Lucene 全文检索实践
基于Lucene的全文检索系统的研究与实现的开题报告

基于Lucene的全文检索系统的研究与实现的开题报告一、选题背景及意义随着互联网时代的到来,信息爆炸式增长已经成为人们必须面对的一个问题。
传统的基于关键字的检索方式已经不能满足人们的需求。
全文检索系统应运而生,它可以从大量的文本中快速准确地查找需要的信息,方便人们的使用。
Lucene是一个流行的全文检索引擎,它是基于Java语言开发的,使用Apache协议开源。
Lucene具有快速、可扩展和高效的特点,在应用领域有广泛的应用,如搜索引擎、电子商务网站、维基百科等。
然而,Lucene作为一个开源的库,仍需要使用者有一定的技术基础才能进行使用。
因此,本文将研究如何利用Lucene实现全文检索系统,并通过分析其架构和实现细节,深入了解全文检索系统的工作原理和技术方法。
二、研究内容1. 全文检索技术的概述2. Lucene的基本原理和架构3. 全文检索系统的需求分析4. Lucene全文检索系统的设计和实现5. 系统优化和性能测试三、预期成果完成本文研究所需的工作,预期可以达到以下成果:1. 掌握全文检索技术的基本原理和方法。
2. 深入了解Lucene的架构和实现细节,掌握Lucene的基本使用方法和技巧。
3. 实现一个基于Lucene的全文检索系统,包括需求分析、系统设计、编码实现、系统优化和性能测试等环节。
4. 对系统的性能进行测试和优化,提高系统的搜索效率和准确性。
四、研究方法1. 文献调研:通过阅读相关的学术论文和技术博客,了解全文检索技术的最新研究进展和应用情况。
2. 系统分析:对基于Lucene全文检索系统的需求进行分析和定位,明确系统的功能和性能要求。
3. 系统设计:根据需求分析,设计系统的架构和流程,确定系统各个模块之间的交互和约束关系。
4. 编码实现:使用Java语言编写全文检索系统,使用Lucene作为底层引擎,实现检索功能和系统界面。
5. 系统测试和优化:进行系统性能测试和故障测试,针对测试结果进行优化和改进。
基于Lucene的全文检索系统研究与实现

、 、▲
L i s t ( 2 字 长 词)
L i s t ( 3 字 长 词)
L i s t ( 4 字 长 洲)
● ● ● ● ● ●
图2 字 典 数 据 结 构
3 . 1 . 2 基 于双 向最大 匹配 的中文分词 算法 基于 字典 的分词方 法 又叫机械 分词算 法 , 这种算 法按 照一定 的策 略将 待分 析 的汉 字 串与一 个 “ 充
7 8
浙 江外 国语 学院 学报
2 0 1 3皋
2 . 1 文 档归 一化模 块
文 档归 一化模 块 主要 完成 对待 检索文 档 的预处理 , 主要有 两个 功能 : 一是 支 持将 . p d f , . p p t , . d o c等
文本解 码并 转化为 . t x t 文件 ; 二是 对文本 内容 进行过 滤 , 取 出可 能存在 的非法 字符 和乱码 . 2 . 2 文 本分 析模块
分 大” 的机 器词典 中的词条进 行 匹配 , 若 在词 典 中 找到某 个 字 符 串 , 则 匹 配成 功 , 识 别 出一 个 词 ] . 文 中, 我们 提出 的匹配算 法是 正 向匹 配 与逆 向匹配 相 结 合 的算 法 , 算 法 流程 如 下 : ( 1 ) 导 人 待 分词 的文 本, 利用 S o u g o u词库构 建按 字长构 建字 典数据结 构 . 然后 , 将 待分 词文本 按照不 同类 型 ( 如 普通 中文 字
文 本分 析模块 主要 实现对 元文件 文档 附属信 息 的提取存 储和 通过 文本 分 析器 对 中文 内容 的分 析
与构建 倒排 索引 . 文档相 关 附属 信 息 ( 如作 者 、 时间、 单位 、 文 件存 放 目录等 ) 直 接存 储 在数 据 库 中; 而 对于摘要 内容 和正 文 内容 信息 , 由于 信息量 较大 , 我们通 过文 本分析 器实 现 中文 自动 分词 , 再 利用 L u — c e n e的索引模 块实 现倒排 索引 的 自动构 建 . L u c e n e自带 有 中文 自动 分 词 系统 , 但 性 能一 般 , 为此 我们
lucene全文检索实现原理

lucene全文检索实现原理Lucene 是一个开源的全文检索引擎库,它提供了用于创建全文索引和执行全文搜索的工具。
以下是Lucene 实现全文检索的基本原理:1. 文档索引:首先,Lucene 需要建立文档的索引。
文档可以是任何文本数据,比如文章、网页或者其他文本文件。
Lucene 将文档拆分成一系列的词条(Terms),并为每个词条建立一个反向索引。
反向索引存储了每个词条出现在哪些文档中,以及在文档中的位置。
2. 分词器(Tokenizer):Lucene 使用分词器将文本拆分成独立的词条。
分词器根据特定的规则和算法来确定什么是一个有效的词条。
例如,标准的分词器可以根据空格和标点符号将文本分成单词。
3. 停用词(Stop Words):Lucene 还可以使用停用词列表来过滤掉一些常见的无关紧要的词,例如“and”、“the”等。
这有助于提高检索效果,排除掉对搜索没有帮助的常见词。
4. 倒排索引(Inverted Index):Lucene 使用倒排索引来存储词条和文档之间的关系。
倒排索引包含了每个词条以及它在哪些文档中出现,以及在每个文档中的位置。
这种结构使得搜索时可以快速定位到包含关键词的文档。
5. 权重(Term Weighting):Lucene 使用一种称为TF-IDF(Term Frequency-Inverse Document Frequency)的权重计算方法,来为每个词条赋予权重。
TF-IDF 考虑了一个词条在文档中的频率以及在整个文档集合中的稀有性,以此确定词条的重要性。
6. 搜索查询:当用户发起搜索查询时,Lucene 解析查询并与建立的倒排索引进行匹配。
Lucene 支持丰富的查询语法,包括布尔查询、范围查询、通配符查询等。
查询的结果根据匹配的程度和权重进行排序。
7. 评分(Scoring):Lucene 根据文档的匹配程度计算得分,并将结果按照得分进行排序。
这使得搜索结果更加符合用户的意图。
全文检索原理及Lucene实现之搜索

全文检索原理及Lucene实之搜索研发中心胡启稳/文搜索处理过程经过前面构建索引的一系列过程,终于到了我们的全文检索的最终目标:搜索。
现在的问题看起来很简单,输入我们的待查询关键字然后在索引里面找到结果返回不就可以了吗?但是问题并不象看起来的那么简单,搜索的处理过程如下:第一步:用户输入查询语句查询语句同普通的语言一样,也是有定的语法的。
不同的查询语句有不同的语法,如SQL 语句、HQL语句等。
查询语句的语法根据全文检索引擎的实现不同而不同。
最基本的有比如:AND、OR、NOT等。
举个例子,用户你输入语句:“Lucene AND learned NOT hadoop”,说是用户想找的是包含“Lucene”和“learned”但不包括“hadoop”的文档。
第二步:对查询语句进入词法分析、语法分析及语言处理由于查询语句有语法,因而也要进行词法分析、语法分析及语言处理1.词法分析主要用来识别单词和关键字。
如上述例子中,经过词法分析,得到的词有“lucene”“learned”“hadoop”关键字有“AND”“NOT”。
如果在词法分析中发现不合法的关键字,则会出现广错误,如上面中的AND,如果用户不小心拼成AMD,则AMD会作为一个普通的单词参与查询2.语法分析主要是根据查询语句的语法规则来形成一棵语法树如果发现查询语句不满足语法规划,则会报错。
如“luceneNOT AND learned”,则会出错。
如上述例子,“门户AND 开发NOT 实施”,则会形成以下语法树:3. 语言处理同索引过程中的语言处理几乎相同。
如learned变成learn等。
经过第二步,我们得到一棵经过语言处理的语法树。
第三步:搜索索引,得到符合语法树的文档。
此步骤有分几小步:1.首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
2.其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
lucene实现全文搜索

lucene实现全文搜索1.什么是全文搜索全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
这个过程类似于通过字典中的检索字表查字的过程。
2.什么是luceneapache lucene是一个开放源程序的搜寻器引擎,利用它可以轻易地为Java软件加入全文搜寻功能。
lucene的最主要工作是替文件的每一个字作索引,索引让搜寻的效率比传统的逐字比较大大提高,lucene提供一组解读,过滤,分析文件,编排和使用索引的API,它的强大之处除了高效和简单外,是最重要的是使使用者可以随时应自已需要自订其功能。
lucene是apache软件基金会项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
3.特点及优势lucene作为一个全文检索引擎,其具有如下突出的优点:1、索引文件格式独立于应用平台。
lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
2、在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。
然后通过与原有索引的合并,达到优化的目的。
3、优秀的面向对象的系统架构,使得对于lucene扩展的学习难度降低,方便扩充新功能。
4、设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
5、已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
Lucene:基于Java的全文检索引擎技术简介

Lucene:基于Java的全文检索引擎技术简介内容摘要:Lucene是一个基于Java的全文索引工具包。
1.基于Java的全文索引引擎Lucene简介:关于作者和Lucene的历史2.全文检索的实现:Luene全文索引和数据库索引的比较3.中文切分词机制简介:基于词库和自动切分词算法的比较4.具体的安装和使用简介:系统结构介绍和演示5.Hacking Lucene:简化的查询分析器,删除的实现,定制的排序,应用接口的扩展6.从Lucene我们还可以学到什么基于Java的全文索引/检索引擎——LuceneLucene不是一个完整的全文索引应用,而是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中,实现针对应用的全文索引/检索功能。
Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。
他贡献出Lucene的目标是为各种中小型应用程序加入全文检索功能。
Lucene的发展历程:早先发布在作者自己的,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:/lucene/已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有:Jive:WEB论坛系统;Eyebrows:邮件列表HTML归档/浏览/查询系统,本文的主要参考文档“TheLucene search engine: Powerful, flexible, and free”的作者就是EyeBrows系统的主要开发者之一,而EyeBrows已经成为目前APACHE项目的主要邮件列表归档系统。
Cocoon:基于XML的web发布框架,全文检索部分使用了LuceneEclipse:基于Java的开放开发平台,帮助部分的全文索引使用了Lucene对于中文用户来说,最关心的问题是其是否支持中文的全文检索。
基于Lucene的全文检索系统的设计与实现

2、查询处理:当用户提交搜索请求时,系统会调用Lucene的查询API对索引 进行搜索。根据用户输入的关键词,系统会在索引中查找包含这些关键词的文 档,并按照相关度进行排序。
3、结果展示:将搜索结果以网页的形式呈现给用户,并在每个搜索结果中展 示关键词的高亮显示,方便用户快速找到感兴趣的内容。
为了提高搜索性能和用户体验,我们还采取了一些优化措施。例如,对索引进 行定期更新以保持最新数据;使用多线程查询以提高并发性能;对搜索结果进 行去重和限流以避免重复和过多结果展示等。
结论
本次演示对基于Lucene的全文检索系统进行了深入研究与开发。
随着信息技术的快速发展,人们对于快速、准确、全面的信息检索需求日益增 长。Lucene全文检索引擎作为开源界的一款强大工具,为各类用户提供了高 效、灵活的信息检索服务。本次演示将从Lucene全文检索引擎的应用研究与 实现两个方面展开讨论。
2、组件选择:全文检索系统需要选用合适的文本解析器、分词器、倒排索引 生成器、查询处理器等组件。这些组件的选择将直接影响到系统的性能和准确 性。
3、数据存储和处理流程:数据存储需要考虑到文本数据的存储格式、索引的 构建与存储方式以及数据的更新与维护等问题;处理流程则包括数据的预处理、 索引构建、查询处理和结果排序等环节。
文献综述
在全文检索系统领域,已经有很多研究者和企业进行了深入的研究和开发。传 统的全文检索系统多采用基于规则和词典的方法来提取关键词和建立索引,但 这种方法对于大规模、多语种和复杂文本的处理能力有限。随着人工智能技术 的发展,尤其是自然语言处理和机器学习领域的进步,越来越多的研究者将新 型技术应用于全文检索,取得了显著的成果。然而,现有的全文检索系统在处 理长文本、识别语义信息等方面仍存在一定局限性。
用JSP调用Lucene包来实现全文检索-精品文档资料

用JSP调用Lucene包来实现全文检索1 Tomcat+JSP+Lvcene1. 1 Tomcat的Web服务器Web服务器是在网络中为实现信息发布、资料查询、数据处理等诸多应用搭建基本平台的服务器。
Tomcat Server 是根据Servlet 和JSP 规范进行执行的,是一个十分有用的网络应用开发服务平台。
它的下载、安装、使用见网站:http :///1. 2 JSP(Java Server Pages)JSP(Java Server Pages) 是由Sun Microsystems 公司倡导、许多公司参与一起建立的一种动态网页技术标准。
JSP技术是用JAVA语言作为脚本语言的,JSP网页为整个服务器端的JAVA库单元提供了一个接口来服务于HTTP的应用程序。
中加入Java 程序在传统的网页HTML文件(*.htm,*.html)片段(Scriptiet) 和JSP标记(tag),就构成了JSP 网页(*.jsp)。
Web服务器在遇到访问JSP网页的请求时,首先执行其中的程序片段,然后将执行结果以HTM1格式返回给客户。
1. 3 LuceneLucene是Apache的开源项目,是用Java写的全文索引弓擎工具包。
它提供了许多简单实用的API,用这些API,就可以方便的嵌入到各种应用中,对任何基于文本的数据进行全文检Lucene 是用 Java 写的, 它的运行、 调试都需要有 JavaSDK 。
Lucene 的下载、安装、使用见网站: http :///2 全文检索的实现2.1 全文检索系统的结构全文检索系统是按照全文检索理论建立起来的用于提供全 文检索服务的软件系统。
一般来说, 全文检索需要具备建立索引 和提供查询的基本功能, 此外现代的全文检索系统还需要具有方 便的用户接口、面向 wwW 勺开发接口、二次应用开发接口等等。
结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析 引擎、对外接口等等, 加上各种外围应用系统等共同构成了全文 检索系统。
信息检索论文基于lucene的实验大学论文

基于Lucene的实验报告信息检索系统介绍信息检索系统是借助信息检索技术,如全文检索等手段帮助用户检索特定信息的工具。
它可以正确地表示,存储和组织信息,同时还提供信息的访问。
在这里,信息的概念是非常广泛的,它可以是一篇文章,一个文本,一个网页,一封电子邮件,一张照片,甚至是一个收集的虚拟信息。
检索的整个过程包括:文本数据库的构建、索引和检索。
信息检索的过程:1 建立一个文本库一个信息检索系统需要准备之前,搜索功能的开发。
首先,必须建立一个文本数据库。
该文本数据库用于存储用户可以检索的所有信息。
在此基础上,确定了检索系统中的文本模型。
文本模型是一种被系统识别的信息格式,具有冗余性低等特点。
当然,在系统的运行过程中,文本数据库的信息可能会不断变化。
2建立索引当您拥有文本模型时,您应该创建一个基于数据库中的文本的索引.。
索引可以大大提高信息检索的速度。
建立索引的方法有多种,这取决于信息检索系统的大小。
大规模的信息检索系统(如百度,谷歌,如搜索引擎)被用来创建一个倒排索引。
3搜索索引文本后,可以开始搜索它。
搜索请求通常由用户提交,请求进行分析,检索结果返回索引中。
Lucene随着系统信息的越来越多,怎么样从这些信息海洋中捞起自己想要的那一根针就变得非常重要了,全文检索是通常用于解决此类问题的方案,而Lucene则为实现全文检索的工具,任何应用都可通过嵌入它来实现全文检索。
Lucene是一个开源全文检索工具包,它是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene工作方式lucene提供的服务实际包含两部分:一入一出。
Lucene是一套全文检索的API
Lucene是一套全文检索的API,对其介绍的文章和应用的案例都多,可参考lucene及本文的参考文献。
此次学习,以实用为主,一是简单应用,二是Web应用,三是汉化,四相关应用(Lucene主页上在SandBox中)。
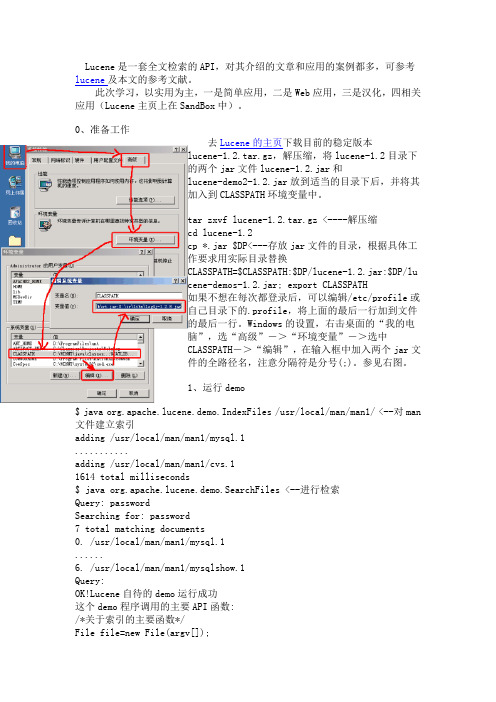
0、准备工作去Lucene的主页下载目前的稳定版本lucene-1.2.tar.gz,解压缩,将lucene-1.2目录下的两个jar文件lucene-1.2.jar和lucene-demo2-1.2.jar放到适当的目录下后,并将其加入到CLASSPATH环境变量中。
tar zxvf lucene-1.2.tar.gz <----解压缩cd lucene-1.2cp *.jar $DP<---存放jar文件的目录,根据具体工作要求用实际目录替换CLASSPATH=$CLASSPATH:$DP/lucene-1.2.jar:$DP/lucene-demos-1.2.jar; export CLASSPATH如果不想在每次都登录后,可以编辑/etc/profile或自己目录下的.profile,将上面的最后一行加到文件的最后一行。
Windows的设置,右击桌面的“我的电脑”,选“高级”->“环境变量”->选中CLASSPATH->“编辑”,在输入框中加入两个jar文件的全路径名,注意分隔符是分号(;)。
参见右图。
1、运行demo$ java org.apache.lucene.demo.IndexFiles /usr/local/man/man1/ <--对man 文件建立索引adding /usr/local/man/man1/mysql.1...........adding /usr/local/man/man1/cvs.11614 total milliseconds$ java org.apache.lucene.demo.SearchFiles <--进行检索Query: passwordSearching for: password7 total matching documents0. /usr/local/man/man1/mysql.1......6. /usr/local/man/man1/mysqlshow.1Query:OK!Lucene自待的demo运行成功这个demo程序调用的主要API函数:/*关于索引的主要函数*/File file=new File(argv[]);IndexWriter writer = new IndexWriter("index", new StandardAnalyzer(), true);Document doc = new Document();doc.add(Field.Text("path", file.getPath()));doc.add(Field.Keyword("modified",DateField.timeToString(stModi fied())));FileInputStream is = new FileInputStream(f);Reader reader = new BufferedReader(new InputStreamReader(is));doc.add(Field.Text("contents", reader));writer.addDocument(doc);writer.optimize();writer.close();/*关于检索的主要函数*/Searcher searcher = new IndexSearcher("index");Analyzer analyzer = new StandardAnalyzer();Query query = QueryParser.parse(lineforsearch, "contents", analyzer); Hits hits = searcher.search(query);for (int i = start; i < hits.length(); i++) {Document doc = hits.doc(i);String path = doc.get("path");System.out.println(i + ". " + path);}3、运行LuceneWeb假定tomcat装在$TOMCATHOME目录下,具体应用时用真实的目录替换$TOMCATHOME。
使用Apache Lucene进行全文检索和信息检索

使用Apache Lucene进行全文检索和信息检索随着数据量的日益增长,信息的获取和管理也变得越来越困难。
在这样的背景下,全文检索技术备受关注。
全文检索是指通过对文本内容进行扫描和分析,快速地查找出包含指定关键字或短语的文本,以满足用户的需求。
Apache Lucene是一款强大的全文检索引擎,具有高效、可靠、易于扩展等特点,广泛被运用于信息检索、文本分类、数据挖掘等领域。
一、Lucene的基本原理Lucene是一款基于Java语言的全文检索引擎,能够快速地在海量数据中查找指定的文本。
Lucene的检索原理可以简单地描述为:将需要检索的文本输入Lucene,Lucene建立索引文件,用户查询文本时,Lucene在索引文件中查找匹配结果,返回用户所需的信息。
Lucene的基本原理如下:1. 建立索引建立索引是Lucene进行全文检索的第一步。
在索引过程中,Lucene会对文本进行解析、分词、词语过滤等处理,然后将这些处理后的词语和其所在的文档信息存储到索引文件中。
通过如此的操作,Lucene做到了在指定时间内,快速地查找指定文本。
2. 查询当用户输入需要检索的文本时,Lucene会对该文本进行同样的预处理,得到其中的每个单独词语,并在索引文件中查找与该词语相匹配的文档。
Lucene采用了先搜索后排名的检索策略,即先找到与关键词匹配的文档,然后再通过算法对得到的结果进行排序,得出匹配度最高的文档。
3. 返回结果Lucene的返回结果是一个文档对象,其中包含了原始文本、关键词匹配的位置和得分等信息。
在大多数情况下,返回的文档对象并不是用户真正想要的结果,需要进行二次过滤和排序,才能得出目标结果。
二、Lucene的基本使用Lucene的使用可以简单地分为以下几个步骤:1. 创建索引创建索引是Lucene进行全文检索的第一步,也是最重要的一步。
在创建索引前,需要准备好需要检索的文本文件。
Lucene支持的文本格式包括txt、doc、pdf等。
JAVAlucene全文检索工具包理解使用

申明:原文来自/98440293.html1 lucene简介1.1 什么是luceneLucene是一个全文搜索框架,而不是应用产品.因此它并不像 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品.1.2 lucene能做什么要回答这个问题,先要了解lucene地本质.实际上lucene地功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索地关键词出现在哪里.知道了这个本质,你就可以发挥想象做任何符合这个条件地事情了.你可以把站内新闻都索引了,做个资料库;你可以把一个数据库表地若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;你也可以写个自己地搜索引擎……1.3 你该不该选择lucene下面给出一些测试数据,如果你觉得可以接受,那么可以选择.测试一:250万记录,300M左右文本,生成索引380M左右,800线程下平均处理时间300ms. 测试二:37000记录,索引数据库中地两个varchar字段,索引文件2.6M,800线程下平均处理时间1.5ms.2 lucene地工作方式lucene提供地服务实际包含两部分:一入一出.所谓入是写入,即将你提供地源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源.2.1写入流程源字符串首先经过analyzer处理,包括:分词,分成一个个单词;去除stopword(可选).将源中需要地信息加入Document地各个Field中,并把需要索引地Field索引起来,把需要存储地Field存储起来.将索引写入存储器,存储器可以是内存或磁盘.2.2读出流程用户提供搜索关键词,经过analyzer处理.对处理后地关键词搜索索引找出对应地Document.用户根据需要从找到地Document中提取需要地Field.3 一些需要知道地概念lucene用到一些概念,了解它们地含义,有利于下面地讲解.3.1 analyzerAnalyzer 是分析器,它地作用是把一个字符串按某种规则划分成一个个词语,并去除其中地无效词语,这里说地无效词语是指英文中地“of”、“the”,中文中地“地”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率.分词地规则千变万化,但目地只有一个:按语义划分.这点在英文中比较容易实现,因为英文本身就是以单词为单位地,已经用空格分开;而中文则必须以某种方法将连成一片地句子划分成一个个词语.具体划分方法下面再详细介绍,这里只需了解分析器地概念即可.3.2 document 用户提供地源是一条条记录,它们可以是文本文件、字符串或者数据库表地一条记录等等.一条记录经过索引之后,就是以一个Document地形式存储在索引文件中地.用户进行搜索,也是以Document列表地形式返回.3.3 field一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过Field在Document中存储地.Field有两个属性可选:存储和索引.通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引.这看起来似乎有些废话,事实上对这两个属性地正确组合很重要,下面举例说明:还是以刚才地文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为真,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域地存储属性设置为真,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域地存储属性设置为假,当需要时再直接读取文件;我们只是希望能从搜索解果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域地存储属性设置为真,索引属性设置为假.上面地三个域涵盖了两个属性地三种组合,还有一种全为假地没有用到,事实上Field不允许你那么设置,因为既不存储又不索引地域是没有意义地.3.4 termterm是搜索地最小单位,它表示文档地一个词语,term由两部分组成:它表示地词语和这个词语所出现地field.3.5 tockentocken是term地一次出现,它包含trem文本和相应地起止偏移,以及一个类型字符串.一句话中可以出现多次相同地词语,它们都用同一个term表示,但是用不同地tocken,每个tocken标记该词语出现地地方.3.6 segment添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同地小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment.4 lucene地结构lucene包括core和sandbox两部分,其中core是lucene稳定地核心部分,sandbox包含了一些附加功能,例如highlighter、各种分析器.Lucene core有七个包:analysis,document,index,queryParser,search,store,util.4.1 analysis Analysis包含一些内建地分析器,例如按空白字符分词地WhitespaceAnalyzer,添加了stopwrod 过滤地StopAnalyzer,最常用地StandardAnalyzer.4.2 documentDocument包含文档地数据结构,例如Document类定义了存储文档地数据结构,Field类定义了Document地一个域.4.3 indexIndex 包含了索引地读写类,例如对索引文件地segment进行写、合并、优化地IndexWriter 类和对索引进行读取和删除操作地IndexReader类,这里要注意地是不要被IndexReader这个名字误导,以为它是索引文件地读取类,实际上删除索引也是由它完成, IndexWriter只关心如何将索引写入一个个segment,并将它们合并优化;IndexReader则关注索引文件中各个文档地组织形式.4.4 queryParserQueryParser 包含了解读查询语句地类,lucene地查询语句和sql语句有点类似,有各种保留字,按照一定地语法可以组成各种查询. Lucene有很多种Query类,它们都继承自Query,执行各种特殊地查询,QueryParser地作用就是解读查询语句,按顺序调用各种Query类查找出结果.4.5 searchSearch包含了从索引中搜索结果地各种类,例如刚才说地各种Query类,包括TermQuery、BooleanQuery等就在这个包里.4.6 storeStore包含了索引地存储类,例如Directory定义了索引文件地存储结构,FSDirectory为存储在文件中地索引,RAMDirectory为存储在内存中地索引,MmapDirectory为使用内存映射地索引.4.7 utilUtil包含一些公共工具类,例如时间和字符串之间地转换工具.5 如何建索引5.1 最简单地能完成索引地代码片断IndexWrite r writer = new IndexWriter(“/data/index/”, new StandardAnalyzer(), true)。
全文检索lucene研究

全文检索lucene研究本文由美白面膜排行榜/doc/4616316215.html,整理全文检索lucene研究1 Lucene简介Lucene是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。
Lucene以其方便使用、快速实施以及灵活性受到广泛的关注。
它可以方便地嵌入到各种应用中实现针对应用的全文索引、检索功能,本总结使用lucene3.0.02 Lucene 的包结构1、analysis对需要建立索引的文本进行分词、过滤等操作2、standard是标准分析器3、document提供对Document和Field的各种操作的支持。
4、index是最重要的包,用于向Lucene提供建立索引时各种操作的支持5、queryParser提供检索时的分析支持6、search负责检索7、store提供对索引存储的支持8、util提供一些常用工具类和常量类的支持Lucene中的类主要组成如下:1)org.apache.1ucene.analysis语言分析器,主要用于的切词Analyzer是一个抽象类,管理对文本内容的切分词规则。
2)org.apache.1uceene.document索引存储时的文档结构管理,类似于关系型数据库的表结构。
3)document包相对而言比较简单,document相对于关系型数据库的记录对象,Field主要负责字段的管理。
4)org.apache.1ucene.index索引管理,包括索引建立、删除等。
索引包是整个系统核心,全文检索的根本就是为每个切出来的词建索引,查询时就只需要遍历索引,而不需要去正文中遍历,从而极大的提高检索效率。
5)org.apache.1ucene.queryParser查询分析器,实现查询关键词间的运算,如与、或、非等。
6)org.apache.1ucene.search检索管理,根据查询条件,检索得到结果。
7)org.apache.1ucene.store数据存储管理,主要包括一些底层的I/0操作。
基于Lucene的PDF文档的全文检索的实现

—— 一 ( 塞挡缉麴1 —
ANAL YZ ER
—
( 查询器)
f ( 访问索引)
s ORAGE T
( 语言分析器)
ACCE SI DE S N X
随着 P F文 档 的应 用 越 来 越 广 泛 , D 怎样 提 取 和 利 用 P F文 D
件 内部 的信 息 资 源就 成 为 另一 研究 的热 点 。由 于 L c n u e e只能 处 理 文 本 和 数 据 , 而 且 L c n 的 内 核 本 身 只 处 理 jv .n . ue e a a1 g a
旦建 立 起 Lc n ue e 文档 和域 , 可 以 就
调 用 Ide Wre n x ir t
( 存储 器 )
Sr g jv . .e d r 象 和本 地 数 字类 型 。 因此 , 用 L c n tn 、 ai R a e 对 i a o 使 uee 索引 数 据 时 , 必须 先 从 数据 中提 取 纯 文本 格 式 信 息 , 便 L c n 以 ue e
S ARCHE E R
lDE E N X R
Байду номын сангаас
( 查询)
OUE ARS , RY P E R
( 索引)
DO UM E T C N
式 信 息 , 以 便
Lc n u e e识 别 该 文 本 并 建 立 对 应 的
Lc n u e e文 档 。 一
( 重询 墨 L
S ARC E HER
on b o co r p ds t an ut ael te ult x s ar o PDF e y ne res on o. d lm t y h f l e t e ch f i — do m e t bu s en ls cu ns。 talo abe PDF do mens o e cu t t r .
基于Lucene的Oracle数据库全文检索

中图分类号:TP311.13 文献标识码:A 文章编号:1009-2552(2010)03-0156-03基于Lucene的Oracle数据库全文检索葛振国,李 建,何林糠,吴 军(西南石油大学计算机科学学院,成都610500)摘 要:全文检索是信息时代必不可少的技术,应用越来越广泛。
文中对开源的搜索引擎工具包Lucene进行研究,并将其应用到全文检索系统中,详细介绍了如何使用Lucene来创建索引和检索数据,然后给出了一个针对Oracle数据库全文检索的实现方法。
关键词:Lucene;全文检索;OracleOracle database full2text search based on LuceneGE Zhen2guo,LI Jian,HE Lin2kang,WU Jun(School of Computer Science,Southw est Petroleum U niversity of China,Chengdu610500,China) Abstract:Full2text search is an indispensable technology for the information age and widely applied.This paper studies the tool kit Lucene of the open s ource search engine,applies it on the full2text search system, describes in detail how to index and search datas using Lucene,then gives an im plementation for Oracle database.K ey w ords:Lucene;full2text search;Oracle0 引言随着企业数据的不断增长,数据量急剧增多,从海量的数据中查找相关信息已经是每个企业必须要解决的问题,而搜索引擎正是解决这一问题的最为合理的方法,搜素引擎比传统的数据库模糊查询速度优势显而易见,也是后者望尘莫及的。
lucene 全文检索数据库

我们以前经常碰到搜索数据库的内容;用like %的sql语句;如果数据量大而且多表查询时;用lucene2那就可以解决速度问题。
lucene2搜索photo表的title,username,tagname,desr内容;用一个例题来说明更直观;此例题能搜索中文分词;(需要mysql5的jdbc包和lucene2的包):1、数据库我用mysql5;建一个photo表;数据库名是test。
photo表有一下几个字段:CREATE TABLE `photo` (`photo_id` int(11) NOT NULL auto_increment,`title` varchar(11) default NULL,`address` varchar(50) default NULL,`descr` text,`user_id` int(11) default NULL,`user_name` varchar(11) default NULL,`upload_time` date default NULL,`tag_name` varchar(11) default NULL,PRIMARY KEY (`photo_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT;2、java文件有4个:文件Photo.java是数据库的photo表的操作文件;内容如下:import java.sql.Connection;import java.util.ArrayList;import java.util.Date;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;public class Photo {private long photoId;private String title;private String description;private String address;private String userName;private long userId;private String tag;private Date date;public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}public String getDescription() {return description;}public void setDescription(String description) { this.description = description;}public long getPhotoId() {return photoId;}public void setPhotoId(long photoId) {this.photoId = photoId;}public String getTag() {return tag;}public void setTag(String tag) {this.tag = tag;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public long getUserId() {return userId;}public void setUserId(long userId) {erId = userId;}public String getUserName() {return userName;}public void setUserName(String userName) {erName = userName;}public static Photo[] loadPhotos(Connection con) throws Exception { ArrayList<Photo> list = new ArrayList<Photo>();PreparedStatement pstm = null;ResultSet rs = null;String sql = "selectphoto_id,title,address,descr,user_id,user_name,upload_time,tag_name from photo";try {pstm = con.prepareStatement(sql);rs = pstm.executeQuery();while (rs.next()) {Photo photo = new Photo();photo.setPhotoId(rs.getLong(1));photo.setTitle(rs.getString(2));photo.setAddress(rs.getString(3));photo.setDescription(rs.getString(4));photo.setUserId(rs.getLong(5));photo.setUserName(rs.getString(6));photo.setDate(rs.getTimestamp(7));photo.setTag(rs.getString(8));list.add(photo);}System.out.println("com.upolestar.kmpm.po.Photo.java ========"+li st.size());} catch (SQLException e) {e.printStackTrace();} finally {if (rs != null) {rs.close();}if (pstm != null) {pstm.close();}}return (Photo[]) list.toArray(new Photo[list.size()]);}public Date getDate() {return date;}public void setDate(Date date) {this.date = date;}}文件IndexerFile.java是把数据库的内容备份成索引文件到磁盘中去;内容如下:package com.upolestar.kmpm.service;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.IndexWriter;import com.upolestar.kmpm.po.Photo;public class IndexerFile {public static int indexFile(String indexDir, Photo[] list)throws IOException {IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(), true);writer.setUseCompoundFile(false);for (int i = 0; i < list.length; i++) {Document doc = new Document();doc.add(new Field("photoId", String.valueOf(list[i].getPhotoId()), Field.Store.YES, Field.Index.NO));if (list[i].getTitle() != null)doc.add(new Field("title", list[i].getTitle(), Field.Store.YES,Field.Index.TOKENIZED));if (list[i].getDescription() != null)doc.add(new Field("description", list[i].getDescription(),Field.Store.YES, Field.Index.TOKENIZED));doc.add(new Field("address", list[i].getAddress(), Field.Store.YES, Field.Index.NO));doc.add(new Field("userName", list[i].getUserName(),Field.Store.YES, Field.Index.TOKENIZED));doc.add(new Field("userId", String.valueOf(list[i].getUserId()), Field.Store.YES, Field.Index.NO));if (list[i].getTag().length() > 0)doc.add(new Field("tag", list[i].getTag(), Field.Store.YES,Field.Index.TOKENIZED));doc.add(new Field("uploadTime", list[i].getDate().toLocaleString(), Field.Store.YES,Field.Index.TOKENIZED));writer.addDocument(doc);}int numIndexed = writer.docCount();writer.optimize();writer.close();return numIndexed;}}文件SearcherFile.java是搜索磁盘索引文件内容的;内容如下:package com.upolestar.kmpm.service;import java.io.IOException;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.queryParser.MultiFieldQueryParser;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.Hits;import org.apache.lucene.search.Query;import org.apache.lucene.search.Searcher;public class SearcherFile {public static void search(Searcher searcher, String[] q)throws IOException, ParseException {Analyzer analyzer = new StandardAnalyzer();String[] fields = { "title", "description", "tag", "userName" };Query query = MultiFieldQueryParser.parse(q, fields, analyzer);Hits hits = searcher.search(query);System.out.println("SearcherFile======"+hits.length());for (int i = 0; i < hits.length(); i++) {Document doc = hits.doc(i);System.out.println(doc.get("photoId") + "==="+ doc.get("uploadTime")+ "==="+ doc.get("title")+ "==="+ doc.get("description")+ "==="+ doc.get("tag")+ "==="+ doc.get("userName"));}}}文件test.java是操作的主文件;内容如下:package com.upolestar.kmpm.test;import java.io.IOException;import java.sql.Connection;import java.sql.SQLException;import java.util.Date;import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Searcher;import com.upolestar.kmpm.po.Photo;import com.upolestar.kmpm.service.IndexerFile;import com.upolestar.kmpm.service.SearcherFile;public class Test {public final static String indexDir = "D:\\TestLucene";private static Connection getConnection() {Connection conn = null;String url = "jdbc:mysql://localhost:3306/opencms";String userName = "root";String password = "1111";try {Class.forName("com.mysql.jdbc.Driver");conn = java.sql.DriverManager.getConnection(url, userName, password);} catch (Exception e) {e.printStackTrace();System.out.println("Error Trace in getConnection() : " + e.getMessage());}return conn;}public static void main(String[] args) throws IOException, ParseException,SQLException {index();// 做索引Searcher searcher = null;try {searcher = new IndexSearcher(indexDir);search(searcher);// 搜索} catch (Exception e) {e.printStackTrace();} finally {if (searcher != null)searcher.close();}}public static void search(Searcher searcher) throws IOException,ParseException {// 以下是搜索的关键词String[] q = { "SVN", "捱三", "null", "null" };long start = new Date().getTime();SearcherFile.search(searcher, q);long end = new Date().getTime();System.out.println("花费时间:" + (double) (end - start) / 1000 + "秒");}public static void index() throws SQLException {Connection conn = null;try {conn = getConnection();Photo[] list = Photo.loadPhotos(conn);IndexerFile.indexFile(indexDir, list);} catch (Exception e) {e.printStackTrace();} finally {if (conn != null) {conn.close();}}}}已经测试过!!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2) 重新编译 PHP,我的 PHP 版本是 4.3.6:
cd php-4.3.6
./configure --with-java=/usr/local/jdk
make
make install
完成之后,会在 PHP 的 lib 下(我的是在 /usr/lib/php)有个 php_java.jar,同时在扩展动态库存放的目录下(我的是在 /usr/lib/php/20020429)有个 java.so 文件。到这一步需要注意一个问题,有些 PHP 版本生成的是 libphp_java.so 文件,extension 的加载只认 libphp_java.so,直接加载 java.so 可能会出现如下错误:
Lucene 全文检索实践(1)
Lucene 是 Apache Jakarta 的一个子项目,是一个全文检索的搜索引擎库。其提供了简单实用的 API,通过这些 API,可以自行编写对文件(TEXT/XML/HTML等)、目录、数据库的全文检索程序。
Features:
* Very fast indexing, minimal RAM required
print 'OS=' . $system->getProperty('') . ' ' .
$system->getProperty('os.version') . ' on ' .
$system->getProperty('os.arch') . '<br />';
java.home = /usr/local/jdk
;java.library =
;java.library.path =
extension_dir=/usr/lib/php/20020429/
extension=java.so
我将 java.library 及 java.library.path 都注释掉了,PHP 会自动认为 java.library=/usr/local/jdk/jre/lib/i386/libjava.so。
* Supports most European languages
* Option to store and display full text of indexed documents
* Search results in relevance order
* APIs for file format conversion, languages and user interfaces
?>
总结
安装配置还算简单,但是在 PHP 运行 Java 的速度感觉较慢,所以下定决心开始实践第二个方案。(待续)
Lucene 全文检索实践(3)
今天总算有些空闲时间,正好说说第二种方案:使用 mod_jk 做桥接的方式,将 servlet 引擎结合到 httpd 中。
环境
3) 实现支持中文查询及检索关键字高亮显示。
4) 通过 PHP / Java Integration 实现对 MySearch.java 的调用。
5) 实现对 PHP 手册(简体中文) 的全文检索。
Lucene 全文检索实践(2)
Java 的程序基本编写完成,实现了对中文的支持。下一步是将其放到 WEB 上运行,首先想到的是使用 JSP,安装了Apache Tomcat/4.1.24,默认的发布端口是 8080。现在面临的一个问题是:Apache httpd 的端口是 80,并且我的机器对外只能通过 80 端口进行访问,如果将 Tomcat 的发布端口改成 80 的话,httpd 就没法对外了,而其上的 PHP 程序也将无法在 80 端口运行。
所以如果生成的是 java.so,需要创建一个符号连接:
ln -s java.so libphp_java.so
3) 修改 Apache Service 启动文件(我的这个文件为 /etc/init.d/httpd),在这个文件中加入:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/jdk/jre/lib/i386/server:/usr/local/jdk/jre/lib/i386
正如你所看到的,我的 JDK 装在 /usr/local/jdk 目录下,如果你的不是在此目录,请做相应改动(下同)。
4) 修改 PHP 配置文件 php.ini,找到 [Java] 部分进行修改:
[Java]
java.class.path = /usr/lib/php/php_java.jar
tar xzf jakarta-tomcat-connectors-jk-1.2.5-src.tar.gz
cd jakarta-tomcat-connectors-jk-1.2.5-src/jk/native
./configure --with-apxs=/usr/local/apache/bin/apxs
* PHP 4.3.6 prefix=/usr
* Apache 1.3.27 prefix=/usr/local/apache
* j2sdk1.4.1_01 prefix=/usr/local/jdk
* jakarta-tomcat-4.1.24 prefix=/usr/local/tomcat
实践任务:
1) 编写 Java 程序 MyIndexer.java,使用 JDBC 取出 MySQL 数据表内容(以某一论坛数据做测试),然后通过 org.apache.lucene.index.IndexWriter 创建索引。
2) 编写 Java 程序 MySearcher.java,通过 org.apache.lucene.search.IndexSearcher 等查询索引。
* Index compression to 30% of original text
* Indexes text and HTML, document classes available for XML, PDF and RTF
* Search supports phrase and Boolean queries, plus, minus and quote marks, and parentheses
对于第一个方案的尝试:使用 PHP 直接调用 Java
环境
* PHP 4.3.6 prefix=/usr
* Apache 1.3.27 prefix=/usr/local/apache
* j2sdk1.4.1_01 prefix=/usr/local/jdk
配置步骤
1) 安装 JDK,这个就不多说了,到 GOOGLE 可以搜索出这方面的大量文章。
AddModule mod_jk.c
这个 LoadModule 语句最好放在其他 LoadModule 语句后边。
同时在配置文件后边加入:
# workers.properties 文件所在路径,后边将对此文件进行讲解
JkWorkersFile /usr/local/apache/conf/workers.properties
# jk 的日志文件存放路径
JkLogFile /usr/local/apache置 jk 的日志级别 [debug/error/info]
JkLogLevel info
# 选择日志时间格式
JkLogStampFormat "[%a %b %d %H:%M:%S %Y] "
worker.worker1.socket_keepalive=1
worker.worker1.socket_timeout=300
# JkOptions 选项设置
JkOptions +ForwardKeySize +ForwardURICompat -ForwardDirectories
# JkRequestLogFormat 设置日志的请求格式
JkRequestLogFormat "%w %V %T"
# 映射 /examples/* 到 worker1,worker1 在 workers.properties 文件中定义
* Allows single and multiple character wildcards anywhere in the search words, fuzzy search, proximity
* Will search for punctuation such as + or ?
* Field searches for title, author, etc., and date-range searching
5) 重新启动 Apache httpd 服务:
service httpd restart
测试
测试脚本 java.php 源代码:
getProperty('java.version').'<br />';
print 'Java vendor=' . $system->getProperty('java.vendor').'<br />';
PHP Fatal error: Unable to load Java Library /usr/local/jdk/jre/lib/i386/libjava.so, error: libjvm.so: