Oracle10g的SQL正则表达式支持
oracle sql 正则表达式

oracle sql 正则表达式
OracleSQL正则表达式是一种强大的工具,可用于在数据库中搜索、替换和提取数据。
它使得查询和操作数据库中文本字段变得更加简单和高效。
正则表达式是一组字符模式,用于在字符串中匹配和查找特定的文本模式。
在 Oracle SQL 中,可以使用正则表达式函数来对文本数据进行操作,这些函数包括 REGEXP_LIKE、REGEXP_REPLACE、REGEXP_INSTR 和 REGEXP_SUBSTR。
为了使用正则表达式函数,需要了解正则表达式的语法和规则。
Oracle SQL 正则表达式支持许多常用的正则表达式元字符和限定符,例如 .、*、+、?、^、$、|、() 等。
通过使用 Oracle SQL 正则表达式,可以轻松地执行以下操作:
1. 在字符串中查找指定的模式并返回匹配的子串。
2. 替换字符串中的特定模式并返回新的字符串。
3. 验证输入字符串是否符合指定的模式。
4. 在字符串中查找一个模式的出现次数。
5. 从字符串中提取一个模式所匹配的子串。
6. 等等。
总之,Oracle SQL 正则表达式是一种非常有用的工具,可以帮
助开发者更加高效地操作数据库中的文本数据。
掌握正则表达式的语法和规则,可以让开发者用更少的代码实现更多的功能。
- 1 -。
oracle的正则表达式语法

oracle的正则表达式语法Oracle的正则表达式语法正则表达式在计算机编程中是非常重要的,它可以帮助我们轻松地匹配、查找和替换文本中的特定字符序列。
Oracle数据库也支持正则表达式,因此,本文将介绍Oracle的正则表达式语法。
1. 字符类:正则表达式中的字符类可以表示一组字符中的任何一个字符。
在Oracle中,我们可以使用方括号([])来表示字符类,如下所示:[abc]:表示a、b或c中的任何一个字符。
[^abc]:表示除a、b或c以外的任何一个字符。
[a-z]:表示从a到z中的任何一个小写字母。
[A-Z]:表示从A到Z中的任何一个大写字母。
[0-9]:表示从0到9中的任何一个数字。
2. 元字符:正则表达式中的元字符有特殊的含义,可以用来表示空格、数字、特殊字符等。
在Oracle中,我们可以使用以下元字符:\d:表示任何一个数字,等效于[0-9]。
\D:表示除数字以外的任何一个字符,等效于[^0-9]。
\s:表示任何一个空格字符,等效于[ \t\n\r\f\v]。
\S:表示除空格字符以外的任何一个字符。
\w:表示任何一个字母、数字或下划线字符,等效于[a-zA-Z0-9_]。
\W:表示除字母、数字和下划线以外的任何一个字符。
.:表示除换行符以外的任何一个字符。
3. 重复符号:正则表达式中的重复符号可以表示重复出现的字符或字符序列。
在Oracle中,我们可以使用以下重复符号:*:表示重复0次或多次。
+:表示重复1次或多次。
:表示重复0次或1次。
{n}:表示重复n次。
{n,}:表示重复n次或多次。
{n,m}:表示重复n到m次。
4. 边界符号:正则表达式中的边界符号可以表示待查找字符串的边界,如单词的开头或结尾。
在Oracle中,我们可以使用以下边界符号:^:表示字符串的开头。
$:表示字符串的结尾。
\b:表示单词边界,例如字母和空格之间的边界。
\B:表示除单词边界以外的任何一个位置。
5. 分组和反向引用:正则表达式中的分组可以一组字符视为一个整体,并对整个字符组进行操作。
oracleplsql中使用正则表达式转

oracleplsql中使⽤正则表达式转使⽤正规表达式编写更好的 SQL作者:Alice RischertOracle Database 10g中的正规表达式特性是⼀个⽤于处理⽂本数据的强⼤⼯具Oracle Database 10g的⼀个新特性⼤⼤提⾼了您搜索和处理字符数据的能⼒。
这个特性就是正规表达式,是⼀种⽤来描述⽂本模式的表⽰⽅法。
很久以来它已在许多编程语⾔和⼤量 UNIX 实⽤⼯具中出现过了。
Oracle 的正规表达式的实施是以各种 SQL 函数和⼀个WHERE⼦句操作符的形式出现的。
如果您不熟悉正规表达式,那么这篇⽂章可以让您了解⼀下这种新的极其强⼤然⽽表⾯上有点神秘的功能。
已经对正规表达式很熟悉的读者可以了解如何在 Oracle SQL 语⾔的环境中应⽤这种功能。
后向引⽤正则表达式的⼀个有⽤的特性是能够存储⼦表达式供以后重⽤;这也被称为后向引⽤(在中对其进⾏了概述)。
它允许复杂的替换功能,如在新的位置上交换模式或显⽰重复出现的单词或字母。
⼦表达式的匹配部分保存在临时缓冲区中。
缓冲区从左⾄右进⾏编号,并利⽤/digit符号进⾏访问,其中 digit 是 1 到 9 之间的⼀个数字,它匹配第 digit 个⼦表达式,⼦表达式⽤⼀组圆括号来显⽰。
接下来的例⼦显⽰了通过按编号引⽤各个⼦表达式将姓名Ellen Hildi Smith转变为Smith, Ellen Hildi。
SELECT REGEXP_REPLACE('Ellen Hildi Smith','(.*) (.*) (.*)', '/3, /1 /2')FROM dualREGEXP_REPLACE('EL------------------Smith, Ellen Hildi该 SQL 语句显⽰了⽤圆括号括住的三个单独的⼦表达式。
每⼀个单独的⼦表达式包含⼀个匹配元字符 (.),并紧跟着*元字符,表⽰任何字符(除换⾏符之外)都必须匹配零次或更多次。
oracle正则表达式用法

Oracle正则表达式基于Perl语言的正则表达式语法,其基本语法和使用方法如下:1. 字符匹配:* .:匹配除了换行外的任意一个字符。
* \d:匹配任何数字,相当于[0-9]。
* \D:匹配任何非数字字符,相当于[^0-9]。
* \w:匹配任何字母数字字符或下划线,相当于[a-zA-Z0-9_]。
* \W:表示匹配任何非字母数字字符或下划线,相当于[^a-zA-Z0-9_]。
2. 限定符:* *:匹配前一个字符出现0次或多次。
* +:匹配前一个字符出现1次或多次。
* ?:匹配前一个字符出现0次或1次。
* {n}:匹配前一个字符出现n次。
* {n,}:匹配前一个字符出现n次或更多。
* {n,m}:匹配前一个字符出现n~m次。
3. 边界匹配:* ^:匹配开始位置。
* $:匹配结束位置。
* \b:匹配单词边界,即单词的开头或结尾位置。
* \B:匹配非单词边界,即不是单词的开头或结尾位置。
4. 分组和引用:* ( ):分组,标记一个子表达式的开始和结束位置。
* \num:引用第num个子表达式,num从1开始。
5. 字符集合:[]表示一组字符中的任意一个。
6. 转义符:\表示转义一个字符。
7. 其他高级语法支持:贪婪匹配、非贪婪匹配、零宽断言(zero-width assertion)、后向引用(backreference)、捕获组等。
另外,Oracle 10g支持正则表达式的四个新函数分别是REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR和REGEXP_REPLACE,它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
请注意,具体使用方法可能因不同的数据库版本或应用场景而有所不同。
建议查阅Oracle官方文档或相关教程以获取更详细和准确的信息。
oracle sql 正则

oracle sql 正则摘要:1.Oracle SQL 简介2.Oracle SQL 正则表达式的概念和用途3.Oracle SQL 正则表达式的语法4.Oracle SQL 正则表达式的示例5.Oracle SQL 正则表达式在实际场景中的应用正文:【1.Oracle SQL 简介】Oracle SQL(结构化查询语言)是一种用于管理关系型数据库的编程语言,它允许用户查询、插入、更新和删除数据库中的数据。
Oracle SQL 具有丰富的功能和高效的性能,被广泛应用于各类企业和组织的数据管理。
【2.Oracle SQL 正则表达式的概念和用途】在Oracle SQL 中,正则表达式是一种用于处理字符串的强大工具。
它可以用来验证数据、提取数据、替换数据等。
正则表达式在Oracle SQL 中主要应用于字符串操作、数据清洗和数据分析等场景。
【3.Oracle SQL 正则表达式的语法】Oracle SQL 正则表达式的基本语法包括以下几个部分:- 模式字符:用于匹配特定字符的元字符,例如:`.`匹配任意字符,`*`匹配零个或多个前面的字符等。
- 字符类:用于匹配特定类别的字符,例如:`[a-z]`匹配小写字母,`[0-9]`匹配数字等。
- 边界匹配符:用于指定匹配的位置,例如:`^`匹配字符串开头,`$`匹配字符串结尾等。
- 分组和捕获:用于将正则表达式的一部分组合在一起,以便进行特定操作,例如:`(pattern)`匹配pattern 并捕获结果,`|`表示或操作等。
【4.Oracle SQL 正则表达式的示例】以下是一些Oracle SQL 正则表达式的示例:- 验证邮箱地址:`SELECTREGEXP_LIKE("****************","^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Z|a-z]{2,}$")`- 提取数字:`SELECT REGEXP_SUBSTR("123abc", "[0-9]+")`- 替换字符串:`SELECT REGEXP_REPLACE("hello, world!", "world", "ocean")`【5.Oracle SQL 正则表达式在实际场景中的应用】在实际的数据管理和分析工作中,Oracle SQL 正则表达式可以用于处理各种复杂场景,例如:- 数据清洗:使用正则表达式验证和提取数据中的特定信息,以确保数据的准确性和完整性。
orcl中用正则表达式

orcl中用正则表达式在Oracle中,你可以使用正则表达式来执行各种字符串操作,例如搜索、替换、提取等。
Oracle的正则表达式功能主要通过`REGEXP_SUBSTR`、`REGEXP_INSTR`、`REGEXP_REPLACE`等函数提供。
以下是一些在Oracle中使用正则表达式的示例:1. 使用`REGEXP_SUBSTR`提取字符串假设你想从某个字符串中提取所有的数字:```sqlSELECT REGEXP_SUBSTR('abc123def456', '[0-9]+') FROM dual;```这会返回`123`和`456`。
2. 使用`REGEXP_INSTR`查找字符串查找某个字符串在另一个字符串中的位置:```sqlSELECT REGEXP_INSTR('abc123def456', '[0-9]+') FROM dual;```这会返回数字`4`,表示第一个数字(123)开始于位置4。
3. 使用`REGEXP_REPLACE`替换字符串替换所有匹配正则表达式的子串:```sqlSELECT REGEXP_REPLACE('abc123def456', '[0-9]+', 'XX') FROM dual;```这会返回`abcXXdefXX`。
4. 使用复杂的正则表达式例如,如果你想从字符串中提取所有由字母组成的子串:```sqlSELECT REGEXP_SUBSTR('abc123def456', '[a-zA-Z]+') FROM dual;```这会返回`abc`和`def`。
5. 分组和捕获使用括号进行分组和捕获:```sqlSELECT REGEXP_SUBSTR('abc123def456', '([a-z]+)([0-9]+)', 1, 1, NULL, 1) FROM dual;```这将返回`abc`,因为它是第一个匹配的子串。
Oracle 10g正则表达式

By flyORACLE终于在10G中提供了对正则表达式的支持,以前那些需要通过LIKE来进行的复杂的匹配就可以通过使用正则表达式更简单的实现。
ORACLE中的支持正则表达式的函数主要有下面四个:1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与INSTR的功能相似3,REGEXP_SUBSTR :与SUBSTR的功能相似4,REGEXP_REPLACE :与REPLACE的功能相似在新的函数中使用正则表达式来代替通配符‘%’和‘_’。
正则表达式由标准的元字符(metacharacters)所构成:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了RegExp 对象的Multiline 属性,则$ 也匹配'n' 或'r'。
'.' 匹配除换行符n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
num 匹配num,其中num 是一个正整数。
对所获取的匹配的引用。
字符簇:[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
oracle sql 年月正则表达式

Oracle SQL中的年月正则表达式是指能够匹配特定格式的年月信息的正则表达式。
在实际的数据处理中,经常需要对年月信息进行提取、比较、筛选等操作,而正则表达式正是一个强大的工具,能够帮助我们轻松地处理这些任务。
1. 年月正则表达式的基本结构在Oracle SQL中,用于匹配年月信息的正则表达式的基本结构是由数字和特定的分隔符组成的。
一般而言,年月信息的格式可以是"yyyy-mm"、"yyyy/mm"、"yyyymm"等形式,因此我们需要编写相应的正则表达式来进行匹配。
2. 匹配四位年份和两位月份如果我们需要匹配的年月信息的格式是"yyyy-mm",那么对应的正则表达式可以是"\b\d{4}-\d{2}\b"。
其中,"\b"表示单词边界,"\d"表示数字,"{4}"表示恰好匹配4个数字,"-"表示匹配连字符,"{2}"表示恰好匹配2个数字。
3. 匹配四位年份和两位月份如果我们需要匹配的年月信息的格式是"yyyy/mm",那么对应的正则表达式可以是"\b\d{4}/\d{2}\b"。
其中,"\b"表示单词边界,"\d"表示数字,"{4}"表示恰好匹配4个数字,"/"表示匹配斜杠,"{2}"表示恰好匹配2个数字。
4. 匹配六位年份和两位月份如果我们需要匹配的年月信息的格式是"yyyymm",那么对应的正则表达式可以是"\b\d{6}\d{2}\b"。
其中,"\b"表示单词边界,"\d"表示数字,"{6}"表示恰好匹配6个数字,"{2}"表示恰好匹配2个数字。
Oracle笔记

查看当前用户所有表:Select * from tab;连接符:||空值:is null除去重复行:distinct查询结果排序:order by 排序字段asc(desc)比较运算符:> < (!= or <>) between andin 操作not in模糊查询Like使用:“ %”:代表匹配任意长度的任意字符。
“_”:代表匹配一个长度的任意字符。
特殊字符使用ESCAPE 标示:select * from posgoods where pgcname like '%*_%' escape '*';查询posgoods表中pgcname 字段中有‘_’字符的结果。
escape '*' 表示* 字符后面的是字符代表其实际意思,不做转义字符。
Oracle 10g支持正则表达式的四个新函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和REGEXP_REPLACE。
它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
特殊字符:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了RegExp 对象的Multiline 属性,则$ 也匹配'\n' 或'\r'。
'.' 匹配除换行符\n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
oracle正则表达式语法

oracle正则表达式语法Oracle正则表达式语法正则表达式是一种常用的文本匹配方法,它可以在文本中搜索特定的字符串、取代或者操作一些文本操作,也有利于开发者更简洁的实现一些文本过滤的需求。
Oracle正则表达式语法是Oracle数据库提供的一种文本匹配方式,在处理大量数据时能够大大提高处理效率。
下面是Oracle正则表达式语法相关内容的详细介绍:1.匹配任意字符通配符可以替代任何字符,用”%”表示。
比如:”%moon%”可以匹配moon、bluemoon、bigmoon等。
2. 匹配单个字符“_”表示匹配单个字符。
比如:”d_g”可以匹配dog、dig、dug等。
3. 简单的字符匹配直接匹配字符即可,比如:'A'可以匹配A,'B'可以匹配B。
4. 区分大小写Oracle正则表达式中区分大小写。
比如:”A”只匹配A,“a”只匹配a。
5. 匹配多个字符可以使用方括号表示多个字符。
比如:[abc123]就可以匹配a、b、c、1、2、3。
6. 匹配任意一个字符用“.”匹配任意一个字符。
比如:”3.”可以匹配31、32、33等。
7. 匹配多个字符之间的内容在[]中使用“-”语法,表示匹配两个字符之间的内容。
比如:[3-8]可以匹配3、4、5、6、7、8。
8. 匹配条件选择使用竖线 | 来表示条件选择。
比如:”java|c++”可以匹配java和c++。
9. 匹配单个字符中的某个条件使用圆括号来设定多项匹配规则。
比如:(Java|Pearl|Python)可以匹配Java或Pearl或Python。
10. 匹配一个或多个使用 + 来表示出现一次或多次,比如:”bo+t”可以匹配bot、boot、bootoot等。
使用*来表示出现零次或多次,比如:”bo*t”可以匹配bt、bot、boot、bootoot等。
使用? 来表示出现零次或一次,比如:”bo?t”可以匹配bt、bot。
oracle数据库正则表达式写法

在数据库的查询和数据处理中,正则表达式(Regular Expression)是一个非常有用的工具。
在Oracle数据库中,正则表达式写法可以帮助我们更灵活、高效地进行数据的匹配和处理。
本文将从简到繁地探讨Oracle数据库正则表达式写法,以帮助读者更深入地理解并灵活应用这一特性。
1. 正则表达式概述正则表达式是一种用来描述字符串模式的工具,它可以帮助我们在文本中进行搜索、匹配和替换操作。
在Oracle数据库中,正则表达式的写法可以极大地扩展我们的数据处理能力,使得数据的查询和操作更加灵活和高效。
2. 基本正则表达式写法在Oracle数据库中,我们可以使用正则表达式进行模式匹配。
我们可以使用'^'来匹配以某个字符开头的字符串,使用'$'来匹配以某个字符结尾的字符串。
还可以使用'.'来匹配任意单个字符,使用'*'来匹配前面的字符零次或多次,使用'+'来匹配前面的字符一次或多次。
3. 高级正则表达式写法除了基本的正则表达式写法外,Oracle数据库还支持一些高级的正则表达式写法。
我们可以使用'\d'来匹配数字字符,使用'\w'来匹配单词字符,使用'\s'来匹配空白字符。
还可以使用'[]'来指定字符集,使用'|'来表示或的关系,使用'()'来分组表达式等。
4. 实际应用示例为了更好地理解Oracle数据库正则表达式的写法,我们可以通过一些实际的应用示例来加深印象。
我们可以使用正则表达式来提取文本中的通信方式号码、电流信箱位置区域等信息;也可以使用正则表达式来对文本中的特定模式进行替换或过滤等操作。
通过这些实际应用示例,我们可以更直观地感受到正则表达式在数据处理中的强大功能。
5. 个人观点和总结对于我个人来说,正则表达式是数据库查询和数据处理中非常重要的一部分。
Oracle正则表达式

Oracle正则表达式Oracle正则表达式正则表达式具有强⼤、便捷、⾼效的⽂本处理功能。
能够添加、删除、分析、叠加、插⼊和修整各种类型的⽂本和数据。
Oracle从10g开始⽀持正则表达式。
下⾯通过⼀些例⼦来说明使⽤正则表达式来处理⼀些⼯作中常见的问题。
1.REGEXP_SUBSTRREGEXP_SUBSTR 函数使⽤正则表达式来指定返回串的起点和终点,返回与source_string 字符集中的VARCHAR2 或CLOB 数据相同的字符串。
语法:--1.REGEXP_SUBSTR与SUBSTR函数相同,返回截取的⼦字符串REGEXP_SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]])注:srcstr 源字符串pattern 正则表达式样式position 开始匹配字符位置occurrence 匹配出现次数match_option 匹配选项(区分⼤⼩写)1.1 从字符串中截取⼦字符串SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+') FROM dual;Output: 1PSN[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符。
SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+', 1, 2) FROM dual;Output: 231与上⾯⼀个例⼦相⽐,多了两个参数1 表⽰从源字符串的第⼀个字符开始查找匹配2 表⽰第2次匹配到的字符串(默认值是“1”,如上例)select regexp_substr('@@/231_3253/ABc','@*[[:alnum:]]+') from dual;Output: 231@* 表⽰匹配0个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符注意:需要区别“+”和“*”的区别select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]*') from dual;Output: @@+ 表⽰匹配1个或者多个@[[:alnum:]]* 表⽰匹配0个或者多个字母或数字字符select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]+') from dual;Output: Null@+ 表⽰匹配1个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符select regexp_substr('@1PSN/231_3253/ABc125','[[:digit:]]+$') from dual;Output: 125[[:digit:]]+$ 表⽰匹配1个或者多个数字结尾的字符select regexp_substr('@1PSN/231_3253/ABc','[^[:digit:]]+$') from dual;Output: /ABc[^[:digit:]]+$ 表⽰匹配1个或者多个不是数字结尾的字符select regexp_substr('Tom_Kyte@','[^@]+') from dual;Output: Tom_Kyte[^@]+ 表⽰匹配1个或者多个不是“@”的字符select regexp_substr('1PSN/231_3253/ABc','[[:alnum:]]*',1,2)from dual;Output: Null[[:alnum:]]* 表⽰匹配0个或者多个字母或者数字字符注:因为是匹配0个或者多个,所以这⾥第2次匹配的是“/”(匹配了0次),⽽不是“231”,所以结果是“Null”1.2 匹配重复出现查找连续2个⼩写字母SELECT regexp_substr('Republicc Of Africaa', '([a-z])\1', 1, 1, 'i')FROM dual;Output: cc([a-z]) 表⽰⼩写字母a-z\1 表⽰匹配前⾯的字符的连续次数1 表⽰从源字符串的第⼀个字符开始匹配1 第⼀次出现符合匹配结果的字符i 表⽰区分⼤⼩写查找连续3个6,7,8,9中的数字SELECT CASEWHEN regexp_like('Patch 10888 applied', '([6-9])\1\1') THEN'Match Found'ELSE'No Match Found'1.3 其他⼀些匹配样式查找⽹页地址信息FROM dual其中:([[:alnum:]]+\.?) 表⽰匹配1次或者多次字母或数字字符,紧跟0次或1次逗号符{3,4} 表⽰匹配前⾯的字符最少3次,最多4次/? 表⽰匹配⼀个反斜杠字符0次或者1次提取csv字符串中的第三个值SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, 3) AS outputFROM dual;Output: Japan其中:[^,]+ 表⽰匹配1个或者多个不是逗号的字符1 表⽰从源字符串的第⼀个字符开始查找匹配3 表⽰第3次匹配到的字符串注:这个通常⽤来实现字符串的列传⾏--字符串的列传⾏SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, LEVEL) AS output FROM dualCONNECT BY LEVEL <= length('1101,Yokohama,Japan,1.5.105') -length(REPLACE('1101,Yokohama,Japan,1.5.105', ',')) + 1;Output: 1101YokohamaJapan1.5.105这⾥通过LEVEL来循环截取匹配到的字符串。
ORACLE SQL 正则表达式
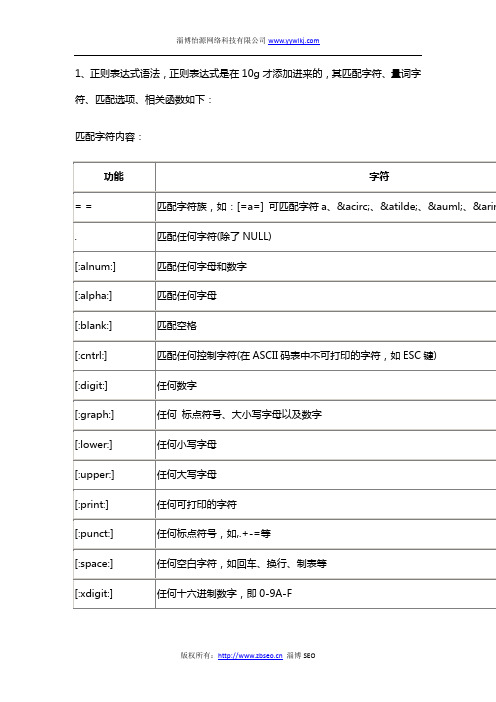
1、正则表达式语法,正则表达式是在10g才添加进来的,其匹配字符、量词字符、匹配选项、相关函数如下:匹配字符内容:匹配字符位置和条件:匹配字符数量:匹配选项:函数:REGEXP_LIKE 是LIKE语句的正则表达式版本语法:REGEXP_LIKE(源字符串, 匹配表达式[,匹配选项])REGEXP_INSTR 返回源字符串中首次匹配正则表达式的起始位置语法:REGEXP_INSTR(srcstr, pattern [, position [, occurrence[,return_option [, match_option]]]])srcstr:源字符串pattern:正则表达式position:搜索开始位置occurrence:返回第几个匹配项return_option:返回选项,0表示开始位置,1表示返回匹配的结束位置match_option:匹配选项REGEXP_SUBSTR 返回源串中匹配正则表达式的子字符串语法:SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]]) srcstr:源字符串pattern:正则表达式position:搜索的开始位置occurrence:返回第几个匹配的字符串match_option:匹配选项REGEXP_REPLACE 用执行字符串替换源文本中与正则表达式匹配的字符串语法:REGEXP_REPLACE(srcstr, pattern [,replacestr [, position[, occurrence [, match_option]]]])srcstr:源字符串pattern:正则表达式replacestr:新的字符串position:搜索起始位置occurrence:第几个匹配项match_option:匹配选项例题说明:Evaluate the following expression using meta. character for regular expression:'[^Ale|ax.r$]'Which two matches would be returned by this expression? (Choose two.)A. AlexB. AlaxC. AlxerD. AlaxendarE. AlexenderAnswer: DE'[^Ale|ax.r$]'中^表示只匹配不在集合{'A','l','e','|','a','x','.','r','$'}中的字符, 此处的'|'、'.'、'$'只是表示普通的字符,而非匹配符本文由淄博SEO(),淄博网站优化()整理发布,转载请注明出处。
Oracle中的正则表达式

Oracle中的正则表达式Oracle使⽤正则表达式离不开这4个函数:1 、regexp_like2 、regexp_substr3、 regexp_instr4 、regexp_replace2.1、REGEXP_SUBSTRREGEXP_SUBSTR函数使⽤正则表达式来指定返回串的起点和终点。
语法:regexp_substr(source_string,pattern[,position[,occurrence[,match_parameter]]])source_string:源串,可以是常量,也可以是某个值类型为串的列。
position:从源串开始搜索的位置。
默认为1。
occurrence:指定源串中的第⼏次出现。
默认值1.match_parameter:⽂本量,进⼀步订制搜索,取值如下:'i' ⽤于不区分⼤⼩写的匹配。
'c' ⽤于区分⼤⼩写的匹配。
'n' 允许将句点“.”作为通配符来匹配换⾏符。
如果省略改参数,句点将不匹配换⾏符。
'm' 将源串视为多⾏。
即将“^”和“$”分别看做源串中任意位置任意⾏的开始和结束,⽽不是看作整个源串的开始或结束。
如果省略该参数,源串将被看作⼀⾏来处理。
如果取值不属于上述中的某个,将会报错。
如果指定了多个互相⽭盾的值,将使⽤最后⼀个值。
如'ic'会被当做'c'处理。
省略该参数时:默认区分⼤⼩写、句点不匹配换⾏符、源串被看作⼀⾏。
例⼦:1. select regexp_substr('MY INFO: Anxpp,23,and boy','[[:digit:]]',1,2) from users;结果:此处会返回3。
注意这⾥同时⽤到了“[]”和“[:digit:]”。
2.2、REGEXP_INSTRREGEXP_INSTR函数使⽤正则表达式返回搜索模式的起点和终点(整数)。
oracle sql正则表达式

oracle sql正则表达式Oracle SQL正则表达式使用`REGEXP_LIKE`和`REGEXP_REPLACE`等函数。
`REGEXP_LIKE`函数用于在查询中应用正则表达式模式匹配。
它的一般语法是:```sqlSELECT column1, column2, ...FROM table_nameWHERE REGEXP_LIKE(column_name, 'pattern', 'start', 'match');```其中,`column_name`是要进行模式匹配的列名,`pattern`是正则表达式模式,`start`是可选的起始位置,`match`是可选的匹配类型。
例如,要查询以数字开头和结尾,长度为7位的字符串,可以使用以下查询:```sqlSELECTFROM fzqWHERE REGEXP_LIKE(value, '^[0-9]{6}[0-9]$');```REGEXP_REPLACE`函数用于在查询中应用正则表达式替换。
它的一般语法是:```sqlSELECT REGEXP_REPLACE(column_name, 'pattern', 'replacement','start', 'count', 'match')FROM table_name;```其中,`column_name`是要进行替换的列名,`pattern`是正则表达式模式,`replacement`是替换字符串,`start`是可选的起始位置,`count`是可选的替换次数,`match`是可选的匹配类型。
例如,要将字符串中的所有数字替换为空字符串,可以使用以下查询:```sqlSELECT REGEXP_REPLACE(column_name, '[0-9]', '', 1, 0, 'i')FROM table_name;```注意:在Oracle SQL中,正则表达式默认是不区分大小写的,如果要进行区分大小写的匹配,可以使用`'i'`作为匹配类型。
Oracle10g 正则表达式

Oracle Database 10g 中的正规表达式特性是一个用于处理文本数据的强大工具Oracle Database 10g 的一个新特性大大提高了您搜索和处理字符数据的能力。
这个特性就是正规表达式,是一种用来描述文本模式的表示方法。
很久以来它已在许多编程语言和大量UNIX 实用工具中出现过了。
Oracle 的正规表达式的实施是以各种SQL 函数和一个WHERE 子句操作符的形式出现的。
如果您不熟悉正规表达式,那么这篇文章可以让您了解一下这种新的极其强大然而表面上有点神秘的功能。
已经对正规表达式很熟悉的读者可以了解如何在Oracle SQL 语言的环境中应用这种功能。
什么是正规表达式?正规表达式由一个或多个字符型文字和/或元字符组成。
在最简单的格式下,正规表达式仅由字符文字组成,如正规表达式cat。
它被读作字母c,接着是字母a 和t,这种模式匹配cat、location 和catalog 之类的字符串。
元字符提供算法来确定Oracle 如何处理组成一个正规表达式的字符。
当您了解了各种元字符的含义时,您将体会到正规表达式用于查找和替换特定的文本数据是非常强大的。
验证数据、识别重复关键字的出现、检测不必要的空格,或分析字符串只是正规表达式的许多应用中的一部分。
您可以用它们来验证电话号码、邮政编码、电子邮件地址、社会安全号码、IP 地址、文件名和路径名等的格式。
此外,您可以查找如HTML 标记、数字、日期之类的模式,或任意文本数据中符合任意模式的任何事物,并用其它的模式来替换它们。
用Oracle Database 10g 使用正规表达式您可以使用最新引进的Oracle SQL REGEXP_LIKE 操作符和REGEXP_INSTR、REGEXP_SUBSTR 以及REGEXP_REPLACE 函数来发挥正规表达式的作用。
您将体会到这个新的功能如何对LIKE 操作符和INSTR、SUBSTR 和REPLACE 函数进行了补充。
oracle sql 正则 -回复

oracle sql 正则-回复正则表达式是一种强大的工具,可用于在Oracle SQL中进行模式匹配和数据处理。
本文将详细介绍如何在Oracle SQL中使用正则表达式。
第一步:了解正则表达式的基本概念和语法正则表达式是用于描述字符串模式的一种语法规则。
它包含了一些特殊的字符和元字符,可以用来匹配、查找和替换字符串中的特定模式。
以下是一些常用的正则表达式元字符:- . : 匹配任意一个字符- * : 匹配前一个字符的零个或多个实例- + : 匹配前一个字符的一个或多个实例- ? : 匹配前一个字符的零个或一个实例- \d : 匹配任何一个数字字符- \w : 匹配任何一个字母数字字符- \s : 匹配任何一个空白字符第二步:学习正则表达式函数和操作符Oracle SQL提供了多个正则表达式函数和操作符,可以在查询中使用。
以下是一些常用的函数和操作符:- REGEXP_LIKE : 检查字符串是否与正则表达式匹配- REGEXP_SUBSTR : 返回与正则表达式匹配的字符串子串- REGEXP_REPLACE : 使用正则表达式替换字符串中的模式- REGEXP_INSTR : 返回与正则表达式匹配的字符串的位置- REGEXP_COUNT : 返回与正则表达式匹配的字符串的数量第三步:使用正则表达式进行模式匹配在Oracle SQL中,可以使用REGEXP_LIKE函数来检查一个字符串是否与正则表达式匹配。
例如,以下查询将返回与正则表达式“[0-9]{4}”匹配的所有字符串:SELECT column_nameFROM table_nameWHERE REGEXP_LIKE(column_name, '[0-9]{4}');这将返回列column_name中包含四个连续数字的所有行。
方括号内的“[0-9]”表示匹配一个数字字符,而“{4}”表示该字符需要匹配四次。
第四步:使用正则表达式进行字符串替换除了模式匹配外,还可以使用REGEXP_REPLACE函数来替换字符串中的模式。
Oracle正则表达式的用法

Oracle正则表达式的用法正则表达式具有强大、便捷、高效的文本处理功能。
能够添加、删除、分析、叠加、插入和修整各种类型的文本和数据。
Oracle从10g开始支持正则表达式一、Oracle预定义的 POSIX 字符类字符类说明[:alpha:]字母字符[:lower:]小写字母字符[:upper:]大写字母字符[:digit:]数字[:alnum:]字母数字字符[:spac e:]空白字符(禁止打印),如回车符、换行符、竖直制表符和换页符[:punct:]标点字符[:cntrl:]控制字符(禁止打印)[:print:]可打印字符[:alnum:]字母和数字混合的字符二、正则表达式运算符和函数1、REGEXP_SUBSTRREGEXP_SUBSTR为指定字符串的一部分与正则表达式建立匹配。
语法如下:REGEXP_SUBSTR(source_string,pattern,start_position,occurrence,match_parameter)说明其中source_string是必须的。
可以是带引号的字符串或者变量。
Pattern是用单引号引用的与正则表达式。
Start_position指定了在字符串中的准确位置,默认值为1。
Occurrence是一个选项,指定在源字符串匹配过程中相对其他字符串,哪个字符串应该匹配。
最后,match_parameter也是一个选项,指定在匹配时是否区分大水写。
实例(1)、返回从ename的第二个位置开始查找,并且是以“L”开头到结尾的字串SQL> select regexp_substr(ename,'L.*','2') substr from emp;(2)、SELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;(3)、SQL 代码复制DECLARE V_RESULT VARCHAR2(255); BEGIN--返回‘light’SELECT REGEXP_SUBSTR('But, soft! What light through yonder window breaks?','l[[:alpha:]]{4}') INTO V_RESULT FROM DUAL;DBMS_OUTPUT.PUT_LINE(V_RESULT); END;2、REGEXP_INSTRREGEXP_INSTR返回与正则表达式匹配的字符和字符串的位置。
在SQL中使用正则表达式

在SQL中使⽤正则表达式 科研管理数据库中由于后台代码中关于项⽬查看的部分出现bug,导致数据库中学科代码如7403510变成了7403510语⾔教学,现在要修复这些问题数据,⾸先需要在数据库中检索出所有的问题数据,在⽹上搜索有关Oracle中在SQL语句中使⽤正则表达式的知识。
起初,我想⽤select c_project_name,c_year, c_discipline from t_general where not regexp_like(c_discipline,'[0-9]') and c_year ='2014';来检索出除学科代码全由数字组成的数据之外的所有数据,但是发现不⾏,具体原因有待考察。
换⼀种思路,检索出除学科代码全由数字结尾的数据之外的所有数据,select c_project_name,c_year, c_discipline from t_general where not regexp_like(c_discipline,'[0-9]$') and c_year = '2014';得到我想要的结果:(转载)当我们要进⾏⼀些简单的糊涂查询时⽤百分号(%),通配符(_)就可以了.其中%表达任意长度的字符串,_表⽰任意的某⼀个字符.⽐如select * from emp where ename like 's%' or ename like 's_';但如果在⼀些复杂的查询中关⽤这两个符号sql语句就会⾮常复杂,⽽且也不⼀定能实现.从Oracle 10g开始引⼊了在其他程序语⾔中普通使⽤的正则表达式.主要有regexp_like,regexp_replace,regexp_substr,regexp_instr四个正则表达式函数.正则表达式中的元字符:元字符意思例⼦\说明要匹配的字符是⼀个特殊字符、常量或者后者引⽤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '3, 2, 1') FROM dual;
REGEXP_REPLACE('ELLENHILDISMIT
cc, bb, aa
'' 转义符。
字符簇:
[[:alpha:]] 任何字母。
? ' ' 允许一个后继字符匹配一次或多次
? '*' 表示零次或多次
可以使用"{m,n}" 指定一个精确地出现范围,其意思是“出现从m 次到n 次”;"{m}" 表示“正好m次”;而"{m,}" 表示“至少m次”。还可以使用圆括号组合字符的集合,使用"|"(竖线)表示可替换。例如,字符串'^([a-z] |[0-9] $'将匹配所有由小写字母或数字组合成的字符串。?)
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
SELECT REGEXP_INSTR('one,two,three','[^,]*') FROM DUAL;
这个查询返回'one',将第一个参数看成一个逗号分隔的列表并返回第一个逗号之前的所有字符。
REGEXP_REPLACE 返回初始参数被匹配子串替换之后的结果。例如:
SELECT REGEXP_REPLACE('The temperature is 23°F',
POSIX 正则表达式由标准的元字符(metacharacters)所构成:
? '^' 表示字符串的开始
? ' $' 表示字符串的结束?
? '.' 表示任何字符
? 字符的范围,比如说'[a-z]',表示任何ASCII 小写字母,与字符类"[[:lower:]]"" 等价
? '?' 允许一个后继字符匹配零次或一次
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
SQL> create table t_userinfo (username varchar2(10), phonenumber varchar2(13));
Table created
SQL> insert into t_userinfo values ('zhansan', '13012323434');
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 'n' 或 'r'。
'.' 匹配除换行符 n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
正则表达式的一个很有用的特点是可以保存子表达式以后使用, 被称为Backreferencing. 允许复杂的替换能力
如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,
缓冲区从左到右编号, 通过数字符号访问。 下面的例子列出了把名字 aa bb cc 变成
insert into test values('991122334455667788');
insert into test values('aabbccddee');
insert into test values('bbaaaccddee');
insert into test values('ccabbddee');
REGEXP_INSTR 与INSTR 函数类似。它返回一个字符串中匹配一个正则表达式的第一个子串的开始位置。例如:
$[[:digit:]]?$400 for your purchase.','?SELECT REGEXP_INSTR('The total is ')
FROM DUAL;
各种操作符的运算优先级
转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
| “或”操作
--测试数据
create table test(mc varchar2(60));
1 row inserted
SQL> insert into t_userinfo values ('lisi', '13512348888');
1 row inserted
SQL> insert into t_userinfo values ('wangwu', '13912328888');
1 row inserted
SQL> commit;
Commit complete
SQL> Select username, phonenumber from t_userinfo
2 where REGEXP_LIKE(phonenumber, '13[5-8][0-9][0-9][0-9][0-9]8{4}');
REGEXP_LIKE 与LIKE 操作符相似。如果第一个参数匹配正则表达式它就解析为TRUE。例如WHERE REGEXP_LIKE(ENAME,'^J[AO]','i') 将在ENAME 以JA 或JO 开始的情况下返回一行数据。'I' 参数指定正则表达式是大小写敏感的。另外还可以在CHECK 约束和函数索引中指定REGEXP_LIKE。例如:
select * from test where regexp_like(mc,'a{1,3}');
select * from test where regexp_like(mc,'^a.*e$');
Select username from t_userinfo
where (phonenumber like '135%8888’
or phonenumber like '136%8888’
or phonenumber like '137%8888’
or phonenumber like '138%8888’)
1 row inserted
SQL> insert into t_userinfo values ('zhaoliu', '13743218888');
1 row inserted
SQL> insert into t_userinfo values ('sunqi', '1361234888');
ALTER TABLE EMP ADD CONSTRAINT REGEX01
CHECK $'));?(REGEXP_LIKE(ENAME,'^[[:alpha:]]
这条语句使得ENAME 字段只能包含字母和数字字符(也就是说没有空格或者标点符号)。试图插入或者更新这些数据将导致一个ORA-2290 异常,或者检查约束的有效性。
USERNAME PHONENUMBER
---------- -------------
lisi 13512348888
zhaoliu 13743218888
Oracle 10g正则表达式提高了SQL灵活性。有效的解决了数据有效性, 重复词的辨认, 无关的空白检测,或者分解多个正则组成
Oracle10g的SQL正则表达式支持。
Oracle 8 和Oracle 9i中缺乏灵活性的SQL 正则表达式最终在Oracle 10g中得到了解决。Oracle 数据库目前内建了符合POSIX 标准的正则表达式。
四个新的函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和 REGEXP_REPLACE。它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
insert into test values('5511 2233 4466778899');