中科院自动化所的中英文新闻语料库
汉语中介语语料库建设研究

三 、 据 库 的设 计 思 路 数
料数 据库 , 以收 集 不 同背 景 和不 同 学 习 阶 段 外 国 学 生 及 少 数 民 族 学 生 可 的汉 语 书面 语 和用 文 字转 写 的 口 语 语 料 , 并对 语 料 属 性 、 汇 、 法 等 单 词 语
构 , 反映 用 户观 点 的 概 念 模 型 , 是 整个 数 据 库 设 计 的 关 键 。一 般语 即 这
言 的基 本 构 成 要 素 是 词 , 词 构 成 句 , 由 句 构 成 篇 蕈 , 汉 语 的 最 小 由 再 但 构 成 元素 却 是 汉 字 , 此 设 计 语 料 库 结 构 组 成 时 需 要 将 字 、 、 和 篇 因 词 句 章 都 考 虑到 。另 外 , 料 库 数据 的 最大 特 点 就 是 真 实 , 就 是 说 需 要 语 也 原样 保 存 语 料 信 息 , 括语 料 中 的大 量 偏 误 , 也 是 需 要 考 虑 的 关 键 问 包 这
法 以及 语 料 数 据库 的设 计 思 路 , 阐 明 了该语 料 库 在 对 外 汉 语 教 学 和研 究 中 的应 用 价 值 。 并 【 键 词】 语 料 库 ; 关 中介 语 ; 语 教 学 汉
语料库是指按一定的语言学原则收集的语言文本或话语片断而建立
的 电 子资 料 库 。本 文所 述 汉语 中 介 语料 库 是基 于 语 言学 中 中 介语 理 论 设 计 与 实施 的 。中 介 语是 心 理语 言 学 中 第 二 语 言 习 得 的 ~ 种 研 究 模 式 , 其 将 语言 学 习者 置 于观 察 中 心 , 研究 他 们 如 何 有意 识 地 向 目 的语 的 正确 去 形 式迁 移 的各 种 动态 表现 。中 介 语理 论 自 2 o世 纪 6 o年代 末 出现 并发 展
关于汉语中介语语料库建设研究报告

汉语中介语语料库建设研究沈锐1,黄薇2(1.红河学院教育技术系2.红河学院国际合作与交流处XX蒙自661100)【摘要】本文探讨母语非汉语学习者的汉语中介语语料库建设的主要思路以及具体实现方法,重点介绍了汉语中介语语料的加工方法以及语料数据库的设计思路,并阐明了该语料库在对外汉语教学和研究中的应用价值。
【关键词】语料库;中介语;汉语教学语料库是指按一定的语言学原则收集的语言文本或话语片断而建立的电子资料库。
本文所述汉语中介语料库是基于语言学中中介语理论设计与实施的。
中介语是心理语言学中第二语言习得的一种研究模式,其将语言学习者置于观察中心,去研究他们如何有意识地向目的语的正确形式迁移的各种动态表现。
中介语理论自20世纪60年代末出现并发展至今,虽然时间并不长,但越来越受到语言学家以及一线教师的关注。
无论是进行中介语研究还是使用中介语理论进行第二语言教学都需要收集分析大量的语料,因而通过信息化手段收集和整理语料变得十分迫切。
在对外汉语教学中,通过建设和使用母语非汉语学习者的汉语中介语语料数据库,可以收集不同背景和不同学习阶段外国学生及少数民族学生的汉语书面语和用文字转写的口语语料,并对语料属性、词汇、语法等单位进行计算机处理,以实现对各种条件和要求下的语料数据进行便捷的机器检索和提取,可以为研究母语非汉语学生学习和习得汉语的规律提供大量的各种单项的或综合的资料和信息。
因此,我们提出了建设汉语中介语语料库的课题,由于语料库建设是一项浩大的工程,限于人力物力条件,本文讨论的是中小规模的语料库。
一、需求分析和框架设计语料库建设不能盲目进行,首先要进行调研,对语料库的应用需求进行分析。
半自动化的语料库构建是目前语料库建设的主流技术,目的是在确保语料库质量的前提下,减少人工参与的比例,增加自动化程度,目标是在较短时间内建设一个有一定规模,质量可靠、可扩充、成本低,能够全面、细致地记录母语非汉语学习者在汉语学习过程中的语言表征和研究他们汉语习得过程的语料库。
蒙古语语音合成语料库的设计及韵律标注规范的建立

2 12 卑 第 3 期 (l
蒙古语 语 音合成 语料库 的设计及 韵律标 注规 范 的建 立
郭淑妮 图 雅 斯 琴 高娃
f 蒙 古 民 族 人 学 计 算 机 科 学 与 技 术 学 院 ,内蒙 古 内 通 辽 O 8 O ) 2 O 0
[ 摘
要] 以蒙古语 中的察哈 尔方言为研 究对 象, 结合 了蒙古语 自身的音节结构特点 , 对蒙语 语音合成语料库 的构建进行 了
型 、 音 类 型 以及 停 顿 指数 。 重
[ 关键 词 ] 蒙 语 ; 音 合 成 ; 料 库 ; 律 标 注 语 语 韵
语 语音合 成 的语 料库 , 同时 , 采用 pat ra 软件 设计 了一套 蒙语
1 引 言 .
的韵律标注 体系 , 标注 系统包括 对拉丁 转写 、 音节 结构类型 、 重音类 型 以及停 顿指数等 的标注 。
性 、 性 之 分 , 短 元 音 具 有 区别 意 义 的 作 用 , 阳 长 同音 字 现 象 出
具 有重要 的意义和 实用价 值 。
在 国 内 , 汉 语 的 语 音 合 成 语 料 库 建 设 方 面 的 研 究 已经
现较 为频繁 [ 。因此 , 2 1 ] 在进 行语料 库 设计 以及标 注 的时候 都 应该考 虑这些 问题 。 本文 的研 究 以察 哈尔 蒙古语方 言为对 象, 察哈 尔方 言是 蒙古语 的标 准音 , 且各 方 言土语 之 间的共
语 料库 建设 初期 ,首 先要进 行 文本 的设计 ,然后 采用
A dt n软 件 在 专 业 录 音 室 中 录 音 , 使 用 该 软 件 和 程 序 设 u io i 并
计相结 合的方法 进行音 段的切分 ,最后使 用 Pat 音分析 ra 语 软件进 行标注 。 语料 建设 中的每一 步都有相 应的软硬 件来进
兰卡斯特汉语语料库

“兰卡斯特汉语语料库”介绍1许家金(北京外国语大学中国外语教育研究中心,北京 100089,北京)提要:本文介绍“兰卡斯特汉语语料库”(简称LCMC)的取样方案、文本构成、标注体系和应用方面的概况。
该语料库是依照英国英语语料库FLOB的取样方案和规模创建的可比汉语语料库,适合开展英、汉语对比研究,同时也适合汉语研究。
关键词:汉语语料库;LCMC;对比研究1.0 前言“兰卡斯特汉语语料库”(The Lancaster Corpus of Mandarin Chinese,简称LCMC)系旅英学者肖忠华博士创建的现代汉语平衡语料库。
该语料库严格按照FLOB (Freiburg-LOB Corpus of British English)模式编制,它的建成有助于开展基于语料库的汉语单语或汉英(英汉)双语对比研究及汉语研究。
2.0 LCMC语料库概况LCMC语料库是一个100万词次(按每1.6个汉字对应一个英文单词折算)的现代汉语书面语通用型平衡语料库。
起先建立时,它是作为英国经社研究委员会资助项目Contrasting Tense and Aspect in English and Chinese的部分成果。
肖忠华最初的设想是要将其建成同FLOB和FROWN对应的现代汉语语料库。
筹建这样的一个语料库的另一个动因是:尽管已经有很多汉语语料库存在,但却没有一个完全免费对公众开放的平衡的汉语语料库2。
2.1 取样模式与文本收集考虑到LCMC主要做对比研究之用,肖忠华创建语料库之初就确定了对比的对象。
一方面,在短期内想要建成像BNC那样的逾亿词次的语料库并不现实。
另一方面,要建立同LOB和Brown平行的语料库的问题在于很难找到1961年前后材料的电子文本。
于是,最后对比目标被锁定在语料出版年份主要是1991、1992年的100万词次的FLOB上。
鉴于同时还有与FLOB对应的美国英语语料库Frown的存在,LCMC建成以后也可与美国英语进行比较。
口语对话语音语料库CADCC与其语音研究

口语对话语音语料库CADCC和其语音研究·李爱军,殷活纲,王茂抹徐波啊宗成庆'矿中田社会科学院语言研究所,Ⅲ中国科学院自动化研究所摘要口语对话和朗读语麓的差别表现在句法、剐语言学现象、音段和韵律等许多方面,这给口语对话的标注带来新的课题.本文介绍自然口语对话语音语料库CADCC(ChineseAnnotatedDialoguoandConvvrsationCorpus)和其文字转写,音段以及韵律标注.CADCC包括两个子库:电话对话库setl和口语对话语篇库set2.其标注内容包括篇章话题、话轮、韵律和音段的标注.音段标注采用SAMPA—C标注系统,韵律标注采用C-ToBI标注系统.本文还报告了标注结果,如篇章话题的长度,口语话轮出现的模式,插入和叠接现象,韵律结构和朗读语篇的差异等等.1自然口语库CADCC语篇(discourse)包括朗读语篇和自然口语语篇,又可以分成独白和对话两种形式。
不同形式的语篇具有不同的特性,比如参与的人数、涉及的话题、话轮顺序和话轮长度等等。
我们已经建立了朗读语篇库ASCCD和独自的自然口语CASS,并且进行了语音学标注【2】.口语对话语篇库CADCC是我们今年开始收集和标注的,我们希望它对言语工程和语音研究会有较大的贡献。
CADCC包括两个子库,其中SET1是电话对话库,SET2是正常通道对话库。
表1给出了CADCC的详细信息。
SET2中的对话双方是同事或同学.有共同的爱好或话题.谈话内容不限.也就是语篇话题可以自由转换。
其中有8位发音人曾经参加朗读语篇ASCCD的录音.这样做的目的是为了详细对比朗读和自然口语的各种差异.录音在普通办公室或宿舍进行,对话者身别无线话筒,无线录音设备放置在另外的房间,这样保证了对话双方完全进入自然谈话状态。
每一对发音人的谈话时间在1个小时左右。
2音字转写所有的声音都进行了汉字转写,特别将口语的副语言学和非语言学现象按照表2的符号进行转写例l:B:我傻OV<B:我印度人A:LA<LA>OV>;例2:A:LE<MO<嗅LE>M09;B:那个就是DS<一一DS>m子的事儿。
Google word2vec 学习基础文档20151018

Google word2vec 学习基础陈良臣2015年10月18日1. word2vec简介word2vec是word to vector 的缩写。
word2vec 是Google 在2013年年中开源的一款将词表征为实数值向量的高效工具,采用的模型有CBOW(Continuous Bag-Of-Words,即连续的词袋模型)和Skip-Gram 两种。
能够把词映射到K维向量空间,甚至词与词之间的向量操作还能和语义相对应。
(word2vec 通过训练,可以把对文本内容的处理简化为K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。
) 因此,word2vec输出的词向量可以被用来做很多NLP相关的工作,比如聚类、找同义词、词性分析等等。
如果换个思路,把词当做特征,那么Word2vec就可以把特征映射到K 维向量空间,可以为文本数据寻求更加深层次的特征表示。
2. 词向量介绍词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词表示成一个向量。
词向量,顾名思义,就是用一个向量来表示一个单词,这个向量不是随便的一个,而是根据单词在语料中的上下文而产生,具有意义的向量。
而word2vec 就是根据语料来生成单词向量的一个工具。
生成单词向量有什么用?最主要的一点就是用来计算相似度。
直接计算两个词的余弦值便可以得到。
一种最简单的词向量方式是one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个1,其他全为0,1 的位置对应该词在词典中的位置。
举个例子,“话筒”表示为[0 0 0 1 00 0 0 0 0 0 0 0 0 0 0 ...]“麦克”表示为[0 0 0 0 00 0 0 1 0 0 0 0 0 0 0 ...]每个词都是茫茫0 海中的一个1。
3. word2vec代码word2vec的原版代码是google code上的,基于c语言。
国家语委语料库

国家语委现代汉语语料库是一个大型的通用的语料库,以语言文字的信息处理、语言文
字规范和标准的制定、语言文字的学术研究、语文教育和语言文字的社会应用为主要服务目
标。国家语委现代汉语语料库作为国家级语料库,在汉语语料库系统开发技术上具有国际领
先水平,在语料可靠、标注准确等方面具有权威性。国家语委现代汉语语料库面向国内外的
b)切分结果层次(结构)化:
8
切分结果层次(结构)化使得语料库能够更好地满足不同研究应用需要。
2.机助人校的语料校对工具软件
校对软件界面:
..校对者可与后台词典交互,直接获取词和词类信息
..软件自动通过色彩标识出语料校对信息
..严格的自动格式检查,防止用户误操作等带来的错误
经完成词语切分和标注加工的约5000万字语料是语料库中1919~1992时间段的大部分语料
以及1992~2002时间段的部分语料。
二、国家语委语料库建设与深加工
1.主要科研成果
国家语委现代汉语语料库建设已经完成的主要内容是:
2
1)完成 5000万字语料词语切分和词性标注加工。词语切分校对精度达到万分之五,词
a14 本版印数
a15 总印数
a16 总页数
a17 开本
a18 选择方式
a19 起止页数
a20 样本字数
a21 样本总字数
a22 文章总字数
a23 简繁体
a24 抽样文章
国家语委现代汉语语料库的数据量包括新增的 1000万字新语料已经达到了 1亿字,已
“大规模”和“真实”这两个特点,因此是最理想的语言知识资源,是直接服务于语言文字
中文文本分类语料

中文文本分类语料文本自动分类就是用电脑对文本按照一定的分类体系或标准进行自动分类标记。
文本分类问题与其它分类问题没有本质上的区别,其方法可以归结为根据待分类数据的某些特征来进行匹配,当然完全的匹配是不太可能的,因此必须(根据某种评价标准)选择最优的匹配结果,从而完成分类。
现如今,统计学习方法已经成为了文本分类领域绝对的主流。
统计学习方法需要一批由人工进行了准确分类的文档作为学习的材料(称为训练集,注意由人分类一批文档比从这些文档中总结出准确的规则成本要低得多),计算机从这些文档中挖掘出一些能够有效分类的规则,这个过程被形象的称为训练,而总结出的规则集合常常被称为分类器。
训练完成之后,需要对计算机从来没有见过的文档进行分类时,便使用这些分类器来进行。
下面提供一些网上能下载到的中文的好语料,供研究人员学习使用。
1.中科院自动化所的中英文新闻语料库/data/13484中文新闻分类语料库从凤凰、新浪、网易、腾讯等版面搜集。
英语新闻分类语料库为Reuters-21578的ModApte版本。
2.搜狗的中文新闻语料库/labs/dl/c.html包括搜狐的大量新闻语料与对应的分类信息。
有不同大小的版本可以下载。
3.李荣陆老师的中文语料库 /data/11968压缩后有240M大小4.谭松波老师的中文文本分类语料/data/11970不仅包含大的分类,例如经济、运动等等,每个大类下面还包含具体的小类,例如运动包含篮球、足球等等。
能够作为层次分类的语料库,非常实用。
5.网易分类文本数据/data/11965包含运动、汽车等六大类的4000条文本数据。
6.中文文本分类语料/data/11963包含Arts、Literature等类别的语料文本。
7.更全的搜狗文本分类语料 /labs/dl/c.html搜狗实验室发布的文本分类语料,有不同大小的数据版本供免费下载8.2002年中文网页分类训练集/data/150212002年秋天北京大学网络与分布式实验室天网小组通过动员不同专业的几十个学生,人工选取形成了一个全新的基于层次模型的大规模中文网页样本集。
英汉语料库汇总

1.英语学习者语料库(书面语及口语)中国学习者语料库 CLEC(100万)广外、上海交大2.大学英语学习者口语语料库 COLSEC (5万) 上海交大3.香港科技大学学习者语料库 HKUST Learner Corpus 香港科技大学4.中国英语专业语料库 CEME (148万) 南京大学5.中国英语学习者口语语料库 SECCL (100万) 南京大学6.国际外语学习者英语口语语料库中国部分 LINSEI-China (10万) 华南师大7.硕士写作语料库 MWC (12万) 华中科技大学9.平行语料库汉英平行语料库 PCCE 北外10.南大-国关平行语料库南京大学11.英汉文学作品语料库;外研社12.冯友兰《中国哲学史》汉英对照语料库13.李约瑟(Joself Needham)《中国科学技术史》英汉对照语料库14.计算机专业的双语语料库;国家语言文字工作委员会语言文字应用研究所15.柏拉图(Plato)哲学名著《理想国》的双语语料库16.英汉双语语料库(15万对) 中科院软件所17.英汉双语语料库:LDC香港新闻英汉双语对齐语料36294段以及香港法律英汉双语对齐语料31万句子对中国科学院自动化研究所18.英汉双语语料库(100万),网上英汉语段电子词典及网上电子英汉搭配词典(1000万) 东北大学19.英汉双语语料库(40-50万句子对) 哈尔滨工业大学20.双语语料库(5万多对) 北京大学计算语言学研究所21.对比语料库 LIVAC(Linguistic variety in Chinese communities) 香港城市理工大学22.平衡语料库(Sinica Corpus);树图语料库(Sinica Treebank) 台湾23.特殊英语语料库中国英语(China English)语料库河南师范大学24.军事英语语料库(Corpus of Military Texts) 解放军外语学院25.新视野大学英语教材语料库上海交通大学26.汉语语料库汉语现代文学作品语料库(1979年,527万字) 武汉大学27.现代汉语语料库(1983年,2000万字) 北京航空航天大学28.中学语文教材语料库(1983年,106万8000字) 北京师范大学29.现代汉语词频统计语料库(1983年,182万字) 北京语言学院30.国家级大型汉语均衡语料库(2000万字) 国家语言文字工作委员会31.《人民日报》语料库(2700万字) 北京大学计算机语言学研究所32.大型中文语料库(5亿字,10分库) 北京语言文化大学33.现代汉语语料库(1亿字) 清华大学34.汉语新闻语料库;(1988年,250万字) 山西大学35.标准语料库(2000年,70万字)36.生语料库(3000万字);《作家文摘》的标注语料库(100万字) 上海师范大学37.现代自然口语语料库中国社会科学院语言所38.旅游咨询口语对话语料库和旅馆预定口语对话语料库中国科学院自动化所39.北京大学汉语语言学研究中心的三个语料库现代汉语语料库/yuliao.asp?item=1古代汉语语料库/yuliao.asp?item=2汉英双语语料库/yuliao.asp?item=3/printthread.php?t=2742汉语语料库使用权限国家语委语料库(http://219.238.40.213:8080/CpsQrySv.srf)”虽说是通用型平衡语料库,但不能完全免费使用;北京语言大学的汉语语料库(http://202.112.195.8)语料产出时间较早,且不能完全免费使用;北京大学汉语语言学研究中心语料库(现代汉语子库)”(/YuLiao_Contents.Asp)规模最大,逾亿字,但取样极不均衡,多半为文学作品;台湾“中央研究院”Sinica Corpus也是可免费使用的平衡汉语语料库。
语料库和知识库的研究现状

语料库和知识库研究现状摘要:语料库是语料库语言学研究的基础资源,也是经验主义语言研究方法的主要资源,它与自然语言处理有着相辅相成的关系,是用统计语言模型的方法处理自然语言的基础资源。
知识库广泛应用于信息检索、机器问答系统、自动文摘、文本分类等领域,为进行大规模的真实性文本的语义分析提供了有利的支持,它也成为自然语言处理不可或缺的基础资源。
由于语料库和知识库的广泛应用,如今国内外对语料库和知识库的研究给与高度的重视,经过过去几十年的发展,各国在语料库和知识库的建设和应用方面都取得了不少成果。
本文通过对语料库与知识库相关文献资料的搜索整理,重点介绍目前国内外在语料库和知识库方面的研究现状。
关键词:语料库;知识库;研究现状1前言语料库是指按照一定的语言学原则,运用随机抽样的方法,收集自然出现的连续的语言文本或者说话片段而建成的具有一定容量的大规模电子文本库[1]。
而知识库是知识工程中结构化、易操作使用,全面有组织的知识集群,是针对某一(或某些)领域问题求解的需要,采用某种(或若干)知识表示方式在计算机存储器中存储、组织、管理和使用的互相联系的知识片集合。
语料库和知识库在传统语言研究、词典编纂、语言教学、自然语言处理等领域有重要作用,所以自从20世纪60年代第一个现代意义上的语料库——美国布朗语料库(Brown Corpus)诞生开始,大批国内外的专家学者致力于语料库和知识库的研究,近年来国内外对于语料库知识库的研究取得了重大的突破,形成了规模不一的各种语料库和知识库,并且涌现了众多有关语料库和知识库的专著、论文等。
对于语料库和知识库发展现状的总结研究,不仅可以帮助人们清楚的了解语料库和知识库当前发展的形势,对今后语料库知识库的发展具有一定的指导作用,而且对于应用语料库知识库发展自然语言处理等领域具有重要意义。
2研究意义从现代意义上第一个语料库出现以来,语料库在国内外的发展均有长足的进步,不但其规模越来越大,加工深度越来越深,而且有关语料库的应用也越来越广泛[2]。
国内主要语料库总汇

英汉双语语料库(100万),网上英汉语段电子词典及网上电子英汉搭配词典(1000万)
东北大学
英汉双语语料库(40-50万句子对)
哈尔滨工业大学
双语语料库(5万多对)
北京大学计算语言学研究所
对比语料库LIVAC(Linguistic variety in Chinese communities)
《人民日报》语料库(2700万字)
北京大学计算机语言学研究所
大型中文语料库(5亿字,10分库)
北京语言文化大学
现代汉语语料库(1亿字)
清华大学
汉语新闻语料库;(1988年,250万字)
山西大学
标准语料库(2000年,70万字)
生语料库(3000万字);《作家文摘》的标注语料库(100万字)
上海师范大学
现代自然口语语料库
中国社会科学院语言所
旅游咨询口语对话语料库和旅馆预定口语对话语料库
中国科学院自动化所
汉语现代文学作品语料库(1979年,527万字)
武汉大学
现代汉语语料库(1983年,2000万字)
北京航空航天大学
中学语文教材语料库(1983年,1083年,182万字)
北京语言学院
国家级大型汉语均衡语料库(2000万字)
国家语言文字工作委员会
李约瑟(Joself Needham)《中国科学技术史》英汉对照语料库
计算机专业的双语语料库;
国家语言文字工作委员会语言文字应用研究所
柏拉图(Plato)哲学名著《理想国》的双语语料库
英汉双语语料库(15万对)
中科院软件所
英汉双语语料库:LDC香港新闻英汉双语对齐语料36294段以及香港法律英汉双语对齐语料31万句子对
The Background Information of Corpus

国 内 已 建 双 语 语 料 库
原始语料库
18世纪-20世纪初
现代语料库
20世纪50-80年代
由手工收集向计算机语料库过渡;初步依照一定语言 学原则进行标注。主要用于语法分析和语言对比研究, 逐渐涉及其它领域。
Randolph Quirk的“英语用法调查”(the Survey of English Usage)语料库;布朗语料库(the Brown Corpus);兰卡斯特 -奥斯陆-卑尔根(LOB)语料库等。
Spoken English Corpus (SEC) &书面语语料库
The earliest corpus in China
Interpretation for TEM-4, composition
Verbal & written translation For English Majors
Developing Stages
5. Bilingual Corpus
a.structure
b.corpuses in China
Definition
在语言学中,语料库(Corpus)指大量文本的集合,库中的文本(称为语料)通 常经过整理,具有既定的格式与标记,特指计算机存储的数字化语料库。 English version :From 豆丁网
1. 语种
① ② ③
单语的(Monolingual ) 双语的(Bilingual) 多语的(Multilingual)
)
2. 采集单位(语篇的、语句的、短语的 3. 组织形式
① ② 比较语料库
平行(对齐)语料库
Types
4. 媒体格式
①
②
书面语语料库
口语语料库
中英句子对齐双语语料库建设——技术报告

“中英句子对齐双语语料库建设”技术报告中科院自动化研究所模式识别国家重点实验室北京1000801研究目标和内容本课题的研究目标是:对中英文篇章对齐的双语文本进行段落对齐、句子对齐加工,建立一个大规模具有统一标准和规范的、多领域、多体裁、句子级对齐的双语语言信息和知识库。
具体研究内容包括:●借助互联网等其他媒体搜集中英文篇章级对齐的双语文本,并进行必要的预处理。
●参照都柏林核元数据元素集制订了双语语料文本标注规范,在973标准讨论会上进行讨论通过。
●大规模文本句子对齐方法:面向多领域多体裁,采用基于双语词典的句子对齐方法进行了文本对齐,并对如何提高对齐精度做了进一步的研究和探讨。
●自动评价:对双语文本句子对齐结果实现自动评价。
目前完成的句子对齐双语语料库可以有以下几方面的应用:➢作为重要的语言资源,为基于统计的各种双语语言建模、分析提供必要的训练数据。
➢可以为机器翻译、跨语言信息检索等领域抽取双语词对、短语对提供真实文本标注素材。
2相关研究现状国内外很多研究机构都致力于双语语料库的建设,并利用这些语料库进行广泛的研究。
加拿大的议会会议录(Canadian Hansards)是非常著名的英法双语语料库,许多最初的基于双语语料库的研究都是在该语料库基础上进行的[1][2]。
有关汉外双语语料库建设及其研究,香港科技大学收集和加工了香港立法委员会的会议记录,形成汉英双语语料库[3]。
此外,北京大学、东北大学、哈尔滨工业大学的研究人员也建立了一定规模的汉英双语语料库[7][8][9]。
但目前汉外双语语料库规模比较小,加工规范也不统一,从而影响了双语语料库知识获取的研究。
实现各个层次的对齐是双语语料库建设的一项重要内容。
本文主要讨论汉英双语句子级对齐技术。
句子对齐方法基本可以分为三类:◆基于长度的方法:最初由Brown[1]和Gale[2]提出,其依据是两种语言译文的长度满足一定比例关系。
他们在英法双语的加拿大议会会议录上取得了较好的对齐效果;清华大学和哈尔滨工业大学的研究人员分别将基于长度的方法应用于Microsoft NT 3.5 Server安装指南和法律文献的汉英双语句子对齐,获得的试验结果。
国内主要语料库总汇

外研社
李约瑟(Joself Needham)《中国科学技 术史》英汉对照语料库
计算机专业的双语语料库;
柏拉图(Plato)哲学名著《理想国》的 双语语料库
国家语言 文字工作委员 会语言文字应 用研究所
中科院软
平
英汉双语语料库(15万对)
件所
行语料
库
英汉双语语料库:LDC香港新闻英汉 中国科学
双语对齐语料36294段以及香港法律英汉 院自动化研究
理工大学
平衡语料库(Sinica Corpus);树图语料 库(Sinica Treebank)
台湾
中国英语(China English)语料库
特 殊英语 语料库
Hale Waihona Puke 军事英语语料库(Corpus of Military Texts)
新视野大学英语教材语料库
河南师范 大学
解放军外 语学院
上海交通 大学
汉语现代文学作品语料库(1979 年,527万字)
北京大学 计算机语言学 研究所
北京语言 文化大学
现代汉语语料库(1亿字)
清华大学
汉语新闻语料库;(1988年,250万字) 标准语料库(2000年,70万字)
山西大学
生语料库(3000万字);《作家文摘》的 上海师范
标注语料库(100万字)
大学
现代自然口语语料库
中国社会 科学院语言所
旅游咨询口语对话语料库和旅馆预定 中国科学
双语对齐语料31万句子对
所
英汉双语语料库(100万),网上英汉语 段电子词典及网上电子英汉搭配词 典(1000万)
东北大学
英汉双语语料库(40-50万句子对)
哈尔滨工 业大学
国内英汉双语平行语料库建构与研究现状及展望_黄立波

摘要:本文在回顾近年来国内英汉双语平行语料库建构与研究方面取得成就的基础上 ,探究现有语料库 研 制 与 应 用 中 存 在 的 一 些 问 题 ,发 现 其 具 体 表 现 为 :第 一 ,语 料 库 建 设 各 自 为 政 ,缺 乏 超 大 规 模 、综 合 性 、多 用 途的国家级平行语料库;第二,语料库的深加工还不够深入;第三,从对语料库的应 用 看,课 题 拓 展 和 对 语 料 库 的 研 究 潜 力 开 发 还 不 够 ;第 四 ,相 关 学 科 之 间 的 沟 通 与 合 作 不 够 。 针 对 这 些 问 题 提 出 的 一 些 对 策 包 括 构 建 更 大 规 模 的 超 级 英 汉 平 行 语 料 库 、自 动 标 注 的 深 化 、开 发 相 关 软 件 以 及 完 善 网 络 检 索 平 台 。
团队,开始 发 展 为 一 种 研 究 范 式。 一 些 有 影 响 的 平 双向对齐。此 外,该 语 料 库 中 的 汉 语 原 文 及 其 对 应
行语料 库,如 加 拿 大 议 会 会 议 录 英 法 平 行 语 料 库 英语译文和英语原文及其对应汉语译文 四 类 语 料 可
(the Canadian Hansard Corpus)、克 姆 尼 茨 英-德 翻 在同一语料库内实现语际对比和语内类 比 方 面 的 研
库(CEXI)、葡-英双向平行 语 料 库 (Compara)相 继 建 2007,2008;王 克 非、秦 洪 武 2009;王 克 非、胡 显 耀
成 ,基 于 这 些 语 料 库 的 翻 译 研 究 成 果 大 量 涌 现 。
2010)、翻译文体(如 黄 立 波 2009)、语 言 与 翻 译 教 学
1998年,哈 尔 滨 工 业 大 学 建 成 容 量 3 万 句 对 的 (王克非2004a;秦洪武、王克非2007;王克非等2007;
国家语言资源监测语料库介绍

国家语言资源监测语料库介绍何婷婷杨尔弘侯敏华中师范大学计算机科学系国家语言资源监测与研究中心网络媒体语言分中心北京语言文化大学国家语言资源监测与研究中心平面媒体语言分中心中国传媒大学国家语言资源监测与研究中心有声媒体语言分中心2005年,教育部语言文字信息管理司开始和国内若干高校陆续联合建设语言资源监测中心,其中包括与北京语言文化大学共建的平面媒体语言分中心、与中国传媒大学共建的有声媒体语言分中心、与华中师范大学共建的平面媒体语言分中心。
这三个分中心分别建设了平面媒体动态流通语料库、有声媒体监测语料库、网络媒体监测语料库,它们共同构成国家语言资源监测语料库。
语料库包括网页、纯文本,并采用中科院自动化所的自动分词工具做了自动分词。
欢迎各界同仁共同开发、建设使用该语料库。
1、语料库现状1.1 平面媒体动态流通语料库(DCC)平面媒体语言分中心自2001年以来,每年根据“发行量、发行地域、发行周期、媒体价值、阅读率”等因素,选择15种网络版报纸的内容,作为平面媒体动态流通语料库的语料采集内容,目前,已经形成了近30亿字的语料库。
语料进行了元数据的标注、自动分词标注,语料库提供了生语料、分词标注语料的检索功能,并能够历时地查询词语使用的情况。
网址/。
根据网页栏目的分类体系,所有语料进行了分类。
类别包括15类:娱乐,游戏,文艺,体育,时政新闻_社会,时政新闻_军事,时政新闻_国内,时政新闻_国际,生活男女,汽车,旅游,科技,经济,教育,房产。
为实现语料库中的文本分类,建立了60万个文本的训练语料,语料规模约6亿字次。
1.2有声媒体监测语料库有声媒体语言分中心自2001年开始语料库的建设。
到目前为止,已建起一个多功能的、跨媒体的汉语传媒有声语言语料库。
每年以收视率为基本条件,综合考虑了“传播媒介(广播、电视)、媒体级别(中央、地方)、播出时间(黄金时间、非黄金时间)、节目样态(独白、对话、综合)、文本现存(是否有转写好的文本)”五个因素,采集了电台、电视台播出的有声节目的录音或录像及由其转写成的文本语料。
专业语料库建立及其在机器翻译中的应用

() 1 这些期 刊对 文章 收 录的要求 比较严 格 . 章 文 格式 规范 . 内容准确 : () 2 每篇文章都有摘 要 . 且摘要 都有 中英 文对 照 , 便 于我们收集 汉英平行语 句 : () 3 摘要 是一篇 文章 的 总体概 括 . 含 了文章 所 包 要 表述 的主要 思想 . 涵盖 的词 汇范 围能够达到 实际 的 翻译 要求 :
_.的 — 自 一 _ —
对 齐 动 分 词
子 语 句 文 筑 句 级
统
句 . 只靠人工处理 , 工作量和错 误率可想 而知 。 若 其
语 料 库 材 料 进 行 了初 期 的 选 取 摘 录后 . 要 经 由 还 下 面 几 个 步骤 来 实 现 语 料 的 对 齐 处 理
( ) 于摘 要 的 重 要 性 , 的 中 英 文 描 述 一 般 不 4由 它
究 的重点 。实践证 明语 料库建立 的好坏 , 最终影 响 将
到译文 的质量 。
会 出现较 大 的误差 , 于语 料库 后期 的对 齐 、 词 等 便 分
处理。
1 专 业 语 料 库 建 立
按照 实际翻译 系统 应用 的要求 . 把语料 库的建立
和 <s g e ; / mn e
图 1 语 料 库 建 立 及 其 应 用 示 意 图
现 11 语料库 的选取 . 代 基 于语料 库的 翻译研 究及 其结 论 的准 确性 和普 计
因此语 料库 的选 算 遍性 取决 于所 用语料 库 的代表 性 . 机 取 至 关 重 要 我 们 选 取 语 料 库 文 本 内容 的 来 源 主 要 是
人民日报1998年中文标注语料库及读取代码
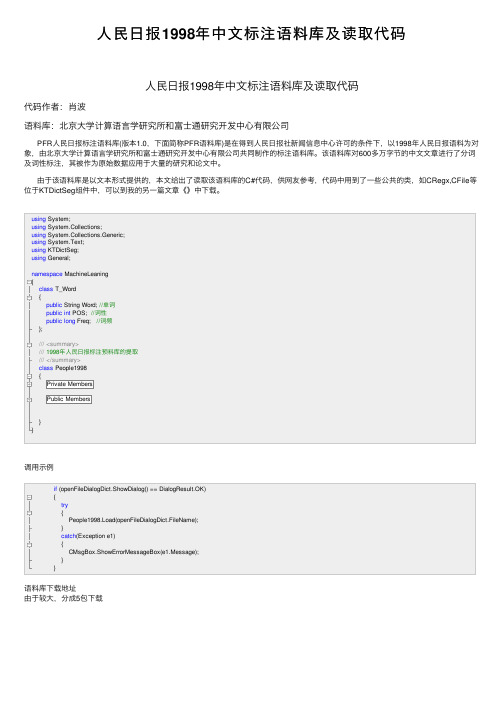
⼈民⽇报1998年中⽂标注语料库及读取代码⼈民⽇报1998年中⽂标注语料库及读取代码代码作者:肖波语料库:北京⼤学计算语⾔学研究所和富⼠通研究开发中⼼有限公司PFR⼈民⽇报标注语料库(版本1.0,下⾯简称PFR语料库)是在得到⼈民⽇报社新闻信息中⼼许可的条件下,以1998年⼈民⽇报语料为对象,由北京⼤学计算语⾔学研究所和富⼠通研究开发中⼼有限公司共同制作的标注语料库。
该语料库对600多万字节的中⽂⽂章进⾏了分词及词性标注,其被作为原始数据应⽤于⼤量的研究和论⽂中。
由于该语料库是以⽂本形式提供的,本⽂给出了读取该语料库的C#代码,供⽹友参考,代码中⽤到了⼀些公共的类,如CRegx,CFile等位于KTDictSeg组件中,可以到我的另⼀篇⽂章《》中下载。
using System;using System.Collections;using System.Collections.Generic;using System.Text;using KTDictSeg;using General;namespace MachineLeaning{class T_Word{public String Word; //单词public int POS; //词性public long Freq; //词频};///<summary>/// 1998年⼈民⽇报标注预料库的提取///</summary>class People1998{Private MembersPublic Members}}调⽤⽰例if (openFileDialogDict.ShowDialog() == DialogResult.OK){try{People1998.Load(openFileDialogDict.FileName);}catch(Exception e1){CMsgBox.ShowErrorMessageBox(e1.Message);}}语料库下载地址由于较⼤,分成5包下载。
4、计算语言学资源-语料库

中文语料库
汉语现代文学作品语料库
(1979年,武汉大学,527万字)
现代汉语语料库
(1983年,北航,2000万字)
中学语文教材语料库
(1983年, 北师大,106万字)
现代汉语词频统计语料库
(1983年,北京语言学院,182万字)
中文语料库
Chinese LDC:国家973 项目资助
average about 2.1 meanings 频率等级: 5000(sqrt=70.7) average about 3 meanings 频率等级: 2000(sqrt=44.7) average about 4.6 meanings
词频和词长
词频和词长是反比例关系
短词经常被使用
“in”, “of”, …...
语料库语言学
语料库研究
收集:
收集大规模真实文本,建设平衡语料库。
加工:
对语料库进行各级语言单位的语言学信息标注。如词法、句法、语 义、语用、篇章层。
标注技术:分词、词性标注、句法标注、语义标注等。
统计:
对语料库进行各级语言单位的统计。
模型化:
根据语料库的统计,对相关的语言问题,构造统计模型。
最高频的100个词覆盖了全部词汇出现次数的一半 一半的词汇在语料库中只出现一次 90%的词形出现10次或更少 文本中的12% 是出现3次或者更少的词
很难预测那些很少出现或者干脆在语料库中从 未出现的词的行为
齐普夫定律
省力原则
讲者希望:使用最少的词汇,没有标点空格 听者希望:使用较多的词汇,丰富的标记
语料库的类型
按加工深度划分
单语语料库
切分 具有词性标注 句法结构信息标注(树库) 语义信息标注
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中科院自动化所的中英文新闻语料库
中科院自动化所(Institute of Automation, Chinese Academy of Sciences)是中国科学院下属的一家研究机构,致力于开展自
动化科学及其应用的研究。
该所的研究涵盖了从理论基础到技术创新的广泛领域,包括人工智能、机器人技术、自动控制、模式识别等。
下面将分别从中文和英文角度介绍该所的相关新闻语料。
[中文新闻语料]
1. 中国科学院自动化所在人脸识别领域取得重大突破
中国科学院自动化所的研究团队在人脸识别技术方面取得了
重大突破。
通过深度学习算法和大规模数据集的训练,该研究团队成功地提高了人脸识别的准确性和稳定性,使其在安防、金融等领域得到广泛应用。
2. 中科院自动化所发布最新研究成果:基于机器学习的智能交通系统
中科院自动化所发布了一项基于机器学习的智能交通系统研
究成果。
通过对交通数据的收集和分析,研究团队开发了智能交通控制算法,能够优化交通流量,减少交通拥堵和时间浪费,提高交通效率。
3. 中国科学院自动化所举办国际学术研讨会
中国科学院自动化所举办了一场国际学术研讨会,邀请了来
自不同国家的自动化领域专家参加。
研讨会涵盖了人工智能、机器人技术、自动化控制等多个研究方向,旨在促进国际间的
学术交流和合作。
4. 中科院自动化所签署合作协议,推动机器人技术的产业化发展
中科院自动化所与一家著名机器人企业签署了合作协议,共同推动机器人技术的产业化发展。
合作内容包括技术研发、人才培养、市场推广等方面,旨在加强学界与工业界的合作,加速机器人技术的应用和推广。
5. 中国科学院自动化所获得国家科技进步一等奖
中国科学院自动化所凭借在人工智能领域的重要研究成果荣获国家科技进步一等奖。
该研究成果在自动驾驶、物联网等领域具有重要应用价值,并对相关行业的创新和发展起到了积极推动作用。
[英文新闻语料]
1. Institute of Automation, Chinese Academy of Sciences achieves
a major breakthrough in face recognition
The research team at the Institute of Automation, Chinese Academy of Sciences has made a major breakthrough in face recognition technology. Through training with deep learning algorithms and large-scale datasets, the research team has successfully improved the accuracy and stability of face recognition, which has been widely applied in areas such as security and finance.
2. Institute of Automation, Chinese Academy of Sciences releases latest research on machine learning-based intelligent transportation
system
The Institute of Automation, Chinese Academy of Sciences has released a research paper on a machine learning-based intelligent transportation system. By collecting and analyzing traffic data, the research team has developed intelligent traffic control algorithms that optimize traffic flow, reduce congestion, and minimize time wastage, thereby enhancing overall traffic efficiency.
3. Institute of Automation, Chinese Academy of Sciences hosts international academic symposium
The Institute of Automation, Chinese Academy of Sciences recently held an international academic symposium, inviting automation experts from different countries to participate. The symposium covered various research areas, including artificial intelligence, robotics, and automatic control, aiming to facilitate academic exchanges and collaborations on an international level.
4. Institute of Automation, Chinese Academy of Sciences signs cooperation agreement to promote the industrialization of robotics technology
The Institute of Automation, Chinese Academy of Sciences has signed a cooperation agreement with a renowned robotics company to jointly promote the industrialization of robotics technology. The cooperation includes areas such as technology research and development, talent cultivation, and market promotion, aiming to strengthen the collaboration between academia and industry and accelerate the application and popularization of robotics technology.
5. Institute of Automation, Chinese Academy of Sciences receives
National Science and Technology Progress Award (First Class) The Institute of Automation, Chinese Academy of Sciences has been awarded the National Science and Technology Progress Award (First Class) for its important research achievements in the field of artificial intelligence. The research outcomes have significant application value in areas such as autonomous driving and the Internet of Things, playing a proactive role in promoting innovation and development in related industries.。