聚类分析练习题
sas练习题(打印版)

sas练习题(打印版)### SAS练习题(打印版)#### 一、基础数据操作1. 数据导入- 题目:使用SAS导入一个CSV文件,并列出前5个观测值。
- 答案:使用`PROC IMPORT`过程导入数据,并用`PROC PRINT`展示前5个观测。
2. 数据筛选- 题目:筛选出某列数据大于50的所有观测。
- 答案:使用`WHERE`语句进行筛选。
3. 数据分组- 题目:根据某列数据对数据集进行分组,并计算每组的均值。
- 答案:使用`PROC MEANS`过程和`BY`语句进行分组和计算。
4. 数据排序- 题目:按照某列数据的升序或降序对数据集进行排序。
- 答案:使用`PROC SORT`过程进行排序。
#### 二、描述性统计分析1. 单变量分析- 题目:计算某列数据的均值、中位数、标准差等统计量。
- 答案:使用`PROC UNIVARIATE`过程进行单变量描述性统计分析。
2. 频率分布- 题目:计算某列数据的频数和频率分布。
- 答案:使用`PROC FREQ`过程进行频率分布分析。
3. 相关性分析- 题目:计算两列数据的相关系数。
- 答案:使用`PROC CORR`过程计算相关系数。
#### 三、假设检验1. t检验- 题目:对两组独立样本的均值进行t检验。
- 答案:使用`PROC TTEST`过程进行t检验。
2. 方差分析- 题目:对多个组别数据进行方差分析。
- 答案:使用`PROC ANOVA`过程进行方差分析。
3. 卡方检验- 题目:对分类变量进行卡方检验。
- 答案:使用`PROC FREQ`过程和`CHI2TEST`选项进行卡方检验。
#### 四、回归分析1. 简单线性回归- 题目:使用一个自变量和一个因变量进行简单线性回归分析。
- 答案:使用`PROC REG`过程进行简单线性回归。
2. 多元线性回归- 题目:使用多个自变量和一个因变量进行多元线性回归分析。
- 答案:同样使用`PROC REG`过程,但包括多个自变量。
10_大数据综合练习

[判断题]1.利用先验原理可以帮助减少频繁项集产生时需要探查的候选项个数。
答案:对2.先验原理可以表述为:如果一个项集是频繁的,那包含它的所有项集也是频繁的。
答案:错3.回归分析通常用于挖掘关联规则。
答案:错4.具有较高的支持度的项集具有较高的置信度。
答案:错5.维归约可以去掉不重要的属性,减少数据立方体的维数,从而减少数据挖掘处理的数据量,提高挖掘效率。
答案:对6.聚类( clustering )是这样的过程:它找出描述并区分数据类或概念的模型( 或函数) ,以便能够使用模型预测类标记未知的对象类。
答案:错7.对于SVM分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果没有影响。
答案:对8. Bayes法是一种在已知后验概率与类条件概率的情况下的模式分类方法,待分样本的分类结果取决于各类域中样本的全体。
答案:错9.在决策树中,随着树中结点数变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题。
答案:错10.在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。
答案:错11.聚类分析可以看作是一种非监督的分类。
答案:对12. K均值是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动地确定。
答案:错13.基于邻近度的离群点检测方法不能处理具有不同密度区域的数据集。
答案:对14.如果一个对象不强属于任何簇,那么该对象是基于聚类的离群点。
答案:对15.大数据的4V 特点是Volume、Velocity 、Variety 、Veracity 。
答案:对16.聚类分析的相异度矩阵是用于存储所有对象两两之间相异度的矩阵,为一个nn 维的单模矩阵。
答案:对。
聚类分析练习题1105

聚类分析和判别分析练习题一、选择题1.需要在聚类分析中保序的聚类分析是( )。
A.两步聚类B.有序聚类C.系统聚类D.k-均值聚类 2.在系统聚类中2R 是( )。
A.组内离差平方和除以组间离差平方和B.组间离差平方和除以组内离差平方和C.组间离差平方和除以总离差平方和D.组间均方除以总均方。
3.系统聚类的单调性是指( )。
A.每步并类的距离是单调增的 B.每步并类的距离是单调减的 C.聚类的类数越来越少 D.系统聚类2R 会越来越小4.以下的系统聚类方法中,哪种系统聚类直接利用了组内的离差平方和。
( ) A.最长距离法 B.组间平均连接法 C.组内平均连接法 D.WARD 法5.以下系统聚类方法中所用的相似性的度量,哪种最不稳健( )。
A.21()pik jk k x x =-∑ B.1pik jk k ik jkx x x x =-+∑C.21pk =∑ D.1()()i j i j -'x -x Σx -x6.以下系统聚类方法中所用的相似性的度量,哪种考虑了变量间的相关性( )。
A.21()pik jk k x x =-∑ B.1pik jk k ik jkx x x x =-+∑C.21pk =∑ D.1()()i j i j -'x -x Σx -x7.以下统计量,可以用来刻画分为几类的合理性统计量为( )? A.可决系数或判定系数2RB.GGW P P -C.()/(1)/()GGW P GP n G---D.()G W PW-8.以下关于聚类分析的陈述,哪些是正确的()A.进行聚类分析的统计数据有关于类的变量B.进行聚类分析的变量应该进行标准化处理C.不同的类间距离会产生不同的递推公式D.递推公式有利于运算速度的提高。
D(3)的信息需要D(2)提供。
9.判别分析和聚类分析所要求统计数据的不同是()A.判别分析没有刻画类的变量,聚类分析有该变量B.聚类分析没有刻画类的变量,判别分析有该变量C.分析的变量在不同的样品上要有差异D.要选择与研究目的有关的变量10.距离判别法所用的距离是()A.马氏距离B. 欧氏距离C.绝对值距离D.欧氏平方距离11.在一些条件同时满足的场合,距离判别和贝叶斯判别等价,是以下哪些条件。
人员素质测评理论与方法章习题(全)

第一章练习题一、名词解释人员素质测评;素质(广义)二、填空题(可出选择题)1.素质包括以下三大类:、、;2.心理素质包括:与;3.人员素质测评的方法包括:、、、;4.人员素质测评的主体包括:、;5.心理测量测查的对象具有、、等特点;6.人员素质测评的对象是及;7.人才测评的三个功能是、、;8.人才测评的作用包括对和对所起的作用;9.人才测评对组织所起的作用包括、、;10.人才测评对个人所起的作用包括、、。
三、简答题1.阐述评价(评定)与测量的联系与区别?2.简述人员素质测评的特点?3.简述人员素质测评与人才素质测评的联系与区别?第二章练习题一、名词解释察举;九品中正制;科举制二、填空题1.中国古代人才选拔制度包括:、、;2.察举制度用来测评人才的方法有许多,仅两汉就有常科:、、、四行,后来规定岁举的科目以、为主;3.九品中正制,又称,是的一种选拔人才的举官制度;4.九品中正制中选拔人才的标准有三:、、;5.科举制是以后历代封建王朝常常采用的通过考试选拔官吏的一种制度;6.科举制度考试有、、三级;7.唐代科举从种类上讲只有和两种;8.三国时魏人所著的《人物志》对人才测评作了较为系统完整的论述;9.春秋时期,就对人的“才能”的观点加以了论述;10.战国时期,提出了“察能予官”,“以德就列”的原则;11.战国时期的把“德才”标准具体化为忠诚、谨慎、才能、智力、信用、廉洁、节守、仪态、行为等指标;12.古代人才测评用、、、以判断人才;13.我国古代使用的测评技术有、、;14.纸笔测验的典型形式有、、、;15.《吕氏春秋》提出了对内用“”,对外用“”的方法识别人才;16.实践鉴别法的核心是根据“”来作为选拔衡量使用人才的标准;17.文官考绩因素包括10项:、、、、、、、、、;18.文官接受培训的形式有、、、、、等;19.西方现代人才测评思想与技术发端于,开始于,最初源于教育实践中的需要;20.19世纪80年代至20世纪前10年,西方心理测验逐渐兴起,最有名的是测量智商的,这一量表是世界上第一个标准化的心理测验,由法国心理学家和医生于年提出,被称为是心理测验的鼻祖;21.美国最著名的比奈西蒙量表修订本是斯坦福大学教授在年指导修订的,即著名的量表;22.美国学者斯特朗于1927年编制出版的世界上第一个职业兴趣测验“”;23.“评价中心”技术综合运用了、和,使测评效果比原来更加可靠和有效;三、简答题1.试述察举制、九品中正制和科举制的特点?2.试述古代人才测评机制的缺点?第三章练习题一、名词解释职业;地位;角色;工作角色;二、填空题1.个人素质差异表现为两个方面,一是个性差异,如、和及其组合;二是个体的差异,如、、、、及等;2.以人员配置所凭借的方法为标准,大致可将人员配置原型划分为和;3.人员配置的经验原型的主要特征是和;4.以经验原型为指导进行人员配置,一般采用两种方法:一是,二是;5.在经验原型中,、是人员配置的核心;6.人员配置的测评原型最显著的两大特征是和;7.美国约翰·霍普金斯大学心理学教授约翰·霍莱特认为人的个性素质基本类型有六种:、、、、、;8.人员素质测评的必要条件是、与的客观存在,充分条件是对个体素质与的探索;9.、、三大主指标及其数十个子指标,是当前比较流行的人员素质测评指标体系;10.职业能力测试子指标包括、、;11.职业人格子指标包括、、、;12.职业兴趣子指标包括、、、;13.人员素质测评应向与的方向发展,应把人员素质测评作为一种重要手段贯穿于整个的组织管理过程之中;14.借助,可以充分发挥素质测评在人力资源开发与管理中的优化作用;15.行为管理科学启示我们,通过素质测评对个体差异的揭示,按;按;16.著名的心理学家马斯洛理论把需求分成、、、、五类;17.提高人员素质测评效用的六大原则:、、、、、;18.人员素质测评的八个主要原则是:、、、、、、、;19.人员素质测评的主要理论依据有、、等学科的知识;20.个性心理品质中的能力特征的两个方面是指和;21.人员素质测评所使用的各类人员的素质量表,是由、、、、五个方面的素质组成的一个复杂的系统,它包括分系统、分系统、分系统、分系统、分系统等;22.模糊数学被广泛应用于、、、等具有模糊现象的学科中;23.1965年美国控制论专家、加利福尼亚大学教授,对大量不确切现象进行了认真的分析,提出了原理;24.查德的模糊集合论原理用二句话概括就是、;25.查德借助经典数学这一工具,创立了用来定量表示模糊概念的模糊数学;26.当刺激情景是以文字或图形设计呈现时,测评即是形式;当刺激情景是经过精心设计,且以面对面的问答或谈话形式出现时,测评则是形式;当各种刺激情景是以自然的实际情形出现时,测评则是形式;三、简答题2.简述人员配置的经验原型的弊端?3.简述人员配置的测评原型与经验原型相比的优势表现在哪几个方面?6.简述素质测评待解决的几个问题?10.为了控制施测者主观性的消极影响,一般采取哪些方法?第四章练习题一、名词解释职业适应性测评的定义、内容;职业能力测评的定义、内容、领导人才测评的定义、内容、管理人才测评的定义、内容、科技人才测评的定义、内容。
第12章聚类分析习题答案
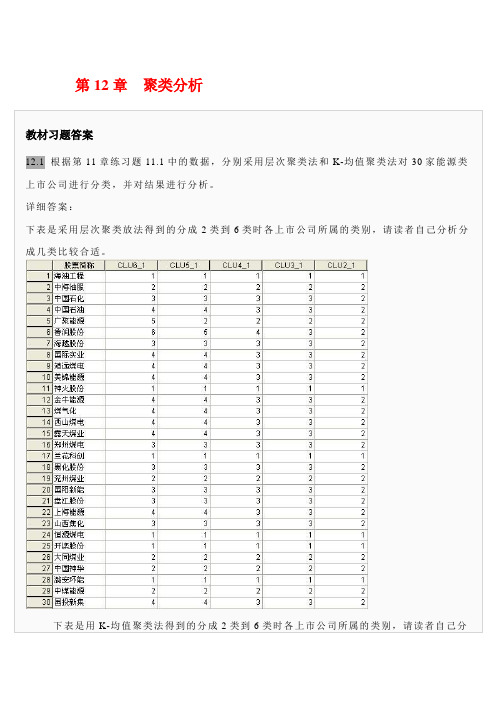
兰花科创
2
1
1
2
4
黑化股份
1
2
3
3
1
兖州煤业
2
22Leabharlann 14国阳新能
2
2
3
3
1
盘江股份
1
2
3
5
1
上海能源
2
2
3
1
1
山西焦化
1
2
3
3
1
恒源煤电
2
1
1
2
3
开滦股份
2
1
1
2
2
大同煤业
2
2
2
1
4
中国神华
2
2
2
1
4
潞安环能
2
1
1
2
2
中煤能源
2
2
2
1
4
国投新集
2
2
3
1
1
12.2下表是摘自《世界竞争力报告——1997》关于20个国家和地区的信息基础设施发展状况数据,各变量的含义为:call——每千人拥有电话线数,movecall——每千户居民蜂窝移动电话数,fee——高峰时期每三分钟国际电话的成本,computer——每千人拥有的计算机数,mips——每千人中计算机功率,net——每千人互联网络户主数。试根据该数据对这些国家和地区进行分层聚类分析,比较不同距离定义下的聚类结果,你会选择分几类?
Cluster6
海油工程
2
1
1
2
2
中海油服
1
2
2
5
5
中国石化
1
3
3
3
多元统计分析练习题

多元统计分析练习题一、主成分练习题填空题1.主成分分析是通过适当的变量替换,使新变量成为原变量的___________,并寻求_________的一种方法。
2.主成分分析的基本思想是______________。
3.主成分的协方差矩阵为_________矩阵。
4.主成分表达式的系数向量是_______________的特征向量。
5.原始变量协方差矩阵的特征根的统计含义是________________。
6.原始数据经过标准化处理,转化为均值为____,方差为____的标准值,且其________矩阵与相关系数矩阵相等。
7.因子载荷量的统计含义是_____________________________。
8.样本主成分的总方差等于_____________。
9.变量按相关程度为,在__________程度下,主成分分析的效果较好。
10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为________________。
11.SPSS 中主成分分析采用______________命令过程。
计算题1.设三个变量(x1,x2,x3)的样本协方差矩阵为:2121002222222<<−⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡r s rs r s s r s r s s 试求主成分及每个主成分的方差贡献率。
2.在一项研究中,测量了376只鸡的骨骼,并利用相关系数矩阵进行主成分分析,见下表: Y1 Y2 Y3 Y4 Y5 Y6 头长x1 头宽x2 肱骨x3 尺骨x4 股骨x5 胫骨x6 0.35 0.33 0.44 0.44 0.43 0.44 0.53 0.70 0.19 0.25 0.28 0.22 0.76 -0.64 -0.05 -0.02 -0.06 -0.05 -0.05 0.00 0.53 0.48 0.51 0.48 -0.04 0.00 0.19 0.15 0.67 0.70 0.00 0.04 0.59 0.63 0.48 0.15 特征值4.570.710.410.170.080.06解释6个主成分的实际意义。
机器学习与人工智能(聚类分析)习题与答案

一、填空题1.EM算法中,E代表期望,M代表()。
正确答案:最大化2.无监督学习中除了聚类,另一种是()。
正确答案:建模3.我们将一个数据可以属于多个类(概率)的聚类称作()。
正确答案:软聚类二、判断题1.聚类算法中的谱聚类算法是一种分层算法。
正确答案:×解析:聚类算法中的谱聚类算法是一种扁平算法。
2.两个向量之间的余弦距离等于1减这两个向量的余弦相似度。
正确答案:√3.K-均值++算法能够克服最远点不能处理离群值的问题。
正确答案:√4.K-means和EM聚类之间的主要区别之一是EM聚类是一种“软”聚类算法。
正确答案:√5.监督学习的训练集时有标签的数据。
正确答案:√6.在文本聚类中,欧氏距离是比较适合的。
正确答案:×三、单选题1.以下哪些方法可以确定K-均值算法已经收敛?()A.划分不再改变B.聚类中心不再改变C.固定次数的迭代D.以上三种均是正确答案:D2.以下哪些算法可以处理非高斯数据?()A.K-means算法B.EM算法C.谱聚类算法D.以上三种算法都可以正确答案:C四、多选题1、无监督学习可以应用于哪些方面?()A.图像压缩B.生物信息学:学习基因组C.客户细分(即分组)D.学习没有任何标签的聚类/群组正确答案:A、B、C、D2、以下哪些选项是K-均值聚类面临的问题?()A.K的选择具有挑战性B.硬聚类并不总是正确的C.贪婪算法存在的问题D.关于数据的球形假设(到聚类中心的距离)正确答案:A、B、C、D3、聚类可以应用于哪些方面?()A.基因表达数据的研究B.面部聚类C.搜索结果聚类D.新闻搜索正确答案:A、B、C、D4、在K-均值算法中,以下哪些方法可以用于随机种子的选择?()A.随机选择数据作为中心B.空间中的随机位置作为中心C.尝试多个初始起点D.使用另一个聚类方法的结果进行初始化正确答案:A、B、C、D5、EM算法可以应用于以下哪些方面?()A.学习贝叶斯网络的概率B.EM-聚类C.训练HMMD.学习微信好友网络正确答案:A、B、C、D。
高中信息技术《数据管理与分析》练习题(附答案解析)

高中信息技术《数据管理与分析》练习题(附答案解析)学校:___________姓名:___________班级:_____________一、选择题1.数据分析报告的基本组成部分包括()A.标题页、前言、正文、结论和建议B.标题页、正文、结论和建议、附录C.前言、正文、结论和建议D.标题页、前言、正文、结论和建议、附录2.数据分析的常见方法包括()A.对比分析、关联分析、平均分析B.对比分析、平均分析、交叉分析C.交叉分析、关联分析、平均分析D.关联分析、对比分析、交叉分析3.数据分析的方法中,下列()不是。
A.特征探索B.建立模型C.线性分析D.聚类与分类4.数据分析的基本方法包括()A.特征探索、关联分析、聚类分析、数据分类B.特征探索、聚类分析、数据分类C.特征探索、数据分类D.关联分析、聚类分析、数据分类5.下列有关数据关联分析的说法正确的是()A.对数据进行预处理,发现和处理缺失值,异常数据、绘制直方图,观察数据分布的特征,求最大值、最小值、极差等描述性统计量。
B.分析发现存在于大量数据之间的关联性和相关性,从而描述一个事物的共同规律和模式。
C.是一种探索性的分析。
不必事先给出一个分类标准,而是让其自动分类。
D.是数据分析中最基本的方法。
先基于样本数据构建分类器,然后进行预测。
6.使用欧式距离度量法对未知鸢尾花进行分类预测,其实施步骤的正确顺序是()①计算待测鸢尾花各属性值与三类鸢尾花属性平均值之间的欧式距离②读入鸢尾花训练集相关数据③计算三类鸢尾花各自特征属性的平均值④读入待测鸢尾花的数据⑤找出欧氏距离的最小值,并确定其对应的鸢尾花类别A.④③②①⑤B.②③④①⑤C.②④③①⑤D.③①④②⑤7.一份有效的数据分析报告,能够帮助用户()A.了解事物发展现状,预判事物发展趋势B.有效判断所需解决问题的影响因素C.有针对性地选择解决问题的方案D.以上都是8.关于数据分析方法,下列说法不正确的是()A.数据分析主要用于现状分析、原因分析和预测分析B.对比有横向对比和纵向对比两种情况C.平均分析是指运用计算平均值的方法反映总体在一定时间、地点条件下某一数量特征的一般水平D.数据分析方法只有对比分析法和平均分析法9.德国男人超市购买婴儿纸尿布的同时往往还购买啤酒,计算机分析超市的购物数据后发现了这一规律,于是将啤酒货架移到了婴儿纸尿布货架旁,啤酒和纸尿布的销量都有所增加。
聚类分析SPSS习题作业答案

4 5.679 2.674 4.565 .000 3.827 4.440 4.068 4.226 3.987 3.861 4.664 4.337 4.059 4.151 4.073 3.943 3.371 3.386 3.090 3.400 2.885
5 6.595 2.069 7.186 3.827 .000 7.130 6.877 6.675 6.741 6.510 6.814 7.430 7.060 7.006 7.002 7.131 6.460 6.438 6.272 6.182 5.293
0.284
2.289
3
-0.193
0.132
0.592
0.282
0.129
0.175
-1.472
3.392
0.292
4
0.477
0.751
-1.220
0.910
0.975
0.091
1.141
0.509
0.983
5
0.285
1.412
-2.148
0.833
3.310
2.599
1.723
-0.311
1.723
表1 某农业生态经济系统各区域单元的有关数据
样本 人口密度 序号 x 1/(人.km-2)
人均耕地 面积x 2/hm2
森林覆盖 农民人均纯收 率x 3/% 入x 4/(元.人-1)
人均粮食 产量x 5 /(kg.人-1)
经济作物 占农作物 播面比例
x 6/%
耕地占土 地面积比 率x 7/%
果园与林 地面积之 比x 8/%
6 9.139 6.193 4.952 4.440 7.130 .000 3.340 1.480 3.363 3.474 4.861 2.831 3.210 4.817 2.514 3.429 3.500 4.074 4.041 3.218 4.169
聚类因子分析试题

六、多元统计分析
数据“考试题6-沿海十省市数据.sav”呈现了某年我国10个沿海省份的资料,共有10个指标,详见数据。
请进行如下分析。
(一)用分层聚类的办法将10个地区聚类。
要求①不输出冰状图,输出树状图,其余默认。
(每题2分共10分)
1. 和(填地区序号)地区是此种聚类法下距离最近的观测。
2.请写出如果将全部10个地区分成三类,在此种分类方法下的各类分别是:
3.在第步聚类时,2、5组成的新类与其它类合并?
4.聚类分析中,对于样品的聚类又叫做型聚类.
5.K均值聚类法是否属于快速聚类法
(二)对于“考试题6-沿海十省市数据.sav”进行因子分析,要求①用方差最大法进行因子旋转②保存因子得分,其余默认。
(每题2分,共18分)
1.因子分析和主成分分析对于数据的要求是
2.用KMO和巴特莱特检验来判断数据是否适合于因子分析和主成分分析时,当出现 p=0.000则认为数据是否合适
3.综合来看,对变量提取公因子后,提取的信息占全部变量信息的 %,特征值大于1的公因子有个。
4.第一个因子的方差贡献率是 %,前两个因子的累计贡献率是 %。
5.因子载荷矩阵与旋转的因子载荷矩阵的区别是(意思对即可)
6.请写出X1变量的因子表达式
7.对于生成的两个因子得分F1、F2,请计算总得分,并“由高到低”将各个地区排序,则总得分排在第一位的是号省市。
聚类分析例题及解答
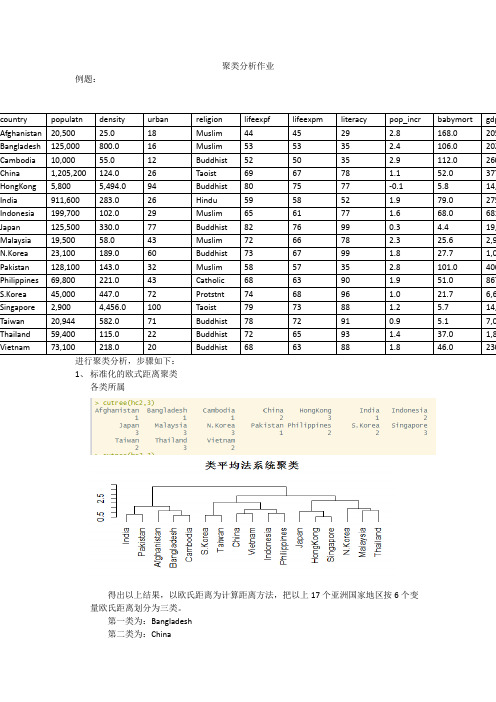
聚类分析作业例题:
进行聚类分析,步骤如下:
1、标准化的欧式距离聚类
各类所属
得出以上结果,以欧氏距离为计算距离方法,把以上17个亚洲国家地区按6个变量欧氏距离划分为三类。
第一类为:Bangladesh
第二类为:China
第三类为:Malaysia 2、尝试其他类间距离方法
其他类间距离方法得出以上结果,以欧氏距离为计算距离方法,把以上17个亚洲国家地区按6个变量欧氏距离也可以划分为以下三类:
第一类为:Bangladesh
第二类为:China
第三类为:Malaysia
3、用样本主成分画图
由图可知,所聚成的3类中:
第1类有5个样本,类间距离较接近,效果较好;
第2类有6个样本,类间距离较接近,效果次之;
第3类有6个样本。
类间距离较离散,效果最差。
二十章数据分析练习题

二十章数据分析练习题一、基础概念题1. 数据分析的定义是什么?2. 数据分析的主要目的是什么?3. 请列举三种常见的数据分析类型。
4. 数据清洗的目的是什么?5. 描述性统计分析主要包括哪些内容?二、数据处理题1. 如何使用Excel对数据进行排序?2. 如何使用Python的Pandas库对数据进行合并?3. 请简述数据清洗的步骤。
4. 如何识别和处理缺失值?5. 如何使用Python对数据进行标准化处理?三、数据分析方法题1. 请简述线性回归模型的原理。
2. 什么是逻辑回归?它适用于哪些场景?3. 如何使用K均值聚类算法对数据进行聚类分析?4. 请解释时间序列分析的基本概念。
5. 主成分分析(PCA)的目的是什么?四、实战应用题2. 给定一组商品的销售数据,如何使用Python计算每种商品的销售额占比?3. 请使用Python对一组数据进行相关性分析,并解释结果。
4. 如何利用Python对一组数据进行异常值检测?5. 请使用Python实现一个简单的线性回归模型,并预测未知数据。
五、综合分析题1. 某公司想要分析用户流失原因,请列出可能的分析步骤。
2. 请简述如何利用数据分析为企业制定营销策略。
3. 如何评估数据分析项目的成功与否?4. 请举例说明数据分析在金融行业的应用。
5. 谈谈大数据时代,数据分析面临的挑战和机遇。
六、统计分析软件应用题1. 如何在SPSS中进行单因素方差分析(ANOVA)?2. 请描述在R语言中如何绘制直方图。
3. 如何使用MATLAB进行数据插值?4. 在SAS中,如何执行多重线性回归分析?5. 请说明在Python的matplotlib库中如何自定义图表的样式。
七、数据可视化题1. 请列举三种常用的数据可视化工具。
2. 如何使用Excel制作折线图?3. 在Python中,如何使用Seaborn库绘制热力图?4. 请简述如何利用Tableau进行数据可视化。
5. 如何在数据可视化中避免常见的误区?八、数据库操作题1. 请写出SQL查询语句,用于从数据库中提取特定时间段的数据。
《统计分析与SPSS的应用(第五版)》课后练习答案(第10章)

《统计分析与S P S S的应用(第五版)》(薛薇)课后练习答案第10章SPSS的聚类分析1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。
要求:1)根据凝聚状态表利用碎石图对聚类类数进行研究。
2)绘制聚类树形图,说明哪些省市聚在一起。
3)绘制各类的科研指标的均值对比图。
4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。
采用欧氏距离,组间平均链锁法利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。
大约聚成4类。
步骤:分析→分类→系统聚类→按如下方式设置……结果:凝聚计划阶段组合的集群系数首次出现阶段集群下一个阶段集群 1 集群 2 集群 1 集群 21 26 30 328.189 0 0 22 26 29 638.295 1 0 73 20 25 1053.423 0 0 54 4 12 1209.922 0 0 155 8 20 1505.035 0 3 66 8 16 1760.170 5 0 97 24 26 1831.926 0 2 108 7 11 1929.891 0 0 119 5 8 2302.024 0 6 2210 24 31 2487.209 7 0 2211 2 7 2709.887 0 8 1612 22 28 2897.106 0 0 1913 6 23 2916.551 0 0 1714 10 19 3280.752 0 0 2515 4 21 3491.585 4 0 2116 2 3 4229.375 11 0 2117 6 13 4612.423 13 0 2018 9 18 5377.253 0 0 2519 14 22 5622.415 0 12 2420 6 15 5933.518 17 0 2321 2 4 6827.276 16 15 2622 5 24 7930.765 9 10 2423 6 27 9475.498 20 0 2624 5 14 14959.704 22 19 2825 9 10 19623.050 18 14 2726 2 6 24042.669 21 23 2827 9 17 32829.466 25 0 2928 2 5 48360.854 26 24 2929 2 9 91313.530 28 27 3030 1 2 293834.503 0 29 0将系数复制下来后,在EXCEL中建立工作表。
聚类判别分析SPSS练习题

聚类判别分析SPSS练习题1. 现有22名⽩⾎病病⼈的九种基因表达的cDNA微阵列扫描数据(X1~X9),根据X1~X9 的变量信息,对该22名⽩⾎病病⼈予以分类。
(具体数据见下表1)采⽤SPSS软件进⾏操作并回答以下问题:(个体聚类。
变量聚类)此题为个体聚类(1)采⽤什么分析⽅法?写出该⽅法在SPSS软件中的路径;聚类分析classify——hierarchical(2)该分析⽅法中采⽤什么统计指标进⾏度量的?个体聚类⽤⽤欧式距离平⽅。
距离越远就不可能聚类。
指标聚类⽤相关系数⼤⼩(3)根据结果中的什么图从⽽将该22名⽩⾎病病⼈分成3类?同时写出归为同⼀类的个体序号。
第⼀类8、21、1、4.第⼆类6、11 第三类剩下的《资料的表现形式是⽆序的、》聚类之后可以判别、、表1 ⽩⾎病⼈的九种基因表达序号X1X2X3X4X5X6X7X8X91 2.57403 2.53782 2.53403 2.12710 2.00000 2.00000 2.00000 2.53656 2.445602 2.87448 2.80686 2.88366 2.74036 2.00000 2.00000 2.30320 3.26623 3.432813 2.55991 2.00000 2.56820 2.00000 2.56348 2.00000 2.45637 2.98543 3.386504 2.65031 2.27646 2.37291 2.01703 2.00000 2.10721 2.00000 2.45637 2.586595 3.12352 2.53656 2.65128 2.34830 2.26482 2.17026 2.43775 3.15746 3.808956 3.14551 2.72263 3.02857 2.00000 3.18724 2.00000 2.85248 3.11327 3.178987 2.77452 2.01703 2.52504 2.22011 2.77452 2.00000 2.00000 2.83442 3.786118 3.05231 2.60097 2.43297 2.16435 2.31597 2.22789 2.65992 2.95182 2.000009 2.97497 2.34044 2.77452 2.35025 2.00000 2.00000 2.00000 2.87448 3.3163910 3.00817 2.81291 2.65992 2.00000 2.03743 2.00000 2.57519 3.02078 3.2195811 2.95617 2.88138 2.61700 2.00000 2.71600 2.00000 2.51188 3.00689 3.3442012 3.01578 2.41996 2.59879 2.22789 2.00000 2.29226 2.34439 2.80209 3.7668613 2.72263 2.41664 2.16137 2.00000 2.60314 2.00000 2.44716 2.87622 3.0751814 2.98046 2.99211 2.69810 2.00000 2.00000 2.16435 2.55751 2.96379 3.3546815 2.95665 2.41996 2.48430 2.00000 2.13354 2.00000 2.00000 2.72916 3.1711416 3.04297 2.37658 2.29885 2.36736 2.30750 2.00860 2.10380 2.78319 3.4026117 2.62221 2.54033 2.54777 2.00000 2.70329 2.00000 2.00000 2.65896 3.1309818 3.13481 2.00000 2.47129 2.08279 2.04139 2.46687 2.66087 2.79029 3.2953519 2.98767 2.47129 2.78032 2.00000 2.09691 2.00000 2.68931 2.77232 2.8561220 2.92993 2.30103 2.58659 2.03743 2.00000 2.02119 2.00000 2.79518 3.2372921 3.05231 2.60097 2.43297 2.16435 2.31597 2.22789 2.65992 2.95182 2.0000022 3.02325 2.83569 2.77525 2.61490 2.00000 2.00000 2.47857 3.46419 3.51322 2. 为明确诊断出⼩⼉肺炎三种类型, 某研究单位测得30名结核性、12名化脓性和18细菌性肺炎患⼉共60名的6项⽣理、⽣化指标(具体数据见下表2), 试进⾏判别分析。
聚类分析习题及答案

第三章 聚类分析一、填空题1.在进行聚类分析时,根据变量取值的不同,变量特性的测量尺度有以下三种类型: 间隔尺度 、 顺序尺度 和 名义尺度 。
2.Q 型聚类法是按___样品___进行聚类,R 型聚类法是按_变量___进行聚类。
3.Q 型聚类统计量是____距离_,而R 型聚类统计量通常采用_相似系数____。
4.在聚类分析中,为了使不同量纲、不同取值范围的数据能够放在一起进行比较,通常需要对原始数据进行变换处理。
常用的变换方法有以下几种:__中心化变换_____、__标准化变换____、____规格化变换__、__ 对数变换 _。
5.距离ij d 一般应满足以下四个条件:对于一切的i,j ,有0≥ij d 、 j i =时,有0=ij d 、对于一切的i,j ,有ji ij d d =、对于一切的i,j,k ,有kj ik ij d d d +≤。
6.相似系数一般应满足的条件为: 若变量i x 与 j x 成比例,则1±=ij C 、 对一1≤ij 和 对一切的i,j ,有ji ij C C =。
7.常用的相似系数有 夹角余弦 和 相关系数 两种。
8.常用的系统聚类方法主要有以下八种: 最短距离法 、最长距离法、中间距离法、重心法、类平均法、可变类平均法、可变法、离差平方和法。
9.快速聚类在SPSS 中由__K-mean_____________过程实现。
10.常用的明氏距离公式为:()pk q jk ik ij x x q d 11⎥⎦⎤⎢⎣⎡-=∑=,当1=q 时,它表示 绝对距离 ;当2=q 时,它表示 欧氏距离 ;当q 趋于无穷时,它表示 切比雪夫距离 。
11.聚类分析是将一批 样品 或 变量 ,按照它们在性质上 的 亲疏、相似程度 进行分类。
12.明氏距离的缺点主要表现在两个方面:第一 明氏距离的值与各指标的量纲有关 ,第二 明氏距离没有考虑到各个指标(变量)之间的相关性 。
聚类分析习题

聚类分析习题
一、填空题
1、系统聚类法是在聚类分析的开始,每个样本自成________;然后,按照某种方法度量所有样本之间的亲疏程度,并把最相似的样本首先聚成一小类;接下来,度量剩余的样本和小类间的___________,并将当前最接近的样本或小类再聚成一类;如此反复,直到所有样本聚成一类为止。
2、常见的两类聚类法分别为:__________________和________________。
二、判断题
1、快速(动态)聚类分析中,分类的个数是确定的,不可改变。
()
2、K均值聚类分析中,样品一旦划入某一类就不可改变。
()
3、系统聚类可以对不同的类数产生一系列的聚类结果。
()
4、K均值聚类和系统聚类一样,可以用不同的方法定义点点间的距离。
()
5、K均值聚类和系统聚类一样,都是以距离的远近亲疏为标准进行聚类的。
()
三、计算题
设有六个样品,每个样品只测量一个指标,分别是1,2,5,7,9,10。
(1)试用最短距离法、最长距离法、中间距离法、类平均法、重心法和离差平方和法将它们分类,并画出聚类谱系图。
(2)自己设置一个距离阈值d,写出最终的聚类结果。
应用多元统计分析习题解答聚类分析

第五章聚类分析5.1 判别分析和聚类分析有何区别?答:即根据一定的判别准则,判定一个样本归属于哪一类。
具体而言,设有n个样本,对每个样本测得p项指标(变量)的数据,已知每个样本属于k个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别幵,并判别该样本属于哪个总体。
聚类分析是分析如何对样品(或变量)进行量化分类的问题。
在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。
通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。
5.2 试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
5.3 对样品和变量进行聚类分析时,所构造的统计量分别是什么?简要说明为什么这样构造?答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。
因为我们把n 个样本看作p维空间的n个点。
点之间的距离即可代表样品间的相似度。
常用的距离为P q他(一)闵可夫斯基距离:d jj (q)(X ik X jk )k 1q取不同值,分为(1)绝对距离(q 1)(2)欧氏距离(q 2)(3)切比雪夫距离(q)(二)马氏距离(三)兰氏距离对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性 进行衡量。
将变量看作p 维空间的向量,一般用 (一) 夹角余弦 (二) 相关系数5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则? 答:设d j 表示样品X 与X 之间距离,用D 表示类G 与G 之间的距离 (1) .最短距离法 (2) 最长距离法(3) 中间距离法21 2 1 2 2 D krj 一 D kp 一 D kq D pq I- I纲 C 24其中(4) 重心法 (5) 类平均法(8)离差平方和法通常选择距离公式应注意遵循以下的基本原则:1)要考虑所选择的距离公式在实际应用中有明确的意义。
聚类分析期末试题题库及答案

聚类分析期末试题题库及答案一、选择题1. 聚类分析属于以下哪一类学习方式?A. 监督学习B. 无监督学习C. 增强学习D. 半监督学习答案:B2. 聚类分析的目标是什么?A. 对样本进行分类B. 预测样本的输出C. 减少数据的维度D. 发现数据中的固有结构答案:D3. 下面哪种方法不适用于聚类分析?A. K-means算法B. 层次聚类C. 支持向量机D. DBSCAN算法答案:C4. 当聚类分析中的聚类数目不事先给定时,以下哪个指标可以帮助我们选择合适的聚类数目?A. 轮廓系数B. 均方误差C. 方差解释比例D. 马氏距离答案:A5. 在使用K-means算法进行聚类分析时,初始聚类中心的选择对结果有何影响?A. 不影响结果B. 会导致陷入局部最优解C. 会导致算法收敛速度变慢D. 使得聚类数目增加答案:B二、填空题1. 聚类分析是一种_____________学习方式。
答案:无监督2. 聚类分析的目标是发现数据中的_____________结构。
答案:固有3. 聚类分析中最常用的算法之一是_____________算法。
答案:K-means4. 聚类分析中的聚类数目可以通过_____________系数来选择。
答案:轮廓5. 初始聚类中心的选择会对K-means算法的结果产生_____________。
答案:影响三、简答题1. 简述聚类分析的步骤及流程。
答:聚类分析的一般步骤包括:数据预处理、选择聚类算法、确定聚类数目、计算聚类中心、分配样本到聚类、评估聚类结果。
首先,需要对数据进行预处理,包括数据清洗、特征选择、数据标准化等。
然后,选择合适的聚类算法,如K-means、层次聚类、DBSCAN等。
接下来,通过轮廓系数等指标选择合适的聚类数目。
然后,计算聚类中心,即确定每个聚类的重心或代表性样本。
再次,将样本分配到各个聚类中心,形成聚类结果。
最后,评估聚类结果的质量,如通过轮廓系数、均方误差等指标进行评价。
聚类分析期末试题及答案

聚类分析期末试题及答案聚类分析被广泛应用于数据挖掘和统计分析领域,用于将一组样本根据相似性分为不同的群组。
本文将提供一些聚类分析的期末试题,并给出相应的答案。
通过阅读本文,您将对聚类分析的原理和应用有更深入的了解。
试题一:1. 请简要说明聚类分析的定义和作用。
2. 聚类分析有哪些常用的算法?3. 请解释层次聚类分析和划分聚类分析的区别。
4. 在聚类分析中,如何确定最佳聚类数目?答案一:1. 聚类分析是一种无监督学习方法,将一组样本划分为不同的群组,使得同一个群组内的样本相似度较高,而不同群组之间的相似度较低。
其作用在于揭示数据内在的结构和模式,发现数据集中的潜在规律和相似性。
2. 常用的聚类算法包括K均值聚类、层次聚类、密度聚类等。
K均值聚类是一种基于中心点的划分聚类算法,层次聚类将样本逐步合并或分割以构建树状结构,密度聚类基于样本之间的密度连接关系进行聚类划分。
3. 层次聚类分析和划分聚类分析的主要区别在于划分聚类将样本直接划分为不同的群组,而层次聚类分析构建样本之间的树状结构,通过剪枝步骤来确定最终的聚类结果。
4. 在确定最佳聚类数目时,可以使用肘部法则、轮廓系数、间隔统计量等方法。
肘部法则通过绘制聚类数目和聚类准则的关系图,选择“肘部”对应的聚类数目作为最佳聚类数目。
轮廓系数衡量了聚类结果的紧密度和分离度,数值越接近1表示聚类质量越好。
间隔统计量是一种基于距离度量的方法,选择统计量较大的聚类数目作为最佳聚类数目。
试题二:1. 请简要说明K均值聚类的原理和步骤。
2. 什么是初始聚类中心?如何确定初始聚类中心的位置?3. K均值聚类算法的优缺点是什么?4. 请论述层次聚类分析的原理和步骤。
答案二:1. K均值聚类是一种划分聚类算法,其原理是将样本划分为K个独立的群组,使得每个样本到其所属群组的质心的距离最小化。
步骤如下:a. 随机确定初始聚类中心。
b. 计算每个样本到各个聚类中心的距离,将其归类到最近的聚类中心所属群组。