二叉排序树
二叉排序树

9
第9章
第三节
二、二叉排序树(插入)
查找
动态查找表
二叉排序树是一种动态查找表
当树中不存在查找的结点时,作插入操作
新插入的结点一定是叶子结点(只需改动一个 结点的指针) 该叶子结点是查找不成功时路径上访问的最后 一个结点的左孩子或右孩子(新结点值小于或 大于该结点值) 10
第9章
第三节
查找
19
在二叉排序树中查找关 键字值等于37,88,94
3
第9章
第三节
查找
动态查找表
二、二叉排序树(查找函数)中结点结构定义 二叉排序树通常采用二叉链表的形式进行存 储,其结点结构定义如下:
typedef struct BiNode { int data; BiNode *lChild, *rChild; }BiNode,*BitTree;
4
第9章
第三节
查找
动态查找表
2、二叉排序树的定义 定义二叉排序树所有用到的变量 BitTree root; int
//查找是否成功(1--成功,0--不成功) //查找位置(表示在BisCount层中的第几个位置
BisSuccess;
int
int
BisPos;
BisCount;
//查找次数(相当于树的层数)
7
第9章
第三节
查找
动态查找表
二、二叉排序树(查找函数)
else { BisSuccess = 0; root=GetNode(k);//查找不成功,插入新的结点}
} BiNode * GetNode(int k) { BiNode *s; s = new BiNode; s->data = k; s->lChild = NULL; s->rChild = NULL; return(s);}
二叉树基本知识

{
int capacity;
int size;
int *elements;
}*tryit;
struct priorityqueue *initialize ( int maxelements )
{
struct priorityqueue *h;
(6)给定N个节点,能构成h(N)种不同的二叉树。
h(N)为卡特兰数的第N项。h(n)=C(n,2*n)/(n+1)。
4.二叉树的存储结构
(1)顺序存储方式
type node=record
Байду номын сангаасata:datatype
l,r:integer;
end;
var tr:array[1..n] of node;
(1)前序遍历
访问根;按前序遍历左子树;按前序遍历右子树
(2)中序遍历
按中序遍历左子树;访问根;按中序遍历右子树
(3)后序遍历
按后序遍历左子树;按后序遍历右子树;访问根
(4)层次遍历
即按照层次访问,通常用队列来做。访问根,访问子女,再访问子女的子女(越往后的层次越低)(两个子女的级别相同)
(2)链表存储方式,如:
type btree=^node;
node=record
data:datatye;
lchild,rchild:btree;
end;
5.普通树转换成二叉树
二叉树很象一株倒悬着的树,从树根到大分枝、小分枝、直到叶子把数据联系起来,这种数据结构就叫做树结构,简称树。树中每个分叉点称为结点,起始结点称为树根,任意两个结点间的连接关系称为树枝,结点下面不再有分枝称为树叶。结点的前趋结点称为该结点的"双亲",结点的后趋结点称为该结点的"子女"或"孩子",同一结点的"子女"之间互称"兄弟"。
二叉排序树

②若*p结点只有左子树,或只有右子树,则可将*p的左子 树或右子树直接改为其双亲结点*f的左子树,即: f->1child=p->1child(或f->1child=p->rchild); free(p); *f
F *p P P1
*f
F
*f
F *p P
*f
F
Pr
P1
Pr
③若*p既有左子树,又有右子树。则:
-1 0
47
-1
47
47
0
31 69
69
25
0
47
0
25
0
47
-1 0
31
0
69
0
40
69
40
69
0
25 76
40
76
(a)
AL、BL、BR 都是空树
(b) AL、BL、BR 都是非空树
LR型调整操作示意图
2
A
-1
0
C
AR C BL CL CR AR
0 0
B BL CL S
B
A
CR
(a) 插入结点*s后失去平衡
31
0 0 -1
31
0 1
28
0
25
0 0
47
0
25
-1
47
0
25
0
31
0
16 0
28
16
28
0
16 30
30
47
(c) LR(R)型调整
RL型调整操作示意图
A B C A BR CR B BR
AL
C
AL
CL CR
数据结构 二叉排序树

9.6.2 哈希函数的构造方法
构造哈希函数的目标:
哈希地址尽可能均匀分布在表空间上——均 匀性好; 哈希地址计算尽量简单。
考虑因素:
函数的复杂度; 关键字长度与表长的关系; 关键字分布情况; 元素的查找频率。
一、直接地址法 取关键字或关键字的某个线性函数值为哈希地址 即: H(key) = key 或: H(key) = a* key + b 其中,a, b为常数。 例:1949年后出生的人口调查表,关键字是年份 年份 1949 1950 1951 … 人数 … … … …
9.4 二叉排序树
1.定义:
二叉排序树(二叉搜索树或二叉查找树) 或者是一棵空树;或者是具有如下特性的二叉树
(1) 若它的左子树不空,则左子树上所有结点的 值均小于根结点的值;
(2) 若它的右子树不空,则右子树上所有结点 的值均大于等于根结点的值; (3) 它的左、右子树也都分别是二叉排序树。
例如:
H(key)
通常设定一个一维数组空间存储记录集合,则 H(key)指示数组中的下标。
称这个一维数组为哈希(Hash)表或散列表。 称映射函数 H 为哈希函数。 H(key)为哈希地址
例:假定一个线性表为: A = (18,75,60,43,54,90,46) 假定选取的哈希函数为
hash3(key) = key % 13
H(key) = key + (-1948) 此法仅适合于: 地址集合的大小 = = 关键字集合的大小
二、数字分析法
假设关键字集合中的每个关键字都是由 s 位数 字组成 (u1, u2, …, us),分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为 地址。 例如:有若干记录,关键字为 8 位十进制数, 假设哈希表的表长为100, 对关键字进行分析, 取随机性较好的两位十进制数作为哈希地址。
二叉排序树

二叉排序树1.二叉排序树定义二叉排序树(Binary Sort Tree)或者是一棵空树;或者是具有下列性质的二叉树:(1)若左子树不空,则左子树上所有结点的值均小于根结点的值;若右子树不空,则右子树上所有结点的值均大于根结点的值。
(2)左右子树也都是二叉排序树,如图6-2所示。
2.二叉排序树的查找过程由其定义可见,二叉排序树的查找过程为:(1)若查找树为空,查找失败。
(2)查找树非空,将给定值key与查找树的根结点关键码比较。
(3)若相等,查找成功,结束查找过程,否则:①当给值key小于根结点关键码,查找将在以左孩子为根的子树上继续进行,转(1)。
②当给值key大于根结点关键码,查找将在以右孩子为根的子树上继续进行,转(1)。
3.二叉排序树插入操作和构造一棵二叉排序树向二叉排序树中插入一个结点的过程:设待插入结点的关键码为key,为将其插入,先要在二叉排序树中进行查找,若查找成功,按二叉排序树定义,该插入结点已存在,不用插入;查找不成功时,则插入之。
因此,新插入结点一定是作为叶子结点添加上去的。
构造一棵二叉排序树则是逐个插入结点的过程。
对于关键码序列为:{63,90,70,55,67,42,98,83,10,45,58},则构造一棵二叉排序树的过程如图6-3所示。
4.二叉排序树删除操作从二叉排序树中删除一个结点之后,要求其仍能保持二叉排序树的特性。
设待删结点为*p(p为指向待删结点的指针),其双亲结点为*f,删除可以分三种情况,如图6-4所示。
(1)*p结点为叶结点,由于删去叶结点后不影响整棵树的特性,所以,只需将被删结点的双亲结点相应指针域改为空指针,如图6-4(a)所示。
(2)*p结点只有右子树或只有左子树,此时,只需将或替换*f结点的*p子树即可,如图6-4(b)、(c)所示。
(3)*p结点既有左子树又有右子树,可按中序遍历保持有序地进行调整,如图6-4(d)、(e)所示。
设删除*p结点前,中序遍历序列为:① P为F的左子女时有:…,Pi子树,P,Pj,S子树,Pk,Sk子树,…,P2,S2子树,P1,S1子树,F,…。
详解平衡二叉树
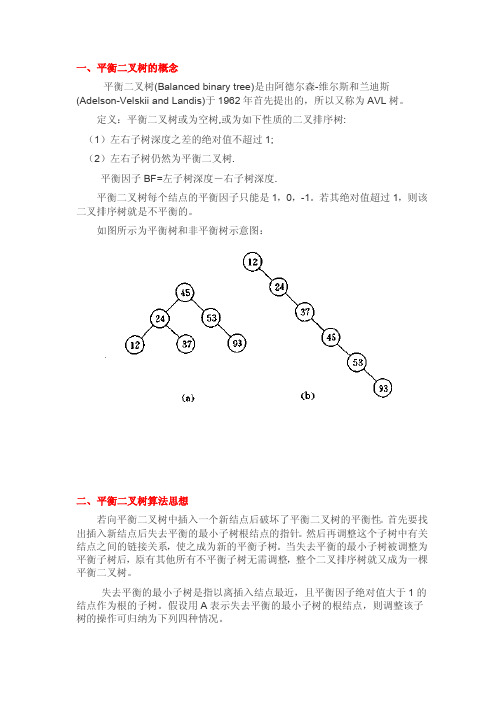
一、平衡二叉树的概念平衡二叉树(Balanced binary tree)是由阿德尔森-维尔斯和兰迪斯(Adelson-Velskii and Landis)于1962年首先提出的,所以又称为AVL树。
定义:平衡二叉树或为空树,或为如下性质的二叉排序树:(1)左右子树深度之差的绝对值不超过1;(2)左右子树仍然为平衡二叉树.平衡因子BF=左子树深度-右子树深度.平衡二叉树每个结点的平衡因子只能是1,0,-1。
若其绝对值超过1,则该二叉排序树就是不平衡的。
如图所示为平衡树和非平衡树示意图:二、平衡二叉树算法思想若向平衡二叉树中插入一个新结点后破坏了平衡二叉树的平衡性。
首先要找出插入新结点后失去平衡的最小子树根结点的指针。
然后再调整这个子树中有关结点之间的链接关系,使之成为新的平衡子树。
当失去平衡的最小子树被调整为平衡子树后,原有其他所有不平衡子树无需调整,整个二叉排序树就又成为一棵平衡二叉树。
失去平衡的最小子树是指以离插入结点最近,且平衡因子绝对值大于1的结点作为根的子树。
假设用A表示失去平衡的最小子树的根结点,则调整该子树的操作可归纳为下列四种情况。
1)LL型平衡旋转法由于在A的左孩子B的左子树上插入结点F,使A的平衡因子由1增至2而失去平衡。
故需进行一次顺时针旋转操作。
即将A的左孩子B向右上旋转代替A作为根结点,A向右下旋转成为B的右子树的根结点。
而原来B的右子树则变成A的左子树。
(2)RR型平衡旋转法由于在A的右孩子C 的右子树上插入结点F,使A的平衡因子由-1减至-2而失去平衡。
故需进行一次逆时针旋转操作。
即将A的右孩子C向左上旋转代替A作为根结点,A向左下旋转成为C的左子树的根结点。
而原来C的左子树则变成A的右子树。
(3)LR型平衡旋转法由于在A的左孩子B的右子数上插入结点F,使A的平衡因子由1增至2而失去平衡。
故需进行两次旋转操作(先逆时针,后顺时针)。
即先将A结点的左孩子B的右子树的根结点D向左上旋转提升到B结点的位置,然后再把该D结点向右上旋转提升到A结点的位置。
(完整word版)特殊二叉树

第6章 特殊二叉树6.1 二叉搜索树6.1。
1 二叉搜索的定义二叉搜索树(Binary Sort Tree )又称二叉排序树(Binany Search Tree ),它或者是一棵空树,或者是一棵具有如下特性的非空二叉树: (1) 若它的左子树非空,则左子树上所有结点的关键字均小于根结点的关键字;(2) 若它的右子树非空,则右子树上所有结点的关键字均大于(若允许具有相同的关键字的结点存在,则大于等于)根结点的关键字; (3) 左、右子树本身又各是一棵二叉搜索树。
在树中当每个结点的元素类型为简单类型时,则结点的关键字就是该结点的值,当每个结点的元素类型为记录类型时,则结点的关键字为该结点的某一个域的值。
对搜索树进行中序遍历得到的结点序列是一个有序序列。
该图的中序遍历得到的结点序列是: 12,15,18,23,26,30,52,63,743015527412236318266。
1。
2 二叉搜索树的抽象数据类型搜索树的抽象数据类型中的数据部分:是具有链接存储结构;操作部分除了已经讨论过的对一般树的操作外,还具有查找、更新、插入和删除元素的操作。
假定搜索树中的结点类型为BTreeNode,指向树的根结点指针为BST,则对搜索树BST的查找、更新、插入和删除元素的操作定义如下:int Find(BTreeNode *BST, ElemType &item);//从搜索树中查找等于给定值item的元素,若查找成功则返回真,并由item返回该元素的值,否则返回假;int Update(BTreeNode * BST,const ElemType &item);// 从二叉搜索树中查找等于给定值item的元素,若查找成功则用item的值重写该元素的值并返回真,否则返回假;void lnsert(BTreeNode *&BST,const ElemType &item);// 按item的大小向搜索树中插入一个元素item,使得插入后仍是一棵搜索树;int Delete(BTreeNode *&BST, const ElemType &item)// 从二叉搜索树中删除值为item的第一个结点,若删除成功则返回1, 否则返回0;下面分别对这四种运算进行讨论.6。
数据结构之二叉树(BinaryTree)

数据结构之⼆叉树(BinaryTree)⽬录导读 ⼆叉树是⼀种很常见的数据结构,但要注意的是,⼆叉树并不是树的特殊情况,⼆叉树与树是两种不⼀样的数据结构。
⽬录 ⼀、⼆叉树的定义 ⼆、⼆叉树为何不是特殊的树 三、⼆叉树的五种基本形态 四、⼆叉树相关术语 五、⼆叉树的主要性质(6个) 六、⼆叉树的存储结构(2种) 七、⼆叉树的遍历算法(4种) ⼋、⼆叉树的基本应⽤:⼆叉排序树、平衡⼆叉树、赫夫曼树及赫夫曼编码⼀、⼆叉树的定义 如果你知道树的定义(有限个结点组成的具有层次关系的集合),那么就很好理解⼆叉树了。
定义:⼆叉树是n(n≥0)个结点的有限集,⼆叉树是每个结点最多有两个⼦树的树结构,它由⼀个根结点及左⼦树和右⼦树组成。
(这⾥的左⼦树和右⼦树也是⼆叉树)。
值得注意的是,⼆叉树和“度⾄多为2的有序树”⼏乎⼀样,但,⼆叉树不是树的特殊情形。
具体分析如下⼆、⼆叉树为何不是特殊的树 1、⼆叉树与⽆序树不同 ⼆叉树的⼦树有左右之分,不能颠倒。
⽆序树的⼦树⽆左右之分。
2、⼆叉树与有序树也不同(关键) 当有序树有两个⼦树时,确实可以看做⼀颗⼆叉树,但当只有⼀个⼦树时,就没有了左右之分,如图所⽰:三、⼆叉树的五种基本状态四、⼆叉树相关术语是满⼆叉树;⽽国际定义为,不存在度为1的结点,即结点的度要么为2要么为0,这样的⼆叉树就称为满⼆叉树。
这两种概念完全不同,既然在国内,我们就默认第⼀种定义就好)。
完全⼆叉树:如果将⼀颗深度为K的⼆叉树按从上到下、从左到右的顺序进⾏编号,如果各结点的编号与深度为K的满⼆叉树相同位置的编号完全对应,那么这就是⼀颗完全⼆叉树。
如图所⽰:五、⼆叉树的主要性质 ⼆叉树的性质是基于它的结构⽽得来的,这些性质不必死记,使⽤到再查询或者⾃⼰根据⼆叉树结构进⾏推理即可。
性质1:⾮空⼆叉树的叶⼦结点数等于双分⽀结点数加1。
证明:设⼆叉树的叶⼦结点数为X,单分⽀结点数为Y,双分⽀结点数为Z。
二叉排序树

就维护表的有序性而言,二叉排序树无须移 动结点,只需修改指针即可完成插入和删 除操作,且其平均的执行时间均为O(lgn), 因此更有效。二分查找所涉及的有序表是 一个向量,若有插入和删除结点的操作, 则维护表的有序性所花的代价是O(n)。当 有序表是静态查找表时,宜用向量作为其 存储结构,而采用二分查找实现其查找操 作;若有序表里动态查找表,则应选择二 叉排序树作为其存储结构。
if(q->lchild) //*q的左子树非空,找*q的左子 树的最右节点r. {for(q=q->lchild;q->rchild;q=q->rchild); q->rchild=p->rchild; } if(parent->lchild==p)parent->lchild=p>lchild; else parent->rchild=p->lchild; free(p); /释放*p占用的空间 } //DelBSTNode
下图(a)所示的树,是按如下插入次序构成的: 45,24,55,12,37,53,60,28,40,70 下图(b)所示的树,是按如下插入次序构成的: 12,24,28,37,40,45,53,55,60,70
在二叉排序树上进行查找时的平均查找长度和二叉树的形态 有关: ①在最坏情况下,二叉排序树是通过把一个有序表的n 个结点依次插入而生成的,此时所得的二叉排序树蜕化为 棵深度为n的单支树,它的平均查找长度和单链表上的顺 序查找相同,亦是(n+1)/2。 ②在最好情况下,二叉排序树在生成的过程中,树的形 态比较匀称,最终得到的是一棵形态与二分查找的判定树 相似的二叉排序树,此时它的平均查找长度大约是lgn。 ③插入、删除和查找算法的时间复杂度均为O(lgn)。 (3)二叉排序树和二分查找的比较 就平均时间性能而言,二叉排序树上的查找和二分查找 差不多。
数据结构二叉排序树

05
13
19
21
37
56
64
75
80
88
92
low mid high 因为r[mid].key<k,所以向右找,令low:=mid+1=4 (3) low=4;high=5;mid=(4+5) div 2=4
05
13
19
low
21
37
56
64
75
80
88
92
mid high
因为r[mid].key=k,查找成功,所查元素在表中的序号为mid 的值
平均查找长度:为确定某元素在表中某位置所进行的比 较次数的期望值。 在长度为n的表中找某一元素,查找成功的平均查找长度:
ASL=∑PiCi
Pi :为查找表中第i个元素的概率 Ci :为查到表中第i个元素时已经进行的比较次数
在顺序查找时, Ci取决于所查元素在表中的位置, Ci =i,设每个元素的查找概率相等,即Pi=1/n,则:
RL型的第一次旋转(顺时针) 以 53 为轴心,把 37 从 53 的左上转到 53 的左下,使得 53 的左 是 37 ;右是 90 ,原 53 的左变成了 37 的右。 RL型的第二次旋转(逆时针)
一般情况下,假设由于二叉排序树上插入结点而失去 平衡的最小子树的根结点指针为a(即a是离插入结点最 近,且平衡因子绝对值超过1的祖先结点),则失去平衡 后进行调整的规律可归纳为下列四种情况: ⒈RR型平衡旋转: a -2 b -1 h-1 a1
2.查找关键字k=85 的情况 (1) low=1;high=11;mid=(1+11) / 2=6
05
13
19
21
数据结构:第9章 查找2-二叉树和平衡二叉树

return(NULL); else
{if(t->data==x) return(t);
if(x<(t->data) return(search(t->lchild,x));
else return(search(t->lchild,x)); } }
——这种既查找又插入的过程称为动态查找。 二叉排序树既有类似于折半查找的特性,又采用了链表存储, 它是动态查找表的一种适宜表示。
注:若数据元素的输入顺序不同,则得到的二叉排序树形态 也不同!
讨论1:二叉排序树的插入和查找操作 例:输入待查找的关键字序列=(45,24,53,45,12,24,90)
二叉排序树的建立 对于已给定一待排序的数据序列,通常采用逐步插入结点的方 法来构造二叉排序树,即只要反复调用二叉排序树的插入算法 即可,算法描述为: BiTree *Creat (int n) //建立含有n个结点的二叉排序树 { BiTree *BST= NULL;
for ( int i=1; i<=n; i++) { scanf(“%d”,&x); //输入关键字序列
– 法2:令*s代替*p
将S的左子树成为S的双亲Q的右子树,用S取代p 。 若C无右子树,用C取代p。
例:请从下面的二叉排序树中删除结点P。
F P
法1:
F
P
C
PR
C
PR
CL Q
CL QL
Q SL
S PR
QL S
SL
法2:
F
PS
C
PR
CL Q
QL SL S SL
数据结构 -第12周查找第3讲-二叉排序树.pdf

以二叉树或树作为表的组织形式,称为树表,它是一类动态查找表,不仅适合于数据查找,也适合于表插入和删除操作。
常见的树表:二叉排序树平衡二叉树B-树B+树9.3.1 二叉排序树二叉排序树(简称BST)又称二叉查找(搜索)树,其定义为:二叉排序树或者是空树,或者是满足如下性质(BST性质)的二叉树:❶若它的左子树非空,则左子树上所有节点值(指关键字值)均小于根节点值;❷若它的右子树非空,则右子树上所有节点值均大于根节点值;❸左、右子树本身又各是一棵二叉排序树。
注意:二叉排序树中没有相同关键字的节点。
二叉树结构满足BST性质:节点值约束二叉排序树503080209010854035252388例如:是二叉排序树。
66不试一试二叉排序树的中序遍历序列有什么特点?二叉排序树的节点类型如下:typedef struct node{KeyType key;//关键字项InfoType data;//其他数据域struct node*lchild,*rchild;//左右孩子指针}BSTNode;二叉排序树可看做是一个有序表,所以在二叉排序树上进行查找,和二分查找类似,也是一个逐步缩小查找范围的过程。
1、二叉排序树上的查找Nk< bt->keybtk> bt->key 每一层只和一个节点进行关键字比较!∧∧p查找到p所指节点若k<p->data,并且p->lchild=NULL,查找失败。
若k>p->data,并且p->rchild=NULL,查找失败。
查找失败的情况加上外部节点一个外部节点对应某内部节点的一个NULL指针递归查找算法SearchBST()如下(在二叉排序树bt上查找关键字为k的记录,成功时返回该节点指针,否则返回NULL):BSTNode*SearchBST(BSTNode*bt,KeyType k){if(bt==NULL||bt->key==k)//递归出口return bt;if(k<bt->key)return SearchBST(bt->lchild,k);//在左子树中递归查找elsereturn SearchBST(bt->rchild,k);//在右子树中递归查找}在二叉排序树中插入一个关键字为k的新节点,要保证插入后仍满足BST性质。
二叉树
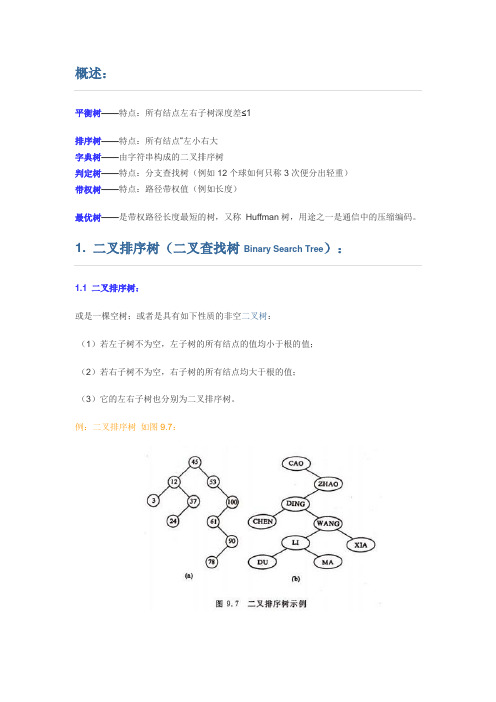
平衡树——特点:所有结点左右子树深度差≤1排序树——特点:所有结点―左小右大字典树——由字符串构成的二叉排序树判定树——特点:分支查找树(例如12个球如何只称3次便分出轻重)带权树——特点:路径带权值(例如长度)最优树——是带权路径长度最短的树,又称Huffman树,用途之一是通信中的压缩编码。
1.1 二叉排序树:或是一棵空树;或者是具有如下性质的非空二叉树:(1)若左子树不为空,左子树的所有结点的值均小于根的值;(2)若右子树不为空,右子树的所有结点均大于根的值;(3)它的左右子树也分别为二叉排序树。
例:二叉排序树如图9.7:二叉排序树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉排序树的存储结构。
中序遍历二叉排序树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉排序树变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。
每次插入的新的结点都是二叉排序树上新的叶子结点,在进行插入操作时,不必移动其它结点,只需改动某个结点的指针,由空变为非空即可。
搜索,插入,删除的复杂度等于树高,期望O(logn),最坏O(n)(数列有序,树退化成线性表).虽然二叉排序树的最坏效率是O(n),但它支持动态查询,且有很多改进版的二叉排序树可以使树高为O(logn),如SBT,AVL,红黑树等.故不失为一种好的动态排序方法.2.2 二叉排序树b中查找在二叉排序树b中查找x的过程为:1. 若b是空树,则搜索失败,否则:2. 若x等于b的根节点的数据域之值,则查找成功;否则:3. 若x小于b的根节点的数据域之值,则搜索左子树;否则:4. 查找右子树。
[cpp]view plaincopyprint?1.Status SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p){2. //在根指针T所指二叉排序樹中递归地查找其关键字等于key的数据元素,若查找成功,3. //则指针p指向该数据元素节点,并返回TRUE,否则指针P指向查找路径上访问的4. //最好一个节点并返回FALSE,指针f指向T的双亲,其初始调用值为NULL5. if(!T){ p=f; return FALSE;} //查找不成功6. else if EQ(key, T->data.key) {P=T; return TRUE;} //查找成功7. else if LT(key,T->data.key)8. return SearchBST(T->lchild, key, T, p); //在左子树继续查找9. else return SearchBST(T->rchild, key, T, p); //在右子树继续查找10.}2.3 在二叉排序树插入结点的算法向一个二叉排序树b中插入一个结点s的算法,过程为:1. 若b是空树,则将s所指结点作为根结点插入,否则:2. 若s->data等于b的根结点的数据域之值,则返回,否则:3. 若s->data小于b的根结点的数据域之值,则把s所指结点插入到左子树中,否则:4. 把s所指结点插入到右子树中。
二叉判定树

二叉判定树
二叉判定树也叫二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;(2)若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;(3)左、右子树也分别为二叉排序树。
扩展资料:
查找
步骤:
二叉树
若根结点的关键字值等于查找的关键字,成功。
否则,若小于根结点的关键字值,递归查左子树。
若大于根结点的关键字值,递归查右子树。
若子树为空,查找不成功。
平均情况分析(在成功查找两种的情况下):
在一般情况下,设P(n,i)为它的左子树的结点个数为i 时的平均查找长度。
如图的结点个数为n = 6 且i = 3; 则P(n,i)= P(6, 3)= [ 1+ ( P(3) + 1) * 3 + ( P(2) + 1) * 2 ] / 6= [ 1+ ( 5/3 + 1) * 3 + ( 3/2 + 1) * 2 ] / 6
注意:这里P(3)、P(2) 是具有3 个结点、2 个结点的二叉分类树的平均查找长度。
在一般情况,P(i)为具有i 个结点二叉分类树的平均查找长度。
平均查找长度= 每个结点的深度的总和/ 总结点数。
二叉排序树的概念

二叉排序树的概念
二叉排序树,也称为二叉搜索树(Binary Search Tree,BST),是一种常用的数据结构,它具有以下特点:
1、结构特点:二叉排序树是一种二叉树,其中每个节点最多有两个子节点(左子节点和右子节点),且满足以下性质:
(1)左子树上的所有节点的值都小于根节点的值;
(2)右子树上的所有节点的值都大于根节点的值;
(3)左右子树都是二叉排序树。
2、排序特性:由于满足上述性质,二叉排序树的中序遍历结果是一个有序序列。
即,对二叉排序树进行中序遍历,可以得到一个递增(或递减)的有序序列。
3、查找操作:由于二叉排序树的排序特性,查找某个特定值的节点非常高效。
从根节点开始,比较目标值与当前节点的值的大小关系,根据大小关系选择左子树或右子树进行进一步的查找,直到找到目标值或者遍历到叶子节点为止。
4、插入和删除操作:插入操作将新节点按照排序规则插入到合适的位置,保持二叉排序树的特性;删除操作涉及节点的重新连接和调整,保持二叉排序树的特性。
二叉排序树的优点在于它提供了高效的查找操作,时间复杂度为O(log n),其中n为二叉排序树中节点的个数。
它也可以支持其他常见的操作,如最小值和最大值查找、范围查找等。
然而,二叉排序树的性能受到数据的分布情况的影响。
当数据分
布不均匀时,树的高度可能会增加,导致查找操作的效率下降。
为了解决这个问题,可以采用平衡二叉树的变种,如红黑树、AVL 树等,以保持树的平衡性和性能。
头歌二叉排序表的基本操作

头歌二叉排序表的基本操作一、概述二叉排序树,也称为二叉搜索树(Binary Search Tree, BST),是一种特殊的二叉树,其中每个节点都满足以下性质:对于任意节点,其左子树中所有节点的值都小于该节点的值,而其右子树中所有节点的值都大于该节点的值。
这种特性使得二叉排序树成为一种非常有效的数据结构,用于在各种算法中实现快速查找、插入和删除操作。
二、基本操作1. 插入操作插入操作是二叉排序树中最常用的操作之一。
其基本步骤如下:(1)创建一个新节点,并将要插入的值赋给该节点。
(2)如果二叉排序树为空,则将新节点作为根节点。
(3)否则,从根节点开始比较新节点的值与当前节点的值。
如果新节点的值小于当前节点的值,则将新节点插入到当前节点的左子树中;否则,将新节点插入到当前节点的右子树中。
(4)重复步骤3,直到找到一个空位置来插入新节点。
2. 删除操作删除操作是二叉排序树中比较复杂的操作之一。
其基本步骤如下:(1)找到要删除的节点。
如果找不到要删除的节点,则无法进行删除操作。
(2)如果找到要删除的节点,则将其从树中删除。
如果该节点只有一个子节点,则直接删除该节点;如果该节点有两个子节点,则可以选择将其中的一个子节点“提升”到该节点的位置,然后删除该子节点。
在提升子节点时,需要考虑子节点的值与要删除的节点的值之间的关系,以确保二叉排序树的性质不变。
(3)如果被提升的子节点仍然包含要删除的节点,则需要重复步骤2,直到找到要删除的节点并将其删除。
3. 查找操作查找操作用于在二叉排序树中查找指定的值。
其基本步骤如下:(1)从根节点开始,比较当前节点的值与要查找的值。
如果它们相等,则查找成功,返回当前节点的位置。
(2)如果当前节点的值大于要查找的值,则进入当前节点的左子树中进行查找;否则进入当前节点的右子树中进行查找。
(3)重复步骤2,直到找到要查找的值或者搜索路径上的所有节点都已访问过。
如果最终没有找到要查找的值,则返回空指针。
数据结构_第9章_查找2-二叉树和平衡二叉树

F
PS
C
PR
CL Q
QL SL S SL
10
3
18
2
6 12
6 删除10
3
18
2
4 12
4
15
15
三、二叉排序树的查找分析
1) 二叉排序树上查找某关键字等于给定值的结点过程,其实 就是走了一条从根到该结点的路径。 比较的关键字次数=此结点的层次数; 最多的比较次数=树的深度(或高度),即 log2 n+1
-0 1 24
0 37
0 37
-0 1
需要RL平衡旋转 (绕C先顺后逆)
24
0
-012
13
3573
0
01
37
90
0 53 0 53
0 90
作业
已知如下所示长度为12的表:
(Jan, Feb, Mar, Apr, May, June, July, Aug, Sep, Oct, Nov, Dec)
(1) 试按表中元素的顺序依次插入一棵初始为空的二叉 排序树,画出插入完成之后的二叉排序树,并求其在 等概率的情况下查找成功的平均查找长度。
2) 一棵二叉排序树的平均查找长度为:
n i1
ASL 1
ni Ci
m
其中:
ni 是每层结点个数; Ci 是结点所在层次数; m 为树深。
最坏情况:即插入的n个元素从一开始就有序, ——变成单支树的形态!
此时树的深度为n ; ASL= (n+1)/2 此时查找效率与顺序查找情况相同。
最好情况:即:与折半查找中的判ห้องสมุดไป่ตู้树相同(形态比较均衡) 树的深度为:log 2n +1 ; ASL=log 2(n+1) –1 ;与折半查找相同。
数据结构第20讲--二叉排序树--2018

二叉排序树
• 任一结点 > 其左子树的所有结点,并且
< 其右子树的所有结点;
结点的左、右子树,也是二叉排序树;
≠
5
5
左孩子 < 父亲 <右孩子 另外,与堆进行区分!
4 9 49
3 12 7 12
×√
二叉排序树
• 任一结点 > 其左子树,并且
parentp->llink = Null;
else
//若*p是父亲的右孩子
parentp->rlink = Null;
free(p); return 1; //释放空间,返回 }
//2.1 若*p只有右孩子,则让右孩子取代*p
if(p->llink==Null && p->rlink!=Null)
18
< 其右子树; • 重要性质:
中序遍历二叉排序树
10 5
73 68 99
递增序列
4 9 27
• 如何判断1棵二叉树
是否是二叉排序树?
8 25 41
-- 中序遍历,得到递增序列才是。 32 51
二叉排序树--存储结构
struct BinSearchNode; //结点类型声明 typedef struct BinSearchNode * PBinSearchNode; struct BinSearchNode //结点类型
q
p = *ptree; //p指向树根
p
q = p; //后续:q用于记录p的父亲
5
49
7 12
while( p != Null) //p指向当前(子)树的根
二叉排序树的例题

二叉排序树的例题一、二叉排序树的例题二叉排序树呢,可有趣啦。
我给你多来点例题哈。
例1:有这么一组数,12,5,18,2,9,15,19。
让你构建二叉排序树。
那咱就开始呗。
先把12当作根节点,5比12小,就放在12的左子树位置,18比12大,就放在12的右子树位置。
然后2比5小,放在5的左子树,9比5大比12小,放在5的右子树。
15比12大比18小,放在18的左子树,19比18大,放在18的右子树。
答案和解析:答案就是构建出来的二叉排序树(这里你可以自己画一下哈,根节点12,左子树5,右子树18,5的左子树2,右子树9,18的左子树15,右子树19)。
解析呢,二叉排序树的构建规则就是,左子树的节点值都小于根节点值,右子树的节点值都大于根节点值。
按照这个规则,一个一个数去放就好啦。
例2:已知一个二叉排序树的前序遍历序列是30,20,10,25,23,39,35,42。
求这个二叉排序树的中序遍历序列。
我们先根据前序遍历序列构建二叉排序树。
30是根节点,20比30小,是左子树,10比20小,是20的左子树,25比20大,是20的右子树,23比25小,是25的左子树,39比30大,是30的右子树,35比39小,是39的左子树,42比39大,是39的右子树。
然后求中序遍历序列。
中序遍历就是先左子树,再根节点,再右子树。
那就是10,20,23,25,30,35,39,42。
答案和解析:答案:10,20,23,25,30,35,39,42。
解析:先根据前序遍历构建二叉排序树,然后按照中序遍历的规则得到序列。
前序遍历第一个数就是根节点,然后根据大小关系构建树,中序遍历的顺序就是左子树、根节点、右子树。
例3:给你一个二叉排序树,根节点为50,左子树节点有30、20、40,右子树节点有70、60、80。
现在要删除节点30。
那我们得按照二叉排序树删除节点的规则来。
因为30有左子树20,我们要找30的中序后继,也就是40。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二叉排序树
二叉排序树(Binary Sort Tree:BST)
1、二叉排序树的定义
二叉排序树(Binary Sort Tree)又称二叉查找(搜索)树(Binary Search Tree)。
其定义为:二叉排序树或者是空树,或者是满足如下性质的二叉树:
①若它的左子树非空,则左子树上所有结点的值均小于根结点的值;
②若它的右子树非空,则右子树上所有结点的值均大于根结点的值;
③左、右子树本身又各是一棵二叉排序树。
上述性质简称二叉排序树性质(BST性质),故二叉排序树实际上是满足BST性质的二叉树。
2、二叉排序树的特点
由BST性质可得:
(1)二叉排序树中任一结点x,其左(右)子树中任一结点y(若存在)的关键字必小(大)于x的关键字。
(2)二叉排序树中,各结点关键字是惟一的。
注意:
实际应用中,不能保证被查找的数据集中各元素的关键字互不相同,所以可将二叉排序树定义中BST性质(1)里的"小于"改为"小于等于",或将BST性质(2)里的"大于"改为"大于等于",甚至可同时修改这两个性质。
(3)按中序遍历该树所得到的中序序列是一个递增有序序列。
【例】下图所示的两棵树均是二叉排序树,它们的中序序列均为有序序列:2,3,4,5,7,8。
3、二叉排序树的存储结构
typedef int KeyType;//假定关键字类型为整数
typedef struct node{//结点类型
KeyType key;//关键字项
InfoType otherinfo;//其它数据域,InfoType视应用情况而定,下面不处理它
struct node*lchild,*rchild;//左右孩子指针
}BSTNode;
typedef BSTNode*BSTree;//BSTree是二叉排序树的类型
二叉排序树的基本操作(pascal):
1.中序遍历所有元素
procedure tree_walk(x:longint);
begin
if x<>0then
begin
tree_walk(left[x]);
write(key[x]);
tree_walk(right[x]);
end;
2.查找给定的元素
function tree_search(x,k:longint):longint;
begin
if(x=0)or(k=key[x])then exit(x);
if k<key[x]then exit(tree_search(left[x],k))
else exit(tree_search(right[x],k));
end;
非递归版本
function tree_search(x,k:longint):longint;
begin
while(x<>0)and(k<>key[x])do
begin
if k<key[x]then x:=left[x]
else x:=right[x];
end;
exit(x);
end;
3.查找最小元素
function tree_minimum(x:longint):longint;
begin
while left[x]<>0do
x:=left[x];
exit(x);
end;
查找最大元素
function tree_maximum(x:longint):longint;
begin
while right[x]<>0do
x:=right[x];
exit(x);
end;
4.求后继
function tree_successor(x:longint):longint;
var
y:longint;
begin
if right[x]<>0then exit(tree_minimum(right[x]));//若右子树不空,则返回右子树中的最小值
y:=p[x];//若右子树为空,则后继y为x的最低祖先节点,且y的左儿子也是x的祖先while(y<>0)and(x=right[y])do
begin
x:=y;
y:=p[y];
end;
exit(y);//注意,若y为0,则x无后继
end;
//注意,函数返回值为节点编号,并不是节点本身的值
5.插入
procedure tree_insert(z:longint);//注意z为节点编号,并非树中的值
var
x,y:longint;
begin
y:=0;
x:=root;
while x<>0do//查找z的父节点,y记录
begin
y:=x;
if key[z]<key[x]then x:=left[x]
else x:=right[x];
end;
p[x]:=y;
if y=0then root:=z//若z为根节点
else begin
if key[z]<key[y]then left[y]:=z//更新父节点的left和right
else right[y]:=z;
end;
end;
6.删除
删除操作是最麻烦的,分3种情况:
(1)若z无子树,则就删除z节点,更新p[z]的值为空
(2)若z有一个子树,删除z节点,更新p[z]的值为z的儿子节点,更新left[p[z]]或right[p[z]]
(3)若z有两棵子树,先找到z的后继y(后继节点无左子树,可证),删除y节点,更新p[y]与left[p[y]]或right[p[y]],最后用节点y的数据覆盖z节点
procedure tree_delete(z:longint);
var
x,y:longint;
begin
if(left[z]=0)or(right[z]=0)then y:=z
else y:=tree_successor(z);
if left[y]<>0then x:=left[y]
else x:=right[y];
if x<>0then p[x]:=p[y];
if p[y]=0then root:=x
else begin
if y=left[p[y]]then left[p[y]]:=x
else right[p[y]]:=x;
end;
if z<>y then key[z]:=key[y];
end;
7.查找数中第k大元素
需要对每个节点新开一个域v[x],记录该节点的有多少子节点,
查找时分三种情况:
(1)k=v[left[x]]+1则当前x节点为所求
(2)k<=v[left[x]]则在左子树中继续查找
(3)k>v[left[x]]+1则在右子树中继续查找,k更新为k-left[x]-1; function find(x,k:longint):longint;
begin
if v[left[x]]+1=k then exit(key[k])
else if v[left[x]]>=k then exit(find(left[x],k))
else exit(find(right[x],k-v[left[x]]-1));
end;。