Oracle Change Data Capture 介绍
flinkcdc sql java 模板

flinkcdc sql java 模板Flink CDC (Change Data Capture) 是一个用于捕获和处理实时数据变化的工具,而SQL 是一种常用的查询语言,而Java 是一种常用的编程语言。
本文将针对Flink CDC、SQL 和Java 进行详细介绍,并提供相关模板和使用案例。
一、Flink CDC 简介Flink 是一个开源的流式计算框架,而Flink CDC 则是Flink 提供的一个用于捕获和处理实时数据变化的组件。
它能够监控数据库中的数据变化,并将变化的数据流式地发送到指定的目标系统。
Flink CDC 支持多种数据源,如MySQL、Oracle、PostgreSQL 等。
它通过订阅数据库的binlog 或者通过轮询方式获取数据变化,并将数据变化以流的形式传输到Flink 中进行实时处理。
二、SQL 介绍SQL(Structured Query Language)是一种用于管理关系型数据库的标准化查询语言。
它具有简洁、易懂、适用于各种数据库系统等特点。
SQL 支持数据的查询、插入、更新、删除等操作,并且可以进行条件查询、排序、分组等数据处理操作。
Flink CDC 结合SQL 可以非常方便地进行数据变化的实时处理。
我们可以通过SQL 查询语句筛选和过滤更新的数据,然后将结果进行进一步的计算和分析。
三、Java 介绍Java 是一种面向对象的编程语言,它具有跨平台、简洁、安全等特点。
在Flink CDC 中,我们可以使用Java 编写自定义的函数、操作符等来对捕获的数据流进行处理。
Java 作为一种通用的编程语言,可以很好地与Flink CDC 和SQL 进行集成,提供更加灵活和强大的数据处理能力。
我们可以通过编写Java 程序来实现复杂的业务逻辑,并对数据进行转换、过滤、聚合等操作。
四、Flink CDC SQL Java 模板使用案例下面以一个具体的使用案例来介绍如何结合Flink CDC、SQL 和Java 进行数据处理。
flink cdc整库同步原理 -回复

flink cdc整库同步原理-回复Flink CDC(Change Data Capture)整库同步原理Change Data Capture(CDC)是一种将数据库中的变化数据捕获并传播到其他系统的技术。
Flink CDC是Apache Flink生态系统中的一个组件,它提供了一种以可容错的方式从数据库中捕获更新、删除和插入操作的能力。
Flink CDC通过将数据库的日志传输到Flink任务中进行处理,使得整库数据的同步变得更加高效和灵活。
本文将详细介绍Flink CDC整库同步的原理和步骤。
1. 数据库日志的获取Flink CDC需要获取数据库的操作日志以实现数据的同步。
数据库通常会将日志以不同的形式进行存储,如二进制文件、文本文件或者以特定格式的数据表。
Flink CDC需要通过适配器将数据库的日志解析为可处理的事件流。
根据不同的数据库类型和版本,Flink CDC提供了不同的适配器例如MySQL、Oracle、PostgreSQL等。
适配器可以解析数据库的特有日志格式,并生成相应的事件流。
2. 日志解析与抽取获取到数据库的日志后,Flink CDC会对日志进行解析与抽取。
解析过程中,Flink CDC会根据日志中的操作类型(插入、更新、删除)和相关字段的值提取出关键信息,如表名、主键、字段名称和值等。
抽取逻辑是根据不同数据库的特点进行设计的,以保证数据的完整性和准确性。
3. 事件流转化在解析和抽取完毕后,Flink CDC将抽取得到的关键信息转化为事件流,以便进行后续的处理。
事件流通常是一个无界数据流,其中每个事件都包含了某个特定操作的详细信息。
事件流可以被持久化、传递给其他系统进行处理,或者用作Flink任务的输入。
4. 数据处理与转换通过Flink任务,对事件流进行处理和转换是实现数据同步的关键步骤。
Flink提供了强大的流处理功能,可以通过编写自定义的算子对事件进行聚合、过滤、变换、连接等操作。
flinkcdc 全量同步数据的原理

flinkcdc 全量同步数据的原理Flink CDC 全量同步数据的原理一、引言随着数据量的不断增大和业务需求的日益复杂,实时数据同步变得越来越重要。
Flink CDC(Change Data Capture)是一种用于实时数据同步的开源技术。
本文将介绍Flink CDC 的原理和工作机制,以及如何实现全量数据的同步。
二、Flink CDC 基本原理Flink CDC 是基于 Apache Flink 的一种数据同步解决方案。
它通过监听源数据的变化,将变化的数据实时同步到目标系统中。
Flink CDC 的基本原理可以概括为以下几个步骤:1. 数据源监听:Flink CDC 通过监听数据源的变化来捕获新的数据。
常见的数据源包括关系型数据库(如MySQL、Oracle 等)和消息队列(如 Kafka)。
2. 数据抓取:一旦有新的数据变化,Flink CDC 就会将变化的数据抓取到内存中进行处理。
这个过程可以通过使用数据库的binlog (二进制日志)或者消息队列的消费者组来实现。
3. 数据解析:抓取到的数据会经过解析,将其转换为Flink 可以处理的格式。
解析的过程中,Flink CDC 会根据数据源的特性进行相应的处理,比如解析数据库的 binlog 日志,或者解析消息队列中的消息。
4. 数据处理:解析后的数据会被送入Flink 的处理引擎中进行进一步的处理。
Flink 提供了强大的数据处理能力,可以进行数据过滤、转换、聚合等操作。
5. 数据同步:经过处理后的数据会被同步到目标系统中。
目标系统可以是另一个数据库、数据仓库、数据湖等。
Flink CDC 提供了各种连接器和输出格式,可以将数据以不同的方式同步到不同的系统中。
三、全量同步数据的实现全量同步是指将源系统中的所有数据都同步到目标系统中,而不仅仅是同步变化的数据。
实现全量同步的关键是获取源系统中的所有数据,并将其转换为Flink 可以处理的格式。
debezium oracle对数据库的要求

debezium oracle对数据库的要求Debezium 是Apache Kafka 的一个Change Data Capture (CDC) 工具,它能够捕获数据库中的更改并发布到Kafka 主题中。
使用Debezium 监控Oracle 数据库时,有一些要求和注意事项:1. 版本要求:Oracle Database 版本必须在11g 或更高。
Debezium 的Oracle connector 版本也需要与之兼容。
2. 监听模式:使用Debezium 时,您需要设置Oracle 的Change Data Capture (CDC) 监听模式。
有两种模式可用:`ROWID` 和`LOGMINER`。
`ROWID` 监听模式适用于较新的Oracle 版本,而`LOGMINER` 监听模式适用于更早的版本。
3. 网络和安全性:Debezium 需要与Oracle 数据库建立网络连接,因此需要确保网络通信是安全的,并且防火墙规则允许这种连接。
如果使用的是远程连接,需要确保Oracle 的TNSNAMES.ORA 文件正确配置,以便Debezium 能够连接到数据库。
4. 日志文件和配置:Debezium 需要读取Oracle 的redo log 文件以捕获更改。
确保redo log 文件的大小、频率和生命周期配置合理,以满足Debezium 的需要。
5. 用户权限:为了捕获更改,Debezium 需要有适当的权限来读取redo log 文件和访问数据。
确保为Debezium 提供的Oracle 用户具有适当的权限。
6. Kafka 设置:Debezium 将更改数据发布到Kafka 主题中,因此需要配置Kafka 并确保有足够的容量来处理这些数据。
7. 性能和资源:由于Debezium 需要实时读取redo log 文件,因此可能会对数据库性能产生影响。
建议在生产环境中进行性能测试,并监控资源使用情况。
OracleCDC简介及异步在线日志CDC部署示例
OracleCDC简介及异步在线⽇志CDC部署⽰例摘要最近由于⼯作需要,花时间研究了⼀下Oracle CDC功能和LogMiner⼯具,希望能找到⼀种稳定、⾼效的技术来实现Oracle增量数据抽取功能。
以下是个⼈的部分学习总结和部署实践。
1. Oracle CDC 简介很多⼈都认为,只要是涉及到数据库数据复制和增量数据抽取,都是需要购买收费软件的。
实际上,我们通过Oracle提供的CDC和LogMiner等免费⼯具也能实现数据库数据复制和增量数据抽取,各种数据复制软件只是使得获取增量数据更加便捷,或者是可以⽀持更多的扩展功能(例如:异构数据库之间的同步,ETL过程的数据清洗、装换),但实际Oracle本⾝是⽀持CDC机制,只是很少有⼈关注,操作起来也有些复杂,⽽且据传⾔并不稳定,常常见到论坛上爆出⼀些莫名其妙的问题。
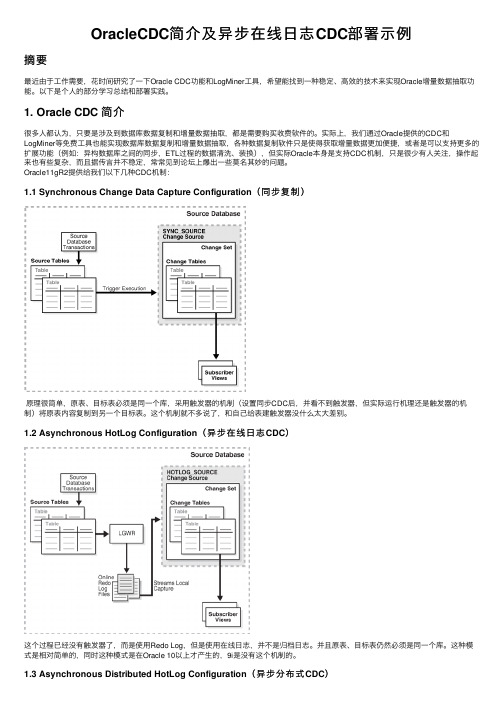
Oracle11gR2提供给我们以下⼏种CDC机制:1.1 Synchronous Change Data Capture Configuration(同步复制)原理很简单,原表、⽬标表必须是同⼀个库,采⽤触发器的机制(设置同步CDC后,并看不到触发器,但实际运⾏机理还是触发器的机制)将原表内容复制到另⼀个⽬标表。
这个机制就不多说了,和⾃⼰给表建触发器没什么太⼤差别。
1.2 Asynchronous HotLog Configuration(异步在线⽇志CDC)这个过程已经没有触发器了,⽽是使⽤Redo Log,但是使⽤在线⽇志,并不是归档⽇志。
并且原表、⽬标表仍然必须是同⼀个库。
这种模式是相对简单的,同时这种模式是在Oracle 10以上才产⽣的,9i是没有这个机制的。
1.3 Asynchronous Distributed HotLog Configuration(异步分布式CDC)实际这个模式是对异步在线⽇志CDC的⼀种优化,也⽐较容易理解,就是加⼊了DB-LINK机制,使原表、⽬标表不在同⼀个数据库。
如何实现ORACLE数据变化捕获
数据仓库技术包含了为分析需要,从一个或多个数据库向一个或多个目标系统中萃取、运送数据过程。
但其萃取和运送的数据往往规模十分巨大,需要占用大量宝贵的资源和时间。
而所谓”数据变化捕捉(CDC)“,则是指一种只捕捉发生了变化的源数据,并将这些数据实时传送给目标系统的功能。
只捕捉变化的数据有效降低了网络中数据的流量,从而减少了实施ETL 需要的时间。
第一步:创建公司的CRM 系统目的:创建一个数据库,存储名为Customer的表格。
在Oracle 中创建一个叫做DATA的新用户。
要实现这一目的,打开您的网络浏览器,登陆您Oracle 的管理页面。
然后连接上系统用户,并点击Home > Administration > Manage > Database Users点击Create,创建该DATA用户,并点击Check All给该用户所有授权许可。
连接系统用户,然后点击Home > Administration > Manage > Database Users。
同样再在Oracle 中建立DWH 用户。
即打开网页浏览器并登陆您的Oracle 管理页面。
然后连接上系统用户,并点击Home > Administration > Manage > Database Users。
点击Create,创建该DWH用户,并点击Check All 给该用户所有授权许可。
第二步:给用户授权点击Home > SQL > SQL Commands > Enter Command。
要授权用户访问所有页面,在Home > SQL > SQL Commands中执行如下查询:GRANT CREATE ANY VIEW to CDC点击Run。
要授权用户访问所有表格,在Home > SQL > SQL Commands中执行如下查询:GRANT CREATE ANY TABLE to CDC点击Run第三步:由TIS 创建数据库连接在TIS studio 中,点击Repository (库)> Metadata(元数据)。
flink cdc 读取oralce 归档日志的原理

flink cdc 读取oralce 归档日志的原理一、引言Flink CDC(Change Data Capture,变更数据捕获)是一种在大数据环境中实现数据库变更数据捕获的技术。
本篇文章将详细介绍Flink CDC如何读取Oracle归档日志的原理。
二、Flink CDC概述Flink CDC是Flink框架的一个子项目,用于捕获数据库(如Oracle)中的数据变更,并生成相应的变更数据流。
它通过监听数据库的变更事件,捕获数据的变化,并将这些变化以CDC的模式进行存储和传输。
三、Oracle归档日志Oracle归档日志是一种数据库日志管理机制,它允许数据库在正常操作期间对重做日志进行存档,并在必要时重用或替换现有的重做日志文件。
这样可以在提高性能的同时,减少磁盘空间的占用。
1. 数据捕获:Flink CDC通过与Oracle数据库的连接器,监听数据库的变更事件,包括数据的插入、更新、删除等操作。
2. 归档日志识别:Flink CDC通过解析归档日志文件,识别出与数据库变更事件相关的信息,如数据表名、数据行ID、变更类型等。
3. 数据更新:Flink CDC将捕获到的变更事件存储到持久化存储中,以便后续处理。
同时,Flink CDC会定期从归档日志中读取新的变更事件,以保持数据的实时性。
4. 增量处理:Flink CDC采用增量处理策略,只处理与上次处理之间有变化的记录,以减少处理的数据量,提高处理效率。
5. 数据传输:Flink CDC将捕获到的变更数据以CDC的模式进行传输,可以实时地将数据变化推送至其他系统或进行进一步的分析处理。
五、实际应用场景Flink CDC可以广泛应用于数据仓库、数据挖掘、实时分析等场景,帮助企业实现数据的实时分析、监控和预警。
例如,在电商领域,Flink CDC可以帮助实时分析用户的购买行为、推荐商品;在金融领域,Flink CDC可以实时监控数据库中的交易数据,实现风险预警和欺诈检测。
数据抽取

product.product_id sales_product_id, sales_customer_id, sales_time_id,
sales_channel_id, sales_quantity_sold, sales_dollar_amount
FROM temp_sales_step1, product
方法三:
Transforming Data Using MERGE
下面我先以一个例子说明:
MERGE INTO products t USING products_delta s
ON (t.prod_id=s.prod_id)
WHEN MATCHED THEN UPDATE SET
WHERE NOT EXISTS (SELECT 1 FROM product p WHERE p.product_name=s.product_name);
这个CTAS statement语句就可以把查询出的新的SALE记录。
咱们也可以做左链接:
CREATE TABLE temp_sales_step2 NOLOGGING PARALLEL AS
FROM temp_sales_step1, product
WHERE temp_sales_step1.upc_code = product.upc_code (+);
把所有在维表中没有找到product_name的记录的sales_product_id设置为空。
数据源非关系数据库
ETL处理的数据源除了关系数据库外,还可能是文件,例如txt文件、excel文件、xml文件等。对文件数据的抽取一般是进行全量抽取,一次抽取前可保存文件的时间戳或计算文件的MD5校验码,下次抽取时进行比对,如果相同则可忽略本次抽取。
cdc同步数据的机制

CDC同步数据的机制一、概述CDC(Change Data Capture)是一种数据同步机制,可实现在源数据发生变化时,将变化的数据捕获并传输到目标系统。
该机制利用数据库的日志文件,以增量的方式同步数据,能够实现实时、高效的数据同步。
二、CDC同步数据的原理CDC同步数据的原理可以简单描述为以下几个步骤:1. 监听数据库日志CDC机制通过监听数据库日志,捕获数据库操作的变化。
数据库引擎会将所有的增、删、改操作记录在日志文件中,包括操作的具体细节和变更数据的位置。
2. 解析日志文件捕获到数据库日志后,CDC系统需要解析日志文件,识别其中的增量变化。
解析过程通常包括对日志格式的解析和提取操作的细节信息,如操作的表名、字段名、变更前后的数据等。
3. 标记增量数据解析日志文件后,CDC系统会将捕获到的增量数据进行标记,以便后续的同步操作。
标记通常包括记录操作类型(增、删、改)、变更数据的位置(如行号或标识字段值)以及变更前后的数据。
4. 同步增量数据在标记完增量数据后,CDC系统会将这些数据同步到目标系统中。
同步方式可以是定时任务、消息队列或实时推送等。
由于CDC数据是增量的,所以同步速度相对较快,可以实现实时同步。
三、常见的CDC同步数据的工具和框架CDC同步数据的机制在业界有很多成熟的工具和框架,下面介绍几种常见的CDC工具和框架。
1. DebeziumDebezium是一种开源的分布式CDC平台,基于Apache Kafka实现。
它支持多种数据库,如MySQL、PostgreSQL、MongoDB等,并提供了简单易用的API和各种连接器,方便用户进行CDC数据同步。
2. MaxwellMaxwell是一款基于MySQL数据库的CDC工具,能够将MySQL数据库的变化以JSON 格式的事件流发送到Kafka或其他系统。
它的设计目标是简单、高效,并提供了丰富的配置选项和灵活的数据映射功能。
3. Oracle GoldenGateOracle GoldenGate是一种企业级CDC解决方案,可以实现源与目标之间的实时数据复制和同步。
flinkcdc oracle 测试案例

flinkcdc oracle 测试案例Flink CDC(Change Data Capture)是一种用于实时数据同步和流式数据处理的开源技术,它可以捕获数据库中的变化,并将这些变化作为数据流进行处理。
本文将以Flink CDC与Oracle数据库的测试案例为题,介绍一些常见的测试场景和案例。
1. 测试CDC连接Oracle数据库在这个测试案例中,我们将测试Flink CDC与Oracle数据库的连接是否正常。
通过配置正确的数据库连接信息和表名,运行CDC作业,并观察是否可以成功捕获变化数据并进行处理。
2. 测试CDC捕获新增数据在这个测试案例中,我们将在Oracle数据库中插入一些新的数据,并观察Flink CDC是否可以及时捕获到这些新增数据,并将其作为数据流进行处理。
3. 测试CDC捕获更新数据在这个测试案例中,我们将在Oracle数据库中更新一些已有的数据,并观察Flink CDC是否可以及时捕获到这些更新数据,并将其作为数据流进行处理。
4. 测试CDC捕获删除数据在这个测试案例中,我们将在Oracle数据库中删除一些已有的数据,并观察Flink CDC是否可以及时捕获到这些删除数据的变化,并将其作为数据流进行处理。
5. 测试CDC处理数据在这个测试案例中,我们将使用Flink CDC捕获到的变化数据,进行一些数据处理操作,比如数据清洗、数据过滤、数据转换等,并观察处理结果是否符合预期。
6. 测试CDC数据写入外部系统在这个测试案例中,我们将使用Flink CDC捕获到的变化数据,将其写入到外部系统,比如Kafka、HDFS等,并观察数据写入是否成功,并且数据是否与源数据保持一致。
7. 测试CDC的容错和恢复能力在这个测试案例中,我们将模拟Flink CDC的异常情况,比如网络中断、数据库故障等,观察CDC作业的容错和恢复能力,以及是否可以正确处理数据流的连续变化。
8. 测试CDC的性能和吞吐量在这个测试案例中,我们将对Flink CDC进行性能测试,包括数据捕获的延迟、数据处理的吞吐量等指标,以评估CDC作业的性能和效率。
cdc数据同步方案

cdc数据同步方案CDC数据同步方案一、背景介绍CDC(Change Data Capture)是一种将数据库中的变更捕获并转换为事件流的技术,可以实现实时数据同步。
在分布式系统中,数据同步是非常重要的一环,因为不同的应用程序需要共享数据,并且需要保证数据的一致性和可靠性。
因此,设计一个高效、稳定、可扩展的CDC数据同步方案是至关重要的。
二、方案设计1. 数据源选择首先需要选择合适的数据源,目前主流的关系型数据库有MySQL、Oracle、SQL Server等。
根据业务需求和预算情况进行选择。
2. CDC技术选型CDC技术有多种实现方式,包括基于日志文件、触发器和轮询等。
其中基于日志文件的方式效率最高,因为它可以直接读取事务日志文件并解析其中的变化信息。
但是该方式对数据库版本有要求,并且需要相应的权限才能访问事务日志文件。
触发器方式可以实现较为精细的控制,但是会对数据库性能产生影响。
轮询方式最简单易用,但是效率较低。
综合考虑效率和可行性等因素,在本方案中选择基于日志文件方式进行CDC。
3. CDC工具选型CDC工具可以帮助我们实现CDC功能,目前市面上有多种CDC工具可供选择。
本方案中选择使用Debezium作为CDC工具,因为它是一个开源的、成熟的、支持多种数据库的CDC工具,且可以与Kafka 等消息队列集成。
4. 消息队列选型消息队列是实现数据异步传输的核心组件之一,它可以将变化数据转换为消息并发送到目标系统。
在本方案中选择使用Kafka作为消息队列,因为它是一个高性能、高可用、分布式的消息队列系统,可以满足大规模数据处理和存储需求。
5. 数据同步流程设计基于以上选型,设计如下数据同步流程:(1)Debezium从数据库事务日志中读取变化信息,并将其转换为Kafka消息;(2)Kafka将变化消息发送到消费端;(3)消费端接收到变化消息后进行处理,并将其写入目标数据库。
6. 高可用性和容错性设计在实际应用中,需要考虑到CDC工具和消息队列等组件的高可用性和容错性。
华为云MRSCDL架构设计与实现

华为云MRSCDL架构设计与实现1 前⾔MRS CDL是华为云FusionInsight MRS推出的⼀种数据实时同步服务,旨在将传统OLTP数据库中的事件信息捕捉并实时推送到⼤数据产品中去,本⽂档会详细为⼤家介绍CDL的整体架构以及关键技术。
2 CDL的概念MRS CDL(Change Data Loader)是⼀款基于Kafka Connect的CDC数据同步服务,可以从多种OLTP数据源捕获数据,如Oracle、MySQL、PostgreSQL等,然后传输给⽬标存储,该⽬标存储可以⼤数据存储如HDFS,OBS,也可以是实时数据湖Hudi等。
2.1 什么是CDC?CDC(Change Data Capture)是⼀种通过监测数据变更(新增、修改、删除等)⽽对变更的数据进⾏进⼀步处理的⼀种设计模式,通常应⽤在数据仓库以及和数据库密切相关的⼀些应⽤上,⽐如数据同步、备份、审计、ETL等。
CDC技术的诞⽣已经有些年头了,⼆⼗多年前,CDC技术就已经⽤来捕获应⽤数据的变更。
CDC技术能够及时有效的将消息同步到对应的数仓中,并且⼏乎对当前的⽣产应⽤不产⽣影响。
如今,⼤数据应⽤越来越普遍,CDC这项古⽼的技术重新焕发了⽣机,对接⼤数据场景已经是CDC技术的新使命。
当前业界已经有许多成熟的CDC to⼤数据的产品,如:Oracle GoldenGate(for Kafka)、 Ali/Canal、Linkedin/Databus、Debezium/Debezium等等。
2.2 CDL⽀持的场景MRS CDL吸收了以上成熟产品的成功经验,采⽤Oracle LogMinner和开源的Debezium来进⾏CDC事件的捕捉,借助Kafka和Kafka Connect的⾼并发,⾼吞吐量,⾼可靠框架进⾏任务的部署。
现有的CDC产品在对接⼤数据场景时,基本都会选择将数据同步到消息队列Kafka中。
MRS CDL在此基础上进⼀步提供了数据直接⼊湖的能⼒,可以直接对接MRS HDFS和Huawei OBS以及MRS Hudi、ClickHouse等,解决数据的最后⼀公⾥问题。
CDC简介

1.CDC简介1.1.CDC是一种数据增量处理技术在构建数据仓库系统的ETL过程中,增量数据的抽取是一个非常关键的环节.对解决方案一般有两点要求:l准确性,能够将业务系统中的数据按一定的频率准确的取到数据仓库中l性能,不能对业务系统造成太大的压力,影响现有业务目前,最为常用的ETL增量数据处理方式有三种:l时间戳l日志对比(CDC)l全面数据对比三种方式各有优劣,时间戳是目前应用比较普遍的方式。
在Oracle=中推出了两种主要的ETL方案,一种是我们熟悉的物化视图(materialized view),另一种就是本文将要介绍的CDC组件(Change Data Capture 改变数据捕获)。
CDC 特性是在Oracle9i数据库中引入的。
CDC能够帮助你识别从上次提取之后发生变化的数据。
利用CDC,在对源表进行INSERT、UPDATE或 DELETE等操作的同时就可以提取数据,并且变化的数据被保存在数据库的变化表中。
这样就可以捕获发生变化的数据,然后利用数据库视图以一种可控的方式提供给目标系统。
1.2.CDC与传统增量处理方式的对比分析我们对比一下CDC方式与传统的全表对比与时间戳方式。
全表对比使用数据仓库中的当前表与业务系统表进行对比,取得变化了的数据,典型是使用minus语句:?1使用全表对比有以下几方面的问题:l需要将业务系统中表全部转输,造成很高的网络负载l需要对两版本的表进行全表扫描,性能代价非常高l无法反映数据的历史状态,如无法捕捉库存的历史变化记录还有一种常用的方式是时间戳, 它是以业务表中某一个字段的值,作为判断新旧数据的标志。
如,”病人费用记录”中的登记时间,每次只抽取上次抽取记录时间以后产生的数据。
时间戳方式存在以下问题:l无法捕获对时间戳以前数据的delete和update操作,在数据准确性上受到了一定的限制。
而类似于ZLHIS这种业务系统对已经发生的数据进行update 和delete操作非常普遍(如划价记录转收费记录),应用场景受到了限制。
flink oracle cdc案例

flink oracle cdc案例Flink Oracle CDC案例1. 什么是Flink Oracle CDC?Flink Oracle CDC是指在Flink流处理框架中使用Change Data Capture(CDC)技术来捕获和处理Oracle数据库中的数据变化。
CDC是一种数据集成技术,可以实时捕获数据库中的数据变化,并将其作为流数据发送到其他系统进行处理或分析。
2. Flink Oracle CDC的优势Flink Oracle CDC具有以下优势:- 实时性:能够准实时地捕获和处理Oracle数据库中的数据变化,使得其他系统可以及时获得最新的数据。
- 可靠性:通过Flink的容错机制,保证数据的可靠性和一致性。
- 灵活性:支持多种数据格式和数据源,可以根据需求进行灵活的配置和定制。
- 高性能:Flink的流处理引擎具备高吞吐和低延迟的特点,能够处理大规模的数据流。
- 可扩展性:可以根据需求水平扩展,以处理大规模的数据变化。
3. Flink Oracle CDC的应用场景Flink Oracle CDC可以应用于以下场景:- 数据仓库更新:将Oracle数据库中的数据变化实时发送到数据仓库,以保证数据仓库中的数据与源数据库保持同步。
- 实时分析:将Oracle数据库中的数据变化实时发送到分析系统,以进行实时的数据分析和处理。
- 业务监控:通过捕获Oracle数据库中的数据变化,实时监控业务指标并生成报警或通知。
- 数据同步:将Oracle数据库中的数据变化实时同步到其他系统,以保持数据的一致性。
4. Flink Oracle CDC的实现原理Flink Oracle CDC的实现原理如下:- 首先,通过Oracle的日志文件(Redo Log)来捕获数据库中的数据变化。
- 然后,将捕获到的数据变化解析成具体的操作(插入、更新、删除)和对应的数据内容。
- 接着,将解析到的数据变化作为流数据发送到Flink流处理引擎进行处理。
oracle cdc 原理

oracle cdc 原理Oracle CDC(Change Data Capture)是一种数据捕获技术,用于捕获数据库中的数据变化,并将这些变化应用于其他系统中。
它可以实时监控数据库的变化,并将这些变化记录下来,以便后续的分析和处理。
Oracle CDC的原理是通过在数据库中创建日志来实现的。
当数据库中的数据发生变化时,Oracle会将这些变化写入日志文件中。
CDC 通过解析这些日志文件来获取数据的变化,并将其应用于其他系统中,以保持数据的一致性。
为了实现CDC,Oracle会记录以下三种类型的日志:1. Redo Log:这是Oracle数据库中最重要的日志类型之一。
当数据发生变化时,Oracle会将变化前后的数据记录到Redo Log中。
CDC 通过解析Redo Log来获取数据的变化。
2. Undo Log:Undo Log记录了事务的撤销信息。
当数据库中的数据发生变化时,Oracle会将原始数据保存到Undo Log中。
CDC可以通过解析Undo Log来获取数据的变化。
3. Archive Log:Archive Log是将Redo Log保存到磁盘上的一种机制。
通过将Redo Log保存到磁盘上,可以确保即使数据库崩溃,数据的变化也不会丢失。
CDC可以通过解析Archive Log来获取数据的变化。
通过解析这些日志文件,CDC可以获取数据的变化信息,并将其应用于其他系统中。
它可以实时监控数据库的变化,并将这些变化同步到其他系统中,以保持数据的一致性。
使用Oracle CDC可以带来许多好处。
首先,它可以实现实时数据同步,确保数据在不同系统之间的一致性。
其次,它可以降低数据同步的延迟,使得数据可以更快地在系统之间流动。
此外,Oracle CDC还可以提供增量备份和恢复的功能,以及实时数据分析和报告的能力。
总结起来,Oracle CDC是一种通过解析数据库日志来捕获数据变化的技术。
它可以实时监控数据库的变化,并将这些变化应用于其他系统中。
oracle cdc原理

Oracle CDC 原理解释概述Oracle CDC(Change Data Capture)是一种用于从Oracle数据库中实时捕获和传送更改数据的技术。
它允许应用程序在数据发生变化时获取这些变化,而无需查询整个数据库。
CDC可以使应用程序更高效地处理数据,提供实时更新和推送,减少对数据库的查询压力,同时还能实现增量数据同步、数据仓库刷新以及实时报表等应用。
CDC 原理Oracle CDC的基本原理是通过监视数据库的日志,捕获数据库中的变更数据,并将这些数据传送到外部系统。
1. Oracle 日志文件Oracle数据库中的日志文件被用于记录所有的数据库更改。
这些更改包括插入、更新和删除操作。
日志文件记录每个事务的详细信息,以便在需要时可以恢复或回滚数据库。
Oracle数据库将日志文件分为两个类型:重做日志文件(Redo Log)和归档日志文件(Archive Log)。
重做日志文件记录了正在进行的事务中的变更信息,而归档日志文件是重做日志文件的备份。
2. CDC 日志监听器CDC日志监听器是一个特殊的后台进程,它负责监听数据库中的日志变更。
当一个事务在数据库上进行插入、更新或删除操作时,CDC监听器会捕获并解析这些变更,并生成相应的日志文件。
3. CDC 表为了能够捕获和记录数据变更,需要在数据库中创建相应的CDC表。
CDC表是一个与源表结构相同的表,用于存储变更数据的副本。
当一个事务更新原始表时,CDC监听器会将变更的数据记录到CDC表中。
CDC表中的每一行代表一个插入、更新或删除操作的变更数据。
4. CDC 进程CDC进程是一个独立的进程,它负责从CDC表中读取变更数据,并将其传送到外部系统。
传送数据的方式可以是轮询查询、消息队列或直接的网络传输等。
CDC进程可以根据需求配置几个参数,如轮询间隔、数据过滤规则等。
它可以根据源表的变更情况动态调整轮询频率,确保数据变更的实时性和及时性。
5. CDC 标记机制为了避免重复处理相同的变更数据,CDC引入了标记机制。
cdc同步数据的机制

cdc同步数据的机制CDC同步数据的机制是指Change Data Capture(变更数据捕获)技术,它可以在数据库中捕获数据的变化,并将这些变化同步到其他系统或数据库中。
CDC技术已经成为了现代企业应用程序集成和数据同步的重要工具,因此对于CDC同步数据的机制有深入的了解非常重要。
一、CDC技术的基本原理1.1 CDC技术的定义CDC技术是一种用于捕获数据库中发生变化的技术,它能够实时地监测数据库中发生的变化,并将这些变化记录下来。
这些记录可以被用来更新其他系统或数据库,从而保证数据在不同系统之间的一致性。
1.2 CDC技术的基本原理CDC技术通过监视数据库事务日志来实现对数据库中发生变化进行捕获。
当一个事务被提交时,其所做出的所有修改都会被写入到事务日志中。
CDC工具会监视这个日志,并将其中包含的修改操作提取出来,然后将其转换成可读格式并储存在一个特定位置上。
1.3 CDC技术与ETL技术虽然CDC和ETL都是用于数据集成和同步的工具,但它们之间还是有很大区别。
ETL(Extract, Transform, Load)是一种批量处理技术,它会定期地从源系统中提取数据,经过转换和清洗后再加载到目标系统中。
而CDC技术则是一种实时处理技术,它能够实时捕获数据库中的变化,并将这些变化同步到其他系统中。
二、CDC技术的应用场景2.1 数据库复制CDC技术可以用于数据库复制,它能够捕获源数据库中的所有变化,并将这些变化同步到目标数据库中。
这种方式可以用于数据备份、灾难恢复和数据分发等场景。
2.2 数据仓库集成CDC技术还可以用于数据仓库集成。
数据仓库需要从多个源系统中提取数据,并将其加载到一个统一的存储位置中。
CDC技术可以帮助数据仓库实现实时或准实时地获取源系统的更新,从而保证仓库中的数据始终保持最新状态。
2.3 业务流程集成CDC技术还可以用于业务流程集成。
企业通常会使用多个应用程序来支持不同的业务流程,这些应用程序之间需要进行数据交换和共享。
Oracle Data Integrator(ODI)安装 使用

1.1.1.软件下载以10.1.3.4 Windows版本为例,地址:/technology/global/cn/software/products/ias/htdocs/101 310.html1.1.2.安装选择1、运行安装盘下的setup\Windows\setup.bat。
2、产品选择第一个选项安装所有组件——ODI和Data Profiling、Data Quality3、类型选择第一个选项同时安装Server和Client1.1.3.安装设置1、Home和路径不要和其它的Oracle产品共用即可2、为Data Profiling和Quality的Server设置端口、管理员及其密码(设为madmin)注:Windows下netstat –a命令可以查看端口占用情况。
3、为Data Profiling和Quality的Client,设置欲连接的主机名和端口因为Server是本机,所以设置为localhost;端口和上面步骤设置的一样。
4、为Data Quality 设置ODBC适配器端口,保持默认1.2.服务和菜单1.2.1.服务1、Oracle Data Quality Inetd2、Oracle Data Quality Scheduler1.2.2.菜单1、Oracle Data Integrator2、Oracle Data Profiling and Quality1.3.基本训练完成官方“Getting Started with an ETL Project”,可比较好的掌握基本概念、功能、集成流程。
请勿跳过。
下面的章节将逐一展开,但基本都是记录精要内容,详细地说明请参阅开始菜单中的Documentation Library。
2.完整的简单例子(资料库、体系结构、项目、模型、接口、包、方案)2.1.ODI理解之22.1.1.什么是资料库ODI资料库可安装在任何支持ANSI ISO 89的数据库中。
Oracle 变化数据捕获

OracleOracle 变化数据捕获变化数据捕获就是我们通常提到的CDC(Change Data Capture),是用来描述捕捉增量变化应用数据到其他数据库或数据源。
Oracle CDC基本原理同步CDC模式简介两种异步模式的创建附:同步模式在ODI中的体现TechTarget 中国《Oracle系列电子书》 1TechTarget中国《Oracle系列电子书》2变化数据捕获就是我们通常提到的CDC (Change Data Capture ),是用来描述捕捉增量变化应用数据到其他数据库或数据源。
随着数据量的不断增长和数据存储日益变化,变化数据捕获在生产系统中特别重要。
——赵宇变化数据捕获就是我们通常提到的CDC (Change DataCapture),是用来描述捕捉增量变化应用数据到其他数据库或数据源。
随着数据量的不断增长和数据存储日益变化,变化数据捕获在生产系统中特别重要,比如做多生产中心、报表分离、容灾备份、数据仓库、数据分发等,特别是要求实时或近实时的生产系统中。
在Oracle、DB2、SQL Server等数据库中,都可以通过数据库的日志提取变化的捕捉,实现变化数据的提取、传输。
而在传统上我们通常都是通过修改源代码的应用,在一些表上增加日期列来捕获增量变化。
Oracle数据库的变化数据捕获可以通过日志的方式实现增量变化捕获而不需对源程序做任何更改。
Oracle数据库从10g R2介绍异步分布式CDC,比原有9i数据库R2有了更大的提高。
但是从Oracle 11g版本开始,Oracle推荐使用GoldenGate来做数据库之间的变化数据捕捉,对CDC的功能不再增加新特性。
所以Oracle 11g中的CDC功能还是之前10g的CDC功能版本。
下面介绍如何设置这样一个异步变化数据捕获环境。
变化数据捕捉的用户:Publishers and subscribers (发布者和用户)publisher 就是发布变化数据捕捉的数据库用户.所以需要先创建一个发布者。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Oracle Change Data Capture 介绍一、概述CDC(Change Data Capture)是oracle在数据库级别实现的增量抽取解决方案。
在一般的ETL过程中,对于增量抽取,无非是在数据上加时间截,全记录比对,关键字段比对,日志分析抽取等几种方法,要么需要修改原表结构,要么需要大量的算法,要么借助第三方的工具实现。
Oracle从9i开始引入的CDC特性,使得有机会在数据库层面上直接实现增量抽取功能,在性能方面由于和数据库引擎的直接集成,比第三方工具应该具有一定的优势。
CDC有两个模式:同步和异步。
两种模式的实现机制是截然不同的。
同步CDC 主要是采用触发器记录新增数据,基本能够做到实时增量抽取。
而异步CDC则是通过分析已经commit的日志记录来得到增量数据信息,有一定的时间延迟,并且提供了到Oracle Streams的接口。
同步CDC在企业版或者标准版中都可以使用,异步CDC则只包含在企业版中。
注意CDC在9i和10g中有了比较大的改变,异步CDC主要采用了和Streams相同的技术。
CDC中将系统分为两个角色:发布者和订阅者。
发布者主要负责捕获增量数据,订阅者则将增量数据传递给实际应用。
这些任务都可以通过oracle提供的PL/SQL包实现。
二、名词解析Change Source增量数据的抽取来源,比如同步CDC模式是通过trigger直接从database中获取的,change source就是source database。
异步CDC模式则是从日志文件中获取的,则change source则表示redo logfile。
Change Set一组逻辑上相关的增量数据,需要保证其一致性。
change set必须是某个change source的成员。
对于异步分布式HotLog模式,同一个change source的所有change set必须在同一个staging database中。
而异步AutoLog模式中一个change source只能有一个change set。
Change Table一个change table对应一个source table,用于保存source table中的增量数据。
Change table中除了需要保存source table的增量数据,还有一些控制列用于保存相关的元数据。
三、CDC模式介绍前面讲到同步CDC和异步CDC模式。
同步的比较简单,就是通过触发器捕获增量数据,类似于物化视图的实现机制。
而异步CDC根据实现的内部机制区别,又可以分为异步HotLog模式,异步分布式HotLog模式和异步AutoLog模式。
有些模式有固定的预先定义change source,有些则没有。
比如同步CDC的change source是SYNC_SOURCE,异步HotLog模式则是HOTLOG_SOURCE,这是因为这两种模式都只有一个source database。
而其他的,像异步分布式Hotlog模式和异步AutoLog模式,除了source database,还需要一个staging database。
同步CDC模式同步CDC模式(Synchronous Mode)通过在源库上建立trigger的方式来捕获增量数据,因此可以做到实时抽取增量数据。
当源库执行commit的时候,增量数据将生成在change table中。
但是同步CDC模式的缺点也是明显的,由于需要在源库创建trigger,对于源库将造成不小的压力,并且change table 也必须在源库中生成,还需要占据源库一定的空间。
同步模式有一个固定的change source:SYNC_SOURCE,表示source database。
该change source不能修改也不能删除。
异步HotLog模式异步HotLog模式(Asynchronous HotLog Mode)直接从source database 的online redo logfile中抽取增量数据,由于需要解析日志文件,会有一定的时间延迟。
change table也必须在源库中生成。
该模式由于是在源数据库中解析日志,对源数据库也会造成一定的压力,但是比同步CDC模式的压力要小一些。
异步HotLog模式也有一个固定的change source:HOTLOG_SOURCE,表示source database的当前连接日志文件。
不能修改也不能删除。
异步分布式HotLog模式异步分布式HotLog模式(Asynchronous Distributed HotLog Mode)和异步HotLog模式相比,主要是将多个source database的当前联机日志中解析出增量数据,然后传递一个staging database中处理,便于集中式数据管理。
在异步分布式HotLog模式中,change source也表示source database的当前联机日志。
但是由于一个staging database可以处理多个源数据库,所以没有预先定义的change source,需要在使用的时候自定义change source。
在该模式中,需要两个发布者。
一个在source database中,一个在staging database中。
异步Autolog模式异步Autolog模式(Asynchronous AutoLog Mode)则是先将日志文件从source database传递到staging database,然后在staging database执行日志分析。
这样可以将对source database的压力减到最小。
日志的传递通过Redo transport services服务来实现,是不是对这个服务名很熟悉?在Data Guard中也是通过该服务将主库的日志传递到备库的,实际上该模式对于日志的处理和Data Guard中基本上是同样的机制。
所以这里也需要在source database中设置相应的LOG_ARCHIVE_DEST_n参数来实现日志的传递。
异步AutoLog模式既可以使用联机日志,也可以使用归档日志来获得增量数据信息。
四、相关系统视图∙CHANGE_SOURCES∙CHANGE_PROPAGATIONS∙CHANGE_PROPAGATION_SETS∙CHANGE_SETS∙CHANGE_TABLES∙DBA_SOURCE_TABLES/ALL_SOURCE_TABLES/USER_SOURCE_TABLES ∙DBA_PUBLISHED_COLUMNS/ALL_PUBLISHED_COLUMNS/USER_PUBL ISHED_COLUMNS∙DBA_SUBSCRIPTIONS/ALL_SUBSCRIPTIONS/USER_SUBSCRIPTIONS ∙DBA_SUBSCRIBED_TABLES/ALL_SUBSCRIBED_TABLES/USER_SUBSCRI BED_TABLES∙DBA_SUBSCRIBED_COLUMNS/ALL_SUBSCRIBED_COLUMNS/USER_S UBSCRIBED_COLUMNS∙9i:DBA_SOURCE_TAB_COLUMNS/ALL_SOURCE_TAB_COLUMNS/US ER_SOURCE_TAB_COLUMNS∙10g:DBA_PUBLISHED_COLUMNS/ALL_PUBLISHED_COLUMNS/USER_ PUBLISHED_COLUMNS五.同步模式的CDC例子说明主要是通过一个实际的例子来演示实现同步模式的CDC的基本步骤。
1.版本SYS@ning>select * from v$version;BANNER-------------------------------------------------------------------------Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - ProdPL/SQL Release10.2.0.3.0 - ProductionCORE10.2.0.3.0ProductionTNS for32-bit Windows: Version10.2.0.3.0 - Production NLSRTL Version10.2.0.3.0 - Production2.设置发布者2.1.首先在source database创建一个用户作为发布者SYS@ning>create user cdcpub identified by cdcpub; User created.2.2.授予相应的权限SYS@ning>grant execute_catalog_role to cdcpub; Grant succeeded.SYS@ning>grant select_catalog_role to cdcpub; Grant succeeded.SYS@ning>grant create table to cdcpub;Grant succeeded.SYS@ning>grant create session to cdcpub;Grant succeeded.SYS@ning>grant execute on dbms_cdc_publish to cdcpub;Grant succeeded.3.设置初始化参数同步CDC,需要将java_pool_size设置为合适的大小,估计是其内部是采用java存储过程来实现的。
SYS@ning>alter system set java_pool_size=48M;System altered.4.发布变化数据4.1.例如要发布用户ning下的sales表SYS@ning>desc ning.sales;Name Null? Type------------------------------ -------- ----------------ID NUMBER(38)PRODUCTID NUMBER(38) PRICE NUMBER(10,2) QUANTITY NUMBER(38) 4.2.授予cdcpub用户对于该表的权限SYS@ning>grant all on ning.sales to cdcpub;Grant succeeded.4.3.创建chang setSYS@ning>begin2dbms_cdc_publish.create_change_set(3change_set_name =>'ning_sales',4description =>'change set for ning.sales',5change_source_name =>'SYNC_SOURCE');6end;7/PL/SQL procedure successfully completed.同步CDC的chang source必须是SYNC_SOURCE。