《语音识别技术介绍》PPT课件
合集下载
《语音识别技术介绍》PPT课件

语音识别概述
21世纪语音识别技术的应用及产品化方面进一步发展。在语音识别产品方面, 各大公司纷纷推出自己产品。目前世界上最先进的语音识别软件,既不是微软生 产的,也非IBM制造,它的名字叫做Naturally Speaking,出自于Nuance Communications公司。Naturally Speaking己经得到了大多数用户的认可。用户 对着麦克风说话,屏幕上就显示出说话的内容,很容易识别和纠正错误.久而久 之,该软件就会适应用户的说话风格。
语音识别系统基本原理
语音识别系统基本构成
语音识别系统基本原理
预处理 预处理部分包括语音信号的采样、反混叠滤波、语音增强,去除声门激励和
口唇辐射的影响以及噪声影响等,预处理最重要的步骤是端点检测。
特征提取 特征提取部分的作用是从语音信号波形中提取一组或几组能够描述语音信号
特征的参数,如平均能量、过零数、共振峰、倒谱、线性预测系数等,以便训练 和识别。参数的选择直接关系着语音识别系统识别率的高低。
目前市场上出现的语音识别器大多数是特定人孤立单词语音识别系统。
孤立词语音识别系统中的难点问题: (1) 语音信号的多变性 语音信号是非平稳随机信号,不但不同发音者发音之间存在重大的差异,即
使同一人同一语音的不同次发音,也存在很大差异。 (2) 噪声影响 当实际环境中有噪声存在时,容易造成训练与测试环境不匹配导致语音识别
语音信号处理与识别
一、语音识别概述 二、语音识别系统基本原理 三、预处理及特征参数提取 四、模板匹配技术及相似性判断方法 五、语音识别系统的设计和实现
语音识别概述
让机器听懂人类的语音,这是人们长期以来梦寐以求的事情。伴随计算机技 术发展,语音识别己成为信息产业领域的标志性技术,在人机交互应用中逐渐进 入我们日常的生活,并迅速发展成为“改变未来人类生活方式厅的关键技术之一。
人工智能语音识别课件

后端处理模块
语言模型
采用统计学习方法(如n-gram、循环神经网络等)对大量文本数据进行训练,得到一个能够将文本表示映射到 最终输出结果的模型。
置信度分析
对每个识别结果进行置信度评估,以过滤掉低置信度的结果,提高识别准确率。
04
CATALOGUE
语音识别技术面临的挑战与解 决方案
环境噪声与干扰问题
机器学习与深度学习在语音识别中的应用
传统机器学习方法
使用高斯混合模型、i-vector和PLDA等传统机器学习方法进行声学建模。
深度学习方法
使用深度神经网络、循环神经网络和长短时记忆网络等深度学习方法进行声学 建模和序列识别。
03
CATALOGUE
语音识别系统架构
前端处理模块
预加重
加窗
通过一个高通滤波器对输入的语音信 号进行预处理,以减少语音信号的延 迟和改善语音信号的频谱特性。
03
定期进行安全审计和监控,及时发现和处理安全漏洞和威胁。
06
CATALOGUE
实践案例分析
智能客服系统中的应用
在此添加您的文本17字
总结词:高效便捷
在此添加您的文本16字
详细描述:智能客服系统通过语音识别技术,能够快速准 确地识别用户语音信息,实现高效便捷的自助服务,提高 客户满意度。
在此添加您的文本16字
倒谱系数(cepstral coefficients)
将语音信号从时域转换到频域,提取出反映语音信号频谱特性的特征。
声学模型与解码模块
声学模型
采用统计学习方法(如隐马尔可可模型、神经网络等)对大量语音数据进行训练, 得到一个能够将语音特征映射到音素级别的模型。
解码
根据声学模型和语言模型,对输入的语音特征进行解码,生成对应的文本表示。
人工智能-语音识别技术PPT学习课件

3/5/2020
12
3/5/2020
13
声学模型
声学模型是把语音转化为声学表示的输出,即找到给定的语音源于某个声学符号的概率。 对于声学符号,最直接的表达方式是词组,但是在训练数据量不充分的情况下,很难得到 一个好的模型。词组是由多个音素的连续发音构成,另外,音素不但有清晰的定义而且数 量有限。因而,在语音识别中,通常把声学模型转换成了一个语音序列到发音序列(音素) 的模型和一个发音序列到输出文字序列的字典。
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观 察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向 量表示,色块的颜色深浅表示向量值的大小。3/5/2020来自 7语音识别的实现(4)
接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念: 音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内
3/5/2020
6
语音识别的实现(3)
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长 25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将 波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每 一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信 息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不 止有MFCC这一种,具体这里不讲。
由贝叶斯公式143162020展开可得po是对每个句子进行计算的而对每个句子来说po是不变的所以可以改写成如下其中pow称做观测最大释然由声学模型计算可得其中pw称做先验概率由语言模型模型计算可得综上所述语音识别就是解码decoding过程如下图所示
语音识别技术PPT课件

11
2.2 语音识别的基本原理
•训练(Training):预先分析出语音特征参数,制作语音模 板(Template)并存放在语音参数库中。
•识别(Recognition):待识语音经过与训练时相同的分析, 得到语音参数,将它与库中的参考模板一一比较,并采用 判决的方法找出最接近语音特征的年11月1日
1
通过语音传递信息是人类最重要、最有效、 最常用和最方便的交换信息形式。 (1)语言是人类特有的功能,声音是人类常用 的工具,是相互传递信息的最主要的手段。
(2)语音和语言与人的智力活动密切相关,是 人们构成思想疏通和感情交流的最主要的途径。
2
讲解重点:
9
2.1语音识别的定义
•语音识别是研究如何采用数字信号处理技术自动提 取以及决定语音信号中最基本、 最有意义的信息的 一门新兴的边缘学科。它是语音信号处理学科的一 个分支。
•语 音 识 别 所 涉 及 的 学 科 领 域 : 信 号 处 理 、 物 理 学 (声学)、模式匹配、通信及信息理论、语言语音 学、生理学、计算机科学(研究软硬件算法以便更 有效地实现用于识别系统中的各种方法)、心理学 等。
6
微软:让计算机能说会听
•Bill Gates 在97年世界计算机博览会(COMDEX)主题 演讲会上描绘IT事业的发展宏图时指出:
下一代操作系统和应用程序的用户界面将是语音识 别。工业界应对语音识别领域的重大突破做好充分准 备,因为那将是一场席卷全球的另一次热潮。 •1998年11月5日,微软中国研究院在北京成立。该中 心的任务是重点研究计算机在中文环境下的易用性。
以比较少的词汇为对象,能够识别每个词。识别的词汇表和标准样板 或模型也是字、词或短语,但识别时可以是它们中间几个的连续。
2.2 语音识别的基本原理
•训练(Training):预先分析出语音特征参数,制作语音模 板(Template)并存放在语音参数库中。
•识别(Recognition):待识语音经过与训练时相同的分析, 得到语音参数,将它与库中的参考模板一一比较,并采用 判决的方法找出最接近语音特征的年11月1日
1
通过语音传递信息是人类最重要、最有效、 最常用和最方便的交换信息形式。 (1)语言是人类特有的功能,声音是人类常用 的工具,是相互传递信息的最主要的手段。
(2)语音和语言与人的智力活动密切相关,是 人们构成思想疏通和感情交流的最主要的途径。
2
讲解重点:
9
2.1语音识别的定义
•语音识别是研究如何采用数字信号处理技术自动提 取以及决定语音信号中最基本、 最有意义的信息的 一门新兴的边缘学科。它是语音信号处理学科的一 个分支。
•语 音 识 别 所 涉 及 的 学 科 领 域 : 信 号 处 理 、 物 理 学 (声学)、模式匹配、通信及信息理论、语言语音 学、生理学、计算机科学(研究软硬件算法以便更 有效地实现用于识别系统中的各种方法)、心理学 等。
6
微软:让计算机能说会听
•Bill Gates 在97年世界计算机博览会(COMDEX)主题 演讲会上描绘IT事业的发展宏图时指出:
下一代操作系统和应用程序的用户界面将是语音识 别。工业界应对语音识别领域的重大突破做好充分准 备,因为那将是一场席卷全球的另一次热潮。 •1998年11月5日,微软中国研究院在北京成立。该中 心的任务是重点研究计算机在中文环境下的易用性。
以比较少的词汇为对象,能够识别每个词。识别的词汇表和标准样板 或模型也是字、词或短语,但识别时可以是它们中间几个的连续。
《语音识别技术介绍》课件

2 语音识别技术的局限性
在复杂环境、多语言等情况下,识别准确性仍存在挑战。
3 语音识别技术的前景展望
随着技术的不断进步,语音识别将在更多领域别技术的应用案例
智能语音助手
如Siri、小爱同学等,提供语音 交互、查询信息、控制设备等 功能。
电话客服系统
利用语音识别技术提供自动语 音导航、语音识别、智能推荐 等服务。
聊天机器人
通过语音识别技术实现与用户 的自然语言对话,提供智能问 答、娱乐等功能。
语音识别技术的挑战和未来
1 声音环境的复杂性
语音识别技术广泛应用于智能语音助手、电话客服系统、聊天机器人等领域。
3 语音识别技术与其他技术的关系
语音识别技术与自然语言处理、机器学习等技术密切相关,共同构成智能语音系统。
语音识别技术的原理
1 语音采样和信号处理
通过麦克风采集语音信号,并对信号进行去噪、增强等处理。
2 特征提取
从语音信号中提取语音特征,如音频频谱、梅尔频率倒谱系数等。
语音识别技术需要应对噪声、回声等干扰,提高在复杂环境下的识别准确性。
2 多语言语音识别技术的发展
对不同语言、方言的准确识别是多语音识别技术发展的重要方向。
3 语音识别技术的未来发展趋势
随着人工智能技术的发展,语音识别技术将更加智能化、个性化、多场景应用。
结论
1 语音识别技术的优点
提供了人机交互的新方式,方便快捷、便于特定场景操作。
《语音识别技术介绍》 PPT课件
# 语音识别技术介绍
语音识别技术是指通过计算机对人类语音进行自动识别和理解的技术。本课 件将介绍语音识别技术的概述、原理、常见技术、应用案例、挑战和未来。
概述
1 什么是语音识别技术?
在复杂环境、多语言等情况下,识别准确性仍存在挑战。
3 语音识别技术的前景展望
随着技术的不断进步,语音识别将在更多领域别技术的应用案例
智能语音助手
如Siri、小爱同学等,提供语音 交互、查询信息、控制设备等 功能。
电话客服系统
利用语音识别技术提供自动语 音导航、语音识别、智能推荐 等服务。
聊天机器人
通过语音识别技术实现与用户 的自然语言对话,提供智能问 答、娱乐等功能。
语音识别技术的挑战和未来
1 声音环境的复杂性
语音识别技术广泛应用于智能语音助手、电话客服系统、聊天机器人等领域。
3 语音识别技术与其他技术的关系
语音识别技术与自然语言处理、机器学习等技术密切相关,共同构成智能语音系统。
语音识别技术的原理
1 语音采样和信号处理
通过麦克风采集语音信号,并对信号进行去噪、增强等处理。
2 特征提取
从语音信号中提取语音特征,如音频频谱、梅尔频率倒谱系数等。
语音识别技术需要应对噪声、回声等干扰,提高在复杂环境下的识别准确性。
2 多语言语音识别技术的发展
对不同语言、方言的准确识别是多语音识别技术发展的重要方向。
3 语音识别技术的未来发展趋势
随着人工智能技术的发展,语音识别技术将更加智能化、个性化、多场景应用。
结论
1 语音识别技术的优点
提供了人机交互的新方式,方便快捷、便于特定场景操作。
《语音识别技术介绍》 PPT课件
# 语音识别技术介绍
语音识别技术是指通过计算机对人类语音进行自动识别和理解的技术。本课 件将介绍语音识别技术的概述、原理、常见技术、应用案例、挑战和未来。
概述
1 什么是语音识别技术?
语音识别 PPT课件

考模板的长度一致,在这一过程中,未知单词的时间轴会 产生扭曲或弯折,以便其特征量与标准模式对应。
1. 原理描述 DTW 是把时间规整和距离测度计算结合起来的一种 非线性规整技术。
测试语音参数共有I 帧矢量,而参考模板共有J 帧矢量,
I 和J 不等,寻找一个时间规整函数 j=w(i),它将测试矢量 的时间轴i 非线性地映射到模板的时间轴 j上,并使该函数
代价函数。
j
j
时间规整函数 j=w(i)
A
i
i
B
图13.4 动态时间规整
为了使T(测试)的第i 个样本与R(参考)的第 j 个样本 对正,其对应的点不在直线对角线上,得到一条弯曲的曲 线j=w(i)。j=w(i) 称为规整函数。
2. 时间规整解决的问题
设 T={a1 , a2 , …… , ai , …… , aI} i=1~I,
矢量量化识别时,将输入语音的K维帧矢量与已有的 码本中M个区域边界比较,按失真测度最小准则找到与该 输入矢量距离最小的码字标号来代替此输入的K维矢量, 这个对应的码字即为识别结果,再对它进行K维重建就得 到被识别的信号。
模型1 码本1
语音 信号 预 处 理
参 数 提 取
模型2 码本2
· · ·
识别输 判决逻辑 出结果
由此来判别出未知语音。
特征提取的基本思想:将信号通过一次变换,去除 冗余部分,将代表语音本质的特征参数抽取出来。 与特征提取相关的内容是特征间的距离测度。 特征的选择对识别效果至关重要。同时,还要考虑特征
参数的计算量。
语音信号的特征主要有时域和频域两种。
时域特征:短时平均能量、短时平均过零率、共 振峰、基音周期等; 频 域 特 征 : 线 性 预 测 系 数 (LPC) 、 LP 倒 谱 系 数 (LPCC)、线谱对参数(LSP) 、短时频谱、 Mel频率倒谱 系数(MFCC)等。 目前已有结合时间和频率的特征,即时频谱,充
1. 原理描述 DTW 是把时间规整和距离测度计算结合起来的一种 非线性规整技术。
测试语音参数共有I 帧矢量,而参考模板共有J 帧矢量,
I 和J 不等,寻找一个时间规整函数 j=w(i),它将测试矢量 的时间轴i 非线性地映射到模板的时间轴 j上,并使该函数
代价函数。
j
j
时间规整函数 j=w(i)
A
i
i
B
图13.4 动态时间规整
为了使T(测试)的第i 个样本与R(参考)的第 j 个样本 对正,其对应的点不在直线对角线上,得到一条弯曲的曲 线j=w(i)。j=w(i) 称为规整函数。
2. 时间规整解决的问题
设 T={a1 , a2 , …… , ai , …… , aI} i=1~I,
矢量量化识别时,将输入语音的K维帧矢量与已有的 码本中M个区域边界比较,按失真测度最小准则找到与该 输入矢量距离最小的码字标号来代替此输入的K维矢量, 这个对应的码字即为识别结果,再对它进行K维重建就得 到被识别的信号。
模型1 码本1
语音 信号 预 处 理
参 数 提 取
模型2 码本2
· · ·
识别输 判决逻辑 出结果
由此来判别出未知语音。
特征提取的基本思想:将信号通过一次变换,去除 冗余部分,将代表语音本质的特征参数抽取出来。 与特征提取相关的内容是特征间的距离测度。 特征的选择对识别效果至关重要。同时,还要考虑特征
参数的计算量。
语音信号的特征主要有时域和频域两种。
时域特征:短时平均能量、短时平均过零率、共 振峰、基音周期等; 频 域 特 征 : 线 性 预 测 系 数 (LPC) 、 LP 倒 谱 系 数 (LPCC)、线谱对参数(LSP) 、短时频谱、 Mel频率倒谱 系数(MFCC)等。 目前已有结合时间和频率的特征,即时频谱,充
第5课语音识别技术课件(共19张PPT)八下信息科技浙教版(2023)

二、语音识别的实践
亲身体验
尝试在人工智能开放平台、APP或相关软件中,将录制的myaudio.wav文件分别转换成文本。
日积月累
语音识别的准确率与声学模型及语言模型都密切相关。如果声学模型是用普通话训练的,那么识别方言语音,正确率就相对较低。通过及时更新地名、网络流行语等词汇,在语言模型中改变单词之间的搭配概率,可以有效地提高新单词的识别率。语音识别的准确率还与录音时周边环境的噪音、录音设备的质量等因素有关。
一、语音识别的过程
3.特征提取特征提取就是每隔一定时间,把声音的音高、音长、音强和音色等特征提取出来的过程。4.模式匹配模式匹配就是将提取出来的特征在声学模型中进行比对,得到一组音素序列。音素是根据语音的自然规律划分出的最小的语音单位。
知识链接
模式识别 人工智能中的模式识别是根据某个类别数据的共有模式,即模型(特征),对数据进行检测识别或分类。模型的建立可以是直接给予某一事物的各种特征描述,或给予某一事物的海量数浙教版八年级下册
第5课 语音识别技术
学习目标
通过对语音识别应用的体验,理解语音识别的基本过程和原理,了解声学模型和语音模型,感受语音识别带来的便利。
探究
1.为什公智能青箱能听懂人们的问题?2.你认为如何让人工智能听懂家乡的方言?
建构
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。其最大优势在于使得人机用户界面更加自然和容易使用。
一、语音识别的过程
语音识别一般会经历以下基本过程:通过数模转化得到一个数字声音信号,再对该声音信号进行预处理和特征提取,将该特征在声学模型中进行模式识别得到音素序列,最后将该音素序列在语言模型中查找概率最高的文本,并输出识别结果。
亲身体验
尝试在人工智能开放平台、APP或相关软件中,将录制的myaudio.wav文件分别转换成文本。
日积月累
语音识别的准确率与声学模型及语言模型都密切相关。如果声学模型是用普通话训练的,那么识别方言语音,正确率就相对较低。通过及时更新地名、网络流行语等词汇,在语言模型中改变单词之间的搭配概率,可以有效地提高新单词的识别率。语音识别的准确率还与录音时周边环境的噪音、录音设备的质量等因素有关。
一、语音识别的过程
3.特征提取特征提取就是每隔一定时间,把声音的音高、音长、音强和音色等特征提取出来的过程。4.模式匹配模式匹配就是将提取出来的特征在声学模型中进行比对,得到一组音素序列。音素是根据语音的自然规律划分出的最小的语音单位。
知识链接
模式识别 人工智能中的模式识别是根据某个类别数据的共有模式,即模型(特征),对数据进行检测识别或分类。模型的建立可以是直接给予某一事物的各种特征描述,或给予某一事物的海量数浙教版八年级下册
第5课 语音识别技术
学习目标
通过对语音识别应用的体验,理解语音识别的基本过程和原理,了解声学模型和语音模型,感受语音识别带来的便利。
探究
1.为什公智能青箱能听懂人们的问题?2.你认为如何让人工智能听懂家乡的方言?
建构
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。其最大优势在于使得人机用户界面更加自然和容易使用。
一、语音识别的过程
语音识别一般会经历以下基本过程:通过数模转化得到一个数字声音信号,再对该声音信号进行预处理和特征提取,将该特征在声学模型中进行模式识别得到音素序列,最后将该音素序列在语言模型中查找概率最高的文本,并输出识别结果。
语音识别技术.pptx
第10页/共14页
语音识别技术
2 语音识别过程总结
第11页/共14页
语音识别技术
3 总结及展望
21世纪,信息和网络飞速发展,信息和网络的时代已经来临,人与人之间的距离随着Internet和移动电话网 的连接和普及变得越来越近,信息资源扩散的越来越迅速,人与机器的交互显得尤为重要。语音识别技术的 研究和应用可以让人无论何时何地都可以通过语音交互的方式实现任何事,可以使人更方便的享受更多的社 会信息资源和现代化服务,所以,如何将这一技术可靠的、低成本的应用于商业和日常生活,是语音识别技 术的发展方向和趋势。
3.智能对话查询系统,根据客户的语音进行操作,为用户提供自然、友 好的数据库检索服务,例如家庭服务、宾馆服务、旅行社服务系统、订 票系统、医疗服务、银行服务、股票查询服务等等。
第4页/共14页
语音识别技术
2 语音识别过程(传统的基于HMM的语音识别)
1. 在开始语音识别之前,通常需要把首尾端的静音切除, 降低对后续步骤造成的干扰。这个静音切除的操作一般称 为VAD。
第9页/共14页
语音识别技术
2 语音识别过程
5.解码。搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在 状态网络中搜索一条最佳路径,语音对应这条路径的概率最大。路径搜索的算法是一种动态规划剪枝的算 法,称之为Viterbi算法,用于寻找全局最优路径。观察概率和转移概率(声学模型)、语言概率(语言模 型)
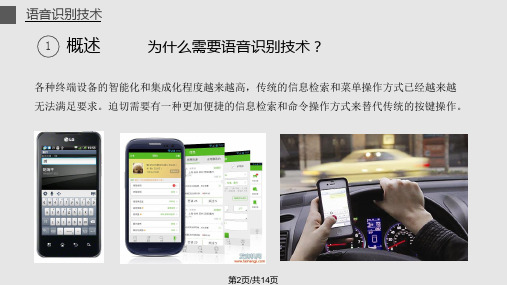
语音识别技术
1 概述
为什么需要语音识别技术?
各种终端设备的智能化和集成化程度越来越高,传统的信息检索和菜单操作方式已经越来越 无法满足要求。迫切需要有一种更加便捷的信息检索和命令操作方式来替代传统的按别技术
语音识别技术
2 语音识别过程总结
第11页/共14页
语音识别技术
3 总结及展望
21世纪,信息和网络飞速发展,信息和网络的时代已经来临,人与人之间的距离随着Internet和移动电话网 的连接和普及变得越来越近,信息资源扩散的越来越迅速,人与机器的交互显得尤为重要。语音识别技术的 研究和应用可以让人无论何时何地都可以通过语音交互的方式实现任何事,可以使人更方便的享受更多的社 会信息资源和现代化服务,所以,如何将这一技术可靠的、低成本的应用于商业和日常生活,是语音识别技 术的发展方向和趋势。
3.智能对话查询系统,根据客户的语音进行操作,为用户提供自然、友 好的数据库检索服务,例如家庭服务、宾馆服务、旅行社服务系统、订 票系统、医疗服务、银行服务、股票查询服务等等。
第4页/共14页
语音识别技术
2 语音识别过程(传统的基于HMM的语音识别)
1. 在开始语音识别之前,通常需要把首尾端的静音切除, 降低对后续步骤造成的干扰。这个静音切除的操作一般称 为VAD。
第9页/共14页
语音识别技术
2 语音识别过程
5.解码。搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在 状态网络中搜索一条最佳路径,语音对应这条路径的概率最大。路径搜索的算法是一种动态规划剪枝的算 法,称之为Viterbi算法,用于寻找全局最优路径。观察概率和转移概率(声学模型)、语言概率(语言模 型)
语音识别技术
1 概述
为什么需要语音识别技术?
各种终端设备的智能化和集成化程度越来越高,传统的信息检索和菜单操作方式已经越来越 无法满足要求。迫切需要有一种更加便捷的信息检索和命令操作方式来替代传统的按别技术
语音识别方法简介

所以任何语音信号的分析和处理必须建
立在“短时”的基础上,即进行“短时分 析”,将语音信号分为一段一段来分析其 特征参数,其中每一段称为“一帧”,帧 长一般取为10-30ms。这样,对整体的语音 信号来讲,分析出的是由每一帧特征参数 组成的特征参数时间序列。
语音信号中含有丰富的信息,但如何从中提取 出对语音识别有用的信息呢?特征提取就是完成这 项工作,它对语音信号进行分析处理,去除对语音 识别无关紧要的冗余信息,获得影响语音识别的重 要信息。特征提取一般要解决两个问题,一个是从 语音信号中提取(或测量)有代表性的合适的特征 参数(即选取有用的信号表示)另一个是进行适当 的数据压缩。目前。语音识别技术中应用最流行的 特征参数是基于人的声道模型和听觉机理的LPCC, LPCMCC, MFCC 和ZCPA(语音的上升过零率和非线性 幅度)方法提取语音的特征参数。
语音识别技术两个发展方向
• 大词汇量连续语音识别系统,主要应用于计算机 的听写机,以及与电话网或者互联网相结合的语 音信息查询服务系统,这些系统都是在计算机平 台上实现的;
• 小型化、便携式语音产品的应用,如无线手机上 的拨号、汽车设备的语音控制、智能玩具、家电 遥控等方面的应用,这些应用系统大都使用专门 的硬件系统实现。
高了系统的抗噪声能力;
◆语音识别系统的分类方式及依据
• 根据对说话人的依赖程度可以分为特定人和非特 定人语音识别系统。
• 根据对说话人说话方式的要求,可以分为孤立字 (词)语音识别系统,连接字语音识别系统以及 连续语音识别系统。
• 根据词汇量大小,可以分为小词汇量、中等词汇 量、大词汇量以及无特征 参数一般构成一个矢量,因此语音特征量 是一个矢量序列。语音信号中提取出来的 矢量序列经过数据压缩后便成为语音的模 板。显然,特征的选取对识别效果至关重 要,选择的标准应尽量满足以下两个要求:
《语音识别技术介绍》课件

智能家居安全
通过语音识别技术,可以实时监测家庭环境,及 时发现异常情况并发出警报,提高家庭安全系数 。
智能家居助手
语音识别技术可以应用于智能家居助手,提供天 气预报、日程提醒、语音记事等服务,方便用户 日常生活。
在医疗领域的应用前景
语音电子病历
通过语音识别技术,医生可以快速录入病历信息 ,提高工作效率,减少医疗差错。
01
语音识别技术面临 的挑战
环境噪音与口音差异
环境噪音
在现实生活中,语音识别技术常常面临着各种环境噪音的干扰,如汽车轰鸣声、 人群喧闹声等。这些噪音可能会影响语音识别的准确性,使技术难以分辨出清晰 、准确的语音信号。
口音差异
不同地区、不同人群的口音和语言习惯可能存在较大差异,这给语音识别技术带 来了挑战。例如,方言、俚语、口音等都可能影响语音识别的准确性。
语音识别技术介绍
THE FIRST LESSON OF THE SCHOOL YEAR
目录CONTENTS
• 语音识别技术概述 • 语音识别技术原理 • 语音识别技术面临的挑战 • 语音识别技术的发展趋势 • 语音识别技术的前景展望 • 语音识别技术案例分析
01
语音识别技术概述
定义与特点
定义
语音识别技术是一种将人类语音转化 为机器可读的文本或命令的技术。
随着传感器技术的发展和人工智能算法的进步,多模态语音识别与交互将成为未来语音识别技术的重 要发展方向。通过结合不同模态的信息,能够提高语音识别的性能,并为用户提供更加智能和自然的 交互体验。
01
语音识别技术的前 景展望
在智能家居领域的应用前景
1 2 3
智能音箱控制
语音识别技术可以应用于智能音箱,实现通过语 音指令控制家电设备,如灯光、空调、电视等。
通过语音识别技术,可以实时监测家庭环境,及 时发现异常情况并发出警报,提高家庭安全系数 。
智能家居助手
语音识别技术可以应用于智能家居助手,提供天 气预报、日程提醒、语音记事等服务,方便用户 日常生活。
在医疗领域的应用前景
语音电子病历
通过语音识别技术,医生可以快速录入病历信息 ,提高工作效率,减少医疗差错。
01
语音识别技术面临 的挑战
环境噪音与口音差异
环境噪音
在现实生活中,语音识别技术常常面临着各种环境噪音的干扰,如汽车轰鸣声、 人群喧闹声等。这些噪音可能会影响语音识别的准确性,使技术难以分辨出清晰 、准确的语音信号。
口音差异
不同地区、不同人群的口音和语言习惯可能存在较大差异,这给语音识别技术带 来了挑战。例如,方言、俚语、口音等都可能影响语音识别的准确性。
语音识别技术介绍
THE FIRST LESSON OF THE SCHOOL YEAR
目录CONTENTS
• 语音识别技术概述 • 语音识别技术原理 • 语音识别技术面临的挑战 • 语音识别技术的发展趋势 • 语音识别技术的前景展望 • 语音识别技术案例分析
01
语音识别技术概述
定义与特点
定义
语音识别技术是一种将人类语音转化 为机器可读的文本或命令的技术。
随着传感器技术的发展和人工智能算法的进步,多模态语音识别与交互将成为未来语音识别技术的重 要发展方向。通过结合不同模态的信息,能够提高语音识别的性能,并为用户提供更加智能和自然的 交互体验。
01
语音识别技术的前 景展望
在智能家居领域的应用前景
1 2 3
智能音箱控制
语音识别技术可以应用于智能音箱,实现通过语 音指令控制家电设备,如灯光、空调、电视等。
人工智能语音识别技术培训ppt

• 语音数据的预处理与标注:语音数据的预处理与标注是语音识别系统的重要环节。本次培训涉及了语音数据的预处理,包 括去噪、增强、规整等,以及语音数据的标注方法,如手动标注和自动标注。
• 语音识别系统的实现与应用:本次培训还讲解了如何实现一个完整的语音识别系统,包括各个模块的组合方式、优化方法 等,并且介绍了语音识别技术在各个领域的应用,如智能家居、车载娱乐、智能客服等。
声学模型与语言模型
声学模型
将语音信号映射到声学特征空间,建立声学模型,用于识别语音中的音素、单 词等。常见的声学模型包括隐马尔可夫模型(HMM)、深度神经网络(DNN )等。
语言模型
基于自然语言处理技术,建立语言模型,用于识别语音中的语法、语义等信息 。常见的语言模型包括n-gram语言模型、循环神经网络(RNN)等。
人工智能语音识别技术培训
汇报人:可编辑
2023-12-22
目录 Contents
• 引言 • 语音识别基础知识 • 深度学习在语音识别中的应用 • 语音识别技术应用场景与案例分析 • 实践操作与技能提升 • 总结与展望未来发展趋势
01
引言
培训背景与目的
人工智能技术的快速发展
培训目的
随着人工智能技术的不断进步,语音 识别技术作为其中的重要分支,在各 个领域得到了广泛应用。
预加重
消除语音信号中的高频噪 声,提高后续处理的准确 性。
分帧和加窗
将语音信号分成若干个短 时帧,并使用窗函数对帧 进行加窗处理,以提取帧 内的特征。
特征提取与降噪
特征提取
从语音信号中提取出反映语音特 征的关键参数,如梅尔频率倒谱 系数(MFCC)、线性预测编码 (LPC)等。
降噪处理
对语音信号进行降噪处理,以减 少环境噪声和其他干扰对语音识 别的影响。常见的降噪方法包括 自适应滤波、卡尔曼滤波等。
• 语音识别系统的实现与应用:本次培训还讲解了如何实现一个完整的语音识别系统,包括各个模块的组合方式、优化方法 等,并且介绍了语音识别技术在各个领域的应用,如智能家居、车载娱乐、智能客服等。
声学模型与语言模型
声学模型
将语音信号映射到声学特征空间,建立声学模型,用于识别语音中的音素、单 词等。常见的声学模型包括隐马尔可夫模型(HMM)、深度神经网络(DNN )等。
语言模型
基于自然语言处理技术,建立语言模型,用于识别语音中的语法、语义等信息 。常见的语言模型包括n-gram语言模型、循环神经网络(RNN)等。
人工智能语音识别技术培训
汇报人:可编辑
2023-12-22
目录 Contents
• 引言 • 语音识别基础知识 • 深度学习在语音识别中的应用 • 语音识别技术应用场景与案例分析 • 实践操作与技能提升 • 总结与展望未来发展趋势
01
引言
培训背景与目的
人工智能技术的快速发展
培训目的
随着人工智能技术的不断进步,语音 识别技术作为其中的重要分支,在各 个领域得到了广泛应用。
预加重
消除语音信号中的高频噪 声,提高后续处理的准确 性。
分帧和加窗
将语音信号分成若干个短 时帧,并使用窗函数对帧 进行加窗处理,以提取帧 内的特征。
特征提取与降噪
特征提取
从语音信号中提取出反映语音特 征的关键参数,如梅尔频率倒谱 系数(MFCC)、线性预测编码 (LPC)等。
降噪处理
对语音信号进行降噪处理,以减 少环境噪声和其他干扰对语音识 别的影响。常见的降噪方法包括 自适应滤波、卡尔曼滤波等。
语音识别(speechrecognition)

差,找出最小的失真误差对应的码本(代表一个
字),将对应的字输出作为识别的结果。
码本 每一个字做一 个码本,共M个字
Y1 Y2 YM
模板库
任意 语音 帧
特征矢量 X 序列形成
计算 输出结果Yi 失真误差 判决
特征矢量序列 模板库
X={X1 , X2 , …… , XN} Y1 , Y2 , …… , YM
语音识别(speech recognition)
语音识别技术的一般概念
语音识别的原理和识别系统的组成
动态时间规整DTW
基于统计模型框架的识别法(HMM)
说话人识别
语种辨识
语音识别技术的一般概念
一、语音识别的定义 二、语音识别的应用
三、语音识别的类型
四、语音识别的方法
五、语音识别的主要问题
一、语音识别的定义
多领域。
随着语音识别技术的逐渐成熟,语音识别技术开
始得到广泛的应用,涉及日常生活的各个方面如电信、
金融、新闻、公共事业等各个行业,通过采用语音识
别技术,可以极大的简化这些领域的业务流程以及操
作;提高系统的应用效率。
语音识别应用实例
1.语音识别以IBM推出的ViaVoice为代表,国内
则推出Dutty ++语音识别系统、天信语音识别系统、
语音识别是指从语音到文本的转换,即让计算
机能够把人发出的有意义的话音变成书面语言。通
俗地说就是让机器能够听懂人说的话。
所谓听懂,有两层意思,一是指把用户所说的
话逐词逐句转换成文本;二是指正确理解语音中所
包含的要求,作出正确的应答。
二、语音识别的应用
语音识别技术是以语音为研究对象,涉及到生理 学、心理学、语言学、计算机科学以及信号处理等诸
语音处理与语音识别简介

主流方法
› Viterbi搜索:HMM内部
› 词网格搜索:HMM之间
11/14/2017
31
说话人自适应
› 根据新的语音重新调整模型参数 › 特定人和非特定人之间的一种折衷
主流方法
› MLLR(最大似然线性回归)
对模型参数寻找一个最优线性变换 y = Ax + b
› MAP(最大后验概率)
Spotting)
根据针对的发音人分类
› 特定人语音识别(SD:Speaker Dependent) › 非特定人语音识别(SI:Speaker Independent)
11/14/2017
25
声学模型
语言模型
语音
前端处理
特征提取
第一遍 识别
自适应
第 n遍 识别
识别结果
识别结果
系统框架
11/14/2017
26
前端处理
› 消除个体的影响 声道长度归一(VTN:Vocal Tract Length Normalization) › 端点检测 短时能量 高阶谱算法 子带能量 › 语音增强(去噪) 维纳滤波
11/14/2017
27
FFT
频谱
美标度三角滤波器组 39维声学特征向量 Log DCT 倒谱均值减
23
主要内容 •数字音频基础知识 •音频处理基础知识
•语音识别技术简介
24
根据处理的语音数据和识别结果分类
› 连续语音识别(Continuous Speech Recognition) › 孤立词识别(Isolate Word Recognition) › 关键词检测(Key Word Recognition,Key Word
语音识别技术25页PPT

➢ 语音识别系统要对用户“友好”。 这种“友好”
的含义是:用户在和系统进行语音对话时感到 舒适;系 统的语音提示既有帮助,又很亲近。
➢ 语音识别系统必须有足够的精度 ➢ 语音识别系统要有实时处理能力;例如 系统对
用户询问的响应时间要很短。
语音识别应用的特点
2.语音识别错误的处理 方法一:错误弱化法 方法二:错误自检纠正法 方法三:拒绝/转向人工座席
例如:碰到了寄给 Joseph Schneider 的邮件,操作 员只需 发出 “J”、“S”、“C”和“H”几个音就可以 得到准确的分拣信息。
姓名
Jennifer Schroeder
J Schriver
技术部
邮局要把邮件按投递路线分发, 分拣员必须熟悉长长 的投递段列表以及各种各样的国际邮件投递信息。 Spell-It 技术把地址、投递路线等信息都存入了系统,这样就大大方 便了分拣工作。 例如,有一件寄往 Stone hollow 路 2036 号的邮件。使用语音识别技术,分拣员仅仅需要发出“2”、 “0”、 “S”、“T”和“O”几个音,数据库就会给出所有可能 和这几 个音相对应的地址及相应的投递路线的。在这个例子 中,有三个投递地址符合这一语音标准,分拣员 知道哪一个
梁玉营
提出及发展
• 语音识别最早是在1952 年由贝尔研究所工
作人员提出,他们研究了世界上第一个能 够识别10 个英文数字发音的试验系统,正 式大规模的研究语音识别是在进入70 年代 后,在一些词汇上取得了实质性的进展, 到了九十年代以后,语音识别技术在应用 及产品化方面有的很大的进展。
我国语音识别的研究较晚,起步于20 世纪50 年代,但是由于科技的不断创新以及国家对科学 技术的重视,近些年来我国语音识别技术发展的 相对较快,研究水平也从实验走向人们的生活。 我国在1973 年开始进行计算机语音识别,但由于 环境所限制,当时的发展仍然很缓慢,进入80 年 代后,随着计算机等技术的普及,我国一些单位 具备了研究语音技术的基本条件,恰好此时国际 上对语音识别技术的研究重视并迅速发展,使得 我国很多企业纷纷投入到语音识别的这项工作中 去。
的含义是:用户在和系统进行语音对话时感到 舒适;系 统的语音提示既有帮助,又很亲近。
➢ 语音识别系统必须有足够的精度 ➢ 语音识别系统要有实时处理能力;例如 系统对
用户询问的响应时间要很短。
语音识别应用的特点
2.语音识别错误的处理 方法一:错误弱化法 方法二:错误自检纠正法 方法三:拒绝/转向人工座席
例如:碰到了寄给 Joseph Schneider 的邮件,操作 员只需 发出 “J”、“S”、“C”和“H”几个音就可以 得到准确的分拣信息。
姓名
Jennifer Schroeder
J Schriver
技术部
邮局要把邮件按投递路线分发, 分拣员必须熟悉长长 的投递段列表以及各种各样的国际邮件投递信息。 Spell-It 技术把地址、投递路线等信息都存入了系统,这样就大大方 便了分拣工作。 例如,有一件寄往 Stone hollow 路 2036 号的邮件。使用语音识别技术,分拣员仅仅需要发出“2”、 “0”、 “S”、“T”和“O”几个音,数据库就会给出所有可能 和这几 个音相对应的地址及相应的投递路线的。在这个例子 中,有三个投递地址符合这一语音标准,分拣员 知道哪一个
梁玉营
提出及发展
• 语音识别最早是在1952 年由贝尔研究所工
作人员提出,他们研究了世界上第一个能 够识别10 个英文数字发音的试验系统,正 式大规模的研究语音识别是在进入70 年代 后,在一些词汇上取得了实质性的进展, 到了九十年代以后,语音识别技术在应用 及产品化方面有的很大的进展。
我国语音识别的研究较晚,起步于20 世纪50 年代,但是由于科技的不断创新以及国家对科学 技术的重视,近些年来我国语音识别技术发展的 相对较快,研究水平也从实验走向人们的生活。 我国在1973 年开始进行计算机语音识别,但由于 环境所限制,当时的发展仍然很缓慢,进入80 年 代后,随着计算机等技术的普及,我国一些单位 具备了研究语音技术的基本条件,恰好此时国际 上对语音识别技术的研究重视并迅速发展,使得 我国很多企业纷纷投入到语音识别的这项工作中 去。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
动态时间规整(DTW)、隐马尔可夫(HMM)理论、矢量量化(VQ)技术。
(3)神经网络的方法 基于ANN的语音识别系统通常由神经元、训练算法及网络结构等三大要素构 成。由于基于神经网络的训练识别算法由于实现起来较复杂,目前仍只是处 于实验室研究阶段。
语音识别概述
目前语音识别的研究主流是大词汇量的非特定人的连续语音系统,但是事实 上,对于许多应用来说,一个语音识别系统只要一组词汇或命令,它就可能为用 户提供一个有效的工具,简单有效的孤立词特定人语音识别系统就能满足要求。 正是孤立词特定人语音识别系统广阔的应用前景以及优越性促使我们继续对它进 行研究
语音识别概述
语音识别的基本方法:
一般来说,语音识别的方法有三种:基于声道模型和语音知识的方法、模 板匹配的方法以及利用人工神经网络的方法。
(1)语音学和声学的方法 该方法起步较早,在语音识别技术提出的开始,就有了这方面的研究,但由
于其模型及语音知识过于复杂,现阶段没有达到实用的阶段.
(2)模板匹配的方法 模板匹配的方法发展比较成熟,目前己达到了实用阶段。常用的技术有三种:
目前市场上出现的语音识别器大多数是特定人孤立单词语音识别系统。
孤立词语音识别系统中的难点问题: (1) 语音信号的多变性 语音信号是非平稳随机信号,不但不同发音者发音之间存在重大的差异,即
使同一人同一语音的不同次发音,也存在很大差异。 (2) 噪声影响 当实际环境中有噪声存在时,容易造成训练与测试环境不匹配导致语音识别
由清华大学电子工程系语音技术与专用芯片设计课题组研发的非特定人汉语 数码串连续语音识别系统,识别精度达到了94.8%(不定长数字串)和96.8%(定长 数字串).
语音识别概述
语音识别系统分类:
从说话者与识别系统的相关性分: (1)特定人语音识别系统:仅考虑对于专人的话音进行识别,与说话的语种没 有关系; (2)非特定人语音识别系统:识别的语音与人无关,通常要用大量不同人的语 音数据库对识别系统进行学习,识别的语言取决于采用的训练语音库; (3)多人的识别系统:通常能识别一组人的语音该系统通常要求对该组人的语 音进行学习,通常可以识别三到五个人的语音。
80年代语音识别研究进一步走向深入,其显著特征是HMM模型和人工神经 元网络(ANN)在语音识别中的成功应用。HMM模型的广泛应用应归功于AT&T Bel实验室的Rabiner等科学家的努力,他们把HMM纯数学模型工程化,从而为 更多研究者了解和认识。研究的重点逐渐转向大词汇量、非特定人连续语音识别。
90年代,随着多媒体时代的来临,在语音识别技术的应用及产品化方面出现 了很大的进展。许多发达国家如美国、日本、韩国以及IBM,Apple,AT&T,NTT 等著名公司都为语音识别系统的实用化开发投以巨资。语音识别技术实用化进程 大大加速,并出现了许多实用化产品。
IBM公司率先推出的汉语ViaVoice语音识别系统,带有一个32,000词的基本 词汇表,可以扩展到65,000词,平均识别率可以达到95%,可以识别上海话、广 东话和四川话等地方口音,是目前具有代表性的汉语连续语音识别系统。
语音识别概述
70年代语音识别领域取得了突破。在理论上,LP 技术得到进一步发展,动 态时间规整技术(DTW)的基本成熟,特别是提出了矢量量化(VQ)和隐马尔可夫模 型(HMM)理论。在实践上,小词汇量孤立词的识别方面取得了实质性的进展 , 实现了基于线性预测倒谱和DTW技术的特定人孤立语音识别系统。这一时期的 语音识别方法基本上是采用传统的模式识别策略。
我国语音识别研究工作起步于五十年代,但近年来发展很快,研究水平也从 实验室逐步走向实用。从1987年开始执行国家863计划后,国家863智能计算机 专家组为语音识别技术研究专门立项,每两年滚动一次。我国语音识别技术的研 究水平己经基本上与国外同步,在汉语语音识别技术上还有自己的特点与优势, 并达到国际先进水平。其中,具有代表性的研究单位是清华大学电子工程系与中 科院自动化研究所模式识别国家重点实验室。
语音识别概述
21世纪语音识别技术的应用及产品化方面进一步发展。在语音识别产品方面, 各大公司纷纷推出自己产品。目前世界上最先进的语音识别软件,既不是微软生 产的,也非IBM制造,它的名字叫做Naturally Speaking,出自于Nuance Communications公司。Naturally Speaking己经得到了大多数用户的认可。用户 对着麦克风说话,屏幕上就显示出说话的内容,很容易识别和纠正错误.久而久 之,该软件就会适应用户的说话风格。
从说话的方式分: (1)孤立词语音识别系统:其输入系统要求输入每个词后要停顿; (2)连接词语音识别系统:其输入系统要求对每个词都清楚发音,开始出现一些 连音现象; (3) 连续语音识别系统:连续语音输入自然流利的语音,会出现大量的连音和 变音。
另外从识别系统的词汇量大小分:小词汇量语音识别系统(几十个词);中等 词汇量语音识别系统(几百到上千个词);大词汇量语音识别系统(几千到几万 个词)。
语音信号处理与识别
一、语音识别概述 二、语音识别系统基本原理 三、预处理及特征参数提取 四、模板匹配技术及相似性判断方法 音,这是人们长期以来梦寐以求的事情。伴随计算机技 术发展,语音识别己成为信息产业领域的标志性技术,在人机交互应用中逐渐进 入我们日常的生活,并迅速发展成为“改变未来人类生活方式厅的关键技术之一。
语音识别技术以语音信号为研究对象,是语音信号处理的一个重要研究方 向 。其最终目标是实现人与机器进行自然语言通信。
发展和现状:
20世纪50年代,AT&T Bell(贝尔)研究所成功研制了世界上第一个能识别10 个英文数字的语音识别系统一Audry系统,这标志着语音识别研究的开始。
60年代计算机的应用推动了语音识别的发展。这一时期的重要成果是动态规 划(Dynamic Programming, DP)和线性预测分析(Linear Predictive)技术。其中后 者较好的解决了语音信号产生的模型问题,对语音识别产生了深远的影响。
(3)神经网络的方法 基于ANN的语音识别系统通常由神经元、训练算法及网络结构等三大要素构 成。由于基于神经网络的训练识别算法由于实现起来较复杂,目前仍只是处 于实验室研究阶段。
语音识别概述
目前语音识别的研究主流是大词汇量的非特定人的连续语音系统,但是事实 上,对于许多应用来说,一个语音识别系统只要一组词汇或命令,它就可能为用 户提供一个有效的工具,简单有效的孤立词特定人语音识别系统就能满足要求。 正是孤立词特定人语音识别系统广阔的应用前景以及优越性促使我们继续对它进 行研究
语音识别概述
语音识别的基本方法:
一般来说,语音识别的方法有三种:基于声道模型和语音知识的方法、模 板匹配的方法以及利用人工神经网络的方法。
(1)语音学和声学的方法 该方法起步较早,在语音识别技术提出的开始,就有了这方面的研究,但由
于其模型及语音知识过于复杂,现阶段没有达到实用的阶段.
(2)模板匹配的方法 模板匹配的方法发展比较成熟,目前己达到了实用阶段。常用的技术有三种:
目前市场上出现的语音识别器大多数是特定人孤立单词语音识别系统。
孤立词语音识别系统中的难点问题: (1) 语音信号的多变性 语音信号是非平稳随机信号,不但不同发音者发音之间存在重大的差异,即
使同一人同一语音的不同次发音,也存在很大差异。 (2) 噪声影响 当实际环境中有噪声存在时,容易造成训练与测试环境不匹配导致语音识别
由清华大学电子工程系语音技术与专用芯片设计课题组研发的非特定人汉语 数码串连续语音识别系统,识别精度达到了94.8%(不定长数字串)和96.8%(定长 数字串).
语音识别概述
语音识别系统分类:
从说话者与识别系统的相关性分: (1)特定人语音识别系统:仅考虑对于专人的话音进行识别,与说话的语种没 有关系; (2)非特定人语音识别系统:识别的语音与人无关,通常要用大量不同人的语 音数据库对识别系统进行学习,识别的语言取决于采用的训练语音库; (3)多人的识别系统:通常能识别一组人的语音该系统通常要求对该组人的语 音进行学习,通常可以识别三到五个人的语音。
80年代语音识别研究进一步走向深入,其显著特征是HMM模型和人工神经 元网络(ANN)在语音识别中的成功应用。HMM模型的广泛应用应归功于AT&T Bel实验室的Rabiner等科学家的努力,他们把HMM纯数学模型工程化,从而为 更多研究者了解和认识。研究的重点逐渐转向大词汇量、非特定人连续语音识别。
90年代,随着多媒体时代的来临,在语音识别技术的应用及产品化方面出现 了很大的进展。许多发达国家如美国、日本、韩国以及IBM,Apple,AT&T,NTT 等著名公司都为语音识别系统的实用化开发投以巨资。语音识别技术实用化进程 大大加速,并出现了许多实用化产品。
IBM公司率先推出的汉语ViaVoice语音识别系统,带有一个32,000词的基本 词汇表,可以扩展到65,000词,平均识别率可以达到95%,可以识别上海话、广 东话和四川话等地方口音,是目前具有代表性的汉语连续语音识别系统。
语音识别概述
70年代语音识别领域取得了突破。在理论上,LP 技术得到进一步发展,动 态时间规整技术(DTW)的基本成熟,特别是提出了矢量量化(VQ)和隐马尔可夫模 型(HMM)理论。在实践上,小词汇量孤立词的识别方面取得了实质性的进展 , 实现了基于线性预测倒谱和DTW技术的特定人孤立语音识别系统。这一时期的 语音识别方法基本上是采用传统的模式识别策略。
我国语音识别研究工作起步于五十年代,但近年来发展很快,研究水平也从 实验室逐步走向实用。从1987年开始执行国家863计划后,国家863智能计算机 专家组为语音识别技术研究专门立项,每两年滚动一次。我国语音识别技术的研 究水平己经基本上与国外同步,在汉语语音识别技术上还有自己的特点与优势, 并达到国际先进水平。其中,具有代表性的研究单位是清华大学电子工程系与中 科院自动化研究所模式识别国家重点实验室。
语音识别概述
21世纪语音识别技术的应用及产品化方面进一步发展。在语音识别产品方面, 各大公司纷纷推出自己产品。目前世界上最先进的语音识别软件,既不是微软生 产的,也非IBM制造,它的名字叫做Naturally Speaking,出自于Nuance Communications公司。Naturally Speaking己经得到了大多数用户的认可。用户 对着麦克风说话,屏幕上就显示出说话的内容,很容易识别和纠正错误.久而久 之,该软件就会适应用户的说话风格。
从说话的方式分: (1)孤立词语音识别系统:其输入系统要求输入每个词后要停顿; (2)连接词语音识别系统:其输入系统要求对每个词都清楚发音,开始出现一些 连音现象; (3) 连续语音识别系统:连续语音输入自然流利的语音,会出现大量的连音和 变音。
另外从识别系统的词汇量大小分:小词汇量语音识别系统(几十个词);中等 词汇量语音识别系统(几百到上千个词);大词汇量语音识别系统(几千到几万 个词)。
语音信号处理与识别
一、语音识别概述 二、语音识别系统基本原理 三、预处理及特征参数提取 四、模板匹配技术及相似性判断方法 音,这是人们长期以来梦寐以求的事情。伴随计算机技 术发展,语音识别己成为信息产业领域的标志性技术,在人机交互应用中逐渐进 入我们日常的生活,并迅速发展成为“改变未来人类生活方式厅的关键技术之一。
语音识别技术以语音信号为研究对象,是语音信号处理的一个重要研究方 向 。其最终目标是实现人与机器进行自然语言通信。
发展和现状:
20世纪50年代,AT&T Bell(贝尔)研究所成功研制了世界上第一个能识别10 个英文数字的语音识别系统一Audry系统,这标志着语音识别研究的开始。
60年代计算机的应用推动了语音识别的发展。这一时期的重要成果是动态规 划(Dynamic Programming, DP)和线性预测分析(Linear Predictive)技术。其中后 者较好的解决了语音信号产生的模型问题,对语音识别产生了深远的影响。