stata中变量描述分析和作图
stata中变量描述分析和作图..

• .tab2也提供双变量的交叉分析表 • .tab和tab2的主要区别在于,前者仅可以用于两个变量的
交互分析(tab后面最多只能有两个变量);tab2可同时 生成多个两两变量之间的交互频数分布表
例1
.tab girl enroll, chi2 column row miss nokey ① ② ③④⑤
6.3.频数分布的常见错误之二
• too many values • 导致这类错误的原因在于,在试图生成两个变量的交叉表
时,每个变量都包含太多的取值。比如:
. tab age weight . too many values
(变量的取值太多)
• 这里,变量age和weight均为连续变量,且都有很多的取值, 尤其是weight
多变量频数分布
. tab1 [变量a 变量b 变量c]
①
②
①:同时获得多个变量频数分布的基本命令
②:需要输出频数分布的变量名称
• 与tab或tabulate不同的是, . tab1可接多个变量 . tab girl urban
– 该命令告诉Stata,给变量girl和urban各自生成一张频数分布表
菜单窗口
• 在Stata的窗口菜单下,有多种描述数据频数分布 特征的选项,每一选项都具有一定独特的功能, 但有些功能是相通的
窗口路径 Table of summary statistics (table) Table of summary statistics (tabstat) One/two-way table of summary statistics One-way tables
Stata统计分析命令

Stata统计分析命令Stata是一种用于数据分析的统计软件,具有广泛的应用领域,可以用于社会科学、健康科学、金融等领域的数据分析。
Stata具有强大的数据处理和统计分析功能,可以对数据进行清洗、整理和分析,还可以进行数据可视化和报告制作。
本文将介绍一些常用的Stata统计分析命令,以供参考。
数据导入与清洗在进行数据分析之前,需要先将数据导入Stata软件中,并进行数据清洗。
以下是常用的数据导入和清洗命令:导入数据•use:使用已有的Stata数据集•import delimited:导入以逗号为分隔符或制表符为分隔符的纯文本数据•import excel:导入Excel数据文件•insheet:将文本文件读入数据集数据清洗•drop:删除变量或数据•keep:保存变量或数据•rename:重命名变量•egen:生成新的变量•recode:将变量值重新编码•merge:合并两个数据集描述性统计分析在进行数据分析之前,需要先对数据进行描述性分析。
以下是常用的描述性统计分析命令:•summarize:计算变量的基本统计量,如均值、标准差、最小和最大值、中位数、1/4和3/4位数•tabulate:计算变量的频数和百分比,可以进行交叉分析•graph box:绘制箱线图•graph scatter:绘制散点图统计分析在进行统计分析时,需要根据变量的类型和分析目的选择不同的统计方法。
以下是常用的统计分析命令:单样本统计分析•ttest:单样本t检验•onesamplewilcoxon:单样本Wilcoxon秩和检验双样本统计分析•ttest:双样本t检验•ranksum:Wilcoxon秩和检验相关分析•correlate:计算两个或多个变量之间的相关系数•pwcorr:计算Pearson相关系数矩阵回归分析•regress:运行普通最小二乘回归•logit:运行二元Logistic回归模型•oprobit:运行有序Logistic回归模型数据可视化数据可视化是Stata的另一个强大特性,可以使分析人员更清晰、更直观地了解数据分析结果。
stata操作介绍之基础部分(一)

精选ppt课件
33
•Stata常用命令及其缩写
精选ppt课件
34
2.2 输入、输出与存储
•数据的输入包括三种方法: 1.直接从键盘输入 2.打开已有数据文件 3.拷贝、粘贴方式交互数据
精选ppt课件
35
1.直接键盘输入 在Stata中可以使用命令行方式直接建立数据集,首先使用input命令制定相 应的变量名称,然后一次录入数据,最后使用end语句表明数据录入结束。
方法二:导入的方式
先做好excel数据文件,并以“xml 表格(*.xml)”的形式保存,注意不能以“xml 数据(*.xml)”的形
式保存。而且注意,保存时不能在第一行中输入变量名,只能全部为数据。
精选ppt课件
40
精选ppt课件
41
•数据的输出可通过命令直接输出和使用菜单栏输出:
1、命令输出格式
精选ppt课件
39
3.拷贝、粘贴方式交互数据
Stata的数据编辑窗口是一个简单的电子表格,可以使用拷贝、粘贴方式直接和EXCEL等软件交互数据, 在数据量不大时,这种方式操作极为方便。
把excel数据导入stata
方法一:拷贝和粘贴方式
先做好excel数据文件, 在stata数据编辑器粘贴,变量名也可以复制过来,应该是最容易的方法。只 有点stata数据编辑器第一格即可复制全部数据。复制会问你是否把第一行作为变量。
1.7 Stata安装
1、首先下载文件然后解压。解压完成后双击 “SetupStata14.exe”进行安装。点击“Next”继续。如下图:
精选ppt课件
11
2、选中“I accept the....”然后点击“Next”
精选ppt课件
stata中变量描述分析和作图

150
6
Percent
4
2
0
Percent
0
1
2
3
4
5
6
7
8 9 10 11 12 13 14 15 16 17 18 age in 2004
0
0
2
4
6
8
10
50
100 children's height in 2004
150
200
正态分布(normal distribution)
• 一个变量的集中位置居中,左右两侧频数基本对称的分布
离散趋势:极差或者全距(range,R)
• 数据分布的另一种表现形式。从中心到两侧,频数分布逐 渐减少。反映了数据的离散程度或变异程度; • 描述离散趋势的方法包括:级差、方差、标准差; • 极差或者全距(range,R):表示变量取值中的最大值 和最小值之差。适合所有分布类型的数据; R=最大值-最小值
---1=girl |
0 |
Freq.
1,248
Percent
53.70
Cum.
53.70
------------+-----------------------------------
1 |
Total |
1,076
2,324
46.30
100.00
100.00
------------+-----------------------------------
• .tab提供、且只能提供双变量的交叉分析,生成二者之间 的交叉频数分布,相当于命令tabulate
– 若其令后面仅有一个变量,则Stata输出该变量的频数分布 – 若多于两个变量,则会出现错误提示
Stata中的图形制作(绝对自己总结)

第三章 Stata 中的图形制作
1.菜单操作
2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
D e n s i t y
3.散点图:反映两个或多个变量之间的关系。
通常用纵轴来表示因变量,用横轴来表示自变量。
4.曲线标绘图
用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
它与散点图类似,实际上它就是将连续型的数值变量点连接起来的一种图形,但由于它还可以用于回归曲线的绘制。
clpattern(样式代码)
consumption_china.dta 数据绘制曲线标绘图。
利用文件中的数据绘制人均消费
5.条形图:是用矩形的长度来表示相互独立的变量大小取值的统计图形。
横向的条形图hbar ,纵向条形图bar 。
在绘制条形图的过程中,需要指明所要展示的统计量,如果不指明统计量,则会默认显示均值(mean )统计量。
10000
15000
6.饼图:用圆形及圆内扇形的大小表示总体中各部分所占比例的统计图,通常用来表示各部分在总体中所占份额。
graph pie x y z
7.箱线图:标明了第一个四分位数、中位数和第三个四分位数
5,000
10,000
15,000。
如何使用Stata进行统计分析和数据可视化

如何使用Stata进行统计分析和数据可视化第一章:Stata统计分析基础Stata是一个功能强大的统计分析软件,广泛应用于社会科学、经济学、医学研究等领域。
在使用Stata进行统计分析之前,我们需要熟悉一些基本概念和操作。
1.1 Stata界面介绍Stata界面分为主窗口和命令窗口。
主窗口用于显示数据和结果,命令窗口用于输入和运行命令。
1.2 导入数据在Stata中,可以通过多种方式导入数据,包括直接输入数据、从其他文件格式导入数据、从数据库导入数据等。
1.3 数据清洗和准备在进行统计分析之前,需要对数据进行清洗和准备。
这包括处理缺失值、异常值,创建新变量,转换数据类型等操作。
1.4 描述统计分析描述统计分析是对数据的基本特征和分布进行描述和分析。
可以使用Stata的命令进行频数统计、均值计算、方差分析等操作。
1.5 统计推断统计推断是通过样本数据对总体特征进行推断。
可以使用Stata进行t检验、方差分析、回归分析等操作。
第二章:Stata数据可视化数据可视化是将统计分析结果以图形或图表的方式展示,可以帮助我们更好地理解和传达数据。
2.1 绘制直方图和箱线图直方图和箱线图可以用来展示数据的分布和异常值情况。
在Stata中,可以使用histogram命令和graph box命令绘制直方图和箱线图。
2.2 绘制散点图和线图散点图和线图可以用来展示变量之间的关系和趋势。
在Stata中,可以使用scatter命令和twoway line命令绘制散点图和线图。
2.3 绘制柱状图和折线图柱状图和折线图适用于展示不同类别或时间点的数据比较。
在Stata中,可以使用bar命令和twoway line命令绘制柱状图和折线图。
2.4 绘制饼图和雷达图饼图和雷达图适用于展示比例或多维数据的分布。
在Stata中,可以使用pie命令和radar命令绘制饼图和雷达图。
第三章:高级统计分析和可视化除了基本的统计分析和数据可视化外,Stata还提供了一些高级功能,可以进行更复杂和深入的统计分析和数据可视化。
stata常用命令总结

stata常用命令总结Stata是一款广泛应用于数据分析与统计建模的统计软件,具有强大的功能和广泛的应用领域。
在Stata中,我们可以通过命令来完成数据的读取、整理、分析和可视化等任务。
本文将对一些常用的Stata命令进行总结和介绍,以帮助读者更好地理解和应用Stata软件。
一、数据的读取与整理1. 读取数据文件:- use 文件名:读取已经存在的Stata数据文件。
- import delimited 文件名:读取以逗号、制表符或其他分隔符分隔的文本文件。
2. 显示数据:- describe:显示数据文件的基本信息,包括变量名、数据类型、有效观测数等。
- browse:以表格形式显示数据文件的部分观测值。
3. 数据整理:- generate 新变量名=计算公式:创建新的变量,并根据指定公式进行计算。
- egen 新变量名=计算函数:根据指定的计算函数对现有变量进行计算,并创建新的变量。
二、数据的统计分析与建模1. 描述性统计:- summarize 变量名:对指定变量进行描述性统计,包括均值、标准差、最小值、最大值等。
- tabulate 变量名:生成指定变量的频数表和百分比表。
2. 数据筛选与子集选择:- keep 如果条件:保留符合条件的观测值,删除不满足条件的观测值。
- drop 如果条件:删除符合条件的观测值,保留不满足条件的观测值。
- qui keep 如果条件:以无输出方式保留符合条件的观测值并生成新数据集。
- qui drop 如果条件:以无输出方式删除符合条件的观测值并生成新数据集。
3. 参数估计与假设检验:- regress 因变量自变量1 自变量2 ...:进行普通最小二乘回归分析。
- ttest 变量名, by(分组变量):进行两组样本均值差异的t检验。
4. 数据可视化:- scatter 变量1 变量2:绘制散点图。
- histogram 变量名:绘制直方图。
- graph twoway line 变量1 变量2:绘制折线图。
Stata中的图形制作绝对自己总结

plabel(_allpercent,gap(9)):显示所有标签,相对位置为9
pie(1,explodecolor(yellow)):对第一个图例变量,突出显示,颜色设定为黄色
legend(position(11)row(1)ring(0))方向为11点,一排显示,内部显示
3.散点图:反映两个或多个变量之间的关系。通常用纵轴来表示因变量,用横轴来表示自变量。
基本
[twoway]scatteryx因变量在前
数据标记的设定
数据标记形状的设定、颜色的设定、大小的设定、散点标签的设定
graphbar/hbarcurrentsolidgross,over(year)blabel(bar,position(outside)yline(30000))stack
blabel(bar,position(outside)):以条柱的高度数值给条柱添加标签,位置在条柱的右;yline(300000):标识线的绘制,注意的是:该函数在blabel的括号内
5.条形图:是用矩形的长度来表示相互独立的变量大小取值的统计图形。横向的条形图hbar,纵向条形图bar。
在绘制条形图的过程中,需要指明所要展示的统计量,如果不指明统计量,则会默认显示均值(mean)统计量。
stack选项
将具有多个y变量的统计量上下堆积,可以了解内部的比例结构
blabel选项
增添条柱的数值标签;改变bar的名称和组合
第三章Stata中的图形制作
1.菜单操作
Plots
STATA软件应用(二)作图、统计描述

/*包含缺失值 /*不显示频数 /*不显示数值标记
分类变量资料的描述
两个变量交叉分类描述 tabulate变量1 变量2 [,cell column missing nofreq nolabel] tab2 变量1 变量2 变量3…… [,tabulate_options]
detail /* 详细描述,缺失时为简单描述 centile(# [# ...]) /* 指定需要计算的百分位数 meansd /* 指定百分位数用近似正态法,缺失时为直接算法 cci /* 指定百分位数的可信区间用保守算法 normal /* 指定百分位数的可信区间用近似正态法 level(#) /* 指定百分位数的可信区间的可信限
箱式图
180 120 140 160
Before
After
Before
After
Male
Female
例ex6
散点图:反应变量之间的关系
graph y x
71
gra y x,c(.) s(O)
y
63 30 x 39
线图
gra y x,c(l) s(d)
71
y
63 30 x 39
线图
gra y x,c(l[-]) s(p) sort
115.4 114.8 116.3 125.6 123 114.7 120.7 124.1
122.5 126.1 120 118.4 121 120.8 120.7 116.8
121.5 113.2 117.7 123.8 119.5 119.6 120.2 112.2
124.4 112.7 122.8 124.4 117.4 114.9 122.4 118.4 120.6 120.7 118.9 123.1 120 127.1
最新stata操作介绍之制图和统计分析(二)教学内容

. describe
• summarize命令: • summarize可以计算和导出描述性统计量的最大值、最小值、均值
和标准差等。summarize的命令格式如下: . summarize [varlist] [if] [in] [weight][,options]
• 完整直线图图例:
数据处理与运算
二、统计分析
•描述性统计
统计分析的第一步就是计算出描述性统计量。这些描述性统计 量使用简单的数字来表示变量的分布特征,包括集中趋势、离散趋 势等。
Stata中实现描述性统计分析的命令主要有: describe; summarize;
tabstat;
• describe 命令: • describe命令用于产生一个对数据集的简明总结表格,其格式如下:
• 例: . tabstat sales,by(advert) statistics(sum mean sd cv median)
此课件下载可自行编辑修改,仅供参考! 感谢您的支持,我们努力做得更好! 谢谢!
• 例:
. summarize sales prices advert
• tabstat命令: tabstat与summarize相似,但它的灵活性高于summarize。该命令可
以通过statistics( )添加各种所需要的统计量。 • tabstat命令格式如下:
. tabstat [varlist] [if] [in] [weight][,options]
stata操作介绍之制图和统 计分析(二)
数据处理与运算
一、Stata制图
Stata制图命令: 1、单个直线图的命令主体:
stata中变量描述分析和作图..

数据描述的方法
• 获得数据的目的是为了描述和分析数据,回答研究问题 • 数据分析的第一步是描述变量的基本特征。只有在熟悉数 据的基本特征和变量分布的基础上,才能决定如何对数据 作进一步处理
• 描述性统计通过一系列的程序帮助组织、归纳、总结样本 的基本特征。常见的方法包括
– 频数分布、百分比、分位数、均值和标准差、中数、众数、最大 值和最小值等单变量分析(univariate analysis)。考察变量的属 性分布 – 二元或多元交叉表、二元相关关系分析 – 图形
---1=girl |
0 |
Freq.
1,248
Percent
53.70
Cum.
53.70
------------+-----------------------------------
1 |
Total |
1,076
2,324
46.30
100.00
100.00
------------+-----------------------------------
菜单窗口
• 在Stata的窗口菜单下,有多种描述数据频数分布 特征的选项,每一选项都具有一定独特的功能, 但有些功能是相通的
窗口路径 Table of summary statistics (table) Table of summary statistics (tabstat) One/two-way table of summary statistics One-way tables Multiple one-way tables Two-way tables with measure of ass. All possible two-way tabulations Table calculator
stata绘图基本知识

3.散点的大小msize(markersizestylelist) 输入graph query markersizestyle可以查找完整的markersizestyles清单
4.散点的整体设定 默认情况下,Stata会为第一个散点图选定p1,为第二个散点图选定p2 scatter y1var y2var xvar scatter y1var y2var xvar, mstyle(p1 p2) 默认情况下,Stata会为第一个散点图选定p1,为第二个散点图选定p2
over( )设定分组变量,变量可以是数值型或者字符型变量,可以设 置多达3个的分组变量。
sort()用于排序,sort(1)表明按照第一个分组变量排序。
例3
散点标签选项
选项mlabel(varname)用于设定标签变量;
选项mlabposition(clockposstyle)和mlabvposition(varname)用于设定 标签的位置,它们之间是可以相互替代的;
么就需要轴线选择选项进行设定。
例7
连线选项connect(connectstyle) 决定了是否以及如何将相邻的两点连接起来,如果不连接,就相当于
设定了(connect(i)),这也正是scatter散点图默认的情况: 如果以直线连接,就相当于设定了(connect(l))。
Stata数据可视化与图形绘制入门说明书
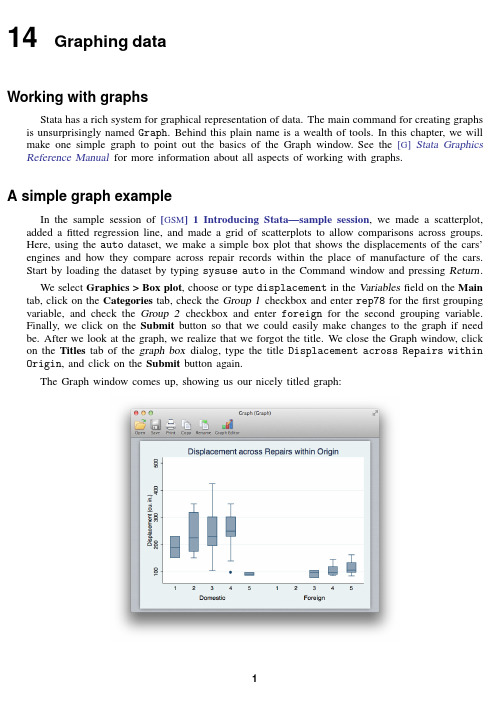
14Graphing dataWorking with graphsStata has a rich system for graphical representation of data.The main command for creating graphs is unsurprisingly named Graph.Behind this plain name is a wealth of tools.In this chapter,we will make one simple graph to point out the basics of the Graph window.See the[G]Stata Graphics Reference Manual for more information about all aspects of working with graphs.A simple graph exampleIn the sample session of[GSM]1Introducing Stata—sample session,we made a scatterplot, added afitted regression line,and made a grid of scatterplots to allow comparisons across groups.Here,using the auto dataset,we make a simple box plot that shows the displacements of the cars’engines and how they compare across repair records within the place of manufacture of the cars.Start by loading the dataset by typing sysuse auto in the Command window and pressing Return.We select Graphics>Box plot,choose or type displacement in the Variablesfield on the Main tab,click on the Categories tab,check the Group1checkbox and enter rep78for thefirst grouping variable,and check the Group2checkbox and enter foreign for the second grouping variable.Finally,we click on the Submit button so that we could easily make changes to the graph if need be.After we look at the graph,we realize that we forgot the title.We close the Graph window,click on the Titles tab of the graph box dialog,type the title Displacement across Repairs within Origin,and click on the Submit button again.The Graph window comes up,showing us our nicely titled graph:12[GSM]14Graphing dataGraph windowWhen the Graph window comes up,it shows our graph in a window with a toolbar.Thefirst four buttons are familiar to us from other Stata windows:Open,Save,Print,and Copy.The next two buttons are new:Rename Graph:This button allows the graph to be renamed.Why would you do this?If you would like to have multiple graphs open at once,the graphs need to be named.So you can click on the Rename button to give a graph a name.This graph will thenremain open when you create your next graph.Graph Editor:Stata has a Graph Editor that allows you to manipulate and edit yourgraph.This feature will be introduced in the next chapter.We decide that we like this graph and would like to save it.We can save it either by clicking on the Save button and choosing a name and a location or by right-clicking on the Graph window itself and selecting Save As....Saving and printing graphsYou can save a graph once it is displayed by right-clicking on its window and selecting Save As....You can print a graph by right-clicking on its window and selecting Print....You can also use the File menu to save or print a graph.Right-clicking on the Graph windowRight-clicking on the Graph window displays a menu from which you can select the following:•Save As...to save the graph to disk.•Copy to copy the graph to the Clipboard.•Start Graph Editor to start the Graph Editor.•Preferences...to edit the preferences for graphs.•Print...to print the graph.The Graph buttonThe Graph button,,is located on the main toolbar.Clicking on the button brings the topmost Graph window to the front of all other windows.Hold down the button to select a Graph window to bring it to the front of all other windows.If you close the Graph window,you can reopen it only by reissuing a Stata command that draws a new graph.。
stata的plot用法

stata的plot用法Stata是一款广泛使用的统计分析软件,它提供了丰富的绘图功能,可以帮助用户更好地理解数据。
在Stata中,plot命令是绘制图形的主要命令之一,它可以绘制各种类型的图形,包括散点图、线图、柱状图等。
本文将介绍Stata中plot命令的用法。
一、plot命令的基本语法plot命令的基本语法如下:plot yvar xvar1 xvar2 ..., options其中,yvar表示纵轴变量,xvar1、xvar2等表示横轴变量,options 表示绘图选项。
下面我们将详细介绍各个参数的用法。
二、绘制散点图散点图是一种常用的数据可视化方式,可以帮助我们观察两个变量之间的关系。
在Stata中,我们可以使用plot命令绘制散点图,具体语法如下:plot yvar xvar, options其中,yvar表示纵轴变量,xvar表示横轴变量,options可以指定图形的样式、颜色等参数。
例如,下面的代码可以绘制一张简单的散点图:sysuse autoplot mpg weight, title("Scatter plot of mpg and weight")xlabel("Weight") ylabel("Miles per gallon")该命令将绘制一张以汽车重量为横轴、每加仑油耗为纵轴的散点图,图形标题为“Scatter plot of mpg and weight”。
三、绘制线图线图是一种常用的数据可视化方式,可以帮助我们观察变量随时间变化的趋势。
在Stata中,我们可以使用plot命令绘制线图,具体语法如下:plot yvar xvar, options其中,yvar表示纵轴变量,xvar表示横轴变量,options可以指定图形的样式、颜色等参数。
例如,下面的代码可以绘制一张简单的线图:webuse sp500tsset dateplot sp500, title("S&P 500 index") xlabel(, format(%tm)) ylabel("Index")该命令将绘制一张以时间为横轴、S&P 500指数为纵轴的线图,图形标题为“S&P 500 index”。
Stata中的图形制作(绝对自己总结)

第三章 Stata 中的图形制作1.菜单操作2.直方图:用矩形的面积(即长度和宽度)来表示频数分布的图形。
D e n s i t y3.散点图:反映两个或多个变量之间的关系。
通常用纵轴来表示因变量,用横轴来表示自变量。
基本[twoway] scatter y x因变量在前数据标记的设定数据标记形状的设定、颜色的设定、大小的设定、散点标签的设定msymbol(散点形状代码);mcolor(red)散点为红色;msize(5)散点大小为5号散点标签:mlabel (标签内容的变量名)和mlabposition(代表钟表点数的数字)例如设定散点的内容为变量city,位置在3点钟处:mlabel (city) mlabposition(3)群组划分:by(foreign)案例:运用usaauto数据文件中的数据绘制mpg和weight关系的散点图。
(1)为图形添加标题“mpg与weight散点图”和副标题“1978年美国汽车数据图”;(2)为图形添加图例,位置在钟表2点钟处;(3)绘制一条拟合的趋势曲线;(4)将散点的形状设置为实心大三角,颜色为黑色;(5)为每个散点添加标签,内容为汽车的品牌(make),位置为9点钟处,颜色为黑色;(6)按照变量foreign分成两个图形进行绘制。
Twoway scatter mpg weight||lfit mpg weight,title(mpg与weight散点图) subtitle(1978年美国汽车数据图) legend(position(6))||表示多个图形在一个坐标轴中显示;lfit mpg weight绘制拟合曲线进一步设置:Msymbol(T) mcolor(black) mlabel(make) mlabpositon(9) by(foreign)4.曲线标绘图用线段的升降趋势来说明现象变化或变量之间关系的一种图形。
它与散点图类似,实际上它就是将连续型的数值变量点连接起来的一种图形,但由于它还可以用于回归曲线的绘制。
Stata_画图专题(2):基础绘图命令汇编

节链接
1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8
图形名称
函数图 散点图 直方图 条形图 点统计图 箱线图
饼图 矩阵图
表 1: Stata 中常用图形
命令关键词
说明
twoway function
[twoway] scatter
[twoway] histogram graph bar graph dot graph box graph pie graph matrix
绘制普通的数学、统计函数图形(与数据库数据无关) 用两组数据构成多个坐标点,考察坐标点的分布a 由一系列高度不等的纵向条纹或线段表示某一组数据分布情况b 用于显示多组数据间某些项目的比较情况,如均值、频数等 用点来描绘统计量的值,进而进行组与组间的比较 只用 5 个点c 对数据集做简单的总结,又因形状如箱子而得名 显示一个数据系列中各项的大小与其占比 将多个变量两两做散点图后类似矩阵元素般放入图中
• “堆叠”,即表示多个柱状图叠在一起(看累计总值及每组占比),命令是 stack。
其余的选项请 help graph bar 来查看。上述两行命令区别是第二行命令只是水平 (horizontal) 形式的条形图。
表 3: 描述统计命令 命令 含义
mean median
STATA-第三章-正态检验与基本作图命令
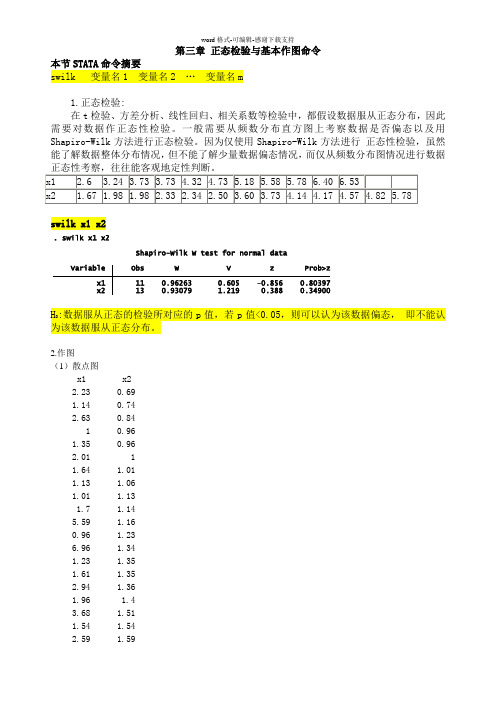
第三章 正态检验与基本作图命令 本节STATA 命令摘要swilk 变量名1 变量名2 … 变量名m1.正态检验:在t 检验、方差分析、线性回归、相关系数等检验中,都假设数据服从正态分布,因此需要对数据作正态性检验。
一般需要从频数分布直方图上考察数据是否偏态以及用Shapiro-Wilk 方法进行正态检验。
因为仅使用Shapiro-Wilk 方法进行 正态性检验,虽然能了解数据整体分布情况,但不能了解少量数据偏态情况,而仅从频数分布图情况进行数据正态性考察,往往能客观地定性判断。
x1 2.6 3.24 3.73 3.73 4.32 4.73 5.18 5.58 5.78 6.40 6.53x2 1.67 1.98 1.98 2.33 2.34 2.50 3.60 3.73 4.14 4.17 4.57 4.82 5.78swilk x1 x2H 0:数据服从正态的检验所对应的p 值,若p 值<0.05,则可以认为该数据偏态, 即不能认为该数据服从正态分布。
2.作图(1)散点图x1x2 2.230.69 1.140.74 2.630.84 10.96 1.350.96 2.011 1.641.01 1.131.06 1.011.13 1.71.14 5.591.16 0.961.23 6.961.34 1.231.35 1.611.352.941.36 1.961.4 3.681.51 1.541.542.59 1.59x2 13 0.93079 1.219 0.388 0.34900 x1 11 0.96263 0.605 -0.856 0.80397Variable Obs W V z Prob>zShapiro-Wilk W test for normal data. swilk x1 x24.5 1.613.92 1.6410.33 1.78.23 1.742.07 1.964.9 2.016.84 2.076.42 2.083.72 2.236 2.491.352.591.062.630.74 2.940.96 31.16 3.682.083.720.69 3.920.68 4.50.84 4.811.34 4.91.4 5.121.51 5.212.49 5.591.74 61.59 6.421.36 6.843 6.964.81 8.235.21 10.33输入:scatter x1 x2(第一个输入变量为纵轴,第二个为横轴)(2)连线散点图scatter x1 x2,connect(1) // connect(1)表示以直线的方式连接相邻的两个点.(3)去散点连线图scatter x1 x2,connect(1) msymbol(i) // msymbol(i)表示散点看不见;msymbol(o)表示以黑圆方式显示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A
14
例1
.tab girl enroll, chi2 column row miss nokey ① ② ③④⑤
①: 提供两个变量关系的卡方 ②: 提供列变量的百分比 ③: 提供行变量的百分比 ④: 提供缺失变量的比例 ⑤: 压缩单元格内容的提示
A
15
girl |
school enrollment
. tab girl
– 该命令告诉Stata,给变量girl生成一张频数分布表
A
10
girl in |
2004, 0=boy |
---1=girl |
Freq. Percent
Cum.
------------+-----------------------------------
0|
1,248
53.70
Multiple one-way tables Two-way tables with measure of ass. All possible two-way tabulations Table calculator
相应的基本命令 .table .tabstat .tabulate…, sum(…) .tabulate …, subpop(…) .tab1 .tab .tab2 .tabi
A
6
频数与频数分布
• 频数也称次数,即分布在各个类别中的数据个数 • 频数分布就是对样本中变量的不同属性出现次数的描述
– 假如一个班60%的同学是女生,40%的同学是男生,则60%和40%是 女生和男生的分布情况
– 2000年人口普查显示,中国7%的人群年龄在65岁及以上,则7%是 当时老年人口在总人口中所占的比例
A
11
多变量频数分布
. tab1 [变量a 变量b 变量c]
①
②
①:同时获得多个变量频数分布的基本命令
②:需要输出频数分布的变量名称
• 与tab或tabulate不同的是, . tab1可接多个变量
. tab girl urban
– 该命令告诉Stata,给变量girl和urban各自生成一张频数分布表
53.70
1|
1,076
46.30
100.00
------------+-----------------------------------
Total |
2,324
100.00
• 输出结果显示,该数据一共有2324个观察值 • 变量girl有两个取值:0代表男孩,1代表女孩 • 样本中有1248个男孩,占53.7%;女孩为1075,占46.3%
A
7
菜单窗口
• 在Stata的窗口菜单下,有多种描述数据频数分布 特征的选项,每一选项都具有一定独特的功能, 但有些功能是相通的
Aห้องสมุดไป่ตู้
8
窗口路径 Table of summary statistics (table) Table of summary statistics (tabstat) One/two-way table of summary statistics One-way tables
A
12
6.2.条件频数分布
条件频数分布也称交叉频数表为或 列联表,同时生成两个变量之间关系 的频数分布,属于相关分析中的一种.
A
13
基本命令
• .tab提供、且只能提供双变量的交叉分析,生成二者之间 的交叉频数分布,相当于命令tabulate
– 若其令后面仅有一个变量,则Stata输出该变量的频数分布
功能 计算展示多种统计量 计算展示多种统计量 提供均值和标准误
单变量的频数分布
多个变量的频数分布 两个变量的交叉表 多个变量的交叉表 利用指定的数值计算
A
9
单变量频数分布
. tab [变量名] ①②
①:. tab也可写为tabulation,是获得频数分布的基本命令 ②:需要输出频数分布的变量名称 • 该命令不对频数分布作任何定义,只提供单个变量的频数分布
0=boy |
1=enrolled --- 0=not
---1=girl |
0
1
.|
Total
-----------+---------------------------------+----------
0|
96
735
294 |
1,125
|
8.53
65.33
26.13 |
100.00
|
59.63
51.91
A
3
数据描述的方法
• 获得数据的目的是为了描述和分析数据,回答研究问题
• 数据分析的第一步是描述变量的基本特征。只有在熟悉数 据的基本特征和变量分布的基础上,才能决定如何对数据 作进一步处理
• 描述性统计通过一系列的程序帮助组织、归纳、总结样本 的基本特征。常见的方法包括
– 频数分布、百分比、分位数、均值和标准差、中数、众数、最大 值和最小值等单变量分析(univariate analysis)。考察变量的属
56.11 |
53.55
-----------+---------------------------------+----------
1|
第三讲 描述性分析与画图
A
1
• 进行描述性统计分析的目的:
• 对数据进行描述性分析的目的是熟悉和了 解数据的基本统计特征,把握数据的总体 分布形态,进而决定如何对数据作进一步 处理,进而回答所要研究的问题。
A
2
本章主要内容
6.1.频数分布 6.2.条件频数分布 6.3.频数分布的常见错误分析及解决方法 6.4.变量的中央趋势和离散趋势 6.5.描述数值型数据统计量的其它方法 6.6.画图
性分布
– 二元或多元交叉表、二元相关关系分析
– 图形
A
4
描述性分析的菜单窗口
该内容是statistics菜单下的首个选项: Statistics – Summaries,tables & tests
A
5
6.1.频数分布
频数、比例(proportion)、百分比 (percentage)和比率(ratio)等描述性统 计方法适用于所有类型数据,包括定性、 定序、定距和定比数据。
– 若多于两个变量,则会出现错误提示
• Stata的默认方法是,tab后面的第一个变量被当成行变量, 第二个变量被当成列变量
• .tab2也提供双变量的交叉分析表
• .tab和tab2的主要区别在于,前者仅可以用于两个变量的 交互分析(tab后面最多只能有两个变量);tab2可同时 生成多个两两变量之间的交互频数分布表