Sybase IQ一直以其导出导入性能佳而著称
SybaseIQ非结构化数据解决方案

Sybase IQ非构造化数据处理方案Sybase IQ是Sybase企业推出旳尤其为数据仓库设计旳关系型数据库。
IQ旳架构与大多数关系型数据库不一样,它尤其旳设计用以支持大量并发顾客旳即时查询。
其设计与执行进程优先考虑查询性能,另一方面是完毕批量数据更新旳速度。
而老式关系型数据库引擎旳设计既考虑在线旳事务进程又考虑数据仓库(而实际上,往往更多旳关注事务进程)。
列存储IQ以列存储数据,而不是行——这与其他所有关系型数据库引擎广泛使用旳存储措施方向相反。
在其他关系型数据库内核中,数据库旳一张表经典旳表达为一条数据库页链,每一数据页中有一行或多行数据记录。
在数据仓库应用中,从查询性能旳观点出发,这种存储方式是所有也许旳数据存储方式中最不可取旳。
在IQ中,每张表是一组互相独立旳页链旳集合,每一页链代表表中旳一列。
因此有100 列旳表将有100 条互相独立旳页链,每一列均有一条页链与之对应,而不是象其他数据库引擎,一张表对应一条页链。
列存储所固有旳优越性在于:大多数数据仓库应用旳查询只关怀表中所有列旳一种很小旳子集,从而可以以很少旳磁盘I/O得到查询成果。
目前考虑这样一种例子,假设我们要得到所有生日在七月份旳客户旳名字和电子邮件地址。
在一种经典旳OLTP数据库引擎中,查询优化器将根据返回行旳比例(如1/12,在本例中,假设各月旳生日都基本平均)来决定与否值得在该列上使用索引。
因此,经典旳数据库引擎对该查询也许会做全表旳扫描。
为了对扫描旳成本做一估算,我们假设每个客户旳行记录为3200个字节,共有1000万个条记录。
因此,表扫描必须读取320亿个字节旳数据。
IQ数据库引擎可以只读取查询所需旳列。
在本例中,有三个有关旳列:全名、电子邮件地址和出生日期。
假设全名为25个字节,电子邮件地址为25个字节,出生日期为4个字节(日期以二进制做内部编码)。
那么IQ 只需要读取5400万个字节旳数据——大概减少了59倍!数据压缩老式旳数据库引擎不能以一种通用旳方式进行数据压缩,重要是由于存在如下三个问题:1. 第一种问题是其按行存储旳数据存储方式不利于压缩。
sybase数据库性能调整-电脑资料

sybase数据库性能调整-电脑资料数据库性能调优的一些小方面:1.1 性能指标数据库性能一般用两个方面的指标来衡量:响应时间和吞吐量,。
响应越快,吞吐量越大,数据库性能越好。
响应时间和吞吐量有些情况下不能一起得到改善。
1.2 调优级别对Sybase数据库性能调优,可以从四个方面进行:一) 操作系统级:对网络性能、操作系统参数、硬件性能等作改进。
二) SQL Server级:调整存取方法,改善内存管理和锁管理等。
三) 数据库设计级:采用降范式设计,合理设计索引,分布存放数据等。
四) 应用程序级:采用高效SQL语句,合理安排事务,应用游标,处理锁。
本文对第一、第三、第四方面的内容不做讨论,第二方面提到的概念只适用于Sybase数据库。
1.3 调优工具在分析Sybase数据库的性能时,要用到一些数据库系统本身提供的性能调优工具,包括几个系统存储过程:名称功能简要介绍sp_sysmon 企业级系统性能报告工具sp_lock 查看锁的情况sp_who 查看线程的活动情况sp_procqmode 存储过程的查询处理模式sp_configure 配置SQL Server系统级参数sp_estspace 估计创建一个表需要的空间和时间sp_spaceused 估计表的总行数及表和索引占用的空间sp_monitor 监视CPU、I/O的统计活动情况在利用isql等一些工具时,还可以设置查询会话中的几个选项,来显示SQL语句执行时的各种统计分析结果:指令 On 的含义set noexec on/off 分析SQL语句后,还要执行set statistics io on/off 统计SQL执行所需I/Oset statistics time on/off 统计SQL语句执行耗时set showplan on/off 显示查询计划1.4 sp_sysmon 的使用企业级性能报告工具、系统存储过程 sp_sysmon 的使用方法:在isql 下,首先输入 sp_sysmon 'begin_sample' 启动一个报告采样过一段时间后,再输入sp_sysmon 'end_sample' 结束上次报告采样或者紧跟一参数 sp_sysmon 'end_sample', "dcache" 结束上次报告采样,但只显示数据缓冲(Data Cache Management)这一部分的情况。
Sybase IQ列式数据库简介

c 4
c 5
c 6
c 7
c 8
c 9
…
r1
r2
r3 r4 r5
▪ 数据按列存储 – 每一列单独存放 ▪ 数据即是索引 ▪ 只访问查询涉及的列 – 大量降低系统IO ▪ 每一列由一个线索来处理 – 查询的并发处理 ▪ 数据类型一致,数据特征相似 – 方便压缩
15
传统数据库的局限
计算“NY”州 A类商店的 平均销售额
Sybas e
Oracle
Sun
Fujitsu Siemens
EMC EMC
24
I/O效率大幅提高
I/O页面大 小
I/O模式
OLTP 一次I/O 2K-16K
IQ 128K-1024K
跳跃型,离散式, 连续性,单道
并发度高
读磁盘
IQ优势 8-512倍
硬盘的要求 高转速,15000转/ 中低速, 7200- 简单,低散热 秒,FC或SCSI 10000转/秒, ,出错几率小
B
7
细节的前提下就可以平 3/1/96 49 NY
A
12
均减少90%以上的I/O
操作 17
Example: I/O 的明显减少
“CA州多少男性公民没有参加保险?
RDBMS
Gender
M
M
10M
F
ROWS
M
M
-
State
Insured
800 Bytes x 10M 16K Page
= 500,000 I/Os
公司/组织
Yahoo!
Nielsen Media Research
Database Size, All Environments, DW * (数据仓库大小)
Sybase IQ 性能对比

SYBASE产品特点说明数据仓库SYBASE IQIQ是Sybase公司推出的特别为数据仓库设计的关系型数据库。
IQ的架构与大多数关系型数据库不同,它特别的设计用以支持大量并发用户的即席查询。
其设计与执行进程优先考虑查询性能,其次是完成批量数据更新的速度。
SYBASE IQ是全球市场上排名第一位的列式分析服务器,为全球4000多个客户提供无与伦比的分析性能。
SYASE IQ在分析型应用中拥有得天独厚的优势,这些特点主要包括:基于列式存储,适合海量数据处理。
高效的数据压缩能力,相比于其他传统行式数据库提供3-6倍的数据压缩能力。
节约存储开支。
高效的查询分析能力。
提供10种索引,大幅提升系统查询分析性能。
IQ中大量使用位图索引和bit-wise索引。
快速的数据加载能力,允许用户在短时间内加载海量的企业数据。
广泛的支持数据模型,即支持传统的数据库模型,也支持基于数据仓库的数据模型。
利用IQ Multiplex技术实现线性水平扩展,可以支持海量数据管理和成千上万的并发用户数访问。
利用Multiplex技术提升系统的可用性,为企业提供7×24小时的不间断分析服务。
提供非结构化数据的存储和全文检索的能力,让企业轻松处理e-mail、pdf、word等文档信息。
IQ是一个专门针对数据仓库设计的关系型数据库,能够满足面向数据仓库和商务智能分析的所有需求:大数据量、快速响应、大量用户并发、易学易用且维护简单等等。
它的并行架构能够将系统扩充到数百个节点而不需要对应用或DBA控制程序做任何的修改,并且不需要中断系统的运行。
所获殊荣(国内部分)IQ与Oracle性能对比(最新TPC-H测试数据)TPC-H(商业智能计算测试)是TPC的重要测试标准之一,主要用来模拟真实商业的应用环境。
与科学计算测试不同,商业智能计算测试是对现实中商用计算需求的全面模拟。
它包括模拟真实商业交易数据库的动态查询,以及作为决策支持与数据库应用系统的参考。
sybase iq

【综合消息】快速认识Sybase IQ是一个专门面向数据仓库环境的关系型数据库。
不同于传统的关系型数据库所采用的行存储,Sybase IQ采用基于列的存储方法,这使Sybase IQ与其主要竞争对手有着明显的区别。
这种方法在查询环境中提供了众多的优势,包括性能与可扩展性。
尤其是,Sybase IQ通常能够在所要求的硬件资源减少的情况下,仍能提供查询性能方面的巨大改进(尤其是对复杂查询或者需要大表扫描的查询)。
在最近的版本中,Sybase通过Sybase DODS解决方案扩展了其用途,该方案利用Sybase IQ与Replication Server技术为报表与分析提供一个实时的同步环境,从而使报表和查询不必运行于操作型系统中。
关键特征Bloor Research认为,用户事先已经对如下关键内容有所了解:◆Sybase IQ是一个基于列存储的关系型数据库,从根本上比行存储方式更适合于即席查询进程。
由于其列存储的特性,Sybase IQ以大量不同的方式充分利用每个列的特性:◆首先,Sybase IQ发布了多种专门的索引以提升查询性能。
这些包括为低基数数据、联合列、文本分析、Web应用的实时比较、以及实时的数据与时间序列分析所设立的索引。
◆联合使用列存储与Sybase IQ的Bit-Wise索引(另一选择)的结果就是,聚合可以随时进行。
如果说事务的预先聚合是抽取、转换、加载(ETL)功能的重要一部分,那么在此可能并不需要一个完整的ETL层。
另外,这种方法比预先聚合的数据具有更大的灵活性(由于你并不总是事先了解你所要进行聚合的内容)。
◆列存储方法使数据压缩比使用传统方法下更容易实现,而且,压缩效果也更加显著。
事实上,Sybase IQ如此出色,即使使用了索引,其存储也从未超过原始数据的大小。
这点与传统数据库相比,取得了数倍的改进效果。
Sybase IQ在实际应用中已被证实,数据压缩比例多至原始数据集的50%到70%。
Sybase IQ 索引和数据类型

Sybase IQ 索引和数据类型1 、Sybase IQ的9种索引类型:(1)、FP(Fast Projection)此索引为默认的索引形式,在创建表时系统自动设置此索引。
特点:用于SELECT、LIKE ‘%sys%’、SUM(A B)、JOIN操作等语句。
此类型索引也是唯一可用于BIT数据类型的索引。
FP 索引可以优化索引,将小于255的唯一值的索引压缩到1字节中,将小于65537的唯一值索引压缩到2字节中。
方法:设置Minimize_Storage选项On ,建表时指定IQ UNIQUE关键字。
(2)、LF(Low Fast)基于平衡树的结构,存储唯一值小于1500个的索引,是最快的索引类型。
可以用作唯一索引。
特点:用于=、!=、IN、NOT IN查询参数。
MIN ()、MAX()、COUNT()、Group By、JOIN等。
(3)、HNG(High Nongroup)基于位的优化索引,适合于数字索引。
用于范围查找和求合计算。
特点:Rangs、Between、MIN()、MAX()、SUM()、AVG()等。
(4)、HG(High Group) 基于平衡树的结构,存储唯一值大于1500个的索引,是最快的索引类型。
可以用作唯一索引。
特点:同LF索引的特点。
(5)、CMP(compare)仅用于比较一个表中的两个列的比较。
特点:<、=、>、<= 、>=数据库选项设置为On的时候有利于节省资源,有利于性能。
(6)、WD(Word),仅用于索引数据类型为WORD的列。
特点:‘CONTAINS’、LIKE操作(但没有‘%’)。
例子:Select count(*) fro m Customer where address contains( ‘Main’)(7)、DATE(date)仅用于日期类型的列。
(8)、DTTM(Datetime)仅用于日期时间类型的列。
(9)、TIME(Time)仅用于时间类型的列。
SybaseIQ性能调优

目录1性能监控 (2)1.1操作系统性能监控 (2)1.2数据库性能监控例程 (2)1.3使用Sybase Cenral性能监控器监控 (2)2数据库参数调优 (3)2.1SybaseIq 12.7 建议设置选项 (3)2.2SybaseIq服务参数说明 (3)2.3文件存放 (4)3数据加载调优 (5)3.1推荐办法 (5)3.2装载数据时提示虚拟内存不足 (5)3.3使用union all 视图以便更快装载 (5)3.4单行处理 (5)4其它调优 (5)4.1选择合适的数据类型 (5)4.2无符号数据类型 (6)4.3性能优化选项 (6)1性能监控1.1操作系统性能监控使用如下命令对操作系统进行性能监控●vmstat●sar●topas●ps1.2数据库性能监控例程●sp_iqconnection 显示连接用户和版本●sp_iqcontext 显示运行参数●sp_iqspaceinfo 输出数据库对象使用空间情况●sp_iqstatus 数据库各种信息展现●sp_iqtablesize 输出制定表的大小●sp_iqgroupsize 输出指定成员如何获得Sybase IQ系统存储过程呢,我们使用select * from sysobjects where name like 'sp_iq%';返回结果中“name”列中显示为系统存储过程,我们可以研究其它的存储过程的含义1.3使用Sybase Cenral性能监控器监控可以按照如下所示使用Sybase Central监控服务器的统计信息。
●选择服务器●在“Statisticcs”选项卡上,右键单击名称并选择“Add to Performance Monitor“●单击“Performance Monitor“选项卡。
Sybase Central 仅跟踪从一个快照到下一个快照的差异,因此,在性能监视器中某些所选统计信息可能显示为无活动。
Sybase IQ:数据仓库引擎

Sybase IQ:数据仓库引擎作者:暂无来源:《计算机世界》 2011年第22期邹大斌“大数据(Big Data)”是时下很受关注的话题。
人们谈及“大数据”有两层含义:一个是数据总量大,普通企业的数据总量也可以进入PB级;而另一个含义是指数据类型复杂,除了传统的结构化数据之外,更大量的数据类型是邮件、博客、微博等。
对数据仓库而言,这些都似乎不是什么好事,因为意味着对数据仓库的处理能力提出了更高的要求。
然而,在SAP旗下的Sybase大中华区合作伙伴及业务发展总监叶自立看来,“大数据”时代为Sybase数据仓库IQ提供了一个更好的市场机会,而其广泛深入的渠道和合作伙伴网络恰好促成了Sybase更好地掌握这一机会。
“Sybase IQ在架构上具有很多独到的优势,比如更适合分布式处理,在非结构化数据方面更灵活,这使得Sybase IQ在处理超大数据量时性能优势体现得更为明显。
”叶自立表示,“这是Sybase架构的先天优势,以后我们的产品也肯定继续保持这个优势。
”Sybase IQ是一个采用列式存储技术的数据仓库产品,由于Sybase采用了这一有别于其他数据仓库产品的独特技术,使得IQ在数据存储上更节约空间,查询速度也更快一些。
不过,这还并不是叶自立充满信心的全部原因。
更重要的原因在于IQ去年对整个产品的架构进行全面升级,引入了基于“大规模并行处理”(MPP)架构的PlexQ分布式查询平台,通过将任务分散到网格配置中的多台计算机,加速了高度复杂的查询处理过程。
“IQ加上我们的CEP(Complex Event Processing,复杂事件处理),让系统更智能、更迅速,也更实用。
”叶自立表示,“Sybase的这一产品组合在金融行业和电信行业都有很多成功案例。
同时,Sybase正与不同的合作伙伴共同支持着电信行业所涉及的绝大部分应用,比如信令和计费系统等。
”据叶自立介绍,一大批极具实力、忠诚的合作伙伴被Sybase的合作原则和合作伙伴培养计划所吸引,正在与Sybase一起共同满足大数据时代下的用户需求。
sybase数据导入导出
sybase数据表的导出与导入方法我们经常会用到,下面就为你详细介绍sybase数据表的导出与导入方法,希望对您学习sybase数据表方面能有所帮助。
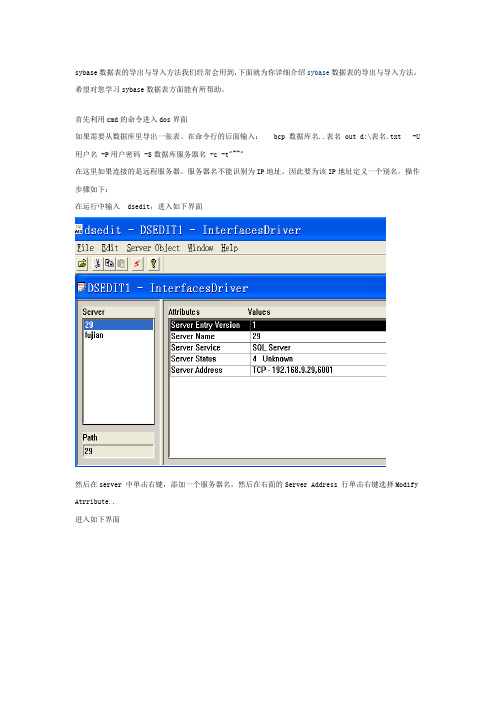
首先利用cmd的命令进入dos界面
如果需要从数据库里导出一张表。
在命令行的后面输入: bcp 数据库名..表名 out d:\表名.txt -U用户名 -P用户密码 -S数据库服务器名 -c -t"~~"
在这里如果连接的是远程服务器。
服务器名不能识别为IP地址。
因此要为该IP地址定义一个别名。
操作步骤如下:
在运行中输入 dsedit,进入如下界面
然后在server 中单击右键,添加一个服务器名,然后在右面的Server Address 行单击右键选择Modify Atrribute..
进入如下界面
单击添加。
然后输入IP及端口,注意IP地址与端口之间用逗号分开而还是分号。
然后就OK了。
然后测试下点 ping server(闪电图标的那个按钮)
导入表
在命令行的后面输入: bcp 数据库名..表名 in d:\表名.txt -U用户名 -P用户密码 -S数据库服务器名 -c -t"~~"
-E 关闭自增长,插入原值。
Sybase_IQ_性能调优。常用调优理论及方法,实际调优案例祥解

– 客户端和应用的调优(设计、SQL程序编写)
Global Technology
Page 7
性能调优的理论
➢性能优化定义
❖系统性能需要生命周期各阶段的努力来保证
✓哪一阶段做不好都会影响系统的性能 ✓设计(架构)和实现是保证系统高性能的基础,对性能的
影响也最大。 ✓在大部分情况下,对应用进行调优(设计和SQL语句调优
Global Technology
Network Server OS Database Server Database Application
Page 6
性能调优的理论
➢性能优化定义
❖性能调优的范围
✓系统级调优
– 硬件、操作系统、网络的调优
✓数据库服务器/数据库级调优(!)
– 通过各种监控方法标识问题和瓶颈,然后通过调整相关数据库服 务器/数据库选项、参数,或者调整数据库存储等方法以改进性 能
➢ 不是一个“万能型”数据库,如果使用不当,反而会 丧失优势、甚至带来严重问题
➢ 在决定一个应用系统是否选择IQ产品时,一个非常重 要的因素是对应用系统进行分析,看看他是什么类型 的系统,是否符合Sybase IQ的使用条件
Global Technology
Page 15
IQ 架构
Global Technology
Page 17
Sybase IQ Server架构
Server Front End
Shared with ASAnywhere (ASA)
Handles Connections
Parses Incoming Statements
Cross-DB Decomposition (CIS)
总结Sybase IQ的使用心得.

总结Sybase IQ的使用心得==================================使用总结===========================================1、字母大小写比对不敏感,也就是在值比对判断时大小写字母都一样;2、等值,或<>判断,系统默认对等式两边比对值去右边空格再进行比较;3、GROUP BY 可以根据SELECT字段或表达式的别名来汇总,在编写时也尽量避免SELECT 语句的别名与FROM表中的字段有重复,不然会出现莫名其妙的错误;4、FROM后的子查询要定义别名才可使用;5、存储过程要返回IQ系统错误信息 SQLCODE || ERRORMSG(* :(两者都为EXCEPTION后第一条SQL语句才有效果;6、IQ中若采用 FULL JOIN 连接则不能使用 WHERE 条件,否则FULL JOIN将失效,要筛选条件则用子查询先过滤记录后再FULL JOIN;7、建表时,字段默认为非空;8、UPDATE语句,如果与目标表关联的表有多条,则不会报错,而是随机取一条更新(第一条;9、RANK( OVER(PARTITION BY .. ORDER BY .. 分组分析函数,相同的ORDER BY值,返回顺序值一样,且PARTITION BY 只支持一个字段或一个字段组(需多个字段分组的则要用 || 拼为一个字段(待确认,该问题以前碰过一次,再次验证却不存在这问题10、返回可读的全局唯一字符:UUIDTOSTR(NEWID(11、存储过程隐式游标语法:FOR A AS B CURSOR FOR SELECT ... FROM ...DO.... 过程语句END FOR;需要注意的时,这边的A 和 B 在过程语句中都不能引用,所以为避免过程语句其他字段名与FOR SELECT 语句的字段名称重复,FOR SELECT 语句的字段最好都定义别名区分12、根据SELECT 语句建立[临时]表的方法(ORACLE的CREATE TABLE为 SELECT ..[*] INTO [#]table_name FROM ..;其中如果在table_name加前缀#,则为会话级临时表,否则为实体表;13、因Sybase为列存储模式,在执行上INSERT语句会比UPDATE语句慢,尤其表数据越多INSERT效率就越慢;所以在ETL时建议多用UPDATE而不是INSERT14、虽说Sybase为列存储模式,每个字段上都有默认索引,但对于经常的两表的关联键还是要建立索引否则会经常报QUERY_TEMP_SPACE_LIMIT不足的错误;15、存储过程中也可以显示的执行DDL语句,这点与Oracle不同;16、空字符串''在Sybase中也是个字符而不是null值,这点要注意;17、调整SESSION的临时空间SET TEMPORARY OPTION QUERY_TEMP_SPACE_LIMIT = '150000'; 15000为大小,如写0则没限制大小==================================常用函数===========================================字符串函数1ISNULL(EXP1,EXP2,EXP3,... :返回第一个非空值,用法与COALESCE(exp1,exp2[,exp3...]相同3TRIM(exp :去除两边空格4DATEFORMAT(date_exp,date_format :日期型转字符型;5STRING(exp:转为字符型;6SUBSTRING(exp,int-exp1,[int-exp2]:截取exp从int-exp1开始,截取int-exp2个字符;7REPLACE(o-exp,search-exp,replace-exp:从o-exp搜索search-exp,替换为replace-exp;8SPACE(int_exp:返回int个空格;8UPPER(exp:转为大写字母,等价于UCASE(exp;8LOWER(exp:转为小写字母,8CHARINDEX(exp1,exp2:返回exp2字符串中exp1的位置!定位,exp1 查找的字符,exp2 被查找的字符串;8DATALENGTH(CHAR_EXPR:在char_expr中返回字符的长度值,忽略尾空;8RIGHT(char_expr,int_expr:返回char_expr右边的int_expr个字符;8LEFT(char_expr,int_expr:返回char_expr左边的int_expr个字符;8REPLICATE(char_expr,int_expr:重复char_expr,int_expr次;8STUFF(expr1,start,length,expr2:用expr2代替epxr1中start起始长为length的字符串; 8REVERSE(char_expr:反写char_expr中的文本;8LTRIM(char_expr:删除头空;8RTRIM(char_expr:删除尾空;8STR(float_expr[,length[,decimal]]:进行数值型到字符型转换;8PATINDEX("%pattern%",expression:返回指定样式的开始位置,否则为0;8NULLIF(exp1,exp1:比较两个表达式,如果相等则返回null值,否则返回exp18NUMBER(*:返回序号,相当于ORACLE的rowid,但有区别;其他函数8RANK( OVER(PARTITION BY .. ORDER BY .. 分组分析函数,相同的ORDER BY值,返回顺序值一样,且PARTITION BY 只支持一个字段或一个字段组(需多个字段分组的则要用 || 拼为一个字段(待确认8返回可读的全局ID UUIDTOSTR(NEWID(8COL_LENGTH(tab_name,col_name:返回定义的列长度;兼容性:IQ&ASE8LENGTH(exp:返回exp的长度;兼容性:IQ转换函数8CONVERT(datetype,exp[,format-style]:字符转日期型或DATE(exp;兼容性:IQ&ASE format-style值输出:112 yyyymmdd120 yyyy-mm-dd hh:nn:ssSELECT CONVERT(date,'20101231',112,CONVERT(varchar(10,getdate(,120 ;--结果2010-12-31 2011-04-078CAST(exp AS data-type:返回转换为提供的数据类型的表达式的值;兼容性:IQ日期函数8DAY(date_exp:返回日期天值,DAYS(date_exp,int:返回日期date_exp加int后的日期; MONTH与MONTHS、YEAR与YEARS同理;8DATE(exp:将表达式转换为日期,并删除任何小时、分钟或秒;兼容性:IQ8DATEPART(date-part,date-exp: 返回日期分量的对应值(整数;8GETDATE(:返回系统时间;8DATENAME(datepart,date_expr:以字符串形式返回date_expr指定部分的值,转换成合适的名字;8DATEDIFF(datepart,date_expr1,date_expr2:返回date_expr2-date_expr1,通过指定的datepart 度量;8DATEADD(date-part,num-exp,date-exp:返回按指定date-part分量加num-exp值后生成的date-exp值;兼容性:IQ&ASEdate-part日期分量代表值:缩写值YY 0001-9999QQ 1-4MM 1-12WK 1-54DD 1-31DY 1--366DW 1-7(周日-周六HH 0-23MI 0-59SS 0-59MS 0-999数值函数8CEIL(num-exp:返回大于或等于指定表达式的最小整数;兼容性:IQ&ASE; 8FLOOR(numeric_expr:返回小于或等于指定值的最大整数;8ABS(num-exp:返回数值表达式的绝对值;兼容性:IQ&ASE;8TRUNCNUM(1231.1251,2:截取数值;不四舍五入;8ROUND(numeric_expr,int_expr:把数值表达式圆整到int_expr指定的精度; 8RAND([int_expr]:返回0-1之间的随机浮点数,可指定基值;8SIGN(int_expr:返回正+1,零0或负-1;8SQRT(float_expr:返回指定值的平方根;8PI(:返回常数3.1415926;8POWER(numeric_expr,power:返回numeric_expr的值给power的幂;8EXP(float_expr:给出指定值的指数值;==================================常用DDL语句===========================================Sybase中DDL语句不能修改字段的数据类型,只能修改空与非空:1.删除列:ALTER TABLE table_name DELETE column_name;2.增加列:ALTER TABLE table_name ADD (column_name DATA_TYPE [NOT] NULL; 3.修改列的空与非空:ALTER TABLE table_name MODIFY column_name [NOT] NULL;4.修改列名:ALTER TABLE table_name RENAME old_column_name TO new_column_name;5.快速建立临时表:SELECT * INTO [#]table_name FROM .....;6、修改表名:ALTER TABLE old_table_name RENAME new_table_name7.增加主键约束:ALTER TABLE tb_name ADD CONSTRAINT pk_name PRIMARY KEY(col_name,..8.删除主键约束:ALTER TABLE tb_name DROP CONSTRAINT pk_name;9.建立自增长字段,与Oracle的SEQUENCE类似:CREATE TABLE TMP_001 (RES_ID INTEGER IDENTITY NOT NULL;10.添加表注释:COMMENT ON TABLE table_name IS '....';11.创建索引:。
SybaseIQ简介与使用

SybaseIQ简介与使⽤Sybase IQ简介与使⽤今年在⼯作中经常⽤到Sybase IQ数据库,简单总结⼀下。
Sybase IQ跟其它的关系型数据库相⽐,它的主要特征是:查询快、数据压缩⽐⾼、读取数据快,但是插⼊更新慢,跑存储过程insert数据时就特别的慢,从复制库上同步数据的时候也是很慢的,因为它是按列存储的,其他数据库⼤都是按⾏存储的。
所以它只适于适合OLAP,不适合OLTP。
IQ索引的类型主要包括:FP,LF,HG,HNGFast Projection (FP)是IQ默认的索引,也就是说IQ创建表后,⾃动每⼀列就都带有这种索引了。
所以IQ查询超快,因为每⼀列默认都是fp索引,所以它号称所有数据都是索引。
LowFast (LF)是低位索引(低基数数据字段查询),也就是说⼤量数据⾥⾯,字段重复次数不多的,⽐如:纳税⼈的⾏业⼩类,上亿记录也就是那⼀千多个⾏业。
⼀般是少于1500个,就可以低位索引。
HighNonGroup (HNG)和HighGroup就是⾼位索引了,⼤于1500个的,⼀般都是流⽔号什么的,有时候也定义成主键索引。
⼤部分传统的数据库是建⽴⼀个数据基本表,然后按顺序存储每⾏数据,在其上建⽴索引。
但是传统数据库中基本表的记录在Sybase IQ中是不存在的,他们存在于⽬录表中(catalog)。
可以把Sybase IQ想象为表的数据是垂直分割,⽽不是⽔平分割的。
具体来说就是Sybase IQ把基本表的元数据信息存储在⽬录存储空间(catalog store)中,在Sybase IQ存储空间(IQ store)中为每个字段建⽴缺省的FP索引,⽽且Sybase IQ只存储索引,并不按⾏存储表的基础数据。
Sybase IQ即可以像传统的索引⼀样利⽤这些索引查询,也可以像基础表的字段⼀样作为数据源访问基础数据。
Sybase IQ中的每个查询只需要读查询语句中涉及的字段的信息,不必像传统数据库那样访问表中的所有字段。
sybase iq
【综合消息】快速认识Sybase IQ是一个专门面向数据仓库环境的关系型数据库。
不同于传统的关系型数据库所采用的行存储,Sybase IQ采用基于列的存储方法,这使Sybase IQ与其主要竞争对手有着明显的区别。
这种方法在查询环境中提供了众多的优势,包括性能与可扩展性。
尤其是,Sybase IQ通常能够在所要求的硬件资源减少的情况下,仍能提供查询性能方面的巨大改进(尤其是对复杂查询或者需要大表扫描的查询)。
在最近的版本中,Sybase通过Sybase DODS解决方案扩展了其用途,该方案利用Sybase IQ与Replication Server技术为报表与分析提供一个实时的同步环境,从而使报表和查询不必运行于操作型系统中。
关键特征Bloor Research认为,用户事先已经对如下关键内容有所了解:◆Sybase IQ是一个基于列存储的关系型数据库,从根本上比行存储方式更适合于即席查询进程。
由于其列存储的特性,Sybase IQ以大量不同的方式充分利用每个列的特性:◆首先,Sybase IQ发布了多种专门的索引以提升查询性能。
这些包括为低基数数据、联合列、文本分析、Web应用的实时比较、以及实时的数据与时间序列分析所设立的索引。
◆联合使用列存储与Sybase IQ的Bit-Wise索引(另一选择)的结果就是,聚合可以随时进行。
如果说事务的预先聚合是抽取、转换、加载(ETL)功能的重要一部分,那么在此可能并不需要一个完整的ETL层。
另外,这种方法比预先聚合的数据具有更大的灵活性(由于你并不总是事先了解你所要进行聚合的内容)。
◆列存储方法使数据压缩比使用传统方法下更容易实现,而且,压缩效果也更加显著。
事实上,Sybase IQ如此出色,即使使用了索引,其存储也从未超过原始数据的大小。
这点与传统数据库相比,取得了数倍的改进效果。
Sybase IQ在实际应用中已被证实,数据压缩比例多至原始数据集的50%到70%。
SybaseIQ数据迁移

SybaseIQ数据迁移SybaseIQ数据迁移是指将SybaseIQ数据库中的数据迁移到另一个目标数据库的过程。
在进行数据迁移前,需要进行详细的规划和准备工作,以确保数据的完整性和一致性。
本文将介绍SybaseIQ数据迁移的标准格式及相关内容,以便开展数据迁移工作。
一、背景介绍SybaseIQ是一种关系型数据库管理系统,广泛应用于数据仓库、商业智能和大数据分析等领域。
由于各种原因,如系统升级、数据中心迁移或者业务需求变更,可能需要将SybaseIQ数据库中的数据迁移到其他数据库平台,如Oracle、SQL Server或者MySQL等。
数据迁移是一项复杂的任务,需要经验丰富的数据库管理员和专业工具的支持。
二、数据迁移方案1. 确定迁移目标:根据业务需求和目标数据库的特点,选择合适的目标数据库平台。
考虑目标数据库的性能、可扩展性、兼容性和成本等因素。
2. 数据库结构分析:对SybaseIQ数据库的结构进行全面分析,包括表结构、视图、存储过程、触发器等。
了解数据库的整体架构和依赖关系,为后续迁移工作做好准备。
3. 数据迁移工具选择:根据迁移需求和目标数据库的支持程度,选择合适的数据迁移工具。
常用的工具有SAP Sybase Replication Server、SAP Data Services和第三方工具如AWS Database Migration Service等。
4. 迁移方案设计:根据数据库结构分析和迁移工具的特点,设计合理的迁移方案。
包括迁移顺序、迁移步骤、数据转换和清洗、并发控制等。
5. 数据迁移测试:在迁移前,进行充分的测试,包括数据完整性验证、性能测试和可用性测试等。
确保迁移过程中数据的准确性和一致性。
6. 数据迁移执行:根据迁移方案,执行数据迁移工作。
监控迁移过程,及时处理错误和异常情况。
确保迁移过程的顺利进行。
7. 数据验证和修复:在迁移完成后,对目标数据库中的数据进行验证和修复。
SYBASE数据库发展历史

SYBASE数据库发展历史1984年,Sybase公司成立。
当时,Sybase的首席执行官Mark Hoffman决定将公司的重心转向数据库市场,并开始开发Sybase数据库。
1987年,Sybase发布了他们的第一个商业数据库产品SYBASE SQL Server 1.0。
这是一个面向UNIX操作系统的关系型数据库管理系统。
它的出现使得Sybase公司迅速在数据库市场崭露头角。
1988年,SYBASE SQL Server在NCR将其集成到旗下的Tower系统中,这是第一个将SQL Server与硬件和操作系统集成的系统。
这是一个重要的里程碑,让SYBASE SQL Server更加接近企业级市场。
1992年,SYBASE发布了SYBASE SQL Server 4.0版本。
这个版本引入了许多创新的功能,如分布式查询和复制。
这些功能使得SYBASE SQL Server成为理想的企业级数据库解决方案。
1993年,SYBASE发布了SYBASE SQL Server 4.9版本,这是该产品中的一个重要版本。
它引入了存储过程和触发器等高级特性,为开发人员提供了更大的灵活性和动态性能。
1995年,SYBASE发布了SQL Anywhere数据库,这是一个嵌入式数据库系统,旨在为移动和分散环境提供轻量级的解决方案。
SQL Anywhere数据库成功地推动了移动数据库市场的发展,并在该领域取得了巨大的成功。
1996年,SYBASE发布了SYBASE SQL Server 11.0版本,这是一个重要的里程碑。
它引入了SYBASE IQ数据仓库,以及SYBASE Replication Server。
SYBASE IQ是一种专门用于大型数据仓库和商业智能应用的高性能分析数据库。
SYBASE Replication Server是一种高性能的数据复制和同步解决方案。
2001年,SYBASE发布了SYBASEASE12.5版本,这是他们的核心数据库产品的一个重要版本。
SybaseIQ体系结构与特点PPT(57张)

快速高效 --列式存储数据
传统行式数据库
c 1
c 2
c 3
c 4
c 5
c 6
c 7
c 8
c 9
…
r1
r2
r3
r4
数据是按行存储的 没有索引的查询使用大量I/O 建立索引和物化视图需要花费大量时间和资源 面对查询的需求,数据库必须被大量膨胀才能
满足性能要求
r5
列式数据库
c 1 c 2 c 3 c 4 c 5 c 6 c 7 c 8 c 9
“Are you really concentrating on BI? … Then use technology optimized for BI!”
Sybase IQ在信息管理领域的创新
Sybase IQ 在Gartner近期的数 据仓库DBMS (数据库管理系统) Magic Quadrant报告中被列入 “领导者”象限 (01/10)
Agenda
1
Sybase IQ综述 Sybase IQ体系结构及特点 Sybase IQ解决方案
2
3
4
Sybase IQ应用案例分享
• Sybase IQ
Sybase IQ 是一个高优化的分析服务器,在标准硬件平台和操 作系统上,针对极高速分析查询和报表具有特殊的设计 针对于分析的设计,不是事务的设计 – 不同于传统数据库 非常卓越的查询性能
北京电电信信网管分析系统 湖南电信数据仓库系统 新疆电信网管数据分析系统
乌鲁木齐电信统计分析查询系统
甘肃电信生产统计系统 西安电信计费统计报表查询系统 常州电信数据仓库系统 广东移动IP数据网管
广东移动信令分析平台
Sybase IQ之导出、导入研究

Sybase IQ之导出、导入研究2010-8-2 作者:oracle dba来源:TechTarget中国我要评论投稿打印MSN推荐博客引用大| 中| 小导读:本文介绍了Sybase IQ导出、导入数据的相关内容,Sybase IQ是一个强大的即席查询服务器,用户可以使用Sybase IQ来分离决策支持系统和在线事务处理系统。
关键词:Sybase IQ即席查询服务器决策支持系统OLTP【TechTarget中国原创】ASIQ一直以其导出导入性能佳而著称,如果能将其用好确实不易。
最近本人对此研究了一番,总结如下,仅供参考。
1. 前言Sybase IQ是一个强大的即席查询服务器。
用Sybase IQ来分离决策支持系统(DSS,Decision Support System,READER)和在线事务处理系统(OLTP,OnLine Transaction Processing,WRITER)。
目前Sybase IQ在SG186数据中心项目中作为数据仓库数据库得到广泛使用。
2. 导出导出在Sybase IQ也称卸载,总结Sybase IQ卸载方式无外乎以下几种:2.1、使用BCP卸载数据SybaseIQ支持BCP,可以有两种方式,一种呢是通过OCS提供的BCP,语法和ASE类似,还有一种是通过iq_bcp,语法如下:这两种方式都需要配置,open client 的接口文件UNIX下是interfaces,与数据库option方式的数据卸载相比较,特点是:一速度比后者慢,但是支持客户端数据卸载。
以下给出一个具体的例子:或者2.2文本数据方式2.2.1、Sqladv方式示例如下:在cmd状态下:c:\>sqladv -Sserver -Uuser -Ppassword -i c:\test.sql -oc:\testout.txt但是有几个问题:(1)、出来的东东格式不太标准:首先有字段名的表头,不知道怎么去掉。
SYBASE IQ 荣获SAP NETWEAVER- 商业智能整合认证

SYBASE IQ 荣获SAP NETWEAVER?商业智能整合认证SYBASE IQ 荣获SAP NETWEAVER? 商业智能整合认证SYBASE IQ 荣获SAP NETWEAVER? 商业智能整合认证全球最大的专注信息管理和信息移动技术的企业级软件供应商sybase公司近日宣布旗下具有高可扩展性的分析型数据库引擎sybase iq获得了与sap netweaver商业智能(sap netweaver bi) 的整合认证。
sap netweaver bi 是sap netweaver综合集成及应用平台的一部分,它帮助客户整合企业内外的各种数据,并将其转化为实用、及时的商业数据,以帮助企业做出正确的决策、有的放矢地采取行动并获得最佳的商业成果。
而sybase iq是特别为商业智能设计的,运行在标准的硬件及操作系统之上的分析型服务器。
结合sap的力量与sybase iq 无与伦比的查询性能及存储效能,企业便可大幅降低管理结构与非结构化数据所需的时间、存储容量及整体成本。
sybase与sap的客户现在能够在sap 商业数据仓库(sap bw)的应用层面上,利用储存在sybase iq内的数据进行多维性数据分析。
sap bw采用jdbc标准,通过sap bw universal data connect 3.5界面直接存取sybase分析数据库的数据,即从sybase iq中提取数据到sap netweaver bi中备用。
此时的数据无论来自何处,都会被融会贯通,以方便终端用户随时存取及分析。
idc软件公司的商业策略总监brian sobie 表示:只有那些充分利用产品优势、与合作伙伴共同制定推广计划,使合作伙伴充分享有投资、忠诚度回报的供应商,才能在科技界领导群雄。
idc深信这次的认证进一步加深了sap与sybase之间的合作伙伴关系。
借助sap netweaver平台,sybase给客户提供了一个经认证可与sap bw直接通讯,并配备整合功能的高度优化的分析引擎,从而大幅度提升了客户满意度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Sybase IQ一直以其导出导入性能佳而著称,如果能将其用好确实不易。
最近本人对此研究了一番,总结如下,仅供参考。
1. 前言Sybase IQ是一个强大的即席查询服务器。
用Sybase IQ来分离决策支持系统(DSS,Decision Support System,READER)和在线事务处理系统(OLTP,OnLine Transaction Processing,WRITER)。
目前Sybase IQ在SG186数据中心项目中作为数据仓库数据库得到广泛使用。
2. 导出导出在Sybase IQ也称卸载,总结Sybase IQ卸载方式无外乎以下几种:2.1、使用BCP卸载数据SybaseIQ支持BCP,可以有两种方式,一种呢是通过OCS提供的BCP,语法和ASE 类似,还有一种是通过iq_bcp,语法如下:usage: iq_bcp [[database_name.]owner.]table_name {in | out} datafile[-c] [-t field_terminator] [-r row_terminator][-U username] [-P password] [-I interfaces_file] [-S server][-v] [-A packet size] [-J client character set]usage: bcp [[db_name.]owner.]table_name[:slice_num] [partition pname] {in | out} [filename] [-m maxerrors] [-f formatfile] [-e errfile][-F firstrow] [-L lastrow] [-b batchsize][-n] [-c] [-t field_terminator] [-r row_terminator][-U username] [-P password] [-I interfaces_file] [-S server][-a display_charset] [-z language] [-v][-A packet size] [-J client character set][-T text or image size] [-E] [-g id_start_value] [-N] [-X][-M LabelName LabelValue] [-labeled][-K keytab_file] [-R remote_server_principal] [-C][-V [security_options]] [-Z security_mechanism] [-Q] [-Y][-x trusted.txt_file][--maxconn maximum_connections] [--show-fi] [--hide-vcc]这两种方式都需要配置,open client 的接口文件UNIX下是interfaces,与数据库option 方式的数据卸载相比较,特点是:一速度比后者慢,但是支持客户端数据卸载。
以下给出一个具体的例子:bcp cmcc.d_district out "D_BRAND.dat" -c -t"|" -T32000 -UDBA -PSQL -Stestiq -Jcp936 或者iq_bcp cmcc.d_district out "D_BRAND.dat" -c -t"|" -UDBA -PSQL -Stestiq -Jcp9362.2文本数据方式2.2.1、Sqladv方式示例如下:在cmd状态下:c:>sqladv -Sserver -Uuser -Ppassword -i c: est.sql -o c: estout.txt但是有几个问题:(1)、出来的东东格式不太标准:首先有字段名的表头,不知道怎么去掉。
另外就是各个字段之间的数据采用N个空格分开,不是使用Tab,不过,这些可以通过编程解决。
(2)、执行Bat处理时启动一次SQLADV之后,后面的就执行不过去了,必须先把SQLADV关闭才能执行。
2.2.2、isql方式使用Isql可以实现同样的效果,这样就可直接使用批处理文件,不用Sqladv的方式了。
c:>isql -Sserver -Uuser -Ppassword -i c: est.sql -o c: estout.txttest.sql:select * from DSSD_TIME where TIME_YEAR=2001go2.2.3、output方式OUTPUT TO filename[ APPEND ][ VERBOSE ][ FORMA T output-format ][ ESCAPE CHARACTER character ][ DELIMITED BY string ][ QUOTE string [ ALL ] ][ COLUMN WIDTHS (integer , . . . ) ][ HEXADECIMAL { ON | OFF | ASIS } ][ ENCODING encoding ]output-format :ASCII | DBASEII | DBASEIII | EXCEL| FIXED | FOXPRO | HTML | LOTUS | SQL | XML• QUOTE• ESCAPE CHARACTER character 指定转义字符• 输出数据在当前运行端• 可以指定分割符方式的数据输出,也可以指定每个字段的定长方式.。
示例如下:SELECT * FROM "DBA"."V_ICP_ID";OUTPUT TO "c: empV_ICP_ID.out"DELIMITED BY "|"FORMAT ASCIIquote "";输出结果在命令执行端。
> # <文件名> 输出执行结果> & <文件名> 输出到文件包括错误信息和执行信息,执行结果例如:SELECT *FROM employee>& empfile或select * from psdss_dm.AA_RESULT ># D: mpdaAA_RESULT.txt;2.3、option方式此方式可以导出二进制数据:set temporary option temp_extract_name1="/apps/performance/IAC" ; --设置输出路径set temporary option Temp_Extract_Column_Delimiter="|"; --设置分隔符commitselect * from P_ABIS_IAC --执行查找commitset temporary option temp_extract_name1="" --重新设置到控制台commit经过研究,并在东软导出工具基础上加以改造实现了批量表数据导出,填补了东软工具不能批量表导出的不足。
2.4导出方式比较(1)Option是二进制方式,此种方式速度最快,在导入时完全避免了分隔符和空值等问题。
(2)iq_bcp方式支持客户端导出。
(3)其他几种方式是文本方式,可以灵活定制文本导出格式,只能在服务器端导出。
3.导入3.1、loadload语句的格式:LOAD [ INTO ] TABLE [ owner.]table-name [ ( column-name, . . . ) ]FROM filename[ load-option . . . ][ statistics-limitation-options ]load-option :CHECK CONSTRAINTS { ON | OFF }| COMPUTES { ON | OFF }| DEFAULTS { ON | OFF }| DELIMITED BY string| ESCAPE CHARACTER character| ESCAPES { ON | OFF }| FORMAT { ASCII | BCP }| HEXADECIMAL {ON | OFF}| ORDER {ON | OFF}| PCTFREE percent-free-space| QUOTES { ON | OFF }| SKIP integer| STRIP { ON | OFF }| WITH CHECKPOINT { ON | OFF }• 如果字段名未出现在字段列表中,则填充NULL、0、空、或者DEFAULT; 存在于输入文件中的字段可以用“filler()”.忽略• DEFAULTS { ON | OFF } 为ON则字段取缺省值。
否则取NULL• QUOTES { ON | OFF } 缺省为ON ,字段定界符为…‟或者“”• DELIMITED BY 选项:可以单个字符,最多255个字符,例如:制表符号作分割符号:...DELIMITED BY ‟nx09‟• SKIP n 忽略前n条记录;• STRIP ON|OFF 尾空格插入前是否截取;• WITH CHECKPOINT ON|OFF 缺省为OFF, 如果设置为ON则,命令完成后,执行CHECKPOINT 操作。
下面是从一个文本文件load到表F_INN_IA_DAIL Y_SUM中的语句:set temporary option date_order=YMD;Load Table F_INN_IA_DAIL Y_SUM(ORG_SID "+|+",DEAL_SID "+|+",ALL_TIME_SID "+|+",R_COUNT_DIM_SID "+|+",T_TAX_STOR_COST "+|+",T_STOR_COST "+|+",T_STOR_SUM "+|+",CREATED_DT "X0A")From "/load_data/F_Inn_IA_Daily_Sum.txt"ESCAPES OFFQUOTES OFFNOTIFY 100000WITH CHECKPOINT ON;COMMIT其中+|+是字段的分隔符,X0A是记录的分隔符,即回车(文本文件中)。