本单位,其功能涉及生命的各个方面。
然而,由于其微小的尺度和复杂的结构,使得人们很难准确捕捉其活动状态。
因此,科学家们致力于开发新的技术,以便能够更好地了解生物大分子的行为和特征。
原位可视化技术能够在生物样本内部,实时、高分辨地观察生物大分子复杂的结构和互动方式。
相较于以往的显微镜观察方法,原位可视化技术更能满足现代科学家对于非侵入性、高灵敏度、高精度、快速成像的要求。
其中比较流行的技术包括荧光显微成像技术、电子显微成像技术、近红外成像技术等。
荧光显微成像技术能够将标记染色的生物大分子视觉化,并且具有较高的时间分辨率和灵敏度。
电子显微成像技术可以在 nm 级别的分辨率下观察样本内部的细节。
近红外成像技术则可以在体内实现对生物分子的追踪和观察。
分子成像技术则是通过标记分子的方式,来获得关于该分子分布、形态、组成及动力学行为等信息的技术。
例如,蛋白质分子成像技术、核磁共振成像技术等,能够在细胞和组织水平上表征生物分子的本地化和相互作用。
通过这些技术,科学家们能够深度挖掘生物体内部的奥秘以及成像技术能够承载,不断探索更多的新领域。
自 2000 年来,大量生物大分子的原位成像研究涉及到神经科学、药物学、生态学等多个领域。
比如,在神经科学领域中,科学家们不断探究脑部中神经元的功能以及神经信号传输的机制。
近年来,基于原位成像技术的脑图谱研究取得了长足进展,对于人类脑部复杂结构的建立和我们对疾病的认识奠定了重要基础。
在药物学领域,分子成像技术还可以帮助人们更好地评估药物治疗效果及其生物代谢产物的分布及治疗效果。
总之,生物大分子的原位可视化和分子成像技术为我们提供了一个更准确、更细化、更可靠的观察生物的方式。
相信未来,在这方面的研究将会有更为广阔的空间,引领出更多有价值的成果,这也为生物学研究的不断推进创造了新的机遇。
A robust kernelized intuitionistic fuzzy c-means clustering algorithm

A robust kernelized intuitionistic fuzzy c-means clustering algorithm in segmentation of noisy medical imagesPrabhjot Kaur a ,⇑,A.K.Soni b ,1,Anjana Gosain c ,2aDepartment of Information Technology,Maharaja Surajmal Institute of Technology,C-4,Janakpuri,New Delhi 110058,India bDepartment of Computer Science,Sharda University,Greater Noida,Uttar Pradesh,India cDepartment of Information Technology,USIT,Guru Gobind Singh Indraprastha University,New Delhi,Indiaa r t i c l e i n f o Article history:Received 22March 2011Available online 4October 2012Communicated by S.SarkarKeywords:Fuzzy clusteringIntuitionistic fuzzy c-means Robust image segmentationRBF kernel based intuitionistic fuzzy c-meansFuzzy c-meansa b s t r a c tThis paper presents an automatic effective intuitionistic fuzzy c-means which is an extension of standard intuitionisitc fuzzy c-means (IFCM).We present a model called RBF Kernel based intuitionistic fuzzy c-means (KIFCM)where IFCM is extended by adopting a kernel induced metric in the data space to replace the original Euclidean norm metric.By using kernel function it becomes possible to cluster data,which is linearly non-separable in the original space,into homogeneous groups by transforming the data into high dimensional space.Proposed clustering method is applied on synthetic data-sets referred from various papers,real data-sets from Public Library UCI,Simulated and Real MR brain images.Experimental results are given to show the effectiveness of proposed method in contrast to conventional fuzzy c-means,pos-sibilistic c-means,possibilistic fuzzy c-means,noise clustering,kernelized fuzzy c-means,type-2fuzzy c-means,kernelized type-2fuzzy c-means,and intuitionistic fuzzy c-means.Ó2012Elsevier B.V.All rights reserved.1.IntroductionMany neurological conditions alter the shape,volume,and dis-tribution of brain tissue;magnetic resonance imaging (MRI)is the preferred imaging modality for examining these conditions.MRI is an important diagnostic imaging technique for the early detection of abnormal changes in tissues and organs.MRI possesses good contrast resolution for different tissues and has advantages over CT for brain studies due to its superior contrast properties.There-fore,the majority of research in medical image segmentation con-cerns MR images.Image segmentation plays an important role in image analysis and computer vision.The goal of image segmentation is partition-ing of an image into a set of disjoint regions with uniform and homogeneous attributes such as intensity,color,tone,etc.In images,the boundaries between objects are blurred and distorted due to the imaging acquisition process.Furthermore,object defini-tions are not always crisp and knowledge about the objects in a scene may be vague.Fuzzy set theory and fuzzy logic are ideally suited to deal with such uncertainties.Fuzzy sets were introduced in 1965by Lofti Zadeh with a view to reconcile mathematicalmodeling and human knowledge in the engineering sciences.Med-ical images generally have limited spatial resolution,poor contrast,noise,and non-uniform intensity variation.The fuzzy c-means (FCM)(Bezdek,1981),algorithm,proposed by Bezdek,is the most widely used algorithm in image segmentation.FCM is the exten-sion of the fuzzy ISODATA algorithm proposed by DUNN (Dunn,1974).FCM has been successfully applied to feature analysis,clus-tering,and classifier designs in fields such as astronomy,geology,medical imaging,target recognition,and image segmentation.An image can be represented in various feature spaces and the FCM algorithm classifies the image by grouping similar data points in the feature space into clusters.In case the image is noisy or dis-torted then FCM technique wrongly classify noisy pixels because of its abnormal feature data which is the major limitation of FCM.Various approaches are proposed by researchers to compen-sate this drawback of FCM.Dave proposed the idea of a noise cluster to deal with noisy data using the technique,known as noise clustering (Dave and Krishnapuram,1997).Another similar technique,PCM,proposed by Krishnapuram and Keller (1993)interpreted clustering as a pos-sibilistic partition.However,it caused clustering being stuck in one or two clusters.Yang and Chung (2009)developed a robust cluster-ing technique by deriving a novel objective function for FCM.Kang et al.(2009)proposed another technique which modified FCM objective function by incorporating the spatial neighborhood infor-mation into the standard FCM algorithm.Rhee and Hwang (2001)proposed type 2fuzzy clustering.Type 2fuzzy set is the fuzziness0167-8655/$-see front matter Ó2012Elsevier B.V.All rights reserved./10.1016/j.patrec.2012.09.015⇑Corresponding author.Tel.:+919810665064/9810165064.E-mail addresses:thisisprabhjot@ (P.Kaur),ak.soni@sharda.ac.in (A.K.Soni),anjana_gosain@ (A.Gosain).1Tel.:+919990021800.2Tel.:+919811055716.R E TRA CT E Din a fuzzy set.In this algorithm,the membership value of each pat-tern in the image is extended as type 2fuzzy memberships by assigning membership grades (triangular membership function)to type 1fuzzy membership.While discussing the uncertainty,another uncertainty arises,which is the hesitation in defining the membership function of the pixels of an image.Since the membership degrees are impre-cise and it varies on person’s choice,hence there is some kind of hesitation present which arises from the lack of precise knowledge in defining the membership function.This idea lead to another higher order fuzzy set called intuitionistic fuzzy set which was introduced by Atanassov ’s in 1983.It took into account the mem-bership degree as well as non-membership degree.Few works on clustering is reported in the literature on intuitionistic fuzzy sets.Zhang and Chen (2009)suggested a clustering approach where an intuitionistic fuzzy similarity matrix is transformed to interval valued fuzzy matrix.Recently,Chaira (2011)proposed a novel intuitionistic fuzzy c-means algorithm using intuitionistic fuzzy set theory.This algorithm incorporated another uncertainty factor which is the hesitation degree that aroused while defining the membership function.This paper proposes a new model called RBF kernel based intui-tionistic fuzzy c-means (KIFCM),which is an extension of intuition-istic fuzzy c-means (IFCM)by adopting a kernel induced metric in the data space to replace the original Euclidean norm metric.By replacing the inner product with an appropriate ‘kernel’function,one can implicitly perform a non-linear mapping to a high dimen-sional feature space in which the data is more clearly separable.The organization of the paper is as follows:Section 2,briefly re-view fuzzy c-means (FCM),type-2fcm (T2FCM)(Rhee and Hwang,2001)and intutionistic fuzzy c-means (IFCM)(Chaira,2011),possi-bilistic c-means (PCM),possibilistic fuzzy c-means (PFCM),and noice clustering (NC).Section 3describes the proposed algorithm;RBF kernel based intuitionistic fuzzy c means (KIFCM).Section 4evaluates the performance of the propose algorithm using syn-thetic data-sets,simulated and real medical images followed by concluding remarks in Section 5.2.Background informationThis section briefly discusses the fuzzy c-means (FCM),type-2fuzzy c-means,and intuitionistic fuzzy c means (IFCM),PCM,PFCM,and NC algorithms.In this paper,the data-set is denoted by ‘X ’,where X ={x 1,x 2,x 3,...,x n }specifying an image with ‘n ’pixels in M -dimensional space to be partitioned into ‘c ’clusters.Centroids of clusters are denoted by v i and d ik is the distance between x k and v i .2.1.The fuzzy c means algorithm (FCM)FCM is the most popular fuzzy clustering algorithm.It assumes that number of clusters ‘c ’is known in priori and minimizes the objective function (J FCM )as:J FCM¼X c i ¼1X n k ¼1u m ik d 2ikð1Þwhere d ik =k x k Àv i k ,and u ik is the membership of pixel ‘x k ’in clus-ter ‘i ’,which satisfies the following relationship:Xc i ¼1u ik ¼1;i ¼1;2;...;nð2ÞHere ‘m ’is a constant,known as the fuzzifier (or fuzziness index),which controls the fuzziness of the resulting partition.Any norm kÁk can be used for calculating d ik .Minimization of J FCM is performed by a fixed point iteration scheme known as the alternating optimi-zation technique.The conditions for local extreme for (1)and (2)are derived using Lagrangian multipliers:u ik ¼1P cj ¼1d ikd jk28k ;i ð3Þwhere 16i 6c ;16k 6n andv i¼P n k ¼1u m ik x kÀÁP n k ¼1u m ikÀÁ8i ð4ÞThe FCM algorithm iteratively optimizes J FCM (U ,V )with the con-tinuous update of U and V ,until j U (l +1)–U (l )j 6e ,where ‘l ’is the number of iterations.FCM works fine for the images which are not corrupted with noise but if the image is noisy or distorted then it wrongly classifies noisy pixels because of its abnormal feature data which is pixel intensity in the case of images,and results in an incorrect membership and improper segmentation.2.2.The type-2fuzzy c-means algorithm (T2FCM)Rhee and Hwang (2001)extended the type-1membership val-ues (i.e.membership values of FCM)to type-2by assigning a mem-bership function to each membership value of type-1.Their idea is based on the fact that higher membership values should contribute more than smaller memberships values,when updating the cluster centers.Type-2memberships can be obtained as per following equation:a ik ¼u ik À1Àu ik2ð5Þwhere a ik and u ik are the type-2and type-1fuzzy membership respectively.From (5),the type-2membership function area can be considered as the uncertainty of the type-1membership contri-bution when the center is updated.Substituting (5)for the mem-berships in the center update equation of the conventional FCM method gives the following equation for updating centers.v i¼P n k ¼1ða ik Þmx kP n k ¼1ða ik Þmð6ÞDuring the cluster center updates,the contribution of a pattern that has low memberships to a given cluster is relatively smaller when using type-2memberships and the memberships may represent better typicality.Cluster centers that are estimated by type-2mem-berships tend to have more desirable locations than cluster centers obtained by type-1FCM method in the presence of noise.T2FCM algorithm is identical to the type-1FCM algorithm except Eq.(6).At each iteration,the cluster center and membership matrix are up-dated and the algorithm stops when the updated membership and the previous membership i.e.max ik a new ik Àa pre vik <e ;e is a user defined value.Although T2FCM has proven effective for spherical data,it fails when the data structure of input patterns is non-spherical and complex.2.3.The intuitionistic fuzzy c-means algorithm (IFCM)Intuitionistic fuzzy c-means clustering algorithm is based upon intuitionistic fuzzy set theory.Fuzzy set generates only member-ship function l (x ),x 2X ,whereas intutitionistic fuzzy set (IFS)given by Atanassov considers both membership l (x )and non-membership v (x ).An intuitionistic fuzzy set A in X ,is written as:A ¼f x ;l A ðx Þ;v A ðx Þj x 2X gwhere l A (x )?[0,1],v A (x )?[0,1]are the membership and non-membership degrees of an element in the set A with the condition:06l (x )+v A (x )61.164P.Kaur et al./Pattern Recognition Letters 34(2013)163–175R E TRA CT E DWhen v A (x )=1Àl A (x )for every x in the set A ,then the set A be-comes a fuzzy set.For all intuitionistic fuzzy sets,Atanassov also indicated a hesitation degree,p A (x ),which arises due to lack of knowledge in defining the membership degree of each element x in the set A and is given by:p A ðx Þ¼1Àl A ðx ÞÀv A ðx Þ;06p A ðx Þ61:Due to hesitation degree,the membership values lie in the interval½l A ðx Þ;l A ðx Þþp A ðx ÞIntuitionistic fuzzy c-means (Chaira,2011)objective func-tion contains two terms:(i)modified objective function ofconventional FCM using Intuitionistic fuzzy set and (ii)intui-tionistic fuzzy entropy (IFE).IFCM minimizes the objective function as:J IFCM¼X c i ¼1X n k ¼1u Ãm ik d 2ik þXc i ¼1p Ãi e 1Àp Ãi ð7Þu Ãik ¼u ik þp ik ,where u Ãik denotes the intuitionistic fuzzy member-ship and u ik denotes the conventional fuzzy membership of the k th data in i th class.p ik is hesitation degree,which is defined as:p ik¼1Àu ik À1Àu a ikÀÁ1=a;a >0;and is calculated from Yager’s intuitionistic fuzzy complement as under:N (x )=(1Àx a )1/a ,a >0,thus with the help of Yager’s intuitionis-tic fuzzy compliment,intuitionistic fuzzy set becomes:A IFS k ¼f x ;l A ðx Þ;ð1Àl A ðx Þa Þ1=a j x 2X g ð8Þandp Ãi¼1N X nk ¼1p ik ;k 2½1;NSecond term in the objective function is called intuitionistic fuzzy entropy (IFE).Initially the idea of fuzzy entropy was given by Zadeh in 1969.It is the measure of fuzziness in a fuzzy set.Similarly in the case of IFS,intuitionistic fuzzy entropy gives the amount of vague-ness or ambiguity in a set.For intuitionistic fuzzy cases,if l A (x i ),v A (x i ),p A (x i )are the membership,non-membership,and hesitation degrees of the elements of the set X ={x 1,x 2,...,x n },then intuition-istic fuzzy entropy,IFE that denotes the degree of intuitionism in fuzzy set,may be given as:IFE ðA Þ¼X n i ¼1p A ðx i Þe ½1Àp A ðx i Þwhere p A (x i )=1Àl A (x i )Àv A (x i ).IFE is introduced in the objective function to maximize the good points in the class.The goal is to minimize the entropy of the his-togram of an image.Modified cluster centers are:v Ãi¼P n k ¼1u Ãik x kP n k ¼1u Ãikð9ÞAt each iteration,the cluster center and membership matrix are up-dated and the algorithm stops when the updated membership and the previous membership i.e.max ik U Ãnew ik ÀU Ãpre vik <e ;e is a user defined value.2.4.Possibilistic c-means clustering (PCM)To avoid the noise sensitivity problem of FCM,Krishnapuram and Keller (1993)relaxed the column sum constraintXc k ¼1u ki ¼1;i ¼1;2;...;nin case of FCM and proposed a possibilistic approach to clustering by minimizing objective function as:J PCM ðU ;V Þ¼X c k ¼1X n i ¼1u m ki d 2ki þX c k ¼1g k Xn i ¼1ð1Àu ki Þmwhere g k are suitable positive numbers.The first term tries to re-duce the distance from data points to the centroids as low as possi-ble and second term forces u ki to be as large as possible,thus avoiding the trivial solution.The updating of centroids is same as that in FCM but the membership matrix of PCM is updated as:u ki ¼11þk x i Àv k k 2g k1m À1PCM sometimes helps when data is noisy.It is very much sensitive to initializations and sometimes results into overlapping or identi-cal clusters.2.5.Possibilistic fuzzy c-means clustering (PFCM)Pal et al.(2005)integrates the fuzzy approach with the possibi-listic approach and hence,it has two types of memberships,viz.a possibilistic (t ki )membership that measures the absolute degree of typicality of a point in any particular cluster and a fuzzy member-ship (u ki )that measures the relative degree of sharing of point among the clusters.PFCM minimizes the objective function as:J PFCM ðU ;V ;T Þ¼X c k ¼1X n i ¼1au m ki þbt g kiÀÁd 2ki þX c k ¼1c k X n i ¼1ð1Àt ki Þg subject to the constraint thatXc k ¼1u ki ¼18i Here,a >0,b >0,m >1,and g >1.The constants ‘a ’and ‘b ’define therelative importance of fuzzy membership and typicality values in the objective function.The minimization of objective function gives the following conditions:u ki ¼1P cj ¼1d kiji2m À18k ;iandt ki ¼11þbc kd 2ki1g À18kandv k¼P n i ¼1au m ki þbt g ki ÀÁx iP n i ¼1au m ki þbt g kiÀÁThough PFCM is found to perform better than FCM and PCM but when two highly unequal sized clusters with outliers are given,it fails to give desired results.2.6.Noise clustering (NC)Noise clustering was introduced by Dave and Krishnapuram (1997)to overcome the major deficiency of the FCM algorithm i.e.its noise sensitivity.He gave the concept of ‘‘noise prototype’’,which is a universal entity such that it is always at the same dis-tance from every point in the data-set.Let ‘v k ’be the noiseP.Kaur et al./Pattern Recognition Letters 34(2013)163–175165R E TRA CT E Dprototype and ‘x i ’be any point in the data-set such that v k ;x i C ÀÀRp .Then noise prototype is the distance,d ki ,given by:d ki ¼d ;8iThe NC algorithm considers noise as a separate class.The member-ship u ⁄i of x i in a noise cluster is defined asu Ãi ¼1ÀXc k ¼1u ki NC reformulates FCM objective function as:J NC ðU ;V Þ¼X c þ1k ¼1X N i ¼1u m ki d 2kiwhere ‘c +1’consists of ‘c ’good clusters and one noise cluster andfor k =n =c +1.d 2¼kPck ¼1P Ni ¼1ðd ki Þ2Nc"#and membership equation is:u ji ¼X k ¼c k ¼1d 2ji d ki!1m À1þd 2ji d !1m À10@1A À1Noise clustering is a better approach than FCM,PCM,and PFCM.Although,it identifies outliers in a separate cluster but does not re-sult into efficient clusters because it fails to identify those outliers which are located in between the regular clusters.Its main objec-tive is to reduce the influence of outliers on the clusters rather than identifying it.Real-life data-sets usually contain cluster structures that differ from our assumptions so a clustering technique should be independent of the number of clusters for the same data-set.In NC,noise distance is given as:d 2¼kPc i ¼1P N k ¼1ðd ik Þ2Nc"#Here,noise distance depends upon distance measure,number of as-sumed clusters,and k ,which is the value of multiplier used to obtain ‘d ’,from the average of distances.From the equation,it is interpreted that if the number of clusters is increased,d assumes high values.NC assigns only those points to noise cluster whose distance from reg-ular clusters is less than the distance from noise distance,d .If the number of clusters is increased for the same data-set,NC does not detect outliers,because in that scenario,the average distance be-tween points and regular clusters decreases and the noise distance remains almost constant or assumes relatively high values.3.The proposed algorithm,radial basis kernel based intuitionistic fuzzy c-means (KIFCM)3.1.Kernel based approachThe present work proposes a way of increasing the accuracy of the intuitionistic fuzzy c-means by exploiting a kernel function in calculating the distance of data point from the cluster centers i.e.mapping the data points from the input space to a high dimen-sional space in which the distance is measured using a radial basis kernel function.The kernel function can be applied to any algorithm that solely depends on the dot product between two vectors.Wherever a dot product is used,it is replaced by a kernel function.When done,lin-ear algorithms are transformed into non-linear algorithms.Those non-linear algorithms are equivalent to their linear originals oper-ating in the range space of a feature space u .However,becausekernels are used,the u function does not need to be ever explicitly computed.This is highly desirable,as sometimes our higher-dimensional feature space could even be infinite-dimensional and thus infeasible to compute.A kernel function is a generalization of the distance metric that measures the distance between two data points as the data points are mapped into a high dimensional space in which they are more clearly separable.By employing a mapping function U (x ),which defines a non-linear transformation:x ?U (x ),the non-linearly separable data structure existing in the original data space can pos-sibly be mapped into a linearly separable case in the higher dimen-sional feature space.Given an unlabeled data set X ={x 1,x 2,...,x n }in the p -dimen-sional space R P ,let U be a non-linear mapping function from this input space to a high dimensional feature space H :U :R p !H ;x !U ðx ÞThe key notion in kernel based learning is that mapping func-tion U need not be explicitly specified.The dot product in the high dimensional feature space can be calculated through the kernel function K (x i ,x j )in the input space R P .K ðx i ;x j Þ¼U ðx i ÞÁU ðx j ÞConsider the following example.For p =2and the mapping function U ,U :R 2!H ¼R 3ðx i 1;x i 2Þ!x 2i 1;x 2i 2;ffiffiffi2p x i 1x i 2Then the dot product in the feature space H is calculated asU ðx i ÞÁU ðx j Þ¼x 2i 1;x 2i 2;ffiffiffi2p x i 1x i 2 Áx 2j 1;x 2j 2;ffiffiffi2p x j 1x j 2¼x 2i 1;x 2i 2ÀÁÁx 2j 1;x 2j 22¼ðx i Áx j Þ2¼K ðx i ;x j Þwhere K -function is the square of the dot product in the input space.We saw from this example that use of the kernel function makes it possible to calculate the value of dot product in the feature space H without explicitly calculating the mapping function U .Some exam-ples of kernel function are:Example 1.Polynomial kernel :K (x i ,x j )=(x i Áx j +c )d ,where c P 0,d 2N .Example 2.Gaussian kernel :K ðx i ;x j Þ¼exp Àk x i Àx j k 22r 2,where r >0.Example 3.Radial basis kernel :K ðx i ;x j Þ¼exp ÀP x a i Àx a j br 20B@1C A ,where r ,a ,b >0.RBF function with a =1,b =2reduces to Gaussian function.Example 4.Hyper tangent kernel :K ðx i ;x j Þ¼1Àtanh Àk x i Àx j k 2r 2,where r >0.3.2.FormulationOur propose model RBF kernel based Intuitionistic fuzzy c-means (KIFCM)adopts a kernel induced metric which is different from the Euclidean norm in the original intuitionistic fuzzy c-means.KIFCM minimizes the objective function:J KIFCM ¼2X c i ¼1X n k ¼1u Ãm ik k U ðx k ÞÀU ðv i Þk 2þX c i ¼1p Ãi e 1Àp Ãi ð10Þwhere k U (x k )ÀU (v i )2k is the square of distance between U (x i )andU (v k ).The distance in the feature space is calculated through the kernel in the input space as follows:166P.Kaur et al./Pattern Recognition Letters 34(2013)163–175R E TRA CT E D1.(a–c)shows Clustering result of NC with k =0.6,KFCM with h (kernel width)=6and KIFCM with h =6,a =2,b =4.2,a =7with Diamond data-set (d–f)shows Clustering result of NC with k =0.17,KFCM with h (kernel width)=100and KIFCM with h =300,a =2,b =2,a =3with Bensaid data-set (g–i)shows result of NC with k =0.17,KFCM with h (kernel width)=55,a =2,b =2.6and KIFCM with h =55,a =2,b =3,a =0.7with non-linear data-set.Centroids are shown with ‘⁄’symbol and the clusters differentiated with ‘.’and ‘+’and ‘Â’symbol.Noise in detected with ‘o’.R E TRA CT Eu Ãik ¼1ð1ÀK ðx k ;v i ÞÞ1m À1P c i ¼11k v i1m À1ð12Þv i¼P n k ¼1u Ãmik ÂK ðx k ;v i ÞÂx k P n k ¼1u Ãmik ÂK ðx k ;v i Þð13ÞProof.We differentiate J KIFCM with respect to u Ãik and v i and set the derivatives to zero.Thus,we get (12)and (13).The details are given in Appendix A .h3.3.Steps involved in KIFCM areRadial basis kernel based intuitionistic fuzzy c-means clustering Input parameters:Image data (X ),number of clusters (K =c +1),number of iterations,stopping criteria ðC ÀÀÞ.Output :Cluster centroids matrix,membership matrix.Step 1:Get data from image.Step 2:Select initial prototypes.Step 3:Obtain the memberships using (12).Step 4:Update the prototypes using (13).Step 5:Update the memberships using (12)with updated prototypes.Step 6:Repeat steps (3)–(5)till the updated membershipsatisfies the condition:u ðt þ1Þik Àu t ik<e 8i ;k is met for successive iterations t and t +1where e is a small number.4.Simulations and resultsIn this section,experimental results are presented to compare the segmentation performance of radial basis kernel based intui-tionistic fuzzy c-means (KIFCM)with FCM,PCM,PFCM,NC,KFCM,T2FCM,KT2FCM and IFCM.Experiments are implemented and sim-ulated using MATLAB Version 7.0.We considered following com-mon parameters:m =2,which is a common choice for fuzzy clustering,e =0.03,a =0.85for IFCM (as referred in (Chaira,2011)),and maximum iterations =200.We used RBF kernel for the kernelized methods.Note that the kernel width ‘h ’in RBK ker-nel has a very important effect on the performances of the algo-rithms.However,how to choose an appropriate value for the kernel width in RBF kernel is still an ‘‘open problem’’.In this paper,we adopt the ‘‘trial-and-error’’technique to find the kernel width.We used synthetic data-set,standard data-sets,and real medical images for the experiments.4.1.Synthetic data-setsThree synthetic data-sets,diamond (D12)data set (referred from Pal et al.(2005)),BENSAID Data-set (Bensaid et al.,1996)and Non-linear synthetic data-set are considered in this section.Diamond Data-set,D11,D12(referred from Pal et al.(2005)).D11is a noiseless data-set of points f x i g 11i ¼1.D12is the union of D11and an outlier x12.BENSAID’s two-dimensional data-set con-sists of one big and two small size clusters.We have saved the structure of this set but have increased count of core points and added uniform noise to it,which is distributed over the region [0,120]Â[10,80].To evaluate the effect of non-linear data struc-ture,a synthetic non-linear data-set consisting of one circularand one elliptic cluster is considered.All the seven algorithms,FCM,IFCM,PCM,PFCM,NC,KFCM,KIFCM are implemented with these data-sets to check the performance.For diamond data-set,it is observed that FCM,IFCM,PCM,and PFCM could not detect the original clusters and their performance is badly affected with the presence of noise,NC and KFCM detected the clusters but the centroid location is still affected with noise.To show the effectiveness of the proposed algorithm,we also calcu-lated the error for recognizing correct cluster centers in case of Dia-mond Data-set with the equation E ⁄=k V ideal ÀV ⁄k 2,where ⁄is PCM/PFCM/NC/KFCM/KIFCM.The ideal (true)centroids of Dia-mond data-set are:V ideal ¼À3:3403:34!FCM and IFCM could not detect the clusters.Average error with PCM,PFCM,NC,KFCM and KIFCM is 11.17,11.82,0.077,0.0362and 0.003respectively.Fig.1shows the clustering results with three best performed algorithms (NC,KFCM and KIFCM)for all the three data-sets.Clearly after observing the results of Fig.1and considering the error percentage,it is observed that proposed method can produce more accurate centroids than other methods and is highly robust against noise.In case of BENSAID data-set PCM,PFCM and NC could not detect the original clusters and the performance of FCM and KFCM is af-fected with the presence of noise.Best performance is achieved in the case of IFCM and KIFCM and the results are not much af-fected as in other cases.In case of non-linear data-set,all the algorithms except KFCM and KIFCM could not detect the elliptical cluster.KFCM although detected the elliptical cluster but misaligned some members of the elliptical cluster into the circular cluster,whereas KIFCM cor-rectly partitioned all the data points.4.1.1.Performance evaluation based upon misclassificationsTo verify the performance of seven algorithm based upon mis-classifications,we calculated their scores defined by the following quantitative index (Masulli and Schenone,1999).r ij ¼A ij \A refj ij refjwhere A ij represents the set of pixels belonging to the j th class found by the i th algorithm and A refj represents the set of pixels belonging to the j th class in the reference segmented image.r ij is a fuzzy similarity measure,indicating the degree of equality be-tween A ij and A refj ,and the larger the r ij ,the better the segmentation is.Table 1lists the misclassifications and comparison scores using seven methods.From Fig.1and Table 1,we observed that although many algo-rithms out of seven detected the right clusters in case of diamond and Bensaid data-set but in case of synthetic non-linear data-set no algorithm except KIFCM detected the original clusters.Apart from that,in case of numerical data-sets,location of cluster centers is the major criteria to compare various algorithms.So considering these points into view,we can say that KIFCM outperformed the other six algorithms.4.2.Real data setsFour real data-sets,Wisconsin Breast cancer,iris,Wine and PIDD (Pima Indians Diabetes database)from public data-bank UCI (UC Irvine Machine Learning Repository)are used to evaluate the performance of these algorithms.168P.Kaur et al./Pattern Recognition Letters 34(2013)163–175R E TRA CT E D。
Fuzzy值可测函数及其构造(英文)

Fuzzy值可测函数及其构造(英文)
何家儒
【期刊名称】《四川师范大学学报:自然科学版》
【年(卷),期】1992(000)001
【摘要】本文引入了Fuzzy值可测函数而且讨论了它的构造.
【总页数】6页(P40-45)
【作者】何家儒
【作者单位】四川师范大学数学系
【正文语种】中文
【中图分类】O159
【相关文献】
1.L-Fuzzy集合上的Fuzzy值函数关于Fuzzy值Fuzzy测度的Fuzzy值Fuzzy积分 [J], 张广全
2.Fuzzy值函数关于Fuzzy值Fuzzy测度的Fuzzy值Fuzzy积分的若干性质 [J], 张广全
3.Fuzzy值可测函数及其构造 [J], 何家儒
4.Fuzzy-Val模糊值Choquet积分(Ⅱ)——函数关于模糊值模糊测度的Choquet 积分(英文) [J], 郭彩梅;张德利
5.论域为R^n的Fuzzy值可测函数 [J], 吴孟达
因版权原因,仅展示原文概要,查看原文内容请购买。
深入详细地讲解邹至庄检验

一、问题提出:我们经常碰到这样的问题。某项政策的出台及实施,其效果如何?不同 地区或不同时期内,我们分别可以得到这两个地区或时期的观测值,我们的问题是:这两个 地区或时期的情况是否不同,经济结构有无差异。 这类问题,被华人经济学家邹至庄用构造的 F 检验解决了(1960 年) 。这样的 F 检验的 统计量,就称为邹至庄检验(Chou-Test) 。 二、问题的模型表述 设 ( Z1 Y1 ), ( Z 2 Y2 ) 分别表示这两个时期的观测值,允许两个时期中系数不同的无约束回 Y Z1 1 1 归是 1 ,我们可以将其改写成一个回归方程 Y2 Z 2 2 2
Z 'Z b ( Z Z ) 1 Z Y 1 1 0
0 Z1'Y1 ( Z1' Z1 ) 1 ' ' Z2 Z2 Z2 Y2 0
1
Z1'Y1 b1 ' ' (Z 2 Z 2 ) 1 Z 2 Y2 b2 0
则
e*' e*
2
~ 2 (n1 n2 k ) ……(4)
Y Y e*' e* ee (Y1'Y2' )( M 2 M 1 ) 1 @ (Y1'Y2' ) M 3 1 Y2 Y2
问
服从和分布? 2 首先证明: M 3 M 1 0
是独立的,所以 F
e*' e* ee ~ F (k , n1 n2 2k ) ee
这个就是邹至庄检验统计量(Chou-Test) 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Geometrically Guided Fuzzy C-means Clustering for Multivariate ImageSegmentationJ.C.Noordam Agrotechnological Research Institute(ATO),dep.P&CS, P.O.Box17,6700AA Wageningen,the Netherlands J.C.Noordam@ato.wag-ur.nlW.H.A.M.van den BroekAgrotechnological ResearchInstitute(ATO),dep.P&CS,P.O.Box17,6700AAWageningen,the NetherlandsW.H.A.M.vandenBroek@ato.wag-ur.nlL.M.C.BuydensLab.for Anal.Chem,University of Nijmegen,Toernooiveld1,6525ED Nijmegenthe NetherlandsL.Buydens@sci.kun.nlAbstractFuzzy C-means(FCM)clustering is an unsupervised clustering technique and is often used for the unsupervised segmentation of multivariate images.The segmentation of the image in meaningful regions with FCM is based on spec-tral information only.The geometrical relationship between neighbouring pixels is not used.In this paper,a semi-supervised FCM technique is used to add geometrical in-formation during clustering.The local neighbourhood of each pixel determines the condition of each pixel,which guides the clustering process.Segmentation experiments with the Geometrically Guided FCM(GG-FCM)show im-proved segmentation above traditional FCM such as more homogeneous regions and less spurious pixels.1.IntroductionThe use of Fuzzy C-Means clustering to segment a mul-tivariate image in meaningful regions has been reported in literature[4,2].It is known as an unsupervised fuzzy clus-tering technique and uses the measurement data only in or-der to reveal the underlying structure of the data and seg-ment the image in regions with similar spectral properties. When FCM is applied as a segmentation technique in im-age processing,the relationship between pixels in the spatial domain is completely ignored.The partitioning of the mea-surement space depends on the spectral information only. As multivariate imaging offers possibilities to differentiate between both objects of similar spectra and different spatial correlations,FCM can never utilise this property.Adding spatial information during the spectral clustering has ad-vantages above a spectral segmentation procedure followed by a spatialfilter,as the spatialfilter cannot always correct segmentation errors.Furthermore,when two overlapping clusters in the spectral domain correspond to two differ-ent objects in the spatial domain,usage of a-priori spatial information can improve the separation of these two over-lapping clusters[3].In this paper,a modification of the unsupervised fuzzy clustering technique[5],is utilised to guide the clustering process by adding a-priori geometri-cal information in order to improve thefinal segmentation results.During each iteration step of the FCM,a condi-tion for each pixel is updated.This condition is based on the membership values of neighbouring pixels in the spatial domain.Thus,the Geometrically Guided FCM(GG-FCM) swaps between the spectral domain and the spatial domain during the clustering process.The principle of geometrical guided FCM presented in this paper uses merely local spa-tial neighbourhood and is therefore considered as afirst step to more sophisticated algorithms to search for a specific ge-ometric shape during clustering.2.Fuzzy C-Means Clustering with partial su-pervisionIn this paragraph,the standard Fuzzy C-means clustering and the modified version of FCM with partial supervision are considered.2.1.Fuzzy C-Means ClusteringGiven a set of data patterns,,the FCM algorithm minimises the weighted within group sum of squared error objective function[1]:(1)where is the--dimensional data vector,is the prototype of the centre of cluster,is the degree of membership of in the-cluster,is a weighting ex-ponent on each fuzzy membership,is a distance measure between object and cluster centre,is the number of objects and is the number of clusters.A solu-tion of the objective function can be obtained via an iterative process where the degrees of membership and the cluster centres are updated via:(2) with the constraints:(3)2.2.Fuzzy C-Means Clustering with partial super-visionClustering is usually seen as an unsupervised routine where no information about the underlying structure of the patterns is known.In cases where clustering is used and some labelled patterns are available,it might be advanta-geous to use these labelled patterns to influence the cluster-ing process.In literature[5],this idea is used and resulted in a modified objective function:(4)Here,is a scaling factor to maintain a balance between the supervised and unsupervised data.It is suggested that this scaling factor is proportional to the ratio unlabeled/labelled data.The variable in the second term represents the membership of the labelled pattern to cluster.Variable is a Boolean variable to distinguish between labelled and unlabeled patterns.If the Boolean variable is zero,the objective function returns to the standard objective function for FCM.This is identical when is set to zero for all clusters.The update procedure for the partition matrixis now changed into:(5)In this paper,the term condition is used to indicate the vari-able instead of membership value,to avoid confusion with the membership values,3.Geometrical Guided FCM(GG-FCM)In literature[5],the values of and arefixed and are manually set beforehand.In the method presented in this paper,the values of are allowed to change and are up-dated during the clustering process.As stated in the previ-ous paragraph,the Boolean variable indicates if labelled patterns are available.If this is not the case,the Boolean is set to zero and the update equation(5)returns to the stan-dard update equation(2)for FCM.However,if the condi-tion is set to zero for all clusters,the result is similar and equation5returns also the standard update equation(2)for FCM(in both situations,the scaling factor is left over).In the algorithm presented in this paper,the Boolean variable is set to1for all objects and the condition is used to guide the clustering process.This means that if the condi-tion is set to zero for cluster,the partition update equa-tion reduces to the update equation of standard FCM(equa-tion2).This approach avoids the use of an extra condition to determine which objects should be considered as labelled and which objects not.Now,all objects are considered as labelled and only the condition determines the enhance-ment or weakening of object for cluster.High values of will enhance the membership of the pixel for class and low values will weaken the membership for class.3.1.Fuzzy neighbourhoodDuring the clustering procedure,the membership values of surrounding neighbouring pixels determine the value of condition of each pixel.The value of the condition is a measure of similarity for a pixel compared to surround-ing neighbours.The value of the condition is low when the surrounding pixels have similar membership values and the condition is high when surrounding pixels have devi-ate membership values.As a result,membership values of spurious pixels in the spatial domain can be influenced in-directly when their neighbours have different membership values.The number of rows in the partition matrix is equal to the number of rows times the number of columns of the original image.Each column in the partition matrix can be rearranged to an image,which is called a partition image.For each pixel in partition image,the mean mem-bership deviation()compared to the memberships of neighbouring pixels is determined:(6)where is the mean membership deviation for the pixel at position of partition image,is the current cluster,is a neighbourhood window with(odd)size, is the degree of membership of the neighbour pixelat position()in the window of partition image, is the degree of membership of the centre pixel in the window of partition image.It is clear that for a homo-geneous region the average membership deviation will be zero.To determine for which cluster the current pixel must be enhanced,the membership values covered by the neigh-bourhood window are added for each cluster.The cluster with the highest sum is considered as the cluster the centre pixel belongs to.For this particular pixel,the conditionis enhanced with the mean membership deviation. The condition is weakened with the mean membership for all remaining clusters.4.ExperimentsTo show the improvements of the geometrical guided FCM compared to traditional FCM,experiments have been carried out on synthetic and real world images.The syn-thetic image demonstrates the principle of the geometri-cally guided clustering and the real-world image demon-strates that the algorithm performs well on real images.Af-ter the clustering procedure,the fuzzy images are converted to crisp images by applying the maximum membership pro-cedure.This means that an object is classified to the cluster with highest membership.4.1.Experiment on synthetic imageThefirst experiment is carried out on a synthetic image consisting of two squares of similar colour(R=150,G=50, B=50)on a background(R=125,G=75,B=50).The amount of foreground pixels is equal to the amount of background pixels.The image is contaminated with Gaussian noise()to simulate cluster overlap.A3x3win-Figure 1.RGB-image with Gaussian noise(left),FCM segmented image(middle)andGG-FCM segmented image(right)dow contains the a-priori information of single distributed pixels.The segmentation results are shown infigures1 and2.The plot infigure2shows the partitioning of the measurement space with traditional FCM.The plot shows two well separated clusters.However,the segmented im-age infigure1(middle)shows that foreground objects are contaminated with background pixels and vice versa.Due to the added noise,background pixels have shifted to the foreground cluster and foreground pixels have shifted to the background cluster.As the traditional FCM uses no in-formation from the spatial domain,this result is to be ex-pected.Figure1(right)shows the segmented image andFigure2.FCM result:the Red versus Greenplot.The cross hair represents the centre ofa clusterFigure 3.GG-FCM result:the Red versusGreen plot.The cross hair represents thecentre of a clusterfigure3shows the plot of GG-FCM.The improvement of the segmentation due to the extra spatial information is ob-vious,the two foreground squares and the background are almost perfectly segmented.The plot infigure3showsthat foreground pixels appear in the background cluster and vice versa.This cluster overlap is a result of the added a-priori spatial information which directs spurious pixels to the other class.4.2.Experiment on real world imageA second experiment is carried out on a classical image in pattern recognition,referred to as the peppers image.ToFigure4.Original peppers image. illustrate the improvement,a sub-image is considered(Fig-ure4).For the initialisation of the FCM routines,5classes are initiated.No noise is added to the image.A3x3win-dow is selected during the GG-FCM clustering.Theim-Figure5.Peppers image segmented by FCM. age shown infigure5is segmented by the standard FCM. It shows that some of segmented regions are enveloped by spurious edges.Most of these spurious envelopes are sev-eral pixels wide.The spurious edges are removed in the image segmented by the GG-FCM,shown infigure6.The extra spatial information sees to it that spurious edgepixelsFigure6.Peppers image segmented by GG-FCM.are merged with the class of the surrounding pixels.The segmented regions are more homogeneous and spurious lit-tle blobs are removed from the segmented image.5.Conclusions and further researchIn this paper,a technique to guide the clustering process of the FCM based on geometrical information is presented. The use of Geometrically Guided FCM as an image seg-mentation process clearly shows improvements above clus-tering with traditional FCM.The addition of a-priori infor-mation from the spatial domain makes it possible to inter-vene in the clustering process and guide the clustering.The segmented images show more homogenous regions in com-parison with standard FCM,which uses no spatial informa-tion.Currently,a local neighbourhood window is used to determine the condition,but the addition of more sophisti-cated techniques to search for a specific shape in the image will be the topic for further research.References[1]J.Bezdek.Pattern recognition with fuzzy objective functions.Plenum Press,New York,1981.[2]J.Bezdek,L.Hall,and L.Clarke.Review of mr imagesegmentation techniques using pattern recognition.Medical Physics,20(4),1993.[3]J.C.Noordam and W.H.A.M.van den Broek.Multivariateimage segmentation based on geometrically guided fuzzy c-means clustering.Submitted for publication,2000.[4]S.H.Park,I.D.Yun,and S.U.Lee.Color image segmenta-tion based on3-d clustering:Morphological approach.Pat-tern Recognition,21(8):1061–1076,1998.[5]W.Pedrycz and J.Waletzky.Fuzzy clustering with partialsupervision.IEEE transactions on systems,man and cyber-netics,27(5):787–795,1997.。