概率论与数理统计 第二讲 随机数的产生数据的统计描述.ppt
概率论与数理统计 第二讲 随机数的产生数据的统计描述49页PPT

2、正态分布随机数
1)R = normrnd(μ, σ,):产生一个正态分布随机数 2)R = normrnd(μ, σ,m,n)产生m行n列的正态分布随机数
②
X x x1 i
若 F (xi 1)R F (xi)(,i2,3, 若 R F (x1)
则X~F(x)
(二)变换抽样法 (三)值序抽样法 (四)舍选抽样法 (五)复合抽样法(合成法) (六)近似抽样法
此定理给出的构造分布函数为F(x)的随机 数的产生方法为:
取U(0,1)随机数Ui,(i=1,2…),令Xi=F-1(Ui),则 Xi ,(i=1,2…),就是F(x)随机数,如果Ui独立,则 Xi也互相独立。
(一)直接抽样法(反函数法)
(1)连续分布的直接抽样法
设连续型随机变量X的分布函数为F(x),
例1、产生U(2,8)上的一个随机数,10个随机数, 2行5列的随机数。
命令:(1) y1=unifrnd(2,8) (2) y2=unifrnd(2,8,1,10) (3) y3=unifrnd(2,8,2,5)
y1=7.7008
y2=3.3868 5.6411 4.9159 7.3478 6.5726 4.7388 2.1110 6.9284 4.6682 5.6926
命令 (1) y1=exprnd(0.1) (2) y2=exprnd(0.1,1,20) (3) y3=exprnd(0.1,2,6)
结果
(1) y1=0.0051
(2) y2=[0.1465 0.0499 0.0722 0.0115 0.0272
概率论与数理统计ch2随机变量及其概率分布精品PPT课件

10
X0
1
2
3
p p p(1-p) (1-p)2p (1-p)3
11
例:若随机变量X的概率分布律为
P( X k ) c k ,k 0,1, 2,, 0
k!
求常数c.
12
解:
1 P{X k}
k 0
k
c
ce
k0 k !
求(1)随机观察1个单位时间,至少有3人候车 的概率; (2)随机独立观察5个单位时间,恰有4个单 位时间至少有3人候车的概率。
29
解:1 P(X 3) 1 P( X 0) P( X 1) P(X 2)
1 e 4.8 (1 4.8 4.82 ) 0.8580 2!
2 设5个单位时间内有Y个单位时间是
15
对于一个随机试验,如果它的样本空间只
包含两个元素,即 S {e1, e2} ,我们总能
在S上定义一个服从(0-1)分布的随机
变量。
0, X X (e) 1,
当e e1, 当e e2.
来描述这个随机试验的结果。
检查产品的质量是否合格,对新生婴儿 的性别进行登记,检验种子是否发芽以 及前面多次讨论过的“抛硬币”试验都 可以用(0-1)分布的随机变量来描述 。
P A 1 2
如果是不放回抽样呢?
21
设A在n重贝努利试验中发生X次,则
P( X k) Cnk pk (1 p)nk,k 0,1,,n
并称X服从参数为p的二项分布,记
X ~ B(n,p)
n
注:1 ( p q)n Cnk pk qnk 其中q 1 p k 0
22
推导:以n=3为例,设Ai={ 第i次A发生 }
概率论与数理统计第2章ppt课件

1 3x
0
1
2
3X
处的离跳散跃型高随度机恰变为量P{的X=分x布i}.函数为跳跃函数,在xi
§4. 连续型随机变量的概率密度
1. 定义:对于随机变量X的分布函F(x), 如果存在非负函数f(x),使对于任意实数x有:
F(x)xf(t)dt
则称X为连续型随机变量;称f(x)为X的概率 密度函数。简称密度函数。
精选课件
21
例4. 3个人抓阄数。
解:X的概率分布: P{X=1}=1/3
P{X=2}=2/3×1/2=1/3
P{X=3}=2/3×1/2×1/1=1/3
X的分布函数:
Y
0 x <1
1
1/3 1 x <2
2/ 3
F(x)=
2/3 2 x <3 1/ 3
则:P{X=k} Cnk pnkqnnk 其中:qn=1-pn
(令=μV; pn=μ△V=μV/n= /n):
考虑当 n +时
P{X=k} =nl imCnkpnkqnnk
limn! ()k(1)nk
nl n i m k1 k !!n(nn (n n k1)) !n (n n kn 1)k((11 n))kn
k
k!
k=0、1、2、3、……
n
Poissn定理:n为正整数,pn=/n, >0。 则对任一非负整数k有:
nl im Cnkpnkqnnk
k
k!
其中:= npn.
例3. 某人打靶命中率为0.001, 重复射击 5000次,求至少命中2次的概率。
解:设X为至命中次数。
P(X2) =1-P(X<2) =1-P(X=0)-P(X=1)
概率论与数理统计--第二章PPT课件
F(x) pk xk x
分布函数F(x)在x xk , 其跳跃值为pk P{X
对k 所1,有2,满足处x有k 跳 x跃的,k求和。
xk }
第26页/共57页
第四节 连续型随机变量及其概率密度
定义 对于随机变量X的分布函数F(x),如果存在非 负函数f (x),使对于任意实数有
售量服从参数为 10的泊松分布.为了以95%以上的
概率保证该商品不脱销,问商店在月底至少应进该商 品多少件? 解 设商店每月销售该种商品X件,月底的进货量为n件,
按题意要求为 PX n 0.95
由X服附从录的泊1松0的分泊布松表分知布k,140 1则k0!k有e1k0n01k00!k.9e1160 6
可以用泊松分布作近似,即
n
k
pk
1
p
nk
np k
k!
enp , k
0,1, 2,
.
例 4 为保证设备正常工作,需要配备一些维修工.如果各台设备
发生故障是相互独立的,且每台设备发生故障的概率都是 0.01.
试求在以下情况下,求设备发生故障而不能及时修理的概率.
(1) 一名维修工负责 20 台设备.
于是PX I P(B) Pw X (w) I.
随机变量的取值随试验的结果而定,而试验的各个 结果出现有一定的概率,因而随机变量的取值有一 定的概率.
按照随机变量可能取值的情况,可以把它们分为两 类:离散型随机变量和非离散型随机变量,而非离 散型随机变量中最重要的是连续型随机变量.因此, 本章主要研究离散型及连续型随机变量.
x
x
4. F(x 0) F(x) 即F(x)是右连续的
第23页/共57页
概率论与数理统计课件第二章

P( X 1) 1 P( X 0) 1 C 0.1 0.9
0 n 0 n 0
1 0.9 0.9
n
n 22.
例4. 某车间有5台车床,由于种种原因(由
于装、卸工作等),时常需要停车.设各 台车床的停车或开车是相互独立的. 若车床在任一时刻处于停车状态的 概率是1/3,求车间中恰有一台车床处 于停车状态的概率。 解:X:处于停车状态的车床数 X~B(5,1/3)
当0 x 1时,F ( x) P( X x) P( X 0) 0.3
当1 x 2时,F ( x) P( X x) P( X 0) P( X 1) 0.9
当x 2时,F ( x) P( X 0) P( X 1) P( X 2) 1
k nk CM CN M P( X k ) , n CN
k 0,1,..., l ,
其中n≤N,M<N,l=min{n,M},n,N,M均为正 整数,则称X服从参数为N,M,n的超几何分 布,记作X~H(N,M,n).
例8. 某班有学生20名,其中有5名女生, 今从班上任选4名学生去参观展览, 求被选到的女同学人数X的分布律。 X~H(20,5,4)
Ω X R X(w)
w
随机变量的分类
离散型随机变量
有限个或可列个 可能值
随 机 多,而且还不能 一一列举,而是充满 一个区间.
许多随机事件都可以通过形如{X≤x}的 事件来表示:
1 { X x} X x k k 1
(5) F ( x)是连续函数, 若f ( x)在x0连续, 有 F ( x0 ) f ( x0 ) .
例1. 设连续型随机变量X的概率密度为
概率论与数理统计PPT课件第二章随机向量及其分布(1)

用这两条性质判断 一个函数是否是 概率分布
ppt课件
25
例1 从1~10这10个数字中随机取出5个数字, X 表示取出的5个数字中的最大值. 试求X 的 分布列
解: X 的取值为5,6,7,8,9,10. 并且
PX kC C k 4 1 5 0 1 k5 , 6 ,, 1 0
即 X 的分布列为
的时候才将自变元 写出来
ppt课件
13
二.随机变量的意义
引入了随机变量, 随机试验中的各种事件, 就可以通过随机变量的关系式表达出来
可见,随机事件这个概念实际上是包容在 随机变量这个更广的概念内. 也可以说,随机 事件是从静态的观点来研究随机现象,而随机 变量则是一种动态的观点. 就象数学分析中常 量与变量的区别那样
其中每一个 i 只取 A 或 A ,共 有 2 n 个
现考虑事件
Bn,k {n 重贝努里试验中事件A 恰好发生k 次}
现求概率 P Bn,k :
ppt课件
44
在 n 次试验中,指定 k 次出现 A(成功),
其余 n – k 次出现 A (失败),这种指定的
方法有
C
k n
种
而对于每一种指定好的方法,有
第二章 随机变量及其分布
• 随机变量 • 离散型随机变量 • 连续型随机变量 • 概率分布函数 • 随机变量函数的分布
ppt课件
1
§1.1 随机变量
一.随机变量的概念
为了更深入地研究随机现象, 就要建立 数学模型,随机变量是随机现象的最基本的 数学模型. 引入了随机变量,我们就可以用 随机变量的值表示随机试验的结果
X 5 6 7 8 9 10
P1
5 15 35 70 126
概率论与数理统计第二章随机变量课件

第二章 随机变量第一节 随机变量及其分布函数上一章中我们讨论的随机事件中有些是直接用数量来标识的,例如,抽样检验灯泡质量试验中灯泡的寿命;而有些则不是直接用数量来标识的,如性别抽查试验中所抽到的性别.为了更深入地研究各种与随机现象有关的理论和应用问题,我们有必要将样本空间的元素与实数对应起来.即将随机试验的每个可能的结果e 都用一个实数X 来表示.例如,在性别抽查试验中用实数“1”表示“出现男性”,用“0”表示“出现女性”.显然,一般来讲此处的实数X 值将随e 的不同而变化,它的值因e 的随机性而具有随机性,我们称这种取值具有随机性的变量为随机变量.定义2.1 设随机试验的样本空间为Ω,如果对Ω中每一个元素e ,有一个实数X (e )与之对应,这样就得到一个定义在Ω上的实值单值函数(e ),称之为随机变量( ).随机变量的取值随试验结果而定,在试验之前不能预知它取什么值,只有在试验之后才知道它的确切值;而试验的各个结果出现有一定的概率,故随机变量取各值有一定的概率.这些性质显示了随机变量与普通函数之间有着本质的差异.再者,普通函数是定义在实数集或实数集的一个子集上的,而随机变量是定义在样本空间上的(样本空间的元素不一定是实数),这也是二者的差别.本书中,我们一般以大写字母如X ,Y ,Z ,W ,…表示随机变量,而以小写字母如,…表示实数.为了研究随机变量的概率规律,并由于随机变量X 的可能取值不一定能逐个列出,因此我们在一般情况下需研究随机变量落在某区间(x 1,x 2]中的概率,即求P {x 1<X ≤x 2},但由于P {x 1<X ≤x 2}{X ≤x 2}{X ≤x 1},由此可见要研究P {x 1<X ≤x 2}就归结为研究形如P {X ≤x }的概率问题了.不难看出,P {X ≤x }的值常随不同的x 而变化,它是x 的函数,我们称这函数为分布函数.定义2.2 设X 是随机变量,x 为任意实数,函数F (x ){X ≤x }称为X 的分布函数( ).对于任意实数x 12(x 1<x 2),有P {x 1<X ≤x 2}{X ≤x 2}{X ≤x 1}(x 2)(x 1), (2.1)因此,若已知X 的分布函数,我们就能知道X 落在任一区间(x 12]上的概率.在这个意义上说,分布函数完整地描述了随机变量的统计规律性.如果将X 看成是数轴上的随机点的坐标,那么,分布函数F (x )在x 处的函数值就表示X 落在区间(-∞]上的概率.分布函数具有如下基本性质: 1°F (x )为单调不减的函数.事实上,由(2.1)式,对于任意实数x 12(x 1<x 2),有F (x 2)(x 1){x 1<X ≤x 2}≥0.2°0≤F (x )≤1,且)(lim x F x +∞→=1,常记为F (+∞)=1.)(lim x F x -∞→=0,常记为F (-∞)=0.我们从几何上说明这两个式子.当区间端点x 沿数轴无限向左移动(x →-∞)时,则“X 落在x 左边”这一事件趋于不可能事件,故其概率P {X ≤x }(x )趋于0;又若x 无限向右移动(x →+∞)时,事件“X 落在x 左边”趋于必然事件,从而其概率P {X ≤x }(x )趋于1.3°F (0)(x ),即F (x )为右连续. 证略.反过来可以证明,任一满足这三个性质的函数,一定可以作为某个随机变量的分布函数. 概率论主要是利用随机变量来描述和研究随机现象,而利用分布函数就能很好地表示各事件的概率.例如,P {X >a }=1{X ≤a }=1(a ){X <a }(0){}(a )(0)等等.在引进了随机变量和分布函数后我们就能利用高等数学的许多结果和方法来研究各种随机现象了,它们是概率论的两个重要而基本的概念.下面我们从离散和连续两种类别来更深入地研究随机变量及其分布函数,另有一种奇异型随机变量超出本书范围,就不作介绍了.第二节离散型随机变量及其分布如果随机变量所有可能的取值为有限个或可列无穷多个,则称这种随机变量为离散型随机变量.容易知道,要掌握一个离散型随机变量X 的统计规律,必须且只须知道X 的所有可能取的值以及取每一个可能值的概率.设离散型随机变量X 所有可能的取值为(1,2,…)取各个可能值的概率,即事件{}的概率P {}, 1,2,… (2.2)我们称(2.2)式为离散型随机变量X 的概率分布或分布律.分布律也常用表格来表示(表2-1):表2-1 X x 1 x 2 x 3 … …p 1 p 2 p 3 … …由概率的性质容易推得,任一离散型随机变量的分布律{},都具有下述两个基本性质: 1°≥0,1,2,…; (2.3) 2°11=∑∞=k kp. (2.4)反过来,任意一个具有以上两个性质的数列{},一定可以作为某一个离散型随机变量的分布律.为了直观地表达分布律,我们还可以作类似图2-1的分布律图.图2-1图2-1中处垂直于x 轴的线段高度为,它表示X 取的概率值.例2.1 设一汽车在开往目的地的道路上需通过4盏信号灯,每盏灯以0.6的概率允许汽车通过,以0.4的概率禁止汽车通过(设各盏信号灯的工作相互独立).以X 表示汽车首次停下时已经通过的信号灯盏数,求X 的分布律.解 以p 表示每盏灯禁止汽车通过的概率,显然X 的可能取值为0,1,2,3,4,易知X 的分布律为或写成P {}=(1),0,1,2,3.P {4}=(1)4.将0.4,10.6代入上式,所得结果如表2-3所示.表2-3(1)两点分布若随机变量X 只可能取x 1与x 2两值,它的分布律是P {1}=1(0<p <1),P {2},则称X 服从参数为p 的两点分布.特别,当x 1=0,x 2=1时两点分布也叫(0-1)分布,记作(0-1)分布.写成分布律表形式见表2-4.表2-4对于一个随机试验,若它的样本空间只包含两个元素,即={e 1,e 2},我们总能在上定义一个服从(0-1)分布的随机变量,,,1,0)(21e e e e e X X ==⎩⎨⎧==当当用它来描述这个试验结果.因此,两点分布可以作为描述试验只包含两个基本事件的数学模型.如,在打靶中“命中”与“不中”的概率分布;产品抽验中“合格品”与“不合格品”的概率分布等等.总之,一个随机试验如果我们只关心某事件A 出现与否,则可用一个服从(0-1)分布的随机变量来描述.(2)二项分布若随机变量X 的分布律为P {}kn C (1), 0,1,…, (2.5)则称X 服从参数为n ,p 的二项分布( ),记作().易知(2.5)满足(2.3)、(2.4)两式.事实上,P ()≥0是显然的;再由二项展开式知n k n k nk k nnk p p p p k X P )]1([)1(C}{0-+=-==-==∑∑=1.我们知道,P {}=kn k k n p p --)1(C 恰好是[(1)]n 二项展开式中出现的那一项,这就是二项分布名称的由来.回忆n 重贝努里试验中事件A 出现k 次的概率计算公式(k )kn C (1), 0,1,…,可知,若(),X 就可以用来表示n 重贝努里试验中事件A 出现的次数.因此,二项分布可以作为描述n 重贝努里试验中事件A 出现次数的数学模型.比如,射手射击n 次中,“中的”次数的概率分布;随机抛掷硬币n 次,落地时出现“正面”次数的概率分布;从一批足够多的产品中任意抽取n 件,其中“废品”件数的概率分布等等.不难看出,(0-1)分布就是二项分布在1时的特殊情形,故(0-1)分布的分布律也可写成P {}1(0,1)(1).例2.2 某大学的校乒乓球队与数学系乒乓球队举行对抗赛.校队的实力较系队为强,当一个校队运动员与一个系队运动员比赛时,校队运动员获胜的概率为0.6.现在校、系双方商量对抗赛的方式,提了三种方案: (1)双方各出3人;(2)双方各出5人;(3)双方各出7人.三种方案中均以比赛中得胜人数多的一方为胜利.问:对系队来说,哪一种方案有利?解 设系队得胜人数为X ,则在上述三种方案中,系队胜利的概率为(1) P {X ≥2}=k kk k -=∑3323)6.0()4.0(C ≈0.352;(2) P {X ≥3}=k kk k -=∑5535)6.0()4.0(C ≈0.317;(3) P {X ≥4}=k kk k -=∑7747)6.0()4.0(C ≈0.290.因此第一种方案对系队最为有利.这在直觉上是容易理解的,因为参赛人数越少,系队侥幸获胜的可能性也就越大.例2.3 某一大批产品的合格品率为98%,现随机地从这批产品中抽样20次,每次抽一个产品,问抽得的20个产品中恰好有k 个(1,2,…,20)为合格品的概率是多少?解 这是不放回抽样.由于这批产品的总数很大,而抽出的产品的数量相对于产品总数来说又很小,那么取出少许几件可以认为并不影响剩下部分的合格品率,因而可以当作放回抽样来处理,这样做会有一些误差,但误差不大.我们将抽检一个产品看其是否为合格品看成一次试验,显然,抽检20个产品就相当于做20次贝努里试验,以X 记20个产品中合格品的个数,那么(20,0.98),即P {}=kk k -2020)02.0()98.0(C ,1,2, (20)若在上例中将参数20改为200或更大,显然此时直接计算该概率就显得相当麻烦.为此我们给出一个当n 很大而p (或1)很小时的近似计算公式.定理2.1(泊松()定理) 设λ(λ>0是一常数,n 是任意正整数),则对任意一固定的非负整数k ,有e lim (1)!k k k n knn n n C p p k λλ-→∞-=-.证 由λ,有().111121111!)1()(!)1()1(1C kn kkn k kn n kn k n n n n k n n k n n k k n n n p p ---⎪⎭⎫ ⎝⎛-⎪⎭⎫ ⎝⎛-⋅⎥⎦⎤⎢⎣⎡⎪⎭⎫ ⎝⎛--⎪⎭⎫ ⎝⎛-⎪⎭⎫ ⎝⎛-⋅=-+--=-λλλλλ对任意固定的k ,当n →∞时,11121111→⎥⎦⎤⎢⎣⎡⎪⎭⎫ ⎝⎛--⎪⎭⎫ ⎝⎛-⎪⎭⎫ ⎝⎛-⋅n k n n ,11,e 1→⎪⎭⎫ ⎝⎛-→⎪⎭⎫ ⎝⎛---kn n n λλλ故e lim (1).!k kk n knn n n C p p k λλ--→∞-=由于λ是常数,所以当n 很大时必定很小,因此,上述定理表明当n 很大p 很小时,有以下近似公式,!e )1(C k p p k kn k k nλλ--≈- (2.6)其中λ.从表2-5可以直观地看出(2.6)式两端的近似程度.表2-5由上表可以看出,两者的结果是很接近的.在实际计算中,当n ≥20≤0.05时近似效果颇佳,而当n ≥100≤10时效果更好.!e k k λλ-的值有表可查(见本书附表3)二项分布的泊松近似,常常被应用于研究稀有事件(即每次试验中事件A 出现的概率p 很小),当贝努里试验的次数n 很大时,事件A 发生的次数的分布.例2.4 某十字路口有大量汽车通过,假设每辆汽车在这里发生交通事故的概率为0.001,如果每天有5000辆汽车通过这个十字路口,求发生交通事故的汽车数不少于2的概率.解 设X 表示发生交通事故的汽车数,则(),此处5000,0.001,令λ5, P {X ≥2}=1{X <2}=1-{}∑==1k k X P=1-(0.999)5000-5(0.999)4999≈1!e 50!e 51550----. 查表可得P {X ≥2}=1-0.00674-0.03369=0.95957.例2.5 某人进行射击,设每次射击的命中率为0.02,独立射击400次,试求至少击中两次的概率.解 将一次射击看成是一次试验.设击中次数为X ,则(400,0.02),即X 的分布律为P {}=k400C (0.02)k (0.98)400, 0,1, (400)故所求概率为P {X ≥2}=1{0}{1}=1-(0.98)400-400(0.02)(0.98)399 =0.9972.这个概率很接近1,我们从两方面来讨论这一结果的实际意义.其一,虽然每次射击的命中率很小(为0.02),但如果射击400次,则击中目标至少两次是几乎可以肯定的.这一事实说明,一个事件尽管在一次试验中发生的概率很小,但只要试验次数很多,而且试验是独立地进行的,那么这一事件的发生几乎是肯定的.这也告诉人们决不能轻视小概率事件.其二,如果在400次射击中,击中目标的次数竟不到两次,由于P {X <2}≈0.003很小,根据实际推断原理,我们将怀疑“每次射击的命中率为0.02”这一假设,即认为该射手射击的命中率达不到0.02.(3)泊松分布若随机变量X 的分布律为P {} =e !k k λλ-,0,1,2,…, (2.7)其中λ>0是常数,则称X 服从参数为λ的泊松分布( ),记为(λ). 易知(2.7)满足(2.3)、(2.4)两式,事实上,P {}≥0显然;再由∑∞=-0!e k k k λλλ·e λ=1,可知∑∞==0}{k k X P =1.由泊松定理可知,泊松分布可以作为描述大量试验中稀有事件出现的次数0,1,…的概率分布情况的一个数学模型.比如:大量产品中抽样检查时得到的不合格品数;一个集团中生日是元旦的人数;一页中印刷错误出现的数目;数字通讯中传输数字时发生误码的个数等等,都近似服从泊松分布.除此之外,理论与实践都说明,一般说来它也可作为下列随机变量的概率分布的数学模型:在任给一段固定的时间间隔内,① 由某块放射性物质放射出的α质点,到达某个计数器的质点数;② 某地区发生交通事故的次数;③ 来到某公共设施要求给予服务的顾客数(这里的公共设施的意义可以是极为广泛的,诸如售货员、机场跑道、电话交换台、医院等,在机场跑道的例子中,顾客可以相应地想象为飞机).泊松分布是概率论中一种很重要的分布.例2.6 由某商店过去的销售记录知道,某种商品每月的销售数可以用参数λ=5的泊松分布来描述.为了以95%以上的把握保证不脱销,问商店在月底至少应进某种商品多少件?解 设该商店每月销售这种商品数为X ,月底进货为a 件,则当X ≤a 时不脱销,故有P {X ≤a }≥0.95.由于(5),上式即为∑=-ak kk 05!5e ≥0.95. 查表可知∑=-95!5e k kk ≈0.9319<0.95, ∑=-105!10e k kk ≈0.9682>0.95 于是,这家商店只要在月底进货这种商品10件(假定上个月没有存货),就可以95%以上的把握保证这种商品在下个月不会脱销.下面我们就一般的离散型随机变量讨论其分布函数.设离散型随机变量X 的分布律如表2-1所示.由分布函数的定义可知F (x ){X ≤x }=∑∑≤≤==xx kxx kk k px X P }{,此处的∑≤xx k 和式表示对所有满足≤x 的k 求和,形象地讲就是对那些满足≤x 所对应的的累加.例2.7 求例2.1中X 的分布函数F (x ). 解 由例2.1的分布律知 当x <0时,F (x ){X ≤x }=0;当0≤x <1时,F (x ){X ≤x }{0}=0.4;当1≤x <2时,F (x ){X ≤x }({0}∪{1}){0}{1}=0.4+0.24=0.64;当2≤x <3时F (x ){X ≤x }({0}∪{1}∪{2}) {0}{1}{2}=0.4+0.24+0.144 =0.784;当3≤x <4时F (x ){X ≤x }({0}∪{1}∪{2}∪{3}) =0.4+0.24+0.144+0.0864=0.8704;当x ≥4时F (x ){X ≤x }({0}∪{1}∪{2}∪{3}∪{4}) =0.4+0.24+0.144+0.0864+0.1296=1.综上所述F (x ){X ≤x }=⎪⎪⎪⎩⎪⎪⎪⎨⎧≥<≤<≤<≤<≤<.4,1,43,8704.0,32,784.0,21,64.0,10,4.0,0,0x x x x x x F (x )的图形是一条阶梯状右连续曲线,在0,1,2,3,4处有跳跃,其跳跃高度分别为0.4,0.24,0.144,0.0864,0.1296,这条曲线从左至右依次从F (x )=0逐步升级到F (x )=1.对表2-1所示的一般的分布律,其分布函数F (x )表示一条阶梯状右连续曲线,在(1,2,…)处有跳跃,跳跃的高度恰为{},从左至右,由水平直线F (x )=0,分别按阶高p 1,p 2,…升至水平直线F (x )=1.以上是已知分布律求分布函数.反过来,若已知离散型随机变量X 的分布函数F (x ),则X 的分布律也可由分布函数所确定:{}()(0).第三节 连续型随机变量及其分布上一节我们研究了离散型随机变量,这类随机变量的特点是它的可能取值及其相对应的概率能被逐个地列出.这一节我们将要研究的连续型随机变量就不具有这样的性质了.连续型随机变量的特点是它的可能取值连续地充满某个区间甚至整个数轴.例如,测量一个工件长度,因为在理论上说这个长度的值X 可以取区间(0,+∞)上的任何一个值.此外,连续型随机变量取某特定值的概率总是零(关于这点将在以后说明).例如,抽检一个工件其长度X 丝毫不差刚好是其固定值(如 1.824)的事件{1.824}几乎是不可能的,应认为P{1.824}=0.因此讨论连续型随机变量在某点的概率是毫无意义的.于是,对于连续型随机变量就不能用对离散型随机变量那样的方法进行研究了.为了说明方便我们先来看一个例子.例2.8 一个半径为2米的圆盘靶,设击中靶上任一同心圆盘上的点的概率与该圆盘的面积成正比,并设射击都能中靶,以X 表示弹着点与圆心的距离,试求随机变量X 的分布函数.解 1°若x <0,因为事件{X ≤x }是不可能事件,所以F (x ){X ≤x }=0.2°若0≤x ≤2,由题意P {0≤X ≤x }2,k 是常数,为了确定k 的值,取2,有P {0≤X ≤2}=22k ,但事件{0≤X ≤2}是必然事件,故P {0≤X ≤2}=1,即221,所以1/4,即P {0≤X ≤x }2/4.于是F (x ){X ≤x }{X <0}{0≤X ≤x }= x 2/4.3°若x ≥2,由于{X ≤2}是必然事件,于是F (x ){X ≤x }=1.综上所述F (x )=⎪⎩⎪⎨⎧≥<≤<,2,1,20,41,0,02x x x x 它的图形是一条连续曲线如图2-2所示.图2-2另外,容易看到本例中X 的分布函数F (x )还可写成如下形式:F (x )=t t f xd )(⎰∞-,其中 f (t )=⎪⎩⎪⎨⎧<<.,0,20,21其他t t这就是说F (x )恰好是非负函数f (t )在区间(-∞,x ]上的积分,这种随机变量X 我们称为连续型随机变量.一般地有如下定义.定义2.3 若对随机变量X 的分布函数F (x ),存在非负函数f (x ),使对于任意实数x 有F (x )=⎰∞-xx t f d )(, (2.8)则称X 为连续型随机变量,其中f (x )称为X 的概率密度函数,简称概率密度或密度函数( ).由(2.8)式知道连续型随机变量X 的分布函数F (x )是连续函数.由分布函数的性质F (-∞)=0,F (+∞)=1及F (x )单调不减,知F (x )是一条位于直线0与1之间的单调不减的连续(但不一定光滑)曲线. 由定义2.3知道,f (x )具有以下性质:1°f (x )≥0;2°⎰+∞∞-x x f d )(=1;3°P {x 1<X ≤x 2}(x 2)-F (x 1)=⎰21d )(x x x x f (x 1≤x 2);4°若f (x )在x 点处连续,则有F ′(x )(x ).由2°知道,介于曲线(x )与0之间的面积为1.由3°知道,X 落在区间(x 1,x 2]的概率P {x 1<X ≤x 2}等于区间(x 1,x 2]上曲线(x )之下的曲边梯形面积.由4°知道,f (x )的连续点x 处有f (x )=.}{)()(lim lim 00x x x X x P x x F x x F x x ∆∆+≤<=∆-∆+++→∆→∆ 这种形式恰与物理学中线密度定义相类似,这也正是为什么称f (x )为概率密度的原因.同样我们也指出,反过来,任一满足以上1°、2°两个性质的函数f (x ),一定可以作为某个连续型随机变量的密度函数.前面我们曾指出对连续型随机变量X 而言它取任一特定值a 的概率为零,即P {}=0,事实上,令Δx >0,设X 的分布函数为F (x ),则由{}⊂{a -Δx <X ≤a },得 0≤P {}≤P {a -Δx <X ≤a }(a )-F (a -Δx ). 由于F (x )连续,所以)(lim 0x a F x ∆-→∆(a ).当Δx →0时,由夹逼定理得P {}=0,由此很容易推导出P {a ≤X <b }{a <X ≤b }{a ≤X ≤b }{a <X <b }.即在计算连续型随机变量落在某区间上的概率时,可不必区分该区间端点的情况.此外还要说明的是,事件{}“几乎不可能发生”,但并不保证绝不会发生,它是“零概率事件”而不是不可能事件.例2.9 设连续型随机变量X 的分布函数为F (x )=⎪⎩⎪⎨⎧≥<≤<.1,1,10,,0,02x x Ax x 试求:(1)系数A ;(2)X 落在区间(0.3,0.7)内的概率; (3)X 的密度函数.解 (1)由于X 为连续型随机变量,故F (x )是连续函数,因此有1(1)=2101lim lim )(Axx F x x -→-→= ,即1,于是有F (x )=⎪⎩⎪⎨⎧≥<≤<.1,1,10,,0,02x x x x (2) P {0.3<X <0.7}(0.7)-F (0.3)=(0.7)2-(0.3)2=0.4; (3) X 的密度函数为f (x )′(x )=⎩⎨⎧<≤.,0;10,2其他x x由定义2.3知,改变密度函数f (x )在个别点的函数值,不影响分布函数F (x )的取值,因此,并不在乎改变密度函数在个别点上的值(比如在0或1上f (x )的值).例2.10 设随机变量X 具有密度函数f (x )=⎪⎩⎪⎨⎧≤≤-<≤.,0,43,22,30,其他x x x kx (1) 确定常数k ;(2) 求X 的分布函数F (x );(3) 求P {1<X ≤72}. 解 (1)由⎰∞∞-x x f d )(=1,得x xx kx d )22(d 4330⎰⎰-+=1, 解得1/6,故X 的密度函数为f (x )=⎪⎪⎪⎩⎪⎪⎪⎨⎧≤≤-<≤.,0,43,22,30,6其他x x x x(2) 当x <0时,F (x ){X ≤x }=⎰∞-xt t f d )( =0;当0≤x <3时,F (x ){X ≤x }⎰∞-xtt f d )(⎰⎰∞-+0d )(d )(xt t f t t f 12d 620x t t x =⎰;当3≤x <4时,F (x ){X ≤x }⎰∞-xtt f d )(033()()()x f t dt f t dt f t dt -∞++⎰⎰⎰=233(2)23;624x t t x dt dt x +-=-+-⎰⎰当x ≥4时,F (x ){X ≤x }⎰∞-xtt f d )(⎰⎰⎰⎰∞-+++030434d )(d )(d )(d )(xt t f t t f t t f t t f=t tt t d )22(d 64330⎰⎰-+ =1.即F (x )=⎪⎪⎪⎩⎪⎪⎪⎨⎧≥<≤-+-<≤<.4,1,43,324,30,12,0,022x x x x x x x(3) P {1<X ≤7/2}(7/2)-F (1)=41/48.下面介绍三种常见的连续型随机变量. (1)均匀分布若连续型随机变量X 具有概率密度f (x )=⎪⎩⎪⎨⎧<<-.,0,,1其他b x a ab (2.9)则称X 在区间(a ,b )上服从均匀分布( ),记为().易知f (x )≥0且⎰⎰∞∞--=ba x ab x x f d 1d )(=1.由(2.9)可得 1°P {X ≥b }=⎰∞bx d 0 =0{X ≤a }⎰∞-ax d 00,即 P {a <X <b }=1-P {X ≥b }-P {X ≤a }=1;2°若a ≤c <d ≤b ,则P {c <X <d }=ab cd x a b dc--=-⎰d 1. 因此,在区间()上服从均匀分布的随机变量X 的物理意义是:X 以概率1在区间()内取值,而以概率0在区间()以外取值,并且X 值落入()中任一子区间()中的概率与子区间的长度成正比,而与子区间的位置无关. 由(2.8)易得X 的分布函数为F (x )=⎪⎩⎪⎨⎧≥<≤--<.,1,,,,0b x b x a a b ax a x (2.10) 密度函数f (x )和分布函数F (x )的图形分别如图2-3和图2-4所示.图2-3 图2-4在数值计算中,由于四舍五入,小数点后第一位小数所引起的误差X ,一般可以看作是一个服从在[-0.5,0.5]上的均匀分布的随机变量;又如在()中随机掷质点,则该质点的坐标X 一般也可看作是一个服从在()上的均匀分布的随机变量.例2.11 某公共汽车站从上午7时开始,每15分钟来一辆车,如某乘客到达此站的时间是7时到7时30分之间的均匀分布的随机变量,试求他等车少于5分钟的概率.解 设乘客于7时过X 分钟到达车站,由于X 在[0,30]上服从均匀分布,即有f (x )=⎪⎩⎪⎨⎧≤≤.,0,300,301其他x显然,只有乘客在7∶10到7∶15之间或7∶25到7∶30之间到达车站时,他(或她)等车的时间才少于5分钟,因此所求概率为P {10<X ≤15}{25<X ≤30}⎰⎰+15103025d 301d 301x x 1/3. (2)指数分布若随机变量X 的密度函数为f (x )=⎩⎨⎧≤>-.00,,0,e x x x λλ (2.11) 其中λ>0为常数,则称X 服从参数为λ的指数分布( ),记作(λ).显然f (x )≥0,且x x x f x d e d )(0⎰⎰∞∞-∞-=λλ=1.容易得到X 的分布函数为F (x )=⎩⎨⎧≤>--.00,,0,e 1x x x λ指数分布最常见的一个场合是寿命分布.指数分布具有“无记忆性”,即对于任意>0,有P {X >>s }{X >t }. (2.12)如果用X 表示某一元件的寿命,那么上式表明,在已知元件已使用了s 小时的条件下,它还能再使用至少t 小时的概率,与从开始使用时算起它至少能使用t 小时的概率相等.这就是说元件对它已使用过s 小时没有记忆.当然,指数分布描述的是无老化时的寿命分布,但“无老化”是不可能的,因而只是一种近似.对一些寿命长的元件,在初期阶段老化现象很小,在这一阶段,指数分布比较确切地描述了其寿命分布情况.(2.12)式是容易证明的.事实上,(){,}{}{}{}{}1()ee {}.1()es t t λsP X s X s t P X s t P X s t X s P X s P X s F s t P X t F s λλ-+->>+>+>+>==>>-+====>--(3)正态分布若连续型随机变量X 的概率密度为f (x )=222)(e π21σμσ--x , -∞<x <+∞, (2.13)其中μ,σ(σ>0)为常数,则称X 服从参数为μ,σ的正态分布( ),记为(μ,σ2).显然f (x )≥0,下面来证明⎰∞∞-x x f d )(=1.令σux -,得到.d eπ21d e π2122)(222t x t x ⎰⎰∞∞--∞∞---=σμσ记t t d e22⎰∞∞--,则有I 2=⎰⎰∞∞-∞∞-+-ds d e222t s t .作极坐标变换:θθ,得到I 2=22π22r redrd πθ∞--∞=⎰⎰,而I >0,,即有.π2d e22=⎰∞∞--t t于是.1π2π21d e 21222)(=⋅=--∞∞-⎰x x σμσπ 正态分布是概率论和数理统计中最重要的分布之一.在实际问题中大量的随机变量服从或近似服从正态分布.只要某一个随机变量受到许多相互独立随机因素的影响,而每个个别因素的影响都不能起决定性作用,那么就可以断定随机变量服从或近似服从正态分布.例如,因人的身高、体重受到种族、饮食习惯、地域、运动等等因素影响,但这些因素又不能对身高、体重起决定性作用,所以我们可以认为身高、体重服从或近似服从正态分布.参数μ,σ的意义将在第四章中说明(x )的图形如图2-5所示,它具有如下性质:图2-5 图2-61°曲线关于μ对称;2°曲线在μ处取到最大值,x 离μ越远,f (x )值越小.这表明对于同样长度的区间,当区间离μ越远,X 落在这个区间上的概率越小;3°曲线在μ±σ处有拐点; 4°曲线以x 轴为渐近线;5°若固定μ,当σ越小时图形越尖陡(图2-6),因而X 落在μ附近的概率越大;若固定σ,μ值改变,则图形沿x 轴平移,而不改变其形状.故称σ为精度参数,μ为位置参数. 由(2.13)式得X 的分布函数F (x )=t xt d eπ21-2)(22⎰∞--σμσ. (2.14)特别地,当μ=0,σ=1时,称X 服从标准正态分布N (0,1),其概率密度和分布函数分别用)(x ϕ,Φ(x )表示,即有22e π21)(x x -=ϕ, (2.15)Φ(x )=t xt d eπ2122⎰∞--. (2.16)易知,Φ(-x )=1-Φ(x ).人们已事先编制了Φ(x )的函数值表(见本书附录).一般地,若(μ,σ2),则有σμ-X (0,1).事实上,σμ-X 的分布函数为P {Z ≤x }=}{x X P ≤-σμ{X ≤μ+σx }=t t xd e π21222)(σμσμσ--+∞-⎰,令σμ-t ,得P {Z ≤x }=s xs d eπ2122⎰∞--=Φ(x ),由此知σμ-X (0,1).因此,若(μ,σ2),则可利用标准正态分布函数Φ(x ),通过查表求得X 落在任一区间(x 12]内的概率,即P {x 1<X ≤x 2}=⎭⎬⎫⎩⎨⎧-≤-<-σμσμσμ21x X x P =⎭⎬⎫⎩⎨⎧-≤--⎭⎬⎫⎩⎨⎧-≤-σμσμσμσμ12x X P x X P=⎪⎭⎫ ⎝⎛-Φ-⎪⎭⎫⎝⎛-Φσμσμ12x x . 例如,设(1.5,4),可得P {-1≤X ≤2}=⎭⎬⎫⎩⎨⎧-≤-≤--25.1225.125.11X P=Φ(0.25)-Φ(-1.25)=Φ(0.25)-[1-Φ(1.25)]=0.5987-1+0.8944=0.4931.设(μ,σ2),由Φ(x )函数表可得P {μ-σ<X <μ+σ}=Φ(1)-Φ(-1)=2Φ(1)-1=0.6826,P {μ-2σ<X <μ+2σ}=Φ(2)-Φ(-2)=0.9544, P {μ-3σ<X <μ+3σ}=Φ(3)-Φ(-3)=0.9974.我们看到,尽管正态变量的取值范围是(-∞,∞),但它的值落在(μ-3σ,μ+3σ)内几乎是肯定的事,因此在实际问题中,基本上可以认为有-μ|<3σ.这就是人们所说的“3σ原则”.例2.12 公共汽车车门的高度是按成年男子与车门顶碰头的机会在1%以下来设计的.设男子身高X 服从μ=170(),σ=6()的正态分布,即(170,62),问车门高度应如何确定?解 设车门高度为h (),按设计要求P {X ≥h }≤0.01或P {X <h }≥0.99,因为(170,62),故P {X <h }=⎪⎭⎫⎝⎛-Φ=⎭⎬⎫⎩⎨⎧-<-617061706170h h X P ≥0.99, 查表得 Φ(2.33)=0.9901>0.99.故取6170-h =2.33,即184.设计车门高度为184()时,可使成年男子与车门碰头的机会不超过1%.例2.13 测量到某一目标的距离时发生的随机误差X (单位:米)具有密度函数f (x )=3200)20(2eπ2401--x .试求在三次测量中至少有一次误差的绝对值不超过30米的概率.解 X 的密度函数为f (x )=222402)20(3200)20(e π2401eπ2401⨯----⨯=x x ,即(20,402),故一次测量中随机误差的绝对值不超过30米的概率为P {≤30}{-30≤X ≤30}=⎪⎭⎫⎝⎛--Φ-⎪⎭⎫⎝⎛-Φ402030402030 =Φ(0.25)-Φ(-1.25)=0.5981-(1-0.8944)=0.4931.设Y 为三次测量中误差的绝对值不超过30米的次数,则Y 服从二项分布b (3,0.4931),故P {Y ≥1}=1-P {0}=1-(0.5069)3=0.8698.为了便于今后应用,对于标准正态变量,我们引入了α分位点的定义. 设(0,1),若z α满足条件P {X >z α}=α,0<α<1, (2.17)则称点z α为标准正态分布的上α分位点,例如,由查表可得z 0.05=1.6450.001=3.16.故1.645与3.16分别是标准正态分布的上0.05分位点与上0.001分位点.第四节 随机变量函数的分布我们常常遇到一些随机变量,它们的分布往往难于直接得到(如测量轴承滚珠体积值Y 等),但是与它们有函数关系的另一些随机变量,其分布却是容易知道的(如滚珠直径测量值X ).因此,要研究随机变量之间的函数关系,从而通过这种关系由已知的随机变量的分布求出与其有函数关系的另一个随机变量的分布.例2.14 设随机变量X 具有表2-6所示的分布律,试求X 2的分布律.“X 2=9”等价,所以P {X 2=0}{0}=0.1, P {X 2=2.25}{1.5}=0.3, P {X 2=9}{3}=0.1.事件“X 2=1”是两个互斥事件“1”及“1”的和,其概率为这两事件概率和,即P {X 2=1}{1}{1}=0.2+0.3=0.5.于是得X 2的分布律如表2-7所示.解 先求Y 的分布函数(y ),由于(X )2≥0,故当y ≤0时事件“Y ≤y ”的概率为0,即(y ){Y ≤y }=0,当y >0时,有(y ){Y ≤y }{X 2≤y }{≤X ≤y }=x x f yyX d )(⎰-.将(y )关于y 求导,即得Y 的概率密度为(y )=()()[]⎪⎩⎪⎨⎧≤>-+.0,0,0,21y y y f y f y XX例如,当(0,1),其概率密度为(2.15)式,则2的概率密度为(y )=⎪⎩⎪⎨⎧≤>--.0,0,0,e π21221y y y y此时称Y 服从自由度为1的χ2分布.上例中关键的一步在于将事件“Y ≤y ”由其等价事件“≤X ≤y ”代替,即将事件“Y ≤y ”转换为有关X 的范围所表示的等价事件,下面我们仅对(X ),其中g (x )为严格单调函数,写出一般结论.定理2.2 设随机变量X 具有概率密度(x ),-∞<x <+∞,又设函数g (x )处处可导且g ′(x )>0(或g ′(x )<0),则(X )是连续型随机变量,其概率密度为(y )=⎩⎨⎧<<'.,0,)()]([其他βαx y h y h f X (2.18)其中α(g (-∞),g (+∞)),β(g (-∞),g (+∞)),h (y )是g (x )的反函数.我们只证g ′(x )>0的情况.由于g ′(x )>0,故g (x )在(-∞∞)上严格单调递增,它的反函数h (y )存在,且在(α,β)严格单调递增且可导.我们先求Y 的分布函数(y ),并通过对(y )求导求出(y ).由于(X )在(α,β)上取值,故 当y ≤α时,(y ){Y ≤y }=0; 当y ≥β时,(y ){Y ≤y }=1; 当α<y <β时,(y ){Y ≤y }{g (X )≤y }{X ≤h (y )}=⎰∞-)(d )(x h X x x f .于是得概率密度(y )=[()](),,0,X f h y h y x .αβ'<<⎧⎨⎩其他对于g ′(x )<0的情况可以同样证明,即(y )=[()][()],,0,fX h y h y x .αβ'<<⎧⎨⎩其他将上面两种情况合并得(y )=(())(),,0,fX h y h y x .αβ'⎧<<⎨⎩其他注:若f (x )在[a ,b ]之外为零,则只需假设在(a ,b )上恒有g ′(x )>0(或恒有g ′(x )<0),此时α{g (a ),g (b )},β{g (a ),g (b )}.例2.16 设随机变量(μ,σ2).试证明X 的线性函数(a ≠0)也服从正态分布. 证 设X 的概率密度(x )=,21222)(σμ--x e π-∞<x <+∞.再令(x ),得g (x )的反函数(y )=y ba-. 所以h ′(y )=1.由(2.18)式(X )的概率密度为(y )=⎪⎭⎫ ⎝⎛-a b y f a X 1, -∞<y <+∞, 即(y )=22)(2)]([21σμσa a b y a +--eπ,-∞<y <+∞,即有(a μ,(a σ)2).例2.17 由统计物理学知分子运动速度的绝对值X 服从麦克斯韦()分布,其概率密度为f (x )=⎪⎩⎪⎨⎧≤>-,0,0,0,42232x x a x a x e π其中a >0为常数,求分子动能221mX (m 为分子质量)的概率密度. 解 已知(x )=221mx (x )只在区间(0,+∞)上非零且g ′(x )在此区间恒单调递增,由。
概率论与数理统计第二章课件PPT

例2 某类灯泡使用时数在1000小时以上 的概率是0.2,求三个灯泡在使用1000 小时以后最多只有一个坏了的概率.
解: 设X为三个灯泡在使用1000小时已坏的灯泡数 .
X ~ B (3, 0.8),
P( X k)C (0.8) (0.2) , k 0,1,2,3
k 3 k
3k
P{X 1} =P{X=0}+P{X=1} =(0.2)3+3(0.8)(0.2)2
X
p
1
0
1
2
3 0.1
a b 0.2 0.3
求a,b满足什么条件。
a b 0.4, a 0, b 0
一旦知道一个离散型随机变量X的分布律后,我们便可求得X
所生成的任何事件的概率。特别地,对任意 a ,有 b
P a X b P X x P X x i i a x b a x b 1 1 pk
解
用泊松定理 取 =np=(400)(0.02)=8, 故 近似地有 P{X2}=1- P{X=0}-P {X=1}
=1-(1+8)e-8=0.996981.
泊松分布(Poisson distribution)
定义2 设随机变量X的可能取值为0,1,2,…,n,…,而X 的分布律为
pk P X k
路口1
路口2
路口3
X表示该汽车首次遇到红灯前已通过的路口的个数
路口1
路口2
路口3
1 1 1 P(X=3)= P( A1 A2 A3 ) =1/8 2 2 2
即
X
p
0
1
2
3
1 2
1 4
随机数的产生课件

伪随机数生成器的实现
线性同余法
线性同余法是一种常见的伪随机数生成器,通 过迭代计算来产生序列。它需要确定种子和一 组参数来控制生成的随机数序列。
梅森旋转演算法
梅森旋转演算法是一种高质量的伪随机数生成 器。它使用位操作和旋转运算来生成随机数序 列,具有较长的周期和良好的统计特性。
真随机数生成器的实现
的游戏乐趣和挑战,如随机胜利条件、
道具生成和敌人行为。
3
密码学
随机数在密码学中起到关键作用,用 于生成密钥、加密数据和验证身份。
数学模型
随机数在数学模型中用于模拟和预测 复杂系统的行为,如气象模型、金融 模型和生态模型。
总结
随机数的重要性
随机数在现代科学和技术中扮演着重要角色, 为众多应用提供随机性、不确定性和安全性。
线性复杂性检测
线性复杂性检测用于检测随 机数生成器的线性复杂性, 即是否存在线性关系。线性 复杂性低的生成器更难预测数 生成器的周期性。长周期生 成器可以提供更长的随机序 列,减小重复和预测的可能 性。
随机数的应用案例
1
游戏设计
2
游戏设计中的随机元素可以提供更多
2. NIST Special Publication 800-90A. (2010). Recommendation for Random Number Generation Using Deterministic Random Bit Generators.
3. Bailey, D. et al. (2007). A Proposal for Truly Random Number Generation in Digital Hardware.
未来随机数生成器的发展方向
《随机数的产生》课件

伪随机数生成器受到初 始种子选择的影响,可 能会导致预测性和周期 性问题。
硬件随机数生成器
1 原理
基于物理过程(例如热 噪声、放电噪声等)生 成真正的随机数。
2 基于物理过程的硬
件随机数生成器
利用物理过程生成随机 数,但实现上存在一些 技术挑战。
3 优缺点分析
硬件随机数生成数生成器
1 原理
利用量子力学中的不确定性原理生成真正的随机数。
2 实现方式
目前有不同的实现方式,如基于光子的实现和基于超导电子的实现。
3 优缺点分析
量子随机数生成器生成的随机数具有绝对的随机性,但技术上尚不成熟且成本较高。
随机数的应用
1 密码学
2 模拟
随机数在密码学中起到重要作用,用于生 成加密密钥和随机挑战。
式的优缺点比较
3 发展趋势及挑战
随机数生成技术仍在不
伪随机数生成器便于实
断发展,量子随机数生
现,但存在周期性问题。
成器的应用前景广阔,
硬件随机数生成器和量
但还需要克服技术难题。
子随机数生成器生成的
随机数质量更高。
《随机数的产生》PPT课件
# 随机数的产生 ## 介绍 - 什么是随机数? - 随机数在计算机中的应用 - 常见的随机数生成方式
伪随机数生成器
1 定义
伪随机数是通过确定性 算法生成的,看起来像 是随机生成的。
2 线性同余法
使用线性同余法生成伪 随机数序列,但它存在 周期性问题。
3 伪随机数生成器的
随机数用于模拟各种现实世界的随机事物, 如天气、股票价格等。
3 游戏
4 科学计算
游戏中的随机性让游戏更有挑战性和趣味 性,使游戏更具变化。
概率论与数理统计 第二讲 随机数的产生数据的统计描述50页PPT

36、“不可能”这个字(法语是一个字 ),只 在愚人 的字典 中找得 到。--拿 破仑。 37、不要生气要争气,不要看破要突 破,不 要嫉妒 要欣赏 ,不要 托延要 积极, 不要心 动要行 动。 38、勤奋,机会,乐观是成功的三要 素。(注 意:传 统观念 认为勤 奋和机 会是成 功的要 素,但 是经过 统计学 和成功 人士的 分析得 出,乐 观是成 功的第 三要素 。
39、没有不老的誓言,没有不变的承 诺,踏 上旅途 ,义无 反顾。 40、对时间的价值没有没有深切认识 的人, 决不会 坚韧勤 勉。
▪
26、要使整个人生都过得舒适、愉快,这是不可能的,因为人类必须具备一种能应付逆境的态度。——卢梭
▪
27、只有把抱怨环境的心情,化为上进的力量,才是成功的保证。——罗曼·罗兰
▪
28、知之者不如好之者,好之者不如乐之者。——孔子
▪
29、勇猛、大胆和坚定的决心能够抵得上武器的精良。——达·芬奇在明眼的跛子肩上。——叔本华
谢谢!
50
概率论与数理统计 第二章随机变量及其分布剖析PPT课件

射手射击击中目标.
这种对应关系在数学上表现为一种实值函数.
w.
X(w) R
对于试验的每一个样本点w,都对应着一个实数 X(w),而X(w)是随着实验结果不同而变化的一个 变量。
机
随机变量的定义
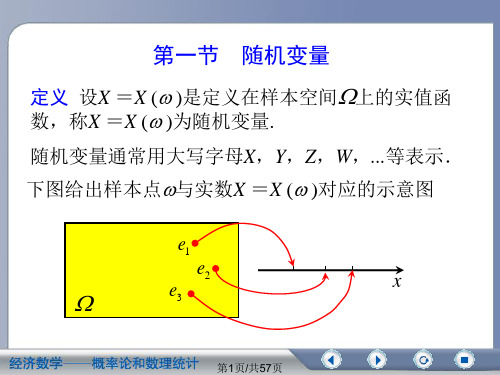
设 随 机 实 验 E的 样 本 空 间 , 若 对 每 一 个 样 本 点
, 都 有 唯 一 的 实 数 X()与 之 对 应 ,则 称 X()为 随 机 变 量 , 简 记 为 X.
P (X k ) ( 1 p )k 1 p , (k 1 ,2 , )
则称随机变量X服从以p为参数的几何分布,
记作
X ~G(p) 。
超几何分布
设N个元素分为两类,有M个属于第一类,N-M
个属于第二类。现在从中不重复抽取n个,其 中包含的第一类元素的个数X的分布律为
P(Xk)CM kC C N n N n kM, (k0,1, ,l) 其中l=min{M,n}, 则称随机变量X服从参数为 的超几何分布,记作 X~H(N,M,n)
由泊松定理,n重贝努里试验中稀有事件 出现的次数近似地服从泊松分布.
例5. 某车间有5台车床,由于种种原因(由 于装、卸工作等),时常需要停车.设各 台车床的停车或开车是相互独立的. 若车床在任一时刻处于停车状态的 概率是1/3,求车间中恰有一台车床处 于停车状态的概率。
解:X:处于停车状态的车床数
密度函数 f (x)在某点处a的高度,并不反映 X取值的概率. 但是,这个高度越大,则X 取a附近的值的概率就越大. 也可以说,在 某点密度曲线的高度反映了概率集中在该 点附近的程度.
f (x)
o
x
例1 :某型号电子管的寿命X(小时)的概率密度为
概率论与数理统计PPT课件

例6: (抽签问题)一袋中有a个红球,b个白球,记a+b=n. 设每次摸到各球的概率相等,每次从袋中摸一球, 不放回地摸n次。 设 { 第k次摸到红球 },k=1,2,…,n.求 解1:
号球为红球,将n个人也编号为1,2,…,n.
----------与k无关
可设想将n个球进行编号: 其中
18
性质:
19
§4 等可能概型(古典概型)
定义:若试验E满足:S中样本点有限(有限性)出现每一样本点的概率相等(等可能性)
称这种试验为等可能概型(或古典概型)。
20
例1:一袋中有8个球,编号为1-8,其中1-3 号为红球,4-8号为黄球,设摸到每一 球的可能性相等,从中随机摸一球, 记A={ 摸到红球 },求P(A).
31
三、全概率公式与Bayes公式
定义:设S为试验E的样本空间,B1,B2,…,Bn 为E的一组事件。若: 则称B1,B2,…,Bn为S的一个划分,或称为一组完备事件组。
即:B1,B2,…,Bn至少有一发生是必然的,两两同时发生又是不可能的。
32
定理:设试验E的样本空间为S,A为E的事件。B1,B2,…,Bn为S的一个划分,P(Bi)>0,i=1,2,…,n; 则称:
试验序号
n =5
n =50
n =500
nH
fn(H)
nH
fn(H)
nH
fn(H)
12345678910
2315124233
0.40.60.21.00.20.40.80.40.60.6
22252125242118242731
0.440.500.420.500.480.420.360.480.540.62
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
a=a+randnum(1,i);%频数 pro(i)=a/i;%频率 end pro=pro; num=1:n; plot(num,pro,num,p)
机械加工得到的零件尺寸的偏差、射击命中点 与目标的偏差、各种测量误差、人的身高、体重等, 都可近似看成服从正态分布。
3、指数分布随机数
1) R = exprnd(λ):产生一个指数分布随机数 2)R = exprnd(λ,m,n)产生m行n列的指数分布随机数
例3、产生E(0.1)上的一个随机数,20个随机数, 2行6列的随机数。
此定理给出的构造分布函数为F(x)的随机 数的产生方法为:
取U(0,1)随机数Ui,(i=1,2…),令Xi=F-1(Ui),则 Xi ,(i=1,2…),就是F(x)随机数,如果Ui独立,则 Xi也互相独立。
(一)直接抽样法(反函数法)
(1)连续分布的直接抽样法
设连续型随机变量X的分布函数为F(x),
例6 频率的稳定性
1、 事件的频率 在一组不变的条件下,重复作n次试验,记m是n
次试验中事件A发生的次数。 频率 f=m/n
2.频率的稳定性 在重复试验中,事件A的频率总在一个定值附近摆动, 而且,随着重复试验次数的增加,频率的摆动幅度 越来越小,呈现出一定的稳定性.
掷一枚硬币,记录掷硬币试验中频率P*的波动情况。
调用格式:
1、y=random(‘name’, A1, A2, A3, m, n) 其中:’name’为相应分布的名称,A1, A2, A3为分布 参数,m为产生随机数的行数,n为列数。
2、直接调用。 如: y=binornd(n, p, 1,10) 产生参数位n,p的1行10 列的二项分布随机数
例1、产生U(2,8)上的一个随机数,10个随机数, 2行5列的随机数。
命令:(1) y1=unifrnd(2,8) (2) y2=unifrnd(2,8,1,10) (3) y3=unifrnd(2,8,2,5)
y1=7.7008
y2=3.3868 5.6411 4.9159 7.3478 6.5726 4.7388 2.1110 6.9284 4.6682 5.6926
s n
( Xi X )2
正态分布偏度为0,偏度反映分布的对称性, g1 >0称为右偏态,此时数据位于均值右边的 比位于左边的多;g1 <0称为左偏态,情况相 反;而g1接近0则可认为分布是对称的.
命令:y=skewness(x) 若x为矢量,返回样本偏度,若x为矩阵, 结果为行向量,每个元素对应x中列元素 的样本偏度。
mean1=mean(x) median1=median(x) std1=std(x) var1=var(x) rang1=range(x)
3.表示分布形状的量—偏度和峰度
E( X E( X ))3
分布偏度: g1
3
其估计量为:
G1
1 n
n i 1
(Xi
X )3
s3
其中
1
在Matlab软件中,可以直接产生满足各种常用 分布的随机数,命令如下:
函数名 binornd chi2rnd exprnd
frnd gamrnd geornd hygernd normrnd poissrnd
trnd unidrnd unifrnd
对应分布的随机数 二项分布的随机数 卡方分布的随机数 指数分布的随机数 f分布的随机数 伽玛分布的随机数 几何分布的随机数 超几何分布的随机数 正态分布的随机数 泊松分布的随机数 学生氏t分布的随机数 离散均匀分布的随机数 连续均匀分2行5列的随机数.
命令 (1) y1=normrnd(10,2) (2) y2=normrnd(10,2,1,10) (3) y3=normrnd(10,2,2,5)
当研究对象视为大量相互独立的随机变量之和, 且其中每一种变量对总和的影响都很小时,可以认 为该对象服从正态分布。
则产生随机数的方法为: 取U(0,1)随机数Ui,(i=1,2…),令Xi=F(Ui),则Xi ,(i=1,2…), 就是F(x)随机数,如果Ui独立,则Xi也互相独立。
(2)离散分布的直接抽样法
设分布律为P(X=xi)= pi , i=1, 2, ...,其分布函数为F(x) ① 产生均匀随机数R,即R~U(0,1)
单位时间.即平均10个单位时间到达1个顾客. 顾 客到达的间隔时间可用exprnd(10)模拟。
4、二项分布随机数
1) R = binornd(n, p):产生一个二项分布随机数 2) R = binornd(n,p,m,n)产生m行n列的二项分布随机数
例4、产生B(10,0.8)上的一个随机数,15个随机数, 3行6列的随机数。
例9:产生5组指数分布随机数,每组100个, 计算样本偏度和峰度。
x=exprnd(10,100,5);
skewness1=skewness(x) kurtosis1=kurtosis(x)
三、分布函数的近似求法(直方图) 1、经验分布函数(累计频率直方图) Empirical Cumulative Distribution Function
0.0207 0.1974 0.1616 0.1301 0.4182 0.0809]
排队服务系统中顾客到达率为常数时的到达间隔、 故障率为常数时零件的寿命都服从指数分布。
指数分布在排队论、可靠性分析中有广泛应用。
例 顾客到达某商店的间隔时间服从参数为0.1的指 数分布
指数分布的均值为1/0.1=10。 指两个顾客到达商店的平均间隔时间是10个
总体分布函数的近似
定义: 设x1,x2,…,xn是总体的容量为n的样
本值,将其按由小到大的顺序排列,并 重新编号,记为
x1* x2* xn*
则经验分布函数为:
0
Fn
(
x)
k n
1
x x1*
x
* k
x
x* k 1
x
x
* n
2、频率直方图——近似概率密度函数
y3=[6.7516 6.4292 4.4342 7.5014 7.3619; 7.5309 3.0576 7.6128 4.4616 2.3473]
2、正态分布随机数
1)R = normrnd(μ, σ,):产生一个正态分布随机数 2)R = normrnd(μ, σ,m,n)产生m行n列的正态分布随机数
命令 (1) y1=binornd(10,0.8) (2) y2=binornd(10,0.8,1,15) (3) y3=binornd(10,0.8,3,6)
20、其他分布随机数的产生方法
定理 设X的分布函数为F(x),连续且严格单调上升, 它的反函数存在,且记为F-1(x),
则① F(X)~U(0,1) ② 若随机变量U~U(0,1),则F-1(U) 的分布函数为F(x)。
分布峰度
E( X E( X ))4
g2
4
其估计量为:
1
G2 n
( Xi X )4 s4
其中
s 1
n
( Xi X )2
峰度是分布形状的另一种度量,正态分布 的峰度为3,若g2比3大很多,表示分布有沉 重的尾巴,说明样本中含有较多远离均值的 数据,因而峰度可用作衡量偏离正态分布的 尺度之一
②
X
xi x1
若F ( xi1 ) R F( xi ),(i 2,3, 若R F( x1 )
则X~F(x)
(二)变换抽样法 (三)值序抽样法 (四)舍选抽样法 (五)复合抽样法(合成法) (六)近似抽样法
详见:高惠璇 北京大学出版社《统计计算》
例5、 设X分布函数为
1、均匀分布U(a,b)
1)unifrnd (a,b)产生一个[a,b] 均匀分布的随机数 2)unifrnd (a,b,m, n)产生m行n列的均匀分布随机数矩
当只知道一个随机变量取值在(a,b)内,但不 知道(也没理由假设)它在何处取值的概率大,在
何处取值的概率小,就只好用U(a,b)来模拟它。
在Matlab命令行中输入以下命令: binomoni(0.5,1000)
在Matlab命令行中输入以下命令: binomoni(0.5,10000)
在Matlab命令行中输入以下命令: binomoni(0.3,1000)
二、常用统计量
1、表示位置的统计量—平均值和中位数
平均值(或均值,数学期望):X
命令 (1) y1=exprnd(0.1) (2) y2=exprnd(0.1,1,20) (3) y3=exprnd(0.1,2,6)
结果
(1) y1=0.0051
(2) y2=[0.1465 0.0499 0.0722 0.0115 0.0272
0.0784 0.3990 0.0197 0.0810 0.0485 0.0233] (3) y3=[0.1042 0.4619 0.1596 0.0505 0.1615 0.0292;
1 n
n i 1
Xi
中位数:将数据由小到大排序后位于中间位置
的那个数值.
平均值:mean(x) 中位数:median(x) 若x为矢量,返回平均值和中位数,若x为 矩阵,结果为行向量,每个元素对应x中 列元素的平均值和中位数
2、表示变异(离散)程度的统计量
—方差、标准差、极差
样本方差:
S2
概率论与数理统计实验