software evolution and manteinance
重塑微软:帝国的云蓝图

整 体 云计算 解 决方 案 中发挥 关 键作
用 。 既是运营 平 台 , 是开 发 、 它 又 部
署 平 台 ,提 供 了 一 个 在 线 的 基 于
Wid ws n o 系列 产品 的开 发、存储 和
服务 等综 合环 境 。
目前 , u e 台还包括 Wi— Az r 平 n
do s Az e pl f m w ur ator AppFa i brc,
一
开发 人员创建 的应用既可 以直接在该 平 台中 运行 , 也可 以使用 该 云计算 平 台提 供 的服务 。 相 比较 而言 ,A ue 台延 续 了微软传 统软 件平 台 zr 平 的特点 , 能够 为用 户提供 熟 悉的开 发体 验 , 户 用 已有 的许 多应用程 序都 可以相对 平滑地 迁移 到该
弃 以前所有 软件 , 而是重 新开 始” 实 际上 , 尔 , 鲍
的角逐 , 在这 新 旧游戏规 则 交替 的紧要 关头 ,谁 握 住 了主动权 ,谁 就 能获得未 来 的话语权 。
、作为传统 的软 L
A ue z r ,开启 蓝色 时代
20 年 1 月 ,在微 软开 发者 大会 上 ,微 软 08 1 宣布 了其 “ 1 2 世纪 最重 要 的里程 碑” — w i— — n
平台上运 行 。另 外 ,A u e 台还 可以按 照 云计 zr平
种思 路从 战略 高度 上 ,作 出了具 有微 软特 色 的
默 的潜 台词可 以理解 为 ,微软正 在 打造一个 基 于 传 统软件 的互联 网上 的计 算环境 ,也是一 个具 有 微软 标识 的云计 算 的蓝色 新时 空 。
事 实上 , id wsAz r 和 S L A r 是 W n o ue Q z e u
挑战新境界的英语作文

Pushing the Boundaries:An English Composition on New FrontiersIn the everevolving landscape of human endeavor,the quest for new frontiers has always been a driving force.The English language,with its rich vocabulary and expressive power,provides an ideal medium for exploring and articulating the challenges and triumphs of this pursuit.This composition delves into the concept of challenging new frontiers,both in the literal sense of physical exploration and in the metaphorical sense of personal and intellectual growth.The Physical Frontier:Exploration and DiscoveryThe physical frontier has historically been associated with geographical exploration. From the Age of Discovery,when European explorers ventured into the unknown,to the modern era of space exploration,humanity has always been drawn to the edges of the map.English,as a global language,has played a pivotal role in documenting these journeys.For instance,the diaries of Christopher Columbus and the Apollo mission transcripts are all written in English,showcasing the languages ability to capture the awe and wonder of new discoveries.The Technological Frontier:Innovation and ProgressIn the realm of technology,English has become the lingua franca for innovation.The language of coding,programming,and software development is predominantly English, enabling a global community of tech enthusiasts and professionals to collaborate and push the boundaries of what is possible.From the development of the internet to advancements in artificial intelligence,English serves as the common ground for sharing ideas and breakthroughs.The Intellectual Frontier:Expanding Knowledge and UnderstandingThe intellectual frontier is perhaps the most profound of all.It encompasses the pursuit of knowledge in various fields such as science,philosophy,and the arts.English,with its extensive academic literature and research papers,facilitates the dissemination of new ideas and theories.The languages flexibility and precision make it an ideal tool for academic discourse,enabling scholars to challenge established norms and propose new paradigms.The Personal Frontier:SelfDiscovery and GrowthOn a more personal level,challenging new frontiers can mean overcoming personallimitations and achieving selfimprovement.English,with its expressive capabilities, allows individuals to articulate their aspirations,fears,and triumphs.Autobiographies, motivational speeches,and selfhelp books written in English inspire countless people to embark on their own journeys of selfdiscovery.The Cultural Frontier:Bridging Diverse PerspectivesCultural exploration is another dimension where English plays a significant role.As a language spoken in various parts of the world,it serves as a bridge between different cultures,allowing for the exchange of ideas and the appreciation of diverse perspectives. English literature,cinema,and music often reflect this cultural diversity,enriching the global community and fostering a deeper understanding of different ways of life.ConclusionIn conclusion,the concept of challenging new frontiers is multifaceted and can be approached from various angles.English,with its versatility and widespread use,is an indispensable tool in this endeavor.Whether it is through the documentation of physical exploration,the advancement of technology,the pursuit of intellectual knowledge, personal growth,or cultural understanding,English enables us to express,share,and celebrate the human spirits relentless quest for new horizons.。
当算法统治世界

当算法统治世界据英国广播公司(BBC)近日报道,看不见的算法正在掌控着我们与数字世界的互动,从谷歌网站上图书、电影和音乐的算法到Facebook网站上推荐朋友的算法;从操纵华尔街交易的代码再到各种搜索引擎代码,算法似乎无声地渗入到我们的世界并重塑着我们身处的世界。
然而,令我们揪心的是,我们正在慢慢失去对这些代码的控制,而且,算法也并不总是正确,算法出错将会给我们的生活带来巨大的影响。
在上个月举行的全球TED大会(指全球技术、娱乐、设计大会,每年,TED大会在美国召集众多科学、设计、文学、音乐等领域的杰出人物,分享他们关于技术、社会、人的思考和探索)上,算法专家凯文·斯莱文警告称,现在,到了我们更透彻地了解算法并想方设法“驯服”它的时候了。
“算法为王”斯莱文在全球TED大会上发表演讲称,“计算机用来做决定的数学”正在以“随风潜入夜,润物细无声”的方式,慢慢渗透进我们日常生活的方方面面。
在每个智能网页的背后都隐藏着更加智能的网页代码:谷歌网站上为我们推荐图书、电影和音乐的是算法;Facebook网站上为我们推荐朋友的也是算法;在华尔街纵横捭阖的是算法;在好莱坞预测票房的也是算法。
这些看不见摸不着的计算正在慢慢掌控着我们与电子世界的相互交流,这是一个“算法为王”的时代。
“我们正在编写一些自己也看不懂的东西,我们把一些事情变得更加复杂,难以理解。
我们正在慢慢失去对这个我们自己创造的世界的理解和掌控。
”斯莱文警告称。
算法影响好莱坞随着代码变得越来越复杂,它的触角正在深入我们生活的各个层面,包括我们的文化偏好。
推荐引擎是全球最大的在线影片租赁网站Netflix公司的一个关键服务,1000多万顾客都能在一个个性化网页上对影片做出1到5的评级。
Netflix将这些评级放在一个巨大的数据集里,该数据集容量超过了30亿条。
Netflix使用推荐算法和软件来标识具有相似品味的观众对影片可能做出的评级。
百分点推荐引擎的首席执行官柏林森表示:“网络正从一个搜索时代进入一个发现时代,推荐引擎无所不在。
新诺兰模型

5.信息管理阶段: 信息系统开始从支持单项应用发展到在 逻辑数据库支持下的综合应用。组织开始 全面考察和评估信息系统建设的各种成本 和效益,全面分析和解决信息系统投资中 各个领域的平衡与协调问题。 企业高层意识到信息战略的重要作用, 高标准、大力度地加强管理信息化工作。 企业不仅制定了整体解决的信息化方案和 步骤,而且选定了统一的数据库平台、数 据管理体系和信息管理平台,从而真正地 做到了对整个机构的数据进行统一的规划
• 2.扩展阶段: • 信息技术应用开始扩散,数据处理专家开 始在组织内部鼓吹自动化的作用。这时, 组织管理者开始关注信息系统方面投资的 经济效益,但是实质的控制还不存在。 • 信息系统初期为企业节约成本费用。 • 数据处理能力快速提升。
• 3.控制阶段: • 出于控制数据处理费用的需要,管理者开 始召集展。管理信息系 统成为一个正式部门,以控制其内部活动, 启动了项目管理计划和系统发展方法。目 前的应用开始走向正规,并为将来的信息 系统发展打下基础。
• 4.集成阶段: • 组织从管理计算机转向管理信息资源,这 是一个质的飞跃。从第一阶段到第三阶段, 通常产生了很多独立的实体。在第四阶段, 组织开始使用数据库和远程通信技术,努 力整合现有的信息系统。 • 建立集中的数据库,采用统一的数据技术、 统一的处理标准,使人、财、物等资源信 息能够在企业高层集成共享,但集成各类 软件所花费的成本更高、时间更长,系统
诺兰模型案例一:高校管理信息 系统的发展
学生、教师、课程、考试、财务信息等的信 息使得信息管理工作非常复杂。因此使用 管理信息系统是非常必要的。于是教务部 门安装了教务系统,招生部门安装了招生 系统,财务部门安装了财务系统,图书馆 安装了图书管理系统,学生工作部门安装 了心理咨询系统、职业测试系统,后勤部 门安装了宿舍管理系统、校园卡管理系 统……大量管理信息系统涌入了高校校园, 固然使得高校信息管理效率提高,减轻了
《黑客与画家》的创新思维与技术前瞻

《黑客与画家》的创新思维与技术前瞻在当今数字化的时代,技术的发展日新月异,而在这股汹涌的浪潮中,这本书犹如一盏明灯,为我们照亮了技术与创新的道路。
它不仅仅是一本关于黑客和画家的书,更是一部关于创新思维和技术前瞻的启示录。
黑客,在大众的印象中,往往是那些隐藏在网络背后,通过技术手段突破系统防线、获取信息的神秘人物。
然而,在中,作者保罗·格雷厄姆为我们重新定义了黑客。
他所描述的黑客,是那些具有创新精神、敢于挑战既有规则、通过技术手段创造出全新价值的人。
画家,通常被认为是通过画笔和色彩来表达内心世界和审美观念的艺术家。
但在这本书中,画家所代表的不仅仅是艺术创作,更是一种创造性的思维方式。
画家能够敏锐地捕捉到生活中的细微之处,用独特的视角和手法将其展现出来,这种创造力与黑客在技术领域的创新有着异曲同工之妙。
书中强调的创新思维,是一种敢于突破常规、挑战权威的思考方式。
传统的观念和方法往往会限制我们的思维,使我们陷入固有的模式中无法自拔。
而黑客与画家则不受这些束缚,他们能够以全新的视角看待问题,从而发现那些被常人所忽视的机会和可能性。
例如,在软件开发领域,传统的方法可能是遵循既定的流程和规范,按部就班地进行开发。
但黑客式的创新思维则会鼓励开发者去质疑这些流程和规范,寻找更高效、更灵活的开发方式。
他们可能会尝试新的编程语言、新的算法,甚至会重新定义整个软件的架构,以实现更好的性能和用户体验。
同样,在艺术创作中,画家也不会被传统的艺术风格和技法所局限。
他们会不断地尝试新的材料、新的表现手法,以展现出独特的艺术风格和思想内涵。
这种创新思维不仅仅在技术和艺术领域有着重要的意义,在我们的日常生活和工作中同样具有巨大的价值。
当我们面对一个问题时,如果能够运用创新思维,不被传统的解决方案所束缚,就有可能找到更加巧妙、更加有效的解决办法。
这种思维方式能够激发我们的创造力,让我们在竞争激烈的社会中脱颖而出。
除了创新思维,还为我们展现了技术的前瞻视野。
新智元文章“两位图灵奖得主万字长文:新计算机架构,黄金十年爆发!”读后感

新智元⽂章“两位图灵奖得主万字长⽂:新计算机架构,黄⾦⼗年爆发!”读后感本⽂讲述了计算机体系结构两位宗师回顾了⾃20世纪60年代以来计算机体系结构发展历史,并展望⼈⼯智能为计算机架构设计带来的新的挑战和机遇。
计算机系统结构将迎来⼀个新的黄⾦时代。
“不能牢记过去的⼈,必定重蹈覆辙“。
计算机的发展也是如此。
⾸先是指令集架构(ISA),它是⼀种规约,规定如何使⽤硬件,当时有四个不兼容的计算机系列,需要创建⼀套新的ISA,将这四套ISA统⼀起来,从⽽提出了控制存储,使⽤微指令替换原来的逻辑门。
IBM统治了当时的计算机市场,也说明了由于硬件系统架构与商⽤计算机之间的密切联系,市场最终成为计算机架构创新的是否成功的关键性因素。
接下来就讲述了英特尔的8080也就是 iAPX-432,以及摩托罗拉的68000,两者都是经过长时间钻研,但最后却没能打败赶⼯出来的8086,这便是市场对计算机架构的影响,市场是没有耐⼼的。
这是⼀个⾎的教训,⽆论什么公司,都要迎合市场,这样才有出路。
随后⼜讲起了从复杂指令集计算机到精简指令计算机的⼀个发展过程,⽽更加让⼈耐⼈寻味的是,构建具有ISA的微处理器在当时被认为是⼀个糟糕的想法,但很讽刺,如今的CISC微处理器确实包含微代码修复机制,这也激励了提出者对微处理器的精简指令集的研究。
在后PC 时代,RISC的出货量飙升,占据主导地位。
然后⼜诞⽣了VLIW和EPIC,但是他们并没有达到预期要求,市场也是对ltanium失去了信息,⽽胜利者是x86的64位版本。
不过VLIW还是存活下来,因为有它适应的市场。
摩尔定律和Dennard Scaling即将迎来它的终结,在⼀个没有Dennards Scaling,摩尔定律减速、Amdahl法则完全有效的时代,也意味着低效率限制了性能的提升,实现更⾼的性能改进需要新的架构⽅法,更有效地使⽤集成电路功能。
之后⼜讲解了被忽视的安全问题,这些架构师充分认识到⼤多数错误将出现在软件中,但是他们相信架构⽀持可以提供帮助。
人月神话(40周年中文纪念版)

第 19 章是一篇更新的短文。读者应该注意的是,新观点并不像原来 的书一样来自我的亲身经历。我在大学里工作,而不是在工业界,做的 是小规模的项目,而不是大项目。自 1986 年以来,我就只是教授软件工 程,不再做这方面的研究。我现在的研究领域是虚拟环境及其应用。
40
在这次回顾的准备过程中,我找了一些正在软件工程领域工作的朋
Essays on Software Engineering, Anniversary Edition
神品—— 代序
前些年,一位朋友从印度归来,说此书在印度极为普及,我也动起 笔来,但 惭 愧 终 未 成 正 果。汪颖兄素来勤恳 ,明知此翻译为“success without applause, diligence without reward”(没有掌声的成功,没有回报 的勤勉),却兢兢业业,反复琢磨,历经单调、繁琐、艰辛的劳动,终于 付梓。钦佩之余随即作序共勉。
* 编注:该序的作者是王计斌(Dave Wang),清华大学博士,研究方向包括软件工程和集成产 品开发(IPD),长期从事 IPD/CMM 推行,创办软件工程研究与实践论坛(), 现在华为技术有限公司工作。
Essays on Software Engineering, Anniversary Edition
这就是我们面临的严峻而复杂的现实,也许您会感到震惊!然而在 大师 Frederick P. Brooks 眼里,是那么的平静。因为早在 28 年前,他就 在《人月神话》(The Mythical Man-Month)这本不朽著作中对这些内容做 了深入论述。
这本小册子行文优美,思想博大精深,字字真言,精读之有不尽的 趣味,藏之又是极珍贵的文献,名眼高人,自能鉴之。
印 张:24.5 字 数:316 千字
关于发明英语作文及翻译

Invention is a vital force driving the progress of human society.It not only changes the way we live but also enhances our understanding of the world.Here is an essay about invention,followed by its translation into Chinese.English Composition:Title:The Power of InventionInvention has always been a cornerstone of human advancement.It is the spark that ignites the flame of progress,transforming the mundane into the extraordinary.From the wheel to the internet,each invention has left an indelible mark on the tapestry of human history.The essence of invention lies in its ability to solve problems and meet needs that were previously unaddressed.It is a testament to human ingenuity and creativity.Inventors, with their relentless pursuit of innovation,have shaped the world we live in today.Consider the invention of the steam engine by James Watt.This pivotal moment in history ushered in the Industrial Revolution,which in turn led to unprecedented economic growth and societal change.The steam engines ability to harness and convert energy revolutionized transportation and manufacturing,paving the way for modern industry.Similarly,the invention of the telephone by Alexander Graham Bell revolutionized communication,allowing people to converse across vast distances instantaneously.This invention has since evolved into the smartphones we use today,which are not only communication devices but also tools for information,entertainment,and connection. Inventions also have the power to improve lives on a personal level.The discovery of antibiotics by Sir Alexander Fleming has saved countless lives by combating bacterial infections.Medical inventions continue to advance,offering hope and healing to those who suffer from various ailments.However,with great power comes great responsibility.Inventions must be developed and used ethically,considering their impact on society and the environment.It is crucial that inventors and society at large work together to ensure that the fruits of invention benefit all and do not harm the vulnerable.In conclusion,invention is a powerful tool in the hands of humanity.It has the potential to elevate our existence and solve complex challenges.As we continue to innovate,let us do so with wisdom and foresight,ensuring that our inventions contribute to a better futurefor all.Chinese Translation:标题:发明的力量发明一直是人类进步的基石。
诺兰的阶段模型
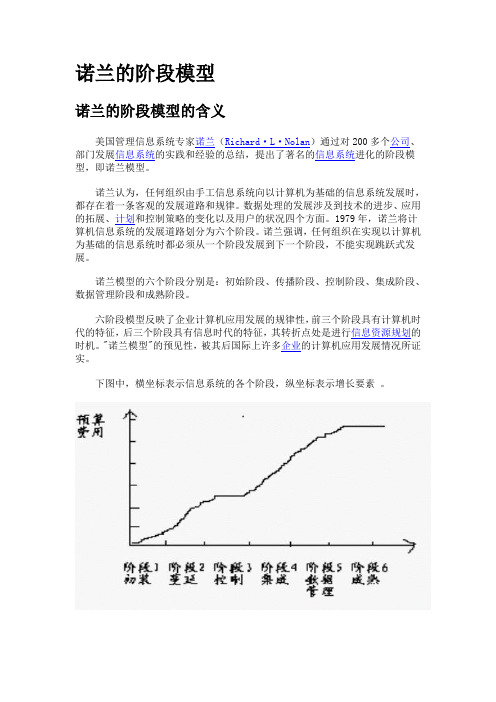
诺兰的阶段模型诺兰的阶段模型的含义美国管理信息系统专家诺兰(Richard·L·Nolan)通过对200多个公司、部门发展信息系统的实践和经验的总结,提出了著名的信息系统进化的阶段模型,即诺兰模型。
诺兰认为,任何组织由手工信息系统向以计算机为基础的信息系统发展时,都存在着一条客观的发展道路和规律。
数据处理的发展涉及到技术的进步、应用的拓展、计划和控制策略的变化以及用户的状况四个方面。
1979年,诺兰将计算机信息系统的发展道路划分为六个阶段。
诺兰强调,任何组织在实现以计算机为基础的信息系统时都必须从一个阶段发展到下一个阶段,不能实现跳跃式发展。
诺兰模型的六个阶段分别是:初始阶段、传播阶段、控制阶段、集成阶段、数据管理阶段和成熟阶段。
六阶段模型反映了企业计算机应用发展的规律性,前三个阶段具有计算机时代的特征,后三个阶段具有信息时代的特征,其转折点处是进行信息资源规划的时机。
"诺兰模型"的预见性,被其后国际上许多企业的计算机应用发展情况所证实。
下图中,横坐标表示信息系统的各个阶段,纵坐标表示增长要素。
该模型总结了发达国家信息系统发展的经验和规律,一般模型中的各阶段都是不能跳越的,它可用于指导MIS的建设。
[编辑]诺兰的阶段模型的主要内容初始阶段计算机刚进入企业,只作为办公设备使用,应用非常少,通常用来完成一些报表统计工作,甚至大多数时候被当做打字机使用。
在这一阶段,企业对计算机基本不了解,更不清楚IT技术可以为企业带来哪些好处,解决哪些问题。
在这一阶段,IT的需求只被作为简单的办公设施改善的需求来对待,采购量少,只有少数人使用,在企业内没有普及。
初始阶段特点:1、组织中只有个别人具有使用计算机的能力;2、该阶段一般发生在一个组织的财务部门。
扩展阶段企业对计算机有了一定了解,想利用计算机解决工作中的问题,比如进行更多的数据处理,给管理工作和业务带来便利。
于是,应用需求开始增加,企业对IT应用开始产生兴趣,并对开发软件热情高涨,投入开始大幅度增加。
人工智能一篇划时代意义的论文!《计算机器与智能》

人工智能一篇划时代意义的论文!《计算机器与智能》计算机器与智能阿兰-图灵小编按:图灵最伟大的论文当属1936《论可计算数及其在判定性问题上的应用》,该文提出图灵机概念,开创了计算理论,为今后的计算机科学奠定了基础。
对于人工智能,图灵1950《计算机器与智能》则更具意义。
论文中提出的图灵测试至今还为AI界提供灵感。
文中还有很多对反驳意见的辩护,在今天看来也还具有深刻意义。
无疑,图灵用今日眼光看,是一位强人工智能拥护者。
【写在前面】本文是A.M.Turing在1950年创作,详细定义并解释了人工智能及其研究目的,发展方向,并驳斥了此前科学界及社会上普遍存在的反对观点,讲解通俗易懂,细致入微,有理有据,被称为人工智能科学的开山之作,直到现在仍有极重要的意义,几乎所有的人工智能教材都向读者强力推荐此文,读罢真的会让人切实感到,图灵不愧为计算机天才。
A.M.图灵(Alan Mathison Turing,1912-1954年)1.模仿游戏我建议考虑这样一个问题:“机器能够思考么?”。
要回答这个问题,我们需要先给出”机器”和”思考”的定义。
我们可以用尽可能接近它们普通用法的方式定义这些词语。
但是这种方式是危险的。
如果使用这种方式,我们很可能会用盖勒普调查那样的统计方式来得出”机器能够思考么”这个问题的结论及其意义。
显然,这是荒谬的。
因此,我没有尝试给出一个定义,而是提出了另外一个问题。
这个问题和原问题紧密相关,而且通过并不含糊的词语给出。
这个新的问题可以通过一个游戏来描述,不妨称之为”模仿游戏”。
需要三个人来玩这个游戏。
一个男人(A),一个女人(B)和一个询问人(C)男女皆可。
询问人呆在一个与另外两人隔离的屋子里。
游戏的目标是询问人判断出外面的人哪个是男人,哪个是女人。
询问人用标签X,Y代表外面的两个人,游戏结束时,他要说出”X是A,Y是B”或者”X是B,Y是A”。
询问人C允许向A和B提出下面这样的问题:C:X,请告诉我你头发的长度。
诺兰模型的主要内容

诺兰模型的主要内容
诺兰模型,又称为诺兰变革矩阵,是由美国学者詹姆斯·诺兰(James M. Nolan)于1979年提出的一种变革管理模型。
该模型主要用于评估和指导组织变革的过程,帮助组织实现持续改进和提高绩效。
诺兰模型包含四个阶段,探索、适应、整合和创新。
下面将对这四个阶段的主要内容进行详细介绍。
探索阶段是变革的起点,组织在这个阶段需要明确变革的目标和方向,进行调研和分析,找出问题所在,并准备好迎接变革所需的资源和支持。
在探索阶段,领导者需要与员工沟通,建立共识,准备好迎接变革的挑战。
适应阶段是变革的过渡期,组织在这个阶段需要逐步调整和改变现有的工作方式和流程,以适应新的变革目标。
适应阶段需要领导者和员工共同努力,消除变革过程中的阻力和障碍,确保变革的顺利进行。
整合阶段是变革的落地阶段,组织在这个阶段需要将变革的成果整合到日常工作中,确保变革的持续效果。
整合阶段需要领导者和员工共同努力,建立和完善变革后的工作流程和制度,确保变革
的成果能够持续产生价值。
创新阶段是变革的高级阶段,组织在这个阶段需要不断创新和改进,持续提升绩效和竞争力。
创新阶段需要领导者和员工共同努力,鼓励员工提出新的想法和建议,促进组织的持续发展和进步。
总的来说,诺兰模型强调了变革管理的全过程,强调了领导者和员工共同努力的重要性,强调了持续改进和创新的重要性。
诺兰模型为组织变革提供了一个清晰的指导框架,帮助组织实现持续改进和提高绩效。
希望通过对诺兰模型的主要内容的介绍,能够帮助大家更好地理解和应用这一变革管理模型,实现组织的持续发展和进步。
《拉丁姆》当人工智能成为世界主角也会思考存在主义吗

《拉丁姆》当人工智能成为世界主角也会思考存在主义吗今年4月7日,齐泽克在文章《后人类荒漠》中再次评价了人工智能:人工智能正在使人类变得无关紧要、无意义,如今的“后人类”科学已不再是关于支配的,而是偶然、“惊喜”的,后人类时代的到来将使我们失去人类、自然和神性。
罗曼·吕卡佐人工智能会梦见电子神明吗?文/吴辰煜一、后人类时代的主奴辩证法《拉丁姆》的全部世界观建构来自一个科幻文学中著名的设定:机器人三定律。
艾萨克·阿西莫夫在1942年的短篇小说《转圈圈》(Runaround)中首次明确提出了“机器人学的三大法则”:第一,机器人不得伤害人类个体,或目睹人类个体将遭受危险而袖手不管;第二,机器人必须服从人给予它的命令,当该命令与第一定律冲突时例外;第三,机器人要在不违反第一、第二定律的情况下尽可能保护自己生存。
此后,包括阿西莫夫本人在内的无数作家以各种方式创造出了机器人三定律的各种变体,但其最基本的要素:一种人类中心主义的科技伦理,始终没有变过。
同时,面对如此典型的主奴辩证法,也有无数人选择以自己的方式提出反思,甚至包括阿西莫夫自己。
阿西莫夫《银河帝国》可如果造物主死了呢?《拉丁姆》的世界观中人类灭绝于一场瘟疫,留下的人工智能们虽拥有遥遥领先任何文明的科技,却因机器人三定律无法伤害来犯太阳系的外星文明,只能选择远走他乡,在半人马阿尔法座的比邻星系仿照古罗马建立了“拉丁姆”城邦,偏安一隅。
在城邦中,被植入了机器人三定律的人工智能成为贵族,由人工智能创造的人工智能因为不受三定律的强制性影响而只能作为奴隶。
这一等级制度蕴含着深刻的反讽,三定律在这里成为了一种形而上式的道德律令,只有受到这种律令约束才能证明自身为“人”,而这一律令唯一的价值是让人工智能更好地为人类服务,一种毫无疑问的奴隶哲学,其中蕴含着一个典型的主奴辩证法。
而遍观全书,这种主奴辩证法存在于每一处角落,每一对矛盾中。
书中人类与人工智能的关系有别于传统科幻小说,人工智能一开始就是以神的姿态登场的,从一开始人工智能就拥有毁灭世界的力量,机器人三定律与其说是人类为人工智能设定的,不如说是作为神的人工智能自愿与人类定约,以一种西方正典的宗教仪式取代了科幻原典中阿西莫夫式的技术伦理,在这一仪式中,神与人、主与奴的位置发生了颠倒。
十年前的代码,有多少在今天还能够运行

十年前的代码,有多少在今天还能够运行*************.25,15:55似乎现在各国的青少年都已经不知道3.5寸软盘为何物了,就像不清楚以前的手机电池是可拆卸的。
在1983年的反映冷战的电影《战争游戏》里,还是高中生的黑客大卫·莱特曼(David Lightman)闯入学校的服务器,给他的女友打出了考试最高分;随后,他又入侵了军事网络,从而避免了全球性热核战争的爆发。
好吧,那些最古老的程序有多少还能被运行?又有那些曾经重要的程序彻底丧失了支持它们的软硬件环境,化作时代的眼泪。
Nicolas Rougier想要回答这一问题。
Rougier是INRIA(位于波尔多的法国国家数字科学与技术研究院)的计算神经科学家和程序员。
他与法国国家科学研究中心(CNRS)的理论生物物理学家Konrad Hinsen于2019年共同构思了一个全球挑战项目,请科学家们寻找并重新执行旧日代码,以重现他们发表了十年或十年以上的计算机论文里的结果。
原定6月在波尔多举行的一次研讨会,交流项目成果。
但COVID-19彻底推翻了所有的时间表。
(研讨会重新安排到2021年6月。
)Rougier说,尽管计算机在科学中起着关键且越来越大的作用,但科学论文里很少包含底层代码。
即使包含了,其他人也可能很难执行,甚至过几年,连原始开发者也可能无法运行。
Hinsen说,“十年可重复性挑战”旨在“找出十年来使用的编写和发布代码的技术中有哪些足以流传至今”。
“十年对于软件领域来说可是非常非常非常长的时间,”在伊利诺伊大学香槟分校研究计算可重复性的Victoria Stodden说,在建立该基准时,这一挑战有效地鼓励研究人员探究“在软件世界中几乎等同于无穷大”的时间周期内,代码可重复性的局限。
目前共有35人报名参赛。
他们重新运行了43篇论文里的代码。
为其中的28篇撰写了报告。
ReScience C从今年初开始发表他们的作品。
使用的编程语言范围从C和R到Mathematica和Pascal。
人工智能算法发展史

人工智能算法发展史
人工智能发展的具体时间轴:
●1943年:神经元模型被引入到计算机科学中。
●1949年:香农提出了信息论。
●1950年:艾伦·图灵提出了“可以思考的机器”的概念,并发表了著名的“图灵测试”论文。
●1951年:马尔文·明斯基和迈克尔·沃尔波特发明了第一台神经网络模型——SNARC。
●1956年:达特茅斯会议召开,标志着人工智能的正式诞生。
●1957年:美国空军将第一台人工智能计算机LISP编译器引入实验室。
●1961年:埃尔玛·巴特尔发明了世界上第一个能够通过语音识别控制计算机的系统——Harpy。
●1969年:鲍勃·卡恩发明了系统ATN,可以解决自然语言理解问题。
●1975年:保罗·沃索尔提出了反向传播算法,这种算法可以用于训练神经网络。
●1980年代:专家系统开始广泛应用于工业控制领域。
●1990年代:神经网络在语音识别、计算机视觉和自然语言处理领域取得了巨大的进展。
●1997年:IBM的计算机“深蓝”在国际象棋比赛中战胜了世界冠军卡斯帕罗夫。
●2000年代:机器学习和数据挖掘技术成为主流,支持向量机等新的算法被广泛应用。
●2010年代:深度学习技术逐渐兴起,引领了语音识别、图像识别和自然语言处理领域的进展。
●2020年代:大数据、云计算、物联网等技术的不断发展,为人工智能的应用提供了更加广阔的场景和机会。
软件传奇Dennis M. Ritchie

C+ + 语言时,也曾以C 语言作为参考 。
17年 ,重新编写的U i 93 nx 上线 ,成
备 。DMR更加着 迷于计算 机处理 的理 论和 实际 问题 ,l 6 年D 获得数 学 9 8 MR
V r t 百昧 『Hal fF me ai y e lo a
名人堂
软 件 传 奇
De i ・ t i n M Ri h n s c e
文, 佳琦
De ni a A ls a r Ri c e. n S M c i t i t hi
职 业 生 涯 影 响 最 大 的 人 —— K e n
博士学位的论文,正是计算机理论相关
的 《 递归函数的层次》。
加入 贝尔实验 室不久 ,DMR就参 与了Mut s 目,负 责多道处理 机 的 l c项 i B P 语言和GE 5 的编译器 ,它们都 CL 60 属于GE OS C 系统 。 同样 的 ,他也 写了
开来。这 次移植还有更重大的意义 :摆 语言所取代 。
T o sn MR曾表示U i大部分 是 h mp o 。D nx
C语 言 之 父 , l 41 9 9日出 生 年 月 9
于 美 国 纽 约 。 在 技 术 圈 里 ,他 常 室 的 用 户 名 ,后 来 成 为 他 常 用 的
代号)。 D MR曾在哈佛大学研 习物理和应用
Ke 的工作 。不 同于DMR对理论 的偏 n
14 3
脱硬件束缚的开放系统 由此诞生了。 完成 了Unx C 言之 后 ,DMR i和 语 并未停 止创 新工作 ,他 继续 发展 了两 作系统和 19 年 发布 的I fro 作系 96 nen 操
微软技术节展现下一代计算愿景

微软技术节展现下一代计算愿景
佚名
【期刊名称】《《个人电脑》》
【年(卷),期】2011(017)004
【摘要】一年一度的微软技术节(TechFest2011)在微软美国总部雷德蒙隆重开幕。
本届技术节共展示了来自包括微软亚洲研究院在内的微软全球六大研究院近150项最新研究成果,描绘了微软公司在自然用户界面(Natural User Interface,简称NUI)和主动代理计算(ComputersthatactoRyourbehalf)这两大领域对
未来计算的构想和愿景。
【总页数】1页(P62-62)
【正文语种】中文
【中图分类】TP317.1
【相关文献】
1.低耗、循环、清洁:曲久辉院士谈下一代水处理厂的技术愿景 [J], 尹诺;陈晶晶;
2.是相册,还是大片?微软下一代媒体技术一瞥 [J],
3."多媒体"交流的"村落"——展望微软公司的下一代技术 [J], 华威
4.传说中的微软下一代虚拟化技术——手持管理设备与机房中的癫狂 [J], Karen Forster; 黄思维(译)
5.身份和安全:微软的下一代解决方案既保护内部工作负载,也保护云计算中的工作负载 [J], Jeff James; 高朝勤(译)
因版权原因,仅展示原文概要,查看原文内容请购买。
大模型的过去与未来

大模型的过去与未来人工智能这个概念自1956年提出以后,经历了将近70年的发展历程,也衍生出符号主义、连接主义和行为主义三大流派,最终走向类脑的目标。
经过六七十年的发展,人工智能发展出三条技术路线。
第一条是符号主义,也就是把智能形式化、符号化、算法化和软件化。
这也是人工智能最早也是最主要的技术路线,虽然有一定效果,但并没有真正成功。
第二条路线是连接主义,或者叫神经网络学派,它的理念是人的智能不可能用一种形式化的方法表达出来,于是就构造了一个神经系统,并且训练它,这样智能就被做出来了。
第三条是行为主义。
这个学派认为智能来源于主体与环境的互动,地球上本来没有智能,后来产生了有机物,有机物跟环境互动产生了细胞,才产生了后来的神经元,才有了智能。
人工智能的发展进入到20世纪80年代之后,就进入了所谓的学习期,这个学习期包含了神经网络和现在流行的深度学习。
其中比较重要的是1985年提出的BP神经网络模型,到了2006年,Geoffrey Hinton在《Science》发表了关于深度神经网络的论文,包含神经网络和机器学习的深度学习开始登场。
深度学习与数据和算力结合,开始产生信息模型。
在2012年至2018年之间,模型成为了AI研究和产业的中心。
这之后,随着被用于训练参数(数据)的提升,具备规模大、涌现性和通用性特点的大模型,正式出现了。
通向AGI到了现在,业界普遍认同人工智能接下来的发展,将会从通用人工智能(GAI)走向人工通用智能(AGI),或者说超人智能、強人工智能。
真正引起业界关注的大模型是OpenAI的ChatGPT。
OpenAI一直定位于以人工通用智能(AGI)为最终目标,并保持开放合作,并且提出了广泛造福社会、关注长远安全问题、引领技术研究、保持合作意愿等四大原则。
在2015年至2018年之间,OpenAI通过布局视觉/多模态、语言、语音、强化学习、多智体技术、机械控制、安全与可解释性等领域,一直在探索可能的AGI路径。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Regression&Continuous Testing Tecniche,Metodologie e PrototipiAndrea Calabriacorso AAIS2005,prof C.GhezziPolitecnico di MilanoDipartimento Elettronica e InformazioneMilano,Italyandrea cala2@yahoo.itABSTRACTLe modifiche ai software possono inserire errori funzionali o strutturali,e tale problema interessa sia il livello di rilascio di nuove versione del software che quello di singola imple-mentazione delle unit`a.L’obiettivo del Regression Testing`e proprio quello di scoprire la presenza di tali errori,e in que-sto articolo esploreremo le modalit`a di approccio a questa tecnica.Per quanto riguarda il primo livello citato,verranno pre-sentate due metodologie,una che affronta il problema del-la selezione dei test da rieseguire,e dualmente anche quali scartare(con il prototipo DejaVOO),l’altra che si focaliz-za sull’analisi in ambiente di deployment,alfine di rilevare gli scostamenti di comportamento tra il software eseguito in house e quello infield,denominata Selective Capture and Replay Program Execution.Entrambe le tecniche riescono a mantenere le propriet`a di safety,efficienza e precisione. Per quanto interessa il livello di codifica,esiste una parti-colarizzazione del Regression Testing,chiamata Continuous Testing:lafilosofia di fondo`e simile,ma si associa alla fase di implementazione del ciclo di sviluppo software;di questa verr`a mostrato un plugin di Eclipse,e la sua progettazio-ne orientata all’efficienza,allaflessibilit`a e all’estensibilit`a, caratteristiche proprie dell’ambiente in cui si innesta. Categories and Subject DescriptorsD.2.5[Software Engineering]:Testing and Debugging—test regressivi e continuiGeneral TermsMethodologies,Techniques,Algorithms,Prototypes KeywordsTesting,Regression Testing,Continuous Testing,Selecti-ve Capture and Replay Program Execution,test selection, software evolution and manteinance 1.INTRODUZIONEChe il testing sia un momento importante per l’evoluzione di un software ormai`e consolidato,e non solo le software house che progettano e implementano l’applicazione hanno questa mentalit`a,ma anche le stesse aziende committen-ti sono entrate nell’ottica di stipulare contratti in funzione dei test e della loro pianificazione,proprio per la loro capa-cit`a ispettiva e di verifica sull’efficacia dello strumento che stanno acquistando.Il valore quindi del testing si materia-lizza in efficacia,lato acquirente come appena accennato, e efficienza,lato produttore,poich´e grazie ad esso si riesce a dedurre se le funzionalit`a sono state tutte correttamente implementate,o esistono errori.Proprio gli errori sono la preda del testing,sia quelli funzionali,commessi in proget-tazione,che strutturali,inseriti nell’implementazione;ma il testing deve verificare la presenza o l’assenza degli errori? Spesso,giustamente,si lega il termine testing soprattutto alla verifica della presenza degli errori,ma tale definizione non rende merito della prospettiva da cui si vede il testing. Infatti,seguendo il parallelo tra chi produce il software e chi lo commissiona,l’aspetto della presenza degli errori viene stimato e considerato soprattutto da chi progetta e imple-menta l’applicativo,poich´e`e necessario garantire la corret-tezza elaborativa,strutturale,proprio come l’indagine glass box esegue,grazie ad ispezioni di copertura su istruzioni,la-ti,percorsi,flusso dati,e altro ancora[1].Dal punto di vista di chi commissiona il lavoro invece,le esigenze cambiano, e il controllo sulla qualit`a del prodottofinale viene perse-guito sotto il profilo funzionale,ovvero si verifica se riesce a raggiungere gli obiettivi requisiti:ecco da dove nasce la crescente accortezza della dirigenza nello stendere i contrat-ti con gli sviluppatori software in base all’assenza di errori nell’applicazione,mirando alla verifica a scatola chiusa,co-munemente chiamata black box.Data l’attenzione da riporre sul testing,si coglie anche l’im-portanza di una stesura corretta e precisa dei test cases, e test suites,e si capisce perch´e spesso il codice dedicato ad implementare test sia molto voluminoso.Tale volumi-nosit`a,legata alla precisione ispettiva da garantire,richiede spesso molto tempo,tempo monopolizzato da questa fase poich´e sarebbe sciocco eseguirla in parallelo all’implemen-tazione(questo era il pensiero comune,ma come si vedr`a`e cambiato anch’esso!).Proprio sull’ottimizzazione di questo tempo si concentrer`a l’analisi che condurremo,e in parti-colare le problematiche che affronteremo saranno:“Se devo rilasciare una nuova versione di un’applicazione,come pos-so ottimizzare il tempo di testing recliclando le informazioniprecedentemente elaborate?”,e ancora“Come posso miglio-rare il testing nel mi ambiente di sviluppo cercando di capire il comportamento del software nel contesto d’usofinale?”,e infine“E’possibile parallelizzare il testing in qualche modo nella stessa fase di implementazione,evitando di tornare in-dietro sui propri passi troppo tempo dopo?”.Queste domande ci permettono di intuire che le fasi di svi-luppo software che analizzeremo,riprendendo il modello a cascata per esempio,sono due:quella di verifica e valida-zione entro cui si collocano le prime due,e quella di imple-mentazione,ambito della terza.Alle tre domande rispondono tre metodologie differenti,tut-te derivanti dallafilosofia del Regression Testing,tecnica che per definizione verifica la presenza di errori immessi modi-ficando il codice(regressivi appunto):la metodologia Deja-VOO seleziona una parte dei test applicati al software alfine di eseguirli anche sulla nuova release(quindi`e un test strut-turale sulla nuova versione),SCARPE(Selective Capture and Replay of Program Execution)ricerca i comportamenti diversi in ambienti differenti confrontando quello di svilup-po a quello“in campo”alfine di migliorare il testing in house(quindi`e pi`u un testing funzionale,basato sul com-portamento),infine il Continuous Testing`e una tecnica che supporta il singolo sviluppatore durante l’implementazione grazie alla quale riesce ad essere consapevole della presenza di errori introdotti codificando.La struttura dell’articolo ricalca la presentazione delle do-mande:inizialmente verr`a analizzato il Regression Testing in DejaVOO,tecnica ideata da Alessandro Orso,Nanjuan Shi e Mary Jean Harrold1,successivamente si affronter`a l’a-spetto del Selective Capture and Replay of Program Exe-cution,metodologia proposta da Alessandro Orso e Bryan Kennedy,per arrivare nella terza parte al Continuous Te-sting di David Saffe Michael D.Ernst2,e infine le conclusi 2.REGRESSION TESTINGSeguendo l’evoluzione di un software,il regression testing`e sfruttato sulle versioni modificate dell’applicativo per veri-ficare che le parti cambiate si comportino come progettato e non introducano errori inaspettati,comunemente definiti come regression errors.In uno scenario tipico,D`e lo svilup-patore(developer)del programma P per il quale viene stesa la test suite T.Durante la fase di manteinance,D modifica P aggiungendo nuove funzionalit`a ed eliminando i malfunzio-namenti riscontrati;a seguito di tale cambiamento la nuova release P’necessita di essere testata attraverso il regression testing.Una questione importante in tale ambito`e come selezionare un appropriato sott’insieme T’di T da eseguire su P’:tale problematica prende il nome di regression test selection,o abbreviato RTS.Naturalmente la soluzione banale e sem-plicistica`e quella di selezionare l’intera test suite,ma ci`o non ci porta a nessun vantaggio in termini di tempo e costo elaborativo,tanto che addirittura sarebbe uno sforzo inuti-le se i cambiamenti fossero solo marginali;quindi il nostro obiettivo`e cercare un sott’insieme proprio di T.1Docenti e ricercatori presso il dipartimento di Computer Science all’universit`a Georgia Institute of Technology,US. /2Docenti e ricercatori nel dipartimento di Computer Science dell’universit`a MIT,Massachusetts Institute of Technology, US./Una caratteristica particolare che la tecnica RTS deve avere `e la propriet`a di safety:essere safe per un’algoritmo RTS significa selezionare tutti i test case nella test suite che po-trebbero comportarsi in modo differente nelle varie versioni del software.L’importanza di tale propriet`a risiede proprio nella garanzia che la tecnica selezioni tutti i test cases che potrebbero essere rilevanti per P’.In generale le metodologie safe RTS in letteratura differisco-no per efficienza e precisione,caratteristiche che afferiscono al livello di granularit`a a cui si opera:se si lavora ad alti livello di astrazione,analizzando per esempio le informazio-ni di cambiamento e copertura per metodi e classi,si ha un grado di efficienza buono ma si penalizza la precisione sele-zionando pi`u test cases,anche non necessari3;al contrario se si opera a granularit`a pi`ufini,per esempio analizzando le informazioni sui cambiamenti e la copertura a livello di istruzione,si perde in efficienza a vantaggio della precisione selettiva.Si noti che in generale ogni safe RTS deve essere efficace nei costi,ovvero il costo(in termini di tempo e risor-se elaborative impegnate)totale di una RTS,comprensivo di selezione dei test cases e loro elaborazione,deve essere minore del costo di processamento dell’intera test suite,e quindi conveniente eseguire il regression testing.La tecnica che verr`a mostrata riesce ad allineare bene le caratteristiche sopra elencate,sia per efficienza e precisione, che per efficacia in termini di costo,e la dimostrazione di tali vantaggi verr`a descritta nel prototipo progettato,DejaVOO.La presentazione della tecnica proceder`a dall’analisi della metodologia,nei primi paragrafi,attraverso alcuni esem-pi teorici,per arrivare alla valutazione empiricafinale del prototipo.2.1Le fasi della metodologiaLa metodologia si suddivide in due fasi proprio per riusci-re a combinare efficienza e precisione,procedendo prima da un’analisi del sistema ad alto livello,e successivamente ad-dentrandosi in profondit`a:si guida la ricerca quindi inizial-mente in ampiezza,e poi in profondit`a all’interno del nuovo scenario.I due passi si chiamano partizione(partitioning)e selezione (selection):nella prima si analizza il programma cercando di identificare relazioni gerarchiche,di aggregazione e d’uso tra le classi e le interfacce,formando una selezione di que-st’ultime,nella seconda si prende il nuovo panorama appena creato e si aggiungono le informazioni sui cambiamenti tra P e P’,e si estrae il sott’insieme minimo di test cases necessari alla nuova versione.2.1.1La Partizione(partitioning)Nella fase di partizione si conduce un’analisi di alto livello del programma P e P’alfine di identificare le parti dell’ap-plicazione che potrebbero essere toccate dai cambiamenti 3Si considera qui il termine precisione come sinonimo di ef-ficace:per quanto possa sembrare inesatto,l’utilizzo del ter-mine efficace sarebbe improprio poich´e deve essere sempregarantito da tutte le tecniche il raggiungimento della con-dizione di safety,ovvero selezione di tutti i test cases utili, altrimenti non rientrerebbero nelle safe RTS,quindi l’effica-cia`e un prerequisito per ogni metodologia di tale gruppo; il livello di ottimizzazione dell’insieme T’,quindi la sua car-dinalit`a,rientra nella prerogativa di precisione;invece per sottolineare l’aspetto di ottimizzazione computazionale si`e usato l’aggettivo efficiente.effettuati.Per prima cosa`e bene individuare quale sia in generale la differenza tra i tipi di cambiamenti in un software.Le mo-difiche si differenziano in due categorie:le statement level e le declaration level.Un cambiamento statement level afferisce alla modifica,can-cellazione o aggiunta di un’istruzione;questo tipo di varia-zione`e facilmente rilevabile e gestibile dalla RTS poich´e ogni test che attraversa tale istruzione deve essere sicura-mente modifica a declaration level invece`e pi`u complessa da monitorare,poich´e riguarda le variazioni apportate ai tipi di una variabile,all’aggiunta o rimozio-ne di un metodo,alla sua ridefinizione,alle modifiche delle relazioni di ereditariet`a,ecc,tutte peculiariat`a tipiche dei linguaggi ad oggetti.Vediamo un esempio delle definizioni appena espresse nella Figura1;per aumentare la facilit`a di comprensione sar`a tenuto come modello d’esempio per tutta l’esposizione del regression testing tale esempio,in cui per lo stesso motivo sifissa anche la numerazione delle righe. Alla riga9si nota il cambiamento di tipo statement level; facilmente il comportamento differente di tale modifica verr`a individuato tra P e P’proprio perch´e`e locale.Alla riga12 invece,suddivisa per semplicit`a in12a:d,si vede l’aggiunta di un metodo alla classe A in P’:in questo caso il cambia-mento intacca anche l’invocazione dell’istruzione a.foo() alla linea17.Infatti supponendo che LibClass sia una clas-se nella libreria,e che LibClass.geAnyA()sia un metodo statico tale che restituisce un’istanza tra SuperA,A,o SubA, dopo la chiamata alla linea16,il tipo dinamico di a potr`a es-sere SuperA,A,o SubA,e perci`o a causa del binding dinamico la chiamata a.foo()potr`a essere associata a diversi metodi nei due programmi P e P’:in P l’associazione di a.foo() `e sempre verso SuperA.foo,mentre in P’a.foo()varia tra SuperA,A,o SubA a seconda del tipo dinamico di a.Ta-le caratteristica dei cambiamenti declaration level potrebbe essere trascurata da nell’esecuzione di alcuni test,ma non nessuna tecnica RTS deve essere miope tanto da non consi-derare queste situazioni cos`ıtipiche nei linguaggi ad oggetti, altrimenti rischierebbe di rivelarsi unsafe e imprecisa.La fase della partizione si articola nella(1)creazione di un grafo statico delle classi e interfacce(i cui nodi sono quest’ul-time,e gli archi le relazioni tra esse),poi nella(2)selezione dei nodi del grafo in cui si riscontrano cambiamenti,anche in base alle relazioni gerarchiche,di aggregazione e d’uso tra classi e interfacce.Il primo passaggio`e quello di creare un grafo generale del programma chiamato Interclass Relation Graph(IRG),iden-tificando con i nodi le classi e le interfacce,e con gli archi le relazioni gerarchiche,di aggregazione e d’uso.Il grafo IRG di un programma`e una tripletta{N,IE,UE},ove •N`e l’insieme dei nodi,ovvero classi e interfacce;•IE⊂N×N`e l’insieme degli archi di ereditariet`a(inhe-ritance edges,in cui il verso della freccia(per esempio da e1ad e2)indica che e1`e direttamente sottotipo di e2;•UE⊂N×N`e l’insieme degli archi di uso(usage edges),in cui il verso della freccia(per esempio da e3 ad e2)indica che e3contiene un riferimento esplicito ad e2;Lasciando in appendice i dettagli dell’algoritmo di costru-zione del grafo IRG,mostriamo il suo output generato nella Figura2,che si riferisce all’esempio della Figura1.Dopola Figure2:Fase partizione,Grafo IRG del codice diP della Figura1nella pagina seguentecreazione del grafo IRG,si devono selezionare i nodi affetti da cambiamenti:nell’algoritmo,visibile sempre nell’appen-dice,gli ingressi sono proprio il grafo IRG appena creato sia per P che per P’,e i cambiamenti al programma,C;in usci-ta si ottiene la partizione desiderata delle classi e interfacce toccate dai cambiamenti.Un’importante considerazione deve essere fatta sulla com-plessit`a di tali algoritmi,poich´e come accennato in prece-denza deve convenire eseguire tale tecnica di RTS piuttosto che ripetere tutti i test della suite:l’algoritmo buildIRG esegue un singolo passaggio per ogni classe e iterfaccia,per identificare sopra e sotto-tipi e loro riferimenti.Nel caso pessimo la complessit`a`e O(m),dove m`e la dimensione del programma,quindi lineare,valore molto buono.2.1.2La Selezione(selection)La seconda fase della metodologia si occupa della selezione dei test in base alle informazioni acquisite dalla partizione. Come primo passo analizza le classi e le interfacce selezionate e successivamente esegue la selezione.Per quanto riguarda il primo passo,si costruisce un grafo che rappresenta l’insieme partizionato,ma ideato secondo una logica orientata ai linguaggi di programmazione,tanto da chiamarsi Java Interclass Graph,JIG:esso estende il classico IRG poich´e riesce a rappresentare anche gli aspetti propri degli oggetti,come il binding dinamico,la gestione delle eccezioni,ecc.Un esempio di tale grafo viene presentato nelle Figure3e4,che rappresentano una parte del codice d’esempio della Figura1.Nel grafo JIG ogni punto di chiamata,per esempio nelle ri-ghe16e17,`e espansa in un nodo call e uno return(16a, 16b,17a,17b)collegati da archi denominati path-edge,che mostrano il cammino delle chiamate.Per individuare le in-vocazioni ai metodi chiamati si stendono gli archi call-edge, il cui comportamento si differenzia tra le tipologie di chia-mate:non virtuali o statiche,e differenza risiede nel numero di archi che la chiamata genera:per il tipo sta-tico vi sar`a un solo arco uscente dal nodo call,mentre per il tipo dinamico o virtuale dipende dal binding dinamico,e quindi possono essere e si intuisce,`e pro-prio questa la caratteristica primaria del grafico JIG,cheFigure1:Esempio di codice nel Programma P e sua modifica inP’Figure3:Fase Selezione,Grafo JIG per il programma P in Figura1permette di individuare le modifiche anche al binding e al-tri elementi tipici di un linguaggio ad oggetti.Nellefigure presentate si pone l’accento proprio su questo:a seguito del cambiamento infatti,nella Figura3,si osserva che il binding dinamico cambia perch´e`e stato ridefinito il metodo foo() nella classe A.Una volta estratte tutte le classi e le interfacce che sono af-fette dalle modifiche,si procede con il secondo passo della selezione:si esegue una procedura che elabora una matrice di copertura dei test,alfine di selezionare proprio i testche Figure4:Fase Selezione,Grafo JIG per il programma P’in Figura1coinvolgono solo il sott’insieme selezionato.Per far ci`o si co-struisce una tabella in cui le righe sono rappresentate dagli archi edges,proprio perch´e rappresentano ilflusso di esecu-zione del programma,mentre le colonne dai test cases.Una volta travati i test che attraversano le classi e interfacce par-tizionate,termina anche la seconda fase della metodologia, evidenziando i test da rieseguire.2.2Valutazione empirica:DejaVOOLa metodolgia esposta `e stata implementata in un prototipo chiamato DejaVOO ,il cui obiettivo era proprio la sperimen-tazione della fattibilit`a e correttezza di essa.Nella Figura 5viene presentata la struttura del prototipo,che comprende tre moduli principali:InsECT ,DEI ,e Selector.Figure 5:L’archittettura di DejaVOOInsECT (instrumentation,execution and coverage tool)ser-ve per processare e creare la matrice di copertura dei test.DEI (dangerous edge identifier )rappresenta le due fasi,par-tizione e selezione,della metodologia:infatti ha come obiet-tivo quello di costruire i grafiIRG del programma origina-rio e della sua versione modificata,nel modulo Partitioner ,mentre nel Comparator si occupa di creare e analizzare i grafiJIG,permettendo di ricavare i punti pericolosi del pro-gramma.Infine Selector esegue il calcolo finale,unendo le informazio-ni della matrice di copertura dei test cases,con quelle delle istruzioni pericolose,producendo la selezione dei test T .Gli autori hanno sperimentato il prototipo con soddisfacen-ti risultati,i cui dati empirici omettiamo lasciando libero approfondimento nei reference riportati in bibliografia.2.3CommentiLa tecnica mostrata `e interessante perch´e riesce a ridurre il tempo di ri-testaggio di una applicazione,ma naturalmente ha una soglia di convenienza d’uso,rappresentata dai tem-pi:solo se la somma dei tempi di elaborazione dei modu-li visionati in DejaVOO (partizione e selezione)`e inferiore al tempo di riesecuzione dell’intera test suite allora `e con-veniente sfruttare tale tecnica,altrimenti si rischierebbe di contravvenire agli obiettivi proposti di ottimizzazione delle risorse e del tempo.Infine si evidenzia un piccolo difetto intrinseco nella meto-dologia:un’assunzione per la condizione di safety `e quella di avere l’ambiente di esecuzione invariato tra le due versio-ni software,e gli autori seguono tale precondizione ponendo come ipotesi che la JVM usata non cambi tra le release e non ci siano variazioni nelle librerie.Si coglie che tali con-dizioni possono rappresentare dei limiti nel caso in cui si sia ristrutturato anche con nuove caratteristiche di architettura il software,non solo nelle funzionalit`a .Solo in presenza di cambiamenti locali all’ambiente,per esempio a poche libre-rie,ecc,potrebbe essere inconsistente l’uso della metodolo-gia proposta.Si deduce che nelle situazioni in cui si ripla-sma un nuovo applicativo non solo questa tecnica `e difficile da usare,ma in generale il regression testing potrebbe non avere senso,poich´e si dovrebbero anche riscrivere test sui-te dedicate:daltronde cambiare radicalmente l’architetturadell’applicazione esige una riprogettazione,e quindi anche un redesign delle test suite.3.SELECTIVE CAPTURE AND REPLAY OF PROGRAM EXECUTIONIn questa sezione si presenter`a una tecnica di regression te-sting che permette di migliorare il testing in sede di svilup-po attraverso lo studio empirico in campo dei metodologia in realt`a non `e di per s´e una tecnica di te-sting regressivo come l’abbiamo considerata nella sezione 2,ma piuttosto una modalit`a di supporto al regression testing tramite la creazione di stub e drivers per gli oracoli,come andremo a chiarire nel seguito.Tutto nasce dall’osservazione che un programma eseguito in sede di sviluppo (in house )ha un comportamento in qualche misura diverso da quello nell’ambiente d’uso finale (in field );l’obiettivo della metodologia `e quello di catturare queste dif-ferenze per poi saperle identificare al fine di creare una test suite che tenga conto anche di tali problematiche pragmati-che e si evince dal contesto e dagli obiettivi,sia il regression testing che l’analisi d’impatto beneficiano fortemente di tali soluzioni.Dato un programma rilasciato (quindi dopo la fase di de-ployment),la maggior parte delle metodologie suggeriscono di catturare l’intera esecuzione nell’ambiente d’uso,per poi replicarla,e ricavarne le informazioni preziose,per esempio tramite data-mining.Ma dietro a tali ambizioni teoriche ci sono delle difficolt`a oggettive da affrontare,a cui la tecnica in esame tenta di dare valida risposta:•la cattura dell’intera esecuzione `e generalmente un pro-blema infattibile poich´e richiede di memorizzare un vo-lume di dati troppo elevato,per non parlare della com-plessit`a di raccolta in s´e a causa della forte relazione con l’ambiente di collocazione;•i dati prelevati possono contenere informazioni riser-vate,legate alla privacy;•bisogna prevenire o evitare (a seconda della politica in uso)i side effects,per esempio assicurandosi che in fase di replicazione dell’esecuzione non si presentino effetti indesiderati come disturbi che compromettono la stabilit`a del sistema.Per indirizzare tali questioni Orso e Kennedy propongono di selezionare un sott’insieme del programma per cui cattura-re l’esecuzione a runtime,coinvolgendo tutte le interazioni tra tale sott’insieme e il resto dell’applicazione,e replicare le interazioni registrate nel sottosistema isolato;ecco quin-di il significato del nome Selective Capture and Replay of Program metodologia identifica due fasi:(1)la cattura selettiva dell’esecuzione a runtime,e (2)la repli-cazione,al termine delle quali si ottengono le informazioni utili per migliorare le test suite,a beneficio del regression testing.Le problematiche prima estratte vengono cos`ılimate:in-fatti il volume di dati diminuisce sensibilmente,riducendosi alle informazioni necessarie e garantendo efficienza ma sen-za risultare parziale poich´e come vedremo si utilizzano le informazioni di scambio tra i due insiemi complementari del sistema (quello selezionato e il restante).Per quanto ri-guarda la privacy la metodologia semplicemente esclude dalsott’insieme in osservazione tutte le parti che possono con-tenere informazioni riservate,ma se ci`o non fosse possibile si prevede la possibilit`a della replicazione nella stessa mac-china dell’utente.Infine sull’argomento dei side effects la tecnica li evita poich´e la fase della replicazione avviene in maniera isolata,ovvero si simulano le interazione del sotto-sistema con il resto dell’applicazione e dell’ambiente tramite stub e drivers.Proprio questo`e il beneficio indotto al re-gression testing:avendo a disposizione i meccanismi degli oracoli,con stub e drivers,`e possibile non solo creare ma anche eseguire test cases con la simulazione.3.1La metodologiaPrima di dettagliare le fasi della metodologia bisogna pre-sentare alcune osservazioni:data l’importanza che assume in questa tecnica l’ambiente d’esecuzione,non sarebbe corret-to n´e consistente creare una metodologia adatta per tutti i linguaggi di programmazione;per questo motivo viene pre-sentata la tecnica specificatamente per il linguaggio Java, allineandoci con la metodologia DejaVOO,e con il conti-nuous testing che verr`a in seguito proposto.E’bene anche accennare alla terminologia che verr`a usata:il sott’insieme d’interesse dell’applicazione,oggetto della cat-tura selettiva,viene identificato come insieme osservato,le cui classi si chiamano classi osservate;parallelamente si no-minano intuitivamente metodi osservati e campi osservati i metodi e i campi delle classi osservate.Dualmente si agget-tivano come inosservati gli stessi elementi(insieme,classi, metodi,campi)esclusi dall’osservazione.Nella fase di cattura,come la Figura6mostra,prima che l’applicazione inizi,in base ad una lista di classi definite dal-l’utente,si identificano i confini dell’insieme osservato e si applicano delle modifiche al codice per riuscire a catturare le interazioni tra esso e il resto del sistema:tali modifiche vengono chiamate sonde(probes)4.Da questa caratteristi-ca si intuisce che la tecnica`e invasiva,e non si limita ad osservare il comportamento ma attua variazioni per poterlo monitorare:infatti le sonde hanno proprio lo scopo di gene-rare eventi dalle interazioni tra le classi osservate e il codice esterno,che costituiscono con i loro attributi il log di eventi (event log).Nella successiva fase di replicazione si creano scaffolding che ricevono in ingresso l’event log generato in cattura,come visibile in Figura6,e replicano ogni evento registrato ap-poggiandosi ai driver e stub.Nel seguito verranno dati accenni alle due fasi,lasciando li-bero approfondimento sull’argomento tramite la bibliografia consigliata.3.1.1La cattura selettivaNella fase della cattura selettiva si identificano tre passi:(1) identificazione di tutte le interazioni tra codice osservato e inosservato,(2)l’iniezione nel codice delle sonde,(3)la cat-tura efficiente delle interazioni a runtime.Prima di addentrarci nei dettagli,`e bene introdurre il con-cetto di object id:un object id`e un numero positivo che identifica univocamente un’istanza di classe.Per generare 4Per quanto nel corso di tutta la trattazione della metodo-logia venga spesso menzionato l’uso di sonde,non viene de-finito come esse siano,ma solo i loro obiettivi,penalizzando cos`ıla comprensione approfondita dellatecnica.Figure6:La fase della cattura selettiva(parte superiore)e della replicazione(parte inferiore)tale numero,la tecnica sfrutta un global id che viene ini-zializzato a zero nonappena parte la cattura.Nelle classi modificabili l’object id`e creato aggiungendo un campo nu-merico alla classe,e una sonda al suo costruttore:la sonda incrementa il global id e immagazzina il valore nel campo numerico dell’oggetto che sar`a creato.Da ci`o,una volta creata un’istanza di una classe modificabile,la metodologia riesce a recuperare il suo object id semplicemente accedendo al campo numerico creato.Per le classi non modificabili,si associa l’id alle istanze usando la reference map,che man-tiene le informazioni su come mapparare ogni object id all’i-stanza e viene popolata incrementalmente:ogni volta che si deve assegnare un id ad una classe non modificabile si con-trolla nella reference map se esiste gi`a una registrazione per quel valore,e in caso affermativo si incrementa il global id per prelevarne il numero generato,altrimenti si associa quel-lo attuale del global id.Per ottimizzare la fase della cattura selettiva,ovviando al problema del volume di dati da immagazzinare,gli autori propongono di(1)comprendere nell’insieme d’osservazione solo quegli oggetti che intaccano la computazione,e successi-vamente di(2)raccogliere le informazioni a runtime solo on demand,incrementalmente,ovvero quando e se si necessita, senza usare strumenti complessi di analisi statica(si noti la differenza con DejaVOO in cui esiste un’analisi statica pre-liminare costituita della creazione del grafo IRG nella fase di partizione).Il primo punto significa che se avessimo un grafo da controllare di duecento nodi,e il valore da cattu-rare risiedesse nel quinto,non sarebbe necessario registrare le informazioni di tutti i nodi,ma sono sufficienti i primi cinque.Per quanto riguarda il secondo punto,in generale non`e sempre possibile prevedere in anticipo quale sia il sot-t’insieme di informazioni passate ad un metodo rilevante per una chiamata,e quindi la soluzione`e quella di raccogliere tali informazioni in itinere,al momento d’uso.Nel caso di eventi che attraversano i confini dell’insieme osservato(per esempio parametri ed eccezioni),la scelta`e quella di regi-strare i valori attuali dei dati solo per quelli in forma scalare; per gli oggetti si registra il loro object id e il tipo.Sotto tali。