【国家自然科学基金】_latent dirichlet allocation_期刊发文热词逐年推荐_20140801
【国家自然科学基金】_迭代扩展卡尔曼滤波_基金支持热词逐年推荐_【万方软件创新助手】_20140730

2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
2011年 科研热词 推荐指数 扩展卡尔曼滤波 2 雷达回波 1 递推非线性滤波 1 选代无味卡尔曼滤波器 1 送代扩展卡尔曼滤波 1 迭代无味卡尔曼滤波 1 迭代扩展卡尔曼滤波器 1 轨道机动 1 自主交会 1 统计线性化误差传播 1 统计正交 1 组合导航 1 离差差分滤波 1 相对导航 1 目标跟踪 1 滤波精度 1 无味卡尔曼滤波器 1 支持向量回归机 1 捷联惯导 1 抗差估计 1 扩展卡尔曼滤波器 1 扩展卡尔曼 1 导航 1 天文导航 1 大气波导 1 多维stirling内插多项式 1 噪声方差阵 1 可观测度 1 再入弹道目标状态估计 1 仅测角 1 不敏卡尔曼滤波 1 gnss/ins 1 ekf 1
科研热词 高斯滤波 非线性估计 采样卡尔曼滤波 递推bayesian滤波 迭代采样卡尔曼滤波 迭代无味卡尔曼滤波 近似栅格法 裂变自举粒子滤波 航天器 粒子滤波 积分卡尔曼滤波器 矩近似法 栅格法 无味变换 无味卡尔曼滤波 扩展卡尔曼滤波 姿态确定 均差滤波器 加权统计线性回归 修正罗德里格参数 中心差分滤波器 monte carlo方法 gauss-hermite滤波器
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
科研热词 推荐指数 迭代扩展卡尔曼滤波 3 非线性 2 迭代 2 粒子滤波 2 目标跟踪 2 测量更新 2 levenberg-marquardt方法 2 高斯牛顿迭代 1 马尔科夫链蒙特卡罗 1 非线性滤波 1 闪烁噪声 1 迭代ekf 1 误差配准 1 红外搜索跟踪系统 1 机动目标跟踪 1 时间校准 1 数据融合 1 扩展卡尔曼滤波 1 异类传感器融合 1 平方根扩展卡尔曼滤波 1 多传感器网络 1 交互式多模型 1 中心差分卡尔曼滤波(cdkf) 1
【国家自然科学基金】_lasalle不变集_基金支持热词逐年推荐_【万方软件创新助手】_20140730

2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13
2014年 科研热词 基本再生数 连续接种 脉冲接种 能量方法 稳定性 欧拉四元数 无源性 平衡点 姿态控制 全局渐近稳定性 传染病模型 siqr传染病模型 3d刚体摆 推荐指数 2 1 1 1 1 1 1 1 1 1 1 5 6 7 8 9 10 11 12 13
科研热词 稳定性 阶段结构 生态流行病模型 庇护所效应 hollingⅰ功能反应 混沌控制 时滞 捕食者-食饵模型 拉萨尔不变集定理 同步磁阻电动机 全局稳定性 lasalle不变集原理 hopf分支
推荐指数 3 2 2 2 2 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13
科研热词 量子系统 模型变换 liapunov函数 lasalle不变集 超混沌liu系统 线性算子半群 渐近稳定性 广义投影同步 反馈控制 参数识别 动态反馈控制 分布参数模型 lasalle不变集原理
推荐指数 2 2 2 2 1 1 1 1 1 1 1 1 1
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
科研热词 线性算子半群 柔性臂 自动控制技术 变结构控制 饱和控制 非线性系统 非线性仿射系统 阈值 连续镇定 输出反馈 耗散实现 竞争系统 渐近稳定性 混杂脉冲控制 正实引理 时滞 无源 数学模型 拉萨尔不变集原理 弱控制lyapunov函数 哈密顿系统 协调运动 力控制 传染病 sontag型控制 lasalle不变集原理 l2增益
2010年 序号 1 2 3 4 5 6 7 8 9
【国家自然科学基金】_话题演化_基金支持热词逐年推荐_【万方软件创新助手】_20140801
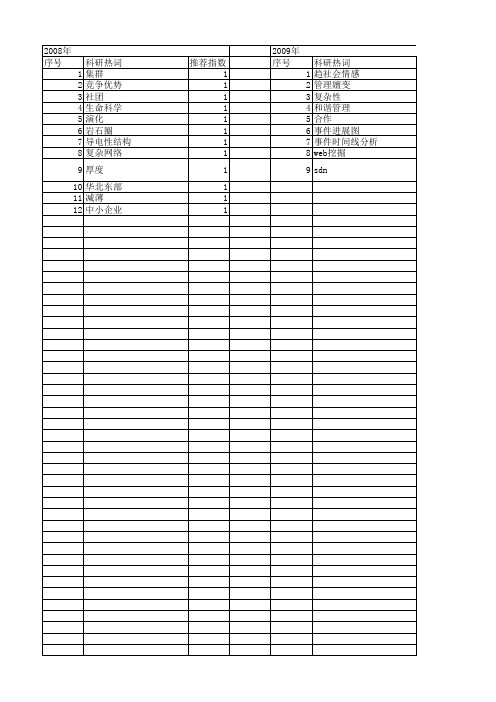
推荐指数 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9
科研热词 推荐指数 话题演化 2 话题模型 1 话题探测 1 话题关联 1 节点重要性 1 网络舆情 1 潜在狄里特里分配 1 拓扑势 1 latent dirichlet allocation 1
推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
2014年 科研热词 话题演化 网络舆情 话题模型 计算实验 衍生效应 舆情话题 舆情传播 社会计算 社交网络 演变特征 演化模式 演化偏斜 文献推荐 数字图书馆 推理线索 手机舆情 情感词表 情感演化 情感分析 子话题抽取 多主体建模 协同演进 信息弱势群体 依存线索 事件核心词 事件关系 事件元素 seirs模型 plsa模型 推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
推荐指数 3 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
图像语义分析与理解综述

*国家自然科学基金资助项目(N o .60875012,60905005)收稿日期:2009-12-21;修回日期:2010-01-27作者简介 高隽,男,1963年生,教授,博士生导师,主要研究方向为图像理解、智能信息处理、光电信息处理等.E-m a i:l gao j un @hfut .edu .cn .谢昭,男,1980年生,博士,讲师,主要研究方向为计算机视觉、智能信息处理、模式识别.张骏,女,1984年生,博士研究生,主要研究方向为图像理解、认知视觉、机器学习.吴克伟,男,1984年生,博士研究生,主要研究方向为图像理解、人工智能.图像语义分析与理解综述*高 隽 谢 昭 张 骏 吴克伟(合肥工业大学计算机与信息学院合肥 230009)摘 要 语义分析是图像理解中高层认知的重点和难点,存在图像文本之间的语义鸿沟和文本描述多义性两大关键问题.以图像本体的语义化为核心,在归纳图像语义特征及上下文表示的基础上,全面阐述生成法、判别法和句法描述法3种图像语义处理策略.总结语义词汇的客观基准和评价方法.最后指出图像语义理解的发展方向.关键词 图像理解,语义鸿沟,语义一致性,语义评价中图法分类号 T P 391.4I m age Se m antic Anal ysis and Understandi ng :A R eviewGAO Jun ,XI E Zhao ,Z HANG Jun ,WU Ke -W ei(S chool of C o m puter and Infor m ation,H e fei University o f T echnology,H efei 230009)ABSTRACTSe m antic ana l y sis is the i m portance and diffi c u lty of high -level i n terpretati o n i n i m age understandi n g ,i n wh ich there are t w o key issues of tex-t i m age se m an tic gap and tex t descri p ti o n po lyse m y .Concentrating on se m antizati o n o f i m ages onto logy ,three soph i s tica ted m et h odolog ies are round l y rev ie w ed as generati v e ,d iscri m ina ti v e and descriptive gra mm ar on the basis of conc l u d i n g i m ages se m antic fea t u res and context expression .The ob jective benchm ark and eva l u ation for se m an tic vocabu lary are i n duced as w e l.l F i n ally ,the summ arized directions fo r furt h er researches on se m antics i n i m age understand i n g are discussed i n tensively .K ey W ords I m age Understanding ,Se m antic G ap ,Se m an tic Consistency ,Se m an tic Evalua ti o n1 引 言图像理解(I m age Understandi n g ,I U )就是对图像的语义解释.它是以图像为对象,知识为核心,研究图像中何位置有何目标(what is w here)、目标场景之间的相互关系、图像是何场景以及如何应用场景的一门科学.图像理解输入的是数据,输出的是知识,属于图像研究领域的高层内容[1-3].语义(Se -第23卷 第2期 模式识别与人工智能 V o.l 23 N o .2 2010年4月 PR &A I A pr 2010m antics)作为知识信息的基本描述载体,能将完整的图像内容转换成可直观理解的类文本语言表达,在图像理解中起着至关重要的作用.图像理解中的语义分析在应用领域的潜力是巨大的.图像中丰富的语义知识可提供较精确的图像搜索引擎(Searching Eng i n e),生成智能的数字图像相册和虚拟世界中的视觉场景描述.同时,在图像理解本体的研究中,可有效形成/数据-知识0的相互驱动体系,包含有意义的上下文(Context)信息和层状结构(H ierarchica-l S truct u red)信息,能更快速、更准确地识别和检测出场景中的特定目标(如,识别出场景中的/显示器0,根据场景语义知识可自动识别附近的/键盘0).尽管语义分析在图像理解中处于非常重要的位置,但传统的图像分析方法基本上全部回避了语义问题,仅针对纯粹的图像数据进行分析.究其原因主要集中于两方面:1)图像的视觉表达和语义之间很难建立合理关联,描述实体间产生巨大的语义鸿沟(Se m antic Gap);2)语义本身具有表达的多义性和不确定性(Am bigu ity).目前,越来越多的研究已开始关注上述/瓶颈0,并致力于有效模型和方法以实现图像理解中的语义表达.解决图像理解中的语义鸿沟需要建立图像和文本之间的对应关系,解决的思路可大致分为三类.第一条思路侧重于图像本身的研究,通过构建和图像内容相一致的模型或方法,将语义隐式地(I m p lici-t l y)融入其中,建立/文本y图像0的有向联系,核心在于如何将语义融于模型和方法中.采用此策略形成的研究成果多集中于生成(Generati v e)方式和判别(D iscri m inati v e)方式中.第二条思路从语义本身的句法(G ra mm ar)表达和结构关系入手,分析其组成及相互关系,通过建立与之类似的图像视觉元素结构表达,将语义描述和分析方法显式地(Exp lici-t l y)植入包含句法关系的视觉图中,建立/图像y文本0的有向联系.核心在于如何构建符合语义规则的视觉关系图.第三条思路面向应用,以基于内容的图像检索(I m age Retrieval)为核心,增加语义词汇规模,构建多语义多用户多进程的图像检索查询系统.解决语义本身的多义性问题需要建立合理的描述规范和结构体系.Princeton大学的认知学者和语言学家早在20世纪80年代就研究构建了较合理统一的类树状结构.如今已被视为视觉图像研究领域公认的语义关系参考标准,用于大规模图像数据集的设计和标记中,有效归类统一了多义性词语.此外,一些客观的语义检索评价标准也在积极的探索过程中.本文将对上述两个图像语义理解中的问题进行方法提炼和总结.针对语义鸿沟问题,介绍已有模型和方法的处理策略.还采用较完备的图像语义/标尺0(B ench m ark)解决语义的主观多义性.2图像内容的语义分析图像内容描述具有/像素-区域-目标-场景0的层次包含关系,而语义描述的本质就是采用合理的构词方式进行词汇编码(Encodi n g)和注解(Annota-tion)的过程.这种过程与图像内容的各层描述密切相关,图像像素和区域信息源于中低层数据驱动,根据结构型数据的相似特性对像素(区域)进行/标记0(Labeli n g),可为高层语义编码提供有效的低层实体对应关系.目标和场景的中层/分类0(C ategor-i zati o n)特性也具有明显的编码特性,每一类别均可视为简单的语义描述,为多语义分析的拓展提供较好的原型描述.本节将针对前述的语义鸿沟问题介绍常用的图像语义表示方法和分析策略.2.1语义化的图像特征图像内容的语义分析借鉴文本分析策略.首先需要构建与之相对应的对象,整幅图像(I m age)对应整篇文档(Docum ent),而文档中的词汇(Lex icon)也需要对应相应的视觉词汇(V isua lW ord).视觉词汇的获取一般通过对图像信息的显著性分析提取图像的低层特征,低层特征大多从图像数据获取,包括简单的点线面特征和一些特殊的复杂特征,再由鲁棒的特征表达方式生成合适的视觉词汇,视觉词汇一般具有高重用性和若干不变特性.点特征提取以图像中周围灰度变化剧烈的特征点或图像边界上高曲率的点为检测对象,根据灰度或滤波函数确定区域极值点(如H arris角点[4]等),并拓展至不同掩膜下的尺度空间中(如高斯-拉普拉斯、高斯差分等),分析极值点的稳定特性,得到仿射不变的H arris二阶矩描述符[5].线特征描述图像中目标区域的外表形状和轮廓特性,这类轮廓线特征以C anny算子等经典边缘检测算法为基础,集中解决边缘曲线的描述、编组以及组合表达等问题.边缘上的双切线点和高曲率点可连接形成有效的边缘链或圆弧,根据聚类策略或某些规则完成线片段编组,形成线特征的视觉词汇[6-8].区域是图像上具有灰度强相关性的像素集合,包含某种相似属性(如灰度值、纹理等),相对于点线特征,面特征有更丰富的结构信息.区域特征以点特征为中心,采用拉普192模式识别与人工智能23卷拉斯尺度下的H arris或H essian仿射区域描述,对特征尺度上的椭圆仿射区域内的初始点集进行参数迭代估计,根据二阶矩矩阵的特征值测量点邻的仿射形状[4,9].另一种策略分析视觉显著区域对象(如直方图、二值分割图等)的熵值统计特性,得到最佳尺度下的最稳定区域,满足视觉词汇的高重用性[10-11].鲁棒特征表达对提取的特征进行量化表示.点特征一般仅具有图像坐标.线特征则充分考虑邻域边缘点的上下文形状特性,以边缘上采样点为圆心,在极坐标下计算落入等距等角间隔区域的边缘像素直方图.椭圆形面特征描述主要以尺度不变特征变换(Sca le I nvariant Fea t u re Transfor m,SI FT)[12-13]为主,SI FT特征对每个高斯窗口区域估计方向直方图,选择峰值作为参考方向基准,计算4@4网格区域内8个方向的梯度直方图,任何区域均可转换为4@4@8 =128维特征向量.该特征对图像尺度、旋转具有不变性,对亮度和视角改变也保持一定稳定性.通过对特征向量的聚类,得到最原始的特征词汇,形成的语义化图像特征也称为/码书0(Codebook)[14].2.2图像语义的上下文表达图像的语义信息描述主要包含外观位置信息和上下文信息,前者如2.1节所述,可表示成/码书0.上下文信息不是从感兴趣的目标外观中直接产生,而来源于图像邻域及其标签注解,与其他目标的外观位置信息密切相关.当场景中目标外观的可视程度较低时,上下文信息就显得尤为重要.B ieder m an将场景中不相关目标关系分为5种,即支撑(Support)、插入(I nterpositi o n)、概率(Proba-b ility)、位置(Positi o n)和大小(Size)[15-16].五类关系均包含/知识0,不需要知道目标信息就可确定支撑和插入关系,而后三类关系对应于场景中目标之间的语义交互关系,可缩短语义分析时间并消除目标歧义,通常称为/上下文特征0(C ontex t Features),譬如一些相对复杂的特征描述(如全局G ist特征[17-18]、语义掩码特征等)融入场景上下文信息,本身就包含语义(关联)信息,是语义分析的基础.如今有很多研究开始挖掘B ieder m an提出的三类语义关系,可分为语义上下文、空间上下文和尺度上下文[19].语义上下文表示目标出现在一些场景中,而没有出现在其他场景中的似然性,表示为与其他目标的共生(Co-O ccurrence)关系,可采用语义编码方式[20-21],也可由共生矩阵判断两类目标是否相关[22-23],此类上下文对应B ieder m an关系中的/概率0关系.空间上下文表示目标相对于场景中其他目标出现在某个位置上的似然性,对应于/位置0关系.空间上下文隐式地对场景中目标的/共生0进行编码,为场景结构提供更加具体的信息,只需确定很少的目标,就可通过合理的目标空间关系降低目标识别的误差,消除图像中的语义歧义[24-25].尺度上下文表示目标在场景中可能的相对尺度范围,对应于/大小0关系.尺度上下文需处理目标之间的特定空间和深度关系,可缩小多尺度搜索空间,仅关注目标可能出现的尺度.尺度上下文在二维图像中较为复杂,目前仅用于简单的视觉分析系统中[26-27].目前大多数上下文方法主要分析图像中的语义上下文和空间上下文.语义上下文可从其他两种上下文中推理获取,与场景中的目标共生相比.尺度和空间上下文的变化范围较大,而共生关系的知识更易获取,处理计算速度更快.融入上下文特征的图像语义形成了全局和局部两种分析策略,即基于场景的上下文分析和基于目标的上下文分析.前者从场景出发[15,27],将图像统计量看作整体,分析目标和场景之间的高频统计特性,获取全局上下文信息,如马路预示着汽车的出现.后者从目标出发[25,28],分析目标间的高频统计特性,获取局部上下文信息,如电脑预示着键盘的出现.总之,上下文特征包含了更丰富的知识,有助于为图像理解提供更准确的语义信息.2.3语义分析的生成方法生成方法基于模型驱动,以概率统计模型和随机场理论为核心,遵循经典的贝叶斯理论,定义模型集合M,观察数据集合D,通过贝叶斯公式,其模型后验概率p(M|D)可以转换为先验概率p(M)和似然概率p(D|M)的乘积.生成方法一般假设模型遵循固定的概率先验分布(如高斯分布等),其核心从已训练的模型中/生成0观察数据,测试过程通过最大似然概率(M ax i m ize L i k e lihood)得到最符合观察数据分布的模型预测似然(Pred icti v e Like li h ood).图像语义分析的生成方法直接借用文本语义分析的图模型结构(G raph ica lM ode ls),每个节点定义某种概念,节点之间的边表示概念间的条件依赖关系,在隐空间(Latent Space)或随机场(Rando m Field)中建立文本词组和视觉描述之间的关联,生成方法无监督性明显,具有较强的语义延展性.2.3.1层状贝叶斯模型图模型的节点之间由有(无)向边连接,建立视觉词汇和语义词语之间的对应关系.朴素贝叶斯理论形成的经典Bags-o-f W ords模型是层状贝叶斯模1932期高隽等:图像语义分析与理解综述型的雏形,该模型将同属某类语义的视觉词汇视为/包0,其图结构模型和对应的视觉关系描述如图1(a)所示,其中灰色节点为观察变量,白色节点为隐变量,N 为视觉词汇的个数,通过训练建立类别语义描述c 和特征词汇w 之间的概率关系,选取最大后验概率p (c |w )对应的类别作为最终识别结果.(a)朴素贝叶斯(b)概率隐语义分析(c)隐狄利克雷分配(a)N a Çve bay es(b)P robab ili stic latent se m antic ana l y si s (c)L atent D irich let a llocati on图1 有向图语义描述F i g .1 Se m antic i nterpre tati on of directed g raphs朴素贝叶斯模型试图直接建立图像和语义之间的联系,但由于视觉目标和场景的多样性导致这种稀疏的离散分布很难捕捉有效的概率分布规律,因此H o f m ann 借鉴文本分析中的概率隐语义分析(Probab ilistic Latent Se m antic Ana l y sis ,pLSA )模型[29-30],将/语义0描述放入隐空间Z 中,生成相应的/话题0(Top ic)节点,其基本描述如图1(b )所示.D 为M 个图像d 组成的集合,z 表示目标的概念类别(称为/Top ics 0),每幅图像由K 个Topics 向量凸组合而成,通过最大似然估计进行参数迭代,似然函数为p (w |d )的指数形式,与语义词汇和图像的频率相关.模型由期望最大化(E xpec ta tion M ax i m ization,E M )算法交替执行E 过程(计算隐变量后验概率期望)和M 过程(参数迭代最大化似然).决策过程的隐变量语义归属满足z*=arg m ax z P (z |d ),pLSA 模型通过隐变量建立特征与图像间的对应关系,每个文本单元由若干个语义概念按比例组合,本质上隐空间内的语义分布仍然是稀疏的离散分布,很难满足统计的充分条件.隐狄利克雷分配(LatentD ir ich let A llocation ,LDA )模型[31-32]在此基础上引入参数H ,建立隐变量z 的概率分布.在图像语义分析中,变量z 反映词汇集合在隐空间的聚类信息,即隐语义概念,参数H (通常标记为P )则描述隐语义概念在图像空间中的分布,超参A (通常标记为c)一般视为图像集合D 中已知的场景语义描述.如图1(c )所示,由参数估计和变分(V aria tiona l)推理,选取c =arg m ax c P (w |c ,P ,B )作为最终结果.LDA 中不同图像场景以不同的比例P 重用并组合隐话题空间全局聚类(G l o ba lC l u ster),形成/场景-目标-部分0的语义表达关系.LDA 中的隐话题聚类满足De Finetti 可交换原理,其后验分布不受参数次序影响,不同隐话题聚类相互独立,无明显的结构特性.一种显而易见的策略就是在此模型基础上融入几何或空间关系,即同时采用话题对应的语义化特征的外观描述和位置信息,这样不同话题的分布大体被限定于图像场景的某个区域,如天空总是出现在场景的上方等,减小模型决策干扰.如L i 等人[14,33]在LDA 模型中融入词汇的外观和位置信息,并将语义词汇描述c 划分为视觉描述词汇(如sky )和非视觉描述词汇(如w i n d)两类,由词汇类别转换标签自动筛选合适的词汇描述.模型采用取样(Sa mp li n g)策略对从超参先验中生成的视觉词汇和语义标签进行后验概率学习,模型中包含位置信息的语义特征显式地体现了空间约束关系,具有更好的分析效果.(a)无结构(b)全互连结构(c)星状结构(a)U nstructured(b)Fu ll structure (c)Sta r struct u re图2 Part -based 模型表示图F i g.2 R epresen tati on for Part -based m ode lsLDA 模型已明确地将隐空间的/话题0语义进行合理聚类,建立与视觉词汇聚类的对应关系.隐话题聚类隐式地对应场景或目标的某些部分(parts),是一种较原始的par-t based 模型.真正的par-t based模型侧重/目标-部分0之间的语义关联表达,不仅具有较强的结构特性,而且直接概念化隐空间的语义聚类,每个part 直接显式对应语义描述(如人脸可分为眼睛、鼻子、嘴等不同部分).如图2所示,一般通过人工设定或交叉验证的方式固定重要参数(如隐聚类个数、part 个数等)并混合其概率密度,其中固定参数的D ir i c h let 生成过程是一种有限混合./星群0(Conste llati o n)模型[34-35]是其中的典型,根据不194模式识别与人工智能 23卷同区域的外观位置信息描述,确定P 个部分的归属及其概率分布,将目标和背景似然比分解为外观项、形状项、尺度项以及杂项的乘积,依次计算概率密度值(一般是高斯分布或均匀分布),并E M 迭代更新参数,最后通过似然比值判断目标的语义属性.部分间的约束关系体现于形状项中,可以假设为全互连结构(Fu ll Str ucture)或星状结构(S tar S tructure),其结构信息体现于高斯分布的协方差矩阵中(满秩或稀疏矩阵),有助于提高语义分析的准确性.固定参数的D irichlet 生成过程是无限混合模型的一种特例,可通过合适的随机过程,很好表达无限混合(I nfi n ite M i x t u re)模型,自动确定混合个数.这种/非参0(Non -Para m etric)模型可捕捉到概率空间的隐性分布,不受特定的概率密度函数形式表达限制.整个D irich let 过程可拓展至层次结构(H ierar -ch ical D irichlet Process ,HDP).H DP 具有明显的结构特性,可以很容易对应于图像中的/场景-目标-部分0层次结构,其混合组成很显式地表达了不同目标实体间的语义包含关系.Sudderth 在HDP 的基础上,引入转换函数(Transfor m ed Function),生成转换D irichlet 过程(T ransfor m ed D irichlet Process ,TDP),每组的局部聚类不再直接/复制0全局聚类参数,而是通过不同转换函数生成变化多样的局部变参,更符合目标多变特性[36-37].层状贝叶斯模型是当前处理图像语义问题的关注热点,其模型特有的参数化层次结构信息参照文本处理直接对应图像中的语义实体,通过图模型的参数估计和概率推理得到合适的语义描述.模型本身的发展也具有一定的递进关系,即/Bags -o-f W ord模型y pLSA 模型y LDA 模型y par-t based 模型y HDP 模型y TDP 模型0等,分析得到的结果具有层次语义包含关系.2.3.2 随机场模型随机场模型以均值场(M ean F ield)理论为基础,图中节点变量集合{x i |i I V }通常呈4-邻域网格状分布,节点之间的边{(x i ,x j )|i ,j I V;(x i ,x j )I E }体现隐性关联,由势函数W ij (x i ,x j )表示,一般具有含参数H 的近高斯指数分布形式,每个隐节点x i 一般对应一个观察变量节点y i ,由势函数W i (x i ,y i )表示.如图3所示,观察节点可对应图像的像素点,也可对应图像中的某个区域或目标语义化特征描述(如2.1节所述),隐变量则对应语义/标记0或/标签0l .随机场模型具有丰富的结构场信息,节点间上下文关联很强,通常分析像素标记解决图像分割问题.近年来,其特定的约束关系(如桌子和椅子经常关联出现)也被用于图像区域化语义分析中,隐节点集的语义标签对应不同的语义化特征和势函数取值,最大化随机场的能量函数得到的标记赋值,就是最终的区域语义标记属性.随机场模型具有较成熟的计算框架,融合其上下文关联信息的层次贝叶斯/生成0模型是分析图像语义的主流趋势[14,33-35,38-40].图3 随机场模型及其图像语义描述F ig .3 R andom field m ode l and its se m antic descr i pti on2.4 语义分析的判别方法判别方法基于数据驱动,根据已知观察样本直接学习后验概率p (M |D ),主要通过对训练样本的(弱)监督学习,在样本空间产生合适的区分函数,采用形成的分类器或结构参数,完成对特定的特征空间中点的划分(或闭包),形成某些具有相似特性的点的集合.这些共性可直接显式对应图像理解中的若干语义信息,如目标和场景的属性、类别信息等,通常以主观形式体现于观察样本中,其本质就在于学习并获取区分不同语义信息的知识规则(如分类器等).由于语义信息主观设定(如判别几种指定类别),因此判别方法主要侧重观察样本(语义)的处理分析,而非观察样本(语义)的获取.判别方法是包含经典的机器学习方法,精确度较高且易于实现,常用于目标检测识别识别.其策略主要包括最近邻分析、集成学习和核方法.2.4.1 最近邻方法最近邻(k -N earestN e ighbo r ,kNN )方法是基于样本间距离的一种分类方法.其基本思想是在任意空间中、某种距离测度下,寻找和观测点距离最接近的集合,赋予和集合元素相似的属性集合.在图像理解中,就是在图像特征空间寻找和近似的特征描述集,将已知的语义作为分析图像的最终结果.最近邻方法非常简单,但对样本要求较高,需要很多先验知1952期 高 隽 等:图像语义分析与理解综述识,随着大规模语义标记图像库的出现(如后 3.2节所述),最近邻方法有了广阔的应用前景,Torra l b a 等人[41]建立80万幅低分辨率彩色图像集合和相应的语义标记,图像集涵盖所有的视觉目标类别,以W ord N et语义结构树(如后3.1节所述)的最短距离为度量,采用最近邻方法分别对其枝干进行投票,选取最多票数对应最终的语义标签输出.也可直接在图像空间中计算像素点的欧式距离,得到与分析图像相类似的语义空间布局(Con fi g uration).Russe ll 等人[42]利用最近邻方法找出与输入图像相似的检索集,通过含有标记信息的检索图像知识转化到输入图像中,完成场景到目标的对齐任务.语义聚类法还被用于视频数据库中[43],具有较好的结果.2.4.2集成学习集成学习将各种方法获得的模型在累加模型下形成一个对自然模型的近似[44-45],将单一学习器解决问题的思想转换为用多个学习器来共同解决问题.Boosti n g是集成学习方法的典型.其基本思想是每次迭代t生成一个带权重A t的弱分类器(W eaker C lassifier)h t,加大误分样本的权重,保证后续学习对此类样本的持续关注,权重A t表示该弱分类器h t 的重要性,分类效果好的权重大,效果差的权重小.其集成学习的结果就是弱分类器的加权组合E T t=1Ex i I DA t h t(x i)构成一个分类能力很强的强分类器(Strong C lassif-i er),完成简单的二值或复杂的多值分类[46-47].集成学习方法经常用于图像理解的语义分类中,其样本数据集既可以是区域块也可以是滤波后的基元乃至包括上下文和空间布局信息.其分类结果具有很明显的语义区分度.多语义分类中经常出现多类共享的情况,因此,联合Boosti n g的提出极大地减少了分类器的最佳参数搜索时间,使单一弱学习器具有多类判别能力[48-51].同时,近年来多标签多实例(M ult-i Instance M u lt-i Labe l Learn i n g,M I M L)的集成学习策略[52]也倍受学者关注,图像理解中的语义划分问题可通过M I M L转化为单纯数据下的机器学习问题,其输出的分类结果就是对既定语义的编码结果.2.4.3核方法核方法(Kernel)是在数据集中寻找合适的共性/基0,由/基0的混合组成共性空间,与图像理解中的低层基元表示异曲同工.使用核方法可将低维输入空间R n样本特征映射到高维空间中H,即5B R n y H,将非线性问题转换为线性问题.其关键是找到合适的核函数K保持样本在不同空间下的区分关系,即K(x i,x j)=5(x i)#5(x j).它能够在学习框架和特定知识之间建立一种自然的分离来完成图像有意义的表达[53-54].支持向量机(S VM)是常用的核方法之一.它以训练误差作为优化问题的约束条件,以置信范围值最小化作为优化目标,在核函数特征空间中有效训练线性学习分类器,通过确定最优超平面(H yper Plane)及判别函数完成高维空间点的分类.SVM方法在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,在图像理解中,能有效解决不同环境、姿态以及视角下的广义目标识别分类问题,是目前最为通用的分类模型[55-58].针对多语义分类问题,Farhad i等人[59]将目标的语义属性细分为部分、形状及材质等,相同或相似的语义对应的样本集表明了某种特有的共性关系,采用L1测度对数回归和线性SVM方法学习不同语义类别的判别属性,其多语义属性的不同划分决定了指定目标的唯一描述,具有很强的语义可拓展性.判别模型是通过模型推理学习得出的后验概率,对应不同类别目标的后验概率或对应图像前景和背景的不同后验概率来划定判决边界,进而完成目标识别,指导图像理解.判别模型在特征选取方面灵活度很高,可较快得出判别边界.2.5图像句法描述与分析人对图像场景理解的本质就是对图像本身内在句法(G ra mm ar)的分析.句法源于对语句结构研究,通过一系列的产生式规则将语句划分为相互关联的若干词汇(组)组合,体现句法内词汇之间的约束关系.图像句法分析直接研究图像语义,随着20世纪70年代句法模式识别的提出,Otha就试图构建统一的基于视觉描述的知识库系统,利用人工智能相关策略进行场景语义推理.但由于视觉模型千变万化,方法针对性很强,句法分析方法曾一度没落.当前图像语义分析的一部分研究重心又重新转向图像句法.由于句法分析本身已较为成熟,因此如何建立和句法描述相对应的图像视觉描述非常关键.2.5.1图像与或图表达图像I内的实体具有一定的层次结构,可用与或图(And-O r G raph)的树状结构表示,即解析树pg.如图4所示,同属一个语义概念的实体尽管在外观上具有很大差异,但与或图表达相似,与节点表示实体的分解(D ecom position),如/场景y目标0, /目标y部分0等,遵循A y BCD,的句法规则,或节点表示可供选择的结构组成,遵循A y B|C|D,196模式识别与人工智能23卷。
一种基于LDA主题模型的话题发现方法

关 键 词 :词 向量 ;LDA模 型 ;话题 发现 ; 困惑度 中图分类 号 :TP391 文献 标志 码 :A 文章 编 号 :1000—2758(2016)04—0698—05
为 了通 过 海量 的社 交 网络数 据及 时 的掌握 热点 话 题 和舆情 的态势 变化 ,需要 对话 题进 行 提取 、追 踪 和预测 。话 题 发 现 是 解 决 该 类 问 题 的关 键 技 术 之 一 。 LDA(1atent dirichlet allocation,隐性 狄 利 克雷 分 布 )主题模 型在新 闻话 题发 现 与检测 方 面获 得 了不 错的效果 ,但 由于社交网络文本 (如微博客短文本) 存在高维性及主题分布不均等问题 ,加之 LDA 自身 的局 限性 ,导致 以概 率化 词汇 抽 取 为基 础 的 LDA主 题 模 型在处 理社 交 网络 文本方 面 还存 在模 型难 以降 维 处 理和 主题 不 明确 的问题 ¨ 。
2016年 8月 第 34卷第 4期
西 北 工 业 大 学 学 报
Jour nal of Northwestern Polytechnieal University
Aug. 2016 Vo1.34 No.4
一 种 基 于 LDA 主 题 模 型 的 话 题 发 现 方 法
郭蓝 天 ,李扬 ,慕德俊 ,杨 涛 ,李哲
为 了减少 代词 和介 词等无 用 文本 信息 对话 题抽 取模 型 的干 扰 ,文 献 [5]提 出在 微 博 话 题 检 测 过 程 中 ,将 中文 词性 标注 后输 入 LDA 主题 模 型进 行话 题 抽取 。该 方法 试 图通 过 剔 除 大 量无 关 词 汇 ,使 向量 空 间 的维 度 降低 。
本 文 研 究话 题 发 现 问 题 ,通 过对 现 有 话题 发 现 常用的 LDA主题模 型的局限性进行分析 ,提 出一种 基 于 CBOW 语 言 模 型 的 向量 表 示 方 法 进 行 文 本 词 相 似性 聚类 ,以聚类 结果 为基 础 利用 LDA 主题模 型 对 文本 进行 隐 含主题 提 取 的话 题 发现 方法 。
【国家自然科学基金】_lasalle不变原理_基金支持热词逐年推荐_【万方软件创新助手】_20140729

推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14
2014年 科研热词 lasalle不变原理 非线性系统 物联网 泛函分析 时滞 广义lyapunov函数 局部稳定性 多主体适配 全局稳定性 偏序 三元空间域 zorn引理 lyapunov稳定性分析 lyapunov函数 推荐指数 3 1 1 1 1 1 1 1 1 1 1 1 1 1
科研热词 量子系统 模型变换 liapunov函数 lasalle不变集 稳定性 控制 sirs模型 lyapunov方法
推荐指数 2 2 2 2 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
科研热词 lasalle不变原理 非线性系统 非线性奇异系统 间断 稳定性 渐近稳定性 梯度系统 急慢性阶段 弱半稳定性 平衡点 基本再生数 半稳定 充分条件 不变性原理 seivr模型 lyapunov稳定性理论
2008年 序号 1 2 3 4 5 6 7 8 9
科研热词 预防接种 稳定性 波动引理 基本再生数 全局稳定 传染病 lyapunov函数 lasalle不变原理 hiv-1
推荐指数 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
科研热词 稳定性 非线性反馈控制 镇定 错位同步 连续接种免疫 连续接种 自适应控制 脉冲接种 混沌系统 时滞 接种 平衡位置 周期解 全局稳定性 传染病模型 sis模型 seir模型
推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
【国家自然科学基金】_再生核hilbert空间_基金支持热词逐年推荐_【万方软件创新助手】_20140802
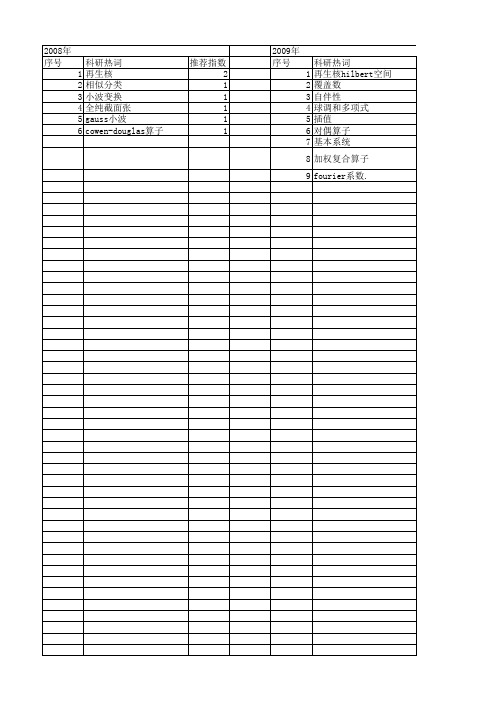
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
科研热词 再生核hilbert空间 领域适应学习 覆盖数 经验过程 系数正则化回归 正则化 模式分类 最小二乘支持向量机 最大散度差 最大均值差 时间窗 支持向量机 密度加权 学习率 在线自适应性 回归算法 回归函数 不确定时延 hoeffding不等式
科研热词 推荐指数 再生核希尔伯特空间 5 支持向量机 3 领域适应学习 2 模式分类 2 核分布一致 2 最大平均差 2 平移不变mercer核 2 局部学习 2 实解析 2 基因调控网络 2 领域自适应 1 预处理 1 重构 1 迭代 1 迁移学习 1 谱算法 1 语音情感识别 1 自适应分类 1 结构辨识 1 紧子集 1 独立性 1 特征融合 1 渐变概念漂移 1 核希尔伯特空间 1 最小二乘回归 1 学习理论 1 多角度 1 多核学习 1 受试者工作特征曲线面积 1 再生核hilbet空间 1 再生核hilbert空间 1 mercer核 1 l2-经验覆盖数 1 hsic方法 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
2011年 科研热词 推荐指数 学习理论 2 再生核hilbert空间 2 高光谱遥感 1 随机积分 1 稳定性 1 泛化性 1 核函数 1 样本依赖型再生核hilbert空间 1 有界差分稳定 1 最小平方回归 1 数据挖掘 1 支持向量机 1 希尔伯特空间 1 属性约简 1 小波支持向量机 1 学习速度 1 再生核 1 信号回归 1 主成分分析 1 lévy过程 1 gel'fand三元组 1
推荐指数 2 1 1 1 1 1 1 1 1
【国家自然科学基金】_dirichlet特征_基金支持热词逐年推荐_【万方软件创新助手】_20140730

科研热词 主题模型 非饱和土 非稳态流 隐含话题模型 隐含狄利克雷分配模型 隐含主题分布特征 迁移学习 路基 语义独立 语义特征 蓄洪 统计语言模型 素数 系统调用 目标检测 猜想 特征选择 特征选取 特征函数 潜在迪利克雷分布 渐近公式 浅层狄利赫雷分配 核反应堆 标签推荐 标签抽取 条件随机场模型 文本聚类 文本—图像特征映射 整数 排序 拥挤人群 意见挖掘 情感文摘 微博 异常检测 图像分类 含水量 变分推理 前景边缘曲线 分类 分层dirichlet过程 共现数据 低质量回帖 估计 人体模型 产品 事件约束 事件检测 事件摘要 主题特征 主题分布 中层语义特征
科研热词 推荐指数 零点密度 2 话题演化 2 尖点形式 2 l函数 2 高斯和 1 配点法 1 语义标注 1 话题模型 1 话题探测 1 话题关联 1 统计主题模型 1 特征 1 潜在狄里特里分配 1 概念 1 本体 1 无网格 1 径向基函数 1 对流扩散方程 1 信息检索 1 二次剩余 1 latent dirichlet allocation 1
推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1
推荐指数 4 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
53 54 55 56 57 58 59 60 61 62 63 64 65
不完整区间特征和 1 不同粒度 1 web论坛 1 lda模型 1 latent dirichlet allocation 1 k近邻算法 1 kummer conjecture, i)irichlet1 l-function, dirich gronwall不等式 1 dirichlet级数 1 dirichlet特征 1 dirichlet l-函数的倒数 1 bp神经网络 1 bof模型 1
主题聚类算法

主题聚类算法主题聚类算法是一类用于将文本数据按照主题或话题进行分组的算法。
这些算法旨在通过分析文本中的词汇、语法和语境等特征,自动将文档划分为不同的主题群组。
以下是一些常见的主题聚类算法:1. K均值聚类(K-Means Clustering):这是一种常见的聚类算法,通过将数据点分配到 k 个簇中,使得每个数据点到其簇中心的距离最小化。
在文本聚类中,数据点可以是文档,而簇则对应于主题。
2. 层次聚类(Hierarchical Clustering):这种算法构建一个层次结构的簇,通过逐步合并或分裂簇,直到达到某个停止条件。
这样的方法可以形成一个层次树,使得用户可以根据需要选择不同层次的聚类结果。
3. 谱聚类(Spectral Clustering):这种方法通过利用数据的谱结构来进行聚类。
在文本聚类中,可以使用文本数据的词汇共现矩阵或 TF-IDF 矩阵,然后应用谱聚类算法来识别主题。
4. LDA(Latent Dirichlet Allocation): LDA 是一种概率主题模型,被广泛应用于文本数据的主题建模。
它假设每个文档是由多个主题混合而成的,每个主题又由多个词汇组成。
LDA 通过迭代推断来发现文档和主题之间的关系。
5. DBSCAN(Density-Based Spatial Clustering of Applications with Noise): DBSCAN 是一种基于密度的聚类算法,不仅可以处理球状簇,还可以发现任意形状的簇。
在文本聚类中,可以使用文本向量的密度信息来进行聚类。
6. NMF(Non-Negative Matrix Factorization): NMF 是一种矩阵分解方法,它可以应用于文本数据的主题建模。
NMF 假设文档矩阵是由两个非负矩阵的乘积组成,这两个矩阵分别对应于文档和主题。
这些算法可以根据具体任务的需求和数据特点来选择。
在实际应用中,通常需要根据数据的特点进行调参和优化。
【国家自然科学基金】_liouville定理_基金支持热词逐年推荐_【万方软件创新助手】_20140801

科研热词 逆问题 势函数 liouville变换 黎曼流形 非线性方程 梯度估计 全局解
推荐指数 2 2 2 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7
2014年 科研热词 椭圆方程组 椭圆方程 梯度估计 改进的p-laplace方程 riemann流形 p-laplace harnack不等式 推荐指数 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10
科研热词 推荐指数 liouville定理 2 降阶法 1 通解 1 调和映射 1 能量慢发散 1 次椭圆 1 径向截曲率 1 外区域 1 二阶变系数方程 1 carnot-caratheodory空间 1
2013年 序号
1 2 3 4 5 6 7 8 9 schr(o)dinger算子 10 pucci算子 11 liouville型定理
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
科研热词 调和函数 liouville型定理 解析函数 泛clifford代数 推广的liouville定理 拟共形映射 抛物型不等式 径向ricci算子 常边值 双重退化 双连通域 fujita临界指标 f-调和映照 f-调和映射 f-稳态映射 blow-up
推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9
2011年 科研热词 非线性liouville定理 薛定谔方程 移动平面法 正解 梯度估计 奇异超线性椭圆方程 增长速度估计 liouville型定理 harnack不等式 推荐指数 1 1 1 1 1 1 1 1 1
LDA模型概述

LDA模型理解来自于原文(Latent Dirichlet Allocation David M. Blei, Andrew Y. Ng, Michael I. Jordan)的定义:Latent Dirichlet allocation (LDA) is a generative probabilistic model of a corpus. The basic idea is that documents are represented as random mixtures over latent topics, where each topic is characterizedby a distribution over words.LDA assumes the following generative process for each document w in a corpus D:1. Choose N ~ Poisson(ξ).2. Choose θ ~ Dir(α).3. For each of the N words wn:(a) Choose a topic zn ~ Multinomial(θ).(b) Choose a word wn from p(wn | zn,β), a multinomial probability conditioned on the topic zn.1. N服从泊松分布。
泊松分布是一个离散分布,主要适合于描述单位时间内随机事件发生的次数。
分布图可以看这里。
这里的N就是文档的长度。
论文里讲泊松分布并不是关键的,可以替换成其他离散分布。
2. θ是一个k维向量。
这个k维向量服从狄利克雷分布。
狄利克雷分布(Dirichlet distribution)是一个连续多随机变量分布。
要理解狄利克雷分布,需要了解共轭先验。
存疑。
具体性质可以看这里。
这里的k是一个定义好的数,怎么定的不知道,反正是要生成这样一个k维向量。
第20章 潜在狄利克雷分布

成单词 wv 的概率
• 所有话题的参数向量构成一个 K x V 矩阵
表示话题 zk 生 。
• 超参数 β 也是一个V维向量
基本想法
• 每一个文本 wm 由一个话题的条件概率分布 p(z|wm) 决定 • 分布 p(z|wm) 服从多项分布(严格意义上类别分布),其参数为 • 参数 服从狄利克雷分布(先验分布),其超参数为 α
• 两者有不同的参数,所以狄利克雷分布是多项分布的共扼先验
• 狄利克雷后验分布的参数等于狄利克雷先验分布参数
加上多项分布的观测
,好像试验之前就已经观察
到计数
,因此也把α叫做先验伪计数(prior
pseudo-counts)。
潜在狄利克雷分配模型
基本想法
• 潜在狄利克雷分配(LDA)是文本集合的生成概率模型
• 根据De Finetti定理,任意一个无限可交换的随机变量序列对一个 随机参数是条件独立同分布的
• 即任意一个 无限可交换的随机变量序列
的基于一个
随机参数Y的条件概率, 等于基于这个随机参数Y的各个随机变量
的条件概率的乘积。
随机变量序列的可交换性
• LDA假设文本由无限可交换的话题序列组成
• 由De Finetti定理知,实际是假设文本中的话题对一个随机参数是 条件独立同分布的
第二十章 潜在狄利克雷分配
潜在狄利克雷分配
• 潜在狄利克雷分配(latent Dirichlet allocation, LDA),作为基于贝 叶斯学习的话题模型,是潜在语义分析、概率潜在语义分析的扩 展,
• LDA 在文本数据挖掘、图像处理、生物信息处理等领域被广泛使 用
潜在狄利克雷分配
• LDA模型是文本集合的生成概率模型
【国家自然科学基金】_dirichlet过程_基金支持热词逐年推荐_【万方软件创新助手】_20140731

科研热词 推荐指数 计算机应用 2 dirichlet过程混合模型 2 马尔可夫链蒙特卡罗 1 非参数化bayes模型 1 转移概率矩阵 1 行为可信 1 行为分析 1 现代分布式软件 1 普适环境 1 无限隐马尔可夫模型 1 无限隐markov模型 1 无限混合模型 1 态势预测 1 徐变函数 1 嵌套的狄利克雷过程 1 变参数贝叶斯模型 1 参数辨识 1 共轭斜量法 1 中文信息处理 1 sar图像分割 1 dirichlet过程 1 dirichlet级数 1 bp2模式 1
推荐指数 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
2013年 科研热词 推荐指数 高斯混合模型 1 马尔科夫随机场 1 非参数贝叶斯模型 1 隐藏狄利克雷分配 1 部分比较性跨文本集lda模型 1 部分比较性 1 通用背景模型 1 边界元方法 1 贝叶斯推断 1 贝叶斯估计 1 话题模型 1 聚类分析 1 水流传热 1 比较性文本挖掘 1 无界区域 1 文本分析 1 数值拉普拉斯变换 1 攻角 1 并行算法 1 局部空化 1 多标记学习 1 图像标注 1 图像分割 1 各向异性扩散 1 半监督聚类 1 分布式系统 1 人工边界 1 三维细长体 1 sql 1 gibbs采样 1 gibbs抽样 1 dirichlet过程混合模型 1 d dirichlet分布 高斯混合实现 边电荷密度 轨迹分段 话题演化 话题关联 视频监控 行为识别 行为模式 聚类 系的随机模型 程的随机热力学 相变 目标出生强度 特征值 热流 潜在狄里克雷分布 潜在狄利克雷分配模型 涨落熵产生 涨落-耗散效应 法向电场强度 油纸绝缘 次分数brown运动 概率图模型 极性反转 有限元 整体分支 接触熔化 换流变压器 拟dirichlet过程 异常行为检测 层次狄利克雷过程-隐马尔科夫模型(hdp-hmm) 多示例学习 多目标跟踪 多层dirichlet过程 场景分类 在线估计 化学反应-传热耦合过 化学反应-传热-扩散体 前景提取 分量删减 分数brown运动 分层dirichlet过程 传热 主题模型 临界涨落展布指数 leray-schauder度 dirichlet过程 brown运动
基于LDA主题模型的制造业选址新闻案例研究

suibe.edu.cn;徐磊(1995—),男,上海对外经贸大学工商管理学院硕士研究生,研究方向为运营管理;徐天骋(1994—),男,莫 纳 什大学商务信息系统硕士研究生。
103
上海管理科学 ShanghaiManagementScience
第41卷第3期 2019年6月 Vol.41 No.3 Jun.2019
1 文献综述
1.1 制 造 业 选 址 相 关 研 究 对于 制 造 企 业 而 言,选 址 属 于 最 为 重 要 的 长 期
决策之一,研发中 心 或 是 工 厂 的 选 址 是 建 立、运 营、 管理企业的开始。企业选址的正确与否往往会直接 影响服务的方式、效 率、质 量 和 成 本 等,进 而 左 右 企 业的利润、市场 份 额 和 市 场 竞 争 力。 而 影 响 企 业 选
LDA (LatentDirichletAllocation)主题模型由 David M Blei提出,属 于 自 然 语 言 处 理 中 主 题 挖 掘 的典型模型,是一 个 基 于 概 率 图 的 三 层 贝 叶 斯 概 率 生成模型。LDA 主 题 模 型 的 主 要 思 想 是 假 设 文 档 集中的每个文档均 由 多 个 主 题 混 合 而 成,每 个 主 题 是固定词表上多个 词 汇 的 多 项 式 分 布,目 的 在 于 采 用高效的概率推断 算 法 处 理 大 规 模 数 据,从 文 本 语 料库中抽取潜在的 主 题,提 供 一 个 量 化 研 究 主 题 的 方法。该方法目前已经被广泛应用到各类主题发现 中 ,如 热 点 挖 掘 、主 题 演 化 、趋 势 预 测 等 。
latent dirichlet allocation详细介绍 -回复

latent dirichlet allocation详细介绍-回复什么是潜在狄利克雷分配(Latent Dirichlet Allocation)?潜在狄利克雷分配(Latent Dirichlet Allocation,简称LDA)是一种生成模型,用于将文本或其他类型的数据组织成主题模型。
它最初由Blei 等人于2003年提出,并成为自然语言处理中主题挖掘的重要方法之一。
LDA的基本思想是假设每个文档是由多个主题组成的,其中每个主题又由多个词语组成。
LDA使用的基础是狄利克雷分布(Dirichlet distribution),该概率分布主要用于多个离散变量的分布建模。
在LDA中,使用狄利克雷分布来建模文档-主题分布和主题-词语分布。
通过计算这些分布,可以推断出每个文档的主题和每个主题的词语分布。
LDA的基本假设是:每个文档都可以看作是多个主题的混合,而每个主题又由多个词语组成。
根据这个假设,LDA的目标就是找到每个文档的主题分布和每个主题的词语分布,从而可以推断出文档中包含的主题和主题中包含的词语。
LDA的工作流程包括以下步骤:1. 数据预处理:首先,需要对原始文本进行预处理,包括去除标点符号、停用词和数字,进行分词等操作。
这样可以将文本转化为可处理的形式。
2. 构建词袋模型:建立一个词袋模型,记录文档中所有不重复的词语和它们的计数。
这个词袋模型可以用于后续的主题建模工作。
3. 设定参数和主题数:设定LDA模型的参数,包括主题数和迭代次数等。
主题数是一个重要的参数,决定了LDA模型对文档中隐含主题的分析程度。
4. 训练LDA模型:使用Gibbs采样等方法对LDA模型进行训练。
通过对每个词语的主题进行抽样,可以得到文档-主题和主题-词语分布。
迭代多次后,可以得到稳定的主题模型。
5. 主题分析和可视化:通过分析每个文档的主题分布和每个主题的词语分布,可以推断出每个文档的主题和每个主题的含义。
可以使用可视化工具,如词云图和主题-主题分布图,来展示主题模型的结果。
latentdirichletallocation learning_method -回复

latentdirichletallocation learning_method -回复什么是潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)?LDA 是一种无监督的机器学习模型,用于发现文本集合中的主题结构。
本文将从LDA的基本概念开始,逐步介绍其学习方法和应用,最后讨论其优缺点和未来发展方向。
第一部分:潜在狄利克雷分配的基本概念潜在狄利克雷分配(LDA)是一种生成模型,用于描述文本集合中的主题结构。
LDA假设每篇文档由多个主题构成,而每个主题又由多个词语组成。
通过学习文档和词语之间的关系,LDA可以自动地发现潜在的主题,并将文本分配到不同的主题中。
LDA模型的核心思想是假设文档中的每个词汇都是从主题中随机生成的。
具体来说,对于每篇文档,LDA首先从一个主题分布中随机选择一个主题,然后从这个主题的词汇分布中随机选择一个词汇。
这个过程被称为生成过程,通过反向推理可以得到主题分布和词汇分布的参数。
第二部分:潜在狄利克雷分配的学习方法LDA的学习方法将通过观察文本集合中的词语出现情况,推导出最有可能生成这些文本的主题分布和词汇分布。
学习过程可以通过EM算法来实现。
首先,需要初始化每个文档的主题和每个主题的词汇分布。
然后,迭代进行以下两个步骤:1. E步骤(Expectation):根据当前的参数估计,计算每个文档中每个词汇属于每个主题的概率。
这个概率可以通过主题分布和词汇分布来计算。
2. M步骤(Maximization):根据E步骤计算得到的概率,更新主题分布和词汇分布的参数。
通过多次迭代,可以逐渐优化参数估计,得到更准确的主题和词汇分布。
第三部分:潜在狄利克雷分配的应用LDA在文本挖掘、信息检索和自然语言处理等领域有广泛的应用。
通过LDA模型,可以自动发现文本集合中的主题结构,帮助理解大规模文本数据的内容和关联关系。
例如,在文本分类任务中,LDA可以将文档分配到不同的主题中,从而实现文本的自动分类。
国家中小学智慧教育平台应用现状调研与路径优化

国家中小学智慧教育平台应用现状调研与路径优化作者:王娟张雅君王冲闵小晶孔婉婷来源:《电化教育研究》2024年第06期基金项目:2023年度国家社科基金教育学一般项目“国家中小学智慧教育平台的区域规模化应用模式与实践成效研究”(项目编号:BCA230269)[摘要] 国家中小学智慧教育平台是推进基础教育数字化转型的重要抓手。
研究以SOR模型、技术接受模型等为理论支撑,从平台的应用现状、影响因素、存在问题与困境以及发展建议等方面,对全国30,605名学生展开问卷调查。
研究发现:平台存在操作流程不够简化、个性化资源不够丰富等问题,而“接入鸿沟、技术鸿沟、素养鸿沟”加剧城乡应用差距、学业压力的上升与数字韧性不足导致学段应用差异、学习满意度不高致使持续使用意愿不强等因素影响平台应用的推进。
研究基于行动者网络理论和生态系统理论,借鉴相关省市平台应用典型案例,从组织、数据、技术、服务等层面,为推动平台应用推广、加强数据融通、提升用户黏性、精准满足个性化需求提供可行方案,以助力基础教育数字化转型战略的稳步推进。
[关键词] 国家中小学智慧教育平台;应用现状;教育数字化;路径优化;问卷调查[中图分类号] G434 [文献标志码] A[作者简介] 王娟(1979—),女,江苏泗洪人。
教授,博士,主要从事智慧教育、教育大数据研究。
E-mail:**************。
一、引言国家中小学智慧教育平台(以下简称“平台”)作为教育数字化转型战略部署的“国家队”和重要抓手,其统筹运用数字化思维、理念和技术,能够全方位、系统性地重塑教育教学和教育治理的体制机制,助推基础教育高质量发展[1]。
平台自2022年上线以来,累计注册用户突破1亿,浏览量超过367亿次[2],其建设和应用已取得初步成效,但深入推进还面临较多困境。
如何有效提升平台的应用效率,助推教育数字化转型的健康发展,已成为当前教育领域备受关注的热点问题。
目前,内蒙古、宁夏、辽宁等地正在大力推进平台整省试点,积极探索平台深度应用,已基本建成具有地方特色的智慧教育平台公共服务体系。
基于LDA模型与政策工具的中国数据主权政策研究

政策与管理研究Policy & Management Research引用格式:乔晗, 徐君如. 基于LDA模型与政策工具的中国数据主权政策研究. 中国科学院院刊, 2024, 39(3): 498-508, doi: 10.16418/j.issn.1000-3045.20231115001.Qiao H, Xu J R. Research on Chinese data sovereignty policy based on LDA model and policy instruments. Bulletin of Chinese Academy of Sciences, 2024, 39(3): 498-508, doi: 10.16418/j.issn.1000-3045.20231115001. (in Chinese)基于LDA模型与政策工具的中国数据主权政策研究乔晗*徐君如1 中国科学院大学经济与管理学院北京1001902 中国科学院大学数字经济监测预测预警与政策仿真教育部哲学社会科学实验室(培育)北京100190摘要在数字经济发展与总体国家安全观的双重时代背景下,数据主权已成为国家主权的重要组成部分。
各主要国家和地区积极开展数据主权战略部署,在数据资源、数据技术和数据规则方面展开激烈竞争与博弈。
文章采用政策文本分析方法研究我国数据主权政策,运用LDA(Latent Dirichlet Allocation)主题模型和政策工具量化分析中国数据主权政策的过程演化、主题特征,并综合考虑全球数据主权态势,提出4条政策建议:积极主导和参与国际规则制定;优化数据出境安全评估流程;完善个人信息出境标准合同模版;强化数据安全法治保障。
关键词数据主权,数据安全,政策工具,LDA模型DOI10.16418/j.issn.1000-3045.20231115001CSTR32128.14.CASbulletin.20231115001数据主权是指一个国家对其政权管辖范围内的网络设施、数据主体、数据行为和数据资源及相关数据产品具有生成、传播、管理、控制、利用和保护的主导权[1-3],其正在成为数字时代国家主权的重要组成部分。
基于LDA的新闻话题子话题划分方法_赵爱华

提出了基于多层聚类的 M LCS 算法对话题
根据主题概率分布和主题间特征词的共现性进行文档聚类,
进行层次化组织, 但是没有明确指出不同层次话题粒度的大
0104 收 修 改 稿 日 期: 20120427 基 金 项 目: 国 家 自 然 科 学 基 金 项 目 ( 60873247 ) 资 助; 山 东 省 自 然 科 学 基 金 项 目 收稿 日 期: 2012( ZR2009GZ007 ) 资助; 山东省教育厅科技项目( J09LG52 ) 资助; 山东省高新自主创新专项工程项目( 2008ZZ28 ) 资助. 作者简介: 赵爱华, 女, 1987 年生, CCF 会员, 1960 年生, 硕士研究生, 研究方向为网络信息安全 、 话题检测; 刘培玉, 男, 教授, 博士生导师, 研究方向为计算机网络信息 1989 年生, 安全、 网络系统规划、 网络信息资源开发和软件开发技术; 郑 燕, 女, 硕士研究生, 研究方向为网络信息安全、 话题追踪.
Subtopic Division in News Topic Based on Latent Dirichlet Allocation
2 2 2 ZHAO Aihua1, , LIU Peiyu1, , ZHENG Yan1, 1 2
( School of Information Science and Engineering ,Shandong Normal University ,Jinan 250014 ,China) ( Shandong Provincial Key Laboratory for Distributed Computer Softw are Novel Technology , Jinan 250014 ,China)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77
关联分析 1 共现数据 1 信息处理技术 1 低质量回帖 1 代价敏感图像层肺癌诊断系统 1 事件约束 1 事件检测 1 事件摘要 1 主题特征 1 主题挖掘 1 主题分布 1 中文自动文摘 1 中层语义特征 1 个性化 1 web论坛 1 topic model 1 tc-lda模型 1 tag 1 semantic knowledge acquisition1 probabilistic author-topic model 1 olda模型 1 lda(latent dirichlet allocation) 1 k近邻算法 1 gibbs抽样 1 bof模型 1
科研热词 推荐指数 主题模型 6 lda模型 3 latent dirichlet allocation 3 标签推荐 2 微博 2 web 2.0 2 隐含狄利克雷分配模型 1 隐含主题分布特征 1 迁移学习 1 语言模型 1 语义独立 1 语义特征 1 语义树 1 话题演化 1 话题关联和演化 1 计算机辅助 1 融合方法 1 自动批注 1 自主意识 1 肺肿瘤/诊断/病理学 1 系统调用 1 社会标签 1 短文本 1 相对熵 1 目标检测 1 狄利特利分布 1 特征选择 1 特征选取 1 潜在迪利克雷分布 1 潜在语义分析 1 潜在狄利克雷分配 1 浅层狄利赫雷分配(lda) 1 浅层狄利赫雷分配 1 模型选择 1 标签预测 1 标签抽取 1 条件随机场模型 1 文档聚类 1 文本聚类 1 文本—图像特征映射 1 文字信息处理 1 排序 1 意见挖掘 1 情感文摘 1 异常检测 1 多文档 1 增量聚类 1 图像处理 1 图像分类 1 变分推理 1 医学文本 1 分类 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
2008年 序号 1 2 3 4
科研热词 隐含狄利克雷分配 文本分类 图模型 变分推断
推荐指数 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11
科研热词 集成分类 隐含狄利克雷分配 隐含狄利克雷分布 随机森林 计算机应用 文本分类 垃圾贴 在线论坛 图模型 向量空间模型 中文信息处理
推荐指数 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
科研热词 推荐指数 主题模型 4 lda 3 潜在狄利克雷分配 2 隐藏狄利克雷分配 1 隐含狄利克雷分配(lda) 1 隐含狄列克雷分配 1 跨语言信息检索 1 谱残差 1 话题标签 1 词袋模型 1 种子词抽取 1 短文本 1 相似度计算 1 相似度 1 潜在狄利克雷分布模型 1 潜在狄利克雷分布(lda) 1 潜在狄利克雷分布 1 混合模型 1 概率模型 1 查询扩展 1 极光图像 1 显著信息 1 文本相似度 1 文本分析 1 推荐系统 1 情感分析 1 异构体表达 1 并行计算 1 子话题划分 1 多源映射 1 多标记学习 1 双语主题 1 协同过滤 1 半监督聚类 1 分类 1 信息融合 1 伪相关反馈 1 主题特征词 1 主题建模 1 主题句抽取 1 topic labeling 1 rna-seq 1 overlapping community 1 news event 1 mapreduce架构 1 link partition 1 latent dirichlet allocation (lda) 1 latent dirichlet allocation 1 k近邻 1 kl距离 1 gibbs抽样 1 community detection 1
ቤተ መጻሕፍቲ ባይዱ
科研热词 推荐指数 主题模型 3 lda 3 话题演化 2 dirichlet分布 2 隐dirichlet分配模型 1 谱聚类 1 语义标注 1 话题模型 1 话题探测 1 话题关联 1 词相似性 1 舆情 1 自动图像标注 1 统计主题模型 1 社群 1 用户评论 1 热点话题识别 1 热点挖掘 1 潜在狄里特里分配 1 潜在狄里克雷分布 1 潜在主题挖掘 1 演化 1 模型 1 概率潜在语义分析 1 概念 1 本体 1 多社群信息融合 1 多文档自动文摘 1 复杂图 1 基于类主题空间的潜在狄里克雷分布 1 场景分类 1 图聚类 1 可见度 1 句子分值计算 1 加权主题模型 1 信息检索 1 主题数目 1 lda(latent dirichlet allocation) 1 latent dirichlet allocation 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
2011年
2012年 科研热词 推荐指数 序号 主题模型 4 1 lda 3 2 逻辑回归 2 3 特征选择 2 4 场景分类 2 5 lda模型 2 6 马尔可夫链蒙特卡洛方法 1 7 餐馆评论 1 8 音乐流派分类 1 9 音乐标签 1 10 隐性语义索引 1 11 隐含狄利克雷分配模型 1 12 隐含狄利克雷分配 1 13 软件缺陷分派 1 14 话题演化 1 15 话题关联 1 16 视觉词袋模型 1 17 观点挖掘 1 18 自然语言处理 1 19 自动文摘 1 20 科学家合作网络 1 21 社区发现 1 22 社区-作者-主题模型 1 23 用户意图 1 24 潜在狄雷克来分配模型 1 25 潜在狄里克雷分布 1 26 潜在狄利克雷分配模型 1 27 期望最大化算法 1 28 文本分类 1 29 排序 1 30 姿态判别 1 31 多文档 1 32 基于特征间相互影响的前向特征选择算法(ibffs) 1 33 垃圾评论 1 34 向量空间模型 1 35 吉布斯采样 1 36 博文 1 37 半监督学习 1 38 动词聚类 1 39 依存关系 1 40 主题 1 41 latent dirichlet allocation 1 42 gibbs采样 1 43 blog 1 44 45 46 47 48 49 50 51 52