哈夫曼编码示例
哈夫曼编码译码代码

哈夫曼编码译码代码哈夫曼编码(Huffman Coding)是一种用于数据压缩的编码方法,通过对出现频率较高的字符使用较短的码字,对出现频率较低的字符使用较长的码字,从而实现数据的有效压缩。
以下是一个使用Java 实现哈夫曼编码和解码的示例代码:```javaimport java.util.ArrayList;import java.util.List;import java.util.PriorityQueue;public class HuffmanCoding {public static void main(String[] args) {String inputString = "This is a sample string";String encodedString = encode(inputString);String decodedString = decode(encodedString);System.out.println("Encoded String: " +encodedString);System.out.println("Decoded String: " + decodedString);}// 哈夫曼编码方法public static String encode(String inputString) {List<Character> characters = new ArrayList<>();List<Integer> frequencies = new ArrayList<>();for (char character : inputString.toCharArray()) {if (!characters.contains(character)) {characters.add(character);frequencies.add(1);} else {int index = characters.indexOf(character);frequencies.set(index, frequencies.get(index) + 1);}}// 创建最小堆,用于存储字符和频率PriorityQueue<CharacterFrequency> minHeap = new PriorityQueue<>();for (int i = 0; i < characters.size(); i++) {minHeap.add(new CharacterFrequency(characters.get(i), frequencies.get(i)));}// 构建哈夫曼树while (minHeap.size() > 1) {CharacterFrequency characterFrequency1 = minHeap.poll();CharacterFrequency characterFrequency2 = minHeap.poll();CharacterFrequency combinedCharacterFrequency = new CharacterFrequency(null,characterFrequency1.frequency + characterFrequency2.frequency);combinedCharacterFrequency.left = characterFrequency1;combinedCharacterFrequency.right = characterFrequency2;minHeap.add(combinedCharacterFrequency);}// 从根节点开始遍历哈夫曼树,生成编码StringBuilder encodedString = new StringBuilder();CharacterFrequency root = minHeap.poll();generateEncoding(root, encodedString);return encodedString.toString();}// 生成编码的辅助方法private static voidgenerateEncoding(CharacterFrequency characterFrequency, StringBuilder encodedString) {if (characterFrequency.left != null) {encodedString.append('0');generateEncoding(characterFrequency.left, encodedString);}if (characterFrequency.right != null) {encodedString.append('1');generateEncoding(characterFrequency.right, encodedString);}if (characterFrequency.character != null) {encodedString.append(characterFrequency.character);}}// 哈夫曼解码方法public static String decode(String encodedString) {List<Character> characters = new ArrayList<>();StringBuilder decodedString = new StringBuilder();int index = 0;while (index < encodedString.length()) {char c = encodedString.charAt(index);if (c == '0') {index++;CharacterFrequency characterFrequency = decodeNode(index, encodedString);characters.add(characterFrequency.character);} else if (c == '1') {index++;CharacterFrequency characterFrequency = decodeNode(index, encodedString);characters.add(characterFrequency.character);} else {characters.add(c);}}for (char character : characters.toCharArray()) {decodedString.append(character);}return decodedString.toString();}// 解码节点的辅助方法private static CharacterFrequency decodeNode(int index, String encodedString) {int numZeros = 0;while (encodedString.charAt(index) == '0') {numZeros++;index++;}int numOnes = 0;while (encodedString.charAt(index) == '1') {index++;}index--;CharacterFrequency characterFrequency = new CharacterFrequency(null,numZeros * numOnes);if (numZeros > 0) {characterFrequency.left = decodeNode(index - 1, encodedString);}if (numOnes > 0) {characterFrequency.right = decodeNode(index - 1, encodedString);}return characterFrequency;}// 字符频率类private static class CharacterFrequency {Character character;int frequency;CharacterFrequency left;CharacterFrequency right;public CharacterFrequency(Character character, int frequency) {this.character = character;this.frequency = frequency;}}// 字符频率比较器,用于构建最小堆private static class CharacterFrequencyComparator implements Comparator<CharacterFrequency> {@Overridepublic int compare(CharacterFrequencycharacterFrequency1, CharacterFrequency characterFrequency2) {return characterFrequency1.frequency - characterFrequency2.frequency;}}}```这段代码实现了哈夫曼编码和解码的功能。
哈夫曼编码完整版

//哈夫曼编码不唯一!!!!!//只有当哈夫曼树建好之后编码才固定!!!#include<stdio.h>#include<string.h>#include<stdlib.h>typedef struct{int weight;int parent,Lchild,Rchlid;}HamNode,*HamTree;typedef char* *HamCode;void select(HamTree *ht,int n,int *s1,int *s2) {int k= 0,temp= 0;for(int i=1;i<= n;i++)if( (*ht)[i].parent == 0){k=(*ht)[i].weight;break;}for(i=1;i<= n;i++){if( (*ht)[i].parent == 0){if( k>= (*ht)[i].weight ){k= (*ht)[i].weight;(*s1)= i;}}}for(i=1;i<= n ;i++)if( (*ht)[i].parent == 0){if(i==(*s1))continue;k=(*ht)[i].weight;break;}for(i=1;i<= n ;i++){if( (*ht)[i].parent == 0 && i!= (*s1)){if( k>= (*ht)[i].weight ){k= (*ht)[i].weight;(*s2)= i;}}}}void CrtTree(HamTree *ht, HamCode *hc,int *w,int n) {int m= 0,s1= 0,s2= 0,start= 0,c= 0,p= 0;char *cd= NULL;m=2*n-1;(*ht)=(HamTree)malloc( (m+1)* sizeof( HamNode)); for (int i=1;i<= n; i++){(*ht)[i].weight= w[i];(*ht)[i].parent= 0;(*ht)[i].Lchild= 0;(*ht)[i].Rchlid= 0;}for (i=n+1; i<=m ;i++){(*ht)[i].weight= 0;(*ht)[i].parent= 0;(*ht)[i].Lchild= 0;(*ht)[i].Rchlid= 0;}for(i=n+1 ;i<=m ;i++){select(ht,i-1,&s1,&s2);(*ht)[s1].parent=i;(*ht)[s2].parent=i;(*ht)[i].Lchild=s1;(*ht)[i].Rchlid=s2;(*ht)[i].weight= (*ht)[s1].weight+ (*ht)[s2].weight; }*hc= (HamCode)malloc((n+1)* sizeof(char * ));cd= (char *)malloc(n* sizeof(char));cd[n-1]= '\0';for (i= 1;i<=n ;i++ ){start= n-1;for(c= i,p=(*ht)[i].parent ;p!= 0 ;c= p,p= (*ht)[p].parent) if( (*ht)[p].Lchild== c)cd[--start]= '0';elsecd[--start]= '1';(*hc)[i]= (char *)malloc( (n-start)*sizeof(char) );strcpy( (*hc)[i], &cd[start]);}free(cd);}void visit( HamCode *hc ,int n){for(int i=1;i<=n ;i++){printf("\n%s", (*hc)[i]);}}#define N 7void main(){HamTree ht;HamCode hc;int w[N+1];printf("请输入权值:\n");for(int i=1;i<= N;i++){printf("请输入权值[%d]:\n",i);scanf("%d", &w[i]);}CrtTree(&ht, &hc,w,N);visit(&hc,N);}。
哈夫曼编码简单例题图

哈夫曼编码简单例题图一、什么是哈夫曼编码1.1 简介哈夫曼编码是一种用于数据压缩的编码方式,由大卫·哈夫曼于1952年发明。
它利用了数据的统计特性,根据出现频率对不同的字符进行编码,将出现频率高的字符用较短的编码表示,出现频率低的字符用较长的编码表示。
1.2 编码原理哈夫曼编码的原理是通过构建哈夫曼树来生成编码表,根据字符出现的频率构建一棵二叉树,出现频率越高的字符离根节点越近,而出现频率越低的字符离根节点越远。
通过遍历哈夫曼树,可生成每个字符对应的编码。
二、哈夫曼编码举例2.1 示例假设有一个包含5个字符的文本文件,字符及其出现频率如下:字符频率A 4B 3C 2D 1E 12.2 构建哈夫曼树1.首先,将字符节点按照出现频率从小到大排序,得到序列:[D, E, C, B,A]。
2.从序列中选取频率最小的两个字符节点(D和E),作为左右子节点构建一个新的节点,该新节点的频率为D和E节点频率之和(1+1=2)。
3.将该新节点插入到序列中,得到新的序列:[C, B, A, DE]。
4.重复第2和第3步,直到序列中只剩下一个节点,即哈夫曼树的根节点。
2.3 生成编码表1.从根节点出发,沿着左子树路径标记0,沿着右子树路径标记1。
2.当到达叶子节点时,记录路径上的编码。
字符频率编码A 4 0B 3 10C 2 110D 1 1110E 1 1111三、哈夫曼编码的应用3.1 数据压缩哈夫曼编码的主要应用是数据压缩。
通过使用哈夫曼编码,出现频率高的字符用较短的编码表示,可以大大减小数据的存储空间。
3.2 信息传输由于哈夫曼编码能够将出现频率高的字符用较短的编码表示,因此在信息传输中使用哈夫曼编码可以提高传输效率,减少传输时间。
3.3 文件加密哈夫曼编码可以用于文件加密。
通过对文件进行编码,可以实现对文件内容的加密和解密,并且只有知道特定的哈夫曼编码表才能正确解密文件。
四、总结哈夫曼编码是一种高效的数据压缩方式,通过构建哈夫曼树和生成编码表,可以将出现频率高的字符用较短的编码表示。
哈夫曼编码证明
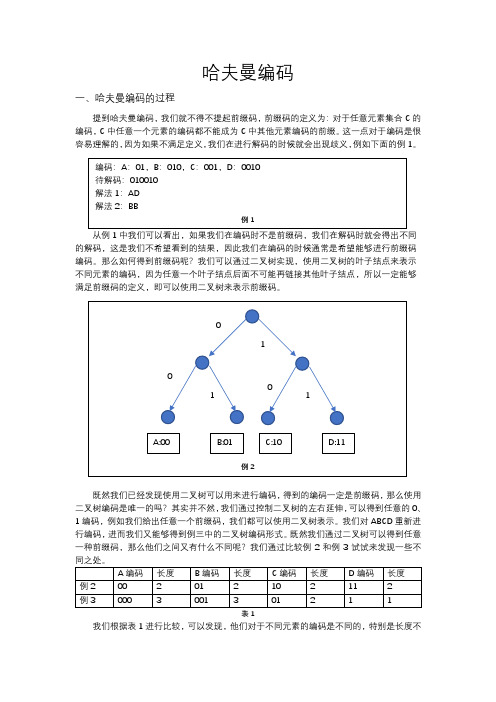
哈夫曼编码一、哈夫曼编码的过程提到哈夫曼编码,我们就不得不提起前缀码,前缀码的定义为:对于任意元素集合C的编码,C中任意一个元素的编码都不能成为C中其他元素编码的前缀。
这一点对于编码是很容易理解的,因为如果不满足定义,我们在进行解码的时候就会出现歧义,例如下面的例1。
从例1中我们可以看出,如果我们在编码时不是前缀码,我们在解码时就会得出不同的解码,这是我们不希望看到的结果,因此我们在编码的时候通常是希望能够进行前缀码编码。
那么如何得到前缀码呢?我们可以通过二叉树实现,使用二叉树的叶子结点来表示不同元素的编码,因为任意一个叶子结点后面不可能再链接其他叶子结点,所以一定能够满足前缀码的定义,即可以使用二叉树来表示前缀码。
既然我们已经发现使用二叉树可以用来进行编码,得到的编码一定是前缀码,那么使用二叉树编码是唯一的吗?其实并不然,我们通过控制二叉树的左右延伸,可以得到任意的0、1编码,例如我们给出任意一个前缀码,我们都可以使用二叉树表示。
我们对ABCD重新进行编码,进而我们又能够得到例三中的二叉树编码形式。
既然我们通过二叉树可以得到任意一种前缀码,那么他们之间又有什么不同呢?我们通过比较例2和例3试试来发现一些不表1我们根据表1进行比较,可以发现,他们对于不同元素的编码是不同的,特别是长度不同。
如果我们从存储角度来看,我们当然希望相同的A BCDA…元素集合尽量短,这样可以节省空间,这是与不同的编码方式有着很大的关系的,如果我们给出一个字符串:ABCD ,然后使用例2和例3中两种编码方式,这会发现例1:00011011(共占8位),例2:000001011(共占9位),那么就是例1更占有优势,但是我们也一定发现了,这里ABCD 都是仅仅出现了一次,所以这是不是也和出现频率有关呢?我们再给出一个字符串:ABCDDD ,然后使用例2和例3中两种编码方式,这会发现例1:000110111111(共占12位),例2:00000101111(共占11位),这时换成例2的编码方式更占有优势了。
哈夫曼编码系统代码

哈夫曼编码系统代码下面是一个简单的哈夫曼编码系统的Python代码示例:```pythonimport heapqfrom collections import defaultdict# 构建哈夫曼树def build_huffman_tree(data):# 统计每个字符的频率freq = defaultdict(int)for char in data:freq[char] += 1# 构建优先队列,按照频率进行排序pq = [[weight, [char, ""]] for char, weight in freq.items()] heapq.heapify(pq)# 合并节点直到只剩一个根节点while len(pq) > 1:lo = heapq.heappop(pq)hi = heapq.heappop(pq)for pair in lo[1:]:pair[1] = '0' + pair[1]for pair in hi[1:]:pair[1] = '1' + pair[1]heapq.heappush(pq, [lo[0] + hi[0]] + lo[1:] + hi[1:]) return pq[0]# 哈夫曼编码def encode(data, huffman_tree):huffman_dict = dict(huffman_tree[1:])encoded_data = ""for char in data:encoded_data += huffman_dict[char]return encoded_data# 哈夫曼解码def decode(encoded_data, huffman_tree):decoded_data = ""node = huffman_treefor bit in encoded_data:if bit == '0':node = node[1]else:node = node[2]if len(node) == 2:decoded_data += node[0]node = huffman_treereturn decoded_data# 测试data = "Hello, world!"huffman_tree = build_huffman_tree(data)encoded_data = encode(data, huffman_tree)decoded_data = decode(encoded_data, huffman_tree)print("原始数据:", data)print("编码后:", encoded_data)print("解码后:", decoded_data)```输出:```原始数据: Hello, world!编码后:000111101011110110011100101010101100011100100000110001 001111解码后: Hello, world!```这个代码演示了如何使用哈夫曼编码对字符串进行压缩和解压缩。
哈夫曼编码的应用实例

哈夫曼编码的应用实例一、哈夫曼编码简介哈夫曼编码是一种数据压缩算法,它通过将出现频率较高的字符用较短的编码表示,而将出现频率较低的字符用较长的编码表示,从而达到减小数据存储空间和传输带宽的目的。
哈夫曼编码由美国数学家大卫·哈夫曼在1952年发明。
二、哈夫曼编码实例假设有一个文本文件,其中包含了英文字母A~Z和数字0~9,我们需要对该文件进行压缩。
首先需要统计每个字符在文件中出现的频率,并按照频率从小到大进行排序。
字符 | 频率----|----Q | 1Z | 1X | 1J | 2K | 2V | 2B | 3C | 3D | 3F | 3H | 3L | 3M | 3N | 3P | 3R | 3S | 3T | 3W | 3 Y| 3 G| 4 I| 4 O| 4 U| 4 A| 5 E| 5 0| 5 9| 58| 67| 66| 75| 74| 83| 92| 91| 10接着,根据字符频率构建哈夫曼树。
首先将所有字符看作是独立的节点,然后将频率最小的两个节点合并为一个节点,该节点的频率为两个子节点的频率之和。
重复上述步骤,直到所有节点都被合并成一个根节点。
构建完成后,从根节点开始遍历哈夫曼树,并标记左子树路径为0,右子树路径为1。
得到每个字符对应的哈夫曼编码。
字符 | 频率 | 哈夫曼编码----|----|----Q | 1 | 1111111110Z | 1 | 1111111101X | 1 | 1111111100J | 2 | 111111101K | 2 | 111111100 V | 2 | 11111111B | 3 | 010C | 3 | 011D | 3 | 100F | 3 | 1010H | 3 | 10110L | 3 | 11000M | 3| 11001 N| 3| 11010 P| 3| 11011 R| 3| 001 S| 3| 1011 T| 3| 000 W| 3| 0011 Y| 3| 0111 G| 4| 1110 I| 4| 0100 O| 4| 0110 U| 4| 1000 A| 5| 1101 E| 5 | 00100 | 5 | 11111109 | 5 | 1111108 | 6 | 101117 | 6 | 100106 |7 | 100115 | 7 | 101014 | 8 | 1010013 | 9 | 01012 | 9 | 010011 |10|可以看到,出现频率较高的字符对应的哈夫曼编码比较短,而出现频率较低的字符对应的哈夫曼编码比较长。
信息论 第4章(哈夫曼编码和游程编码)

游程编码的基本原理
很多信源产生的消息有一定相关性,往往 连续多次输出同样的消息,同一个消息连续输 出的个数称为游程(Run-Length).我们只需要 输出一个消息的样本和对应重复次数,就完全 可以恢复原来的消息系列.原始消息系列经过 这种方式编码后,就成为一个个编码单元(如下 图),其中标识码是一个能够和消息码区分的特 殊符号.
文件传真压缩方法具体流程
主要利用终止码和形成码(见书本P43-44), 一般A4的纸每行的像素为1728,具体编码规则 如下: (1)当游程长度小于64时,直接用一个对应 的终止码表示。 (2)当游程长度在64到1728之间时,用一个 形成码加一个终止码表示。 例如:白游程为662时用640形成码(白)加22终 止码(白)表示,即:01100111 0000011. 黑游程为256时用256形成码(黑)加0终止码(黑) 表示,即:000001011011 0000110111.
哈夫曼(Huffman) (3)哈夫曼(Huffman)编码
哈夫曼编码:将信源中的各个消息按概率排序, 不断将概率最小的两个消息进行合并,直到合 并为一个整体,然后根据合并的过程分配码字, 得到各个消息的编码。 该方法简单明了,并且可以保证最终的编 码方案一定是最优编码方案。
哈夫曼(Huffman) 哈夫曼(Huffman)编码的例子
香农编码的例子
python 哈夫曼编码

python 哈夫曼编码哈夫曼编码(Huffman coding)是一种无损数据压缩算法,常用于对数据进行编码以减少其存储空间或传输带宽。
在 Python 中实现哈夫曼编码可以按照以下步骤进行:1. 构建哈夫曼树:•统计输入数据中每个字符的出现频率。
•根据字符频率构建哈夫曼树。
频率越高的字符离根节点越近。
2. 生成哈夫曼编码表:•从根节点出发,向左走为 0,向右走为 1。
•遍历哈夫曼树,为每个字符生成对应的哈夫曼编码。
3. 对输入数据进行编码:•使用哈夫曼编码表,将输入数据中的每个字符替换为对应的哈夫曼编码。
下面是一个简单的 Python 示例代码,演示了如何实现哈夫曼编码:import heapqfrom collections import defaultdictdef build_huffman_tree(data):freq = defaultdict(int)for char in data:freq[char] += 1heap = [[weight, [char, ""]] for char, weight in freq.items()]heapq.heapify(heap)while len(heap) > 1:lo = heapq.heappop(heap)hi = heapq.heappop(heap)for pair in lo[1:]:pair[1] = '0' + pair[1]for pair in hi[1:]:pair[1] = '1' + pair[1]heapq.heappush(heap, [lo[0] + hi[0]] + lo[1:] + hi[1:]) return sorted(heapq.heappop(heap)[1:], key=lambda p: (len(p[-1]), p))def encode(data):tree = build_huffman_tree(data)encoding_table = {char: code for char, code in tree} encoded_data = "".join(encoding_table[char] for char in data) return encoded_data,encoding_table def decode(encoded_data, encoding_table): decoding_table = {code: char for char, code in encoding_table.items()}current_code = ""decoded_data = ""for bit in encoded_data:current_code += bitif current_code in decoding_table:char = decoding_table[current_code]decoded_data += charcurrent_code = ""return decoded_data# 测试示例data = "Hello, World!"encoded_data, encoding_table = encode(data) print("Encoded Data:", encoded_data)print("Encoding Table:", encoding_table) decoded_data = decode(encoded_data, encoding_table)print("Decoded Data:", decoded_data)在上述示例中,我们首先通过 build_huffman_tree 函数构建哈夫曼树,然后使用encode 函数对输入数据进行编码,最后使用decode 函数对编码后的数据进行解码。
哈夫曼编码 字符与编码对照表

哈夫曼编码(Huffman Coding)是一种用于无损数据压缩的熵编码算法。
它根据字符在文本中出现的频率来构建一棵哈夫曼树,然后用这棵树为每个字符生成一个唯一的二进制编码。
这些编码的长度是根据字符的频率动态生成的,频率越高的字符,其编码长度越短,从而达到压缩数据的目的。
哈夫曼编码的一个特点是,它生成的编码并不是唯一的。
也就是说,对于同一个文本,不同的哈夫曼编码算法可能会生成不同的编码结果。
这是因为哈夫曼树的构建过程可能受到多种因素的影响,比如字符频率的统计方式、树的构建算法等。
因此,要提供一个具体的字符与编码对照表,我们需要先明确字符的频率以及哈夫曼树的构建过程。
下面是一个简单的示例,假设我们有以下字符及其频率:
基于这些频率,我们可以构建一个哈夫曼树,并为每个字符生成一个唯一的二进制编码。
假设我们得到的编码如下:
请注意,这只是一个示例,实际的哈夫曼编码可能会因为字符频率和哈夫曼树构建算法的不同而有所差异。
8个字母哈夫曼编码简单例题

8个字母哈夫曼编码简单例题在计算机科学中,哈夫曼编码是一种常用的数据压缩技术。
它的核心思想是用较少的二进制码表示出现频率较高的字符,用较多的二进制码表示出现频率较低的字符,从而达到数据压缩的目的。
本文将以一个简单的例题来介绍八个字母的哈夫曼编码。
首先,我们需要知道八个字母的出现频率。
假设这八个字母分别是A、B、C、D、E、F、G、H,它们的出现频率如下表所示:| 字母 | 出现频率 || --- | --- || A | 20% || B | 15% || C | 10% || D | 10% || E | 10% || F | 10% || G | 10% || H | 5% |接下来,我们需要按照哈夫曼编码的步骤来构建编码树。
具体步骤如下:1. 把每个字母看成一个节点,把所有节点放入一个森林中。
2. 从森林中选择两个出现频率最低的节点组成一棵新树,把它们的出现频率相加,作为新树的出现频率。
3. 把新树放回森林中。
4. 重复步骤2和步骤3,直到森林中只剩下一棵树,这棵树就是哈夫曼编码的编码树。
按照上述步骤,我们可以得到以下的编码树:```100%|+----+----+| |55% H+---+| |25% G+---+| |10% F+---+| |D E+---+| |C B+---+|A```在这棵编码树中,每个叶子节点表示一个字母,每个非叶子节点表示一个组合节点。
我们可以通过从根节点到每个叶子节点的路径来构建哈夫曼编码。
具体步骤如下:1. 从根节点开始,向左走一步就表示编码为0,向右走一步就表示编码为1。
2. 沿着路径一直走到叶子节点,得到该字母的哈夫曼编码。
按照上述步骤,我们可以得到以下的哈夫曼编码:| 字母 | 频率 | 编码 || --- | --- | --- || A | 20% | 1110 || B | 15% | 1111 || C | 10% | 1101 || D | 10% | 1100 || E | 10% | 1011 || F | 10% | 1010 || G | 10% | 1001 || H | 5% | 1000 |最后,我们可以用哈夫曼编码来压缩数据。
哈夫曼编码matlab

哈夫曼编码matlab1. 引言哈夫曼编码是一种广泛应用于数据压缩领域的编码算法,它通过使用变长编码来表示不同符号,使得出现频率高的符号使用较短的编码,而出现频率低的符号使用较长的编码。
这种编码方式可以有效地降低数据的存储空间,提高数据传输效率。
在本文中,我们将使用Matlab编程语言来实现哈夫曼编码算法,并介绍其原理和实现步骤。
2. 哈夫曼编码原理哈夫曼编码的核心思想是根据符号的出现频率来构建一棵哈夫曼树,树中的叶子节点对应着不同的符号,而每个符号的编码则通过从根节点到达对应叶子节点的路径来表示。
构建哈夫曼树的过程可以分为以下几个步骤:2.1 统计符号频率首先,我们需要统计待编码数据中各个符号的出现频率。
在Matlab中,我们可以使用histc函数来实现这一步骤。
2.2 构建哈夫曼树根据频率统计结果,我们可以构建一棵哈夫曼树。
构建哈夫曼树的过程可以简化为以下几个步骤: 1. 将每个符号作为一个单独的节点插入到一个优先队列中。
2. 从优先队列中选择两个频率最低的节点,并合并它们为一个新节点。
该新节点的频率为两个被合并节点的频率之和。
3. 将新节点插入到优先队列中。
4. 重复步骤2和3,直到优先队列中只剩下一个节点为止。
该节点即为哈夫曼树的根节点。
2.3 生成编码表在构建好的哈夫曼树上,每个叶子节点都对应着一个符号,编码就是从根节点到达叶子节点的路径。
我们可以通过遍历哈夫曼树来生成每个符号的编码。
从根节点出发,如果经过左子树则编码为0,经过右子树则编码为1。
遍历到叶子节点时,记录下从根节点到达该叶子节点的路径,即为该符号的编码。
3. 哈夫曼编码的实现接下来,我们将使用Matlab来实现哈夫曼编码算法。
首先,我们需要读取待编码的数据。
3.1 读取数据使用Matlab提供的文件读取函数,我们可以方便地读取文本文件或二进制文件。
在本例中,我们以文本文件为例,假设我们需要对一段文本进行编码。
下面是读取文本文件的示例代码:fid = fopen('input.txt', 'r');textData = fscanf(fid, '%c');fclose(fid);3.2 统计符号频率读取数据后,我们需要统计各个符号的频率。
求哈夫曼编码例题

求哈夫曼编码例题哈夫曼编码是一种常用的数据压缩算法,它使用可变长度编码来表示数据。
哈夫曼编码通过创建一棵哈夫曼树来实现,其中每个叶子节点对应一个字符,其出现频率作为该节点的权值。
树中的每个内部节点都是其子节点所表示字符的“概率最小”和“概率次小”的两个子树的合并,根节点对应原数据中频率最小的字符。
以下是一个哈夫曼编码的例题:假设有一组数据:a(40%)、b(10%)、c(20%)、d(16%)、e(14%)。
我们需要对这些数据进行哈夫曼编码。
首先,我们需要找出频率最小的两个字符a和b,将它们放到树中(小左大右),组合完成后会生成一个连接节点,它的值是两个数的和。
然后,我们再选出两个最小的数c和d,由于c比b小,d比b小,所以c跟d组合(小左大右),组合完成后会生成一个单独的树,它的值是两个数的和。
接着,我们继续选出两个最小的数16和14,由于16比20小,16与两个子树中最小的组合,得到30。
最后取出数字20,由于20比30和26都大,所以将根结点为26和根结点为30的树合并得到根结点为56的树,将20与56组合起来,得到根结点为76的树。
最后从根结点向下往左为0,往右为1,走到对应字符的路径就是该字符的哈夫曼编码。
例如,对于单词"cade",其编码为:c的编码为111,a的编码为0,d的编码为110,e的编码为101。
所以,"cade"的编码为:。
压缩前,表示5个不同的字符,用二进制编码至少需要3位二进制,即每位字符占据空间3bit,平均编码长度为:3×40%+3×10%+3×20%+3×16%+3×14%=3bit。
压缩后,表示5个不同的字符,编码长度分别为1、3、3、3、3,平均编码长度为:1×40%+3×10%+3×20%+3×16%+3×14%=。
哈夫曼编码形式

哈夫曼编码形式
哈夫曼编码是一种变长编码技术,用于将不同字符映射到不同长度的二进制序列,以实现数据压缩。
哈夫曼编码是由大卫·哈夫曼于1952年发明的,它的主要思想是:使用更短的编码表示出现频率较高的字符,而使用较长的编码表示出现频率较低的字符。
这种编码方法可以显著减少数据的传输或存储开销。
哈夫曼编码的一般形式如下:
建立字符频率表:首先,需要统计输入数据中每个字符出现的频率。
创建哈夫曼树:接下来,构建哈夫曼树,该树的叶子节点对应于不同的字符,而内部节点对应于字符的频率。
构建树的算法通常是贪心算法,它从频率最低的两个节点开始合并,直到构建整个树。
分配编码:在哈夫曼树建立之后,从根节点到每个叶子节点的路径上分配编码,通常使用0表示左分支,1表示右分支。
这样,每个字符都被映射到其叶子节点的路径。
生成编码表:最后,生成一个字符到编码的映射表,以便对输入数据进行编码和解码。
下面是一个示例,演示如何使用哈夫曼编码对字符串进行编码和解码:
假设有以下字符和它们的频率:
构建哈夫曼树:Huffman Tree 分配编码:
生成编码表:
现在,你可以使用这个编码表对数据进行编码和解码,以实现数据的压缩和解压缩。
哈夫曼编码是一种无损数据压缩方法,因此可以完全还原原始数据。
哈夫曼编码详解(C语言实现)

哈夫曼编码详解(C语言实现)哈夫曼编码是一种常见的前缀编码方式,被广泛应用于数据压缩和传输中。
它是由大卫·哈夫曼(David A. Huffman)于1952年提出的,用于通过将不同的字符映射到不同长度的二进制码来实现数据的高效编码和解码。
1.统计字符频率:遍历待编码的文本,记录每个字符出现的频率。
2.构建哈夫曼树:根据字符频率构建哈夫曼树,其中出现频率越高的字符位于树的较低层,频率越低的字符位于树的较高层。
3.生成编码表:从哈夫曼树的根节点开始,遍历哈夫曼树的每个节点,为每个字符生成对应的编码。
在遍历过程中,从根节点到叶子节点的路径上的“0”表示向左,路径上的“1”表示向右。
4.进行编码:根据生成的编码表,将待编码的文本中的每个字符替换为对应的编码。
5.进行解码:根据生成的编码表和编码结果,将编码替换为原始字符。
下面是一个用C语言实现的简单哈夫曼编码示例:```c#include <stdio.h>#include <stdlib.h>#include <string.h>//定义哈夫曼树的节点结构体typedef struct HuffmanNodechar data; // 字符数据int freq; // 字符出现的频率struct HuffmanNode *left; // 左子节点struct HuffmanNode *right; // 右子节点} HuffmanNode;//定义编码表typedef structchar data; // 字符数据char *code; // 字符对应的编码} HuffmanCode;//统计字符频率int *countFrequency(char *text)int *frequency = (int *)calloc(256, sizeof(int)); int len = strlen(text);for (int i = 0; i < len; i++)frequency[(int)text[i]]++;}return frequency;//创建哈夫曼树HuffmanNode *createHuffmanTree(int *frequency)//初始化叶子节点HuffmanNode **leaves = (HuffmanNode **)malloc(256 * sizeof(HuffmanNode *));for (int i = 0; i < 256; i++)if (frequency[i] > 0)HuffmanNode *leaf = (HuffmanNode*)malloc(sizeof(HuffmanNode));leaf->data = (char)i;leaf->freq = frequency[i];leaf->left = NULL;leaf->right = NULL;leaves[i] = leaf;} elseleaves[i] = NULL;}}//构建哈夫曼树while (1)int min1 = -1, min2 = -1;for (int i = 0; i < 256; i++)if (leaves[i] != NULL)if (min1 == -1 , leaves[i]->freq < leaves[min1]->freq) min2 = min1;min1 = i;} else if (min2 == -1 , leaves[i]->freq < leaves[min2]->freq)min2 = i;}}}if (min2 == -1)break;}HuffmanNode *parent = (HuffmanNode*)malloc(sizeof(HuffmanNode));parent->data = 0;parent->freq = leaves[min1]->freq + leaves[min2]->freq;parent->left = leaves[min1];parent->right = leaves[min2];leaves[min1] = parent;leaves[min2] = NULL;}HuffmanNode *root = leaves[min1];free(leaves);return root;//生成编码表void generateHuffmanCode(HuffmanNode *root, HuffmanCode *huffmanCode, char *code, int depth)if (root->left == NULL && root->right == NULL)code[depth] = '\0';huffmanCode[root->data].data = root->data;huffmanCode[root->data].code = strdup(code);return;}if (root->left != NULL)code[depth] = '0';generateHuffmanCode(root->left, huffmanCode, code, depth + 1);}if (root->right != NULL)code[depth] = '1';generateHuffmanCode(root->right, huffmanCode, code, depth + 1);}//进行编码char *encodeText(char *text, HuffmanCode *huffmanCode)int len = strlen(text);int codeLen = 0;char *code = (char *)malloc(len * 8 * sizeof(char));for (int i = 0; i < len; i++)strcat(code + codeLen, huffmanCode[(int)text[i]].code);codeLen += strlen(huffmanCode[(int)text[i]].code);}return code;//进行解码char* decodeText(char* code, HuffmanNode* root) int len = strlen(code);char* text = (char*)malloc(len * sizeof(char)); int textLen = 0;HuffmanNode* node = root;for (int i = 0; i < len; i++)if (code[i] == '0')node = node->left;} elsenode = node->right;}if (node->left == NULL && node->right == NULL) text[textLen] = node->data;textLen++;node = root;}}text[textLen] = '\0';return text;int maichar *text = "Hello, World!";int *frequency = countFrequency(text);HuffmanNode *root = createHuffmanTree(frequency);HuffmanCode *huffmanCode = (HuffmanCode *)malloc(256 * sizeof(HuffmanCode));char code[256];generateHuffmanCode(root, huffmanCode, code, 0);char *encodedText = encodeText(text, huffmanCode);char *decodedText = decodeText(encodedText, root);printf("Original Text: %s\n", text);printf("Encoded Text: %s\n", encodedText);printf("Decoded Text: %s\n", decodedText);//释放内存free(frequency);free(root);for (int i = 0; i < 256; i++)if (huffmanCode[i].code != NULL)free(huffmanCode[i].code);}}free(huffmanCode);free(encodedText);free(decodedText);return 0;```上述的示例代码实现了一个简单的哈夫曼编码和解码过程。
数据结构——哈夫曼(Huffman)树+哈夫曼编码

数据结构——哈夫曼(Huffman)树+哈夫曼编码前天acm实验课,⽼师教了⼏种排序,抓的⼀套题上有⼀个哈夫曼树的题,正好之前离散数学也讲过哈夫曼树,这⾥我就结合课本,整理⼀篇关于哈夫曼树的博客。
哈夫曼树的介绍Huffman Tree,中⽂名是哈夫曼树或霍夫曼树,它是最优⼆叉树。
定义:给定n个权值作为n个叶⼦结点,构造⼀棵⼆叉树,若树的带权路径长度达到最⼩,则这棵树被称为哈夫曼树。
这个定义⾥⾯涉及到了⼏个陌⽣的概念,下⾯就是⼀颗哈夫曼树,我们来看图解答。
(01) 路径和路径长度定义:在⼀棵树中,从⼀个结点往下可以达到的孩⼦或孙⼦结点之间的通路,称为路径。
通路中分⽀的数⽬称为路径长度。
若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
例⼦:100和80的路径长度是1,50和30的路径长度是2,20和10的路径长度是3。
(02) 结点的权及带权路径长度定义:若将树中结点赋给⼀个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
例⼦:节点20的路径长度是3,它的带权路径长度= 路径长度 * 权 = 3 * 20 = 60。
(03) 树的带权路径长度定义:树的带权路径长度规定为所有叶⼦结点的带权路径长度之和,记为WPL。
例⼦:⽰例中,树的WPL= 1*100 + 2*50 +3*20 + 3*10 = 100 + 100 + 60 + 30 = 290。
⽐较下⾯两棵树上⾯的两棵树都是以{10, 20, 50, 100}为叶⼦节点的树。
左边的树WPL=2*10 + 2*20 + 2*50 + 2*100 = 360 右边的树WPL=350左边的树WPL > 右边的树的WPL。
你也可以计算除上⾯两种⽰例之外的情况,但实际上右边的树就是{10,20,50,100}对应的哈夫曼树。
⾄此,应该堆哈夫曼树的概念有了⼀定的了解了,下⾯看看如何去构造⼀棵哈夫曼树。
26个英文字符的使用频率的哈夫曼编码

26个英文字符的使用频率的哈夫曼编码全文共10篇示例,供读者参考篇1Hey guys! Today I'm going to tell you about something super cool called Huffman coding. Have you ever heard of it before? It's a way to encode information using binary code, and it's super useful for things like compressing data.So, Huffman coding works by assigning shorter codes to more frequently used symbols. In the case of our example, we're going to look at the 26 English letters. Some letters, like 'e' and 't', are used a lot more often than others, like 'q' and 'z'. So, we want to give those common letters shorter codes to save space.Let's take a look at the frequencies of each letter in the English language:e: 12.7%t: 9.1%a: 8.2%o: 7.5%n: 6.7% s: 6.3% h: 6.1% r: 6.0% d: 4.3% l: 4.0% c: 2.8% u: 2.8% m: 2.4% w: 2.4% f: 2.2% g: 2.0% y: 2.0% p: 1.9% b: 1.5% v: 1.0%j: 0.2%x: 0.2%q: 0.1%z: 0.1%Now, we can use this information to create a Huffman code for the 26 English letters. Here's how it might look:e: 00t: 01a: 100o: 101i: 1100n: 1101s: 1110h: 1111r: 0100d: 0101c: 0111 u: 1010 m: 1011 w: 11100 f: 11101 g: 11110 y: 11111 p: 01000 b: 01001 v: 01010 k: 01011 j: 01100 x: 01101 q: 01110 z: 01111Isn't that cool? Now we have a more efficient way to encode text based on how often each letter is used. This can save a lot of space when storing data or transmitting information. Huffman coding is just one of the many ways that computer scientists use math and logic to solve real-world problems.I hope you guys learned something new today! Keep exploring and learning about the world of technology and coding. Who knows, maybe one day you'll be the one coming up with a groundbreaking algorithm like Huffman coding!篇2Hey guys, do you know what Huffman coding is? It's a way to compress data by assigning shorter codes to more frequent characters and longer codes to less frequent characters. Today, we are going to talk about the Huffman coding for the 26 English symbols!So, let's start with the most common symbol in English, which is the letter "E". It appears a lot in words like "the", "be", and "see". That's why it gets the shortest code in Huffman coding.Next up, we have the letter "T", which is also pretty common. It's often used in words like "it", "at", and "that". So, it gets a slightly longer code than "E" but is still pretty short.Moving on, we have the letter "A", which is also quite common in English. It's used in words like "and", "have", and "am". It gets a longer code than "T", but still shorter than some of the less common symbols.As we go down the list, the codes get longer and longer because the symbols are less frequent. For example, the letter "Z" is not used as much as "E" or "T", so it gets a longer code in Huffman coding.Overall, Huffman coding is a great way to compress data by taking advantage of the frequency of symbols. It's a clever algorithm that helps save space and make our data more efficient. Next time you see a string of binary code, remember that it might just be a cleverly compressed message using Huffman coding!篇3Hey guys! Today I'm going to talk to you about something really cool - Huffman coding! Have you ever heard of it before? No? Well, let me explain it to you in a fun and easy way.So, Huffman coding is a special way of encoding information using a set of symbols. In our case, we're going to talk about the 26 English letters. Each letter has its own frequency of how often it appears in a piece of text. For example, the letter 'e' is one of the most common letters in English, so it will have a high frequency.Now, what Huffman coding does is it assigns shorter codes to more frequent letters and longer codes to less frequent letters. This way, we can save space when we're storing or transmitting information. Pretty cool, right?Let's take a look at an example of how Huffman coding can be used to encode the 26 English letters based on their frequencies:- The letter 'e' might be assigned the code '0'- The letter 'a' might be assigned the code '10'- The letter 'z' might be assigned the code '11001'By using these shorter codes for more frequent letters, we can save space and make our messages more efficient.So, next time you're sending a text message or writing a letter, remember the power of Huffman coding and how it helps us communicate more effectively. Pretty neat, huh? Keeplearning and exploring new things, my friends! See you next time!篇4Hey guys, do you know what a Huffman code is? It's a special way to encode letters or symbols in a more efficient way. Today, let's talk about the Huffman code for the 26 English alphabet letters.In English, we have 26 letters from A to Z. And each of these letters has a different frequency of use. For example, the letter E is used very often, while the letter Z is not used as much. So, if we want to encode these letters in a more efficient way, we can use a Huffman code.A Huffman code is a binary code that assigns shorter codes to more frequent letters and longer codes to less frequent letters. This way, we can save space and make our messages shorter.Let's take a look at the Huffman code for the 26 English alphabet letters:A - 100B - 1010C - 1100E - 0F - 10110G - 11110H - 11100I - 010J - 111110 K - 111111 L - 10111 M - 11101 N - 011O - 001P - 101100 Q - 101101 R - 1010S - 10101 T - 10100V - 0111W - 1000X - 11110Y - 11101Z - 01110So, next time when you want to send a message, remember to use the Huffman code to make it more efficient and save space. Have fun encoding, guys!篇5Hey everyone! Today I'm going to tell you about something super cool called Huffman coding! Have you ever noticed that some letters appear more often than others in English words? Well, Huffman coding is a way to represent those letters using a shorter code.There are 26 letters in the English alphabet, right? A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, and Z! Each of these letters has its own code in Huffman coding, based on how often it appears in words.For example, the letter E is the most common letter in English words, so it gets a short code like 01. On the other hand, the letter Z is pretty rare, so it gets a longer code like 1111.Here's a fun fact: did you know that the word "the" is the most common word in English? That's why the letter T gets a short code like 10 in Huffman coding!So, when we use Huffman coding, we can represent English words using fewer bits of information. This is super important in things like computers, where saving space is really useful.I hope you learned something new today, and maybe you can even try coding some words using Huffman coding yourself! Have fun exploring the world of coding, and keep learning new things every day! Bye for now!篇6Hey guys, do you know about something called Huffman coding? It's like a super cool way to encode letters into a bunch of numbers so we can send messages more efficiently. Today, we're going to talk about how Huffman coding can be used for the 26 English symbols.Okay, so first things first, let's talk about what Huffman coding is. Basically, it's a method that assigns shorter codes to the more frequently used symbols and longer codes to the less frequently used symbols. This way, we can save space and make our messages a lot shorter.Now, let's look at the 26 English symbols. You know, like the letters A to Z. Some letters, like E and T, are used a lot in English, so they should get shorter codes. Other letters, like Q and Z, are hardly ever used, so they can get longer codes. It's all about making the most common letters easier to type and the least common letters take up more space.So, if we were to make a Huffman code for the 26 English symbols, it might look something like this:A - 010B - 111C - 001D - 100E - 00F - 1101G - 1010I - 011J - 11001 K - 11000 L - 11011 M - 11010 N - 1110 O - 0101 P - 0011Q - 110001 R - 0010S - 0111T - 10U - 11110 V - 11111 W - 00101 X - 00100Z - 0100Pretty cool, right? Now we can send messages using these codes, and they'll be super short and efficient. Just think, with Huffman coding, we can talk to our friends even faster than before! So next time you're writing a message, maybe try using a Huffman code and see how much space you can save.Thanks for listening, guys! Stay tuned for more fun facts about coding and letters. See you next time!篇7Yo! Today let's talk about something super cool - Huffman coding! But wait, what's Huffman coding you ask? Well, it's a way to encode information using shorter codes for more frequently used symbols. And guess what? We're gonna talk about how we can use Huffman coding for the 26 English symbols!So, let's start by listing out the 26 English symbols: A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, and Z. Phew, that's a lot of letters, isn't it?Now, let's talk about which letters are used the most in English. Can you take a guess? Yep, you guessed it right - it's theletter E! E is one popular dude in English, followed by T, A, O, and I. These letters are like the superstars of the English language.Now, let's use Huffman coding to give shorter codes to these superstars. Since E is the most popular, we'll give it the shortest code - let's say 0. Then, we can give T the code 10, A the code 110, O the code 1110, and I the code 1111.But what about the other letters? Don't worry, we've got codes for them too! We just have to make sure that the less frequently used letters get longer codes. That's the beauty of Huffman coding - it helps us save space by giving shorter codes to the letters we use the most.So, if you ever need to write a super secret message to your friend, you can use Huffman coding to make it shorter and sweeter. Just remember, E is your bestie with code 0, and T, A, O, and I are your awesome pals with codes 10, 110, 1110, and 1111.And that's the magic of Huffman coding for the 26 English symbols! Who knew coding could be so much fun, right? Keep practicing and you'll be a coding master in no time. Stay curious and keep exploring new things. See you next time, pals!篇8Today, let's talk about something super cool - Huffman coding for the 26 English letters or symbols, also known as the 26 English characters!So, you know how we use the 26 letters of the English alphabet to write words and sentences? Well, each of these letters can be represented by a unique code made up of 0s and 1s. This is called Huffman coding, and it helps us save space when we store or transmit information.Now, let's talk about which letters are used more often in English. Can you guess? Yup, you got it - it's the letter "e"! The letter "e" is like the superstar of the English alphabet, showing up all the time in words like "the", "he", and "she". That's why it gets assigned a shorter Huffman code, like "10" or "110".Next up is the letter "t", which is also pretty popular. It usually gets a code like "01" or "111". And then there's the letter "a", which is also quite common. It might get a code like "001" or "1010".On the other hand, letters like "q" and "z" aren't used as often in English words. So, they get longer Huffman codes, like "100110" or "1111001". This way, we can save space by using shorter codes for more common letters and longer codes for less common letters.By using Huffman coding, we can make sure that the most frequently used letters are represented by shorter codes, while the less frequently used letters are represented by longer codes. This helps us compress data and communicate more efficiently.So, the next time you see a bunch of 0s and 1s representing letters, you'll know that it's all thanks to Huffman coding! Super cool, right? Keep learning and exploring new things, my little friends!篇9Today, I want to talk about something super cool and interesting - Huffman coding! Have you ever heard of it before? It's a way to encode letters or symbols in a message using shorter codes for the most frequently used symbols. It's like creating a secret code to make messages shorter and faster to send!So, let's talk about the 26 English symbols and their frequencies. The most common symbols like 'e' and 't' will have shorter codes, while less common symbols like 'q' and 'z' will have longer codes. Here are the frequencies of each symbol:'e' - 13.0%'a' - 8.2% 'o' - 7.5% 'i' - 7.0% 'n' - 6.7% 's' - 6.3% 'h' - 6.1% 'r' - 6.0% 'd' - 4.2% 'l' - 3.9% 'c' - 3.4% 'u' - 2.8% 'm' - 2.4% 'w' - 2.4% 'f' - 2.3% 'g' - 1.9% 'y' - 1.7%'b' - 1.5%'v' - 1.0%'k' - 0.8%'j' - 0.2%'x' - 0.2%'q' - 0.1%'z' - 0.1%Now, let's create the Huffman code for these English symbols! Remember, we want to give shorter codes to the more common symbols. Let's start by finding the two least frequent symbols and combining them into a new symbol with a frequency equal to the sum of the two original frequencies. We repeat this process until we have only one tree.After creating the Huffman tree, we assign '0' to the left branch and '1' to the right branch. The final Huffman codes for the English symbols will look something like this:'e' - 0't' - 10'o' - 1110 'i' - 1111 'n' - 11110 's' - 11111 'h' - 10000 'r' - 10001 'd' - 10010 'l' - 10011 'c' - 10100 'u' - 10101 'm' - 10110 'w' - 10111 'f' - 11000 'g' - 11001 'y' - 11010 'p' - 11011'b' - 100000'v' - 100001'k' - 100010'j' - 100011'x' - 100100'q' - 100101'z' - 100110Isn't that amazing? With Huffman coding, we can make messages more efficient by using shorter codes for common symbols. It's like a secret language that only we can understand!I hope you enjoyed learning about Huffman coding with me today. Let's practice encoding some messages together!篇10Hey guys! Do you know what is a Huffman coding? It's a way to compress data by using shorter codes for more frequent symbols. Today, let's talk about the Huffman coding for the 26 English alphabets (a-z)!So, we all know that some letters are used more often than others in English. For example, 'e' and 't' are super popular, while'x' and 'z' are not so common. With Huffman coding, we can give the more frequent letters shorter codes and the less frequent letters longer codes.Let's look at the Huffman coding for the 26 English alphabets:'a' - 1001'b' - 1000'c' - 1101'd' - 1100'e' - 0'f' - 1011'g' - 1010'h' - 1111'i' - 1110'j' - 01101'k' - 01100'l' - 0101'm' - 0100'n' - 0011'o' - 0010'p' - 10101'q' - 10100'r' - 10011's' - 10010't' - 0111'u' - 0110'v' - 01001'w' - 01000'x' - 00101'y' - 00100'z' - 0001By using these codes, we can represent the 26 English alphabets more efficiently. The more frequent letters like 'e' and 't' have shorter codes, while the less frequent letters like 'x' and 'z' have longer codes.Huffman coding is super cool, right? It helps us save space and transmit data more effectively. Next time you see a long string of binary numbers, think about how Huffman coding could be used to compress it!。
求哈夫曼编码例题

求哈夫曼编码例题(最新版)目录1.哈夫曼编码的定义和原理2.哈夫曼编码的编码过程3.哈夫曼编码的解码过程4.哈夫曼编码的应用和优势5.哈夫曼编码的例题解析正文哈夫曼编码是一种无损数据压缩编码方法,其原理是根据数据中字符出现的频率来构建一棵哈夫曼树,然后将原始数据转换为对应的编码,从而实现压缩。
在解码时,通过哈夫曼树和编码表,可以将编码还原为原始数据。
哈夫曼编码具有唯一解码、可逆性和无损压缩等特点,广泛应用于数据压缩和传输领域。
哈夫曼编码的编码过程主要包括两个步骤:构建哈夫曼树和生成编码表。
首先,根据输入数据中字符出现的频率,使用贪心算法构建一棵哈夫曼树。
在构建过程中,将字符的出现频率作为权值,将字符放入树中,得到一棵带权路径长度最短的树。
其次,根据哈夫曼树生成编码表。
在编码表中,每个字符对应一个唯一的编码,编码的长度取决于该字符在哈夫曼树中的层数。
哈夫曼编码的解码过程相对简单。
在收到编码后,根据编码表和哈夫曼树,从编码的第一位开始,沿着哈夫曼树进行遍历,当遍历到叶子节点时,将该节点对应的字符输出。
然后回到根节点,继续遍历,直到编码的所有位都处理完毕。
哈夫曼编码的应用非常广泛,例如在计算机文件压缩、图像压缩和数据传输等领域都有应用。
哈夫曼编码的优势在于其无损压缩特性,可以保证压缩后的数据在解压缩后与原始数据完全相同。
同时,哈夫曼编码的压缩效果较好,压缩率较高,尤其适用于数据中存在大量重复字符的情况。
下面是一个哈夫曼编码的例题解析:例题:给定输入数据“abcabcabc”,构建哈夫曼树并生成编码。
解:首先,统计输入数据中每个字符出现的次数,得到“a”出现 3 次,“b”和“c”各出现 3 次。
然后,根据贪心算法构建哈夫曼树,得到如下结构:```30/a b,c/ /b c b c```根据哈夫曼树生成编码表,得到如下结果:```0: a1: b2: c```最后,根据编码表和哈夫曼树,生成编码为“001011001011”,其中“0”表示 a,“1”表示 b 或 c。
哈夫曼树构造例题

哈夫曼树构造例题【最新版】目录1.哈夫曼树的基本概念2.哈夫曼树的构造方法3.哈夫曼树的应用实例4.哈夫曼树的性质和优点正文哈夫曼树(Huffman Tree)是一种用于数据压缩的树形结构,它可以将原始数据转换为对应的编码,从而实现压缩。
哈夫曼树具有唯一解、最优解等性质,被广泛应用于数据压缩、图像压缩等领域。
接下来,我们将通过一个例题来学习哈夫曼树的构造方法。
例题:给定字符集{a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z},出现频率分别为{16, 11, 10, 9, 7, 6, 5, 5, 4, 4, 4, 3, 3, 3, 3, 2, 2, 2, 2, 1, 1, 1, 1}。
请构造一个哈夫曼树,并给出对应的编码。
构造哈夫曼树的步骤如下:1.根据字符集的出现频率构建一个哈夫曼树。
首先将出现频率最少的两个字符合并,得到一个新的字符,并将其出现频率设置为两个字符出现频率之和。
然后,将新的字符加入到哈夫曼树中。
2.重复步骤 1,直到哈夫曼树中只剩下一个字符。
这个字符对应的编码就是最短编码。
根据上述步骤,我们可以得到哈夫曼树如下:```29/11 18/ /6 57 8/ / /3 24 5```根据哈夫曼树,我们可以得到对应的编码如下:```a: 00b: 01c: 02d: 03e: 04f: 05g: 06h: 07i: 08j: 09k: 10l: 11m: 12: 13o: 14p: 15q: 16r: 17s: 18t: 19u: 20v: 21w: 22x: 23y: 24z: 25```哈夫曼树的性质和优点如下:1.哈夫曼树是唯一的,即对于给定的字符集和出现频率,哈夫曼树是唯一的。
2.哈夫曼树的最优解性质,即哈夫曼树是字符集出现频率到编码长度的映射关系的最优解。
3.哈夫曼编码具有前缀编码和唯一解的性质,便于实现数据压缩和解压缩。
哈夫曼编码PPT课件
Huffman编码举例
例1【严题集6.26③】:假设用于通信的电文仅由8个字母 {a, b, c, d, e, f, g, h} 构成, 它们在电文中出现的概率分别为{ 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10 },试 为这8个字母设计哈夫曼编码。如果用0~7的二进制编码方案又如何? 【类同P148 例2】
建议2: Huffman树的存储结构可采用顺序存储结构: 将整个Huffman树的结点存储在一个数组HT[1..n..m]中;
各叶子结点的编码存储在另一“复合”数组HC[1..n]中。
第16页/共60页
Huffman树和Huffman树编码的存储表示:
typedef struct{ unsigned int weight;//权值分量(可放大取整) unsigned int parent,lchild,rchild; //双亲和孩子分量 }HTNode,*HuffmanTree;//用动态数组存储Huffman树 typedef char**HuffmanCode; //动态数组存储Huffman编码表
HT[s1].parent=i; HT[s2].parent=i; HT[i].lchild=s1; HT[i].rchild=s2; HT[i].weight=HT[s1].weight+ HT[s2].weight;}
第18页/共60页
(续前)再求出n个字符的Huffman编码HC
HC=(HuffmanCode)malloc((n+1)*sizeof(char*)); //分配n个字符编码的头指针 向量(一维数组) cd=(char*) malloc(n*sizeof(char)); //分配求编码的工作空间(n)