计量经济学答案(第八章)
计量经济学(安徽财经大学)知到章节答案智慧树2023年

计量经济学(安徽财经大学)知到章节测试答案智慧树2023年最新第一章测试1.计量经济学是( )的一个分支学科参考答案:经济学2.计量经济分析工作的基本步骤是( )参考答案:模型设定、模型估计、模型检验、模型应用3.下列各种数据中,以下不应该作为经济计量分析所用数据的是( )参考答案:计算机随机生成的数据4.在( )中,为了全面描述经济变量之间的关系,合理构造模型体系,有时需要引入一些非随机的恒等方程。
参考答案:联立方程模型5.从变量的因果关系看,经济变量可分为( )参考答案:被解释变量;解释变量6.使用时序数据进行经济计量分析时,要求指标统计的( )参考答案:对象及范围可比;时间可比;计算方法可比;口径可比7.一个计量经济模型由以下哪些部分构成( )参考答案:方程式;随机误差项;变量;参数8.计量经济学模型研究的经济关系有两个基本特征:随机关系和相关关系。
( )参考答案:错9.计量经济模型检验仅包括经济意义检验、统计检验、计量经济学检验。
( )参考答案:错10.参数反映计量经济模型中经济变量之间的数量联系,通常具有不稳定性。
( )参考答案:错第二章测试1.在一元线性回归模型中,样本回归方程可表示为( )参考答案:2.回归分析中定义( )参考答案:被解释变量是随机变量,解释变量是非随机变量3.最常用的统计检验包括拟合优度检验、解释变量显著性检验和( )参考答案:方程显著性检验4.最小二乘准则是指使( )达到最小值的原则确定样本回归方程参考答案:5.对于经典线性回归模型,回归系数的普通最小二乘估计量具有的优良性有( )参考答案:方差最小性;线性性;无偏性6.利用普通最小二乘法求得的样本回归直线具有以下特点( )参考答案:必然通过点();的平均值与的平均值相等;残差的均值为07.随机误差项产生的原因有( )参考答案:数据的测量与归并误差;随机因素的影响;模型中被忽略因素的影响;模型函数形式设定误差8.只有满足基本假设条件的计量经济模型的普通最小二乘参数估计量才具有无偏性和有效性()参考答案:对9.可决系数不仅反映了模型拟合程度的优劣,而且有直观的经济含义:它定量地描述了Y的变化中可以用回归模型来说明的部分,即模型的可解释程度()参考答案:对10.在计量经济模型中,通常是就参数而言判断是否为线性回归模型,而对解释变量X则可以是线性的也可以是非线性的()参考答案:对第三章测试1.( )表示由解释变量所解释的部分,表示x对y的线性影响参考答案:回归平方和2.用一组有40个观测值的样本估计模型后,在0.05的显著性水平上对的显著性作t检验,则显著地不等于零的条件是其统计量t大于等于( )参考答案:3.多元线性回归分析中,调整后的判定系数与判定系数之间的关系是( )参考答案:4.在多元回归分析中,F检验是用来检验( )参考答案:回归模型的总体线性关系是否显著5.对于线性回归模型,各回归系数的普通最小二乘估计具有的优良特性有( )参考答案:有效性;一致性;无偏性6.若模型满足古典假定,则下列各式成立的有( )参考答案:;;7.常见的非线性回归模型主要有( )参考答案:半对数模型;倒数模型;多项式模型;对数模型8.如果模型对样本有较高的拟合优度,F检验一般都能通过()参考答案:对9.若建立计量经济模型的目的是用于预测,则要求模型的远期拟合误差较小。
计量经济学课后习题答案第八章_答案

第八章虚拟变量模型1. 回归模型中引入虚拟变量的作用是什么?答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。
加法方式与乘法方式是最主要的引入方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
2. 虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况?答:在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
3.什么是虚拟变量陷阱?答:根据虚拟变量的设置原则,一般情况下,如果定性变量有m个类别,则需在模型中引入m-1个变量。
如果引入了m个变量,就会导致模型解释变量出现完全的共线性问题,从而导致模型无法估计。
这种由于引入虚拟变量个数与类别个数相等导致的模型无法估计的问题,称为“虚拟变量陷阱”。
4.在一项对北京某大学学生月消费支出的研究中,认为学生的消费支出除受其家庭的每月收入水平外,还受在学校中是否得到奖学金,来自农村还是城市,是经济发达地区还是欠发达地区,以及性别等因素的影响。
试设定适当的模型,并导出如下情形下学生消费支出的平均水平:(1) 来自欠发达农村地区的女生,未得到奖学金;(2) 来自欠发达城市地区的男生,得到奖学金;(3) 来自发达地区的农村女生,得到奖学金;(4) 来自发达地区的城市男生,未得到奖学金。
解答: 记学生月消费支出为Y,其家庭月收入水平为X,则在不考虑其他因素的影响时,有如下基本回归模型:Y i=β0+β1X i+μi有奖学金1 来自城市无奖学金0 来自农村来自发达地区 1 男性0 来自欠发达地区0 女性Y i=β0+β1X i+α1D1i+α2D2i+α3D3i+α4D4i+μi由此回归模型,可得如下各种情形下学生的平均消费支出:(1) 来自欠发达农村地区的女生,未得到奖学金时的月消费支出:E(Y i|= X i, D1i=D2i=D3i=D4i=0)=β0+β1X i(2) 来自欠发达城市地区的男生,得到奖学金时的月消费支出:E(Y i|= X i, D1i=D4i=1,D2i=D3i=0)=(β0+α1+α4)+β1X i(3) 来自发达地区的农村女生,得到奖学金时的月消费支出:E(Y i |= X i , D 1i =D 3i =1,D 2i =D 4i =0)=(β0+α1+α3)+β1X i (4) 来自发达地区的城市男生,未得到奖学金时的月消费支出: E(Y i |= X i ,D 2i =D 3i =D 4i =1, D 1i =0)= (β0+α2+α3+α4)+β1X i5. 研究进口消费品的数量Y 与国民收入X 的模型关系时,由数据散点图显示1979年前后Y 对X 的回归关系明显不同,进口消费函数发生了结构性变化:基本消费部分下降了,而边际消费倾向变大了。
计量经济学精要习题参考答案(第四版)

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学第二版课后习题答案1-8章 - 编辑版
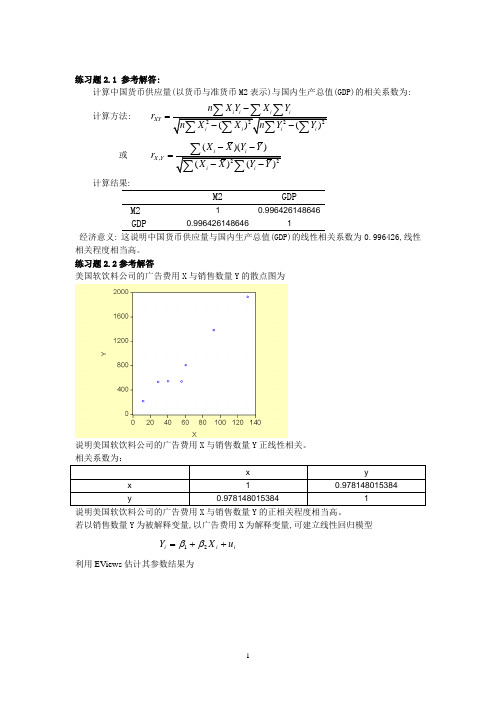
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答: 1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
计量经济学第二版第八章答案

计量经济学第二版第八章答案【篇一:庞皓计量经济学课后答案第八章】业1、①在给定的数据中可以看出人均收入的系数的t值t(?2)?0.857,di(lnxi?7)系数的t值t(?3)?2.42,在给定显著性水平??0.05下n=101,t0.025(101)?1.984。
所以人均收入对期望寿命并没有显著影响。
而di(lnxi?7)对期望寿命有显著影响。
当人均收入超过1097美元时,即di=1为富国时:???2.40?9.39lnx?3.36(lnx?7)?21.12?6.03lnx yiiii当人均收入未超过1097美元时,即di=0为穷国时:???2.40?9.39lnx yii②引入di(lnxi?7)的原因是从截距和斜率两个方面来考虑收入对期望寿命的影响。
③对穷国进行回归时,yi取xi?1097时的值。
对富国进行回归时,yi取xi?1097时的值④结论:富国的期望寿命高于穷国的期望寿命。
贫富国之间的期望寿命的确存在显著差异。
2、①d1t???1,t为1987年及以后?0,t为1987年以前 d2t??年及以后?1,t为1994年以前?0,t为1994年及以后年及以后?1,t为2006?1,t为2008 d3t?? d4t?? 0,t为2006年以前0,t为2008年以前??②从图形上看。
consume和income 及employment存在线性相关关系。
而与burden从图形上看不出线性关系。
所以对模型的设定保持怀疑态度。
③?umecons.16?0.63incomeconsume.51employmentt?1674t?0.0 86t?1?537t?202.50burden.27d2t?127.04d3t?172.2d4tt?7.22d1t?194r2?0.9998672?0.99979 2 f=13189.98 dw=2.921拟合效果好,且通过dw检验由回归可知consumet,d1td3t的系数未能通过显著性水平??0.05下的tt?1,burden检验。
伍德里奇---计量经济学第8章部分计算机习题详解(STATA)
伍德⾥奇---计量经济学第8章部分计算机习题详解(STATA)班级:⾦融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAWsleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出⼀个模型,容许u的⽅差在男⼥之间有所不同。
这个⽅差不应该取决于其他因素。
在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u⽅差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。
所以,当⽅差在male=1时,即为男性时,结果为δ0+δ1;当为⼥性时,结果为δ0。
将sleep对totwork,educ,age,age2,yngkid和male进⾏回归,回归结果如下:(ⅱ)利⽤SLEEP75.RAW的数据估计异⽅差模型中的参数。
u的估计⽅差对于男⼈和⼥⼈⽽⾔哪个更⾼?由截图可知:u2=189359.2?28849.63male+r20546.36 (27296.36)由于male 的系数为负,所以u 的估计⽅差对⼥性⽽⾔更⼤。
(ⅲ)u 的⽅差是否对男⼥⽽⾔有显著不同?因为male 的 t 统计量为?1.06,所以统计不显著,故u 的⽅差是否对男⼥⽽⾔并没有显著不同。
C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利⽤HPRICE 1.RAW 中的数据得到⽅程(8.17)的异⽅差—稳健的标准误。
讨论其与通常的标准误之间是否存在任何重要差异。
●先进⾏⼀般回归,结果如下:●再进⾏稳健回归,结果如下:由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms29.48 0.00064 0.013 (9.01)37.13 0.00122 0.018 [8.48]n =88,R 2=0.672⽐较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较⼤。
计量经济学课后习题1-8章

计量经济学课后习题1-8章计量经济学课后习题总结第一章绪论1、什么事计量经济学?计量经济学就是把经济理论、经济统计数据和数理统计学与其他数学方法相结合,通过建立经济计量模型来研究经济变量之间相互关系及其演变的规律的一门学科。
2、计量经济学的研究方法有那几个步骤?(1)建立模型:包括模型中变量的选取及模型函数形式的确定。
(2)模型参数的估计:通过搜集相关是数据,采用不同的参数估计方法,进行模型参数估计。
(3)模型参数的检验:包括经济检验、以及统计学方面的检验。
(4)经济计量模型的应用:经济预测、经济结构分析、经济政策评价。
3、经济计量模型有哪些特点?经济计量模型是一个代数的、随即的数学模型,它可以是线性或非线性(对参数而言)形式。
4、经济计量模型中的数据有哪几种类型(1)定量数据:时间序列数据、截面数据、面板数据(2)定型数据:虚拟变量数据第二章一元线性回归模型1、什么是相关关系?它有那几种类型?(书上没有确切的答案)(1)相关关系:当一个或几个相互联系的变量取一定的数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定的范围内变化。
变量间的这种相互关系,称为具有不确定性的相关关系(2)相关关系的种类1.按相关程度分类:(1)完全相关:一种现象的数量变化完全由另一种现象的数量变化所确定。
在这种情况下,相关关系便称为函数关系,因此也可以说函数关系是相关关系的一个特例。
(2)不完全相关:两个现象之间的关系介于完全相关和不相关之间(3)不相关:两个现象彼此互不影响,其数量变化各自独立2.按相关的方向分类:(1)正相关:两个现象的变化方向相同(2)负相关:两个现象的变化方向相反3.按相关的形式分类(1)线性相关:两种相关现象之间的关系大致呈现为线性关系(2)非线性相关:两种相关现象之间的关系并不表现为直线关系,而是近似于某种曲线方程的关系4.按相关关系涉及的变量数目分类(1)单相关:两个变量之间的相关关系,即一个因变量与一个自变量之间的依存关系(2)复相关:多个变量之间的相关关系,即一个因变量与多个自变量的复杂依存关系(3)偏相关:当研究因变量与两个或多个自变量相关时,如果把其余的自变量看成不变(即当作常量),只研究因变量与其中一个自变量之间的相关关系,就称为偏相关。
计量经济学第八章第5、8题答案

第8章练习5证明:对方程εβtttX Y1+=两边同时减去Yt 1-,得:εβt t ttYX Y11+-=∆-然后对该式等号右边加上再减去一个Xt 1-β,得:εβββt t t t t t XXYX Y 1111+-+-=∆---()εββtt t tX YX 111+--=--∆将第二个方程εαt t tX X21+∆=∆-代入,得:()()εεβαβtt t t t t X Y X Y 11121+--+∆=∆--- ()εεβββαttt t t X Y X21111++--∆=---()εαβδtt t t X Y X +-+∆=---1111其中,βαα=1,1-=δ,εεεβt t t 21+=第8章练习8(1) 解:根据Eview 软件操作得:对1978-2007年中国货物进、出口额的自然对数系列LX , LM 的单位根检验分别如下: 对LX 的单位根检验:Null Hypothesis: LX has a unit root Exogenous: NoneLag Length: 2 (Fixed)t-Statistic Prob.*Augmented Dickey-Fuller test statistic 3.660835 0.9998Test critical values: 1% level -2.6534015% level -1.95385810% level -1.609571*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(LX)Method: Least SquaresDate: 05/28/11 Time: 12:13Sample (adjusted): 1981 2007Included observations: 27 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.LX(-1) 0.022104 0.006038 3.660835 0.0012D(LX(-1)) 0.089362 0.198210 0.450844 0.6561D(LX(-2)) -0.056822 0.179525 -0.316512 0.7544R-squared 0.165948 Mean dependent var 0.155844Adjusted R-squared 0.096444 S.D. dependent var 0.094091S.E. of regression 0.089439 Akaike info criterion -1.886086Sum squared resid 0.191983 Schwarz criterion -1.742104Log likelihood 28.46216 Hannan-Quinn criter. -1.843273Durbin-Watson stat 2.075404根据上表得”Augmented Dickey-Fuller test statistics”的数值为 3.660835,大于5% critical values:的数值-1.953858,即3.660835>-1.953858。
计量经济学第8章

6443.33 8631.94 1
最高收入户
7593.95 10962.1 0
8262.42 12083.79 1
表 回归结果
这表明1998年、1999年我国城镇居民消费函数并没有显著差 异。因此,可以将两年的样本数据合并成一个样本,估计城镇居 民的消费函数,结果如下:
回归结果
虚拟变量的特殊应用
–契约因素:合同,定期存款 –管理因素:管理层次过多,信息不灵
滞后变量模型
定义:带有滞后变量的模型称为滞后变量模型。
Yt = b0 + b1 Yt-1 + b2 Yt-2 + … + bjYt-j
+ a0 Xt + a1 Xt-1 + a2 Xt-2 + … + ak Xt-k + u 式中:
Yt-j :因变量的第 j 期滞后 Xt-k:自变量的第 k 期滞后
计量经济学第8章
2021年8月5日星期四
8.1 虚拟变量
• 问题的提出 • 虚拟变量的定义 • 虚拟变量的引入方式 • 虚拟变量的特殊应用 • 模型中引入虚拟变量的作用 • 虚拟变量设置的原则
问题的提出
• 经济变量
– 定性变量 – 定量变量
建立和应用计量经济学模型时,除了要考虑定 量变量的影响外,经常还要考虑定性变量的影响。 例如,职业对个人收入的影响、战争与和平对发展 经济的影响、繁荣与萧条对就业的影响、文化程度 对工资的影响、自然灾害对农业生产的影响、季节 对销售量的影响等。所以需要考虑在模型中引入定 性变量。
1
0
0
1982.3
2912.7 3
0
1
0
1986.1
2881.8 17
计量经济学第八章第5、8题答案

第8章练习5证明:对方程εβtttX Y1+=两边同时减去Yt 1-,得:εβt t ttYX Y11+-=∆-然后对该式等号右边加上再减去一个Xt 1-β,得:εβββt t t t t t XXYX Y 1111+-+-=∆---()εββtt t tX YX 111+--=--∆将第二个方程εαt t tX X21+∆=∆-代入,得:()()εεβαβtt t t t t X Y X Y 11121+--+∆=∆--- ()εεβββαttt t t X Y X21111++--∆=---()εαβδtt t t X Y X +-+∆=---1111其中,βαα=1,1-=δ,εεεβt t t 21+=第8章练习8(1) 解:根据Eview 软件操作得:对1978-2007年中国货物进、出口额的自然对数系列LX , LM 的单位根检验分别如下: 对LX 的单位根检验:Null Hypothesis: LX has a unit root Exogenous: NoneLag Length: 2 (Fixed)t-Statistic Prob.*Augmented Dickey-Fuller test statistic 3.660835 0.9998Test critical values: 1% level -2.6534015% level -1.95385810% level -1.609571*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(LX)Method: Least SquaresDate: 05/28/11 Time: 12:13Sample (adjusted): 1981 2007Included observations: 27 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.LX(-1) 0.022104 0.006038 3.660835 0.0012D(LX(-1)) 0.089362 0.198210 0.450844 0.6561D(LX(-2)) -0.056822 0.179525 -0.316512 0.7544R-squared 0.165948 Mean dependent var 0.155844Adjusted R-squared 0.096444 S.D. dependent var 0.094091S.E. of regression 0.089439 Akaike info criterion -1.886086Sum squared resid 0.191983 Schwarz criterion -1.742104Log likelihood 28.46216 Hannan-Quinn criter. -1.843273Durbin-Watson stat 2.075404根据上表得”Augmented Dickey-Fuller test statistics”的数值为 3.660835,大于5% critical values:的数值-1.953858,即3.660835>-1.953858。
《计量经济学导论》伍德里奇-第四版-笔记和习题答案(2-8章)

inc e inc incE e inc 0 。
inc e inc
inc
2
Var e inc inc e2 。
(Ⅲ)低收入家庭支出的灵活性较低,因为低收入家庭必须首先支付衣食住行等必需品。而高收入家庭具有 较高的灵活性,部分选择更多的消费,而另一部分家庭选择更多的储蓄。这种较高的灵活性暗示高收入家庭中储 蓄的变动幅度更大。
(Ⅲ)在(Ⅱ)的方程中,如果备考课程有效,那么 1 的符号应该是什么? (Ⅳ)在(Ⅱ)的方程中, 0 该如何解释? 答: (Ⅰ)构建实验时,首先随机分配准备课程的小时数,以保证准备课程的时间与其他影响 SAT 的因素是
houri :i 1 , , n , n 表示试验中所包括的学 独立的。然后收集实验中每个学生 SAT 的数据,建立样本 sati ,
因此 GPA 0.5681 0.1022 ACT 。 此处截距没有一个很好的解释, 因为对样本而言,ACT 并不接近 0。 如果 ACT 分数提高 5 分,预期 GPA 会提高 0.1022× 5=0.511。 (Ⅱ)每次观测的拟合值和残差表如表 2-3 所示: 表 2-3
i
GPA
GPA^^源自 7.利用 Kiel and McClain(1995)有关 1988 年马萨诸塞州安德沃市的房屋出售数据,如下方程给出了房屋 价格( price )和距离一个新修垃圾焚化炉的距离( dist )之间的关系:
log price 9.40 0.312log dist n 135 , R 2 0.162
y 0 0 1 x u 0
令新的误差项为 e u 0 ,因此 E e 0 。 新的截距项为 0 0 ,斜率不变为 1 。 2.下表包含了 8 个学生的 ACT 分数和 GPA(平均成绩) 。平均成绩以四分制计算,且保留一位小数。 GPA ACT student 1 2 3 4 5 6 7 8
计量经济学习题及答案第八章 联立方程的识别和估计

第八章 联立方程的识别和估计一、习题(一)简答题1.内生变量;2.外生变量;3.前定变量;4.(1)行为方程;(2)技术方程;(3)制度方程;(4)恒等式;5.(1)联立方程系统的结构型; (2)联立方程组的简化型;(二)计算题1.某联立方程计量经济学模型有3个方程、3个内生变量(,,)y y y 123、3个外生变量(,,)x x x 123和样本观测值始终为1的虚变量C ,样本容量为n 。
其中第二个方程为 y x y x 201123332=++++ααααμ⑴ 能否采用OLS 方法估计该结构方程?为什么?⑵ 该方程是否可以识别?2.下列为一完备的联立方程计量经济模型tt t t t t t tt t t G I C Y Y I C Y C ++=++=+++=-21011210μββμααα其中C 为居民消费总额、I 为投资总额、Y 为国内生产总值、t G 为政府消费总额,样本取自1978—2000年。
⑴ 说明:对于消费方程,用IV 、ILS 、2SLS 方法分别估计,参数估计结果是等价的。
⑵ 说明:对于投资方程,能否用IV 、ILS 方法估计?为什么?⑶ 对于该联立方程计量经济模型,如果采用2SLS 估计指出其优缺点。
⑷ 如果该模型的每个结构方程的随机项具有同方差性和序列不相关性,而不同结构方程的随机项之间具有同期相关性。
写出它们的方差协方差矩阵。
3.投资函数模型t t t t Y Y I μβββ+++=-1210为一完备的联立方程计量经济模型中的一个方程,模型系统包含的内生变量为C (居民消费总额)、I (投资总额)和Y (国内生产总值),先决变量为t G (政府消费)、1-t C 和1-t Y 。
样本容量为n 。
⑴ 可否用狭义的工具变量法估计该方程?为什么?⑵ 如果采用2SLS 估计该方程,分别写出2SLS 估计量和将它作为一种工具变量方法的估计量的矩阵表达式;⑶ 如果采用GMM 方法估计该投资函数模型,写出一组等于0的矩条件。
计量经济学(山东联盟)知到章节答案智慧树2023年山东财经大学

计量经济学(山东联盟)知到章节测试答案智慧树2023年最新山东财经大学第一章测试1.计量经济学是一门学科。
参考答案:经济学2.计量经济学的创始人是:参考答案:弗里希3.计量经济学主要由、和三门学科的内容有机结合而成。
参考答案:数学;经济学;统计学4.国际计量经济学会成立标志着计量经济学作为一门独立学科地位的正式确立。
参考答案:对5.计量经济学具有综合性、交叉性和边缘性的特点。
参考答案:对6.计量经济模型一般由、、、等四个要素构成。
参考答案:经济变量、参数、随机误差项和方程的形式7.对计量经济模型进行检验的三个常用准则是:参考答案:经济意义准则、统计检验准则和计量检验准则8.判断模型参数估计量的符号、大小、相互之间关系的合理性属于经济意义准则。
参考答案:对9.在同一时间不同统计单位的相同统计指标组成的数据列是横截面数据。
参考答案:对10.建立计量经济模型的一般步骤是:参考答案:模型设定,参数估计,模型检验,模型应用第二章测试1.进行回归分析时,当x取各种值时,y的条件均值的轨迹接近一条直线,该直线称为y对x的回归直线。
参考答案:对2.将总体被解释变量y的条件均值表现为解释变量x的函数,这个函数称为总体回归函数。
参考答案:对3.计量经济模型中引进随机扰动项的主要原因有:参考答案:作为众多细小影响因素的综合代表;经济现象的内在随机性;作为无法取得数据的已知因素的代表;作为未知影响因素的代表;可能存在模型的设定误差和变量的观测误差4.参考答案:可解释分量;系统分量5.回归分析中,最小二乘法的准则是指:参考答案:6.参考答案:无偏估计量7.当回归模型满足假定SLR.1~SLR.3时, OLSE具有无偏性,如果还满足SLR.4,则OLSE具有有效性。
参考答案:对8.参考答案:错9.利用一元回归模型对被解释变量平均值E(yf| xf )进行区间预测的上界是:参考答案:10.一元线性回归模型对回归系数显著性进行t检验,构造的t统计量为:参考答案:第三章测试1.k元线性回归模型参数βj的置信度为1-α的置信区间为,n为样本个数。
李子奈-计量经济学分章习题与答案

第一章 导 论一、名词解释1、截面数据2、时间序列数据3、虚变量数据4、内生变量与外生变量二、单项选择题1、同一统计指标按时间顺序记录的数据序列称为 ( )A 、横截面数据B 、虚变量数据C 、时间序列数据D 、平行数据2、样本数据的质量问题,可以概括为完整性、准确性、可比性和 ( )A 、时效性B 、一致性C 、广泛性D 、系统性3、有人采用全国大中型煤炭企业的截面数据,估计生产函数模型,然后用该模型预测未来 煤炭行业的产出量,这是违反了数据的哪一条原则。
( ) A 、一致性 B 、准确性 C 、可比性 D 、完整性4、判断模型参数估计量的符号、大小、相互之间关系的合理性属于什么检验? ( )A 、经济意义检验B 、统计检验C 、计量经济学检验D 、模型的预测检验5、对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值? ( )A 、i C (消费)5000.8i I =+(收入)B 、di Q (商品需求)100.8i I =+(收入)0.9i P +(价格)C 、si Q (商品供给)200.75i P =+(价格)D 、i Y (产出量)0.60.65i K =(资本)0.4i L (劳动)6、设M 为货币需求量,Y 为收入水平,r 为利率,流动性偏好函数为012M Y r βββμ=+++,1ˆβ和2ˆβ分别为1β、2β的估计值,根据经济理论有 ( ) A 、1ˆβ应为正值,2ˆβ应为负值 B 、1ˆβ应为正值,2ˆβ应为正值 C 、1ˆβ应为负值,2ˆβ应为负值 D 、1ˆβ应为负值,2ˆβ应为正值三、填空题1、在经济变量之间的关系中, 因果关系 、 相互影响关系 最重要,是计量经济分析的重点。
2、从观察单位和时点的角度看,经济数据可分为 时间序列数据 、 截面数据 、 面板数据 。
3、根据包含的方程的数量以及是否反映经济变量与时间变量的关系,经济模型可分为 时间序列模型 、 单方程模型 、 联立方程模型 。
计量经济学课后题答案

第十三章面板数据模型一简单题1、简述面板数据模型的优点和局限性它能综合利用样本信息,同时反映应变量在截面和时序两个方向上的变化规律及特征。
由于面板数据模型在经济定量分析中,起着只用截面或只用时序数据模型不可替代的独特优点,而具有很高的应用价值。
总之:1.增加了样本容量;2. 可多层面分析经济问题局限性:模型设定错误与数据手机不慎引起较大的偏差;研究截面或者平行数据时,由于样本非随机性造成观测值的偏差,从而导致模型选择上的偏差。
2、你是如何理解面板数据的?在经济领域中,同时具有截面与时序特征的数据很多。
如统计年鉴中提供的各地区或各国的若干系列的年度(季度或月度)经济总量数据;在企业投资分析中,要用到多个企业若干指标的月度或季度时间序列数据;在城镇居民消费分析中,要用到不同省市反映居民消费和收入的年度时序数据。
我们将上述的企业、或地区等统称为个体,从行的方向看,是由若干个体在某个时期构成的截面观察值(截面样本),从列的方向看,是各时间序列。
这种具有三维(截面、时期、变量)信息的数据结构称为面板。
这是“面板”数据的由来,面板数据也称为时序截面数据或混合数据(Pooled Data)。
3、简述建立面板数据模型的过程。
(1)建立面板数据对象,即建立工作文件;(2)面板时序变量平稳性检验;(3)协整检验;(4)模型识别;(5)建立模型;(6)结论。
二填空题1、GDP界面变量是一维变量,面板变量为三维变量。
2、面板数据模型是无斜率系数非齐性、而截距齐性的模型。
3、面板数据模型识别包括效应模型识别和具体模型识别。
4、建立面板数据模型之前,要对面板变量进行平稳性检验和协整检验。
第十二章向量自回归(VAR)模型和向量误差修正(VEC)模型一简答题1、VAR模型的特点VAR模型不以经济理论为指导,它根据样本数据统计特征建模。
VAR模型对参数不施加零约束(如t检验),故称其为无约束VAR模型。
VAR模型的解释变量中不含t期变量,所有与线性联利方程组模型有关的问题均不存在。
计量经济学第八章答案(第二版_庞皓_科学出版社)

第八章答案8.1 Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型:2.409.39ln3.36((ln 7))i i i i Y X D X =-+--(4.37) (0.857) (2.42) R 2=0.752其中:X 是以美元计的人均收入;Y 是以年计的期望寿命;Sen 和Srivastava 认为人均收入的临界值为1097美元(ln10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。
括号内的数值为对应参数估计值的t-值。
1)解释这些计算结果。
2)回归方程中引入()ln 7i i D X -的原因是什么?如何解释这个回归解释变量? 3)如何对贫穷国进行回归?又如何对富国进行回归? 4)从这个回归结果中可得到的一般结论是什么? 练习题8.1参考解答: 1. 结果解释依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时,()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ⎧-+⨯+---==⎨-+=⎩富国时穷国时 表明贫富国之间的期望寿命存在差异。
2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。
这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。
3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命;4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意义上,富国的期望寿命的增加变化趋势优于穷国,贫富国之间的期望寿命的确存在显著差异。
计量经济学 第三版 (潘省初 著) 人民大学出版社 课后答案--第8章_课后答案

ˆ 代替方程右端的Y t ,D t ,进行OlS回归, 第二步:在原结构方程中用 Yt 、 D t
即估计
ˆ + β2C Ct = β0 + β1 D t ˆ + α2R It = α0 + α1 Y t
t-1
+ u +ν t
t
t-1
8.7
(1)本模型中 K=10,G=4。不难看出,各方程中“零约束”的数目都大于
案 网
co
C1 C n I1 Yi= In M1 M n
1 1 0 Z 1i = 0 0 0
0 0 I0 Z 6i = I n1 0 0
0 0 0 Z 7i = 0 1 1
da
+ u
t t-1
方程(1): 变量个数 m1=2, k-m1=3>G-1=2,因而为过度识别.
后 答
+ν t
t-1
ww
,C
t-1
(2) 第一步:进行简化式回归,要估计的方程是: Y t = П 10 +П 11 T t +П 12 C t-1 +П 13 R t-1 +П 14 G t +П 15 X t +ν 1t
D t = П 20 +П 21 T t +П 22 C t-1 +П 23 R t-1 +П 24 G t +П 25 X t +ν 2t
w.
Tt; .
计量经济学各章习题及答案

计量经济学各章习题及答案第一章习题一、单项选择1.( ) 是经济计量学的主要开拓者人和奠基人。
A.费歇(fisher) B .费里希(frisch)C.德宾(durbin)D.戈里瑟(glejer)2.随机方程又称为()。
A.定义方程 B.技术方程C.行为方程 D.制度方程3.计量经济分析工作的研究对象是()。
A.社会经济系统B.经济理论C.数学方法在经济中的应用D.经济数学模型二、多项选择1.经济计量学是下列哪些学科的统一()。
A.经济学B.统计学C.计量学D.数学E.计算机2.对一个独立的经济计量模型来说,变量可分为()、A.内生变量B独立变量C外生变量D.相关变量E虚拟变量3.经济计量学分析工作的工作步骤包括()。
A设定模型B估计参数C检验模型D应用模型E收集数据三、名词解释1.时序数据2.横截面数据3.内生变量4.解释变量5.模型6.外生变量第一章习题答案一、单项选择B\C\A二、多项选择1C\D 2A\C 3A\B\C\D三、名词解释1.时序数据指同一指标按时间顺序记录的数据列,在同一数据列中的数据必须是同口径的,有可比性2.横截面数据同一时间,在不同统计单位的相同统计指标组成的数据列,要求统计的时间相同,不要求统计对象及范围相同。
要求数据统计口径和计算方法具有可比性 3.内生变量具有一定概率分布的随机变量,数据由模型本身决定 4.解释变量在模型中方程右边作为影响因素的变量,即自变量 5.模型对经济系统的数学抽象 6.外生变量非随机变量,取值由模型外决定,是求解模型时的已知数第二章习题一、单项选择1.一元线性回归分析中有TSS=RSS+ESS 。
则RSS 的自由度为()。
A nB 1C n-1D n-22.一元线性会规中,0β∧、1β∧的值为( )∑∑---=∧2i)()(0X X Y Y X X ii )(βXY 01∧∧-=ββ XY 10∧∧-=ββ∑∑---=∧2i)()(1X X Y Y X X ii )(βY X =+∧∧10ββ∑∑---=∧2i)()(0X X Y Y X X ii )(βXY 10∧∧+=ββ∑∑---=∧2i)()(1X X Y Y X X ii )(β3.一元线性回归中,相关系数r=( ) A.∑∑∑----222)()()))(Y Y X X Y Y X X i i i i (( B.∑∑∑----22)()())(Y Y X X Y Y X X iiii( C ∑∑∑----22)()())(Y Y X XY Y X X iii i ( D∑∑∑---222)()()(Y Y X XY Y iii4.对样本相关系数r,以下结论中错误的是ABDC( )。
计量经济学导论智慧树知到答案章节测试2023年对外经济贸易大学

第一章测试1.计量经济学研究中,不需要用到:A:医学B:数学C:统计学D:经济学答案:A2._____对_____有因果影响?A:收入,失业率B:收入,消费C:年龄,智商D:身高,健康答案:B3.下列那些指标可用于描述两个变量之间的关系?A:方差B:协方差C:均值D:中位数答案:B4.下列哪条不是横截面数据的特征?A:在横截面数据分析中,观察值的顺序并不重要B:每一条观察值都是一个不同的个体,可视为独立样本C:横截面数据常见的计量问题是异方差D:横截面数据往往来自于宏观经济调查答案:D5.研究金砖四国2001-2019年的GDP增长率需要用到下列哪种数据?A:时间序列数据B:面板数据C:横截面数据D:混合截面数据答案:B6.在经济学的分析中,因果关系只能通过实验数据来估计。
A:对B:错答案:B7.时间序列数据又被称为纵向数据。
A:对B:错答案:B8.建立计量经济学模型时,只需考虑我们感兴趣的变量。
A:错B:对答案:A9.相关系数只能描述两个变量之间的线性关系。
A:错B:对答案:B10.建立预测模型不需要严格的因果关系。
A:对B:错答案:A第二章测试1.在简单回归模型中,u 一般用来表示A:变量B:误差项C:残差项D:系数答案:B2.OLS估计量是通过()推导的:A:将对应Xi的最小值的Yi与对应Xi的最大值的Yi相连B:最小化残差绝对值之和C:最小化残差的平方之和D:最小化残差之和答案:C3.将因变量的值扩大10,将自变量的值同时扩大100,则:A:OLS估计量的方差不变B:斜率的估计值不变C:截矩的估计值不变D:回归的R^2不变答案:D4.在一个带截矩项的一元线性模型中,下列哪条OLS的代数性质不成立?A:解释变量与残差之间的样本协方差为零B:回归线总是经过样本均值()C:误差项的均值为0D:残差项的和为0答案:C5.估计量具有抽样分布的原因是:A:在现实数据中你往往会重复得到多组样本B:在给定X的情况下,误差项的不同实现会导致Y的取值有所不同C:经济数据是不精确的D:不同的人可能有不同的估计结果答案:B6.误差项的异方差会影响OLS估计量的A:线性性B:最优性C:无偏性D:一致性答案:B7.回归模型不可以用OLS估计,因为它是一个非线性模型。
计量经济学(第二版) 庞皓 西南财经大学出版社 第八章

1
0.000000 2.660000 20.00000 0.000000 17 0.000000 2.750000 25.00000 0.000000
2
0.000000 2.890000 22.00000 0.000000 18 0.000000 2.830000 19.00000 0.000000
第八章练习题参考解答:
练习题
8.1 Sen 和 Srivastava(1971)在研究贫富国之间期望寿命的差异时,利用 101 个国家
的数据,建立了如下的回归模型:
⌢ Yi = −2.40 + 9.39 ln Xi − 3.36(Di (ln Xi − 7))
(4.37) (0.857)
(2.42)
X
2
=债券的资本化率,作为杠杆的测度(
=
长期债券的市值 ×100
总资本的市值
)
X3
=
利润率( =
税后收入 ×100 ) 总资产净值
X 4 = 利润率的标准差,测度利润率的变异性
X 5 = 总资产净值,测度规模
上述模型中 β 2 和 β 4 事先期望为负值,而 β3 和 β5 期望为正值(为什么)。
对于 LPM,Cappeleri 经过异方差和一阶自相关校正,得到以下结果:
5
1.000000 4.000000 21.00000 0.000000 21 0.000000 2.060000 22.00000 1.000000
6
0.000000 2.860000 17.00000 0.000000 22 1.000000 3.620000 28.00000 1.000000
3
0.000000 3.280000 24.00000 0.000000 19 0.000000 3.120000 23.00000 1.000000
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
案例通过构建虚拟变量,建立了分段线性回归模型,结果如下:Variable Coefficient Std. Error t-Statistic Prob.C -697.0977 944.8734 -0.737768 0.4673GNI 0.132616 0.030143 4.399560 0.0002 (GNI-70142.5)*D1 -0.185777 0.111182 -1.670927 0.1067(GNI-98000)*D2 0.230666 0.110988 2.078301 0.0477(GNI-184088.6)*D3 -0.273652 0.075943 -3.603403 0.0013(GNI-251483.2)*D4 0.458678 0.082565 5.555380 0.0000R-squared 0.965855 Mean dependent var 10428.57Adjusted R-squared 0.957976 S.D. dependent var 13612.43S.E. of regression 2790.516 Akaike info criterion 18.89167Sum squared resid 2.02E+08 Schwarz criterion 19.20911Log likelihood -304.7126 F-statistic 122.5782Durbin-Watson stat 2.989812 Prob(F-statistic) 0.000000可决系数很大,拟合优度很高;F统计量的P值很小,模型显著性很强;T的P值很小,显著性很强,但第二个解释变量的p值较大,只能在0.10水平勉强通过。
8_3(1)利用excel做方差分析,结果如下:方差分析差异源SS df MS F P-value F crit组间 3.05E+08 1 3.05E+08 17.11138 9.91E-05 3.981896组内 1.21E+09 68 17828696总计 1.52E+09 69F值较大,P值很小,城镇和农村这一因素对消费水平有显著影响。
(2)C -378.5949 50.52334 -7.493464 0.0000X1 1.996761 0.259904 7.682677 0.0000R-squared 0.997087 Mean dependent var 3441.571Adjusted R-squared 0.996905 S.D. dependent var 3709.172S.E. of regression 206.3361 Akaike info criterion 13.57871Sum squared resid 1362387. Schwarz criterion 13.71202Log likelihood -234.6274 F-statistic 5477.540Durbin-Watson stat 0.270419 Prob(F-statistic) 0.000000(1) 由能源消费的时间序列图,可以发现:在2000年后我国的能源消耗增长速度加快,故设定虚拟变量d ,有d ={0 t ≤20001 t >2000简单线性模型:Variable Coefficient Std. Error t-Statistic Prob. C -16460359 1114924. -14.76366 0.0000 T8327.553558.852014.901180.0000 R-squared0.870611 Mean dependent var 153108.8 Adjusted R-squared 0.866690 S.D. dependent var 91453.42 S.E. of regression 33391.11 Akaike info criterion 23.72541 Sum squared resid 3.68E+10 Schwarz criterion 23.81429 Log likelihood -413.1947 F-statistic 222.0451 Durbin-Watson stat0.061020 Prob(F-statistic)0.000000(2)指数模型:拟合参数及检验:Variable Coefficient Std. Error t-Statistic Prob. C -822.2541 21.60236 -38.06316 0.0000 LT109.76432.84301938.608380.0000 R-squared0.978341 Mean dependent var 11.77784 Adjusted R-squared 0.977685 S.D. dependent var 0.570001 S.E. of regression0.085149 Akaike info criterion-2.0333871000002000003000004000008085909500051010.511.011.512.012.513.07.5857.5907.5957.6007.6057.610LTL YSum squared resid 0.239261 Schwarz criterion -1.944510Log likelihood 37.58427 F-statistic 1490.607Durbin-Watson stat 0.160793 Prob(F-statistic) 0.000000有虚拟变量的线性模型:C -12549532 1799724. -6.973031 0.0000T 6358.489 904.8343 7.027241 0.0000DD*T 25.37381 9.594945 2.644497 0.0126 R-squared 0.893817 Mean dependent var 153108.8Adjusted R-squared 0.887180 S.D. dependent var 91453.42S.E. of regression 30717.97 Akaike info criterion 23.58490Sum squared resid 3.02E+10 Schwarz criterion 23.71822Log likelihood -409.7357 F-statistic 134.6828Durbin-Watson stat 0.171680 Prob(F-statistic) 0.000000指数模型的拟合效果最好。
8_5(1)首先,通过excel做有重复的双因素方差分析,结果如下:方差分析差异源SS df MS F P-value F crit样本 1.35E+08 2 67374615 33.4505 1.15E-07 3.402826列 4.48E+08 1 4.48E+08 222.2067 1.24E-13 4.259677交互89518873 2 44759437 22.2224 3.46E-06 3.402826内部48339805 24 2014159总计7.2E+08 29由F统计量可知,无论是学历还是是否管理层,都对各自和交互对工资有显著影响。
设学历的虚拟变量和管理层的虚拟变量,其中e1代表本科学历,e2代表研究生学历,m代表管理层,做多元线性回归,结果如下:C 8035.598 386.6893 20.78050 0.0000X546.1840 30.51919 17.89641 0.0000E1 3144.035 361.9683 8.685941 0.0000E2 2996.210 411.7527 7.276723 0.0000R-squared 0.956767 Mean dependent var 17270.20Adjusted R-squared 0.952549 S.D. dependent var 4716.632S.E. of regression 1027.437 Akaike info criterion 16.80984Sum squared resid 43280719 Schwarz criterion 17.00861Log likelihood -381.6264 F-statistic 226.8359Durbin-Watson stat 2.236925 Prob(F-statistic) 0.000000T统计值很大,各个变量的显著性都很强;DW统计值接近2,无自相关;若考虑交互作用,分别设本科生和管理层的乘积变量M1和研究生和管理层的乘积变量M2;做多元线性回归,结果如下:Variable Coefficient Std. Error t-Statistic Prob. C 9472.685 80.34365 117.9021 0.0000 X 496.9870 5.566415 89.28314 0.0000 E1 1381.671 77.31882 17.86978 0.0000 E2 1730.748 105.3339 16.43107 0.0000 M 3981.377 101.1747 39.35150 0.0000 M1 4902.523 131.3589 37.32158 0.0000 M23066.035149.330420.531880.0000 R-squared0.998823 Mean dependent var 17270.20 Adjusted R-squared 0.998642 S.D. dependent var 4716.632 S.E. of regression 173.8086 Akaike info criterion 13.29305 Sum squared resid 1178168. Schwarz criterion 13.57133 Log likelihood -298.7403 F-statistic 5516.596 Durbin-Watson stat2.244104 Prob(F-statistic)0.000000无自相关。
由残差图可见,误差较小,围绕0水平上下波动。
模型拟合效果很好。
格兰杰因果检验S does not Granger Cause M2440.11809 0.88893 M2 does not Granger Cause S 0.85619 0.43261 X does not Granger Cause S44 5.73103 0.00658 S does not Granger Cause X 0.25219 0.77835 S does not Granger Cause M144 1.85559 0.16990 M1 does not Granger Cause S 4.26486 0.02113 S does not Granger Cause M44 0.75865 0.47508 M does not Granger Cause S 1.96170 0.15425 S does not Granger Cause E244 2.60713 0.08656 E2 does not Granger Cause S 0.86068 0.43075 S does not Granger Cause E144 1.17365 0.31992 E1 does not Granger Cause S0.006430.99359但是,通过格兰杰因果检验发现,虚拟变量对S 的影响多数不通过检验。