第五章聚类分析
聚类分析_精品文档

1聚类分析内涵1.1聚类分析定义聚类分析(Cluste.Analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术.也叫分类分析(classificatio.analysis)或数值分类(numerica.taxonomy), 它是研究(样品或指标)分类问题的一种多元统计方法, 所谓类, 通俗地说, 就是指相似元素的集合。
聚类分析有关变量类型:定类变量,定量(离散和连续)变量聚类分析的原则是同一类中的个体有较大的相似性, 不同类中的个体差异很大。
1.2聚类分析分类聚类分析的功能是建立一种分类方法, 它将一批样品或变量, 按照它们在性质上的亲疏、相似程度进行分类.聚类分析的内容十分丰富, 按其聚类的方法可分为以下几种:(1)系统聚类法: 开始每个对象自成一类, 然后每次将最相似的两类合并, 合并后重新计算新类与其他类的距离或相近性测度. 这一过程一直继续直到所有对象归为一类为止. 并类的过程可用一张谱系聚类图描述.(2)调优法(动态聚类法): 首先对n个对象初步分类, 然后根据分类的损失函数尽可能小的原则对其进行调整, 直到分类合理为止.(3)最优分割法(有序样品聚类法): 开始将所有样品看成一类, 然后根据某种最优准则将它们分割为二类、三类, 一直分割到所需的K类为止. 这种方法适用于有序样品的分类问题, 也称为有序样品的聚类法.(4)模糊聚类法: 利用模糊集理论来处理分类问题, 它对经济领域中具有模糊特征的两态数据或多态数据具有明显的分类效果.(5)图论聚类法: 利用图论中最小支撑树的概念来处理分类问题, 创造了独具风格的方法.(6)聚类预报法:利用聚类方法处理预报问题, 在多元统计分析中, 可用来作预报的方法很多, 如回归分析和判别分析. 但对一些异常数据, 如气象中的灾害性天气的预报, 使用回归分析或判别分析处理的效果都不好, 而聚类预报弥补了这一不足, 这是一个值得重视的方法。
应用多元统计分析习题解答聚类分析

第五章聚类剖析5.1鉴别剖析和聚类剖析有何差别?答:即依据必定的鉴别准则,判断一个样本归属于哪一类。
详细而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类型(或整体)中的某一类,经过找出一个最优的区分,使得不一样类其余样本尽可能地域别开,并鉴别该样本属于哪个整体。
聚类剖析是剖析怎样对样品(或变量)进行量化分类的问题。
在聚类以前,我们其实不知道整体,而是经过一次次的聚类,使邻近的样品(或变量)聚合形成整体。
平常来讲,鉴别剖析是在已知有多少类及是什么类的状况下进行分类,而聚类剖析是在不知道类的状况下进行分类。
5.2试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离邻近的样品(或变量)先聚成类,距离相远的后聚成类,过程向来进行下去,每个样品(或变量)总能聚到适合的类中。
5.3对样品和变量进行聚类剖析时,所结构的统计量分别是什么?简要说明为何这样结构?答:对样品进行聚类剖析时,用距离来测定样品之间的相像程度。
由于我们把n 个样本看作 p 维空间的 n 个点。
点之间的距离即可代表样品间的相像度。
常用的距离为pq)1/ q(一)闵可夫斯基距离: d ij (q) ( X ik X jkk 1q取不一样值,分为( 1)绝对距离(( 2)欧氏距离(q 1)q 2 )( 3)切比雪夫距离( q) (二)马氏距离(三)兰氏距离对变量的相像性, 我们更多地要认识变量的变化趋向或变化方向, 所以用有关性进行权衡。
将变量看作 p 维空间的向量,一般用(一)夹角余弦(二)有关系数5.4 在进行系统聚类时,不一样类间距离计算方法有何差别?选择距离公式应按照哪些原则?答: 设 d ij 表示样品 X i 与 X j 之间距离,用 D ij 表示类 G i 与 G j 之间的距离。
( 1) . 最短距离法( 2)最长距离法( 3)中间距离法D kr 21D kp21D kq 2D pq 22 2此中(4)重心法(5)类均匀法(6)可变类均匀法D kr2 (1 )( np D kp2nq D kq2 )D pq2 n r? <1n r此中 ?是可变的且( 7)可变法D kr21(D kp2 D kq2 )D pq2 此中 ?是可变的且 ? <12(8)离差平方和法往常选择距离公式应注意按照以下的基根源则:(1)要考虑所选择的距离公式在实质应用中有明确的意义。
第五讲聚类分析

第五讲聚类分析聚类分析是一种无监督学习方法,旨在将样本数据划分为具有相似特征的若干个簇。
它通过测量样本之间的相似性和距离来确定簇的划分,并试图让同一簇内的样本点相似度较高,而不同簇之间的样本点相似度较低。
聚类分析在数据挖掘、模式识别、生物信息学等领域有着广泛的应用,它可以帮助我们发现隐藏在数据中的模式和规律。
在实际应用中,聚类分析主要包含以下几个步骤:1.选择合适的距离度量方法:距离度量方法是聚类分析的关键,它决定了如何计算样本之间的相似性或距离。
常用的距离度量方法包括欧氏距离、曼哈顿距离、切比雪夫距离等。
2.选择合适的聚类算法:聚类算法的选择要根据具体的问题和数据特点来确定。
常见的聚类算法有K-means算法、层次聚类算法、DBSCAN算法等。
3.初始化聚类中心:对于K-means算法等需要指定聚类中心的方法,需要初始化聚类中心。
初始化可以随机选择样本作为聚类中心,也可以根据领域知识或算法特点选择合适的样本。
4.计算样本之间的相似度或距离:根据选择的距离度量方法,计算样本之间的相似度或距离。
相似度越高或距离越小的样本越有可能属于同一个簇。
5.按照相似度或距离将样本划分为不同的簇:根据计算得到的相似度或距离,将样本划分为不同的簇。
常用的划分方法有硬聚类和软聚类两种。
硬聚类将样本严格地分到不同的簇中,而软聚类允许样本同时属于不同的簇,并给出属于每个簇的概率。
6.更新聚类中心:在K-means等迭代聚类算法中,需要不断迭代更新聚类中心,以找到最优划分。
更新聚类中心的方法有多种,常用的方法是将每个簇内的样本的均值作为新的聚类中心。
7.评估聚类结果:通过评估聚类结果的好坏,可以判断聚类算法的性能。
常用的评估指标有轮廓系数、Dunn指数、DB指数等。
聚类分析的目标是让同一簇内的样本点尽量相似,而不同簇之间的样本点尽量不相似。
因此,聚类分析常常可以帮助我们发现数据中的分组结构,挖掘出数据的内在规律。
聚类分析在市场细分、社交网络分析、基因表达数据分析等领域都有广泛的应用。
多元统计分析 第5章 聚类分析

余弦相似性 Cosine Similarity
A document can be represented by thousands of attributes,
p (such as each recording the frequency of a particular word keywords) or phrase in the document. xi yi
feature mapping, ... Cosine measure: If d1 and d2 are two vectors (e.g., termfrequency vectors), then cos(d1, d2) = (d1 d2) /||d1|| ||d2|| ,
where indicates vector dot product, ||d||: the length of vector d
d1 = (5, 0, 3, 0, 2, 0, 0, 2, 0, 0) d2 = (3, 0, 2, 0, 1, 1, 0, 1, 0, 1) d1 d2 = 5*3+0*0+3*2+0*0+2*1+0*1+0*1+2*1+0*0+0*1 = 25 ||d1||= (5*5+0*0+3*3+0*0+2*2+0*0+0*0+2*2+0*0+0*0)0.5=(42)0.5 = 6.481 ||d2||= (3*3+0*0+2*2+0*0+1*1+1*1+0*0+1*1+0*0+1*1)0.5=(17)0.5 = 4.12 cos(d1, d2 ) = 0.94
第5章聚类分析.

5.3 基于试探的聚类搜索算法
2.3.2 最大最小距离算法 • [算法(实例)]
第十九页,编辑于星期日按距离准则逐步分类,类别 由多到少,直到获得合适的分类要求为 止。
• [算法]
第二十页,编辑于星期日:十六点 五十七分。
系统聚类也称为Hierarchical Clustering
neirest neighbor algorithm • If data points are thought as nodes of a graph
with edges forming a path between the nodes in the same subset Di, the merging of Di and Dj corresponds to adding an edge between the neirest pair of node in Di and Dj • The resulting graph has any closed loop and it is a tree, if all subsets are linked we have a spanning tree
第二十五页,编辑于星期日:十六点 五十七分。
距离准则函数 To find the nearest clusters, one can use
dmin (Di , Dj )
min
xDi ,x'D j
x x'
dmax (Di , Dj )
max
xDi ,x'Dj
x x'
davg (Di , Dj )
dendrogram
第二十二页,编辑于星期日:十六点 五十七分。
• Another representation is based on set, e.g., on the Venn diagrams
多元统计分析课件第五章_聚类分析

止。如果某一步距离最小的元素不止一个,则对应ቤተ መጻሕፍቲ ባይዱ些
最小元素的类可以同时合并。
【例5.1】设有六个样品,每个只测量一个指标,分别是1, 2,5,7,9,10,试用最短距离法将它们分类。
(1)样品采用绝对值距离,计算样品间的距离阵D(0) ,见 表5.1
一、系统聚类的基本思想
系统聚类的基本思想是:距离相近的样品(或变量)先聚成 类,距离相远的后聚成类,过程一直进行下去,每个样品 (或变量)总能聚到合适的类中。系统聚类过程是:假设总 共有n个样品(或变量),第一步将每个样品(或变量)独 自聚成一类,共有n类;第二步根据所确定的样品(或变量) “距离”公式,把距离较近的两个样品(或变量)聚合为一 类,其它的样品(或变量)仍各自聚为一类,共聚成n 1类; 第三步将“距离”最近的两个类进一步聚成一类,共聚成n 2类;……,以上步骤一直进行下去,最后将所有的样品 (或变量)全聚成一类。为了直观地反映以上的系统聚类过 程,可以把整个分类系统画成一张谱系图。所以有时系统聚 类也称为谱系分析。除系统聚类法外,还有有序聚类法、动 态聚类法、图论聚类法、模糊聚类法等,限于篇幅,我们只 介绍系统聚类方法。
在生物、经济、社会、人口等领域的研究中,存在着大量量 化分类研究。例如:在生物学中,为了研究生物的演变,生 物学家需要根据各种生物不同的特征对生物进行分类。在经 济研究中,为了研究不同地区城镇居民生活中的收入和消费 情况,往往需要划分不同的类型去研究。在地质学中,为了 研究矿物勘探,需要根据各种矿石的化学和物理性质和所含 化学成分把它们归于不同的矿石类。在人口学研究中,需要 构造人口生育分类模式、人口死亡分类状况,以此来研究人 口的生育和死亡规律。
《Python数据分析与应用》教学课件第5章聚类分析

图 5<16 运行结果
553 算法实例
运行结果如图5-16所示。 由图5-16可以看出 ,300个数据点被 分成三类 ,聚类中心分别为( 3,3 )、
( -3 ,-3 )和( 3 ,-3 ) ,符合原始数
据的分布趋势 ,说明sklearn库中的近 邻传播算法 AffinityPropagation能够
按预期完成聚类功能。
5.1基本概NTENTS
DBSCAN聚类算法
5.4 谱聚类算法
5.5 近邻传播算法
学习目标
( 1 )了解聚类分析的定义 ,并了解几种聚类分析方法。
(2 )了解簇的定义及不同的簇类型。
( 3 )学习K means聚类算法、DBSCAN聚类算法、谱聚类 ( spectral clustering )算法和近邻传播( affinity propagation )算法。 ( 4 )通过算法的示例进一步理解算法的过程。 ( 5 )了解聚类分析的现状与前景。
5.5.3 算法实例
23. plt.plot(cluster_center [ 0 ] ,cluster_center [ 1 ] , o ,
markerfacecolor=col, \
24.
markeredgecolor= k , markersize=14)
25. for x in X [ class_members ] :
26.
plt.plot( [ cluster_center [ 0 ] , x [ 0 ] ] , [ cluster_center
[l],x[l] ] , col)
27.plt.title( Estimated number of clusters: %d % n_clustersJ
聚类分析原理及步骤

聚类分析原理及步骤
一,聚类分析概述
聚类分析是一种常用的数据挖掘方法,它将具有相似特征的样本归为
一类,根据彼此间的相似性(相似度)将样本准确地分组为多个类簇,其中
每个类簇都具有一定的相似性。
聚类分析是半监督学习(semi-supervised learning)的一种,半监督学习的核心思想是使用未标记的数据,即在训
练样本中搜集的数据,以及有限的标记数据,来学习模型。
聚类分析是实际应用中最为常用的数据挖掘算法之一,因为它可以根
据历史或当前的数据状况,帮助组织做出决策,如商业分析,市场分析,
决策支持,客户分类,医学诊断,质量控制等等,都可以使用它。
二,聚类分析原理
聚类分析的本质是用其中一种相似性度量方法将客户的属性连接起来,从而将客户分组,划分出几个客户类型,这样就可以进行客户分类、客户
细分、客户关系管理等,更好地实现客户管理。
聚类分析的原理是建立在相似性和距离等度量概念之上:通过对比一
组数据中不同对象之间的距离或相似性,从而将它们分成不同的类簇,类
簇之间的距离越近,则它们之间的相似性越大;类簇之间的距离越远,则
它们之间的相似性越小。
聚类分析的原理分为两类,一类是基于距离的聚类。
数据挖掘原理、 算法及应用第5章 聚类方法

第5章 聚类方法
5.1 概述 5.2 划分聚类方法 5.3 层次聚类方法 5.4 密度聚类方法 5.5 基于网格聚类方法 5.6 神经网络聚类方法:SOM 5.7 异常检测
第5章 聚类方法
5.1 概 述
聚类分析源于许多研究领域,包括数据挖掘、统计学、 机器学习、模式识别等。它是数据挖掘中的一个功能,但也 能作为一个独立的工具来获得数据分布的情况,概括出每个 簇的特点,或者集中注意力对特定的某些簇作进一步的分析。 此外,聚类分析也可以作为其他分析算法 (如关联规则、分 类等)的预处理步骤,这些算法在生成的簇上进行处理。
凝聚的方法也称为自底向上的方法,一开始就将每个对 象作为单独的一个簇,然后相继地合并相近的对象或簇,直 到所有的簇合并为一个,或者达到终止条件。如AGNES算法 属于此类。
第5章 聚类方法
(3) 基于密度的算法(Density based Methods)。 基于密度的算法与其他方法的一个根本区别是: 它不是 用各式各样的距离作为分类统计量,而是看数据对象是否属 于相连的密度域,属于相连密度域的数据对象归为一类。如 DBSCAN (4) 基于网格的算法(Grid based Methods)。 基于网格的算法首先将数据空间划分成为有限个单元 (Cell)的网格结构,所有的处理都是以单个单元为对象的。这 样处理的一个突出优点是处理速度快,通常与目标数据库中 记录的个数无关,只与划分数据空间的单元数有关。但此算 法处理方法较粗放,往往影响聚类质量。代表算法有STING、 CLIQUE、WaveCluster、DBCLASD、OptiGrid算法。
(3) 许多数据挖掘算法试图使孤立点影响最小化,或者排除 它们。然而孤立点本身可能是非常有用的,如在欺诈探测中, 孤立点可能预示着欺诈行为的存在。
聚类分析 PPT课件
f is binary or nominal: dij(f) = 0 if xif = xjf , or dij(f) = 1 otherwise f is ordinal Compute ranks rif and Treat zif as interval-scaled
x1 x2 x3 x4
x1 0 3.61 5.1 4.24
x2 0 5.1 1
x3
x4
5
0 5.39
0
第二节 相似性的量度
一 样品相似性的度量
二 变量相似性的度量
含名义变量样本相似性度量
例: 学员资料包含六个属性:性别(男或女);外语语种
(英、日或俄);专业(统计、会计或金融);职业(教师 或非教师);居住处(校内或校外);学历(本科或本科以 下) 现有两名学员: X1=(男,英,统计,非教师,校外,本科)′ X2=(女,英,金融,教师,校外,本科以下)′ 对应变量取值相同称为配合的,否则称为不配合的 记配合的变量数为m1,不配合的变量数为m2,则样本之间 的距离可定义为
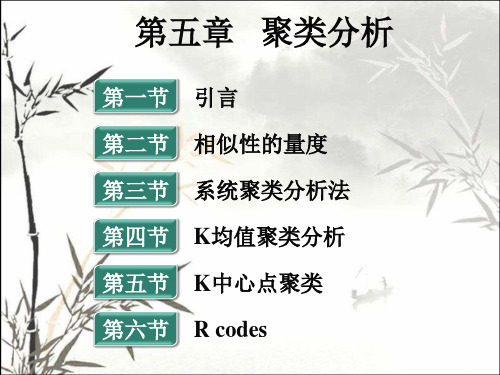
第五章 聚类分析
第一节 第二节 第三节 第四节 第五节 引言 相似性的量度 系统聚类分析法 K均值聚类分析 K中心点聚类
第六节
R codes
第一节 引言
“物以类聚,人以群分” 无监督分类聚类分析 分析如何对样品(或变量)进行量化分类的 问题 Q型聚类—对样品进行分类 R型聚类—对变量进行分类
用他们的序代替xif
zif
rif 1 M f 1
10
混合型属性
A database may contain all attribute types Nominal, symmetric binary, asymmetric binary, numeric, ordinal 可以用加权法计算合并的影响
聚类分析解析课件

类间距的度量
类:一个不严格的定义
定义9.1:距离小于给定阀值的点的集合 类的特征
◦ 重心:均值 ◦ 样本散布阵和协差阵 ◦ 直径
类间距的定义
最短距离法 最长距离法 重心法 类平均法 离差平方和法 等等
最小距离法(single linkage method)
极小异常值在实际中不多出现,避免极 大值的影响
类的重心之间的距离
对异常值不敏感,结果更稳定
离差平方和法(sum of squares
method或ward method)
W代表直径,D2=WM-WK-WL
即
DK2L
nL nk nM
XK XL XK XL
Cluster K
Cluster M
Cluster L
◦ 对异常值很敏感;对较大的类倾向产生较大的距 离,从而不易合并,较符合实际需要。
如表9.2所示,每个样品有p个指标,共 有n个样品
每个样品就构成p维空间中的一个点
:第i个样品的第k个指标对应的取值
◦ i=1……n; k=1……p
:第i个样品和第j个样品之间的距离
◦ i=1……n; j=1……n
点间距离测量问题
样品间距离与指标间距离 间隔尺度、有序尺度与名义尺度 数学距离与统计距离 相似性与距离:一个硬币的两面
类图上发现相同的类
饮料数据
16种饮料的热量、咖啡因、钠及价格四种变量
SPSS实现
选择Analyze-Classify-Hierarchical Cluster, 然 后 把 calorie ( 热 量 ) 、 caffeine ( 咖 啡
因)、sodium(钠)、price(价格)选入 Variables, 在Cluster选Cases(这是Q型聚类:对观测 值聚类),如果要对变量聚类(R型聚类) 则选Variables, 为 了 画 出 树 状 图 , 选 Plots , 再 点 Dendrogram等。 可以在Method中定义点间距离和类间距 离
聚类分析的思路和方法

一种叫相似系数,性质越接近的变量或样本,它们的相似系数越接近于1或一l,而彼此无关的变量或样本它们的相似系数则越接近于0,相似的为一类,不相似的为不同类。
3
另一种叫距离,它是将每一个样本看作p维空间的一个点,并用某种度量测量点与点之间的距离,距离较近的归为一类,距离较远的点应属于不同的类。
设有n个样本单位,每个样本测得p项指标(变量),原始资料矩阵为:
聚类分析终止的条件
*
迭代次数:当目前的迭代次数等于指定的迭代次数(SPSS默认为10)时终止迭代。
类中心点偏移程度:新确定的类中心点距上个类中心点的最大偏移量小于等于指定的量(SPSS默认为0)时终止聚类。
壹
贰
例子1:31个省区小康和现代化指数的聚类分析
利用2001年全国31个省市自治区各类小康和现代化指数的数据,对地区进行聚类分析。
夹角余弦
相关系数
计数变量(Count)(离散变量)的聚类统计量
对于计数变量或离散变量,可用于度量样本(或变量)之间的相似性或不相似性程度的统计量主要有卡方测度(Chi-square measure)和Phi方测度(Phi-square measure)。
二值(Binary)变量的聚类统计量
*
组间平均连接法(Between-group linkage)
03
组内平均连接法(Within-group linkage)
04
重心法(Centroid clustering)
05
中位数法(Median clustering)
06
离差平方和法(Ward’s method)
07
最短距离法(Nearest Neighbor) 以两类中距离最近的两个个体之间的距离作为类间距离。
多元统计分析聚类分析

[ ( xi xi ) ][ ( xj x j ) ]
2 2
n
n
1
1
相似矩阵
第三节 八种系统聚类方法
(hierarchical clustering method)
系统聚类法是诸聚类分析方法中使用最多 的一种,按下列步骤进行:
将n个样品各作为一类
计算n个样品两两之间的距离,构成距离矩阵 合并距离最近的两类为一新类 计算新类与当前各类的距离。再合并、计算 ,直至只有一类为止
如果在某一步将类Gp与Gq类合并为Gr,任一类Gk和新 Gr的距离公式为:
当
时,由初等几何知就是上面三角形的中线。
D2(0)
G1={X1}
G1
0
G2
G3
G4
G5
G2={X2}
G3={X3} G4={X4} G5={X5}
1
6.25 36 64
0
2.25 25 49 0 12.25 30.25 0 4 0
(2)相似系数
研究样品间的关系常用距离,研究指标( 变量)间的关系常用相似系数。 相似系数常用的有:夹角余弦与相关系数
2、对指标(变量)分类(R型)
相似系数的定义
夹角余弦(Cosine)
相似矩阵
变量间相似矩阵
相关系数
ij
( x x )( x x )
1 i i j j n
64
49
30.25
4
0
D2(1)
G6
G3 0
G4
G5
G6={X1, X2}
G3={X3}
0
4
={X4}
G5={X5}
30.25
56.25
聚类分析步骤

聚类分析步骤以教材第五章习题8的数据为例,演示并说明聚类分析的详细步骤:原始数据的输入:丈件(D 霸甸〔口锻国(蜀散惭直I 转快(D 分折(幻圈解〔⑤ 密坏賤序〔史Mt加内容(Q)SUM 帮肋S暗事?* ™ S?鮒*ffl ft韶亟蔚粤箱「专.选项操作:1. 打开SPSS的“分析”-“分类”-“系统聚类”,打开“系统聚类”对话框。
把“食品”、“衣着”等6变量输入待分析变量框;把“地区”输入“标注个案”;“分群”选中“个案”;“输出”选中“统计量”和“图”。
(如下图)相关说明:(1) 系统聚类法是最常用的方法,其他的方法较少使用。
(2) “标注个案”里输入“地区”,在输出结果的距离方阵和聚类树状图里会显示出“北京”、“天津”等,否则SPSS自动用“ 1”、“2”等代替。
(3) “分群”选中“个案”,也就是对北京等16个样本进行分类,而不是对食品等6个变量分类。
(4) 必须选中“输出”中的“统计量”和“图”。
在该例中会输出16个地区的欧氏距离方阵和聚类树状图。
密Ife鸟駝£臭* I必炮区H-qI 1E曲前 -------------输出v熨计養y岡2. 设置分析的统计量打开最右上角的“统计量”对话框,选中“合并进程表”和“相似性矩阵” “聚类成员”选中“无”。
然后点击“继续”。
打开第二个“绘制”对话框,必须选中“树状图”,其他的默认即可打开第三个对话框“方法”:聚类方法选中“最邻近元素”;“度量标准” 选中“区间”的“欧氏距离”;“转换值”选中“标准化”的“ Z 得分”,并且是“按照变量”。
+区町(LD : E uclidean 肚屈7" T计徹D ; 卡方度豪▼二鼻細^?TEuclicteeri■|i |g |打开第四个对话框“保存”,“聚类成员”选默认的“无”即可 三•分析结果的解读:按照SPSS 俞出结果的先后顺序逐个介绍:1. 欧氏距离矩阵:是16个地区两两之间欧氏距离大小的方阵, 该方阵是应用各 种聚类方法进行聚类的基础。
第五章聚类分析

▪ 概述 ▪ 距离与相似系数 ▪ 系统聚类法
(hierarchical clustering )
▪ 快速聚类法
(k-means clustering)
▪ 变量聚类
聚类分析是多元分析的 主要方法之一,主要用 来对大量的样品或变量 进行分类,是初步数据 分析的重要工具之一。
”
DM2 J
nK nM
DK2J
nL nM
DL2J
J
其中D.2. 为欧氏距离的平方
n.为各类类中所含样品
(五)质心法(centroid method)
K
M
J
L 类与类间的距离用各自 重心间的欧式距离表示
DM2 J
nK nM
DK2J
nL nM
DL2J
nK nL nM2
DK2L
比中间距离多(
nK nL nM
聚类分析数据格式
k
二、距离与相似系数
▪ 样本间的亲疏关系通常用距离描述,变 量间的亲疏关系通常用相似系数或相关 系数描述
▪ 不同测量尺度的数据,其距离的计算方 法不同
(一)、距离:样本间的亲疏关系
▪ 距离的定义:
假设每个样品由p个变量描述,则每个样品 都可以看成p维空间中的一个点,n个样品就 是p维空间中的n个点,则第i样品与第j样品 之间的距离记为dij
▪ 距离的大小与各指标的观测单位有关, 有时会出现不合理结果
▪ 没有考虑指标之间的相关性
当各指标的测量值相差悬殊时,可以先 对数据标准化,然后用标准化后的数据 计算距离
3. 马氏(Mahalanobis) 距离
明氏距离没有考虑数据中的协方差模式,马 氏距离则考虑了协方差,且不受指标测量单 位的影响:
应用多元统计分析习题解答_第五章(1)

第五章 聚类分析5.1 判别分析和聚类分析有何区别?答:即根据一定的判别准则,判定一个样本归属于哪一类。
具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。
聚类分析是分析如何对样品(或变量)进行量化分类的问题。
在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。
通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。
5.2 试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造?答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。
因为我们把n 个样本看作p 维空间的n 个点。
点之间的距离即可代表样品间的相似度。
常用的距离为 (一)闵可夫斯基距离:1/1()()pq qij ik jk k d q X X ==-∑q 取不同值,分为 (1)绝对距离(1q =)1(1)pij ik jk k d X X ==-∑(2)欧氏距离(2q =)21/21(2)()pij ik jk k d X X ==-∑(3)切比雪夫距离(q =∞)1()max ij ik jkk pd X X ≤≤∞=-(二)马氏距离(三)兰氏距离对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。
21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jkij k ik jk X X d L p X X =-=+∑将变量看作p 维空间的向量,一般用(一)夹角余弦(二)相关系数5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则?答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
d 21 ( x21 x11 ) 2 ( x22 x12 ) 2
k 1 p
x22 x11
x21- x11 ② x21 x1
2. 明氏(Minkowski )距离
dij [ xik x jk ]
k 1 p 1 q q
q=2
q=1 q=∞
dij满足下列条件
dij≥0
dii =0
dij = dji dij ≤ dik + dkj
1. 欧式(Euclidian )距离
d ij ( xi1 x j1 ) 2 ( xi 2 x j 2 ) 2 ( xip x jp ) 2 [ ( xik x jk ) 2 ]1 2
k 1 p
Euclidian距离的平方
2
Euclidian距离
明氏距离的缺点
各指标同等对待(权数相同),不能反 映各指标变异程度上的差异 距离的大小与各指标的观测单位有关, 有时会出现不合理结果
没有考虑指标之间的相关性
当各指标的测量值相差悬殊时,可以先 对数据标准化,然后用标准化后的数据 计算距离
(五)质心法(centroid method)
K M L 类与类间的距离用各自 重心间的欧式距离表示
D
2 MJ
nK 2 nL 2 nK nL 2 DKJ DLJ 2 DKL nM nM nM
J
nK nL 2 比中间距离多( DKL ) nM
(六)Ward最小方差法 (Ward’ minimum variance method)
距离标准化
“保存”对话框
生成一个新变量,表明 每个个体所属类
指定范围内的结果, 生成若干个新变量
系统聚类例:轿车的市场细分
对151名MBA学生的轿车偏好进行调查,要求 他们对10种轿车打分,分值1-10(最高分)。 10种轿车型号为:BMW328i, Ford Explorer, Infiniti J30, Jeep Grand Cherikee, Lexus ES300, Chrysler Town&Country, Merceds C280, Saab 9000, Porsche Boxster, Volvo V90.
类间距离
重复步骤2、3,直至合并成一类为止,形成谱系图
类与类间距离
Agglomerative Methods:各种不同方法的基本步骤相同, 只是类与类之间距离的计算方法不同。
类与类之间的距离
1.最短距离法(single linkage) 2.最长距离法(complete linkage) 3.中位数法(median method) 4.类平均法(average linkage) 5.可变类平均法(flexible-beta method) 6.质心法(centroid method) 7.Ward离差平方和法(Ward's minimumvariance method)
点A到μ的欧氏距离 12 12 2 , 点B到μ的欧氏距离 12 12 2
点A到μ的马氏距离
1 0.9 1 1 1 1 点B到μ的马氏距离 1.05 0 . 9 1 1 0.19
欧式等距离线
欧氏距离、标准化变量的欧式距 离与马氏距离的比较
不配合数 配合数 23 5
配合距离例
4种品牌的软饮料在4个方面的特性:是否可乐口味?是 否含有咖啡因?是否节食饮料?是否可口可乐公司产?
可乐味 咖啡因 节食 可口可乐
Coke Pepsi Diet Coke Caffeine-free Diet Coke
距离矩阵
Coke Pepsi Diet Caf free
D J
2 MJ
1 2 1 2 1 2 DKJ DLJ DKL 2 2 4
(四)类平均法 (average linkage between group)
K M L SPSS作为默认方法 ,称为“组间联接 ”
D
J
2 MJ
nK 2 nL 2 DKJ DLJ nM nM
2 ..
其中D 为欧氏距离的平方 n.为各类类中所含样品
快速聚类(k-means clustering)
模糊聚类
聚类分析数据格式
k
二、距离与相似系数
样本间的亲疏关系通常用距离描述,变 量间的亲疏关系通常用相似系数或相关 系数描述
不同测量尺度的数据,其距离的计算方 法不同
(一)、距离:样本间的亲疏关系
距离的定义:
假设每个样品由p个变量描述,则每个样品 都可以看成p维空间中的一个点,n个样品就 是p维空间中的n个点,则第i样品与第j样品 之间的距离记为dij
x
k 1 n k 1
ki kj n
x
2 2 12 [( xki )( xkj )] k 1
(二)相似系数
2. Pearson相关系数
SPSS的“分析” →“相 关”→“距离”
Measures对话框
定距尺度 定序尺度
定类尺度
三、系统聚类法
通常分为两步:先做出类别 距离谱系图,再根据谱系图 的特点确定分类数并分类
1 1 1 1
1 1 1 0
0 0 1 1
1 0 1 1
Coke Pepsi Diet Caf free 1/4 1/4 2/4 2/4 3/4 1/4
(二)相似系数:变量间的亲疏关系
1. 夹角余弦(Cosine)
受相似形的启发而来,AB和CD尽管 长度不一,但形状相似 A C B D
n
Cij
列出指定类 数的类成员
显示指定范围中 每一步类成员
“图”对话框
树状结构图 冰柱图 显示聚类的每一步
指定显示的聚 类范围
不生成冰柱图
冰柱的方向
距离测度方法: 不同尺度变量选 择不同方法
定距尺度变量 定序尺度变量
“方法”对话框聚类方法选项
01变量
确定标准化的方法:只有前两 种尺度的数据才能标准化
测度转换方法 距离值取绝对值 相似度变为不相似度
朝 鲜 族 X X
满 族 X X X X X
X X X X X
X X X X X
X X X X X
2 1 融合在一起的为一类
3
4
5
(二)最长距离法
类与类之间的 距离是两类间 两两样品间的 最长距离
前例:最长距离法
第1次合并仍取 最短欧式距离
新类和各类的距离:取最大值
第2次合并
新类和各类的距离:取最大值
聚合法 分解法
Agglomerative系统聚类法基本步骤
步骤1:将n个样品各作为一类,共n类:C1、 C2、…、 Cn。计算各类之间的距离,构成距离矩 阵:dcicj=dij 单样本类,类与类之间的距离为样品距离 步骤2:找到距离最近的两类合并为一新类 步骤3:计算新类与当前各类的距离。 根据谱系图确定如何分类
(一)最短距离法
类与类之间的 距离是两类间 两两样品间的 最短距离
6个民族的粗死亡率与期望寿命
哈萨克与藏族的距离最短, 最先合并形成新类CL7
新类CL7和其 余四类的距离
第二次合并
新类和各类的距离
D8i min(D4i, D7i) i 1,2,3
第三次合并
第四次合并
最后合并成一类
(七)各种系统聚类方法的统一
以上聚类方法的计算步骤完全相同,仅 类与类之间的定义不同。Lance和Williams 于1967年将其统一为:
D
2 MJ
K D L D D D D
2 KJ 2 LJ 2 KL 2 KJ
2 LJ
八种系统聚类法公式的参数
注意:几种聚类方法获得的结果不一定相同
源于方差分析。 类内离差平方和:类中各样品到类重心(均值)的 平方欧式距离之和。 基本思路:两类合并后,离差平方和就会增加。每 次选择使离差平方和增加(SSM-SSK-SSL) 最小的两类进行合并,直至所有的样品归为一类。
D
2 MJ
n J nK 2 n J nL 2 nJ 2 DKJ DLJ DKL n J nM nJ nM nJ nM
4. Lance和Williams 距离
对标准化变量:
xik x jk 1 d ij p k 1 xik x jk
p
5. 配合距离
前几类距离多用于定距和定比尺度数据 ,对于定类和定序变量:
X 1 (V , Q, S , T , K ) X 2 (V , M , S , F , K ) m2 配合数 d12 不配合数 2 2 d12 m 1 m2 不配合数 配合数 2 2 = = 23 5
3. 马氏(Mahalanobis) 距离
明氏距离没有考虑数据中的协方差模式,马 氏距离则考虑了协方差,且不受指标测量单 位的影响:
2 dij ( Xi X j ) ' 1 ( Xi X j )
其中为p维随机向量的协方差矩 阵
Mahalanobis 距离例
已知二维正态总体G的分布为:G~N(,),其 中 0.9 0 1
在儿童生长发育研究中,把以形态学为主的指 标归于一类,以机能为主的指标归于另一类
聚类分析的类型
根据分类的对象
Q型聚类(即样本聚类clustering for individuals) R型聚类(变量聚类clustering for variables)
根据分类的方法:
系统聚类(hierarchical clustering )
第3次合并
第4次合并
最后合并