在对语料库信息的加工处理过程中,词类标注是
词性标注的名词解释

词性标注的名词解释词性标注是自然语言处理中的一项重要任务,其主要目的是确定文本中每个单词的词性。
在计算机领域中,词性标注通常被称为词性标签或词类标签。
它是自然语言处理技术的基础,对于诸如机器翻译、文本分类、信息检索等任务具有重要的影响。
词性是语法学中的一个概念,用于描述一个单词在句子中的语法属性和词义特征。
在英语中,常用的词性包括名词、动词、形容词、副词、代词、冠词、连词、介词和感叹词等。
而在中文中,常见的词性有名词、动词、形容词、副词、量词、代词、连词、介词、助词、语气词和标点符号等。
词性标注的目标是为每个词汇选择正确的词性。
这个过程通常涉及到构建一个标注模型,在已知的语料库中学习每个词汇的词性,并根据上下文的语法规则判断未知词汇的词性。
词性标记常用的方法有规则匹配、基于统计的方法和机器学习方法。
规则匹配是最简单的词性标注方法之一,它基于事先定义好的语法规则。
通过匹配文本中的规则模式,为每个单词分配一个预设的词性。
尽管规则匹配的方法简单易行,但它的局限性在于无法充分利用上下文信息,难以处理歧义问题。
基于统计的方法则通过统计大规模语料库中词汇在不同上下文环境中出现的概率,来预测词性。
这种方法基于频率统计的结果,假设一个单词在给定上下文中具有最大概率的词性,从而进行标注。
其中,隐马尔可夫模型(HMM)是最常用的统计方法之一。
HMM模型通过学习词性之间的转移概率和词性与单词之间的发射概率,来进行词性标注。
与基于统计的方法相比,机器学习方法更加灵活。
机器学习方法通过训练样本学习词汇和其对应的词性之间的潜在关系,并根据这种关系对未知词汇进行标注。
常见的机器学习方法包括最大熵模型、条件随机场(CRF)等。
这些方法通过结合上下文信息和词汇特征,提高了标注的准确性和泛化能力。
词性标注在自然语言处理中具有广泛的应用。
在机器翻译中,词性标注的结果能帮助翻译系统区分单词的不同含义,提高翻译质量。
在文本分类中,词性标注可以辅助判断文本的属性或情感倾向。
词法分析:词性标注

词法分析:词性标注词法分析(lexical analysis):将字符序列转换为单词(Token)序列的过程分词,命名实体识别,词性标注并称汉语词法分析“三姐妹”。
在线演⽰平台:词性标注(Part-Of-Speech tagging, POS tagging)也被称为语法标注(grammatical tagging)或词类消疑(word-category disambiguation)是语料库语⾔学(corpus linguistics)中将语料库内单词的词性按其含义和上下⽂内容进⾏标记的⽂本数据处理技术。
语料库(corpus,复数corpora)指经科学取样和加⼯的⼤规模电⼦⽂本库。
所谓词性标注就是根据句⼦的上下⽂信息给句中的每个词确定⼀个最为合适的词性标记。
⽐如,给定⼀个句⼦:“我中了⼀张彩票”。
对其的标注结果可以是:“我/代词中/动词了/助词/ ⼀/数词/ 张/量词/ 彩票/名词。
/标点”词性标注的难点主要是由词性兼类所引起的。
词性兼类是指⾃然语⾔中⼀个词语的词性多余⼀个的语⾔现象。
(⼀词多性)常⽤的词性标注模型有 N 元模型、隐马尔科夫模型、最⼤熵模型、基于决策树的模型等。
其中,隐马尔科夫模型是应⽤较⼴泛且效果较好的模型之⼀。
【jieba】import jieba.posseg as psegwords = pseg.cut("⽼师说⾐服上除了校徽别别别的")for word, flag in words:print('%s %s' % (word, flag))⽼师 n 说 v ⾐服 n 上 f 除了 p 校徽 n 别 d 别 d 别的 r【hanLP】from pyhanlp import *content = "⽼师说⾐服上除了校徽别别别的"print(HanLP.segment(content))⽼师/nnt, 说/v, ⾐服/n, 上/f, 除了/p, 校徽/n, 别/d, 别/d, 别的/rzv ref:。
现代汉语语料库加工规范词语切分和词性标注词...
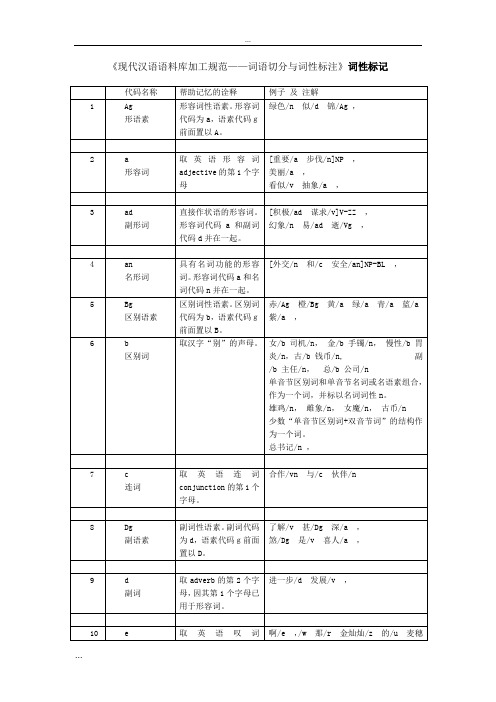
[芜湖/ns专区/n] NS,
[宣城/ns地区/n]ns,
[内蒙古/ns自治区/n]NS,
[深圳/ns特区/n]NS,
[厦门/ns经济/n特区/n]NS,
[香港/ns特别/a行政区/n]NS,
甲/Mg减下/v的/u人/n让/v乙/Mg背上/v ,
凡/d“/w寅/Mg年/n”/w中/f出生/v的/u人/n生肖/n都/d属/v虎/n ,
18
m数词
取英语numeral的第3个字母,n,u已有他用。
1.数量词组应切分为数词和量词。三/m个/q, 10/m公斤/q,一/m盒/q点心/n ,
但少数数量词已是词典的登录单位,则不再切分。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
取英语叹词exclamation的第1个字母。
啊/e,/w那/r金灿灿/z的/u麦穗/n,
约/d一百/m多/m万/m,仅/d一百/m个/q,四十/m来/m个/q,二十/m余/m只/q,十几/m个/q,三十/m左右/m,
两个数词相连的及“成百”、“上千”等则不予切分。
五六/m年/q,七八/m天/q,十七八/m岁/q,成百/m学生/n,上千/m人/n,
4.表序关系的“数+名”结构,应予切分。
[宝山/ns钢铁/n总/b公司/n]NT,(/w宝钢/j)/w
语料库中语料的标注

语料库中语料的标注董爱华【摘要】In the application of corpora, annotation is a must to ESP text analysis, learner’s language analysis and bilingual translation study. To guarantee the validity of the research results based on corpora, annotation of the corpora must be accurate. This paper starts from introducing the principles, methods and patterns of annotation, then it tries to analyzehow to control the quality of annotation from several aspects, and it also aims to help the corpora users to test the quality of a certain corpus.%在语料库应用过程中,ESP文本分析、学习者语言分析及双语翻译研究等都要用到标注。
语料库语料标注的准确性是基于语料库的学术研究结果可靠性的前提。
文章介绍了语料库标注的原则、方法模式,并分析了控制标注质量的相关因素,目的是为标注语料库的使用者检验标注质量提供帮助。
【期刊名称】《北京印刷学院学报》【年(卷),期】2016(024)005【总页数】4页(P67-70)【关键词】语料库标注;原则;方法;模式;质量【作者】董爱华【作者单位】北京印刷学院外语部,北京102600【正文语种】中文【中图分类】H0从现代语料库语言学的角度来看,语料库应该具备三个方面的基本条件,即样本的代表性、规模的有限性和语料的机读化[1]。
信息处理用现代汉语词类标记规范

信息处理用现代汉语词类标识规范1范围本原则规定了信息处理中现代汉语词类及其他切分单位旳标识代码。
合用于汉语信息处理, 也可供现代汉语教学与研究参照。
2术语和定义下列术语和定义合用于本原则。
2.1汉语信息处理 Chinese Information Processing, CIP用计算机对汉语形、音、义等信息进行输入、排序、存储、输出、记录、提取等。
2.2切分单位 Segment Unit汉语信息处理使用旳、具有确定语法功能旳基本单位。
它包括本原则旳规则所限定旳词、短语及其他单位。
2.3词类 parts of speech, POS词旳语法分类, 重要是根据语法功能划分出来旳类。
2.4标识 Tag对文本中切分单位旳类别进行标注旳代码。
3总则3.1切分单位旳范围本原则旳切分单位包括词、短语和其他切分单位, 如习用语、缩略语、前接成分、后接成分、语素字、非语素字、标点符号、非中文符号等。
3.2词类划分旳原则本原则旳词类分类体系参照了吕叔湘、朱德熙、胡裕树等先生旳语法体系和《中学教学语法系统提纲》。
本原则根据汉语信息处理旳特点和规定, 重要根据语法功能原则划分词类。
3.3标识代码旳制定原则根据国际一般做法, 标识代码重要采用英文术语旳字母。
例如, “名词”, 采用英文术语“noun”旳首字母“n”作为标识代码;“数词”, 采用英文术语“numeral”旳第三个字母“m”作为标识代码。
汉语独有旳, 或使用英文术语字母不便旳, 根据国内一般做法, 标识代码采用汉语拼音字母。
如, “缩略语”, 采用中文“简”汉语拼音旳首字母“j”作为标识代码;“语素字”, 采用中文“根”汉语拼音旳首字母“g”作为标识代码。
4词类及其他切分单位分类本原则将词类划分为13个一级类, 16个二级类;其他切分单位划分为7个一级类, 13个二级类。
顾客可根据需要自行增补。
4.1词类划分及标识代码名词(n), 表达人或事物旳名称, 在句子中重要充当主语和宾语。
自然语言处理中的词性标注与句法分析

自然语言处理中的词性标注与句法分析自然语言处理(Natural Language Processing,简称NLP)是人工智能领域中的一个重要分支,主要研究如何让计算机能够理解、处理和生成人类语言。
在NLP领域中,词性标注与句法分析是两个重要的任务,它们可以帮助计算机更好地理解和处理自然语言。
本文将介绍词性标注与句法分析的基本概念、常见方法以及应用场景,并探讨它们在NLP领域的意义和作用。
一、词性标注词性标注(Part-of-Speech Tagging,简称POS Tagging)是NLP领域中的一个基础任务,其主要目标是为一个句子中的每个单词确定其词性。
词性标注可以帮助计算机理解句子的结构和含义,从而更好地进行后续处理和分析。
词性标注通常使用词性标记集合(如标注集)来标注每个单词的词性,常见的标注集包括Penn Treebank标注集、Universal标注集等。
词性标注的方法主要包括基于规则的方法和基于统计的方法。
基于规则的方法通过定义一系列的语法规则和模式来确定单词的词性,但这种方法需要大量的人工设置和维护规则,且适用性有限。
而基于统计的方法则是通过学习语料库中单词与其词性之间的统计关系来确定单词的词性,常见的统计方法包括隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)等。
词性标注在NLP领域中有着广泛的应用,例如在文本分类、信息检索和机器翻译等任务中都需要对文本进行词性标注来帮助计算机理解和处理文本。
此外,词性标注也可以作为更复杂的NLP任务的预处理步骤,如句法分析、语义分析等。
二、句法分析句法分析(Syntactic Parsing)是NLP领域中的另一个重要任务,其主要目标是确定一个句子的句法结构,即句子中单词之间的语法关系。
句法分析可以帮助计算机理解句子的结构和含义,从而更好地进行后续处理和分析。
当代汉语文本语料库分词词性标注加工规范

973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
信息处理用现代汉语词类标记规范

本标准规定了信息处理中现代汉语词类及其他切分单位的标记代码。 本标准适用于汉语信息处理,也可供现代汉语教学与研究参考。
2 术语和定义
下列术语和定义适用于本标准。 2.1 汉语信息处理 Chinese Information Processing; CIP
用计算机对汉语形、音、义等信息进行输入、排序、存储、输出、统计、提取等。 2.2 切分单位 Segment Unit
五粮液 宫爆鸡丁 桑塔纳 4.1.2 动词(v),表示动作、行为,心理活动、生理状态及事物的存现、变化等,在句子中主要充当 谓语。 4.1.2.1 及物动词(vt),能够带宾语。如:
吃打擦洗喂借送买捧提填 喜欢 告诉 接受 羡慕 考虑 调查 同意 发动 4.1.2.2 不及物动词(vi),不能够带宾语。如: 病 休息 咳嗽 瘫痪 游泳 睡觉 4.1.2.3 联系动词(vl),表示关系的判断。如:
殊遥伟
4.2.6 非语素字(x),汉字字符集中单独使用时不具有意义的汉字,如:
垃琵蜘踌鸯蜻
4.2.7 其他 (w) 4.2.7.1 标点符号(wp),如:
, 。 、 ; ? ! : “” 4.2.7.2 非汉字字符串(ws),如:
……
office windows 4.2.7.3 其他未知的符号(wu)。
人 马 书 教师 飞机 电冰箱 阿姨 桌子 木头
1
GB/T 20532—2006
道德 理论 历史 思想 文化 因素 作风 哲学 4.1.1.2 时间名词(nt),包括一般所说的时量词。如:
年月日分秒 现在 过去 昨天 去年 将来 宋朝 星期一 4.1.1.3 方位名词(nd),表示位置的相对方向。如: 上下左右前后里外中东西南北 前边 左面 里头 中间 外部 4.1.1.4 处所名词(nl),表示处所。如: 空中 高处 隔壁 门口 附近 边疆 一旁 野外 4.1.1.5 人名(nh),表示人的名称的专有名词。 华罗庚 阿凡提 诸葛亮 司马相如 松赞干布 卡尔·马克思 4.1.1.6 地名(ns),表示地理区域名称的专有名词。如: 亚洲 大西洋 地中海 阿尔卑斯山 加拿大
现代汉语语料库加工规范——词语切分与词性标注

现代汉语语料库加工规范——词语切分与词性标注1999年3月版北京大学计算语言学研究所1999年3月14日⒈ 前言北大计算语言学研究所从1992年开始进行汉语语料库的多级加工研究。
第一步是对原始语料进行切分和词性标注。
1994年制订了《现代汉语文本切分与词性标注规范V1.0》。
几年来已完成了约60万字语料的切分与标注,并在短语自动识别、树库构建等方向上进行了探索。
在积累了长期的实践经验之后,最近又进行了《人民日报》语料加工的实验。
为了保证大规模语料加工这一项重要的语言工程的顺利进行,北大计算语言学研究所于1998年10月制订了《现代汉语文本切分与词性标注规范V2.0》(征求意见稿)。
因这次加工的任务超出词语切分与词性标注的范围,故将新版的规范改名为《现代汉语语料库加工规范》。
制订《现代汉语语料库加工规范》的基本思路如下:⑴ ⑴ 词语的切分规范尽可能同中国国家标准GB13715“信息处理用现代汉语分词规范” (以下简称为“分词规范”)保持一致。
由于现在词语切分与词性标注是结合起来进行的,而且又有了一部《现代汉语语法信息词典》(以下有时简称“语法信息词典”或“语法词典”)可作为词语切分与词性标注的基本参照,这就有必要对“分词规范”作必要的调整和补充。
⑵ ⑵ 小标记集。
词性标注除了使用《现代汉语语法信息词典》中的26个词类标记(名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w)外,增加了以下3类标记:①专有名词的分类标记,即人名nr,地名ns,团体机关单位名称nt,其他专有名词nz;②语素的子类标记,即名语素Ng,动语素Vg,形容语素Ag,时语素Tg,副语素Dg等;③动词和形容词的子类标记,即名动词vn(具有名词特性的动词),名形词an(具有名词特性的形容词),副动词vd(具有副词特性的动词),副形词ad(具有副词特性的形容词)。
(整理)现代汉语语料库加工规范词语切分与词性标注词
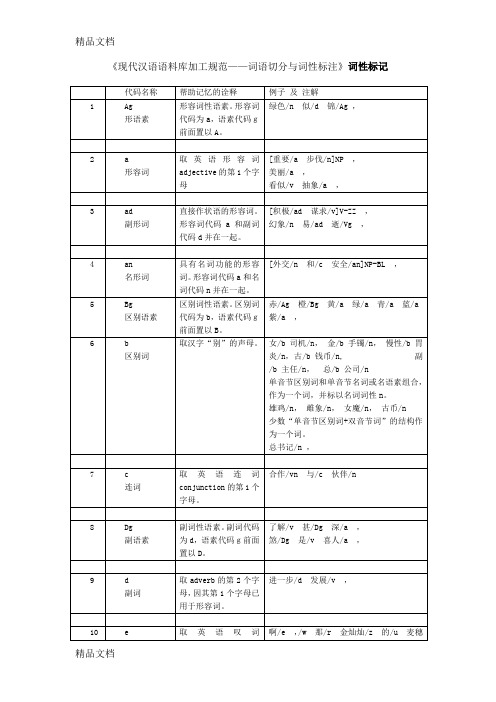
出/v过/u两/m天/q差/Ng,
疾病成本法和人力资本法将环境污染引起人体健康的经济损失分为直接经济损失和间接经济损失两部分。直接经济损失有:预防和医疗费用、死亡丧葬费;间接经济损失有:影响劳动工时造成的损失(包括病人和非医务人员护理、陪住费)。这种方法一般通常用在对环境有明显毒害作用的特大型项目。理/v了/u一/m次/q发/Ng,
一个/m ,一些/m ,
2.基数、序数、小数、分数、百分数一律不予切分,为一个切分单位,标注为m。
一百二十三/m,20万/m,123.54/m,一个/m,第一/m,第三十五/m,20%/m,三分之二/m,千分之三十/m,几十/m人/n,十几万/m元/q,第一百零一/m个/q ,
3.约数,前加副词、形容词或后加“来、多、左右”等助数词的应予分开。
岗位/n ,城市/n ,机会/n ,
[例题-2006年真题]下列关于建设项目环境影响评价实行分类管理的表述,正确的是( )她/r是/v责任/n编辑/n ,
(编辑/v科技/n文献/n )
21
nr人名
名词代码n和“人(ren)”的声母并在一起。
1.汉族人及与汉族起名方式相同的非汉族人的姓和名单独切分,并分别标注为nr。
张/nr仁伟/nr,欧阳/nr修/nr,阮/nr志雄/nr,朴/nr贞爱/nr
汉族人除有单姓和复姓外,还有双姓,即有的女子出嫁后,在原来的姓上加上丈夫的姓。如:陈方安生。这种情况切分、标注为:陈/nr方/nr安生/nr;唐姜氏,切分、标注为:唐/nr姜氏/nr。
2.姓名后的职务、职称或称呼要分开。
江/nr主席/n,小平/nr同志/n,江/nr总书记/n,张/nr教授/n,王/nr部长/n,陈/nr老总/n,李/nr大娘/n,刘/nr阿姨/n,龙/nr姑姑/n
信息处理用现代汉语词类标记集规范

助词(u)
• 助词不能单独充任句子成分,大都附着在词、短语或 句子后面,个别的附着在词前面,起不同的句法作用。 例:“的”、“地”、“得”、“了”、“着”、 “过”、“所”、“似的”、“等等”、“罢”等。 • 小类
– – – – – 结构助词(us):如“的”、“地”、“得”等助词。 动态助词(ua):如“着”、“了”、“过”等助词。 比况助词(uc):如“似的”、“一样”等助词。 替代助词(ur):如“等”、“等等”、“云云”等助词。 语气助词(um)/语气词(y):如“了”、“的”、“呢”、 “吗”、“吧”语是汉语中的固定用法,包括成语、惯用语、谚 语、格言等。它们在汉语中语义内容丰富,稳定性强。 • 小类
– 名词性习用语 (in):如:“海市蜃楼”、“井底之蛙”等。 – 谓词性习用语 (ip):如:“众口难调”、“吃老本”、“碰钉 子” 、“通情达理”等。 – 连词性习用语(ic):如:“总而言之”、“由此可见”、“一方 面……,一方面……”、“一则……二则……”等在句段间起关 联作用并且习惯上常在一起搭配使用的词或短语。
叹词(e)
• 叹词在句中的位置比较灵活,通常不与其他词 发生特定的关系,也不充任句子成分,能独立 成句;叹词后一定有停顿,因此书面上叹词后 常有标点符号。例:“唉”、“哎呀”、 “嗯”、“哼”、“喂”等。
拟声词(o)
• 可以独立成句或在句中作插入语。拟声词加 “的”可以作定语加“地”可以作状语。例: “哗啦”、“唧哩咕咚”、“扑通通”、“滴 答”、“轰轰”等。
– 名后接成分 (kn):如:“子”、“儿”、“性”、 “家”、“派”、“界”等可构成名词的后接成分。 – 动后接成分 (kv):如:“化”等可构成动词的后接 成分。
语素字(g)
国家语委现代汉语通用平衡语料库 标注语料库数据及使用说明

国家语委现代汉语通用平衡语料库标注语料库数据及使用说明肖航教育部语言文字应用研究所1. 国家语委现代汉语通用平衡语料库1.1 语料库全库国家语委现代汉语通用平衡语料库全库约为1亿字符,其中1997年以前的语料约7000万字符,均为手工录入印刷版语料;1997之后的语料约为3000万字符,手工录入和取自电子文本各半。
语料库的通用性和平衡性通过语料样本的广泛分布和比例控制实现。
语料库类别分布如下所示:1.2 标注语料库标注语料库为国家语委现代汉语通用平衡语料库全库的子集,约5000万字符。
标注是指分词和词类标注,已经经过3次人工校对,准确率大于>98%。
语料库全库按照预先设计的选材原则进行平衡抽样,以期达到更好的代表性。
标注语料库在样本分布方面近似于全库,不破坏语料选材的平衡原则。
标注语料库类别分布如下所示:标注语料库与全库的样本分布比较如下所示:(蓝色曲线为语料库全库;红色曲线为标注语料库)2. 国家语委现代汉语通用平衡语料库语料选材与样本分布2.1 选材原则依据材料内容,选材大体作如下分类:(下文字数为建库时数据)2.1.1 教材大中小学教材单作一类,约2000万字。
2.1.2 人文与社会科学的语言材料约占全库的60%,共3000万字,包括:·政法(含哲学、政治、宗教、法律等);·历史(含民族等)·社会(含社会学、心理、语言、教育、文艺理论、新闻学、民俗学等);·经济;·艺术(含音乐、美术、舞蹈、戏剧等);·文学(含口语);·军体;·生活(含衣食住行等方面的普及读物)。
2.1.3 自然科学(含农业、医学、工程与技术)的语言材料,应涉及其发展的各个领域。
拟从大、中、小学教材和科普读物中选取。
其中,科普读物约占6%,共300万字。
教材字数另计。
2.1.4 报刊。
以1949年以后正式出版的由国家、省、市及各个部委主办的报纸和综合性刊物为主,兼顾1949年以前的报纸和综合性刊物。
Web新闻语料分词和标注错误分析

Web 新闻语料分词和标注错误分析张永奎1, 2, 张彦1, 2, 安增波3, 刘睿1, 2ZHANG Yong-kui1, 2, ZHANG Ya n1, 2, AN Ze ng-bo3, LIU Rui1, 21.山西大学计算机与信息技术学院, 太原0300062.计算智能与中文信息处理省部共建教育部重点实验室, 太原0300063.中国人民解放军91708 部队自动化工作站, 广州5103201.Department of Computer & Information Technolog y, Shanxi University, Taiyuan 030006, China2.Key Laboratory of Ministry of Education for Computation Intelligence and Chinese Information Processing, Taiyuan 030006, China3.Workstation Automation of 91708 PLA, Guang zhou 510320, ChinaE- mail: z**************.cnZ H AN G Yong-kui, Z H ANG Ya n, AN Z eng-bo, et al.Ana lysis of ina ccu r at e st yle in pr ocessing W eb t r ue news t ext———about word segmentation and p art of speech puter Engineering and Applications, 2007, 43( 15) : 166- 169. Abstract: Eleven inaccurate styles are obtained through analyzing the processing of Web accidental news text, we propose resolvent for some styles.This not only illuminates the improvement of word segmentation and part of speech tagging methods in early process of corpora, but also provides references to automatic check, another branch of Chinese information processing.Key words: Chinese information processing; word segmentation; part of speech tagging; inaccurate style; Web accidental news corpora摘要: 通过分析Web 突发事件语料库文本的加工统计得出11 类错误类型, 并对其中的一些错误提出了解决方案。
一种切词和词性标注相融合的汉语语料库多级加工方法

一种切词和词性标注相融合的汉语语料库多级加工方法*周强, 俞士汶(北京大学计算语言学研究所北京100871)摘要 : 本文通过深入研究汉语切词和词性标注处理的内在联系,提出了一种将两者结合起来处理的方法,并详细介绍了词性标注的基本设计思想,讨论了规则方法和统计方法相结合的排歧策略。
用此方法对约40万字的语料进行了实际的切分和标注处理,其准确度分别达到了96%和94%。
关键词 : 汉语自动切词,语料库词性标注。
一引言在汉语中,短语(与词组同义)类型,是一种很特殊的语法形式。
它具有与汉语句子结构相类似的主谓、述宾、联合等种种不同的构造方法,这和英语中的短语有很大差别。
“如果我们把各类词组的结构和功能都足够详细地描写清楚了,那么句子的结构实际上也就描写清楚了,因为句子不过是独立的词组而已。
”[1]从这个意义上看,现代汉语短语结构研究的重要性是不言而明的。
要进行汉语短语结构的研究,就必须对大量的汉语语言事实进行调查研究,从中总结出有关短语组成的规律。
在这方面,一个带多种标记的大规模汉语语料库就可以提供大量有用的信息。
从本质上看,汉语语料库的多级加工,即从文本语料库(‘生’语料库),经过自动切词,词性标注及短语结构标注而得到带不同标记的‘熟’语料库,和汉语短语分析处理中的切词,词性标注,短语结构分析等各个阶段有着内在联系,完全可以把两者结合起来处理。
一方面,利用短语分析中的各种技术对语料库进行多级自动标注,形成准确度较高的带多标记的语料库;另一方面,以新的语料库为基础,利用不同的统计工具,从中提取出大量的汉语语言事实,通过总结提炼,再结合到自动分析程序中,可以大大提高自动分析的效率和准确性。
正是基于这个基本思路,笔者实现了一个汉语短语分析和语料库多级标注处理相结合的系统。
从结构上看,此系统分为两大处理系统:切词及词性标注处理和短语结构分析。
本文主要介绍一下切词和词性标注处理的基本思想和相关的处理技术。
有关短语分析的处理将另行撰文介绍。
现代汉语语料库加工规范词语切分与词性标注词...
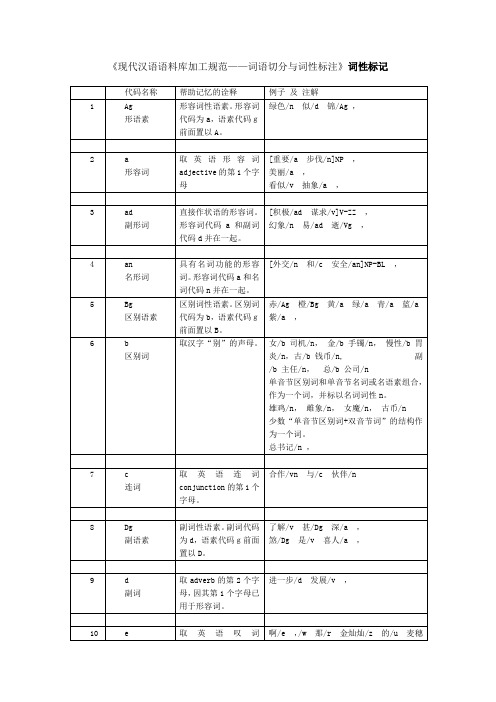
[全国/n总/b工会/n]NT,
[全国/n人民/n代表/n大会/n]NT,
美国的“国务院”,其他国家的“外交部、财政部、教育部”,必须在其所属国的国名之后出现时,才联合标注为NT。
[美国/ns国务院/n]NT,
[法国/ns外交部/n]NT,
[美/j国会/n]NT,
[香港/ns特区/n]NS,
[华盛顿/ns特区/n]NS,
4.地名后有表示地形地貌的一个字的普通名词,如“江、河、山、洋、海、岛、峰、湖”等,不予切分。
鸭绿江/ns,亚马逊河/ns,喜马拉雅山/ns,珠穆朗玛峰/ns,地中海/ns,大西洋/ns,洞庭湖/ns,塞普路斯岛/ns
5.地名后接的表示地形地貌的普通名词若有两个以上汉字,则应切开。然后将地名同该普通名词标成短语NS。
[积极/ad谋求/v]V-ZZ,
幻象/n易/ad逝/Vg,
4
an
名形词
具有名词功能的形容词。形容词代码a和名词代码n并在一起。
[外交/n和/c安全/an]NP-BL,
5
Bg
区别语素
区别词性语素。区别词代码为b,语素代码g前面置以B。
赤/Ag橙/Bg黄/a绿/a青/a蓝/a紫/a,
6bBiblioteka 区别词取汉字“别”的声母。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
语料库标记与标注_以中国英语语料库为例_李文中

外语教学与研究 ( 外国语文双月刊 ) ) F o r e i n L a n u a e T e a c h i n a n d R e s e a r c h( b i m o n t h l g g g g y
M a 2 0 1 2 y V o l . 4 4N o . 3
?
本文涉及的软件系统由该团队韩朝阳负责开发 。 相关设计及技术思想在团队讨论与研究生课堂
上得到很多启发 , 特此致谢 。 此外 , 相关标记方案也分别由团队各成员负责 。
·3 3 8·
李文中 语料库标记与标注 : 以中国英语语料库为例
入库 。 、 包括文本分类信息 ( 来 源、 检 索 日 期、 类 型、 状 态、 标记方案) A.标记模块 : 、 。 这 些 在 XML 文 文本领域 ( 开放标记 , 可添加 ) 作者信息( 开 放 标 记, 可添加) _ ” 、 “ _ ” _ 文本信息 d 文件信息f 和“ 位置信息l 本中分别组织为 “ a t a i n f o i l e i n f o o c a l ” 。 i n f o 允 许 以 压 缩 文 件 格 式 提 交 以 下 文 件 类 型: 纯 文 本、 B.源文本 入 库 模 块 : 音频 、 视频 。 DO C、 P D F、 HTML、 纯文本文件提交入库 。 C.纯文本入库模块 : 2. 2 难题与解决方案 我们认为 , 由于文本体裁千 差 万 别 , 目前的分类标准大多属于定 性 分 类, 计 所 以 须 由 人 来 判 断 。 但 XML 是 一 种 非 常 严 谨 算机很难自动识别并做出判 断 , 几乎不可能手工添加而不出错 , 因此这一步由计算机自动完成 。 软 的标记语言 , 件会把人工添加的信息自动 转 换 为 标 准 的 XML 文 件 并 进 一 步 处 理 , 这样既保 也保证了元信息的信度 。 同时 , 考虑到不同类型文本元 证了所添加信息的效度 , 信息的多元性特征 , 我们设计了 8 种不同的标记方案 , 包括著作 、 一般文件 、 法律 条文 、 期刊 、 新闻 、 论文 、 杂志和网页 。 新的标记参数和标记方案可通过修改控制 由 于 分 类 庞 杂, 多有交叉和重 标记界面的 XML 文 件 来 添 加 。 对 于 文 本 领 域 , 叠, 我们对它的标记设计成开放型 , 使之能够兼容不同的领域分类 。 语料库标记 的作用在于基于类型的研究和分析 , 基于标记信息 , 使用者可根据自己的研究目 的选择文本或重新组 建 子 语 料 库 并 进 行 检 索 。 对 于 源 格 式 文 本 的 对 应 入 库 问 我们的考虑是 , 原文本中的结构 、 布局 、 非文字元素 , 如插图 、 链接等都对文本 题, 我们对格式文本分步进行处 的意义理解和分析产生影 响 。 但 由 于 技 术 的 局 限 , 理: 第一步 , 文本对应 , 即在语料库中把源格式文本与纯文本整体对应 , 这样使用 者在查询语料库时可调出 原 文 本 观 察 。 第 二 步 , 实现格式文本在统一平台的查 询, 使用者可选 择 检 索 纯 文 本 或 原 格 式 文 本 , 如 DO C、 P D F 与 HTML 网 页 文 但相关思想和技术需要 进 一 步 探 索 。 第 三 步 , 多 媒 体 文 件 与 文 本 文 件 对 应, 本, 。 并实现双向检索 , 为此我们开发了多媒体语料库平行定位检索系统 ( 另文讨论 ) 此外 , 我们还尝试把软件平台与 C 开发完成了 “ 开放语料库建设平 E C 剥离 , ( , 台” 使之能够满足建设小型语料库的标 O e n C o r u s D e v e l o m e n t P l a t f o r m) p p p 记需求 。 使用者通过修改控制 建 库 界 面 的 XML 文 件 , 就可以设计自己的语料 库标记方案 , 使语料库标记开放化和动态化 。 尽管各种可用的大中型语 料 库 已 有 很 多 , 但由于网络时代的文本增长速度 极快 , 语言发展和变化的速度也前所未有 , 现有的静态语料库已很难满足个人研 究者和教师对语料库资源的个性需求 。 语料库开发向两极发展 , 一是超大型化 ,
现代汉语语料库加工中的切词与词性标注处理

现代汉语语料库加工中的切词与词性标注处理周强, 段惠明北京大学计算语言学研究所北京,100871目前,大规模真实文本处理已成为计算语言学界的一个热门话题。
一个重要的原因是因为它给我们提供了一种新的研究思路,即从大规模的语料库中提取所需要的知识。
而汉语语料库的加工和处理,又涉及到汉语语法研究的许多问题,如:词的定义,词类的划分,短语的确定等等。
在这方面,我们进行了一些探索,积累了一些经验。
本文只讨论切词与词性标注问题。
1. 汉语语料库的多级加工总结国内外语料库建设的经验,可以看到:一个计算机语料库的功能主要和下面三种因素密切相关,即库的规模、语料分布和语料的加工深度。
因为库容量的大小直接影响到统计结果的可靠性,语料分布的考虑则关系到统计结果的适用范围,而加工深度则决定了该语料库能为自然语言处理提供什么样的知识。
对于汉语语料库的处理,可以设想有以下几个阶段,如图1所示[5]。
这样,经过不同阶段的处理,语料库所携带的各类消息也不断增加,最终将成为一个名副其实的语言知识库。
这样的知识库可以为汉语统计分析、汉语理解和机器翻译提供重要的资源和有力的支持。
┌────┐┌────┐┌────┐┌────┐│"生图 1 库存语料的加工顺序2. 关于切词和标注结合处理的规范从92年初开始, 北大计算语言学研究所开始进行汉语语料库的多级加工处理的研究,其第一步工作是对原始语料进行切分和词性标注, 并且我们是将切词和标注结合起来进行的。
通过使用一个带词类标记的切词词典, 在自动切词的同时, 给每个切分单位标上初始词性标记, 然后通过规则与统计相结合的方法排歧, 实现词类的自动标注, 再利用构词规则, 发现一些符合汉语构词规律的未定义词并确定其词类。
[6]以上工作的基础是“信息处理用现代汉语分词规范”[1](下简称为“分词规范”)、现代汉语词语分类体系[2]、汉语构词法理论[3]和现代汉语语法电子词典[4]。
在对约40万字语料的切分与标注的实践基础上, 我们发现了一些新的处理规律, 积累了许多有益的经验。
多义词词义搭配知识库与词义标注

多义词词义搭配知识库与词义标注苏新春【摘要】“多义词词义搭配知识库与词义标注”是国家社科基金课题“基于国家语委‘通用语料库’的汉语义频词库的开发”的研究成果.研究过程中对最初设计的目标定位、处理的词语数量、语料规模都作了较大调整,表现为由义频研究转至义频获得,由部分多义词转至现代汉语的整体双音高频多义词,由2000万字的核心语料库转至2.5亿字的通用语料库.研究成果由7个资源库与3个软件处理平台构成,从而达到词义自动标注的目的.【期刊名称】《江西科技师范大学学报》【年(卷),期】2014(000)002【总页数】5页(P1-5)【关键词】多义词词义搭配知识库;多义词;词义自动标注;SCT【作者】苏新春【作者单位】厦门大学国家语言资源监测与研究教育教材中心,福建厦门361005【正文语种】中文【中图分类】H032一、课题目标与研究过程(一)最初目标与调整我们向全国社科基金办递交的《基于国家语委“通用语料库”之上的汉语义频词库的开发》“课题申请书”对研究目标与意义作了这样的阐述:“汉语义频词库的开发是汉语词汇知识库、汉语词汇教学、对外汉语词汇教学、中文信息处理等领域的一项基础应用工程。
……编纂义频词库,准确地体现不同常用级别的词量与分布,细致反映出每个词的‘义项’使用的多寡繁疏,有着紧迫的现实需要与理论意义,是词汇理论与词汇应用中的一项具有广泛用途的基础性工程。
……由国家语委主持经十年研制的“通用语料库”已经完成,这给义频词库的开发和研制提供了十分优越的条件。
”课题的基本思路与方法是:“⑴语言材料立足于大规模的经过严格检测、计算的语料库之上。
⑵以义项为语义频率的基本单位。
⑶全面反映义项的使用环境、搭配对象等语义功能。
⑷成果形式为能够方便服务于语言教学、语言规范、词典编纂及中文信息处理等众多领域的词库——ACCESS数据库。
”特点为:注重词汇学词义学理论问题研究;注重对多义词内多个义项分布规律与特点的描述;研究对象有着确定的语料范围,即2000万字的“通用语料库”;有形成果为含有义频的词表词库。
中文信息学报语料库中熟语的标记问题

中 文 信 息 学 报第18卷第1期 JOURNAL OF CHINESE INFORMATION PR OCESSING V ol118No11文章编号:1003-0077(2004)01-0020-06语料库中熟语的标记问题①安 娜,刘海涛,侯 敏(北京广播学院应用语言学系,北京 100024)摘要:熟语是自然语言中普遍存在的语言现象。
本文分析了国内现有语料库对熟语的标注方式,发现这种方式对语料库的进一步加工是有问题的。
为了在语料库标注阶段把熟语问题处理好,本文从信息处理的角度将熟语中的成语、惯用语、歇后语、习用语、专门语以及缩略语归为固定语的范畴,进而提出根据固定语的语法功能给定词性标记,再根据它们的词汇特征给定词汇范畴标记的双层标记法,这样在一定程度上解决了熟语的语料库标注问题。
关键词:人工智能;自然语言处理;熟语;固定语;标注;语料库中图分类号:TP391 文献标识码:AT agging of the Idiom in the CorpusAN Na,L IU Hai2tao,HOU Min(Applied Linguistics Department,Beijing Broadcasting Institute,Beijing100024,China)Abstract:Idiomaticity is a common phenomenon in natural languages.This paper analyses some known means of tagging the idiom in Chinese corpus.These tagging methods are problematic for the further syntactic tagging and parsing of corpus.To find a suitable solution for application in natural language processing,the authors introduce a new concept“fixed expression”,which consist of idioms,customary usages,two2part allegorical sayings,terms and abbreviations.These fixed expressions have the same grammatical function as common words,thus we can tag them according to their function in text and give suitable vocabulary category of fixed expressions.This is called two2level tagging method.The proposed solution is useful to build a parsed corpus as knowledge source of NL P.K ey w ords:artificial intelligence;natural language processing;idiom;fixed expression;tagging of corpus;parsed corpus1 引言在建设传媒语言语料库的过程中,我们根据对语料库加工的通行做法,先对原始语料作词性标注。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
规则和统计相结合的汉语词类标注方法*周强北京大学计算语言学研究所北京,100871摘要:本文分析了汉语的多类词现象与汉语词类标注的困难,介绍了汉语词类标注中的规则排歧和统计排歧的处理策略以及规则和统计相结合的处理思路。
按此思路设计的软件系统,对封闭语料和开放语料的标注正确率分别达到了 96.06% 和 95.82%。
1. 引言在对语料库信息的加工处理过程中,词类标注是一项很重要的工作。
它的任务就是给语料库中的每个词赋一个合适的词类标记。
由于英语、汉语等许多自然语言中都存在着大量的词的兼类现象,因此给语料库的自动词类标注带来了很大困难。
词类歧义消解(Grammatical Category Disambiguation)已成为自动词类标注研究的主要课题。
国外对英语语料库的自动词类标注研究可以分为以下几个阶段:七十年代初,主要采用了基于规则的处理方法。
其代表是TAGGIT系统[3]它主要利用了3300条上下文框架规则(Context Frame Rules)对100万词次的Brown语料库[5]进行了自动词类标注,处理正确率达到了77%。
七十年代末到八十年代初,随着经验主义方法在计算语言学研究中的不断流行,基于统计的词类排歧方法开始得到应用。
1983年的语料库标注系统 CLAWS[6]最先采用了Shannon的噪声信道模型思想[7]进行词类自动标注。
通过利用Brown语料库的正确标注语料训练参数,达到了96%的正确率。
从此以后,随着正确标注语料数量的不断增长和统计处理技术的不断完善,基于统计的方法在英语语料库的自动词类标注器设计中占有了主导地位,如:[1],[2],[4]等。
相比之下,国内对汉语语料库的词类标注研究则起步较晚。
近几年来,清华大学和山西大学对基于统计的汉语语料库自动标注方法进行了一些研究和探索,提出了一套用于汉语语料库标注的词类标记集,标注正确率也达到了95%左右的([8],[9])。
但由于训练语料规模的限制(约20万字),并没有进一步进行大规模汉语语料库的标注。
而有关规则和统计相结合的处理方法,在[16],[17]中也作了一些有益的探索.从92年初开始,北大计算语言所开始进行汉语语料库的多级加工处理研究,提出了一种切分和标注相融合的汉语语料库多级加工方法[14],其中的重要内容是规则和统计相结合的处理思想。
我们的出发点是充分发挥基于统计方法和基于规则方法各自的优势,为大规模汉语语料库的词类自动标注寻找一种较好的处理方法。
对约四十万字的汉语语料的实际处理结果显示,标注正确率达到了96% 左右,处理效果还是比较令人满意的。
在下面的几节中,第二节将讨论汉语词的多词类现象,第三、四节分别介绍基于规则处理和基于统计方法的基本思想,然后第五节说明规则和统计相结合的处理方法,第六节给出一些实验结果,并对不同方法的处理性能进行比较和分析,最后是结束语。
2. 汉语词的多词类现象由于计算机处理文本数据时通常不考虑读音,同形词和兼类词的识别处理没有区别,致使在词类标注过程中遇到的词类歧义现象比传统语言学意义上的兼类现象范围更广。
它主要包括以下几种情况:1). 字同音不同的词:*本论文相关的研究工作得到国家自然科学基金的支持,项目号为 69483003如: “好”— (hǎo) — a :他很好— (hào) — v :他好吃2). 字同音同义不同的词:如:“编辑”——n [指人]:他是编辑“编辑”——v[指动作]:他在编辑教材3). 字同音同的兼类词:如:“丰富”—— a-v :[生活很丰富/a;丰富/v业余生活]“把”—— q-p :[把/p书放上面;一把/q刀]4). 1)、2)、3)的各种混合体:如:“了”:既有字同音同的兼类词(u-y),又有字同音不同的不同类词(v(liǎo)-u(・le))对于汉语中的这些语言现象,我们统称为词的同形异类现象,而把具有这些现象的词,则称为多类词。
在这里,我们利用了北大提出的信息处理用现代汉语词语语法功能分类 [11],其词类与代码列在表1中。
表1. 汉语词类代码表名词n 区别词b助词u 简称略语j语素 g成语i时间词t 形容词a语气词y 习用语l字x处所词s 状态词z象声词o 前接成分h数词 m方位词 f 动词v叹词 e 标点符号w副词 d量词q 介词p代词r 后接成分k连词 c汉语中多类词还是挺普遍的。
通过对《动词用法词典》[10]的约40万字语料的切词结果的统计,我们得到了表2的结果:表2:多词类现象统计表总词次291623(个)总词条10813(个)多类词词次107406(个)多类词词条463(个)多词类现象102(种)由于语料的主要是研究各种动词用法的例句,因此句型比较规范,单字词较多。
这些特点在统计结果中也有所体现。
表3,表4分别列出了语料中出现频率最高的前20个多类词和前10种同形异类现象。
表3. 多类词词表(前20个)序号词条词类集频度序号词条词类集频度1 一m-d-c 6371 11 了 v-u-y 19072 上v-f 4046 12 起 v-q 17803 过d-u-v 3447 13 就 d-v-c-p 17704 把q-p 3239 14 里 q-f 17465 来m-v 3185 15 在 p-d-v 6806 着u-n-v-q 2485 16 得 u-v 15257 到p-v 2278 17 次 q-a 15068 下q-v-f 2250 18 出 v-q 13859 两q-m 2198 19 好 v-a-d 120810 开v-q 1994 20 没 v-d 1169从这些统计结果中,不难发现以下特点:1). 多类词数量虽不多(占词条总数的4.28%),但出现频度却很高(约占总词次的36.8%)。
2). 越是常用的词歧义现象越严重。
表2中前20个多类词总共出现了47187次,占了多类词总次数的43.9%。
3). 同形异类现象错综复杂,但分布很不均匀,一些常见词类歧义组合占很大比例。
了解了语料中多词类现象的分布规律,对我们在语料的自动词类标注中采取正确的策略是有重要启示意义的。
表4. 同形异类现象表(前10种) 序号词类集频度序号词类集频度1 v-q 7605 6 v-f-n40642 m-d-c 6371 7 d-u-v34473 p-v 6325 8 p-q 32394 v-n 6015 9 m-v 31855 q-n 4792 10 v-d 2854____________________________________________________________________________3. 规则排歧处理规则处理的基本思路是利用上下文框架规则描述在特定的语境下一个多类词到底应标上什么词类标记,这里的语境包括词语信息、词类信息、甚至还有某些词语的特征信息。
由于我们的汉语词语分类体系[11]主要依据了“按照词的语法功能进行分类”[15]的思想,对每类词所具有的不同语法功能都进行了详细的描述,从而为我们构造不同的上下文框架规则提供了大量有用的信息。
在实际应用过程中,为提高工作效率,又可把规则处理分为以下几个不同的阶段:1). 特征词排歧:对于那些出现频度很高,词类标记又较多的词(如:“一”,“着”,“了”,“过”,“好”,“就”,……),设置特定的规则,检查这些词在句子中出现的上下文环境,以确定不同的标注情况。
这相当于基于词的排歧方法。
例如:对多类词“了”/v-u-y,可总结出以下的排歧规则:a. “了”+句尾标记→ y 这里的句尾标记包括标点符号:句号、感叹号、问号及其它语气词。
b. v +“得”|“不”+“了”→ v c. v|a + “了”→ u 2). 特定词类组合排歧:统计语料中经常出现的一些词类组合,如:v-q,p-v,v-n,v-d,a-v 等,调查这些组合在不同语境下选取某个词类的可能性大小。
通过利用词类划分的语法功能特征,特别是某类词区别于其它词类的它本身所特有的语法分布信息,构造相应的上下文规则描述,来选择正确度较高的词类标记。
这相当于基于词类组合的排歧方法。
例如:对词类组合 v-a ,可提取以下的排歧规则:a.{“很”,“太”,“最”,“非常”,……} + v-a → a b. q + v-a + n → a c. v + v-a + n|u|y → a 其它情况取v d.3).上下文关系排歧:设置一些上下文词类标记匹配模式,描述在一定的词类环境下可能出现的词类标记的集合。
在实际处理过程中,如果句子中多类词的前后词类描述与这些规则模式相匹配,则将多词类集与规则描述中可能出现的词类集合进行交运算。
若所得结果只有一个词类标记,则排歧成功。
这相当于基于模式的排歧方法。
例如:若我们有模式:v+{p,u,a}+n ,表明动词(v)和名词(n)中间可能为 p,u,a ,则对于句子片段:有/v 怪/a-d-v 招/n 中的多类词“怪”,进行集合运算 {p,u,a}∧{a,d,v},得到a ,从而给出了正确的词类标记“怪/a ”,完成了词类排歧。
规则知识库是基于规则的处理的基础,而它的构造则需考虑两个基本问题:规则对语言现象的覆盖率和规则处理的正确率。
一般而言,对于一条规则,这两种性能往往显示反比关系,即如果一条规则覆盖的语言现象越多,则它处理的正确率越低;反之,若一条规则只描述一种特定的语言现象,则它可以保持较高的正确率。
在我们上面的三种排歧规则中,特征词排歧是基于词的,可以对有关信息描述得很深入,因此处理正确率也较高。
而多类词排歧规则和上下文排歧规则则是基于词类的,因此对某些词的处理效果不太令人满意,但它们能覆盖较多的语言现象,提高规则处理的覆盖面。
因此,一个好的规则库应该综合考虑这两方面的因素,合理安排不同规则的分布,使规则处理的整体效果达到最佳。
在我们目前的系统中,这三部分规则的数量分布大致为3:5:2 ,从第六节中给出的一些实验结果来看,整体排歧效果还是比较好的。
4. 统计排歧处理首先,构造如下的统计计算模型:令 W w w w n =12... 为一多词类词串,C c c c n =12... 为可能的词类标注结果串。
P(C|W)为给定W条件下C出现的概率。
如果不考虑更大的上下文,我们可以认为使得 P(C |W)的值取得最大时的C出现的可能性最大。
这样就把词类标注问题转化为寻找一组标记串C′,使得:C P C W 'arg max (|)= (1) 根据贝叶斯定律,可以得到: P C W P C P W C P W (|)()(|)()=(2)其中P(W)为常量,不需要考虑,关键在于对P(C)和P(W |C)的计算。
由于两者的参数估计极为复杂,在实际应用中,往往需进行简化。