正态分布做法
怎么画标准正态分布

怎么画标准正态分布标准正态分布是统计学中非常重要的概念,它在各个领域都有着广泛的应用。
在绘制标准正态分布曲线时,需要遵循一定的步骤和方法。
下面我将详细介绍如何画标准正态分布曲线。
首先,我们需要了解标准正态分布的概念。
标准正态分布是指均值为0,标准差为1的正态分布。
它的概率密度函数图形呈现为一个钟形曲线,左右对称,且曲线下面积为1。
在实际绘制标准正态分布曲线时,我们通常使用统计软件或者计算机绘图工具来完成。
其次,我们需要明确标准正态分布曲线的特点。
标准正态分布曲线的中心位于均值处,曲线在均值处达到最高点,然后逐渐向两侧下降。
曲线的形状由标准差决定,标准差越大,曲线越矮胖;标准差越小,曲线越瘦高。
接下来,我们可以开始绘制标准正态分布曲线。
首先,确定横轴和纵轴的范围。
横轴通常表示变量的取值范围,纵轴表示概率密度。
然后,我们需要计算出各个取值点对应的概率密度值,这可以通过标准正态分布表或者统计软件来进行计算。
接着,将这些点连成平滑的曲线,就得到了标准正态分布曲线。
在绘制标准正态分布曲线时,需要注意一些细节。
首先,曲线的平滑程度要求较高,可以使用光滑曲线工具或者增加取值点来实现。
其次,标注均值和标准差的位置,这有助于更直观地理解曲线的特点。
最后,可以添加一些辅助信息,如曲线下面积表示概率,或者在曲线上标注一些特定取值点的概率密度值。
总之,绘制标准正态分布曲线需要我们对标准正态分布的特点有深入的理解,同时需要掌握一定的绘图技巧。
通过本文的介绍,相信大家对如何画标准正态分布曲线有了更清晰的认识。
希望本文能够对大家有所帮助。
正态分布图制图步骤知识讲解

操作说明
1.统计数据个数;任意选个单元格,如B1,输入
count(A1:A10);
2.求最大值;如B2中输入:max(A1:A10)
3.求最小值;如B3中输入:min(A1:A10)
4.求平均值;如B4中输入:average(A1:A10)
5.求标准偏差:如B5中输入:stdev(A1:A10)
6.获得数据区间;用最大值减最小值;如B6中输入:B3-B2
7.获得直方图个数;个数的开放加1
,如B7中输入:sqrt
(B1)+1
8.获得直方图组距;用区间除以(直方图个数-1),如B8中输入B7/(B7-1)
下面就开始作图了:
1.任选个空单元格:如C列第一个单元格C1,令C1等于最小值,即输入=B3
2.在C2中输入=C1+$B$8 (最小值逐渐累加,绝对引用)
3.选中C2,然后向下拉,直到数据大于最大值就可以了;比如你拉到C5了。
4.统计频数,如在D1中输入frequency(A1:A10,C1:C5)确定,然后将选中D1到D5,将光标定位到公式栏,同时按住Ctrl+Shift+Enter
5.统计正态分布的数据,E1中输入normdist(C1,
$B$4,$B$5,0)回车;然后选中E1,下拉到E5。
正态分布详解(很详细)

f (x)
1
e ,
(
x )2 2 2
x
2
用求导的方法可以证明, x=μσ
为f (x)的两个拐点的横坐标。
这是高等数学的内容,如果忘记了,课下 再复习一下。
根据对密度函数的分析,也可初步画出正 态分布的概率密度曲线图。
回忆我们在本章第三讲中遇到过的 年降雨量问题,我们用上海99年年降雨 量的数据画出了频率直方图。
定理1
设 X ~ N (, 2 ) ,则Y X ~N(0,1)
根据定理1,只要将标准正态分布的分布 函数制成表,就可以解决一般正态分布的概 率计算问题.
四、正态分布表
书末附有标准正态分布函数数值表,有了
它,可以解决一般正态分布的概率计算查表.
(x) 1
x t2
e 2 dt
2
表中给的是x>0时, Φ(x)的值.
下面我们在计算机上模拟这个游戏: 街头赌博
高尔顿钉板试验
平时,我们很少有人会去关心小球 下落位置的规律性,人们可能不相信 它是有规律的。一旦试验次数增多并 且注意观察的话,你就会发现,最后 得出的竟是一条优美的曲线。
高 尔 顿 钉 板 试 验
这条曲线就近似我们将要介 绍的正态分布的密度曲线。
正态分布的定义是什么呢?
由于连续型随机变量唯一地由它 的密度函数所描述,我们来看看正态 分布的密度函数有什么特点。
请看演示 正态分布
二、正态分布 N (, 2 ) 的图形特点
正态分布的密度曲线是一条关于 对
称的钟形曲线. 特点是“两头小,中间大,左右对称”.
正态分布 N (, 2 ) 的图形特点
决定了图形的中心位置, 决定了图形
P(|Y | 3 ) 0.9974
正态分布计算方法

正态分布计算方法嘿,咱今儿就来聊聊正态分布计算方法!这正态分布啊,就像是生活中的很多事儿一样,有它自己的规律呢!你看哈,正态分布就像是一群人站成一排,大部分人都在中间,两边的人就比较少。
这中间的“大部队”就是最常见的情况呀!那怎么去算它呢?咱先得搞清楚几个关键的东西。
比如说均值,这就像是这群人的平均位置,是个很重要的参考点呢。
还有标准差,它就像是衡量这群人站得有多开或者多集中的一个指标。
计算正态分布的时候,咱可以想象成在给这些人排队分位置呢。
先找到均值这个中心,然后根据标准差来看看两边的范围有多大。
比如说,咱假设有个正态分布,均值是 50,标准差是 10。
那离均值一个标准差范围内的,不就是 40 到 60 之间嘛。
这一段里的情况就比较常见咯。
然后呢,咱可以通过一些公式来具体算算某个值出现的概率。
这就好像是在问,在这群人里,找到一个特定身高的人的可能性有多大。
哎呀,这正态分布计算方法其实也不难理解嘛,对吧?咱把它想象成生活中的例子,不就好懂多啦!你想想,考试成绩很多时候不就是正态分布嘛!大部分人都在中间的分数段,特别高和特别低的都比较少。
那咱要是会算正态分布,不就能大概知道自己的成绩在整个群体里处于啥位置啦?再比如说,人的身高啊、体重啊,很多也都符合正态分布呢。
咱知道了计算方法,就能更好地了解这些数据背后的意义呀!总之呢,正态分布计算方法虽然听起来有点高大上,但只要咱用心去理解,把它和生活中的例子联系起来,就会发现它其实挺有趣,也挺有用的呢!别被那些公式和概念吓住啦,勇敢地去探索,你肯定能掌握它的!就像咱生活中遇到困难,只要勇敢面对,总能找到解决办法一样!加油吧!。
生成正态分布-概述说明以及解释

生成正态分布-概述说明以及解释1.引言1.1 概述概述部分的内容如下:正态分布,也被称为高斯分布或钟形曲线,是统计学和概率论中最重要的分布之一。
它在自然界、社会科学和经济学等领域都有广泛应用。
正态分布的形状呈现出对称的钟形曲线,其特点是均值处有最大密度,随着离均值的距离增加,密度逐渐减小。
其概率密度函数是通过一个简单的数学公式来描述的。
生成正态分布的方法有多种,其中一种常用的方法是使用随机数生成器。
通过使用特定的算法和随机种子,可以生成服从正态分布的随机数。
另一种常用的方法是利用中心极限定理,当多个独立同分布的随机变量相加时,其分布趋近于正态分布。
这种方法在模拟实验和推断统计中经常被使用。
本文将详细介绍正态分布的概念和性质,并探讨生成正态分布的方法。
在正文部分,我们将从数学和统计的角度解释正态分布的含义,并介绍其重要的特性,如均值和标准差。
然后,我们将详细介绍生成正态分布的方法,包括随机数生成器和中心极限定理的原理和应用。
总结部分将对文章进行总结,并探讨正态分布的应用前景。
正态分布在各个领域都有广泛的应用,如自然科学中的测量误差分析、社会科学中的人口统计和经济学中的金融市场分析等。
正态分布的生成方法对于模拟实验、数据分析和统计推断都具有重要的意义。
通过深入了解正态分布的生成方法,我们可以更好地理解和应用这一重要的概率分布。
综上所述,本文旨在介绍正态分布及其生成方法,并探讨其应用前景。
通过阅读本文,读者将对正态分布有更深入的理解,并能够灵活运用生成正态分布的方法进行数据分析和模拟实验。
1.2文章结构文章结构是指文章整体的布局和组织方式。
一个良好的文章结构可以使读者更好地理解文章内容,并且有助于文章的逻辑性和连贯性。
本文的结构如下:1. 引言1.1 概述引言部分将简要介绍正态分布的基本概念和重要性,引起读者的兴趣,并提出本文的研究目的。
1.2 文章结构本文将主要分为引言、正文和结论三个部分。
其中,引言部分将介绍本文的研究背景和目的;正文部分将详细探讨正态分布的定义、性质以及生成正态分布的方法;结论部分将总结文章的主要内容并展望正态分布的未来应用前景。
正态分布怎么标准化

正态分布怎么标准化正态分布是统计学中非常重要的一种分布形式,也称为高斯分布。
在实际应用中,我们经常会遇到需要对正态分布进行标准化的情况,以便进行统计分析和比较。
那么,正态分布怎么标准化呢?接下来,我们将详细介绍正态分布的标准化方法。
首先,让我们来回顾一下正态分布的概念。
正态分布是一种连续概率分布,其概率密度函数呈钟形曲线,左右对称,呈现出集中趋势和稳定性的特点。
正态分布的均值为μ,标准差为σ。
在实际应用中,我们经常需要对不同的正态分布进行比较和分析,而这就需要将它们标准化为标准正态分布。
标准正态分布是均值为0,标准差为1的正态分布,其概率密度函数可以用Z来表示。
标准化正态分布的目的是为了使不同的正态分布具有可比性,便于进行统计推断和分析。
接下来,我们将介绍正态分布的标准化方法。
要将一个正态分布标准化为标准正态分布,我们需要进行以下步骤:1. 计算Z分数。
Z分数是用来衡量一个数值与均值之间的差异程度的标准化分数。
计算Z分数的公式为,Z = (X μ) / σ,其中X为原始数值,μ为均值,σ为标准差。
通过这个公式,我们可以将原始数值转化为与标准正态分布相对应的Z分数。
2. 利用Z分数表。
一旦得到了Z分数,我们就可以利用Z分数表来查找对应的概率值。
Z分数表是用来帮助我们找到标准正态分布下对应Z分数的累积概率值的工具。
通过查表,我们可以得到标准正态分布下对应Z分数的累积概率值,从而进行统计推断和分析。
3. 应用标准化结果。
一旦得到了标准化的结果,我们就可以利用这些结果进行统计推断和分析。
通过标准化,我们可以比较不同的正态分布,计算置信区间,进行假设检验等统计分析,从而得出科学、准确的结论。
总结一下,正态分布的标准化方法主要包括计算Z分数、利用Z分数表和应用标准化结果三个步骤。
通过这些步骤,我们可以将不同的正态分布标准化为标准正态分布,从而进行统计推断和分析。
希望本文的介绍能够帮助大家更好地理解正态分布的标准化方法,为实际应用提供帮助。
一步一步教你作正态分布图

=NORMDI ST(A2,Av gValue,S DValue,F ALSE) NORMDIS T函数帮助 信息:
=IF((ROU
ND(A2,Ma
in!$C$2)=
控制上限
ROUND(U pValue,M
ain!$C$2))
,MAX(B:B)
*1.15,NA()
=IF((ROU
ND(A2,Ma
in!$C$2)=
目标值
ROUND(T gtValue,M
ain!$C$2))
,MAX(B:B)
*1.15,NA() 定义名称:
数据的小数位数
1
数据个数
298
最大值
479
最小值
406
平均值
441
标准偏差
11.6
目标值
440
控制上限
460
控制下限
420
控制下限
目标值
控制上限
1 2
34正态来自分布图
5
391.4 398.4 405.4 412.4 419.4 426.4 433.4 440.4 447.4 454.4 461.4 468.4 475.4 482.4 489.4
(目的是作
图时易于控
制数据源) =OFFSET
(Calculati
on!$A$1,1
ChartData ,0,COUNT
A(Calculat
ion!$A:$A)
如何用EXCEL制作正态分布图

0
0.0000
499 499.3 499.6 499.9 500.2 500.5 500.8 501.1 501.4 501.7 502 502.3 502.6 502.9 503.2 503.5
你会做了吗 ?
先介绍一个函数
正态分布函数的语法是 =NORMDIST(x,mean,standard,cumulative)
X是变量; mean是均值; standard是标准偏差; Cumulative是一个逻辑值,如果为0则是密度函 数,如果为1则是累积分布函数。如果画正态分布 图,则为0。
1、统计完数据,录入EXCEL表格
如何用EXCEL制作正态分布图
查阳春
2013年6月W5净含量直方图 --正态分布图
40
0.5
35
0.45
0.4 30
0.35
25
0.3
20
0.25
15
0.2
0.15 10
0.1
5
0.05
0
0
499 499.3 499.6 499.9 500.2 500.5 500.8 501.1 501.4 501.7 502 502.3 502.6 502.9 503.2 503.5
2、统计完数据后,数据初步分析
3.做好直方图数据的准备 正态分布密度函数的录入
4、选中数据源,准备作图
选择堆积柱状图
将此系列删除
选择顶部正态分布系列
选择平滑曲线散点图
选择正态分布图系列,更改数据系列格式
选择次纵坐标
有点像了,还要优化
更改曲线颜色及标记
更改直方图间距、颜色、边框
现在更像了,底部的坐标要修改
选择底部坐标,选择数据
Excel表格中如何制作正态分布数据图和正态曲线模板

Excel表格中如何制作正态分布数据图和正态曲线模板Excel制作模板主要是方便直接使用,以后只要将新的样本数据替换,就可以随时做出正态分布图来,很简单。
以下是店铺为您带来的关于Excel表格中制作正态分布数据图和正态曲线模板,希望对您有所帮助。
Excel表格中制作正态分布数据图和正态曲线模板计算均值,标准差及相关数据1、假设有这样一组样本数据,存放于A列,首先我们计算出样本的中心值(均值)和标准差。
如下图,按图写公式计算。
为了方便对照着写公式,我在显示“计算结果”旁边一列列出了使用的公式。
公式直接引用A列计算,这样可以保证不管A列有多少数据,全部可以参与计算。
因为是做模板,所以这样就不会因为每次样本数据量变化而计算错误。
Excel在2007版本以后标准差函数有STDEV.S和STDEV.P。
STDEV.S是样本标准偏差,STDEV.P是基于样本的总体标准偏差。
如果你的Excel里没有STDEV.S函数,请使用STDEV函数。
2、正态分布直方图需要确定分组数,组距坐标上下限等。
如下图写公式计算。
分组数先使用25,上下限与中心值距离(多少个sigma)先使用4。
因为使用公式引用完成计算,所以这两个值是可以任意更改的。
这里暂时先这样放3、计算组坐标。
“组”中填充1-100的序列。
此处列了100个计算值。
原因后面再解释。
在G2,G3分别填入1,2。
选中G2,G3单元格,将鼠标放在右下角选中框的小黑方块上。
当鼠标变成黑色十字时,下拉。
直至数值增加至100。
如下两图4、如下图,H2输入公式=D9,H3单元格输入公式=H2+D$7。
为了使公式中一直引用D7单元格,此处公式中使用了行绝对引用。
5、选中H3单元格,将鼠标放在右下角选中框的小黑方块上。
当鼠标变成黑色十字时双击,填充H列余下单元格。
6、计算频数。
如图所示,在I2,I3分别填写公式计算频数。
同样,选中I3单元格,将鼠标放在右下角选中框的小黑方块上。
当鼠标变成黑色十字时双击,填充I列余下单元格。
正态分布的计算方法

正态分布的计算方法
正态分布那可是老厉害了!咱先说说计算方法吧。
首先得确定均值和标准差呀!这就好比盖房子得先有个牢固的地基一样。
有了均值和标准差,就可以根据公式来计算概率密度啦。
计算的时候可一定要小心仔细,一个数算错了,那可就全乱套了。
你想想,要是盖房子的时候尺寸量错了,那房子还能结实吗?
在计算过程中,安全性那是杠杠的。
只要你按照正确的方法来,就不会出啥大问题。
就像走在平坦的大路上,只要你不瞎跑乱跳,就不会摔倒。
稳定性也没得说,每次计算结果都比较可靠。
这就像你信任的好朋友,关键时刻绝对不掉链子。
那正态分布的应用场景可多了去了。
在统计分析、质量控制等方面都大显身手。
比如说,生产产品的时候,可以用正态分布来判断产品是否合格。
这多方便呀!你说要是没有正态分布,那得费多大劲才能保证产品质量呢?正态分布的优势也很明显,它能很好地描述很多自然现象和社会现象。
就像一把万能钥匙,能打开很多难题的大门。
咱来举个实际案例吧。
比如说考试成绩,很多时候就符合正态分布。
成绩好的和成绩差的都是少数,大多数人都在中间水平。
通过正态
分布,老师就能更好地了解学生的学习情况,调整教学方法。
你想想,如果没有正态分布,老师怎么知道学生的整体水平呢?
总之,正态分布就是个超级厉害的工具,能帮我们解决很多问题。
咱可得好好掌握它,让它为我们服务。
一种正态分布随机数的生成方法

一种正态分布随机数的生成方法正态分布(Normal Distribution)是概率论和统计学中常见的一种连续型概率分布。
生成正态分布随机数的方法有很多,下面介绍几种常用的方法。
1.使用中心极限定理中心极限定理告诉我们,当随机变量的样本量足够多时,其均值的分布会趋近于正态分布。
因此,我们可以使用均匀分布的随机数来模拟正态分布。
具体方法如下:(2)计算这些随机数的平均值;(3)重复上述步骤多次,得到一组均值;(4)对这组均值进行标准化处理,即减去平均值再除以标准差,即可获得标准正态分布随机数。
这种方法的缺点是需要较多的随机数进行平均,因此生成较多的随机数时,效率较低。
2. 使用Box-Muller变换Box-Muller变换是一种经典的生成标准正态分布随机数的方法。
具体步骤如下:(1)生成两个服从均匀分布的独立随机数U1,U2(0~1之间);(2)计算变量Z1 = sqrt(-2 * log(U1)) * cos(2 * pi * U2) 和Z2 = sqrt(-2 * log(U1)) * sin(2 * pi * U2);(3)Z1和Z2分别服从标准正态分布。
这种方法的优点在于生成两个正态分布随机数,因此效率较高。
3.使用反函数法反函数法是一种基于累积分布函数(CDF)的方法。
正态分布的累积分布函数(CDF)是一个数学上比较复杂的函数,但可通过其他数学方法进行近似计算。
(1)计算累积分布函数的逆函数,即给定一个概率的值p(0~1之间),可以计算出对应的随机变量X;(2)使用均匀分布的随机数U(0~1之间),通过逆函数计算出对应的X;(3)得到一组服从正态分布的随机数。
这种方法需要事先计算好逆函数的值,并且逆函数的计算通常是比较复杂的。
4. 使用Ziggurat算法Ziggurat算法是一种高效生成正态分布随机数的方法。
它结合了Box-Muller变换和反函数法,并利用了一种特殊的分层结构,使得生成正态分布随机数的效率更高。
python 正态分布的运算

Python 是一种功能强大的编程语言,它提供了各种库和工具,可以用来进行数据分析、统计计算等操作。
其中,对正态分布的运算也是Python 可以很好地完成的工作之一。
正态分布在统计学中非常重要,在许多领域都有着广泛的应用,比如财务、自然科学、工程等。
本文将介绍使用 Python 进行正态分布相关运算的方法和技巧。
一、导入相关库要使用 Python 进行正态分布的运算,首先需要导入相关的库,最常用的库是 NumPy 和 SciPy。
NumPy 是 Python 中用于数值计算的一个强大库,它提供了高效的数组操作和数学函数。
而 SciPy 则是在NumPy 的基础上进一步扩展,提供了更多的科学计算工具和算法。
我们首先需要导入这两个库:import numpy as npfrom scipy.stats import norm二、生成正态分布随机数要生成服从正态分布的随机数,可以使用 NumPy 提供的 random 模块中的 normal 函数。
该函数的参数包括均值、标准差和生成的随机数个数。
我们可以生成均值为 0、标准差为 1 的正态分布随机数:np.random.seed(0)data = np.random.normal(0, 1, 1000)这段代码可以得到一个包含 1000 个服从正态分布的随机数的数组data。
在实际应用中,可以根据需要调整均值和标准差,生成符合要求的随机数序列。
三、计算正态分布概率密度函数值对于给定的正态分布随机变量 X,可以使用 SciPy 提供的 norm 模块中的 pdf 方法来计算其概率密度函数值。
概率密度函数可以用来描述随机变量落在某个区间内的概率密度,其计算公式为:其中μ 为正态分布的均值,σ 为正态分布的标准差。
通过调用 pdf 方法,可以得到某个特定数值的概率密度函数值。
计算 X=0 处的概率密度函数值:pdf_value = norm.pdf(0, loc=0, scale=1)四、计算累积分布函数值累积分布函数是概率密度函数的积分,描述了随机变量 X 小于等于某个数值的概率。
正态分布经验法则

正态分布经验法则正态分布经验法则是指在一组数据服从正态分布时,其中68%的数据落在均值加减标准差的范围内,95%的数据落在均值加减两倍标准差的范围内,99.7%的数据落在均值加减三倍标准差的范围内。
首先,我们需要了解什么是正态分布。
正态分布又称高斯分布,是一种常见的连续概率分布。
它以均值为中心,标准差为基础,呈现出钟型曲线的形态。
正态分布在统计学、自然科学、社会科学等领域中应用广泛。
第一步,计算均值和标准差。
均值是指数据集中的“平均值”,标准差是指数据偏离平均值的“平均值”。
通过这两个数据可以确定正态分布的中心位置和分布范围。
第二步,根据经验法则计算范围。
首先,均值加减一个标准差的范围内包含了数据集中的68%。
例如,若均值为100,标准差为10,则有68%的数据在90到110之间。
其次,均值加减两个标准差的范围内包含了数据集中的95%。
例如,若均值为100,标准差为10,则有95%的数据在80到120之间。
最后,均值加减三个标准差的范围内包含了数据集中的99.7%。
例如,若均值为100,标准差为10,则有99.7%的数据在70到130之间。
第三步,验证结果。
我们可以通过直方图等图表来验证正态分布经验法则的结果。
直方图可以将数据集分成若干个区间,并统计每个区间中数据的数量。
从直方图中可以看出数据集是否符合正态分布的特征。
正态分布经验法则的应用范围很广。
在金融领域,我们可以通过统计股票收益率的正态分布来预测股价波动范围。
在教育领域,我们可以通过统计学生成绩的正态分布来判断学生的表现。
在医学领域,我们可以通过统计健康数据的正态分布来评估人群的健康状况。
总之,正态分布经验法则能够准确预测数据分布的范围,为我们提供了一种简单有效的统计分析方法。
应用正态分布经验法则,我们可以更好地理解数据,准确预测结果。
说明利用正态分布近似计算二项分布的依据和具体做法

说明利用正态分布近似计算二项分布的依据
和具体做法
1二项分布及其正态分布近似
二项分布是统计学中一种广泛使用的概率分布,声明为随机试验的一系列有限次尝试中有正确结果的比率。
一般情况下,使用该分布的实验可以划分为两类:成功/失败或者对/错。
比如,发动机在试车中是发动/不发动,电子元器件在试验中是好/坏,抛物线上点是在/不在给定的位置等。
由于二项分布在实际应用中非常普遍,所以有一些计算它的推断统计量有用。
通常,这些推断统计量在一定条件下可以利用正态分布进行近似估计。
2正态分布近似的依据
要近似估计二项分布的推断统计量,必须先满足一些条件。
在该条件为真的前提下,正态分布可以很好地近似二项分布。
第一,试验的成功概率必须可以认为是小的(一般小于0.5);第二,每次试验的成功概率相当接近;第三,样本大小应当足够大(一般大于20)。
3正态分布近似的具体做法
在满足了上述三个条件后,我们可以用正态分布来近似估计二项分布的推断统计量。
具体过程如下:
第一步:计算二项分布的平均值μ和标准差σ。
μ表示成功的概率,σ表示误差的程度;
第二步:根据样本容量n和μ、σ,构造与二项分布同形的正态分布;
第三步:根据正态分布计算实际分布值;
第四步:以正态分布近似估计二项分布的推断统计量。
4结论
总而言之,在满足一定条件(试验的成功概率小,每次试验的成功概率接近,样本容量足够大)的情况下,我们可以用正态分布来近似估计二项分布的推断统计量,从而实现对二项分布的快速估计。
Excel制作学生成绩正态分布图
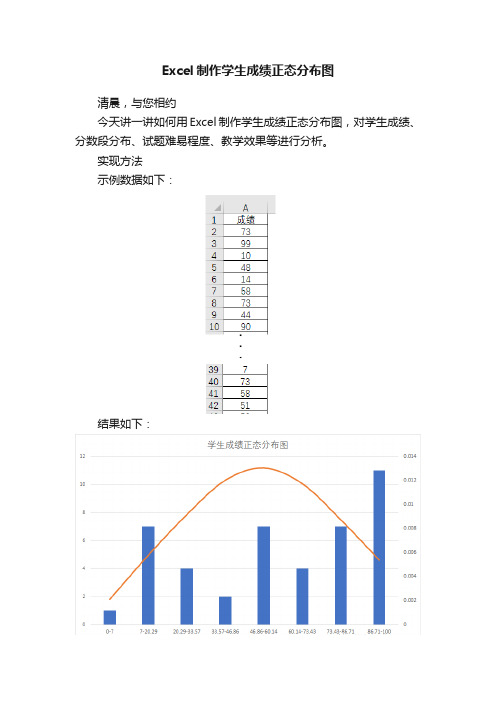
Excel制作学生成绩正态分布图清晨,与您相约今天讲一讲如何用Excel制作学生成绩正态分布图,对学生成绩、分数段分布、试题难易程度、教学效果等进行分析。
实现方法示例数据如下:结果如下:正态分布图中:1.成绩分数段直方图,显示各个分数段的人数;2.正态分布曲线的高峰位于平均成绩位置,由平均成绩所在处开始,分别向左右两侧逐渐均匀下降;3.直方图与曲线的对比分析,可以得到各种信息。
第一步:分析成绩对成绩进行分析,分析出最大值、最小值、极差(最大值—最小值)、成绩分段数量、分段间距。
下图是分析的结果及对应公式:第二步:确定分数段“分段点”就是确定直方图的横轴坐标起止范围和每个分数段的起止位置。
第一个分段点要小于等于最小成绩,然后依次加上“分段间距”,直到最后一个数据大于等于最高成绩为止。
实际分段数量可能与计算的“分段数”稍有一点差别。
如下图:第一个分段点7是手工输入,在第二个分段点H2处输入公式=H2+$D$6,往下填充,填出各个分段点。
第三步:计算段内人数选中I2:I9,输入公式:=FREQUENCY(A2:A44,H2:H9),<Ctrl+Shift+Enter>三键结束,即可算出各分数段人数。
关于FREQUENCY函数,请参考:Excel108 | FREQUENCY函数分段计数)第四步:计算成绩正态分布值选中J2,输入公式:=NORMDIST(I2,AVERAGE($A$2:$A$44),STDEV($A$2:$A$44), 0),确定并往下填充,即可得到每个成绩段的正态分布值,正态分布概率密度正态分布函数“NORMDIST”获取。
NORMDIST 函数:•返回指定平均值和标准偏差的正态分布函数语法:•NORMDIST(x,mean,standard_dev,cumulative)•NORMDIST 函数语法具有下列参数:•X 必需。
需要计算其分布的数值。
•Mean 必需。
分布的算术平均值。
正态分布随机数生成算法

正态分布随机数生成算法正态分布(也称为高斯分布)是统计学中非常重要的概率分布之一、生成服从正态分布的随机数是许多应用程序和模型的基本要求之一、下面将介绍几种常见的正态分布随机数生成算法。
1. Box-Muller算法:Box-Muller算法是最常见的生成服从标准正态分布(均值为0,标准差为1)的随机数的方法之一、它的基本思想是利用两个独立的、均匀分布的随机数生成一个标准正态分布的随机数对。
具体步骤如下:-生成两个独立的、均匀分布在(0,1)区间的随机数u1和u2- 计算z1 = sqrt(-2 * ln(u1)) * cos(2 * pi * u2)和z2 =sqrt(-2 * ln(u1)) * sin(2 * pi * u2)两个服从标准正态分布的随机数。
2. Marsaglia极坐标法:Marsaglia极坐标法也是一种生成服从标准正态分布随机数的方法。
它基于极坐标系的性质,即生成的随机数对所对应的点的距离(模长)服从Rayleigh分布,方向(角度)均匀分布。
具体步骤如下:-生成两个独立的、均匀分布在(-1,1)区间的随机数u1和u2-计算s=u1^2+u2^2,如果s>=1,则重新生成u1和u2- 计算f = sqrt(-2 * ln(s) / s)和z1 = f * u1,z2 = f * u2即为两个服从标准正态分布的随机数。
3. Box-Muller/Box-Muller Transformation组合方法:此方法是将两种算法结合起来,先用Box-Muller算法生成两个服从标准正态分布的随机数,然后进行线性变换得到多种均值和标准差的正态分布随机数。
4. Ziggurat算法:Ziggurat算法是一种近似生成服从标准正态分布随机数的算法,它基于分段线性逼近的思想。
Ziggurat算法将正态分布的概率密度函数拆分成多个长方形和一个截尾尾巴(tail)部分。
具体步骤如下:- 初始化一个包含n个长方形的Ziggurat结构,每个长方形包括一个x坐标、一个y坐标、一个面积。
正态分布如何标准化

正态分布如何标准化
首先,我们需要了解正态分布的特点。
正态分布是一种连续型的概率分布,其
曲线呈钟形,均值μ位于曲线的中心,标准差σ决定了曲线的宽窄。
正态分布的概率密度函数可以用数学公式表示为:
f(x) = (1/σ√(2π)) e^(-(x-μ)²/(2σ²))。
其中,f(x)表示随机变量X的概率密度函数,μ表示均值,σ表示标准差,e
表示自然对数的底。
接下来,我们来介绍正态分布的标准化方法。
标准化是将原始数据按照一定的
方法进行变换,使得其均值为0,标准差为1。
对于正态分布而言,标准化的方法
是利用z分数来实现的。
z分数的计算公式为:
z = (x μ) / σ。
其中,z表示标准化后的数值,x表示原始数值,μ表示均值,σ表示标准差。
通过标准化,我们可以将不同正态分布的数据进行比较和分析,消除了原始数
据的量纲和单位的影响,使得数据更加直观和易于理解。
在实际操作中,我们可以通过计算原始数据与均值的差值,再除以标准差,即
可得到标准化后的z分数。
在统计学中,z分数还可以用来计算累积概率,从而进
行概率统计和推断。
需要注意的是,标准化并不改变原始数据的分布形态,只是改变了其均值和标
准差,因此在进行数据分析时,我们仍然需要结合原始数据的特点进行综合分析。
总之,正态分布的标准化是一种重要的数据处理方法,通过标准化,我们可以
更好地理解和比较不同的正态分布数据,为统计分析提供了便利。
希望本文对您理解正态分布的标准化方法有所帮助。
正态分布做法
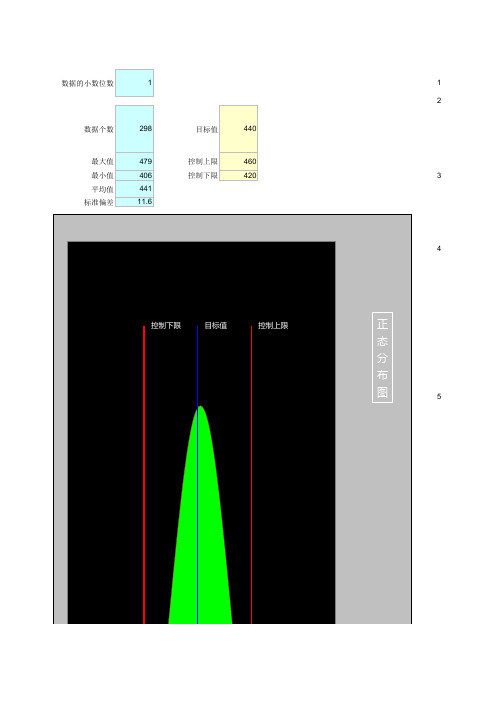
数据的小数位数112数据个数298目标值440最大值479控制上限460最小值406控制下限4203平均值441标准偏差11.64567在系列里将每个X=Normaldistrib Y=NormalDistri控制下限控制上限目标值391.4398.4405.4412.4419.4426.4433.4440.4447.4454.4461.4468.4475.4482.4489.4正态分布图不合格区域合格区域正态分布图数据控制上限第ab第三步,图表修第四步,如何去第制作步骤:在工作表Data里输入你的原始数据定义名称:Time=OFFSET(Data!$A$1,1,0,COUNTA(Data!$A:$A)-1,1)Data=OFFSET(Time,0,1)计算下列值:数据的小数位数可选数据个数可选最大值最小值平均值标准偏差定义名称:AvgValue=Main!$C$7LowValue=Main!$F$6MaxValue=Main!$C$5MinValue=Main!$C$6SDValue=Main!$C$8TgtValue=Main!$F$4UpValue=Main!$F$5在工作表Calculation里计算:数据刻度A2=ROUND(AvgValue-340*(MaxValue-MinValue)/500,Main!$C$2)A3~A1001=ROUND(A2+(MaxValue-MinValue)/500,Main!$C$2)正态分布图数据=NORMDIST(A2,AvgValue,SDValue,FALSE)NORMDIST函数帮助信息:NORMDIST(x,mean,standard_dev,cumulative)X 为需要计算其分布的数值。
Mean 分布的算术平均值。
Standard_dev 分布的标准偏差。
Cumulative 为一逻辑值,指明函数的形式。
如果 cumulative 为 TRUE,函数 NORMDIST 返回累积分布函数;如果为 FALSE,返回概率密度函数。
正态分布图作图指导-Normal distribution curve
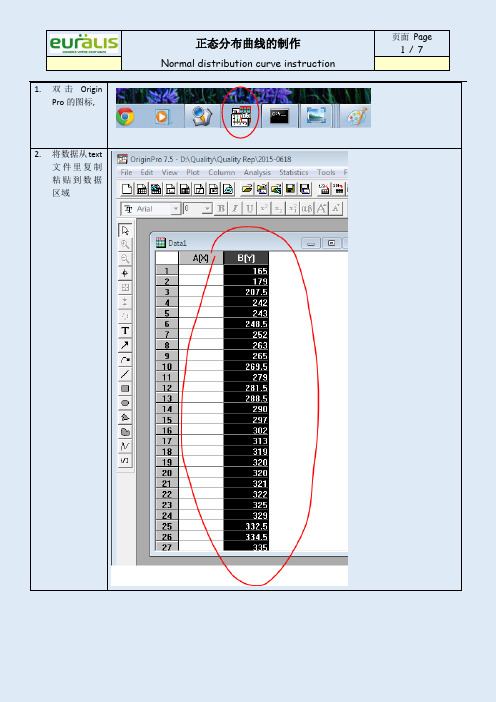
1.双击Origin
Pro的图标,
2.将数据从text
文件里复制
粘贴到数据
区域
3.按照如下路
径,选择频率
分
析.Frequency
Count
4.设置起点终
点和步进,一
般步进50,单
击ok
5.选择生成的
X,Y列数据,点
击plot,按如
下路径画图,
--------------------
6.对得到的柱
形图进行颜
色调整,默认
是红色。
7.单击菜单栏
的Analysis选
项,按照图中
路径,选择高
级拟合
(Advanced
Fitting Tool)
8.在Advanced
Fitting Tool
菜单界面选
择Action-Fit
9.弹出的对话
框,选择
Active
Dateset。
10.选择100Iter,
单击Done。
11.对模型的解
释框内容进
行删除,只保
留Model,
Equation,and
R2的信息。
12.右击边框,在
属性
Properties窗
口中去掉边
框。
13.对坐标轴进
行命名
14.右击空白区
域,弹出菜单
中单击添加
Text选项,添
加本图表的
制作日期。
15.右击图标空
白区域,探出
菜单中选择
Export Page
导出图片,图
片DPI选择
200,格式选
择png or jpg
16.最后,保存数
据。