log_network
做深度学习训练记录log文件

做深度学习训练记录log文件深度学习训练记录是对训练过程中的各种参数和结果进行记录和分析的重要工作。
通过记录和分析训练过程,我们可以更好地了解模型的学习过程,发现问题,并进行针对性的优化和改善。
在这篇文章中,我将介绍如何做一个有效的深度学习训练记录log文件。
首先,一个有效的深度学习训练记录log文件应包括以下几个主要部分:1.模型参数和超参数:记录每次训练中所使用的模型结构,包括网络层数、每层的节点数、激活函数等;以及超参数,如学习率、批大小、迭代次数等。
这些参数对于最终的模型效果有着重要的影响,因此需要进行详细记录。
2.数据预处理:记录对训练数据的预处理过程,如数据的标准化、归一化、降噪等。
这些预处理过程对于模型的训练效果往往也有着重要的影响,因此需要进行记录,以便复现和验证。
3.损失和指标:记录训练过程中的损失函数值和评估指标的变化情况,如准确率、召回率等。
这些指标能够反映模型的训练效果和泛化能力,在训练过程中需要进行监控和记录。
4. 训练过程可视化:通过可视化工具,如TensorBoard,记录模型的训练过程,包括损失函数值、评估指标的变化曲线、参数的分布情况等。
可视化能够直观地展示模型的学习过程和效果,帮助我们更好地理解和改进模型。
5.错误分析:记录训练过程中的错误样例,对错误样例进行分析,并提出改善模型的建议。
通过错误分析,可以帮助我们发现模型的问题,并进行有针对性的改进。
除了以上主要部分,深度学习训练记录log文件还可以包括其他一些额外信息,如训练时间、计算资源的使用情况、模型的保存和加载等。
这些信息可以帮助我们更好地管理和追踪训练过程。
在记录深度学习训练过程中,我们可以使用各种工具来方便地进行记录和分析。
常用的工具有TensorBoard、Visdom等,它们提供了丰富的可视化功能,能够帮助我们更好地理解和改进模型。
最后,记录深度学习训练过程是一个长期的工作,需要我们持续地进行记录和分析。
2000 words of the classic book _2000 word classics reading essays _ _ Xuan log network the opposite

2000 word classics reading a during the summer vacation, I read a Book - "Robinson drift travels", the hero of Robinson's extraordinary experience has given me great inspiration, also increased my courage to overcome difficulties.after reading this book, is really seem to have hit the jackpot. This book is about a ship after the crash, the only survivor Robinson in no human habitation of the island, to retire in the environment, life twenty-eight years of adventure and heart activity. Robinson on the island alone, in the face of difficulties and setbacks, overcome many difficulties of ordinary people can not imagine, themselves, have ample food and clothing, with amazing perseverance, tenacious alive. He from the wrecked ship, found some wood, on the island built houses, in order to prevent the beast, is still around the house on the stake. Came to the island, facing the first is the problem of food.ship things after eating, Robinson began hunting, sometimes may be hungry. So he decided to sow, after a few years, he can finally eat the fruits of their labor. Then he returned to his country. These things without knowledge, simply can not do, let me understand the knowledge of how important it is!when a person independent life, and this life is full of confidence, it is praiseworthy for one's excellent conduct. Because people can not be intimidated by the difficulties, but the difficulties, overcome difficulties, challenges. Always maintain a positive, optimistic attitude. Only in this way can we overcome the difficulties. Imagine, if you are lost in an uninhabited island, eyes full of hot sun, blue sea, look very romantic adventures, the best place in your eyes is probably the. However, if left alone in the uninhabited island what will happen? There is no water, no gas furnace, get through mobile phone, also can't take-out meals. In addition to the earth, animals and plants outside the sea and has been living there, no one on the island there is nothing there to let the human survival. A drop of water to personally go to, a flame will be lit, even the food also want you to be very careful in reckoning calculation when eating and where to go? In this case, you will feel romantic? Robinson is not a genius, but he has a strong curiosity. He went through many dangers, be. He had no water pain, but also overcome the fear of living alone, through the uninhabited island long rainy period, to overcome its own spiritual despair, finally by British ships, to hope's hometown. Although Robinson lived far away from the island, the fullness of life, but he never got out of society: the use of previously learned knowledge in society to survive. If he is born from life on the island, the situation will be? People can not be divorced from society, it is an undeniable fact. Robinson was able to live on the island for several decades, is not he does not concede the thought, strong survival ability, the most important thing is he rich social experience and infinite knowledge. Robinson on the island, never gave up to return to his original life, this, >。
创建网络数据集
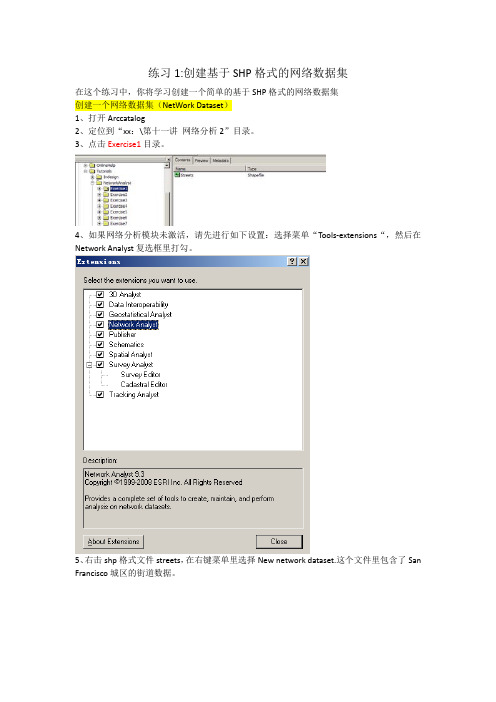
练习1:创建基于SHP格式的网络数据集在这个练习中,你将学习创建一个简单的基于SHP格式的网络数据集创建一个网络数据集(NetWork Dataset)1、打开Arccatalog2、定位到“xx:\第十一讲网络分析2”目录。
3、点击Exercise1目录。
4、如果网络分析模块未激活,请先进行如下设置:选择菜单“Tools-extensions“,然后在Network Analyst复选框里打勾。
5、右击shp格式文件streets,在右键菜单里选择New network dataset.这个文件里包含了San Francisco城区的街道数据。
6、网络数据集的默认名称为streets_ND,点击Next按钮继续。
网络连通性定义了参与的要素之间的网络连接。
默认的连通性将所有的数据放在同一个连通组,并且设置所有的边界数据端点连通。
在这个shp文件中只有一个边界数据,因此,不需要多个连通组。
7、你可以选择默认的连通性设置,因此,点击next按钮继续。
8、点击next按钮选择默认的高程字段设置。
如果ArcGIS 的网络分析发现了数据里的高程字段,会自动选择Yes。
ArcGIS 的网络分析支持转向规则。
默认的通用转向将被选中。
通用转向规则,例如,所有的左转弯都必须延迟15秒,右转弯有优先权。
9、点击Yes设置网络的转向规则。
10.点击next按钮继续。
网络属性是用于控制导航的属性。
一般的例子:成本,用于阻抗整个网络;限制,如单行道(oneway)。
ArcGIS 网络分析会分析shpfile数据,查找常见字段如,米(Meters)、分钟(minutes)和单行道(oneway)。
一旦找到这样的字段,ArcGIS会自动创建对应的网络属性。
设置相关的字段。
11、既然属性被自动定义了并安排了相应的值,点击next按钮继续。
为了在网络分析中使用行使方向,他们应该在网络数据集中被设置。
12、选中yes,设置行使方向。
expdp的network_link用法_概述及解释说明

expdp的network_link用法概述及解释说明1. 引言1.1 概述本篇长文将对expdp命令的network_link参数进行详细的概述和解释说明。
expdp命令是Oracle数据库中用于数据导出的工具,而network_link参数是该工具中一个非常重要且常用的功能。
通过使用network_link参数,我们可以实现在不同的数据库之间进行数据导入导出操作,以实现数据库之间的数据共享和同步。
本文将详细介绍expdp命令的概念、作用及常用参数,并着重解析和探讨network_link参数的相关概念、应用场景以及配置方法。
同时,本文还将通过实际应用与案例分析来进一步展示如何使用network_link参数来配置数据导入导出操作,并对其优缺点进行分析。
最后,在结论与展望部分,我们将总结主要观点和结论,探讨可能的未来发展方向,并给予适当的结语及致谢。
1.2 研究背景随着信息技术的不断发展和应用需求的增加,各个企业或组织往往需要在多个数据库之间进行数据共享和同步。
传统上,在不同数据库之间进行数据迁移是一项繁琐而复杂的任务。
为了简化这个过程并提高工作效率,Oracle数据库提供了expdp和impdp这两个工具来进行数据导出和导入操作。
其中,expdp命令的network_link参数允许用户在不同数据库之间建立链接,并通过网络进行数据传输,大大简化了跨数据库的数据迁移过程。
1.3 目的本篇长文的目的是通过详细解释和分析network_link参数的使用方法和应用场景,帮助读者更好地理解和掌握expdp命令中这个重要的功能。
通过对实际案例的分析,并结合优缺点的评估,读者将能够更加全面地了解如何配置network_link参数来实现跨数据库之间的数据导入和导出。
最后,我们也会对expdp命令及其相关功能进行总结,并展望可能的未来发展方向,以进一步推动数据库领域的研究与应用。
2. expdp命令概述:2.1 expdp简介expdp是Oracle数据库提供的一个用于导出数据的工具,它可以以二进制格式将数据库中的数据、对象和表空间导出到一个文件中。
Linux网络连接监控脚本使用Shell脚本实时监控网络连接状态

Linux网络连接监控脚本使用Shell脚本实时监控网络连接状态在Linux系统中,网络连接状态的实时监控对于系统管理员来说是一个重要的任务。
为了帮助管理员更好地管理和掌握网络连接情况,我们可以使用Shell脚本编写一个监控脚本,实时监控网络连接状态。
本文将介绍如何使用Shell脚本来编写一个简单而实用的网络连接监控脚本。
1. 脚本功能我们的监控脚本将实时监控网络连接状态,并将连接信息输出到一个日志文件中。
脚本将定期执行,并根据设定的时间间隔来更新日志文件。
管理员可以通过查看日志文件来了解当前网络连接的状态,以及网络连接的变化情况。
2. 编写脚本首先,我们需要在Linux系统中创建一个新的Shell脚本文件。
可以使用任何文本编辑器,在文件中添加以下内容:```shell#!/bin/bash# 定义日志文件路径log_file="/var/log/network_connections.log"# 定义时间间隔(单位:秒)interval=10# 循环执行监控任务while truedo# 使用ss命令获取当前网络连接状态connections=$(ss -tuan)# 将连接信息写入日志文件echo "$(date):" >> $log_fileecho "$connections" >> $log_fileecho "=========================" >> $log_file# 等待指定时间间隔sleep $intervaldone```在上述脚本中,我们首先定义了一个保存连接信息的日志文件路径,即`log_file`变量。
然后,我们定义了一个时间间隔变量`interval`,表示监控脚本每次执行的时间间隔(单位为秒)。
接下来,在一个无限循环中,我们使用`ss`命令来获取当前的网络连接状态,并将连接信息写入日志文件。
python selenium抓包network 的方法

python selenium抓包network 的方法网络抓包是网络调试和分析中常用的技术手段,通过抓取网络数据包,可以了解网络传输的情况,分析网络问题,优化网络性能。
在Python中,可以使用Selenium自动化工具来模拟浏览器操作,并借助Network抓包工具来获取网络数据包信息。
下面介绍使用Python Selenium抓包Network的方法。
一、准备工作1. 安装Selenium首先需要安装Selenium库,可以通过以下命令进行安装:```shellpip install selenium```2. 安装Network抓包工具常用的Network抓包工具包括Chrome开发者工具中的Network面板、Fiddler、Wireshark等。
这里以Chrome开发者工具为例,需要先安装Chrome浏览器。
1. 启动浏览器并启用Network抓包打开Chrome浏览器,进入开发者工具,在Network面板中选择“允许跨域资源共享”(CORS)并启用抓包。
2. 运行Selenium脚本使用Python Selenium库运行自动化脚本,模拟浏览器操作,例如打开网页、点击链接等。
在脚本中添加需要抓取的网络请求,并设置请求头、请求参数等。
3. 获取网络数据包信息脚本执行后,Chrome开发者工具中的Network面板会显示所有请求的数据包信息,包括请求URL、请求方法、请求头、响应状态码、响应时间等。
可以使用Python代码从Network面板中导出数据包信息,并进行进一步的分析和处理。
三、示例代码下面是一个简单的示例代码,演示如何使用Python Selenium和Chrome开发者工具的Network面板来抓取网络数据包:```pythonfrom selenium import webdriverimport time# 启动Chrome浏览器并打开开发者工具driver = webdriver.Chrome()driver.get("about:blank") # 打开空白页面,避免影响真实网络请求time.sleep(2) # 等待一段时间,让浏览器完成初始化driver.switch_to.options.enable_network_logs() # 启用Network抓包# 运行Selenium脚本# 在这里编写需要抓取的网络请求代码,例如打开网页、点击链接等# 导出数据包信息到文件with open("network_logs.txt", "w") as f:for log in driver.log_types["Log Entry"]: # 从Chrome开发者工具中导出数据包信息到文件中f.write(log["level"].ljust(8) + log["message"] + "\n") # 按照指定的格式输出数据包信息到文件中```以上代码中,首先启动Chrome浏览器并打开开发者工具,然后运行Selenium脚本,模拟浏览器操作。
李宏毅-B站机器学习视频课件BP全

Gradient Descent
Network parameters
Starting
0
Parameters
L
L w1
L w
2
L b1
L b2
w1 , w2 ,, b1 , b2 ,
b
4
2
=
′
’’
′ ′′
(Chain rule)
=
+
′ ′′
Assumed
?
?
3
4
it’s known
Backpropagation – Backward pass
Compute Τ for all activation function inputs z
Chain Rule
y g x
Case 1
z h y
x y z
Case 2
x g s
y hs
x
s
z
y
dz dz dy
dx dy dx
z k x, y
dz z dx z dy
ds x ds y ds
Backpropagation
2
Compute Τ for all parameters
Backward pass:
Compute Τ for all activation
function inputs z
Backpropagation – Forward pass
set_ideal_network -no_propagation用法 -回复

set_ideal_network -no_propagation用法-回复“set_ideal_network no_propagation用法”指的是在构建神经网络时,采用了无传播(no propagation)的理想网络(ideal network)设置。
本文将逐步介绍这个用法,包括它的定义、作用、使用场景以及具体操作步骤。
通过阐述这些内容,读者将能够深入了解set_ideal_networkno_propagation的用途和实践方法。
一、定义与作用在开始之前,我们先来了解“set_ideal_network no_propagation”的定义和作用。
set_ideal_network是指在神经网络构建的过程中,创建一个没有传播的理想网络。
no_propagation表示网络在训练过程中不进行传播,即不计算梯度。
这种设置的主要作用是为了比较网络在完全无传播的情况下的性能表现。
通过与其他传统的网络进行对比,可以验证传统网络中传递的信息对模型的训练和性能产生的影响。
二、使用场景接下来,我们来探讨一些使用set_ideal_network no_propagation的典型场景。
这种设置通常用于以下情况:1. 网络设计和优化:理想网络的设置可以帮助设计者更好地理解各个网络层级之间的复杂关系,提供参考用于优化网络的结构和参数。
2. 梯度分析和网络评估:通过与传统网络进行比较,可以分析并评估梯度对训练过程和模型效果的影响。
这有助于深入研究网络的训练机制以及隐藏层间的信息流动。
3. 比较不同模型结构:使用理想网络进行比较可以帮助研究人员更好地理解不同模型结构对学习能力和权重更新的影响,进而优化网络架构。
三、操作步骤现在,我们将介绍一些具体的操作步骤来使用set_ideal_networkno_propagation。
1. 定义理想网络:首先,我们需要定义一个不进行传播的理想网络。
这可以通过在定义网络模型时注意不进行反向传播来实现。
chromium net_log 解读

chromium net_log 解读一、概述Chromium是Google主导的开源网络浏览器项目,其目标是构建一个安全、快速、稳定的网络浏览器。
在Chromium中,net_log是一个用于记录网络请求和响应的详细信息的日志系统。
通过对net_log的解读,开发人员可以深入了解网络请求的处理过程,诊断网络问题,优化网络性能。
二、net_log的基本结构Chromium的net_log采用JSON格式进行记录,每个日志条目都包含以下基本结构:1. "source_id":标识产生日志条目的源,如网络请求、网络连接等。
2. "phase":表示日志条目的阶段,如"BEGIN"、"END"等。
3. "time":记录日志条目的时间戳。
4. "params":包含与日志条目相关的参数信息,如URL、HTTP 请求头等。
三、net_log的解读方法1. 查找关键日志条目:首先,可以根据需要查找特定的日志条目,如HTTP请求的开始和结束、DNS解析等。
通过搜索"source_id"和"phase",可以快速定位到关键日志条目。
2. 分析时间消耗:通过观察日志条目中的时间戳,可以计算出网络请求的各个阶段所消耗的时间。
这有助于发现网络请求过程中的性能瓶颈。
3. 检查HTTP请求头:在"params"字段中,可以查看HTTP请求的具体内容,如请求方法、URL、请求头等。
这些信息有助于分析网络请求的正确性和合理性。
4. 查看响应结果:同样在"params"字段中,可以查看HTTP响应的结果,如响应状态码、响应头等。
这些信息有助于判断网络请求是否成功以及响应数据的正确性。
5. 追踪网络连接状态:通过观察日志条目中的"source_id"和"phase",可以追踪网络连接的状态变化,如连接的建立、断开等。
google network实现原理

google network实现原理全文共四篇示例,供读者参考第一篇示例:Google Network是指谷歌基础设施中的网络部分,是支持谷歌服务正常运行的关键组成部分。
Google Network的实现原理非常复杂,是谷歌多年研发和积累的成果。
本文将重点介绍Google Network的实现原理,包括底层网络架构、数据中心网络、全球网络互联等方面。
1. 底层网络架构Google Network的底层网络架构是建立在Google自主设计的数据中心网络之上的。
在数据中心内部,谷歌采用了全自主设计的网络设备,包括交换机、路由器、负载均衡器等。
这些设备通过高速光纤互联,构成了一个高效、稳定的数据中心网络。
在数据中心网络中,谷歌采用了多层架构,包括核心层、汇聚层和接入层。
核心层负责数据中心之间的互联,汇聚层负责数据中心内部的流量聚合,而接入层则连接着服务器和各种网络设备。
2. 数据中心网络数据中心网络是Google Network的核心部分,是支持Google各种云服务正常运行的基础设施。
在数据中心网络中,谷歌采用了大量的创新技术,包括软件定义网络(SDN)、可编程交换机等。
SDN技术使得数据中心网络变得更加灵活、可扩展,可以根据需求对网络拓扑进行动态调整,提高了数据中心网络的利用率和性能。
可编程交换机则使得谷歌能够更加灵活地控制网络流量的处理方式,根据具体应用来定制网络规则,提高了网络的安全性和性能。
3. 全球网络互联Google拥有全球化的网络基础设施,可以使得用户可以在全球范围内使用Google的云服务。
Google在全球范围内建立了大量的数据中心和网络设备,通过高速光纤连接,构成了一个强大的全球网络。
在全球网络互联方面,Google采用了由BGP协议构建的全球负载均衡系统,可以动态地将用户的请求导向到最近的数据中心,提高了用户体验和服务的可用性。
Google还使用了大量的网络加速技术,包括CDN、TCP加速等,提高了网络传输速度和安全性。
load_network函数

load_network函数“load_network函数”是一个非常常见的函数,它主要用于加载网络模型。
对于经验丰富的内容创作者来说,理解并掌握“load_network函数”的使用方法是非常重要的。
在本篇文章中,我们将对“load_network函数”进行重新整理,并以此为基础,为读者讲解如何正确使用该函数。
一、load_network函数的定义load_network函数是一种自定义的函数,它可以用于加载指定的网络模型,并返回已经加载好的网络模型。
load_network函数通常包括以下几个参数:- network_file:表示网络模型的文件路径。
- input_shape:表示输入的数据形状。
- num_classes:表示分类的个数。
二、load_network函数的实现步骤load_network函数通常实现的步骤如下:1. 导入必要的模块,如tensorflow等。
2. 定义一个模型对象,如Sequential等。
3. 加载指定的网络模型文件,如.h5文件等。
4. 定义输入数据的形状。
5. 定义分类的个数。
6. 设置模型对象的结构。
7. 返回模型对象。
三、load_network函数的使用方法在使用load_network函数时,我们需要进行以下几个步骤:1. 确定网络模型文件的路径和名称。
2. 确定输入数据的形状。
3. 确定分类的个数。
4. 调用load_network函数并传递参数。
5. 可以对返回的模型对象进行预测等操作。
四、load_network函数的注意事项使用load_network函数时,需要注意以下几点:1. 确保网络模型文件的路径和名称正确。
2. 确保输入数据的形状与网络模型中的一致。
3. 确保分类的个数与网络模型中的一致。
4. 可以在返回的模型对象上进行相关的操作。
五、总结本文对“load_network函数”进行了重新整理,并对其使用方法、实现步骤和注意事项进行了详细讲解。
lggnet代码解析 -回复

lggnet代码解析-回复什么是LGGNet?LGGNet(Laplacian-based Gated Graph Neural Network)是一种基于拉普拉斯图的门控图神经网络。
它是由Lu等人于2020年提出的,旨在解决图数据中的节点分类和图分类问题。
LGGNet通过学习图中节点之间的关系,有效地捕捉图数据中的局部和全局信息,并通过门控机制进行特征选择和整合,从而实现高效的图数据分析与处理。
拉普拉斯图是图数据领域中常用的一种图表示方法,它能够刻画节点之间的连接和相似性。
在LGGNet中,首先根据输入的图数据构建拉普拉斯图。
具体地,将每个节点表示为一个特征向量,并根据节点之间的相似度计算构建连接。
这样,原始的图数据就被转化为一个稀疏的二维矩阵,称为拉普拉斯矩阵。
拉普拉斯矩阵包含了图中节点的连接信息,可用于表示节点之间的关系。
LGGNet利用拉普拉斯矩阵,通过一系列的卷积和池化操作对输入的图数据进行特征学习和表示。
具体来说,LGGNet使用了一种新颖的门控机制,即图卷积门控模块(GGCN)。
GGCN通过对节点的特征向量和自身权重进行门控操作,实现了特征选择和整合。
这样,对于每个节点,LGGNet能够自适应地选择和组合邻居节点的特征,从而提取更有效的图表征。
在LGGNet的训练过程中,Lu等人提出了一种基于拉普拉斯矩阵的正则化方法,即图拉普拉斯正则化(GLR)。
GLR通过对拉普拉斯矩阵进行归一化处理,将节点特征的结构化信息纳入考虑,提高了模型的稳定性和泛化能力。
此外,为了进一步提高LGGNet的性能,还引入了一种基于自注意力机制的金字塔门控模块(PGCN)。
PGCN能够更好地捕捉图数据的多尺度特征,提高模型的准确性和鲁棒性。
LGGNet已经在多个图数据集上进行了广泛的实验评估,结果表明,它在节点分类和图分类任务上取得了优秀的性能。
与传统的图神经网络相比,LGGNet具有更强的特征选择和整合能力,能够更好地处理图数据中的复杂关系。
tensor的log函数 -回复

tensor的log函数-回复Tensor的log函数是一种基本的数学函数,它在深度学习和其他数学领域中扮演着重要的角色。
在本文中,我们将逐步论述和回答与tensor的log 函数相关的问题。
首先,我们需要了解tensor的概念。
Tensor是一个多维数组或矩阵的概念的推广,它在数学、物理学和计算领域中广泛应用。
通常,我们将一维数组称为向量,二维数组称为矩阵,而三维及以上的数组称为tensor。
Tensor的log函数是一个数学函数,它对tensor中的每个元素进行对数运算。
将一个tensor的每个元素取对数后得到的新tensor,记作log(tensor)或者ln(tensor)。
log函数的作用是将非线性的数值范围映射到线性的数值范围上,从而方便我们在数据分析和模型训练中进行处理。
接下来,让我们来看一下tensor的log函数的一些常见应用。
首先,log 函数在数据的归一化和标准化中具有重要的作用。
通过对数据取对数,我们可以将数据的范围从原本的指数级转化为线性级,使得数据更便于处理和比较。
例如,在图像处理中,我们可以通过对像素值取对数来增强图像的对比度和细节。
其次,log函数在回归模型和分类模型中也被广泛使用。
在回归模型中,通过对目标变量和预测变量取对数,可以将非线性的关系转化为线性的关系,从而更容易进行模型拟合和参数估计。
而在分类模型中,log函数被用作损失函数的一部分,用于衡量模型预测结果与真实标签的差异,并用梯度下降等优化算法来最小化这个差异。
另外,log函数还在信息论和熵的计算中发挥重要作用。
在信息论中,熵是评估随机变量不确定性的度量。
通过对概率分布取对数,并乘以对应的概率,可以计算每个事件的信息量,再求和得到熵。
而在深度学习中,熵被广泛应用于训练过程中的模型不确定性估计和正则化。
在应用log函数时,需要注意一些潜在的问题。
首先,将小于等于零的值作为log函数的输入是无效的,因为log函数在这些区间是无定义的。
lgvl的各个函数用法

lgvl的各个函数用法lgvl是一个Python库,其主要提供了一些方便的工具函数,能够有效地协助开发者处理数据集和模型。
以下是lgvl的各个函数用法及拓展:1. get_dataset_path(dataset_name: str) -> str:用法:获取指定数据集名称的绝对路径。
示例:get_dataset_path('mnist') ->'/home/user/data/mnist/'拓展:可以添加新的数据集路径到配置文件中,并使用此函数获得路径。
2. load_model(model_path: str) -> Any:用法:从指定路径加载模型。
示例:model = load_model('/home/user/models/mnist')拓展:可以添加模型名称到配置文件中,并使用此函数获得模型路径。
3. save_model(model: Any, model_name: str) -> None:用法:将模型保存到指定的路径。
示例:save_model(model, 'mnist')拓展:可以添加模型保存路径到配置文件中,并使用此函数保存模型。
4. get_logger(log_path: str) -> logging.Logger:用法:获取一个日志记录器,在指定的路径创建记录文件。
示例:logger = get_logger('/home/user/logs/mnist.log')拓展:可以添加日志路径到配置文件中,并使用该函数获得一个日志记录器。
5. memoize(func: Callable[[Any], Any]) -> Callable[[Any], Any]:用法:装饰器,用于缓存函数的结果,避免重复计算。
示例:@memoizedef func(x):...return result拓展:也可以使用functools.lru_cache,其实现与memoize类似。
set_ideal_network -no_propagation用法

set_ideal_network -no_propagation用法set_ideal_network 是一个用于设置网络的理想传播模式的函数。
该函数可以用于优化和调整网络节点之间的连接方式,以实现更高效、更可靠的数据传输和通信。
传统的网络传播模式存在一些缺陷和局限性,例如信号衰减、干扰、延迟等问题,这些问题可能导致数据传输的错误和不稳定性。
为了解决这些问题,研究人员提出了一种新的传播模式——no_propagation(无传播)。
no_propagation 模式的基本原理是消除传播过程中产生的影响和干扰,使数据能够直接从发送节点到达接收节点,从而提高数据传输的效率和成功率。
下面将详细介绍set_ideal_network 函数的用法,并讨论它在不同领域的应用。
首先,我们需要了解set_ideal_network 函数的基本调用方法。
该函数接受一个参数,即网络对象的引用,通过修改网络对象的属性来设置传播模式。
以下是函数的调用示例:pythonset_ideal_network(network)接下来,我们将一步一步地回答set_ideal_network 函数的用法以及它在不同领域的应用。
一、理论基础no_propagation 模式的原理基于无线通信中的近场传输原理。
传统的无线通信模式中,信号会通过空气或其他介质的传播而衰减、受到干扰,从而导致数据传输的不可靠性。
而no_propagation 模式通过直接将信号传递到接收节点,避免了传播过程中的干扰,从而提高了数据传输的效率和可靠性。
二、函数参数说明set_ideal_network 函数需要一个网络对象的引用作为参数。
网络对象是一个数据结构,用于表示网络中的节点和它们之间的连接关系。
通过修改网络对象的属性,我们可以对网络的连接方式进行调整。
三、函数实现步骤set_ideal_network 函数的实现步骤如下:1. 创建一个空的理想网络对象。
fs7 log2 工作流程 -回复

fs7 log2 工作流程-回复[fs7 log2 工作流程]在现代科技快速发展的时代,人们对于日常生活中产生的大量数据需要进行有效地管理和分析,以便更好地进行决策和优化业务。
而fs7 log2则是一种用于管理和分析大数据的工具,本文将为您详细介绍fs7 log2的工作流程。
第一步:数据收集fs7 log2的工作流程开始于数据的收集阶段。
数据可以来自各种各样的来源,例如服务器日志、网络传输记录、应用程序输出等。
这些数据都被视为日志文件,记录了各种事件和活动。
要收集这些日志文件,可以通过多种方式进行,例如使用fs7 log2的集成数据采集功能、使用代理工具收集日志等。
无论使用哪种方式,都需要确保数据可以高效地被收集和保存。
第二步:数据处理在收集到数据之后,接下来需要进行数据处理。
fs7 log2提供了许多内置的工具和算法,用于预处理和清洗数据,以便更好地进行后续分析。
在数据处理阶段,可以进行诸如过滤、去重、转换等操作,以便使数据更加规范和易于分析。
例如,可以根据特定的关键字或时间范围进行数据过滤,以便筛选出感兴趣的数据subset。
同时,还可以将数据转换为更容易理解和分析的形式,例如将时间戳格式化为可读的日期和时间格式。
第三步:数据存储在数据处理完成后,需要将处理后的数据存储到合适的位置,以便后续的查询和分析。
fs7 log2支持多种数据存储方式,例如文件系统、数据库等。
通过将数据存储在文件系统中,可以方便地对数据进行备份和恢复。
而将数据存储到数据库中,可以更方便地进行灵活的查询和分析。
根据具体需求和情况,选择合适的数据存储方式非常重要。
第四步:数据分析在数据存储完成后,接下来进行的是数据分析阶段。
fs7 log2提供了丰富的分析工具和算法,帮助用户深入挖掘数据中隐藏的关联和信息。
数据分析可以通过多种方式进行,例如基于特定指标的统计分析、基于机器学习算法的模式识别和异常检测等。
这些分析工具不仅可以帮助用户对数据进行概览和分析,还可以为业务决策和优化提供有力的支持。
nlog 目标 自定义方法-定义说明解析

nlog 目标自定义方法-概述说明以及解释1.引言1.1 概述NLog是一个功能强大、灵活且可扩展的日志记录库,它允许开发人员在应用程序中轻松地实现日志记录功能。
与其他日志记录工具相比,NLog提供了更多的自定义选项和配置灵活性,使开发人员能够根据自己的需求来定义日志记录行为。
NLog具有广泛的目标支持,例如文件、数据库、邮件和网络等。
通过选择不同的目标,开发人员可以将日志记录到不同的介质中,以满足不同的需求。
此外,NLog还支持自定义目标,使开发人员能够实现自己的特定需求。
在本文中,我们将重点讨论如何使用NLog来实现自定义方法。
通过使用自定义方法,开发人员可以在日志记录过程中执行各种操作,例如数据处理、附加额外信息或发送警报等。
这为开发人员提供了极大的灵活性和扩展性,以实现更高级的日志记录需求。
为了实现自定义方法,我们需要定义一个自定义目标,该目标将处理日志事件并执行我们所需的操作。
通过继承NLog的Target类并重写ProcessLogEvent方法,我们可以编写自己的目标逻辑。
在ProcessLogEvent方法中,我们可以访问日志事件的各个属性,例如日志消息、级别和时间戳等。
在本文的后续部分,我们还将介绍如何配置NLog以使用自定义目标。
我们将讨论如何在应用程序的配置文件中定义和配置目标,并将目标与日志规则和目标规则关联起来。
总而言之,本文将详细介绍NLog的自定义方法功能,并提供了使用自定义目标进行高级日志记录的实现指南。
无论您是初学者还是有经验的开发人员,都能从本文中获得有关NLog自定义方法的深入理解和实践经验。
我们希望通过本文的阅读,您能够更好地掌握NLog并在实际项目中灵活应用。
1.2文章结构1.2 文章结构本文主要分为引言、正文和结论三个部分。
具体的文章结构如下:1. 引言部分(Introduction)1.1 概述(Overview)在引言的概述部分,将介绍本文所要涉及的主题,即NLog目标和自定义方法。
multilayernetwork 使用 和 训练

multilayernetwork 使用和训练
多层网络是一种深度学习模型,由多个节点层组成,各层之间通过连接权重进行信息传递。
每个节点接收上一层的输出并通过激活函数进行非线性转换后输出到下一层。
多层网络可以用于各种任务,如图像分类、自然语言处理等。
使用多层网络可以通过以下步骤:
1. 定义网络结构:确定网络的层数和每层的节点数。
选择适当的激活函数以及其他超参数。
2. 初始化参数:对网络的连接权重和偏置进行初始化,可以使用随机初始化方法。
3. 前向传播:将输入数据输入到网络中,通过多层的计算得到输出值。
4. 计算损失:将网络的输出与实际的标签进行比较,计算损失函数的值。
5. 反向传播:根据损失函数的值,计算每个参数对损失的梯度,并根据梯度更新参数。
6. 重复步骤3至5,直到达到停止条件或训练次数。
训练多层网络可以使用梯度下降算法或其变种进行优化。
常用的优化算法包括随机梯度下降(SGD)、动量法、Adam等。
在训练过程中,可以使用批量训练或小批量训练的方式进行参数更新。
为了提高多层网络的泛化能力,还可以采用一些正则化技术,如L1、L2正则化、dropout等。
此外,还可以使用交叉验证、
早停法等技术进行模型选择和调优。
训练多层网络可能需要大量的计算资源和时间,特别是在深层网络中。
因此,通常使用图形处理器(GPU)进行并行计算来加速训练过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
[2016-03-21 16:38:45.890] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:45.890] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:43.859] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:43.859] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:43.859] <DEBUG> [network] CXHttpConnection::OnClosed(441) [reconnect]:search.video.qiyi.domain/qiso3/?if=pc&type=list&pos=1&pageNum=1&pageSize=100&ctgname=%E7%94%B5%E5%BD%B1&mode=10&site=iqiyi&p=11&p1=114&source_type=1&platform=1&three_category_id=1;must&has_item_link=1 0 10049
[2016-03-21 16:38:45.875] <DEBUG> [network] CXHttpConnection::OnClosed(441) [reconnect]:search.video.qiyi.domain/qiso3/?if=pc&type=list&pos=1&pageNum=1&pageSize=200&ctgname=%E7%94%B5%E8%A7%86%E5%89%A7&mode=10&site=iqiyi&p=11&p1=114&source_type=1&platform=1&three_category_id=15;must&has_item_link=1 0 10049
[2016-03-21 16:38:47.890] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:47.890] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:43.875] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:43.875] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:41.859] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:41.859] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:47.890] <DEBUG> [network] CXHttpConnection::OnClosed(441) [reconnect]:search.video.qiyi.domain/qiso3/?if=pc&type=list&pos=1&pageNum=1&pageSize=100&ctgname=%E7%94%B5%E8%A7%86%E5%89%A7&mode=10&site=iqiyi&p=11&p1=114&source_type=1&platform=1&three_category_id=18;must&has_item_link=1 0 10049
[2016-03-21 16:38:47.906] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:41.859] <ERROR> [network] CTcpConnection::OnClosed(99) Connect failed iError code is 10049
[2016-03-21 16:38:43.859] <ERROR> [network] CWebParser::GetVLFolderData(183) begin get GetVLFolderData
[2016-03-21 16:38:41.859] <DEBUG> [network] CXHttpConnection::HandlePacket(474) [ConnectionFinal]:search.video.qiyi.domain/qiso3/?if=pc&type=list&pos=1&pageNum=1&pageSize=100&ctgname=%E7%94%B5%E5%BD%B1&mode=10&site=iqiyi&p=11&p1=114&source_type=1&platform=1&three_category_id=2;must&has_item_link=1 decode error
[2016-03-21 16:38:31.562] <ERROR> [network] CWebParser::GetVLUpdateConfig(100) begin get GetVLUpdateConfig
[2016-03-21 16:38:36.687] <ERROR> [network] CHttpPacketStreamer::GetPacketInfo(126) receive trucked data end
[2016-03-21 16:38:45.890] <ERROR> [network] CTcpConnection::OnClosed(99) Connect failed iErro16-03-21 16:38:47.890] <ERROR> [network] CWebParser::GetVLFolderData(183) begin get GetVLFolderData
[2016-03-21 16:38:41.843] <ERROR> [network] SocketAddress::StringToIP(293) gethostbyname error: 11004, search.video.qiyi.domain
[2016-03-21 16:38:41.843] <DEBUG> [network] CXHttpConnection::OnClosed(441) [reconnect]:search.video.qiyi.domain/qiso3/?if=pc&type=list&pos=1&pageNum=1&pageSize=100&ctgname=%E7%94%B5%E5%BD%B1&mode=10&site=iqiyi&p=11&p1=114&source_type=1&platform=1&three_category_id=2;must&has_item_link=1 0 10049