MPI基础
MPI基本框架语句详解

MPI基本框架语句详解//转载请注出处 design by:lhl 于2016.12.14最近刚开始接触mpi并⾏运算,感觉⽆从下⼿,找了好多资料看完之后吧⾃⼰的⼀些笔记整理⼀下,万⼀也有初学者有困惑也能帮⼀把。
Let’s go:⼀.Mpi程序编译与运⾏⽅法⼀:1. 安装mpich,搭建mpi运⾏环境(linux中安装mpich即可)(其中mpi_pi.c是⽤来测试的计算pi的程序)2. 编译:mpicc mpi_pi.c -Wall -o mpi_pi(不同于gcc编译,需注意)3. 运⾏:mpiexec -n 4 ./mpi_pi⽅法⼆:⽣成可执⾏⽂件1.运⾏:mpicc mpi_pi.c进⾏编译,会⽣成a.out的可执⾏⽂件2.mpirun -np 4 ./a.out⼆.基本框架语句与详解1.main(int argc,char **argv)2.MPI_Init(&argc,&argv);进⾏MPI程序的初始化,⼀般MPI程序从这⼀句开始。
开始进⾏MPI运算。
3.MPI_Comm_rank(MPI_COMM_WORLD,&myid);先看第4条吧,相当于是当前进程的逻辑编号,是总进程p中的第⼏个进程。
4.MPI_Comm_size(MPI_COMM_WORLD,&numprocs);MPI程序获得进程数p,设置总的进程数5.MPI_Finalize();MPI程序的结束语句,到这说明程序都结束了,不然程序get不到结束语句就不知道该什么时候停下来了。
下次会发⼀个计算pi的MPI程序,和我⼀样新⼿的可以看懂那个就容易多了。
MPI使用操作流程

《mpi使用操作流程》xx年xx月xx日contents •MPI介绍•MPI安装与配置•MPI基本使用方法•MPI并行文件IO操作•MPI并行计算实例•MPI错误处理与调试目录01 MPI介绍Multiple Processor Interface:一种并行计算编程模型,用于多处理器或多线程并行计算。
Message Passing Interface:一种消息传递编程模型,用于分布式或并行计算系统中的进程间通信。
MPI含义MPI标准由美国Argonne国家实验室开发,成为并行计算领域的重要工具。
1993年MPI-2标准发布,增加了对异步通信和动态进程管理的支持。
1997年MPI-3标准发布,优化了并行计算性能和可扩展性。
2008年MPI发展历程MPI应用场景并行数据库MPI可以用于并行数据库系统中的数据分发和通信,提高数据处理速度和效率。
并行图处理MPI可以用于大规模图处理中的并行计算,提高图算法的效率和速度。
高性能计算MPI是高性能计算中常用的并行计算编程模型,被广泛应用于天气预报、物理模拟、数据分析等领域。
02MPI安装与配置确认操作系统版本和支持的MPI版本准备MPI安装所需组件和工具确认网络连接和远程访问能力下载对应版本的MPI安装包解压缩MPI安装包执行安装脚本,如`.bin/install.sh`等待安装过程完成,不要手动中断按照提示进行下一步操作,如选择安装路径、配置环境变量等MPI配置步骤进入MPI安装目录下的`etc`子目录编辑`mpd.conf`文件,配置MPI守护进程的参数配置MPI启动脚本,如`mpd.sh`、`mpdstart.sh`等设置启动脚本属性为可执行,如`chmod +x mpd.sh`使用启动脚本启动MPI守护进程,如`./mpd.sh &`确认MPI守护进程是否成功启动,可以使用`ps -ef |grep mpd`命令查看进程状态03MPI基本使用方法MPI运行环境设置安装MPI选择适合的MPI版本并按照说明进行安装。
MPI通信技术.ppt

7.1.3 设置MPI参数
❖
设置MPI参数可分为两部分:PLC
侧和PC侧MPI的参数设置。
1. PLC侧参数设置:
在通过HW Config进行硬件组态时 双击“CPU313C”后出现如图7.5所示
图7.5 “HW Config”对话框中配置硬件
再点击上图中的“Properties”按钮来设置CPU的 MPI属性,包括地址及通信速率,具体操作如图7.6所示。
法,使读者可以快速、准确的掌握S7-
300PLC的MPI的使用方法。
7.2.1 掌握全局数据块进行MPI通讯的
方法
❖ 1. 全局数据块通讯方式的概述
在MPI网络中的各个中央处理单元(CPU)之间 能相互交换少量数据,只需关心数据的发送区和 接收区,这一过程称做全局数据块通讯。全局数据 块的通讯方式是在配置PLC硬件的过程中,组态所 要通讯的PLC站之间的发送区和接收区,不需要任 何程序处理,这种通讯方式只适合S7-300/400 PLC 之间相互通讯。下面以例子说明全局数据块通讯 的具体方法和步骤。
❖ 4) 如果机架上安装有功能模块(FM) 和通信模板,则它们的MPI地址是由 CPU的MPI地址顺序加1构成, 如图7.3所 示。
CPU
CP
CP
MPI
MPI
MPI
地址
地址+1
地址+2
图7.3 为可编程模板自动分配MPI地址
5)表7.1 给出了出厂时一些装置 的MPI地址缺省值。
❖ 表7.1 缺省的MPI地址
2. 网络配置图7.9
图7.9 网络配置图
❖ 3. 硬件和软件需求
硬件:
CPU313C
CPU313C
MPI电缆
MPI使用操作流程

MPI的编程语言与环境
总结词
MPI的编程语言与环境包括使用C/C、Fortran等编程语言编写MPI程序,以及使用MPI开发环境进行 调试和优化等操作。
详细描述
MPI是一种并行计算编程接口,支持多种编程语言,如C、C和Fortran等。在使用MPI进行并行程序设 计时,需要了解MPI提供的各种函数和库,以及相应的使用方法。同时,还需要掌握如何使用MPI开 发环境进行程序的调试和优化,以确保程序的正确性和性能。
数据分析
MPI还可以用于大规模数据 分析,如处上述领域,MPI还在金 融、医疗、图像处理等领域 得到了应用。
02
MPI的基本原理
MPI的通信方式
点对点通信
MPI允许两个进程之间直接发送和接收消息,实现同步通信。
广播和汇聚通信
MPI也支持广播和汇聚操作,让一个进程发送消息给所有其他进程或让所有进 程聚集到一个进程。
MPI将进一步推动标准化和开放性发展,促进不同厂商 和平台的互操作性和兼容性,以降低使用门槛和成本。
可扩展性和灵活性
MPI将进一步增强可扩展性和灵活性,支持更大规模和 不同类型的并行计算任务,以满足不断增长的计算需求 。
安全性与可靠性
MPI将进一步关注安全性与可靠性,确保并行计算过程 中的数据安全和系统稳定性,以满足重要应用的需求。
3
处理单元与通信单元分离
MPI将处理单元和通信单元分离,让程序员更 加专注于算法实现,而不需要过多考虑通信细 节。
03
MPI的使用方法
MPI的安装与配置
总结词
MPI的安装与配置是使用MPI进行并行计算的第一步 ,包括安装MPI运行时环境、设置环境变量和配置网 络等步骤。
详细描述
MPI基础ppt全文

分子动力学等模拟计算。
MPI在工程仿真领域也发挥着重 要作用,如结构力学、电磁场仿
真、热传导等。
随着大数据时代的到来,MPI在 数据分析、机器学习等领域也展 现出巨大的潜力。
未来,随着计算机硬件和网络的 不断发展,MPI将继续优化和完 善,为更广泛的应用场景提供高 效、可靠的并行计算支持。
负载不均衡度(Load Imbalance)
基准测试程序设计与实现
基准测试程序选择 NAS Parallel Benchmarks (NPB)
High Performance Linpack (HPL)
基准测试程序设计与实现
Parallel Research Kernels (PRK)
代表性:能反映实际 应用的计算和通信模 式。
计算优化
采用更高效的算法,优化循环结构,减少浮点运算量。
通信优化
减少通信次数,优化通信模式,使用非阻塞通信等。
性能评估结果分析与改进
• I/O优化:采用并行I/O,减少I/O操作次数,优化数据读 写方式。
性能评估结果分析与改进
性能改进实施 重新编译并运行修改后的程序。
修改源代码,实现优化策略。 再次进行性能评估,验证改进效果。
02
通过具体案例,如矩阵乘法、排序算法等,详细讲解并行化实
现的过程和技巧。
并行化性能评估
03
介绍如何评估并行算法的性能,包括加速比、效率等指标的计
算和分析。
性能优化策略
01
02
03
通信优化
讲解如何通过减少通信量、 优化通信方式等手段来提 高MPI程序的性能。
计算优化
介绍如何通过优化计算过 程、提高计算效率等方式 来提升程序性能。
mpi基础操作

MPI(Message Passing Interface)是一种并行计算中常用的通信协议,主要用于进程间的消息传递。
以下是MPI的一些基础操作:
1.初始化MPI环境:通过MPI_Init函数完成MPI环境的初始化。
int MPI_Init(int *argc, char ***argv);
2.获取进程编号和总进程数:通过MPI_Comm_rank和MPI_Comm_size函
数获取当前进程的编号和总进程数。
int MPI_Comm_rank(MPI_Comm comm, int *rank);
int MPI_Comm_size(MPI_Comm comm, int *size);
3.发送和接收消息:通过MPI_Send和MPI_Recv函数进行消息的发送和接
收。
int MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status);
4.结束MPI环境:通过MPI_Finalize函数结束MPI环境。
int MPI_Finalize(void);
以上是MPI的一些基本操作,实际上MPI还提供了许多其他的功能,如广播、散列、收集等,可以满足各种并行计算的需求。
MPI

• 并行计算粒度大,适合大规模可扩展并行算法
– 消息传递程序设计要求用户很好地分解问题,组织不同进 程间的数据交换,并行计算粒度大,特别适合于大规模可 扩展并行算法
什么是MPI?
• Massage Passing Interface:是消息传递函数库 的标准规范,由MPI论坛开发,支持Fortran和C
Hello Hello Hello Hello
World! World! World! World!
开始写MPI程序 • 写MPI程序时,我们常需要知道以下两 个问题的答案:
– 任务由多少进程来进行并行计算?
– 我是哪一个进程?
开始写MPI程序
• MPI提供了下列函数来回答这些问题:
– 用MPI_Comm_size 获得进程个数p
– hello,要运行的MPI并行程序
运行MPI程序
• 编译:mpicc -o hello hello.c • 运行:./hello
[0] Aborting program ! Could not create p4 procgroup.Possible missing fileor program started without mpirun.
C和Fortran中MPI函数约定(续)
• MPI函数的参数被标志为以下三种类型
– IN:参数在函数的调用中不会被修改 – OUT:参数在函数的调用中可能会被修改 – INOUT:参数在一些函数中为IN,而在另一些函数中为OUT
MPI初始化- MPI_INIT
• int MPI_Init(int *argc, char **argv)
– 之后串行代码仍可在主进程(rank = 0)上运行(如果必须)
mpi规约

MPI规约1. 什么是MPIMPI(Message Passing Interface)是一种用于并行计算的通信协议和编程模型。
它定义了一组函数、常量和数据类型,用于在并行计算中进行进程间的通信和同步操作。
MPI的目标是提供一个标准化的并行编程接口,使得开发者可以方便地编写并行程序,并在不同的计算平台上进行移植。
MPI最初由一些高性能计算领域的研究人员发起,目前已成为广泛使用的并行编程框架之一。
MPI的设计理念是基于消息传递的分布式内存模型,它允许开发者在多个进程之间进行通信,通过发送和接收消息来共享数据和进行协作计算。
2. MPI的特点MPI具有以下几个特点:2.1 并行性MPI是一种并行编程模型,它允许开发者将计算任务划分为多个子任务,并在多个进程之间进行并行计算。
每个进程都可以独立地执行指定的计算任务,通过消息传递来交换数据和协调计算。
2.2 分布式内存模型MPI采用分布式内存模型,每个进程都拥有独立的内存空间。
进程之间通过消息传递来进行通信,而不需要共享内存。
这种模型使得MPI程序可以在分布式计算环境中运行,充分利用多台计算机的计算资源。
2.3 灵活性MPI提供了丰富的通信和同步操作函数,开发者可以根据具体需求选择合适的函数来实现进程间的通信和同步。
MPI支持点对点通信、广播、规约、散射、聚集等常见的通信模式,同时也支持自定义通信操作。
2.4 可移植性MPI的标准化设计使得开发者可以方便地编写可移植的并行程序。
只要目标计算平台支持MPI标准,就可以在该平台上运行MPI程序,而不需要对程序进行修改。
这种可移植性使得MPI成为并行计算领域的重要工具。
3. MPI的规约操作MPI规约操作(MPI Reduction)是一种在并行计算中常用的操作,用于将多个进程的数据合并为一个结果。
MPI规约操作可以用于求和、求积、求最大值、求最小值等各种聚合计算。
MPI规约操作的基本思想是将多个进程的数据按照指定的操作进行合并,然后将合并结果发送给指定的进程。
从零开始学PLC之MPI通信

从零开始学PLC之MPI通信调用系统功能SFC用系统功能SFC65~69,可以在无组态情况下实现PLC之间的MPI的通讯,这种通讯方式适合于S7-300、S7-400和S7-200之间的通讯。
无组态通讯又可分为两种方式:双向通讯方式和单向通讯方式。
无组态通讯方式不能和全局数据通讯方式混合使用。
1.双向通讯方式双向通讯方式要求通讯双方都需要调用通讯块,一方调用发送块发送数据,另一方就要调用接收块来接收数据。
适用S7-300/400之间通讯,发送块是SFC65(X_SEND),接收块是SFC66(X_RCV)。
下面举例说明如何实现无组态双向通讯。
例:设2个MPI站分别为MPI_Station_1(MPI地址为设为2)和MPI_Station_2(MPI地址设为4),要求MPI_Station_1站发送一个数据包到MPI_Station_2站。
生成MPI硬件工作站打开STEP 7,创建一个S7项目,并命名为“双向通讯”。
在此项目下插入两个S7-300的PLC站,分别重命名为MPI_Station_1和MPI_Station_2。
MPI_Station_1包含一个CPU315-2DP;MPI_Station_2包含一个CPU313C-2DP。
设置MPI地址完成2个PLC站的硬件组态,配置MPI地址和通信速率,在本例中CPU315-2DP和CPU313C-2DP的MPI地址分别设置为2号和4号,通信速率为187.5kbit/s。
完成后点击按钮,保存并编译硬件组态。
最后将硬件组态数据下载到CPU。
编写发送站的通讯程序在MPI_Station_1站的循环中断组织块OB35中调用SFC65,将I0.0~I1.7发送到MPI_Station_2站。
MPI_Station_1站OB35中的通讯程序如图所示。
编写接收站的通讯程序在MPI_Station_2站的主循环组织块OB1中调用SFC66,接收MPI_Station_1站发送的数据,并保存在MB10和MB11中。
MPI简介

MPI简介MPI简介MPI(Message Passing Interface)是消息传递并行程序设计的标准之一,当前通用的是MPI1.1规范。
正在制定的MPI2.0规范除支持消息传递外,还支持MPI的I/O规范和进程管理规范。
MPI正成为并行程序设计事实上的工业标准。
MPI的实现包括MPICH、LAM、IBM MPL等多个版本,最常用和稳定的是MPICH,曙光天潮系列的MPI以MPICH为基础进行了定制和优化。
MPICH含三层结构,最上层是MPI的API,基本是点到点通信,和在点到点通信基础上构造的集群通信(Collective Communication);中间层是ADI层(Abstract Device Interface),其中device可以简单地理解为某一种底层通信库,ADI就是对各种不同的底层通信库的不同接口的统一标准;底层是具体的底层通信库,例如工作站机群上的p4通信库、曙光1000上的NX库、曙光3000上的BCL通信库等。
MPICH的1.0.12版本以下都采用第一代ADI接口的实现方法,利用底层device提供的通信原语和有关服务函数实现所有的ADI接口,可以直接实现,也可以依靠一定的模板间接实现。
自1.0.13版本开始,MPICH采用第二代ADI接口。
我们将MPICH移植到曙光3000高效通信库BCL(Basic Communication Library)上(简称MPI_BCL)。
MPI_BCL的接口标准与MPICH版本1.1完全一致,满足MPI1.1标准。
同时,也支持ch_p4的通信库,即利用TCP/IP通信机制。
从网络硬件角度说,MPI_BCL针对系统网络,MPI_ch_p4针对高速以太网。
1.MPI的程序设计MPI1.1标准基于静态加载,即所有进程在加载完以后就全部确定,直至整个程序结束才终止,在程序运行期间没有进程的创建和结束。
一个MPI程序的所有进程形成一个缺省的组,这个组被MPI预先规定的Communicator MPI_COMM_WORLD所确定。
MPI并行编程入门

MPI几个基本函数
• 获取处理器的名称 C:
int MPI_Get_processor_name(char *name, int *resultlen)
Fortran 77:
MPI_GET_PROCESSOR_NAME(NAME, RESULTLEN, IERR) CHARACTER *(*) NAME INTEGER RESULTLEN, IERROR • 在返回的name中存储所在处理器的名称 • resultlen存放返回名字所占字节 • 应提供参数name不少于MPI_MAX_PRCESSOR_NAME个字
MPI基础知识
• 进程与消息传递 • MPI重要概念 • MPI函数一般形式 • MPI原始数据类型 • MPI程序基本结构 • MPI几个基本函数 • 并行编程模式
进程与消息传递
• 单个进程(process) – 进程与程序相联,程序一旦在操作系统中运行即成为进程。 进程拥有独立的执行环境(内存、寄存器、程序计数器等) ,是操作系统中独立存在的可执行的基本程序单位 – 串行应用程序编译形成的可执行代码,分为“指令”和“数据”两 个部分,并在程序执行时“独立地申请和占有”内存空间,且 所有计算均局限于该内存空间。
MPI几个基本函数
• 得到通信器的进程数和进程在通信器中的标号 C:
int MPI_Comm_size(MPI_Comm comm, int *size) int MPI_Comm_rank(MPI_Comm comm, int *rank)
Fortran 77:
MPI_COMM_SIZE(COMM, SIZE, IERROR) INTEGER COMM, SIZE, IERROR
MPI重要概念
• 进程组(process group) 指MPI 程序的全部进程集合的一个有序
MPI并行编程入门

S SISD
S I
MISD
M 指令个数
SMP- Symmetric MultiProcessing
多个CPU连接于统一的内存总线 内存地址统一编址,单一操作系统映像 可扩展性较差,一般CPU个数少于32个 目前商用服务器多采用这种架构
聚集方式:
归约
扫描
通信模式
一对一:点到点(point to point) 一对多:广播(broadcast),播撒(scatter) 多对一:收集(gather), 归约(reduce) 多对多:全交换(Tatal Exchange), 扫描(scan) , 置
换/移位(permutation/shift)
Work Pool
P1
P2
并行算法
• 并行算法设计基本原则
– 与体系结构相结合——线性结构,二维网络结 构……
– 具有可扩展性——并行算法是否随处理机个数 增加而能够线性或近似线性的加速
– 粗粒度——通常情况,粒度越大越好 – 减少通信——减少通信量和通信次数 – 优化性能——单机计算效率和并行效率
流水线计算示意图
并行化分解方法
– 分而治之方法:
• 以一个简单的求和问题为例,说明什么是分而治之方法。假设在q = 2*2*2个处理机上计算:
可以将计算依次分解为两个小的求和问题,用下图简单的描述(图中给出 的是处理机号)。在图中,从上至下是分解的过程,从下至上是求部分 和的过程。这就是有分有治的一个简单过程,也既是一种分而治之方法。
sp (q) q
–
MPI编程入门&MPI编程进阶

MPI编程入门一、MPI概述1.1 MPI的发展史MPI标准化涉及到大约60个国家的人们,他们主要来自于美国和欧洲的40个组织,这包括并行计算机的多数主要生产商,还有来自大学、政府实验室和工厂的研究者们。
1992年4月,并行计算研究中心在Williamsburg,Virginia,召开了一个关于消息传递的标准的工作会议,会议上讨论了标准消息传递的必要的、基本的特点,并建立了工作组继续进行标准化工作。
1992年10月,MPI的初步草稿MPI1形成,MPI1主要包含的是在Williamsburg工作组会议上讨论的基本消息传递的接口,因为它的基本目的就是促进讨论并继续此项工作,所以它主要集中在点对点的通信。
1993年1月,第一届MPI会议在Dallas举行,1993年2月MPI1修定版本公布;之后定期召开了一系列关于MPI的核心的研讨会;1993年11月MPI的草稿和概述分别发表于Supercomputing'93和the proceedings。
直到1994年5月,MPI标准正式发布。
1994年7月发布了MPI标准的勘误表。
现在该工作组正在着手扩展MPI、完善MPI,从事于MPI2(MPI的扩展标准)的制定工作。
1.2 MPI的优点●可移植性和易于使用。
以低级消息传递程序为基础的较高级和(或)抽象程序所构成的分布存储通信环境中,标准化的效益特别明显。
●MPI是被正式的详细说明的:它已经成为一个标准。
消息传递标准的定义能提供给生产商清晰定义的程序库,以便他们能有效地实现这些库或在某些情况下为库程序提供硬件支持,因此加强了可扩展性。
●MPI有完备的异步通信:使得send,recieve能与计算重叠。
●可以很有效的在MPP上或Cluster上用MPI编程:MPI的虚拟拓扑反映了应用程序所申请的一组结点的通信模式,在MPP上实现的MPI便可以利用这种信息来优化处理器间的通信路径。
1.3 主要内容●点对点通信(point_to_point communication)●群体操作(collective operations)●进程组(process groups)●通信上下文(communication contexts)●进程拓扑结构(process topologies)●与Fortran 77和C语言的邦定(bindings for Fortran 77 and C)●环境的管理与查询(environmental management and inquiry)●轮廓管理(profiling interface)1.4 MPI的各种实现在国外有许多自从MPI标准制定以来在各种机器上的MPI的portable的实现,并且他们仍从事于自己的MPI实现的性能改进,其中最著名的一些见表1。
mpi的介绍

MPI使用C語言學校:台北科技大學編寫者:呂宗螢指導教授:梁文耀 老師MPI簡介MPI全名Message Passing Interface,MPI is a language-independent communications protocol used to program parallel computers定義了process和process之間傳送訊息的一個標準,適用於各種不同的傳遞媒介。
不止是單一電腦內的process和process傳送訊息,還可以在網路上不同電腦間的process與process的溝通。
目的是希望能提供一套可移值性和高效率的傳送訊息的標準。
有相同功能的是PVM (Parallel Virtual Machine),但現在一般較多人使用的是MPI。
因為他只是一個標準(interface/ standard),所以MPI本身不是library,只是提供給各個單位自行製作MPI時所必須遵循標準。
所以市面上有許多的ex:MPICH、MS MPI、Lan/MPI…等,均是遵循MPI的標準所實作出來的MPI,而各廠商亦可以針對自己的硬體做最佳化。
MPICH便是其中之一實作MPI標準的library,提供了MPI的function,以便程式設計師撰寫平行運算程式,也是最基本MPI實作,其優點是可以跨平台(只能要能裝mpich的環境均可,但程式的撰寫不能相依於OS,ex:使用pthread.h),提供語言有C、Fortan 77、C++、Fortan 90(c++和fortan 90在mpich2才支援)。
撰寫程式和執行的步驟1.啟動MPI環境(亦可以在Compiler完再啟動,mpd.hosts定義了一些mpi環境的主機名稱)mpdboot -n 4 -f mpd.hosts (-n 是指啟動主機的數目,-f 是指定義主機的檔案)2.撰寫MPI程式vi hello.cpilempicc hello.c –o hello.o4.執行程式mpiexec –n 4 ./hello.o (-n 是指process(行程)的數目)5.結束MPImpdallexit撰寫平行程式的基本觀念1.需由程式設計師來規畫平行化程式:所謂平行程式並不是指說你寫好一個程式,只要丟到平行運算環境,該環境便會自動幫你把程式分開,然後做平行處理。
MPI基础PPT课件

2020/9/28
10
4.2 6个基本函数组成的MPI子集
▪ 消息发送:MPI_Send函数用于发送一个消息到目标进 程。
▪ int MPI_Send(void *buf, int count, MPI_Datatype dataytpe, int dest, int tag, MPI_Comm comm)
现代密码学理论与实践之五
2020/9/28
13
4.3 MPI消息(数据类型)
▪ MPI的消息类型分为两种:预定义类型和派生数据类型 (Derived Data Type)
▪ 预定义数据类型:MPI支持异构计算(Heterogeneous Computing),它指在不同计算机系统上运行程序,每 台计算可能有不同生产厂商,不同操作系统。
现代密码学理论与实践之五
2020/9/28
6
4.2 6个基本函数组成的MPI子集
#include "mpi.h" /*MPI头函数,提供了MPI函数和数据类型定义*/ int main( int argc, char** argv ) { int rank, size, tag=1; int senddata,recvdata; MPI_Status status; MPI_Init(&argc, &argv); /*MPI的初始化函数*/ MPI_Comm_rank(MPI_COMM_WORLD, &rank); /*该进程编号*/ MPI_Comm_size(MPI_COMM_WORLD, &size); /*总进程数目*/
现代密码学理论与实践之五
2020/9/28
7
4.2 6个基本函数组成的MPI子集
hyper mpi遵循的mpi标准

主题:Hyper MPI遵循的MPI标准随着并行计算技术的不断发展,MPI(Message Passing Interface)作为一种用于编写并行程序的通信库标准,对于实现高性能计算具有重要意义。
而Hyper MPI作为一种基于MPI标准的并行计算框架,其遵循的MPI标准成为了其优势之一。
本文将从以下几个方面来介绍Hyper MPI遵循的MPI标准。
1. MPI标准的基本概念MPI标准是一种为分布式内存系统设计的编程接口,它定义了一组函数和语义,用于在并行计算环境中进行进程间的通信和数据交换。
MPI标准的设计理念是兼顾通用性和性能,旨在提供高效、可移植和灵活的并行编程接口。
2. Hyper MPI的特点Hyper MPI是一个基于MPI标准的并行计算框架,它在遵循MPI 标准的基础上,针对大规模并行计算系统进行了优化和改进。
Hyper MPI具有以下几个特点:- 高性能:Hyper MPI通过优化通信模式和算法,实现了在大规模并行计算环境下的高性能通信和计算能力。
- 可扩展性:Hyper MPI支持在成百上千甚至成千上万的处理器核上运行,并能够有效地利用大规模计算资源。
- 灵活性:Hyper MPI提供了丰富的并行编程接口和功能,支持复杂的并行计算模型和算法。
3. Hyper MPI遵循的MPI标准在遵循MPI标准的基础上,Hyper MPI在以下几个方面进行了扩展和优化:- 支持新的通信模式:为了更好地兼顾大规模并行计算系统的特点,Hyper MPI引入了一些新的通信模式,如异步通信、流式通信等,以满足不同应用场景的需求。
- 优化集体通信算法:针对不同规模的并行计算系统,Hyper MPI针对不同规模的并行计算系统,优化了集体通信算法,提高了在大规模并行计算系统上的通信性能。
- 支持新的数据类型和操作:为了更好地支持各种复杂的并行计算模型和算法,Hyper MPI引入了一些新的数据类型和操作,包括复数类型、自定义数据类型等,以提高并行程序的灵活性和通用性。
MPI并行程序开发基础MPI是什么

同构性:每台计算机在计算功能方面可以认பைடு நூலகம்是相同 的
实际的计算机一般是异构的,CPU、拥有的内存、甚至OS 都是不同的
站在P2P应用(例如BT)的角度看,这些机器是同构的
计算模式:计算机在求解问题P时,向周围的“邻居” 请求,帮助完成子任务Ti
网络环境稳定:计算机的数量、每台计算机的功能和 性能都是确定的
异构性:每台计算机可以具有不同的计算功能和性能。 例如,一台计算机是数据库服务器、一台计算机是图 形工作站、五台机器是高性能计算工作站
编写程序时,为每个子任务明确指定计算机
P2P计算
(多数情况下)网络环境是动态的:计算机随时可能加 入、退出
至今为止,主要用于数据密集型应用:文件下载、在 线视频播放、……
实例:下载软件BT
并行计算 网络环境是局域、专用、稳定的 计算机之间是同构的:性能、功能 计能算完模成式,:具计体算的机分在配求取解决问于题并P行时算,法子任务Ti在任何机器上都 主要用在科学工程计算领域。在非科学工程领域,例如银行 和图书馆等领域要求数据库支持大规模并发用户,并行计算 更关注于SMP这样的平台
MPI是什么
MPI:Message Passing Interface, an interface specification for programming distributed memory system,consisting of a collection of routines for facilitating communication(exchange of data and synchronization of tasks) among the processors in a distributed memory parallel program.
MPI的初步使用
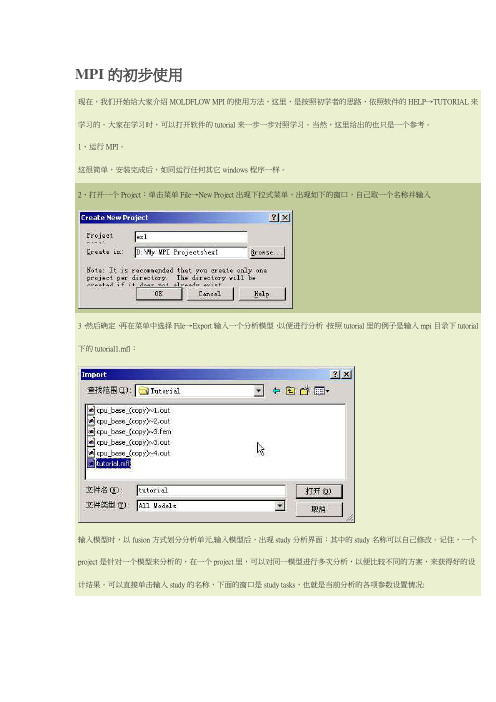
MPI的初步使用现在,我们开始给大家介绍MOLDFLOW MPI的使用方法,这里,是按照初学者的思路,依照软件的HELP→TUTORIAL来学习的。
大家在学习时,可以打开软件的tutorial来一步一步对照学习。
当然,这里给出的也只是一个参考。
1、运行MPI。
这很简单,安装完成后,如同运行任何其它windows程序一样。
2、打开一个Project:单击菜单File→New Project出现下拉式菜单,出现如下的窗口,自己取一个名称并输入3、然后确定,再在菜单中选择File→Export输入一个分析模型,以便进行分析。
按照tutorial里的例子是输入mpi目录下tutorial 下的tutorial1.mfl:输入模型时,以fusion方式划分分析单元,输入模型后,出现study分析界面:其中的study名称可以自己修改。
记住,一个project是针对一个模型来分析的,在一个project里,可以对同一模型进行多次分析,以便比较不同的方案,来获得好的设计结果。
可以直接单击输入study的名称,下面的窗口是study tasks,也就是当前分析的各项参数设置情况:study窗口的第一项是part的文件名,study窗口的第二项是mesh单元形式和2504个单元数量,study窗口的第三项是fill 成形工艺。
4、查看模型,可以用下面的工具栏:如按下旋转工具可以将模型旋转到其它角度来观察5、选择成型所用材料。
可以用菜单方式操作,也可以双击如图所示位置(英文名称可能不一样,这是已选了材料的情况,只要双击此处就行)快速进入材料选择窗口:材料选择窗口如下:其中第一行是已经选用过的材料,第二行是材料生产的厂商名,第三行是材料的品牌。
由于是国外软件,这里的材料基本都是国外的,对于国内的材料,要自己在材料库中输入其参数才能用。
这里,作为学习,按tutorial里面的提示,先选定厂商名:再选定材料品牌:最后确定,即完成材料的选择。
MPI基本函数

消息标识
通信子
请求句柄(返回的)
启动非锁定发送
相关的例程:
MPI_Ibsend()启动缓冲
MPI_Irsend()启动就绪
MPI_Issend()启动同步
int MPI_Irecv(void *buf,
int count,
MPI_Datatype datatype,
int source,
int recvcount,
MPI_Datatype recvtype,
int root,
MPI_Comm comm)
发送缓冲区
发送缓冲区内元素数
发送元素的数据类型
接收缓冲区(已装载)
每次接收的元素数
接收元素的数据类型
接收进程序号
通信子
从根进程部分地散播缓冲区中的值到进程组
相关例程:
MPI_Scatterv()从散播根进程按特定部分散播缓冲区中的值到进程组
接收缓冲区(已装载)
缓冲区内最大项数
项的数据类型
根进程序号
通信子
从根进程向comm中的所有进程和自身广播消息
int MPI_ALLtoall(void *sendbuf
int sendcount,
MPI_Datatype,sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
int root,
MPI_Comm comm)
发送缓冲区
发送缓冲区内元素数
发送元素的数据类型
MPI学习总结

在编程中学习和运用MPI
对等模式的例子:Jacobi迭代
Jacobi迭代是一种比较常见的迭代方法,矩阵中得到的新值是原来旧值点相邻数值 点的平均,核心代码是:
for(i=begin_col;i<=end_col;i++) { for(j=1;j<15;j++) { b[i][j]=(a[i][j+1]+a[i][j-1]+a[i+1][j]+a[i-1][j])/4; } } for(i=begin_col;i<=end_col;i++) { for(j=1;j<15;j++) { a[i][j]=b[i][j]; } }
在编程中学习和运用MPI
由于MPI是一个库,所以接下来我们将在编程中来学习和掌握MPI,通过 实际问题的求解,我们来讲MPI的内容学习整合。
在编程中学习和运用MPI
MPI并行设计模式
从实际的物理问题到并行求解模型,或者说从并行机到并行 计算模型,对于MPI而言,两种最基本的设计模式就是主从模式 和对等模式。可以说绝大部分MPI程序都是这两种模式之一或结 合,掌握这两种模式,可以说就掌握了MPI程序的主线,能够比 较容易将一个实际问题转化为可操作的编程模型。 MPI程序一般是SPMD,当然也可以来编写MPMD,PPT中的程 序都是SPMD事实上MPMD的程序都可以用SPMD来表达。 下面通过两个例子来说明主从模式中讲解主从进程功能的划分 和主从进程之间的交互作用,以及对等模式下各个进程间平等地 位下的协作。
MPI基本概念和知识
从一个简单的程序看MPI的基本知识:
#include "mpi.h" #include <iostream> using namespace std; void Hello(void); void main(int argc,char *argv[]) { int me, namelen, size; char processor_name[MPI_MAX_PROCESSOR_NAME]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&me); MPI_Comm_size(MPI_COMM_WORLD,&size);/*得到当前进程标识和总的进程数*/ if (size < 2) /*若总进程数小于则出错退出*/{ cout<<"systest requires at least 2 processes" <<endl; MPI_Abort(MPI_COMM_WORLD,1);} MPI_Get_processor_name(processor_name,&namelen);/*得到当前机器名字*/ cout<<"Process "<<me<<" is alive on "<<processor_name<<endl; MPI_Barrier(MPI_COMM_WORLD);/*同步*/ Hello();/*调用问候过程*/ MPI_Finalize(); }
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
▪ int MPI_Finalize(void)
国家高性能计算中心(合肥)
2021/4/18
9
4.2 6个基本函数组成的MPI子集
▪ 获取进程的编号:调用MPI_Comm_rank函数获得当前 进程在指定通信域中的编号,将自身与其他程序区分。
国家高性能计算中心(合肥)
2021/4/18
7
4.2 6个基本函数组成的MPI子集
if (rank==0){ senddata=9999; MPI_Send( &senddata, 1, MPI_INT, 1, tag,
MPI_COMM_WORLD); /*发送数据到进程1*/ } if (rank==1) MPI_Recv(&recvdata, 1, MPI_INT, 0, tag, MPI_COMM_WORLD,
▪ 首先声明一个类型为MPI_Data_type的变量EvenElements
▪ 调用构造函数MPI_Type_vector(count, blocklength, stride, oldtype, &newtype)来定义派生数据类型
▪ 新的派生数据类型必须先调用函数MPI_Type_commit获得MPI系 统的确认后才能调用MPI_Send进行消息发送
国家高性能计算中心(合肥)
2021/4/18
6
4.2 6个基本函数组成的MPI子集
#include "mpi.h" /*MPI头函数,提供了MPI函数和数据类型定义*/ int main( int argc, char** argv ) { int rank, size, tag=1; int senddata,recvdata; MPI_Status status; MPI_Init(&argc, &argv); /*MPI的初始化函数*/ MPI_Comm_rank(MPI_COMM_WORLD, &rank); /*该进程编号*/ MPI_Comm_size(MPI_COMM_WORLD, &size); /*总进程数目*/
▪ int MPI_Comm_rank(MPI_Comm comm, int *rank)
▪ 获取指定通信域的进程数:调用MPI_Comm_size函数 获取指定通信域的进程个数,确定自身完成任务比例。
▪ int MPI_Comm_size(MPI_Comm comm, int *size)
国家高性能计算中心(合肥)
国家高性能计算中心(合肥)
2021/4/18
3
第四章 MPI编程指南
▪ 4.1 引言 ▪ 4.2 6个基本函数组成的MPI子集 ▪ 4.3 MPI消息 ▪ 4.4 点对点通信 ▪ 4.5 群集通信 ▪ 4.6 MPI扩展 ▪ 4.7 小结
国家高性能计算中心(合肥)
2021/4/18
4
4.1 引言
▪ 派生数据类型可以用类型图来描述,这是一种通用的类型描述方 法,它是一系列二元组<基类型,偏移>的集合,可以表示成如下 格式:
▪ {<基类型0,偏移0>,···,<基类型n-1,偏移n-1>}
▪ 在派生数据类型中,基类型可以是任何MPI预定义数据类型,也 可以是其它的派生数据类型,即支持数据类型的嵌套定义。
▪ TempBuffer = malloc(BufferSize);
▪ j = sizeof(MPI_DOUBLE);
▪ Position = 0;
▪ for (i=0;i<50;i++)
▪
MPI_Pack(A+i*j,1,MPI_DOUBLE,TempBuffer,BufferSize,&Position,
时缓冲区
国家高性能计算中心(合肥)
2021/4/18
17
4.3 MPI消息(数据类型)
▪ 消息打包,然后发送 MPI_Pack(buf, count, dtype, //以上为待打包消息描述 packbuf, packsize, packpos, //以上为打包缓冲区描述 communicator)
MPI_FLOAT
float
MPI_REAL
REAL
MPI_INT
int
MPI_INTEGER
INTEGER
MPI_LOGICAL
LOGICAL
MPI_LONG
long
MPI_LONG_DOUBLE long double
MPI_PACKED
MPI_PACKED
MPI_SHORT
short
MPI_UNSIGNED_CHAR unsigned char
▪ MPI_BYTE表示一个字节,所有的计算系统中一个字 节都代表8个二进制位。
▪ MPI_PACKED预定义数据类型被用来实现传输地址空 间不连续的数据项 。
国家高性能计算中心(合肥)
2021/4/18
16
4.3 MPI消息(数据类型)
▪ double A[100];
▪ MPI_Pack_size (50,MPI_DOUBLE,comm,&BufferSize);
▪ MPI中,消息缓冲由三元组<起始地址,数据个数,数 据类型>标识
▪ 消息信封由三元组<源/目标进程,消息标签,通信域> 标识 MPI_Send (buf, count, datatype, dest, tag, comm)
消息缓冲
消息信封
▪ 三元组的方式使得MPI可以表达更为丰富的信息,功能 更强大
▪ MPI通过提供预定义数据类型来解决异构计算中的互操作性问 题,建立它与具体语言的对应关系。
▪ 派生数据类型:MPI引入派生数据类型来定义由数据类 型不同且地址空间不连续的数据项组成的消息。
国家高性能计算中心(合肥)
2021/4/18
14
4.3 MPI消息(数据类型)
表 2.1 MPI 中预定义的数据类型
comm);
▪ MPI_Send(TempBuffer,Position,MPI_PACKED,destination,tag,comm);
▪ MPI_Pack_size函数来决定用于存放50个MPI_DOUBLE数据项 的临时缓冲区的大小
▪ 调用malloc函数为这个临时缓冲区分配内存 ▪ for循环中将数组A的50个偶序数元素打包成一个消息并存放在临
MPI_Type_commit
提交一个派生数据类型
MPI_Type_free
释放一个派生数据类型
国家高性能计算中心(合肥)
2021/4/18
20
4.3 MPI消息(数据类型)
double A[100]; MPI_Datatype EvenElements; ··· MPI_Type_vector(50, 1, 2, MPI_DOUBLE, &EvenElements); MPI_Type_commit(&EvenElements); MPI_Send(A, 1, EvenElements, destination, ···);
函数名
含义
MPI_Type_contiguous 定义由相同数据类型的元素组成的类型
MPI_Type_vector
定义由成块的元素组成的类型,块之间具有相同间隔
MPI_Type_indexed
定义由成块的元素组成的类型,块长度和偏移由参数 指定
MPI_Type_struct
定义由不同数据类型的元素组成的类型
2021/4/18
11
4.3 MPI消息
▪ 一个消息好比一封信
▪ 消息的内容即信的内容,在MPI中称为消息缓冲 (Message Buffer)
▪ 消息的接收/发送者即信的地址,在MPI中称为消息信 封(Message Envelop)
国家高性能计算中心(合肥)
2021/4/18
12
4.3 MPI消息
▪ 消息接受:MPI_Recv函数用于从指定进程接收一个消 息
▪ int MPI_Recv(void *buf, int count, MPI_Datatype datatyepe,int source, int tag, MPI_Comm comm, MPI_Status *status)
国家高性能计算中心(合肥)
并行算法实践
上篇 并行程序设计导论
并行算法实践 上篇 并行程序设计导论
▪ 单元I 并行程序设计基础
▪ 单元II 并行程序编程指南
▪ 单元III 并行程序开发方法
国家高性能计算中心(合肥)
2021/4/18
2
单元II 并行程序编程指南
▪ 第四章 MPI编程指南 ▪ 第五章 PVM编程指南 ▪ 第六章 HPF编程指南 ▪ 第七章 OpenMP编程指南
5
4.1 引言
▪ MPI的版本
▪ MPICH:/mpi/mpich ▪ LAM (Local Area Multicomputer): ▪ Open-MPI: / ▪ CHIMP: ftp:///pub/chimp/release/
▪ 消息接收,然后拆包 MPI_Unpack(packbuf, packsize, packpos, //以上为拆包缓冲区描述 buf, count, dtype, // 以上为拆包消息描述 communicatior)
国家高性能计算中心(合肥息(数据类型)
&status); /*从进程0接收数据*/ MPI_Finalize(); /*MPI的结束函数*/ return (0); }
国家高性能计算中心(合肥)
2021/4/18