代码转换汇编
汇编代码.386将十进制按位转换成为二进制互相转化实验报告

汇编代码.386将十进制按位转换成为二进制互相转化实验报告全文共四篇示例,供您参考第一篇示例:引言汇编语言是一种底层的计算机语言,它直接面向计算机的硬件和指令集架构。
在计算机科学领域中,对汇编语言的理解和掌握是非常重要的,因为它可以帮助程序员更深入地理解计算机系统的工作原理。
本文将围绕着汇编语言中的十进制到二进制的转换,展开一项实验报告,通过编写汇编代码.386实现十进制和二进制的相互转换,并对实验结果进行分析和总结。
实验目的1. 了解汇编语言中的数据处理、位操作等基本概念和指令;2. 掌握利用汇编语言将十进制数字转换为二进制数,并将二进制数转换为十进制数的方法;3. 加深对计算机底层原理的理解,提高汇编语言编程能力。
实验过程1. 十进制转为二进制我们使用汇编语言编写代码,将给定的十进制数字转换为二进制数。
我们可以选择一个整数N作为输入,然后使用位操作指令将其转换为对应的二进制数。
在汇编语言中,可以使用移位操作来实现这一转换。
我们可以将整数N的每一位通过移位操作得到对应的二进制位,直到整个数转换完成。
2. 二进制转为十进制接下来,我们利用汇编语言编写代码,实现将给定的二进制数转换为十进制数的功能。
对于一个二进制数,我们可以通过相应的位操作和乘法操作将其转换为对应的十进制数。
具体来说,我们可以取得二进制数的每一位,并将其乘以相应位数的权值,然后求和得到十进制数。
实验结果在实验过程中,我们成功地编写了汇编代码.386来实现十进制和二进制的相互转换。
通过实际的测试和验证,我们得到了正确的转换结果。
这证明了我们的汇编代码在功能上是正确的,能够准确地进行十进制和二进制之间的转换。
实验总结通过这次实验,我们深入探讨了汇编语言中的数据处理和位操作等基本概念。
我们不仅了解了如何使用汇编语言进行十进制和二进制的转换,还加深了对计算机底层原理的理解。
我们也发现了汇编语言在实现这种功能上的高效性和灵活性。
结论本次实验通过汇编代码.386将十进制按位转换成为二进制,并实现了二进制到十进制的互相转化。
keil c语言转汇编

keil c语言转汇编
在Keil C中,可以使用内置的编译器和调试器将C语言代码转换为汇编代码。
以下是将C语言代码转换为汇编代码的步骤:
1.打开Keil C并创建一个新的C项目。
2.在项目中创建一个C源文件(.c文件),并将的C代码写在这个文件中。
3.在Keil C的菜单栏中,选择“Project” > “Options for Target”。
4.在弹出的对话框中,选择“C/C++”选项卡。
5.在“C Compiler”下拉菜单中,选择要使用的编译器。
通常情况下,可以选择“ARM”或“C51”编译器,具体取决于的目标硬件。
6.在“Output”下拉菜单中,选择“Assemble only”选项。
这将指示编译器只生成汇编代码而不进行编译。
7.点击“OK”保存设置。
8.在Keil C的菜单栏中,选择“Project” > “Build Target”。
这将使用选定的编译器将的C代码编译为汇编代码。
9.编译过程完成后,打开生成的目标文件(.obj文件)。
10.在目标文件中,将找到已转换为汇编代码的C代码。
可以使用文本编辑器打开目标文件并查看其中的汇编代码。
请注意,转换后的汇编代码可能会被优化和重排,以适应目标硬件的要求。
因此,生成的汇编代码可能与在C源文件中编写的代码有所不同。
c++编译顺序

c++编译顺序c++编译顺序是指c++程序从源代码到可执行文件的转换过程中,各个源文件和目标文件的生成和处理的先后顺序。
c++程序一般由多个源文件(.cpp)和头文件(.h)组成,每个源文件都需要经过预处理(preprocess),编译(compile),汇编(assemble)和链接(link)四个阶段,才能最终生成可执行文件(.exe)。
不同的源文件之间可能存在依赖关系,比如一个源文件调用了另一个源文件中定义的函数或变量,或者一个源文件包含了另一个头文件中声明的内容。
因此,c++编译顺序需要考虑这些依赖关系,保证每个源文件在被处理之前,它所依赖的其他源文件或头文件已经被正确地处理过。
原理c++编译是基于c++程序的运行原理和编译器的工作原理。
c++程序的运行原理是基于计算机硬件和操作系统的,计算机只能执行机器语言指令,而操作系统负责加载可执行文件到内存,并调用入口函数开始执行。
因此,c++程序需要将人类可读的高级语言代码转换为机器可执行的二进制代码,并且按照操作系统规定的格式组织成可执行文件。
这个转换过程就是由编译器完成的。
编译器是一种软件,它可以将一种语言(源语言)翻译成另一种语言(目标语言)。
为了提高翻译效率和质量,编译器一般分为多个模块,每个模块负责完成一部分翻译工作,并生成中间结果。
这些中间结果可以是文本文件,也可以是二进制文件。
最后一个模块负责将所有中间结果合并成最终结果。
这些模块之间也有依赖关系,后面的模块需要使用前面模块生成的中间结果作为输入。
步骤c++编译可以分为四个阶段:预处理(preprocess),编译(compile),汇编(assemble)和链接(link)。
每个阶段都会生成对应的中间结果,并且有自己的工作内容和注意事项。
下面分别介绍每个阶段的具体内容。
预处理预处理是指对源代码进行一些文本替换和拷贝操作,以便于后续阶段进行语法分析和翻译。
预处理主要完成以下工作:-处理预处理指令(preprocessor directive),即以#开头的指令,比如#include, #define, #ifdef, #endif等。
代码转换(大小写字母转换)

北华航天工业学院课程设计报告(论文)设计课题:代码转换大小写字母转换专业班级:电子信息工程学生姓名:指导教师:设计时间: 2010-12-16北华航天工业学院电子工程系微机原理课程设计任务书指导教师:教研室主任:年月日内容摘要在课程设计之前,具备微机原理的理论知识和实践能力;熟悉汇编语言编程技术;熟悉80X86的CPU结构和指令系统;熟悉相关常用接口电路的设计使用方法是必不可少的。
因此原理部分重新温习并整理了相关知识。
课程设计要求进行大小写字母的转换。
其实字母大小写的区别在于他们的ASCII码范围,它们之间的转换其实就是加减相应的ASCII码值。
在判断输入的字母是大写的还是小写的(即判断输入符号ASCII码在41H~5AH还是在61H~7AH内)之后,决定判断是加上还是减去ASCII码值。
关键词:汇编代码转换大小写目录一、概述 (1)二、方案设计与论证 (1)1.汇编语言基础 (1)2.方案设计 (2)三、程序设计 (3)1.程序设计流程图 (3)2.程序代码 (4)四、运行结果 (5)五、心得体会 (6)六、参考文献 (6)一、概述:在计算机系统中有多种数制和编码,常用的数制有二进制、八进制以及十六进制,常用的代码有BCD码、ASCll码和七段显示码等。
这些数制和编码根据其作用的不同,在存储形式上也有差异。
在实际应用中,它们也因使用的要求不同而有所差异。
在配备操作系统管理程序的计算机中,有些代码转换程序已在系统管理软件中编好。
还有些代码转换需要根据使用要求通过编程完成。
因此,代码转换是非数据处理中最常见的情况。
二、方案设计:1、汇编语言基础汇编:计算机不能直接识别和执行汇编语言程序,而要通过“翻译”把源程序译成机器语言程序(目标程序)才能执行,这一“翻译”工作称为汇编。
汇编有人工汇编和计算机汇编两种方法。
汇编语言是面向机器的,每一类计算机分别有自己的汇编语言。
汇编语言占用的内存单元少,执行效率高,广泛应用于工业过程控制与检测等场合。
浅谈单片机中C语言与汇编语言的转换
浅谈单⽚机中C语⾔与汇编语⾔的转换⼀、单⽚机课设题⽬要求与软件环境介绍做了⼀单⽚机设计,要⽤C语⾔与汇编语⾔同时实现,现将这次设计的感受和收获,还有遇到的问题写下,欢迎感兴趣的朋友交流想法,提出建议。
单⽚机设计:基于51单⽚机的99码表设计软件环境:Proteus8.0 + Keil4要求:1,开关按⼀下,数码管开始计时。
2,按两下,数码管显⽰静⽌。
3,按三下,数码管数值清零。
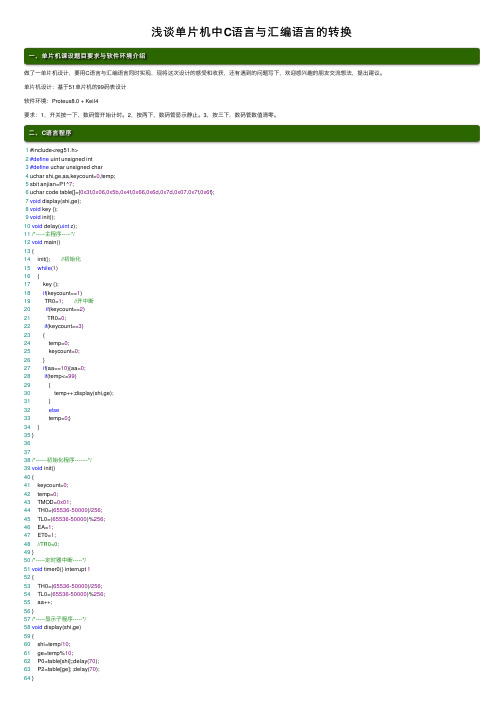
⼆、C语⾔程序1 #include<reg51.h>2#define uint unsigned int3#define uchar unsigned char4 uchar shi,ge,aa,keycount=0,temp;5 sbit anjian=P1^7;6 uchar code table[]={0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f};7void display(shi,ge);8void key ();9void init();10void delay(uint z);11/*-----主程序-----*/12void main()13 {14 init(); //初始化15while(1)16 {17 key ();18if(keycount==1)19 TR0=1; //开中断20if(keycount==2)21 TR0=0;22if(keycount==3)23 {24 temp=0;25 keycount=0;26 }27if(aa==10){aa=0;28if(temp<=99)29 {30 temp++;display(shi,ge);31 }32else33 temp=0;}34 }35 }363738/*------初始化程序-------*/39void init()40 {41 keycount=0;42 temp=0;43 TMOD=0x01;44 TH0=(65536-50000)/256;45 TL0=(65536-50000)%256;46 EA=1;47 ET0=1;48//TR0=0;49 }50/*-----定时器中断-----*/51void timer0() interrupt 152 {53 TH0=(65536-50000)/256;54 TL0=(65536-50000)%256;55 aa++;56 }57/*-----显⽰⼦程序-----*/58void display(shi,ge)59 {60 shi=temp/10;61 ge=temp%10;62 P0=table[shi];;delay(70);63 P2=table[ge]; ;delay(70);64 }65/*-----按键检测⼦程序-----*/66void key ()67 {68if(anjian==0)69 {70 delay(5); //消抖71if(anjian==0)72 keycount++;73 }74//while(anjian==0);75//display(shi,ge); //等待按键弹起76 }77/*-----延时⼦程序-----*/78void delay(uint z) //延时约1ms79 {80uint x,y;81for(x=z;x>0;x--)82for(y=100;y>0;y--);83 }电路仿真结果如下:三、C语⾔转汇编语⾔步骤好了,那么接下来我们就开始C语⾔——>汇编语⾔之旅(1)C语⾔1-10⾏改为1 ORG 0000H //汇编起始伪指令,功能是规定程序存储器中源程序或数据块存放的起始地址2 ajmp STAR //ajmp⽆条件跳转指令3 ORG 000bh4 ajmp timer05 anjian equ P1.7 //位定义6 keycount equ 40h7 shi equ 41h8 gewei equ 42h9 aa equ 43h10 temp equ 44h11tab: db 3fh,6h,5bh,4fh,66h //建表12 db 6dh,7dh,7h,7fh,6fh(2)C语⾔中的初始化函数 12-14⾏和39-49⾏改为1STAR:2 acall init //⼦程序近程调⽤指令,功能是主程序调⽤⼦程序,调⽤⼦程序的范围为2kb1init:2mov keycount,#0 //keycount=03mov temp,#0 //temp=14mov tmod,#01h //TMOD=0x015mov TH0,#606mov TL0,#1767setb EA //位置位指令,对操作数所指出的位进⾏置1操作8setb ET09setb TR010retacall为⼦程序近程调⽤指令,返回⽤ret。
gcc的四个步骤

gcc的四个步骤第一步:预处理预处理是GCC的第一个步骤,也是代码编译过程的第一步。
在预处理阶段,预处理器将根据一些特殊的预处理指令,对源代码进行一系列的处理,包括宏扩展、头文件包含、条件编译等等。
预处理的目的是提前处理一些不会因代码中的变化而改变的内容,为后续的编译步骤做准备。
预处理器首先会替换代码中的宏定义,将宏名称替换为其对应的宏代码。
然后进行头文件包含,将头文件中的内容插入到源文件中。
预处理器还会处理条件编译指令,根据条件对代码进行选择性编译。
最后生成一个经过预处理的中间文件,供下一步的编译使用。
第二步:编译编译是GCC的第二个步骤,也是代码编译过程的核心。
在编译阶段,编译器将预处理得到的中间文件进一步处理,将其转换为汇编语言代码。
编译器会对代码进行一系列的语法分析、语义分析、优化等操作,以保证代码的正确性和性能。
语法分析是指编译器对源代码进行词法分析和语法分析,将代码分解为基本的语法单元,并构建语法树。
语义分析是指编译器对语法树进行类型检查、语义检查等操作,确保代码的合法性和一致性。
优化是指编译器对代码进行一系列的优化操作,以提高代码的执行效率。
编译器将经过处理的代码转换为汇编语言代码,并生成一个汇编语言文件,作为下一步的汇编过程的输入。
第三步:汇编汇编是GCC的第三个步骤,也是代码编译过程的重要一环。
在汇编阶段,汇编器将编译得到的汇编语言文件进行处理,将其转换为机器码或者可重定位文件。
汇编器将汇编语言代码按照特定的指令格式和地址方式进行翻译,生成与特定处理器架构相兼容的机器码。
汇编器首先会解析汇编语言指令,将其转换为二进制机器码指令。
然后将地址符号转换为实际地址,生成指令和数据的链接关系。
最后生成一个与目标处理器兼容的机器码文件或可重定位文件。
第四步:链接链接是GCC的最后一个步骤,也是代码编译过程的最后一环。
在链接阶段,链接器将多个汇编产生的可重定位文件进行处理,将其合并成一个单一的可执行文件。
汇编实验报告--二进制到BCD码转换

实验二:二进制到BCD码转换学生姓名:何茂杰学号:2010305104 专业班级:计算机本科一班指导老师:文远熔实验日期:实验成绩:一、实验目的1.掌握无条件转移指令、条件转移指令;2.掌握利用DOS功能调用INT21H的2号和9号功能进行屏幕显示的方法;3.掌握直接向视频RAM送ASCII码进行屏幕显示的方法;4.掌握屏幕字符显示程序编写与调试。
二、实验内容将存放在BIN的一个16位无符号数转换为BCD码,结果的万、千,百、十、个位依次存放在BCD+0、BCD+1、BCD+2、BCD+3、BCD+4单元内三、实验环境PC微机DOS操作系统或Windows 操作系统四、实验要求对操作数的寻址、转换方法至少要由两种以上。
五、主要实验步骤及结果1.直接向VRAM送ASCII码显示字符(1)用A命令在100H处键入下列程序MOV AX,B000MOV DS,AXXOR AL,ALXOR BX,BXMOV CX,100LOP:MOV [BX],ALINC BXINC ALPUSH CXMOV CX,8DELY:PUSH CXMOV CX,0J:LOOP JPOP CXLOOP DELYPOP CXLOOP LOPINT 20(2)用N命令和W命令将此程序存入文件中。
(一定要先存入!)(3)用G命令运行此程序,仔细观察每一个ASCII码显示结果,并和字符表及上一道程序运行情况进行对照,其控制字符区(07-0DH)显示结果和INT 21H 2号功能调用有何不同?控制字符区在该程序中没有显示,在上一个程序中显示为笑脸等符号。
(4)自编程序:将存放在BIN的一个16位无符号数转换为BCD码反汇编;-U10013A3:0100 BB0010 MOV BX,100013A3:0103 8B07 MOV AX,[BX]13A3:0105 BB0000 MOV BX,000013A3:0108 BA0000 MOV DX,000013A3:010B BB0A00 MOV BX,000A13A3:010E F7F3 DIV BX13A3:0110 A21310 MOV [1013],AL13A3:0113 89161410 MOV [1014],DX13A3:0117 BB6400 MOV BX,006413A3:011A F7F3 DIV BX13A3:011C A21210 MOV [1012],AL13A3:011F 89D0 MOV AX,DX执行情况:-t=100AX=0000 BX=1000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000DS=13A3 ES=13A3 SS=13A3 CS=13A3 IP=0103 NV UP EI PL NZ NA PO NC 13A3:01038B07 MOV AX,[BX] DS:1000=0000六、思考题利用INT 21H 显示和直接向VRAM送ASCII码显示方法在显示结果上有什么不同?答:利用INT 21H显示时,07H-0DH的控制符会用笑脸之类的符号显示;直接向VRAM 送ACSII码时,07H-0DH的控制符不显示。
build 用法

build 用法
“build”在C语言中通常用于与程序的编译过程相关的操作。
在开发过程中,在写好C代码后,需要将代码编译成可执行的程序,以便在计算机上运行。
这个编译过程就是“build”。
“Build”过程主要包括以下步骤:
1. 预处理(Preprocessing):处理代码中的预处理指令,比如宏定义和条件编译等。
预处理器会根据预处理指令对源文件进行替换和处理。
2. 编译(Compilation):将预处理后的源文件转换为汇编代码。
3. 汇编(Assembly):将汇编代码转换为机器码或可重定位目标文件,这些文件包含了可以在计算机上执行的二进制指令。
4. 链接(Linking):将多个目标文件以及可能需要的库文件(如标准库)合并在一起,生成最终的可执行文件。
链接器会解决符号引用、地址重定位等问题。
通过“build”,我们可以将C代码转换为可执行的二进制文件,以便在计算机上运行和测试程序。
编译过程中的错误和警告也会被报告出来,方便开发者进行调试和修复。
c语言 编译

c语言编译C语言是一种通用的高级编程语言,由美国计算机科学家丹尼斯·里奇于1972年在贝尔实验室开发。
C语言具有简洁、高效、可移植等特点,被广泛应用于系统软件、嵌入式软件、游戏开发、科学计算等领域。
C语言的编译过程是将源代码转换为可执行文件的过程,下文将详细介绍C语言的编译过程。
一、C语言的编译过程C语言的编译过程包括预处理、编译、汇编和链接四个阶段。
下面分别介绍这四个阶段的作用和实现方式。
1. 预处理预处理阶段是在编译之前进行的,其作用是将源代码中的预处理指令替换为实际的代码。
预处理指令以#号开头,包括#include、#define、#ifdef、#ifndef等指令。
预处理器将这些指令替换为实际的代码,生成一个新的源文件。
预处理后的源文件通常以.i作为扩展名。
2. 编译编译阶段是将预处理后的源代码转换为汇编代码的过程。
编译器将C语言源代码转换为一种称为中间代码的形式,中间代码是一种类似汇编语言的低级语言。
中间代码具有平台无关性,可以在不同的平台上进行优化和执行。
编译后的结果通常以.s作为扩展名。
3. 汇编汇编阶段是将编译生成的汇编代码转换为机器代码的过程。
汇编器将汇编代码转换为可执行的机器代码,并生成一个目标文件。
目标文件包括可执行代码、数据段、符号表等信息。
目标文件通常以.o 或.obj作为扩展名。
4. 链接链接阶段是将多个目标文件合并为一个可执行文件的过程。
链接器将目标文件中的符号和地址进行解析,生成一个可执行文件。
可执行文件包括操作系统可以直接执行的代码和数据,通常以.exe、.dll 或.so作为扩展名。
二、C语言编译器C语言编译器是将C语言源代码转换为可执行文件的工具,包括预处理器、编译器、汇编器和链接器四个部分。
C语言编译器可以在不同的平台上运行,生成可在目标平台上运行的可执行文件。
下面分别介绍常用的C语言编译器。
1. GCCGCC(GNU Compiler Collection)是一款开源的C语言编译器,由GNU组织开发。
反汇编c代码

反汇编c代码反汇编C代码是将C代码转换成相应的汇编代码的过程。
可以使用工具如IDA Pro、objdump等来进行反汇编操作。
以下是一个示例的C代码及其反汇编结果:```c#include <stdio.h>int main() {int a = 5;int b = 10;int c = a + b;printf("The sum of %d and %d is %d\n", a, b, c);return 0;}```反汇编结果:```Disassembly of section .text:0000000000401000 <main>:401000: 55 push %rbp401001: 48 89 e5 mov %rsp,%rbp401004: c7 45 fc 05 00 00 00 movl $0x5,-0x4(%rbp)40100b: c7 45 f8 0a 00 00 00 movl $0xa,-0x8(%rbp)401012: 8b 55 f8 mov -0x8(%rbp),%edx401015: 8b 45 fc mov -0x4(%rbp),%eax401018: 01 d0 a dd %edx,%eax40101a: 89 45 f4 mov %eax,-0xc(%rbp)40101d: 8b 45 f4 mov -0xc(%rbp),%eax401020: 89 c6 mov %eax,%esi401022: bf 00 00 00 00 mov $0x0,%edi401027: b8 00 00 00 00 mov $0x0,%eax40102c: e8 df ff ff ff callq 401010 <printf@plt>401031: b8 00 00 00 00 mov $0x0,%eax401036: c9 leaveq401037: c3 retq```这里展示了`main`函数的反汇编结果。
C语言编译执行的全过程

C语言编译执行的全过程1.预处理预处理是编译过程的第一步,主要作用是对源代码进行一些处理,生成预处理后的文件。
预处理主要包括以下几个操作:-删除注释:删除源代码中的注释。
注释对于程序的执行没有影响,但会增加源代码长度,降低可读性。
- 处理预处理指令:处理以"#"开头的预处理指令,如#include、#define等。
-展开宏定义:将源代码中的宏定义展开为对应的代码。
-处理条件编译指令:根据条件编译指令的条件判断结果,选择性地编译部分代码。
2.编译编译是将预处理后的文件转换为汇编代码的过程。
编译主要包括以下几个步骤:-词法分析:将源代码分割为一个个的词法单元,如关键字、标识符、常量、操作符等。
-语法分析:根据词法单元组成规则进行语法分析,生成抽象语法树。
-语义分析:对抽象语法树进行语义检查,如类型检查、函数调用检查等。
-生成中间代码:根据语法分析和语义分析的结果,生成中间代码。
3.汇编汇编是将编译后的中间代码转换成机器码的过程。
中间代码并不是直接可执行的,在汇编过程中,会将中间代码转换为与目标硬件平台相对应的机器指令。
汇编主要包括以下几个步骤:-词法分析:将中间代码分割为一个个的词法单元。
-语法分析:根据词法单元组成规则进行语法分析,生成抽象语法树。
-生成目标代码:根据抽象语法树生成目标代码。
4.链接链接是将编译后的目标代码与库函数进行合并,生成可执行文件的过程。
链接主要包括以下几个步骤:-符号解析:解析目标代码中的符号引用,确定其所对应的符号定义。
-重定位:根据符号解析的结果,将目标代码中的符号引用跳转至对应的符号定义。
-地址和空间分配:为所有的可执行代码和数据分配内存空间。
5.执行执行是将可执行文件加载到计算机内存中,并按照指令序列依次执行。
执行主要包括以下几个步骤:-内存加载:将可执行文件加载到内存中。
-程序入口:开始执行程序的入口点。
-按顺序执行指令:根据程序计数器(PC)指向的地址,按顺序执行一条条的机器指令。
c语言程序编译的流程

c语言程序编译的流程C语言是一种高级编程语言,它是一种通用的编程语言,可以用于开发各种类型的应用程序。
C语言程序编译的流程是指将C语言源代码转换为可执行文件的过程。
本文将详细介绍C语言程序编译的流程。
C语言程序编译的流程可以分为以下几个步骤:1. 预处理预处理是C语言程序编译的第一步。
在这个步骤中,编译器会对源代码进行一些预处理操作,例如宏替换、头文件包含等。
预处理器会将源代码中的宏定义替换为宏定义中的内容,并将头文件中的内容插入到源代码中。
预处理后的代码称为预处理文件。
2. 编译编译是C语言程序编译的第二步。
在这个步骤中,编译器会将预处理文件转换为汇编代码。
汇编代码是一种低级语言,它是机器语言的一种表现形式。
编译器会将C语言代码转换为汇编代码,这个过程称为编译。
3. 汇编汇编是C语言程序编译的第三步。
在这个步骤中,汇编器会将汇编代码转换为机器语言代码。
机器语言是计算机可以直接执行的语言,它是由0和1组成的二进制代码。
汇编器会将汇编代码转换为机器语言代码,这个过程称为汇编。
4. 链接链接是C语言程序编译的最后一步。
在这个步骤中,链接器会将机器语言代码和库文件链接在一起,生成可执行文件。
库文件是一些预编译的代码,它们可以被多个程序共享。
链接器会将程序中使用到的库文件链接到程序中,生成可执行文件。
以上就是C语言程序编译的流程。
下面我们将详细介绍每个步骤的具体内容。
1. 预处理预处理是C语言程序编译的第一步。
在这个步骤中,编译器会对源代码进行一些预处理操作,例如宏替换、头文件包含等。
预处理器会将源代码中的宏定义替换为宏定义中的内容,并将头文件中的内容插入到源代码中。
预处理后的代码称为预处理文件。
预处理器的工作原理是将源代码中的宏定义和头文件包含替换为实际的代码。
例如,下面是一个简单的宏定义:#define PI 3.1415926在预处理阶段,预处理器会将源代码中的所有PI替换为3.1415926。
这样,程序中所有使用到PI的地方都会被替换为3.1415926。
gcc编译过程的四个阶段

gcc编译过程的四个阶段
gcc编译过程的四个阶段为:
预处理:预处理是在运行编译器之前完成的,它负责处理通过预编译
指令生成的源代码文件。
在这一阶段,编译器会删除所有注释,然后负责
处理宏定义,头文件包含和宏展开。
经过这一阶段之后,被编译器处理的
源代码文件会生成。
编译:编译器在这一阶段将预处理之后的代码翻译成汇编语言。
此外,编译器还会检查源文件的语法和语义错误,并在发现错误时给出错误消息。
如果一切正常,这一阶段会生成目标文件。
汇编:汇编器的任务是把编译器产生的汇编源代码翻译成机器语言。
在这一阶段,汇编器会把汇编语言的指令转换成机器语言的指令,并为代
码分配存储空间。
经过汇编阶段,一个可重定位的目标文件会生成。
链接:链接是最后一个阶段,它使用一个链接器来结合由编译器和汇
编器产生的模块。
除了将模块结合起来之外,链接器还会处理函数调用,
并为程序的初始化提供支持。
经过完成整个编译过程之后,一个操作系统
可以执行的文件就会产生。
汇编语言中的字符串、代码转换

一个字符串中包含的字符个数,称为这个字符串的长度。长度为 零的字符串称为空串,它不包含任何字符。字符串通常用单引号或 双引号括起来,例如:
Hale Waihona Puke 3.LODS取串指令格式:可有三种 LODS SRC;源串元素由DS:SI指定的存储单元,目的串元素隐 含在由DS:AL或DS:AX指定的存储单元 LODSB; 8位字符串操作,省略源串和目的串不写 LODSW; 16位字符串操作,省略源串和目的串不写 功能:该指令把由SI指定的数据段中某单元[SI]的内容送到AL或 AX中,并根据方向标志及数据类型修改SI的内容。 说明: 1)如果是字节操作则先将由SI指定的单元内容送入AL中,然后 SI再自加/减1;如果是字操作则将[SI]送入AX,然后SI再自加/减 2。 2)该指令不影响标志位。
(1) ” X1 ” (2) ’ABC’
返回本节
字符串所能包含的字符,依赖于具体机器的字符集。目前世 界上应用最广的字符集是ASCII码字符集。 存储字符串的方法也就是存储列表的一般方法。最简单最普遍的 方法是顺序存储,还有链接存储等,这里仅讨论顺序存储的字符 串。 字符串的表示在8086/8088宏汇编语言中,可以借助数据定义语 句DB(因一个ASCII码是7位)来定义,字符串的特征表示一般有 两种,一种是在字符串的尾部用00H作标记,另一种是在字符串的 前面空出一个单元,放置字符串的长度。例: STRI DB ’ I am a student’,0 STR2 DB 4,’ABCD’
易语言代码转汇编

易语言代码转汇编1 概述易语言是一种广泛使用的编程语言,在国内拥有相当多的程序员和用户群体。
相对于其他语言,易语言的语法结构更简单,容易上手,但实现的功能也更加有限。
同时,易语言存在一些效率比其他语言低的问题,这也成为了一些程序员不使用易语言的原因之一。
因此,为了提高易语言的效率,一些程序员将易语言代码转换为汇编代码。
本文就将介绍使用易语言代码转换成汇编代码的一些技巧和方法。
2 易语言转汇编的方法易语言转汇编可以通过两种方式进行,一种是使用易语言的自带工具,将易语言代码转换为汇编代码。
另一种是使用第三方工具,在把易语言代码转换为C语言代码后,再将其转换为汇编代码。
2.1 使用易语言自带工具易语言自带的工具是易语言汇编器,将生成的汇编代码通过编译即可生成相应的可执行程序。
易语言汇编器可支持独立模式或内嵌模式,这也是其一个优点。
使用易语言汇编器打开需要转换的代码文件,点击“编译”按钮即可将代码转换为汇编代码。
2.2 使用第三方工具使用第三方工具可以将易语言代码先转化成C语言代码,然后再将其转换为汇编代码。
这种方式的好处是可以针对C语言进行优化,从而提高程序的性能。
第三方工具有许多,下面介绍使用LLVM转换的方式。
首先将易语言代码转换为C语言代码:```compile plaininclude <easyc.h>int main(){int a=0,b=2,c=3;for(int i=0;i<10;i++){if(i%2==0){a+=b;}else{b+=a;}c--;}printf("%d\n",a);return 0;}```将上述代码保存为C代码文件,例如为example.c。
接下来,使用LLVM生成汇编代码:```llc example.c -o example.asm```将上述命令输入到终端中,即可生成example.asm文件,即易语言代码对应的汇编代码。
LLVM生成中间码以及汇编代码

LLVM⽣成中间码以及汇编代码⾸先先贴⼀个LLVM安装的教程:原⽂地址:打不开就⽤:这个⽂章整合了klee和llvm的安装,由于这两个软件都要⽤到,所以这样装上之后问题⽐较少。
如果直接安装llvm,会造成⼀⼤堆乱七⼋糟的错误,特别是找不到⼀些lib,也有可能是我安装的⽅法不对?使⽤的帖⼦:虽然是个台湾的帖⼦,但是是我看到的llvm使⽤分析的最全⾯的了。
也有可能因为墙的原因,没有看到国外的⼀些帖⼦。
其中稍微有点区别,⽂章⾥使⽤的clang,但是我⼀般使⽤llvm-gcc,在⾼版本的llvm⾥已经没有llvm-gcc了,因为要使⽤klee,klee限制了llvm的版本,所以还能使⽤llvm-gcc。
下⾯的命令⽤了有⼀段时⽇了,下次试⼀下确认⼀下如果有错再来编辑原⽂吧(果然有更新,修改⼀次)。
利⽤llvm-gcc很容易得到中间码IR:llvm-gcc -emit-llvm -c hello.c -o hello.bc (先编译⼆进制码)llvm-dis hello.bc (llvm-dis出来的就是IR)好像llvm-gcc -S -emit-llvm test.c -o test.ll 也是中间码。
.ll的后缀是中间码利⽤objdump可以得到机器码:objdump -S test.o (这⾥的-S⼀定是⼤写)更新:以上命令其实都在绕弯⼦,果然当时没有吃透。
但是也能⽤。
⽣成⼆进制(汇编): llvm-gcc -S test.c -o test 可以增加参数⽤于⽣成INTEL格式的汇编。
llvm-dis 可以将llvm⼆进制码转换为中间码,⽽llvm-as则是相反的。
当利⽤ llvm-gcc -c -emit-llvm test.c -o test⽣成test之后,可以利⽤llvm-dis转换为中间码。
下⾯放⼀个例⼦:源代码test2.c:int func(int a,int b){char var[128]="A";a=0x4455;b=0x6677;return a+b;}int main(){func(0x8899,0x1100);return0;}中间码IR:; ModuleID = 'test2.bc'target datalayout = "e-p:32:32:32-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:32:64-f32:32:32-f64:32:64-v64:64:64-v128:128:128-a0:0:64-f80:32:32-f128:128:128-n8:16:32"target triple = "i386-pc-linux-gnu"@.str = private unnamed_addr constant [128 x i8] c"A\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\ define i32 @func(i32 %a, i32 %b) nounwind {entry:%a_addr = alloca i32, align 4%b_addr = alloca i32, align 4%retval = alloca i32%0 = alloca i32%var = alloca [128 x i8]%"alloca point" = bitcast i32 0 to i32store i32 %a, i32* %a_addrstore i32 %b, i32* %b_addr%var1 = bitcast [128 x i8]* %var to i8*call void @llvm.memcpy.p0i8.p0i8.i32(i8* %var1, i8* getelementptr inbounds ([128 x i8]* @.str, i32 0, i32 0), i32 128, i32 1, i1 false)store i32 17493, i32* %a_addr, align 4store i32 26231, i32* %b_addr, align 4%1 = load i32* %a_addr, align 4%2 = load i32* %b_addr, align 4%3 = add nsw i32 %1, %2store i32 %3, i32* %0, align 4%4 = load i32* %0, align 4store i32 %4, i32* %retval, align 4br label %returnreturn:; preds = %entry%retval2 = load i32* %retvalret i32 %retval2}declare void @llvm.memcpy.p0i8.p0i8.i32(i8* nocapture, i8* nocapture, i32, i32, i1) nounwinddefine i32 @main() nounwind {entry:%retval = alloca i32%0 = alloca i32%"alloca point" = bitcast i32 0 to i32%1 = call i32 @func(i32 34969, i32 4352) nounwindstore i32 0, i32* %0, align 4%2 = load i32* %0, align 4store i32 %2, i32* %retval, align 4br label %returnreturn:; preds = %entry%retval1 = load i32* %retvalret i32 %retval1}View Code汇编码:test2.o:⽂件格式 elf32-i386Disassembly of section .text:00000000 <func>:0: 55push %ebp1: 89 e5 mov %esp,%ebp3: 81 ec a8 000000sub $0xa8,%esp9: 8b 450c mov 0xc(%ebp),%eaxc: 8b 4d 08mov 0x8(%ebp),%ecxf: 8d 9570 ff ff ff lea -0x90(%ebp),%edx15: 89 4d fc mov %ecx,-0x4(%ebp)18: 8945 f8 mov %eax,-0x8(%ebp)1b:89 e0 mov %esp,%eax1d:8910mov %edx,(%eax)1f: c7 400880000000 movl $0x80,0x8(%eax) 26: c7 400400000000 movl $0x0,0x4(%eax)2d: e8 fc ff ff ff call 2e <func+0x2e>32: c7 45 fc 55440000 movl $0x4455,-0x4(%ebp) 39: c7 45 f8 77660000 movl $0x6677,-0x8(%ebp) 40: 8b 45 fc mov -0x4(%ebp),%eax43: 0345 f8 add -0x8(%ebp),%eax46: 8945 f0 mov %eax,-0x10(%ebp) 49: 8b 45 f0 mov -0x10(%ebp),%eax4c:8945 f4 mov %eax,-0xc(%ebp)4f: 8b 45 f4 mov -0xc(%ebp),%eax52: 81 c4 a8 000000add $0xa8,%esp58: 5d pop %ebp59: c3 ret5a: 8d b6 00000000lea 0x0(%esi),%esi 00000060 <main>:60: 55push %ebp61: 89 e5 mov %esp,%ebp63: 83 ec 28sub $0x28,%esp66: b8 99880000mov $0x8899,%eax6b: b9 00110000mov $0x1100,%ecx70: c7 042499880000 movl $0x8899,(%esp) 77: c7 442404001100 movl $0x1100,0x4(%esp) 7e:007f:8945 f4 mov %eax,-0xc(%ebp)82: 89 4d f0 mov %ecx,-0x10(%ebp) 85: e8 fc ff ff ff call86 <main+0x26>8a: c7 45 f8 00000000 movl $0x0,-0x8(%ebp) 91: 8b 4d f8 mov -0x8(%ebp),%ecx94: 89 4d fc mov %ecx,-0x4(%ebp)97: 8945 ec mov %eax,-0x14(%ebp)9a: 8b 45 fc mov -0x4(%ebp),%eax9d:83 c4 28add $0x28,%espa0: 5d pop %ebpa1: c3 retView Code。
scala代码转java

scala代码转javaScala 与 Java 是两个非常常见的编程语言,尤其是在大数据和人工智能领域得到了广泛的应用。
虽然它们都可以编译为 JVM 字节码,但是 Scala 有更多的语言特性,包括函数式编程、隐式转换等等。
这些特性在 Java 中并不常见,因此,有时候将 Scala 代码转换成Java 代码(比如给那些只支持 Java 的平台使用)是很有必要的。
本文将介绍如何使用 Scala 的反编译工具,将 Scala 代码转换成 Java 代码,以及如何处理转换后的 Java 代码。
1. 下载并安装 Scala 反编译工具有一个 Scala 反编译工具名为 scala反编译器(Scala Decompiler),它可以将 Scala 代码反汇编为 Java 代码。
可以在GitHub 上下载源码,或者直接下载已编译的可执行 Jar 包,使用非常方便。
2. 反编译 Scala 代码首先,需要将要转换的 Scala 代码编译成 Jar 包。
在 IDEA 或Eclipse 等常见的开发工具中,可以直接将 Scala 代码编译成 Jar包或者 War 包。
然后,使用 Java 命令行运行反编译工具,将 Jar 包反编译为Java 代码:java -jar scala-decompiler.jar <jarfile><outputdir>其中,scala-decompiler.jar 是反编译工具的 Jar 包,<jarfile> 是要反编译的 Scala Jar 包文件,<outputdir> 是生成的Java 代码的存放目录。
3. 处理生成的 Java 代码由于 Scala 有很多 Java 没有的语言特性,所以在生成的 Java 代码中可能存在一些问题。
本节将介绍如何解决这些问题。
3.1 将函数内部的 var 转换为 finalScala 中的 var 表示可变变量,而 Java 中的 var 特指Java10 中的 var 类型推断。
c++反编译还原代码

c++反编译还原代码C++反汇编和还原代码是一种非常有用的技能,它允许我们将编译后的代码转换为汇编代码和C++源代码,从而更好地理解程序的运行方式和原理。
在本文中,我们将介绍如何使用IDA Pro和OllyDbg对C++程序进行反汇编和还原代码。
IDA Pro反汇编IDA Pro是一个强大的反汇编工具,可以自动将二进制文件转换为汇编代码,并显示函数和变量的引用关系。
以下是反汇编C++程序的基本步骤:1. 打开二进制文件在IDA Pro中,选择“File”->“Open”菜单,然后浏览并选择要反汇编的二进制文件。
一旦打开了二进制文件,IDA Pro将开始分析文件,并在分析期间自动识别函数、结构体和变量。
分析完成后,可以在左侧窗格中看到反汇编结果。
3. 选择函数要查看特定函数的汇编代码,请选择左侧窗格中的该函数。
4. 查看汇编代码在IDA Pro的主界面中,您可以看到选择函数的汇编代码。
这是我们分析代码的关键部分。
OllyDbg反汇编OllyDbg是另一个强大的反汇编工具,它允许我们单步运行程序,查看寄存器和内存,以及动态修改代码。
以下是使用OllyDbg反汇编C++程序的步骤:2. 运行程序在程序运行之前,我们需要设置断点。
选择要调试的函数,右键单击它,并选择“BreakPoint->Toggle”。
然后,启动程序并等待程序暂停在断点处。
3. 单步运行一旦程序停止在断点处,我们可以使用OllyDbg的单步运行功能逐步执行程序并查看寄存器和内存。
4. 动态修改代码如果您希望动态修改代码,请在命令窗口中输入“e”来进入修改模式。
然后,将光标移动到要修改的指令上,对它进行修改,然后按“F2”以保存修改。
尽管IDA Pro和OllyDbg具有功能强大的反汇编功能,但它们不能生成C++源代码,这使得还原代码变得更加困难。
尽管如此,在某些情况下,您可能需要还原一些C++代码。
以下是还原C++代码的方法:1. 手动编写代码在一些简单的情况下,您可以通过手动编写C++代码来还原程序的功能。
汇编二进制转十进制,十六进制代码

特注:代码可以优化,请读者自己思考,运行结果绝对没问题!实验二数制转换程序代码二进制到十进制转换DATAS SEGMENTS0 DB "please input a binary (length<16):",0AH,0DH,"$"S1 DB 18S2 DB ; 总长度S3 DB 16 DUP(0); 存放首地址S4 DW ; 存放输入的二进制数S5 DB "The nuber is not a binary!","$"S6 DB "Do you want to continue(Y or N):",0AH,0DH ,"$"TEMP DB 0BUF DB 5 DUP (); 此处输入数据段代码DATAS ENDSSTACKS SEGMENTDB 256 DUP () ; 初始化堆栈大小为100; 此处输入堆栈段代码STACKS ENDSCODES SEGMENTASSUME CS:CODES,DS:DATAS,SS:STACKSSTART:MOV AX,DATASMOV DS,AXMOV AX,STACKSMOV SS,AX; 输入一个二进制数LOOPP:CALL CLSCALL HCMOV DX,OFFSET S0 ; 显示字符串s0CALL G9 ;"please input a binary (length<16):",0AH,0DH,"$"MOV DX,OFFSET S1 ; 申请16个内存空间MOV AH,0AH ; 将数输入到缓冲区INT 21H;将输入的数据整合放到AX中MOV SI,OFFSET S3MOV CL,S2MOV CH,0HMOV AX,0HLOOP1:CMP BYTE PTR [SI],30H ; 判断是否为二进制数JL EXITCMP BYTE PTR [SI],31HJG EXITMOV BL,[SI]SUB BL,30HMOV BH,0HINC SISHL AX,1ADD AX,BXLOOP LOOP1MOV S4,AXCALL HC ; 二进制转换成十进制MOV SI,5MOV AX,S4MOV CX,5MOV BX,10LP: CWDMOV DX,0DIV BXADD DL,30HMOV BUF [SI-1],DLDEC SILOOP LP ; 显示结果CALL COUNT ; 找到第一个非零元的位置MOV AL,TEMPMOV AH,0MOV SI,AXMOV CX,5LOOPPP:MOV DL,BUF[SI]MOV AH,02HINT 21HINC SILOOP LOOPPPJMP EXIT1EXIT:CALL HCMOV DX,OFFSET S5 ; 显示字符串S5CALL G9 ;"The nuber is not a binary!","$"EXIT1:CALL HCMOV DX,OFFSET S6 ; 显示字符串S6CALL G9 ;"Do you want to continue(Y or N):",0AH,0DH ,"$" MOV AH,1 INT 21HCMP AL,'Y'JE LOOPPCMP AL,'y'JE LOOPPMOV AH,4CHINT 21HCOUNT: ; 判断第一个非零元的位置MOV TEMP,0MOV SI,0MOV CX,4LOO:MOV DL,BUF[SI]CMP DL,30HJNE EXIT3MOV AL,TEMPADD AL,1MOV TEMP,ALINC SILOOP LOOEXIT3: RETG9:MOV AH,9 ; 显示功能调用INT 21HCALL HCRETHC: ; 回车换行MOV DL,0AHMOV AH,2INT 21HMOV DL,0DHMOV AH,2INT 21HRETCLS:MOV AH,6 ; 屏幕初始化MOV AL,0MOV BH,7HMOV CH,0MOV CL,0MOV DH,24MOV DL,79INT 10HMOV BH,0 ; 置光标位子MOV DX,0MOV AH,2INT 10HRETCODESENDSEND START 二进制到十六进制转换DATAS SEGMENTS0 DB "please input a binary (length<16):",0AH,0DH,"$"S1 DB 17S2 DB ; 总长度S3 DB 16 DUP(0); 存放首地址S4 DW ; 存放输入的二进制数S5 DB "The nuber is not a binary!","$"S6 DB "Do you want to continue(Y orN):",0AH,0DH ,"$"S7 DB "The length of the numbei is not 16","$" DATAS ENDS STACKS SEGMENTSTACKS ENDS CODES SEGMENTASSUME CS:CODES,DS:DATAS,SS:STACKS START:MOV AX,DATASMOV DS,AXMOV AX,STACKSMOV SS,AX ; 输入一个二进制数LOOPP:CALL CLSCALL HCMOV DX,OFFSET S0 ; 显示字符串S0CALL G9 ;"please input a binary(length<16):",0AH,0DH,"$"MOV DX,OFFSET S1 ; 申请16个内存空间MOV AH,0AH ; 将数输入到缓冲区INT 21H判断是否为 16为二进制;将输入的数据整合放到AX 中MOV SI,OFFSET S3MOV CL,S2MOV CH,0HMOV AX,0HLOOP1:CMP BYTE PTR [SI],30H ; 判断是否为 2 进制 JL EXITCMP BYTE PTR [SI],31HJG EXIT CMP S2,10H ;JNE EXIT2MOV BL,[SI]SUB BL,30HMOV BH,0HINC SISHL AX,1ADD AX,BXLOOP LOOP1MOV S4,AXCALL HC ; 二进制变 16进制并输出MOV BX,S4CMP BX,0JZ ZEROMOV CH,04HMOV CL,04HNEXT:ROL BX,CLMOV DL,BLAND DL,0FHADD DL,30HCMP DL,3AHJB LADD DL,7HL:CALL XSDEC CHJNZ NEXTJMP WEISHUZERO:MOV DL,'0'CALL XSWEISHU:MOV DL,'H'CALL XSis notJMP EXIT1 ; 选择用的程序EXIT:CALL HCMOV DX,OFFSET S5 ; 显示字符串 S5CALL G9 ; "The nuber is not a binary!","$" JMP EXIT1EXIT2:CALL HCMOV DX,OFFSET S7 ; 显示字符串 S7CALL G9 ; "The length of the numbei 16","$" EXIT1:CALL HCMOV DX,OFFSET S6CALL G9 ; 显示字符串 S6MOV AH,1 ;"Do you want to continue(Y or N):",0AH,0DH ,"$"INT 21HCMP AL,'Y'JE LOOPPCMP AL,'y'JE LOOPPMOV AH,4CHINT 21HG9:MOV AH,9 ; 显示功能调用INT 21HCALL HCRETHC: ; 回车换行MOV DL,0AHMOV AH,2INT 21HMOV DL,0DHMOV AH,2INT 21HRETCLS:MOV AH,6 ; 屏幕初始化MOV AL,0MOV BH,70HMOV CH,0MOV CL,0MOV DH,24MOV DL,79INT 10HMOV BH,0 ; 置光标位子MOV DX,0MOV AH,2INT 10HRETXS: ;2 号功能显示MOV AH,2INT 21HRETCODES ENDSEND START。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二进制编码的十进制数,简称BCD码(Binarycoded Decimal). 这种方法是用4位二进制码的组合代表十进制数的0,1,2,3,4,5,6 ,7,8,9 十个数符。
4位二进制数码有16种组合,原则上可任选其中的10种作为代码,分别代表十进制中的0,1,2,3,4,5,6,7,8,9 这十个数符。
最常用的BCD码称为8421BCD码,8.4.2.1 分别是4位二进数的位取值。
点击此处将给出十进制数和8421BCD编码的对应关系表。
1、BCD码与十进制数的转换BCD码与十进制数的转换.关系直观,相互转换也很简单,将十进制数75.4转换为BCD码如:75.4=(0111 (0101.0100)BCD 若将BCD码1000 0101.0101转换为十进制数如: (1000 0101.0101)BCD=85.5注意:同一个8位二进制代码表示的数,当认为它表示的是二进制数和认为它表示的是二进制编码的十进制数时,数值是不相同的。
例如:00011000,当把它视为二进制数时,其值为24;但作为2位BCD码时,其值为18。
又例如00011100,如将其视为二进制数,其值为28,但不能当成BCD码,因为在8421BCD 码中,它是个非法编码 .2、BCD码的格式计算机中的BCD码,经常使用的有两种格式,即分离BCD码,组合BCD码。
所谓分离BCD码,即用一个字节的低四位编码表示十进制数的一位,例如数82的存放格式为:_ _ _1 0 0 0 _ _ _ _0 0 1 0 其中_表示无关值。
组合BCD码,是将两位十进制数,存放在一个字节中,例82的存放格式是1000 0010 3、BCD码的加减运算由于编码是将每个十进制数用一组4位二进制数来表示,因此,若将这种BCD码直接交计算机去运算,由于计算机总是把数当作二进制数来运算,所以结果可能会出错。
例:用BCD码求38+49。
解决的办法是对二进制加法运算的结果采用"加6修正,这种修正称为BCD调整。
即将二进制加法运算的结果修正为BCD码加法运算的结果,两个两位BCD数相加时,对二进制加法运算结果采用修正规则进行修正。
修正规则:(1)如果任何两个对应位BCD数相加的结果向高一位无进位,若得到的结果小于或等于9,则该不需修正;若得到的结果大于9且小于16时,该位进行加6修正。
(2)如果任何两个对应位BCD数相加的结果向高一位有进位时(即结果大于或等于16),该位进行加6修正.(3)低位修正结果使高位大于9时,高位进行加6修正。
下面通过例题验证上述规则的正确性。
用BCD码求35+21 BCD码求25+37 用BCD码求38+49 用BCD码求42+95用BCD码求91+83 用BCD码求94+7 用BCD码求76+45两个组合BCD码进行减法运算时,当低位向高位有借位时,由于"借一作十六"与"借一作十"的差别,将比正确的结果多6,所以有借位时,可采用"减6修正法"来修正.两个BCD码进行加减时,先按二进制加减指令进行运算,再对结果用BCD调整指令进行调整,就可得到正确的十进制运算结果。
实际上,计算机中既有组合BCD数的调整指令,也有分离BCD数的调整指令。
另外,BCD码的加减运算,也可以在运算前由程序先变换成二进制数,然后由计算机对二进制数运算处理,运算以后再将二进制数结果由程序转换为BCD码131 将ASCII码表示的十进制数转换为二进制数汇编代码1.将ASCII码表示的十进制数转换为二进制数十进制数可以表示为:Dn×10n+Dn-1×10n-1+…+D0×100=Di×10i 其中Di代表十进制数1、2、3…9、0。
上式可以转换为:ΣDi×10i=((…(Dn×10+Dn-1)×10)+Dn-2)×10+…+D1)×10+D0由上式可归纳十进制数转换为二进制的方法:从十进制数的最高位Dn开始作乘10加次位的操作,依次类推,则可求出二进制数结果。
本实验要求将缓冲区中的一个五位十进制数00012的ASCII码转换成二进制数,并将转换结果按位显示在屏幕上。
;***********************************************************************data SEGMENT ;定义数据段msg DB ' hua xian asks you to input ASCLL numbers:$'msg2 DB 0DH,0AH,'OverFlow!!$',0DH,0AHmsg3 DB 0DH,0AH,'The Binary number:$'array DW 100 dup(0)TEN DW 10TAB DB 4data ENDS;*********************************************************************** STACK SEGMENT PARA STACK ;定义堆栈段DW 64 DUP(?)STACK ENDS;***********************************************************************code SEGMENT ;定义代码段;-------------------------------------------------------------------MAIN PROC FARASSUME CS:code,DS:data,SS:STACKMOV AX,data ;data送到DS中MOV DS,AXLEA DX,msg ;输出要求MOV AH,9HINT 21HLEA BX,array ;array数组的地址传送到BX中SUB CX,CX ;使CX = 0CALL INPUT ;调用INPUT子程序CALL CONVERT ;调用CONVERT子程序PUSH AX ;保护AX中的数据因为AX中的数据有用,但在此后又;必须用到axLEA DX,msg3 ;输出“The Binary number:”MOV AH,9H ;INT 21H ;中断POP AX ;返回受保护的AX中的数据CALL DISPLAY ;输出二进制数OUT0:MOV AX,4C00h ;返回DOSINT 21hMAIN ENDP;-------------------------------------------------------------------INPUT PROC NEARWAIT_HERE:MOV AH,7 ;等待输入INT 21HCMP AL,0DH ;是否是回车键JE OUT1 ;如果是则跳转道OUT1否则继续执行CMP AL,'0' ;AL < '0'?JL WAIT_HERE ;如果是则跳转到WAIT_HERE否则继续执行CMP AL,'9' ;AL > '9'?JG WAIT_HERE ;如果是则跳转到WAIT_HERE否则继续执行MOV [BX],AL ;把键盘输入的数字送到array[bx]中ADD BX,2 ;增加bx的值,能够使得下一个数存放到array 数组中的下;一个位置, 因为是字节型所以加2INC CX ;增加计数器的值MOV AH,2H ;输出刚刚输入的数字,若不是数字则永远不会到此步MOV DL,AL ;dl中存放要显示的值INT 21H ;中断JMP WAIT_HERE ;显示完后跳转到WAIT_HEREOUT1:ret ;退出次过程INPUT ENDP;-----------------------------------------------------------------CONVERT PROC NEARSUB CX,1 ;计数器减1LEA BX,array ;bx为array数组的首地址MOV AX,[BX] ;把数组中的值送到ax中SUB AX,30H ;减30h是将ascll码转换为十进制数CMP CX,0 ;如果仅仅输入了一个数字则跳出JE OUT3LOOP1: ;否则就开始运行MUL TEN ;把刚才的十进制数*10,再加下一位数ADD BX,2ADD AX,[BX]SUB AX,30HLOOP LOOP1OUT3:retCONVERT ENDP;-----------------------------------------------------------------DISPLAY PROC NEARMOV BX,AX ;ax中存放着答案,但是因为后面要用到ax所以把值放到;bx中MOV CX,16 ;计数器设置为16MOV AH,2H ;为输出作准备此处用到ax,若不做上面的处理LOOP2:ROL BX,1 ;把bx左移1位,若有进位cf=1JC PRINT1 ;监测cf如果是1,则跳转道print1MOV DX,'0' ;到这说明他不是,则把‘0’送入dx.dx为输出的内容JMP PRINT0 ;然后跳转道print0PRINT1:MOV DX,'1'PRINT0:PUSH AX ;判断如果cx能被4整除,则输出空格PUSH DX ;这里是保护ax dx cx让他们进栈。
PUSH CXMOV AL,CLDIV TABCMP AH,0JNE OUT4MOV AH,2HMOV DX,' 'INT 21HOUT4:POP CXPOP DXPOP AX ;栈的特点是先进后出,所以要反序出栈INT 21H ;中断,跳转到dos所提供的功能,输出LOOP LOOP2 ;cx-1 然后进行循环,直到cx==0终止; LEA BX,array;LOOP2:; MOV DX,[BX]; MOV AH,2H ;print the number; INT 21H; INC BX; LOOP LOOP2retDISPLAY ENDP;-------------------------------------------------------------------code ENDSEND MAIN2 十进制ASCII码转BCD码code segmentassume cs:codestart:push cspop dsmov dx,offset tipsmov ah,9int 21hmov si,3500h;十进制ASCII存于3500H起单元mov di,350ah;BCD后再存于350AH起内存mov cx,10;只够输入10个字符Q0:mov ah,1int 21hcmp al,'0'jb Q1cmp al,'9'ja Q1mov [si],alsub al,30hmov [di],aljmp Q2Q1:mov al,0ffhmov [si],almov [di],alQ2:inc siinc diQ3:loop Q0mov ah,0int 16hmov ah,4chint 21htips db 'Press any key...',0dh,0ah,'$'code endsend start3从键盘输入一个16进制数,转换成十进制数然后输出,汇编程序实现DATA SEGMENTDATA1 DB ?DATA2 DB 2 DUP(?)DATA20 DB 2 DUP(?)DATA3 DB 'Input Error, Please Enter Again!','$'DATA ENDSSTACK SEGMENTDB 5 DUP(?)STACK ENDSCODE SEGMENTASSUME CS:CODE, DS:DATA,SS:STACKSTART:MOV AX,DATAMOV DS,AXMOV AX,STACKMOV SS,AXMOV BX,0INPUT:MOV AH,01HINT 21HCMP AL,51H;判断输入的字符是否为QJE EXIT ;如果是Q就退出CMP AL,71H;判断输入的字符是否为qJE EXIT ;如果是Q就退出PUSH AX ;把从键盘输入的字符的ASCII存到堆栈段SUB AL,30H ;判断是否为数字CMP AL,00HJL INDI ;如果不是就提示错误CMP AL,09H ;MOV BL,AL ;JLE OUTPUT2;如果是数字就输出POP AX ;把AL的值取出来PUSH AX ;MOV BL,ALSUB AL,41H;判断是否为大写字母A到FCMP AL,00HJL INDI ;如果不是就提示错误CMP AL,06HJL CHANGEPOP AXPUSH AXMOV BL,ALSUB AL,61H;判断是否为小写字母a到fCMP AL,00HJL INDI ;如果不是就提示错误CMP AL,06HJL CHANGEPOP AXJMP INDICHANGE:MOV SI,0MOV DI,0MOV CL,4MOV AL,BLAND AL,11011111B;统一换为大写字母再转换,如果是大写字母就不变SUB AL,31HMOV BL,ALAND AL,0FH ;与运算,取低位MOV [DATA2+SI],AL ;把个位数存到DATA2中MOV AL,BLSAR AL,CL ;算术右移,取高位MOV[DATA20+DI],AL;把十位数存到DATA20中OUTPUT1: MOV DL,48H;输出十六进制符号HMOV AH,02HINT 21HMOV DL,3DH ;输出等号‘=’MOV AH,02HINT 21HMOV DL,[DATA20+DI];输出十位数ADD DL,30HMOV AH,02HINT 21HMOV DL,[DATA2+SI];输出个位数ADD DL,30HMOV AH,02HINT 21HMOV DL,20HMOV AH,02HINT 21HJMP INPUT;跳到输入数字OUTPUT2: MOV DL,48H ;输出数字MOV AH,02HINT 21HMOV DL,3DHMOV AH,02HINT 21HMOV DL,BLADD DL,30HMOV AH,02HINT 21HMOV DL,20HMOV AH,02HINT 21HJMP INPUTINDI:MOV DL,20H ;提示子程序MOV AH,02HINT 21HMOV DX,OFFSET DATA3 ;显示提示信息MOV AH,09HINT 21HJMP INPUTEXIT:MOV AH,4CHINT 21HCODE ENDSEND START4 用汇编语言将BCD码转换成二进制码,并以二进制串的形式输出,在屏幕上显示出来DATAS SEGMENTbuffer1 dw 1657hbuffer2 dw ? ;分配两个字节的空间DATAS ENDSCODES SEGMENTASSUME CS:CODES,DS:DATASSTART:MOV AX,DATASMOV DS,AXmov ax,[buffer1]and ax,0f000hmov cl,12shr ax,clmov dx,ax ;至此,已将5678h(BCD)中的5(十进制)取出,并放入dx中call change ;调用chang,将5乘以10mov ax,dxmov bx,[buffer1]and bx,0f00hmov cl,8shr bx,cladd ax,bxmov dx,axcall changemov ax,dxmov bx,[buffer1]and bx,00f0hmov cl,4shr bx,cladd ax,bxmov dx,axcall changemov ax,dxmov bx,[buffer1]and bx,000fhadd ax,bx ;至此,ax中的值已是5678(十进制),但电脑是将其以二进制的形式存储的,故应是0679h,二进制就是0000011001111001mov buffer2,ax ;因为后面会用到ah,为避免在其过程中丢失ax中的数据,故将ax中的数据放入buffer2中mov cx,16again:shl buffer2,1 ;将已经转换成二进制的数逐个显示出来mov dl,0adc dl,30hmov ah,2int 21hloop againMOV AH,4CHINT 21Hchange proc ;子程序change的功能是实现dx乘以10 add dx,dxmov cx,dxadd dx,dxadd dx,dxadd dx,cxretchange endpCODES ENDSEND START。