基于共词聚类与可视化的国内科技查新系统研究分析
中国外语自主学习研究二十年的文献计量分析——基于共词聚类与战略坐标图

基金项目:本文是湖北省高校省级教学改革研究项目(编号:2016227)的阶段性成果。
主学习的研究取得了丰硕的成果。
为了研究的进一步开展,本文对国内外语自主学习研究二十年的成果进行了一次全面的梳理。
徐锦芬(2004b)、高吉利(2005;2006)、尹华东(2014)等进行过类似的研究总结,但是,相关研究没有借助文献计量工具和统计软件,图文结合的直观呈现较少,且仅限于2012年前的研究成果。
因此,前人研究不能完全准确地反映我国外语自主学习研究二十年的全貌。
鉴于此,为帮助读者系统把握我国外语自主学习研究二十年来的发展脉络,本文以1998—2017年CNKI数据库中外语自主学习领域CSSCI期刊文献为研究对象,采用BICOMB 软件,梳理近二十年相关研究的文献计量特征,并借助SPSS软件进行共词聚类,确定相关研究的核心主题,通过绘制战略坐标图,对各核心主题的内部结构及发展趋势进行分析和预测。
研究设计本文以国内前人研究文献为基础,通过提取客观数据对外语自主学习研究文献进行计量和统计分析,研究进展得以直观呈现。
本文数据采集自CNKI学术期刊数据库,为保证研究文献的学术水平,研究文献采集范围确定为CSSCI期刊,时间跨度限为1998—2017年,检索后共得到相关研究文献966篇,剔除无效论文,最后确定有效研究文献共961篇。
2 数据分析与结果2.1 中国外语自主学习研究主题关键词是作者学术思想和观点的高度凝练。
研究者通过对文献高频关键词进行统计分析,可以挖掘某一研究领域的核心主题或热点内容(邰杨芳等,2017:133)。
本文将关键词Salton矩阵导入SPSS进行聚类,再根据每个类团中关键词黏合度值大小确定每个类团研究主题及主要内容。
2.1.1 共词聚类分析确定研究主题的核心技术是对关键词进行聚类分析,主要包括5个步骤:高频关键词确定、高频关键词矩阵构建、关键词S alton矩阵构建、关键词聚类以及研究主题确定。
信息检索相关性

近十年我国信息检索相关性研究现状分析——基于共词分析的视角摘要:相关性是信息检索领域的核心研究的内容之一,对其进行深入研究将有助于提高信息检索的效率,推动信息检索的研究。
本文将通过共词分析的方法,利用知识图谱对其进行可视化分析研究。
关键词:信息检索;相关性;共词分析前言相关性一直以来都是信息检索领域的核心研究内容之一,其概念的起源可以追溯到17世纪的早期图书馆用户认识到查找相关信息的问题。
但由于客观原因,相关性只是作为一种朦胧意识停留在人们头脑中,直到20世纪20年代少数学者Lotka(1926)、Zipf(1949)、Urquhart (1959)、Price(1965)才陆续从各个领域开始了相关性的研究工作。
在信息科学界Saracevic 认为Bradford是最先使用相关性一词的学者。
其在20世纪30年代发表的《文献的混沌状态》一文中首次提出“主题相关”的概念。
而此后关于“相关性”的探讨并未引起学界更大范围的关注。
直到1958年国际科学信息会议(ICSI)的召开,相关性(Relevance)才作为信息科学领域的一个重要概念被学术界认可。
至此“相关性”逐渐成为信息科学尤其是信息检索领域经久不衰的研究课题,甚至知识交流学派的代表人物Saracevic认为信息科学之所以成为独立学科,而不再隶属于图书馆学或文献学的原因就在于它开展了相关性的研究也在于相关性能够解释科学交流中的诸多问题。
足见“相关性”在信息科学中的重要地位。
当前,各国学者已对信息检索的相关性问题展开了深入研究,本文将通过共词分析法,使用知识图谱对其进行可视化处理分析。
1.信息检索相关性基本概念对信息检索相关性基本概念方面的研究工作始于20世纪50年代末,各国学者借助数学工具及各种概念提取方法从各个角度对“相关性”的含义及内容进行了深入剖析。
而相关性的基本概念研究以1976年为边界经历了前后两个阶段第一阶段1959-1976的主要成果有Maron和Kuhns利用概率论定义相关性的概念,提出相关性并非只是简单的是/非选择问题。
共词分析法的基本原理及实现

共词分析法的基本原理及实现共词分析法是一种通过分析一组关键词之间共同出现的频率来揭示它们之间关联强度的方法。
这种分析方法在各个领域都有广泛的应用,如文献计量学、信息科学、社会科学等。
本文将详细介绍共词分析法的基本原理和实现过程,并举例说明其在文章撰写中的应用。
共词分析法的基本原理共词分析法的基本原理是建立在词汇共现理论基础上的。
词汇共现是指一组词汇在文本中出现位置相邻或相近的情况。
通过统计一组关键词在文本中共同出现的频次,可以衡量它们之间的关联程度。
共词分析法利用这一点,将文本中出现的词汇视为一个有向图中的节点,而词汇之间的共现关系则视为有向图中的边,从而构建出一个词汇共现网络。
在具体实现过程中,共词分析法需要解决三个关键问题:词典编写、扫描策略和挖掘算法。
词典编写词典编写是共词分析法的第一步。
它通过选择一组具有一定代表性的关键词作为初始节点,然后在文本中搜索这些关键词的同义词、近义词以及相关词汇,将其添加到词典中。
在这个过程中,需要考虑词汇的规范化和停用词的去除等问题。
扫描策略扫描策略是共词分析法的核心环节之一。
它通过扫描文本中的每个句子,统计每个句子中出现的词汇,并记录它们之间共同出现的次数。
一般来说,扫描策略可以分为两种:全局扫描和局部扫描。
全局扫描统计整个文本中词汇的共现次数,而局部扫描则只统计特定领域或主题范围内的词汇共现次数。
挖掘算法挖掘算法是共词分析法的另一个核心环节。
它通过一定的统计方法和算法,从词汇共现网络中挖掘出有用的关联规则和知识结构。
常用的挖掘算法包括聚类算法、关联规则算法、复杂网络分析算法等。
共词分析法的实现共词分析法的具体实现步骤包括数据准备、特征提取和模型构建三个阶段。
数据准备数据准备是共词分析法的第一步。
它包括数据收集、清洗和预处理等环节。
在数据收集环节,需要从多个来源收集相关领域的文本数据。
在清洗环节,需要去除数据中的噪声和无用信息,如停用词、标点符号、数字等。
国内大概念教学研究的热点领域和现状分析——基于CNKI文献的共词分析研究

系统的开发[J]. 现代图书情报技术,2008(8):7075. [3] 钟伟金,李佳 . 共词分析法研究(二)——类团分析 [J]. 情报杂志,2008(06):141-143.
(上接第 11 页) 办学经验。
二、国内大概念教学研究的分布统计与 分析
1. 时间分布 2010 年杨晓慧发表的文章《从“大概念”看 幼儿需要什么样的数学知识》,是知网收录的第
一篇“大概念”主题文献,之后数年关注大概念的 文献屈指可数。2017 年普通高中新课标的正式公 布,明确了大概念在教学中的价值和地位之后, 相关研究呈爆发式增长,2020 年关注该主题的文 献数量为 285 篇。
(作者单位:北京汇文中学)
参考文献:
[1] 教育部 . 教育部关于印发《普通高中课程方案和语 文等学科课程标准(2017 年版 2020 年修订)》的通 知[EB/OL]. (2020-06-03)[2021-03-18]. http:// /srcsite/A26/S8001/202006/t20200603_
领域(1)位于第一象限,大概念、核心素养、 单元教学也是排名最靠前的高频关键词,说明这些 关键词是大概念教学研究领域的热点,在整个学科 大概念教学领域处于核心地位,研究成果较多。领 域(2)和领域(4)位于第四象限,即属于研究核 心但研究还有待加强的领域。领域(4)的向心度 明显大于领域(2),且和领域(1)的向心度接近, 说明关注大概念下的课程开发与设计属于研究的 热点,但研究较为分散,组内相互关联度较小。 领域(2)的密度大于领域(4),说明生物学科 关注大概念教学的研究较为集中。领域(3)和领 域(5)均位于第三象限,这说明大概念在达成学 生深度学习等方面还没能形成共识,并可能存在 研究的分歧。领域(5)关注的是科学学科的大概 念教学,理论和内容的梳理较为全面,研究起步相 对较早,但是由于科学学科现在还不是中、高考科 目,多属于小学课程,受关注度不足,可能存在 研究止步不前的现象。同时从图中可以看出位于 第二象限的研究内容缺失,这说明大概念的研究 处于起步阶段,大概念主题研究的辐射效应存在 但仍有限,周边领域的研究未达到成熟阶段。
基于共词聚类与可视化的高校图书馆学科资源建设研究分析_裴丽

基于共词聚类与可视化的高校图书馆学科资源建设研究分析*裴丽刘景亮曹霞齐明明【摘要】文章以学科资源建设为研究对象,以中国学术期刊网(CNKI)作为获取文献信息的来源,运用SPSS,UCINET软件,对与学科资源建设相关的高频词进行聚类、共现图谱,以呈现国内高校图书馆学科资源建设的研究现状和相关研究领域,并论述学科资源建设与相关研究领域的关系。
【关键词】高校图书馆学科资源建设共词聚类可视化SPSS UCINETAbstract:Taking subject resources as the object of study,and China Academic Journal Network(CNKI)database as the source,the paper uses SPSS,UCINET software to cluster the high-frequency words related to the construction of subject resource and get the maps of co-occurrence,which presents Chinese research status of university library subject resources construction and related research fields.And at last the authors discuss the relationship of the subject resources construction and related research field.Key words:university library construction of subject resources co-word clustering visualization SPSS UCINET1引言高校图书馆学科资源建设是以学科为基础,以学科馆员为服务主体,以读者对学科文献的需求为服务客体,为读者提供学科化、个性化的文献信息资源保障。
基于词频分析和可视化共词网络图的国内创客研究热点分析_秦琴琴

5
19
公共图书馆
2
10 创客运动
3
20
3D 打印
2
从表 1 可以看出,20 个高频关键词的总呈现频次为 147 次,占关键词总频次的 63.9%。其
115
Vol.26 No.1 2016
中,词频排在前十位的分别是:创客空间、创客、高校图书馆、创新服务、图书馆、众创空间、 创客文化、图书馆服务、服务创新和创客运动。
图 3 国内创客高频关键词的共词网络图
从图 3 可以直观地看出:①创客处于整个共词网络图的中心位置,几乎与其它所有关键词 都发生联系。除创客外,创客空间、创客文化、众创空间等与其它关键词的关系也很紧密,说 明很多研究者正在重点研究这些关键词,并且其它相关研究也围绕着这些关键词而开展,因此 可以推断这些关键词是国内创客领域研究的热点。②处于边缘地带的一些关键词,如智慧学习、 互联网+、3D 打印等,这些节点虽然处于边缘,与其它关键词的联系较少,但这并不表示这些 关键词不重要、不值得研究。就目前来看,研究者对这些词的研究虽然相对较少,但这些词大 多出自最近发表的文章中,反映出这些关键词是创客领域未来的研究方向和趋势,更值得本研 究关注。③像清华 iCenter、项目式教学、创客运动等处于中间的关键词,它们是连接中心关键 词和边缘关键词的桥梁。
一 研究设计
1 研究样本的来源 本研究的样本来源于中国知网(CNKI)数据库。在 CNKI 上以“创客”、“创客空间”、“众 创空间”为关键词进行检索,截止到 2015 年 6 月 28 日,共检索到 73 篇相关文献;剔除政策宣 传、通知广告、领导讲话和内容重复等无关样本后,最终获得有效样本 58 篇。将这 58 篇文献 的题录信息导出并保存成文本文件,以便为后续的引文分析、词频分析和共词分析做准备。 2 研究方法 本研究主要采用引文分析法、词频分析法和共词分析法。 引文分析法就是利用各种数学及统计学的方法进行比较、归纳、抽象、概括等的逻辑方法; 也是对科学期刊、论文、著者等分析对象的引用和被引用现象进行分析,以揭示其数量特征和 内在规律的一种信息计量研究方法[3]。
共词分析法——精选推荐

共词分析法共词分析法属于内容分析法的一种,其原理主要是对一组词两两统计它们在同一篇文献中出现的次数,对这些词进行聚类分析,从而反映出这些词之间的亲疏关系,进而分析这些词所代表的学科和主题的结构变化的方法。
共词分析法演进:(1)基于包容指数和邻近指数的共词分析法包容指数和邻近指数主要用于测量款目之间关系的强度。
包容指数主要用来计算主题领域的层次,计算公式如下:Lij=Cij/min(Ci,Cj)其中,Cij代表关键词对Mi和Mj在文献集合中的数量;Ci代表关键词Mi在文献集合中的出现频次;Cj代表关键词Mj在文献集合中的出现频次;min(Ci,Cj)代表Ci和Cj两个频次的最小值。
这个公式可以用来计算那些出现频次相对高的关键词。
当存在着一些中间关键词,而且这些关键词的相对出现频次比较低,但是仍然在这些非重要的关键词之间存在着一定的关系,于是用邻近指数来计算潜在的领域,计算公式如下:Pij=(Cij/CiCj)*N其中Cij、Ci和Cj意思同上,N代表集合中文献的数量。
Callon等提出等价系数(Equivalence Coefficient,简化为E),用来计算关键词之间的关联值。
Eij=(Cij/Ci)*(Cij/Cj)=(Cij)2/(Ci*Cj)其中Eij值在0~1之间。
由于Eij可以同时计算关键词i和j出现在对方集合的频次,因此Turner和他的同事称这个参数为相互包含的系数。
以上面3个指数为基础,把主题词或关键词聚类成组,并以网络地图的方式表现出来。
通过比较不同时期的网络地图,就可以表现出科学的结构和动态变化。
(2)基于战略坐标的共词分析法战略坐标是在建立主题词的共词矩阵和聚类的基础上,用可视化的形式来表示产生的结果。
用“战略坐标”来描述某一研究领域内部联系情况和领域间相互影响情况。
在战略坐标中,x轴为向心度,表示领域间相互影响的强度;y轴为密度,表示某一领域内部联系强度。
其中,向心度用来测量一个学科领域和其他学科领域的相互影响程度。
聚类分析法

2020/7/31
30
2.模糊聚类分析步骤 第二步:建立模糊相似矩阵。
2020/7/31
31
2.模糊聚类分析步骤 第三步:获得模糊分类关系。
2020/7/31
3糊相似矩阵 进行聚类处理。将 类逐渐合并,最后得到聚类谱系图,从而进行合理的分类。
2020/7/31
6
xij
1.1 聚类与聚类分析
1.1.2聚类分析的原理
▪中心化变换
对于一个样本数据,观测p各指标,n个样品的数据资料
阵为
x11 x12
X
x21
x22
x1 p
x2
p
xn1 xn2
xnp
2020/7/31
7
xij
1.1 聚类与聚类分析
1.1.2聚类分析的原理 ▪标准化变换
②动态聚类分析法。是将n个样品初步分类,然后根据分类函数尽可能小的 原则,对初步分类进行调整优化,直到分类合理为止。这种分类方法一般称为 动态聚类法,也称调优法。
③模糊聚类分析法。是利用模糊数学中模糊集理论来处理分类问题的方法, 他对经济领域中具有模糊特征的两态数据或多态数据具有明显的分类效果。
④图论聚类分析法。是利用图论中最小支撑树(MST)的概念来处理分类问 题,是一种独具风格的方法。
1.2 聚类分析的种类
1.2.1 系统聚类分析法
1.2.2 动态聚类分析法
1.2.3 模糊聚类分析法
1.2.4 图论聚类分析法
2020/7/31
13
1.2.1 系统聚类分析法
1.基本思想和分析步骤
(1)基本思想 系统聚类分析的基本思想是,把n个样品看成p维(p个 指标)空间的点,而把每个变量看成p维空间的坐标轴,根据
基于共词分析的信息构建研究热点分析

词共 同出现在某一篇 文献 中的频 次 ,形成 共现矩 阵 ,如 果
两个词 的共现频次越 大 ,表明二者 之 间的距离 越近 ,相 似 度也越大 ,进而利用 多元 统计方法对 这些 高频关键 词进 行 聚类 ,进而反映某学科或主题 的研究热点。
开始这 一概念并没有 得到人们 的认 同和重 视。直到上世 纪 9 年代末 ,信息构建才受到 国内信息 科学 相关 学者 的广 泛 o 关注 ,对 其 的 理 论 研 究 和 实践 应 用 都 取 得 了一 定 的 成
Su y o n o ma in Ar h tcu eBa e n Co- W o d An l s td n I fr t c i tr sd o o e — r ay i s
Zh ne 1 Du Z ii2 u We fn h yn
( .C l g f us g hn q ei l nvr t,C ogig 0 0 6 h a 1 o ee r n ,C o i M d a U i sy hnq 0 1 ,C i ; l oN i g n g c ei n 4 n
2 eate t f n rai ngm n,C o q ei l nvr t,C o qn 0 0 6 h a .D pr n o f m t nMaae e t hn i M dc i e i m Io o g n g a U s y hn i 4 0 1 ,C i ) g g n
21 02年 8月
现 代 情 报
Jun l f d m Ifr t n ora Mo e noma o o i
Al ,2 1 唱. 0 2 Vo. 2 N . 13 o 8
第 3 卷第 8期 2
・
信 词 分 析 的信 息 构 建研 究 热 点 分 析
国内SPOC研究热点和发展趋势分析r——基于词频分析法、共词聚类法和多维尺度分析法的研究

国内SPOC研究热点和发展趋势分析r——基于词频分析法、共词聚类法和多维尺度分析法的研究冯甜甜;马炅【期刊名称】《中国教育信息化·高教职教》【年(卷),期】2018(000)006【摘要】本文以2014年1月1日到2017年12月31日为时间节点,在教育技术学领域SPOC研究方向选取了423篇论文为研究对象,利用Bicomb 2.0软件生成了SPOC的高频关键词和共词矩阵;并利用SPSS软件进行共词分析,对近4年国内SPOC研究现状与发展趋势进行了量化分析与总结.本文研究发现,国内SPOC研究主要围绕两条主线和四个研究热点进行.两条主线是SPOC的理论特点和SPOC教学模式的设计与实现;四个研究热点是SPOC教学模式、SPOC教学设计、SPOC应用及SPOC的在线学习.而对发展趋势的预测认为,未来SPOC的应用领域将更加趋于专业化,更注重教学效率的提高,SPOC将有可能替代MOOC成为在线学习的主流,小规模、个性化的在线学习将成为未来发展的主流趋势.【总页数】5页(P5-9)【作者】冯甜甜;马炅【作者单位】西北民族大学教育科学与技术学院,甘肃兰州730030;西北民族大学教育科学与技术学院,甘肃兰州730030【正文语种】中文【中图分类】G434【相关文献】1.我国智慧教育领域的研究热点与发展趋势分析——基于词频分析法、共词聚类法和多维尺度分析法 [J], 王米雪;张立国2.国内SPOC研究热点和发展趋势分析——基于词频分析法、共词聚类法和多维尺度分析法的研究 [J], 冯甜甜;马炅;3.我国中学地理核心素养研究热点的嬗变与演进——基于词频分析法、共词聚类法和多维尺度分析法的研究 [J], 刘斌;王涛耕;刘桂侠4.国内学前融合教育研究热点及趋势分析——基于CNKI文献关键词的词频和共词网络分析 [J], 刘静静5.我国心血管护理研究的热点及趋势—基于共词聚类及多维尺度分析法 [J], 张瑛;管玉香因版权原因,仅展示原文概要,查看原文内容请购买。
共词分析法研究共词分析的过程与方式

共词分析法研究共词分析的过程与方式一、本文概述共词分析法是一种广泛应用于信息科学、图书馆学、社会学、管理学等领域的文献计量学方法。
它通过统计和分析一组词汇在特定领域文献中共同出现的频次,揭示这些词汇之间的关联性和聚类性,从而反映该领域的热点主题、研究趋势和知识结构。
本文旨在深入探讨共词分析的过程与方式,包括数据准备、共词矩阵构建、聚类分析、结果解读等关键环节,以期为相关领域的研究者提供一套系统、实用的方法论参考。
在本文中,我们首先将对共词分析法的基本原理进行简要介绍,阐述其相较于其他文献计量学方法的独特优势。
随后,我们将详细介绍共词分析的具体步骤,包括如何从海量文献中筛选和提取关键词,如何构建共词矩阵并计算关键词之间的关联强度,以及如何运用聚类分析等统计方法对共词矩阵进行解读和可视化展示。
我们将通过实例分析,展示共词分析法在实际研究中的应用效果,并探讨其可能存在的局限性和改进方向。
通过本文的阐述,我们期望能够帮助读者更加深入地理解共词分析法的核心思想和操作步骤,掌握其在实际研究中的应用技巧,从而推动该方法在相关领域的研究中得到更广泛的应用和发展。
二、共词分析法的理论基础共词分析法是一种基于文献计量学的方法,它的理论基础主要源自信息科学、文献学和情报学等领域。
该方法通过统计和分析一组关键词或主题词在同一篇文献中共同出现的频次,来揭示这些关键词或主题词之间的关联程度,从而反映某一学科或领域的热点、结构和发展趋势。
共词分析法的理论基础主要包括词频分析理论、共现分析理论和聚类分析理论。
词频分析理论认为,关键词的出现频次能够反映其在某一学科或领域的重要性,频次越高,说明该关键词越受关注,其研究价值也越大。
共现分析理论则强调关键词之间的关联性,认为如果两个关键词在同一篇文献中频繁共现,那么它们之间就存在一定的关联或相似性。
聚类分析理论则是将共现频次较高的关键词进行聚类,形成不同的主题或研究领域,从而揭示学科或领域的结构和发展趋势。
国内开放存取的研究热点:基于共词分析的文献计量研究

研 究 热 点 的揭 示 方 面 存 在 一 定 的局 限性 。
1 引言
本 研 究 采 用 共 词 分 析 法 , 图 克 服 以 往 研 试
究中存在 的不足 , 更加完整 、 客观地 反映开放 存 开放存取( pnA cs) 为一种新 的出版 取在我 国的研究热 点情 况。共词分析 法属于 内 O e ces作 模式和学术传 播模 式 , 引起 了国际社 会越 来越 容分析方法 的一 种 , 其原 理是对 一组 词 两两统
ABS TRACT B s d o o wo d a a y i f k y w r s o a es o e c s u ls e r m 0 3 o 2 0 a e n c — r n lss o e o d f p p r n Op n Ac e s p b ih d fo 2 0 t 0 9, t e h
广 泛 的 关 注 。 开 放 存 取 不 仅 是 一 种 机 构 的 战 计 它 们 在 同一 篇 文 献 中 出 现 的 次 数 , 以此 为 基 略 , 应 该 是 国 家 的 战 略 … 。 自从 该 概 念 引 入 础 对 这 些 词 进 行 聚 类 分 析 , 而 反 映 出这 些 词 更 从
r lt n h p b t e n c o a l o e ai s i ewe n OA a d s h l ry c mmu ia i n s se o n c t y t m. T e a t o s p i t o t OA e e r h r h u d p t moe o h uh r on u rs ac es s o l u r
n h r ocuet thr em ils e os to erhi C iaO mas ulhn ,slacii ,O atoscn ld a tee l an vnh t os f Arsac hn: Aju l pbi ig ef rhv g A h a ye p O e n o s - n
科研文献的可视化分析(Citespace)PPT课件

数据清洗是数据准备的重要步骤,需要删除无关数据、处理缺失值、异常值等。可以使用 Excel等工具进行数据清洗。
参数设置与可视化效果
参数设置
在Citespace中,可以通过调整参数 来控制可视化效果。常见的参数包括 时间分割、阈值设置、节点类型和连 线等。
可视化效果
Citespace可以将科研文献数据以可 视化的方式呈现出来,常见的可视化 效果包括聚类图、时间线图、网络图 等。可以根据需要选择合适的可视化 效果来展示数据。
启动
安装完成后,双击桌面上的Citespace图标,即可启动软件。
数据准备
数据来源
科研文献数据主要来源于学术数据库,如Web of Science、CNKI等,也可以通过其他途 径获取数据。
数据格式
Citespace支持多种数据格式,如CNKI的TXT格式、EndNote的ENW格式等。在导入数 据前,需要将数据转换成Citespace支持的格式。
Citespace的未来发展方向
跨数据库整合
未来Citespace可能会整合更多类型的数据库,包括中文数据库和 其他小语种数据库,以扩大数据来源。
算法优化
随着技术的进步,Citespace的算法可能会进一步优化,以提高处 理大规模数据和复杂网络结构的效率。
智能化分析
Citespace可能会引入更多智能化分析功能,如自动识别关键节点、 自动推荐研究主题等。
核心主题、研究前沿和知识流动。相比之下,文献管理软件的可视化功能相对较弱,难以提供深入的洞察。
Citespace与科学计量软件比较
总结词:分析深度
详细描述:Citespace不仅提供了传统的科学计量指标,如论文数量、作者合作 网络等,还通过可视化手段揭示了知识结构和演进规律。这使得Citespace在分 析深度上超越了传统的科学计量软件。
共词分析报告

共词分析报告1. 引言共词分析(Co-occurrence Analysis)是一种文本分析方法,用于揭示词语之间的关联性和共现概率。
通过分析大量文本数据,可以找到词语之间常一起出现的模式和关系,进而帮助理解文本中的主题和语义。
本文将介绍共词分析的原理和方法,并通过一个实例进行分析和解读。
2. 共词分析原理共词分析基于词语在文本中的共现情况,通过计算词语之间的共现频率和相关性,来推断它们之间的关联性和共现概率。
常用的共词分析方法包括共现矩阵、点互信息(Pointwise Mutual Information)和相关性分析等。
2.1 共现矩阵共现矩阵是最常用的共词分析方法之一,它使用一个矩阵来记录词语在文本中的共现情况。
矩阵的行和列分别表示不同的词语,矩阵的元素表示两个词语在同一文本中同时出现的次数。
共现矩阵的构建过程包括分词、文本预处理和矩阵计算等步骤。
2.2 点互信息点互信息是一种用于衡量两个词语之间关联性的指标,它可以通过词语的共现概率来计算。
点互信息越大,表示两个词语之间的关联性越强。
点互信息公式如下:PMI(x, y) = log(P(x, y) / (P(x) * P(y)))其中,P(x, y)表示两个词语同时出现的概率,P(x)和P(y)分别表示词语x和y的出现概率。
2.3 相关性分析相关性分析是一种用于衡量词语之间相关关系的方法,它基于统计学中的相关系数来计算词语之间的相关性。
常用的相关系数包括皮尔逊相关系数和斯皮尔曼相关系数等。
相关系数越接近于1,表示两个词语之间的相关性越强。
3. 共词分析方法共词分析的具体方法取决于所使用的工具和数据集。
下面介绍一种常见的基于Python的共词分析方法:3.1 分词和预处理首先,将原始文本进行分词处理,将文本拆分成一个个单独的词语。
常用的分词工具有jieba和NLTK等。
然后,对分词结果进行预处理,包括去除停用词、词干化和词形还原等。
预处理可以提高共词分析的质量和准确性。
基于共词分析的国内文献传递领域可视化研究

【 K e y w o r d s ]d o c u m e n t d e l i v e r y ;C O —w o r d a n a l y  ̄ s ;d u s t e r a n a l y s i s ;m u l i t d i me n s i o n a l s c 8 l i I 1 g a n a l y s i s ;s 印n e g i c c o o r d i -
d e l i v e r y s e r v i c e s y  ̄e m .t I B n s m ̄ o n ̄ t w a r e a r e t h e f o c u s p o i n t 0 f r e s e a r c h i n f u t u r e .
马 迪倩 张 红莉
( 南开大学图书馆,天津 3 0 0 0 7 1 )
[ 摘 要 】以共词分析为研 究方法,结合聚类分析、多堆尺度分析等多元统计方法 ,对 C N K I 数据库 中 1 9 9 9 — 2 0 1 1 年 国内文
献传递领域 的研 究主题进行可视化 分析 。从 3 6 3 篇 文献中提炼 出 1 1 大类主题 ,其 中馆际互借 与资源共事主题是 谈领域的研 究核
[ 中图分类号]G 2 5 0 ;G 2 5 2 [ 文献标识码]A ( 文章编号]1 0 0 8 — 0 8 2 1( 2 0 1 3 )0 2 — 0 0 9 0 — 0 5
Vi s u a l i z a i t o n S t u d y f o r t h e Do me s t i c Do c u me n t
心,高频词 图书馆 、馆际互借和读者服务是持续性的研 究热点 ,研究者对文献传递服 务体 系、传 输软件等 主题 的探索则是今后
共词分析法研究共词聚类分析法的原理与特点

共词分析法研究共词聚类分析法的原理与特点一、本文概述本文旨在深入探讨共词分析法及其重要应用——共词聚类分析法的原理与特点。
作为一种在文献计量学、内容分析和信息科学等领域广泛应用的文本分析方法,共词分析法通过对文献中共同出现的词汇进行分析,揭示出词汇之间的内在关联和知识结构。
而共词聚类分析法则是在此基础上,利用聚类算法对共词矩阵进行聚类,进一步挖掘出主题结构、研究热点和发展趋势。
本文将首先介绍共词分析法的基本原理和方法步骤,然后重点阐述共词聚类分析法的实现过程、优势和局限性,以期为读者提供全面而深入的理解,并为其在相关领域的实际应用提供指导和参考。
二、共词分析法的理论基础共词分析法是一种基于文献计量学的分析方法,其理论基础主要包括词频分析、共现分析和聚类分析三个部分。
词频分析是共词分析法的基础。
通过统计特定领域文献中词汇的出现频率,可以揭示出该领域的研究热点和趋势。
高频词汇往往代表了该领域的研究重点和方向,而低频词汇则可能反映了新的研究动向或未受足够关注的领域。
共现分析是共词分析法的核心。
它通过分析同一篇文献中不同词汇的共同出现情况,来揭示这些词汇之间的关联性和相关性。
共现频率高的词汇对往往具有紧密的内在联系,可能代表着同一研究主题或方向的词汇群体。
聚类分析是共词分析法的重要手段。
通过运用聚类算法,可以将共现频率高的词汇对进行聚类,形成不同的聚类群体。
这些聚类群体反映了文献中不同研究主题或方向的分布情况,有助于研究者快速识别出该领域的主要研究方向和热点。
共词分析法的理论基础包括词频分析、共现分析和聚类分析三个部分。
通过这些分析手段,共词分析法能够有效地揭示出文献中词汇的关联性、相关性以及研究主题和方向的分布情况,为研究者提供有力的研究工具和方法。
三、共词聚类分析法的原理共词聚类分析法是一种基于共词分析的信息挖掘方法,它通过对特定领域文献中词汇共现情况的统计和分析,揭示出该领域的研究热点、研究前沿和发展趋势。
聚类算法在信息检索中的应用探究

聚类算法在信息检索中的应用探究随着信息技术的不断发展,我们所拥有的信息量也越来越大。
如何有效地获取所需信息成为当下亟待解决的问题之一。
信息检索作为一个庞大的领域,一直在寻求新的技术和方法,以便更好地服务人们。
在这方面,聚类算法被广泛应用并收到了许多成功的应用案例。
本文将深入探究聚类算法在信息检索中的应用。
一、聚类算法简述聚类算法是一种非监督学习算法,简单说就是将一组数据根据相似度划分为若干组,同一个组内的数据相似度较高,不同组之间的相似度较低。
聚类算法的应用范围广泛,适用于数据挖掘、模式识别、图像分割等领域。
常见的聚类算法包括K-means算法、DBSCAN算法、层次聚类等。
K-means算法是一种常见的基于距离的聚类算法,通过不断迭代调整聚类中心来达到最优化的聚类效果。
DBSCAN算法则是一种基于密度的聚类算法,对密度相对较高的数据点进行聚类。
层次聚类则是一种将数据按照一定规则从上到下分成若干层,同时也可以从下到上分成若干层的算法。
每种算法都有其特点和适用范围。
二、聚类算法在信息检索中的应用1. 文本聚类随着文本数据的急剧增加,如何更加高效地组织和管理这些文本数据也成为了亟待解决的问题。
文本聚类技术通过将相似的文本数据划分为同一组,实现了大规模文本数据的高效管理。
以搜索引擎为例,搜索引擎将所有网页都爬取下来以后,就需要将这些网页进行分类管理。
通过对网页进行文本聚类,搜索引擎可以将相同主题的网页划分到一组中,从而简化管理操作,提高用户体验。
2. 推荐系统推荐系统是一个非常流行的应用场景,我们可以把所有的产品或者服务看成是一件件数据。
推荐系统通过聚类算法将相同类型的数据划分到一个组中,进而给用户推荐相应的产品或服务。
以电商平台为例,聚类算法可以将相同类型或相似属性的商品划分到一组中。
当用户浏览某一种商品时,推荐系统可以根据用户行为和购买记录,从相应的组中推荐类似的商品,提高用户购物体验。
3. 搜索引擎排名搜索引擎的核心在于排名,在所有的搜索结果中,如何让用户看到最相关的结果是关键。
基于CiteSpace国内慕课研究的知识图谱可视化分析

高师理科学刊Journal of Science of Teachers' College and University第41卷第1期2021年 1月Vol. 41 No.1Jan. 2021文章编号:1007-9831 ( 2021 ) 01-0075-05基于CiteSpace 国内慕课研究的知识图谱可视化分析岳新1张剑飞1王金环2(1.黑龙江科技大学计算机与信息工程学院,黑龙江哈尔滨150022; 2.黑龙江中医药大学第一临床医学院,黑龙江哈尔滨150040)摘要:在新冠肺炎疫情期间,教育部提出“停课不停教、停课不停学”,慕课等线上教学资源得 到充分利用,基于CiteSpace 软件,对知网上慕课研究的文献进行知识图谱可视化分析.通过对关键词节点、聚类和突现词的细节分析,发现研究者不同时期共同关注的热点问题,分析慕课模式 的发展演化过程,寻找慕课研究重点和未来趋势.关键词:CiteSpace ;知识图谱;慕课;在线课堂;可视化分析中图分类号:TP311 : G642.0文献标识码:A doi : 10.3969/j.issn.1007-9831.2021.01.019Visualization analysis of knowledge graph of domestic research ofMOOC based on CiteSpaceYUE Xin 1, ZHANG Jianfei 1, WANG Jinhuan 2(1. School of Computer and Information Engineering, Heilongjiang University of Science and Technology, Harbin 150022, China;2. Heilongjiang University of Chinese Medicine, First School of Clinical Medicine, Harbin 150040, China )Abstract : During the epidemic period of Covid-19, the Ministry of Education put forward the idea of stopping classeswithout stopping teaching , stopping classes without stopping learning , and massive open online course ( MOOC ) andother online teaching resources were fully utilized. Based on CiteSpace software , carry out the knowledge mapvisualization analysis on the literature of MOOC research on the CNKI. Through the detailed analysis of key wordnodes,clusters and emergent words,the hot issues of common concern to researchers in different periods were found,and the development and evolution process of MOOC model was analyzed to seek out the research focus and futuretrend of it.Key words : CiteSpace ; mapping knowledge domains ; MOOC ; online course ; visualization analysis2020年新冠肺炎在全球蔓延,教育部要求各高校应充分利用线上的慕课和省、校两级优质在线课程教学资源,在慕课平台等支持带动下,实现“停课不停教、停课不停学” [T.慕课(Massive Open Online Course,MOOC,大规模开放在线课程),大规模化、开放性、在线网络化和创新性是它的4个主要特征.今年第一季度,慕课新增约5 000门,疫情期间学习慕课人数成爆炸性增长[3-4],国内慕课资源得到了充分的应用.本文利用知识图谱对国内慕课研究重点和未来趋势进行可视化分析.收稿日期:2020-08-17基金项目:黑龙江省教育规划科学"十二五”规划重点课题(GJB1319128);黑龙江中医药大学创新团队项目(2019TD03)作者简介:岳新(1977-),男,黑龙江绥化人,副教授,硕士,从事知识图谱、大数据分析研究.E-mail: **************通信作者:王金环(1977-),女,黑龙江绥化人,主任医师,博士,从事中医血液病学及其教学的研究.E-mail : ****************76高师理科学刊第41卷1研究方案1.1研究工具CiteSpace是一款用于分析和可视化展示科学文献的趋势及动态的Java应用程序,是一个多元、分时、动态和可视化分析工具.主要包括合作分析、共现分析和共被引分析,提供时间切片功能,可以按照年份对文献进行切片分析[5-7].对于数据庞大的学科,可以使用网络切割,主要方法是最小树切割法和网络切片法.将数据以Refworks格式导出后通过CiteSpace将数据转换,设置时间切片阈值,确定文献的时间区间,选择需要分析的类型节点,采用节点、聚类和突现词显示整个网络的方法将数据以可视化的形式呈现.将知识图谱中信息以图或表的形式显示出来以供细节分析[7-8].1.2数据来源和阈值选择文献以知网数据库平台期刊为来源数据进行统计.以主题“慕课”或“MOOC”或“MOOCS”或“大规模开放在线课程”或“大规模开放性在线课程”,来源选择知网上SC I来源期刊,EI来源期刊,核心期刊,CSSCI,CSCD期刊的中文文献.统计时间为2012-01-01—2020-03-31.共统计出2824条相关文献,经过筛选、剔除报告类文章,最终有效文献2697条.采用CiteSpace软件5.7.R2.7z版本对其进行可视化分析.选取时间间隔2012—2020年,时区切片为1年,选择N=30,Top N%=5%up to50(C,CC,CCV)默认原值,进行共词分析,算法选择Pathfinder,Pruning sliced networks,Pruning the merged network,可视化采用Cluster View-Static,Show Merged Network®7].2国内慕课研究的知识图谱分析2.1合作作者分析设置节点为作者进行分析,了解重要学者分布与合作关系.样本中共有288个节点,141个边,网络密度为0.003 4.从网络图(见图1)可以了解,当前作者合作分散不密切,形成陈丽、郑勤华研究团队;从图片边线蓝色绿色橙色看,该团队从2013年到现在一直有持续的研究,经阅读相关文献发现,陈丽、郑勤华[9-14]团队主要进行慕课的理论和调查研究.汪琼[15-16]的研究多为慕课的理论和发展.肖俊洪[17-18]研究的合作者多为外籍研究者,主要进行慕课发展理论研究.张立彬[19-20]的研究较晚,从2016年开始主要研究图书馆慕课版权.钱小龙[21-22]的研究多以加州大学欧文分校为例,进行结构和商业模式研究.从图谱可以看出陈丽、郑勤华有合作构成一个研究团队,汪琼不能称为一个研究团队但有一位合作研究者,其他几位作者都是单独节点,没有形成研究团队.从这主要的6位研究者看,大部分进行慕课理论和发展研究,涉及具体应用的较少.谟逸洲'苗|3锡斌韭建钢哦小龙械杰济晓明徐晓E(H甫中狂*富砂立彬\C许涛\療新民個洪罚丽/7\券成如花/\\I硝俊洪嘗/\\旭图1作者合作网络可视化图M S A RSK4-MI■:xr呂益i常*'urm>CC”H和2.2研究机构分析设置节点为机构进行分析,可以了解机构之间合作关系(见图2).样本中共有181个节点,61个边,网络密度为0.0037.从网络图谱中可以看出,主要研究机构为师范类大学或者大学的教育学院或信息技术类学院,也有图书馆或出版社等机构,符合慕课的研究群体.北京大学和北京师范大学有合作,主要是陈丽、郑勤华研究团队.慕课早期建设一般都是以学校为单位各个学科进行,学校与学校之间较少形成合作关系.随着慕课研究和建设的逐渐成熟,将会形成多个学校进行慕课研究和建设的合作.2.3研究热点分析2.3.1关键词共词分析节点设置为关键词,运行CiteSpace生成关键词共现知识图谱(见图3),有140个节点,155个边,网络密度为0.0159.节点圈的大小选择表示关键词频率大小,连线颜色表示时间,绘制出热点关键词频率排序表(见表1),包括频率、中心性、首次出现年份、关键词4个属性.从知识图谱的角度分析,中心性和频次高的关键词代表研究者共同关注的问题,即研究热点.频次越高,点中心性第1期岳新,等:基于CiteSpace 国内慕课研究的知识图谱可视化分析77越高,说明节点在该领域愈重要."卜怖楹犬技术7院【西师柜人学教務华人学菽冇餅允IK$内前祖大技术7院"ll头广播电8!大学. ■鲁教ff ill版社鱼逖学院申?fdM 理学屁 q、 I 师越大佯远Wttff研宛中心图2研究机构网络图图3关键词共现图表1热点关键词频率排序频率中心性年份关键词频率中心性年份关键词9620.112013MOOC540.042013在线课程6120.812013慕课5402014在线学习2200.552014翻转课堂490.182014微课990.262014SPOC 482013大数据940.042014教学模式440.262014图书馆900.042014教学改革4402015在线开放课程880.112014高校图书馆430.142015互联网+860.042013高等教育370.222014“慕课”830.642013在线教育370.112014教学设计590.082015混合式教学360.082014思想政治理论课580.482013大规模开放在线课程320.482013远程教育时区视图(timezone )是一种侧重于从时间维度上来表示知识演进的视图(见图4),它可以清 晰地展示出文献的更新和相互影响,其中图中文字显示的是关键词中心度大于0.1的关键词,中心性 大于0.1的关键词有研究意义.2.3.2关键词聚类分析CiteSpace 依据谱聚类算 法提供了自动聚类的功能,并提供了从聚类施引文 献中提取聚类主题词的3种算法,对检索的文献信 息进行关键词共现网络分析,共现网络形成大小聚类共15个.按照聚类大小和研究的相关度,结合TF*IDF 加权算法和 LLR (log-likelihood ratio )算法 抽取的标识词,代表了当前该领域研究的主要热点图4关键词时区视图领域和基本的研究主题.CiteSpace 依据网络结构和聚类的清晰度,提供了模块值(Q 值)和平均轮廓值(S值)2个指标,它可以作为评判图谱绘制效果的一个依据.一般而言,Q 值在[0,1]区间内,Q>0.3就意味着划分出来的社团结构是显著的.当S 值在0.5以上,聚类一般认为是合理的,当S 值在0.7以上,聚类是高效率令人信服的.聚类视图(cluster )见图5,节点数100,连线数106,密度0.021 4, Q 值0.783 6, S值0.633 2.它侧重于体现聚类间的结构特征,突出关键节点及重要连接.时间线视图(Timeline )见图6,侧重于勾画聚类之间的关系和某个聚类中文献的历史跨度.主要介绍4个最大聚类,规模最大聚类#0开放 教育资源,轮廓值0.952,最活跃的文章是袁莉[23]等(2013 )大规模开放在线课程的国际现状分析.文章对大规模开放在线课程(MOOCs )进行了综述分析,讨论了可持续发展、教学方法和质量以及考核和学分方78高 师 理 科 学 刊第 41 卷面的问题.第二大规模聚类# 1xMOOC,轮廓值0.932,最活跃的文章是王萍[24](2013 )大规模在线开放课程的新发展与应用:从cMOOC 到xMOOC.文章对MOOC 主要有2种模式进行了探讨,即基于关联主义学习理论的cMOOC 模式和基于行为主义学习理论的xMOOC 模式.第三大规模聚类#2高校图书馆,轮廓值0.951,最活跃的文章是郑伟[25](2014)MOOCs 背景下的高校图书馆服务探索与思考.文章探讨高校图书馆在面向慕课学生、教师提供服务等,以及对版权保护和数字化技术提供支持服务.第四大规模聚类#3成人 教育,轮廓值0.841,最活跃的文章是陈豪[26](2014)“慕课”对高校思想政治理论课教学改革的启示.文 章讨论了慕课对高校思想政治理论课教学改革的启示,提岀慕课可以作为思想政治理论课教学的重要补 充.育!学模式I 转课堂#0开放教冇资源女敕玮/ 蘇而在线课'#2商校图蝶[J 刀OOC€线课程\ #1 cmooc-車联网+#3心人教育#9网络课程课#6微谍图5关键词聚类视图#8教育信息化世跌治理论课 、栽育#5教v 模式:践 职业戲育"圮联网+” 混合敦孚2.3.3关键词突现性研究 突现性(Burstness )通过对关 键词跟踪分析它们在不同时间区间内出现频率的突然变 化(激增),识别出代表研究前沿的若干关键词,以辨识研究前沿的结构及发展演化(见图7).结合图7突现词 时间可知,信息技术、“互联网+”是近4年的研究热点;在线开放课程、混合式教学、在线课程是近3年的研究热点,其中混合式教学突现值最大.通过关键词的频率、中心性、突现性等综合判断,发现关键词:信息技术、在线教育、开放教育资源、混合式教学、学习者、微课程、“互联网+”实验教学、个性化学习等是未来慕课研究的方向.3结语通过可视化分析,了解到慕课从2012年出现,迅速发展,关键词在线开放课程、混合式教学和在线课程是近图6关键词时间线视图Top 17 Keywords with the Strongest Citation BurstsKeywords Year Strength Begin End 2012 - 2020在线教育2012 3.3174 20137014 __课程20123 1469 20132014__开放教育资源2012 4.2396 20137014 7-—201223336 20137014 na ._ __尢抑橙开能在线谗袒232 3.3846 20137014 na .___网络课稈20124.0298 20142015 ■■微课程2012 3.6926 20142015 ■■个性怦学习2012 3.3556 20142015 ■■中华人民共和国2012 5.3816 20142015■■20124 5282 20152016 ■■信息素养教育2012 4.022 ******** ■■实验教学2012 3.6658 20172018 ■■20124.7172 20172020 ■■■■信息技术20125.9846 20172020 ■■■■在线开放课程2012 5.9598 20182020 ■■■混合式教学20129.8146 20182020 ■■■在线课程201277S7 201R2020 —图7关键词突变性图3年研究的突现关键词,说明慕课在不断演化.而2014年出现的关键词SPOC (频率99,中心性0.26)更是提出了小规模限制性在线课程的许多优点.同年出现的关键词微课(频率49,中心性0.18 )强调短时间微视频,碎片化学习.2019年出现的新关键词金课(中心性0.61),是教育部提出的五大金课总称,其中包括线上金课和线上线下金课,线上金课更像是慕课模式的改进版,线上线下金课和SPOC 模式比较接近.第1期岳新,等:基于CiteSpace国内慕课研究的知识图谱可视化分析79最高突现值(9.8146)关键词混合式教学一直都是慕课研究的重点,它可以和包括MOOC在内的许多在线教学模式相结合.这些慕课模式的发展演化,是在外部条件正常情况下进行的,但现在外部条件发生了巨大变化,疫情期间,所有教师完全线上授课.这就使包括慕课模式在内的线上课程成为唯一的教学方式,线上教学模式大部分选择“慕课+线上答疑”或线上直播课.截止2020年4月3日教育部高教司统计全国在线开学的普通高校共计1454所,95万余名教师开设94.2万门、713.3万门次在线课程,参加在线课程学习的学生达11.8亿人次.可以看出,包括慕课等在线教学模式在经历这次大规模高校师生参与后,未来将会更快更好地发展,其相应的理论研究也会更深入.参考文献:[1]杨海军,张惠萍,程鹏.新冠肺炎疫情期间高校在线教学探析[J].中国多媒体与网络教学学报:上旬刊,2020(4):194-196[2]余闯.教育部印发指导意见一疫情防控期间做好高校在线教学组织与管理工作[J].现代教育技术,2020,30(2):1[3]张鸯远.“慕课”(MOOCs)发展对我国高等教育的影响及其对策[J].河北师范大学学报:教育科学版,2014,16(2):116-121[4]冯智文.中国外语金课的内涵及其建设方略[J].外语教学,2020,41(2):59-63[5]陈悦,陈超美,刘则渊,等.CiteSpace知识图谱的方法论功能[J].科学学研究,2015,33(2):242-253[6]侯剑华,胡志刚.CiteSpace软件应用研究的回顾与展望[J].现代情报,2013,33(4):99-103[7]胡玥,董永权,杨淼.基于CiteSpace的国内翻转课堂研究现状与趋势研究[J].高教探索,2017(11):50-57[8]王晴.我国MOOCs研究的网络结构与主题聚类一基于CiteSpace皿的知识图谱分析[J].中国远程教育,2015(5):18-23,79[9]郑勤华,李秋菊,陈丽.中国M O OCs教学模式调查研究[J].开放教育研究,2015,21(6):71-79[10]王志军,陈丽,郑勤华.MOOCs的发展脉络及其三种实践形式[J].中国电化教育,2014(7):25-33[11]郭文革,陈丽,陈庚.互联网基因与新、旧网络教育——从MOOC谈起[J].北京大学教育评论,2013,11(4):173-184[12]李小杉,陈丽,王文静,等.联通主义视阈下的cMOOC知识生产的实证研究一基于机器学习的对比分析[J].中国远程教育,2020(1):23-34,76[13]陈丽,逯行,郑勤华.“互联网+教育”的知识观:知识回归与知识进化[J].中国远程教育,2019(7):10-18,92[14]陈丽.“互联网+教育”的创新本质与变革趋势[J].远程教育杂志,2016,34(4):3-8[15]汪琼.高校面对慕课:机遇与挑战[J]中国高等教育,2015(24):7-8[16]汪琼.美国慕课评优原则分析[J].现代远程教育研究,2017(3):50-57[17]梅雷亚德•尼克•朱拉•梅西尔,马克•布朗,肖俊洪.慕课同心圈式发展:从高等教育破坏性创新向持续性创新模式的转变[J]中国远程教育,2019(3):58-68,93[18]杰里米•诺克斯,肖俊洪.慕课革命进展如何:慕课的三大变化主题[J].中国远程教育,2018(1):53-62,80[19]张立彬.慕课环境中图书馆版权服务的内容与思考[J].图书馆工作与研究,2016(3):32-35[20]张立彬,吴嘉敏.慕课环境下美国高校图书馆的MOOC版权指南文件探赜[J].图书馆学研究,2019(14):88-97[21]钱小龙.大学慕课商业模式的成本结构解析一以加州大学欧文分校为例[J].教育学术月刊,2019(7):103-111[22]钱小龙,盖瑞•马特金.加州大学欧文分校慕课商业模式的客户关系解析[J].现代远距离教育,2017(4):75-83[23]袁莉,斯蒂芬•鲍威尔,马红亮.大规模开放在线课程的国际现状分析[J].开放教育研究,2013,19(3):56-62, 84[24]王萍.大规模在线开放课程的新发展与应用:从cMOOC到xMOOC[J].现代远程教育研究,2013(3):13-19[25]郑伟,梁霞.MOOCs背景下的高校图书馆服务探索与思考[J].图书馆理论与实践,2014(9):59-63[26]陈豪.“慕课”对高校思想政治理论课教学改革的启示[J].思想理论教育,2014(4):70-73。
Bicomb共词可视化分析方法操作技巧过程
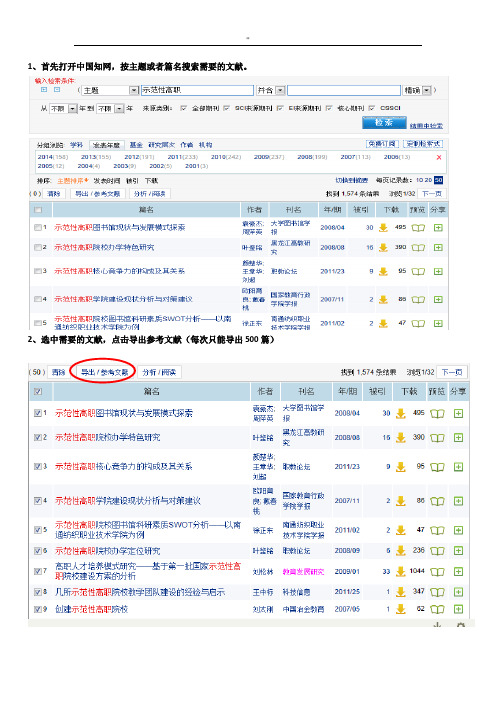
1、首先打开中国知网,按主题或者篇名搜索需要的文献。
2、选中需要的文献,点击导出参考文献(每次只能导出500篇)3、全部选中,点击导出参考文献4、点击自定义模式。
5、按需要选择相应的输出字段,如图所示,然后点击导出,保存在相应的文件夹中。
格式为.TXT6、打开导出的文本文件,如下图,将所有的英文去掉,具体做法为编辑—替换。
将英文替换为空格,即可去掉英文,成为如下版本。
接着根据研究需要进行关键词的合并,合并成功后,选择另存为,文件编码一定要改成ANSI。
7、打开bicomb,点击增加,建立一个新的项目,编号自己随意输入一个数字,格式类型为cnki自定义。
8、点击最下方的提取,进入提取界面。
关键字段选择为关键词,点击选择文档,打开刚才导出的txt格式的文档,打开成功后,点击提取。
9、点击最下方的统计,进入统计界面。
关键字段选择为关键词。
域值一般为6,根据实际情况可调整,然后点击红色的统计按钮。
关键词的排位顺序就会统计出来。
10、点击最下方的矩阵按钮,进入矩阵界面。
关键字选择为关键词。
阈值一般大于之前选择的最低阈值,比如12,小于统计出来的最多的关键词出现的频次,上图可发现关键词最多出现202.然后点击生成按钮,可出现词篇矩阵。
共现矩阵操作方法同样。
最后点击导出矩阵TXT。
保存在相应文件夹。
11、打开spss19.0.点击文件—打开—数据,打开刚才导出的词篇矩阵。
注:一直点击下一步,直到完成。
12、点击工具栏的分析—分类—系统聚类。
出现对话框后,将左边框内的V1选择为标注个案,其他剩下的变量全选,放在右边的变量框中。
13、点击统计量,出现对话框,选择相似性矩阵。
在选择单一方案,聚类数根据自己的研究情况选择,一般是4到6类,如选择5类。
然后点击继续。
14、点击绘制按钮。
选择树状图。
然后点击聚类的指定全聚,停止聚类树为5,就是你所要聚的类树。
如聚6类,那么停止聚类就输入6。
然后点击继续。
15、然后点击方法按钮,区间选择为Euclidean。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2 数据 获取 与分析 处理
2 . 1 数据 来源与 获取
矩 阵 中的参数做差 , 转化成 2 9  ̄ 2 9 共词相 异矩阵 ,具 体如表 3 所示 。 2 . 2 - 3利用 S P S S聚类 分析 频一 一 他 如 o o 8 3 2 l ¨ o 9 0 把2 9  ̄ 2 9 共词相异矩阵导人 S P S S软件 中 ,利用层 次 聚类分析 中 “ 组 间平 均链锁距 离 ”方法 .可得到 聚 类分析过程的树状 图,具体 如图 1 所示。 由图 1 层 次 聚类 分析 的 “ 躺倒 树n ”所 示" .其 上方 塑 M ∞ 据 0 - 2 5的标度代表各类间的距离映射 ,下方是 聚类过程 。
例如 :查新工作 ( 4号关键词 )和查 新人员 ( 1 2号关
笔 者 选 择 中 国知 网的 期 刊库 作 为 数 据 来 源 ,以
“ 主题 ”为检索项 , “ ( 查新 a n d系统 ) o r( 查新 a n d 平
台) ” 为检索条件 ,截 至 2 0 1 4年 6月 1日,共检 索到 相关 文献 5 0 7 篇 。此 5 0 7篇论文涉及 关键词 1 6 6 0 个,
农业图书情报学刊: 网络 技 术
第2 6卷
强大 的社会 网络分析软件 ,它集成 了一维与二维数据分 析的 N e t d r a w软件 ,可以直观地将分析数据图形化显示翻 。 基于 U C I N E T集成 的 N e t d r a w软件 。分 析科 技查新 系 统 的高频关键词的共词矩 阵,可生成社会 网络 图谱 。
数据库
医 药 卫 生 查 新 人 员
查 新检 索
科 技 成 果 信 息 服 务
文 献 检 索
鉴 定 委 员 会
Di al o g
图 书 馆
查 新 咨 询 工 作
科 技 查 新 工 作
信 息系 统
卫 生 系 统
检 索 查 新
质 量
频一 一 5 嬲 3 0 5 3 ¨ 1 m 0 0 , 网络 信息 资 源
查 新 结 论
2 8
检 索工 具
8
2 9
ቤተ መጻሕፍቲ ባይዱ
检 索
8
词频 累计 2 9 1 8次 。抽取词频 大于 7的 2 9个关键词 作 为 主要关键词 ,具体如表 1 所 示。 2 . 2 数 据 处理与 分析
2 . 2 . 1 共词矩阵 的构建
从表 1 可 以看 出 ,当前 国内科技查 新 系统研究 的 热点 ,但是 它仅是对 高频关键 词的简单 统计 ,并不 能 揭示 之 间 的关 系 。笔 者构 建一个 2 9  ̄ 2 9的共 词矩 阵 , 对这 些高频关 键词 间的关系进行 深人 的数据挖 掘 ,如
频 一7 " 4 0 " 7 ¨ 3 2 0 0 . ,
表1 前2 9位高频关键词排序表
序 号 关 键 词 科 技 查 新 关 键 词 查 新 管 理 系 统
查 新 咨 询 查 新 质 量
序 号
查 新 报 告
查 新工 作
高 校 图 书 馆 检 索 策 略
表 2 所示。
键词 )距离最 近 ,最先合 并成一 类 ,然后 与查新 咨询
工作 ( 1 8 号关键 词 )合并 ,其它同理 。
2 . 2 - 4 利用 Uc i n e t 网络图谱分析
将 表 2科 技查新 系统 共词矩 阵导人 U C I NE T集成 的N e t d r a w软件 中,生成 相关 网络 图谱 ,揭示科技查新 系统与其它高频关键词的相 互关系 ,具体如图 2 所示 。
2 . 2 . 2 O c h i i a 系数相异矩阵 的构建 笔者 为得到适 合分析 的标准 数据形式 ,进行 如下 的处理 :首先利用公式 O c h i i a系数 =A、B两词共现频 次 /( 、 / 词恧西现 ×、 / 诃恧西丽 瘌 ),对
表 2矩阵进行处 理 ,得 到相关矩 阵 ,然后 以 1 与相关