jvm指令学习笔记
Java之JVM必备知识点

Java之JVM必备知识点1.JVM为什么可以跨平台JVM能跨计算机体系结构(操作系统)来执行Java字节码(JVM 字节码指令集),屏蔽可与各个计算机平台相关的软件或者硬件之间的差异,使得与平台相关的耦合统一由JVM提供者来实现。
指令集:计算机所能识别的机器语言的命令集合。
每个运行中的java程序都是一个JVM实例。
2.描述JVM体系结构(1)类加载器:JVM启动时或者类运行时将需要的class加载到JVM 中。
每个被装载的类的类型对应一个Class实例,唯一表示该类,存于堆中。
(2)执行引擎:负责执行JVM的字节码指令(CPU)。
执行引擎是JVM的核心部分,作用是解析字节码指令,得到执行结果(实现方式:直接执行,JIT(just in time)即时编译转成本地代码执行,寄存器芯片模式执行,基于栈执行)。
本质上就是一个个方法串起来的流程。
每个Java线程就是一个执行引擎的实例,一个JVM 实例中会有多个执行引擎在工作,有的执行用户程序,有的执行JVM内部程序(GC).(3)内存区:模拟物理机的存储、记录和调度等功能模块,如寄存器或者PC指针记录器。
存储执行引擎执行时所需要存储的数据。
(4)本地方法接口:调用操作系统本地方法返回结果。
3.描述JVM工作机制机器如何执行代码:源代码-预处理器-编译器-汇编程序-目标代码-链接器-可执行程序。
Java编译器将高级语言编译成虚拟机目标语言。
JVM执行字节码指令是基于栈的架构,所有的操作数必须先入栈,然后根据操作码选择从栈顶弹出若干元素进行计算后将结果压入栈中。
通过Java编译器将源代码编译成虚拟机目标语言,然后通过JVM 执行引擎执行。
4.为何JVM字节码指令选择基于栈的结构JVM要设计成平台无关性,很难设计统一的基于寄存器的指令。
为了指令的紧凑性,让编译后的class文件更加紧凑,提高字节码在网络上的传输效率。
5.描述执行引擎的架构设计创建新线程时,JVM会为这个线程创建一个栈,同时分配一个PC 寄存器(指向第一行可执行的代码)。
java内存使用情况的命令

java内存使用情况的命令Java是一种面向对象的编程语言,它在开发应用程序时需要使用内存来存储数据和执行代码。
因此,了解Java的内存使用情况对于开发人员来说是非常重要的。
Java虚拟机(JVM)负责管理Java应用程序的内存,它使用垃圾回收机制来自动管理内存的分配和释放。
JVM的内存可以分为以下几个部分:1. 堆(Heap):堆是Java程序运行时动态分配的内存区域,用于存储对象实例。
堆的大小可以通过命令行参数-Xmx和-Xms来设置。
-Xms表示JVM启动时初始分配的堆内存大小,-Xmx表示堆能够达到的最大内存大小。
2. 方法区(Method Area):方法区用于存储已加载的类信息、常量、静态变量等数据。
方法区的大小可以通过命令行参数-XX:PermSize和-XX:MaxPermSize来设置。
-XX:PermSize表示JVM启动时初始分配的方法区大小,-XX:MaxPermSize表示方法区能够达到的最大大小。
3. 栈(Stack):栈用于存储Java方法中的局部变量以及方法调用时的状态信息。
每个Java线程都有一个独立的栈,栈的大小是固定的,并且在线程创建时被分配。
栈的大小可以通过命令行参数-Xss来设置。
除了上述部分,JVM还会使用一些额外的内存空间,如直接内存(DirectMemory)和本地方法栈(Native Method Stack),用于存储一些特殊的数据和执行本地方法。
了解Java的内存使用情况对于定位内存泄漏和优化程序性能非常有帮助。
下面是几个常用的命令,可以用于监控和调整Java程序的内存使用情况:1. jps:该命令用于列出当前运行的Java进程,以及对应的进程ID。
2. jstat:该命令用于监控Java虚拟机的各种运行状态,包括堆的使用情况、类加载数量、垃圾回收情况等。
常用的参数包括-jstat -gcutil <pid>和-jstat-gccapacity <pid>。
[Java性能剖析]JVM内存机制-笔记
![[Java性能剖析]JVM内存机制-笔记](https://img.taocdn.com/s3/m/0a3770273169a4517723a371.png)
JVM内存机制-笔记内存管理来源:在程序运行过程当中,会创建大量的对象,这些对象,大部分是短周期的对象,小部分是长周期的对象,对于短周期的对象,需要频繁地进行垃圾回收以保证无用对象尽早被释放掉,对于长周期对象,则不需要频率垃圾回收以确保无谓地垃圾扫描检测。
为解决这种矛盾,Sun JVM的内存管理采用分代的策略。
Sun JVM有4垃圾回收器:∙Serial Collector[默认]:序列垃圾回收器,垃圾回收器对Young Gen和Tenured Gen都是使用单线的垃圾回收方式,对Young Gen,会使用拷贝策略避免内存碎片,对Old Gen,会使用压缩策略避免内存碎片。
基本上,在对内核的服务器上应该避免使用这种方式。
在JVM启动参数中使用-XX:+UseSerialGC启用Serial Collector。
∙Parallel Collector:并发垃圾回收器,垃圾回收器对Young Gen和Tenured Gen都是使用多线程并行垃圾回收的方式,对Young Gen,会使用拷贝策略避免内存碎片,对Old Gen,会使用压缩策略避免内存碎片。
在JVM启动参数中使用-XX:+UseParallelGC启用Parallel Collector。
∙Parallel Compacting Collector:并行压缩垃圾回收器,与Parallel Collector垃圾回收类似,但对Tenured Gen会使用一种更有效的垃圾回收策略,此垃圾回收器在暂停时间上会更短。
在JVM启动参数中使用-XX:+UseParallelOldGC启用ParallelCompacting Collector。
∙Concurrent Mark-Sweep (CMS) Collector:并发标志清除垃圾回收器,对Young Gen会使用与Parallel Collector同样的垃圾回收策略,对Tenured Gen,垃圾回收的垃圾标志线程与应用线程同时进行,而垃圾清除则需要暂停应用线程,但暂停时间会大大缩减,需要注意的是,由于垃圾回收过程更加复杂,会降低总体的吞吐量。
Jvm工作原理学习笔记
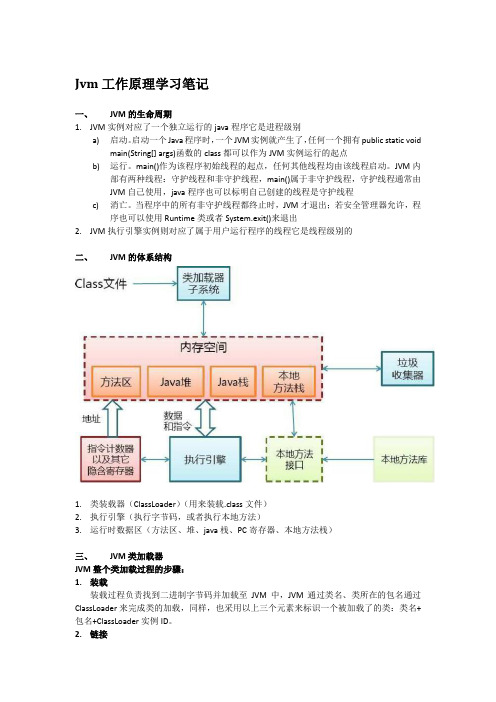
Jvm工作原理学习笔记一、JVM的生命周期1.JVM实例对应了一个独立运行的java程序它是进程级别a)启动。
启动一个Java程序时,一个JVM实例就产生了,任何一个拥有public static voidmain(String[] args)函数的class都可以作为JVM实例运行的起点b)运行。
main()作为该程序初始线程的起点,任何其他线程均由该线程启动。
JVM内部有两种线程:守护线程和非守护线程,main()属于非守护线程,守护线程通常由JVM自己使用,java程序也可以标明自己创建的线程是守护线程c)消亡。
当程序中的所有非守护线程都终止时,JVM才退出;若安全管理器允许,程序也可以使用Runtime类或者System.exit()来退出2.JVM执行引擎实例则对应了属于用户运行程序的线程它是线程级别的二、JVM的体系结构1.类装载器(ClassLoader)(用来装载.class文件)2.执行引擎(执行字节码,或者执行本地方法)3.运行时数据区(方法区、堆、java栈、PC寄存器、本地方法栈)三、JVM类加载器JVM整个类加载过程的步骤:1.装载装载过程负责找到二进制字节码并加载至JVM中,JVM通过类名、类所在的包名通过ClassLoader来完成类的加载,同样,也采用以上三个元素来标识一个被加载了的类:类名+ 包名+ClassLoader实例ID。
2.链接链接过程负责对二进制字节码的格式进行校验、初始化装载类中的静态变量以及解析类中调用的接口、类。
完成校验后,JVM初始化类中的静态变量,并将其值赋为默认值。
最后对类中的所有属性、方法进行验证,以确保其需要调用的属性、方法存在,以及具备应的权限(例如public、private域权限等),会造成NoSuchMethodError、NoSuchFieldError 等错误信息。
3.初始化初始化过程即为执行类中的静态初始化代码、构造器代码以及静态属性的初始化,在四种情况下初始化过程会被触发执行:调用了new;反射调用了类中的方法;子类调用了初始化;JVM启动过程中指定的初始化类。
JVM学习笔记

JVM学习笔记一Java内存模型1、运行时数据区域1.1 程序计数器程序计数器(Program Counter Register)是一块较小的内存空间,可以看成是当前线程所执行的字节码的行号指示器。
字节码解释器工作时就是通过改变这个计数器的值来选取吓一跳需要执行的字节码指令。
线程私有,每条线程都需要有一个独立的程序计数器,各条线程之间互不影响,独立存储。
如果线程正在执行一个Java Method,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的Native Method,这个计数器的值为空(Undefined)。
此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError的区域。
1.2 Java虚拟机栈Java虚拟机栈(Java Virtual Machine Stacks)线程私有,生命周期与线程相同。
虚拟机栈描述的Java方法执行的内存模型: 每个方法在执行的同时,都会创建一个栈帧(Stack Frame),用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
每个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
局部变量表存放了编译期可知的各种基本数据类型(boolean, byte, char, short, int, float, long ,double), 对象引用(reference类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是一个代表对象的句柄或其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)其中64位长度的long,double类型的数据会占用2个局部变量空间(slot),其余的数据类型只占用1 个。
局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,这个方法在运行期间不会改变局部变量表的大小。
JVM从零学习(六)堆

JVM从零学习(六)堆1|0堆1|1堆的核心概述•一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域。
•Java堆区在JVM启动的时候即被创建,其空间大小也就确定了。
是JVM管理的最大一块内存空间。
o堆内存的大小是可以调节的。
•《Java虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。
•所有的线程共享Java堆,在这里还可以划分线程私有的缓冲区•《Java虚拟机规范》中对Java堆的描述是:所有的对象实例以及数组都应当运行时分配在堆上。
•数组和对象可能永远不会存储在栈上,因为栈桢中保存引用,这个引用指向对象或者数组在堆中的位置。
•在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除。
•堆,是GC(Garbage Collection,垃圾收集器)执行垃圾回收的重点区域。
1|0内存细分现代垃圾收集器大部分基于分代收集理论设计,堆空间细分为:•Java 8 及以后堆内存逻辑上分为三部分:新生代、老年代、元空间o Young Generation Space 新生代 Young/New▪又被划分为Eden区和Survivor区o Tenure Generation Space 老年代 Old/Tenureo Meta Space 元空间 Metao1|2堆空间大小设置•Java堆区用于存储Java对象实例,那么堆的带下在JVM启动时就已经设定好了,可以通过选项“-Xmx” 和“-Xms”来进行设置。
o“-Xms”用于表示堆区的初始内存,等价于-XX:InitialHeapSizeo“-Xmx”用于表示堆区的最大内存,等价于-XX:MaxHeapSize•一旦堆区中的内存大小超过“-Xmx”所指定的最大内存时,将会抛出OutOfMemoryError异常。
•通常会将-Xms和-Xmx设置相同的值,其目的是为了能够在Java垃圾回收机制清理完堆区后不需要重新分隔计算堆区大小,从而提高性能。
JVM,Java虚拟机基础知识新手入门教程(超级通熟易懂)

JVM,Java虚拟机基础知识新⼿⼊门教程(超级通熟易懂)⼀.写在前⾯ ⾸先,本篇⽂章并没有涉及原理,⽽是在笔者撸了《深⼊理解Java虚拟机》好⼏遍的基础上讲解⾃⼰的经验,从⼀个新⼿到现在明⽩JVM是个什么玩意,怎么去理解和明⽩,讲解这样⼀个经验⽽已。
这篇⽂章并对JVM并没有挖掘得很深,在下⽬前暂时也没有这个能⼒,只是以通熟易懂的⽅式,让读者理解JVM是个什么玩意。
下⾯开始我的讲解。
⼆.谁说⼈神不得相爱——Java的跨平台 理解Java的跨平台特性,是对JVM最直观的认识。
所谓的“⼀次编译,到处运⾏”,为什么C/C++ 却不能实现呢?这⼀类语⾔直接使⽤物理硬件(或者说操作系统的内存模型),那么不同系统之间的内存模型是不同的,⽐如说Linux和Window,这就意味,在Window编译好的代码,却不能在Linux上运⾏。
《深⼊理解Java虚拟机》记录说,Java虚拟机规范中试图定义⼀种Java内存模型(JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台上都能达到⼀致性的并发效果。
举个现实的例⼦,⼀个只会听说中⽂的⼈,要如何和⼀个只会听说英⽂的⼈交流,在Java的世界⾥,采⽤的⽅式即是给两边的⼈各配⼀名翻译官(JVM),所以,这就是为什么JVM要有window版本,也要有Linux版本。
众所周知,Java的程序编译的最终样⼦是.class⽂件,不同虚拟机的对每⼀个.class⽂件的翻译结果都是⼀致的。
⽽对于C/C++⽽⾔,编译⽣成的是纯⼆进制的机器指令,是直接⾯对计算机系统的内存,但是,java程序的编译结果是⾯向JVM,是要交付给JVM,让他再做进⼀步处理从⽽让计算机识别运⾏,这就是所谓的“屏蔽掉各种硬件和操作系统的内存访问差异”。
这⾥的特点⼜和⾯向对象推崇的⾯向接⼝有着不可描述的关系,我只需要有这么个规范,不需要去知道接触你的底层原理实现。
三.活在梦⾥的真实——虚拟机 JVM,全称Java Virtual Machine,英⽂为Java虚拟机,简单的探讨⼀下虚拟机这三个字,对后⾯的学习也是挺舒服的。
JVM内存机制资料笔记

JVM内存机制资料笔记参考JDK5.0垃圾收集优化之--Don't Pause/calvinxiu/archive/2007/05/18/1614473.aspxJVM内存模型以及垃圾回收/xuwanbest/blog/item/0587d82f2c44a73d1e30892e.html对jvm内存的一些理解/midstr/archive/2008/09/21/230292.html了解JVM的内存管理与垃圾回收/jiaozhenqing/blog/item/f18b85d4c1063a07a08bb77e.htmlJava内存溢出的解决方案/yanghlcn/blog/item/029e7303917b528dd43f7cc3.htmlJava内存组成堆(Heap)运行时数据区域,所有类实例和数组的内存均从此处分配。
Java 虚拟机启动时创建。
对象的堆内存由称为垃圾回收器的自动内存管理系统回收。
组成News Generation(Young Generation即图中的Eden + From Space + To Space)Eden 存放新生的对象Survivor Space 两个存放每次垃圾回收后存活的对象Old Generation(Tenured Generation 即图中的Old Space)主要存放应用程序中生命周期长的存活对象非堆内存JVM具有一个由所有线程共享的方法区。
方法区属于非堆内存。
它存储每个类结构,如运行时常数池、字段和方法数据,以及方法和构造方法的代码。
它是在 Java 虚拟机启动时创建的。
除了方法区外,Java 虚拟机实现可能需要用于内部处理或优化的内存,这种内存也是非堆内存。
例如,JIT 编译器需要内存来存储从 Java 虚拟机代码转换而来的本机代码,从而获得高性能。
组成Permanent Generation(图中的Permanent Space)存放JVM自己的反射对象,比如类对象和方法对象native heapGC策略堆JVM采用一种分代回收 (generational collection) 的策略,用较高的频率对年轻的对象(young generation)进行扫描和回收,这种叫做minor collection,而对老对象(old generation)的检查回收频率要低很多,称为major collection。
JVM 学习笔记

JVM 学习笔记摘要:JVM 作为Java 的核心技术,很多朋友想必也有研究。
一直都在关注JVM 方面的技术,以前看过一些书籍和网上的资料,自己也发了些Blog 文章,不过还是没有彻底的了解JVM 机制,最近有时间研究了研究,特此写下一篇文章并结合笔者多年实践以揭露JVM 实现机理。
关键字:JVM,Java 技术,虚拟机,Java 架构1JVM 架构引言Java 的平台独立,安全和网络可移植性是的Java 最适合网络计算环境,java 的四大核心技术是,Java 语言,字节码格式,Java API,JVM。
每次你编写Java程序时你就用到了这四项技术,那么你是否对他们有足够的了解呢?很多人把JVM 看成是Java 的解释器,这是错误的理解,并不是所有的JVM 实现都Java 的解释器,有的也用到了JIT (Just-In-Time) 技术。
Java 是不允许直接操作本地机器指令的,对于Java方法来说有两种:Java和native,对于native我更习惯用C++ 写DLL,但Java并不提倡你这么做,因为有损Java平台独立性。
JVM 中除了执行引擎就是类加载器了,ClassLoader也分为两种:原始加载器和加载器Object,原始加载器使用和写JVM 一样的语言写的,比如用C写的类加载器,而加载器Object就是用Java 实现的类加载器,方便我们扩展,比如你自己可以New 一个URLClassLoader 从网络上下载字节码到本地运行。
一个类的加载和他参考的类的加载应该用同一个ClassLoader。
这一点在发生异常的时候很难找出,比如OSGI 中每个bundle 都有自己独立的ClassLoader,对于新手很容易犯错误而无从下手,我们熟悉的WEB 服务器Tomcat 的类加载器是分层(有继承关系)的,所以在应用整合的时候也很容易发生ClassLoader 相关的异常,而这样的异常往往很难定位。
JAVA学习完整版详细笔记

Java基础知识总结Java基础知识总结写代码:1,明确需求。
我要做什么?2,分析思路。
我要怎么做?1,2,3。
3,确定步骤。
每一个思路部分用到哪些语句,方法,和对象。
4,代码实现。
用具体的java语言代码把思路体现出来。
学习新技术的四点:1,该技术是什么?2,该技术有什么特点(使用注意):3,该技术怎么使用。
demo4,该技术什么时候用?test。
-----------------------------------------------------------------------------------------------一:java概述:1991 年Sun公司的James Gosling等人开始开发名称为 Oak 的语言,希望用于控制嵌入在有线电视交换盒、PDA等的微处理器;1994年将Oak语言更名为Java;Java的三种技术架构:JAVAEE:Java Platform Enterprise Edition,开发企业环境下的应用程序,主要针对web程序开发;JAVASE:Java Platform Standard Edition,完成桌面应用程序的开发,是其它两者的基础;JAVAME:Java Platform Micro Edition,开发电子消费产品和嵌入式设备,如手机中的程序;1,JDK:Java Development Kit,java的开发和运行环境,java的开发工具和jre。
2,JRE:Java Runtime Environment,java程序的运行环境,java运行的所需的类库+JVM(java虚拟机)。
3,配置环境变量:让java jdk\bin目录下的工具,可以在任意目录下运行,原因是,将该工具所在目录告诉了系统,当使用该工具时,由系统帮我们去找指定的目录。
环境变量的配置:1):永久配置方式:JAVA_HOME=%安装路径%\Java\jdkpath=%JAVA_HOME%\bin2):临时配置方式:set path=%path%;C:\Program Files\Java\jdk\bin特点:系统默认先去当前路径下找要执行的程序,如果没有,再去path中设置的路径下找。
传智播客刘意老师JAVA全面学习笔记(word文档良心出品)

JAVA 学习路线第一天1:计算机概述(了解)22:键盘功能键的认识和快捷键(掌握)2 3:常见的DOS命令(掌握)34:Java语言概述(了解)35:JDK,JRE,JVM的作用及关系(掌握) 3 6:JDK的下载,安装,卸载(掌握)47:第一个程序:HelloWorld案例(掌握)4 8:常见的问题(掌握)59:path环境变量(掌握)510:classpath环境变量(理解)5第二天1:关键字(掌握)62:标识符(掌握)63:注释(掌握)74:常量(掌握)75:进制转换(了解)76:变量(掌握)87:数据类型(掌握)88:数据类型转换(掌握)8第三天1:运算符(掌握)102:键盘录入(掌握)113:流程控制语句124:if语句(掌握)12第四天1:switch语句(掌握)142:循环语句(掌握)153:控制跳转语句(掌握)17第五天1:方法(掌握)182:数组(掌握)19第六天1:二维数组(理解)232:两个思考题(理解)233:面向对象(掌握)23第七天1:成员变量和局部变量的区别(理解)252:类作为形式参数的问题?(理解)253:匿名对象(理解)254:封装(理解)255:private关键字(掌握)256:this关键字(掌握)267:构造方法(掌握)268:代码:Student s = new Student();做了哪些事情?(理解)27 9:面向对象的练习题(掌握)27第八天1:如何制作帮助文档(了解)282:通过JDK提供的API学习了Math类(掌握)283:代码块(理解)284:继承(掌握)28第九天1:final关键字(掌握)302:多态(掌握)303:抽象类(掌握)324:接口(掌握)33第十天1:形式参数和返回值的问题(理解)352:包(理解)353:导包(掌握)354:权限修饰符(掌握)365:常见的修饰符(理解)366:内部类(理解)37第十一天1:Eclipse的概述使用(掌握)402:API的概述(了解)403:Object类(掌握)40第十二天1:Scanner的使用(了解)412:String类的概述和使用(掌握)41第十三天1:StringBuffer(掌握)442:数组高级以及Arrays(掌握)443:Integer(掌握)464:Character(了解)47第十四天1:正则表达式(理解)472:Math(掌握)493:Random(理解)494:System(掌握)495:BigInteger(理解)506:BigDecimal(理解)507:Date/DateFormat(掌握)508:Calendar(掌握)51第十五天1:对象数组(掌握)522:集合(Collection)(掌握)523:集合(List)(掌握)55第十六天1:List的子类(掌握)572:泛型(掌握)583:增强for循环(掌握)584:静态导入(了解)585:可变参数(掌握)596:练习(掌握)597:要掌握的代码59第十七天1:登录注册案例(理解)602:Set集合(理解)603:Collection集合总结(掌握)604:针对Collection集合我们到底使用谁呢?(掌握)61 5:在集合中常见的数据结构(掌握)61第十八天1:Map(掌握)622:Collections(理解)63第十九天1:异常(理解)642:File(掌握)65第二十天1:递归(理解)662:IO流(掌握)663:自学字符流第二十一天1:字符流(掌握)69第二十一天1:字符流(掌握)692:IO流小结(掌握)703:案例(理解练习一遍)71第二十二天1:登录注册IO版本案例(掌握)722:数据操作流(操作基本类型数据的流)(理解)72 3:内存操作流(理解)724:打印流(掌握)725:标准输入输出流(理解)736:随机访问流(理解)737:合并流(理解)738:序列化流(理解)739:Properties(理解)7410:NIO(了解)74第二十三天1:多线程(理解)75第二十四天1:多线程(理解)772:设计模式(理解)77第二十五天1:如何让Netbeans的东西Eclipse能访问79 2:GUI(了解)79第二十六天1:网络编程(理解)80第二十七天1:反射(理解)822:设计模式823:JDK新特性82JA V A学习总结姓名:陈鑫第一天1:计算机概述(了解)(1)计算机(2)计算机硬件(3)计算机软件系统软件:window,linux,mac应用软件:qq,yy,飞秋(4)软件开发(理解)软件:是由数据和指令组成的。
JVM字节码指令

JVM字节码指令本文部分摘自《深入理解 Java 虚拟机》简介Java 虚拟机的指令由操作码 + 操作数组成,其中操作码是代表某种特定操作含义的数字,长度为一个字节,而操作数就是此操作所需的一个或多个参数。
由于 Java 虚拟机采用面向操作数栈而非寄存器的架构,所以大多数指令都不包括操作数,只有一个操作码既然限制了 JVM 操作码的长度为一个字节(0 ~ 255),也意味着指令集的操作码总数不超过256 条。
Class 文件格式放弃了编译后代码的操作数长度对齐,因此虚拟机在处理那些超过一个字节的数据时,不得不在运行时从字节中重建出具体数据的结构,这会损失一些性能,但也省略了大量的填充和间隔符号,尽可能得到短小精悍的编译代码字节码和数据类型在 Java 虚拟机的指令集中,大多数指令都包含其操作所对应的数据类型信息,每种数据类型都有特殊的字符来表示。
但 Java 虚拟机的操作码长度只有一个字节,如果为每一种与数据类型相关的指令都支持 Java 虚拟机所有运行时数据类型的话,那指令的数量恐怕就会超过一字节所能表示的数量范围了因此,Java 虚拟机对于特定的操作只提供了有限的类型相关指令去支持它,即并非每种数据类型和每一种操作都有对应的指令。
下表就是特定操作与其支持数据类型的关系图,指令中的T 可以替换为对应的数据类型,空格表示不支持这种数据类型执行这项操作opcode byte short int long float double char referenceTipush bipush sipushTconst iconst lconst fconst dconst aconst Tload iload lload fload dload aload Tstore istore lstore fstore dstore astore Tinc iincTaload baload saload iaload laload faload daload caload aaloadTastore bastoresastoreiastorelastorefastoredastorecastoreaastoreTadd iadd ladd fadd dadd Tsub isub lsub fsub dsub Tmul imul lmul fmul dmul Tdiv idiv ldiv fdiv ddiv Trem irem lrem frem drem Tneg ineg lneg fneg dneg Tshl ishl lshlTshr ishr lshrTushr iushr lushrTand iand landTor ior lorTxor ixor lxori2T i2b i2s i2l i2f i2d l2T l2i l2f l2d f2T f2i f2l f2d d2T d2i d2l d2fTcmp lcmpTcmpl fcmpl dcmpl Tcmpg fcmpg dcmpgif_TcmpO P if_icmpOPif_acmpOPTreturn ireturn lreturnfreturndreturnareturn可以发现,大部分指令都没有支持byte、char、short、boolean,编译器会在编译期或运行期将 byte 和 short 类型的数据带符号扩展为相应的 int 类型数据,将 boolean 和 char 类型数据零位扩展为相应的 int 类型数据,然后使用对应 int 类型的字节码指令来处理。
jvm基础知识点总结

jvm基础知识点总结本文将系统地介绍JVM的基础知识点,包括JVM的结构、内存管理、垃圾回收、类加载机制等内容,帮助读者了解JVM的工作原理和性能调优的基本方法。
JVM的结构JVM由三个子系统组成:类加载器子系统、运行时数据区和执行引擎。
类加载器子系统负责将.class文件加载到内存中,并在运行时对类进行初始化。
JVM中有三个内置的类加载器:启动类加载器、扩展类加载器和应用程序类加载器。
它们按照"双亲委派模型"来加载类,即如果一个类加载器收到类加载请求,它会先将请求委托给其父加载器来完成,只有在所有父加载器都无法完成加载请求时,该加载器才会尝试自行加载类。
运行时数据区包括方法区、堆、虚拟机栈、本地方法栈和程序计数器。
方法区用于存储类的结构信息、静态变量、常量和运行时常量池。
堆用于存储对象实例。
虚拟机栈用于存放方法的局部变量表、操作数栈、动态链接、方法返回地址等信息。
本地方法栈用于支持native方法的执行。
程序计数器用于记录当前线程执行的字节码指令地址。
执行引擎包括解释器和即时编译器。
解释器将字节码指令逐条翻译成对应的本地机器指令并执行。
即时编译器则将热点代码(经常被执行的代码)编译成本地机器代码,以提高执行效率。
内存管理JVM内存管理主要涉及堆内存和方法区的管理。
堆内存分为新生代和老年代。
新生代又分为Eden空间和两个Survivor空间。
新创建的对象首先被分配到Eden空间,如果Eden空间不足,将触发一次Minor GC,将存活的对象复制到其中一个Survivor空间,并清空Eden空间。
经过多次Minor GC后,存活时间较长的对象将被移到老年代。
老年代空间主要用于存放存活时间较长的对象。
方法区用于存放类的结构信息、静态变量、常量和运行时常量池。
方法区的垃圾回收主要针对永久代,通过触发Full GC进行垃圾收集。
垃圾回收垃圾回收是JVM的一个重要功能,主要用于释放无用对象所占用的内存空间。
jvm知识点总结

jvm知识点总结JVM(Java Virtual Machine)是Java平台的核心组件,它是一个在实际计算机上运行的虚拟计算机,用于执行Java字节码。
它是Java语言的核心,也是Java跨平台特性的基础。
本文将就JVM的相关知识点进行总结。
一、JVM的概述JVM是Java应用程序运行的环境,它负责解释和执行Java字节码。
它是一个虚拟机,它将Java源代码编译成字节码,然后在JVM上运行。
二、JVM的架构JVM的架构可以分为三个主要部分:类加载器、运行时数据区和执行引擎。
1. 类加载器:类加载器负责将编译后的字节码加载到JVM中。
JVM中存在三个层次的类加载器:启动类加载器、扩展类加载器和应用程序类加载器。
2. 运行时数据区:JVM的运行时数据区包括方法区、堆、栈、本地方法栈和程序计数器。
3. 执行引擎:执行引擎负责解释字节码并执行相应的指令。
JVM有两种执行引擎:解释器和即时编译器(JIT)。
三、JVM的内存模型JVM的内存模型包括方法区、堆、栈和程序计数器。
1. 方法区:方法区用于存储类信息、常量、静态变量等。
它是线程共享的区域。
2. 堆:堆是JVM中最大的一块内存区域,用于存储对象实例。
它是线程共享的区域。
3. 栈:栈用于存储方法的局部变量、方法参数、返回值等。
每个线程都有自己的栈。
4. 程序计数器:程序计数器用于存储当前线程执行的字节码指令的地址。
四、垃圾回收机制JVM提供了自动内存管理机制,即垃圾回收。
垃圾回收机制通过标记-清除、复制、标记-整理等算法来回收无用的对象,以释放内存空间。
五、即时编译器(JIT)JIT是JVM的一种执行引擎,它将热点代码(频繁执行的代码)编译成本地机器码,以提高程序的执行效率。
六、JVM的调优JVM的调优是为了提高程序的性能和稳定性。
常见的调优手段包括调整堆大小、调整垃圾回收算法、调整线程数等。
七、JVM的安全性JVM提供了一些安全机制来保护系统免受恶意代码的侵害,如安全沙箱、字节码验证等。
Java性能优化权威指南-读书笔记(二)-JVM性能调优-概述

Java性能优化权威指南-读书笔记(⼆)-JVM性能调优-概述概述:JVM性能调优没有⼀个⾮常固定的设置,⽐如堆⼤⼩设置多少,⽼年代设置多少。
⽽是要根据实际的应⽤程序的系统需求,实际的活跃内存等确定。
正⽂:JVM调优⼯作流程整个调优过程是不断重复的⼀个迭代,后⾯的步骤有可能影响前⾯的配置,可能需要重新调优。
应⽤程序的系统需求确定应⽤程序的系统需求是性能调优的基础,后⾯的调优都会依赖这个要求。
⼀个应⽤不会⽆休⽌地调优下去。
1.可⽤性2.可管理性3.启动时间4.吞吐量TPS: 每秒多少次事务QPS: 每秒多少次查询5.延迟⽐如关键请求必须60ms完成响应6.内存占⽤选择JVM的部署模式单JVM部署模式:可以⽤更多的物理内存多JVM部署模式:减少了单点,不过分布式部署也解决了这个问题JVM运⾏模式32位JVM:内存空间限制为4G,关键是还进⼀步受限于操作系统,Windows⼤约1.5G,Linux⼤约3G。
64位JVM:对象指针的长度从32位变为64位,导致CPU⾼速缓存可以缓存的指针变少,降低了缓存效率。
可以开启指针压缩,解决这个问题,指针压缩在堆⼩于等于26GB时,性能最好。
JVM会根据堆⼤⼩⾃动开启这个。
垃圾收集调优基础基本原则1. 每次MinorGC都尽可能多地收集垃圾对象。
可以减少FullGC的频率,因为FullGC的持续时间总是最长;2. 处理吞吐量和延迟问题时,GC能使⽤的内存越⼤,垃圾收集的效果越好,应⽤越流畅;3. 在这三个属性(吞吐量、延迟、内存占⽤)中任意选择两个进⾏JVM垃圾收集器调优,因为三个属性肯定不能同时满⾜;GC⽇志GC⽇志是收集调优所需信息的最好途径,下⾯是⼀次MinorGC的⽇志,FullGC的⽇志和这个类似:5.483: [GC (Allocation Failure)[PSYoungGen: 142650K->16873K(145408K)]168504K->48298K(189440K), 0.0769590 secs][Times: user=0.22 sys=0.00, real=0.08 secs]1). 各属性说明5.483:是JVM启动到现在的时间戳Allocation Failure:Eden区分配内存失败,导致GC142650K(新⽣代回收前⼤⼩)->16873K(新⽣代回收后⼤⼩)(145408K(新⽣代总⼤⼩))168504K(回收前堆占⽤⼤⼩)->48298K(回收后堆占⽤⼤⼩)(189440K(堆总⼤⼩))Times:user(GC⾮操作系统指令占⽤的CPU时间)sys(GC操作系统调⽤占⽤的CPU时间)real(实际占⽤的CPU时间)2). 计算⽼年代⽅法根据上⾯这个MinorGC⽇志,可以推算出⽼年代在GC前后的⼤⼩。
JVM学习心得总结记录

JVM学习⼼得总结记录1.JVM内存区域 Java虚拟机在运⾏时,内存分为若⼲区域;Java虚拟机管理的内存区域有:⽅法区、堆内存、虚拟机栈、本地⽅法栈、程序计数器。
①⽅法区:主要⽤于存储虚拟机加载的类信息、常量、静态变量、以及编译后的代码。
②堆内存:主要⽤于存放对象和数组,是jvm管理的内存中最⼤的区域。
和⽅法区都被所有线程共享。
在虚拟机启动时创建。
③程序计数器:当前线程执⾏字节码的⾏号指⽰器,每个线程都有⼀个独⽴的程序计数器,所以程序计数器时线程私有的⼀块空间。
程序计数器是虚拟机规定的唯⼀不会发⽣内存溢出的区域。
④虚拟机栈:描述的是⽅法的内存模型,是每个线程私有的⼀块内存空间。
每个虚拟机栈中都有若⼲个栈帧(存储局部变量,操作数栈,动态链接,返回地址等),⼀个栈帧对应代码中的⼀个⽅法,当线程执⾏到这个⽅法时,就代表这个⽅法对应的栈帧进⼊虚拟机栈并处于栈顶,⼀个⽅法从被调⽤到结束,就是⼀个栈帧从⼊栈到出栈的过程。
⑤本地⽅法栈:执⾏本地⽅法(注意:虚拟机栈执⾏的java⽅法)2,JVM内存溢出①堆内存溢出:堆内存主要存放对象,数组等,不断的new对象并且不会被回收,当对象所占空间超过堆内存容量时就会堆内存溢出outofmemory; 常见堆内存溢出原因:加载数据过多,对象引⽤过多且使⽤完没有清空,代码死循环,堆内存分配不合理,⽹络问题等。
②虚拟机栈/本地⽅法栈溢出:stackoverflow 线程请求的栈的深度⼤于虚拟机所允许的最⼤深度(栈帧数量过多,线程嵌套调⽤的⽅法数量过多)时就会栈溢出,栈内存空间 = 可⽤物理内存 - 最⼤堆内存 - 最⼤⽅法区内存假如栈占⽤内存512M,每个线程栈⼤⼩1M,此时虚拟机最多创建512个线程,超出时没有空间可⽤就会报outofmemory。
常见栈内存溢出:递归找不到出⼝。
③⽅法区溢出:⽅法区主要⽤于存储虚拟机加载的类信息、常量、静态变量、以及编译后的代码等,当没有⾜够的内存来存放这些数据时就就是⽅法区溢出。
JVM原理速记复习Java虚拟机总结思维导图面试必备

JVM原理速记复习Java虚拟机总结思维导图⾯试必备良⼼制作,右键另存为保存JVM喜欢可以点个赞哦Java虚拟机⼀、运⾏时数据区域线程私有程序计数器记录正在执⾏的虚拟机字节码指令的地址(如果正在执⾏的是Native⽅法则为空),是唯⼀⼀个没有规定OOM(OutOfMemoryError)的区域。
Java虚拟机栈每个Java⽅法在执⾏的同时会创建⼀个栈桢⽤于存储局部变量表、操作数栈、动态链接、⽅法出⼝等信息。
从⽅法调⽤直到执⾏完成的过程,对应着⼀个栈桢在Java虚拟机栈中⼊栈和出栈的过程。
(局部变量包含基本数据类型、对象引⽤reference和returnAddress类型)本地⽅法栈本地⽅法栈与Java虚拟机栈类似,它们之间的区别只不过是本地⽅法栈为Native⽅法服务。
线程公有Java堆(GC区)(Java Head)⼏乎所有的对象实例都在这⾥分配内存,是垃圾收集器管理的主要区域。
分为新⽣代和⽼年代。
对于新⽣代⼜分为Eden空间、FromSurvivor空间、To Survivor空间。
JDK1.7 ⽅法区(永久代)⽤于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
对这块区域进⾏垃圾回收的主要⽬的是对常量池的回收和对类的卸载,但是⼀般难以实现。
HotSpot虚拟机把它当做永久代来进⾏垃圾回收。
但很难确定永久代的⼤⼩,因为它受到很多因素的影响,并且每次Full GC之后永久代的⼤⼩都会改变,所以经常抛出OOM异常。
从JDK1.8开始,移除永久代,并把⽅法区移⾄元空间。
运⾏时常量池是⽅法区的⼀部分Class⽂件中的常量池(编译器⽣成的字⾯量和符号引⽤)会在类加载后被放⼊这个区域。
允许动态⽣成,例如String类的intern()JDK1.8 元空间原本存在⽅法区(永久代)的数据,⼀部分移到了Java堆⾥⾯,⼀部分移到了本地内存⾥⾯(即元空间)。
元空间存储类的元信息,静态变量和常量池等放⼊堆中。
jvm知识点总结

jvm知识点总结JVM(Java Virtual Machine)是Java程序的执行环境,它是Java 应用程序运行的核心组件。
本文将从JVM的定义、工作原理、内存管理、垃圾回收机制等方面进行总结和介绍。
一、JVM的定义和作用JVM是一个虚拟的计算机,它是在物理计算机上通过软件来模拟实现的。
JVM的主要作用是将Java字节码文件(.class文件)转换为机器码并执行,从而实现对Java程序的解释和执行。
它提供了一个独立于具体操作系统的平台,使得Java程序具有了跨平台的特性。
二、JVM的工作原理1. 类加载:JVM通过类加载器将Java源文件编译生成的字节码文件加载到内存中。
类加载器会根据类的全限定名定位字节码文件,并将其加载到方法区中。
2. 字节码解释执行:JVM将字节码文件解析成可以执行的机器码,并通过解释器执行。
解释器每次只执行一条字节码指令,效率较低。
3. 即时编译:JVM在运行过程中会对热点代码进行即时编译,将其编译成本地机器码。
这样可以提高执行效率。
4. 垃圾回收:JVM通过垃圾回收器来自动管理内存,回收不再使用的对象。
垃圾回收会暂停程序的执行,将不再使用的内存释放出来。
三、JVM的内存管理JVM将内存分为不同的区域,每个区域有不同的用途和生命周期。
1. 方法区:存储类的结构信息、常量池、静态变量等。
方法区是线程共享的,用于存储类相关的元数据。
2. 堆区:存储对象实例。
堆区是线程共享的,用于存储动态创建的对象。
3. 栈区:存储局部变量和方法调用信息。
栈区是线程私有的,每个线程都有自己的栈帧。
4. 程序计数器:记录当前线程执行的字节码指令的地址。
5. 本地方法栈:用于支持本地方法调用。
四、JVM的垃圾回收机制JVM通过垃圾回收器自动回收不再使用的内存。
垃圾回收的过程可以分为以下几个步骤:1. 标记:从根对象开始,标记所有可达的对象。
2. 清除:清除所有未被标记的对象,释放它们所占用的内存空间。
常用jvm参数

常用jvm参数常用JVM参数Java虚拟机(JVM)是Java程序的运行环境,它是Java语言的核心部分。
JVM的性能对于Java程序的运行速度和稳定性有着至关重要的影响。
在JVM的运行过程中,我们可以通过设置一些参数来优化JVM的性能,提高Java程序的运行效率和稳定性。
本文将介绍一些常用的JVM参数。
1. -Xms和-Xmx-Xms和-Xmx是JVM的两个重要参数,它们分别用于设置JVM的初始堆大小和最大堆大小。
JVM的堆是Java程序运行时的内存空间,用于存储Java对象。
如果程序需要创建的对象超过了堆的大小,就会导致OutOfMemoryError异常。
因此,合理设置-Xms和-Xmx参数可以避免这种情况的发生。
-Xms参数用于设置JVM的初始堆大小,它的默认值是物理内存的1/64。
例如,如果物理内存是4GB,那么-Xms的默认值就是64MB。
可以通过以下命令来设置-Xms参数:java -Xms512m Main这个命令将JVM的初始堆大小设置为512MB。
-Xmx参数用于设置JVM的最大堆大小,它的默认值是物理内存的1/4。
例如,如果物理内存是4GB,那么-Xmx的默认值就是1GB。
可以通过以下命令来设置-Xmx参数:java -Xmx1024m Main这个命令将JVM的最大堆大小设置为1GB。
2. -XX:PermSize和-XX:MaxPermSize-XX:PermSize和-XX:MaxPermSize是JVM的两个参数,它们用于设置JVM的永久代(Permanent Generation)大小。
永久代是JVM的一部分,用于存储Java类的元数据,例如类名、方法名、字段名等。
如果永久代的大小不够,就会导致OutOfMemoryError 异常。
-XX:PermSize参数用于设置JVM的永久代初始大小,它的默认值是物理内存的1/64。
例如,如果物理内存是4GB,那么-XX:PermSize的默认值就是64MB。
JavaJVM相关基础知识

JavaJVM相关基础知识1.JMM Java内存模型1)Java的并发采⽤“共享内存”模型,线程之间通过读写内存的公共状态进⾏通讯。
多个线程之间是不能通过直接传递数据交互的,它们之间交互只能通过共享变量实现;2)主要⽬的是定义程序中各个变量的访问规则;3)Java内存模型规定所有变量都存储在主内存中,每个线程还有⾃⼰的⼯作内存:线程的⼯作内存中保存了被该线程使⽤到的变量的拷贝(从主内存中拷贝过来),线程对变量的所有操作都必须在⼯作内存中执⾏,⽽不能直接访问主内存中的变量;不同线程之间⽆法直接访问对⽅⼯作内存的变量,线程间变量值的传递都要通过主内存来完成主内存主要对应Java堆中实例数据部分;⼯作内存对应于虚拟机栈中部分区域4)Java线程之间的通信由内存模型JMM(Java Memory Model)控制:JMM决定⼀个线程对变量的写⼊何时对另⼀个线程可见。
线程之间共享变量存储在主内存中每个线程有⼀个私有的本地内存,⾥⾯存储了读/写共享变量的副本。
JMM通过控制每个线程的本地内存之间的交互,来为程序员提供内存可见性保证。
5)可见性、有序性:当⼀个共享变量在多个本地内存中有副本时,如果⼀个本地内存修改了该变量的副本,其他变量应该能够看到修改后的值,此为可见性。
保证线程的有序执⾏,这个为有序性。
(保证线程安全6)内存间交互操作:lock(锁定):作⽤于主内存的变量,把⼀个变量标识为⼀条线程独占状态。
unlock(解锁):作⽤于主内存的变量,把⼀个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read(读取):作⽤于主内存变量,把主内存的⼀个变量读取到⼯作内存中。
load(载⼊):作⽤于⼯作内存,把read操作读取到⼯作内存的变量载⼊到⼯作内存的变量副本中use(使⽤):作⽤于⼯作内存的变量,把⼯作内存中的变量值传递给⼀个执⾏引擎。
assign(赋值):作⽤于⼯作内存的变量。
把执⾏引擎接收到的值赋值给⼯作内存的变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0x3d
istore_2
将栈顶int型数值存入第三个本地变量
0x3e
istore_3
将栈顶int型数值存入第四个本地变量
0x3f
lstore_0
将栈顶long型数值存入第一个本地变量
0x40
lstore_1
将栈顶long型数值存入第二个本地变量
0x41
lstore_2
0x4b
astore_0
将栈顶引用型数值存入第一个本地变量
0x4c
astore_1
将栈顶引用型数值存入第二个本地变量
0x4d
astore_2
将栈顶引用型数值存入第三个本地变量
0x4e
astore_3
将栈顶引用型数值存入第四个本地变量
0x4f
iastore
将栈顶int型数值存入指定数组的指定索引位置
0x50
lastore
将栈顶long型数值存入指定数组的指定索引位置
0x51
fastore
将栈顶float型数值存入指定数组的指定索引位置
0x52
dastore
将栈顶double型数值存入指定数组的指定索引位置
0x53
aastore
将栈顶引用型数值存入指定数组的指定索引位置
0x54
bastore
将栈顶boolean或byte型数值存入指定数组的指定索引位置
0x93
i2s
将栈顶int型数值强制转换成short型数值并将结果压入栈顶
0x94
lcmp
比较栈顶两long型数值大小,并将结果(1,0,-1)压入栈顶
0x95
fcmpl
比较栈顶两float型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将-1压入栈顶
0x96
fcmpg
比较栈顶两float型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将1压入栈顶
0x06
iconst_3
将int型3推送至栈顶
0x07
iconst_4
将int型4推送至栈顶
0x08
iconst_5
将int型5推送至栈顶
0x09
lconst_0
将long型0推送至栈顶
0x0a
lconst_1
将long型1推送至栈顶
0x0b
fconst_0
将float型0推送至栈顶
0x0c
fconst_1
0x12
ldc
将int, float或String型常量值从常量池中推送至栈顶
0x13
ldc_w
将int, float或String型常量值从常量池中推送至栈顶(宽索引)
0x14
ldc2_w
将long或double型常量值从常量池中推送至栈顶(宽索引)
0x15
iload
将指定的int型本地变量推送至栈顶
0x37
lstore
将栈顶long型数值存入指定本地变量
0x38
fstore
将栈顶float型数值存入指定本地变量
0x39
dstore
将栈顶double型数值存入指定本地变量
0x3a
astore
将栈顶引用型数值存入指定本地变量
0x3b
istore_0
将栈顶int型数值存入第一个本地变量
0x3c
istore_1
0x8b
f2i
将栈顶float型数值强制转换成int型数值并将结果压入栈顶
0x8c
f2l
将栈顶float型数值强制转换成long型数值并将结果压入栈顶
0x8d
f2d
将栈顶float型数值强制转换成double型数值并将结果压入栈顶
0x8e
d2i
将栈顶double型数值强制转换成int型数值并将结果压入栈顶
将int型数值左移位指定位数并将结果压入栈顶
0x79
lshl
将long型数值左移位指定位数并将结果压入栈顶
0x7a
ishr
将int型数值右(符号)移位指定位数并将结果压入栈顶
0x7b
lshr
将long型数值右(符号)移位指定位数并将结果压入栈顶
0x7c
iushr
将int型数值右(无符号)移位指定位数并将结果压入栈顶
fstore_3
将栈顶float型数值存入第四个本地变量
0x47
dstore_0
将栈顶double型数值存入第一个本地变量
0x48
dstore_1
将栈顶double型数值存入第二个本地变量
0x49
dstore_2
将栈顶double型数值存入第三个本地变量
0x4a
dstore_3
将栈顶double型数值存入第四个本地变量
0x5f
swap
将栈最顶端的两个数值互换(数值不能是long或double类型的)
0x60
iadd
将栈顶两int型数值相加并将结果压入栈顶
0x61
ladd
将栈顶两long型数值相加并将结果压入栈顶
0x62
fadd
将栈顶两float型数值相加并将结果压入栈顶
0x63
dadd
将栈顶两double型数值相加并将结果压入栈顶
0x16
lload
将指定的long型本地变量推送至栈顶
0x17
fload
将指定的float型本地变量推送至栈顶
0x18
dload
将指定的double型本地变量推送至栈顶
0x19
aload
将指定的引用类型本地变量推送至栈顶
0x1a
iload_0
将第一个int型本地变量推送至栈顶
0x1b
iload_1
将第二个int型本地变量推送至栈顶
ifne
当栈顶int型数值不等于0时跳转
0x9b
iflt
当栈顶int型数值小于0时跳转
0x9c
ifge
当栈顶int型数值大于等于0时跳转
0x9d
ifgt
当栈顶int型数值大于0时跳转
0x9e
ifle
drem
将栈顶两double型数值作取模运算并将结果压入栈顶
0x74
ineg
将栈顶int型数值取负并将结果压入栈顶
0x75
lneg
将栈顶long型数值型数值取负并将结果压入栈顶
0x77
dneg
将栈顶double型数值取负并将结果压入栈顶
0x78
ishl
0x87
i2d
将栈顶int型数值强制转换成double型数值并将结果压入栈顶
0x88
l2i
将栈顶long型数值强制转换成int型数值并将结果压入栈顶
0x89
l2f
将栈顶long型数值强制转换成float型数值并将结果压入栈顶
0x8a
l2d
将栈顶long型数值强制转换成double型数值并将结果压入栈顶
0x97
dcmpl
比较栈顶两double型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将-1压入栈顶
0x98
dcmpg
比较栈顶两double型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将1压入栈顶
0x99
ifeq
当栈顶int型数值等于0时跳转
0x9a
将栈顶long型数值存入第三个本地变量
0x42
lstore_3
将栈顶long型数值存入第四个本地变量
0x43
fstore_0
将栈顶float型数值存入第一个本地变量
0x44
fstore_1
将栈顶float型数值存入第二个本地变量
0x45
fstore_2
将栈顶float型数值存入第三个本地变量
0x46
0x1c
iload_2
将第三个int型本地变量推送至栈顶
0x1d
iload_3
将第四个int型本地变量推送至栈顶
0x1e
lload_0
将第一个long型本地变量推送至栈顶
0x1f
lload_1
将第二个long型本地变量推送至栈顶
0x20
lload_2
将第三个long型本地变量推送至栈顶
0x21
lload_3
0x64
isub
将栈顶两int型数值相减并将结果压入栈顶
0x65
lsub
将栈顶两long型数值相减并将结果压入栈顶
0x66
fsub
将栈顶两float型数值相减并将结果压入栈顶
0x67
dsub
将栈顶两double型数值相减并将结果压入栈顶
0x68
imul
将栈顶两int型数值相乘并将结果压入栈顶
0x69
0x55
castore
将栈顶char型数值存入指定数组的指定索引位置
0x56
sastore
将栈顶short型数值存入指定数组的指定索引位置
0x57
pop
将栈顶数值弹出(数值不能是long或double类型的)
0x58
pop2
将栈顶的一个(long或double类型的)或两个数值弹出(其它)
0x59
dup
0x32
aaload
将引用型数组指定索引的值推送至栈顶
0x33
baload
将boolean或byte型数组指定索引的值推送至栈顶
0x34
caload
将char型数组指定索引的值推送至栈顶
0x35
saload
将short型数组指定索引的值推送至栈顶