(1) 词法分析与有穷自动机.
编译原理第三章

例3.4 Z→ A→ B→
有正规文法G: 0A 0A | 0B 1A | ε
例3.5 A→ B→ C→
有正规文法G: aB | bB aC | a | b aB
例3.6 Z→ U→ V→
有正规文法G: Z=0(0|01)*0 U0 | V1 A=(a|b)(aa)*(a|b) Z1 | 1 Z=(10|01)(10|01)* Z0 | 0
A
B
r2 ε
A C
A
B
ε
B
r1
④R为复合正规式?
例3.12 3.13 P41
教学进度
3.4.4 NFA确定化为DFA
方法(子集法) 1、改造M为M’: ①引进新的初态结点X、终态结点Y; ②对M的状态转换图实施分裂(替换)
计算机科学与工程系
2、将M’进一步变换为DFA :
①状态子集T的闭包_CLOSURE(T) ②定义状态集Ta = _CLOSURE(J) ③从DFA的初态_CLOSURE({X})开始计算状态转换矩阵;直到 不再产生新的状态子集为止。
第三章
• • • • • •
词法分析与有穷自动机
计算机科学与工程系
词法分析器的功能与输出 单词符号的两种定义方式 正规表达式与有穷自动机 正规文法与有穷自动机 词法分析器的设计 词法分析程序自动构造工具LEX简介
教学进度
3.1 词法分析器的功能
计算机科学与工程系
词法分析:对字符串表示的源程序进行从左到右的扫描和 分解,根据语言的词法规则识别出一个个具有独立意义的 单词符号。
教学进度
3.3 单词符号的两种定义方式
单词符号结构的描述方法:
计算机科学与工程系
正规文法(3型文法)(regular grammar)
第三章 词法分析和有穷自动机
ε
ε
2
ε
6 b
ε
f
3.4.5 DFA的最小化(化简)
• 最少状态DFA 对于一个DFA M,存在一个最少状态DFA M’, 使得L(M’)=L(M)。 (a)没有多余状态 (b)没有两个状态是互相等价的 结论: 一个NFA 对应的DFA不惟一 但它对应的最小化DFA不计同构是惟一的
• 多余状态的例子 a
例
正规式 φ
ε
a a|b ab (a|b)(a|b) a* ba* (a|b)*
正规集 φ {ε } {a} L(a|b)=L(a) ∪ L(b)={a,b} L(ab)=L(a)L(b)={ab} {aa,ab,ba,bb} { ε ,a,aa,aaa,…} {b,ba,baa,baaa,…} {所有由a和b组成的字}
• 例 DFA M=({0,1,2,3},{a,b}, f ,0,{3}) 其中 f 为: f (0,a)=1 f (0,b)=2 f (1,a)=3 f (1,b)=2 f (2,a)=1 f (2,b)=3 f (3,b)=3 f (3,a)=3
3.4.1 确定有穷自动机(DFA) • DFA的表示方法 两种:矩阵和图形的方式 矩阵称为状态转换矩阵 图形称为状态转换图
• NFA M所接受字符串的集合称为NFA M所能 识别的语言,记为L(M)。 • NFA的确定化 DFA是NFA的特例
NFA M存在与之等价的DFA M’,L(M)=L(M’) 与某一NFA等价的DFA不惟一 正规式 NFA 正规文法 DFA
3.4.4 NFA 确定化
• 状态集合I的空闭包:ε -closure(I) 它是一个状态集合,包含 : ♠ I中任何状态q ♠ I中任何状态q经任意条空弧到达的任何状态 • 状态集合I的a弧转换:Ia 定义一个状态集J,J是I中所有状态经一条a 弧到达的状态的全体 Ia=ε -closure(J)
sun编译原理第3章词法分析与有穷自动机第4 8讲 优质课件

={a,b}*{aa,bb}{a,b}*
练习:若S=a|bb,则L((a|bb)*)=?
2019/11/24
信息学院 孙丽云
5
第3章 词法分析与有穷自动机
■正规式中运算的优先级
括号优先,* 次之,•(连接)再次之,| 最后 例:a|bc* ≌ a|(b(c*))
ab|c*d ≌ (ab)|((c*)d)
其中 U、W∈N t∈T 其中 U、W∈N t∈T
2019/11/24
信息学院 孙丽云
8
第3章 词法分析与有穷自动机
■正规文法到正规式的转换
(1)将正规文法中的每个非终结符表示成关于它的一 个正规式方程,获得一个联立方程组。 (2)依照求解规则:
若x=αx|β(或x=αx+β),则解为x=α*β; 若x=xα|β(或x=xα+β),则解为x=βα*; 以及正规式的分配律、交换律和结合律求关于文法 开始符号的正规式方程组的解. 这个解是关于该文法开始符号S的一个正规式,显然 它表示了由该正规文法所描述的语言。
信息学院 孙丽云
2
第3章 词法分析与有穷自动机
3.3 语言单词符号的两种定义方式 多数程序设计语言的单词符号都能用正规文法或正规 式来定义。
■ 正规式与正规集
设有字母表={a1,a2,…,an},在字母表上的正 规式和它所表示的正规集可用如下规则定义: (1) Φ是上的正规式,它所表示的正规集是Φ, 即空集{} (2)ε是上的正规式,它所表示的正规集是{ε} (3)ai是上的正规式,它所表示的正规集由单个符 号ai组成,即{ai}
③ (e1)*是上的一个正规式,它所表示的正规集为 L((e1)*) =L((e1))*
正规式描述了单词符号的构成规则,正规集是正规 式能描述的所有的单词的集合。
有穷自动机在词法分析器建模中的应用研究

界符= l 1 I , ; . (I) 其中l 示 a 表 —— z中 的 任 何 一 个 字 母 , 示 d表 9中的任何一 个数 字 。 e*也 都 是 正 规 式 , 们 所 表 示 的 正 规 集 分 别 为 l 它 关 键字 也 是一 种单 词 ,关 键 字集 合是 标 识符集 合 Le) (1ULe) (1・(2, (1 ; (1Le) (2, e)Le)Le) , L ( ) 的子集 , 关键字 与标 识符 的构 词原则 相 同。 ()仅 由有 限次 使 用上 述 三个 步骤 而 定 义 的表 达 4 式才 是 ∑上 的正 规式 , 由这些 正 规式 所 表示 的字 集 仅 整数 前 面 的正 负 号 在 词 法 分 析 中可看 作 运 算 符 , 因此 只定 义无 符号 整数 的词法 。 才是 ∑上 的正 规集 。[ 1 1 - . 正 规式 可 用 来 描述 符 号 串所 遵从 的规则 ,用 正规 232将词法 转化 为有穷 自动机形 式 的词法模 型
2 1 年第 1 0 1 1期
福 建 电
脑
9 5
有 穷 自动机在词 法分 析器建模 中的应 用研究
罗 海 丽
(内 蒙古科技 大 学 信息工程 学院 内蒙古 包头 0 4 1 1 0 0)
【 摘 要】 :有 穷自动机可用于描述语言的词法模型,有穷自动机形式的词法模型与特定的控制程序 相 配合 可构 成语 言 的词 法分析 器 。介 绍 了利 用有 穷 自动机 建 立语 言的词 法模 型及 以此 词 法模 型为基础 构 建词 法分析 器的过程 。实例 证 明 , 方 法构造 的词 法 分析 器正确 、 该 有效 。 【 关键词】 :有穷 自 动机; 正规文法; 控制程序; 词法模型; 词法分析器
编译原理 第3章 词法分析与有穷自动机(第5-8讲)

它所对应的状态表如图:
状态 0 1 2 3 a 1 3 1 3 后继 状态 b 2 2 3 3
输入字符 接受 否 否 否 是
式的转化
22
第3章 词法分析与有穷自动机
■DFA所识别的语言
给定DFA M,对于字符c1,c2,…,cn,当以下条件成立时, 称M接受由c1,c2,…,cn组成的字符串c1c2…cn: 存在状态序列s0,s1,s2,…,sn,使得s1=f(S,c1), s2=f(s1,c2),…,sn=f(sn-1,cn),且sn∈Z。 由DFA M接受的语言L(M)是所有M接受的字符串组成的集 合。
25
第3章 词法分析与有穷自动机
判断下图是DFA还是NFA的状态转换图,并 写出其他2种表示形式
26
第3章 词法分析与有穷自动机
■由正规表达式R构造NFA
1.基本正规表达式 (a)对于正规式φ,所构造NFA: (b)对于正规式ε,所构造NFA: (c)对于正规式a,a∈Σ,则 NFA:
x ε y
练习:若S=a|bb,则L((a|bb)*)=?
5
第3章 词法分析与有穷自动机
■正规式中运算的优先级
括号优先,* 次之,•(连接)再次之,| 最后 例:a|bc* ≌ a|(b(c*)) ab|c*d ≌ (ab)|((c*)d)
■ 正规式与正规集举例
L(a|bc*)=L(a)∪L(bc*) 思考:L(ab|c*d)=? =L(a)∪L(b)L(c*) =L(a)∪L(b)(L(c))* ={a}∪{b}{ε,c,cc,ccc……} ={a,b,bc,bcc,bccc,……}
17
第3章 词法分析与有穷自动机
■有穷自动机的状态转移图表示方法
第3章词法分析与有穷自动机20090319

单词的种类 (1)关键字:if、for、while (2)标识符: (3) 常数: (4) 运算符:+、-、* (5)分界符:, 、;、(、)
编译原理
2013年8月27日
词法分析程序的输出形式-----二元式
单词类别 单词的属性值
单词类别可以用整数编码表示:一类一种或一字一种
单词类别 关键字 标识符 常数 运算符 分界符
编译原理
2013年8月27日
【例3.9】将描述标识符的正规式R=l(l∣d)*转换 成相应的正规文法。
• 令S为文法的开始符号, 根据规则(2) 有 • S→l(l∣d)* • 根据规则(3)变换为: • S→lA • A→(l∣d)* • 根据规则(4)变换为: • S→lA • A→(l∣d)A∣ε •
有穷自动机的作用
实质上是提供了一种逻辑的探测方式,去探测一 些输入串是否属于某种语言,即: 它可以作为一种 语法检查器。
编译原理
2013年8月27日
3.4.1
确定的有穷自动机(DFA)
M=(Σ, Q, f,S, Z)
Σ:有穷字母表,它的每个元素称为一个输入符号 Q:有穷状态集,它的每个元素称为一个状态 S∈K,是唯一的初态
运算符的优先级: 先*, 后 • , 最后 | • 在正规式中可以省略.
正规式相等 这两个正规式表示的语言相等
编译原理
2013年8月27日
正规式举例
• 例:设有字母表 ∑={a,b},根据正规式与正规集的定义,有以 下的正规式和正规集 正规式 正规集 a {a} a∣b {a,b} ab {ab} ( a∣b)( a∣b) {aa,ab,ba,bb} a* {ε,a,aa,aaa,…,任意个a的串} (a∣b)* {ε,a,b,aa,ab,ba,bb,…所有a,b组成的串} (a︱b) *(aa︱bb) (a︱b) * ∑*上所有含两个连续的a 或两 个连续的b组成的串
第3章 词法分析与有穷自动机PPT课件

或作为一个联合
typedef struct {
TokenType tokenval;
unon { char* stringval;
int numval; } attribute;
} TokenRecord;
10
【例】试给出程序段 if (a>1) b = 100;输出 的单词符号串。
假定基本字、运算符和界符都是一符一种,标识符自身 的值是字符串,常数是二进制值。
(2,)
基本字 if
(29,)
左括号 (
(10,‘a’)
标识符 a
(23,)
大于号 >
(11,‘1’的二进制)
常数 1
(30,)
右括号 )
(10,‘b’)
标识符 b
(17,)
赋值号 =
(11,‘100’的二进制) 常数 100
(26,)
分号 ;
11
【例】考虑下述 C++ 代码段:
另一种 表示
while ( i >= j ) i--;
第三章 词法分析
人们理解一篇文章(或一个程序)起码是在单 词的级别上来思考的。同样,编译程序也是在单 词的级别上来分析和翻译源程序的。词法分析的 任务是:从左至右逐个字符地对源程序进行扫描, 产生一个个的,把作为字符串的源程序改造成为 单词符号串的中间程序。因此,词法分析是编译 的基础。
执行词法分析的程序称为词法分析器。本章讨 论词法分析程序的手工构造方法和自动构造方法。
将字符组合成记号与在一个英语句子中将字母构成单词 并确定单词的含义很相像,此时的任务很像拼写。
5
程序语言的单词符号一般可分为下列五种:
1) 关键字:是由程序语言定义的具有固定意义的标识符, 也称保留字或基本字。如Pascal中的 begin、end、 if、integer等,C 中的if、else、do、while, C++ 中的class、int、switch、break等都是保 留字,它们一般不用作一般标识符。
编译原理分知识点习题(全)

表 6.2
分析输入符号串“*0*1#”的过程
符 号 栈S S1 S2 S3 S4 S5 S6 S7
关系
输入串 R1 R2 R3 R4 R5
#
<
*0*1 #
最左素短语
#< *
<
0*1 #
#< *< 0
<
*1 #
#< *< 0< *
>
1#
*
#< *< 0 V
=
#
#< *< 0 V= 1
>
#
0V1
#<* V
>
#V 3.试为下列优先矩阵构造优先函数。 (1)
#
*V
#
接受
S1
S2
S3
S4
S1
S2
±
±
S3
>
>
S4 (2)
>
>
S1
S2
S1
S2
S3
<
±
S4
±
解:本题考查优先函数的构造方法。
(1) 采用迭代法求优先函数,过程如下。
(2) 初始状态:
S1
S2
f
1
1
g
1
1
第 1 次迭代:
S3
S4
>
>
>
< ±
S3
S4
1
A→aB|bB|cC B→aB|bD|aE|cC|b|a
C→bB|cC|cE|c D→bD|b E→aE|a
b
b
a
2
4
a
b
编译原理-第3章 词法分析--习题答案

第3章词法分析习题答案1.判断下面的陈述是否正确。
(1)有穷自动机接受的语言是正规语言。
(√)(2)若r1和r2是Σ上的正规式,则r1|r2也是Σ上的正规式。
(√)(3)设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
(× )(4)设Σ={a,b},则Σ上所有以b为首的符号串构成的正规集的正规式为b*(a|b)*。
(× )(5)对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
(√)(6)对一个右线性文法G,必存在一个左线性文法G',使得L(G)=L(G'),反之亦然。
(√) (7)一个DFA,可以通过多条路识别一个符号串。
(× )(8)一个NFA,可以通过多条路识别一个符号串。
(√)(9)如果一个有穷自动机可以接受空符号串,则它的状态图一定含有 边。
(× )(10)DFA具有翻译单词的能力。
(× )2.指与出正规式匹配的串.(1)(ab|b)*c 与后面的那些串匹配?ababbc abab c babc aaabc(2)ab*c*(a|b)c 与后面的那些串匹配? acac acbbc abbcac abc acc(3)(a|b)a*(ba)* 与后面的那些串匹配? ba bba aa baa ababa答案(1) ababbc c babc(2) acac abbcac abc(3) ba bba aa baa ababa3. 为下边所描述的串写正规式,字母表是{0, 1}.(1)以01 结尾的所有串(2)只包含一个0的所有串(3) 包含偶数个1但不含0的所有串(4)包含偶数个1且含任意数目0的所有串(5)包含01子串的所有串(6)不包含01子串的所有串答案注意 正规式不唯一(1)(0|1)*01(2)1*01*(3)(11)*(4)(0*10*10*)*(5)(0|1)*01(0|1)*(6)1*0*4.请描述下面正规式定义的串. 字母表{x, y}.(1) x(x|y)*x(2)x*(yx)*x*(3) (x|y)*(xx|yy) (x|y)*答案(1)必须以 x 开头和x结尾的串(2)每个 y 至少有一个 x 跟在后边的串 (3)所有含两个相继的x或两个相继的y的串5.处于/* 和 */之间的串构成注解,注解中间没有*/。
编译原理第二版第3章词法分析

1. ε和φ都是∑上的正规式,它所表示的正规集分
别为{ε}和Ф; 2. 任何a∈∑,a是∑上的正规式,它所表示的正 规集为{a}; 3. 假定e1和e2都是∑上的正规式,他们所表示的 正规集分别为L(e1)和L(e2),那么,以下也 都是正规式和他们所表示的正规集;
一、正规式与正规集的递归定义
3.2 单词符号及输出单词的形式
单词自身值
对常数,基本字,运算符,界符就是他们本 身的值 对标识符,将标识符的名字登记在符号表中, ‚自身值‛是指向该标识符所在符号表中位 置的指针。
假定基本字、运算符和界符都是一符一种 例:if(a>1) b=100; 词法分析后输出的单词序列是: (2, ) if (29, ) ( (10,‘a’) a (23, ) > (11,‘1’) 1 (30, ) ) (10,’b’) b (17, ) = (11,‘100’) 100 (26, ) ;
4. 仅由有限次使用上述三步定义的表达式才是∑上的 正规式,仅由这些正规式所表示的字集才是∑上 的正规集。
重点回顾
四、将正规文法转换成正规式 求非终结符的正规式 将正规文法中的每个非终结符表示成关 于它的一个正规式方程,获得一个联立 方程组 用代入法解正规式方程组 最后只剩下一个开始符号定义的正规式, 其中不含非终结符
3.3 语言单词符号的两种定义方式
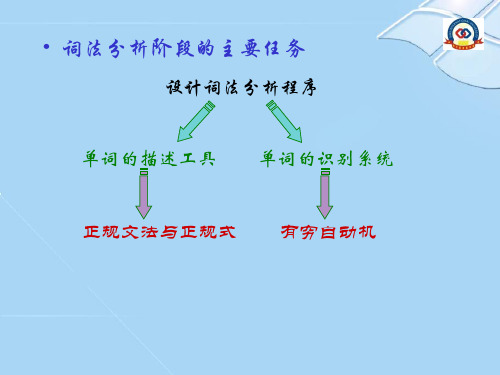
作用: 描述单词的构成规则,基于这类描 述工具建立词法分析技术,进而实现词法 分析程序的自动构造。 工具有: 正规文法 正规式(Regular Expression)
多数程序设计语言的单词符号都能用正 规文法或正规式来定义。
3.3.1 正规文法
多数程序设计语言单词的语法都能用正 规文法(3型文法)描述 正规文法回顾 文法的任一产生式α →β 的形式都为 A→aB或A→a,其中A ,B∈VN ,a∈VT A→Ba或A→a,其中A ,B∈VN ,a∈ VT 正规文法描述的是VT*上的正规集
第三章有穷自动机

C
01 S0 S1 S5 0 S1 S2 S7 1 S2 S2 S5 1 S3 S5 S7 0 S5 S3 S1 0 S7 S0 S1 1
3.2.3 合并等价状态
等价状态
若s和t是M的两个不同状态,称s和t等 价:如果从状态s出发能读出某个字而停 于终态,同样从t 出发也能读出同一个字 而停于终态;反之若从t 出发能读出某个字 而停于终态,则从s出发也能读出同一个 字而停于终态。
第三章 有穷自动机
本章介绍有关有穷自动机的基本概念和 理论以及正规文法、正规表达式与有穷自动 机之间的相互关系。
§3.1 有穷自动机的形式定义
有穷状态自动机(Finite-state Automata 或简称FA)在识别功能上与正 规文法类等价,而且也等价于一个特殊类 型的语言产生器——正规表达式(Regular Expression)。因此许多简单的程序语言 都可由FA所识别。事实上,它是描述词法 的有效工具,也是进行词法分析的主要理 论基础。
消除多余状态
多余状态是指从该自动机的开始状态出发, 任何 0 S1 S2 S7 1 S2 S2 S5 1 S3 S5 S7 0 S4 S5 S6 0 S5 S3 S1 0 S6 S8 S0 1 S7 S0 S1 1 S8 S0 S6 0
B
01 S0 S1 S5 0 S1 S2 S7 1 S2 S2 S5 1 S3 S5 S7 0 S5 S3 S1 0 S6 S8 S0 1 S7 S0 S1 1 S8 S0 S6 0
l, d
l, d
l
q0
q1
l q0
q1
q2
非 l,d
图(a)
图(b)
如果赋予状态q0、q1与q2一定的操作,则
编译原理词法分析__有穷自动机_算法_DFA化简

1 2
a a
3
4
a a
b
两个状态s和t等价的条件
①一致性条件
终态和非终态不等价
②蔓延性条件
对于所有输入符号,状态s和状态t必须转换到 等价的状态里 a a a 1 3 0 b 2
a 4 a
定义: 两个状态可区别- 两个状态s和t不等价
• 终态和非终态可区别
例:
填空 : 等价 可区别
可区别 的 0和4是__________ 可区别 的 2和3是__________
确定有穷自动机的化简
• DFA的最小化 - 寻求等价的最少状态的DFA 没有多余状态 • 不可到达 • 不可终止 没有两个状态互相等价
定义: 两个状态s和t等价
假定s和t是M的两个不同状态,我们称s和t等价 • 如果从s出发能读出某个字w而停于终态, 则从t出发也能读出同样的字w而停于终态; • 如果从t出发能读出某个字w而停于终态, 则从s出发也能读出同样的字w而停于终态。 a 0
例: DFA最小化
a
a 0
b
1
a
3
b
a
4
b 2
a
b b 5 b
a
6
b
a
最小化结果 a
0 b
1
a
a,b
b
2
a
b
3
b 3 3 5 6 3 1 2
a
b 3 5 6 3 1
{1, 2} {3} {4} {5} {6, 7}
1 3 4 5 6
6 1 4 6 4
为∏中的每一子集选取一个代表
最小化结果 a
1 3 4 5 6 6 1 4 6 4
b
3 5 6 3 1
实验3--词法分析-FA的应用(已完成)

实验三词法分析——有穷自动机的应用一、实验目的:一:输入正则文法二:FA1.生成FA(DFA或NFA)2.运行FA,DFA(自动);NFA(交互)3.**NFA→DFA二、实验设想:对输入的文法存储并判断是确定的有穷状态自动机还是不确定是有穷状态自动机,并给出标准的表示形式,若是DFA,可直接测试一个符号串是否是文法的句子,即能否被有穷状态机接受,给出过程及结果;若是NFA,首先将其转化为DFA,再测试一个符号串是否是文法的句子,亦即是否能被DFA接受。
例如:输入文法规则的数目:7输入开始状态: S输入文法Z::=Za Z::=Bb Z::=Aa B::=Ab B::=b A::=Ba A::=a此为确定有穷状态自动机!DFA D=({Z,A,B},{a,b},M,S,{Z})其中M:M(Z,a)=ZM(B,b)=ZM(B,a)=AM(A,a)=ZM(A,b)=BM(S,b)=BM(S,a)=A输入要推导的符号串:ababaaM(S,ababaa)=M(M(S,a),babaa)=M(A,babaa)=M(M(A,b),abaa)=M(B,abaa)=M(M(B,a),baa)=M(A,baa)=M(M(A,b),aa)=M(B,aa)=M(M(B,a),a)=M(A,a)=Z该符号串能被有穷状态所接受!输入文法规则的数目:7输入开始状态: S输入规则:Z::=Ab Z::=Ba Z::=Zc A::=Ba A::=a B::=Ab B::=b 文法规则存储完毕!此为非确定有穷状态自动机!NFA N=({Z,B,A},{b,a,c},M,{S},{Z})其中M:M(A,a)=$M(A,b)={Z,B}M(A,c)=$M(B,a)={Z,A}M(B,b)=$M(B,c)=$M(Z,a)=$M(Z,b)=$M(Z,c)={Z}M(S,a)={A}M(S,b)={B}M(S,c)=$将NFA转化为DFA!DFA N'=({[S],[B],[A],[AZ],[BZ],[Z]},{[b],[a],[c]}, M',[S],F')其中M':M'([S],b)=[B]M'([S],a)=[A]M'([B],a)=[AZ]M'([A],b)=[BZ]M'([AZ],b)=[BZ]M'([AZ],c)=[Z]M'([BZ],a)=[AZ]M'([BZ],c)=[Z]M'([Z],c)=[Z]其中F'={[AZ],[BZ],[Z]}输入要推导的字符串:ababcM'([S],ababc)=M'(M'([S],a),babc)=M'([A],babc)=M'(M'([A],b),abc)=M'([BZ],abc)=M'(M'([BZ],a),bc)=M'([AZ],bc)=M'(M'([AZ],b),c)=M'([BZ],c)=[Z][Z]属于终止状态集合!该字符串能被有穷状态所接受!三、参考程序#include<iostream.h>#include<String.h>struct LeftItem;struct RightNode //存储状态转换关系中弧与终止状态结点结构{char tran;char nextstate;RightNode* nextsibling;RightNode(char x,char y){tran=x; nextstate=y; nextsibling=NULL;}};struct LeftItem //存储状态转换关系中初始状态结点结构{char state;RightNode* link;};struct StateItem //存放确定化的NFA状态结点结构{char newstates[10];StateItem(){newstates[0]='\0';}};////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// int CheckState(LeftItem Array[],int size){RightNode* p;RightNode* q;for(int i=0;i<size;i++){p=Array[i].link;q=p->nextsibling;if(q==NULL) return 1;while(q!=NULL){if(p->tran==q->tran) return 0;q=q->nextsibling;}}return 1;}int CheckExist(StateItem SArray[],int& length,char temp[])//将NFA确定化创建二维矩阵时判别新产生的状态是否在状态数组中存储过{int i=0,k,m;while(i<=length){if(strlen(SArray[i].newstates)==strlen(temp)){if(strcmp(SArray[i].newstates,temp)==0){k=i;break;}}i++;}if(i>length){length++;m=length;return m;}elsereturn k;}int getcount1(LeftItem Array[],int size) //取得FA中状态的个数{char temp[20];int len=0,count=0;int i,j;RightNode* pNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode){for(j=0;j<len;j++)if(pNode->nextstate==temp[j]) break;if(j==len){count++;temp[len]=pNode->nextstate;len++;}pNode=pNode->nextsibling;}}return count;}int getcount2(LeftItem Array[],int size) //取得FA中输入字母的个数{char temp[20];int len=0,count=0;int i,j;RightNode* pNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode){for(j=0;j<len;j++)if(pNode->tran==temp[j]) break;if(j==len){count++;temp[len]=pNode->tran;len++;}pNode=pNode->nextsibling;}}return count;}int getstate(RightNode* pNode,char arc) //判定一个状态是否能通过一条弧进入下一状态{while(pNode){if(pNode->tran==arc) return 1;pNode=pNode->nextsibling;}return 0;}void Sort(char A[],int n) //将取得的新状态进行排序{for(int i=n-1;i>0;i--)for(int j=0;j<i;j++){if(A[j+1]<A[j]){char temp=A[j+1];A[j+1]=A[j];A[j]=temp;}}}void Bianli1(LeftItem Array[],int size) //输出FA中有穷非空的状态集合{char temp[20];int len=0;int i,j;RightNode* pNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode){for(j=0;j<len;j++)if(pNode->nextstate==temp[j]) break;if(j==len){if(len==0) cout<<pNode->nextstate;elsecout<<","<<pNode->nextstate;temp[len]=pNode->nextstate;len++;}pNode=pNode->nextsibling;}}}void Bianli2(LeftItem Array[],int size)//输出FA中有穷的输入字母表{char temp[20];int len=0;int i,j;RightNode* pNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode){for(j=0;j<len;j++)if(pNode->tran==temp[j]) break;if(j==len){if(len==0) cout<<pNode->tran;elsecout<<","<<pNode->tran;temp[len]=pNode->tran;len++;}pNode=pNode->nextsibling;}}}void Bianli31(LeftItem Array[],int size)//输出DFA状态转换关系的集合M{int i;RightNode* pNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode!=NULL){cout<<" M("<<Array[i].state<<","<<pNode->tran<<")="<<pNode->nextstate<<endl;pNode=pNode->nextsibling;}}}void Bianli32(LeftItem Array[],int size) //输出NFA状态转换关系集合M {char K[20];int len=0;int i,j;RightNode* pNode;RightNode* qNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode){for(j=0;j<len;j++)if(pNode->tran==K[j]) break;if(j==len){K[len]=pNode->tran;len++;}pNode=pNode->nextsibling;}}Sort(K,len);for(i=0;i<size;i++){for(j=0;j<len;j++){pNode=Array[i].link;cout<<" M("<<Array[i].state<<","<<K[j]<<")=";if(getstate(pNode,K[j])){cout<<"{";while(pNode){if(pNode->tran==K[j]){qNode=pNode->nextsibling;cout<<pNode->nextstate;break;}pNode=pNode->nextsibling;}while(qNode){if(qNode->tran==K[j])cout<<","<<qNode->nextstate;qNode=qNode->nextsibling;}cout<<"}"<<endl;}elsecout<<"$"<<endl;}}}void Initiate(LeftItem Array[],int size,char TArray[]) //将FA中的输入字母表存入数组TArray[] {int len=0;int i,j;RightNode* pNode;for(i=0;i<size;i++){pNode=Array[i].link;while(pNode){for(j=0;j<len;j++)if(pNode->tran==TArray[j]) break;if(j==len){TArray[len]=pNode->tran;len++;}pNode=pNode->nextsibling;}}}void GetState(LeftItem Array[],int size,char nstate[],char arc,char temp[])//将NFA确定化创建二维矩阵时取得新状态{int i=0;while(nstate[i]!='\0'){for(int j=0;j<size;j++){if(Array[j].state==nstate[i]){RightNode* p=Array[j].link;while(p!=NULL){if(p->tran==arc){int k=0;while(temp[k]!='\0'){if(p->nextstate==temp[k]) break;k++;}if(temp[k]=='\0'){temp[k]=p->nextstate;temp[k+1]='\0';}}p=p->nextsibling;}}}i++;}}void Change(StateItem SArray[],char temp[],int& length,int MArray[][20],int index,int i) //取得新状态后对状态数组以及状态转换矩阵进行对应变化{int k;if(temp[0]!='\0'){k=CheckExist(SArray,length,temp);MArray[index][i]=k;if(k==length)strcpy(SArray[length].newstates,temp);}}char FindNewState(LeftItem Array[],int size,char S,char arc) //得到当前状态的下一状态{int i;for(i=0;i<size;i++){if(Array[i].state==S){RightNode* p=Array[i].link;while(p!=NULL){if(p->tran==arc) return p->nextstate;p=p->nextsibling;}}}return NULL;}int Findy(char TArray[],char s) //取得输入字母在字母表中的下表{int i=0;while(TArray[i]!='\0'){if(TArray[i]==s) return i;i++;}}void CreateFA1(LeftItem Array[],int size,char start,char end)//根据输入文法创建FA{if(CheckState(Array,size)){cout<<"此为确定有穷状态自动机!"<<endl;cout<<"DFA D=(";}else{cout<<"此为非确定有穷状态自动机!"<<endl;cout<<"NFA N=(";cout<<"{";Bianli1(Array,size);cout<<"},{";Bianli2(Array,size);cout<<"},M,";if(CheckState(Array,size)) cout<<start;else cout<<"{"<<start<<"}";cout<<","<<"{"<<end<<"})"<<endl;cout<<"其中M:"<<endl;if(CheckState(Array,size))Bianli31(Array,size);elseBianli32(Array,size);}void CreateFA2(LeftItem Array[],int size,char start,char end,StateItem SArray[],char TArray[],int& length,int MArray[][20])//将NFA转换为DFA{char temp[20];int index=0;int i;do{i=0;while(TArray[i]!='\0'){temp[0]='\0';GetState(Array,size,SArray[index].newstates,TArray[i],temp);Sort(temp,strlen(temp));Change(SArray,temp,length,MArray,index,i);i++;}index++;}while(index<=length);}void Display(StateItem SArray[],char TArray[],int MArray[][20],int x,int y,char start,char end)//输出确定化的NFA{int i,j,k;cout<<"将NFA转化为DFA!"<<endl;cout<<"DFA N'=({";for(i=0;i<x;i++)if(i==0) cout<<"["<<SArray[i].newstates<<"]";else cout<<",["<<SArray[i].newstates<<"]";}cout<<"},{";for(i=0;i<y;i++){if(i==0) cout<<"["<<TArray[i]<<"]";elsecout<<",["<<TArray[i]<<"]";}cout<<"}, M',["<<start<<"],F')"<<endl;cout<<"其中M':"<<endl;for(i=0;i<x;i++)for(j=0;j<y;j++){if(MArray[i][j]!=-1){k=MArray[i][j];cout<<"M'(["<<SArray[i].newstates<<"],"<<TArray[j]<<")=["<<SArray[k].newstates<<"]"<<endl;}}cout<<"其中F'={";k=0;for(i=0;i<x;i++){j=0;while(SArray[i].newstates[j]!='\0'){if(SArray[i].newstates[j]==end) break;j++;}if(SArray[i].newstates[j]!='\0'){if(k==0) cout<<"["<<SArray[i].newstates<<"]";elsecout<<",["<<SArray[i].newstates<<"]";k++;}}cout<<"}"<<endl;}void RunFA1(LeftItem Array[],int size,char start,char end){char TD[20];int i=0,j;char s=start;cout<<"请输入要推导的符号串:";cin>>TD;cout<<" M("<<s<<",";for(j=0;TD[j]!='\0';j++)cout<<TD[j];cout<<")"<<endl;while(TD[i]!='\0'){if(TD[i+1]!='\0'){cout<<"=M(M("<<s<<","<<TD[i]<<"),";for(j=i+1;TD[j]!='\0';j++)cout<<TD[j];cout<<")"<<endl;}s=FindNewState(Array,size,s,TD[i]);if(s==NULL) break;if(TD[i+1]=='\0')cout<<"="<<s<<endl;else{cout<<"=M("<<s<<",";for(j=i+1;TD[j]!='\0';j++)cout<<TD[j];cout<<")"<<endl;}i++;}if(TD[i]=='\0'){if(s==end)cout<<"该符号串能被有穷状态所接受!"<<endl<<endl;elsecout<<"该符号串不能被有穷状态所接受!"<<endl<<endl;}elsecout<<"该符号串不能被有穷状态所接受!"<<endl<<endl;void RunFA2(StateItem SArray[],char TArray[],int start,int end,int MArray[][20]){char TD[20];int i,j,k,x,y;char s=start;cout<<"请输入要推导的字符串:";cin>>TD;cout<<" M'(["<<s<<"],";for(i=0;TD[i]!='\0';i++)cout<<TD[i];cout<<")"<<endl;x=0;i=0;while(TD[i]!='\0'){if(TD[i+1]!='\0'){cout<<"=M'(M'([";cout<<SArray[x].newstates;cout<<"]";cout<<","<<TD[i]<<"),";for(j=i+1;TD[j]!='\0';j++)cout<<TD[j];cout<<")"<<endl;}y=Findy(TArray,TD[i]);x=MArray[x][y];if(x==-1) break;if(TD[i+1]=='\0'){cout<<"=";cout<<"["<<SArray[x].newstates<<"]"<<endl;}else{cout<<"=M'(";cout<<"["<<SArray[x].newstates<<"],";for(j=i+1;TD[j]!='\0';j++)cout<<TD[j];cout<<")"<<endl;}i++;}if(TD[i]=='\0'){for(k=0;SArray[x].newstates[k]!='\0';k++)if(SArray[x].newstates[k]==end) break;if(SArray[x].newstates[k]!='\0'){cout<<"["<<SArray[x].newstates<<"]"<<"属于终止状态集合!"<<endl;cout<<"该字符串能被有穷状态所接受!"<<endl<<endl;}elsecout<<"该字符串不能被有穷状态所接受!"<<endl<<endl;}elsecout<<"该字符串不能被有穷状态所接受!"<<endl<<endl;}////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// void main(){int size=0,sign=0;int i,j,n,sel;int count1,count2;int length=0;char start;char end;char temp[10];int MArray[20][20];RightNode* p;cout<<"请输入文法规则的数目:";cin>>n;cout<<"请输入开始状态: ";cin>>start; //得到初始状态LeftItem* Array=new LeftItem[n];for(i=0;i<n;i++){do{cout<<"请输入第"<<i+1<<"条规则:";cin>>temp;}while(strlen(temp)>6);if(strlen(temp)==6){for(j=0;j<size;j++)if(Array[j].state==temp[4]) break;if(j==size){Array[size].state=temp[4];Array[size].link=new RightNode(temp[5],temp[0]);size++;}else{for(p=Array[j].link;p->nextsibling!=NULL;p=p->nextsibling) {}p->nextsibling=new RightNode(temp[5],temp[0]);}}else{for(j=0;j<size;j++)if(Array[j].state==start) break;if(j==size){Array[size].state=start;Array[size].link=new RightNode(temp[4],temp[0]);size++;}else{for(p=Array[j].link;p->nextsibling!=NULL;p=p->nextsibling) {}p->nextsibling=new RightNode(temp[4],temp[0]);}}}end=Array[0].link->nextstate; //得到终止状态cout<<endl<<"文法规则存储完毕!"<<endl<<endl;count1=getcount1(Array,size);count2=getcount2(Array,size);StateItem* SArray=new StateItem[100];char* TArray=new char[count2+1];SArray[0].newstates[0]=start;SArray[0].newstates[1]='\0';Initiate(Array,size,TArray);TArray[count2]='\0';for(i=0;i<20;i++)for(j=0;j<20;j++)MArray[i][j]=-1;cout<<endl;aaa:cout<<"-----生成FA请按1-----"<<endl;cout<<"-----运行FA请按2-----"<<endl;cout<<"-----退出请按3-------"<<endl;do{cin>>sel;}while(sel!=1&&sel!=2&&sel!=3);switch(sel){case 1:CreateFA1(Array,size,start,end); //根据输入文法建立FAif(!CheckState(Array,size)) //将NFA确定化{CreateFA2(Array,size,start,end,SArray,TArray,length,MArray);Display(SArray,TArray,MArray,length+1,count2,start,end);}sign++;break;case 2:if(sign==0){cout<<"请先生成FA!"<<endl;goto aaa;}if(CheckState(Array,size))RunFA1(Array,size,start,end); //运行DFA elseRunFA2(SArray,TArray,start,end,MArray); //运行确定化的NFAbreak;case 3:break;}if(sel!=3) goto aaa;}四、实验截图1、DFA2、NFA- 21 -- 21 -。
有穷自动机在词法分析中的应用

有穷自动机在词法分析中的应用郝亮11北京林业大学,北京100083(heroleo@)The application of finite automaton in lexical analysis of compiling principleLiang Hao11(Beijing Forestry University , Beijing 100083)AbstractLexical analysis is a sequence of characters in the computer science convert word sequence process, lexical analysis is the first stage of t he compilation process, and its task is left to right, a character, a character read into the source code or documentation of the constitutioncharacter stream source or document scanning and decomposition, thereby identifying words and sent a grammar program. Lexical anal yzer output but the system is often expressed as a binary notation style forms, such as (the word species do not, the property value of word symbols). The finite automata (FA) is divided into a deterministic finite automaton (DFA) and non-deterministic finite automata (NF A), which is used to describe a specific type of algorithm of mathematical methods. In particular, a finite automaton can be used as descr ibed in the identification process in the input string, using analytical methods can process more intuitive understanding of lexical analysis of finite automata. Finite state machine diagram indicates also simplifies our lexical analysis of state transitions of understanding. Finite Automata Lexical analysis is widely used.Key words Lexical analysis; finite automata; DFA; NFA; regular expression摘要词法分析是计算机科学中将字符序列转换为单词序列的过程,词法分析是编译过程的第一个阶段,它的任务是从左到右一个字符,一个字符地读入源程序或文档,对构成源程序或文档的字符流进行扫描和分解,从而识别出一个个单词并发送给语法程序。