数据结构习题答案 耿国华主编 第六章
数据结构课后习题及解析第六章

第六章习题1.试分别画出具有3个结点的树和3个结点的二叉树的所有不同形态。
2.对题1所得各种形态的二叉树,分别写出前序、中序和后序遍历的序列。
3.已知一棵度为k的树中有n1个度为1的结点,n2个度为2的结点,……,nk个度为k的结点,则该树中有多少个叶子结点并证明之。
4.假设一棵二叉树的先序序列为EBADCFHGIKJ,中序序列为ABCDEFGHIJK,请画出该二叉树。
5.已知二叉树有50个叶子结点,则该二叉树的总结点数至少应有多少个?6.给出满足下列条件的所有二叉树:①前序和后序相同②中序和后序相同③前序和后序相同7. n个结点的K叉树,若用具有k个child域的等长链结点存储树的一个结点,则空的Child 域有多少个?8.画出与下列已知序列对应的树T:树的先根次序访问序列为GFKDAIEBCHJ;树的后根次序访问序列为DIAEKFCJHBG。
9.假设用于通讯的电文仅由8个字母组成,字母在电文中出现的频率分别为:0.07,0.19,0.02,0.06,0.32,0.03,0.21,0.10请为这8个字母设计哈夫曼编码。
10.已知二叉树采用二叉链表存放,要求返回二叉树T的后序序列中的第一个结点指针,是否可不用递归且不用栈来完成?请简述原因.11. 画出和下列树对应的二叉树:12.已知二叉树按照二叉链表方式存储,编写算法,计算二叉树中叶子结点的数目。
13.编写递归算法:对于二叉树中每一个元素值为x的结点,删去以它为根的子树,并释放相应的空间。
14.分别写函数完成:在先序线索二叉树T中,查找给定结点*p在先序序列中的后继。
在后序线索二叉树T中,查找给定结点*p在后序序列中的前驱。
15.分别写出算法,实现在中序线索二叉树中查找给定结点*p在中序序列中的前驱与后继。
16.编写算法,对一棵以孩子-兄弟链表表示的树统计其叶子的个数。
17.对以孩子-兄弟链表表示的树编写计算树的深度的算法。
18.已知二叉树按照二叉链表方式存储,利用栈的基本操作写出后序遍历非递归的算法。
(完整版)数据结构---C语言描述-(耿国华)-课后习题答案

第一章习题答案2、××√3、(1)包含改变量定义的最小范围(2)数据抽象、信息隐蔽(3)数据对象、对象间的关系、一组处理数据的操作(4)指针类型(5)集合结构、线性结构、树形结构、图状结构(6)顺序存储、非顺序存储(7)一对一、一对多、多对多(8)一系列的操作(9)有限性、输入、可行性4、(1)A(2)C(3)C5、语句频度为1+(1+2)+(1+2+3)+…+(1+2+3+…+n)第二章习题答案1、(1)一半,插入、删除的位置(2)顺序和链式,显示,隐式(3)一定,不一定(4)头指针,头结点的指针域,其前驱的指针域2、(1)A(2)A:E、AB:H、L、I、E、AC:F、MD:L、J、A、G或J、A、G(3)D(4)D(5)C(6)A、C3、头指针:指向整个链表首地址的指针,标示着整个单链表的开始。
头结点:为了操作方便,可以在单链表的第一个结点之前附设一个结点,该结点的数据域可以存储一些关于线性表长度的附加信息,也可以什么都不存。
首元素结点:线性表中的第一个结点成为首元素结点。
4、算法如下:int Linser(SeqList *L,int X){ int i=0,k;if(L->last>=MAXSIZE-1){ printf(“表已满无法插入”);return(0);}while(i<=L->last&&L->elem[i]<X)i++;for(k=L->last;k>=I;k--)L->elem[k+1]=L->elem[k];L->elem[i]=X;L->last++;return(1);}5、算法如下:#define OK 1#define ERROR 0Int LDel(Seqlist *L,int i,int k){ int j;if(i<1||(i+k)>(L->last+2)){ printf(“输入的i,k值不合法”);return ERROR;}if((i+k)==(L->last+2)){ L->last=i-2;ruturn OK;}else{for(j=i+k-1;j<=L->last;j++)elem[j-k]=elem[j];L->last=L->last-k;return OK;}}6、算法如下:#define OK 1#define ERROR 0Int Delet(LInkList L,int mink,int maxk){ Node *p,*q;p=L;while(p->next!=NULL)p=p->next;if(mink<maxk||(L->next->data>=mink)||(p->data<=maxk)) { printf(“参数不合法”);return ERROR;}else{ p=L;while(p->next-data<=mink)p=p->next;while(q->data<maxk){ p->next=q->next;free(q);q=p->next;}return OK;}}9、算法如下:int Dele(Node *S){ Node *p;P=s->next;If(p= =s){printf(“只有一个结点,不删除”);return 0;}else{if((p->next= =s){s->next=s;free(p);return 1;}Else{ while(p->next->next!=s)P=p->next;P->next=s;Free(p);return 1;}}}第三章习题答案2、(1)3、栈有顺序栈和链栈两种存储结构。
耿国华数据结构习题答案完整版

1.3 计算下列程序中x=x+1 的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;【解答】x=x+1 的语句频度为:T(n)=1+(1+2)+ (1+2+3 )+⋯⋯+(1+2+⋯⋯+n )=n(n+1)(n+2)/61. 4 试编写算法,求p n(x)=a 0+a1x+a 2x2+⋯⋯.+a n x n 的值p n(x 0),并确定算法中每一语句的执行次数和整个算法的时间复杂度,要求时间复杂度尽可能小,规定算法中不能使用求幂函数。
注意:本题中的输入为a i(i=0,1, ⋯n、) x 和n,输出为P n(x 0)。
算法的输入和输传递。
讨论出采用下列方法(1)通过参数表中的参数显式传递(2)通过全局变量隐式两种方法的优缺点,并在算法中以你认为较好的一种实现输入输出。
【解答】(1)通过参数表中的参数显式传递持,函数通优点:当没有调用函数时,不占用内存,调用结束后形参被释放,实参维用性强,移置性强。
缺点:形参须与实参对应,且返回值数量有限。
(2)通过全局变量隐式传递耗时的时间消优点:减少实参与形参的个数,从而减少内存空间以及传递数据缺点:函数通用性降低,移植性差算法如下:通过全局变量隐式传递参数PolyValue(){ int i,n;float x,a[],p;printf( “n n=”);scanf( “%f”,&n);printf( “n x=”);scanf( “%f”,&x);for(i=0;i<n;i++)scanf( “%f ”,&a[i]); /*执行次数:n 次*/p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x; /*执行次数:n 次*/x=x*x;}printf( “%f”,p); }算法的时间复杂度:T(n)=O(n)传递通过参数表中的参数显式float PolyValue(float a[ ], float x, int n){float p,s;int i; p=x;s=a[0];for(i=1;i<=n;i++){s=s+a[i]*p; /*执行次数:n 次*/p=p*x;}return(p);}算法的时间复杂度:T(n)=O(n)1.4 试分别以不同的存储结构实现单线表的就地逆置算法,即在原表的存储空间将线性表(a1,a2, ⋯,a n )逆置为(a n,a n-1, ⋯,a1)。
数据结构答案(耿国华)

SubString(sub2,s,7,1)= 空格
StrIndex(s,’A’,4)= 6 StrReplace(s,’STUDENT’,q)= I AM A WORKER
StrCat(StrCat(sub1,t),StrCat(sub2,q)) = I AM A GOOD WORKER
B
C A
先:ABC 中:CBA 后:CBA
A
B C
先:ABC 中:BAC 后:BCA
6
A
先:ABC B 中:ACB 后:CBA
B C
C
先:ABC 中:ABC 后:CBA
第6章 树和二叉树习题
3.已知一棵度为k的树中有n1个度为1的结点,n2个度 为2的结点,…nk个度为k的结点,则该树中有多少个 叶子结点,并证明之。
3)前序和后序相同 空树、只有一个结点的树
9
第6章 树和二叉树习题
数 据 结 构
补充:写出下面二叉树的前序、中序、后序 遍历序列 先序序列: A ABCDEFGHIJ E B 中序序列: G C F BCDAFEHJIG D H I J 后序序列: DCBFJIHGEA
10
第6章 树和二叉树习题
13
解:设n为总结点数,则有
数 据 结 构
(总结点数) n=n0+n1+n2+…nk (总边数) n-1=1*n1+2*n2+…k*nk 两式相减得:1=n0-n2-2n3-…-(k-1)nk n0=1+n2+2n3+…+(k-1)nk =1+∑(i-1)ni
i=1
7
k
第6章 树和二叉树习题
4.假设一棵二叉树的先序序列和中序序列,试画出该二叉树, 并写出后序遍历序列。
数据结构课后习题(第6章)

【课后习题】第6章树和二叉树网络工程2010级()班学号:姓名:一、填空题(每空1分,共16分)1.从逻辑结构看,树是典型的。
2.设一棵完全二叉树具有999个结点,则此完全二叉树有个叶子结点,有个度为2的结点,有个度为1的结点。
3.由n个权值构成的哈夫曼树共有个结点。
4.在线索化二叉树中,T所指结点没有左子树的充要条件是。
5.在非空树上,_____没有直接前趋。
6.深度为k的二叉树最多有结点,最少有个结点。
7.若按层次顺序将一棵有n个结点的完全二叉树的所有结点从1到n编号,那么当i为且小于n时,结点i的右兄弟是结点,否则结点i没有右兄弟。
8.N个结点的二叉树采用二叉链表存放,共有空链域个数为。
9.一棵深度为7的满二叉树有___ ___个非终端结点。
10.将一棵树转换为二叉树表示后,该二叉树的根结点没有。
11.采用二叉树来表示树时,树的先根次序遍历结果与其对应的二叉树的遍历结果是一样的。
12.一棵Huffman树是带权路径长度最短的二叉树,权值的外结点离根较远。
二、判断题(如果正确,在对应位置打“√”,否则打“⨯”。
每题0.5分,共5分)1.对于一棵非空二叉树,它的根结点作为第一层,则它的第i层上最多能有2i-1个结点。
2.二叉树的前序遍历并不能唯一确定这棵树,但是,如果我们还知道该二叉树的根结点是那一个,则可以确定这棵二叉树。
3.一棵树中的叶子结点数一定等于与其对应的二叉树中的叶子结点数。
4.度≤2的树就是二叉树。
5.一棵Huffman树是带权路径长度最短的二叉树,权值较大的外结点离根较远。
6.采用二叉树来表示树时,树的先根次序遍历结果与其对应的二叉树的前序遍历结果是一样的。
7.不存在有偶数个结点的满二叉树。
8.满二叉树一定是完全二叉树,而完全二叉树不一定是满二叉树。
9.已知二叉树的前序遍历顺序和中序遍历顺序,可以惟一确定一棵二叉树;10.已知二叉树的前序遍历顺序和后序遍历顺序,不能惟一确定一棵二叉树;三、单项选择(请将正确答案的代号填写在下表对应题号下面。
耿国华大数据结构习题问题详解完整版

第一章答案1.3计算下列程序中x=x+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;【解答】x=x+1的语句频度为:T(n)=1+(1+2)+(1+2+3)+……+(1+2+……+n)=n(n+1)(n+2)/61.4试编写算法,求p n(x)=a0+a1x+a2x2+…….+a n x n的值p n(x0),并确定算法中每一语句的执行次数和整个算法的时间复杂度,要求时间复杂度尽可能小,规定算法中不能使用求幂函数。
注意:本题中的输入为a i(i=0,1,…n)、x和n,输出为P n(x0)。
算法的输入和输出采用下列方法(1)通过参数表中的参数显式传递(2)通过全局变量隐式传递。
讨论两种方法的优缺点,并在算法中以你认为较好的一种实现输入输出。
【解答】(1)通过参数表中的参数显式传递优点:当没有调用函数时,不占用内存,调用结束后形参被释放,实参维持,函数通用性强,移置性强。
缺点:形参须与实参对应,且返回值数量有限。
(2)通过全局变量隐式传递优点:减少实参与形参的个数,从而减少内存空间以及传递数据时的时间消耗缺点:函数通用性降低,移植性差算法如下:通过全局变量隐式传递参数PolyValue(){ int i,n;float x,a[],p;printf(“\nn=”);scanf(“%f”,&n);printf(“\nx=”);scanf(“%f”,&x);for(i=0;i<n;i++)scanf(“%f ”,&a[i]); /*执行次数:n次 */p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x; /*执行次数:n次*/x=x*x;}printf(“%f”,p);}算法的时间复杂度:T(n)=O(n)通过参数表中的参数显式传递float PolyValue(float a[ ], float x, int n){float p,s;int i;p=x;s=a[0];for(i=1;i<=n;i++){s=s+a[i]*p; /*执行次数:n次*/p=p*x;}return(p);}算法的时间复杂度:T(n)=O(n)第二章答案2.7试分别以不同的存储结构实现单线表的就地逆置算法,即在原表的存储空间将线性表(a1,a2,…,a n)逆置为(a n,a n-1,…,a1)。
《数据结构——C语言描述》习题及答案 耿国华

第1章绪论之阳早格格创做习题一、问问题1. 什么是数据结构?2. 四类基础数据结构的称呼与含意.3. 算法的定义与个性.4. 算法的时间搀纯度.5. 数据典型的观念.6. 线性结构与非线性结构的不共.7. 里背对于象步调安排谈话的个性.8. 正在里背对于象步调安排中,类的效率是什么?9. 参数传播的主要办法及个性.10. 抽象数据典型的观念.二、推断题1. 线性结构只可用程序结构去存搁,非线性结构只可用非程序结构去存搁.2. 算法便是步调.3. 正在下档谈话(如C、大概 PASCAL)中,指针典型是本子典型.三、估计下列步调段中X=X+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;[提示]:i=1时: 1 = (1+1)×1/2 = (1+12)/2i=2时: 1+2 = (1+2)×2/2 = (2+22)/2i=3时: 1+2+3 = (1+3)×3/2 = (3+32)/2…i=n时:1+2+3+……+n = (1+n)×n/2 = (n+n2)/2f(n) = [ (1+2+3+……+n) + (12 + 22 + 32 + …… + n2 ) ] / 2=[ (1+n)n/2 + n(n+1)(2n+1)/6 ] / 2=n(n+1)(n+2)/6=n3/6+n2/2+n/3区别语句频度战算法搀纯度:O(f(n)) = O(n3)四、试编写算法供一元多项式Pn(x)=a0+a1x+a2x2+a3x3+…a n x n的值P n(x0),并决定算法中的每一语句的真止次数战所有算法的时间搀纯度,央供时间搀纯度尽大概的小,确定算法中不克不迭使用供幂函数.注意:本题中的输进a i(i=0,1,…,n), x战n,输出为P n(x0).常常算法的输进战输出可采与下列二种办法之一:(1)通过参数表中的参数隐式传播;(2)通过局部变量隐式传播.试计划那二种要领的劣缺面,并正在本题算法中以您认为较佳的一种办法真止输进战输出.[提示]:float PolyValue(float a[ ], float x, int n) {……}核心语句:p=1; (x的整次幂)s=0;i从0到n循环s=s+a[i]*p;p=p*x;大概:p=x; (x的一次幂)s=a[0];i从1到n循环s=s+a[i]*p;p=p*x;真习题安排真止抽象数据典型“有理数”.基础支配包罗有理数的加法、减法、乘法、除法,以及供有理数的分子、分母.第一章问案估计下列步调中x=x+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;【解问】x=x+1的语句频度为:T(n)=1+(1+2)+(1+2+3)+……+(1+2+……+n)=n(n+1)(n+2)/6 1.4试编写算法,供p n(x)=a0+a1x+a2x2+…….+a n x n的值p n(x0),并决定算法中每一语句的真止次数战所有算法的时间搀纯度,央供时间搀纯度尽大概小,确定算法中不克不迭使用供幂函数.注意:本题中的输进为a i(i=0,1,…n)、x战n,输出为P n(x0).算法的输进战输出采与下列要领(1)通过参数表中的参数隐式传播(2)通过局部变量隐式传播.计划二种要领的劣缺面,并正在算法中以您认为较佳的一种真止输进输出.【解问】(1)通过参数表中的参数隐式传播便宜:当不调用函数时,不占用内存,调用中断后形参被释搁,真参保护,函数通用性强,移置性强.缺面:形参须与真参对于应,且返回值数量有限.(2)通过局部变量隐式传播便宜:缩小真介进形参的个数,进而缩小内存空间以及传播数据时的时间消耗缺面:函数通用性落矮,移植性好算法如下:通过局部变量隐式传播参数PolyValue(){ int i,n;float x,a[],p;printf(“\nn=”);scanf(“%f”,&n);printf(“\nx=”);scanf(“%f”,&x);for(i=0;i<n;i++)scanf(“%f ”,&a[i]); /*真止次数:n次 */p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x; /*真止次数:n次*/x=x*x;}printf(“%f”,p);}算法的时间搀纯度:T(n)=O(n)通过参数表中的参数隐式传播float PolyValue(float a[ ], float x, int n){float p,s;int i;p=x;s=a[0];for(i=1;i<=n;i++){s=s+a[i]*p; /*真止次数:n次*/p=p*x;}return(p);}算法的时间搀纯度:T(n)=O(n)第2章线性表习题2.1 形貌以下三个观念的辨别:头指针,头结面,尾元素结面.2.2 挖空:(1)正在程序表中拔出大概简略一个元素,需要仄衡移动__一半__元素,简曲移动的元素个数与__拔出大概简略的位子__有闭.(2)正在程序表中,逻辑上相邻的元素,其物理位子______相邻.正在单链表中,逻辑上相邻的元素,其物理位子______相邻.(3)正在戴头结面的非空单链表中,头结面的保存位子由______指示,尾元素结面的保存位子由______指示,除尾元素结面中,其余任一元素结面的保存位子由__其间接前趋的next 域__指示.2.3 已知L是无表头结面的单链表,且P结面既不是尾元素结面,也不是尾元素结面.按央供从下列语句中采用符合的语句序列.a. 正在P结面后拔出S结面的语句序列是:_(4)、(1)_.b. 正在P结面前拔出S结面的语句序列是:(7)、(11)、(8)、(4)、(1).c. 正在表尾拔出S结面的语句序列是:(5)、(12).d. 正在表尾拔出S结面的语句序列是:(11)、(9)、(1)、(6).供采用的语句有:(1)P->next=S;(2)P->next= P->next->next;(3)P->next= S->next;(4)S->next= P->next;(5)S->next= L;(6)S->next= NULL;(7)Q= P;(8)while(P->next!=Q) P=P->next;(9)while(P->next!=NULL) P=P->next;(10)P= Q;(11)P= L;(12)L= S;(13)L= P;2.4 已知线性表L递加有序.试写一算法,将X拔出到L的适合位子上,以脆持线性表L的有序性.[提示]:void insert(SeqList *L; ElemType x)< 要领1 >(1)找出应拔出位子i,(2)移位,(3)……< 要领2 > 参P. 2292.5 写一算法,从程序表中简略自第i个元素启初的k个元素.[提示]:注意查看i战k的合法性.(普遍搬家,“新房”、“旧房”)< 要领1 > 以待移动元素下标m(“旧房号”)为核心,估计应移进位子(“新房号”):for ( m= i-1+k; m<= L->last; m++)L->elem[ m-k ] = L->elem[ m ];< 要领2 > 共时以待移动元素下标m战应移进位子j为核心:< 要领3 > 以应移进位子j为核心,估计待移动元素下标:已知线性表中的元素(整数)以值递加有序排列,并以单链表做保存结构.试写一下效算法,简略表中所有大于mink且小于maxk的元素(若表中存留那样的元素),领会您的算法的时间搀纯度(注意:mink战maxk是给定的二个参变量,它们的值为任性的整数).[提示]:注意查看mink战maxk的合法性:mink < maxk不要一个一个的简略(多次建改next域).(1)找到第一个应删结面的前驱prepre=L; p=L->next;while (p!=NULL && p->data <= mink){ pre=p; p=p->next; }(2)找到末尾一个应删结面的后继s,边找边释搁应删结面s=p;while (s!=NULL && s->data < maxk){ t =s; s=s->next; free(t); }(3)pre->next = s;试分别以分歧的保存结构真止线性表的便天顺置算法,即正在本表的保存空间将线性表(a1, a2..., a n)顺置为(a n, a n-1,..., a1).(1)以一维数组做保存结构,设线性表存于a(1:arrsize)的前elenum个分量中.(2)以单链表做保存结构.[要领1]:正在本头结面后沉新头插一遍[要领2]:可设三个共步移动的指针p, q, r,将q的后继r改为p2.8 假设二个按元素值递加有序排列的线性表A战B,均以单链表动做保存结构,请编写算法,将A表战B表归并成一个按元素值递减有序的排列的线性表C,并央供利用本表(即A表战B表的)结面空间存搁表C.[提示]:参P.28 例2-1< 要领1 >void merge(LinkList A; LinkList B; LinkList *C){ ……pa=A->next; pb=B->next;*C=A; (*C)->next=NULL;while ( pa!=NULL && pb!=NULL ){if ( pa->data <= pb->data ){smaller=pa; pa=pa->next;smaller->next = (*C)->next; /* 头插法 */(*C)->next = smaller;}else{smaller=pb; pb=pb->next;smaller->next = (*C)->next;(*C)->next = smaller;}}while ( pa!=NULL){smaller=pa; pa=pa->next;smaller->next = (*C)->next;(*C)->next = smaller;}while ( pb!=NULL){smaller=pb; pb=pb->next;smaller->next = (*C)->next;(*C)->next = smaller;}< 要领2 >LinkList merge(LinkList A; LinkList B){ ……LinkList C;pa=A->next; pb=B->next;C=A; C->next=NULL;…………return C;2.9 假设有一个循环链表的少度大于1,且表中既无头结面也无头指针.已知s为指背链表某个结面的指针,试编写算法正在链表中简略指针s 所指结面的前趋结面.[提示]:设指针p指背s结面的前趋的前趋,则p与s有何闭系?2.10 已知有单链表表示的线性表中含有三类字符的数据元素(如字母字符、数字字符战其余字符),试编写算法去构制三个以循环链表表示的线性表,使每个表中只含共一类的字符,且利用本表中的结面空间动做那三个表的结面空间,头结面可另辟空间.2.11 设线性表A=(a1, a2,…,a m),B=(b1, b2,…,b n),试写一个按下列准则合并A、B为线性表C的算法,使得:C= (a1, b1,…,a m, b m, b m+1,…,b n)当m≤n时;大概者 C= (a1, b1,…,a n, b n, a n+1,…,a m) 当m>n时.线性表A、B、C均以单链表动做保存结构,且C表利用A表战B 表中的结面空间形成.注意:单链表的少度值m战n均已隐式保存.[提示]:void merge(LinkList A; LinkList B; LinkList *C)大概:LinkList merge(LinkList A; LinkList B)2.12 将一个用循环链表表示的稠稀多项式领会成二个多项式,使那二个多项式中各自仅含奇次项大概奇次项,并央供利用本链表中的结面空间去形成那二个链表.[提示]:证明用头指针仍旧尾指针.2.13 建坐一个戴头结面的线性链表,用以存搁输进的二进制数,链表中每个结面的data域存搁一个二进制位.并正在此链表上真止对于二进制数加1的运算.[提示]:可将矮位搁正在前里.2.14 设多项式P(x)采与课本中所述链接要领保存.写一算法,对于给定的x值,供P(x)的值.[提示]:float PolyValue(Polylist p; float x) {……}真习题1.将若搞皆会的疑息存进一个戴头结面的单链表,结面中的皆会疑息包罗皆会名、皆会的位子坐标.央供:(1)给定一个皆会名,返回其位子坐标;(2)给定一个位子坐标P战一个距离D,返回所有与P的距离小于等于D的皆会.2.约瑟妇环问题.约瑟妇问题的一种形貌是:编号为1,2,…,n的n部分按顺时针目标围坐一圈,每人持有一个暗号(正整数).一启初任选一个整数动做报数上限值m,从第一部分启初顺时针自1启初程序报数,报到m时停止报数.报m的人出列,将他的暗号动做新的m值,从他正在顺时针目标上的下一部分启初沉新从1报数,如许下去,曲至所有的人局部出列为止.试安排一个步调,供出出列程序.利用单背循环链表动做保存结构模拟此历程,依照出列程序挨印出各人的编号.比圆m的初值为20;n=7,7部分的暗号依次是:3,1,7,2,4,8,4,出列的程序为6,1,4,7,2,3,5.第二章问案真习题二:约瑟妇环问题约瑟妇问题的一种形貌为:编号1,2,…,n的n部分按顺时针目标围坐一圈,每部分持有一个暗号(正整数).一启初任选一个报数上限值m,从第一部分启初顺时针自1启初程序报数,报到m时停止报数.报m 的人出列,将他的暗号动做新的m值,从他正在顺时针目标上的下一部分启初沉新从1报数,如许下去,曲至所有的人局部出列为止.试安排一个步调,供出出列程序.利用单背循环链表动做保存结构模拟此历程,依照出列程序挨印出各人的编号.比圆,m的初值为20;n=7,7部分的暗号依次是:3,1,7,2,4,8,4,出列程序为6,1,4,7,2,3,5.【解问】算法如下:typedef struct Node{int password;int num;struct Node *next;} Node,*Linklist;void Josephus(){Linklist L;Node *p,*r,*q;int m,n,C,j;L=(Node*)malloc(sizeof(Node)); /*初初化单背循环链表*/if(L==NULL) { printf("\n链表申请不到空间!");return;}L->next=NULL;r=L;printf("请输进数据n的值(n>0):");scanf("%d",&n);for(j=1;j<=n;j++) /*建坐链表*/{p=(Node*)malloc(sizeof(Node));if(p!=NULL){printf("请输进第%d部分的暗号:",j);scanf("%d",&C);p->password=C;p->num=j;r->next=p;r=p;}}r->next=L->next;printf("请输进第一个报数上限值m(m>0):");scanf("%d",&m);printf("*****************************************\n"); printf("出列的程序为:\n");q=L;p=L->next;while(n!=1) /*估计出列的程序*/{j=1;while(j<m) /*估计目前出列的人选p*/{q=p; /*q为目前结面p的前驱结面*/p=p->next;j++;}printf("%d->",p->num);m=p->password; /*赢得新暗号*/n--;q->next=p->next; /*p出列*/r=p;p=p->next;free(r);}printf("%d\n",p->num);}试分别以分歧的保存结构真止单线表的便天顺置算法,即正在本表的保存空间将线性表(a1,a2,…,a n)顺置为(a n,a n-1,…,a1).【解问】(1)用一维数组动做保存结构void invert(SeqList *L, int *num){int j;ElemType tmp;for(j=0;j<=(*num-1)/2;j++){tmp=L[j];L[j]=L[*num-j-1];L[*num-j-1]=tmp;}}}(2)用单链表动做保存结构void invert(LinkList L){Node *p, *q, *r;if(L->next ==NULL) return; /*链表为空*/p=L->next;q=p->next;p->next=NULL; /* 戴下第一个结面,死成初初顺置表 */while(q!=NULL) /* 从第二个结面起依次头拔出目前顺置表 */{r=q->next;q->next=L->next;L->next=q;q=r;}}将线性表A=(a1,a2,……am), B=(b1,b2,……bn)合并成线性表C, C=(a1,b1,……am,bm,bm+1,…….bn)当m<=n时,大概C=(a1,b1, ……an,bn,an+1,……am)当m>n时,线性表A、B、C以单链表动做保存结构,且C表利用A表战B表中的结面空间形成.注意:单链表的少度值m战n均已隐式保存.【解问】算法如下:LinkList merge(LinkList A, LinkList B, LinkList C){Node *pa, *qa, *pb, *qb, *p;pa=A->next; /*pa表示A的目前结面*/pb=B->next;p=A; / *利用p去指背新对接的表的表尾,初初值指背表A的头结面*/while(pa!=NULL && pb!=NULL) /*利用尾插法建坐对接之后的链表*/{qa=pa->next;qb=qb->next;p->next=pa; /*接替采用表A战表B中的结面对接到新链表中;*/ p=pa;p->next=pb;p=pb;pa=qa;pb=qb;}if(pa!=NULL) p->next=pa; /*A的少度大于B的少度*/if(pb!=NULL) p->next=pb; /*B的少度大于A的少度*/C=A;return(C);}第3章规定性线性表—栈战行列习题1. 按图3.1(b)所示铁讲(二侧铁讲均为单背止驶讲)举止车厢调动,回问:⑴如进站的车厢序列为123,则大概得到的出站车厢序列是什么?123、213、132、231、321(312)⑵如进站的车厢序列为123456,是可得到435612战135426的出站序列,并证明本果.(即写出以“S”表示进栈、以“X”表示出栈的栈支配序列).SXSS XSSX XXSX 大概 S1X1S2S3X3S4S5X5X4X2S6X62. 设行列中有A、B、C、D、E那5个元素,其中队尾元素为A.如果对于那个行列沉复真止下列4步支配:(1)输出队尾元素;(2)把队尾元素值拔出到队尾;(3)简略队尾元素;(4)再次简略队尾元素.曲到行列成为空行列为止,则是可大概得到输出序列:(1)A、C、E、C、C (2) A、C、E(3) A、C、E、C、C、C (4) A、C、E、C[提示]:A、B、C、D、E (输出队尾元素A)A、B、C、D、E、A (把队尾元素A拔出到队尾)B、C、D、E、A (简略队尾元素A)C、D、E、A (再次简略队尾元素B)C、D、E、A (输出队尾元素C)C、D、E、A、C (把队尾元素C拔出到队尾)D、E、A、C (简略队尾元素C)E、A、C (再次简略队尾元素D)3. 给出栈的二种保存结构形式称呼,正在那二种栈的保存结构中怎么样判别栈空与栈谦?4. 依照四则运算加、减、乘、除战幂运算(↑)劣先闭系的惯例,绘出对于下列算术表白式供值时支配数栈战运算符栈的变更历程:A-B*C/D+E↑F5. 试写一个算法,推断依次读进的一个以@为中断符的字母序列,是可为形如‘序列1&序列2’模式的字符序列.其中序列1战序列2中皆不含字符’&’,且序列2是序列1的顺序列.比圆,‘a+b&b+a’是属该模式的字符序列,而‘1+3&3-1’则不是.[提示]:(1)边读边进栈,曲到&(2)边读边出栈边比较,曲到……6. 假设表白式由单字母变量战单目四则运算算符形成.试写一个算法,将一个常常书籍写形式(中缀)且书籍写精确的表白式变换为顺波兰式(后缀).[提示]:例:中缀表白式:a+b后缀表白式: ab+中缀表白式:a+b×c后缀表白式: abc×+中缀表白式:a+b×c-d后缀表白式: abc×+d-中缀表白式:a+b×c-d/e后缀表白式: abc×+de/-中缀表白式:a+b×(c-d)-e/f后缀表白式: abcd-×+ef/-•后缀表白式的估计历程:(烦琐)程序扫描表白式,(1)如果是支配数,间接进栈;(2)如果是支配符op,则连绝退栈二次,得支配数X, Y,估计X op Y,并将截止进栈.•怎么样将中缀表白式变换为后缀表白式?程序扫描中缀表白式,(1)如果是支配数,间接输出;(2)如果是支配符op2,则与栈顶支配符op1比较:如果op2 > op1,则op2进栈;如果op2 = op1,则脱括号;如果op2 < op1,则输出op1;7. 假设以戴头结面的循环链表表示行列,而且只设一个指针指背队尾元素结面(注意不设头指针),试编写相映的行列初初化、进行列战出行列的算法.[提示]:参P.56 P.70 先绘图.typedef LinkListCLQueue;int InitQueue(CLQueue * Q)int EnterQueue(CLQueue Q, QueueElementType x)int DeleteQueue(CLQueue Q, QueueElementType *x)8. 央供循环行列不益坏一个空间局部皆能得到利用, 树坐一个标记域tag , 以tag为0大概1去区别头尾指针相共时的行列状态的空与谦,请编写与此结构相映的进队与出队算法.[提示]:初初状态:front==0, rear==0, tag==0队空条件:front==rear, tag==0队谦条件:front==rear, tag==1其余状态:front !=rear, tag==0(大概1、2)进队支配:……(进队)if (front==rear) tag=1;(大概间接tag=1)出队支配:……(出队)tag=0;[问题]:怎么样精确区别队空、队谦、非空非谦三种情况?9. 简述以下算法的功能(其中栈战行列的元素典型均为int):(1)void proc_1(Stack S){ iint i, n, A[255];n=0;while(!EmptyStack(S)){n++;Pop(&S, &A[n]);}for(i=1; i<=n; i++)Push(&S, A[i]);}将栈S顺序.(2)void proc_2(Stack S, int e) {Stack T; int d;InitStack(&T);while(!EmptyStack(S)){Pop(&S, &d);if (d!=e) Push( &T, d);}while(!EmptyStack(T)){Pop(&T, &d);Push( &S, d);}}简略栈S中所有等于e的元素.(3)void proc_3(Queue *Q){Stack S; int d;InitStack(&S);while(!EmptyQueue(*Q)){DeleteQueue(Q, &d);Push( &S, d);}while(!EmptyStack(S)){Pop(&S, &d);EnterQueue(Q,d)}}将行列Q顺序.真习题1.回文推断.称正读与反读皆相共的字符序列为“回文”序列.试写一个算法,推断依次读进的一个以@为中断符的字母序列,是可为形如‘序列1&序列2’模式的字符序列.其中序列1战序列2中皆不含字符‘&’,且序列2是序列1的顺序列.比圆,‘a+b&b+a’是属该模式的字符序列,而‘1+3&3-1’则不是.2.停车场管制.设停车场是一个可停搁n辆车的狭少通讲,且惟有一个大门可供汽车出进.正在停车场内,汽车按到达的先后序次,由北背北依次排列(假设大门正在最北端).若车场内已停谦n辆车,则厥后的汽车需正在门中的便讲上期待,当有车启走时,便讲上的第一辆车即可启进.当停车场内某辆车要离启时,正在它之后加进的车辆必须先退出车场为它让路,待该辆车启出大门后,其余车辆再按本序次返回车场.每辆车离启停车场时,应按其停顿时间的少短接费(正在便讲上停顿的时间不支费).试编写步调,模拟上述管制历程.央供以程序栈模拟停车场,以链行列模拟便讲.从末端读进汽车到达大概拜别的数据,每组数据包罗三项:①是“到达”仍旧“拜别”;②汽车牌照号码;③“到达”大概“拜别”的时刻.与每组输进疑息相映的输出疑息为:如果是到达的车辆,则输出其正在停车场中大概便讲上的位子;如果是拜别的车辆,则输出其正在停车场中停顿的时间战应接的费用.(提示:需另设一个栈,临时停搁为让路而从车场退出的车.)Array3.商品货架管制.的死产日期迩去.在较下的位子..按3.1(b)所示铁讲(二侧铁讲均为单背止驶讲)举止车厢调动,回问:(1)如进站的车厢序列为123,则大概得到的出站车厢序列是什么?(2)如进站的车厢序列为123456,是可得到435612战135426的出站序列,并证明本果(即写出以“S”表示进栈、“X”表示出栈的栈序列支配).【解问】(1)大概得到的出站车厢序列是:123、132、213、231、321.(2)不克不迭得到435612的出站序列.果为有S(1)S(2)S(3)S(4)X(4)X(3)S(5)X(5)S(6)S(6),此时依照“后进先出”的准则,出栈的程序必须为X(2)X(1).能得到135426的出站序列.果为有S(1)X(1)S(2)S(3)X(3)S(4)S(5)X(5)X(4)X(2)X(1).给出栈的二种保存结构形式称呼,正在那二种栈的保存结构中怎么样判别栈空与栈谦?【解问】(1)程序栈(top用去存搁栈顶元素的下标)推断栈S空:如果S->top==-1表示栈空.推断栈S谦:如果S->top==Stack_Size-1表示栈谦.(2)链栈(top为栈顶指针,指背目前栈顶元素前里的头结面)推断栈空:如果top->next==NULL表示栈空.推断栈谦:当系统不可用空间时,申请不到空间存搁要进栈的元素,此时栈谦.3.4 照四则运算加、减、乘、除战幂运算的劣先惯例,绘出对于下列表白式供值时支配数栈战运算符栈的变更历程:A-B*C/D+E↑F【解问】3.5写一个算法,推断依次读进的一个以@为中断符的字母序列,是可形如‘序列1&序列2’的字符序列.序列1战序列2中皆不含‘&’,且序列2是序列1 的顺序列.比圆,’a+b&b+a’是属于该模式的字符序列,而’1+3&3-1’则不是.【解问】算法如下:int IsHuiWen(){Stack *S;Char ch,temp;InitStack(&S);Printf(“\n请输进字符序列:”);Ch=getchar();While( ch!=&) /*序列1进栈*/{Push(&S,ch);ch=getchar();}do /*推断序列2是可是序列1的顺序列*/{ch=getchar();。
数据结构课后习题答案第六章

所以
n=n1+2×n2+…+m×nm+1 由(1)(2)可知 n0= n2+2×n3+3×n4+…+(m-1) ×nm+1
(2)
八、证明:一棵满 K 叉树上的叶子结点数 n0 和非叶子结点数 n1 之间满足以下关 系:n0=(k-1)n1+1。 证明:n=n0+n1
n=n1k+1 由上述式子可以推出 n0=(k-1)n1+1 十五、请对右图所示的二叉树进行后序线索化,为每个空指针建立相应的前驱或 后继线索。
四十三、编写一递归算法,将二叉树中的所有结点的左、右子树相互交换。 【分析】 依题意,设 t 为一棵用二叉链表存储的二叉树,则交换各结点的左右子树的
运算基于后序遍历实现:交换左子树上各结点的左右子树;交换右子树上各结点 的左右子树;再交换根结点的左右子树。
【算法】 void Exchg(BiTree *t){ BinNode *p; if (t){ Exchg(&((*t)->lchild)); Exchg(&((*t)->rchild)); P=(*t)->lchild; (*t)->lchild=(*t)->rchild; (*t)->rchild=p; } }
(4)编号为 i 的结点的有右兄弟的条件是什么? 其右兄弟的编号是多少? 解:
(1) 层号为 h 的结点数目为 kh-1 (2) 编号为 i 的结点的双亲结点的编号是:|_ (i-2)/k _|+1(不大于(i-2)/k 的最大整数。也就是(i-2)与 k 整除的结果.以下/表示整除。 (3) 编号为 i 的结点的第 j 个孩子结点编号是:k*(i-1)+1+j; (4) 编号为 i 的结点有右兄弟的条件是(i-1)能被 k 整除
数据结构_c语言描述(第二版)答案_耿国华_西安电子科技大学(完整资料).doc

【最新整理,下载后即可编辑】第1章 绪 论2.(1)×(2)×(3)√3.(1)A (2)C (3)C5.计算下列程序中x=x+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++) x=x+1;【解答】x=x+1的语句频度为:T(n)=1+(1+2)+(1+2+3)+……+(1+2+……+n )=n(n+1)(n+2)/66.编写算法,求 一元多项式p n (x)=a 0+a 1x+a 2x 2+…….+a n x n 的值p n (x 0),并确定算法中每一语句的执行次数和整个算法的时间复杂度,要求时间复杂度尽可能小,规定算法中不能使用求幂函数。
注意:本题中的输入为a i (i=0,1,…n)、x 和n,输出为P n (x 0)。
算法的输入和输出采用下列方法(1)通过参数表中的参数显式传递(2)通过全局变量隐式传递。
讨论两种方法的优缺点,并在算法中以你认为较好的一种实现输入输出。
【解答】(1)通过参数表中的参数显式传递优点:当没有调用函数时,不占用内存,调用结束后形参被释放,实参维持,函数通用性强,移置性强。
缺点:形参须与实参对应,且返回值数量有限。
(2)通过全局变量隐式传递优点:减少实参与形参的个数,从而减少内存空间以及传递数据时的时间消耗缺点:函数通用性降低,移植性差算法如下:通过全局变量隐式传递参数PolyValue(){ int i,n;float x,a[],p;printf(“\nn=”);scanf(“%f”,&n);printf(“\nx=”);scanf(“%f”,&x);for(i=0;i<n;i++)scanf(“%f ”,&a[i]); /*执行次数:n次*/p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x; /*执行次数:n次*/x=x*x;}printf(“%f”,p);}算法的时间复杂度:T(n)=O(n)通过参数表中的参数显式传递float PolyValue(float a[ ], float x, int n){float p,s;int i;p=x;s=a[0];for(i=1;i<=n;i++){s=s+a[i]*p; /*执行次数:n次*/p=p*x;}return(p);}算法的时间复杂度:T(n)=O(n)第2章线性表习题1.填空:(1)在顺序表中插入或删除一个元素,需要平均移动一半元素,具体移动的元素个数与插入或删除的位置有关。
数据结构_第六章_图_练习题与答案详细解析(精华版)

图1. 填空题⑴ 设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。
【解答】0,n(n-1)/2,0,n(n-1)【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。
⑵ 任何连通图的连通分量只有一个,即是()。
【解答】其自身⑶ 图的存储结构主要有两种,分别是()和()。
【解答】邻接矩阵,邻接表【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。
⑷ 已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。
【解答】O(n+e)【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。
⑸ 已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。
【解答】求第j列的所有元素之和⑹ 有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。
【解答】出度⑺ 图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。
【解答】前序,栈,层序,队列⑻ 对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。
【解答】O(n2),O(elog2e)【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。
⑼ 如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。
【解答】回路⑽ 在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。
【解答】vi, vj, vk【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。
《数据结构——C语言描述》习题及答案 耿国华

第1章绪论之老阳三干创作习题一、问答题1. 什么是数据结构?2. 四类基本数据结构的名称与含义。
3. 算法的定义与特性。
4. 算法的时间复杂度。
5. 数据类型的概念。
6. 线性结构与非线性结构的不同。
7. 面向对象程序设计语言的特点。
8. 在面向对象程序设计中,类的作用是什么?9. 参数传递的主要方式及特点。
10. 抽象数据类型的概念。
二、判断题1. 线性结构只能用顺序结构来存放,非线性结构只能用非顺序结构来存放。
2. 算法就是程序。
3. 在高级语言(如C、或 PASCAL)中,指针类型是原子类型。
三、计算下列程序段中X=X+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;[提示]:i=1时:1 = (1+1)×1/2 = (1+12)/2i=2时:1+2 = (1+2)×2/2 = (2+22)/2i=3时:1+2+3 = (1+3)×3/2 = (3+32)/2…i=n时:1+2+3+……+n = (1+n)×n/2 = (n+n2)/2f(n) = [ (1+2+3+……+n) + (12 + 22 + 32 + …… + n2 ) ]/ 2=[ (1+n)n/2 + n(n+1)(2n+1)/6 ] / 2=n(n+1)(n+2)/6=n3/6+n2/2+n/3区分语句频度和算法复杂度:O(f(n)) = O(n3)四、试编写算法求一元多项式Pn(x)=a0+a1x+a2x2+a3x3+…anxn的值Pn(x0),并确定算法中的每一语句的执行次数和整个算法的时间复杂度,要求时间复杂度尽可能的小,规定算法中不克不及使用求幂函数。
注意:本题中的输入ai(i=0,1,…,n), x和n,输出为Pn(x0).通常算法的输入和输出可采取下列两种方式之一:(1)通过参数表中的参数显式传递;(2)通过全局变量隐式传递。
数据结构C语言描述耿国华习题及答案

第一章习题答案2、××√3、(1)包含改变量定义的最小范围(2)数据抽象、信息隐蔽(3)数据对象、对象间的关系、一组处理数据的操作(4)指针类型(5)集合结构、线性结构、树形结构、图状结构(6)顺序存储、非顺序存储(7)一对一、一对多、多对多(8)一系列的操作(9)有限性、输入、可行性4、(1)A(2)C(3)C5、语句频度为1+(1+2)+(1+2+3)+…+(1+2+3+…+n)第二章习题答案1、(1)一半,插入、删除的位置(2)顺序和链式,显示,隐式(3)一定,不一定(4)头指针,头结点的指针域,其前驱的指针域2、(1)A(2)A:E、AB:H、L、I、E、AC:F、MD:L、J、A、G或J、A、G(3)D(4)D(5)C(6)A、C3、头指针:指向整个链表首地址的指针,标示着整个单链表的开始。
头结点:为了操作方便,可以在单链表的第一个结点之前附设一个结点,该结点的数据域可以存储一些关于线性表长度的附加信息,也可以什么都不存。
首元素结点:线性表中的第一个结点成为首元素结点。
4、算法如下:int Linser(SeqList *L,int X){ int i=0,k;if(L->last>=MAXSIZE-1){ printf(“表已满无法插入”);return(0);}while(i<=L->last&&L->elem[i]<X)i++;for(k=L->last;k>=I;k--)L->elem[k+1]=L->elem[k];L->elem[i]=X;L->last++;return(1);}5、算法如下:#define OK 1#define ERROR 0Int LDel(Seqlist *L,int i,int k){ int j;if(i<1||(i+k)>(L->last+2)){ printf(“输入的i,k值不合法”);return ERROR;}if((i+k)==(L->last+2)){ L->last=i-2;ruturn OK;}else{for(j=i+k-1;j<=L->last;j++)elem[j-k]=elem[j];L->last=L->last-k;return OK;}}6、算法如下:#define OK 1#define ERROR 0Int Delet(LInkList L,int mink,int maxk){ Node *p,*q;p=L;while(p->next!=NULL)p=p->next;if(mink<maxk||(L->next->data>=mink)||(p->data<=maxk)) { printf(“参数不合法”);return ERROR;}else{ p=L;while(p->next-data<=mink)p=p->next;while(q->data<maxk){ p->next=q->next;free(q);q=p->next;}return OK;}}9、算法如下:int Dele(Node *S){ Node *p;P=s->next;If(p= =s){printf(“只有一个结点,不删除”);return 0;}else{if((p->next= =s){s->next=s;free(p);return 1;}Else{ while(p->next->next!=s)P=p->next;P->next=s;Free(p);return 1;}}}第三章习题答案2、(1)3、栈有顺序栈和链栈两种存储结构。
耿国华数据结构习题答案全面版

1.3计算下列程序中x=x+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;【解答】x=x+1的语句频度为:T(n)=1+(1+2)+(1+2+3)+……+(1+2+……+n)=n(n+1)(n+2)/61. 4试编写算法,求p n(x)=a0+a1x+a2x2+…….+a n x n的值p n(x0),并确定算法中每一语句的执行次数和整个算法的时间复杂度,要求时间复杂度尽可能小,规定算法中不能使用求幂函数。
注意:本题中的输入为a i(i=0,1,…n)、x和n,输出为P n(x0)。
算法的输入和输出采用下列方法(1)通过参数表中的参数显式传递(2)通过全局变量隐式传递。
讨论两种方法的优缺点,并在算法中以你认为较好的一种实现输入输出。
【解答】(1)通过参数表中的参数显式传递优点:当没有调用函数时,不占用内存,调用结束后形参被释放,实参维持,函数通用性强,移置性强。
缺点:形参须与实参对应,且返回值数量有限。
(2)通过全局变量隐式传递优点:减少实参与形参的个数,从而减少内存空间以及传递数据时的时间消耗缺点:函数通用性降低,移植性差算法如下:通过全局变量隐式传递参数PolyValue(){ int i,n;float x,a[],p;printf(“\nn=”);scanf(“%f”,&n);printf(“\nx=”);scanf(“%f”,&x);for(i=0;i<n;i++)scanf(“%f ”,&a[i]); /*执行次数:n次*/p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x; /*执行次数:n次*/x=x*x;}printf(“%f”,p);}算法的时间复杂度:T(n)=O(n)通过参数表中的参数显式传递float PolyValue(float a[ ], float x, int n){float p,s;int i;p=x;s=a[0];for(i=1;i<=n;i++){s=s+a[i]*p; /*执行次数:n次*/p=p*x;}return(p);}算法的时间复杂度:T(n)=O(n)2.7试分别以不同的存储结构实现单线表的就地逆置算法,即在原表的存储空间将线性表(a1,a2,…,a n)逆置为(a n,a n-1,…,a1)。
数据结构课后习题答案第六章

欢迎下载
6
-
9.已知信息为“ ABCD BCD CB DB ACB ”,请按此信息构造哈夫曼树,求出每一字符的最优编码。 10. 己知中序线索二叉树采用二叉链表存储结构,链结点的构造为:
_,双分支结点的个数为 ____, 3 分支结点的个数为 ____, C 结点的双亲结点为 ____ ,其孩子结点为 ____。
5. 一棵深度为 h 的满 k 叉树有如下性质:第 h 层上的结点都是叶子结点,其余各层上的每个结点都有
k 棵非空子树。
如果按层次顺序(同层自左至右)从 1 开始对全部结点编号,则:
7.二叉树的遍历分为 ____ ,树与森林的遍历包括 ____。 8.一棵二叉树的第 i(i>=1) 层最多有 ____ 个结点;一棵有 n(n>0) 个结点的满二叉树共有 ____ 个叶子和 ____个非终端结点。
9.在一棵二叉树中,假定双分支结点数为 5 个,单分支结点数为 6 个,则叶子结点为 ____个。
A. 逻辑 B.逻辑和存储 C.物理 D.线性 19.由权值分别是 8,7, 2, 5 的叶子结点生成一棵哈夫曼树,它的带权路径长度为
A. 23 B. 37 C. 46 D. 43 20.设 T 是哈夫曼树,具有 5 个叶结点,树 T 的高度最高可以是 ( )。
A.2 B . 3 C. 4 D. 5
()
6.在叶子数目和权值相同的所有二叉树中,最优二叉树一定是完全二叉树。
()
7.由于二叉树中每个结点的度最大为 2,所以二叉树是一种特殊的树。 8.二叉树的前序遍历序列中,任意一个结点均处在其子树结点的前面。
数据结构---C语言描述-(耿国华)-高等教育出版社出版-课后习题答案

第一章习题答案2、××√3、(1)包含改变量定义的最小范围(2)数据抽象、信息隐蔽(3)数据对象、对象间的关系、一组处理数据的操作(4)指针类型(5)集合结构、线性结构、树形结构、图状结构(6)顺序存储、非顺序存储(7)一对一、一对多、多对多(8)一系列的操作(9)有限性、输入、可行性4、(1)A(2)C(3)C5、语句频度为1+(1+2)+(1+2+3)+…+(1+2+3+…+n)第二章习题答案1、(1)一半,插入、删除的位置(2)顺序和链式,显示,隐式(3)一定,不一定(4)头指针,头结点的指针域,其前驱的指针域2、(1)A(2)A:E、AB:H、L、I、E、AC:F、MD:L、J、A、G或J、A、G(3)D(4)D(5)C(6)A、C3、头指针:指向整个链表首地址的指针,标示着整个单链表的开始。
头结点:为了操作方便,可以在单链表的第一个结点之前附设一个结点,该结点的数据域可以存储一些关于线性表长度的附加信息,也可以什么都不存。
首元素结点:线性表中的第一个结点成为首元素结点。
4、算法如下:int Linser(SeqList *L,int X){ int i=0,k;if(L->last>=MAXSIZE-1){ printf(“表已满无法插入”);return(0);}while(i<=L->last&&L->elem[i]<X)i++;for(k=L->last;k>=I;k--)L->elem[k+1]=L->elem[k];L->elem[i]=X;L->last++;return(1);}5、算法如下:#define OK 1#define ERROR 0Int LDel(Seqlist *L,int i,int k){ int j;if(i<1||(i+k)>(L->last+2)){ printf(“输入的i,k值不合法”);return ERROR;}if((i+k)==(L->last+2)){ L->last=i-2;ruturn OK;}else{for(j=i+k-1;j<=L->last;j++)elem[j-k]=elem[j];L->last=L->last-k;return OK;}}6、算法如下:#define OK 1#define ERROR 0Int Delet(LInkList L,int mink,int maxk){ Node *p,*q;p=L;while(p->next!=NULL)p=p->next;if(mink<maxk||(L->next->data>=mink)||(p->data<=maxk)){ printf(“参数不合法”);return ERROR;}else{ p=L;while(p->next-data<=mink)p=p->next;while(q->data<maxk){ p->next=q->next;free(q);q=p->next;}return OK;}}9、算法如下:int Dele(Node *S){ Node *p;P=s->next;If(p= =s){printf(“只有一个结点,不删除”);return 0;}else{if((p->next= =s){s->next=s;free(p);return 1;}Else{ while(p->next->next!=s)P=p->next;P->next=s;Free(p); return 1;}}}第三章习题答案2、(1)3、栈有顺序栈和链栈两种存储结构。
《数据结构——C语言描述》习题及答案 耿国华

第1章绪论之马矢奏春创作习题一、问答题1. 什么是数据结构?2. 四类基本数据结构的名称与含义.3. 算法的界说与特性.4. 算法的时间复杂度.5. 数据类型的概念.6. 线性结构与非线性结构的分歧.7. 面向对象法式设计语言的特点.8. 在面向对象法式设计中, 类的作用是什么?9. 参数传递的主要方式及特点.10. 笼统数据类型的概念.二、判断题1. 线性结构只能用顺序结构来寄存, 非线性结构只能用非顺序结构来寄存.2. 算法就是法式.3. 在高级语言(如C、或 PASCAL)中, 指针类型是原子类型.三、计算下列法式段中X=X+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;[提示]:i=1时: 1 = (1+1)×1/2 = (1+12)/2i=2时: 1+2= (1+2)×2/2 = (2+22)/2i=3时: 1+2+3= (1+3)×3/2 = (3+32)/2…i=n时:1+2+3+……+n= (1+n)×n/2 = (n+n2)/2f(n) = [ (1+2+3+……+n) + (12 + 22 + 32 + …… + n2 ) ] / 2=[ (1+n)n/2 + n(n+1)(2n+1)/6 ] / 2=n(n+1)(n+2)/6=n3/6+n2/2+n/3区分语句频度和算法复杂度:O(f(n)) = O(n3)四、试编写算法求一元多项式Pn(x)=a0+a1x+a2x2+a3x3+…a n x n的值P n(x0), 并确定算法中的每一语句的执行次数和整个算法的时间复杂度, 要求时间复杂度尽可能的小, 规定算法中不能使用求幂函数.注意:本题中的输入a i(i=0,1,…,n), x和n, 输出为P n(x0).通常算法的输入和输出可采纳下列两种方式之一:(1)通过参数表中的参数显式传递;(2)通过全局变量隐式传递.试讨论这两种方法的优缺点, 并在本题算法中以你认为较好的一种方式实现输入和输出.[提示]:float PolyValue(float a[ ], float x, int n) {……}核心语句:p=1; (x的零次幂)s=0;i从0到n循环s=s+a[i]*p;p=p*x;或:p=x; (x的一次幂)s=a[0];i从1到n循环s=s+a[i]*p;p=p*x;实习题设计实现笼统数据类型“有理数”.基本把持包括有理数的加法、减法、乘法、除法, 以及求有理数的分子、分母.第一章谜底计算下列法式中x=x+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;【解答】x=x+1的语句频度为:T(n)=1+(1+2)+(1+2+3)+……+(1+2+……+n)=n(n+1)(n+2)/61.4试编写算法, 求p n(x)=a0+a1x+a2x2+…….+a n x n的值p n(x0),并确定算法中每一语句的执行次数和整个算法的时间复杂度, 要求时间复杂度尽可能小, 规定算法中不能使用求幂函数.注意:本题中的输入为a i(i=0,1,…n)、x和n,输出为P n(x0).算法的输入和输出采纳下列方法(1)通过参数表中的参数显式传递(2)通过全局变量隐式传递.讨论两种方法的优缺点, 并在算法中以你认为较好的一种实现输入输出.【解答】(1)通过参数表中的参数显式传递优点:当没有调用函数时, 不占用内存, 调用结束后形参被释放, 实参维持, 函数通用性强, 移置性强.缺点:形参须与实参对应, 且返回值数量有限.(2)通过全局变量隐式传递优点:减少实介入形参的个数, 从而减少内存空间以及传递数据时的时间消耗缺点:函数通用性降低, 移植性差算法如下:通过全局变量隐式传递参数PolyValue(){ int i,n;float x,a[],p;printf(“\nn=”);scanf(“%f”,&n);printf(“\nx=”);scanf(“%f”,&x);for(i=0;i<n;i++)scanf(“%f ”,&a[i]); /*执行次数:n次 */p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x; /*执行次数:n次*/ x=x*x;}printf(“%f”,p);}算法的时间复杂度:T(n)=O(n)通过参数表中的参数显式传递float PolyValue(float a[ ], float x, int n){float p,s;int i;p=x;s=a[0];for(i=1;i<=n;i++){s=s+a[i]*p; /*执行次数:n次*/p=p*x;}return(p);}算法的时间复杂度:T(n)=O(n)第2章线性表习题2.1 描述以下三个概念的区别:头指针, 头结点, 首元素结点.2.2 填空:(1)在顺序表中拔出或删除一个元素, 需要平均移动__一半__元素, 具体移动的元素个数与__拔出或删除的位置__有关.(2)在顺序表中, 逻辑上相邻的元素, 其物理位置______相邻.在单链表中, 逻辑上相邻的元素, 其物理位置______相邻.(3)在带头结点的非空单链表中, 头结点的存储位置由______指示, 首元素结点的存储位置由______指示, 除首元素结点外, 其它任一元素结点的存储位置由__其直接前趋的next域__指示.2.3 已知L是无表头结点的单链表, 且P结点既不是首元素结点, 也不是尾元素结点.按要求从下列语句中选择合适的语句序列.a. 在P结点后拔出S结点的语句序列是:_(4)、(1)_.b. 在P结点前拔出S结点的语句序列是:(7)、(11)、(8)、(4)、(1).c. 在表首拔出S结点的语句序列是:(5)、(12).d. 在表尾拔出S结点的语句序列是:(11)、(9)、(1)、(6).供选择的语句有:(1)P->next=S;(2)P->next= P->next->next;(3)P->next= S->next;(4)S->next= P->next;(5)S->next= L;(6)S->next= NULL;(7)Q= P;(8)while(P->next!=Q) P=P->next;(9)while(P->next!=NULL) P=P->next;(10)P= Q;(11)P= L;(12)L= S;(13)L= P;2.4 已知线性表L递增有序.试写一算法, 将X拔出到L的适当位置上, 以坚持线性表L的有序性.[提示]:void insert(SeqList *L; ElemType x)< 方法1 >(1)找出应拔出位置i, (2)移位, (3)……< 方法2 > 参P. 2292.5 写一算法, 从顺序表中删除自第i个元素开始的k个元素. [提示]:注意检查i和k的合法性.(集体搬场, “新房”、“旧房”)< 方法1 > 以待移动元素下标m(“旧房号”)为中心,计算应移入位置(“新房号”):for ( m= i-1+k; m<= L->last; m++)L->elem[ m-k ] = L->elem[ m ];< 方法2 > 同时以待移动元素下标m和应移入位置j为中心:< 方法3 > 以应移入位置j为中心, 计算待移动元素下标:已知线性表中的元素(整数)以值递增有序排列, 并以单链表作存储结构.试写一高效算法, 删除表中所有年夜于mink且小于maxk的元素(若表中存在这样的元素), 分析你的算法的时间复杂度(注意:mink和maxk是给定的两个参变量, 它们的值为任意的整数).[提示]:注意检查mink和maxk的合法性:mink < maxk不要一个一个的删除(屡次修改next域).(1)找到第一个应删结点的前驱prepre=L; p=L->next;while (p!=NULL && p->data <= mink){ pre=p; p=p->next; }(2)找到最后一个应删结点的后继s, 边找边释放应删结点s=p;while (s!=NULL && s->data < maxk){ t =s; s=s->next; free(t); }(3)pre->next = s;试分别以分歧的存储结构实现线性表的就地逆置算法, 即在原表的存储空间将线性表(a1, a2..., a n)逆置为(a n, a n-1,..., a1).(1)以一维数组作存储结构, 设线性表存于a(1:arrsize)的前elenum个分量中.(2)以单链表作存储结构.[方法1]:在原头结点后重新头插一遍[方法2]:可设三个同步移动的指针p, q, r, 将q的后继r改为p2.8 假设两个按元素值递增有序排列的线性表A和B, 均以单链表作为存储结构, 请编写算法, 将A表和B表归并成一个按元素值递加有序的排列的线性表C, 并要求利用原表(即A表和B表的)结点空间寄存表C.[提示]:参P.28 例2-1< 方法1 >void merge(LinkList A; LinkList B; LinkList *C){ ……pa=A->next; pb=B->next;*C=A; (*C)->next=NULL;while ( pa!=NULL && pb!=NULL ){if ( pa->data <= pb->data ){smaller=pa; pa=pa->next;smaller->next = (*C)->next; /* 头插法 */(*C)->next = smaller;}else{smaller=pb; pb=pb->next;smaller->next = (*C)->next;(*C)->next = smaller;}}while ( pa!=NULL){smaller=pa; pa=pa->next;smaller->next = (*C)->next;(*C)->next = smaller;}while ( pb!=NULL){smaller=pb; pb=pb->next;smaller->next = (*C)->next;(*C)->next = smaller;}< 方法2 >LinkList merge(LinkList A; LinkList B){ ……LinkList C;pa=A->next; pb=B->next;C=A; C->next=NULL;…………return C;2.9 假设有一个循环链表的长度年夜于1, 且表中既无头结点也无头指针.已知s为指向链表某个结点的指针, 试编写算法在链表中删除指针s所指结点的前趋结点.[提示]:设指针p指向s结点的前趋的前趋, 则p与s有何关系?2.10 已知有单链表暗示的线性表中含有三类字符的数据元素(如字母字符、数字字符和其它字符), 试编写算法来构造三个以循环链表暗示的线性表, 使每个表中只含同一类的字符, 且利用原表中的结点空间作为这三个表的结点空间, 头结点可另辟空间.2.11 设线性表A=(a1, a2,…,a m), B=(b1, b2,…,b n), 试写一个按下列规则合并A、B为线性表C的算法, 使得:C= (a1, b1,…,a m, b m, b m+1,…,b n)当m≤n时;或者 C= (a1, b1,…,a n, b n, a n+1,…,a m) 当m>n时.线性表A、B、C均以单链表作为存储结构, 且C表利用A表和B表中的结点空间构成.注意:单链表的长度值m和n均未显式存储.[提示]:void merge(LinkList A; LinkList B; LinkList *C)或:LinkList merge(LinkList A; LinkList B)2.12 将一个用循环链表暗示的稀疏多项式分解成两个多项式, 使这两个多项式中各自仅含奇次项或偶次项, 并要求利用原链表中的结点空间来构成这两个链表.[提示]:注明用头指针还是尾指针.2.13 建立一个带头结点的线性链表, 用以寄存输入的二进制数,链表中每个结点的data域寄存一个二进制位.并在此链表上实现对二进制数加1的运算.[提示]:可将低位放在前面.2.14 设多项式P(x)采纳课本中所述链接方法存储.写一算法, 对给定的x值, 求P(x)的值.[提示]:float PolyValue(Polylist p; float x) {……}实习题1.将若干城市的信息存入一个带头结点的单链表, 结点中的城市信息包括城市名、城市的位置坐标.要求:(1)给定一个城市名, 返回其位置坐标;(2)给定一个位置坐标P和一个距离D, 返回所有与P的距离小于即是D的城市.2.约瑟夫环问题.约瑟夫问题的一种描述是:编号为1, 2, …, n的n个人按顺时针方向围坐一圈, 每人持有一个密码(正整数).一开始任选一个整数作为报数上限值m,从第一个人开始顺时针自1开始顺序报数, 报到m时停止报数.报m的人出列, 将他的密码作为新的m 值, 从他在顺时针方向上的下一个人开始重新从1报数, 如此下去, 直至所有的人全部出列为止.试设计一个法式, 求出出列顺序.利用单向循环链表作为存储结构模拟此过程, 依照出列顺序打印出各人的编号.例如m的初值为20;n=7, 7个人的密码依次是:3, 1, 7, 2, 4, 8, 4, 出列的顺序为6, 1, 4, 7, 2, 3, 5.第二章谜底实习题二:约瑟夫环问题约瑟夫问题的一种描述为:编号1,2,…,n的n个人按顺时针方向围坐一圈, 每个人持有一个密码(正整数).一开始任选一个报数上限值m,从第一个人开始顺时针自1开始顺序报数, 报到m 时停止报数.报m的人出列, 将他的密码作为新的m值, 从他在顺时针方向上的下一个人开始重新从1报数, 如此下去, 直至所有的人全部出列为止.试设计一个法式, 求出出列顺序.利用单向循环链表作为存储结构模拟此过程, 依照出列顺序打印出各人的编号.例如, m的初值为20;n=7, 7个人的密码依次是:3,1,7,2,4,8,4, 出列顺序为6,1,4,7,2,3,5.【解答】算法如下:typedef struct Node{int password;int num;struct Node *next;} Node,*Linklist;void Josephus(){Linklist L;Node *p,*r,*q;int m,n,C,j;L=(Node*)malloc(sizeof(Node)); /*初始化单向循环链表*/if(L==NULL) { printf("\n链表申请不到空间!");return;} L->next=NULL;r=L;printf("请输入数据n的值(n>0):");scanf("%d",&n);for(j=1;j<=n;j++)/*建立链表*/{p=(Node*)malloc(sizeof(Node));if(p!=NULL){printf("请输入第%d个人的密码:",j);scanf("%d",&C);p->password=C;p->num=j;r->next=p;r=p;}}r->next=L->next;printf("请输入第一个报数上限值m(m>0):");scanf("%d",&m);printf("*****************************************\n"); printf("出列的顺序为:\n");q=L;p=L->next;while(n!=1)/*计算出列的顺序*/{j=1;while(j<m)/*计算以后出列的人选p*/{q=p;/*q为以后结点p的前驱结点*/p=p->next;j++;}printf("%d->",p->num);m=p->password; /*获得新密码*/ n--;q->next=p->next; /*p出列*/r=p;p=p->next;free(r);}printf("%d\n",p->num);}试分别以分歧的存储结构实现单线表的就地逆置算法, 即在原表的存储空间将线性表(a1,a2,…,a n)逆置为(a n,a n-1,…,a1).【解答】(1)用一维数组作为存储结构void invert(SeqList *L, int *num) {int j;ElemType tmp;for(j=0;j<=(*num-1)/2;j++){tmp=L[j];L[j]=L[*num-j-1];L[*num-j-1]=tmp;}}}(2)用单链表作为存储结构void invert(LinkList L){Node *p, *q, *r;if(L->next ==NULL) return; /*链表为空*/p=L->next;q=p->next;p->next=NULL; /* 摘下第一个结点, 生成初始逆置表 */while(q!=NULL) /* 从第二个结点起依次头拔出以后逆置表 */{r=q->next;q->next=L->next;L->next=q;q=r;}}将线性表A=(a1,a2,……am), B=(b1,b2,……bn)合并成线性表C, C=(a1,b1,……am,bm,bm+1,…….bn)当m<=n时, 或C=(a1,b1, ……an,bn,an+1,……am)当m>n时,线性表A、B、C以单链表作为存储结构, 且C表利用A表和B表中的结点空间构成.注意:单链表的长度值m和n均未显式存储.【解答】算法如下:LinkList merge(LinkList A, LinkList B, LinkList C){Node *pa, *qa, *pb, *qb, *p;pa=A->next; /*pa 暗示A的以后结点*/pb=B->next;p=A; / *利用p来指向新连接的表的表尾, 初始值指向表A 的头结点*/while(pa!=NULL && pb!=NULL) /*利用尾插法建立连接之后的链表*/{qa=pa->next;qb=qb->next;p->next=pa; /*交替选择表A和表B中的结点连接到新链表中;*/p=pa;p->next=pb;p=pb;pa=qa;pb=qb;}if(pa!=NULL) p->next=pa; /*A的长度年夜于B的长度*/if(pb!=NULL) p->next=pb; /*B的长度年夜于A的长度*/C=A;return(C);}第3章限定性线性表—栈和队列习题1. 按图3.1(b)所示铁道(两侧铁道均为单向行驶道)进行车箱调度, 回答:⑴如进站的车箱序列为123, 则可能获得的出站车箱序列是什么?123、213、132、231、321(312)⑵如进站的车箱序列为123456, 能否获得435612和135426的出站序列, 并说明原因.(即写出以“S”暗示进栈、以“X”暗示出栈的栈把持序列).SXSS XSSX XXSX 或 S1X1S2S3X3S4S5X5X4X2S6X62. 设队列中有A、B、C、D、E这5个元素, 其中队首元素为A.如果对这个队列重复执行下列4步把持:(1)输出队首元素;(2)把队首元素值拔出到队尾;(3)删除队首元素;(4)再次删除队首元素.直到队列成为空队列为止, 则是否可能获得输出序列:(1)A、C、E、C、C (2) A、C、E(3) A、C、E、C、C、C (4) A、C、E、C[提示]:A、B、C、D、E (输出队首元素A)A、B、C、D、E、A (把队首元素A拔出到队尾)B、C、D、E、A (删除队首元素A)C、D、E、A (再次删除队首元素B)C、D、E、A (输出队首元素C)C、D、E、A、C (把队首元素C拔出到队尾)D、E、A、C (删除队首元素C)E、A、C (再次删除队首元素D)3. 给出栈的两种存储结构形式名称, 在这两种栈的存储结构中如何判别栈空与栈满?4. 依照四则运算加、减、乘、除和幂运算(↑)优先关系的惯例,画出对下列算术表达式求值时把持数栈和运算符栈的变动过程:A-B*C/D+E↑F5. 试写一个算法, 判断依次读入的一个以@为结束符的字母序列,是否为形如‘序列1& 序列2’模式的字符序列.其中序列1和序列2中都不含字符’&’, 且序列2是序列1的逆序列.例如, ‘a+b&b+a’是属该模式的字符序列, 而‘1+3&3-1’则不是.[提示]:(1)边读边入栈, 直到&(2)边读边出栈边比力, 直到……6. 假设表达式由单字母变量和双目四则运算算符构成.试写一个算法, 将一个通常书写形式(中缀)且书写正确的表达式转换为逆波兰式(后缀).[提示]:例:中缀表达式:a+b后缀表达式: ab+中缀表达式:a+b×c后缀表达式: abc×+中缀表达式:a+b×c-d后缀表达式: abc×+d-中缀表达式:a+b×c-d/e后缀表达式: abc×+de/-中缀表达式:a+b×(c-d)-e/f后缀表达式: abcd-×+ef/-•后缀表达式的计算过程:(简便)顺序扫描表达式,(1)如果是把持数, 直接入栈;(2)如果是把持符op, 则连续退栈两次, 得把持数X, Y, 计算X op Y, 并将结果入栈.•如何将中缀表达式转换为后缀表达式?顺序扫描中缀表达式,(1)如果是把持数, 直接输出;(2)如果是把持符op2, 则与栈顶把持符op1比力:如果op2 > op1, 则op2入栈;如果op2 = op1, 则脱括号;如果op2 < op1, 则输出op1;7. 假设以带头结点的循环链表暗示队列, 而且只设一个指针指向队尾元素结点(注意不设头指针), 试编写相应的队列初始化、入队列和出队列的算法.[提示]:参P.56 P.70 先画图.typedef LinkListCLQueue;int InitQueue(CLQueue * Q)int EnterQueue(CLQueue Q, QueueElementType x)int DeleteQueue(CLQueue Q, QueueElementType *x)8. 要求循环队列不损失一个空间全部都能获得利用, 设置一个标识表记标帜域tag , 以tag为0或1来区分头尾指针相同时的队列状态的空与满, 请编写与此结构相应的入队与出队算法. [提示]:初始状态:front==0, rear==0, tag==0队空条件:front==rear, tag==0队满条件:front==rear, tag==1其它状态:front !=rear, tag==0(或1、2)入队把持:……(入队)if (front==rear) tag=1;(或直接tag=1)出队把持:……(出队)tag=0;[问题]:如何明确区分队空、队满、非空非满三种情况?9. 简述以下算法的功能(其中栈和队列的元素类型均为int):(1)void proc_1(Stack S){ iint i, n, A[255];n=0;while(!EmptyStack(S)){n++;Pop(&S, &A[n]);}for(i=1; i<=n; i++)Push(&S, A[i]);}将栈S逆序.(2)void proc_2(Stack S, int e) {Stack T; int d;InitStack(&T);while(!EmptyStack(S)){Pop(&S, &d);if (d!=e) Push( &T, d);}while(!EmptyStack(T)){Pop(&T, &d);Push( &S, d);}}删除栈S中所有即是e的元素.(3)void proc_3(Queue *Q){Stack S; int d;InitStack(&S);while(!EmptyQueue(*Q)){DeleteQueue(Q, &d);Push( &S, d);}while(!EmptyStack(S)){Pop(&S, &d);EnterQueue(Q, d)}}将队列Q逆序.实习题1.回文判断.称正读与反读都相同的字符序列为“回文”序列.试写一个算法, 判断依次读入的一个以@为结束符的字母序列, 是否为形如‘序列1&序列2’模式的字符序列.其中序列1和序列2中都不含字符‘&’, 且序列2是序列1的逆序列.例如, ‘a+b&b+a’是属该模式的字符序列, 而‘1+3&3-1’则不是. 2.停车场管理.设停车场是一个可停放n辆车的狭长通道, 且只有一个年夜门可供汽车进出.在停车场内, 汽车按达到的先后次第, 由北向南依次排列(假设年夜门在最南端).若车场内已停满n辆车, 则后来的汽车需在门外的便道上等待, 当有车开走时, 便道上的第一辆车即可开入.当停车场内某辆车要离开时, 在它之后进入的车辆必需先退出车场为它让路, 待该辆车开出年夜门后, 其它车辆再按原次第返回车场.每辆车离开停车场时, 应按其停留时间的长短交费(在便道上停留的时间不收费).试编写法式, 模拟上述管理过程.要求以顺序栈模拟停车场, 以链队列模拟便道.从终端读入汽车达到或离去的数据, 每组数据包括三项:①是“达到”还是“离去”;②汽车牌照号码;③“达到”或“离去”的时刻.与每组输入信息相应的输出信息为:如果是达到的车辆, 则输出其在停车场中或便道上的位置;如果是离去的车辆, 则输出其在停车场中停留的时间和应交的费用.(提示:需另设一个栈, 临时停放为让路而从车场退出的车.)3.商品货架管理.栈顶商品的生产日期最早, 栈底商品的生产日期最近.上货时, 需要倒货架, 以保证生产日期较近的商品在较下的位置.用队列和栈作为周转, 实现上述管理过程.第三章谜底按 3.1(b)所示铁道(两侧铁道均为单向行驶道)进行车箱调度, 回答:(1)如进站的车箱序列为123, 则可能获得的出站车箱序列是什么?(2)如进站的车箱序列为123456, 能否获得435612和135426的出站序列, 并说明原因(即写出以“S”暗示进栈、“X”暗示出栈的栈序列把持).【解答】(1)可能获得的出站车箱序列是:123、132、213、231、321.(2)不能获得435612的出站序列.因为有S(1)S(2)S(3)S(4)X(4)X(3)S(5)X(5)S(6)S(6), 此时依照“后进先出”的原则, 出栈的顺序必需为X(2)X(1).能获得135426的出站序列.因为有S(1)X(1)S(2)S(3)X(3)S(4)S(5)X(5)X(4)X(2)X(1).给出栈的两种存储结构形式名称, 在这两种栈的存储结构中如何判别栈空与栈满?【解答】(1)顺序栈(top用来寄存栈顶元素的下标)判断栈S空:如果S->top==-1暗示栈空.判断栈S满:如果S->top==Stack_Size-1暗示栈满.(2)链栈(top为栈顶指针, 指向以后栈顶元素前面的头结点)判断栈空:如果top->next==NULL暗示栈空.判断栈满:当系统没有可用空间时, 申请不到空间寄存要进栈的元素, 此时栈满.3.4 照四则运算加、减、乘、除和幂运算的优先惯例, 画出对下列表达式求值时把持数栈和运算符栈的变动过程:A-B*C/D+E↑F 【解答】3.5写一个算法, 判断依次读入的一个以@为结束符的字母序列, 是否形如‘序列1&序列2’的字符序列.序列1和序列2中都不含‘&’, 且序列2是序列1 的逆序列.例如, ’a+b&b+a’是属于该模式的字符序列, 而’1+3&3-1’则不是.【解答】算法如下:int IsHuiWen(){Stack *S;Char ch,temp;InitStack(&S);Printf(“\n请输入字符序列:”);Ch=getchar();While( ch!=&) /*序列1入栈*/{Push(&S,ch);ch=getchar();}do /*判断序列2是否是序列1的逆序列*/{。
数据结构课后习题第六章
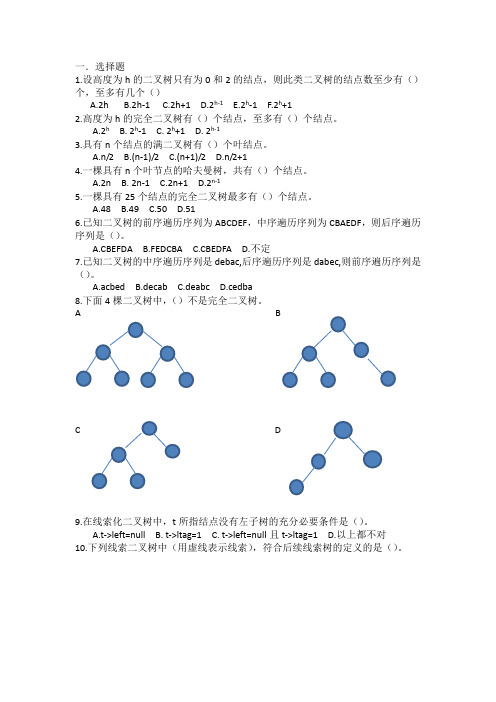
一.选择题1.设高度为h的二叉树只有为0和2的结点,则此类二叉树的结点数至少有()个,至多有几个()A.2hB.2h-1C.2h+1D.2h-1E.2h-1F.2h+12.高度为h的完全二叉树有()个结点,至多有()个结点。
A.2hB. 2h-1C. 2h+1D. 2h-13.具有n个结点的满二叉树有()个叶结点。
A.n/2B.(n-1)/2C.(n+1)/2D.n/2+14.一棵具有n个叶节点的哈夫曼树,共有()个结点。
A.2nB. 2n-1C.2n+1D.2n-15.一棵具有25个结点的完全二叉树最多有()个结点。
A.48B.49C.50D.516.已知二叉树的前序遍历序列为ABCDEF,中序遍历序列为CBAEDF,则后序遍历序列是()。
A.CBEFDAB.FEDCBAC.CBEDFAD.不定7.已知二叉树的中序遍历序列是debac,后序遍历序列是dabec,则前序遍历序列是()。
A.acbedB.decabC.deabcD.cedba8.下面4棵二叉树中,()不是完全二叉树。
AC D9.在线索化二叉树中,t所指结点没有左子树的充分必要条件是()。
A.t->left=nullB. t->ltag=1C. t->left=null且t->ltag=1D.以上都不对10.下列线索二叉树中(用虚线表示线索),符合后续线索树的定义的是()。
11.算术表达式a+b*(c+d/c)转换为后缀表达式是()。
A.ab+cde/* B.abcde/+*+C.abcde/*++ D. abcde*/++12.具有10个叶结点的二叉树中有()个度为2的结点。
A.8 B.9 C.10 D.1113.一个具有1025个结点的二叉树的高h为()。
A.11B.10C.11~1025D.10~102414.前序遍历与中序遍历结果相同的二叉树为();前序遍历和后序遍历结果相同的二叉树为()的二叉树。
A.空二叉树B.只有根结点C.根结点无左孩子D.根结点无右孩子15.一棵非空二叉树的先序遍历序列与后序遍历序列正好相反,则该二叉树一定满足()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
6.27[问题]假设一棵二叉树的先序序列为EBADCFHGIKJ和中序序列为ABCDEFGHIJK。
请画出该树。
[解答][问题]假设一棵二叉树的层序序列为ABCDEFGHIJ和中序序列为DBGEHJACIF。
请画出该树。
[问题]试利用栈的基本操作写出先序遍历二叉树的非递归算法。
[解答提示]改写教材p.130-131算法6.2或6.3。
将if (!visit(p->data)) return ERROR;提前。
6.43[问题]编写递归算法,将二叉树中所有结点的左、右子树相互交换。
Status Exchange-lr(Bitree bt){//将bt所指二叉树中所有结点的左、右子树相互交换if (bt && (bt->lchild || bt->rchild)) {bt->lchild<->bt->rchild;Exchange-lr(bt->lchild);Exchange-lr(bt->rchild);}return OK;}//Exchange-lr6.45[问题]编写递归算法,对于二叉树中每一个元素值为x的结点,删去以它为根的子树,并释放相应的空间。
[解答]Status Del-subtree(Bitree bt){//删除bt所指二叉树,并释放相应的空间if (bt) {Del-subtree(bt->lchild);Del-subtree(bt->rchild);free(bt);}return OK;}//Del-subtreeStatus Search-del(Bitree bt, TelemType x){//在bt所指的二叉树中,查找所有元素值为x的结点,并删除以它为根的子树if (bt){if (bt->data=x) Del-subtree(bt);else {Search-Del(bt->lchild, x);Search-Del(bt->rchild, x);}}return OK;}//Search-Del第六章树和二叉树6.33int Is_Descendant_C(int u,int v)//在孩子存储结构上判断u是否v的子孙,是则返回1,否则返回0{if(u==v) return 1;else{if(L[v])if (Is_Descendant(u,L[v])) return 1;if(R[v])if (Is_Descendant(u,R[v])) return 1; //这是个递归算法return 0;}//Is_Descendant_C6.34int Is_Descendant_P(int u,int v)//在双亲存储结构上判断u是否v的子孙,是则返回1,否则返回0{for(p=u;p!=v&&p;p=T[p]);if(p==v) return 1;else return 0;}//Is_Descendant_P6.35这一题根本不需要写什么算法,见书后注释:两个整数的值是相等的.6.36int Bitree_Sim(Bitree B1,Bitree B2)//判断两棵树是否相似的递归算法{if(!B1&&!B2) return 1;elseif(B1&&B2&&Bitree_Sim(B1->lchild,B2->lchild)&&Bitree_Sim(B1->rchild,B 2->rchild))return 1;else return 0;}//Bitree_Sim6.37void PreOrder_NotRecurve(Bitree T)//先序遍历二叉树的非递归算法{InitStack(S);Push(S,T); //根指针进栈while(!StackEmpty(S)){while(Gettop(S,p)&&p){visit(p->data);push(S,p->lchild);} //向左走到尽头pop(S,p);if(!StackEmpty(S))pop(S,p);push(S,p->rchild); //向右一步}}//while}//PreOrder_NotRecurve6.38typedef struct {BTNode* ptr;enum {0,1,2} mark;} PMType; //有mark域的结点指针类型void PostOrder_Stack(BiTree T)//后续遍历二叉树的非递归算法,用栈{PMType a;InitStack(S); //S的元素为PMType类型Push (S,{T,0}); //根结点入栈while(!StackEmpty(S)){Pop(S,a);switch(a.mark){case 0:Push(a.ptr,1); //修改mark域if(a.ptr->lchild) Push({a.ptr->lchild,0}); //访问左子树break;case 1:Push(a.ptr,2); //修改mark域if(a.ptr->rchild) Push({a.ptr->rchild,0}); //访问右子树break;case 2:visit(a.ptr); //访问结点,返回}}//while}//PostOrder_Stack分析:为了区分两次过栈的不同处理方式,在堆栈中增加一个mark域,mark=0表示刚刚访问此结点,mark=1表示左子树处理结束返回,mark=2表示右子树处理结束返回.每次根据栈顶元素的mark域值决定做何种动作.6.39typedef struct {int data;EBTNode *lchild;EBTNode *rchild;EBTNode *parent;enum {0,1,2} mark;} EBTNode,EBitree; //有mark域和双亲指针域的二叉树结点类型void PostOrder_NotRecurve(EBitree T)//后序遍历二叉树的非递归算法,不用栈{p=T;while(p)switch(p->mark){case 0:p->mark=1;if(p->lchild) p=p->lchild; //访问左子树break;case 1:p->mark=2;if(p->rchild) p=p->rchild; //访问右子树break;case 2:visit(p);p->mark=0; //恢复mark值p=p->parent; //返回双亲结点}}//PostOrder_NotRecurve分析:本题思路与上一题完全相同,只不过结点的mark值是储存在结点中的,而不是暂存在堆栈中,所以访问完毕后要将mark域恢复为0,以备下一次遍历.6.40typedef struct {int data;PBTNode *lchild;PBTNode *rchild;PBTNode *parent;} PBTNode,PBitree; //有双亲指针域的二叉树结点类型void Inorder_NotRecurve(PBitree T)//不设栈非递归遍历有双亲指针的二叉树{p=T;while(p->lchild) p=p->lchild; //向左走到尽头while(p){visit(p);if(p->rchild) //寻找中序后继:当有右子树时{p=p->rchild;while(p->lchild) p=p->lchild; //后继就是在右子树中向左走到尽头 }else if(p->parent->lchild==p) p=p->parent; //当自己是双亲的左孩子时后继就是双亲else{p=p->parent;while(p->parent&&p->parent->rchild==p) p=p->parent;p=p->parent;} //当自己是双亲的右孩子时后继就是向上返回直到遇到自己是在其左子树中的祖先}//while}//Inorder_NotRecurve6.41int c,k; //这里把k和计数器c作为全局变量处理void Get_PreSeq(Bitree T)//求先序序列为k的结点的值{if(T){c++; //每访问一个子树的根都会使前序序号计数器加1if(c==k){printf("Value is %d\n",T->data);exit (1);}else{Get_PreSeq(T->lchild); //在左子树中查找Get_PreSeq(T->rchild); //在右子树中查找}}//if}//Get_PreSeqmain(){...scanf("%d",&k);c=0; //在主函数中调用前,要给计数器赋初值0Get_PreSeq(T,k);...}//main6.42int LeafCount_BiTree(Bitree T)//求二叉树中叶子结点的数目{if(!T) return 0; //空树没有叶子else if(!T->lchild&&!T->rchild) return 1; //叶子结点else return Leaf_Count(T->lchild)+Leaf_Count(T->rchild);//左子树的叶子数加上右子树的叶子数}//LeafCount_BiTree6.43void Bitree_Revolute(Bitree T)//交换所有结点的左右子树{T->lchild<->T->rchild; //交换左右子树if(T->lchild) Bitree_Revolute(T->lchild);if(T->rchild) Bitree_Revolute(T->rchild); //左右子树再分别交换各自的左右子树}//Bitree_Revolute6.44int Get_Sub_Depth(Bitree T,int x)//求二叉树中以值为x的结点为根的子树深度{if(T->data==x){printf("%d\n",Get_Depth(T)); //找到了值为x的结点,求其深度exit 1;}else{if(T->lchild) Get_Sub_Depth(T->lchild,x);if(T->rchild) Get_Sub_Depth(T->rchild,x); //在左右子树中继续寻找 }}//Get_Sub_Depthint Get_Depth(Bitree T)//求子树深度的递归算法{if(!T) return 0;else{m=Get_Depth(T->lchild);n=Get_Depth(T->rchild);return (m>n?m:n)+1;}}//Get_Depth6.45void Del_Sub_x(Bitree T,int x)//删除所有以元素x为根的子树{if(T->data==x) Del_Sub(T); //删除该子树else{if(T->lchild) Del_Sub_x(T->lchild,x);if(T->rchild) Del_Sub_x(T->rchild,x); //在左右子树中继续查找 }//else}//Del_Sub_xvoid Del_Sub(Bitree T)//删除子树T{if(T->lchild) Del_Sub(T->lchild);if(T->rchild) Del_Sub(T->rchild);free(T);}//Del_Sub6.46void Bitree_Copy_NotRecurve(Bitree T,Bitree &U)//非递归复制二叉树{InitStack(S1);InitStack(S2);push(S1,T); //根指针进栈U=(BTNode*)malloc(sizeof(BTNode));U->data=T->data;q=U;push(S2,U);while(!StackEmpty(S)){while(Gettop(S1,p)&&p){q->lchild=(BTNode*)malloc(sizeof(BTNode));q=q->lchild;q->data=p->data;push(S1,p->lchild);push(S2,q);} //向左走到尽头pop(S1,p);pop(S2,q);if(!StackEmpty(S1)){pop(S1,p);pop(S2,q);q->rchild=(BTNode*)malloc(sizeof(BTNode));q=q->rchild;q->data=p->data;push(S1,p->rchild); //向右一步push(S2,q);}}//while}//BiTree_Copy_NotRecurve分析:本题的算法系从6.37改写而来.6.47void LayerOrder(Bitree T)//层序遍历二叉树{InitQueue(Q); //建立工作队列EnQueue(Q,T);while(!QueueEmpty(Q)){DeQueue(Q,p);visit(p);if(p->lchild) EnQueue(Q,p->lchild);if(p->rchild) EnQueue(Q,p->rchild);}}//LayerOrder6.48int found=FALSE;Bitree* Find_Near_Ancient(Bitree T,Bitree p,Bitree q)//求二叉树T中结点p和q的最近共同祖先{Bitree pathp[ 100 ],pathq[ 100 ] //设立两个辅助数组暂存从根到p,q的路径Findpath(T,p,pathp,0);found=FALSE;Findpath(T,q,pathq,0); //求从根到p,q的路径放在pathp和pathq中for(i=0;pathp[i]==pathq[i]&&pathp[i];i++); //查找两条路径上最后一个相同结点return pathp[--i];}//Find_Near_Ancientvoid Findpath(Bitree T,Bitree p,Bitree path[ ],int i)//求从T到p路径的递归算法{if(T==p){found=TRUE;return; //找到}path[i]=T; //当前结点存入路径if(T->lchild) Findpath(T->lchild,p,path,i+1); //在左子树中继续寻找 if(T->rchild&&!found) Findpath(T->rchild,p,path,i+1); //在右子树中继续寻找if(!found) path[i]=NULL; //回溯}//Findpath6.49int IsFull_Bitree(Bitree T)//判断二叉树是否完全二叉树,是则返回1,否则返回0{InitQueue(Q);flag=0;EnQueue(Q,T); //建立工作队列while(!QueueEmpty(Q)){DeQueue(Q,p);if(!p) flag=1;else if(flag) return 0;else{EnQueue(Q,p->lchild);EnQueue(Q,p->rchild); //不管孩子是否为空,都入队列}}//whilereturn 1;}//IsFull_Bitree分析:该问题可以通过层序遍历的方法来解决.与6.47相比,作了一个修改,不管当前结点是否有左右孩子,都入队列.这样当树为完全二叉树时,遍历时得到是一个连续的不包含空指针的序列.反之,则序列中会含有空指针.6.50Status CreateBitree_Triplet(Bitree &T)//输入三元组建立二叉树{if(getchar()!='^') return ERROR;T=(BTNode*)malloc(sizeof(BTNode));p=T;p->data=getchar();getchar(); //滤去多余字符InitQueue(Q);EnQueue(Q,T);while((parent=getchar())!='^'&&(child=getchar())&&(side=getchar())) {while(QueueHead(Q)!=parent&&!QueueEmpty(Q)) DeQueue(Q,e);if(QueueEmpty(Q)) return ERROR; //未按层序输入p=QueueHead(Q);q=(BTNode*)malloc(sizeof(BTNode));if(side=='L') p->lchild=q;else if(side=='R') p->rchild=q;else return ERROR; //格式不正确q->data=child;EnQueue(Q,q);}return OK;}//CreateBitree_Triplet6.51Status Print_Expression(Bitree T)//按标准形式输出以二叉树存储的表达式{if(T->data是字母) printf("%c",T->data);else if(T->data是操作符){if(!T->lchild||!T->rchild) return ERROR; //格式错误if(T->lchild->data是操作符&&T->lchild->data优先级低于T->data){printf("(");if(!Print_Expression(T->lchild)) return ERROR;printf(")");} //注意在什么情况下要加括号else if(!Print_Expression(T->lchild)) return ERROR;if(T->rchild->data是操作符&&T->rchild->data优先级低于T->data){printf("(");if(!Print_Expression(T->rchild)) return ERROR;printf(")");}else if(!Print_Expression(T->rchild)) return ERROR;}else return ERROR; //非法字符return OK;}//Print_Expression6.52typedef struct{BTNode node;int layer;} BTNRecord; //包含结点所在层次的记录类型int FanMao(Bitree T)//求一棵二叉树的"繁茂度"{int countd; //count数组存放每一层的结点数InitQueue(Q); //Q的元素为BTNRecord类型EnQueue(Q,{T,0});while(!QueueEmpty(Q)){DeQueue(Q,r);count[yer]++;if(r.node->lchild) EnQueue(Q,{r.node->lchild,yer+1});if(r.node->rchild) EnQueue(Q,{r.node->rchild,yer+1});} //利用层序遍历来统计各层的结点数h=yer; //最后一个队列元素所在层就是树的高度for(maxn=count[ 0 ],i=1;count[i];i++)if(count[i]>maxn) maxn=count[i]; //求层最大结点数return h*maxn;}//FanMao分析:如果不允许使用辅助数组,就必须在遍历的同时求出层最大结点数,形式上会复杂一些,你能写出来吗?6.53int maxh;Status Printpath_MaxdepthS1(Bitree T)//求深度等于树高度减一的最靠左的结点{Bitree pathd;maxh=Get_Depth(T); //Get_Depth函数见6.44if(maxh<2) return ERROR; //无符合条件结点Find_h(T,1);return OK;}//Printpath_MaxdepthS1void Find_h(Bitree T,int h)//寻找深度为maxh-1的结点{path[h]=T;if(h==maxh-1){for(i=1;path[i];i++) printf("%c",path[i]->data);exit; //打印输出路径}else{if(T->lchild) Find_h(T->lchild,h+1);if(T->rchild) Find_h(T->rchild,h+1);}path[h]=NULL; //回溯}//Find_h6.54Status CreateBitree_SqList(Bitree &T,SqList sa)//根据顺序存储结构建立二叉链表{Bitree ptr[st+1]; //该数组储存与sa中各结点对应的树指针if(!st){T=NULL; //空树return;}ptr[ 1 ]=(BTNode*)malloc(sizeof(BTNode));ptr[ 1 ]->data=sa.elem[ 1 ]; //建立树根T=ptr[ 1 ];for(i=2;i<=st;i++){if(!sa.elem[i]) return ERROR; //顺序错误ptr[i]=(BTNode*)malloc(sizeof(BTNode));ptr[i]->data=sa.elem[i];j=i/2; //找到结点i的双亲jif(i-j*2) ptr[j]->rchild=ptr[i]; //i是j的右孩子else ptr[j]->lchild=ptr[i]; //i是j的左孩子}return OK;}//CreateBitree_SqList6.55int DescNum(Bitree T)//求树结点T的子孙总数填入DescNum域中,并返回该数{if(!T) return -1;else d=(DescNum(T->lchild)+DescNum(T->rchild)+2); //计算公式T->DescNum=d;return d;}//DescNum分析:该算法时间复杂度为O(n),n为树结点总数.注意:为了能用一个统一的公式计算子孙数目,所以当T为空指针时,要返回-1而不是0.6.56Bitree PreOrder_Next(Bitree p)//在先序后继线索二叉树中查找结点p的先序后继,并返回指针{if(p->lchild) return p->lchild;else return p->rchild;}//PreOrder_Next分析:总觉得不会这么简单.是不是哪儿理解错了?6.57Bitree PostOrder_Next(Bitree p)//在后序后继线索二叉树中查找结点p的后序后继,并返回指针{if(p->rtag) return p->rchild; //p有后继线索else if(!p->parent) return NULL; //p是根结点else if(p==p->parent->rchild) return p->parent; //p是右孩子else if(p==p->parent->lchild&&p->parent->tag)return p->parent; //p是左孩子且双亲没有右孩子else //p是左孩子且双亲有右孩子{q=p->parent->rchild;while(!q->ltag||!q->rtag){if(!q->ltag) q=q->lchild;else q=q->rchild;} //从p的双亲的右孩子向下走到底return q;}//else}//PostOrder_Next6.58Status Insert_BiThrTree(BiThrTree &T,BiThrTree &p,BiThrTree &x)//在中序线索二叉树T的结点p下插入子树x{if(!p->ltag&&!p->rtag) return INFEASIBLE; //无法插入if(p->ltag) //x作为p的左子树{s=p->lchild; //s为p的前驱p->ltag=Link;p->lchild=x;q=x;while(q->lchild) q=q->lchild;q->lchild=s; //找到子树中的最左结点,并修改其前驱指向sq=x;while(q->rchild) q=q->rchild;q->rchild=p; //找到子树中的最右结点,并修改其前驱指向p}else //x作为p的右子树{s=p->rchild; //s为p的后继p->rtag=Link;p->rchild=x;q=x;while(q->rchild) q=q->rchild;q->rchild=s; //找到子树中的最右结点,并修改其前驱指向sq=x;while(q->lchild) q=q->lchild;q->lchild=p; //找到子树中的最左结点,并修改其前驱指向p}return OK;}//Insert_BiThrTree6.59void Print_CSTree(CSTree T)//输出孩子兄弟链表表示的树T的各边{for(child=T->firstchild;child;child=child->nextsib){printf("(%c,%c),",T->data,child->data);Print_CSTree(child);}}//Print_CSTree6.60int LeafCount_CSTree(CSTree T)//求孩子兄弟链表表示的树T的叶子数目{if(!T->firstchild) return 1; //叶子结点else{count=0;for(child=T->firstchild;child;child=child->nextsib)count+=LeafCount_CSTree(child);return count; //各子树的叶子数之和}}//LeafCount_CSTree6.61int GetDegree_CSTree(CSTree T)//求孩子兄弟链表表示的树T的度{if(!T->firstchild) return 0; //空树else{degree=0;for(p=T->firstchild;p;p=p->nextsib) degree++;//本结点的度for(p=T->firstchild;p;p=p->nextsib){d=GetDegree_CSTree(p);if(d>degree) degree=d; //孩子结点的度的最大值}return degree;}//else}//GetDegree_CSTree6.62int GetDepth_CSTree(CSTree T)//求孩子兄弟链表表示的树T的深度{if(!T) return 0; //空树else{for(maxd=0,p=T->firstchild;p;p=p->nextsib)if((d=GetDepth_CSTree(p))>maxd) maxd=d; //子树的最大深度return maxd+1;}}//GetDepth_CSTree6.63int GetDepth_CTree(CTree A)//求孩子链表表示的树A的深度{return SubDepth(A.r);}//GetDepth_CTreeint SubDepth(int T)//求子树T的深度{if(!A.nodes[T].firstchild) return 1;for(sd=1,p=A.nodes[T].firstchild;p;p=p->next)if((d=SubDepth(p->child))>sd) sd=d;return sd+1;}//SubDepth6.64int GetDepth_PTree(PTree T)//求双亲表表示的树T的深度{maxdep=0;for(i=0;i<T.n;i++){dep=0;for(j=i;j>=0;j=T.nodes[j].parent) dep++; //求每一个结点的深度if(dep>maxdep) maxdep=dep;}return maxdep;}//GetDepth_PTree6.65char Pred,Ind; //假设前序序列和中序序列已经分别储存在数组Pre和In中Bitree Build_Sub(int Pre_Start,int Pre_End,int In_Start,int In_End)//由子树的前序和中序序列建立其二叉链表{sroot=(BTNode*)malloc(sizeof(BTNode)); //建根sroot->data=Pre[Pre_Start];for(i=In_Start;In[i]!=sroot->data;i++); //在中序序列中查找子树根leftlen=i-In_Start;rightlen=In_End-i; //计算左右子树的大小if(leftlen){lroot=Build_Sub(Pre_Start+1,Pre_Start+leftlen,In_Start,In_Start+l eftlen-1);sroot->lchild=lroot;} //建左子树,注意参数表的计算if(rightlen){rroot=Build_Sub(Pre_End-rightlen+1,Pre_End,In_End-rightlen+1,In_E nd);sroot->rchild=rroot;} //建右子树,注意参数表的计算return sroot; //返回子树根}//Build_Submain(){...Build_Sub(1,n,1,n); //初始调用参数,n为树结点总数...}分析:本算法利用了这样一个性质,即一棵子树在前序和中序序列中所占的位置总是连续的.因此,就可以用起始下标和终止下标来确定一棵子树.Pre_Start,Pre_End,In_Start和In_End分别指示子树在前序子序列里的起始下标,终止下标,和在中序子序列里的起始和终止下标.6.66typedef struct{CSNode *ptr;CSNode *lastchild;} NodeMsg; //结点的指针和其最后一个孩子的指针Status Bulid_CSTree_PTree(PTree T)//由树T的双亲表构造其孩子兄弟链表{NodeMsg Treed;for(i=0;i<T.n;i++){Tree[i].ptr=(CSNode*)malloc(sizeof(CSNode));Tree[i].ptr->data=T.node[i].data; //建结点if(T.nodes[i].parent>=0) //不是树根{j=T.nodes[i].parent; //本算法要求双亲表必须是按层序存储if(!(Tree[j].lastchild)) //双亲当前还没有孩子Tree[j].ptr->firstchild=Tree[i].ptr; //成为双亲的第一个孩子 else //双亲已经有了孩子Tree[j].lastchild->nextsib=Tree[i].ptr; //成为双亲最后一个孩子的下一个兄弟Tree[j].lastchild=Tree[i].ptr; //成为双亲的最后一个孩子}//if}//for}//Bulid_CSTree_PTree6.67typedef struct{char data;CSNode *ptr;CSNode *lastchild;} NodeInfo; //结点数据,结点指针和最后一个孩子的指针Status CreateCSTree_Duplet(CSTree &T)//输入二元组建立树的孩子兄弟链表{NodeInfo Treed;n=1;k=0;if(getchar()!='^') return ERROR; //未按格式输入if((c=getchar())=='^') T=NULL; //空树Tree[ 0 ].ptr=(CSNode*)malloc(sizeof(CSNode));Tree[ 0 ].data=c;Tree[ 0 ].ptr->data=c;while((p=getchar())!='^'&&(c=getchar())!='^'){Tree[n].ptr=(CSNode*)malloc(sizeof(CSNode));Tree[n].data=c;Tree[n].ptr->data=c;for(k=0;Tree[k].data!=p;k++); //查找当前边的双亲结点if(Tree[k].data!=p) return ERROR; //未找到:未按层序输入r=Tree[k].ptr;if(!r->firstchild)r->firstchild=Tree[n].ptr;else Tree[k].lastchild->nextsib=Tree[n].ptr;Tree[k].lastchild=Tree[n].ptr; //这一段含义同上一题n++;}//whilereturn OK;}//CreateCSTree_Duplet6.68Status CreateCSTree_Degree(char node[ ],int degree[ ])//由结点的层序序列和各结点的度构造树的孩子兄弟链表{CSNode * ptrd; //树结点指针的辅助存储ptr[ 0 ]=(CSNode*)malloc(sizeof(CSNode));i=0;k=1; //i为当前结点序号,k为当前孩子的序号while(node[i]){ptr[i]->data=node[i];d=degree[i];if(d){ptr[k++]=(CSNode*)malloc(sizeof(CSNode)); //k为当前孩子的序号 ptr[i]->firstchild=ptr[k]; //建立i与第一个孩子k之间的联系for(j=2;j<=d;j++){ptr[k++]=(CSNode*)malloc(sizeof(CSNode));ptr[k-1]->nextsib=ptr[k]; //当结点的度大于1时,为其孩子建立兄弟链表}//for}//ifi++;}//while}//CreateCSTree_Degree6.69void Print_BiTree(BiTree T,int i)//按树状打印输出二叉树的元素,i表示结点所在层次,初次调用时i=0{if(T->rchild) Print_BiTree(T->rchild,i+1);for(j=1;j<=i;j++) printf(" "); //打印i个空格以表示出层次printf("%c\n",T->data); //打印T元素,换行if(T->lchild) Print_BiTree(T->rchild,i+1);}//Print_BiTree分析:该递归算法实际上是带层次信息的中序遍历,只不过按照题目要求,顺序为先右后左.6.70Status CreateBiTree_GList(BiTree &T)//由广义表形式的输入建立二叉链表{c=getchar();if(c=='#') T=NULL; //空子树else{T=(CSNode*)malloc(sizeof(CSNode));T->data=c;if(getchar()!='(') return ERROR;if(!CreateBiTree_GList(pl)) return ERROR;T->lchild=pl;if(getchar()!=',') return ERROR;if(!CreateBiTree_GList(pr)) return ERROR;T->rchild=pr;if(getchar()!=')') return ERROR; //这些语句是为了保证输入符合A(B,C)的格式}return OK;}//CreateBiTree_GList6.71void Print_CSTree(CSTree T,int i)//按凹入表形式打印输出树的元素,i表示结点所在层次,初次调用时i=0{for(j=1;j<=i;j++) printf(" "); //留出i个空格以表现出层次printf("%c\n",T->data); //打印元素,换行for(p=T->firstchild;p;p=p->nextsib)Print_CSTree(p,i+1); //打印子树}//Print_CSTree6.72void Print_CTree(int e,int i)//按凹入表形式打印输出树的元素,i表示结点所在层次{for(j=1;j<=i;j++) printf(" "); //留出i个空格以表现出层次printf("%c\n",T.nodes[e].data); //打印元素,换行for(p=T.nodes[e].firstchild;p;p=p->next)Print_CSTree(p->child,i+1); //打印子树}//Print_CSTreemain(){...Print_CTree(T.r,0); //初次调用时i=0...}//main6.73char c; //全局变量,指示当前字符Status CreateCSTree_GList(CSTree &T)//由广义表形式的输入建立孩子兄弟链表{c=getchar();T=(CSNode*)malloc(sizeof(CSNode));T->data=c;if((c=getchar())=='(') //非叶结点{if(!CreateCSTree_GList(fc)) return ERROR; //建第一个孩子T->firstchild=fc;for(p=fc;c==',';p->nextsib=nc,p=nc) //建兄弟链if(!CreateCSTree_GList(nc)) return ERROR;p->nextsib=NULL;if((c=getchar())!=')') return ERROR; //括号不配对}else T->firtchild=NULL; //叶子结点return OK;}//CreateBiTree_GList分析:书后给出了两个间接递归的算法,事实上合成一个算法在形式上可能更好一些.本算法另一个改进之处在于加入了广义表格式是否合法的判断.6.74void PrintGlist_CSTree(CSTree T)//按广义表形式输出孩子兄弟链表表示的树{printf("%c",T->data);if(T->firstchild) //非叶结点{printf("(");for(p=T->firstchild;p;p=p->nextsib){PrintGlist_CSTree(p);if(p->nextsib) printf(","); //最后一个孩子后面不需要加逗号}printf(")");}//if}//PrintGlist_CSTree6.75char c;int pos=0; //pos是全局变量,指示已经分配到了哪个结点Status CreateCTree_GList(CTree &T,int &i)//由广义表形式的输入建立孩子链表{c=getchar();T.nodes[pos].data=c;i=pos++; //i是局部变量,指示当前正在处理的子树根if((c=getchar())=='(') //非叶结点{CreateCTree_GList();p=(CTBox*)malloc(sizeof(CTBox));T.nodes[i].firstchild=p;p->child=pos; //建立孩子链的头for(;c==',';p=p->next) //建立孩子链{CreateCTree_GList(T,j); //用j返回分配得到的子树根位置p->child=j;p->next=(CTBox*)malloc(sizeof(CTBox));}p->next=NULL;if((c=getchar())!=')') return ERROR; //括号不配对}//ifelse T.nodes[i].firtchild=NULL; //叶子结点return OK;}//CreateBiTree_GList分析:该算法中,pos变量起着"分配"结点在表中的位置的作用,是按先序序列从上向下分配,因此树根T.r一定等于0,而最终的pos值就是结点数T.n.6.76void PrintGList_CTree(CTree T,int i)//按广义表形式输出孩子链表表示的树{printf("%c",T.nodes[i].data);if(T.nodes[i].firstchild) //非叶结点{printf("(");for(p=T->firstchild;p;p=p->nextsib){PrintGlist_CSTree(T,p->child);if(p->nextsib) printf(","); //最后一个孩子后面不需要加逗号}printf(")");}//if}//PrintGlist_CTree。