保险数据仓库数据抽取的设计与实现
保险业决策支持系统的数据仓库的设计与实现
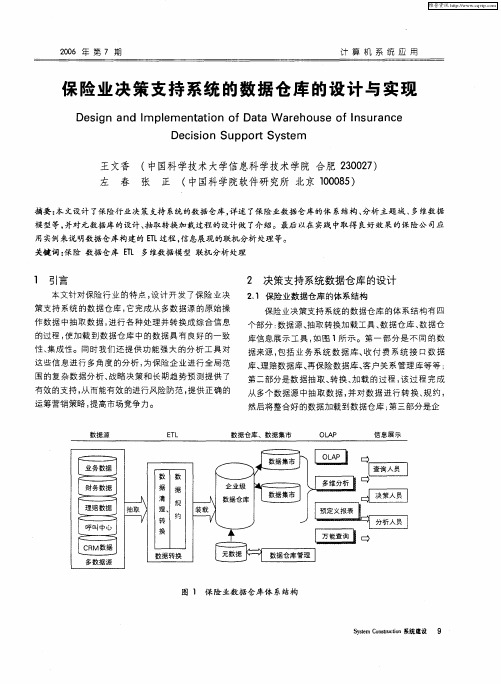
第二部分是数 据抽取 、 转换 、 加载 的过 程 , 过 程完 成 该
从多个数据源 中抽取 数 据 , 对数据 进行 转 换 、 约 , 并 规
然后将整合好 的数据加载 到数据仓库 ; 第三部分 是企
数据源
EL T
数据仓库 、数据集市
OL P A
信息展示
图 1 保 险业数据仓库体 系结构
的 EL T 过程。
的多个维度 表组成 。事 实是决策 者分析 的 目标数 据 ,
如保额、 费、 续 费、 款金额 等。维是 事实 的信 息 保 手 赔
属性 , 是观察事 实的角度 , 也 如保单的承保机构 、 险种 、
起 保 日期、 经办 人、 代理 人等。本文以保单分析事 实表 为例构造 其星型模 式如 图 2所示 , 们可 以汇 总各个 我 层次的承 保公司的保费收入情况 、 手续 费情 况等 , 也可 以从险种 、 起保 日期、 经办人等 角度按照各 种层次进行
维普资讯
20 年 第 7 期 06
计 算 机 系 统 应 用
保 险业 决 策 支持 系统 的数 据 仓 库 的 设 计 与 实现
De i n a d I p e e t ton o t a e o s fI s r n e sg n m l m n a i fDa a W r h u e o n u a c
邮编
联系电话 上级机构
数据格式 、 访问方法及使 用限制 、 数据源 的业 务内容说明、 数据源 的更 新频率 、 据抽取 需 数 设置的参数、 抽取 的进度安排等信息 。
2 3 2 预 处理数 据元数 据 ..
据 的对 应规 则 , 包括 数 据源 的关 系表和 数据
保险行业数据仓库(PDF 12页)

构建保险数据仓库的一个实例一、前言几乎所有行业都面对着激烈的竞争,正确及时的决策是企业生存与发展的最重要环节。
越来越多的企业认识到,只有靠充分利用、发掘其现有数据,才能实现更大的效益。
日常的业务应用生成了大量的数据,这些数据若用于决策支持则会带来显著的附加值。
若再加上行业分析报告、独立的市场调查、评测结果和顾问评估等外来数据时,上述处理过程产生的效益可进一步增强。
数据仓库正是汇总这些信息的基础,进而支持数据发掘、多维数据分析等当今尖端技术和传统的查询及报表功能。
这些对于在当今激烈的竞争中保持领先是至关重要的。
调查研究表明,大多数企业并不缺少数据,而是受阻于过量的冗余数据和数据不一致;而且它们变得越来越难于访问、管理和用于决策支持;其数据量正以成倍的速度增长。
这样,信息中心面临着不断增长的决策支持的需求,但是,开发应用变得越来越复杂和耗费人力。
那么怎样把大量的数据转换成可靠的、商用的信息以便于决策支持呢?数据仓库正广泛地被公认为是最好的解决方案。
PLATINUM technology 是世界上最大的数据仓库完整解决方案提供商之一。
在许多行业,我们都已经成功实施了数据仓库。
我们的成功来自于以下方面。
PLATINUM technology. Inc.保险业数据仓库解决方案全面提供商丰富的行业知识成功的用户实例完善的咨询服务先进的数据仓库构造过程完整的数据仓库产品系列24-10-98我们为国内一家保险公司建立的数据仓库系统,是结合了国际先进的保险业管理模式和中国国情的系统。
因此,我们的经验应该说具有实践意义和针对我国情况的现实性。
二、为什么需要数据仓库背景——保险公司在最近几年得到了迅猛的发展,未来预计将以更快的速度增长。
高速发展的保险公司面临激烈的竞争,从而产生越来越多的预测与决策支持需求。
比如想了解:您能够确定哪些险种正在恶化或已成为不良险种?您能够用有效的方式制定新增和续保的政策吗?您的理赔过程有欺诈的可能吗?您的理赔过程有不必要的额外花费吗?您现在能得到的报表是否只是月报或季报?数据仓库技术正是解决这些需求的最先进技术。
数据仓库中的多维数据模型设计与实现教程

数据仓库中的多维数据模型设计与实现教程在数据仓库中,多维数据模型设计与实现是一项关键任务。
它不仅可以帮助企业组织和分析庞大的数据量,还能提供决策支持和洞察力。
本文将介绍数据仓库中多维数据模型的概念、设计原则以及实现方法,帮助读者全面了解和掌握这一重要主题。
一、多维数据模型的概念多维数据模型是基于数据的特征和关联性来组织数据的一种模型。
它通过将数据按照不同的业务维度进行分组和分类,将数据以多维方式呈现,从而提供了更加直观和灵活的数据分析能力。
多维数据模型主要由维度、度量和层次结构组成。
1. 维度:维度是描述业务问题的属性,它可以是时间、地理位置、产品、客户等。
维度用来描述数据的特征,例如销售额可以按照时间、地理位置和产品维度进行分析。
2. 度量:度量是可以进行数值计算和分析的数据,例如销售额、利润、数量等。
度量用来描述数据的量度,便于进行各种统计分析。
3. 层次结构:层次结构是维度之间的关系,它描述了维度之间的层次结构和上下级关系。
例如时间维度可以由年、月、日等层次结构组成。
二、多维数据模型的设计原则在设计多维数据模型时,需要遵循一些原则,以确保模型的合理性和有效性。
1. 简单性:多维数据模型应该尽可能简单,避免过于复杂的维度和层次结构。
简单的模型易于理解和维护,提高数据分析效率。
2. 一致性:多维数据模型中的维度和度量应该保持一致性,避免冗余和重复。
一致的模型有助于提高查询效率和数据一致性。
3. 可扩展性:多维数据模型应该具有良好的扩展性,能够容纳未来的需求变化和数据增长。
设计时需要考虑到未来可能发生的维度扩展和度量变化。
4. 性能优化:多维数据模型的设计也要考虑到查询性能的优化。
根据实际需求和查询模式,合理设计维度的层次结构、聚集表和索引等,以提高查询效率。
三、多维数据模型的实现方法在实现多维数据模型时,需要选择合适的工具和技术来支持模型的构建和数据的加载。
1. 数据抽取和转换:多维数据模型的实现通常需要进行数据抽取和转换,将源系统的数据转化为可用于多维模型的格式。
一个医保基金风险防控数据仓库的设计和实现

不 同的风险因素有效地采取 风险控 制手段 , 医保基金进行 行 对 之有效的风险管理 。数据仓库技术为我们提供 了有效的技术和
方 法 , 过 对 数 据 不 同 的 组 织 方 式 为 决 策 的 制 定 过 程 提 供 了 良 通
wa e o s ,we h v u h a me ia s r n e f n ik p e e t n a d c nr l aawa e o s h c t ga e i t- aa ma a e n rh u e a eb i d c l n u a c u d rs rv n i n o t t r h u e w ih i i e r td w t mea d t n g me t i o od sn h a d E L tc n l g o r aie t e efc ie i tg ain o ee o e e u d c n u a c aa s u c st r vd n a a a e p a om r n T h oo y t e s h f t n e t f t rg n o sme ia i s r ed t o r e o p ie a f e d t s lt r f e l e v r o h l n o i b f o
0 引 言
社会医疗 保险制度 作为一项 关系 国计 民生 的重要政 策 , 已
得 到 了社 会 的 高 度 重 视 。 上 海 医 疗 保 险 信 息 管 理 系 统 于 2 0 01
构建数据仓库是一项复杂 的系统工程。 目前 市场上 已有的
数据仓库产 品, 数据抽取 、 转换与加载等数据仓库工具不能完全
寿险行业数据治理规划架构设计方案

13
目录
•1
数据架构 - 定位、设计目标、设计原则、设计思路
•2
数据架构 - 高效数据操作
•3
数据架构 - 规划设计
•4
数据架构 - 数据源、数据的准备、存储、加工、交换
•5
数据治理 - 概述、数据现状、分阶段实施与当前进展
•6
数据治理 - 元数据管理
•7
数据治理 - 主数据管理
数 据 治 理
元 数 据 管 理
描述数据的数据比一般意义上的数据范畴更加广泛在分析型项目中,帮助数据仓库设计和开发 人员快速查找数据在OLAP系统中,用来描述分析型应用的内 部数据结构、建立方法和流程
建立数据应用标准消除不一致性,实现数据广泛共享提升组织的数据质量将数据资产应用到业务、管理和战略决策发挥数据资产的商业价值
22
数据现状
数据现状不符合业务或技术规则键值重复、属性重复数据格式错误无效数据多套重复编码*,码表取值范围不统一命名规则不统一*数据类型不统一*(类型、长度/精度/小数位)数据列冗余,难以找寻基准数据,一致性难以 维护大量废弃不用的表*、空值字段
引发问题影响数据一致性影响数据完整性影响数据准确性系统间数据交换共享困难重复统计造成误差数据迁移困难开发运维效率低数据库性能降低
19
数据架构 - 数据交换平台(DEP)
合作商DMZ区
互联网DMZ区
非核心生产网
核心生产网
交换前置
中间表 文本XML 非结构化 文件
银保通
信保通
中介
邮保通
官网
电商
移动展业
其他
个险核心
团险核心
销售管理
其他
数据仓库设计和数据模型的实现

数据仓库设计和数据模型的实现数据仓库是指企业或组织集成多个数据源,根据业务需求建立的一个集中存储、管理和分析数据的系统。
在数据仓库的设计和建模过程中,数据模型起到了关键作用。
本文将探讨数据仓库设计的关键要素以及数据模型的实现方法。
一、数据仓库设计要素数据仓库的设计是建立一个高效、灵活、可维护的系统,需要考虑以下几个关键要素:1. 数据源:识别和收集企业内部和外部的数据源,包括操作型数据库、文件、传感器和外部数据接口等。
应清楚数据源的格式、结构和存储方式。
2. 数据抽取和清洗:通过ETL(抽取、转换和加载)工具对数据源进行抽取和清洗。
这一步骤是将源数据整理成可用于数据仓库的格式。
3. 数据仓库模型:设计合适的数据模型是数据仓库设计的核心步骤。
常用的模型包括星型模型、雪花模型和事实表-维度模型等。
合理选择数据模型可以提高数据查询和分析的效率。
4. 元数据管理:元数据是描述数据的数据,用于管理和理解数据仓库中的数据。
元数据管理需要定义元数据的结构和管理方法,以支持数据的查询、分析和维护。
5. 数据存储和索引:在数据仓库中,数据的存储和索引策略对查询和分析的性能有着直接的影响。
常用的存储方式包括关系型数据库、列式数据库和NoSQL数据库等。
6. 数据安全和权限控制:由于数据仓库中存储了企业重要的数据,安全和权限控制是必不可少的。
需要采取措施保护数据的机密性、完整性和可用性,并对用户进行权限的控制和管理。
二、数据模型的实现方法数据模型是数据仓库设计的核心,合理选择数据模型有助于提高数据查询和分析的效率。
以下是几种常用的数据模型及其实现方法:1. 星型模型:星型模型是最常用的数据模型之一,它由一个中心的事实表和多个维度表组成。
事实表记录了业务事实的度量指标,维度表包含了与事实表相关的维度信息。
星型模型使用简单,易于理解和查询。
2. 雪花模型:雪花模型是在星型模型的基础上进一步细化和扩展的模型。
维度表可以继续细分为多个维度表,形成更复杂的层次结构。
数据仓库设计方案

数据仓库设计方案【正文】一、引言数据驱动的决策已经成为企业中不可或缺的一部分。
为了有效地管理和分析海量的数据,数据仓库设计方案应运而生。
本文将介绍数据仓库的概念、设计原则和关键步骤,帮助企业构建高效可靠的数据仓库。
二、数据仓库概述数据仓库是指将各类数据整合、清洗、转化并存储于统一的数据存储区域,旨在为决策支持系统提供准确可靠的数据服务。
其设计方案需要考虑多个方面,包括数据源、数据的抽取与转换、数据建模和数据的加载等。
三、数据仓库设计原则1. 一致性:数据仓库应该保持与源系统的数据一致性,确保决策所依据的数据准确无误。
2. 高性能:数据仓库需要具备高性能的查询和分析能力,以满足用户对数据的实时性和响应性要求。
3. 安全性:严格管理数据仓库的访问权限,确保敏感数据的安全性和隐私保护。
4. 可扩展性:数据仓库需要具备良好的扩展能力,能够适应数据量的增长和业务需求的变化。
5. 可维护性:数据仓库的设计应该具备良好的可维护性,便于数据的更新、维护和监控。
四、数据仓库设计步骤1. 需求分析:明确数据仓库的功能和目标,分析业务需求和数据源的特点,为后续的设计提供指导。
2. 数据抽取与转换:根据需求分析的结果,选择合适的数据抽取方式,并进行数据的清洗、转换和集成。
3. 数据建模:根据业务需求和数据源的特点,设计数据仓库的物理和逻辑模型,并建立相应的维度表和事实表。
4. 数据加载:将清洗和转换后的数据加载到数据仓库中,并进行合理的存储和索引,以便进行后续的查询和分析。
5. 数据质量控制:定期监控数据仓库的数据质量,并进行必要的修复和优化,确保数据准确无误。
6. 安全管理:建立合适的权限控制机制,确保数据仓库的安全性和合规性。
五、数据仓库设计工具和技术1. ETL工具:ETL(Extract-Transform-Load)工具可以帮助实现数据的抽取、转换和加载,实现数据仓库的数据集成和清洗。
2. 数据建模工具:数据建模工具可以辅助设计数据仓库的物理和逻辑模型,提供建模、维护和文档化的功能。
数据仓库的设计和构建

数据仓库的设计和构建数据仓库(Data Warehouse)是指将组织机构内部各种分散的、异构的数据整合起来,形成一个共享的、一致的、易于查询和分析的数据环境。
数据仓库的设计和构建是数据管理和分析的重要环节。
本文将结合实践经验,介绍数据仓库的设计与构建过程。
一、需求分析数据仓库的设计与构建首先需要进行需求分析。
在需求分析阶段,我们需要明确以下几个问题:1. 数据来源:确定数据仓库所需要的数据来源,包括内部系统和外部数据源。
2. 数据维度:确定数据仓库中需要关注的维度,如时间、地理位置、产品等。
3. 数据粒度:确定数据仓库中的数据粒度,即需要对数据进行何种程度的聚合。
4. 数据可用性:确定数据仓库中数据的更新频率和可用性要求。
5. 分析需求:明确数据仓库所需满足的分析需求,如报表查询、数据挖掘等。
二、数据模型设计在数据仓库设计过程中,数据模型的设计尤为重要。
常用的数据模型包括维度建模和星型模型。
维度建模是基于事实表和维度表构建的,通过定义事实和维度之间的关系,建立多维数据结构。
星型模型则将事实表和各个维度表之间的关系表示为星型结构,有助于提高查询效率。
根据具体需求和数据特点,选择合适的数据模型进行设计。
三、数据抽取与转换数据仓库的构建过程中,需要从各个数据源中抽取数据,并进行清洗和转换。
数据抽取常用的方法包括全量抽取和增量抽取。
全量抽取是指将数据源中的全部数据抽取到数据仓库中,适用于数据量较小或变动频率较低的情况。
增量抽取则是在全量抽取的基础上,只抽取发生变动的数据,提高了数据抽取的效率。
数据在抽取到数据仓库之前还需要进行清洗和转换。
清洗的目标是去除数据中的错误、冗余和不一致之处,保证数据的准确性和完整性。
转换的目标是将数据格式进行统一,并进行必要的计算和整合,以满足数据仓库的需求。
四、数据加载与存储数据加载是指将抽取、清洗和转换后的数据加载到数据仓库中的过程。
数据加载的方式可以分为批量加载和实时加载。
数据仓库设计与建模的流程与方法

数据仓库设计与建模的流程与方法数据仓库是一个用于集中存储、管理和分析企业中各类数据的系统。
它旨在帮助企业更好地理解和利用自己的数据资源,支持决策和战略制定。
数据仓库的设计与建模是数据仓库开发的关键步骤之一。
本文将介绍数据仓库设计与建模的流程与方法。
数据仓库设计与建模流程数据仓库设计与建模是一个迭代的过程,包括以下主要步骤:1.需求收集和分析在数据仓库设计与建模之前,首先需要与业务用户和决策者进行充分的沟通和需求收集。
了解用户的需求和业务流程对于数据仓库的设计和建模至关重要。
通过与用户的交流,收集到的需求可以被细化和明确以指导后续的工作。
2.数据源选择和数据抽取确定需要从哪些数据源抽取数据,并选择合适的数据抽取工具或技术。
根据需求收集和分析的结果,进行数据抽取和转换,将源系统的数据导入到数据仓库中。
这个步骤是数据仓库设计与建模中的重要部分,关系到数据质量和数据一致性。
3.物理数据模型设计在物理数据模型设计阶段,将逻辑数据模型转化为物理数据模型。
物理数据模型设计包括确定表、字段、索引、分区等物理数据库对象的详细定义。
需要考虑到性能和存储方面的因素,并根据数据仓库的查询需求进行优化设计。
4.维度建模维度建模是数据仓库设计与建模的核心技术之一。
它通过标识和定义业务过程中的关键业务概念,如事实表、维度表和维度属性,来描述业务应用中的事实和维度关系。
维度建模的目标是提供用户友好的数据表示,支持灵活且高效的数据查询和分析。
5.粒度定义和聚合设计决定数据仓库的数据粒度是数据仓库设计与建模的一个重要决策。
粗粒度数据更适合用于高层次的分析和决策,而细粒度数据则支持更详细的数据分析。
聚合设计是为了提高数据仓库的性能和查询响应时间而进行的,它通过预计算和存储汇总数据来减少复杂查询的计算量。
6.元数据管理元数据是指描述数据的数据,是数据仓库设计与建模过程中不可忽视的一部分。
元数据管理包括收集、维护和管理数据仓库中的元数据信息,为数据仓库开发、运维和使用提供支持。
数据仓库设计与构建实践

数据仓库设计与构建实践第一章:引言在信息化时代,数据的积累和分析已经成为企业决策的重要依据。
为了更好地管理和利用海量的数据,数据仓库技术应运而生。
本文将探讨数据仓库的设计与构建实践,从数据仓库的概念、架构到实际应用进行详细介绍。
第二章:数据仓库概念与特点2.1 数据仓库的定义数据仓库是一个面向主题的、集成的、历史的、非易失性的数据集合,用于支持企业决策。
2.2 数据仓库的特点数据仓库具有主题性、集成性、非易失性、时间性、稳定性和查询性能等特点,为企业的决策提供了强有力的基础。
第三章:数据仓库架构设计3.1 三层架构设计模型数据仓库的架构通常包括数据源层、数据仓库层和OLAP(联机分析处理)层。
介绍了三层架构的设计原则和各层的功能。
3.2 数据仓库的数据模型数据仓库一般采用星型或雪花型数据模型,对模型的设计进行了详细说明,包括维度表的设计、事实表的设计等。
3.3 元数据管理元数据是数据仓库的重要组成部分,介绍了元数据管理的意义和实践方法,包括元数据存储、元数据管理工具等。
第四章:数据仓库构建实践4.1 数据清洗与集成数据清洗和集成是数据仓库构建的首要任务,介绍了数据清洗的流程和方法,包括数据去重、数据格式转换等技术。
4.2 数据加载与转换数据加载和转换是将清洗后的数据导入数据仓库的过程,介绍了数据加载和转换的方法,包括ETL(抽取、转换和加载)工具的使用。
4.3 数据建模与优化数据建模是数据仓库构建过程中的关键环节,介绍了数据建模的原则和方法,如维度建模和星型模型等。
同时,还介绍了数据仓库的性能优化技术,如索引的设计和查询优化等。
第五章:数据仓库应用与管理5.1 数据仓库的查询与分析数据仓库的价值在于支持企业的决策分析,介绍了数据仓库的查询与分析工具,如OLAP工具和数据挖掘工具等。
5.2 数据安全与权限控制数据安全与权限控制是数据仓库管理的重要内容,介绍了数据仓库的安全性设计和权限控制的方法。
5.3 数据仓库的维护与监控数据仓库的维护与监控是保障数据仓库稳定运行的重要工作,介绍了数据仓库的维护策略和监控手段。
数据仓库设计作业指导书

数据仓库设计作业指导书一、背景介绍数据仓库是一种面向主题的、集成的、相对稳定的、不可操作的数据集合,用于支持业务分析和决策制定。
在数据仓库设计作业中,我们需要按照一定的步骤和方法,将原始数据进行抽取、转换和加载,构建一个适合分析和查询的数据仓库模型。
本指导书将引导您完成数据仓库设计作业,并提供相应的步骤和要点。
二、数据仓库设计步骤1. 需求分析在设计数据仓库之前,首先需要进行需求分析。
通过与业务用户的交流和调研,明确数据仓库的目标和用途,确定数据仓库要解决的问题,并明确需要提供的报表和查询需求。
2. 数据抽取与清洗在数据仓库设计中,数据抽取和清洗是非常重要的环节。
从各个数据源中抽取所需数据,并进行清洗,包括去重、去除空值、数据格式转换等,以确保数据的质量和准确性。
3. 数据转换与集成在数据仓库设计中,数据转换和集成是将原始数据转化为适合分析的形式,同时将来自不同数据源的数据整合在一起。
这一步骤包括数据规范化、数据合并、数据聚合等操作,以得到一致的数据模型。
4. 维度建模在数据仓库设计中,维度建模是一种常用的设计方法。
通过定义维度和事实表,建立维度模型,以支持灵活的数据分析和查询。
在维度建模过程中,需要定义维度表中的属性和层次,并与事实表进行关联。
5. 数据加载数据加载是将经过转换和整合的数据加载到数据仓库中的过程。
这一步骤包括数据加工和数据加载两个环节。
数据加工是对数据进行清洗和处理,数据加载是将清洗后的数据加载到数据仓库中的操作。
6. 数据访问数据访问是数据仓库设计的最终目标,通过各种工具和技术,实现数据的查询和分析。
数据访问可以通过数据仓库工具、OLAP工具、报表工具等方式进行。
三、数据仓库设计要点1. 主题导向:数据仓库的设计要以业务主题为导向,按照业务需求进行设计和建模,以支持相关业务的决策和分析。
2. 一致性和准确性:设计过程中需要确保数据的一致性和准确性,对于抽取的数据进行清洗和转换,去除重复值和不合法数据。
数据仓库设计与建模的数据抽取与数据加载的设计方法

数据仓库设计与建模的数据抽取与数据加载的设计方法数据仓库在现代企业中扮演着重要的角色。
它不仅是数据分析和决策支持的基础,还可以帮助企业实现数据的整合和共享。
而数据仓库的设计与建模是数据仓库实现的关键环节之一。
在数据仓库设计与建模过程中,数据抽取与数据加载是不可或缺的重要步骤。
本文将从数据抽取与数据加载的设计方法的角度,探讨数据仓库设计与建模的相关要点。
一、数据抽取数据抽取是从各个数据源中提取数据并加工为数据仓库所需的格式和结构的过程。
在数据抽取过程中,有以下几种常用的设计方法。
1. 批量抽取批量抽取是指定时间周期内将数据源中的数据一次性全部抽取到数据仓库中的方法。
这种方式适合数据量较小、数据更新频率较低的情况。
采用批量抽取的设计方法可以减少对源系统的访问次数,降低对源系统性能的影响。
2. 增量抽取增量抽取是指每次只抽取源系统中发生变化的数据,将这部分数据加载到数据仓库中。
这种方式适合数据量较大、数据更新频率较高的情况。
采用增量抽取的设计方法可以缩短数据抽取的时间,并实现数据实时更新。
3. 基于事件的抽取基于事件的抽取是指根据数据源中发生的事件来触发数据抽取的方法。
例如,当源系统中某个表的数据发生变化时,就触发数据抽取。
这种方式适合需要实现数据实时同步的情况。
采用基于事件的抽取的设计方法可以保证数据的准确性和及时性。
二、数据加载数据加载是指将抽取到的数据按照事实表和维度表的关系进行整合和加载到数据仓库中的过程。
在数据加载过程中,有以下几种常用的设计方法。
1. 全量加载全量加载是将每次抽取到的数据全部加载到数据仓库中的方法。
这种方式适合数据量较小、数据更新频率较低的情况。
采用全量加载的设计方法可以简化数据加载的逻辑和流程,减少加载过程中的错误。
2. 增量加载增量加载是将每次抽取到的数据与已有数据进行比对,只将新增的或更新的数据加载到数据仓库中的方法。
这种方式适合数据量较大、数据更新频率较高的情况。
采用增量加载的设计方法可以降低数据加载的时间和成本,并保证数据仓库的及时性。
数据库中的数据湖与数据仓库的设计与实现

数据库中的数据湖与数据仓库的设计与实现数据湖和数据仓库是现代企业在管理大规模数据时经常使用的两种架构模式。
它们在存储、处理和分析大量结构化和非结构化数据方面起着关键作用。
本文将介绍数据库中的数据湖和数据仓库的设计与实现,并分析它们在企业中的应用和优势。
一、数据湖的设计与实现1. 数据湖的概念数据湖是一个存储大规模数据的系统,它将多种类型的数据以原始的形式进行存储,包括结构化数据、半结构化数据和非结构化数据。
传统的数据仓库模式往往需要对数据进行预处理和转换,而数据湖则将数据以原始格式存储,提供了更大的数据灵活性和可扩展性。
2. 数据湖的设计原则在设计数据湖时,需考虑以下原则:(1)数据湖应该支持多样化的数据类型,包括结构化、半结构化和非结构化数据。
(2)数据湖需具备高度可扩展性,可以容纳海量数据并支持快速的数据写入和读取。
(3)数据湖的架构应支持数据的元数据管理,以提供数据的可发现性和可管理性。
(4)数据湖需要具备强大的数据安全性和隐私保护措施,以保护敏感数据的存储和处理过程。
3. 数据湖的实现技术实现数据湖可以采用一些现有的开源技术,如:(1)分布式文件系统(如HDFS):用于存储大规模数据,并提供可靠的数据备份和高可用性。
(2)分布式计算框架(如Spark):用于对大规模数据进行处理和分析,并实现复杂的数据转换操作。
(3)元数据管理工具(如Apache Hive):用于管理数据湖中的数据模式和表结构信息。
(4)数据安全和隐私保护工具(如Apache Ranger):用于实现对敏感数据的访问控制和权限管理。
4. 数据湖的应用场景数据湖适用于下列应用场景:(1)数据探索和发现:通过数据湖,用户可以直接访问和探索各种类型的数据,发现新的关联和洞见。
(2)大数据分析和机器学习:数据湖提供了海量数据的存储和处理能力,支持大数据分析和机器学习算法的运行。
(3)实时数据处理:数据湖可以接收实时数据流,并支持实时数据的处理和实时分析。
面向保险业的数据仓库模型分析与设计

面向保险业的数据仓库模型分析与设计吴菊华;曹强;莫赞;孙德福【摘要】The insurance industry has gone through the computer informationlization construction development during the last decade, the scale of business data is constantly increasing. Enterprise executives face tremendous information from different business systems and more severe competition pressure, they need faster and more accurate analysis for the issue of enterprise decision-making. In this paper, based on the ECIF project of a life insurance company, data warehouse modeling problems and solutions are elaborated and analysed from business and management perspective of the entire insurance industry. The boundary of the data warehouse system is defined, the subject field is determined, and the insurance subject-oriented data warehouse model is built with conceptual model, logical model and physical model. Since the number and type of indicators in different industry differ from each other, the data warehouse indicators for the insurance industry is also tested. The whole process has a good reference value for the building of the insurance industry data warehouse.%保险业经历了十几年的计算机信息化建设发展,业务的数据规模也在不断地增大,需要对企业决策问题进行更准确的深度分析。
数据仓库与数据挖掘课程设计

通信与信息工程学院数据仓库与数据挖掘分析课程设计班级:XXXX姓名:XXX学号:XXXXXX指导教师:XXXXX设计时间:XXXXX成绩:评通信与信息工程学院二〇一X年工作完成统计表:教师签名:目录1.绪论 (1)1.1项目背景 (1)1.2提出问题 (1)2.数据仓库与数据集市的概念介绍 (1)2.1数据仓库介绍 (1)2.2数据集市介绍 (2)3.数据仓库 (3)3.1数据仓库的设计 (3)3.1.1数据仓库的概念模型设计 (4)3.1.2数据仓库的逻辑模型设计 (5)3.2 数据仓库的建立 (5)3.2.1数据仓库数据集成 (5)3.2.2建立维表 (8)4.OLAP操作 (10)5.数据预处理 (12)5.1描述性数据汇总 (12)5.2数据清理与变换 (13)6.数据挖掘操作 (13)6.1关联规则挖掘 (13)6.2 分类和预测 (17)6.3决策树的建立 (18)6.4聚类分析 (22)7.总结 (25)8.任务分配 (26)1、绪论1.1项目背景在现在大数据时代,各行各业需要对商品及相关关节的数据进行收集处理,尤其零售行业,于企业对产品的市场需求进行科学合理的分析,从而预测出将来的市场,制定出高效的决策,给企业带来经济收益。
1.2 提出问题对于超市的商品的购买时期和购买数量的如何决定,才可以使销售量最大,不积压商品,不缺货,对不同时期季节和不同人群制定不同方案,使企业收益最大,通过数据挖掘对数据进行决策树分析,关联分析,顺序分析与决策分析等可以制定出最佳方案。
2、数据库仓库与数据集的概念介绍2.1数据仓库数据仓库介绍:数据仓库是为企业所有级别的决策制定过程提供支持的所有类型数据的战略集合。
它是单个数据存储,出于分析性报告和决策支持的目的而创建。
为企业提供需要业务智能来指导业务流程改进和监视时间、成本、质量和控制。
数据仓库是决策系统支持(dss)和联机分析应用数据源的结构化数据环境。
数据库数据仓库的ETL流程设计与实现方法

数据库数据仓库的ETL流程设计与实现方法数据仓库(Data Warehouse)是指为了支持决策和分析而专门构建的、面向主题的、集成的、稳定的、非易失的数据存储库。
而ETL (Extract-Transform-Load)流程则是将来自不同数据源的数据提取、转换和加载到数据仓库中的一种方法。
本文将介绍数据库数据仓库的ETL流程设计与实现方法。
一、概述在数据库数据仓库的建设过程中,ETL流程起到了至关重要的作用。
ETL流程的设计和实现方法将直接影响数据仓库的建设效果和数据质量。
下面将从数据提取、数据转换和数据加载这三个方面来介绍ETL流程的设计与实现方法。
二、数据提取数据提取是将数据从源系统中抽取到数据仓库中的过程。
在数据提取过程中,需要考虑以下几个方面:1. 选择合适的数据提取方式:常见的数据提取方式包括全量提取和增量提取。
全量提取是指从源系统中提取所有数据,适用于首次建设数据仓库或数据仓库与源系统之间的数据结构和业务规则变化较大的情况。
增量提取是指仅提取源系统中发生变化的数据,适用于数据仓库的定期更新需求。
2. 设计数据提取逻辑:根据数据仓库的需求,确定提取哪些数据以及如何提取。
可以根据业务需求选择提取特定时间范围内的数据、特定条件下的数据等。
3. 选择数据提取工具:根据实际情况选择合适的数据提取工具,如Sqoop、Flume等。
三、数据转换数据转换是将提取的数据转换为数据仓库需要的格式和结构的过程。
在数据转换过程中,需要考虑以下几个方面:1. 数据清洗:对提取的数据进行清洗,去除重复数据、处理缺失值、处理异常值等。
2. 数据集成:将来自不同源系统的数据进行集成,确保数据格式一致、字段对应正确。
3. 数据转换:根据数据仓库的需求,对数据进行转换,如添加计算字段、合并数据等。
4. 数据归约:将转换后的数据进行归约,减少数据冗余,提高存储和查询效率。
四、数据加载数据加载是将转换后的数据加载到数据仓库中的过程。
数据仓库分析系统整体设计方案

数据仓库分析系统整体设计方案一、引言数据仓库分析系统(Data Warehouse Analytics System)是指通过对企业数据仓库中的数据进行提取、清洗、转化和加载(ETL)等处理,为企业提供分析和决策支持的系统。
本文将对数据仓库分析系统的整体设计方案进行详细阐述。
二、系统架构设计1.数据提取:数据提取模块负责从企业各个数据源(如ERP系统、CRM系统等)中抽取数据。
根据不同的数据源,可以采用适当的技术,如数据库连接、API调用等,将数据提取到数据仓库中。
2.数据清洗:数据清洗模块负责对提取的数据进行清洗和处理,以确保数据的准确性和完整性。
此模块包括数据去重、数据格式化、数据校验等功能,可以使用数据质量工具和ETL工具来实现。
3.数据转化:数据转化模块负责将清洗后的数据进行转化和整合,使其符合企业分析和决策的需求。
此模块可以进行数据的聚合、计算衍生指标、数据分割等操作,以便进行更深入的数据分析。
4.数据加载:数据加载模块负责将转化后的数据加载到数据仓库中,以供后续的分析和决策支持。
此模块可以使用数据加载工具或者自定义的脚本来实现。
三、系统功能设计1.数据管理:系统支持数据源的管理和配置,可以添加、修改和删除数据源的连接信息和抽取规则。
同时,还提供数据仓库的管理功能,包括数据仓库的创建、维护和备份等。
2.数据分析:系统提供多种数据分析功能,如数据的查询、统计、趋势分析和关联分析等。
用户可以根据需要进行自定义的数据查询和分析操作,以满足不同业务需求。
3. 报表生成:系统支持报表的生成和导出,用户可以选择不同的报表模板,根据自己的需求进行报表设计和配置,并将报表导出为常见的格式,如Excel、PDF等。
四、系统技术选型在系统设计过程中,需要选择合适的技术和工具来支持系统的功能实现。
以下是一些常用的技术和工具:1. 数据库:选择适合大规模数据处理的数据库,如Oracle、MySQL 等。
根据实际情况,可以考虑采用分布式数据库或者数据仓库专用数据库。
工伤保险数据仓库的设计与实现

图 1 主 题 划 分 图 社 保 系 统 由养 老 、 业 、 伤 、 失 工 医疗 、 育 等 险 种 系统 组 成 , 生 . 据 库 多 维 模 型设 计 2数 工 伤 社 保 系 统是 其 中 的一 个 子 系统 。 伤 社 保 M S 是将 现 代 信 2 工 I, 构 建 D 使 用 多 维 建 模 法 .使 用 P w r ei e 设 计 各 主 W o e s n r D g 息 技 术 与 通 讯技 术 结 合 起 来完 成工 伤 保 险 中 有关 的待 遇 补 偿 的 形 其 不 相 关 业 务处 理 . 工伤 申报 、 伤 认 定 、 由 工 医务 劳 动 鉴 定 、 伤 待 遇 题 事 实 表 和 维 表 , 成 多 个 星 模 , 中 维 表 可 以 共 享 , 必 重 复 工 设 计 . 于 星 型 以事 实 表 为 中 周 围是 从 多 个 角 度 多个 层 次进 由 b。 核 定 、 养 关 系 、 案 反馈 和专 业 统 计 等 功 能 组 成 。 供 办
每 所 原有 的 MI 统 采 用 BSS架 构 。 数 据集 中并 分级 处 理 , 行 汇 总形 成 的 维 表 , 个 维 表 可 分 不 同粒 度 . 以 当 维 表需 要 细 S系 // 将 考 将 即采 用 分 站 、 局 、 局 三 层处 理模 式 ; 供 业 务 协 作 机 制 。 现 分 时 . 虑将 高层 次 对 应 的 描 述 信息 用 单 独 表 来 存 放 , 星 型变 分 市 提 实 雪 避免 社保 机 构 、 点 医 院 、 疗 鉴 定 机构 、 行 间 协 同 办公 。 定 医 银 系统 中 问 为雪 花 型 。 花 型 的 优 点是 可 以减 少 复杂 维 中的 数 据沉 余 。 缺 从 件 采 用 Weshr A piao evr 前 端 及 程 序 开 发 使 用 占用 过 多 的 存 储 空 问 : 点 是 会 使表 问 的连 接 关 系 复 杂 化 , 而 bp ee p l t n Sre . ci
数据仓库设计与建模的数据抽取与加载的性能优化方法(六)

数据仓库设计与建模的数据抽取与加载的性能优化方法一、引言随着互联网和大数据时代的到来,数据的规模和复杂度呈现出爆炸式的增长,使得数据管理和分析变得更加重要。
数据仓库设计与建模是数据管理的关键环节之一,而其中数据抽取与加载的性能优化则是提高数据仓库效率的关键。
本文将从不同的角度探讨数据仓库设计与建模中数据抽取与加载的性能优化方法。
二、数据抽取性能优化方法1. 增量抽取在进行数据抽取时,若每次都是全量抽取,不仅浪费了时间和资源,还可能造成数据重复。
因此,采用增量抽取的方式可以有效提高性能。
增量抽取是指仅抽取发生变化的数据,可以通过使用时间戳或者日志文件来判断数据是否有更新。
同时,可以借助ETL工具来进行增量抽取的操作,提高数据抽取的效率。
2. 并行抽取对于大规模的数据集,采用串行的方式进行抽取会导致较长的执行时间。
而采用并行抽取的方式,可以同时运行多个任务,提高抽取速度。
可以通过使用分布式计算框架来实现并行抽取,如Hadoop、Spark等。
通过将数据切分为多个部分,分别进行抽取,并最后合并结果,可以显著缩短抽取时间。
三、数据加载性能优化方法1. 批量加载在数据加载过程中,逐条插入数据会导致较长的执行时间和数据库性能问题。
因此,采用批量加载的方式可以提高性能。
可以将数据分批次加载,每次加载一定数量的数据,减少了数据库操作的次数,从而提高了加载速度。
此外,可以利用数据库的批处理功能,将多条数据放入一个批次进行加载,减少了交互次数,提高了加载效率。
2. 并行加载类似于数据抽取的并行化,在数据加载过程中采用并行加载的方式,可以同时进行多个加载任务,以提高加载速度。
可以通过使用并行计算框架或者数据库的并发处理机制来实现并行加载,充分利用系统资源,提高性能。
3. 数据压缩在进行数据加载时,对数据进行压缩可以减少存储空间的占用,从而提高加载效率。
可以采用常用的压缩算法,如GZip、LZO等。
但需要注意的是,在进行数据加载时需要进行解压操作,因此需要权衡压缩比和解压缩性能,选择适合的压缩算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
性 、近实时数据发布和 当前数 据 ,是数据进入数据 仓 本 次抽取 开 始 日期
库前 的缓 冲区 。
[n i i t NULL, e dd][ ] n
一
( 数 据 仓 库 和 数据 集 市 包 含 大 量 从 O S 传送 5) D 层 来 的 历史 数据 ,传 入 数 据一 般不 再 修 改 ,是 面 向分析 型
上次 成功 结 束i d
[u i ] i t NU L c rd [ ] L n
数据处理 ,支持分析决策。它不 同于操作型数据库 ,具
备 以下 四个 特 点 :面 向 主题 、集 成 的 、相 对稳 定 的 以及
一
本 次 抽取 开始 i d
CONS TRAI NT [ ቤተ መጻሕፍቲ ባይዱ— tl g c RI ARY KEY P d s o i ]P M
娩}l \ p lai e e p e t fI A pct nD v l m n \ l发 J i o o
O T 数据库表结构的不同之处在于 ,O T 轨迹库表 除 表 的抽 取 ,情 况更 为复 杂 ,不 便 查错 。因此 ,设 计 O S LP LP D I O T 数据 库表多三个字段 ,其他字段结构相 同,多 非 常必 要 ,这 样 也 确保 了 0 s 数据 仓 库的 抽取 基本 上  ̄ LP L D 到 的三个字段分别表示 :变化类型标识 、更新时间戳 、标 是 一对 一 的抽 取 。
情况的出现 , 造成数据质量差并影响公司信息决策。
一
、
数据 抽取 设计 原 理
由于保险业务系统处理逻辑复杂 ,数据量大 ,开发 存 在轨 迹 库 中。 平台和技术规范不统一等原 因,给数据仓库抽取设计带 ( O T 轨迹库 ,即保存反映O T 数据变化的 2) L P L P
来了不小的难度 。因此 ,在数据抽取设计时 ,既要考虑 轨迹数据库 ,与O T 数据源是一对一关系 ,且尽量选 L P 满足数据仓库之初管理需求的实现 ,又要考虑实现数据 择相 同数据库 ,这样确保对OL P 能影响较小 。它与 T性
I I 圈
保险数据仓库数据抽取的设计与实现
中国人寿保险股份有限公司重庆市分公 司 陈鸿雁
L P( 随着保险行业竞争的加剧和信息化建设进程的推 规范 的统一 、避免对O T 联机事 务处理 )数据库性
T 库结 构 的修 改 等 的 约束 ,在 保 进,各家保险公司逐步实施了数据仓库建设 ,而数据抽取 能 的影 响 、减 少 对OL P
E TL
— —
— — — — —
一
- —
三
( 多个 ) ( 多个)
:
—
』 f 掳 数
I 署
(个 多 )
0T数据源 LP
O T  ̄ 迹 库 LP L
O T 同构库 LP
图 1 数 据 仓 库 数 据 抽 取体 系 结 构
4 FAcL oPTR FHA 8 lNI MuE。 l N Ac cN
二 、关 键抽 取技 术 的设计 思 路
数 据抽 取 主要 有 全量 抽取 和 增 量抽 取 ,全 量 抽取 较
为简单 。增量抽取主要有触发器 、时问戳 、全表比对 、 日志比对等方式 ,在此就触发器和时间戳增量抽取方式
O T 数据库平 台的统 一 ,其库结 构与O T 轨迹 库相 L P L P
( 操作 数据存储 ,是 对多个O T 库经过 E L 4) L P T
过程按照主题进行有效 成集成 。它定期刷新 ,包 含当 上 次成 功结 束 日期
前 有 效 数 据 , 同 时 具 备 四 个 特 点 :面 向 主 题 、集 成
[u t ] d tt ] c r me [ aei i me NUL L, 一 一
1 各数据抽取层 的概述 . ( O T 数据 源 ,即所有保险联机 事务处 理数 1) L P 据库 以及其他非结构化数据 。为减少对O T 的性能影 L P 响,我们对各生产库要抽取的源数据表增加了插入、删 除、修改触发器 ,由触发器调用数据库 内核捕获O T LP 数据源的表记录变化 ,并按事务处理前后将这种变化保
识型 字段 ,如 一 条记录 在 生 产库 中先被 插 入 ,而 后修 改 再删 除 ,这样 在轨 迹库 中将 保 存三 条记 录 。 ( 3)O T 同构 库 ,它 选 择 与 后 续 操 作 数 据 存储 L P (D O S)、数据 仓 库相 同的数 据 库平 台 ,实 现 各异 构 的
同,而记录信息除要保存删除记录外 ,其他 与O T 数 中的一些关键技术进行探讨。 L P
据 源 表 一致 。它 是 通过 E L 即数 据 抽 取 、转 换 、装 载 ) T ( 工 具 获 取O T 轨 迹库 中最 后 记 录状 态 信 息 ,仅反 映生 L P 产库 的 当前状 态 。
1 抽取控 制表 的设计 .
CR AT ABL [ b ] E l t ( E ET E d o. t 1 [ C ]
[l 1 [ rhr 5 ) O L , 源表 名称 e t ]v ca (0 N TNU L一 tb a ]
[ di ]d tt ] L , e t n me [aei me NU L 一 一
作为数据仓库建设的关键技术之一 ,其 设计的好坏将直 障数据抽取质量和效率的前提下,我们提出了保险数据 如图1 所示 )。 接影响整个数据仓库建设的成败 。在数据抽取的设计过 仓库数据抽取解决方案 ( 程中,经常 由于数据源质量不高 、数据源修改主键 、多
表 对一 表 抽取 数 据不 同步 和 数据 源 不 支持数 据仓 库的抽 取等 ,导 致数据抽 取过程 中出现数据遗 漏 、冗 佘 、错误 等
反映历史变化。数据仓库是满足企业级管理决策需要 ,
数据 集 市是 满 足部 门级 管 理 决策 需要 而 设置 ,可看 成 是 的数 据仓 库 的子集 。
CLUS TERED