44数字乘法器设计
乘法器的verilog实现(并行、移位相加、查找表)

乘法器的verilog实现(并⾏、移位相加、查找表)并⾏乘法器,也就是⽤乘法运算符实现,下⾯的代码实现8bit⽆符号数的乘法。
代码:1module mult_parrell(rst_n,2 clk,3 a,4 b,5 p6 );7parameter DATA_SIZE = 8;89input rst_n;10input clk;11input [DATA_SIZE - 1 : 0] a;12input [DATA_SIZE - 1 : 0] b;1314output [2*DATA_SIZE - 1 : 0] p;1516reg [DATA_SIZE - 1 : 0] a_r;17reg [DATA_SIZE - 1 : 0] b_r;1819wire [2*DATA_SIZE - 1 : 0] p_tmp;20reg [2*DATA_SIZE - 1 : 0] p;2122//输⼊数据打⼀拍23always@(posedge clk)24if(!rst_n)25begin26 a_r <= 8'd0;27 b_r <= 8'd0;28end29else30begin31 a_r <= a;32 b_r <= b;33end3435assign p_tmp = a*b; //只能做⽆符号数的相乘,若要做有符号数乘法,需将数据声明为signed类型3637//输出数据打⼀拍38always@(posedge clk)39if(!rst_n)40begin41 p <= 16'd0;42end43else44begin45 p <= p_tmp;46end4748endmodule移位相加乘法器,下⾯的代码可实现8bit有符号数的相乘,注意符号扩展以及MSB位的处理://输⼊数据取反assign a_r_inv = ~a_r + 1;assign a_shift0 = b_r[0] ? {{8{a_r[7]}},a_r} : 0;assign a_shift1 = b_r[1] ? {{7{a_r[7]}},a_r,1'b0} : 0;assign a_shift2 = b_r[2] ? {{6{a_r[7]}},a_r,2'b0} : 0;assign a_shift3 = b_r[3] ? {{5{a_r[7]}},a_r,3'b0} : 0;assign a_shift4 = b_r[4] ? {{4{a_r[7]}},a_r,4'b0} : 0;assign a_shift5 = b_r[5] ? {{3{a_r[7]}},a_r,5'b0} : 0;assign a_shift6 = b_r[6] ? {{2{a_r[7]}},a_r,6'b0} : 0;assign a_shift7 = b_r[7] ? {{1{a_r_inv[7]}},a_r_inv,7'b0} : 0; //被乘数为⽆符号数时,特别处理代码:1module mult_shift_add(rst_n,2 clk,3 a,4 b,5 p6 );7parameter DATA_SIZE = 8;89input rst_n;10input clk;11input [DATA_SIZE - 1 : 0] a;12input [DATA_SIZE - 1 : 0] b;1314output [2*DATA_SIZE - 2 : 0] p;1516//输⼊数据打⼀个时钟节拍17reg [DATA_SIZE - 1 : 0] a_r;18reg [DATA_SIZE - 1 : 0] b_r;1920//输⼊数据取反21wire [DATA_SIZE - 1 : 0] a_r_inv;2223//输⼊数据移位24wire [2*DATA_SIZE - 1 : 0] a_shift0;25wire [2*DATA_SIZE - 1 : 0] a_shift1;26wire [2*DATA_SIZE - 1 : 0] a_shift2;27wire [2*DATA_SIZE - 1 : 0] a_shift3;28wire [2*DATA_SIZE - 1 : 0] a_shift4;29wire [2*DATA_SIZE - 1 : 0] a_shift5;30wire [2*DATA_SIZE - 1 : 0] a_shift6;31wire [2*DATA_SIZE - 1 : 0] a_shift7;3233//输出数据打⼀个时钟节拍34wire [2*DATA_SIZE - 1 : 0] p_tmp;35reg [2*DATA_SIZE - 1 : 0] p;3637//输⼊数据打⼀个时钟节拍38always@(posedge clk)39if(!rst_n)40begin41 a_r <= 8'd0;42 b_r <= 8'd0;43end44else45begin46 a_r <= a;47 b_r <= b;48end49//输⼊数据取反50assign a_r_inv = ~a_r + 1;5152//输⼊数据移位,注意符号扩展,不仅仅是最⾼位扩展53//对每⼀个bit都需扩展54assign a_shift0 = b_r[0] ? {{8{a_r[7]}},a_r} : 0;55assign a_shift1 = b_r[1] ? {{7{a_r[7]}},a_r,1'b0} : 0;56assign a_shift2 = b_r[2] ? {{6{a_r[7]}},a_r,2'b0} : 0;57assign a_shift3 = b_r[3] ? {{5{a_r[7]}},a_r,3'b0} : 0;58assign a_shift4 = b_r[4] ? {{4{a_r[7]}},a_r,4'b0} : 0;59assign a_shift5 = b_r[5] ? {{3{a_r[7]}},a_r,5'b0} : 0;60assign a_shift6 = b_r[6] ? {{2{a_r[7]}},a_r,6'b0} : 0;61assign a_shift7 = b_r[7] ? {{1{a_r_inv[7]}},a_r_inv,7'b0} : 0; //被乘数为⽆符号数时,特别处理6263assign p_tmp = a_shift0 + a_shift1 + a_shift2 + a_shift3 + a_shift464 + a_shift5 + a_shift6 + a_shift7;6566always@(posedge clk)67if(!rst_n)68begin69//p <= 16'd0;70 p <= 15'd0;71end72else73begin74//p <= p_tmp[15:0];75 p <= p_tmp[14:0];76end7778endmoduletestbench:1module mult_shift_add_tb;23// Inputs4reg rst_n;5reg clk;6reg [7:0] a;7reg [7:0] b;89// Outputs10wire [14:0] p;1112// Instantiate the Unit Under Test (UUT)13 mult_shift_add uut (14 .rst_n(rst_n),15 .clk(clk),16 .a(a),17 .b(b),18 .p(p)19 );2021parameter CLK_PERIOD = 10;2223initial begin24 rst_n = 0;25 clk = 0;2627 #100;28 rst_n = 1;29end3031always #(CLK_PERIOD/2) clk = ~clk;3233always@(posedge clk)34if(!rst_n)35begin36 a = 8'd0;37 b = 8'd0;38end39else40begin41 a = a + 1;42 b = b - 1;43end4445endmoduleISIM仿真结果:移位相加乘法器树:将assign p_tmp = a_shift0 + a_shift1 + a_shift2 + a_shift3 + a_shift4 + a_shift5 + a_shift6 + a_shift7;换为:assign sum_01 = a_shift0 + a_shift1;assign sum_23 = a_shift2 + a_shift3;assign sum_45 = a_shift4 + a_shift5;assign sum_67 = a_shift6 + a_shift7;assign sum_0123 = sum_01 + sum_23;assign sum_4567 = sum_45 + sum_67;assign p_tmp = sum_0123 + sum_4567;就成为乘法器树。
十四周实验五 8位硬件乘法器设计

3X3位十进制移位相加原理分析
当被乘数被加载于8位右移寄存器SREG8B后,随着
每一时钟节拍,最低位在前,由低位至高位逐位移出。 当为1时,1位乘法器ANDARITH打开,8位乘数 B[7..0]在同一节拍进入8位加法器,与上一次锁存在 16位锁存器REG16B中的高8位进行相加,其和在下
一时钟节拍的上升沿被锁进此锁存器。而当被乘数的 移出位为0时,与门全零输出。如此往复,直至8个时 钟脉冲后,最后乘积完整出现在REG16B端口。在这 里,1位乘法器ANDARITH的功能类似于1个特殊的与 门,即当ABIN为‘1’时,DOUT直接输出DIN,而当 ABIN为‘0’时,DOUT输出全“00000000”。
(3)实验内容1:根据给出的乘法器逻辑原理图及其 各模块的VHDL描述,在MAX+plusII上完成全部设计 ,包括编辑、编译、综合和仿真操作等。以87H乘以 F5H为例,进行仿真,对仿真波形作出详细解释,包 括对8个工作时钟节拍中,每一节拍乘法操作的方式和 结果,对照波形图给以详细说明根据顶层设计,结合 图8-3,画出乘法器的详细电路原理框图。
(4)实验内容2:编程下载,进行实验验证。实验电 路可选择电路模式1,8位乘数可分别用键2、键1输入 、8位被乘数用键4和键3输入;16位乘积可由4个数码 管(数码管8,7,6,5显示)显示;用键8输入CLK ,键7输入START。详细观察每一时钟节拍的运算结 果,并与仿真结果进行比较。
图8-4 8位移位相加乘法器运算逻辑波形图
END ANDARITH;
ARCHITECTURE behav OF ANDARITH IS
BEGIN
PROCESS(ABIN, DIN)
BEGIN
乘法器的工作原理

乘法器的工作原理
乘法器是一种用于实现数字乘法运算的电路或器件。
它将两个输入的数字进行相乘,并得到其乘积作为输出。
乘法器的工作原理基于逻辑门电路的组合与串联。
乘法器通常是由多个部分组成的,其中包括乘法器的位数、运算规则以及乘法器内部的逻辑门电路。
这些部分协同工作以实现精确且高效的乘法运算。
在一个典型的乘法器中,输入信号将首先被分为不同的位数。
每一位数将被独立处理,并最终合并以得到最终的乘积结果。
每个位数的处理过程包括了多个逻辑运算,例如与门、或门和异或门。
为了完成乘法运算,乘法器将两个输入位进行逐位相乘。
这里的位可以是二进制位,也可以是十进制位。
逐位相乘的方法可以通过一系列的逻辑门电路来实现。
这些逻辑门电路可以对输入位进行操作,并生成相乘位的输出。
在乘法器中,最低有效位(LSB)的运算最先进行。
在相邻的
位运算完成后,它们的结果会被以并行的方式传递给下一位的运算。
这样一直进行到最高有效位(MSB)的运算完成。
最后,所有位的乘法结果会被整合在一起,形成最终的乘积。
乘法器的性能取决于其位数和逻辑门电路的设计。
更高的位数会产生更精确的乘法结果,但也会增加乘法器的复杂性和功耗。
因此,在设计乘法器时需要权衡精确性和性能之间的关系。
总之,乘法器是一种通过组合逻辑门电路来实现数字乘法运算的电路或器件。
它将输入信号分解为不同的位数,并使用逻辑门电路逐位相乘。
最后,将每个位的乘法结果合并在一起,得到总体的乘积输出。
EDA4位乘法器的程序

实验四、4位乘法器的实现一、实验前准备本实验例子使用独立扩展下载板EP1K10_30_50_100QC208(芯片为EP1K100QC208)。
EDAPRO/240H实验仪主板的VCCINT跳线器右跳设定为3.3V;EDAPRO/240H实验仪主板的VCCIO跳线器组中“VCCIO3.3V”应短接,其余VCCIO均断开;独立扩展下载板“EP1K10_30_50_100QC208”的VCCINT跳线器组设定为 2.5V;独立扩展下载板“EP1K10_30_50_100QC208”的VCCIO跳线器组设定为3.3V。
请参考前面第二章中关于“电源模块”的说明。
二、实验目的1、掌握利用V erilog HDL语言实现乘法器的方法2、掌握利用8位数码显示模块的设计三、实验内容1、用Verilog HDL语言按照移位循环相加方法实现4x4乘法器模块。
2、用Verilog HDL语言实现8位数码显示模块。
三、实验原理乘法运算模块可采用移位相加原理实现,本实验采用乘法器模块和显示模块在顶层模块中例化的方法实现。
四、实验步骤1、按照以下步骤完成每一个模块的设计:新建设计文件夹(不可用中文)-》新建设计文件-》输入设计项目(原理图/Verilog HDL文本代码)-》存盘(注意原理图/文本取名)-》将设计项目设置成Project-》选择目标器件-》启动编译-》(可选:建立仿真波形文件-》仿真测试和波形分析)2、新建顶层原理图文件,调入第1步中设计好的各模块,以原理图方式实现顶层设计-》存盘(注意原理图/文本取名)-》将设计项目设置成Project-》选择目标器件-》启动编译-》建立仿真波形文件-》(可选:建立仿真波形文件-》仿真测试和波形分析)-》引脚锁定并编译-》编程下载/配置-》硬件测试五、硬件测试说明1、乘数与被乘数接8位数字开关A组。
2、结果显示接动态数码管。
六、硬件连线说明如果独立扩展板芯片为EP1K30QC208 PIN分配CLK 79 接GCLK1Rst 71 接按键F12,需要连线到右下角F12的连线插孔Display[6] 93 接数码管段位引线ADisplay[5] 92 接数码管段位引线BDisplay[4] 90 接数码管段位引线CDisplay[3] 89 接数码管段位引线DDisplay[2] 88 接数码管段位引线EDisplay[1] 87 接数码管段位引线FDisplay[0] 86 接数码管段位引线GSel[2] 70 接SS2Sel[1] 69 接SS1Sel[0] 68 接SS0data_a[3] 39 接8位数字开关A SW1data_a[2] 40 接8位数字开关A SW2data_a[1] 41 接8位数字开关A SW3data_a[0] 44 接8位数字开关A SW4data_b[3] 45 接8位数字开关A SW5data_b[2] 46 接8位数字开关A SW6data_b[1] 47 接8位数字开关A SW7data_b[0] 53 接8位数字开关A SW8如果独立扩展板芯片为EP1K 30TC144 PIN分配CLK 55 接CLK(T)-CLOCK(P)Rst 67 接按键F12,需要连线到右下角F12的连线插孔Display[6] 91 接数码管段位引线ADisplay[5] 90 接数码管段位引线BDisplay[4] 88 接数码管段位引线CDisplay[3] 87 接数码管段位引线DDisplay[2] 86 接数码管段位引线EDisplay[1] 83 接数码管段位引线FDisplay[0] 81 接数码管段位引线GSel[2] 70 接SS2Sel[1] 69 接SS1Sel[0] 68 接SS0data_a[3] 37 接8位数字开关A SW1data_a[2] 38 接8位数字开关A SW2data_a[1] 39 接8位数字开关A SW3data_a[0] 41 接8位数字开关A SW4data_b[3] 42 接8位数字开关A SW5data_b[2] 43 接8位数字开关A SW6data_b[1] 44 接8位数字开关A SW7data_b[0] 46 接8位数字开关A SW8程序:module CFQ4梁一一(input clk,input wire [4:1] ain, //输入ainput wire [4:1] bin, //输入binput rest_n,output reg [2:0] sel, //位选output reg [6:0] display);reg [15:0] count_clk; // 分频计数器,最大2^16=64K分频reg [3:0] a; //输入ain寄存器reg [3:0] b; //输入bin寄存器reg [7:0] mul_num; //乘得结果reg [3:0] g_bit; //个位reg [3:0] s_bit; //十位reg [3:0] b_bit; //百位reg [3:0] disp_temp;integer i;//assign a=ain;//assign b=bin;//分频always @ (posedge clk or negedge rest_n) beginif(rest_n ==0) begincount_clk=16'b0;endelse beginif(count_clk==16'hffff) begincount_clk=16'b0;endelse begincount_clk=count_clk+1'b1;endendend//乘法运算always @ (ain or bin ) beginmul_num=8'b0;for (i=1;i<=4;i=i+1) beginif(bin[i]) mul_num=mul_num+(ain<<(i-1));else mul_num=mul_num+1'b0;endb_bit=(mul_num/100)%10;s_bit=(mul_num/10)%10;g_bit=mul_num%10;end// 位选always @ (posedge count_clk[3] or negedge rest_n) begin if(rest_n ==0) beginsel=3'b0;endelse beginif (sel==3'b111) beginsel=3'b0;endelse beginsel=sel+1'b1;endendendalways @ (sel) begincase(sel)3'b000: disp_temp=4'b1010;3'b001: disp_temp=4'b1010;3'b010: disp_temp=4'b1010;3'b011: disp_temp=4'b1010;3'b100: disp_temp=4'b1010;3'b101: disp_temp=b_bit;3'b110: disp_temp=s_bit;3'b111: disp_temp=g_bit;default: disp_temp=4'b1010;endcaseend//显示译码,共阴数码管,a:对应高位,g:对应低位always @ (disp_temp) begincase (disp_temp)4'b0000: display=7'b1111110; //04'b0001: display=7'b0110000; //14'b0010: display=7'b1101101; //24'b0011: display=7'b1111001; //34'b0100: display=7'b0110011; //44'b0101: display=7'b1011011; //54'b0110: display=7'b1011111; //64'b0111: display=7'b1110000; //74'b1000: display=7'b1111111; //84'b1001: display=7'b1111011; //94'b1010: display=7'b0000001; //-default: display=7'b0000000; //全灭endcaseend endmodule。
改进Booth4位乘法器

改进Booth4位乘法器(verilog)(1)原理本质还是Booth算法,也就是重新编码以后,来决定操作(移位或者加法运算).不过这次用的是牧猫同学介绍的改良Booth编码本,后来经过比较官方的定义应该叫”比特对编码”.只不过一次对乘数检测三个位,并生成一个两位代码来决定操作方式1)被乘数相加,2)移一位后相加/相减再移位3)仅仅移位运算…汗…截取百科里面的资料来说明吧.判断位yi-1yiyi+1 操作内容000[zi+1]补=2-2[zi]补001[zi+1]补=2-2{[zi]补+[x]补}010[zi+1]补=2-2{[zi]补+[x]补}011[zi+1]补=2-2{[zi]补+2[x]补}100[zi+1]补=2-2{[zi]补+2[-x]补}101[zi+1]补=2-2{[zi]补+ [-x]补}110[zi+1]补=2-2{[zi]补+-x}补}111[zi+1]补=2-2[zi]补由上表可见,操作中出现加2[x]补和加2[-x]补,故除右移两位的操作外,还有被乘数左移一位的操作;而加2[x]补和加2[-x]补,都可能因溢出而侵占双符号位,故部分积和被乘数采用三位符号位.简化下来可以这么看算法是比较简单的,这次笔记的重点在于体验一下数据通路控制器设计的思路.所以,仅仅是描写4位乘法器,当然,改良版的Booth算法的优点在4位运算中并不明显,仅仅是减少了2次加法运算,然而n位数愈多,就会发现,加法运算的次数减少了n/2.虽然这么简单,但是划分成了数据通道和控制器的确便于系统结构清晰,下图就是这次乘法器综合后结构.控制单元组织,协调和同步数据通道单元的操作,状态及控制单元产生装载,读取,移动存储内容的信号.写乘法器的草稿之一如下图首先,当然是研究Booth算法了,然后就是那一组数举例,对着每一次运算分析,理解算法每一步骤原因,再后就是画状态图,确定每一步的作用.然后就是写了…不过,这次写的时候,懂哥觉得难以平衡multiplier和multiplicant的移位和运算,于是参考了西里提书上的一个思路,就是在处理时序乘法器处理011(或者100)情况时,十分精巧地将被乘数移一位后和乘积相加,然后再移动一位,在这些动作之后,位置指针都同时到了下一位Yi中当两次移位后,正确地移到了运算结束后的位置.丢状态图(真的就将就了嘛….word不好使)然后丢程序module mul(clk,res_n,start,mul1,mul2,ready,product);parameter width=3'd4;input clk,res_n;input start;//signal to begin operateinput [width-1:0]mul1,mul2;//multiplier &multiplicantoutput ready;//signal to end operateoutput [2*width-1:0]product;wire [2:0]Yi;wire shift_2,shift_1,add,sub,load;controller m1(clk,res_n,start,Yi,shift_1,shift_2,add,sub,load,ready); datapath m2(clk,res_n,mul1,mul2,load,shift_1,shift_2,add,sub,Yi,product);endmodule改进Booth4位乘法器(Verilog)(2)module controller(clk,res_n,start,Yi,shift_1,shift_2,add,sub,load,ready);parameter [8:0]idle=0,S1=9'b0000_0000_1,S2=9'b0000_0001_0,S3=9'b0000_0010_0,S4=9'b0000_0100_0,S5=9'b0000_1000_0,S6=9'b0001_0000_0,S7=9'b0010_0000_0,S8=9'b0100_0000_0,S9=9'b1000_0000_0;input clk,res_n;input start;input [2:0]Yi;//from datapath to decide instructions output shift_1,shift_2,add,sub,load;//instructionsoutput ready;reg ready;reg [8:0]current_S,next_S;reg shift_1,shift_2,add,sub,load;always@(posedge clk or negedge res_n)beginif(!res_n)begincurrent_S<=idle;endelse current_S<=next_S;endalways@(current_S or start or Yi)beginshift_2=0;shift_1=0;add=0;sub=0;load=0;case(current_S)idle:beginif(start)beginload=1;next_S=S1;endelse next_S=idle;//test if move out the "else"endS1:begincase(Yi)3'b000:beginshift_2=1;next_S=S2;end3'b010:beginadd=1;next_S=S3;end3'b100:beginshift_1=1;next_S=S4;end3'b110:beginsub=1;next_S=S3;enddefault:next_S=idle;endcaseendbegincase(Yi)3'b000:beginshift_2=1;next_S=S6;end3'b001:beginadd=1;next_S=S7;end3'b010:beginadd=1;next_S=S7;end3'b011:beginshift_1=1;next_S=S8;end3'b100:beginshift_1=1;next_S=S8;end3'b101:beginsub=1;next_S=S7;end3'b110:beginsub=1;next_S=S7;end3'b111:beginshift_2=1;next_S=S6;end endcaseS3:beginshift_2=1;next_S=S2;endS4:beginsub=1;next_S=S5;endS5:beginshift_1=1;next_S=S2;endS6:beginready=1;next_S=idle;endS7:beginshift_2=1;next_S=S6;endS8:begincase(Yi[1:0])3'b01:beginadd=1;next_S=S9;end3'b10:beginsub=1;next_S=S9;end default:next_S=idle;endcaseendS9:beginshift_1=1;next_S=S6;enddefault:next_S=idle;endcaseendendmodule改进Booth4位乘法器(Verilog)(3)module datapath(clk, res_n, mul1, mul2, load, shift_1, shift_2, add, sub, Yi,product);parameter width=3'd4;input clk,res_n;input [width-1:0]mul1,mul2;//multiplier &multiplicant for 4bitinput load,shift_1,shift_2,add,sub;//instructions from controlleroutput [2:0]Yi;//send to controller to decide instructionsoutput [2*width-1:0]product;reg [width-1:0]multiplier;reg [2*width-1:0]multiplicant,product;reg Q;//the additon bit ;assign Yi={multiplier[1:0],Q};always@(posedge clk or negedge res_n)beginif(!res_n)beginmultiplier<=0;multiplicant<=0;Q<=0;product<=0;endelse if(load)begincase(mul1[width-1])//extent multiplicant1:multiplicant<={4'b1111,mul1};//注意符号位的一起扩展!!0:multiplicant<={4'b0000,mul1};endcasemultiplier<=mul2;Q<=0;product<=0;endelse if(shift_2)beginmultiplier<=multiplier>>2;multiplicant<=multiplicant<<2;endelse if(shift_1)beginmultiplier<=multiplier>>1;multiplicant<=multiplicant<<1;endelse if(add)beginproduct<=multiplicant+product;endelse if(sub)beginproduct<=product-multiplicant;endendendmoduletestbench`timescale 1ns/1nsmodule t_mul4;parameter width=4'd4;reg clk,res_n,start;reg[width-1:0]mul1,mul2;wire[2*width-1:0]product;wire ready;mul m(clk,res_n,start,mul1,mul2,ready,product);initialbeginclk=0;res_n=1'b1;mul1=4'b0111;mul2=4'b1101;#5 res_n=0;#5 res_n=1'b1;#5 start=1'b1;#400 $stop;endalways #5 clk=~clk;endmodule。
数字电路课程设计之乘法器

X
Y
C
S
0
0
0
0
0
1
0
1
1
0
0
1
1
1
1
0
最简积之和式为 S=X`Y+XY`=X○+ Y;C=XY.
电路图为:
X`
1
3
Y
2
X
1
3
Y`
2
X
1
3
S
Y
2
1
3
S
2
X
1
Y
2
3
C
1
3
C
2
2.2 全加器
全加器是为三输入两输出,输入存在进位,真值表如下图所示,输入 X,Y,Z,输出 C,S
X
Y
Z
C
S
0
0
0
0
0
0
0
1
0
carry_look_add cla1 (.A(v),.B(w),.Cin(0),.Cout(d[4]),.S(d[3:0])); assign S[1]= d[0]; and (z[0],A[2],B[0]); and (z[1],A[2],B[1]); and (z[2],A[2],B[2]); and (z[3],A[2],B[3]); carry_look_add cla2 (.A(d[4:1]),.B(z),.Cin(0),.Cout(d1[4]),.S(d1[3:0])); assign S[2]=d1[0];
and (x[0],A[3],B[0]); and (x[1],A[3],B[1]); and (x[2],A[3],B[2]); and (x[3],A[3],B[3]); carry_look_add cla3 (.A(d1[4:1]),.B(x),.Cin(0),.Cout(d2[4]),.S(d2[3:0])); assign S[7:3]=d2[4:0]; endmodule 3.6 Verilog 测试平台语言编写 `timescale 1ns/1ps module mul_tb(); reg[3:0] A,B; wire [7:0] S; mul mu (.A(A),.B(B),.S(S)); initial begin
【微电子学与计算机】_算法设计_期刊发文热词逐年推荐_20140726
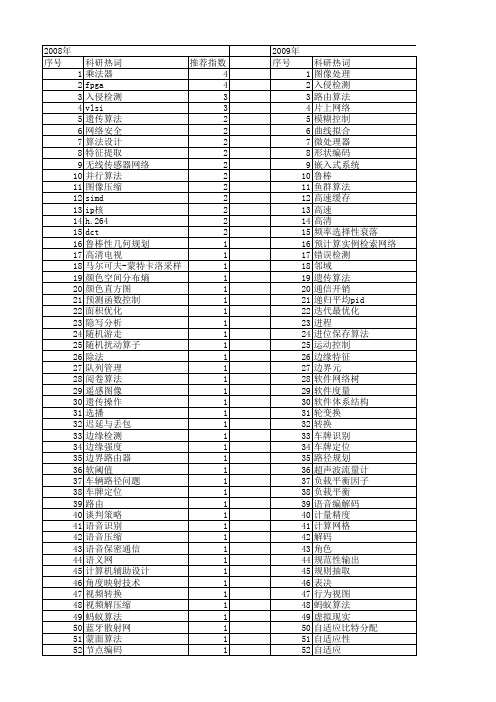
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
科研热词 图像处理 入侵检测 路由算法 片上网络 模糊控制 曲线拟合 微处理器 形状编码 嵌入式系统 鲁棒 鱼群算法 高速缓存 高速 高清 频率选择性衰落 预计算实例检索网络 错误检测 邻域 遗传算法 通信开销 递归平均pid 迭代最优化 进程 进位保存算法 运动控制 边缘特征 边界元 软件网络树 软件度量 软件体系结构 轮变换 转换 车牌识别 车牌定位 路径规划 超声波流量计 负载平衡因子 负载平衡 语音编解码 计量精度 计算网格 解码 角色 规范性输出 规则抽取 表决 行为视图 蚂蚁算法 虚拟现实 自适应比特分配 自适应性 自适应
乘法器原理

乘法器原理乘法器原理是计算机科学中非常重要的原理,它是实现计算机高效计算的基础。
本文将详细介绍乘法器原理的相关知识,包括乘法器的基本概念、实现原理、应用场景等方面。
一、乘法器的基本概念乘法器是一种用于计算两个数的乘积的计算机硬件。
它是计算机中最常用的算术电路之一,可以用来进行乘法运算,是实现计算机高效计算的关键组件之一。
乘法器通常由多个门电路组成,其中最常用的是AND门、OR门和XOR门。
它的输入是两个二进制数,输出是它们的乘积。
乘法器的输出通常是一个二进制数,它的位数等于输入的两个二进制数的位数之和。
乘法器的输出可以通过一系列的加法器进行加法运算,从而得到最终的结果。
乘法器的性能取决于它的位宽、延迟和功耗等因素。
在实际应用中,乘法器的位宽通常是32位或64位,延迟时间通常在几个时钟周期内,功耗通常在几个瓦特以下。
二、乘法器的实现原理乘法器的实现原理可以分为两种,即基于布斯算法的乘法器和基于蒙哥马利算法的乘法器。
1、布斯算法乘法器布斯算法乘法器是一种基于移位和加法的乘法器。
它通过将一个数分解成多个部分,然后逐位进行计算,最后将它们相加得到最终结果。
布斯算法乘法器的核心是部分积的计算,它可以通过移位和相加操作来实现。
例如,假设要计算两个8位二进制数A和B的乘积,可以将A和B分别分解成4位二进制数A1、A0和B1、B0,然后按照如下方式计算部分积:P1 = A1 × B0P2 = A0 × B1P3 = A0 × B0P4 = A1 × B1最终的结果可以通过将这些部分积相加得到:P = P1 × 2^8 + P2 × 2^4 + P3 + P4 × 2^12布斯算法乘法器的主要优点是简单、易于实现,但它的缺点是速度较慢,需要多次移位和加法操作。
2、蒙哥马利算法乘法器蒙哥马利算法乘法器是一种基于模重复平方和模乘的算法。
它利用模运算的性质,将乘法转化为模运算和加法运算,从而减少了乘法器的复杂度和延迟时间。
QuartusII及其原理图设计
QuartusII及其原理图设 计
3
QUARTUS II 设计开发流程
QuartusII及其原理图设 计
4
QUARTUS II 文件格式介绍
QuartusII及其原理图设 计
5
QUARTUS II –图表和原理图编辑器
QuartusII及其原理图设 计
25
QUARTUS II –原理图设计例子
QuartusII及其原理图设 计
26
QUARTUS II –原理图设计例子
QuartusII及其原理图设 计
27
QUARTUS II –原理图设计例子
QuartusII及其原理图设 计
28
QUARTUS II –原理图设计例子
QuartusII及其原理图设 计
41
编译注意
要查找器件的资料,确保管脚定义,及其管脚工作状态 注意总线的画法和定义
注意同步清零和异步清零的方法
QuartusII及其原理图设 计
42
QUARTUS II –习题一
1-3 基于Quartus II软件,用部分积右移方式设计实现一个 4位二进制乘法器,选择合适的器件,画出电路连接
QuartusII及其原理图设 计
47
QUARTUS II –习题一
1-9 用D触发器构成按循环码(000-001-011-111-101100-000)规律工作的六进制同步计数器。 1-10 用74194、74273、D触发器等器件组成8位串入并 出的转换电路,要求在转换过程中数据不变,只有当8位一 组数据全部转换结束后,输出才变化一次。
AD9914_CN

DDS内核 ..................................................................................... 19 12位DAC输出............................................................................ 20 DAC校准输出............................................................................ 20 重构滤波器 ................................................................................ 20 时钟输入(REF_CLK/REF_CLK) ............................................ 21 PLL锁定指令.............................................................................. 22 输出幅度键控(OSK)................................................................. 22 数字斜坡发生器(DRG) ........................................................... 23 省电控制..................................................................................... 27 编程和功能引脚............................................................................. 28 串行编程 .......................................................................................... 31 控制接口——串行I/O.............................................................. 31 通用串行I/O操作...................................................................... 31 指令字节..................................................................................... 31 串行I/O端口引脚功能描述 .................................................... 31 串行I/O时序图 .......................................................................... 32 MSB/LSB传输 ............................................................................ 32 并行编程(8/16位)........................................................................... 33 寄存器图和位功能描述................................................................ 34 寄存器位功能描述 ................................................................... 39 外形尺寸 .......................................................................................... 45 订购指南..................................................................................... 45
采用CSA与4-2压缩器改进Wallace树型乘法器的设计

采用CSA与4-2压缩器改进Wallace树型乘法器的设计引言在微处理器芯片中,乘法器是进行数字信号处理的核心,同时也是微处理器中进行数据处理的关键部件。
乘法器完成一次操作的周期基本上决定了微处理器的主频。
乘法器的速度和面积优化对于整个CPU的性能来说是非常重要的。
为了加快乘法器的执行速度,减少乘法器的面积,有必要对乘法器的算法、结构及电路的具体实现做深入的研究。
乘法器工作的基本原理是首先生成部分积,再将这些部分积相加得到乘积。
在目前的乘法器设计中,基4Booth算法是部分积生成过程中普遍采用的算法。
对于N位有符号数乘法A×B来说,常规的乘法运算会产生N个部分积。
如果对乘数B进行基4Booth编码,每次需考虑3位:相邻高位、本位和相邻低位,编码后产生部分积的个数可以减少到[(N+1)/2]??([X]取值为不大于X的整数),确定运算量0、±1A、±2A。
对于2A的实现,只需要将A左移一位。
因此,对于符号数乘法而言,基4 Booth算法既方便又快捷。
而对于无符号数来说,只需对其高位作0扩展,而其他处理方法相同。
虽然扩展后可能导致部分积的个数比有符号数乘法多1,但是这种算法很好地保证了硬件上的一致性,有利于实现。
对于32位乘法来说,结合指令集的设计,通常情况下需要相加的部分积不超过18个。
对部分积相加,可以采用不同的加法器阵列结构。
而不同的阵列结构将直接影响完成一次乘法所需要的时间,因此,加法器阵列结构是决定乘法器性能的重要因素。
重复阵列(Iterative Array,简称IA)和Wallace树型结构是最为典型的两种加法器阵列结构。
IA结构规整,易于版图实现,但速度最慢且面积大;理论上,Wallace树型结构是进行乘法操作最快的加法器阵列结构,但传统的Wallace树型结构电路互连复杂,版图实现困难。
为了解决这个问题,人们推出了一些连接关系较为简单的树型结构,例如ZM树和OS树。
乘法器的布斯算法原理与verilog实现

乘法器的布斯算法原理与VERILOG实现1 乘法器基本原理乘法器是处理器设计过程中经常要面对的运算部件。
一般情况下,乘法可以直接交由综合工具处理或者调用EDA厂商现成的IP,这种方式的好处是快捷和可靠,但也有它的不足之处,比如影响同一设计在不同工具平台之间的可移植性、时序面积可采取的优化手段有限、个性化设计需求无法满足等。
所以,熟悉和掌握乘法器的底层实现原理还是有必要的,技多不压身,总有用得上的时候,同时也是一名IC设计工程师扎实基本功的体现。
不采用任何优化算法的乘法过程,可以用我们小学就学过的列竖式乘法来说明。
从乘数的低位开始,每次取一位与被乘数相乘,其乘积作为部分积暂存,乘数的全部有效位都乘完后,再将所有部分积根据对应乘数数位的权值错位累加,得到最后的乘积。
如下图,左边为十进制乘法过程,基数为10,右图为二进制乘法过程,基数为2。
PP0~PP3分别表示每次相乘后的部分积。
可见,二进制乘法与十制乘法本质上是没有差别的。
1 2 31 2 3×3 6 92 4 6 1 2 3+1 5 12 9……3×123 PP0……2×123 PP1……1×123 PP21 1 0 11 0 0 1×1 1 0 10 0 0 00 0 0 01 1 0 1+1 1 1 0 1 0 1……1×1101 PP0……0×1101 PP1……0×1101 PP2……1×1101 PP3如果表示成通用形式,则如下图所示(以4位乘法器为例,其它位宽类似)这样原始的乘法在设计上是可以实现的,但在工程应用上几乎不会采用,在时延与面积上都需要优化。
一个N位的乘法运算,需要产生N个部分积,并对它们进行全加处理,位宽越大,部分积个数越多,需要的加法器也越多,加法器延时也越大,那么针对乘法运算的优化,主要也就集中在两个方面:一是减少部分积的个数,二是减少加法器带来的延时。
EDA教程 第四章_原理图输入方法

KX
康芯科技
最后点击" 最后点击"OK"
图4-9 列出并选择需要观察的信号节点
用此键选择左窗 中需要的信号 进入右窗
KX
康芯科技
(3) 设置波形参量. 设置波形参量.
消去这里的勾, 消去这里的勾, 以便方便设置 输入电平
图4-9 列出并选择需要观察的信号节点
菜单中消去网格对齐Snap to Grid的选择 消去对勾 的选择(消去对勾 图4-10 在Options菜单中消去网格对齐 菜单中消去网格对齐 的选择 消去对勾)
目 标 器 件 引 脚 名 和 引 脚 号 对 照 表
KX
康芯科技
选择实验板上 插有的目标器件
键8的引脚名 的引脚名 键8的引脚名 的引脚名 对应的引脚号
KX
康芯科技
引脚对应情况
实验板位置 1, 8: 1, 键 8: 2,键7 , 3,发光管8 ,发光管 4,发光管7 ,发光管 半加器信号 a b co so 通用目标器件引脚名 PIO13 PIO12 PIO23 PIO22 目标器件EP1K30TC144引脚号 引脚号 目标器件 27 26 39 38
(4) 设定仿真时间. 设定仿真时间.
KX
康芯科技
选择END TIME 选择 调整仿真时间 区域. 区域.
选择60微秒 选择 微秒 比较合适
图4-11 设定仿真时间
(5) 加上输入信号. 加上输入信号.
KX
康芯科技
(6) 波形文件存盘. 波形文件存盘.
用此键改变仿真 区域坐标到合适 位置. 位置.
(3) 了解设计项目速度 延时特性 了解设计项目速度/延时特性
KX
康芯科技
图4-37 寄存器时钟特性窗
数字信号处理(第三版)教程及答案第4章

第 4 章 时域离散系统的网络结构及数字信号处理的实现
4.4 例
[例4.4.1] 例
题
设FIR滤波器的系统函数为
1 H ( z ) = (1 + 0.9 z −1 + 2.1z − 2 + 0.9 z −3 + z − 4 ) 10
求出其单位脉冲响应, 判断是否具有线性相位, 画出直 接型结构和线性相位结构(如果存在)。
第 4 章 时域离散系统的网络结构及数字信号处理的实现
4.1 教材第 章学习要点 教材第5章学习要点
数字信号处理系统设计完毕后, 得到的是该系统的系 统函数或者差分方程, 要实现还需要按照系统函数设计一 种具体的算法。 不同的算法会影响系统的成本、 运算的复 杂程度、 运算时间以及运算误差等。 教材第5章的学习要点 如下: (1) 由系统流图写出系统的系统函数或者差分方程。
: 解: 上式的分子分母是因式分解形式, 再写成下式:
− 8 + 20 z −1 − 6 z −2 H ( z ) = 16 + (1 − 0.5 z −1 )(1 − z −1 + 0.5 z −2 )
上式的第二项已是真分式, 可以进行因式分解。
第 4 章 时域离散系统的网络结构及数字信号处理的实现
时域离散系统的网络结构及数字信号处理的实现41教材第5章学习要点42按照系统流图求系统函数或者差分方程43按照系统函数或者差分方程画系统流图44例题45教材第章学习要点46教材第章习题与上机题解答时域离散系统的网络结构及数字信号处理的实现41教材第5章学习要点数字信号处理系统设计完毕后得到的是该系统的系统函数或者差分方程要实现还需要按照系统函数设计一种具体的算法
− 8 + 20 z −1 − 6 z −2 H1 ( z) = (1 − 0.5 z −1 )(1 − z −1 + 0.5 z − 2 )
乘法器实验报告

library ieee;use ieee.std_logic_1164.all;entity multi8 isport(a,b:in std_logic_vector(7 downto 0);y:out std_logic_vector(15 downto 0));end entity multi8;architecture behavioral of multi8 isbeginbehavior:process(a,b) isvariable a_in:std_logic_vector(7 downto 0);variable b_in:std_logic_vector(7 downto 0);variable y_out:std_logic_vector(15 downto 0);variable carry_in,carry:std_logic;begina_in:=a;b_in:=b;y_out:=(others=>'0');for count in 0 to 7 loopcarry:='0';if(b_in(count)='1') thenfor index in 0 to 7 loopcarry_in:=carry;carry:=(y_out(index+count) and a_in(index))or (carry_in and (y_out(index+count) xor a_in(index)));y_out(index+count):=y_out(index+count) xor a_in(index) xor carry_in;end loop;y_out(count+8):=carry;end if;end loop;y<=y_out;end process behavior;end architecture behavioralVHDL语言实现乘法器嵌入式系统实验报告全文3页1063字叙述详尽实验四:乘法器1. 实验前准备(4分)1.继续学习VHDL。
《EDA技术实用教程(第五版)》课后习题答案(第1~10章)

《EDA技术实用教程(第五版)》课后习题及答案1 习题1-1EDA技术与ASIC设计和FPGA开发有什么关系?FPGA在ASIC设计中有什么用途?P3~4EDA技术与ASIC设计和FPGA开发有什么关系?答:利用EDA 技术进行电子系统设计的最后目标是完成专用集成电路ASIC的设计和实现;FPGA和CPLD是实现这一途径的主流器件。
FPGA和CPLD的应用是EDA技术有机融合软硬件电子设计技术、SoC(片上系统)和ASIC设计,以及对自动设计与自动实现最典型的诠释。
FPGA在ASIC设计中有什么用途?答:FPGA和CPLD通常也被称为可编程专用IC,或可编程ASIC。
FPGA实现ASIC设计的现场可编程器件。
1-2 与软件描述语言相比,VHDL有什么特点? P4~6 答:编译器将软件程序翻译成基于某种特定CPU的机器代码,这种代码仅限于这种CPU而不能移植,并且机器代码不代表硬件结构,更不能改变CPU的硬件结构,只能被动地为其特定的硬件电路结构所利用。
综合器将VHDL程序转化的目标是底层的电路结构网表文件,这种满足VHDL设计程序功能描述的电路结构,不依赖于任何特定硬件环境;具有相对独立性。
综合器在将VHDL(硬件描述语言)表达的电路功能转化成具体的电路结构网表过程中,具有明显的能动性和创造性,它不是机械的一一对应式的“翻译”,而是根据设计库、工艺库以及预先设置的各类约束条件,选择最优的方式完成电路结构的设计。
l-3什么是综合?有哪些类型?综合在电子设计自动化中的地位是什么?P6什么是综合? 答:在电子设计领域中综合的概念可以表示为:将用行为和功能层次表达的电子系统转换为低层次的便于具体实现的模块组合装配的过程。
有哪些类型?答:(1)从自然语言转换到VHDL语言算法表示,即自然语言综合。
(2)从算法表示转换到寄存器传输级(RegisterTransport Level,RTL),即从行为域到结构域的综合,即行为综合。
8数字系统设计习题解答

A.字母
B.数字
C.字母或数字
D.下划线
23. 在 VHDL 中,目标信号的赋值符号是
。
A. =:
B.=
C. :=
D.<=
习题
1.说明自顶向下的设计方法及步骤。 首先从系统设计入手,在顶层将整个系统划分成几个子系统,然后逐级向下,再将每 个子系统分为若干功能模块,每个功能模块还可以继续向下划分成子模块,直至分成许多 最基本模块实现。 2.说明 CPLD I/O 控制块的功能。 I/O 控制块允许每个 I/O 引脚单独地配置为输入、输出和双向工作方式。所有 I/O 引脚 有一个三态缓冲器,它控制的信号来自一个多路选择器,可以选择全局输出使能信号中的 一个或者直接连接到地(GND)或电源(Vcc)上。当三态缓冲器的控制端接地时,输出 为高阻态,此时 I/O 引脚可用作专用输入引脚。当三态缓冲器的控制端接高电平(Vcc)时, 输出被使能 3.以 Cyclone IV 系列 FPGA 为例,逻辑单元 LE 能否同时实现组合逻辑电路和时序逻 辑电路? 从图 8.2-18 可知,LUT 输入除了来自互连阵列,也来自触发器的输出,也就是说触发 器的输出反馈到 LUT 的输入端,便于构成计数器、状态机等时序电路。LUT 的输出可以 直接送到互连阵列,触发器的输入也可以不来自 LUT 的输出,而来自触发器链输入。LUT 和触发器可以独立工作,这意味着一个逻辑单元可以同时实现组合电路和时序电路。 4.CPLD 和 FPGA 有什么不同? FPGA 可以达到比 CPLD 更高的集成度,同时也具有更复杂的布线结构和逻辑实现。 FPGA 更适合于触发器丰富的结构,而 CPLD 更适合于触发器有限而积项丰富的结构。 在编程上 FPGA 比 CPLD 具有更大的灵活性;CPLD 功耗要比 FPGA 大;且集成度越高 越明显;CPLD 比 FPGA 有较高的速度和较大的时间可预测性,产品可以给出引脚到引脚 的最大延迟时间。CPLD 的编程工艺采用 E2 CPLD 的编程工艺,无需外部存储器芯片,使 用简单,保密性好。而基于 SRAM 编程的 FPGA,其编程信息需存放在外部存储器上,需
5.4 硬件乘法器

1. 硬件乘法器步骤 第一操作数OP1,来源于寄存器MPY, MPYS, MAC或MACS之一。 写第二操作数OP2,写入完毕,乘法运算立即开始。 读结果,乘法结果存放在RESHI、RESLO及SUMEXT。 2. 硬件乘法器操作时的注意事项 第二个操作数写入完毕,乘法运算就开始。一般在取出结果之前插入 1~2条指令,以保证运算时间的需要。 在一个器件中只有一个硬件乘法器,如果遇到多处使用的情况,必须 在每一次使用完成后再进行下一次使用。 结果扩展寄存器(SUMEXT)内容,与运算类型及结果都有关系。 无论进行何种运算,只要操作数类型为8×8型,操作过程就要使用寄 存器的绝对地址,而不能使用符号形式。但是16×16位运算就可以使 用寄存器符号形式。 在最初两步操作,即传送第一及第二操作数给乘法器之间,不允许接 受中断请求。
第5章 MSP430单片机片内外围 章 单片机片内外围 模块
5.4 硬件乘法器
5.4.1 硬件乘法器的结构
硬件乘法器的特性:
能够实现16×16位、8×16位、16×8位或8×8 位运算。 支持无符号乘法(MPY)。 有符号乘法(MPYS)。 无符号乘加(MAC)。 有符号乘加(MACS)。
ห้องสมุดไป่ตู้
5.4.2 硬件乘法器寄存器
5.4.3 硬件乘法器的操作
硬件乘法寄存器的乘数来源于两个操作数寄存器OP1和OP2,OP1可来源于4 个寄存器MPY、MPYS、MAC及MACS,它们能确定乘法的类型。 乘法运算执行之后,一般需要4个周期数,结果暂存在紧接着的32位乘积寄存 器中。如果执行乘加运算,则将用到累加器ACC, 结果保存到硬件乘法器的3个16位寄存器中,即结果高字寄存器(RESHI)、 结果低字寄存器(RESLO)及结果扩张寄存器(SUMEXT)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4*4数字乘法器设计1.设计任务试设计一4位二进制乘法器。
4位二进制乘法器的顶层符号图如图1所示。
ENDP A B 1 0 1 11 1 0 1×1 0 1 10 0 0 01 0 1 11 0 1 111011001图1 4位乘法器顶层符号图 图2 4位乘法运算过程输入信号:4位被乘数A (A 3 A 2 A 1 A 0),4位乘数B (B 3 B 2 B 1 B 0),启动信号START 。
输出信号:8位乘积P (P 7 P 6 P 5 P 4 P 3 P 2 P 1 P 0),结束信号END 。
·当发出一个高电平的START 信号以后,乘法器开始乘法运算,运算完成以后发出高电平的END 信号。
2.顶层原理图设计从乘法器的顶层符号图可知,这是一个9输入9输出的逻辑电路。
一种设计思想是把设计对象看作一个不可分割的整体,采用数字电路常规的设计方法进行设计,先列出真值表,然后写出逻辑表达式,最后画出逻辑图。
这种设计方法有很多局限性,比如,当设计对象的输入变量非常多时,将不适合用真值表来描述,同时,电路功能任何一点微小的改变或改进,都必须重新开始设计。
另一种设计思想是把待设计对象在逻辑上看成由许多子操作和子运算组成,在结构上看成有许多模块或功能块构成。
这种设计思想在数字系统的设计中得到了广泛的应用。
对于4位乘法器而言,设A =1011,B =1101,则运算过程可由图2所示。
从乘法运算过程可知,乘法运算可分解为移位和相加两种子运算,而且是多次相加运算,所以是一个累加的过程。
实现这一累加过程的方法是,把每次相加的结果用部分积P 表示,若B 中某一位 B i =1,把部分积P 与A 相加后右移1位;若B 中某一位B i = 0,则部分积P 与0相加后右移1位(相当于只移位不累加)。
通过4次累加和移位,最后得到的部分积P 就是A 与B 的乘积。
为了便于理解乘法器的算法,将乘法运算过程中部分积P 的变化情况用图3表示出来。
存放部分积的是一个9位的寄存器,其最高位用于存放在做加法运算时的进位输出。
先把寄存器内容清零,再经过4次的加法和移位操作就可得到积。
注意,每次做加法运算时,被乘数A 与部分积的D 7~D 4位相加。
000000000初始状态010110000与1011相加001011000右移1位001011000与0000相加000101100右移1位011011100与1011相加001101110右移1位100011110与1011相加011111右移1位D 0D 1D 2D 3D 4D 5D 6D 7D88位积图3 乘法运算过程中部分积P 的变化情况示意图乘法器的算法可以用如图4所示的算法流程图来描述。
当START 信号为高电平时,启动乘法运算。
在运算过程中,共进行4次累加和移位操作。
当i =4时,表示运算结束,END 信号置为高电平。
图4 乘法器的算法流程图在明确乘法器的算法之后,便可将电路划分成数据处理单元和控制单元。
数据处理单元实现算法流程图规定的寄存、移位、加法运算等各项运算及操作。
控制单元接收来自数据处理单元的状态信号并向其发出控制信号。
经过划分成控制单元和数据处理单元的乘法器顶层原理图如图5所示。
积PSTART B i END CPB i图5 乘法器的顶层原理图REGA 和REGB 为4位寄存器,分别用于存放被乘数A 、乘数B 。
REGS 为一5位寄存器,用于存放加法器输出的结果(考虑进位时为5位)。
在运算过程中,寄存器REGS 和REGB 合起来用于存放部分积P ,因此,REGS 和REGB 还应具有右移功能,以实现部分积的右移。
寄存器REGS 的移位输出送寄存器REGB ,寄存器REGB 的移位输出信号B i 送至控制器,以决定部分积是与被乘数相加还是与零相加。
并行加法器ADDER 用于实现4位二进制加法运算。
计数器CNT 用于控制累加和移位的循环次数。
当计数值等于4时,计数器的输出信号i 4输出高电平。
控制器MULCON 的功能是接收来自寄存器REGB 的移位输出信号B i 和计数器输出信号i 4,发出CA 、CB 0、CB 1、CS 0、CS 1、CLR 、CC 等控制信号。
其中,CA 为寄存器REGA 的控制信号,用于选择置数或保持功能;CS 0、CS 1为寄存器REGS 的控制信号,用于选择置数、右移和保持等功能;CB 0、CB 1为寄存器REGB 的控制信号,用于选择置数、右移和保持等功能;CLR 为寄存器REGS 和计数器CNT 的异步清零信号;CC 为计数器CNT 计数使能信号。
乘法器的控制单元采用CP 脉冲上升沿触发,而数据处理单元采用CP 的下降沿触发。
其目的有二:一是使控制器无需产生数据处理单元的时钟信号,降低了控制器复杂程度;二是为了避免时钟偏移对电路的不良影响。
需要指出的是,在设计顶层原理图时,只是从系统的功能和工作时序的关系上分析了各功能模块必须满足的要求,并没有考虑各模块所采用元器件的型号和工艺。
根据如图4所示的乘法器逻辑框图,寄存器A 和寄存器B 选择4位多功能移位寄存器74LS194,寄存器S采用8位多功能移位寄存器74LS198,加法器选用4位二进制超前进位加法器74LS283,计数器则选用74LS161,以上这些模块均可以从Max+plusII元件库直接调用。
将这些模块连接起来如图6所示的乘法器数据处理单元的原理图。
74LS194(1)只需置数、保持操作,因此将M0M1连在一起由一根控制线CA控制,当CA为高电平(M1M0=11)时,选择置数功能;当CA为低电平(M1M0=00)时,选择保持功能。
74LS194(2)和74LS198既要置数(M1M0=11)又要右移(M1M0=01),因此M1M0分别由两根控制线CB1、CB0和CS1、CS0控制。
乘法器的控制单元采用CP脉冲上升沿触发,而数据处理单元采用CP的下降沿触发。
其目的有二:一是使控制器无需产生数据处理单元的时钟信号,降低了控制器复杂程度;二是为了避免时钟偏移对电路的不良影响。
STARTENDBiCP76543210图6数据处理单元原理图4.控制单元的设计乘法器控制单元实际上是一同步时序逻辑电路,或者说是一有限状态机。
根据乘法器的算法流程图,乘法器控制单元应具有如下逻辑功能:(1)当启动信号START变为高电平后,控制器发出CLR信号(低电平有效)对寄存器74LS198和计数器74LS161清零,并通过CA和CB0、CB1信号将被乘数和乘数分别置入寄存器74LS194(1)和寄存器74LS194(2)。
(2)控制器根据输入信号B i实现不同的操作:若B i为1,则把加法器的结果置入寄存器74LS198;否则,不对寄存器置数(相当于不做累加操作)。
通过CC信号使能计数器加1。
(3)通过CS1、CS0与CB1、CB0信号使寄存器74LS198和寄存器74LS194(2)右移一位。
(4)重复(2)、(3)步骤4次,当输入信号i4有效时,电路回到等待状态,一次乘法运算结束。
根据上述逻辑功能,将乘法器控制单元定义4个状态:S0、S1、S2、S3。
S0为初始状态;S1完成对计数器和寄存器清零,同时将两个乘数置入寄存器;S2完成加法运算;S3完成移位操作。
为了更加简洁明了,乘法器控制单元的逻辑功能通常采用ASM(Algorithmic State Machine)图来描述,如图7所示。
在ASM图中,矩形框用来表示一个状态框,其左上角表示该状态的名称,右上角的一组二进制码表示该状态的二进制编码。
为了消除输出信号中的毛刺,状态编码采用Gray码。
状态框内定义该状态的输出信号。
菱形框表示条件分支框,将外部输入信号放入条件分支框内。
当控制算法存在分支时,次态不仅决定于现态,还与外输入有关。
椭圆框表示条件输出框,表示在某些状态下只有满足一定条件才能输出的命令。
图7 乘法器控制单元的ASM图乘法器控制单元可设计为摩尔型状态机,其基本结构由同步时序逻辑电路和组合逻辑电路组成。
同步时序逻辑电路在外部时钟的作用下实现状态转移,组合逻辑电路对时序电路的状态译码发出控制信号。
根据控制单元的ASM图,每个状态发出的控制信号如表1所示。
S0为初始状态;S1完成对计数器和寄存器清零,同时将两个乘数置入寄存器;S2完成加法运算;S3完成移位操作。
然后s2 s3重复四次结束。
直到4次结束。
移位寄存器:“11”载入,“00”保持,“01”右移表1 控制器每个状态发出的控制信号在以上分析的基础上,得到控制单元的VHDL语言源程序如下:LIBRARY IEEE;USE IEEE.STD_LOGIC_1164.ALL;ENTITY mulcon ISPORT (start,i4,bi,clk:IN STD_LOGIC;endd,clr,ca,cb1,cb0,cs1,cs0,cc:OUT STD_LOGIC);END mulcon;ARCHITECTURE one OF mulcon ISSIGNAL current_state,next_state:BIT_VECTOR(1 DOWNTO 0);CONSTANT s0:BIT_VECTOR(1 DOWNTO 0):=“00”;CONSTANT s1:BIT_VECTOR(1 DOWNTO 0):=“01”;CONSTANT s2:BIT_VECTOR(1 DOWNTO 0):=“11”;CONSTANT s3:BIT_VECTOR(1 DOWNTO 0):=“10”;BEGINcom1:PROCESS(current_state,start,i4)BEGINCASE current_state ISwhen s0 => IF (start='1') THEN next_state<=s1;ELSE next_state<=s0;END IF;when s1 => next_state<=s2;when s2 => next_state<=s3;when s3 => IF (i4='1') THEN next_state<=s0;--4次运算完成ELSE next_state<=s2;END IF;END CASE;END PROCESS com1;com2:PROCESS(current_state,bi)BEGINCASE current_state ISwhen s0 => endd<='1';clr<='1';ca<='0';cb1<='0';cb0<='0';--cs1<='0';cs0<='0';cc<='0';when s1 => endd<='0';clr<='0';ca<='1';cb1<='1';cb0<='1';--并行存入Bcs1<='0';cs0<='0';cc<='0';when s2 => IF (bi='1') THEN endd<='0';clr<='1';ca<='0';cb1<='0';cb0<='0';cs1<='1';cs0<='1';cc<='1';ELSE endd<='0';clr<='1';ca<='0';cb1<='0';cb0<='0';cs1<='0';cs0<='0';cc<='1';END IF;when s3 => endd<='0';clr<='1';ca<='0';cb1<='0';cb0<='1';cs1<='0';cs0<='1';cc<='0';END CASE;END PROCESS com2;reg:PROCESS (clk)BEGINIF clk='1' AND clk'EVENT THENcurrent_state<=next_state;END IF;END PROCESS reg;END;上述乘法控制单元的VHDL源程序的结构体由三个进程组成。