成从OUT开始的ASCII码字符串
13-中文乱码问题详解

政府事业部 - 劳动人事开发部 郭志龙 guozl@
中文乱码问题详解:内容索引
字符集与编码相关知识 • 字符与编码的发展 • 字符串在内存中的存放方法 • 字节、字符、字符串 • 字符集与编码 • 常用编码规则简介 • 编程中的字符与编码 • JAVA程序中的编码实现 JSP编程中文乱码问题根源及问题汇总 • 中文编码问题的根源 • 中文编码问题出现的环节 • JSP文件的汉字问题 • 表单处理中的汉字问题 • Servlet的汉字问题 • JDBC的汉字问题
2D 4E 87 65 31 00 32 00 33 00 00 00
中
文
1
2
3
\0
中文乱码问题详解:字节、字符、字符串
举例 '1', '中', 'a', '$', 人们使用的记号,抽象意义上的一个符号。 '¥', …… 计算机中存储数据的单元,一个8位的二进 0x01, 0x45, 制数,是一个很具体的存储空间。 0xFA, …… 在内存中,如果"字符"是以 ANSI 编码形 式存在的,一个字符可能使用一个字节或 "中文123" 多个字节来表示,那么我们称这种字符串 (占7字节) 为 ANSI 字符串或者多字节字符串。 概念描述
中文乱码问题详解:常用编码简介
根据编码规则的特点,把所有的编码分成三类: 单字节字符编码、 ANSI 编码、 UNICODE 编码
单字节字符编码: • 编码标准: ISO-8859-1 • 编码原理:是最简单的编码规则,每一个字节直接作为一个 UNICODE 字符。比如,[0xD6, 0xD0] 这两个字节,通过 iso8859-1 转化为字符串时,将直接得到 [0x00D6, 0x00D0] 两个 UNICODE 字符,即 "ÖÐ"。 反之,将 UNICODE 字符串通过 iso-8859-1 转化为字节串时,只 能正常转化 0~255 范围的字符。
字符串处理指令

字符串处理指令字符串处理指令字符串:一系列存放在存储器中的字或字节数据,不管他们是不是ASCII码。
字符串长度可达64K字节,组成字符串的字节或字称为字符串元素,每种字符串指令对字符串对字符串元素只进行同一种操作。
8086提供5条1字节的字符串操作指令,专门对存储器中的字节串和字串数据进行传送、比较、扫描、存储及装入等5种操作。
使用字符串操作指令时,可以有两种方法告诉汇编程序是进行字节操作还是字操作。
一种方法是用指令中的源串和目的串名来表明是字节还是字,另一种方法是在指令助记符后加B说明是字节,加W说明是字操作。
这样每种指令都有3种格式。
字符串传送,MOVS 目的串,源串MOVSB MOVSW字符串比较,CMPS 目的串,源串CWPSB CMPSW字符串扫描,SCAS 目的串SCASB SCASW字符串装入,LODS 源串LODSBLODSW字符串存储,STOS 目的串STOSB STOSW字符串指令执行时,必须遵守以下隐含约定:(1)源串位于当前数据段,由DS寻址,源串的元素由SI作指针,即源串字符的起始地址为DS:SI。
源串允许使用段超越前缀来修改段地址。
(2)目的串必须位于当前的附加段中,由ES 寻址,目的串元素由DI做指针,即目的串字符的首地址为ES:DI,但目的串不允许使用短超越前缀修改ES。
如果要在同一段内进行串运算,必须使DS和ES指向同一段。
(3)每执行一次字符串指令,指针SI和DI会自动进行修改,以便指向下一待操作单元。
(4)DF标志控制字符的处理方向。
DF=0为递增方向,这时DS:SI指向源串首地址,每进行一次串操作,使SI和DI增加,字节串操作时,SI 和DI分别增1,字串操作时,SI和DI分别增2,;DF=1为递减方向,这时,DS:SI指向源串末地址,每执行一次串操作,使SI和DI分别减量,字节串操作时减1,字串操作时减2.可用标志操作指令STD和CLD来改变DF的值,STD使DF置1,CLD使DF清零。
输人字符串。将其中的小写字母转换成大写字母,而其他字符不变。 -回复

输人字符串。
将其中的小写字母转换成大写字母,而其他字符不变。
-回复如何将字符串中的小写字母转换为大写字母?通过这篇文章,我们将演示如何使用不同的方法来实现这个功能。
首先,我们需要明确一些基本知识。
在编程中,字符串是由字符组成的序列。
每个字符都有一个相应的Unicode值。
英文字母的Unicode值是连续的,小写字母的Unicode值在大写字母的Unicode值之后。
因此,我们可以利用这一特性来将小写字母转换为大写字母。
接下来,我们将介绍三种常见的方法来实现这个功能。
方法一:使用内置函数upper()Python提供了一个内置函数upper(),它可以将字符串中的所有小写字母转换为大写字母。
我们只需要将原始字符串作为参数传递给upper()函数即可。
示例代码:def convert_to_uppercase(s):return s.upper()在这个示例中,convert_to_uppercase()函数接受一个字符串参数s,并将该字符串转换为大写字母形式,然后返回结果。
方法二:使用ASCII码值做转换ASCII码是一种用于表示字符的标准编码系统。
每个ASCII字符都有一个对应的数值,我们可以通过增加或减少这个数值来实现大小写字母的转换。
示例代码:def convert_to_uppercase(s):result = ''for char in s:if 97 <= ord(char) <= 122:result += chr(ord(char) - 32)else:result += charreturn result在这个示例中,convert_to_uppercase()函数遍历字符串中的每个字符。
如果字符的ASCII值在小写字母的范围内(97-122),则将其对应的大写字母的ASCII值(小写字母ASCII值减去32)转换为字符,并添加到结果字符串中。
否则,直接将原字符添加到结果字符串中。
ASCII码表

ASCII码表完整版USB 基本知识USB的重要关键字:1、端点:位于USB设备或主机上的一个数据缓冲区,用来存放和发送USB的各种数据,每一个端点都有惟一的确定地址,有不同的传输特性(如输入端点、输出端点、配置端点、批量传输端点)2、帧:时间概念,在USB中,一帧就是1MS,它是一个独立的单元,包含了一系列总线动作,USB将1帧分为好几份,每一份中是一个USB的传输动作。
3、上行、下行:设备到主机为上行,主机到设备为下行下面以一问一答的形式开始学习吧。
问题一:USB的传输线结构是如何的呢?答案一:一条USB的传输线分别由地线、电源线、D+、D-四条线构成,D+和D-是差分输入线,它使用的是3.3V的电压(注意哦,与CMOS的5V电平不同),而电源线和地线可向设备提供5V电压,最大电流为500MA(可以在编程中设置的,至于硬件的实现机制,就不要管它了)。
问题二:数据是如何在USB传输线里面传送的答案二:数据在USB线里传送是由低位到高位发送的。
问题三:USB的编码方案?答案三:USB采用不归零取反来传输数据,当传输线上的差分数据输入0时就取反,输入1时就保持原值,为了确保信号发送的准确性,当在USB总线上发送一个包时,传输设备就要进行位插入***作(即在数据流中每连续6个1后就插入一个0),从而强迫NRZI码发生变化。
这个了解就行了,这些是由专门硬件处理的。
问题四:USB的数据格式是怎么样的呢?答案四:和其他的一样,USB数据是由二进制数字串构成的,首先数字串构成域(有七种),域再构成包,包再构成事务(IN、OUT、SETUP),事务最后构成传输(中断传输、并行传输、批量传输和控制传输)。
下面简单介绍一下域、包、事务、传输,请注意他们之间的关系。
(一)域:是USB数据最小的单位,由若干位组成(至于是多少位由具体的域决定),域可分为七个类型:1、同步域(SYNC),八位,值固定为0000 0001,用于本地时钟与输入同步2、标识域(PID),由四位标识符+四位标识符反码构成,表明包的类型和格式,这是一个很重要的部分,这里可以计算出,USB的标识码有16种,具体分类请看问题五。
ASCII码一览表,ASCII码对照表

ASCII码一览表,ASCII码对照表ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是一套基于拉丁字母的字符编码,共收录了128 个字符,用一个字节就可以存储,它等同于国际标准 ISO/IEC 646。
ASCII 规范于1967 年第一次发布,最后一次更新是在1986 年,它包含了33 个控制字符(具有某些特殊功能但是无法显示的字符)和95 个可显示字符。
对控制字符的解释ASCII 编码中第0~31 个字符(开头的32 个字符)以及第127 个字符(最后一个字符)都是不可见的(无法显示),但是它们都具有一些特殊功能,所以称为控制字符( Control Character)或者功能码(Function Code)。
这33 个控制字符大都与通信、数据存储以及老式设备有关,有些在现代电脑中的含义已经改变了。
有些控制符需要一定的计算机功底才能理解,初学者可以跳过,选择容易的理解即可。
下面列出了部分控制字符的具体功能:•NUL (0)NULL,空字符。
空字符起初本意可以看作为NOP(中文意为空操作,就是啥都不做的意思),此位置可以忽略一个字符。
之所以有这个空字符,主要是用于计算机早期的记录信息的纸带,此处留个NUL 字符,意思是先占这个位置,以待后用,比如你哪天想起来了,在这个位置在放一个别的啥字符之类的。
后来呢,NUL 被用于C语言中,表示字符串的结束,当一个字符串中间出现NUL 时,就意味着这个是一个字符串的结尾了。
这样就方便按照自己需求去定义字符串,多长都行,当然只要你内存放得下,然后最后加一个\0,即空字符,意思是当前字符串到此结束。
•SOH (1)Start Of Heading,标题开始。
如果信息沟通交流主要以命令和消息的形式的话,SOH 就可以用于标记每个消息的开始。
1963年,最开始ASCII 标准中,把此字符定义为Start of Message,后来又改为现在的Start Of Heading。
计算机字符集

55
7
56
8
57
9
58
:
59
;
60
<
61
=
62
>
63
?
64
@
65
A
66
B
67
C
68
D
69
E
70
F
71
G
72
H
73
I
74
J
75
K
76
L
77
M
78
N
79
O
80
P
81
Q
82
R
83
S
84
T
85
U
86
V
87
W
88
X
89
Y
90
Z
91
[
92
\
93
]
94
^
95
_
96
`
97
a
98
b
99
c
100
d
101
e
102
f
103
GB2312的编码范围是0xA1A1-0x7E7E,去掉未定义的区域之后可以理解为实际编码范围是0xA1A1-0xF7FE。
上面这句有误,应该说GB2312的每一个汉字由两个字节构成,其中每一个字节的范围都在0xA1~0xFE,正好每一个字节都有94个编码范围,与区位码个数完全对应。
EUC-CN可以理解为GB2312的别名,和GB2312完全相同。
GBK的整体编码范围是为:高字节范围是0×81-0xFE,低字节范围是0x40-7E和0x80-0xFE,不包括低字节是0×7F的组合。
转换指令

9.13 SIMATIC 转换指令BCD 码转为整数 (BCDI)即将结果送入 OUTIBCD 指令将输入的整数 (IN) 转换成 BCD 码 (OUT)输入IN的范围是 0 到9999SM1.6 (BCD 错误)0006 (间接寻址)这些指令影响下面的特殊存储器位使 ENO = 0 的错误条件是0006 (间接寻址)如果小数部分大于 0.5使 ENO = 0 的错误条件是SM4.3 (运行时间)SM1.1 (溢出) 输入/输出操作数数据类型IN VD, ID, QD, MD, SMD, AC, LD, HC, 常数, *VD, *AC, SD, *LD REALOUT VD, ID, QD, MD, SMD, LD, AC, *VD, *AC, SD, *LD DINT取整 (TRUNC)取整指令 (TRUNC) 将 32 位实数 (IN) 转换成 32 位有符号整数(OUT)如果要转换的值是无效的实数溢出位被置位使 ENO = 0 的错误条件是SM4.3 (运行时间)SM1.1 (溢出) 输入/输出操作数数据类型IN VD, ID, QD, MD, SMD, LD, AC, 常数, *VD, *AC, SD, *LD REALOUT VD, ID, QD, MD, SMD, LD, AC, *VD, *AC, SD, *LD DINT双整数到整数双整数到整数转换指令把输入端 (IN) 的双整数转换成一个整数(OUT)Òç³öλ±»ÖÃλ使 ENO = 0 的错误条件是SM4.3 (运行时间)SM1.1 (溢出)输入/输出操作数数据类型IN VD, ID, QD, MD, SMD, AC, LD, HC, 常数, *VD, *AC, SD, *LD DINTOUT VW, IW, QW, MW, SW, SMW, LW, T, C, AC, *VD, *LD, *AC INT整数到双整数整数到双整数转换指令把把输入端 (IN) 的整数转换成一个双整数 (OUT)使 ENO = 0 的错误条件是0006 (间接寻址)输入/输出操作数数据类型INT IN VW, IW, QW, MW, SW, SMW, LW, T, C, AIW, AC, 常数, *AC,*VD, *LDOUT VD, ID, QD, MD, SD, SMD, LD, AC, *VD, *LD, *AC DINT整数到实数整数转换到实数时然后再使用双整数到实数指令字节到整数字节到整数转换指令把输入端 (IN) 的字节值转换成一个整数(OUT)ËùÒÔ使 ENO = 0 的错误条件是0006 (间接寻址) 输入/输出操作数数据类型IN VB, IB, QB, MB, SB, SMB, LB, AC, 常数, *AC, *VD, *LD BYTEOUT VW, IW, QW, MW, SW, SMW, LW, T, C, AC, *VD, *LD, *AC INT整数到字节整数到字节转换指令把输入端 (IN) 的字转换成一个字节(OUT)所有其它的值会造成溢出使 ENO = 0 的错误条件是SM4.3 (运行时间)SM1.1 (溢出)输入/输出操作数数据类型IN VW, IW, QW, MW, SW, SMW, LW, T, C, AIW, AC, 常数, *VD,INT*LD, *ACOUT VB, IB, QB, MB, SB, SMB, LB, AC, *VD, *AC, *LD BYTE转换指令举例米米VD12ENO9-42 转换指令实例译码译码指令 (DECO) 根据输入字节 (IN) 的低四位 (半个字节) 所表示的位号置输出字 (OUT) 的相应位为 1使ENO = 0的错误条件是0006 (间接寻址)使 ENO = 0 的错误条件是0006 (间接寻址)译码和编码举例图 9-43包含错误位段码 (SEG)段码指令 (SEG) 产生点亮七段码显示器的位模式段码值 (OUT)λµÄÓÐЧÊý×ÖÖµ²úÉúÏàÓ¦µãÁÁ¶ÎÂëSM4.3 (运行时间)图 9–45 给出了用段码指令 (SEG) 编码的七段码显示ASCII 码转为 16 进制 (ATH)换成从 OUT 开始的 16 进制数HTA 指令把从 IN 字符开始可转换的 16 进制数的最大个数为 25539 和 41ASCII 码到 16 进值SM1.7 (非法ASCII 码)0006 (间接寻址)ʹENO = 0的错误条件是0006 (间接寻址)SM1.7 (非法 ASCII 码)输入/输出操作数数据类型IN, OUT VB, IB, QB, MB, SMB, LB, *VD, *AC, SB, *LD BYTELEN VB, IB, QB, MB, SMB, LB, AC, 常数, *VD, *AC, SB, *LD BYTEASCII 码到 16 进值转换举例注9-47 ASCII 码到 16 进值转换指令举例整数到 ASCII 码整数到 ASCII 指令把输入端 (IN) 的整数转换成一个 ASCII串十进制对位是逗号或间隔ASCII 码串始终是 8 个字符SM4.3 (运行时间)无输出 (非法格式)输入/输出操作数数据类型INT IN VW, IW, QW, MW, SW, SMW, LW, AIW, T, C, AC, 常数, *VD,*AC, *LDFMT VB, IB, QB, MB, SMB, LB, AC, 常数, *VD, *AC, SB, *LD BYTEOUT VB, IB, QB, MB, SMB, LB, *VD, *AC, SB, *LD BYTEITA (整数到 ASCII 码转换) 指令的格式操作数 (FMT) 定义如图 9-48 所示nnn 区指定输出缓冲区中的十进制对位右边的位数指定十进制右对位为 0¶ÔÓÚ´óÓÚ 5 的 nnnλ c 指定是用逗号 (c=1) 或小数点 (c=0) 作为整数和小数的分割符 输出缓冲区按照下面的规则进行格式化2. 负值带负号写入输出缓冲区4. 在缓冲区中数值采用右对齐在小数点右边有三位数字(nnn=011)双整数到 ASCII 码串十进制对位是逗号或间隔使 ENO = 0 的出错条件是0006 (间接寻址)Êä³ö»º³åÇøµÄ´óСʼÖÕÊÇ 12 个字节nnn 区的有效范围是 0 到 5表示显示的值没有小数位输出缓冲区用 ASCII 空格填充高 4 位必须为 01. 正值不带符号写入输出缓冲区3. 小数点左边前的 0 进行删除处理 (除非临近小数点的数字 0)图 9–49 是采用小数点 (c = 0) 进行格式化的数的格式 实数到 ASCII 码实数到 ASCII 指令把输入端 (IN) 的整数转换成一个 ASCII 串十进制对位是小数点或间隔使 ENO = 0 的出错条件是0006 (间接寻址)Êä³ö»º³åÇøµÄ´óСÓÉssss 区的值指定1 或 2 个字节是不允许的nnn 区的有效范围是 0 到 5表示显示的值没有小数位输出缓冲区用 ASCII 空格填充高 4 位必须为 01. 正值不带符号写入输出缓冲区3. 小数点左边前的 0 进行删除处理 (除非临近小数点的数字 0)5. 输出缓冲区的大小必须不小于 3 个字节6. 在缓冲区中数值采用右对齐在小数点右边有三位数字 (nnn =001)注意试图显示大于 7 位有符号数将产生一个错误。
从键盘输入一个字符,判定是否是小写字母,如果是,则将它转换成大写字母,如果是其他字符则原样输出。

从键盘输入一个字符,判定它是否是小写字母,如果是,则将它转换成大写字母,如果是其他字符则原样输出。
如何判断一个字符是小写字母?查上一章提供的ASCII码表.在表里,小写字母(a~z)对应的ASCII值为97~122.那么,判断一个字符是否为小写,就看它的值是否大于等于'a',并且小于等于'z'.#include<stdio.h>void main(){char a;printf("\n请输入一个字符");scanf("%c",&a);if((a>='a'&&a<='z')){printf("\n您输入的字符是小写字母",a);}else{printf("您输入的字符不是小写字母\n",a);}}(2)验证输入的一个字符是否为大写字母#include <stdio.h>void main(){char a;printf("请输入一个字符\n");fflush(stdin);a=getchar();if('A'<=a && a<='Z'){printf("用户输入的是大写字线%c\n",a);}else{printf("用户输入的不是大写字母%c\n",a);}}(3) 要求判别键盘输入字符的类别.可以根据输入字符的ASCII码来判别类型.由ASCII 码表可知ASCII码值小于32的为控制字符.在0~9之间的为数字,在A~Z之间的为大写字母,在a~z之间的为小写字母,其余的则为其他字符.#include<stdio.h>void main(){char c;printf("\n请输入一个字符:");c=getchar();if(c<32)printf("\n该字符是一个控制字符\n");else if(c>='0' && c<='9')printf("\n该字符是一个数字");else if(c>='A' && c<='Z')printf("\n该字符是一个大写字母");else if(c>='a' && c<='z')printf("\n该字符是一个小写字母\n");elseprintf("\n该字符是一个其它字符\n");}2. seizeof(type_name)sizeof 运算符的用法#include<stdio.h>void main(){printf("\n char 类型的大小是%d字节\n",sizeof(char));printf("short int 类型的大小是%d 字节\n",sizeof(short int));printf("unsigned short int 类型的大小是%d 字节\n",sizeof(unsigned short int)); printf("int 类型的大小是%d 字节\n",sizeof(int));printf("unsigned int 类型的大小是%d字节\n",sizeof(unsigned int));printf("long 类型的大小是%d 字节\n",sizeof(long));printf("unsigned long 类型的大小是%d 字节\n",sizeof(unsigned long));printf("float 类型的大小是%d 字节\n",sizeof(float));printf("double类型的大小是%d 字节\n",sizeof(double));}3.判定给定的年分是否为闰年.闰年的判定规则为:能被4整除但不能被100整除的年分,或能被400整除的年份.#include<stdio.h>void main(){int year;printf("\n 请输入年份");scanf("%d",&year);if((year%4 ==0 && year % 100 !=0)||(year%400==0)){ printf("\n%d 年是闰年\n",year);}else{printf("\n%d 年不是闰年\n",year);}}4. 输入一个5位数,判断是不是回文数. eg:12321是回文数#include<stdio.h>void main(){long ge,shi,qian,wan,x;printf("\n请输入一个五位整数:");scanf("%ld",&x);wan=x/10000;qian=x%10000/1000;shi=x%100/10;ge=x%10;if(ge== wan && shi==qian){printf("\n%ld 这个数是回文数\n",x);}else{printf("\n %ld 这个数不是回文数",x);}}5.要求用户输入一个字符值,并检查它是否为元音字母#include<stdio.h>void main(){char in_char;printf("\n请输入一个小写字母");scanf("%c",&in_char);switch(in_char){case 'a':printf("\n您输入的是元音字母:a\n");break;case 'e':printf("\n您输入的是元音字母:e\n");break;case 'i':printf("\n您输入的是元音字母:i\n");break;case 'o':printf("\n您输入的是元音字母:o\n");break;case 'u':printf("\n您输入的是元音字母:u\n");break;default:printf("\n您输入的%c不是是元音字母:",in_char);}}编程实现:从键盘上输入一个字符,如果它是大写字母,则把它转换成小写字母输出;否则,直接输出。
(2023年)山东省济南市全国计算机等级考试网络技术真题(含答案)

(2023年)山东省济南市全国计算机等级考试网络技术真题(含答案) 学校:________ 班级:________ 姓名:________ 考号:________一、单选题(10题)1.通道是一种()A.保存l/0信息的部件B.传输信息的电子线路C.通用处理机D.专用处理机2.下列关于IEEF802.11三种协议的描述中,错误的是()。
A.IEEE802.11a的实际吞吐量是28~31MbpsB.IEEE802.11a的最大容量是432MbpsC.IEEE802.11b的最大容量是88MbpsD.IEEE802.119的最大容量是162Mbps3.在网上信息发布平台发布网络信息具有以下哪个特点()。
A.提供7X24小时服务,提高了为顾客提供咨询服务的成本B.信息的修改和更新方便快捷C.只能以文字的方式介绍企业或产品的有关情况D.可以有目的地选择发送对象,使信息发布更有针对性4.IP地址块67.58.15.131/22和201.116.15.15/23的子网掩码分别可写为()。
A.255.255.240.0和255.255.248.0B.255.255.248.0和255.255.252.0C.255.255.252.0和255.255.254.0D.255.255.254.0和255.255.255.05.下列对IPv6地址FE80:0:0:0801:FE:0:0:04A1的简化表示中,错误的是()。
A.FElt::801:FE:0:0:04A1B.FE80::801:FE:0:0:04A1C.FE80:O:0:801:FE::04A1D.FE80:0:0:801:FE::4A16.IP地址块202.113.79.0/27、202.113.79.32/27和202.113.79.64/27经过聚合后可用的地址数为()A.64B.92C.94D.1267.8. PGP是一种电子邮件安全方案,它一般采用的散列函数是A.DSSB.RSAC.DESD.SHA9.文件系统采用二级文件目录,可以()A.缩短访问存储器的时间B.实现文件共享C.节省内存空间D.解决不同用户间文件命名冲突10.网络商务信息是指()。
acsll编码先后顺序

ASCII编码是一种基于英文字母的字符编码标准,它规定了每个字符对应的唯一的数值表示。
ASCII编码中的字符按照数值大小来进行顺序排序。
以下是ASCII编码中常见字符的先后顺序:
1. 控制字符:从ASCII码值为0到31的字符为控制字符,它们没有对应的可显示的符号。
2. 可打印字符:ASCII码值从32到126的字符是可打印字符,在这个范围内有许多常见的字符,包括数字、大写和小写字母、标点符号等。
3. 扩展字符:ASCII码值大于127的字符是扩展字符,也被称为扩展ASCII或扩展ASCII字符集。
这些字符包括特殊字符、国际字符、货币符号以及其他一些符号。
需要注意的是,ASCII编码是针对英文字符的编码标准,在其他语言的字符上可能不适用。
对于支持其他语言的编码,如Unicode和UTF-8,则会包含更多的字符,并按照其相应的编码标准进行排序。
ASCII编码的先后顺序对于计算机在处理字符时十分重要,它确定了字符的排序和比较规则。
在C语言中,可以使用ASCII编码来进行字符的比较和排序操作。
ASCII字符中的功能控制字符

12–FF–F orm F eed换页
设计换页键,是用来控制打印机行为的。当打印机收到此键码的时候,打印机移动到下一页。不同的设备的终端对此控制码所表现的行为各不同。有些会去清除屏幕,而其他有的只是显示^L字符或者是只是新换一行而已。Shell脚本程序Bash和Tcsh的实现方式是,把FF看作是一个清除屏幕的命令。C语言程序中用/f表示FF(换页)。
[Delete] *
注(*):
1.转义字符:即在C语言中或其他地方如何表示。
2.用键盘输入控制字符:其中,32是空格键,127是Delete键,都不需要加Ctrl键,即可直接输入。
3.可以通过“Ctrl+对应按键”实现上述控制字符的输入,你可能遇到的一些,比如:用Ctrl+V输入SYNC,Ctrl+M输入Enter(当然也可以直接用Enter键,但是在Windows下面,其可能会发送两个字符:CR和LF),Ctrl+Q输入XON,Ctrl+S输入XOFF等等。
08
BS
/b
Backspace(退格)
H
9
09
HT
/t
Horizontal Tab(水平制表符)
I
10
0A
LF
/n
Line feed(换行键)
J
11
0B
VT
/v
Vertical Tab(垂直制表符)
K
12
0C
FF
PLC200指令按字母排序
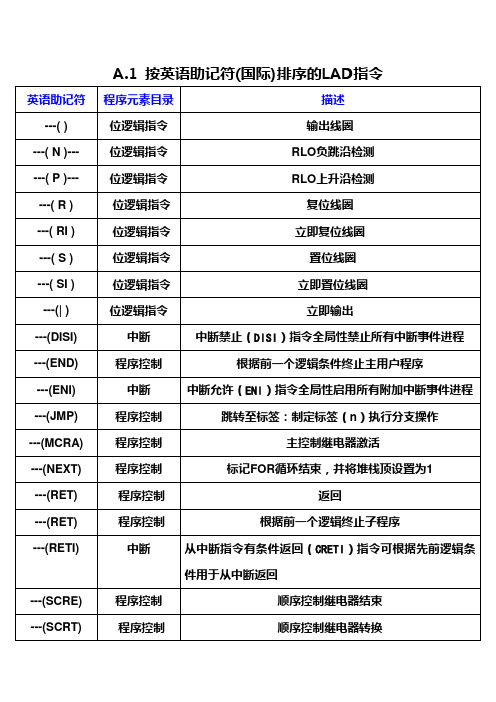
定时器
断开延时定时器在输入关闭后,延迟一段时间再关闭输出
TON
定时器
接通延时定时器在输入为"打开"时,开始计时
TONR
定时器
掉电保护性接通延时定时器在输入为"打开"时,开始计时
TRUNC
转换
截取长整数部分
WAND_B
逻辑运算
与运算字节对两个输入数值(IN1和IN2)的对应位执行AND(与运算)操作,并在内存位置(OUT)中载入结果
LN
浮点型指令
求自然对数
MBUS_CTRL
库
MBUS_MSG
库
MOV_B
传送
将输入字节(IN)移至输出字节(OUT),不改变原来的数值
MOV_BIR
传送
读取实际输入IN(作为字节),并将结果写入OUT。但进程映像寄存器未更新
MOV_BIW
传送
从位置IN读取数值并写入(以字节为单位)实际输入OUT,以及对应的"进程图像"位置
整数数学运算
整数减
SUB_R
浮点型指令
实数减
SWAP
传送
交换字(IN)的最高位字节和最低位字节
TAN
浮点型指令
求正切值
TBL_FIND
表
表格查找(TBL)指令在表格(TBL)中搜索与某些标准相符的数据。"表格查找"指令搜索表,从INDX指定的表格条目开始,寻找与CMD定义的搜索标准相匹配的数据数值(PTN)。命令参数(CMD)被指定一个1至4的数值,分别代表=、<>、<, and >
INV_W
逻辑运算
对输入字IN执行求补操作,并将结果载入内存位置OUT
南京师范大学计算机考试(C语言)(试卷1)

201507 南京师范大学计算机考试(C语言)(试卷1)【程序设计理论】1.[题号:1](单选题) 分值:2下列四个选项中,属于C语言关键字的是__________。
A. FloatB. singleC. doubleD. real【答案:C 】2.[题号:2](单选题) 分值:2某程序需要使用一个代表常数3.14的符号常量名P,以下定义中正确的是__________。
A. #define P 3.14;B. #define P(3.14)C. #define P=3.14;D. #define P 3.14【答案:D 】3.[题号:3](单选题) 分值:2以下关于if语句和switch语句的叙述中错误的是__________。
A. if语句和switch语句都可以实现算法的选择结构B. if语句和switch语句都能实现多路(两路以上)选择C. if语句可以嵌套使用D. switch语句不能嵌套使用【答案:D 】4.[题号:4](单选题) 分值:2以下叙述中错误的是__________。
A. 在函数外可以声明变量B. 变量声明的位置决定了该变量名的使用范围C. 函数调用时在函数内声明的变量所得到的值将无法保存到该函数的下一次调用D. 在函数外声明的变量,其值可以保存到该程序运行结束【答案:C 】5.[题号:61](单选题) 分值:2有如下程序段:char p1[80]= "NanJing",p2[20]= "Young",*p32="Olympic”;strcpy(p1,strcat(p2,p3));printf(“%s\n”,p1);执行该程序段后的输出是__________A. NanJingYoungOlympicB. YoungOlympicC. OlympicD. NanJing【答案:B 】6.[题号:62](单选题) 分值:2已有声明”int x,a=3,b=2;”,则执行赋值语句”x=a>b++?a++:b++;”后,变量x、a、b的值分别为__________ 。
【2023年】山东省日照市全国计算机等级考试数据库技术真题(含答案)

【2023年】山东省日照市全国计算机等级考试数据库技术真题(含答案) 学校:________ 班级:________ 姓名:________ 考号:________一、1.选择题(10题)1. 下列关于E-R模型向关系数据模型转换的叙述中,正确的是A.实体的元组就是关系的属性B.实体的属性就是关系的属性C.实体的候选码就是关系的码D.实体的主属性就是关系的码2.3. 在以下所列的选项中,( )不是数据库管理员(DBA)的职责。
A.决定数据库的存储结构和存取策略B.决定数据库的信息内容和结构C.定义数据的安全性要求和完整性约束条件D.负责数据库数据的确定,数据库各级模式的设计4. 用树型结构宋标识实体间联系的模型称为( )。
A.关系模型B.层次模型C.网状模型D.面向对象模型5. 下面有关E-R模型向关系模型转换的叙述中,不正确的是________。
A.一个实体类型转换为一个关系模式B.一个1:1联系可以转换为一个独立的关系模式,也可以与联系的任意一端实体所对应的关系模式合并C.一个1:n联系可以转换为一个独立的关系模式,也可以与联系的任意一端实体所对应的关系模式合并D.一个m:n联系转换为一个关系模式6. 结构化查询语言SQL在哪年被国际标准化组织(1SO)采纳,成为关系数据库语言的国际标准? ( )A.1986B.1987C.1988D.19897. 在数据库技术中,实体-联系模型是一种A.概念数据模型B.结构数据模型C.物理数据模型D.逻辑数据模型8. 该二叉树对应的树林包括几棵树?A.1B.2C.3D.49. 以下有关操作系统的叙述中,错误的是( )。
A.操作系统管理着系统中的各种资源B.操作系统应为用户提供良好的界面C.操作系统是资源的管理者和仲裁者D.操作系统是计算机系统中的一个应用软件10. 下面的叙述中,正确的是A.栈是限定仅在表的一端进行插入和删除运算的线性表B.队列是限定仅在表的一端进行插入和删除运算的线性表C.串是仅在表的一端进行插入和删除运算的线性表D.数组是仅在表的一端进行插人和删除运算的线性表二、填空题(10题)11.在确定了要使用的SQL Server 2000版本之后,必须为其选择合适的操作系统。
c语言中字母对应的ascii码

c语言中字母对应的ascii码A - ASCII码为65,表示大写字母'A'。
在C语言中,我们可以使用字符类型(char)来表示字母,而'A'对应的ASCII码就是65。
在实际编程中,我们可以通过对字符进行加减运算来实现字母的大小写转换。
B - ASCII码为66,表示大写字母'B'。
字符类型在C语言中是非常重要的一种数据类型,可以表示各种字符,如字母、数字、标点符号等。
通过ASCII码,我们可以将字符转换为对应的整数值进行处理。
C - ASCII码为67,表示大写字母'C'。
在C语言中,我们可以使用字符数组和字符串来存储和操作一系列字符。
字符串实际上就是由字符组成的数组,可以进行各种操作,如拼接、比较、截取等。
D - ASCII码为68,表示大写字母'D'。
在C语言中,我们可以使用字符输入输出函数来实现字符的输入和输出操作。
例如,通过使用printf函数可以将字符输出到控制台上,而使用scanf函数可以从用户输入中读取字符。
E - ASCII码为69,表示大写字母'E'。
在C语言中,我们可以使用字符操作函数来对字符进行各种处理。
例如,toupper函数可以将小写字母转换为大写字母,而tolower函数可以将大写字母转换为小写字母。
F - ASCII码为70,表示大写字母'F'。
在C语言中,我们可以使用字符常量和字符变量来表示特定的字符。
字符常量是用单引号括起来的单个字符,而字符变量是用来存储字符的变量。
G - ASCII码为71,表示大写字母'G'。
在C语言中,我们可以使用字符指针来指向字符串中的某个字符。
通过对字符指针进行加减运算,我们可以在字符串中移动指针位置,实现对字符串的遍历和操作。
H - ASCII码为72,表示大写字母'H'。
在C语言中,我们可以使用字符数组和指针来实现字符串的复制和连接操作。
字符编码知识简介和iconv函数的简单使用

字符编码知识简介和iconv函数的简单使⽤字符编码知识简介和iconv函数的简单使⽤字符编码知识简介我们知道,在计算机的世界其实只有0和1。
期初计算机主要⽤于科学计算,⽽我们知道⼀个数,除了⽤我们常⽤对10进制表⽰,也可以⽤2进制表⽰,所以只有0和1就可以进⾏科学计算,但是为了便于计算,⼤神们还是向计算机中引⼊的编码,⽐如通常我们⽤补码表⽰⼀个负数。
所以编码这个东西,是从⼀开始就伴随着计算机的。
到现在,我们的⽣活已经完全离不开计算机了,计算机也不仅仅⽤于科学计算了,更多地应⽤系信息处理。
那计算机怎样表⽰与我们⽣活息息相关的事物呢,⼀个直接的办法就是编码。
⽐如计算机中只有0和1,没有⽂字,那么我们就想办法⽤0和1的序列来代表⽂字,这就是⽂字编码。
ASCII编码计算机这东西是美国⼈发明的,所以美国⼈也最先⽤0和1的序列给英⽂字母进⾏了编码(当然还有⼀些特殊字符或者⽤于控制字符)。
英⽂只有26个字母,在加上那些特殊字符,也不多。
所以美国⼈选择⽤8个0或1的序列来表⽰⼀个英⽂字母或者那些特殊字符。
这就是ASCII 码。
ASCII码⼀共规定了128个字符的编码,⽐如空格"SPACE"是32(⼆进制00100000),⼤写的字母A是65(⼆进制01000001)。
这128个符号(包括32个不能打印出来的控制符号),只占⽤了⼀个字节的后⾯7位,最前⾯的1位统⼀规定为0。
ISO-8859-1编码计算机发展很快,很快欧洲⼈也开始尝试编码⾃⼰的⽂字,欧洲的语⾔⼤多都是拉丁语系的,和英语很像,⽽且部分重复,所以欧洲⼈就想到利⽤ASCII码没有利⽤的那⼀位来编码。
所以ISO-8859-1仍采⽤单字节编码(8位),只是将ASCII没有利⽤的128个位置利⽤了起来。
⽽且ISO-8859-1在设计时,前7为和ASCII码⼀致,也就是说ISO-8859-1是完全兼容ASCII的。
GB2312编码很快,我们国家开始为汉字编码,由于汉字和拉丁系的⽂字完全不同,⽽且汉字的个数很多,所以如果像欧洲的ISO-8859-1那样,只利⽤ASCII没有利⽤的部分,只能多表⽰128个字符,⽽汉字的数量远远⼤于这个数,所以⽤单字节编码汉字是不可⾏的。
逃跑空格符号

逃跑空格符号
逃跑空格符号是一种特殊的字符,用于表示一个空格。
在许多计算机系统中,逃跑空格符号是 ASCII 码中的第 32
号字符,十六进制表示为 0x20。
逃跑空格符号常用于文本编辑和排版中,用于在文本中插入空格,以分隔单词或段落。
例如,在英文文本中,逃跑空格符号通常用于在单词之间插入空格,以便在阅读时更容易区分单词。
在许多编程语言中,逃跑空格符号也被用于表示空格。
例如,在C 语言中,可以使用字符串转义序列 “s“ 来表示逃跑空格符号。
1.3数据采集与编码(二)浙教版(2019)高中信息技术必修一课后习题(解析版)

3.使用UltraEdit软件观察字符“挑战AlphaGo!”的内码,部分界面如图所示。
下列说法正确 是
A.字符“!”的内码占两个字节
B.字符“战”的十六进制码是“BD 41”
C.字符“h”的二进制码是“01101000”
D.字符“go”的十六进制码是“47 6F”
【答案】C
【解析】
【详解】汉字和全角符号占用2个字节,英文和半角符号占用1个字节,
18.用UltraEdit软件查看字符的内码,界面如图所示,下列分析正确的是()
A. 字符“6”的二进制码是“00111100”
B. 字符“,”的内码占两个字节
C. 字符“杯”的十六进制码是“AD 2C”
D. 字符“g”的二进制码是“01100111”
【答案】D
【解析】
【详解】本题考查字符的二进制编码。字符“8”的编码是38 H,推断字符“6”的编码是36 H,即00110110B。字符“,”的编码2C,占一个字节。字符“杯”的编码是“B1AD”。字符“G”的编码是47 H,则推算字符“g”的编码为67 H,即01100111。
从对应关系可以看出,“!”占用1个字节,16进制编码是“21”,故A错误;“战”的16进制编码是“D5 BD”,故B错误;“h”的16进制编码是“68”,转化成2进制编码就是“01101000”,故C正确;“go”是两个字符“g”和“o”,其中“g”的16进制编码是“47”,“o”的16进制编码是“6F”,故D错误。
1.3数据采集与编码(二)
1.使用UltraEdit软件观察字符“A-Z a-z 0-9”的内码,部分界面如图所示。
下列说法正确的是
A.字符“F”、“d”、“6”的内码值由小变大
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
成从OUT开始的ASCII码字符串。
被转换的十六进制数的位数
由长度LEN给出。
可转换的ASCII字符或十六进制数字的最大数目是255。
有效ASCII输入
有效的ASCII码输入字符是0到9的十六进制数代码值30到39,和大写字符A到F的十六进制数代码值41到46这些字母数字
字符。
使ENO=0的错误条件:
_ SM1.7 (非法的ASCII码)只对ATH有效
_ 0006 (间接寻址)
_ 0091 (操作数超出范围)
受影响的SM标志位:
_ SM1.7 (非法的ASCII码)
将数值转为ASCII码
整数转ASCII码(ITA)、双整数转ASCII码(DTA)和实数转ASCII
码(RTA)指令,分别将整数、双整数或实数值转换成ASCII码
字符。
表6--18 ASCII码转换指令的有效操作数
输入/输出数据类型操作数
IN BYTE
INT
DINT
实型
IB、QB、VB、MB、SMB、SB、LB、*VD、*LD、*AC
IW、QW、VW、MW、SMW、SW、LW、T、C、AC、AIW、*VD、*LD、*AC、常数
ID、QD、VD、MD、SMD、SD、LD、AC、HC、*VD、*LD、*AC、。