Oracle+总结 (1)
oracle数据库工程师转正工作总结

转眼间,来公司已经2个月了。
这段时间的收获很多,知识的丰富,经验的增长,清楚地感受到自己在成长。
以下是我两个月以来的工作总结。
主要工作内容:1、学习工作所需具备知识,快速融入工作。
2、针对客户系统出现的问题,处理与解决。
3、每月到客户现场或远程对系统进行巡检。
4、领导安排的其他工作等。
从接触工作,包括与客户沟通、与公司同事的交流、在外出差、对相关设备的认识、以及遇到问题时的处理方法,这些事情让我明白了:工作需要细致认真和热情对待,并且还要具备一定的行业知识。
只有这样,才能把工作做的更好。
刚进入公司,接触很多的事物对我都是新鲜陌生的。
但是我愿意让自己由不知道变为知道,也愿意去接触各类新鲜事物。
加上领导和同事的关心和帮助,我不再对这些新事物感到陌生,慢慢地熟悉了一些行业相关的知识。
当然,在工作中还存在一定的问题和不足,比如:处理问题沟通不及时,导致领导对工作情况不明;处理问题不能得心应手,有时候需要同事协助,工作经验方面还有待提高,对相关知识没有提前了解,情况了解的还不够,掌握的技术手段还不够多,需要继续学习和提高;自己的业务能力,沟通能力也需要进一步加强等。
对于这些不足,会在以后的日子里提升自己。
在入职两个月最大的收获就是敢于接受任务并想尽办法完成,每一个任务对于我都是一个挑战,如何保质保量完成任务是最基本的要求。
在今后的工作过程中,我会更加严格要求自己,同时也有几个大方向是我需要努力。
掌握数据库技能,RAC、DG,它是我的核心工作。
我会努力做好本职工作。
还有,VMware相关知识,因为时间的分配,有很多知识未能及时学习巩固,同时也需要紧抓时间实践操纵,并参加到实际工作,使自己能更加灵活应用相关知识,并积累处理相关异常经验。
同时,自己也要不断努力与充实自己,研究数据库,使自己处理处理突发事件的效率提高,以及存储这些常用的设备。
在今后的一年里,也会参加OCP证书考核,不断晋升自己,并且利用业余时间努力学习,包括学习小型机跟进步英语水平等,不断提升自己的专业水平及综合素质,以为公司尽自己的一份力量。
ORACLE数据库基础知识总结

ORACLE数据库基础知识总结1、RMAN全备备份⽂件的顺序备份归档⽇志、所有的数据⽂件、控制⽂件、spfile、再次备份归档⽇志2、redo⽇志丢失恢复redo⽇志的三种状态是current、active、inactiveinactive,可以重建 clear logactive、current不能变成inactive,只能通过不完全恢复进⾏恢复,然后重建⽇志⽂件3、⼝令⽂件丢失恢复丢失可重建 orapwd file= password= enfries=重建完成之后ORACLE正常使⽤4、控制⽂件丢失恢复a> rman 可以备份控制⽂件b> 控制⽂件可以cp⼀份备⽤c> 控制⽂件可以重建⼿写5、体系结构物理:ORACLE数据库包括instance、database两部分。
instance包括SGA(系统全局区)跟⼀些后台进程组成的。
SGA包括:share pool、db buffer cache、redo log buffer、流池、⼤型池、JAVA POOL、share pool(共享池) :库缓存:缓存最近执⾏的代码,同样的sql多次执⾏不需要频繁读取数据字典中得数据数据字典缓存:存储oracle中得对象定义PL/SQL区:缓存存储过程、函数触发器等数据库对象。
db buffer cache(数据库缓存区)redo log buffercache(⽇志缓存区)常见的后台进程:DBWn:⽤于数据库缓存写⼊磁盘LGWn:⽤于log⽇志写⼊磁盘CKPT:检查点进程SMON:实例维护进程,系统监视器MMON:AWR主要进程PMON:维护⽤户进程,进程监视器ARCN:归档进程database包括数据⽂件、控制⽂件、⽇志⽂件等。
逻辑:oracle数据块-区-段-表空间-数据库-⽅案多个oracle数据块组成⼀个区,多个区组成⼀个段,多个段组成⼀个表空间,多个表空间组成⼀个数据库表空间和数据⽂件的关系:表空间是由⼀个或多个数据⽂件组成的,⼀个数据⽂件只属于⼀个表空间,表空间的⼤⼩是所有数据⽂件⼤⼩的总和。
oracle优化方法总结

千里之行,始于足下。
oracle优化方法总结Oracle优化是提高数据库性能和响应能力的重要步骤。
本文总结了一些常见的Oracle优化方法。
1. 使用索引:索引是提高查询性能的主要方法。
通过在表中创建适当的索引,可以加快查询速度,并减少数据访问的开销。
但是要注意不要过度使用索引,因为过多的索引会增加写操作的开销。
2. 优化查询语句:查询语句的效率直接影响数据库的性能。
可以通过合理地编写查询语句来提高性能。
例如,使用JOIN来替代子查询,尽量避免使用通配符查询,使用LIMIT来限制结果集的大小等。
3. 优化表结构:表的设计和结构对数据库的性能也有很大的影响。
合理的表设计可以减少数据冗余和不必要的数据存储,提高查询速度。
例如,适当地使用主键、外键和约束,避免过多的数据类型和字段等。
4. 优化数据库参数设置:Oracle有很多参数可以用来调整数据库的性能。
根据具体的应用场景和需求,可以根据情况调整参数的值。
例如,调整SGA和PGA的大小,设置合适的缓冲区大小,调整日志写入方式等。
5. 使用分区表:当表的数据量很大时,可以考虑将表分成多个分区。
分区表可以加速查询和维护操作,提高数据库的性能。
可以按照时间、地域、业务等来进行分区。
6. 优化存储管理:Oracle提供了多种存储管理选项,如表空间和数据文件管理。
合理地分配存储空间和管理数据文件可以提高数据库的性能。
例如,定期清理无用的数据文件,使用自动扩展表空间等。
第1页/共2页锲而不舍,金石可镂。
7. 数据压缩:对于大量重复数据或者冷数据,可以考虑使用Oracle的数据压缩功能。
数据压缩可以减少磁盘空间的使用,提高IO性能。
8. 使用并行处理:对于大型计算或者批处理任务,可以考虑使用Oracle的并行处理功能。
并行处理可以将任务分成多个子任务,并行执行,提高处理能力和效率。
9. 数据库分区:对于大型数据库,可以考虑将数据库分成多个独立的分区。
数据库分区可以提高数据的并行处理能力,减少锁竞争和冲突,提高数据库的性能。
oracle 工作总结

oracle 工作总结
《Oracle 工作总结》。
在过去的一段时间里,我一直在公司的Oracle团队工作。
在这段时间里,我学到了很多关于Oracle数据库管理和优化的知识,也积累了丰富的工作经验。
在这篇文章中,我将对我的工作进行总结,并分享一些我在Oracle工作中的收获和体会。
首先,我要谈谈我在Oracle数据库管理方面的工作。
在这个岗位上,我负责监控数据库的运行状态,确保数据库的稳定性和安全性。
我学会了如何定期备份数据库,以防止数据丢失。
我还学会了如何优化数据库的性能,通过调整参数和索引来提高数据库的查询效率。
在这个过程中,我遇到了很多问题,但通过不断学习和实践,我逐渐掌握了数据库管理的技巧和方法。
其次,我还要谈谈我在Oracle数据库优化方面的工作。
在这个岗位上,我负责分析数据库的性能问题,并提出优化建议。
我学会了如何通过SQL调优来提高数据库的查询速度,如何通过合理的索引设计来减少数据库的IO负载。
我还学会了如何通过分区表和分区索引来提高数据库的并发处理能力。
通过这些工作,我深入了解了Oracle数据库的优化原理和方法,也提高了自己的技术水平。
总的来说,我的Oracle工作经历让我受益良多。
我不仅学会了数据库管理和优化的技术,也锻炼了自己的分析和解决问题的能力。
我相信,在未来的工作中,我会继续努力学习,不断提高自己的技术水平,为公司的发展贡献自己的力量。
感谢公司给予我这次宝贵的工作机会,我会继续努力,不辜负公司的期望。
oracle日常运维操作总结

oracle日常运维操作总结一、硬件维护1.确保服务器硬件运行正常,定期检查硬件设备,如服务器、存储设备、网络设备等。
2.根据需要及时更新硬件设备,包括升级内存、硬盘等。
3.确保服务器周边设备运行正常,如UPS电源、空调等。
二、软件维护1.确保Oracle数据库软件运行正常,定期检查软件版本、补丁等。
2.更新Oracle数据库软件,包括升级Oracle版本、打补丁等。
3.定期清理无用文件,包括日志文件、临时文件等。
4.定期备份数据库,确保数据安全。
三、性能优化1.定期检查数据库性能,包括CPU使用率、内存使用率等。
2.根据性能检查结果,进行性能优化,如调整数据库参数、优化SQL语句等。
3.定期对数据库进行优化,包括重建索引、优化表空间等。
四、安全加固1.配置Oracle数据库的安全设置,如用户密码、权限管理等。
2.确保数据库账户的安全性,如定期修改密码、禁用无效账户等。
3.防止SQL注入等攻击行为,如使用参数化查询、限制用户输入等。
4.定期检查数据库的安全日志,包括登录日志、操作日志等。
五、数据备份1.制定数据备份计划,并按照计划执行备份操作。
2.采用多种备份方式,如全备份、增量备份等。
3.确保备份数据的可用性和完整性,如定期测试备份数据的恢复能力。
4.对备份数据进行存储和管理,确保数据安全。
六、故障处理1.建立故障处理流程,明确故障处理责任人和流程步骤。
2.对发生的故障进行及时处理,如系统崩溃、网络故障等。
3.对故障进行分类和总结,建立故障处理知识库。
4.定期对系统进行健康检查和性能测试,预防故障发生。
七、监控管理1.建立监控管理体系,包括监控指标、监控周期等。
2.使用监控工具,如OracleEnterpriseManager、Nagios等,对系统进行实时监控。
3.对监控数据进行分析和处理,及时发现和处理潜在问题。
4.定期对监控数据进行存储和管理,方便后续查询和分析。
八、应急预案1.制定应急预案,明确应急响应流程和责任人。
oracle数据库sqlload常用技巧总结 (1)
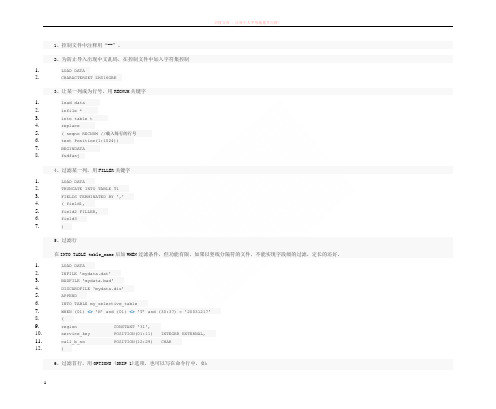
1、控制文件中注释用“--”。
2、为防止导入出现中文乱码,在控制文件中加入字符集控制1.LOAD DATA2.CHARACTERSET ZHS16GBK3、让某一列成为行号,用RECNUM关键字1.load data2.infile *3.into table t4.replace5.( seqno RECNUM //载入每行的行号6.text Position(1:1024))7.BEGINDATA8.fsdfasj4、过滤某一列,用FILLER关键字1.LOAD DATA2.TRUNCATE INTO TABLE T13.FIELDS TERMINATED BY ','4.( field1,5.field2 FILLER,6.field37.)5、过滤行在INTO TABLE table_name后加WHEN过滤条件,但功能有限,如果以竖线分隔符的文件,不能实现字段级的过滤,定长的还好。
1.LOAD DATA2.INFILE 'mydata.dat'3.BADFILE 'mydata.bad'4.DISCARDFILE 'mydata.dis'5.APPEND6.INTO TABLE my_selective_table7.WHEN (01) <> 'H' and (01) <> 'T' and (30:37) = '20031217'8.(9.region CONSTANT '31',10.service_key POSITION(01:11) INTEGER EXTERNAL,11.call_b_no POSITION(12:29) CHAR12.)6、过滤首行,用OPTIONS (SKIP 1)选项,也可以写在命令行中,如:sqlldr sms/admin control=test.ctl skip=17、TRAILING NULLCOLS的使用,作用是表的字段没有对应的值时允许为空如:1.LOAD DATA2.INFILE *3.INTO TABLE DEPT4.REPLACE5.FIELDS TERMINATED BY ','6.TRAILING NULLCOLS // 其实下面的ENTIRE_LINE在BEGINDATA后面的数据中是没有直接对应的列的值的如果第一行改为 10,Sales,Virginia,1/5/2000,, 就不用TRAILING NULLCOLS了7.(DEPTNO,8.DNAME "upper(:dname)", // 使用函数9.LOC "upper(:loc)",ST_UPDATED date 'dd/mm/yyyy', // 日期的一种表达方式还有'dd-mon-yyyy' 等11.ENTIRE_LINE ":deptno||:dname||:loc||:last_updated"12.)13.BEGINDATA14.10,Sales,Virginia,1/5/200015.20,Accounting,Virginia,21/6/199916.30,Consulting,Virginia,5/1/200017.40,Finance,Virginia,15/3/20018、添加、修改数据(1)、1.LOAD DATA2.INFILE *3.INTO TABLE tmp_test4.( rec_no "my_db_sequence.nextval",5.region CONSTANT '31',6.time_loaded "to_char(SYSDATE, 'HH24:MI')",7.data1 POSITION(1:5) ":data1/100",8.data2 POSITION(6:15) "upper(:data2)",9.data3 POSITION(16:22)"to_date(:data3, 'YYMMDD')"10.)11.BEGINDATA12.11111AAAAAAAAAA99120113.22222BBBBBBBBBB990112(2)、1.LOAD DATA2.INFILE 'mail_orders.txt'3.BADFILE 'bad_orders.txt'4.APPEND5.INTO TABLE mailing_list6.FIELDS TERMINATED BY ","7.( addr,8.city,9.state,10.zipcode,11.mailing_addr "decode(:mailing_addr, null, :addr, :mailing_addr)",12.mailing_city "decode(:mailing_city, null, :city, :mailing_city)",13.mailing_state14.)9、合并多行记录为一行记录通过关键字concatenate 把几行的记录看成一行记录:1.LOAD DATA2.INFILE *3.concatenate 3 // 通过关键字concatenate 把几行的记录看成一行记录4.INTO TABLE DEPT5.replace6.FIELDS TERMINATED BY ','7.(DEPTNO,8.DNAME "upper(:dname)",9.LOC "upper(:loc)",ST_UPDATED date 'dd/mm/yyyy'11.)12.BEGINDATA13.10,Sales, // 其实这3行看成一行 10,Sales,Virginia,1/5/200014.Virginia,15.1/5/200010、用”|+|”分隔符,避免数据混淆:fields terminated by "|+|"11、如果数据文件包含在控制文件中,用INFILE *如下:1.LOAD DATA2.INFILE *3.append4.INTO TABLE tmp_test5.FIELDS TERMINATED BY ","6.OPTIONALLY ENCLOSED BY '"'7.TRAILING NULLCOLS8.( data1,9.data210.)11.BEGINDATA12.11111,AAAAAAAAAA13.22222,"A,B,C,D,"12、一次导入多个文件到同一个表1.LOAD DATA2.INFILE file1.dat3.INFILE file2.dat4.INFILE file3.dat5.APPEND6.INTO TABLE emp7.( empno POSITION(1:4) INTEGER EXTERNAL,8.ename POSITION(6:15) CHAR,9.deptno POSITION(17:18) CHAR,10.mgr POSITION(20:23) INTEGER EXTERNAL11.)13、将一个文件导入到不同的表(1)、1.LOAD DATA2.INFILE *3.INTO TABLE tab1 WHEN tab = 'tab1'4.( tab FILLER CHAR(4),5.col1 INTEGER6.)7.INTO TABLE tab2 WHEN tab = 'tab2'8.( tab FILLER POSITION(1:4),9.col1 INTEGER10.)11.BEGINDATA12.tab1|113.tab1|214.tab2|215.tab3|316.==============(2)、1.LOAD DATA2.INFILE 'mydata.dat'3.REPLACE4.INTO TABLE emp5.WHEN empno != ' '6.( empno POSITION(1:4) INTEGER EXTERNAL,7.ename POSITION(6:15) CHAR,8.9.deptno POSITION(17:18) CHAR,10.mgr POSITION(20:23) INTEGER EXTERNAL11.)12.INTO TABLE proj13.WHEN projno != ' '14.( projno POSITION(25:27) INTEGER EXTERNAL,15.empno POSITION(1:4) INTEGER EXTERNAL16.)14、过滤掉的数据文件路径指定1./opt/app/oracle/product/10.2.0/bin/sqlldr APS/APS control=/home/oracle/APS_LOAD/ctl/AP_CONTRACT.CTL LOG=/home/oracle/APS_LOAD/log/$yesterday/AP_CONTRACT_$yesterday.log bad=/home/oracle/APS_LOAD/bad/DUE_BILL_$yesterday.bad rows=10000readsize=20000000bindsize=20000000DISCARD=/home/oracle/APS_LOAD/bad /discard_ts.dis15、附:测试用控制文件1.LOAD DATA2.INFILE '/home/oracle/APS_LOAD/dat/APS_AP_CONTRACT.dat'3.TRUNCATE4.INTO TABLE AP_CONTRACT5.WHEN (01)<>'1'6.FIELDS TERMINATED BY "|"7.TRAILING NULLCOLS8.(9.AGMT_NO "(TRIM(:AGMT_NO ))",10.CONTRACT_NO FILLER, -- "(TRIM(:CONTRACT_NO ))",11.LOAN_AMT "(TRIM(:LOAN_AMT ))",12.AGMT_HOLDER "(TRIM(:AGMT_HOLDER ))",13.LOAN_TYPE_CD "(TRIM(:LOAN_TYPE_CD ))",14.CURR_CD "(TRIM(:CURR_CD ))",15.BALANCE "(TRIM(:BALANCE ))",16.LOAN_DIRC_CD "(TRIM(:LOAN_DIRC_CD ))",17.AGMT_START_DATE "(TRIM(:AGMT_START_DATE ))",18.AGMT_END_DATE "(TRIM(:AGMT_END_DATE ))",19.AGMT_BELONG_ORG_NO "(TRIM(:AGMT_BELONG_ORG_NO ))",20.MANAGER_NO "(TRIM(:MANAGER_NO ))",21.PROCESS_RATE "(TRIM(:PROCESS_RATE ))",22.INSURE_METH_TYPE_CD "(TRIM(:INSURE_METH_TYPE_CD ))",23.AGMT_SIGN_DATE "(TRIM(:AGMT_SIGN_DATE ))",24.LOAN_PROP_CD "(TRIM(:LOAN_PROP_CD ))",25.LOAN_USE_TYPE "(TRIM(:LOAN_USE_TYPE ))",26.ENTRUST_LOAN_FLAG "(TRIM(:ENTRUST_LOAN_FLAG ))",27.ENTRUST_NAME "(TRIM(:ENTRUST_NAME ))",28.FARM_LOAN_FLAG "(TRIM(:FARM_LOAN_FLAG ))",29.FARM_LOAN_TYPE_CD "(TRIM(:FARM_LOAN_TYPE_CD ))",30.LOAN_BIZ_TYPE_CD "(TRIM(:LOAN_BIZ_TYPE_CD ))",31.ID_TEST RECNUM ,32.CHAR_TEST CONSTANT '31',33.SQ "sqlldr.nextval",34.TEST_4 "TO_CHAR(SYSDATE,'YYYYMMDD HH24:MI:SS')",35.TEST_5 "(TRIM(:LOAN_BIZ_TYPE_CD)||'---'||TRIM(:AGMT_NO))"36.)来源:网络编辑:联动北方技术论坛。
Oracle实训总结

Oracle数据库管理与应用实训总结
在这一周Oracle数据库管理与应用的实训的时间里,实训老师针对我们本学期的学习,有针对性地对我们进行了很有价值的实训工作,从最基础的字段类型,到一般的Oracle语句,如创建数据表、视图、存储过程、触发器等,给我们细心讲解,虽然Oracle数据库管理与应用的课已经学习了将近一学期,但对其简单的知识点运用的都不是很熟练,没能真正去融会贯通。
不过,经过为期一周的针对性实训,我学到了很多知识,把以前学的所有知识点都贯穿到一起,又温习了一遍,让我们能从真正意义上了解到Oracle数据库的用处。
不论再用到什么软件编写网站,都会用到数据库连接,都要从那个数据库中调用数据,这说明了数据库的重要性,认识到学习数据库的必要性。
Oracle数据库是很重要的数据库系统。
在数据库实训过程中,难免会出现小错误,但经过我们的讨论研究,加上老师认真的辅导,我们会解决这些错误,从而更加熟练掌握Oracle 数据库。
这一周不仅学到了Oracle数据库的知识,还培养了我们的团队合作精神,互相帮助,讨论研究,解决问题。
实训一周,收获颇多,更是受益匪浅。
Oracle数据库语法总结

Oracle数据库语法总结一、DDL(数据定义语言)1、创建、删除表(1)CREATE TABLE 语句用于在Oracle数据库中创建新表:CREATETABLE表名(列1数据类型(大小/长度)[NOTNULL][CONSTRAINT约束名]列2数据类型(大小/长度)[NOTNULL][CONSTRAINT约束名]……(2)DROP TABLE 语句用于从Oracle数据库中删除表:DROPTABLE表名2、更改表(1)ALTERTABLE语句用于更改现有的表:ALTERTABLE表名ADD(添加新的列),MODIFY(修改现有的列),DROP(删除现有的列)(2)RENAME语句用于更改表名:RENAME表名1TO表名23、创建索引(1)CREATEINDEX语句用于在表中创建索引:CREATEINDEX索引名ON表名(列1,列2,...)(2)DROPINDEX语句用于从表中删除索引:DROPINDEX索引名4、创建约束(1)Primary Key 约束:ALTERTABLE表名ADDCONSTRAINT主键名PRIMARYKEY(列名)(2)Foreign Key约束:ALTERTABLE表名ADDCONSTRAINT外键名FOREIGNKEY(列名)REFERENCES参照表名(参照列);(3)Unique 约束:ALTERTABLE表名ADDCONSTRAINT唯一约束名UNIQUE(列1,列2,...);(4)NOTNULL约束:ALTERTABLE表名ADDCONSTRAINT非空约束名NOTNULL(列1,列2,...);5、删除约束(1)Primary Key 约束:ALTERTABLE表名DROPCONSTRAINT主键名PRIMARYKEY;(2)Foreign Key约束:ALTERTABLE表名DROPCONSTRAINT外键名FOREIGNKEY;(3)Unique 约束:。
oracle表空间总结(个人笔记总结)

表空间含义:表空间是数据库的逻辑组成部分。
从物理上讲,数据库数据存放在数据文件中;从逻辑上讲,数据库则是存放在表空间中,表空间由一个或多个数据文件组成1,oracle 中逻辑结构包括表空间、段、区和块。
说明一下数据库由表空间构成,而表空间又是由段构成,而段又是由区构成,而区又是由oracle 块构成的这样的一种结构,可以提高数据库的效率。
表空间用于从逻辑上组织数据库的数据。
数据库逻辑上是由一个或是多个表空间组成的2,创建表空间:create tablespace data01 datafile 'd:\test\dada01.dbf' size 20m uniform size 128k;或SQL> create tablespace lqb datefile 'e:\lqb.dbf' size 50M autoextend on next 50M maxsize unlimited extend mangement local;-------------extend mangement local;本地管理表空间。
autoextend on next 50M maxsize unlimited 在50M后最大的扩展时没有限制的3,第3步:创建用户并指定表空间*/ create user USERNAME identified by PASSWORD default tablespace USER_DATE temporary tablespace user_temp;-------------temporary 临时的,暂时的4,如何将表移动到指定表空间alter table TABLE_NAME move tablespace TABLESPACE_NAME;如何将索引移动到指定的表空间alter index INDEX_NAME REBUILD tablespace TABLESPACE_NAME;5,改变表空间的状态a,使表空间脱机alter tablespace 表空间名offline; b,使表空间联机alter tablespace 表空间名online; c,只读表空间alter tablespace 表空间名read only; (修改为可写是alter tablespace 表空间名read write;)6, 知道表空间名,显示该表空间包括的所有表select * from all_tables where tablespace_name='表空间名';7,知道表名,查看该表属于那个表空间select tablespace_name, table_name from user_tables where table_name='emp';8,扩展该表空间,为其增加更多的存储空间。
oracle总结

oracle总结Oracle是一种关系型数据库管理系统(RDBMS),由Oracle公司开发和发布。
它具有强大的功能和广泛的应用领域,在企业数据管理中有着重要的地位。
本文将总结Oracle的主要特点、优点和应用场景,并对其未来发展进行展望。
首先,Oracle具有以下主要特点:1.可靠性高:Oracle具有事务管理、崩溃恢复和故障转移等功能,能够保证数据的完整性和可靠性。
2.性能优秀:Oracle采用先进的查询优化和缓存技术,可以处理大量的数据并快速响应用户请求。
3.可扩展性强:Oracle支持集群和分布式数据库,可以根据需要扩展服务器和存储资源。
4.安全性好:Oracle具有高级的安全控制功能,包括用户认证、权限管理和数据加密等,可以保护数据不受非法访问和损坏。
其次,Oracle有许多优点使其在企业中得到广泛应用。
首先,Oracle具有良好的数据一致性和完整性,可以保证数据的准确性和可靠性。
其次,Oracle具有强大的查询和分析能力,可以快速地检索和处理大量的数据。
此外,Oracle还具有较低的维护成本和良好的兼容性,可以与多种操作系统和应用程序集成使用。
最重要的是,Oracle有着庞大的用户群体和广泛的生态系统,可以获得丰富的技术支持和在线资源。
Oracle在各个行业和领域都有广泛的应用。
首先,在金融领域,Oracle被广泛用于银行、保险和证券等机构的核心业务系统和风险管理系统中,可以处理大量的交易数据并提供实时的分析报告。
其次,在制造业领域,Oracle可以用于企业资源规划(ERP)、供应链管理(SCM)和客户关系管理(CRM)等系统,协助企业管理生产流程和提高运营效率。
再次,在电信和互联网行业,Oracle可以用于大数据分析、用户行为分析和网络性能管理等关键业务系统中,可以帮助企业实现智能化决策和个性化服务。
此外,Oracle还在政府、医疗、教育等领域得到广泛应用,可以支持大规模的数据管理和业务处理。
oracle面试知识点总结

oracle面试知识点总结1. 数据库基础在Oracle面试中,首先要掌握数据库的基础知识,包括关系型数据库的概念、数据库管理系统(DBMS)的作用以及Oracle数据库的特点和优势。
此外,还需要了解数据库的体系结构、数据库管理的基本原则以及数据库设计和规范等相关概念。
2. SQL语言SQL(结构化查询语言)是关系型数据库管理系统中的一门标准查询语言,Oracle的面试中通常会涉及到SQL语言的相关知识。
包括SQL语法、基本查询、条件查询、排序和分组、连接查询、子查询、聚合函数、数据操作语句等内容。
3. 数据库设计数据库设计是数据库管理员的重要工作之一,也是Oracle面试中的重点知识点。
数据库设计包括实体关系模型(ER模型)、范式化、表设计、索引设计、视图设计等内容,面试官通常会问到数据库设计的相关问题以考察应聘者的设计能力。
4. 数据库管理数据库管理是数据库管理员的核心职责,也是Oracle面试的重要内容之一。
数据库管理涉及到数据库安装、配置、备份和恢复、性能优化、安全管理、存储管理、事务管理等方面的知识,应聘者需要熟悉Oracle数据库的管理工具和相关技术。
5. 数据库性能优化数据库性能优化是数据库管理员的重要工作之一,也是Oracle面试中关注的重点。
应聘者需要了解如何通过索引优化、查询优化、存储优化、缓存优化等手段来提升数据库的性能,以及如何识别和解决数据库性能问题。
6. PL/SQL编程PL/SQL是Oracle数据库中的一种过程化编程语言,面试中通常会涉及到PL/SQL的相关知识。
包括PL/SQL的基本语法、存储过程和函数的编写、异常处理、游标和触发器等内容,应聘者需要熟悉PL/SQL编程的相关技术。
7. 数据库安全数据库安全是数据库管理中的重要内容之一,也是Oracle面试中的考察点。
应聘者需要了解数据库安全的基本原则,包括用户管理、权限管理、加密和认证、审计和监控等方面的内容,以及相关的安全技术和工具。
Oracle基础必学知识点

Oracle基础必学知识点1. 数据库概念:Oracle是一种关系型数据库管理系统(RDBMS),用于存储和管理大量结构化数据。
它支持SQL语言,可以通过SQL语句进行数据查询、插入、更新和删除操作。
2. 数据库对象:Oracle数据库由多个对象组成,包括表、视图、索引、序列、存储过程等。
这些对象用于存储和处理数据,可以通过SQL语句进行操作。
3. 数据类型:Oracle支持多种数据类型,包括数字、字符、日期、大对象(LOB)等。
不同的数据类型用于存储不同类型的数据,可以根据需求选择合适的数据类型。
4. 表操作:在Oracle中,表用于存储数据。
可以使用CREATE TABLE语句创建表,使用INSERT语句插入数据,使用SELECT语句查询数据,使用UPDATE语句更新数据,使用DELETE语句删除数据。
5. 索引:索引是一种用于提高查询性能的数据结构。
在Oracle中,可以使用CREATE INDEX语句创建索引,通过索引可以快速定位到需要查询的数据,提高查询效率。
6. 数据约束:数据约束是用于保证数据的完整性和有效性的规则。
在Oracle中,可以使用约束来限制数据的取值范围、保证数据的唯一性等。
常见的约束类型包括主键约束、外键约束、唯一约束、非空约束等。
7. 视图:视图是一种虚拟表,它是从一个或多个表中获取数据的查询结果。
在Oracle中,可以使用CREATE VIEW语句创建视图,通过视图可以简化复杂的查询操作,提高数据的安全性。
8. 存储过程:存储过程是一组预先编译的SQL语句,存储在数据库中,并可以通过调用来执行。
在Oracle中,可以使用CREATE PROCEDURE语句创建存储过程,通过存储过程可以实现复杂的数据处理逻辑。
9. 事务控制:事务是一组逻辑操作,要么全部执行成功,要么全部回滚。
在Oracle中,可以使用BEGIN/END语句或者显式的事务语句(如COMMIT和ROLLBACK)来控制事务的提交或回滚。
学习oracle的心得体会

学习oracle的心得体会学习Oracle,这是一段充满挑战和收获的旅程。
在这个过程中,我获得了许多宝贵的经验和知识。
下面是我对学习Oracle的心得体会,总结成1000字来与大家分享。
首先,学习Oracle需要具备一定的基础知识和技能。
Oracle是一个强大的关系数据库管理系统,它的复杂性要求学习者具备一定的编程和数据库知识。
在开始学习之前,我首先学习了SQL语言的基础知识,掌握了基本的增删改查等操作。
同时,我还了解了数据库的基本原理和概念,例如关系模型、数据库范式等。
这些基础知识为我后续的学习打下了扎实的基础。
其次,学习Oracle需要进行系统的学习和实践。
Oracle的学习不仅仅是简单地阅读教材或者观看视频,更需要进行大量的实践。
只有通过亲自动手操作,才能更加深入地理解和体会Oracle的各种特性和功能。
我通过搭建本地Oracle数据库环境,并实际操作和验证SQL语句的执行结果,不断提高了自己的技能。
在实践中,我也遇到了许多问题和困难,但通过阅读文档、查询论坛和向导师请教,我逐渐克服了这些困难,并积累了丰富的经验。
此外,学习Oracle还需要不断地学习和更新知识。
Oracle是一个庞大而复杂的系统,它的功能和特性不断更新和演进。
为了跟上这个快速发展的节奏,学习者需要不断地学习和更新知识。
我通过阅读官方文档、参加培训班和关注相关的技术社区,不断掌握最新的技术和最佳实践。
同时,我也参加了一些Oracle 认证考试,通过考试可以检验自己的学习效果,并获得相关的证书。
在学习Oracle的过程中,我也注意到了一些学习技巧和方法,可以帮助提高学习效果。
首先,我发现通过实际的项目来学习Oracle可以提高学习效率和动力。
通过将所学的知识应用于实际项目中,可以更好地理解和记忆。
其次,我发现与他人交流和讨论是很有益的。
与他人的讨论可以帮助我发现自己的不足之处,也可以从他人那里学习到新的知识和经验。
此外,我还发现通过写博客或者记录学习笔记可以帮助巩固所学的知识,并可以与他人分享经验。
OracleTuning的一些总结

OracleTuning的一些总结关于Oracle的性能调整,一样包括两个方面,一是指Oracle数据库本身的调整,比如SGA、PGA的优化设置,二是连接Oracle的应用程序以及SQL 语句的优化。
做好这两个方面的优化,就能够使一套完整的Oracle应用系统处于良好的运行状态。
本文要紧是把一些Oracle Tuning的文章作了一个简单的总结,力求以实际可操作为目的,配合讲解部分理论知识,使大部分具有一样Oracle知识的使用者能够对Oracle Tuning有所了解,同时能够依照实际情形对某些参数进行调整。
关于更加详细的知识,请参见本文终止部分所提及的举荐书籍,同时由于该话题内容太多且复杂,本文必定有失之偏颇甚至错误的地点,请不吝赐教,并共同进步。
1. SGA的设置在Oracle Tuning中,对SGA的设置是关键。
SGA,是指Shared Global Area , 或者是System Global Area , 称为共享全局区或者系统全局区,结构如下图所示。
关于SGA区域内的内存来说,是共享的、全局的,在UNIX 上,必须为oracle 设置共享内存段(能够是一个或者多个),因为oracle 在UNIX上是多进程;而在WINDOWS上oracle是单进程(多个线程),因此不用设置共享内存段。
1.1 SGA的各个组成部分下面用sqlplus 查询举例看一下SGA 各个组成部分的情形:SQL> select * from v$sga;NAME VALUE-------------------- ----------Fixed Size 104936Variable Size 823164928Database Buffers 1073741824Redo Buffers 172032或者SQL> show sgaTotal System Global Area 1897183720 bytesFixed Size 104936 bytesVariable Size 823164928 bytesDatabase Buffers 1073741824 bytesRedo Buffers 172032 bytesFixed Sizeoracle 的不同平台和不同版本下可能不一样,但关于确定环境是一个固定的值,里面储备了SGA 各部分组件的信息,能够看作引导建立SGA的区域。
oracle日常运维总结

千里之行,始于足下。
oracle日常运维总结以下是Oracle日常运维总结的一些要点:1. 定期备份数据:重要性不言而喻,确保数据安全。
可以使用Oracle的备份工具或者第三方工具进行备份,定期检查备份的完整性和可用性。
2. 监控数据库性能:使用Oracle的性能监控工具,如AWR报告、ASH报告等,分析数据库性能瓶颈,并及时采取措施进行优化。
3. 维护数据库统计信息:定期收集和更新数据库的统计信息,以便优化查询性能。
可以使用Oracle的DBMS_STATS包来进行统计信息的收集和更新。
4. 定期检查表空间使用情况:监控数据库的表空间使用情况,及时扩展表空间或调整表空间大小,以确保数据库的正常运行。
5. 定期检查数据库日志和告警日志:定期检查数据库的日志文件和告警日志,及时处理数据库异常或错误。
6. 定期进行数据库滚动备份:数据库滚动备份可以保证数据库的连续备份,避免因备份过程中的数据变更造成备份不完整。
7. 定期进行数据库性能调优:定期进行数据库性能调优,如优化SQL语句、调整数据库参数等,以提高数据库的运行效率和性能。
8. 定期进行数据库安全审计:定期审计数据库的安全性,检查数据库的用户权限、网络安全等,并及时修复和加固数据库的安全漏洞。
第1页/共2页锲而不舍,金石可镂。
9. 定期进行数据库版本升级和补丁安装:定期检查Oracle官方网站,了解最新的数据库版本和补丁,并根据需要进行升级和安装,以保证数据库的安全和稳定。
10. 定期进行数据库容量规划:根据业务需求和数据增长情况,定期进行数据库容量规划,以确保数据库能够满足业务的需求并保持良好的性能。
以上是Oracle日常运维总结的一些要点,根据实际情况进行调整和补充。
oracle日常运维总结

oracle日常运维总结Oracle是一种功能强大的关系型数据库管理系统,广泛应用于各种企业级应用程序中。
作为一名Oracle数据库管理员(DBA),日常运维是我们工作的重要组成部分。
在这篇文章中,我将总结一些Oracle日常运维的经验和注意事项,希望对其他DBA或使用Oracle 的人员有所帮助。
一、备份与恢复备份和恢复是数据库管理中至关重要的一环。
我们需要定期进行数据库备份,以防止数据丢失和系统故障。
在备份过程中,我们可以使用Oracle提供的工具和功能,如RMAN(Recovery Manager)和Data Pump。
RMAN提供了完整的备份和恢复解决方案,可以进行全库备份和增量备份,并且支持备份集和归档日志的管理。
Data Pump 可以用于导出和导入数据库对象和数据,可以选择全库导出或指定对象导出。
恢复也是DBA必须掌握的技能之一。
当数据库遇到故障或数据损坏时,我们需要根据备份文件进行恢复。
在恢复过程中,我们需要了解不同的恢复场景和方法,如完全恢复、不完全恢复和点恢复。
同时,我们还要考虑日志文件的应用和恢复集的管理,确保数据的一致性和完整性。
二、性能优化Oracle数据库的性能优化是DBA不可或缺的工作之一。
通过监控和调整数据库的各个方面,我们可以提高数据库的响应速度和吞吐量,提升用户体验。
以下是一些常见的性能优化技巧:1. SQL调优:通过分析和改进SQL语句,优化查询计划和执行效率。
我们可以使用Oracle提供的SQL调优工具,如SQL Tuning Advisor和SQL Access Advisor。
2. 系统监控:通过监控数据库的系统资源利用率和性能指标,及时发现和解决性能瓶颈。
我们可以使用Oracle Enterprise Manager 或自定义脚本进行系统监控。
3. 索引优化:通过创建和维护合适的索引,加快数据检索和查询速度。
我们需要了解不同类型的索引和索引的使用场景,避免创建过多或不必要的索引。
Oracle数据库一些不常见但很重要的使用技巧总结篇

Oracle数据库一些不常见但很重要的使用技巧总结篇发布时间: 2011-7-22 10:43 作者: 鹤冲天(cnblogs) 来源: 51Testing软件测试网采编字体: 小中大|上一篇下一篇|打印|我要投稿|推荐标签:数据库OracleOracle数据库使用过程中,有一些技巧是使用过程中需要去了解和掌握的,掌握这些技巧我们在以后使用数据库的过程中就可以避免走很多弯路,提高查询效率。
本文主要介绍一下七点技巧,希望能对各位有所帮助,接下来我们就一一介绍。
使用技巧:1. procedure和function中的select后面不要跟变量,否则会极大的波及SQL效率。
2. TRUNCATE 在procedure中无法利用,可写成:3. 当运行DML(数据垄断语言,增删改查)语句时,PL/SQL敞开一个内建游标并处理收获,游标是维护查询收获的内存中的一个区域,游标在运行DML语句时敞开,告终后关闭。
隐式游标只利用SQL%FOUND,SQL%NOTFOUND,SQL%ROWCOUNT三个属性。
SQL%FOUND,SQL%NOTFOUND 是布尔值,SQL%ROWCOUNT是整数值。
告终循环时能够此作为退出循环的推断规范。
4. 为了不重复解析雷同的SQL语句,在第顺次解析尔后,ORACLE将SQL语句储藏在内存中。
这块位于系统大局区域SGA(system global area)的分享池(shared buffer pool)中的内存能够被所有的数据库用户分享。
因而,当你厉行一个SQL语句(有时被称为一个游标)时,万一它和之前的厉行过的语句全面雷同,ORACLE就能很快获得曾经被解析的语句以及良好的厉行路径。
分享的语句定然中意三个条件:a. 字符级的比拟:目前被厉行的语句和分享池中的语句定然全面雷同。
包括所有的空格和字母大小写。
b. 两个语句所指的对象定然全面雷同。
例如两个用户对于统一个表,一个是table owner,一个是引用同义词,那么是无法SQL分享的。
Oracle索引(Btree与Bitmap)的学习总结

Oracle索引(B*tree与Bitmap)的学习总结本篇文章是对Oracle索引(B*tree与Bitmap)进行了详细的分析介绍,需要的朋友参考下在Oracle中,索引基本分为以下几种:B*Tree索引,反向索引,降序索引,位图索引,函数索引,interMedia全文索引等,其中最常用的是B*Tree索引和Bitmap索引。
(1)、与索引相关视图查询DBA_INDEXES视图可得到表中所有索引的列表;访问USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。
(2)、组合索引概念当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。
注意:只有在使用到索引的前导索引时才可以使用组合索引(3)、B*T ree索引B*Tree索引是最常见的索引结构,默认建立的索引就是这种类型的索引。
B*Tree索引在检索高基数数据列(高基数数据列是指该列有很多不同的值)时提供了最好的性能。
DML语句:Create index indexname on tablename(columnname[columnname...])B-tree特性:适合与大量的增、删、改(OLTP);不能用包含OR操作符的查询;适合高基数的列(唯一值多);典型的树状结构;每个结点都是数据块;大多都是物理上一层、两层或三层不定,逻辑上三层;叶子块数据是排序的,从左向右递增;在分支块和根块中放的是索引的范围。
(4)、Bitmap索引位图索引主要用于决策支持系统或静态数据,不支持行级锁定。
位图索引最好用于低cardi nality列(即列的唯一值除以行数为一个很小的值,接近零)。
DML语句:Create BITMAP index indexname on tablename(columnname[columnname...])Bitmap特性:适合与决策支持系统;做UPDA TE代价非常高;非常适合OR操作符的查询;基数比较少的时候才能建位图索引。
Oracle_Ebs_开发总结

技术心得一、SQL查询:1、”列出同部门中工资高于1000的员工数量超过2人的部门,显示部门名字、地区名称”.查询语句如下:selectdistinct dept.department_name,loc.cityfrom employeesemp,departmentsdept,locationslocwhere emp.department_id=dept.department_idandfromwhereand)子,fromwhereandandhavingcount(*)>2对于groupby来说每一条emp.department_id必对应唯一dept.department_id、dept.department_name因此不论groupbydepartment_id还是groupbydepartment_name,loc.city达到的效果是一样的2、用一条语句查询出scott.emp表中每个部门工资前三位的数据:selectdepartment_id,max(salary)max_salary,max(decode(rank,2,salary,salary))mid_s alary,min(salary)min_salaryfrom(selectdepartment_id,salary,rankfrom(selectemp.department_id,emp.employee_id,emp.salary,row_number()over(partitionby emp.department_idorderbyemp.salary)asrankfromemployeesemp)EwhereE.rank<=3)groupbydepartment_idSQL%ISOPEN FALSE FALSE FALSE FALSESQL%FOUND TRUE有结果成功成功-20,999之间的参数.可在程序块中自定义异常,并捕捉在其他函数或存储过程中RAISE_APPLICATION_ERROR抛出的异常,与Oracle交互.4、PRAGMAAUTONOMOUS_TRANSACTIONORACLE8i可以支持事务处理中的事务处理的概念.这种子事务处理可以完成它自己的工作,独(2)不使用自动事务处理:CREATEORREPLACEPROCEDURE log_message(p_message varchar2)ASBEGININSERTINTO logtable VALUES(user,sysdate,p_message);COMMIT;END log_message;(select*fromtemp_table查询结果有数据)流程:1、以2、3、4、实例:1为’GL’)件:and'yyy y-mm-ddHH24:MI:SS'))and(to_date(p_End_Date,'yyyy-mm-ddHH24:MI:SS'));!!!注意’HH24:MI:SS’必不可少,因为请求程序要求的数据一定是带时分秒的数据否则解析报表时会报错.如下所示:**Starts**23-08-201111:53:42**Ends**23-08-201111:53:42ORA-01830:日期格式图片在转换整个输入字符串之前结束2、根据借方数量与借方金额求出借方单价同理求贷方单价,每发生一笔,统计当前数量与当前金额,然后得出当前数量当前总价与当前单价其中借方与贷方金额的获取,如:select(case cila.inv_typewhen'IN'then(case cila.type_codewhen'GL'thenACCOUNTED_DRwhen'AP'thenAP_ACCOUNTEDend)end3四、1即是多OUview_all_orgnization_flagFROMper_security_profilesWHEREsecurity_profile_id=to_number(fnd_profile.value(‘XLA_MO_SECURITY_PROFILE_LEVEL’));可以通过以下语句获取当前安全性配置文件和当前用户在当前职责下可访问的OU nazation_id,organization_id,nameFROMper_orgnazation_listper,Hr_operating_unitshrWHEREper.secutity_profile_id=to_number(fnd_profile.VALUE(‘XLA_MO_SECURITY_PROFILE_LEVEL’))nization_id=nization_idable_flagisnull;如我在CUX_INV_MATERIAL_ALL表中建立的Org_Id字段,可在策略函数中通过此字段产生Where 子句,筛选可操作客户化职责下物料维护菜单的OU.当用户进入YD_GL_ALL_总账超级用户职责时将初始化用户的上下文,通过MO_GLOBAL的一系列方法设置CONTEXT的值(包括访问模式和当前Org_Id)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
OracleSQL datebase (DB)Structured query language 结构化查询语言DDL(数据定义语言)Date definition languagecreate table 建表alter table 修改表结构drop table 删表column data type width constraints(约束)DML(数据操作语言)Data manipulation languageinsert update deletedata row recordTCL(事物控制语句)Transcation control languagecommit(提交) rollback(回滚) savepointDQL(数据查询语言)Data query languageselectInstall software rdbms 安装软件create database 创建数据库登录数据库sqlplus username/passwordORACLE_SID(环境变量) 数据库对应的实例的名字,该名字决定了连接哪个具体的数据库show user查看当前用户desc tablename查看表结构desc describe的缩写查询员工的姓名,和工资select first_name,salary from s_emp;查询员工的名字和职位select first_name,title from s_emp;edit修改sql语句l 查看/运行select * from s_dept; 列出部门表的所有信息列出每个员工的年薪select first_name,salary*12 from s_emp;列出每个员工的总收入select first_name,salary*12*(1+commission_pct/100) "tol sal" from s_emp;空值会导致算术表达式为空,Oracle认为null为无穷大select first_name,salary*12*(1+nvl(commission_pct,0)/100) tol_sal,Commission_pctfrom s_empnvl(p1,p2)if(p1 is null) then return p2;else return p1;coalesce 和nvl实现的是同样的功能,nvl只能用在Oracle,coalesce可以用在多种数据库,nvl的两个参数的类型必须一致给列起别名在列后直接跟别名,别名有空格,或者大小写敏感,要给别名加“”将姓和名拼接起来''表示字符串,“”表示别名,||表示字符串的拼接select first_name||last_name employee from s_emp;select first_name||' '||last_name employee from s_emp;select first_name||' is in department '||dept_id||'.' from s_emp;列出有哪些部门select distinct name from s_dept;distinct 去重(null值夜只保留一个),只能放在select后列出公司有哪些不同的职位select distinct title from s_emp;set feed on显示查询返回的记录数各个部门有哪些不同的职位select title,dept_id from s_emp;部门号和职位联合起来唯一列出工资大于1000的员工select first_name,salary from s_emp where salary>1000;年薪大于12000的员工(where语句后的字段最好不要使用表达式,影响效率) select first_name,salary*12 from s_emp where salary>1000;where子句不能跟列的别名列出Carmen的年薪select first_name,salary from s_emp where first_name='Carmen';哪些人的职位是Stock Clerkselect first_name,title from s_emp where title='Stock Clerk';哪些员工的工资在1550-2000之间select first_name,salary from s_emp where salary>=1550 and salary<=2000;select first_name,salary from s_emp where salary between 1550 and 2000;列出部门号为31,41,43的员工的工资select first_name,salary,dept_id from s_emp where dept_id=31 ordept_id=41 or dept_id=43;select first_name,salary,dept_id from s_emp where dept_id in (31,41,43);select first_name,salary,dept_id from s_emp where dept_id =any (31,41,43); %表示0或多个字符_表示任意一个字符select last_name from s_emp where last_name like 'M%';系统表,user_tables 记录数据库中有哪些表查询当前用户下有哪些表select table_name from user_tables;查找用户下所有以“s_”的表名select table_name from user_tables where table_name like 'S\_%' escape '\';escape '\' 表示定义\为转义字符哪些员工没有提成select first_name,commission_pct from s_emp where commission_pct is null; 判断字段的值是否为空is null 而不是=null哪些员工有提成select first_name,commission_pct from s_emp where commission_pct is not null;列出除了31,41,43部门的员工的工资select first_name,dept_id,salary from s_emp where dept_id not in (31,41,43);select first_name,dept_id,salary from s_emp where dept_id <>31 anddept_id <>41 and dept_id <>43;select first_name,dept_id,salary from s_emp where dept_id <>all (31,41,43); 如果集合里面包含null值,not in 一定查不出结果,null与任何值比较都为false列出部门号为32,42,工资大于1500的员工select first_name,dept_id,salary from s_emp where salary>1500 and dept_id in(32,42);列出员工的姓名和工资,并按工资由大到小排序select first_name,salary from s_emp order by salary desc;order by 后的字段要想使用索引,必须保证不能为nullselect first_name,salary from s_emp where salary is not null order by salary desc;列出42部门的员工信息,按年薪降序排列select first_name,dept_id,salary*12 ann_sal from s_emp where dept_id=42 order by salary desc;select first_name,dept_id,salary*12 ann_sal from s_emp where dept_id=42 order by ann_sal desc;select first_name,dept_id,salary*12 ann_sal from s_emp where dept_id=42 order by 3 desc;按部门号升序排列,同一部门按工资的降序排列select first_name,dept_id,salary from s_emp order by dept_id,salary desc;函数单行函数:每一条记录都对应有结果集字符类型lower()将字符串转化为小写select lower('SQL') from dual;upper()将字符串转化为大写initcap()将字符的首字母大写concat(string,string)字符串的拼接substr(string,1,3)字符串的截取,第二个参数表示字符串的起始位置,第三个表示截取的长度length(string) 字符串的长度lpad(string,10,'*')字符串的长度是10,不足的在左边补'*'rpad(string,10,'*')字符串的长度是10,不足的在右边补'*'调文字值和表没有关系的时候使用系统表dual查询Carmen的工资(不知道大小写)select first_name,salary from s_emp where lower(first_name)='carment';找出每个人名字的最后两个字符select first_name,substr(first_name,length(first_name)-1,2) from s_emp;select first_name,substr(first_name,-2,2) from s_emp;负数表示从右向左数值类型round(处理的数字,保留小数点后几位)四舍五入trunc(处理的数字,截取几位)截取日期类型转换函数to_number('1550')转化为数字to_number(字段,'xx')按16进制处理字段值隐式数据类型转换,默认字符转为数字,可能导致索引用不了to_char(字段,'$99,999,99')按格式转化成字符串格式:9代表数字位0代表定义宽度大于实际值宽度,有0补齐L 表示本地货币如果显示位数不足(定义宽度小于实际值宽度),用#代替更改本地语言NLS_LANG='SIMPLIFIED CHINESE_CHINA.ZHS16GBK'export NLS_LANGNLS_LANG=AMERICAN_7ASCII将没有领导的员工的领导位置设为bossselect first_name,nvl(to_char(manger_id),'Boss') from s_emp; 多行函数多表查询列出员工的名字,和部门的名称cross join笛卡尔积,两个表的每条记录都匹配select first_name,dept_id,name from s_emp cross join s_dept;300条select e.first_name,e.dept_id,d.id, from s_emp e cross join s_dept d;300条如果两个表里有字段名相同,必须指出是哪个表的字段inner join 内连接(将满足条件的记录匹配,精确匹配)可省略的写成join select e.first_name,e.dept_id,d.id, from s_emp e inner join s_dept d on e.dept_id=d.id; 25条列出部门号,地区号,地区名称select d.id,,r.id, from s_dept d join s_region r ond.region_id=r.id;内连接等值连接:两张表有描述共同属性的列非等值连接:可以用between and把两张表中的列写成表达式自连接:同一张表的列之间有关系实际反映的是同一张表的行之间有关系,通过给表起别名将同一张表的列之间的关系转换成不同表的列之间的关系所谓表之间的关系,实际指表中的行之间的关系,该关系通过将表中的列写成表达式来体现Carmen在哪个部门上班select e.first_name, from s_emp e join s_dept d on e.dept_id=d.id and e.first_name='Carmen';先做过滤在做连接亚洲地区有哪些部门select d.id,, from s_dept d join s_region r on d.region_id=r.id and ='Asia';Carmen在哪个地区上班select e.first_name, from s_emp e join s_dept d on e.dept_id=d.id and e.first_name='Carmen' join s_region r on d.region_id=r.id;亚洲地区有哪些员工select e.first_name, from s_emp e join s_dept d on e.dept_id=d.id join s_region r on d.region_id=r.id and ='Asia';列出员工的工资,名字,及工资的级别select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal betweens.losal and s.hisal;3级和5级有哪些员工select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal betweens.losal and s.hisal and s.grade in (3,5);列出每个员工的领导select e.first_name,m.first_name from emp e join emp m one.manager_id=m.id;哪些人是领导select distinct m.first_name from emp e join emp m on e.manager_id=m.id;外连接left outer join right outer join outer可以省略from t1 left join t2 on t1.c1=t2.c2 表示t1做驱动表from t1 right join t2 on t1.c1=t2.c2 表示t2做驱动表外连接把驱动表不能匹配的记录也会放在结果集里,没有匹配上的字段设置为null,驱动表里的数据一个都不能少外连接的结果集=内连接的结果集+t1表中匹配不上的记录和一条null记录的组合关键:谁做驱动表列出每个员工的领导,并且打印出bossselect e.first_name,nvl(m.first_name,'Boss') from emp e left join emp m on e.manager_id=m.id;哪个部门没有员工select e.ename,d.deptno from emp e right join dept d on e.deptno=d.deptno where e.empno is null;这里用where不用and,因为and是先过滤在连接哪些人是员工(哪些人不是领导)select e.first_name,m.first_name from s_emp e right join s_emp m one.manager_id=m.id where e.id is null;哪个部门没有叫SMITH的员工select d.deptno,d.dname from emp e right join dept d on e.deptno=d.deptno and e.ename='SMITH' where e.empno is null;哪个部门没有叫SMITH的部门(Oracle)select d.dname from emp e,dept d where e,deptno(+)=d.deptno ande.ename(+)='SMITH' and e.ename is null;第一个+表示dept表为驱动表,第二个+表示在连接之前过滤组函数操作在一组记录上,每组返回一个结果处理的是所有的非空值(count(*)表示记录数)如果所有记录都是null,count返回0,其他返回空avg平均值(数值)sum求和(数值)count计数(字符,数字,日期)max最大值(字符,数字,日期)min最小值(字符,数字,日期)工资的平均值,提成的平均值,和提成的平均值select avg(salary),avg(commission_pct),max(commission_pct) from s_emp;所有人提成的平均值select sum(commission_pct)/count(*) from s_emp;select avg(nvl(commission_pct,0)) from s_emp;group by给记录分组根据group by子句指定的表达式,将要处理的数据(若有where子句即为通过条件过滤后的数据)分成若干组,每组有唯一标识,组内有若干条记录,根据select语句后的组函数处理每个组的记录,每个组返回一直值各个部门的平均工资select avg(salary),dept_id from s_emp group by dept_id;各个职位的平均工资select title avg(salary) from s_emp group by title;每个提成有多少人select commission_pct,count(*) from s_emp group by commission_pct;分组时所有的空值都在同一个组各个部门有多少种不同的职位select dept_id,count(distinct title) from s_emp group by dept_id;各个部门不同职位的平均工资select dept_id,title,avg(salary) from s_emp group by dept_id,title;42部门的平均工资,列出部门号select max(dept_id),round(avg(salary)) from s_emp where dept_id=42;select dept_id,round(avg(salary)) from s_emp where dept_id=42 group by dept_id;若没有group by子句,select后面有一个是组函数,其他都必须是组函数有group by子句,select后面可跟group by后面跟的表达式以及组函数,其他会报错每个工资级别有多少人select s.grade,count(e.empno) from emp e right join salgrade s on e.sal between s.losal and s.hisal group by s.grade order by s.grade;各个部门的平均工资(列出部门名称:部门名称+地区名称)select ,,avg(e.salary) from s_emp e join s_dept d one.dept_id=d.id join s_region r on d.region_id=r.id group by ,r,name;select max(),max(),avg(e.salary) from s_emp e join s_dept d on e.dept_id=d.id join s_region r on d.region_id=r.id group by d.id;having对分组后的结果进行过滤(后面跟组函数)过滤组,而where是过滤记录哪些部门的平均工资比2000高select dept_id,avg(salary) from s_emp group by dept_id havingavg(salary)>2000;32部门和42部门的平均工资select dept_id,avg(salary) from s_emp where dept_id in (32,42) group by dept_id;优化select dept_id,avg(salary) from s_emp group by dept_id having dept_idin(32,42);where和having的区别where子句过滤的是行(记录)having子句过滤的是分组(组标识,每组数据的聚合结果)where子句包含单行函数having子句只能包含group by 后面的表达式和组函数where子句执行在前,having子句执行在后where子句和having子句都不允许用列别名子查询就是在一条SQL语句中嵌入select语句先执行子查询,子查询的返回结果作为主查询的条件,在执行主查询子查询只执行一遍若子查询的返回结果为多个值,Oracle会去掉重复值后,再将结果返回给主查询非关联子查询:主查询和子查询之间没有表连接单列子查询谁的工资最低select first_name,title from s_emp where salary=(select min(salary) froms_emp);谁和SMITH的职位一样select last_name,title from s_emp where title=(select title from s_emp where last_name='Smith') and last_name<>'Smith';哪些人是领导select first_name from s_emp where id in (select manager_id from s_emp);哪些人是员工select first_name from s_emp where id not in (select manager_id from s_emp where manager_id is not null);not in 比外连接的效率低哪个部门的平均工资比32部门的平均工资高select dept_id,avg(salary) from s_emp group by dept_id havingavg(salary)>(select avg(salary) from s_emp where dept_id = 32);多列子查询哪个员工的工资等于本部门的平均工资select first_name,dept_id,salary from s_emp where (dept_id,salary) in (select dept_id ,avg(salary) from s_emp group by dept_id);关联子查询先做主查询,再执行子查询执行顺序1.外部查询得到一条记录(查询先从outer表中读取数据)并将其传入到内部查询2.内部查询基于传入的值执行3.内部查询从其结果中把值传回外部查询,外部查询使用这些值来完成其处理,若符合条件,outer表中得到的那条记录放入结果集中,否则放弃,该记录不符合条件4.重复执行步骤1-3,直到把outer表中的所有记录判断一边哪个员工的工资比本部门的平均工资高select first_name,dept_id,salary from s_emp o where salary>(selectavg(salary) from s_emp i where o.dept_id=i.dept_id);exists运算符(存在)主查询与子查询的条件是否匹配(一旦匹配就返回,不会继续找下去)exists采用的是循环方式,判断outer表中是否存在记录只要在inner表中找到一条匹配的记录即可1.外部查询得到一条记录(查询先从outer表中的去数据)并将其传入到内部查询表2.对inner表中的记录依次扫描,若根据条件存在一条记录与outer表中的记录匹配,立即停止扫描,返回true,将outer表中的记录放入结果集中,若扫描了全部的记录,没有任何一条记录符合匹配条件,返回false,outer表中的该记录被过滤掉3.重复执行步骤1-2,直到把outer表中的所有记录判断一边哪些人是领导select first_name,dept_id from s_emp outer where exists (select 'x' froms_emp where manager_id=outer.id);哪个部门有员工select dname from dept d where exists (select 1 from emp e wheree.deptno=d.deptno);not exists 不存在哪些人是员工select first_name,dept_id from s_emp outer where not exists (select 'x' from s_emp where manager_id=outer.id);in和exists的比较exists是用循环的方式,由outer表的记录数决定循环的次数,对于exists的影响最大,所以,外表的记录数要少in先执行子查询,子查询的返回结果去重之后,在执行主查询,所以,子查询的返回结果越少,越适合用该方式标量子查询列出员工的名字和领导名字的对应关系select first_name,nvl((select first_name from s_emp i whereo.manager_id=i.id),'Boss') from s_emp o;查出每个工资级别的人数select grade,(select count(empno) from emp e where e.sal between s.losal and s.hisal) from salgrade;基于数据库的开发将业务需求转换成可操作的数据库E-R 图E 实体,有共同属性的一类对象的集合属性,描述实体,区分实体R 关系,描述实体和实体的关系虚线表示可选的,可以表示实体 实线表示强制的,必须* 表示强制属性o 表示可选属性# 表示唯一属性实体和实体的关系从实例之间的数量关系的角度分为一对一,一对多,多对多 实体和实体之间的关系从紧密程度上分为必须和可以递归关系:同一实体里的实例之间有关系完整性约束保证数据的一致性通过数据库的特性或应用程序完成数据库约束主键(primary key ),唯一键(unique key ),外键(foreign key )实体完整性:主键值唯一且非空(PK )引用完整性:外键值必须是已存在的主键值或为空(FK )主键主键值要求唯一且非空联合主键:多列联合唯一,任意一列都可以重复,每一列都不能为null 表中只能有一个主键外键外键是定义在子表(child table )上一列,它的取值要引用父表(parent table ) CUSTOMER #*id * name o phone EMPLOYEE #* id * last name O first name上的主键列或唯一列外键的定义是基于数据值的,是纯逻辑概念外键的取值必须匹配主键值或唯一键值还可以是空值若外键是主键的一部分,它的取值不能为空1.先create parent table(pk,uk),再create child table(fk)2.先insert into parent table,再insert into child table3.先delete from child table,再delete from parent table4.先drop child table,再drop parent tableE-R图向表转换表和列分别对应实体和属性1.将实体映射成表2.将属性映射成列强制属性定义成非空列名不能用保留字3.将唯一标识映射成主键一个表只能有一个主键4.将关系映射成外键一对多:一的那边定义成主键,或唯一键,多的那边定义成外键一对一:合表在外键列上增加唯一约束主键即外键多对多:通过增加中间表将一个多对多关系转换成两个一对多关系三个范式最小化数据冗余减少完整性问题标识丢失的实体,关系,表第一范式:表中不会有重复的记录,即有主属性(pk);每个属性值不可再分第二范式:每个非主属性必须完全依赖于主属性第三范式:每个非主属性不能依赖于另一个非主属性DDL建表语句命名规则首字母必须是字符长度是1-30只能包含A-Z,a-z,0-9,_,$,#同一个区域不能定义相同的对象不能定义Oracle的保留字create table tablename(字段数据类型默认值约束,……);数据类型字符varchar2后面必须跟宽度,按照实际长度存,最大4000个字节,列取值长度不固定用varchar2,比较时按实际字符长度比,对空格是敏感的char默认一个字符,按照定义长度存,最大2000个字节,取值长度固定用char,比较时,会将短字符串补齐后,在与长字符串比较,对空格不敏感数字number(p,s)可以不定义长度,缺省38位,p表示数值中所有数字位的个数,最大38位,s表示刻度范围,s为正数,表示小数点右边的数字的个数,为负数,表示小数点开始向左进行计算数字位的个数。