Extensions allowing the Integer Pair Representation
Blast使用方法攻略

Blast使⽤⽅法攻略结果12列Query id,Subject id,% identity,alignment length,mismatches,gap openings,q. start,q. end,s. start,s. end,e-value,bit scoreBlast,全称Basic Local Alignment Search Tool,即"基于局部⽐对算法的搜索⼯具",由Altschul等⼈于1990年发布。
Blast能够实现⽐较两段核酸或者蛋⽩序列之间的同源性的功能,它能够快速的找到两段序列之间的同源序列并对⽐对区域进⾏打分以确定同源性的⾼低。
Blast的运⾏⽅式是先⽤⽬标序列建数据库(这种数据库称为database,⾥⾯的每⼀条序列称为subject),然后⽤待查的序列(称为 query)在database中搜索,每⼀条query与database中的每⼀条subject都要进⾏双序列⽐对,从⽽得出全部⽐对结果。
Blast是⼀个集成的程序包,通过调⽤不同的⽐对模块,blast实现了五种可能的序列⽐对⽅式:blastp:蛋⽩序列与蛋⽩库做⽐对,直接⽐对蛋⽩序列的同源性。
blastx:核酸序列对蛋⽩库的⽐对,先将核酸序列翻译成蛋⽩序列(根据相位可以翻译为6种可能的蛋⽩序列),然后再与蛋⽩库做⽐对。
blastn:核酸序列对核酸库的⽐对,直接⽐较核酸序列的同源性。
tblastn:蛋⽩序列对核酸库的⽐对,将库中的核酸翻译成蛋⽩序列,然后进⾏⽐对。
tblastx:核酸序列对核酸库在蛋⽩级别的⽐对,将库和待查序列都翻译成蛋⽩序列,然后对蛋⽩序列进⾏⽐对。
Blast提供了核酸和蛋⽩序列之间所有可能的⽐对⽅式,同时具有较快的⽐对速度和较⾼的⽐对精度,因此在常规双序列⽐对分析中应⽤最为⼴泛。
可以毫不夸张的说,blast是做⽐较基因组学乃⾄整个⽣物信息学研究所必须掌握的⼀种⽐对⼯具。
AD820

Single-Supply, Rail-to-Rail,Low Power FET-Input Op AmpAD820 Rev. EInformation furnished by Analog Devices is believed to be accurate and reliable. However, noresponsibility is assumed by Analog Devices for its use, nor for any infringements of patents or other rights of third parties that may result from its use. Specifications subject to change without notice. No license is granted by implication or otherwise under any patent or patent rights of Analog Devices. T rademarks and registered trademarks are the property of their respective owners. One Technology Way, P.O. Box 9106, N orwood, MA 02062-9106, U.S.A. Tel: 781.329.4700 Fax: 781.461.3113 ©1996–2007 Analog Devices, Inc. All rights reserved.FEATURESTrue single-supply operationOutput swings rail-to-railInput voltage range extends below ground Single-supply capability from 5 V to 36 V Dual-supply capability from ±2.5 V to ±18 V Excellent load driveCapacitive load drive up to 350 pF Minimum output current of 15 mA Excellent ac performance for low power800 μA maximum quiescent currentUnity gain bandwidth: 1.8 MHzSlew rate of 3.0 V/μsExcellent dc performance800 μV maximum input offset voltage1 μV/°C typical offset voltage drift25 pA maximum input bias currentLow noise13 nV/√Hz @ 10 kHz APPLICATIONSBattery-powered precision instrumentation Photodiode preampsActive filters12- to 14-bit data acquisition systems Medical instrumentationLow power references and regulators PIN CONFIGURATIONS NC = NO CONNECTNULL–IN+IN–V SNC+V SV OUTNULL873-1 Figure 1. 8-Lead PDIPNC = NO CONNECTNC–IN+IN–V SNC+V SV OUTNC873-2Figure 2. 8-Lead SOICGENERAL DESCRIPTIONThe AD820 is a precision, low power FET input op amp that can operate from a single supply of 5.0 V to 36 V, or dual supplies of ±2.5 V to ±18 V. It has true single-supply capability, with an input voltage range extending below the negative rail, allowing the AD820 to accommodate input signals below ground in the single-supply mode. Output voltage swing extends to within10 mV of each rail, providing the maximum output dynamic range. Offset voltage of 800 μV maximum, offset voltage drift of1 μV/°C, typical input bias currents below 25 pA, and low input voltage noise provide dc precision with source impedances upto 1 GΩ. 1.8 MHz unity gain bandwidth, −93 dB THD at10 kHz, and 3 V/μs slew rate are provided for a low supply current of 800 μA. The AD820 drives up to 350 pF of direct capacitive load and provides a minimum output current of15 mA. This allows the amplifier to handle a wide range of load conditions. This combination of ac and dc performance, plus the outstanding load drive capability, results in an exceptionally versatile amplifier for the single-supply user. The AD820 is available in two performance grades. The A and B grades are rated over the industrial temperature range of−40°C to +85°C. The AD820 is offered in two 8-lead package options: plastic DIP (PDIP) and surface mount (SOIC).873-4 Figure 3. Gain of 2 Amplifier; V S =5 V, 0 V, V IN = 2.5 V Sine Centered at 1.25 VAD820Rev. E | Page 2 of 24TABLE OF CONTENTSFeatures..............................................................................................1 Applications.......................................................................................1 Pin Configurations...........................................................................1 General Description.........................................................................1 Revision History...............................................................................2 Specifications.....................................................................................3 Absolute Maximum Ratings............................................................9 ESD Caution..................................................................................9 Typical Performance Characteristics...........................................10 Application Notes...........................................................................16 Input Characteristics..................................................................16 Output Characteristics...............................................................17 Offset Voltage Adjustment............................................................18 Applications.....................................................................................19 Single Supply Half-Wave and Full-Wave Rectifiers...............19 4.5 V Low Dropout, Low Power Reference.............................19 Low Power 3-Pole Sallen Key Low-Pass Filter.......................20 Outline Dimensions.......................................................................21 Ordering Guide.. (22)REVISION HISTORY2/07—Rev. D to Rev. EUpdated Format..................................................................Universal Updated Outline Dimensions.......................................................21 Changes to the Ordering Guide. (22)5/02—Rev. C to Rev. DChange to SOIC Package (R-8) Drawing....................................15 Edits to Features................................................................................1 Edits to Product Description..........................................................1 Delete Specifications for AD820A-3 V..........................................5 Edits to Ordering Guide..................................................................6 Edits to Typical Performance Characteristics. (8)AD820Rev. E | Page 3 of 24SPECIFICATIONSV S = 0 V , 5 V @ T A = 25°C, V CM = 0 V , V OUT = 0.2 V , unless otherwise noted. Table 1.AD820A AD820B Parameter Conditions Min Typ Max Min Typ Max Unit DC PERFORMANCE Initial Offset 0.1 0.8 0.1 0.4 mV Maximum Offset over Temperature 0.5 1.2 0.5 0.9 mV Offset Drift 2 2 μV/°C Input Bias Current V CM = 0 V to 4 V 2 25 2 10 pA at T MAX 0.5 5 0.5 2.5 nA Input Offset Current 2 20 2 10 pA at T MAX 0.5 0.5 nA Open-Loop Gain V OUT = 0.2 V to 4 V T MIN to T MAX R L = 100 kΩ 400 1000 500 1000 V/mV 400 400 V/mV T MIN to T MAX R L = 10 kΩ 80 150 80 150 V/mV 80 80 V/mV T MIN to T MAX R L = 1 kΩ 15 30 15 30 V/mV 10 10 V/mV NOISE/HARMONIC PERFORMANCE Input Voltage Noise 0.1 Hz to 10 Hz 2 2 μV p-p f = 10 Hz 25 25 nV/√Hz f = 100 Hz 21 21 nV/√Hz f = 1 kHz 16 16 nV/√Hz f = 10 kHz 13 13 nV/√Hz Input Current Noise 0.1 Hz to 10 Hz 18 18 fA p-p f = 1 kHz 0.8 0.8 fA/√Hz Harmonic Distortion R L = 10 kΩ to 2.5 V f = 10 kHz V OUT = 0.25 V to 4.75 V −93 −93 dB DYNAMIC PERFORMANCE Unity Gain Frequency 1.8 1.8 MHz Full Power Response V OUT p-p = 4.5 V 210 210 kHz Slew Rate 3 3 V/μs Settling Time to 0.1% V OUT = 0.2 V to 4.5 V 1.4 1.4 μs to 0.01% 1.8 1.8 μs INPUT CHARACTERISTICSCommon-Mode Voltage Range 1−0.2 +4 –0.2 +4 V T MIN to T MAX −0.2 +4 –0.2 +4 V CMRR V CM = 0 V to 2 V 66 80 72 80 dB T MIN to T MAX 66 66 dB Input ImpedanceDifferential 1013||0.5 1013||0.5 Ω||pF Common Mode 1013||2.8 1013||2.8 Ω||pFAD820Rev. E | Page 4 of 24AD820A AD820B Parameter Conditions Min Typ Max Min Typ Max Unit OUTPUT CHARACTERISTICSOutput Saturation Voltage 2V OL − V EE I SINK = 20 μA 5 7 5 7 mV T MIN to T MAX 10 10 mV V CC − V OH I SOURCE = 20 μA 10 14 10 14 mV T MIN to T MAX 20 20 mV V OL − V EE I SINK = 2 mA 40 55 40 55 mV T MIN to T MAX 80 80 mV V CC − V OH I SOURCE = 2 mA 80 110 80 110 mV T MIN to T MAX 160 160 mV V OL − V EE I SINK = 15 mA 300 500 300 500 mV T MIN to T MAX 1000 1000 mV V CC − V OH I SOURCE = 15 mA 800 1500 800 1500 mV T MIN to T MAX 1900 1900 mV Operating Output Current 15 15 mA T MIN to T MAX 12 12 mA Short-Circuit Current 25 25 mA Capacitive Load Drive 350 350 pF POWER SUPPLY Quiescent Current T MIN to T MAX 620 800 620 800 μA Power Supply Rejection V S + = 5 V to 15 V 70 80 66 80 dB T MIN to T MAX 70 66 dB1This is a functional specification. Amplifier bandwidth decreases when the input common-mode voltage is driven in the range (+ V S – 1 V) to +V S . Common-mode error voltage is typically less than 5 mV with the common-mode voltage set at 1 V below the positive supply. 2V OL − V EE is defined as the difference between the lowest possible output voltage (V OL ) and the minus voltage supply rail (V EE ). V CC − V OH is defined as the difference between the highest possible output voltage (V OH ) and the positive supply voltage (V CC ).AD820Rev. E | Page 5 of 24V S = ±5 V @ T A = 25°C, V CM = 0 V , V OUT = 0 V , unless otherwise noted. Table 2.AD820A AD820B Parameter Conditions Min Typ Max Min Typ Max Unit DC PERFORMANCE Initial Offset 0.1 0.8 0.3 0.4 mV Maximum Offset over Temperature 0.5 1.5 0.5 1 mV Offset Drift 2 2 μV/°C Input Bias Current V CM = –5 V to 4 V 2 25 2 10 pA at T MAX 0.5 5 0.5 2.5 nA Input Offset Current 2 20 2 10 pA at T MAX 0.5 0.5 nA Open-Loop Gain V OUT = 4 V to –4 V R L = 100 kΩ 400 1000 400 1000 V/mV T MIN to T MAX 400 400 V/mV R L = 10 kΩ 80 150 80 150 V/mV T MIN to T MAX 80 80 V/mV R L = 1 kΩ 20 30 20 30 V/mV T MIN to T MAX 10 10 V/mV NOISE/HARMONIC PERFORMANCE Input Voltage Noise 0.1 Hz to 10 Hz 2 2 μV p-p f = 10 Hz 25 25 nV/√Hz f = 100 Hz 21 21 nV/√Hz f = 1 kHz 16 16 nV/√Hz f = 10 kHz 13 13 nV/√Hz Input Current Noise 0.1 Hz to 10 Hz 18 18 fA p-p f = 1 kHz 0.8 0.8 fA/√Hz Harmonic Distortion R L = 10 kΩ f = 10 kHz V OUT = ±4.5 V −93 −93 dB DYNAMIC PERFORMANCE Unity Gain Frequency 1.9 1.8 MHz Full Power Response V OUT p-p = 9 V 105 105 kHz Slew Rate 3 3 V/μs Settling Time to 0.1% V OUT = 0 V to ±4.5 V 1.4 1.4 μs to 0.01% 1.8 1.8 μs INPUT CHARACTERISTICSCommon-Mode Voltage Range 1−5.2 +4 −5.2 +4 V T MIN to T MAX −5.2 +4 −5.2 +4 V CMRR V CM = −5 V to +2 V 66 80 72 80 dB T MIN to T MAX 66 66 dB Input ImpedanceDifferential 1013||0.5 1013||0.5 Ω||pF Common Mode 1013||2.8 1013||2.8 Ω||pFAD820Rev. E | Page 6 of 24AD820A AD820B Parameter Conditions Min Typ Max Min Typ Max Unit OUTPUT CHARACTERISTICSOutput Saturation Voltage 2V OL − V EE I SINK = 20 μA 5 7 5 7 mV T MIN to T MAX 10 10 mV V CC − V OH I SOURCE = 20 μA 10 14 10 14 mV T MIN to T MAX 20 20 mV V OL − V EE I SINK = 2 mA 40 55 40 55 mV T MIN to T MAX 80 80 mV V CC − V OH I SOURCE = 2 mA 80 110 80 110 mV T MIN to T MAX 160 160 mV V OL − V EE I SINK = 15 mA 300 500 300 500 mV T MIN to T MAX 1000 1000 mV V CC − V OH I SOURCE = 15 mA 800 1500 800 1500 mV T MIN to T MAX 1900 1900 mV Operating Output Current 15 15 mA T MIN to T MAX 12 12 mA Short-Circuit Current 30 30 mA Capacitive Load Drive 350 350 pF POWER SUPPLY Quiescent Current T MIN to T MAX 650 800 620 800 μA Power Supply Rejection V S + = 5 V to 15 V 70 80 70 80 dB T MIN to T MAX 70 70 dB1This is a functional specification. Amplifier bandwidth decreases when the input common-mode voltage is driven in the range (+ V S – 1 V) to +V S . Common-mode error voltage is typically less than 5 mV with the common-mode voltage set at 1 V below the positive supply. 2V OL − V EE is defined as the difference between the lowest possible output voltage (V OL ) and the minus voltage supply rail (V EE ). V CC − V OH is defined as the difference between the highest possible output voltage (V OH ) and the positive supply voltage (V CC ).AD820Rev. E | Page 7 of 24V S = ±15 V @ T A = 25°C, V CM = 0 V , V OUT = 0 V , unless otherwise noted. Table 3.AD820A AD820B Parameter Conditions Min Typ Max Min Typ Max Unit DC PERFORMANCE Initial Offset 0.4 2 0.3 1.0 mV Maximum Offset over Temperature 0.5 3 0.5 2 mV Offset Drift 2 2 μV/°C Input Bias Current V CM = 0 V 2 25 2 10 pA V CM = −10 V 40 40 pA at T MAX V CM = 0 V 0.5 5 0.5 2.5 nA Input Offset Current 2 20 2 10 pA at T MAX 0.5 0.5 nA Open-Loop Gain V OUT = +10 V to –10 V R L = 100 kΩ 500 2000 500 2000 V/mV T MIN to T MAX 500 500 V/mV R L = 10 kΩ 100 500 100 500 V/mV T MIN to T MAX 100 100 V/mV R L = 1 kΩ 30 45 30 45 V/mV T MIN to T MAX 20 20 V/mV NOISE/HARMONIC PERFORMANCE Input Voltage Noise 0.1 Hz to 10 Hz 2 2 μV p-p f = 10 Hz 25 25 nV/√Hz f = 100 Hz 21 21 nV/√Hz f = 1 kHz 16 16 nV/√Hz f = 10 kHz 13 13 nV/√Hz Input Current Noise 0.1 Hz to 10 Hz 18 18 fA p-p f = 1 kHz 0.8 0.8 fA/√Hz Harmonic Distortion R L = 10 kΩ f = 10 kHz V OUT = ±10 V −85 −85 dB DYNAMIC PERFORMANCE Unity Gain Frequency 1.9 1.9 MHz Full Power Response V OUT p-p = 20 V 45 45 kHz Slew Rate 3 3 V/μs Settling Time to 0.1% V OUT = 0 V to ±10 V 4.1 4.1 μs to 0.01% 4.5 4.5 μs INPUT CHARACTERISTICS Common-Mode Voltage Range 1 −15.2 +14 −15.2 +14 V T MIN to T MAX −15.2 +14 −15.2 +14 V CMRR V CM = –15 V to +12 V 70 80 74 90 dB T MIN to T MAX 70 74 dB Input Impedance Differential 1013||0.5 1013||0.5 Ω||pF Common Mode 1013||2.8 1013||2.8 Ω||pFAD820Rev. E | Page 8 of 24AD820A AD820B Parameter Conditions Min Typ Max Min Typ Max Unit OUTPUT CHARACTERISTICS Output Saturation Voltage 2 V OL − V EE I SINK = 20 μA 5 7 5 7 mV T MIN to T MAX 10 10 mV V CC − V OH I SOURCE = 20 μA 10 14 10 14 mV T MIN to T MAX 20 20 mV V OL − V EE I SINK = 2 mA 40 55 40 55 mV T MIN to T MAX 80 80 mV V CC − V OH I SOURCE = 2 mA 80 110 80 110 mV T MIN to T MAX 160 160 mV V OL − V EE I SINK = 15 mA 300 500 300 500 mV T MIN to T MAX 1000 1000 mV V CC − V OH I SOURCE = 15 mA 800 1500 800 1500 mV T MIN to T MAX 1900 1900 mV Operating Output Current 20 20 mA T MIN to T MAX 15 15 mA Short-Circuit Current 45 45 mA Capacitive Load Drive 350 350 POWER SUPP L Y Quiescent Current T MIN to T MAX 700 900 700 900 μA Power Supply Rejection V S + = 5 V to 15 V 70 80 70 80 dB T MIN to T MAX 70 70 dB1This is a functional specification. Amplifier bandwidth decreases when the input common-mode voltage is driven in the range (+ V S – 1 V) to +V S . Common-mode error voltage is typically less than 5 mV with the common-mode voltage set at 1 V below the positive supply. 2V OL − V EE is defined as the difference between the lowest possible output voltage (V OL ) and the minus voltage supply rail (V EE ). V CC − V OH is defined as the difference between the highest possible output voltage (V OH ) and the positive supply voltage (V CC ).AD820Rev. E | Page 9 of 24ABSOLUTE MAXIMUM RATINGSTable 4.Parameter Rating Supply Voltage ±18 VInternal Power Dissipation 1Plastic DIP (N) 1.6 W SOIC (R) 1.0 W Input Voltage (+V S + 0.2 V) to −(20 V + V S ) Output Short-Circuit Duration Indefinite Differential Input Voltage ±30 V Storage Temperature Range N −65°C to +125°C R −65°C to +150°C Operating Temperature Range AD820A/B −40°C to +85°C Lead Temperature 260°C (Soldering 60 sec)18-lead plastic DIP package: θJA = 90°C/W 8-lead SOIC package: θJA = 160°C/WStresses above those listed under Absolute Maximum Ratings may cause permanent damage to the device. This is a stress rating only; functional operation of the device at these or any other conditions above those indicated in the operationalsection of this specification is not implied. Exposure to absolute maximum rating conditions for extended periods may affect device reliability.ESD CAUTIONAD820Rev. E | Page 10 of 24TYPICAL PERFORMANCE CHARACTERISTICS500–0.50.5OFFSET VOLTAGE (mV)N U M B E R O F U N I T S00873-00540302010–0.4–0.3–0.2–0.100.10.20.30.4Figure 4. Typical Distribution of Offset Voltage (248 Units)480–1010OFFSET VOLTAGE DRIFT (µV/ºC)% I N B I N00873-006403224168–8–6–4–202468Figure 5. Typical Distribution of Offset Voltage Drift (120 Units) 500010INPUT BIAS CURRENT (pA)N U M B E R O F U N I T S00873-00745403530252015105123456789Figure 6. Typical Distribution of Input Bias Current (213 Units)5–5–55COMMON-MODE VOLTAGE (V)I N P U T B I A S C U R R E N T (p A )00873-008–4–3–2–101234Figure 7. Input Bias Current vs. Common-Mode Voltage;V S = +5 V, 0 V and V S = ±5 V1k0.1–1616COMMON-MODE VOLTAGE (V)I N P U T B I A S C U R R E N T (p A )00873-009110100–12–8–404812Figure 8. Input Bias Current vs. Common-Mode Voltage; V S = ±15 V100k0.120140TEMPERATURE (ºC)I N P U T B I A S C UR R E N T (p A )1101001k10k00873-010406080100120Figure 9. Input Bias Current vs. Temperature; V S = 5 V, V CM = 0 V10M10k 100100k LOAD RESISTANCE (Ω)O P E N -L O O P G A I N (V /V )00873-0111k10k 100k1MFigure 10. Open-Loop Gain vs. Load Resistance10M10k –60140TEMPERATURE (ºC)O P E N -L O O P G A I N (V /V )00873-012100k1M–40–2020406080100120Figure 11. Open-Loop Gain vs. Temperature 300–300OUTPUT VOLTAGE (V)I N P U T V O L T A G E (µV )00873-013200100–100–200Figure 12. Input Error Voltage vs. Output Voltage for Resistive Loads40–403OUTPUT VOLTAGE FROM RAILS (mV)I N P U T V O LT A G E (µV )0000873-014200–2060120180240Figure 13. Input Error Voltage vs. Output Voltage within 300 mV of EitherSupply Rail for Various Resistive Loads; V S = ±5 V1k111FREQUENCY (Hz)I N P U T V O L T A G E N O I S E (n V /√H z )0k00873-015101001k 10100Figure 14. Input Voltage Noise vs. Frequency–40–110100100kFREQUENCY (Hz)T H D (d B )00873-0161k 10k–50–60–70–80–90–100Figure 15. Total Harmonic Distortion vs. Frequency00873-017100–201010M FREQUENCY (Hz)O P E N -L O O P G A I N (d B )1001k10k100k1M806040200P H A S E M A R G I N (D E G R E E S )100–2080604020Figure 16. Open-Loop Gain and Phase Margin vs. Frequency 1k 0.0110010MFREQUENCY (Hz)O U T P U T I M P E D A N C E (Ω)00873-0181k 10k 100k 1M0.1110100Figure 17. Output Impedance vs. Frequency16–1605SETTLING TIME (µs)O U T P U T S W I N G F R O M 0 T O ±V00873-01912840–4–8–121234Figure 18. Output Swing and Error vs. Settling Time 10001010MFREQUENCY (Hz)C O M M O N -M ODE R E J E C T I O N (d B )00873-0201001k10k 100k 1M 908070605040302010Figure 19. Common-Mode Rejection vs. Frequency50–13COMMON-MODE VOLTAGE FROM SUPPLY RAILS (V)C O M M O N -M ODE E R R O R V O L T A G E (m V )00873-0214321012Figure 20. Absolute Common-Mode Error vs. Common-Mode Voltagefrom Supply Rails (V S − V CM )1k10.001100LOAD CURRENT (mA)O U T P U T S A T U R A T I O N V O L T A G E (m V )00873-0220.010.111010100Figure 21. Output Saturation Voltage vs. Load Current1k1–60140TEMPERATURE (ºC)O U T P U T S A T U R A T I O N V O L T A G E (m V )00873-023–40–2002040608010012010100Figure 22. Output Saturation Voltage vs. Temperature 800–60140TEMPERATURE (ºC)S H O R T C I R C U I T C U R R E N T L I M I T (m A )00873-024–40–2002040608010012070605040302010 Figure 23. Short Circuit Current Limit vs. Temperature 800003TOTAL SUPPLY VOLTAGE (V)Q U I E S C E N T C U R R E N T (µA )600873-02570060050040030020010048121620242832Figure 24. Quiescent Current vs. Supply Voltage over Different Temperatures12001010MFREQUENCY (Hz)P O W E R S U P P L Y R E J E C T I O N (d B )00873-0261001k10k100k1M110100908070605040302010Figure 25. Power Supply Rejection vs. Frequency30010k10MFREQUENCY (Hz)O U T P U T V O L T A G E (V )00873-027100k1M 252015105Figure 26. Large Signal Frequency Response00873-028+V OUT VFigure 27. Unity-Gain Follower, Used for Figure 28 Through Figure 3200873-029Figure 28. 20 V, 25 kHz Sine Input; Unity-Gain Follower; R L = 600 Ω, V S = ±15 V 00873-03Figure 29. V S = 5 V, 0 V; Unity-Gain Follower Response to 0 V to 4 V Step 00873-031Figure 30. Large Signal Response Unity-Gain Follower; V S = ±15 V, R L = 10 kΩ00873-032Figure 31. Small Signal Response Unity-Gain Follower; V S = ±15 V, R L = 10 kΩ00873-033Figure 32. V S = 5 V, 0 V; Unity-Gain Follower Response to 0 V to 5 V Step00873-035V OUT00873-034OUT V INFigure 33. Unity-Gain Follower, Used for Figure 34Figure 35. Gain of Two Inverter, Used for Figure 36 and Figure 3700873-03700873-036Figure 34. V S = 5 V, 0 V; Unity-Gain Follower Response to 40 mV StepCentered 40 mV Above Ground Figure 36. V S = 5 V, 0 V; Gain of Two Inverter Response to 2.5 V Step,Centered −1.25 V Below Ground00873-038Figure 37. V S = 5 V, 0 V; Gain of Two Inverter Response to 20 mV Step,Centered 20 mV Below GroundAPPLICATION NOTESINPUT CHARACTERISTICSIn the AD820, n-channel JFETs are used to provide a low offset, low noise, high impedance input stage. Minimum input common-mode voltage extends from 0.2 V below –V S to 1 V less than+V S. Driving the input voltage closer to the positive rail causes a loss of amplifier bandwidth (as can be seen by comparing the large signal responses shown in Figure 29 and Figure 32) and increased common-mode voltage error, as illustrated inFigure 20.The AD820 does not exhibit phase reversal for input voltages up to and including +V S. Figure 38a shows the response of anAD820 voltage follower to a 0 V to 5 V (+V S) square wave input. The input and output are superimposed. The output polarity tracks the input polarity up to +V S with no phase reversal. The reduced bandwidth above a 4 V input causes the rounding of the output wave form. For input voltages greater than +V S, a resistor in series with the AD820’s positive input prevents phase reversal, at the expense of greater input voltage noise. This is illustrated in Figure 38b.Since the input stage uses n-channel JFETs, input current during normal operation is negative; the current flows out from the input terminals. If the input voltage is driven more positive than +V S − 0.4 V, the input current reverses direction as internal device junctions become forward biased. This is illustrated in Figure 7.A current-limiting resistor should be used in series with the input of the AD820 if there is a possibility of the input voltage exceeding the positive supply by more than 300 mV, or if an input voltage is applied to the AD820 when ±V S = 0. The amplifier will be damaged if left in that condition for more than 10 seconds. A 1 kΩ resistor allows the amplifier to withstand up to 10 V of continuous overvoltage, and increases the input voltage noise by a negligible amount.Input voltages less than −V S are a completely different story.The amplifier can safely withstand input voltages 20 V below the negative supply voltage as long as the total voltage from the positive supply to the input terminal is less than 36 V. In addition, the input stage typically maintains picoamp level input currents across that input voltage range.The AD820 is designed for 13 nV/√Hz wideband input voltage noise and maintains low noise performance to low frequencies (refer to Figure 14). This noise performance, along with theAD820’s low input current and current noise means that the AD820 contributes negligible noise for applications with source resistances greater than 10 kΩ and signal bandwidths greater than 1 kHz. This is illustrated in Figure 39.873-39+VS5VOUTV(b)(a)Figure 38. (a) Response with R P = 0 Ω; V IN from 0 V to +V S(b) V IN = 0 V to +V S + 200 mV,V OUT = 0 V to +V S, R P = 49.9 kΩ100k0.110k10GSOURCE IMPEDANCE (Ω)INPUTVOLTAGENOISE(µVrms)873-40 10k1k100101100k1M10M100M1GFigure 39. Total Noise vs. Source ImpedanceOUTPUT CHARACTERISTICSThe AD820’s unique bipolar rail-to-rail output stage swings within 5 mV of the negative supply and 10 mV of the positive supply with no external resistive load. The AD820’s approxi-mate output saturation resistance is 40 Ω sourcing and 20 Ω sinking. This can be used to estimate output saturation voltage when driving heavier current loads. For instance, when sourcing 5 mA, the saturation voltage to the positive supply rail is 200 mV; when sinking 5 mA, the saturation voltage to the negative rail is 100 mV .The amplifier’s open-loop gain characteristic changes as a function of resistive load, as shown in Figure 10 through Figure 13. For load resistances over 20 kΩ, the AD820 input error voltage is virtually unchanged until the output voltage is driven to 180 mV of either supply.If the AD820 output is driven hard against the output saturation voltage, it recovers within 2 μs of the input returning to the amplifier’s linear operating region.Direct capacitive load interacts with the amplifier’s effective output impedance to form an additional pole in the amplifier’s feedback loop, which can cause excessive peaking on the pulse response or loss of stability. Worst case occurs when the amplifier is used as a unity-gain follower. Figure 40 shows AD820 pulse response as a unity-gain follower driving 350 pF. This amount of overshoot indicates approximately 20 degrees of phase margin—the system is stable, but is nearing the edge. Configurations with less loop gain, and as a result less loop bandwidth, are much less sensitive to capacitance load effects. Figure 41 is a plot of noise gain vs. the capacitive load that results in a 20 degree phase margin for the AD820. Noise gain is the inverse of the feedback attenuation factor provided by the feedback network in use.00873-041Figure 40. Small Signal Response of AD820 as Unity-Gain Follower Driving350 pF Capacitive Load00873-0425130030kCAPACITIVE LOAD FOR 20º PHASE MARGIN (pF)N O I S E G A I N (1+ )P I P F4321k 3k 10kFigure 41. Noise Gain vs. Capacitive Load ToleranceFigure 42 shows a possible configuration for extendingcapacitance load drive capability for a unity-gain follower. With these component values, the circuit drives 5000 pF with a 10% overshoot.00873-043+V OUT VFigure 42. Extending Unity-Gain Follower Capacitive Load CapabilityBeyond 350 pFOFFSET VOLTAGE ADJUSTMENTThe offset voltage of the AD820 is low, so external offset voltage nulling is not usually required. Figure 43 shows the recom-mended technique for AD820 packaged in plastic DIP . Adjusting offset voltage in this manner changes the offset voltage temperature drift by 4 μV/°C for every millivolt of induced offset. The null pins are not functional for AD820s in the 8-lead SOIC package.+V Figure 43. Offset NullAPPLICATIONSSINGLE SUPPLY HALF-WAVE AND FULL-WAVE RECTIFIERSAn AD820 configured as a unity-gain follower and operated with a single supply can be used as a simple half-wave rectifier. The AD820 inputs maintain picoamp level input currents even when driven well below the negative supply. The rectifier puts that behavior to good use, maintaining an input impedance of over 1011 Ω for input voltages from 1 V from the positive supply to 20 V below the negative supply.The full- and half-wave rectifier shown in Figure 44 operates as follows: when V IN is above ground, R1 is bootstrapped through the unity-gain follower, A1, and the loop of amplifier A2. This forces the inputs of A2 to be equal; thus, no current flowsthrough R1 or R2, and the circuit output tracks the input. When V IN is below ground, the output of A1 is forced to ground. The noninverting input of amplifier A2 sees the ground level output of A1; therefore, A2 operates as a unity-gain inverter. The output at Node C is then a full-wave rectified version of the input. Node B is a buffered half-wave rectified version of the input. Input voltages up to ±18 V can be rectified, depending on the voltage supply used.00873-045R1R2V AC HALF-WAVEBA BCFigure 44. Single-Supply Half- and Full-Wave Rectifier4.5 V LOW DROPOUT, LOW POWER REFERENCEThe rail-to-rail performance of the AD820 can be used to provide low dropout performance for low power reference circuits powered with a single low voltage supply. Figure 45 shows a 4.5 V reference using the AD820 and the AD680, a low power 2.5 V band gap reference. R2 and R3 set up the required gain of 1.8 to develop the 4.5 V output. R1 and C2 form a low-pass RC filter to reduce the noise contribution of the AD680.00873-0462.5VOUTPUT4.5VOUTPUTFigure 45. Single Supply 4.5 V Low Dropout ReferenceWith a 1 mA load, this reference maintains the 4.5 V output with a supply voltage down to 4.7 V . The amplitude of the recovery transient for a 1 mA to 10 mA step change in load current is under 20 mV , and settles out in a few microseconds. Output voltage noise is less than 10 μV rms in a 25 kHz noise bandwidth.。
拉马努金恒等式的证明

∞ k=−∞
(q/a, q/b, q/c, q/d, q/e)k (aq, bq, cq, dq, eq)k
(abcdeq−1)k
=
(q, ab, bc, ac)∞ (aq, bq, cq, abc/q)∞
∞ k=0
(q/a, (q, q2
q/b, q/c, /abc, dq,
de)k eq)k
qk
jouhet@math.univ-lyon1.fr, http://math.univ-lyon1.fr/~jouhet
3Universit´e de Lyon, Universit´e Lyon 1, UMR 5208 du CNRS, Institut Camille Jordan, F-69622, Villeurbanne Cedex, France
∞ k=−∞
(q/a)k (a)k
ak
qk2
−k
=
(q)∞ (a)∞
,
while the right-hand side of (1.7) is equal to 0 (since ab/q = 1). Similarly, if bc = 1, the left-hand side of (1.8) becomes
=
(q, ab/q, bc/q, ac/q)∞ (a, b, c, abc/q2)∞
∞ k=0
(q/a, q/b, q/c)k (q, q3/abc)k
qk
,
∞ k=−∞
(q/a, q/b, q/c)k (aq, bq, cq)k
(abc)k
q
k2
=
(q, ab, bc, ac)∞ (aq, bq, cq, abc/q)∞
rfc2661.Layer Two Tunneling Protocol L2TP

Network Working Group W. Townsley Request for Comments: 2661 A. Valencia Category: Standards Track cisco Systems A. Rubens Ascend Communications G. Pall G. Zorn Microsoft Corporation B. Palter Redback Networks August 1999 Layer Two Tunneling Protocol "L2TP"Status of this MemoThis document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions forimprovements. Please refer to the current edition of the "InternetOfficial Protocol Standards" (STD 1) for the standardization stateand status of this protocol. Distribution of this memo is unlimited.Copyright NoticeCopyright (C) The Internet Society (1999). All Rights Reserved.AbstractThis document describes the Layer Two Tunneling Protocol (L2TP). STD 51, RFC 1661 specifies multi-protocol access via PPP [RFC1661]. L2TP facilitates the tunneling of PPP packets across an interveningnetwork in a way that is as transparent as possible to both end-users and applications.Table of Contents1.0 Introduction (3)1.1 Specification of Requirements (4)1.2 Terminology (4)2.0 Topology (8)3.0 Protocol Overview (9)3.1 L2TP Header Format (9)3.2 Control Message Types (11)4.0 Control Message Attribute Value Pairs (12)4.1 AVP Format (13)4.2 Mandatory AVPs (14)4.3 Hiding of AVP Attribute Values (14)Townsley, et al. Standards Track [Page 1]4.4.1 AVPs Applicable To All Control Messages (17)4.4.2 Result and Error Codes (18)4.4.3 Control Connection Management AVPs (20)4.4.4 Call Management AVPs (27)4.4.5 Proxy LCP and Authentication AVPs (34)4.4.6 Call Status AVPs (39)5.0 Protocol Operation (41)5.1 Control Connection Establishment (41)5.1.1 Tunnel Authentication (42)5.2 Session Establishment (42)5.2.1 Incoming Call Establishment (42)5.2.2 Outgoing Call Establishment (43)5.3 Forwarding PPP Frames (43)5.4 Using Sequence Numbers on the Data Channel (44)5.5 Keepalive (Hello) (44)5.6 Session Teardown (45)5.7 Control Connection Teardown (45)5.8 Reliable Delivery of Control Messages (46)6.0 Control Connection Protocol Specification (48)6.1 Start-Control-Connection-Request (SCCRQ) (48)6.2 Start-Control-Connection-Reply (SCCRP) (48)6.3 Start-Control-Connection-Connected (SCCCN) (49)6.4 Stop-Control-Connection-Notification (StopCCN) (49)6.5 Hello (HELLO) (49)6.6 Incoming-Call-Request (ICRQ) (50)6.7 Incoming-Call-Reply (ICRP) (51)6.8 Incoming-Call-Connected (ICCN) (51)6.9 Outgoing-Call-Request (OCRQ) (52)6.10 Outgoing-Call-Reply (OCRP) (53)6.11 Outgoing-Call-Connected (OCCN) (53)6.12 Call-Disconnect-Notify (CDN) (53)6.13 WAN-Error-Notify (WEN) (54)6.14 Set-Link-Info (SLI) (54)7.0 Control Connection State Machines (54)7.1 Control Connection Protocol Operation (55)7.2 Control Connection States (56)7.2.1 Control Connection Establishment (56)7.3 Timing considerations (58)7.4 Incoming calls (58)7.4.1 LAC Incoming Call States (60)7.4.2 LNS Incoming Call States (62)7.5 Outgoing calls (63)7.5.1 LAC Outgoing Call States (64)7.5.2 LNS Outgoing Call States (66)7.6 Tunnel Disconnection (67)8.0 L2TP Over Specific Media (67)8.1 L2TP over UDP/IP (68)Townsley, et al. Standards Track [Page 2]9.0 Security Considerations (69)9.1 Tunnel Endpoint Security (70)9.2 Packet Level Security (70)9.3 End to End Security (70)9.4 L2TP and IPsec (71)9.5 Proxy PPP Authentication (71)10.0 IANA Considerations (71)10.1 AVP Attributes (71)10.2 Message Type AVP Values (72)10.3 Result Code AVP Values (72)10.3.1 Result Code Field Values (72)10.3.2 Error Code Field Values (72)10.4 Framing Capabilities & Bearer Capabilities (72)10.5 Proxy Authen Type AVP Values (72)10.6 AVP Header Bits (73)11.0 References (73)12.0 Acknowledgments (74)13.0 Authors’ Addresses (75)Appendix A: Control Channel Slow Start and CongestionAvoidance (76)Appendix B: Control Message Examples (77)Appendix C: Intellectual Property Notice (79)Full Copyright Statement (80)1.0 IntroductionPPP [RFC1661] defines an encapsulation mechanism for transportingmultiprotocol packets across layer 2 (L2) point-to-point links.Typically, a user obtains a L2 connection to a Network Access Server (NAS) using one of a number of techniques (e.g., dialup POTS, ISDN,ADSL, etc.) and then runs PPP over that connection. In such aconfiguration, the L2 termination point and PPP session endpointreside on the same physical device (i.e., the NAS).L2TP extends the PPP model by allowing the L2 and PPP endpoints toreside on different devices interconnected by a packet-switchednetwork. With L2TP, a user has an L2 connection to an accessconcentrator (e.g., modem bank, ADSL DSLAM, etc.), and theconcentrator then tunnels individual PPP frames to the NAS. Thisallows the actual processing of PPP packets to be divorced from thetermination of the L2 circuit.One obvious benefit of such a separation is that instead of requiring the L2 connection terminate at the NAS (which may require along-distance toll charge), the connection may terminate at a (local) circuit concentrator, which then extends the logical PPP session over Townsley, et al. Standards Track [Page 3]a shared infrastructure such as frame relay circuit or the Internet.From the user’s perspective, there is no functional difference between having the L2 circuit terminate in a NAS directly or using L2TP.L2TP may also solve the multilink hunt-group splitting problem.Multilink PPP [RFC1990] requires that all channels composing amultilink bundle be grouped at a single Network Access Server (NAS).Due to its ability to project a PPP session to a location other thanthe point at which it was physically received, L2TP can be used tomake all channels terminate at a single NAS. This allows multilinkoperation even when the calls are spread across distinct physicalNASs.This document defines the necessary control protocol for on-demandcreation of tunnels between two nodes and the accompanyingencapsulation for multiplexing multiple, tunneled PPP sessions.1.1 Specification of RequirementsThe key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT","SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in thisdocument are to be interpreted as described in [RFC2119].1.2 TerminologyAnalog ChannelA circuit-switched communication path which is intended to carry3.1 kHz audio in each direction.Attribute Value Pair (AVP)The variable length concatenation of a unique Attribute(represented by an integer) and a Value containing the actualvalue identified by the attribute. Multiple AVPs make up ControlMessages which are used in the establishment, maintenance, andteardown of tunnels.CallA connection (or attempted connection) between a Remote System and LAC. For example, a telephone call through the PSTN. A Call(Incoming or Outgoing) which is successfully established between a Remote System and LAC results in a corresponding L2TP Sessionwithin a previously established Tunnel between the LAC and LNS.(See also: Session, Incoming Call, Outgoing Call).Townsley, et al. Standards Track [Page 4]Called NumberAn indication to the receiver of a call as to what telephonenumber the caller used to reach it.Calling NumberAn indication to the receiver of a call as to the telephone number of the caller.CHAPChallenge Handshake Authentication Protocol [RFC1994], a PPPcryptographic challenge/response authentication protocol in which the cleartext password is not passed over the line.Control ConnectionA control connection operates in-band over a tunnel to control the establishment, release, and maintenance of sessions and of thetunnel itself.Control MessagesControl messages are exchanged between LAC and LNS pairs,operating in-band within the tunnel protocol. Control messagesgovern aspects of the tunnel and sessions within the tunnel.Digital ChannelA circuit-switched communication path which is intended to carrydigital information in each direction.DSLAMDigital Subscriber Line (DSL) Access Module. A network device used in the deployment of DSL service. This is typically a concentrator of individual DSL lines located in a central office (CO) or local exchange.Incoming CallA Call received at an LAC to be tunneled to an LNS (see Call,Outgoing Call).Townsley, et al. Standards Track [Page 5]L2TP Access Concentrator (LAC)A node that acts as one side of an L2TP tunnel endpoint and is apeer to the L2TP Network Server (LNS). The LAC sits between anLNS and a remote system and forwards packets to and from each.Packets sent from the LAC to the LNS requires tunneling with theL2TP protocol as defined in this document. The connection fromthe LAC to the remote system is either local (see: Client LAC) or a PPP link.L2TP Network Server (LNS)A node that acts as one side of an L2TP tunnel endpoint and is apeer to the L2TP Access Concentrator (LAC). The LNS is thelogical termination point of a PPP session that is being tunneled from the remote system by the LAC.Management Domain (MD)A network or networks under the control of a singleadministration, policy or system. For example, an LNS’s Management Domain might be the corporate network it serves. An LAC’sManagement Domain might be the Internet Service Provider that owns and manages it.Network Access Server (NAS)A device providing local network access to users across a remoteaccess network such as the PSTN. An NAS may also serve as an LAC, LNS or both.Outgoing CallA Call placed by an LAC on behalf of an LNS (see Call, IncomingCall).PeerWhen used in context with L2TP, peer refers to either the LAC orLNS. An LAC’s Peer is an LNS and vice versa. When used in context with PPP, a peer is either side of the PPP connection.POTSPlain Old Telephone Service.Townsley, et al. Standards Track [Page 6]Remote SystemAn end-system or router attached to a remote access network (i.e.a PSTN), which is either the initiator or recipient of a call.Also referred to as a dial-up or virtual dial-up client.SessionL2TP is connection-oriented. The LNS and LAC maintain state foreach Call that is initiated or answered by an LAC. An L2TP Session is created between the LAC and LNS when an end-to-end PPPconnection is established between a Remote System and the LNS.Datagrams related to the PPP connection are sent over the Tunnelbetween the LAC and LNS. There is a one to one relationshipbetween established L2TP Sessions and their associated Calls. (See also: Call).TunnelA Tunnel exists between a LAC-LNS pair. The Tunnel consists of aControl Connection and zero or more L2TP Sessions. The Tunnelcarries encapsulated PPP datagrams and Control Messages betweenthe LAC and the LNS.Zero-Length Body (ZLB) MessageA control packet with only an L2TP header. ZLB messages are usedfor explicitly acknowledging packets on the reliable controlchannel.Townsley, et al. Standards Track [Page 7]2.0 TopologyThe following diagram depicts a typical L2TP scenario. The goal is to tunnel PPP frames between the Remote System or LAC Client and an LNS located at a Home LAN.[Home LAN][LAC Client]----------+ |____|_____ +--[Host]| | |[LAC]---------| Internet |-----[LNS]-----+| |__________| |_____|_____ :| || PSTN |[Remote]--| Cloud |[System] | | [Home LAN]|___________| || ______________ +---[Host]| | | |[LAC]-------| Frame Relay |---[LNS]-----+| or ATM Cloud | ||______________| :The Remote System initiates a PPP connection across the PSTN Cloud to an LAC. The LAC then tunnels the PPP connection across the Internet, Frame Relay, or ATM Cloud to an LNS whereby access to a Home LAN isobtained. The Remote System is provided addresses from the HOME LANvia PPP NCP negotiation. Authentication, Authorization and Accounting may be provided by the Home LAN’s Management Domain as if the userwere connected to a Network Access Server directly.A LAC Client (a Host which runs L2TP natively) may also participatein tunneling to the Home LAN without use of a separate LAC. In thiscase, the Host containing the LAC Client software already has aconnection to the public Internet. A "virtual" PPP connection is then created and the local L2TP LAC Client software creates a tunnel tothe LNS. As in the above case, Addressing, Authentication,Authorization and Accounting will be provided by the Home LAN’sManagement Domain.Townsley, et al. Standards Track [Page 8]3.0 Protocol OverviewL2TP utilizes two types of messages, control messages and datamessages. Control messages are used in the establishment, maintenance and clearing of tunnels and calls. Data messages are used toencapsulate PPP frames being carried over the tunnel. Controlmessages utilize a reliable Control Channel within L2TP to guarantee delivery (see section 5.1 for details). Data messages are notretransmitted when packet loss occurs.+-------------------+| PPP Frames |+-------------------+ +-----------------------+| L2TP Data Messages| | L2TP Control Messages |+-------------------+ +-----------------------+| L2TP Data Channel | | L2TP Control Channel || (unreliable) | | (reliable) |+------------------------------------------------+| Packet Transport (UDP, FR, ATM, etc.) |+------------------------------------------------+Figure 3.0 L2TP Protocol StructureFigure 3.0 depicts the relationship of PPP frames and ControlMessages over the L2TP Control and Data Channels. PPP Frames arepassed over an unreliable Data Channel encapsulated first by an L2TP header and then a Packet Transport such as UDP, Frame Relay, ATM,etc. Control messages are sent over a reliable L2TP Control Channelwhich transmits packets in-band over the same Packet Transport.Sequence numbers are required to be present in all control messagesand are used to provide reliable delivery on the Control Channel.Data Messages may use sequence numbers to reorder packets and detect lost packets.All values are placed into their respective fields and sent innetwork order (high order octets first).3.1 L2TP Header FormatL2TP packets for the control channel and data channel share a common header format. In each case where a field is optional, its space does not exist in the message if the field is marked not present. Notethat while optional on data messages, the Length, Ns, and Nr fieldsmarked as optional below, are required to be present on all controlmessages.Townsley, et al. Standards Track [Page 9]This header is formatted:0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+|T|L|x|x|S|x|O|P|x|x|x|x| Ver | Length (opt) |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Tunnel ID | Session ID |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Ns (opt) | Nr (opt) |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Offset Size (opt) | Offset pad... (opt)+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+Figure 3.1 L2TP Message HeaderThe Type (T) bit indicates the type of message. It is set to 0 for a data message and 1 for a control message.If the Length (L) bit is 1, the Length field is present. This bitMUST be set to 1 for control messages.The x bits are reserved for future extensions. All reserved bits MUST be set to 0 on outgoing messages and ignored on incoming messages.If the Sequence (S) bit is set to 1 the Ns and Nr fields are present. The S bit MUST be set to 1 for control messages.If the Offset (O) bit is 1, the Offset Size field is present. The Obit MUST be set to 0 (zero) for control messages.If the Priority (P) bit is 1, this data message should receivepreferential treatment in its local queuing and transmission. LCPecho requests used as a keepalive for the link, for instance, should generally be sent with this bit set to 1. Without it, a temporaryinterval of local congestion could result in interference withkeepalive messages and unnecessary loss of the link. This feature is only for use with data messages. The P bit MUST be set to 0 for allcontrol messages.Ver MUST be 2, indicating the version of the L2TP data message header described in this document. The value 1 is reserved to permitdetection of L2F [RFC2341] packets should they arrive intermixed with L2TP packets. Packets received with an unknown Ver field MUST bediscarded.The Length field indicates the total length of the message in octets. Townsley, et al. Standards Track [Page 10]Tunnel ID indicates the identifier for the control connection. L2TPtunnels are named by identifiers that have local significance only.That is, the same tunnel will be given different Tunnel IDs by eachend of the tunnel. Tunnel ID in each message is that of the intended recipient, not the sender. Tunnel IDs are selected and exchanged asAssigned Tunnel ID AVPs during the creation of a tunnel.Session ID indicates the identifier for a session within a tunnel.L2TP sessions are named by identifiers that have local significanceonly. That is, the same session will be given different Session IDsby each end of the session. Session ID in each message is that of the intended recipient, not the sender. Session IDs are selected andexchanged as Assigned Session ID AVPs during the creation of asession.Ns indicates the sequence number for this data or control message,beginning at zero and incrementing by one (modulo 2**16) for eachmessage sent. See Section 5.8 and 5.4 for more information on usingthis field.Nr indicates the sequence number expected in the next control message to be received. Thus, Nr is set to the Ns of the last in-ordermessage received plus one (modulo 2**16). In data messages, Nr isreserved and, if present (as indicated by the S-bit), MUST be ignored upon receipt. See section 5.8 for more information on using thisfield in control messages.The Offset Size field, if present, specifies the number of octetspast the L2TP header at which the payload data is expected to start. Actual data within the offset padding is undefined. If the offsetfield is present, the L2TP header ends after the last octet of theoffset padding.3.2 Control Message TypesThe Message Type AVP (see section 4.4.1) defines the specific type of control message being sent. Recall from section 3.1 that this is only for control messages, that is, messages with the T-bit set to 1. Townsley, et al. Standards Track [Page 11]This document defines the following control message types (seeSection 6.1 through 6.14 for details on the construction and use ofeach message):Control Connection Management0 (reserved)1 (SCCRQ) Start-Control-Connection-Request2 (SCCRP) Start-Control-Connection-Reply3 (SCCCN) Start-Control-Connection-Connected4 (StopCCN) Stop-Control-Connection-Notification5 (reserved)6 (HELLO) HelloCall Management7 (OCRQ) Outgoing-Call-Request8 (OCRP) Outgoing-Call-Reply9 (OCCN) Outgoing-Call-Connected10 (ICRQ) Incoming-Call-Request11 (ICRP) Incoming-Call-Reply12 (ICCN) Incoming-Call-Connected13 (reserved)14 (CDN) Call-Disconnect-NotifyError Reporting15 (WEN) WAN-Error-NotifyPPP Session Control16 (SLI) Set-Link-Info4.0 Control Message Attribute Value PairsTo maximize extensibility while still permitting interoperability, a uniform method for encoding message types and bodies is usedthroughout L2TP. This encoding will be termed AVP (Attribute-ValuePair) in the remainder of this document.Townsley, et al. Standards Track [Page 12]4.1 AVP FormatEach AVP is encoded as:0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+|M|H| rsvd | Length | Vendor ID |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Attribute Type | Attribute Value...+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+[until Length is reached]... |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+The first six bits are a bit mask, describing the general attributes of the AVP.Two bits are defined in this document, the remaining are reserved for future extensions. Reserved bits MUST be set to 0. An AVP receivedwith a reserved bit set to 1 MUST be treated as an unrecognized AVP. Mandatory (M) bit: Controls the behavior required of animplementation which receives an AVP which it does not recognize. If the M bit is set on an unrecognized AVP within a message associatedwith a particular session, the session associated with this messageMUST be terminated. If the M bit is set on an unrecognized AVP within a message associated with the overall tunnel, the entire tunnel (and all sessions within) MUST be terminated. If the M bit is not set, an unrecognized AVP MUST be ignored. The control message must thencontinue to be processed as if the AVP had not been present.Hidden (H) bit: Identifies the hiding of data in the Attribute Value field of an AVP. This capability can be used to avoid the passing of sensitive data, such as user passwords, as cleartext in an AVP.Section 4.3 describes the procedure for performing AVP hiding.Length: Encodes the number of octets (including the Overall Lengthand bitmask fields) contained in this AVP. The Length may becalculated as 6 + the length of the Attribute Value field in octets. The field itself is 10 bits, permitting a maximum of 1023 octets ofdata in a single AVP. The minimum Length of an AVP is 6. If thelength is 6, then the Attribute Value field is absent.Vendor ID: The IANA assigned "SMI Network Management PrivateEnterprise Codes" [RFC1700] value. The value 0, corresponding toIETF adopted attribute values, is used for all AVPs defined withinthis document. Any vendor wishing to implement their own L2TPextensions can use their own Vendor ID along with private Attribute Townsley, et al. Standards Track [Page 13]values, guaranteeing that they will not collide with any othervendor’s extensions, nor with future IETF extensions. Note that there are 16 bits allocated for the Vendor ID, thus limiting this featureto the first 65,535 enterprises.Attribute Type: A 2 octet value with a unique interpretation acrossall AVPs defined under a given Vendor ID.Attribute Value: This is the actual value as indicated by the Vendor ID and Attribute Type. It follows immediately after the AttributeType field, and runs for the remaining octets indicated in the Length (i.e., Length minus 6 octets of header). This field is absent if the Length is 6.4.2 Mandatory AVPsReceipt of an unknown AVP that has the M-bit set is catastrophic tothe session or tunnel it is associated with. Thus, the M bit shouldonly be defined for AVPs which are absolutely crucial to properoperation of the session or tunnel. Further, in the case where theLAC or LNS receives an unknown AVP with the M-bit set and shuts down the session or tunnel accordingly, it is the full responsibility ofthe peer sending the Mandatory AVP to accept fault for causing annon-interoperable situation. Before defining an AVP with the M-bitset, particularly a vendor-specific AVP, be sure that this is theintended consequence.When an adequate alternative exists to use of the M-bit, it should be utilized. For example, rather than simply sending an AVP with the M- bit set to determine if a specific extension exists, availability may be identified by sending an AVP in a request message and expecting a corresponding AVP in a reply message.Use of the M-bit with new AVPs (those not defined in this document)MUST provide the ability to configure the associated feature off,such that the AVP is either not sent, or sent with the M-bit not set.4.3 Hiding of AVP Attribute ValuesThe H bit in the header of each AVP provides a mechanism to indicate to the receiving peer whether the contents of the AVP are hidden orpresent in cleartext. This feature can be used to hide sensitivecontrol message data such as user passwords or user IDs.The H bit MUST only be set if a shared secret exists between the LAC and LNS. The shared secret is the same secret that is used for tunnel authentication (see Section 5.1.1). If the H bit is set in any Townsley, et al. Standards Track [Page 14]AVP(s) in a given control message, a Random Vector AVP must also bepresent in the message and MUST precede the first AVP having an H bit of 1.Hiding an AVP value is done in several steps. The first step is totake the length and value fields of the original (cleartext) AVP and encode them into a Hidden AVP Subformat as follows:0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Length of Original Value | Original Attribute Value ...+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+... | Padding ...+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+Length of Original Attribute Value: This is length of the OriginalAttribute Value to be obscured in octets. This is necessary todetermine the original length of the Attribute Value which is lostwhen the additional Padding is added.Original Attribute Value: Attribute Value that is to be obscured.Padding: Random additional octets used to obscure length of theAttribute Value that is being hidden.To mask the size of the data being hidden, the resulting subformatMAY be padded as shown above. Padding does NOT alter the value placed in the Length of Original Attribute Value field, but does alter thelength of the resultant AVP that is being created. For example, If an Attribute Value to be hidden is 4 octets in length, the unhidden AVP length would be 10 octets (6 + Attribute Value length). After hiding, the length of the AVP will become 6 + Attribute Value length + sizeof the Length of Original Attribute Value field + Padding. Thus, ifPadding is 12 octets, the AVP length will be 6 + 4 + 2 + 12 = 24octets.Next, An MD5 hash is performed on the concatenation of:+ the 2 octet Attribute number of the AVP+ the shared secret+ an arbitrary length random vectorThe value of the random vector used in this hash is passed in thevalue field of a Random Vector AVP. This Random Vector AVP must beplaced in the message by the sender before any hidden AVPs. The same random vector may be used for more than one hidden AVP in the same Townsley, et al. Standards Track [Page 15]message. If a different random vector is used for the hiding ofsubsequent AVPs then a new Random Vector AVP must be placed in thecommand message before the first AVP to which it applies.The MD5 hash value is then XORed with the first 16 octet (or less)segment of the Hidden AVP Subformat and placed in the Attribute Value field of the Hidden AVP. If the Hidden AVP Subformat is less than 16 octets, the Subformat is transformed as if the Attribute Value field had been padded to 16 octets before the XOR, but only the actualoctets present in the Subformat are modified, and the length of theAVP is not altered.If the Subformat is longer than 16 octets, a second one-way MD5 hash is calculated over a stream of octets consisting of the shared secret followed by the result of the first XOR. That hash is XORed with the second 16 octet (or less) segment of the Subformat and placed in the corresponding octets of the Value field of the Hidden AVP.If necessary, this operation is repeated, with the shared secret used along with each XOR result to generate the next hash to XOR the next segment of the value with.The hiding method was adapted from RFC 2138 [RFC2138] which was taken from the "Mixing in the Plaintext" section in the book "NetworkSecurity" by Kaufman, Perlman and Speciner [KPS]. A detailedexplanation of the method follows:Call the shared secret S, the Random Vector RV, and the AttributeValue AV. Break the value field into 16-octet chunks p1, p2, etc.with the last one padded at the end with random data to a 16-octetboundary. Call the ciphertext blocks c(1), c(2), etc. We will also define intermediate values b1, b2, etc.b1 = MD5(AV + S + RV) c(1) = p1 xor b1b2 = MD5(S + c(1)) c(2) = p2 xor b2. .. .. .bi = MD5(S + c(i-1)) c(i) = pi xor biThe String will contain c(1)+c(2)+...+c(i) where + denotesconcatenation.On receipt, the random vector is taken from the last Random VectorAVP encountered in the message prior to the AVP to be unhidden. The above process is then reversed to yield the original value.Townsley, et al. Standards Track [Page 16]。
rfc3281中文

3
2.术语
为了方便起见,在这个说明中我们使用了术语“客户端”和“服务器端” 。这不表示属 性证书只能用于 C/S 环境。例如,属性证书可以用于 S/MIME v3,在这种环境中使用这些 术语时,邮件客户代理既代表“客户端” ,同时也代表“服务器端” 。 术语 AA AC AC user AC verifier AC issuer AC holder Client Proxying PKC 含义 属性管理机构,颁发属性证书的实体,在本文档中和 AC issuer 同义 属性证书 解析或处理属性证书的实体 检查属性证书有效性的实体并且决定最后如何使用属性证书 签发属性证书的实体,在本文档中和 AA 同义 属性证书持有者字段中(可能是间接的)对应的实体 发出请求动作的实体,请求动作需要接受权限检查 在本文档中,Proxying 通常是指应用服务器端充当应用客户端,代表一个用 户的情况,并不是指授权机构的授权 公钥证书——使用 ASN.1 标准,在 X.509 中定义的证书格式和 RFC2459 中 定义的框架。使用这个(不规范的)缩略词是为了避免与术语“X.509 证书”混 淆 要求进行权限检查的实体
2
这意味着构造这样的应用只要求一次处理一个属性证书。 需要处理超过一个属性证书的 话, 一个接一个地处理。 然而要注意, 属性证书的有效性可能依赖于 PKCs 证书链的有效性, PKCs 证书链有效性的定义请参考[PKIXPROF]。
1.2 属性证书的分发(“推”和“拉”)
如上面讨论, 属性证书提供了一种机制, 这种机制安全地提供了授权信息来实现例如访 问控制决策等功能。然而,属性证书还有很多种可能的通信路径。 在一些环境下,比较适合的方法是从客户端“推”一个属性证书到服务器端。这样客户 端和服务器端不需要建立新的连接, 服务器端没有附加的搜索负担, 这样就改进了性能而且 属性证书验证者只提取“需要知道”的内容。 “推”模式适合于客户端的权限被分配在客户 端的“home”域以内的情况。 另一种情况, 它更适合于服务器端对客户端的简单鉴别, 服务器端从属性证书颁发者请 求或“拉”客户端的属性证书。使用“拉”模式主要的好处是它可以在不改变客户端或者客 户端/服务器端协议的情况下实现。 “拉”模式适合于客户端的权限被分配在服务器的域中, 而不是在客户端的域的情况。 可以交互信息的实体有三个:客户端,服务器端,还有属性证书颁发者。此外,为支 持属性证书检索还应该有一个目录服务器或者其他证书仓库。 图 1 描述了在各个实体间的交互信息(包括属性证书)的抽象视图。本文档没有对这 些交互规定特定的协议。
Introduction_to_x64_Assembly

DF
10 Direction
Direction string instructions operate (increment or decrement)
ID
21 Identification Changeability denotes presence of CPUID instruction
The floating point unit (FPU) contains eight registers FPR0-FPR7, status and control registers, and a few other specialized registers. FPR0-7 can each store one value of the types shown in Table 2. Floating point operations conform to IEEE 754. Note that most C/C++ compilers support the 32 and 64 bit types as float and double, but not the 80-bit one available from assembly. These registers share space with the eight 64-bit MMX registers.
Assembly is often used for performance-critical parts of a program, although it is difficult to outperform a good C++ compiler for most programmers. Assembly knowledge is useful for debugging code – sometimes a compiler makes incorrect assembly code and stepping through the code in a debugger helps locate the cause. Code optimizers sometimes make mistakes. Another use for assembly is interfacing with or fixing code for which you have no source code. Disassembly lets you change/fix existing executables. Assembly is necessary if you want to know how your language of choice works under the hood – why some things are slow and others are fast. Finally, assembly code knowledge is indispensable when diagnosing malware.
Rcpp快速参考指南说明书

return sum/n; // Obtain and return the Mean }
// Place dependent functions above call or // declare the function definition with: double muRcpp(NumericVector x);
double y0 = yy["foo"]; double y1 = yy["bar"];
// Matrix of 4 rows & 5 columns (filled with 0) NumericMatrix xx(4, 5);
// Fill with value int xsize = xx.nrow() * xx.ncol(); for (int i = 0; i < xsize; i++) {
for(int i = 0; i < n; i++){ sum += pow(x[i] - mean, 2.0); // Square
// [[Rcpp::export]]
2 | https:///package=Rcpp
Eddelbuettel and François
double varRcpp(NumericVector x, bool bias = true){ // Calculate the mean using C++ function double mean = muRcpp(x); double sum = 0; int n = x.size();
fortran for 用法

fortran for 用法Fortran is a programming language that was developed in the 1950s and is primarily used for scientific and engineering computations. In this article, we will explore the usage of Fortran, step by step, examining its features, syntax, and application areas.1. Introduction to Fortran:Fortran, short for Formula Translation, was developed by IBM as the first high-level programming language designed specifically for scientific and engineering calculations. It became popular due to its efficiency in handling numerical computations and remains extensively used in these fields.2. Features of Fortran:Fortran is known for its strong support for floating-point calculations, making it ideal for numerical simulations, mathematical modeling, and data analysis. It provides a range of built-in mathematical functions and libraries for complex mathematical operations. Fortran also supports arrays andmulti-dimensional data structures, allowing efficient data manipulation and processing.3. Syntax and Structure:Fortran programs are written in fixed-format style, where columns 1-6 are used for line labels, 7 is for a continuation character, and columns 8-72 are for statements and comments. The general structure of a Fortran program consists of declarations, executable statements, and subroutines or functions.4. Declaring Variables and Constants:In Fortran, variables and constants are declared using the "type" statement. The commonly used types include integer, real, and character. For example, to declare an integer variable called "count", we use the statement "integer :: count".5. Input and Output Operations:Fortran provides various standard input and output functions to interact with the user. The "read" statement is used to accept input from the user, while the "write" statement displays output on the screen or writes it to a file. For example, "read(*,*) x" reads a value into variable x from the default input source, and "write(*,*) x" displays the value of x on the screen.6. Control Structures:Fortran supports the standard control structures such as if-else, do-while, and do-loop. These control structures enable the program to make decisions and iterate over a set of statements based on specified conditions. Loops are particularly useful in performing repetitive tasks and computing over large datasets.7. Modular Programming:Modular programming, which promotes code reusability and organization, is supported in Fortran through the use of subroutines and functions. Subroutines are blocks of code that perform specific tasks and can be called from other parts of the program. Functions, on the other hand, return a value and can be used in expressions.8. Libraries and Extensions:Fortran provides a wide range of libraries and extensions to facilitate scientific and engineering computations. The most commonly used library is the Mathematical Library (MKL), which offers optimized routines for linear algebra, fast Fourier transforms, and numerical integration. Additionally, Fortran can be extended with modules written in other languages like C or C++.9. Parallel Computing:Fortran has excellent support for parallel computing, which allows programs to utilize multiple processors or cores for simultaneous execution. Libraries like OpenMP and MPI (Message Passing Interface) can be used to implement parallel algorithms in Fortran, increasing the speed and efficiency of computation-intensive tasks.10. Applications:Fortran is widely used in various scientific and engineering domains, including weather forecasting, computational physics, computational chemistry, and aerospace engineering. Its efficiency in handling large datasets and complex calculations makes it indispensable for numerical simulations and research purposes.In conclusion, Fortran is a powerful programming language that excels in numerical computations and is widely used in scientific and engineering fields. Its features, syntax, and extensive libraries make it an ideal choice for complex mathematical modeling, data analysis, and simulation tasks. With its continued development and support, Fortran remains a critical tool for scientists and engineers worldwide.。
系统出错提示(中英对照及对策)

系统出错提示(中英对照及对策)最近一些朋友一见到系统出错提示英文时,是一筹莫展,现介绍一些中英对照及对策,供朋友们在学习中参考。
[英文提示] Abort,Retry, Ignore,fail?[中文] 退出,重试,忽略,取消?[原因] 不能识别给出的命令、或发生了使命令不能执行的磁盘或设备错误,可能是磁盘损坏或软驱门没关。
[对策] 按A键彻底终止,并回到DOS提示符。
按R键重复执行该命令。
按I键继续处理,忽略错误,非常冒险,建议不要采用按F键不执行有问题的命令,继续下述处理。
有时会用到。
[英文提示] Access Denied[中文] 拒绝存取[原因] 试图打开一个标记为只读、存贮在写保护的磁盘上或锁定在网络上的文件。
如果在子目录上使用“Type”命令,或在文件上使用“CD(chdir)”命令,也会产生这个信息。
[对策] 应该用“Attrib”命令删除文件的只读状态或从磁盘中去掉写保护,然后再试试。
[英文提示] Bad Command or file name[中文] 错误的命令或文件名[原因] 不能识别输入的命令[对策] 应该检查以确保输入命令的正确性确认在指定目录或用Path命令指定的搜索路径上能找到命令文件。
[英文提示] Boot error[中文] 引导错误[原因] 在引导时检测不到应该的外设。
[对策] 应该检查计算机的设置参数,如用户自己不能解决这个问题,请找专门维修人员。
[英文提示] Cannot find system files[中文] 不能找到系统文件[原因] 试图从没有包含系统文件的驱动器上装入操作系统。
[对策] 应该用sys命令将系统文件复制到根目录中。
除非真的是不能恢复系统文件了,才可用Format/s命令重新格式化磁盘。
[英文提示] Cannot load command,system halted[中文] 不能加载command,系统中止[原因] 应用程序覆盖了内存中的所有或部分。
Contents

8
Zentrum fur ¨ Technomathematik Strong Symbols
Fachbereich 3 Mathematik und Informatik Henning Thielemann
Example: Computer algebra system Mathematica: In> Out> Replace all occurences of x by 2 ReplaceAll[Log [x],x->2] Log [2] Derive Log [x] with respect to x D[Log [x],x]
• Chemical formulas contain not enough information for synthesising substances or simulating reactions. • Musical scores allow for much interpretation. • Theorems in mathematical articles cannot be proven with a machine, calculations can’t be executed. • Computer programs can be executed by a machine, they can be processed by other programs, certain properties can even be proven! But programming language differ very much in robustness, simplicity, orthogonality, consistency, expressiveness.
x64文档

x641. Introduction to x64 Architecturex64, also known as x86-64 or AMD64, is a 64-bit extension of the x86 instruction set architecture. It was developed by AMD and later adopted by Intel. The x64 architecture offers several advantages over its 32-bit predecessor, including increased memory addressing capabilities, improved floating-point performance, and support for more general-purpose registers.2. Memory Addressing in x64In x64 architecture, the memory addressing space is expanded from 32 bits to 48 bits, allowing for a theoretical maximum of 256 TB of addressable memory. This increase in memory space is particularly beneficial for applications that require large amounts of memory, such as scientific simulations, database management systems, and virtualization.3. Registers in x64One of the key differences between x64 and x86 is the increased number of general-purpose registers. While x86 architecture has only 8 general-purpose registers, x64 architecture provides 16 general-purpose registers, including 8 integer registers (RAX, RBX, RCX, RDX, RSI, RDI, RBP, RSP) and 8 additional registers (R8, R9, R10, R11, R12, R13, R14, R15).4. Instruction Set ExtensionsThe x64 architecture introduced several new instruction set extensions, including SSE (Streaming SIMD Extensions), SSE2, SSE3, SSSE3, SSE4, AVX (Advanced Vector Extensions), AVX2, and AVX-512. These extensions provide support for parallel processing, floating-point operations, and other performance-enhancing features. Software developers can take advantage of these extensions to optimize their applications for the x64 architecture.5. Software CompatibilityOne important consideration when migrating from x86 to x64 is software compatibility. Most 32-bit applications can still run on a 64-bit operating system using a compatibility layer called WoW64 (Windows-on-Windows 64). However, some applications may require updates or modifications to work properly in a 64-bit environment. It is recommended to test and validate applications before deploying them on a x64 system.6. Performance BenefitsThe x64 architecture offers several performance benefits over its 32-bit predecessor. The increased memory addressing space allows applications to access more memory, resulting in improved performance for memory-intensive tasks. The additional general-purpose registers provide more storage for data manipulation, reducing the need for memory access. Furthermore, the instruction set extensions enable more efficient parallel processing and floating-point operations, resulting in faster execution of many applications.7. ConclusionThe x64 architecture provides significant enhancements over the previous x86 architecture. With its increased memory addressing capabilities, improved floating-point performance, and expanded set of general-purpose registers, x64 can handle more demanding applications and deliver better overall performance. Software developers should consider optimizing their applications for the x64 architecture to take full advantage of its benefits.。
Chapter02 Functions

volatile while
Not allowed, because an identifier is a token
7 Copyright © 2012 by The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
format_string plain characters – displayed directly unchanged on the screen, e.g. “This is C” conversion specification(s) – used to convert, format and display argument(s) from the argument_list escape sequences – control the cursor, for example, the newline ‘\n’
equal
10 Copyright © 2012 by The McGraw-Hill Companies, Inc. Permission required for reproduction or display.
printf
To display the value of a variable or constant on the screen printf(format_string,argument_list);
Need to make up your own variable names, e.g. lengths: a, b, c angles: a, b, g
For programming in C, the situation is similar choose the variable names, consist of entire words rather than single characters easier to understand your programs if given very descriptive names to each variable
on random graphs

The acyclic orientation gameon random graphsNoga Alon∗Zsolt Tuza†Dedicated to Professor Paul Erd˝o s on the occasion of his80th birthdayAbstractIt is shown that in the random graph G n,p with(fixed)edge probability p>0,the number of edges that have to be examined in order to identify anacyclic orientation isΘ(n log n)almost surely.For unrestricted p,an upperbound of O(n log3n)is established.Graphs G=(V,E)in which all edgeshave to be examined are considered,as well.1IntroductionIn this note we investigate the typical length of the following2-person game.Given a graph G=(V,E),in each step of the game player A(Algy)selects an edge e∈E and player S(Strategist)orients e in the way he likes;the only restriction is that S must not create a directed circuit.The game is over when the actually obtained partial orientation of G extends to a unique acyclic orientation.The goal of A is to locate such an orientation with as few questions as possible,while S aims at the opposite.Assuming that both A and S play optimally,the number of questions during the game on G is denoted by c(G).A different but equivalent formulation of this nice game wasfirst given by Manber and Tompa[8],who were motivated by a problem of testing whether a given coloring of a graph is a proper coloring.Some recent results concerning c(G)have been obtained by Aigner,Triesch and the second author in[1],including the generalestimatesn log nα−O(n)≤c(G)≤αn(lognα+1)(1)where n is the number of vertices,αdenotes the(vertex)independence number, and“log”means logarithm in base2.Let us note that a related lower bound can ∗Department of Mathematics,Raymond and Beverly Sackler Faculty of Exact Sciences,Tel Aviv University,Tel Aviv,Israel and School of Mathematics,Institute for Advanced Study,Princeton, NJ08540,USA.Research supported in part by a USA-Israeli BSF Grant and by the Sloan Foun-dation Grant No.93-6-6.†Computer and Automation Institute,Hungarian Academy of Sciences,H-1111Budapest, Kende u.13–17,Hungary.Research supported in part by the OTKA Research Fund of the Hun-garian Academy of Sciences,grant no.2569.1be deduced also from one of the results of[7]stating that a graph G with degree sequence d1,...,d n has at least n i=1((d i+1)!)1/(d i+1)acyclic orientations.This clearly implies that for any such G,c(G)≥ni=1logd i+1e.Let G n,p denote,as usual,the random graph on n labelled vertices with edge probability p.(See,e.g.,[6]for the model and some of its properties.)When the edge probability p isfixed,the above inequalities determine c(G n,p)within the accuracy of a multiplicative factor of O(log n)(with probability that tends to1as n tends to infinity).In the present note wefirst derive a more exact estimate,showing that in fact O(n log n)is the correct order of magnitude,i.e.,the lower bound is tight for all(fixed)p>0.Theorem1For anyfixed edge probability p>0,the random graph G=G n,p has c(G)=Θ(n log n)with probability1−o(1).Our argument proving the above theorem supplies very little information for the case where p(n)tends to zero as n gets large,and it remains an open problem to analyze the exact behavior of c(G n,p)where the edge probability p=p(n)tends to zero as n→∞.It may be true,however,that c(G n,p)=O(n log n)holds for all p. By(1),this bound,if true,would be tight for p=cn−c for all admissible choices of the constants c>0and0≤c <1.Note that the gap between the upper and lower bounds in(1)increases when p(n)decreases,and is a power of n when1/p(n)is a power of n.The next theorem supplies a much sharper estimate for sparse random graphs. Theorem2For any edge probability p=p(n),the random graph G=G n,p has c(G)=O(n log3n)with probability1−o(1).The proofs of Theorems1and2are different,but both combine some of the techniques used in the study of parallel comparison algorithms(see[3],[4],[2],[9]) with several new ideas.We note that the exponent of log n in Theorem2can be reduced slightly below3at the cost of making the argument somewhat more complicated,but—as this would not reduce the exponent to less than2,and as we suspect that the optimum value of the exponent is1actually—we do not present the more complicated proof.Let us recall from[1]that another challenging unsolved problem is to prove that c(G)≤1n2+o(n2)for all graphs G on n vertices.If valid,this upper bound would be best possible in general.We also note that there is no known sequence(G n)n>0of graphs,where G n has n vertices,for which the difference c(G n)−14n2tends toinfinity with n.The proofs of Theorems1and2are presented in Sections2and3,respectively. Thefinal Section4contains some comments on graphs G=(V,E)for which c(G)= |E|.22Fixed edge probabilityIn this section we prove Theorem1.For simplicity,we denote G n,p by G,where p is anyfixed positive edge probability.The argument is based on the following properties that hold for G almost surely.(Here and in what follows,“almost surely”always means“with probability that tends to1as n tends to infinity”.In addition, as usual,for two positive real functions f(x)and g(x),the notation f(x)=Θ(g(x)) means“f(x)=O(g(x))and g(x)=O(f(x))”.)1.For some function k=k(n)of orderΘ(log n),any two disjoint sets of k verticeseach are joined by at least one edge.2.There is a function k =k (n)=Θ(log n)such that,for any two disjoint setsX and Y of k vertices each,there is a vertex x∈X with at least k neighbors in Y,where k=k(n)is a function satisfying the requirements of(1)above. Thefirst property is well-known,and the second one is a fairly simple consequence of the Chernoffinequality.Indeed,the expected number of edges between X and Y is pc2log2n for k =c log n,while the nonexistence of x∈X with sufficiently many neighbors in Y would admit no more than kc log n edges;and the pair X,Y can be chosen in at most exp(2c log2n)different ways.Thus,choosing c sufficiently large (here“large”also depends on the value of the edge probability p)the requirement holds for all X and Y almost surely.An essential step in the proof of Theorem1is the following“deterministic”statement concerning linear extensions of partial orders.Tofix the notation,for an oriented acyclic digraph D=(V,A)we denote by D∗the transitive closure of D, i.e.,D∗=(V,A∗)is the smallest digraph in which A⊂A∗and xy,yz∈A∗implies xz∈A∗for all x,y,z∈V.Two vertices x,y∈V are comparable if xy∈A∗or yx∈A∗;for xy∈A∗we also say“x is smaller than y”or“y is larger than x”.A linear extension L of D is an ordering v1v2...v n of V such that i<j holds whenever v i is smaller than v j.In the next assertion we need not assume that the values of k and k are propor-tional to log n.Lemma3Suppose that the underlying undirected graph of an acyclic oriented graph D=(V,A)of order n satisfies the properties(1)and(2)above,for some k and k . Then,in every linear extension L=v1v2...v n of D,for every integer r between1 and n there is a subscript i(r−2k <i<r+2k )for which there are at least r−2k vertices smaller than v i and at least n−r−2k vertices larger than v i.Proof.Consider the set Y+={v i|r+k <i≤r+2k }.By(2),there are fewer than k vertices in{v j|1≤i≤r+k }having at most k−1neighbors in Y+.Denote by Z+the set of vertices v j having at least k neighbors in Y+,with j≤r+k .By(2),|Z+|>r holds.For each v j∈Z+,the(at least)k neighbors of v j in Y+dominate all but at most k−1vertices of{v i|r+2k <i≤n},by(1). Thus,every vertex v j∈Z+is smaller than at least k vertices in Y+and at least3n−r−k−2k vertices following Y+,i.e.,v j is smaller than at least n−r−2k vertices of D.Similarly,for the set Y−={v i|r−2k <i≤r−k }we canfind a set Z−⊆{v j|r−k <j≤n}of cardinality|Z−|>n−r such that every v j∈Z−is larger than k vertices of Y−and r−k−2k vertices preceding Y−,i.e.,v j is larger than at least r−2k vertices of D.Since|Z−|+|Z+|>n,we can choose a vertex w∈Z−∩Z+;this w=v i satisfies the requirements of the lemma.2We now turn to the proof of Theorem1,locating the acyclic orientation to be found,by applying an inductive algorithm.Let v be an arbitrary vertex of the random graph G=G n,p.Assuming that we have complete information about the orientation of G−v,we are going to show that the orientations of all edges incident to v can be determined by O(log n)questions(provided that G satisfies(1)and(2) above).If the orientation of G−v is not transitive,wefirst take its transitive closure, denoted D∗.Let D =(V ,E )be the subdigraph of D∗induced by the neighbors of v.Denoting n =|V |,let v1v2...v n be a linear extension of D .Tofind the orientations of all edges from v to V ,we are going to apply binary search on an appropriately chosen restricted set V ⊆V ,and then complete the algorithm with a few further questions.As we already know,by the properties(1)and(2),Lemma3implies that for every r(1≤r≤n )there is a vertex v i which is larger than r−2c log n vertices of V and smaller than n −r−2c log n vertices of V ,for some appropriately chosen constant c(we have taken k =c log n here;note that if G satisfies(1)and(2),so does its induced subgraph on the neighbors of v).Define V as the set of those i satisfying the above requirements for at least one value of r.Note that the gap between any two consecutive members of V is smaller than4c log n.Now,by a binary search on V we can locate a pair v i,v j∈V of vertices in log|V |<log n steps,such that v i is smaller than v,v is smaller than v j,and moreover i<j<i+4c log n.Since i and j belong to some initial values r=r i,r j of Lemma3with|r i−i|<2c log n and|r j−j|<2c log n,we can immediately conclude that v is larger than at least i−4c log n vertices of V ,and smaller than at least n −j−4c log n vertices of V .Thus,with at most12c log n further questions we can detect all orientations between v and V not known so far.Since the number of steps involving v is less than13c log n,the total number of questions required for G n,p does not exceed O(n log n).23Sparse random graphsIn this section we prove Theorem2.Given a graph G=(V,E),let the random strategy be the following strategy of player A:pick a random permutation e1,e2,...,e m of the edges of G and ask for the orientation of the edges in this order,where the orientation of the edge e i is probed if and only if it does not follow from the orientations of the edges e1,...,e i−1 (and the assumption that the orientation is acyclic).We claim that for every edge probability p,if player A applies this strategy on the random graph G=G n,p,then4almost surely he will not have to ask more than O(n log3n)questions even if hetells the order in which he is going to ask the questions to the Strategist already atthe beginning.This clearly implies the assertion of Theorem2.The advantage inconsidering this variation of the game is that since thefirst player A announces hisfull strategy already at the beginning,the second player S does not have to decidestep by step;instead,he can create his strategy at once,by choosing an acyclicorientation of G.Therefore,the version of the game we consider now is as follows.Player Achooses a random permutation e1,e2,...of the edges of G=G n,p and reports it tothe Strategist.The Strategist next chooses a linear order on the vertices of G andorients its edges according to this order(by orienting each edge from its smaller endto its larger end).The value of the game is the number of edges e i in the orientedgraph G that do not lie in the transitive closure of the oriented edges e1,...,e i−1,asthis is the number of questions A will actually have to ask.Therefore,our objectiveis to prove the following.Proposition4For any edge probability p and for a random ordering e1,e2,...ofthe set of edges of the random graph G n,p,the following holds almost surely.Forevery linear order of the vertices of G and for the associated acyclic orientation ofG,the number of oriented edges e i that do not lie in the transitive closure of theoriented edges e1,...,e i−1does not exceed O(n log3n).Notice that the subgraph of G n,p=(V,E)consisting of itsfirst i randomlychosen edges e1,...,e i—denoted by G i—is simply a random graph with i edges andn vertices.This fact plays a crucial role in our proof.It is worth noting that inview of this fact it suffices to prove the above proposition for the case p=1,i.e.,for the case that G is the complete graph.However,since this does not simplify theargument,we consider the general case G=G n,p.The proof relies on some of the ideas applied in the study of parallel comparisonalgorithms for approximation problems(see[2],[9],[3],[4]).In particular,we needthe following known result implicit in[2](cf.[9],[3]).Lemma5There exists an absolute constant b>0with the following property.LetG be a graph on n vertices in which there is at least one edge between any two disjointsets of q vertices each.Then,the number of edges in the transitive closure of anyacyclic orientation of G is at least n2 −bnq log n.2 The next lemma can be proved by a straightforward calculation which we omit. Lemma6There exists an absolute constant c so that for every i,n log n≤i≤ n2 , if G i is a random graph with n vertices and i edges,then the probability that G i hasat least one edge between any two disjoint sets of(cn2log n)/i vertices each is atleast1−1/n log n.2 Proof of Proposition 4.Throughout the proof we assume,whenever this is needed,that n is sufficiently large.To simplify the presentation,we make no attempt5to optimize the various multiplicative constants appearing here.Recall that for eachadmissible i≥1,G i denotes the subgraph of G=G n,p consisting of the edgese1,...,e i.By Lemma6,and since each G i is a random graph with i edges,thefollowing event denoted by E occurs almost surely:for every i≥n log n there is anedge of G i between any two disjoint sets of(cn2log n)/i vertices each.Fix a linear order L on the vertices of G,and let E L denote the event that thenumber of edges e i that do not lie in the transitive closure of the edges e1,...e i−1once these are oriented according to L exceeds32bcn log3n,where b and c are theconstants from Lemmas5and6,respectively.We next show that for eachfixedL,the conditional probability P rob[E L|E]is much smaller than1/n!.To do so,let us split the choice of the edges of G n,p and the random permutation on them intophases as follows.For each power of2,i.e.2j≥1,phase j consists of the choice of the edges e r for all2j≤r<2j+1of G(assuming G has at least that many edges). An equivalent,more precise,description of the random procedure of choosing the edges e i in the various phases is as follows.First choose the number m of edges of G according to a binomial distribution:P rob[m=s]= N s p s(1−p)N−s,where N= n2 .Next,starting with j=0,in phase j choose2j edges at random among the ones not chosen so far,as long as2j+1−1≤m.In the last phase,the one corresponding to the largest j for which2j≤m,we choose only m−2j+1random edges.Let E L,j denote the event that during phase j the number of edges e r that do not lie in the transitive closure of thefirst2j−1oriented edges exceeds16bcn log2n. Since E L is contained in the union∪j≥0E L,j(as the number of phases is less than 2log n),we haveP rob[E L|E]≤ j≥0P rob[E L,j|E].If2j≤16bcn log2n,then clearly P rob[E L,j|E]=0.For any larger j,observe thatP rob[E L,j|E]=P rob[E L,j∧E]P rob[E]≤2P rob[E L,j∧E].(Here we used the fact that P rob[E]≥1/2;in fact this probability is1−o(1).)However,if E happens then,by Lemma5,the transitive closure of the graph G2j−1 (oriented according to L)contains at least n2 −bcn3log2n j edges.If2j−1≥n2/16, then certainly the event E L,j will not occur,as the total number of edges which arenot in the transitive closure we consider is at most16bcn log2n.Otherwise,in phasej we are choosing2j(≤n2/16+1)edges at random among the n2 −2j+1≥(1+o(1))716n2remaining ones,and the number of edges among those which are notin the transitive closure of G2j−1is at most bcn3log2nj,i.e.,a fraction of at most(1+o(1))16bcn log2n7(2j−1)<3bcn log2n/2jof the remaining edges(here we assumed that n is large enough).Therefore,the expected number of edges chosen in the j th phase which are not in the transitive6closure of G2j−1is smaller than3bcn log2n.By standard estimates(see,e.g.,[5],Ap-pendix A,Theorem A.12)it follows that the probability that more than16bcn log2n such edges are chosen(i.e,that E L,j happens)is at most exp{−Ω(n log2n)}.This bounds P rob[E L,j∧E]and hence P rob[E L,j|E]as well,and implies that for every fixed L,P rob[E L|E]≤2log n exp{−Ω(n log2n)}.To complete the proof of the proposition,observe now that the probability that there exists a linear order L for which there are more than32bcn log3n edges e i that do not lie in the transitive closure of the previous edges is at mostP rob[E]+ L P rob[E L|E]·P rob[E]≤o(1)+2n!log n exp{−Ω(n log2n)},which tends to zero as n tends to infinity.This completes the proof of Proposition 4,and implies the assertion of Theorem2.24Exhaustive graphsTrivially,any(acyclic)orientation of a graph G=(V,E)can be identified by|E| questions.Call G exhaustive if it admits nothing better than this trivial algorithm, i.e.,if c(G)=|E|.We do not know too much about the structure of exhaustive graphs.It is observed in[1]that every bipartite graph is exhaustive,and it is alsoshown there that exhaustive graphs on n vertices have at most14n2edges(for alln≥6).Using arguments similar to those used in the proof of Theorem2we can show that a random graph with n vertices and more than n log n log log n edges is almost surely non-exhaustive.Similar techniques can be used to show that there are non-exhaustive graphs of arbitrarily high girth.A couple of small non-exhaustive graphs are mentioned in[1].The next proposition exhibits a further explicit example and answers a question raised in[1],where the authors wonder if there are line graphs of triangle-free cubic graphs which are non-exhaustive.Proposition7The line graph L(K3,3)of the complete bipartite graph K3,3is non-exhaustive.Proof.If three vertices x,y,z induce a triangle in an exhaustive graph and the orientation of precisely one edge,say x→z,is known,then the next answer concerning the edge xy or yz is determined,namely if xy(yz)is probed next then the answer must be x→y(y→z),for otherwise the orientation of the third edge of the triangle were determined by the other two.For such situations we shall use the shorthand“x→z forces x→y”or“x→z forces y→z”which will also mean that the next edge asked is xy or yz,respectively.Suppose now on the contrary that L(K3,3)is exhaustive.Assuming that the vertex classes of K3,3are{x1,x2,x3}and{y1,y2,y3},we denote by v ij the vertex of L(K3,3)that represents the edge x i y j;hence,v ij and v i j are adjacent if and only if i=i or j=j .At the beginning we ask about the orientations of v11v12and v13v23. By symmetry,we may assume without loss of generality that these two orientations7are v11→v12and v13→v23.Then we ask about v21v31and prove that either answer will allow us to save at least one question.Supposefirst v21→v31.Then v21→v31forces v21→v11and v11→v12 forces v11→v13,therefore the directed path v21→v11→v13→v23determines the orientation of v21→v23and this question need not be asked.Hence,suppose v31→v21.Then v31→v21forces v31→v11,v11→v12forces v11→v13,and v13→v23forces v13→v33.Thus,the directed path v31→v11→v13→v33 determines the orientation of v31→v33.2 We note that apart from the density-type results,so far the non-exhaustiveness of particular graphs has been proved by ad hoc arguments.It would be interesting to know more about the structural reasons that make a graph non-exhaustive.References[1]M.Aigner,E.Triesch and Zs.Tuza,Searching for acyclic orientations of graphs,to appear.[2]M.Ajtai,J.Koml´o s,W.L.Steiger and E.Szemer´e di,Almost sorting in one round,Advances in Computing Research,Vol.5,1989,JAI Press,117-126.[3]N.Alon and Y.Azar,Sorting,approximate sorting and searching in rounds,SIAMJ.Discrete Math.1(1988),269-280.[4]N.Alon and Y.Azar,Parallel comparison algorithms for approximation problems,Proc.29th IEEE FOCS,Yorktown Heights,NY,1988,194-203.Also:Combina-torica11(1991),97-122.[5]N.Alon and J.H.Spencer,“The Probabilistic Method”,Wiley,1991.[6] B.Bollob´a s,“Random Graphs”,Academic Press,1985.[7]N.Kahale and L.Schulman,Bounds on the chromatic polynomial and on thenumber of acyclic orientations of a graph,to appear.[8]U.Manber and M.Tompa,The effect of the number of Hamiltonian paths on thecomplexity of a vertex coloring problem,Proc.25th IEEE FOCS,Singer Island, Florida1984,220-227.[9]N.Pippenger,Sorting and selecting in rounds,SIAM put.6(1987),1032-1038.8。
The Small World Phenomenon An Algorithmic Perspective小世界现象,算法的角度

• Disproves usefulness of Watts & Strogatz model (r=0). • Only for special case of r = k, possible to find short
chains always of length O((log n)2) and dia = O(log n) (dia bound not proved by Kleinberg in this paper). • Cues used in small world networks propounded to be provided through a correlation between structure and distribution of long-range connections.
11
Major Ideas Contributed
• Gives a model of a small world network where local routing is possible using small paths.
• Shows the more generalized results for k dimensions in a subsequent publication.
ElmerParam 参数计算工具用户手册说明书

. If this keyword
is active all the input parameters and the function return value are
saved to a line that is appended in the given le.
Read parameters from the output le fname1 using the model le fname2. If fname2 isn't given, fname1.model is assumed.
Save File = fname
fname Save history data of all the computations in le
3 ElmerParam Files
ElmerParam routines need a number of dierent les with information on the problem to be solved.
• The ELMERPARAM_STARTINFO le has a xed name and has only one
tions of some parameters. It provides functions which take real and/or integer parameters as arguments, and return a scalar or vector of real output values:
f :Rn × Zm −→ R
or
f :Rn × Zm −→ Rk
n m where is the number of real parameters, the number of integer paramk eters, and the length of the return vector. These functions are from the
lam_MPI

Ohio Supercomputer Center The Ohio State UniversityUPERCOMPUTER S OHIOC E N T E R LAM is a parallel processing environment and development system for a network of independent computers. It features the Message-Passing Interface (MPI)programming standard,supported by extensive monitoring and debugging M / MPI Key Features:•full implementation of the MPI standard •extensive monitoring and debugging tools,runtime and post-mortem •heterogeneous computer networks •add and delete nodes •node fault detection and recovery •MPI extensions and LAM programming supplements •direct communication between application processes •robust MPI resource management •MPI-2 dynamic processes •multi-protocol communication (shared memory and network)MPI Primer /Developing With LAM2This document is organized into four major chapters. It begins with a tuto-rial covering the simpler techniques of programming and operation. New users should start with the tutorial. The second chapter is an MPI program-ming primer emphasizing the commonly used routines. Non-standard extensions to MPI and additional programming capabilities unique to LAM are separated into a third chapter. The last chapter is an operational refer-ence.It describes how to configure and start a LAM multicomputer,and how to monitor processes and messages.This document is user oriented. It does not give much insight into how the system is implemented. It does not detail every option and capability of every command and routine.An extensive set of manual pages cover all the commands and internal routines in great detail and are meant to supplement this document.The reader will note a heavy bias towards the C programming language,especially in the code samples.There is no Fortran version of this document.The text attempts to be language insensitive and the appendices contain For-tran code samples and routine prototypes.We have kept the font and syntax conventions to a minimum.code This font is used for things you type on the keyboard orsee printed on the screen.We use it in code sections andtables but not in the main text.<symbol>This is a symbol used to abstract something you wouldtype. We use this convention in commands.Section Italics are used to cross reference another section in thedocument or another document. Italics are also used todistinguish LAM commands.How to UseThisDocument3How to Use This Document 2LAM Architecture 7Debugging 7MPI Implementation 8How to Get LAM 8LAM / MPI Tutorial IntroductionProgramming Tutorial 9The World of MPI 10Enter and Exit MPI 10Who Am I; Who Are They? 10Sending Messages 11Receiving Messages 11Master / Slave Example 12Operation Tutorial 15Compilation 15Starting LAM 15Executing Programs 16Monitoring 17Terminating the Session 18MPI Programming PrimerBasic Concepts 19Initialization 21Basic Parallel Information 21Blocking Point-to-Point 22Send Modes 22Standard Send 22Receive 23Status Object 23Message Lengths 23Probe 24Nonblocking Point-to-Point 25Request Completion 26Probe 26Table ofContents4Message Datatypes 27Derived Datatypes 28Strided Vector Datatype 28Structure Datatype 29Packed Datatype 31Collective Message-Passing 34Broadcast 34Scatter 34Gather 35Reduce 35Creating Communicators 38Inter-communicators 40Fault Tolerance 40Process Topologies 41Process Creation 44Portable Resource Specification 45 Miscellaneous MPI Features 46Error Handling 46Attribute Caching 47Timing 48LAM / MPI ExtensionsRemote File Access 50Portability and Standard I/O 51 Collective I/O 52Cubix Example 54Signal Handling 55Signal Delivery 55Debugging and Tracing 56LAM Command ReferenceGetting Started 57Setting Up the UNIX Environment 575 Node Mnemonics 57Process Identification 58On-line Help 58Compiling MPI Programs 60Starting LAM 61recon 61lamboot 61Fault Tolerance 61tping 62wipe 62Executing MPI Programs 63mpirun 63Application Schema 63Locating Executable Files 64Direct Communication 64Guaranteed Envelope Resources 64Trace Collection 65lamclean 65Process Monitoring and Control 66mpitask 66GPS Identification 68Communicator Monitoring 69Datatype Monitoring 69doom 70Message Monitoring and Control 71mpimsg 71Message Contents 72bfctl 72Collecting Trace Data 73lamtrace 73Adding and Deleting LAM Nodes 74lamgrow 74lamshrink 74File Monitoring and Control 75fstate 75fctl 756Writing a LAM Boot Schema 76Host File Syntax 76Low Level LAM Start-up 77Process Schema 77hboot 77Appendix A: Fortran Bindings 79 Appendix B: Fortran Example Program 857LAM runs on each computer as a single daemon (server) uniquely struc-tured as a nano-kernel and hand-threaded virtual processes.The nano-kernel component provides a simple message-passing,rendez-vous service to local processes. Some of the in-daemon processes form a network communica-tion subsystem,which transfers messages to and from other LAM daemons on other machines.The network subsystem adds features such as packetiza-tion and buffering to the base synchronization. Other in-daemon processes are servers for remote capabilities, such as program execution and parallel file access.The layering is quite distinct:the nano-kernel has no connection with the network subsystem, which has no connection with the ers can configure in or out services as necessary.The unique software engineering of LAM is transparent to users and system administrators, who only see a conventional daemon. System developers can de-cluster the daemon into a daemon containing only the nano-kernel and several full client processes. This developers’ mode is still transparent to users but exposes LAM’s highly modular components to simplified indi-vidual debugging.It also reveals LAM’s evolution from Trollius,which ran natively on scalable multicomputers and joined them to a host network through a uniform programming interface.The network layer in LAM is a documented,primitive and abstract layer on which to implement a more powerful communication standard like MPI (PVM has also been implemented).A most important feature of LAM is hands-on control of the multicomputer.There is very little that cannot be seen or changed at runtime. Programs residing anywhere can be executed anywhere,stopped,resumed,killed,and watched the whole time. Messages can be viewed anywhere on the multi-computer and buffer constraints tuned as experience with the application LAMArchitecturelocal msgs, client mgmt network msgs MPI, client / server cmds, apps, GUIs Figure 1: LAM’s Layered Design Debugging8dictates.If the synchronization of a process and a message can be easily dis-played, mismatches resulting in bugs can easily be found. These and other services are available both as a programming library and as utility programs run from any shell.MPI synchronization boils down to four variables:context,tag,source rank,and destination rank.These are mapped to LAM’s abstract synchronization at the network layer. MPI debugging tools interpret the LAM information with the knowledge of the LAM / MPI mapping and present detailed infor-mation to MPI programmers.A significant portion of the MPI specification can be and is implemented within the runtime system and independent of the underlying environment.As with all MPI implementations, LAM must synchronize the launch of MPI applications so that all processes locate each other before user code is entered. The mpirun command achieves this after finding and loading the program(s) which constitute the application. A simple SPMD application can be specified on the mpirun command line while a more complex config-uration is described in a separate file, called an application schema.MPI programs developed on LAM can be moved without source code changes to any other platform that supports M installs anywhere and uses the shell’s search path at all times to find LAM and application executables.A multicomputer is specified as a simple list of machine names in a file, which LAM uses to verify access, start the environment, and remove M is freely available under a GNU license via anonymous ftp from.MPIImplementationHow to Get LAM9LAM / MPI Tutorial Introduction The example programs in this section illustrate common operations in MPI.You will also see how to run and debug a program with LAM.For basic applications, MPI is as easy to use as any other message-passing library.The first program is designed to run with exactly two processes.Oneprocess sends a message to the other and then both terminate.Enter the fol-lowing code in trivial.c or obtain the source from the LAM source distribu-tion (examples/trivial/trivial.c)./** Transmit a message in a two process system.*/#include <mpi.h>#define BUFSIZE 64int buf[64];intmain(argc, argv)int argc;char *argv[];{int size, rank;MPI_Status status;/** Initialize MPI.*/MPI_Init(&argc, &argv);/** Error check the number of processes.* Determine my rank in the world group.ProgrammingTutorial10 * The sender will be rank 0 and the receiver, rank 1. */MPI_Comm_size(MPI_COMM_WORLD, &size);if (2 != size) {MPI_Finalize();return(1);}MPI_Comm_rank(MPI_COMM_WORLD, &rank);/* * As rank 0, send a message to rank 1. */if (0 == rank) {MPI_Send(buf, sizeof(buf), MPI_INT, 1, 11,MPI_COMM_WORLD);}/* * As rank 1, receive a message from rank 0. */else {MPI_Recv(buf, sizeof(buf), MPI_INT, 0, 11,MPI_COMM_WORLD, &status);}MPI_Finalize();return(0);}Note that the program uses standard C program structure, statements, vari-able declarations and types, and functions.Processes are represented by a unique “rank” (integer) and ranks are num-bered 0, 1, 2, ..., N-1. MPI_COMM_WORLD means “all the processes in the MPI application.” It is called a communicator and it provides all infor-mation necessary to do message-passing. Portable libraries do more with communicators to provide synchronization protection that most other mes-sage-passing systems cannot handle.As with other systems, two routines are provided to initialize and cleanup an MPI process:MPI_Init(int *argc, char ***argv);MPI_Finalize(void);Typically, a process in a parallel application needs to know who it is (its rank)and how many other processes exist.A process finds out its own rankby calling MPI_Comm_rank().The World ofMPIEnter and ExitMPIWho Am I; WhoAre They?MPI_Comm_rank(MPI_Comm comm, int *rank);The total number of processes is returned by MPI_Comm_size().MPI_Comm_size(MPI_Comm comm, int *size);A message is an array of elements of a given datatype.MPI supports all the basic datatypes and allows a more elaborate application to construct new datatypes at runtime.A message is sent to a specific process and is marked by a tag (integer)spec-ified by the user. Tags are used to distinguish between different message types a process might send/receive.In the example program above,the addi-tional synchronization offered by the tag is unnecessary.Therefore,any ran-dom value is used that matches on both sides.MPI_Send(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm);A receiving process specifies the tag and the rank of the sending process.MPI_ANY_TAG and MPI_ANY_SOURCE may be used to receive a mes-sage of any tag and from any sending process.MPI_Recv(void *buf, int count, MPI_Datatypedtype, int source, int tag, MPI_Comm comm,MPI_Status *status);Information about the received message is returned in a status variable. If wildcards are used, the received message tag is status.MPI_TAG and the rank of the sending process is status.MPI_SOURCE.Another routine, not used in the example program, returns the number of datatype elements received.It is used when the number of elements received might be smaller than number specified to MPI_Recv().It is an error to send more elements than the receiving process will accept.MPI_Get_count(MPI_Status, &status,MPI_Datatype dtype, int *nelements);SendingMessagesReceivingMessagesThe following example program is a communication skeleton for a dynam-ically load balanced master/slave application. The source can be obtainedfrom the LAM source distribution (examples/trivial/ezstart.c).The program is designed to work with a minimum of two processes:one master and one slave.#include <mpi.h>#define WORKTAG 1#define DIETAG 2#define NUM_WORK_REQS 200static void master();static void slave();/**main* This program is really MIMD, but is written SPMD for * simplicity in launching the application.*/intmain(argc, argv)int argc;char *argv[];{int myrank;MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD,/* group of everybody */&myrank);/* 0 thru N-1 */if (myrank == 0) {master();} else {slave();}MPI_Finalize();return(0);}/**master* The master process sends work requests to the slaves * and collects results.*/static voidmaster(){int ntasks, rank, work;double result;MPI_Status status;MPI_Comm_size(MPI_COMM_WORLD,&ntasks);/* #processes in app */Master / SlaveExample/** Seed the slaves.*/work = NUM_WORK_REQS;/* simulated work */for (rank = 1; rank < ntasks; ++rank) {MPI_Send(&work,/* message buffer */1,/* one data item */MPI_INT,/* of this type */rank,/* to this rank */WORKTAG,/* a work message */MPI_COMM_WORLD);/* always use this */ work--;}/** Receive a result from any slave and dispatch a new work* request until work requests have been exhausted.*/while (work > 0) {MPI_Recv(&result,/* message buffer */1,/* one data item */MPI_DOUBLE,/* of this type */MPI_ANY_SOURCE,/* from anybody */MPI_ANY_TAG,/* any message */MPI_COMM_WORLD,/* communicator */&status);/* recv’d msg info */MPI_Send(&work, 1, MPI_INT, status.MPI_SOURCE,WORKTAG, MPI_COMM_WORLD);work--;/* simulated work */ }/** Receive results for outstanding work requests.*/for (rank = 1; rank < ntasks; ++rank) {MPI_Recv(&result, 1, MPI_DOUBLE, MPI_ANY_SOURCE,MPI_ANY_TAG, MPI_COMM_WORLD, &status);}/** Tell all the slaves to exit.*/for (rank = 1; rank < ntasks; ++rank) {MPI_Send(0, 0, MPI_INT, rank, DIETAG,MPI_COMM_WORLD);}}/**slave* Each slave process accepts work requests and returns* results until a special termination request is received. */static voidslave(){double result;int work;MPI_Status status;for (;;) {MPI_Recv(&work, 1, MPI_INT, 0, MPI_ANY_TAG,MPI_COMM_WORLD, &status);/** Check the tag of the received message.*/if (status.MPI_TAG == DIETAG) {return;}sleep(2);result = 6.0;/* simulated result */MPI_Send(&result, 1, MPI_DOUBLE, 0, 0,MPI_COMM_WORLD);}}The workings of ranks,tags and message lengths should be mastered before constructing serious MPI applications.Before running LAM you must establish certain environment variables and search paths for your shell. Add the following commands or equivalent to your shell start-up file (.cshrc,assuming C shell).Do not add these to your .login as they would not be effective on remote machines when rsh is used to start LAM.setenv LAMHOME <LAM installation directory>set path = ($path $LAMHOME/bin)The local system administrator,or the person who installed LAM,will know the location of the LAM installation directory. After editing the shell start-up file,invoke it to establish the new values.This is not necessary on subse-quent logins to the UNIX system.% source .cshrc Many LAM commands require one or more nodeids.Nodeids are specified on the command line as n<list>, where <list> is a list of comma separated nodeids or nodeid ranges.n1n1,3,5-10The mnemonic ‘h’refers to the local node where the command is typed (as in ‘here’).Any native C compiler is used to translate LAM programs for execution.All LAM runtime routines are found in a few libraries. LAM provides a wrap-ping command called hcc which invokes cc with the proper header and library directories, and is used exactly like the native cc.% hcc -o trivial trivial.c -lmpi The major,internal LAM libraries are automatically linked.The MPI library is explicitly linked.Since LAM supports heterogeneous computing,it is up to the user to compile the source code for each of the various CPUs on their respective machines. After correcting any errors reported by the compiler,proceed to starting the LAM session.Before starting LAM,the user specifies the machines that will form the mul-ticomputer. Create a host file listing the machine names, one on each line.An example file is given below for the machines “ohio” and “osc”. Lines starting with the # character are treated as comment lines.OperationTutorialCompilationStarting LAM# a 2-node LAM ohio osc The first machine in the host file will be assigned nodeid 0, the second nodeid 1,etc.Now verify that the multicomputer is ready to run LAM.The recon tool checks if the user has access privileges on each machine in the multicomputer and if LAM is installed and accessible.% recon -v <host file>If recon does not report a problem, proceed to start the LAM session with the lamboot tool.% lamboot -v <host file>The -v (verbose)option causes lamboot to report on the start-up process as it progresses. You should return to the your own shell’s prompt. LAM pre-sents no special shell or interface environment.Even if all seems well after start-up,verify communication with each node.tping is a simple confidence building command for this purpose.% tping n0Repeat this command for all nodes or ping all the nodes at once with the broadcast mnemonic,N.tping responds by sending a message between the local node (where the user invoked tping)and the specified node.Successful execution of tping proves that the target node, nodes along the route from the local node to the target node,and the communication links between them are working properly. If tping fails, press Control-Z, terminate the session with the wipe tool and then restart the system.See Terminating the Session .To execute a program,use the mpirun command.The first example program is designed to run with two processes.The -c <#>option runs copies of thegiven program on nodes selected in a round-robin manner.% mpirun -v -c 2 trivialThe example invocation above assumes that the program is locatable on the machine on which it will run. mpirun can also transfer the program to the target node before running it.Assuming your multicomputer for this tutorial is homogeneous, you can use the -s h option to run both processes.% mpirun -v -c 2 -s h trivialExecutingProgramsIf the processes executed correctly,they will terminate and leave no traces.If you want more feedback,try using tprintf()functions within the program.The first example program runs too quickly to be monitored.Try changingthe tag in the call to MPI_Recv() to 12 (from 11). Recompile the program and rerun it as before. Now the receiving process cannot synchronize with the message from the send process because the tags are unequal.Look at the status of all MPI processes with the mpitask command.You will notice that the receiving process is blocked in a call to MPI_Recv()- a synchronizing message has not been received. From the code we know this is process rank 1in the MPI application,which is confirmed in the first column,the MPI task identification.The first number is the rank within the world group.The second number is the rank within the communicator being used by MPI_Recv(), in this case (and in many applications with simple communication structure)also the world group.The specified source of the message is likewise identified.The synchronization tag is 12and the length of the receive buffer is 64 elements of type MPI_INT.The message was transferred from the sending process to a system buffer en route to process rank 1.MPI_Send()was able to return and the process has called MPI_Finalize().System buffers,which can be thought of as message queues for each MPI process,can be examined with the mpimsg command.The message shows that it originated from process rank 0 usingMPI_COMM_WORLD and that it is waiting in the message queue of pro-cess rank 1, the destination. The tag is 11 and the message contains 64 ele-ments of type MPI_INT. This information corresponds to the arguments given to MPI_Send(). Since the application is faulty and will never com-plete, we will kill it with the lamclean command.% lamclean -vMonitoring % mpitaskTASK (G/L)FUNCTION PEER|ROOT TAG COMM COUNT DATATYPE 0/0 trivialFinalize 1/1 trivial Recv 0/012WORLD 64INT % mpimsgSRC (G/L)DEST (G/L)TAG COMM COUNT DATATYPE MSG 0/01/111WORLD 64INT n1,#0The LAM session should be in the same state as after invoking lamboot.You can also terminate the session and restart it with lamboot,but this is a much slower operation. You can now correct the program, recompile and rerun.To terminate LAM, use the wipe tool. The host file argument must be the same as the one given to lamboot.% wipe -v <host file>Terminating theSessionMPI Programming PrimerBasic ConceptsThrough Message Passing Interface(MPI)an application views its parallelenvironment as a static group of processes.An MPI process is born into theworld with zero or more siblings. This initial collection of processes iscalled the world group.A unique number,called a rank,is assigned to eachmember process from the sequence0through N-1,where N is the total num-ber of processes in the world group.A member can query its own rank andthe size of the world group.Processes may all be running the same program(SPMD) or different programs (MIMD). The world group processes maysubdivide,creating additional subgroups with a potentially different rank ineach group.A process sends a message to a destination rank in the desired group.A pro-cess may or may not specify a source rank when receiving a message.Mes-sages are further filtered by an arbitrary, user specified, synchronizationinteger called a tag, which the receiver may also ignore.An important feature of MPI is the ability to guarantee independent softwaredevelopers that their choice of tag in a particular library will not conflictwith the choice of tag by some other independent developer or by the enduser of the library.A further synchronization integer called a context is allo-cated by MPI and is automatically attached to every message.Thus,the fourmain synchronization variables in MPI are the source and destination ranks,the tag and the context.A communicator is an opaque MPI data structure that contains informationon one group and that contains one context.A communicator is an argumentto all MPI communication routines.After a process is created and initializes MPI, three predefined communicators are available.MPI_COMM_WORLD the world groupMPI_COMM_SELF group with one member, myselfMPI_COMM_PARENT an intercommunicator between two groups:my world group and my parent group (SeeDynamic Processes.)Many applications require no other communicators beyond the world com-municator.If new subgroups or new contexts are needed,additional commu-nicators must be created.MPI constants, templates and prototypes are in the MPI header file, mpi.h. #include <mpi.h>MPI_Init Initialize MPI state.MPI_Finalize Clean up MPI state.MPI_Abort Abnormally terminate.MPI_Comm_size Get group process count.MPI_Comm_rank Get my rank within process group.MPI_Initialized Has MPI been initialized?The first MPI routine called by a program must be MPI_Init(). The com-mand line arguments are passed to MPI_Init().MPI_Init(int *argc, char **argv[]);A process ceases MPI operations with MPI_Finalize().MPI_Finalize(void);In response to an error condition,a process can terminate itself and all mem-bers of a communicator with MPI_Abort().The implementation may report the error code argument to the user in a manner consistent with the underly-ing operation system.MPI_Abort (MPI_Comm comm, int errcode);Two numbers that are very useful to most parallel applications are the total number of parallel processes and self process identification. This informa-tion is learned from the MPI_COMM_WORLD communicator using the routines MPI_Comm_size() and MPI_Comm_rank().MPI_Comm_size (MPI_Comm comm, int *size);MPI_Comm_rank (MPI_Comm comm, int *rank);Of course, any communicator may be used, but the world information is usually key to decomposing data across the entire parallel application.InitializationBasic ParallelInformationMPI_Send Send a message in standard mode.MPI_Recv Receive a message.MPI_Get_count Count the elements received.MPI_Probe Wait for message arrival.MPI_Bsend Send a message in buffered mode.MPI_Ssend Send a message in synchronous mode.MPI_Rsend Send a message in ready mode.MPI_Buffer_attach Attach a buffer for buffered sends.MPI_Buffer_detach Detach the current buffer.MPI_Sendrecv Send in standard mode, then receive.MPI_Sendrecv_replace Send and receive from/to one area.MPI_Get_elements Count the basic elements received.This section focuses on blocking,point-to-point,message-passing routines.The term “blocking”in MPI means that the routine does not return until the associated data buffer may be reused. A point-to-point message is sent by one process and received by one process.The issues of flow control and buffering present different choices in design-ing message-passing primitives. MPI does not impose a single choice but instead offers four transmission modes that cover the synchronization,data transfer and performance needs of most applications.The mode is selected by the sender through four different send routines, all with identical argu-ment lists. There is only one receive routine. The four send modes are:standard The send completes when the system can buffer the mes-sage (it is not obligated to do so)or when the message is received.buffered The send completes when the message is buffered in application supplied space, or when the message is received.synchronous The send completes when the message is received.ready The send must not be started unless a matching receive has been started. The send completes immediately.Standard mode serves the needs of most applications.A standard mode mes-sage is sent with MPI_Send().MPI_Send (void *buf, int count, MPI_Datatypedtype, int dest, int tag, MPI_Comm comm); BlockingPoint-to-PointSend ModesStandard SendAn MPI message is not merely a raw byte array. It is a count of typed ele-ments.The element type may be a simple raw byte or a complex data struc-ture. See Message Datatypes .The four MPI synchronization variables are indicated by the MPI_Send()parameters. The source rank is the caller’s. The destination rank and mes-sage tag are explicitly given.The context is a property of the communicator.As a blocking routine, the buffer can be overwritten when MPI_Send()returns.Although most systems will buffer some number of messages,espe-cially short messages,without any receiver,a programmer cannot rely upon MPI_Send() to buffer even one message. Expect that the routine will not return until there is a matching receiver.A message in any mode is received with MPI_Recv().MPI_Recv (void *buf, int count, MPI_Datatype dtype, int source, int tag, MPI_Comm comm,MPI_Status *status);Again the four synchronization variables are indicated,with source and des-tination swapping places. The source rank and the tag can be ignored with the special values MPI_ANY_SOURCE and MPI_ANY_TAG.If both these wildcards are used, the next message for the given communicator is received.An argument not present in MPI_Send()is the status object pointer.The sta-tus object is filled with useful information when MPI_Recv()returns.If the source and/or tag wildcards were used,the actual received source rank and/or message tag are accessible directly from the status object.status.MPI_SOURCE the sender’s rank status.MPI_TAG the tag given by the sender It is erroneous for an MPI program to receive a message longer than thespecified receive buffer. The message might be truncated or an error condi-tion might be raised or both.It is completely acceptable to receive a message shorter than the specified receive buffer. If a short message may arrive, the application can query the actual length of the message withMPI_Get_count().MPI_Get_count (MPI_Status *status,MPI_Datatype dtype, int *count);ReceiveStatus ObjectMessage Lengths。
BBC Microcomputer Model B ISO-Pascal说明书

for the BBC Microcomputer Model BContentsISO-Pascal on two language ROMsA disc (suitable for 40 or 80 track disc drives) containing an extended compiler for systems with a 6502 Second Processor and various extensions and demon-stration programs, details of which are given overleafInstructions for inserting the ISO-Pascal language ROMs in the BBC Microcomputer (leaflet enclosed)Pascal from BASIC - a tutorial course in PascalISO-Pascal on the BBC Microcomputer and Acorn Electron - the reference manual for Acornsoft ISO-PascalA reference cardA function key card for use with the editorLoading instructionsInstructions for entering ISO-Pascal are given at the beginning of ISO-Pascal on the BBC Microcomputer and Acorn Electron.Command summaryThe immediate mode commands available in Acornsoft ISO-Pascal are as follows: CLOSEClose all open files on the selected filing systemCOMPILECompile to and from memory.COMPILE source fileCompile from source file memory.COMPILE > object-fileCompile from memory to object file.COMPILE source-file object-fileCompile from source file to object file.EDIT [source-file]Call the editor, optionally loading a source file.GO [arguments]RUN the object file in memory, passing the optional arguments if the T option was used at compilation.LOAD object-fileLoad the specified object file.MODE numberChange the display mode to the one specifiedRUN object-file [arguments]Load and run the specified code file.SAVE object-fileSave the memory code file under the name givenTRACE [0, 1 or 2]Set the current TRACE levelEditor pattern matchingPatterns used by the search and replace commands in the ISO-Pascal text editor consist of combinations of literal text with special characters. Literal text is case independent except when used with the special characters (to indicate ranges etc).The special search characters are as follows:matches any charactermatches any alphanumeric (0-9, A-Z, a-z and _)matches any digit (0-9)matches any of ‘x’, ‘y’ and ‘z’matches any character between ‘a’ and ‘z’ (inclusive)matches the carriage return charactermatches CTRL. cmatches the DELETE character (ASCII127)matches character code c+128matches anything but c (c may be wildcard)matches c (where c would otherwise have a special meaning)matches zero or more of c (shortest match)Examples:$* $matches all blank lines#*#~#matches all integer constantsThe special characters available for replacements are:carriage returnCTRL cDELETEcharacter code c+128c (where c would otherwise have a special meaning)whatever was matched by the patternfield number n (0-9). where a field is a wildcard character, a multiplematch (* c), an inverted match ( ~c), a range (a-z) or a choice([13579]). Fields are numbered from the leftmost (which is 0). Examples:#/&&duplicates all digits (eg 12 becomes 1122).. /%1%0 reverses alternate characters (eg r2d3 becomes 2r3d)E d i t o r c o m m a n d s u m m a r yThe cursor movement and function key commands available in the editor are as follows:BBC editor Up arrow Down arrow Left arrow Right arrow SHIFT up SHIFT down SHIFT left SHIFT right CTRL up CTRL down DELETE COPY SHIFT COPY TABf0flf2f3f4f5f6f7f8f9 SHIFT f0 SHIFT fl SHIFT f2 SHIFT f3 SHIFT f4 SHIFT f5 SHIFT f6 SHIFT f7 SHIFT f8 SHIFT f9FunctionMove up to a lineMove down a lineMove left a characterMove right a characterMove up a pageMove down a pageMove to start of lineMove to end of lineMove to top of textMove to end of textDelete left of the cursorDelete at the cursorInitiate cursor-edit modeMove cursor to non-spaceFind a line numberIssue MOS commandLoad the text in a fileSave the text to a fileFind and replace a stringGlobal count/replace stringSet markerCopy a block of textSend text to printerRestore old textToggle <CR> displayToggle insert/overtypeInsert text from a file*** NOT USED ***Quit from the editor*** NOT USED ***Clear marker(s)Move a block of textDelete a block of textDelete the textElectron editorUp arrowDown arrowLeft arrowRight arrowFUNC NFUNC MFUNC <FUNC >FUNC ZFUNC XDELETECOPYFUNC :FUNC AFUNC QFUNC WFUNC EFUNC RFUNC TFUNC YFUNC UFUNC IFUNC OFUNC PFUNC 1FUNC 2FUNC 3FUNC 4FUNC 5FUNC 6FUNC 7FUNC 8FUNC 9FUNC 0E r r o r n u m b e r s/m e s s a g e s p r o d u c e d b y t h e c o m p i l e rThe table below lists all of the error numbers that the compiler produces, and the messages that are associated with them These messages are printed automatically when {$F+} compiler option is specified when using discs Additional information is printed by specifying the {$<CTRL@> +} option in the first lime of the source file.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16Variable identifier expectedComma expected / missing parameter.‘ ’ expected.‘ : ’ expected’ ; ’ expectedType mismatch‘(’ expected‘)’ expected‘(’ expected‘]’ expectedCan’t assign a real to an integer.RHS not compatible with LHS type mismatchBad statement startNot LSO-Pascal (use compiler option X+ to allow extensions). Equals expectedIf INPUT or OUTPUT is used then it must be declared in program header.17 18 19 20Missing parameter(s). Parameter can’t be a packed var. Missing semicolon21 22 23 24 25 26 27For loop control variable must be declared in the variable declaration part of this procedure / functionAssignment operator ‘:=’ expected‘..’ expectedActual and formal parameters should both be either packed or unpacked A label was declared in this block but was not definedHex number too large.Variable too big for memory.Too much code for code buffer, claim larger area using compiler option ‘C’.28 29 30 31 32 33 34Set base type must be max0 .. 255. BEGIN expectedToo many procedures (max 127). Missing body of FORWARD pro/func DO expectedLabel not declared35 36This label does not prefix a statement which is in the same statement sequence that contains the GOTO statementEND expected / missing semicolonThis label should prefix a statement at the outermost level of statement nesting in a block37Label not declared in this block 38Label already defined39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80Label already declaredLabel must be a sequence of digits 0 to 9999.Array element selector is not the same type as the array’s index type. Unpacked array variable expectedComponent types of both arrays must be the same.OF expectedPacked array variable expectedCan’t pass a conformant array as a value parameter.PROGRAM expectedCan’t pass a bound identifier as a var parameter.Function result type mismatchFormal parameter is a procedure and actual parameter is a function or vice versaTHEN expectedTO expectedProcedural/functional parameter expectedUNTIL expectedCan’t altar the value of this variable because it is the control variable of an active FOR loop.Control variable must be an entire variable ie not an array element or field of a recordToo many digitsPremature end of file.Can only output integers in hexToo many parametersString parameter expectedUndeclared identifier expectedFor loop initial & final values must be same type as control variable.For loop control variable must be ordinal type.Record’s field identifier expectedCan only assign value to current function identifier.Current function identifier is only allowed on LHS of assignment Ordinal parameter expectedParameter must be a file variable.Parameter must be a textfile.Constant already specifies a variant part in this recordConstant does not specify a variantVariant constant/ tag-type mismatchToo many variant constants.Pointer’s base type must be record in order to have variant constants Formal parameters have the same conformant array type but the actual parameters are not of the same type.Can only have variant constants if type pointed to is a recordSet base type and IN operand are not the same type.Real parameter expectedReal / integer parameter expected81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127Integer parameter expectedText file variable expectedFilename string expectedTemp files do not have filenamesCan’t have a file as a parameter to READ/WRITE.File and parameter type mismatchCan’t read / write this type.Only reals can have a decimal place.File must be of type TEXT to do WRITELN/READLN.Type mismatch between actual and formal parameter.Procedure/function has no arguments.File variable expectedBad filename.Control variable threatened by nested procedure / function Procedural parameter list mismatchFunction id is unassignedStructured types containing a file component cannot be assigned to each other.File type must be TEXT to allow use of field widthsCan’t assign value to function parameter identifier.Set of all tag-constants does not equal the set of all values specified by the tag- type.Can’t pass tag-field as var paramA variable appeared in the program header but was not definedToo many stmt sequences (max 255).Can’t redefine identifier because it has been used earlier in this block No hex reals allowedCan only pack conformant arrays.Case value must be ordinal type.Index limits out of range.Standard file already declaredFile variable expectedConstant expectedCan’t sign non-numeric expressions.Type mismatch between case constant and case expressionBad pointer type.Type identifier expectedDuplicate case constantSubrange limits must be scalar.Upper and lower limits must be same type.Low bound exceeds high boundOrdinal type expectedToo many dimensions for interpreter.Set member must have ordinal type.Can’t have file of file(s).Set member must have an ordinal value of 0 to 255.Unresolved pointer type.Function type expectedD i g i t e x p e c t e d.128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164Function type must be ordinal, real or pointer.Illegal character detectedUnexpected EOF in a comment or a string constantFile already declared permanentUnresolved pointer base type.Pointer base type identifier is not a type identifier.Structured type expectedTag type expectedOrdinal constant expectedField does not belong to this recordProcedure or function id expectedSets are not of the same base type.Procedure/function already declaredVariant selector type does not match variant constant type. Pointer type expectedPermanent files must be declared in global variable section. Packed conformant arrays must be single dimensionCan’t change this compiler option once it is setComponent type mismatchSet members must have the same type.Variable is not a file or pntr type.Missing index / spurious commaVariable is not a recordVariable is not an array.Numbers must be terminated by a non alphabetic character. Permanent file not declared in global variable sectionDecimal places field-width must be an integer expressionField-width must be integer value.Can’t assign a value to a conformant array bound identifier. Can’t have EOLN in string constantsCan’t have a file variable contained in a value parameter.Illegal operation on these operands.Index type mismatchBoolean type expectedCan’t use function id in this way.Integer operands needed for this operation.Procedure identifier has been used before its defining occurrence.{ These are fatal errors and cause termination of the compilation }165Id table overflow (increase table size using compiler option ‘I’). 166Too many nested records / procedures167To compile using disc Pascal, use DCOMP <source> <object>. 168Code and source filenames the same.。
Intel X64位简介
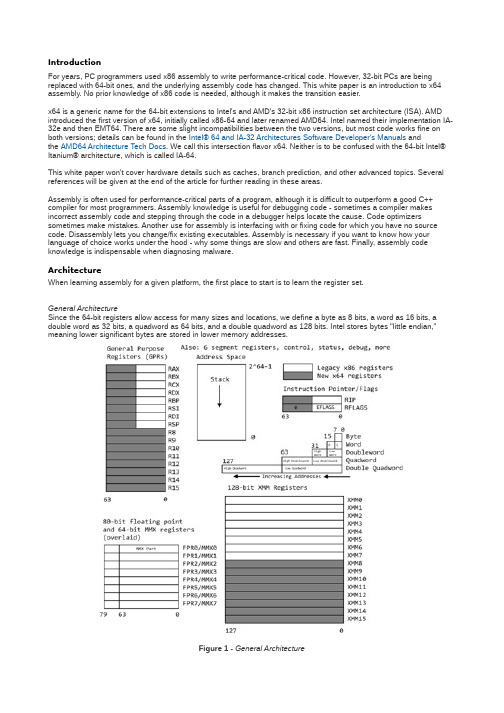
IntroductionFor years, PC programmers used x86 assembly to write performance-critical code. However, 32-bit PCs are being replaced with 64-bit ones, and the underlying assembly code has changed. This white paper is an introduction to x64 assembly. No prior knowledge of x86 code is needed, although it makes the transition easier.x64 is a generic name for the 64-bit extensions to Intel's and AMD's 32-bit x86 instruction set architecture (ISA). AMD introduced the first version of x64, initially called x86-64 and later renamed AMD64. Intel named their implementation IA-32e and then EMT64. There are some slight incompatibilities between the two versions, but most code works fine on both versions; details can be found in the Intel® 64 and IA-32 Architectures Software Developer's Manuals andthe AMD64 Architecture Tech Docs. We call this intersection flavor x64. Neither is to be confused with the 64-bit Intel® Itanium® architecture, which is called IA-64.This white paper won't cover hardware details such as caches, branch prediction, and other advanced topics. Several references will be given at the end of the article for further reading in these areas.Assembly is often used for performance-critical parts of a program, although it is difficult to outperform a good C++ compiler for most programmers. Assembly knowledge is useful for debugging code - sometimes a compiler makes incorrect assembly code and stepping through the code in a debugger helps locate the cause. Code optimizers sometimes make mistakes. Another use for assembly is interfacing with or fixing code for which you have no source code. Disassembly lets you change/fix existing executables. Assembly is necessary if you want to know how your language of choice works under the hood - why some things are slow and others are fast. Finally, assembly code knowledge is indispensable when diagnosing malware.ArchitectureWhen learning assembly for a given platform, the first place to start is to learn the register set.General ArchitectureSince the 64-bit registers allow access for many sizes and locations, we define a byte as 8 bits, a word as 16 bits, a double word as 32 bits, a quadword as 64 bits, and a double quadword as 128 bits. Intel stores bytes "little endian," meaning lower significant bytes are stored in lower memory addresses.Figure 1 - General ArchitectureFigure 1 shows sixteen general purpose 64-bit registers, the first eight of which are labeled (for historical reasons) RAX, RBX, RCX, RDX, RBP, RSI, RDI, and RSP. The second eight are named R8-R15. By replacing the initial R with an E on the first eight registers, it is possible to access the lower 32 bits (EAX for RAX). Similarly, for RAX, RBX, RCX, and RDX, access to the lower 16 bits is possible by removing the initial R (AX for RAX), and the lower byte of the these by switching the X for L (AL for AX), and the higher byte of the low 16 bits using an H (AH for AX). The new registers R8 to R15 can be accessed in a similar manner like this: R8 (qword), R8D (lower dword), R8W (lowest word), R8B (lowest byte MASM style, Intel style R8L). Note there is no R8H.There are odd limitations accessing the byte registers due to coding issues in the REX opcode prefix used for the new registers: an instruction cannot reference a legacy high byte (AH, BH, CH, DH) and one of the new byte registers at the same time (such as R11B), but it can use legacy low bytes (AL, BL, CL, DL). This is enforced by changing (AH, BH, CH, DH) to (BPL, SPL, DIL, SIL) for instructions using a REX prefix.The 64-bit instruction pointer RIP points to the next instruction to be executed, and supports a 64-bit flat memory model. Memory address layout in current operating systems is covered later.The stack pointer RSP points to the last item pushed onto the stack, which grows toward lower addresses. The stack is used to store return addresses for subroutines, for passing parameters in higher level languages such as C/C++, and for storing "shadow space" covered in calling conventions.The RFLAGS register stores flags used for results of operations and for controlling the processor. This is formed from the x86 32-bit register EFLAGS by adding a higher 32 bits which are reserved and currently unused. Table 1 lists the most useful flags. Most of the other flags are used for operating system level tasks and should always be set to the value previously read.Table 1 - Common FlagsSymbol Bit Name Set if...CF0Carry Operation generated a carry or borrowPF2Parity Last byte has even number of 1's, else 0AF4Adjust Denotes Binary Coded Decimal in-byte carryZF6Zero Result was 0SF7Sign Most significant bit of result is 1OF11Overflow Overflow on signed operationDF10Direction Direction string instructions operate (increment or decrement)ID21Identification Changeability denotes presence of CPUID instructionThe floating point unit (FPU) contains eight registers FPR0-FPR7, status and control registers, and a few other specialized registers. FPR0-7 can each store one value of the types shown in Table 2. Floating point operations conform to IEEE 754. Note that most C/C++ compilers support the 32 and 64 bit types as float and double, but not the 80-bit one available from assembly. These registers share space with the eight 64-bit MMX registers.Table 2 - Floating Point TypesData Type Length Precision (bits)Decimal digitsPrecisionDecimal RangeSingle Precision32247 1.18*10^-38 to 3.40*10^38Double Precision6453152.23 *10^-308 to 1.79*10^308Extended Precision 8064193.37*10^-4932 to1.18*10^4932Binary Coded Decimal (BCD) is supported by a few 8-bit instructions, and an oddball format supported on the floating point registers gives an 80 bit, 17 digit BCD type.The sixteen 128-bit XMM registers (eight more than x86) are covered in more detail.Final registers include segment registers (mostly unused in x64), control registers, memory management registers, debug registers, virtualization registers, performance registers tracking all sorts of internal parameters (cachehits/misses, branch hits/misses, micro-ops executed, timing, and much more). The most notable performance opcode is RDTSC, which is used to count processor cycles for profiling small pieces of code.Full details are available in the five-volume set "Intel® 64 and IA-32 Architectures Software Developer's Manuals"at /products/processor/manuals/. They are available for free download as PDF, order on CD, and often can be ordered for free as a hardcover set when listed.SIMD ArchitectureSingle Instruction Multiple Data (SIMD) instructions execute a single command on multiple pieces of data in parallel and are a common usage for assembly routines. MMX and SSE commands (using the MMX and XMM registers respectively) support SIMD operations, which perform an instruction on up to eight pieces of data in parallel. For example, eight bytes can be added to eight bytes in one instruction using MMX.The eight 64-bit MMX registers MMX0-MMX7 are aliased on top of FPR0-7, which means any code mixing FP and MMX operations must be careful not to overwrite required values. The MMX instructions operate on integer types, allowing byte, word, and doubleword operations to be performed on values in the MMX registers in parallel. Most MMX instructions begin with 'P' for "packed". Arithmetic, shift/rotate, comparison, e.g.: PCMPGTB "Compare packed signed byte integers for greater than".The sixteen 128-bit XMM registers allow parallel operations on four single or two double precision values per instruction. Some instructions also work on packed byte, word, doubleword, and quadword integers. These instructions, called the Streaming SIMD Extensions (SSE), come in many flavors: SSE, SSE2, SSE3, SSSE3, SSE4, and perhaps more by the time this prints. Intel has announced more extensions along these lines called Intel® Advanced Vector Extensions (Intel® AVX), with a new 256-bit-wide datapath. SSE instructions contain move, arithmetic, comparison, shuffling and unpacking, and bitwise operations on both floating point and integer types. Instruction names include such beauties as PMULHUW and RSQRTPS. Finally, SSE introduced some instructions for memory pre-fetching (for performance) and memory fences (for multi-threaded safety).Table 3 lists some command sets, the register types operated on, the number of items manipulated in parallel, and the item type. For example, using SSE3 and the 128-bit XMM registers, you can operate on 2 (must be 64-bit) floating point values in parallel, or even 16 (must be byte sized) integer values in parallel.To find which technologies a given chip supports, there is a CPUID instruction that returns processor-specific information. Table 3Technology Register size/type Item type Items in Parallel MMX64 MMX Integer8, 4, 2, 1SSE64 MMX Integer8,4,2,1SSE128 XMM Float4SSE2/SSE3/SSSE3...64 MMX Integer2,1SSE2/SSE3/SSSE3...128 XMM Float2SSE2/SSE3/SSSE3...128 XMM Integer16,8,4,2,1T oolsAssemblersAn Internet search reveals x64-capable assemblers such as the Netwide Assembler NASM, a NASM rewritecalled YASM, the fast Flat Assembler FASM, and the traditional Microsoft MASM. There is even a free IDE for x86 andx64 assembly called WinASM. Each assembler has varying support for other assemblers' macros and syntax, but assembly code is not source-compatible across assemblers like C++ or Java* are.For the examples below, I use the 64-bit version of MASM, ML64.EXE, freely available in the platform SDK. For the examples below note that MASM syntax is of the form Instruction Destination, SourceSome assemblers reverse source and destination, so read your documentation carefully.C/C++ CompilersC/C++ compilers often allow embedding assembly in the code using inline assembly, but Microsoft Visual Studio* C/C++ removed this for x64 code, likely to simplify the task of the code optimizer. This leaves two options: use separate assembly files and an external assembler, or use intrinsics from the header file "intrn.h" (see Birtolo and MSDN). Other compilers feature similar options.Some reasons to use intrinsics:•Inline asm not supported in x64.•Ease of use: you can use variable names instead of having to juggle register allocation manually.•More cross-platform than assembly: the compiler maker can port the intrinsics to various architectures.•The optimizer works better with intrinsics.For example, Microsoft Visual Studio* 2008 has an intrinsicunsigned short _rot16(unsigned short a, unsigned char b)which rotates the bits in a 16-bit value right b bits and returns the answer. Doing this in C givesunsigned short a1 = (b>>c)|(b<<(16-c));which expands to fifteen assembly instructions (in debug builds - in release builds whole program optimization made it harder to separate, but it was of a similar length), while using the equivalent intrinsicunsigned short a2 = _rotr16(b,c);expands to four instructions. For more information read the header file and documentation.Instruction BasicsAddressing ModesBefore covering some basic instructions, you need to understand addressing modes, which are ways an instruction can access registers or memory. The following are common addressing modes with examples:•Immediate: the value is stored in the instruction. ADD EAX, 14 ; add 14 into 32-bit EAX•Register to register ADD R8L, AL ; add 8 bit AL into R8L•Indirect: this allows using an 8, 16, or 32 bit displacement, any general purpose registers for base and index, and a scale of 1, 2, 4, or 8 to multiply the index. Technically, these can also be prefixed with segment FS: or GS: but this is rarely required. MOV R8W, 1234[8*RAX+RCX] ; move word at address 8*RAX+RCX+1234 into R8WThere are many legal ways to write this. The following are equivalentMOV ECX, dword ptr table[RBX][RDI]MOV ECX, dword ptr table[RDI][RBX]MOV ECX, dword ptr table[RBX+RDI]MOV ECX, dword ptr [table+RBX+RDI]The dword ptr tells the assembler how to encode the MOV instruction.•RIP-relative addressing: this is new for x64 and allows accessing data tables and such in the code relative to the current instruction pointer, making position independent code easier to implement.MOV AL, [RIP] ; RIP points to the next instruction aka NOPNOPUnfortunately, MASM does not allow this form of opcode, but other assemblers like FASM and YASM do. Instead, MASM embeds RIP-relative addressing implicitly.MOV EAX, TABLE ; uses RIP- relative addressing to get table address•Specialized cases: some opcodes use registers in unique ways based on the opcode. For example, signed integer division IDIV on a 64 bit operand value divides the 128-bit value in RDX:RAX by the value, storing the resultin RAX and the remainder in RDX.Instruction SetTable 4 lists some common instructions. * denotes this entry is multiple opcodes where the * denotes a suffix.Table 4 - Common OpcodesOpcode Meaning Opcode MeaningMOV Move to/from/betweenmemory and registersAND/OR/XOR/NOT Bitwise operationsCMOV*Various conditionalmovesSHR/SARShift rightlogical/arithmeticXCHG Exchange SHL/SAL Shift left logical/arithmeticBSWAP Byte swap ROR/ROL Rotate right/leftPUSH/POP Stack usage RCR/RCL Rotate right/left through carry bitADD/ADC Add/with carry BT/BTS/BTR Bit test/and set/and resetSUB/SBC Subtract/with carry JMP Unconditional jumpMUL/IMUL Multiply/unsigned JE/JNE/JC/JNC/J*Jump if equal/not equal/carry/not carry/ many othersDIV/IDIV Divide/unsigned LOOP/LOOPE/LOOPNELoop with ECXINC/DEC Increment/Decrement CALL/RET Call subroutine/return NEG Negate NOP No operationCMP Compare CPUID CPU informationA common instruction is the LOOP instruction, which decrements RCX, ECX, or CX depending on usage, and then jumps if the result is not 0. For example,XOR EAX, EAX ; zero out eaxMOV ECX, 10 ; loop 10 timesLabel: ; this is a label in assemblyINX EAX ; increment eaxLOOP Label ; decrement ECX, loop if not 0Less common opcodes implement string operations, repeat instruction prefixes, port I/O instructions, flag set/clear/test, floating point operations (begin usually with a F, and support move, to/from integer, arithmetic, comparison, transcendental, algebraic, and control functions), cache and memory opcodes for multithreading and performance issues, and more. The Intel® 64 and IA-32 Architectures Software Developer's Manual Volume 2, in two parts, covers each opcode in detail.Operating Systems64-bit systems allow addressing 264 bytes of data in theory, but no current chips allow accessing all 16 exabytes (18,446,744,073,709,551,616 bytes). For example, AMD architecture uses only the lower 48 bits of an address, and bits 48 through 63 must be a copy of bit 47 or the processor raises an exception. Thus addresses are 0 through00007FFF`FFFFFFFF, and from FFFF8000`00000000 through FFFFFFFF`FFFFFFFF, for a total of 256 TB(281,474,976,710,656 bytes) of usable virtual address space. Another downside is that addressing all 64 bits of memory requires a lot more paging tables for the OS to store, using valuable memory for systems with less than all 16 exabytes installed. Note these are virtual addresses, not physical addresses.As a result, many operating systems use the higher half of this space for the OS, starting at the top and growing down, while user programs use the lower half, starting at the bottom and growing upwards. Current Windows* versions use 44 bits of addressing (16 terabytes = 17,592,186,044,416 bytes). The resulting addressing is shown in Figure 2. The resulting addresses are not too important for user programs since addresses are assigned by the OS, but the distinction between user addresses and kernel addresses are useful for debugging.A final OS-related item relates to multithreaded programming, but this topic is too large to cover here. The only mention is that there are memory barrier opcodes for helping to keep shared resources uncorrupted.Figure 2 - Memory AddressingCalling ConventionsInterfacing with operating system libraries requires knowing how to pass parameters and manage the stack. These details on a platform are called a calling convention.A common x64 calling convention is the Microsoft 64 calling convention used for C style function calling(see MSDN, Chen, and Pietrek). Under Linux* this would be called an Application Binary Interface (ABI). Note the calling convention covered here is different than the one used on x64 Linux* systems.For the Microsoft* x64 calling convention, the additional register space let fastcall be the only calling convention (under x86 there were many: stdcall, thiscall, fastcall, cdecl, etc.). The rules for interfacing with C/C++ style functions:•RCX, RDX, R8, R9 are used for integer and pointer arguments in that order left to right.•XMM0, 1, 2, and 3 are used for floating point arguments.•Additional arguments are pushed on the stack left to right.•Parameters less than 64 bits long are not zero extended; the high bits contain garbage.•It is the caller's responsibility to allocate 32 bytes of "shadow space" (for storing RCX, RDX, R8, and R9 if needed) before calling the function.•It is the caller's responsibility to clean the stack after the call.•Integer return values (similar to x86) are returned in RAX if 64 bits or less.•Floating point return values are returned in XMM0.•Larger return values (structs) have space allocated on the stack by the caller, and RCX then contains a pointer to the return space when the callee is called. Register usage for integer parameters is then pushed one to the right. RAX returns this address to the caller.•The stack is 16-byte aligned. The "call" instruction pushes an 8-byte return value, so the all non-leaf functions must adjust the stack by a value of the form 16n+8 when allocating stack space.•Registers RAX, RCX, RDX, R8, R9, R10, and R11 are considered volatile and must be considered destroyed on function calls.•RBX, RBP, RDI, RSI, R12, R14, R14, and R15 must be saved in any function using them.•Note there is no calling convention for the floating point (and thus MMX) registers.•Further details (varargs, exception handling, stack unwinding) are at Microsoft's site.ExamplesArmed with the above, here are a few examples showing x64 usage. The first is a simple x64 standalone assembly program that pops up a Windows MessageBox.; Sample x64 Assembly Program; Chris Lomont 2009 extrn ExitProcess: PROC ; external functions in system librariesextrn MessageBoxA: PROC.datacaption db '64-bit hello!', 0message db 'Hello World!', 0.codeStart PROCsub rsp,28h ; shadow space, aligns stackmov rcx, 0 ; hWnd = HWND_DESKTOPlea rdx, message ; LPCSTR lpTextlea r8, caption ; LPCSTR lpCaptionmov r9d, 0 ; uType = MB_OKcall MessageBoxA ; call MessageBox API functionmov ecx, eax ; uExitCode = MessageBox(...)call ExitProcessStart ENDPEndSave this as hello.asm, compile this with ML64, available in the Microsoft Windows* x64 SDK as follows:ml64 hello.asm /link /subsystem:windows /defaultlib:kernel32.lib /defaultlib:user32.lib /entry:Startwhich makes a windows executable and links with appropriate libraries. Run the resulting executable hello.exe and you should get the message box to pop up.The second example links an assembly file with a C/C++ file under Microsoft Visual Studio* 2008. Other compiler systems are similar. First make sure your compiler is an x64-capable version. Then1.Create a new empty C++ console project. Create a function you'd like to port to assembly, and call it from main.2.To change the default 32-bit build, select Build/Configuration Manager.3.Under Active Platform, select New...4.Under Platform, select x64. If it does not appear figure out how to add the 64-bit SDK tools and repeat.pile and step into the code. Look under Debug/Windows/Disassembly to see the resulting code and interfaceneeded for your assembly function.6.Create an assembly file, and add it to the project. It defaults to a 32 bit assembler which is fine.7.Open the assembly file properties, select all configurations, and edit the custom build step.8.Put command lineml64.exe /DWIN_X64 /Zi /c /Cp /Fl /Fo $(IntDir)\$(InputName).obj $(InputName).asmand set outputs to$(IntDir)\$(InputName).obj9.Build and run.For example, in main.cpp we put a function CombineC that does some simple math on five integer parameters and one double parameter, and returns a double answer. We duplicate that functionality in assembly in a separate file CombineA.asm in a function called CombineA. The C++ file is:// C++ code to demonstrate x64 assembly file linking#include <iostream>using namespace std;double CombineC(int a, int b, int c, int d, int e, double f){return (a+b+c+d+e)/(f+1.5);}// NOTE: extern "C" needed to prevent C++ name manglingextern "C" double CombineA(int a, int b, int c, int d, int e, double f);int main(void){cout << "CombineC: " << CombineC(1,2,3,4, 5, 6.1) << endl;cout << "CombineA: " << CombineA(1,2,3,4, 5, 6.1) << endl;return 0;}Be sure to make functions extern "C" linkage to prevent C++ name mangling. Assembly file CombineA.asm contains; Sample x64 Assembly Program.datarealVal REAL8 +1.5 ; this stores a real number in 8 bytes.codePUBLIC CombineACombineA PROCADD ECX, DWORD PTR [RSP+28H] ; add overflow parameter to first parameterADD ECX, R9D ; add other three register parametersADD ECX, R8D ;ADD ECX, EDX ;MOVD XMM0, ECX ; move doubleword ECX into XMM0CVTDQ2PD XMM0, XMM0 ; convert doubleword to floating pointMOVSD XMM1, realVal ; load 1.5ADDSD XMM1, MMWORD PTR [RSP+30H] ; add parameterDIVSD XMM0, XMM1 ; do division, answer in xmm0RET ; returnCombineA ENDPEndRunning this should result in the value 1.97368 being output twice.ConclusionThis has been a necessarily brief introduction to x64 assembly programming. The next step is to browse the Intel® 64 and IA-32 Architectures Software Developer's Manuals. Volume 1 contains the architecture details and is a good start if you know assembly. Other places are assembly books or online assembly tutorials. To get an understanding of how your code executes, it is instructive to step through code in debugger, looking at the disassembly, until you can read assembly code as well as your favorite language. For C/C++ compilers, debug builds are much easier to read than release builds so be sure to start there. Finally, read the forums at for a lot of material.。
Euphoria编程语言快速指南说明书

as export procedurebreak fallthru publicby for retrycase function returnconstant global routinecontinue goto switchdo if thenelse ifdef toelsedef include typeelsif label untilelsifdef loop whileend namespace withentry not withoutenum or xorEXPRESSIONS:Euphoria lets you calculate results by forming expressions. However, in Euphoria you can perform calculations on entire sequences of data with one expression.You can handle a sequence much as you would a single number. It can be copied, passed to a subroutine, or calculated upon as a unit. For example:{1,2,3} + 5is an expression that adds the sequence {1,2,3} and the atom 5 to get the resulting sequence {6,7,8}. You would learn sequences in subsequent chapters.BLOCKS OF CODE:One of the first caveats programmers encounter when learning Euphoria is the fact that there are no braces to indicate blocks of code for procedure and function definitions or flow control. Blocks of code are denoted by associated keywords.Following is the example of if...then...end if block:if condition thencode block comes hereend ifMULTI-LINE STATEMENTS:Statements in Euphoria typically end with a new line. Euphoria does, however, allows to write a single statement in multiple lines. For example:total = item_one +item_two +item_threeESCAPE CHARACTERS:Escape characters may be entered using a back-slash. For example:Following table is a list of escape or non-printable characters that can be represented with backslash notation.DescriptionBackslashnotation\n Newline\r Carriage return\t Tab\\Backslash\"Double quote\'Single quoteCOMMENTS IN EUPHORIA:Any comments are ignored by the compiler and have no effect on execution speed. It is advisable to use more comments in your program to make it more readable.There are three forms of comment text:1. Euphoria comments are started by two dashes and extend to the end of the current line.2. The multi-line format comment is kept inside /*...*/, even if that occurs on a different line.3. On the first line only of your program, you can use a special comment beginning with the twocharacter sequence #!.Examples:#!/home/euphoria-4.0b2/bin/eui-- First commentputs(1, "Hello, Euphoria!\n") -- second comment/* This is a comment which extends over a numberof text lines and has no impact on the program*/This will produce following result:Hello, Euphoria!VARIABLE DECLARATION:Euphoria variables have to be explicitly declared to reserve memory space. Thus declaration of a variable is mandatory before you assign a value to a variable.Variable declarations have a type name followed by a list of the variables being declared. For example:integer x, y, zsequence a, b, xASSIGNING VALUES:The equal sign = is used to assign values to variables. The operand to the left of the = operator is the name of the variable, and the operand to the right of the = operator is the value stored in the variable. For example:#!/home/euphoria/bin/eui-- Here is the declaration of the variables.integer counterinteger milessequence namecounter = 100 -- An integer assignmentmiles = 1000.0 -- A floating pointname = "John" -- A string ( sequence )printf(1, "Value of counter %d\n", counter )printf(1, "Value of miles %f\n", miles )printf(1, "Value of name %s\n", {name} )Here 100, 1000.0 and "John" are the values assigned to counter, miles and name variables, respectively. While running this program, this will produce following result:Value of counter 100Value of miles 1000.000000Value of name JohnEUPHORIA CONSTANTS:Constants are also variables that are assigned an initial value that can never change. Euphoria allows to define constants using constant keyword as follows:constant MAX = 100constant Upper = MAX - 10, Lower = 5constant name_list = {"Fred", "George", "Larry"}THE ENUMS:An enumerated value is a special type of constant where the first value defaults to the number 1 and each item after that is incremented by 1. Enums can only take numeric values. Examples:#!/home/euphoria-4.0b2/bin/euienum ONE, TWO, THREE, FOURprintf(1, "Value of ONE %d\n", ONE )printf(1, "Value of TWO %d\n", TWO )printf(1, "Value of THREE %d\n", THREE )printf(1, "Value of FOUR %d\n", FOUR )This will produce following result:Value of ONE 1Value of TWO 2Value of THREE 3Value of FOUR 4EUPHORIA DATA TYPES:EUPHORIA INTEGERS:Euphoria integer data types store numeric values. They are declared and defined as follows:integer var1, var2var1 = 1var2 = 100The variables declared with type integer must be atoms with integer values from -1073741824 to +1073741823 inclusive. You can perform exact calculations on larger integer values, up to about 15 decimal digits, but declare them as atom, rather than integer.EUPHORIA ATOMS:operand, if yes then condition becomestrue.and Called Logical AND operator. If both theoperands are non zero then thencondition becomes true.AandB is false.or Called Logical OR Operator. If any of thetwo operands are non zero then thencondition becomes true.AorB is true.xor Called Logical XOR Operator. Condition istrue if one of them is true, if bothoperands are true or false then conditionbecomes false.AxorB is true.not Called Logical NOT Operator whichnegates the result. Using this operator,true becomes false and false becomestruenot B is true.=Simple assignment operator, Assignsvalues from right side operands to leftside operand C = A + B will assigne value of A + B into C+=Add AND assignment operator, It addsright operand to the left operand andassign the result to left operandC += A is equivalent to C = C + A-=Subtract AND assignment operator, Itsubtracts right operand from the leftoperand and assign the result to leftoperandC -= A is equivalent to C = C - A*=Multiply AND assignment operator, Itmultiplies right operand with the leftoperand and assign the result to leftoperandC *= A is equivalent to C = C * A/=Divide AND assignment operator, Itdivides left operand with the rightoperand and assign the result to leftoperandC /= A is equivalent to C = C / A&=Concatenation operator C &= {2} is same as C = {C} & {2} PRECEDENCE OF EUPHORIA OPERATORS:Category Operator AssociativityPostfix function/type callsUnary + - ! not Right to leftMultiplicative * / Left to rightAdditive + - Left to rightConcatenation & Left to rightRelational > >= < <= Left to rightEquality = != Left to rightLogical AND and Left to rightLogical OR or Left to rightLogical XOR xor Left to rightComma , Left to rightTHE IF STATEMENT:An if statement consists of a boolean expression followed by one or more statements.Syntax:The syntax of an if statement is:if expression then-- Statements will execute if the expression is trueend ifTHE SWITCH STATEMENT:The switch statement is used to run a specific set of statements, depending on the value of an expression. It often replaces a set of if-elsif statements giving you more control and readability of your program.Syntax:The syntax of simple switch statement is:switch expression docase <val> [, <val-1>....] then-- Executes when the expression matches one of the valuescase <val> [, <val-1>....] then-- Executes when the expression matches one of the values.....................case else-- Executes when the expression does not matches any case.end ifTHE IFDEF STATEMENT:The ifdef statement is executed at parse time not runtime. This allows you to change the way your program operates in a very efficient manner.Syntax:The syntax of ifdef statement is:ifdef macro then-- Statements will execute if the macro is defined.end ifTHE WHILE STATEMENT:A while loop is a control structure that allows you to repeat a task a certain number of times. Syntax:The syntax of a while loop is:while expression do-- Statements executed if expression returns trueend whileTHE LOOP UNTIL STATEMENT:A loop...until loop is similar to a while loop, except that a loop...until loop is guaranteed to execute at least one time.Syntax:The syntax of a loop...until is:loop do-- Statements to be executed.until expressionTHE FOR STATEMENT:A for loop is a repetition control structure that allows you to efficiently write a loop that needs to execute a specific number of times.Syntax:The syntax of a for loop is:for "initial value" to "last value" by "inremental value" do-- Statements to be executed.end forTHE EXIT STATEMENT:Exiting a loop is done with the keyword exit. This causes flow to immediately leave the current loop and recommence with the first statement after the end of the loop.Syntax:The syntax of an exit statement is:exit [ "Label Name" ] [Number]THE BREAK STATEMENT:The break statement works exactly like the exit statement, but applies to if statements or switch statements rather than to loop statements of any kind.Syntax:The syntax of an break statement is:break [ "Label Name" ] [Number]THE CONTINUE STATEMENT:The continue statement continues execution of the loop it applies to by going to the next iteration and skipping the rest of an iteration.Going to the next iteration means testing a condition variable index and checking whether it is still within bounds.Syntax:The syntax of an continue statement is:continue [ "Label Name" ] [Number]THE RETRY STATEMENT:The retry statement continues execution of the loop it applies to by going to the next iteration and skipping the rest of an iteration.Syntax:The syntax of an retry statement is:retry [ "Label Name" ] [Number]THE GOTO STATEMENT:The goto statement instructs the computer to resume code execution at a labeled place.The place to resume execution is called the target of the statement. It is restricted to lie in thecurrent routine, or the current file if outside any routine.Syntax:The syntax of an goto statement is:goto "Label Name"PREOCEDURE DEFINITION:Before we use a procedure we need to define that procedure. The most common way to define a procedure in Euphoria is by using the procedure keyword, followed by a unique procedure name, a list of parameters thatmightbeempty, and a statement block which ends with end procedure statement. The basic syntax is shown here:procedure procedurename(parameter-list)statements..........end procedureFUNCTION DEFINITION:Before we use a function we need to define that function. The most common way to define a function in Euphoria is by using the function keyword, followed by a unique function name, a list of parameters thatmightbeempty, and a statement block which ends with end function statement. The basic syntax is shown here:function functionname(parameter-list)statements..........return [Euphoria Object]end functionProcessing math: 100%。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Integer Pair Representation for Multiple-Output LogicRafael A.Arce NazarioAdvisor:Manuel JimenezElectrical and Computer Engineering DepartmentUniversity of Puerto Rico,Mayag¨u ez CampusMayag¨u ez,Puerto Rico00681-5000rafael.arce@AbstractExtensions allowing the Integer Pair Representation (IPR)format to work with multiple-output binary valued ex-pressions are presented.The structure and semantics of the new format,IPR-M,are discussed as well as algorithms to aid in using this format for the representation and minimiza-tion of Boolean functions.1IntroductionThe representation and manipulation of two-level com-binational logic is essential to the design,synthesis and im-plementation of digital systems.Several formats support-ing two-level combinational logic representations and cor-responding manipulation algorithms have been proposed. Among these,binary decision diagrams(BDDs)and posi-tional cube notation(PCN)are worth mentioning.As de-veloped as these two models are,their implementations still provide room for improvement in the way they use mem-ory for representation of literals.For example,BDDs use a graph structure to represent a function,where each node is a literal and the vertices represent it’s relation to the other literals[3].PCN uses two characters per binary-valued vari-able[2].Memory usage in these methods is dictated by their structure and semantics,and therefore,a mechanism to op-timize the memory usage of BDD or PCN would probably render useless the representations and operators.A more compact representation of Boolean functions, the Integer Pair Representation(IPR),was suggested by Diaz et al.[1].In this representation,each product term is identified by an ordered pair(c x,c y)of positive integers including zero,where the bits that compose each integer are determined by the state of the variable in each product term. Because of the structure of this notation,each literal can be implemented using only two bits.A discussion of the con-version rules,operators and algorithms for an Espresso-like minimization heuristic algorithm is provided in[1].An important aspect missing from IPR Algebra is its ability to represent(and process)multiple-output Boolean expressions.In the case of logic minimization,it is gen-erally known that when several functions are to be imple-mented,it is often possible to obtain a multiple-output min-imized expression requiring fewer gates than separate cir-cuits implementing the individual optimized functions[4]. So,to be considered a full-fledged2-value logic representa-tion notation,the IPR Algebra should be expanded to repre-sent and manipulate multiple-output expressions.We shall call our adaptation of IPR for multiple-output capability the IPR-M.In the rest of this paper,structure, semantics and algorithms for the algebra of IPR-M are dis-cussed.The implementation of a minimization program us-ing this new scheme is presented and its results are com-pared with Espresso.2DefinitionsBefore we proceed to explain the structure,operators, and algorithms proposed for IPR-M,some terms used throughout the paper are defined.Most of these definitions were adopted from[1],[5],[6]and[7].An incompletely specified,binary-valued multiple-output Boolean function f is a mappingf:{0,1}n→{0,1,∗}m(1) Y=(y1,...,y m)=(f1(X),...,f m(X)),(2) where n is the number of inputs,m is the number of outputs, X=(x1,x2,...,x n)∈{0,1}n is the input vector,and Y is the output vector of f.The onset F,offset R,and don’t care set D are sets of minterms which are mapped by Y to 0,1,and*,respectively.A literal is a binary Boolean variable or its complement.A cube is a product of one or more literals such that no two literals are complement of each other.A variable missing in a cube is called a don’t care variableA cube A is said to cover another cubeB if the set of minterms represented by B is a subset of that represented by A.A cube A is an implicant of f if A⊆F∪D.If there is no other cube B such that A is covered by B then A is a prime implicant.A prime cube is essential if it has at least a single minterm covered by this and only this prime cube.A prime cube is redundant if every minterm it covers is also covered by essential prime cubes.A prime cube which is neither essential nor redundant is a selective prime cube.The distance between two cubes A and B is the number of variables that appear in both A and B and are uncomple-mented in A and complemented in B or viceversa.3Structure3.1Single Output IPRIn the IPR notation proposed in[1],each cube C of an n-variable Boolean expression is mapped to an ordered pair (c x,c y),where c x and c y are n-bit binary-valued vectors, and are referred to as the position and expansion parts of the IPR term,respectively.Each of the binary-valued vectors c x and c y are constructed as follows:c x=c x1,c x2,c x3,...,c xn(3)c y=c y1,c y2,c y3,...,c yn(4)where each c xi,c yi are determined according to Table1. Table1.IPR values for the position(c xi)and expansion(c yi)terms.Condition c xi c yi Meaning that in C¯x1∈C00x1appears invertedx1∈C10x1appears non invertedx1/∈C01x1is a don’t care variable−−11Cube is not valid3.2IPR-MTo account for the representation of multiple-output functions,we propose the addition of a third term for each cube(we shall call this term the function term).Thus,for an m-output expression,each cube would now be represented by an ordered triplet(c x,c y,c z),where c x,c y will be as-signed according to the IPR rules,and c z is an n-tuple where each bit c zi indicates if the cube belongs(c zi=1)or does not belong(c zi=0)to function f i.A cube with every f i=0is not a valid cube.To maintain compatibility with the original IPR scheme, single-output expressions can be expressed IPR-M by con-verting each ordered pair to an ordered triplet with the same position,and expansion terms,and a single‘1’in the func-tion term.4Cube operatorsThe implementation in IPR of two common cube opera-tors:coverage and orthogonality was described in[1].We proceed to expand the original implementation to handle multi-output expressions.4.1CoverageLet A=(a x,a y,a z)and B=(b x,b y,b z)be a pair of cubes and their representation in IPR-M.Cube A covers cube B, written B⊆A,if every literal in A also appears in B and A appears in all the functions where B appears.In IPR-M,coverage is guaranteed if and only if the fol-lowing is satisfied:b x∧¯a y=a x(5)and b y∨a y=a y(6)and b z∧a z=b z(7)4.2OrthogonalityTwo cubes A and B are said to be orthogonal(writ-ten A⊥B)if their intersection is an empty set(they do not have any minterms in common).In IPR-M,two multi-output cubes A and B are orthogonal if and only if:a x∧¯b y=b x∧¯a y(8)or a z∧b z=0(9) 4.3Multi-Output Shared CubeLet A and B be cubes that that belong to different func-tions(a z∧b z=0).The multi-output shared cube(MOSC) of A and B(written A∓B)is the cube that covers the minterms common to A and B and nothing more.We ob-tain the MOSC of two cubes(C=A∓B)in IPR-M by:c x=a x∨b x(10)c y=a y∧b y(11)c z=a z∨b z(12) 5AlgorithmsVirtually any Boolean manipulation algorithm can be implemented using IPR-M.Below we present several fre-quently used algorithms for Boolean manipulation.5.1Single Output ExpansionThis operation,representedζ(F,D,f i),expands every cube in F that appears in function f i considering the on minterms in f i and the don’t care minterms in f i. Algorithm1Single Output ExpansionInput:Input:Function onset F,don’t care set D,and single output function f i.Output:Expanded function for single output.1.C←∅.2.F ={A∈F,a zi=1}3.D ={B∈D,b zi=1}4.While F =∅do:4.1.Select a cube Y∈F .4.2.X←Y♦((F ∪C),D ).4.3.C←C∪X.4.4.F ←F ◦X.5.Return C.The operation X=Y♦(F,D)invoked in step4.2is called cube expansion and is performed exactly as in[1].It expands every cube in the offset F of a function considering the minterms in the don’t care set D.The operation F ◦X invoked in step4.4is called cube removal(defined in[1]). It removes the cubes in set F that are covered by X.5.2Border CubesThe border of a cube C is to be defined as the set of cubes that exactly cover the cube C and the minterms that are at a distance of1from C.Algorithm2Border CubesInput:Cube C.Output:Border cube set H.1.H←∅.2.∀w xi ∈c x,w xi=0do:2.1.Make D←C.2.2.Make d xi =0,d yi=1.2.3.H←H∪D.3.Return H.5.3Adjacent and Intersecting CubesRao and Jacob[7]propose a method for determining if a cube is essential by using it’s Adjacent and Intersecting Cube(AIC)set.The AIC of a prime cube A are those cubes: 1.In the onset or the dcset which are logically adjacentto A.2.In the don’t care set which intersect A.3.In the onset which intersect A without covering A.One way of determining which cubes are adjacent to cube A is by obtaining which cubes are at a distance of ex-actly1from cube A.However,the distance operation is costly when implemented in software as it involves count-ing the number of ones on a binary word.The algorithm described below utilizes the border set of cube A to deter-mine its AIC.Algorithm3Adjacent and Intersecting CubesInput:Cube A,function onset F,and don’t care set D Output:Adjacent and intersecting cube set G.1.G←∅.2.H←Border(A).3.∀C∈(F∪D)do:3.1.If C⊥H Then3.1.1.If C∈F or A⊆C Then G←G∪C4.Return G.5.4Essential Primes CubesRao and Jacob[7]establish that,given a prime cube A∈F,it can be determined if A is an essential prime cube (EPC)using the following procedure:1.For every literal a i that appears in cube A,change thecorresponding literal in each of the Adjancent and In-tersecting Cubes AIC(A).2.If the new modified AIC(A)does not cover A,then Ais an essential prime cube.Algorithm4Essential Primes CubeInput:Cube A,function onset F,and don’t care set D Output:True if cube A is an EPC.1.B←AIC(A)2.∀a yi∈a y,a yi=0do:2.1.∀C∈B do:2.1.1.Make c xi=a xi,c yi=0.3.Return A CThe operation A C is called tautology test and is de-scribed in[1].It verifies that all minters in A are covered by function C.6Multiple output minimizationTo illustrate IPR-M’s ability to support more complex operations we present the implementation of a heuristic al-gorithm,previously proposed by Guranath et al.[5],for minimizing multiple-output logic functions,using the algo-rithms described in Section5.The chosen heuristic algorithm uses a divide and conquer approach wherein the minimization is carried out by four main procedures:1.Selection of essential prime cubes:Each cube is ex-panded within a single function and any redundant cubes are removed.If it is determined that the ex-panded cube is essential and it is shared among two or more functions or that it is orthogonal to all other functions,it will be included in the solution.Whenever a cube is added to the solution,it will be added to the don’t care function.This will allow re-maining cubes to expand,if needed,using the solution terms.Algorithm5Select essential prime cubesInput:Function onset F and don’t care set D.Output:Set of essential cubes E and preliminarysolution set S with shared and exclusive essentialcubes.1.E=∅,S=∅.2.∀f i∈F do:2.1.G=ρ(ζ(F,D,f i)).2.2.∀B∈G do:2.2.1.If EP C(B)Then E←E∪B3.∀f i∈F do:3.1.∀C∈E do:3.1.1.If C f i Or C⊥f i ThenS←S∪C,E←E◦C,D=D∪C.4.Return S,E.2.Selection of valid selective primes:Selective primecubes are detected.If a selective cube is shared by two or more functions,or if it is orthogonal to all other functions then it is included in the solution.To determine selective cubes we use the fact that prime cubes are either essential,selective,or redundant.The expand and irredundancy step of the previous algo-rithm eliminates all redundant primes.Thus,after the algorithm for essential cubes is executed,F contains only selective prime cubes.Algorithm6Selective CubesInput:Function onset F,don’t care set D,and pre-liminary solution set S from previous algorithm.Output:Preliminary solution set S with shared andexclusive selective cubes.1.∀f i∈F do:1.1.∀C∈F do:1.1.1.If C f i Or C⊥f i ThenS←S∪C,E←E◦C,D=D∪C.2.Return S,E.3.Selection of intersecting cubes:Find the intersectionamong functions of the remaining essential and se-lective primes.The process of selecting intersect-ing cubes simply involves determining if a given cube A∈f i has an intersection with a cube B∈f j that covers the uncovered minterms in A and B.Algorithm7Intersecting CubesInput:Function onset F,don’t care set D,and pre-liminary solution set S from previous algorithm.Output:Preliminary solution set S with intersect-ing cubes.1.F=F∪E1.1.∀X∈f i,Y∈f j,i=j1.1.1.Z=X∓Y1.1.2.If Z=∅And(X\Y) D And(Y\X) D ThenS=S∪Z,F←F◦X,F←F◦Y,D=D∪X,D=D∪Y.2.Return S,F.The operation X\Y is called cube difference[1]and it obtains the set of cubes that cover the minterms cov-ered by X but not by Y,and nothing more.4.Select exclusive cubes:The terms not yet chosen byprevious steps are exclusive cubes(either essential or selective).This step expands them in their particular function.Algorithm8Select Exclusive CubesInput:Function onset F,don’t care set D.Output:Solution set S.1.∀f i∈F1.1.ζ(F,D,f i)2.Return F.7Preliminary ResultsTo verify the correctness of the presented algorithms,we implemented them in C++as part of a logic minimization program.Table2shows preliminary results obtained for several multiple-output examples provided with Espresso Version2.3,when minimized with the IPR-M-based pro-gram and Espresso.For each test,the table shows the num-ber of cubes c,input variables(In),and output variables (Out)of the multi-output function,as well as the number of cubes c and literals l in the minimized result.As evidenced by the results,the algorithm implementa-tion still needs some validation because,although for some of the examples the results were the same,for others Espres-sos’results contain considerably less literals and cubes.Table2.Minimization results for the IPR-based andstandard Espresso algorithms.Circuit Input set IPR EspressoName c In Out c l c la2pair164311321132mlp425688163899128735Z5xp11287107931265287stial2214822140221408Conclusions and Future WorkIPR-M’s ability to represent and manipulate multiple-output logic functions has been discussed and justified through the presentation of common multiple-output min-imization operators and algorithms.To establish more meaningful comparisons with other representations(such as BDD and PCN)our future work will be directed towards an-alyzing the time and space complexity of IPR-M algorithms and comparing them with established methods. References[1] A.Diaz,M.Jimenez,E.Strangas,and M.Shanblatt.Integerpair representation of binary terms and equations.In1998 Midwest Symposium on Circuits and Systems,pages172–175.IEEE,August1998.[2]G.D.Micheli.Synthesis and Optimization of Digital Circuits.McGraw Hill,Inc.,New York,NY02061,1994.[3]R.Drechsler and D.Sieling.Binary decision diagrams in the-ory and practice.Internal Journal of STTT,pages112–136, 2001.[4] A.Friedman and P.Menon.Theory and Design of Switch-ing puter Science Press,Inc.,Maryland,USA 20850,1975.[5] B.Gurunath and N.Biswas.An algorithm for multiple outputminimization.IEEE Transactions on Computer-Aided De-sign of Integrated Circuits and Systems,pages1007–1013, September1989.[6]H.J.Mathony.Universal logic design algorithm and its ap-plication to the synthesis of two-level switching circuits.In Computers and Digital Techniques,IEE Proceedings,volume 136,pages171–177,May1989.[7]P.Rao and J.Jacob.A fast two-level logic minimizer.In Pro-ceedings Eleventh International Conference on VLSI Design, 1998,pages528–533,January1998.。