ORACLE第四章单行函数
oracle函数

SQL> SELECT empno, ename, deptno
2 FROM
emp
3 WHERE ename = 'blake';
no rows selected
SQL> SELECT 2 FROM 3 WHERE
empno, ename, deptno emp ename = UPPER('blake');
学习改变命运,知 识创造未来
oracle函数
数值型函数
使用ceil函数: SELECT ceil(2.35) FROM dual; 执行结果: CEIL(2.35) ------------3 说明:该函数求得大于等于2.35的最小整数,结果
为3。
学习改变命运,知 识创造未来
oracle函数
数值型函数
--------------- -------------- -----------------
45.92
46
50
学习改变命运,知 识创造未来
oracle函数
使用 TRUNC函数
SQL> SELECT TRUNC(45.923,2), TRUNC(45.923),
2
TRUNC(45.923,-1)
45.92
ØMOD: 取余数 MOD(1600, 300) 100
学习改变命运,知 识创造未来
oracle函数
使用 ROUND 函数
SQL> SELECT ROUND(45.923,2), ROUND(45.923,0),
2
ROUND(45.923,-1)
3 FROM DUAL;
单行函数——精选推荐

单⾏函数所谓的单⾏函数指的就是完成某⼀具体功能的操作函数,例如:转⼤⼩写等。
⼀般⽽⾔,单⾏函数的格式:返回值函数名称(参数)。
单⾏函数分为以下⼏种:字符串函数、数值函数、⽇期函数、转换函数、通⽤函数。
1.字符串函数字符串函数是处理字符串数据的(对于字符串的数据有可能是从列上找到的,或者是直接设置的字符串常量)。
包含的函数有如下⼏种:No函数名称返回类型描述1 UPPER(列|字符串)字符串将传⼊的字符串变成⼤写形式2 LOWER(列|字符串)字符串将传⼊的字符串变成⼩写形式3 INITCAP(列|字符串)字符串开头⾸字母⼤写,其他的字母变为⼩写4 LENGTH(列|字符串)数字取得指定字符串的长度5SUBSTR(列|字符串,开始索引,[长度])字符串进⾏字符串的截取,如果没有设置长度,表⽰从截取全部6REPLACE(列|字符串,旧内容,新内容)字符串将指定的字符串数据以新数据替换旧数据范例:在Oracle⾥⾯,所有的函数如果要想进⾏验证,也必须编写SQL语句。
为了⽅便⽤户进⾏⼀些验证或者是⼀些不需要查询表的查询操作,专门提供了⼀个dual的虚拟表。
1.转⼤写⼩写操作 1)转⼤写SELECT UPPER('hello') FROM dual; 2).将所有姓名转⼩写SELECT LOWER(ename) FROM emp;⼀般在⼀些不区分数据⼤⼩写的情况都会同意的将所有的内容转成⼤写或⼩写的形式处理。
2.⾸字母⼤写其他字母⼩写 1)将所有的雇员姓名以⾸字母⼤写的形式保存SELECT INITCAP(ename) FROM emp;3.取得字符串的长度 1)基础操作SELECT LENGTH('ddffgg') FROM dual; 2)查询雇员姓名长度为5的全部雇员信息SELECT * FROM emp WHERE LENGTH(ename)=5;4.字符串截取 1)验证函数SQL> SELECT SUBSTR('helloworld',6) FROM dual;SUBSTR('HE----------worldSQL> SELECT SUBSTR('helloworld',0,5) FROM dual;SUBSTR('HE----------hello 在程序之中所有的字符串的⾸字母的索引都是0,但是在Oracle⾥⾯,所有的字符串的⾸字母索引都是1,如果设置的是0 ,那么它也会按照1的⽅式进⾏处理。
oracle常用函数使用大全_最新整理

单值函 数在查询 中返回单 个值,可 被应用到 select, where子 句,start with以及 connect by 子句 和having 子句。 (一).数值 型函数 (Number Functions ) 数值型函 数输入数 字型参数 并返回数 值型的值 。多数该 类函数的 返回值支 持38位小 数点,诸 如:COS, COSH, EXP, LN, LOG, SIN, SINH, SQRT, TAN, and TANH 支 持36位小 数点。 ACOS, ASIN, ATAN, and ATAN2支 持30位小
n1<0,则 oracle从 右向左数 确认起始 位置 例如: SELECT SUBSTR( 'What is this',-5,3) FROM DUAL;
n1>c1.len gth则返 回空 例如: SELECT SUBSTR( 'What is this',50,3) FROM DUAL; 然后再请 你猜猜, 如果 n2<1,会 如何返回 值呢
3、 TRUNC(n 1[,n2] 返 回截尾到 n2位小数 的n1的 值,n2缺 省设置为 0,当n2为 缺省设置 时会将n1 截尾为整 数,如果 n2为负 值,就截 尾在小数 点左边相 应的位上 。 例如: SELECT TRUNC(2 3.56),TRU NC(23.56, 1),TRUNC (23.56,-1) FROM DUAL;
例如: SELECT REPLAC E('WWhhh hhaT is tHis w W','W','-') FROM
9、 SOUNDE X(c) 神奇 的函数 啊,该函 数返回字 符串参数 的语音表 示形式, 对于比较 一些读音 相同,但 是拼写不 同的单词 非常有用 。计算语 音的算法 如下:
(完整版)ORACLE函数大全

ORACLE函数大全SQL中的单记录函数1.ASCII返回与指定的字符对应的十进制数;SQL〉 select ascii('A')A,ascii(’a') a,ascii('0’) zero,ascii(' ') space from dual;A A ZERO SPACE————-——-— -—---———- ---—----- ---————-—65 97 48 322.CHR给出整数,返回对应的字符;SQL〉 select chr(54740) zhao,chr(65) chr65 from dual;ZH C—— -赵 A3.CONCAT连接两个字符串;SQL> select concat('010—’,'88888888')||'转23’高乾竞电话 from dual;高乾竞电话—-——-———-—--——-—010—88888888转234.INITCAP返回字符串并将字符串的第一个字母变为大写;SQL〉 select initcap('smith’) upp from dual;UPP—————Smith5.INSTR(C1,C2,I,J)在一个字符串中搜索指定的字符,返回发现指定的字符的位置;C1 被搜索的字符串C2 希望搜索的字符串I 搜索的开始位置,默认为1J 出现的位置,默认为1SQL> select instr(’oracle traning’,’ra',1,2) instring from dual;INSTRING—-—------96.LENGTH返回字符串的长度;SQL> select name,length(name),addr,length(addr),sal,length(to_char(sal)) from gao.nchar_tst;NAME LENGTH(NAME) ADDR LENGTH(ADDR) SALLENGTH(TO_CHAR(SAL))————-———---————-—- —--——---——----—- -———--—-—-—— ----———-————----—-——--—--—---高乾竞 3 北京市海锭区 6 9999.99 77。
Oracle中文使用手册

1.Oracle的使用1.1. SQLPLUS的命令初始化表的位置:set NLS_LANG=american_7ascii (设置编码才可以使用下面脚本)cd $ORACLE_HOME/rdbms cd demo summit2.sql*********************************我们目前使用的是oralce 9i 9201 版本select * from v$version;恢复练习表命令:sqlplus **/** @summit2.sql //shell要在这个文件的位置。
登陆oracle的命令:sqlplus 用户名/密码show user 显示当前登陆的身份.set pause onset pause off 分页显示.oracle中默认日期和字符是左对齐,数字是右对齐table or view does not exist ; 表或示图不存在edit 命令用于自动打开vi修改刚修执行过的sql的命令。
修改方法二:l 3 先定位到行 c /旧串/新串执行出错时,利用错误号来查错误:!oerr ora 942 (装完系统后会装一个oerr工具,用于通过错误号来查看错误的具体信息)想在sql中执行unix命令时,把所有的命令前加一个!就可以,或者host( 用于从sql从切换至unix环境中去)/*** 初次使用时注意 ****运行角本时的命令:先切换到unix环境下,cd $oracle_home cd sqlplus cd demo 下面有两个角本建表语句。
@demobld.sqlsqlplus nanjing/nanjing @demobid.sql 直接运行角本,后面跟当前目录或者是绝对路径保存刚才的sql语句:save 命令第二次保存时要替换之前的角本 save 文件名 replace把刚才保的sql重新放入 buffer中spool on 开启记录spool off 关闭记录spool 文件名此命令会把所有的操作存在某个文件中去常见缩写:nls national language support 国家语言支持1.2. SQL的结构|DDL 数据库定义|DML 数据库管理SQL――Commit rollback|DCL 数据库控制|grant+revoke 权限管理表分为:系统表(数据字典),用户表注:知道数据字典可以更便于使用数据库。
ORACLE常用函数功能演示
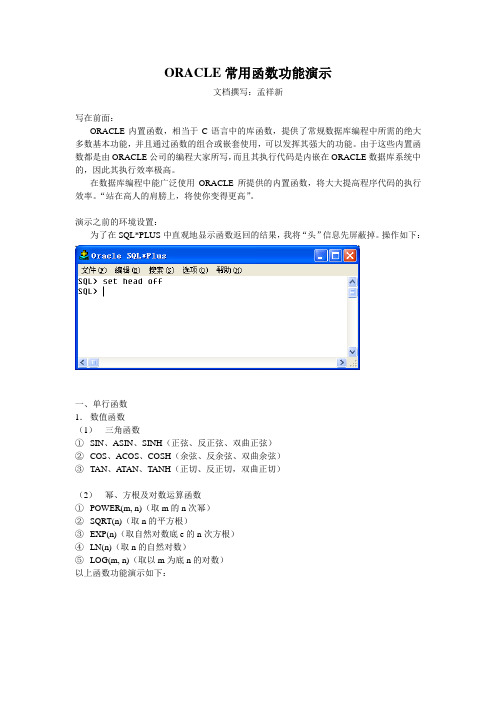
ORACLE常用函数功能演示文档撰写:孟祥新写在前面:ORACLE内置函数,相当于C语言中的库函数,提供了常规数据库编程中所需的绝大多数基本功能,并且通过函数的组合或嵌套使用,可以发挥其强大的功能。
由于这些内置函数都是由ORACLE公司的编程大家所写,而且其执行代码是内嵌在ORACLE数据库系统中的,因此其执行效率极高。
在数据库编程中能广泛使用ORACLE所提供的内置函数,将大大提高程序代码的执行效率。
“站在高人的肩膀上,将使你变得更高”。
演示之前的环境设置:为了在SQL*PLUS中直观地显示函数返回的结果,我将“头”信息先屏蔽掉。
操作如下:一、单行函数1.数值函数(1)三角函数①SIN、ASIN、SINH(正弦、反正弦、双曲正弦)②COS、ACOS、COSH(余弦、反余弦、双曲余弦)③TAN、ATAN、TANH(正切、反正切,双曲正切)(2)幂、方根及对数运算函数①POWER(m, n)(取m的n次幂)②SQRT(n)(取n的平方根)③EXP(n)(取自然对数底e的n次方根)④LN(n)(取n的自然对数)⑤LOG(m, n)(取以m为底n的对数)以上函数功能演示如下:(3)数值处理函数①ABS(n)(取绝对值)②SIGN(n)(符号函数)③CEIL(n)(取不小于n的最小整数)④FLOOR(n)(取不大于n的最大整数)⑤ROUND(n, [m])(按m精度对n进行4舍5入)⑥TRUNC(n, [m])(按m精度对n进行截取)⑦MOD(m, n)(取m除以n的余数)以上函数功能演示如下:2.字符处理函数(1)对字符串的大小写处理的函数①INITCAP(功能:将字符串中每个单词的首字母,变换为大写。
)②UPPER(功能:将字符串中的所有字母,转换为大写。
)③LOWER(功能:将字符串中的所有字母,转换为小写。
)以上函数功能演示如下:(2)对字符串进行处理的函数①CONCAT(字符串连接函数,也可用|| 替代)功能演示如下:②ASCII(取字符的编码)③CHR(将编码转换为对应的字符)以上函数功能演示如下:④LTRIM(去除左侧空格/指定字符)⑤RTRIM(去除右侧空格/指定字符)⑥TRIM(去除两侧的空格/去除指定字符)以上函数去除空格功能演示如下:以上函数去除指定字符功能演示如下:请注意:在用TRIM去除字符串中指定字符(非空格)时的特殊用法。
极好的 sql oracle 培训资料03

下转换:
从 VARCHAR2 or CHAR 到 NUMBER
VARCHAR2 or CHAR
DATE
显式转换
TO_NUMBER TO_DATE
NUMBER
CHARACTER
DATE
TO_CHAR
TO_CHAR
TO_CHAR 用于日期型
TO_CHAR(date, 'fmt')
日期格式模型: − 必须用单引号引起来并且是大小写敏感的 − 可以包含任何有效的日期元素 − 可以用fm来消除前导空格或零 − 使用逗号与日期型数据分隔开
RR 日期格式
当前年份 1995 1995 2001 2001 指定的日期 27-OCT-95 27-OCT-17 27-OCT-17 27-OCT-95 RR 格式 1995 2017 2017 1995 YY 格式 1995 1917 2017 2095
如果指定两位数年份是: 0–49 如果当前年 份的两位数 是: 0–49 返回的日期是当前世 纪的日期 返回的日期是下一个 世纪的日期 50–99 返回的日期是上一个 世纪的日期 返回的日期是当前世 纪的日期
EMPNO ENAME DEPTNO --------- ---------- --------7698 BLAKE 30
字符处理函数
字符处理函数
函数 CONCAT('Good', 'String') SUBSTR('String',1,3) LENGTH('String') INSTR('String', 'r') 结果 GoodString Str 6 3
Single-Row Functions 单行函数
数据库操作语言

数据库操作语⾔⼀、基本知识 1、Oracle服务器由两⼤部分组成:Oracle数据库和Oracle实例 Oracle数据库:位于硬盘上实际存放数据的⽂件,以.DBF结束的⽂件 Oracle实例:位于物理内存⾥的数据结构 2、数据库中的语⾔: DML:数据库操作语⾔(select、insert、update、delete) DDL:数据库定义语⾔(create table、alter table、drop table、create view) DCL:数据库控制语⾔(commit、rollback、grant、revoke)⼆、:数据库操作语⾔-select 1、简单的查询: select * from 表名; --查询表的所有信息 select 列名1,列名2,列名3... from 表名; --查询表的部分信息 select e.ename 姓名, e.sexl 性别, e.age 年龄 from emp e; --查询语句中别名的使⽤ 2、条件查询where select * from emp where deptno = 10; select * from emp where hiredate='09-6⽉ -81'; --正确,'09-6⽉ -81'为⽇期默认格式 DD-MON-RR 对于⽇期有两种修改⽅式: a)修改系统默认⽇期格式:alter session set NLS_DATE_FORMAT='yyyy-mm-dd'; b)使⽤to_date:select * from emp where hiredate = to_date('1981-6-9', 'yyyy-mm-dd'); to_date(要转换的内容, 格式) 3、⽐较运算符 a)、between ... and ... 在两个值之间(包含边界值),⼩值在前⼤值在后,可以作⽤于数字、⽇期 select * from emp where sal between 1000 and 2000; --查询薪⽔1000-2000的员⼯: b)、[not] in(set) select * from emp where deptno in (10, 20); --查询10号和20号部门的员⼯: 如果使⽤not in,那么括号⾥不能有null值 c)、like 模糊查询% 代表零个或多个字符 _ 代表⼀个字符 select * from emp where ename like 'S%'; --查询以S开头的员⼯: select * from emp where ename like '____'; --查询名字是4个字的员⼯ select e.ename from emp e where e.ename not like '%R%' order by e.ename; --显⽰不带有"R"的员⼯的姓名 4、逻辑运算 and:逻辑并 or:逻辑或 not:逻辑⾮ 5、排序 --order by:排序(升序asc(默认);降序desc) order by 后⾯可以跟:列名、表达式、别名、序号 如果后⾯的多列都按降序排,那么每列后⾯跟desc select e.ename,e.sal,e.hiredate from emp e order by e.ename; ----(1)查询EMP表显⽰所有雇员名、⼯资、雇佣⽇期,并以雇员名的升序进⾏排序。
oracle(数据类型函数)

select lpad(ename,'10','*') from emp;
rpad //右侧填充 smith***** 10填充长度
select rpad(ename,'10','*') from emp;
trim //清除空格
round(314.1415,-2)结果 300
trunc()//截断
Select trunc(100.256,2) from dual; //结果 100.25
trunc(3.1415,3) 截断 3.141
ceil //向上取整
ceil(3.14)//结果 4 注意:ceilபைடு நூலகம்3.0)结果为3 返回不比3.14小的数据
//输出日期字段对应日后的第一个星期二
ROUND(x,y) //将日期x四舍五入到y指定日期单位(月或年)的第一天
select ename,hiredate,round(hiredate,'month') from emp;
//输出hiredate指定的月四舍五入的数据(如3月16就往前加一月等于4月1日,如3月15就不变还是3月1日)
//格式化输出数字(9代表一位数字,没有就不显示,但对于小数点后的强制显示)
2)select to_char(sal, '$00,000.0000') from emp;
//0代表一位数字,没有显示为0
3)select to_char(sal, 'L99,999.9999') from emp; //L代表本地货币
Oracle聚合函数分析

COVAR_POP,返回一对表达式的总体协方差。
COVAR_SAMP,返回一对表达式的样本协方差。
COUNT,对组内发生的事情进行累计。如果指定*或一些非空常数,count将对所有行计数,如果指定一个表达式,count返回表达式非空赋值的计数,当有相同值出现时,这些相等的值都会被纳入被计算的值;可以使用DISTINCT来记录去掉一组中完全相同的数据后出现的行数。
RATIO_TO_REPORT,该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比,即当前行对sum(expression)的贡献。
REGR_ (Linear Regression) Functions
功能描述:这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用。
FIRST,从DENSE_RANK返回的集合中取出排在最前面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录。
FIRST_VALUE,返回组中数据窗口的第一个值。
LAG,可以访问结果集中的其它行而不用进行自连接。它允许去处理游标,就好像游标是一个数组一样。在给定组中可参考当前行之前的 行,这样就可以从组中与当前行一起选择以前的行。Offset是一个正整数,其默认值为1,若索引超出窗口的范围,就返回默认值(默认返回的是组中第一 行),其相反的函数是LEAD
REGR_SLOPE:返回斜率,等于COVAR_POP(expr1, expr2) / VAR_POP(expr2)
REGR_INTERCEPT:返回回归线的y截距,等于
AVG(expr1) - REGR_SLOPE(expr1, expr2) * AVG(expr2)
Oracle数据库培训-SQL基础篇

连字运算符
连字运算符: •连接列或者字符串到其它的列 •用两个竖线表示(||) •构造一个字符表达式的合成列 SELECT first_name||last_name AS Employees FROM employees;
文字字符串
•文字字符串是包含在SELECT列表中的一个字符 串,一个数字或者一个日期 •日期和字符的文字字符串值必须用单引号括起来 •每个文字字符串在每行输出一次 SELECT last_name||' is a '||job_id
空值
•null 是一个未分配的、未知的,或不适用的值 •null不是0,也不是空格 •包含空值的算术表达式计算结果为空 SELECT last_name, job_id, salary,
commission_pct FROM employees;
定义列别名
列别名: •改变列标题的名字 •可用于计算结果 •紧跟在列名后面–在列名和别名之间可以有选项 AS 关键字 •如果别名中包含有空格、或者特殊字符、或者大 小写敏感,要求用双引号 SELECT last_name AS name, commission_pct comm FROM employees;
SQL 函数
• 函数是SQL的一个非常强有力的特性,函数能够 用于下面的目的:
– 执行数据计算 – 修改单个数据项 – 操纵输出进行行分组 – 格式化显示的日期和数字 – 转换列数据类型
• SQL函数有输入参数,并且总有一个返回值。 注:在本课中讲述的大多数函数是针对SQL的 Oracle版的。
SQL 函数 (续)
AS "Employee Details” FROM employees;
约束和排序数据
ORACLE-SQL语句学习教程

目录概述 (2)第一章SQL*PLUS 工具软件的使用 (5)第二章基本查询 (9)第三章条件查询 (13)第四章单行函数 (16)第五章多表查询 (20)第六章组函数 (23)第七章子查询 (25)第八章运行期间指定变量 (29)第九章创建基表 (31)第十章ORACLE数据字典 (36)第十一章操纵数据 (38)第十二章修改基表及其约束 (42)第十三章创建序列 (45)第十四章创建视图 (47)第十五章创建索引 (50)概述20世纪70年代初,E.F.Codd 在计算机学会(Association of Computer Machinery, 简写为ACM)期刊Communications of the ACM(ACM 通讯)发表了题为”A Relational Model of Data for Large Shared Data Banks”(大型共享数据库的数据关系模型)的论文,该论文提出的关系数据库模型成为今天最为权威的关系型数据库管理模型。
IBM公司首先使用该模型开发出了结构化英语查询语言SEQUEL(Structured English Query Language),作为其关系数据库原型System R的操作语言,实现对关系数据库的信息检索。
SEQUEL后来简写为SQL,即Structured Query Language(结构化查询语言)的缩写。
ORACLE公司于1997年推出了第一个商业应用的SQL软件。
20世纪80年代初,美国国家标准化组织(ANSI)开始着手制订SQL标准,最早的ANSI标准于1986年颁布,它也被称为SQL-86。
标准的出台使SQL作为标准的关系数据库语言的地位得到加强。
SQL标准几经修改和完善,目前SQL语言方面新的ANSI标准是1992年制定的ANSI X3.135-1992,“Database Language SQL”。
此标准也被国际电工委员会(International Electro technical Commission, 即IEC)所属的国际标准化组织(International Standards Organization, 即ISO)所接受,并将它命名为ISO/IEC9075:1992, “Database Language SQL”。
PL-SQL Oracle教程

目录第二章基本的SQL SELECT语句 (1)第三章限制行和对数据排序 (2)第四章联接多个表 (3)迪卡尔连接 (3)相等连接 (3)不等连接 (3)自我连接 (4)外部连接 (4)集合运算符 (4)第五章单行函数 (5)大小写转换函数 (5)字符串处理函数 (5)数字函数 (6)Date函数 (6)其它函数 (7)NESTRING函数 (9)DUAL表 (9)第六章组函数 (10)第七章子查询 (11)单行子查询 (11)多行子查询 (11)多列子查询 (12)NULL值 (13)嵌套的子查询 (13)第八章表的创建和维护 (15)表设计 (15)创建表 (16)修改现有的表 (17)删除表 (19)第九章约束 (20)创建约束 (20)使用Primary Key约束 (20)使用Foreign Key约束 (21)使用Unique约束 (21)使用Check约束 (21)使用Not NULL约束 (22)在创建表的过程中包括约束 (22)查看约束 (22)禁用约束 (23)删除约束 (23)第十章数据操作 (24)插入新行 (24)修改现有的行 (25)替换变量 (25)事务控制语句 (25)删除行 (25)表锁 (26)第十一章视图 (27)创建视图 (27)创建复杂视图 (27)删除视图 (28)创建内联视图 (28)第十五章PL/SQL简介 (29)基本结构 (30)声明部分 (30)可执行部分 (31)执行控制 (31)循环语句 (32)第十六章游标和异常 (34)游标 (34)异常处理 (36)PL/SQL——第二章基本的SQL SELECT语句 1 第二章基本的SQL SELECT语句PL/SQL——第三章限制行和对数据排序 2 第三章限制行和对数据排序第四章联接多个表A表BP◆迪卡尔连接(A表每个记录与B表每个纪录配对。
A*B)1.select A_ID , B_IDfrom A , B2.select A_ID , B_IDfrom A cross join B◆相等连接(A表中某列与B表中某列相等)1.select A . A_name , B . B_namefrom A , Bwhere A . A_ID = B . B_ID2.select A . A_name , B . B_namefrom A join Bon A . A_ID = B . B_ID如果A表与B表关联的列名相等,则可以用Natural Join(此时不能使用修饰符)select A_name , B_namefrom A Natural Join B或:select A_name , B_namefrom A Join Busing(ID)◆不等连接(不存在可以关联的相同行,即一定范围内的连接)1.select A_name , P_namefrom A , Pwhere A_Pricebetween Min and Max2.select A_name , P_namefrom A join Pon A_Price between Min and Max◆自我连接(同一张表内的自身连接)1.select r . B_ID , c . C_IDfrom B r, B cwhere r . B_ID =c . C_ID2.select r . B_ID , c . C_IDfrom B r join B con r . B_ID =c . C_ID◆外部连接(连接查询的结果中包括存在与一个表中但是另一个表中没有相应行的纪录)1.select A . A_name , B . B_name 左外连接from A , Bwhere A . A_ID = B . B_ID(+)2.select A . A_name , B . B_name 左外连接from A left(left/right/all)outer join Bon A . A_ID = B . B_ID◆集合运算符()Select* from A_nameUnion(Union / Union all / Intersect / Minus)Select* from B_nameUnion:返回结合的select语句的结果,删除重复的纪录。
Oracle函数手册

1. 单行函数1.1 字符函数LOWER 使字符串小写;select LOWER('HeLp') from dual --->helpUPPER 使字符串大写;select UPPER('HeLp') from dual --->HELPINITCAP 使字符串的第一个字母大写,其它为小写select INITCAP('hELp') from dual --->HelpLENGTH 返回表达式中的字符串长度select LENGTH('hELP') from dual ---->4CONCAT 将值连接到一起(,对于此函数,只能使用2个参数)select CONCAT('Hello', 'World') from dual --->HelloWorldSUBSTR 抽取确定长度的字符串select SUBSTR('HelloWorld',1,5) from dual ---->HelloINSTR 查找指定字符的数字位置select INSTR('HelloWorld', 'W') from dual --->6LPAD 按右对齐填充字符串select LPAD(salary,10,'*') from dual --->*****24000RPAD 按左对齐填充字符串select RPAD(salary, 10, '*') from dual --->24000*****TRIM(leading|trailing|both,trim_character FROM trim_source) 从字符串中截去头部或者尾部的字符(或者头尾都截掉)(如果trim_character或trim_source是一个字符型文字值,则必须将它包含在单引号之内。
oracle rowtype单行数据用法

题目:深入探讨Oracle Rowtype的单行数据用法我很高兴能为你写这篇关于Oracle Rowtype的文章。
Oracle Rowtype是Oracle数据库中非常重要的一个概念,对于数据库管理和应用开发都有着重要的意义。
在这篇文章中,我将按照你的要求,深入探讨Oracle Rowtype的单行数据用法,以便你能更深入地理解这个主题。
让我们来了解一下Oracle Rowtype的基本概念。
在Oracle数据库中,每一行数据都可以看作是一个记录,拥有特定的字段和对应的数值。
而Rowtype则是一种特殊的数据类型,用来表示表中的一行数据,实际上就是一个表的结构。
通过使用Rowtype,我们可以定义一个变量,其数据类型就是对应表的行类型,这样就可以轻松地操作表中的数据。
在实际应用中,Oracle Rowtype可以带来很多便利之处。
它使得我们能够方便地进行表中数据的读取和写入操作,而不需要逐个字段地定义变量。
通过使用Rowtype,可以减少代码量,提高开发效率,同时也减少了出错的可能性。
另外,Rowtype还可以用来进行数据的转换和验证,将表中的数据直接映射到相应的变量中,从而更加方便地进行数据处理和计算。
单行数据用法是Oracle Rowtype的一个重要应用场景。
当我们需要操作一行表数据时,可以通过定义Rowtype类型的变量,将表的结构映射到对应的变量中。
这样,在对数据进行操作时,可以直接通过这个变量来引用数据,而不需要逐个字段地操作,大大简化了代码逻辑。
在实际开发过程中,单行数据用法的应用非常广泛。
在存储过程或触发器中,我们经常需要对表中的数据进行操作,使用Rowtype就可以方便地引用和处理表中的数据,提高了开发效率和代码的可读性。
另外,在数据处理和转换中,单行数据用法也能发挥重要作用,通过定义Rowtype类型的变量,可以方便地进行数据的转换和验证,减少了代码量,提高了开发效率。
总结来说,Oracle Rowtype的单行数据用法是一个非常重要的概念,它为我们在Oracle数据库中操作表中数据带来了很多便利。
oracle语法大全

oracle语法大全SQL>desc s_emp脚本sql.txt sql.sql1.上传脚本2.运行脚本@绝对路径/文件名@文件名(存眷说话情形)select userenv('lang') from dual;USERENV('LANG')----------------USUSERENV('LANG')----------------ZHSdesc 一张表Name Null? Type----------------------------------------- -------- -----------------ID 职员id NOT NULL NUMBER(7)LAST_NAME 姓NOT NULL VARCHAR2(25) FIRST_NAME 名V ARCHAR2(25) USERID 职员描述V ARCHAR2(8) START_DATE 入职日期DA TECOM MENTS 备注V ARCHAR2(255) MANAGER_ID 引导的职员id NUMBER(7) TITLE 职位V ARCHAR2(25)DEPT_ID 部分id NUMBER(7) SALARY 月薪NUMBER(11,2) COMMISSION_PCT 提成NUMBER(4,2)sql语句的分类:数据检索select数据操作insert delete update数据定义create drop alter事务操纵commit rollback savepoint数据操纵grant revoke选择投影连接查询语句:A from 子句1.查询出随便率性一个字段select 字段名from 表名;select salary from s_emp;2.查询多个字段(用逗号瓜分)select first_name,salary from s_emp;3.* 号能够替代所有的字段select * from s_emp;4.表头的原样显示----应用双引号select first_name,salary sal from s_emp;select first_name,salary "sal" from s_emp;能够让别号中包含空格select first_name,salary "emP sal" from s_emp;5.字段的数学运算求每小我的年薪select salary*12 yearsal from s_emp;换一种年薪运算方法推敲提成select salary*12*(1+commission_pct/100) yearsal from s_emp;select salary*12*(1+commission_pct/100) yearsal from s_emp;nvl 空值处理函数nvl(值/字段,假如是空要获得的值)第一个参数是NULL 就返回第二个参数假如第一个参数不是NULL 返回第一个参数select nvl(salary*12*(1+commission_pct/100),0)yearsal from s_emp;//logic error空值要尽早处理空值和任何值做运算差不多上NULLselect salary*12*(1+nvl(commission_pct,0)/100)yearsal from s_emp;6.想把姓名显示出来select first_name,last_name from s_emp;字符串连接||select first_name||last_name from s_emp;字符串的表达'hello' '_' ' ' ''select first_name||'_'||last_name from s_emp;this'sselect first_name||''''||last_name from s_emp;7.排重显示---distinctselect salary from s_emp;select distinct salary from s_emp;补偿:结合排重select distinct salary,id from s_emp;clear screen!clearB 前提子句wherewhere 字段表达式表达式找出工资大年夜于1400的first_name,salaryselect first_name,salary from s_emp where 1=1;//全部显示select first_name,salary from s_emp where 1=2;//无显示select first_name,salary from s_emp where salary>1400;where 前提限制行的返回相符前提返回不相符过滤掉落字段表达式中能够应用的比较运算符= 一个等号确信相等找出first_name ,manager_id 是Carmen 的工资select first_name,salary,manager_id from s_emp wherefirst_name='Carmen';数字类型能够直截了当用等号确信相等字符串不要不记得单引号oracle sql 大年夜小写不敏锐单字符串的值大年夜小写敏锐><<=>=!= <> ^=between and not between andin not inlike not likeis null is not nulloracle(sql) 也供给了一些运算符字段between a and b 表达一个闭区间[a,b]工资salary 在[800,1400]select first_name,salary from s_emp where salarybetween 800 and 1400;字段in (list) list用逗号隔开的一组值查询一下部分号在41 42 50 人first_name,salary select first_name,salary,dept_id from s_emp where dept_id in (41,42,50);次序对最终成果没有阻碍但对效力可能产生阻碍字段is null 确信一个字段是不是NULLid 是1的人manager_id 是不是NULLselect id,first_name from s_emp wheremanager_id is null;like -----模糊查询成龙配套成龙李小龙龙飞凤舞first_name 中带a字符的统配符:% 代表n个随便率性字符_ 一个随便率性字符'%a%''%a''a%''_a%''%a_'select first_name from s_emp wherefirst_name like '%a%';找出第二个字符是aselect first_name from s_emp wherefirst_name like '_a%';user_tables----数据字典表,储备了数据库中所有表的信息desc user_tablesTABLE_NAME 表名select table_name from user_tables;s_emp s_dept s找出所有s_开首的表名select table_name from user_tables where table_namelike 's_%';user_tables 数据字典表----默认处理成大年夜写select table_name from user_tables where table_namelike 'S_%';select table_name from user_tables where table_namelike 'S__%';//logic error转义select table_name from user_tables where table_namelike 'S\_%' escape '\';select table_name from user_tables where table_namelike 'S'||'_'||'%';//logic逻辑连接符号andor!工资salary 在[800,1400]select first_name,salary from s_emp where salarybetween 800 and 1400 ;select first_name,salary from s_emp where salary>=800and salary<=1400;工资salary 在(800,1400)select first_name,salary from s_emp where salary>800and salary<1400;字段in (list) list用逗号隔开的一组值查询一下部分号在41 42 50 人first_name,salary select first_name,salary,dept_id from s_emp where dept_id in (41,42,50);select first_name,salary,dept_id from s_empwhere dept_id=41 or dept_id=42 or dept_id=50;非关系> <=< >== != <> ^=between and not between andin not inlike not likeis null is not nullmanager_id 不是NULL的first_name ,salary,manager_id select first_name ,salary,manager_id from s_empwhere manager_id is not null;xml ----dom sax ui前提能够用小括号改变优先级别select first_name from s_emp where dept_id=41 or dept_id=42 and salary>1000;select first_name from s_emp where (dept_id=41 ordept_id=42) and salary>1000;假如不确信你的逻辑能够经由过程小括号改变逻辑优先select salary*12+100 from s_emp;select (salary+100)*12 from s_emp;C 排序排序的种类:升序字典次序天然次序asc 默认次序降序desc按照工资排序显示first_name,salaryorder by 排序字段必定涌现在sql语句最后select first_name,salary from s_emp order by salary;select first_name,salary from s_emporder by salary asc;降序select first_name,salary from s_emporder by salary desc;补偿:第一排序字段第二排序排序按照工资排序显示first_name,salary 工资雷同按first_name 降序select first_name,salary from s_emp where 1=1order by salary desc,first_name desc;D 单行函数单行函数:对一行操作之后获得一个成果组函数:对一组数据数据处理之后获得一个成果upperselect first_name,upper(first_name) from s_emp;countselect count(id) from s_emp;s_emp 表中数据专门多对单行函数的测试不是专门便利测试表dual 单行单列desc dualselect * from dual;测试字符串的函数upperlower select lower('ONE DREAM ONE WORLD') from dual;initcap select initcap('ONE DREAM ONE WORLD') from dual;length select length('ONE') from dual;edit -----进入vi 编辑界面x 删除字符dd 删除一行a i o敕令下ZZ 储存退出nvl()select nvl(NULL,'is null') from dual;select nvl('','is null') from dual;select nvl(' ','is null') from dual;nvl 要求能够处理任何类型但两个参数的类型必须一致substr(字段/值,开端的地位,截取多长)留意开端的地位是从1开端也能够负数负数从后往前编号从-1开端编号select substr('hello',1,3) from dual;select substr('hello',0,3) from dual;select substr('hello',2,4) from dual;从后编号select substr('hello',-2,2) from dual;把s_emp中first_name 的后三个字符截取下来select first_name,substr(first_name,-3,3) from s_emp;要求早年往后编号hello12345select first_name,substr(first_name,length(first_name)-2,3)from s_emp;数字select first_name from s_emp where id=1;select first_name from s_emp where id='1';//隐式类型转换select first_name from s_emp where id=to_number('1');to_number('abc') //logic errorselect initcap('one world one world') from s_emp;round(字段/值) 四舍五入取整select round(99.99) from dual;//100select round(99.94,1) from dual;//99.9select round(99.96,1) from dual;//100select round(94.96,-1) from dual;//90trunc(字段/值) 截取取整select trunc(99.99) from dual;//99select trunc(99.94,1) from dual;//99.9select trunc(99.96,1) from dual;//99.9select trunc(94.96,-1) from dual;//90select round(99.96,-2) from dual;//100to_char() 字符转换函数to_char(字段) 把那个字段变成字符串按照格局显示数字to_char(字段/值,'格局')fm 格局说明$ 美元符号L 本地泉币符号¥RMB9 随便率性数字0 强迫显示0 100 000,100.00, 国际泉币瓜分符. 小数点select salary ,to_char(salary,'fmL099,999.00')from s_emp;select salary ,to_char(salary,'fmL099,999.99')from s_emp;select userenv('lang') from dual;select to_char(9999.97,'fmL099,999.00') from dual;select to_char(9999.97,'fmL099,999.99') from dual;切换说话情形对显示的本地泉币符号的阻碍对日期格局产生了阻碍select sysdate from dual;SYSDA TE-----------26-APR-12现在切换成中文NLS_LANGbash修改.bash_profileexport NLS_LANG='SIMPLIFIED CHINESE_CHINA.ZHS16GBK'source .bash_profile从新进入sqlplusselect userenv('lang') from dual;ZHSselect sysdate from dual;select salary ,to_char(salary,'fmL099,999.00')from s_emp;演习:select first_name, salary,nvl(to_char(manager_id),'''boss''')from s_emp where salary>1000 order by salary desc;把first_name,salary,manager_id 显示出来要求工资大年夜于1000 同时按照工资降序manager_id 假如是NULL则显示manager_id 为'boss'select first_name,salary,nvl(manager_id,'boss')from s_emp where salary>1000order by salary desc;select first_name,salary,nvl(to_char(manager_id),'boss')from s_emp where salary>1000order by salary desc;select first_name,salary,nvl(to_char(manager_id),'''boss''')from s_emp where salary>1000order by salary desc;E 多表查询我们须要的数据不储备在一张表中把每个职员的first_name,dept_id 查询出来select first_name,dept_id from s_emp;部分表s_dept名称是否为空? 类型----------------------------------------- -------- -------------ID 部分id NOT NULL NUMBER(7) NAME 部分名称NOT NULL VARCHAR2(25) REGION_ID 地区id NUMBER(7)地区表s_region名称是否为空? 类型----------------------------------------- -------- --------------ID 地区id NOT NULL NUMBER(7) NAME 地区名称NOT NULL VARCHAR2(50)select * from s_region;select first_name,dept_id,name from s_emp,s_dept;笛卡尔集select first_name,dept_id,name from s_emp,s_deptwhere dept_id=s_dept.id;解决两个表直截了当的关系表的连接:内连接:相符连接前提就放入成果集不相符就过滤掉落等值连接:用等号做两个表的连接select first_name,dept_id,name from s_emp,s_deptwhere dept_id=s_dept.id;把每个部分的名字和地点的地区名称列出来select s_ ,s_from s_dept,s_regionwhere region_id=s_region.id;表的别号select ,from s_dept d,s_region rwhere d.region_id=r.id;非等值连接:不消等号做表的连接desc salgrade 工资级别表名称-------------------GRADE 工资级别LOSAL 低工资HISAL 高工资把s_emp 表中first_name,salary,grade 列一个清单select first_name,salary,gradefrom s_emp e,salgrade gwhere salary between losal and hisal;自连接:须要把一张表算作两张表谁是引导?把s_emp 逻辑上算作两张表然后找出这两张表的关系select distinct m.first_name,m.idfrom s_emp e,s_emp mwhere e.manager_id=m.id;select first_name,idfrom s_emp where manager_id=id;select id,manager_id from s_emp;谁不是引导?select distinct m.first_name,m.id,from s_emp e,s_emp mwhere e.manager_id!=m.id;外连接:外连接的成果集等于内连接的成果集+匹配不上的记录(和直截了当选择出是不合的)<<<----m中没匹配上的对应于e中的Manager_id=NULL>>>>>>>>.一个也不克不及少自连接select distinct m.first_name,m.idfrom s_emp e,s_emp mwhere e.manager_id(+)=m.idand e.manager_id is null;//哪些不是引导select distinct m.first_name,m.idfrom s_emp e,s_emp mwhere e.manager_id(+)=m.idand e.manager_id is not null;scotttigerselect * from s_dept;insert into s_dept values(100,'mytest1',1);commit;s_emp2 中没人在我新增长的部分中把每个职员地点部分名列出来(内连接)select first_name,namefrom s_emp,s_deptwhere dept_id(+)=s_dept.id;依照上面的提示找出没有职员的部分(外连接)select first_name,namefrom s_emp,s_deptwhere dept_id(+)=s_dept.id and dept_id is null;(+) 对面的表的数据全部匹配出来等值连接非等值连接找出每个职员的工资级别first_name,salary,gradeselect first_name,salary,gradefrom s_emp,salgradewhere salary between losal and hisal;update s_emp set salary=12500 where id=1;commit;更新之后老总不相符内连接的连接前提把老总的工资级别显示成10select first_name,salary,nvl(grade,10)from s_emp,salgradewhere salary between losal(+) and hisal(+);外连接的标准实现:sql99left outer join onright outer join onfull outer join on找出那些部分中还没有职员select first_name,namefrom s_emp,s_deptwhere dept_id(+)=s_dept.idand dept_id is null; 《《《精确显示mytest1行》》》》》》那张表提议连接那张表中的数据就被全部匹配出来select first_name,namefrom s_dept left outer join s_emp 《《表示s_dept提议连接,其数据全部显示出来》》》》》on s_dept.id=s_emp.dept_idwhere dept_id is null;《《《精确显示mytest1行》》》》》》select first_name,namefrom s_emp left outer join s_depton s_dept.id=s_emp.dept_idwhere dept_id is null;<<<<<无显示》》》*******************把上面的查询改成右外连接select first_name,namefrom s_emp right outer join s_depton s_dept.id=s_emp.dept_idwhere dept_id is null;《《《精确显示mytest1行》》》》》》full outer join on:全外连接的成果集等于右外连接的成果集+ 左外连接的成果集然后清除反复的记录oracle 不支撑两边都加括号加union 归并两个成果集然后清除反复union all 归并两个成果集select id from s_emp union select id from s_emp;select id from s_emp union all select id from s_emp;sql99 的内连接select first_name,dept_id,name from s_emp,s_deptwhere dept_id=s_dept.id;select first_name,dept_id,name from s_emp inner joins_dept on dept_id=s_dept.id;select first_name,dept_id,name from s_emp joins_dept on dept_id=s_dept.id;内连接把每个职员的first_name,salary,部分名,地区名列出来select first_name,salary,,from s_emp e,s_dept d,s_region rwhere e.dept_id=d.id and d.region_id=r.id;col name for a20select first_name,salary,,from s_emp e join s_dept d on e.dept_id=d.idjoin s_region r on d.region_id=r.id;select first_name,salary,,from s_emp e inner join s_dept d on e.dept_id=d.idinner join s_region r on d.region_id=r.id;update s_emp set dept_id=NULL where id=1;commit;那个老总就不在所有的部分信息中要把所有的职员信息列出来包含老总的话就须要外连接F 组函数和分组组函数能把一组数据处理之后获得一个成果count() 统计个数sum() 乞降avg() 求平均值max() 求最大年夜值min 求最小值group by 分组标准select dept_id,count(id)from s_emp group by dept_id;select count(id) from s_emp where dept_id=44;组函数用在select 后是分组后处理的组函数还能够涌现在having 后边where 对行数据的过滤having 是对组数据的过滤那个部分的人数大年夜于1select dept_id,count(id)from s_emp group by dept_idhaving count(id)>1;按照部分号分组统计每个部分的平均工资select dept_id,avg(salary)from s_emp group by dept_id;按照部分号分组统计每个部分的平均工资找出平均工资大年夜于1200的组select dept_id,avg(salary)from s_emp group by dept_idhaving avg(salary)>1200;select dept_id,avg(salary) asalfrom s_emp group by dept_idhaving avg(salary)>1200order by asal;按照部分号分组统计每个部分的平均工资找出平均工资大年夜于1200的组显示部分名称select dept_id,name,avg(salary) asalfrom s_emp,s_deptwhere dept_id=s_dept.idgroup by dept_idhaving avg(salary)>1200order by asal;因为部分号可不能反复所有在那个分组的标准再追加额外的标准没有阻碍select dept_id,name,avg(salary) asalfrom s_emp,s_deptwhere dept_id=s_dept.idgroup by dept_id,name --》》第一行有name,分组标准里必须有namehaving avg(salary)>1200order by asal;select dept_id,max(name),avg(salary) asalfrom s_emp,s_deptwhere dept_id=s_dept.idgroup by dept_idhaving avg(salary)>1200order by asal;-->> 第一行不max(name) 换成name 会掉足max()感化有时和distinct(去重)类似。
Oracle分析函数参考手册.doc

GROUP BY manager_id
) b
WHERE a.manager_id=b.manager_id
ORDER BY a.manager_id
--Order by按相应的值(hire_date)进行排序并累计统计
SELECT
manager_id,
first_name||' '||last_name employee_name,
--Partition by Order by首先按相应的值(manager_id,hire_date)排序,并按order by的值(hire_date)进行累计统计
--该平均值由当前员工和与之具有相同经理的前一个和后两个三者的平均数得来
SELECT
manager_id,
first_name||' '||last_name employee_name,
Oracle分析函数——SUM,AVG,MIN,MAX,COUNT
SUM
功能描述:该函数计算组中表达式的累积和。
SAMPLE:下例计算同一经理下员工的薪水累积值
MIN
功能描述:在一个组中的数据窗口中查找表达式的最小值。
SAMPLE:下面例子中dept_min返回当前行所在部门的最小薪水值
CUBE:按照OLAP的CUBE方式进行数据统计,即各个维度均需统计
ROLLUP:
SELECT
department_id,
manager_id,
employee_id,
first_name||' '||last_name employee_name,
ORACLE数据库sql语言、函数及常用命令

ORACLE结构查询语言SQL语言(新增内容为红色)一、概念介绍:数据库DATABASE、表TABLE、列COLUMN、行ROW、关键字PRIMARY KEY、索引INDEX二、列的类型:字符CHAR和V ARCHAR2、数值NUMBER、长整形LONG、双浮点FLOAT、超长大型数据LONG RAM(照片、图形、描述等不定长数据)、日期DATE(包含日期和时间)。
CHAR (5) 和V ARCHAR2(5)的区别是CHAR不足5位后面自动加上空格,V ARCHAR2不加。
三、列的非空属性NOT NULL:如果一个列具有非空属性,则在给该表增加、修改数据时必须保证该列有内容,否则会出错。
如果一个列允许为空,该列可以不放任何内容,即空值(在SQL中书写为NULL),空值不是空格,如果一个列内容为空值,则该列不等于任何值(包括空值)。
例如:列SAGE1、SAGE2的内容为空,列SAGE3内容为20,则下面的逻辑表达式全部为NULL:SAGE1=SAGE2、SAGE1<>SAGE2、SAGE1=SAGE3、SAGE3>SAGE1。
下面的逻辑表达式全部为真:SAGE1 IS NULL、SAGE3 IS NOT NULL。
下列表达式全为空:sage1+100,sage2+sage3 四、特殊约定:1.所有SQL语句以分号结束不是以回车换行结束。
2.中扩号代表选项,就是其中的内容可有可无。
3.下面讲的列名在很多情况下也可以是表达式。
4.表名格式:[用户名.]表名,例如:user001.student,如果不注名用户,则说明是当前用户的表。
五、建表或视图语句CREATE格式:CREATE TABLE 表名(列名类型长度[NOT NULL],列名类型长度[NOT NULL],列名类型长度[NOT NULL],列名类型长度[NOT NULL],列名类型长度[NOT NULL]);CREATE VIEW 视图名AS SELECT ……;CREATE TABLE 表名AS SELECT ……;Create table as 经常在修改一个表前备份该表,而且运行速度很快且不用提交例如:Select table a_student as select * from student;Create table as 还可以用来复制表结构假设目前有三张表Student(sno,sname,ssex,sage,sdept) 学生表Sno:学号Sname:姓名Ssex:性别Sage:年龄Sdept:所在系Course(cno,cname,cpno,ccredit) 课程表Cno:课程号Cname:课程名Cpno:先行课Ccredit:学分Sc(sno,cno,grade) 学生选课表Sno:学号Cno:课程号Grade:分数Create table student1 as select sno,name from student;利用student创建一个仅仅有两个列的student1。