3 第三章 参数估计与非参数估计
统计学中的参数估计方法

统计学中的参数估计方法统计学中的参数估计方法是研究样本统计量与总体参数之间关系的重要工具。
通过参数估计方法,可以根据样本数据推断总体参数的取值范围,并对统计推断的可靠性进行评估。
本文将介绍几种常用的参数估计方法及其应用。
一、点估计方法点估计方法是指通过样本数据来估计总体参数的具体取值。
最常用的点估计方法是最大似然估计和矩估计。
1. 最大似然估计(Maximum Likelihood Estimation)最大似然估计是指在给定样本的条件下,寻找最大化样本观察值发生的可能性的参数值。
它假设样本是独立同分布的,并假设总体参数的取值满足某种分布。
最大似然估计可以通过求解似然函数的最大值来得到参数的估计值。
2. 矩估计(Method of Moments)矩估计是指利用样本矩与总体矩的对应关系来估计总体参数。
矩估计方法假设总体参数可以通过样本矩的函数来表示,并通过求解总体矩与样本矩的关系式来得到参数的估计值。
二、区间估计方法区间估计是指根据样本数据来估计总体参数的取值范围。
常见的区间估计方法有置信区间估计和预测区间估计。
1. 置信区间估计(Confidence Interval Estimation)置信区间估计是指通过样本数据估计总体参数,并给出一个区间,该区间包含总体参数的真值的概率为预先设定的置信水平。
置信区间估计通常使用标准正态分布、t分布、卡方分布等作为抽样分布进行计算。
2. 预测区间估计(Prediction Interval Estimation)预测区间估计是指根据样本数据估计出的总体参数,并给出一个区间,该区间包含未来单个观测值的概率为预先设定的置信水平。
预测区间估计在预测和判断未来观测值时具有重要的应用价值。
三、贝叶斯估计方法贝叶斯估计方法是一种基于贝叶斯定理的统计推断方法。
贝叶斯估计将先验知识与样本数据相结合,通过计算后验概率分布来估计总体参数的取值。
贝叶斯估计方法的关键是设定先验分布和寻找后验分布。
参数统计与非参数统计

参数统计与非参数统计参数统计和非参数统计是统计学中两个重要的概念。
它们是用来描述和推断数据的统计特征的方法。
在统计学中,参数是用于描述总体特征的统计量,而非参数是不依赖于总体分布的统计方法。
本文将从定义、应用、优劣势等方面对参数统计和非参数统计进行详细分析。
首先,我们来了解一下参数统计。
参数统计是基于总体参数的估计和推断的统计方法。
总体参数是指对整个数据集进行总结的数量,如平均值、方差、标准差等。
参数统计的方法是通过从样本中获取数据来估计总体参数。
常见的参数估计方法包括样本均值估计总体均值、样本方差估计总体方差等。
参数统计的优点是可以提供关于总体的精确估计和推断结果。
然而,参数统计要求总体数据必须服从特定的概率分布,例如正态分布、二项分布等。
如果总体数据不符合这些分布,参数统计的结果可能会有偏差。
接下来,我们来介绍非参数统计。
非参数统计是不依赖于总体分布的统计方法。
这意味着非参数统计不对总体的概率分布做出任何假设。
相反,它使用基于排序和排名的方法进行统计推断。
常见的非参数统计方法包括Wilcoxon符号秩检验、Kruskal-Wallis检验等。
非参数统计的优点是可以在数据不符合特定分布情况下使用,并且对异常值不敏感。
然而,非参数统计通常需要更多的数据以获得稳健的结果,并且在处理大规模数据时的计算负担较重。
参数统计与非参数统计的应用领域不同。
参数统计主要应用于数据符合特定分布的情况下,例如医学研究中对患者的生存率进行分析、工业生产中对产品质量的控制等。
非参数统计则主要应用于数据分布不明确或数据不符合特定分布的情况下,例如社会科学中对调查结果的分析、财务领域中对公司经营绩效的评估等。
在参数统计和非参数统计的比较中,我们可以看到它们各自的优势和劣势。
参数统计的优势是可以提供精确的估计和推断,并且通常需要较少的数据。
然而,参数统计对总体数据的分布有严格的要求,如果分布假设不正确,结果可能产生误差。
非参数统计的优势是可以在数据分布不明确的情况下进行分析,并且对异常值不敏感。
五种估计参数的方法

五种估计参数的方法在统计学和数据分析中,参数估计是一种用于估计总体的未知参数的方法。
参数估计的目标是通过样本数据来推断总体参数的值。
下面将介绍五种常用的参数估计方法。
一、点估计点估计是最常见的参数估计方法之一。
它通过使用样本数据计算出一个单一的数值作为总体参数的估计值。
点估计的核心思想是选择一个最佳的估计量,使得该估计量在某种准则下达到最优。
常见的点估计方法有最大似然估计和矩估计。
最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种常用的点估计方法。
它的核心思想是选择使得样本观测值出现的概率最大的参数值作为估计值。
最大似然估计通常基于对总体分布的假设,通过最大化似然函数来寻找最优参数估计。
矩估计(Method of Moments,简称MoM)是另一种常用的点估计方法。
它的核心思想是使用样本矩和总体矩之间的差异来估计参数值。
矩估计首先计算样本矩,然后通过解方程组来求解参数的估计值。
二、区间估计点估计只给出了一个参数的估计值,而没有给出该估计值的不确定性范围。
为了更全面地描述参数的估计结果,我们需要使用区间估计。
区间估计是指在一定的置信水平下,给出一个区间范围,该范围内包含了真实参数值的可能取值。
常见的区间估计方法有置信区间和预测区间。
置信区间是对总体参数的一个区间估计,表示我们对该参数的估计值的置信程度。
置信区间的计算依赖于样本数据的统计量和分布假设。
一般来说,置信区间的宽度与样本大小和置信水平有关,较大的样本和较高的置信水平可以得到更准确的估计。
预测区间是对未来观测值的一个区间估计,表示我们对未来观测值的可能取值范围的估计。
预测区间的计算依赖于样本数据的统计量、分布假设和预测误差的方差。
与置信区间类似,预测区间的宽度也与样本大小和置信水平有关。
三、贝叶斯估计贝叶斯估计是一种基于贝叶斯理论的参数估计方法。
它将参数看作是一个随机变量,并给出参数的后验分布。
贝叶斯估计的核心思想是根据样本数据和先验知识来更新参数的分布,从而得到参数的后验分布。
统计学习理论中的非参数估计

统计学习理论中的非参数估计统计学习理论是一门研究如何从数据中学习模型和进行预测的学科。
在这一领域中,非参数估计是一种重要的统计方法,它的目标是根据给定的数据,估计出未知的概率分布或者密度函数。
与参数估计相比,非参数估计不需要事先对概率分布做出明确的假设,因此更加灵活和适应性强。
一、什么是非参数估计非参数估计是指在统计学中,对数据的概率分布形式不做出具体的假设,而仅从数据本身出发,通过统计方法推断出未知的概率分布或者密度函数。
换句话说,非参数估计不依赖于具体的参数模型。
二、非参数估计的基本思想非参数估计的基本思想是通过使用核密度估计或直方图等方法,对数据本身的分布进行估计。
核密度估计是一种常用的非参数估计方法,其中密度函数由一系列核函数的线性组合表示。
三、核密度估计的原理核密度估计的原理是通过在每个数据点附近放置一个核函数,并对所有的核函数求和来估计密度函数。
核函数的选取可以采用高斯核函数等,通过调整带宽参数,可以控制核函数的宽窄,从而对密度函数进行估计。
四、非参数估计的优缺点非参数估计的优点在于它不需要对概率分布的形式做出明确的假设,更加灵活和适应性强。
它可以适用于各种类型的数据,并能够准确地反映数据的分布情况。
然而,非参数估计的缺点在于它需要更多的数据量来进行估计,计算复杂度较高。
五、非参数估计的应用领域非参数估计在统计学习理论中有广泛的应用。
在分类问题中,可以使用非参数估计来估计不同类别的概率分布,进而进行分类预测。
在回归问题中,非参数估计可以用于拟合曲线或者曲面,从而进行预测。
六、非参数估计的发展和展望随着统计学习理论的发展,非参数估计方法也在不断改进和扩展。
目前,一些新的非参数估计方法,如支持向量机,随机森林等,已经广泛应用于各个领域。
未来,非参数估计方法将进一步优化,并在更多的实际问题中得到应用。
总结起来,非参数估计是统计学习理论中的重要方法之一,它不需要对概率分布的形式做出明确的假设,更加灵活和适应性强。
非参数估计(完整)PPT演示课件

P p xdx p xV R
Pˆ k N
pˆ x k / N
V
对p(x) 在小区域内的平均值的估计
9
概率密度估计
当样本数量N固定时,体积V的大小对估计的 效果影响很大。
过大则平滑过多,不够精确; 过小则可能导致在此区域内无样本点,k=0。
此方法的有效性取决于样本数量的多少,以 及区域体积选择的合适。
11
概率密度估计
理论结果:
设有一系列包含x 的区域R1,R2,…,Rn,…,对 R1采用1个样本进行估计,对R2用2 个,…, Rn 包含kn个样本。Vn为Rn的体积。
pn
x
kn / N Vn
为p(x)的第n次估计
12
概率密度估计
如果要求 pn x 能够收敛到p(x),那么必须满足:
分布,而不必假设密度函数的形式已知。
2
主要内容
概率密度估计 Parzen窗估计 k-NN估计 最近邻分类器(NN) k-近邻分类器(k-NN)
3
概率密度估计
概率密度估计问题:
给定i.i.d.样本集: X x1, x2 , , xl
估计概率分布: p x
4
概率密度估计
10.0
h1 0.25
1.0
0.1
0.01
0.001 10.0
1.0
0.1
0.01
0.001 10.0
1.0
0.1
0.01
0.001 10.0
1.0
0.1
0.01
0.001 2 0 2
h1 1 2 0 2
h1 4 2 0 2 27
由图看出, PN(x)随N, h1的变化情况 ①当N=1时, PN(x)是一个以第一个样本为中心的正
贝叶斯 参数估计 和 非参数估计

贝叶斯参数估计和非参数估计下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!贝叶斯参数估计与非参数估计在统计学中,参数估计是通过样本数据来推断总体参数的方法。
参数估计与非参数估计的联系与区别

参数估计与非参数估计的联系与区别参数估计要求明确参数服从什么分布,明确模型的具体形式,然后给出参数的估计值。
根据从总体中抽取的样本估计总体分布中包含的未知参数。
和参数估计不同,非参数估计并不加入任何先验知识,而是根据数据本身的特点、性质来拟合分布,这样能比参数估计方法得出更好的模型。
非参数估计对解释变量的分布状况与模型的具体形式不做具体规定,运用核密度函数与窗宽去逐步逼近,找出相应的模型。
统计学中常见的一些典型分布形式不总是能够拟合实际中的分布。
此外,在许多实际问题中经常遇到多峰分布的情况,这就迫使必须用样本来推断总体分布,常见的总体类条件概率密度估计方法有Parzen窗法和Kn 近邻法两种。
非参数估计也有人将其称之为无参密度估计,它是一种对先验知识要求最少,完全依靠训练数据进行估计,而且可以用于任意形状密度估计的方法。
最简单的直方图估计,把所有可能取值的范围分成间隔相等的区间,然后看每个区间内有多少个数据?这样就定义出了直方图,因此直方图就是概率密度估计的最原始的模型。
直方图用的是矩形来表示纵轴,当样本在某个小区间被观测到,纵轴就加上一个小矩形。
非参数估计更适合对原函数关系进行模拟,但不能预测;而参数估计则可以预测。
参数模型与非参数模型

参数模型与非参数模型
参数模型是通过对数据的分布进行参数估计来描述数据的统计性质。
它假设数据的分布属于一些已知的概率分布,通过估计分布的参数来确定数据的分布。
常见的参数模型包括正态分布、泊松分布、指数分布等。
参数模型具有计算简单、参数估计准确等优点。
然而,参数模型也有一些局限性,对数据的分布做出了强假设,缺乏灵活性,不能适应复杂的真实场景。
相比之下,非参数模型对数据的分布不做出明确的假设,而是通过直接估计数据的分布函数来描述数据的特性。
非参数模型一般不依赖于预先定义的参数,而是根据数据的本身推断出分布函数的形式。
非参数模型的优点是具有更高的灵活性,可以适应各种复杂的数据形式。
然而,非参数模型的计算复杂度较高,并且由于没有明确的参数假设,可能存在过拟合问题。
参数模型和非参数模型各有优缺点,在具体应用中需要根据数据的特点和建模需求来选择。
当数据的分布已知或形式相对简单,参数模型可以通过对参数进行估计来提供准确的描述和预测。
而当数据的分布复杂或未知时,非参数模型可以通过对数据的直接建模来获取更为灵活和准确的结果。
总结起来,参数模型和非参数模型是统计建模中的两种不同方法。
参数模型通过对数据的分布进行参数估计来描述数据的统计性质,具有计算简单和参数估计准确的优点;非参数模型不依赖于预先定义的参数,通过直接估计数据的分布函数来描述数据的特性,具有更高的灵活性,可以适应各种复杂的数据形式。
在具体应用中需要根据数据的特点和建模需求来选择适合的方法。
第三章 概率密度函数的估计

当 0 ≤ x ≤ θ 时 , p (x | θ ) = 的最大似然估计是
解: 定义似然函数 l (θ ) =
k
1
θ
, 否则为0。证明θ
max x k 。
∏ p (x
k =1
N
k
|θ )
1 dH = 0, 即 − N ⋅ = 0 H (θ ) = ln l (θ ) = − N ln θ ,令 dθ θ 方程的解 θ = ∝ ,但实际问题中,θ ≠∝ 。 1 已知有N个随机样本, 且 0 ≤ x ≤ θ 时 , p (x | θ ) =
参数估计中的基本概念 统计量 参数空间 点估计、估计量和估计值 区间估计 参数估计判断标准 无偏性 有效性 一致性
3.2最大似然估计
(1)前提假设
参数θ(待估计)是确定(非随机)而未知的量 样本集分成c类,为A1,A2,…,Ac,Aj的样本是 从概率密度为 p x | ω j 的总体中独立抽取出来的。
i =1 i =1 i =1 i =1
N
(
)
N
N
例3.2:设x服从正态分N(μ,σ2),其中参数μ、 σ2未知,求它们的最大似然估计量。
N
解: 设样本集 A = {x1 , x2 ,..., xN }, 定义似然函数 l (θ ) = ∏ p(xi | θ )
i =1 2 ⎧ ⎡ ( xi − μ ) ⎤ ⎫ ⎪ ⎪ 1 exp⎢− H (θ ) = ln l (θ ) = ∑ ln p (xi | θ ) = ∑ ln ⎨ ⎥⎬ 2 2σ ⎪ i =1 i =1 ⎣ ⎦⎪ ⎭ ⎩ 2π σ 2 N ⎧ ⎫ ( ) x − 1 1 μ 2 i = ∑ ⎨− ln 2π − ln σ − ⎬ 2 2 2σ i =1 ⎩ 2 ⎭ N N 2
第3章 ML估计和Bayesian参数估计

θ μ 未知
x ~N , 2
给定样本集
~N 0 , 02
,已知随机变量
均值未知而方差已知。均值变量的先验分布 求μ 的后验概率 p D
p D pD p p D
吸收所有与μ 无关的项
p D p
p D p D p 1 xi 2 1 1 0 2 1 exp exp 2 2 2 2 0 2 0 2 i 1
ˆ 2 但当n->∞时: 2
——渐近无偏估计
最大似然估计(ML)
ML估计总结
简单性 收敛性:无偏或者渐近无偏 如果假设的类条件概率模型 p x i , θi
正确,
则通常能获得较好的结果。但果假设模型出现偏 差,将导致非常差的估计结果。
参数估计
参数估计(parametric
的解。而只有θ点使得 似然函数最大。
方程组没有唯一解的情况
最大似然估计(ML)
1 ,1 x 2 p x 2 1 0, 其他
H N ln 2 1
H 1 N 0 1 2 1
均匀分布的情况
H 1 N 0 2 2 1
0 xi 2 i 1 0
N
由两式指数项中对应的系数相等得:
N 1 1 2 2 2 N 0 N N N ˆN 2 2 N 02
1 ˆ 其中: N N
x
i 1
N
i
2 p D ~N N , N 求解方程组得:
N p D p
3 第三章 参数估计与非参数估计
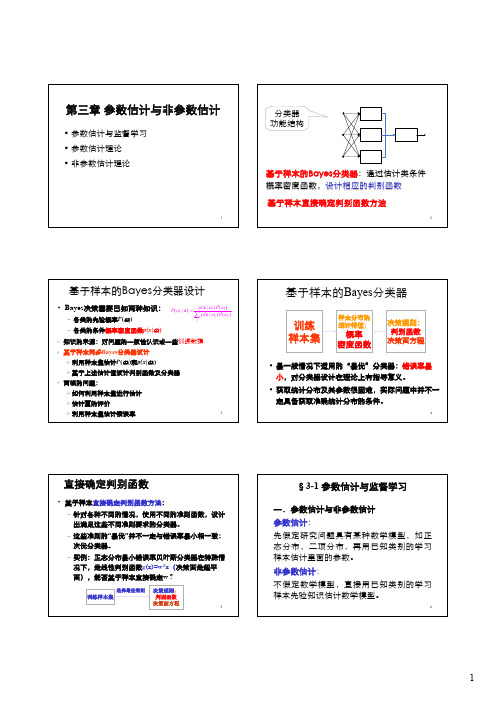
1第三章参数估计与非参数估计•参数估计与监督学习•参数估计理论•非参数估计理论2基于样本的Bayes分类器:通过估计类条件概率密度函数,设计相应的判别函数分类器功能结构基于样本直接确定判别函数方法3基于样本的Bayes 分类器设计•Bayes 决策需要已知两种知识:–各类的先验概率P (ωi )–各类的条件概率密度函数p(x |ωi )(|)()(|)(|)()i i i j j jp P P p P ωωωωω=∑x x x 知识的来源:对问题的一般性认识或一些训练数据基于样本两步Bayes 分类器设计¾利用样本集估计P (ωi )和p(x |ωi )¾基于上述估计值设计判别函数及分类器面临的问题:¾如何利用样本集进行估计¾估计量的评价¾利用样本集估计错误率4基于样本的Bayes 分类器训练样本集样本分布的统计特征:概率密度函数决策规则:判别函数决策面方程•最一般情况下适用的“最优”分类器:错误率最小,对分类器设计在理论上有指导意义。
•获取统计分布及其参数很困难,实际问题中并不一定具备获取准确统计分布的条件。
5直接确定判别函数•基于样本直接确定判别函数方法:–针对各种不同的情况,使用不同的准则函数,设计出满足这些不同准则要求的分类器。
–这些准则的“最优”并不一定与错误率最小相一致:次优分类器。
–实例:正态分布最小错误率贝叶斯分类器在特殊情况下,是线性判别函数g (x)=w T x (决策面是超平面),能否基于样本直接确定w ?训练样本集决策规则:判别函数决策面方程选择最佳准则6一.参数估计与非参数估计参数估计:先假定研究问题具有某种数学模型,如正态分布,二项分布,再用已知类别的学习样本估计里面的参数。
非参数估计:不假定数学模型,直接用已知类别的学习样本先验知识估计数学模型。
§3-1 参数估计与监督学习13¾估计量:样本集的某种函数f (X),X ={X 1, X 2 ,…, X N }¾参数空间:总体分布未知参数θ所有可能取值组成的集合(Θ)12ˆ(,,...,)N d θθ=x x x 的()是样本集的函数,它对样本集的一次实现估计称计量点估为估计值¾点估计的估计量和估计值§3-2 参数估计理论14¾估计量评价标准: 无偏性,有效性,一致性–无偏性:E ( )=θ–有效性:D ( )小,估计更有效–一致性:样本数趋于无穷时,依概率趋于θ:ˆθˆlim ()0N P θθε→∞−>=ˆθˆθ15最大似然估计计算方法•Maximum Likelihood (ML)估计–估计参数θ是确定而未知的,Bayes 估计方法则视θ为随机变量。
非参数估计方法

非参数估计方法非参数估计方法是统计学中一类基于数据本身的分析方法,它不依赖于已知的分布,也不需要事先假设数据的分布形式,并且可以适用于各类数据类型。
非参数估计方法在数据分析、机器学习、统计建模等领域应用广泛。
本文将全面介绍非参数估计方法的概念、优点、方法以及应用场景。
一、概念在统计学中,非参数估计方法是指以数据为基础,不考虑样本的分布函数形式,通过建立统计模型来估计总体的未知参数。
与之相反,参数估计方法是指在假设该样本来自特定的分布下,计算总体的未知参数。
一般情况下,非参数估计方法较为通用,适用范围更广。
二、优点与参数估计方法相比,非参数估计方法的优点主要有以下几个方面:1、不需要对总体的假设分布形式做出严格的假设,因而可以针对各种数据类型进行估计。
2、其估计结果的方差不依赖于总体分布,但只依赖于样本自身的属性,能更全面地反映样本真实的性质。
3、可使用的样本数量较少,就可以得到较为准确的估计结果。
4、非参数方法可以被用于估计多种不同的总体参数,因此具有较高的通用性。
三、方法1、核密度估计核密度估计是一种常用的非参数密度估计方法。
该方法假定数据点具有局部性质(即在某个位置附近的样本是相似的),并涉及构建出一种估计函数(核函数),以估算数据的概率密度曲线。
核密度估计方法通常使用高斯核函数,有时也会使用其他类型的核函数。
在这种情况下,核密度估计可以准确地估计连续型随机变量的密度函数。
2、经验分布函数经验分布函数也是一种常用的非参数方法。
该方法使用具体样本点上的概率密度函数对总体概率分布进行估计。
经验分布函数是一个阶梯函数,它在每个数值点上的高度均等于数据集中小于该数值的数据点的个数除以总数。
这种方法可以用于将样本数据的概率分布转化为累积分布,使研究者更直观地得出各种数据分布类型的特征,如平均值、分位数等。
3、最大似然估计最大似然估计是一个广泛使用的参数估计方法,也可以看作是一种非参数方法。
最大似然估计可以使用最大化该总体数据的似然函数确定总体参数的估计值。
参数估计理论与应用(第三章 )

那么它仍然有可能是一个好的估计。
考虑实随机过程{xk}的相关函数的两种估计量:
Rˆ1( )
1
N
N
xk xk ,
k 1
Rˆ2 ( )
1 N
N k 1
xk
xk
假定数据{xk}是独立观测的,容易验证
E[
Rˆ1
(
)]
E[
N
1
N
xk xk ]
k 1
1
N
N
E[ xk xk ]
k 1
Fisher 信息 Fisher 信息用J(θ)表示,定义为
J ( )
E{[
ln
p(x
| ]2}
E[
2
2
ln
p(x
| )]
(3.1.1)
2020/4/9
第三章 参数估计理论与应用
当考虑 N 个观测样本 X={ x1,…,xN }, 此时,联合条件分 布密度函数可表示为
p(x | ) p(x1, , xN | )
0
lim P{|
N
1 N
N
xi2 x 2 (E[ x2 ] E2[x]) | }
i 1
lim
N
P{|
ˆ
2 N
2
|
}
0,
0
2020/4/9
第三章 参数估计理论与应用
于是
lim
N
P{ | ˆ1
1
|
}
3
lim
N
P{|ˆ N
|
}
0
lim
N
P{ | ˆ2
2
|
}
2
3
第三章 概率密度函数的参数估计

均值的后验概率
均值的后验概率仍满足正态分布,其中:
1 n n = ∑ xi n i =1
2 nσ 0 σ2 n = 2 + 2 0 2 n 2 nσ 0 + σ nσ 0 + σ
σ σ σ = nσ + σ 2
2 n 2 0 2 0 2
均值分布的变化
类条件概率密度的计算
p ( x D) = ∫ p ( x ) p ( D) d
模型在时刻t处于状态wj的概率完全由t-1时刻 的状态wi决定,而且与时刻t无关,即:
P w(t ) W
(
T
) = P ( w ( t ) w ( t 1))
P w ( t ) = ω j w ( t 1) = ωi = aij
(
)
Markov模型的初始状态概率 模型的初始状态概率
模型初始于状态wi的概率用 π i 表示。 完整的一阶Markov模型可以用参数 θ = ( π, A ) 表示,其中:
3.0 引言
贝叶斯分类器中最主要的问题是类条件概 率密度函数的估计。 问题可以表示为:已有c个类别的训练样 本集合D1,D2,…,Dc,求取每个类别的 类条件概率密度 p ( x ωi ) 。
概率密度函数的估计方法
参数估计方法:预先假设每一个类别的概 率密度函数的形式已知,而具体的参数未 知;
最大似然估计(MLE, Maximum Likelihood Estimation); 贝叶斯估计(Bayesian Estimation)。
p ( x θ ) = ∑ ai pi ( x θi ),
i =1 M
∑a
i =1
M
i
=1
最常用的是高斯混合模型(GMM,Gauss Mixture Model):
参数检验和非参数检验

一.单因素方差分析(one-way ANOVA),用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。
完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。
在实验研究中按随机化原则将受试对象随机分配到一个处理因素的多个水平中去,然后观察各组的试验效应;在观察研究(调查)中按某个研究因素的不同水平分组,比较该因素的效应。
二.T检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
它与Z检验、卡方检验并列。
t检验t检验分为单总体检验和双总体检验。
单总体t检验时检验一个样本平均数与一个已知的总体平均数的差异是否显著。
当总体分布是正态分布,如总体标准差未知且样本容量小于30,那么样本平均数与总体平均数的离差统计量呈t分布。
单总体t检验统计量为:双总体t检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。
双总体t 检验又分为两种情况,一是独立样本t检验,一是配对样本t检验。
独立样本t检验统计量为:S1 和S2 为两样本方差;n1 和n2 为两样本容量。
(上面的公式是1/n1 + 1/n2 不是减!)配对样本t检验统计量为:t检验的适用条件(1) 已知一个总体均数;(2) 可得到一个样本均数及该样本标准差;(3) 样本来自正态或近似正态总体。
t检验步骤以单总体t检验为例说明:问题:难产儿出生体重n=35,X拔=3.42,S =0.40,一般婴儿出生体重μ0=3.30(大规模调查获得),问相同否?解:1.建立假设、确定检验水准αH0:μ = μ0 (无效假设,null hypothesis)H1:μ≠μ0(备择假设,alternative hypothesis,)双侧检验,检验水准:α=0.052.计算检验统计量3.查相应界值表,确定P值,下结论查附表1,t0.05 / 2.34 = 2.032,t < t0.05 / 2.34,P >0.05,按α=0.05水准,不拒绝H0,两者的差别无统计学意义例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。
统计学(参数估计)ppt课件

13
令最大似然估计的求法
14
3、矩法和最大似然法的比较
令矩估计法是采用样本矩替换总体矩来估 计参数,相当于使用了分布函数的部分信息;
令最大似然估计法是采用似然函数来求得 参数的估计,理论上相当于使用了分布函数的 全部信息;
在已知总体分布的前提下,采用最大似然 估计法的理由更充分,而在总体分布函数未知 但有关的总体矩已知的情况下,采用矩估计法 更合适。
通常可以认为,区间估计是在点估计的基 础上,给出未知总体参数的一个取值范围,及 这个范围的可靠程度。
24
区间估计——就是用一个区间去估计未知 总体参数,把未知总体参数值界定在两个数值 之间。即根据样本估计量,以一定的置信度估 计和推断总体参数的区间范围。
令总体参数的估计区间,通常是由样本统 计量加减抽样极限误差而得到的。
44
【解】 本题的总体方差未知,但属于大样本 抽样极限误差为: 所以,在90%的置信水平下,置信区间为:
表明在90%的置信水平下,投保人的平均年龄在 37.37至41.63岁之间。
45
【练习2】在大兴安岭林区,随机抽取了100块面 积为1公顷的样地,根据调查测量求得每公顷林 地平均出材量为88m3 ,标准差为10m3。
17
一、无偏性
无偏性——是指样本估计量抽样分布的均 值等于被估总体参数的真实值。
无偏性实际是指:不同的样本,会有不同 的估计值。虽然从某一个具体样本来看,估计 值有时会大于 θ ,有时会小于 θ ,有误差。但 从所有可能样本的角度来看,估计值的平均水 平等于总体参数的真实值,即平均说来,估计 是无偏的。
令样本均值、样本方差和样本比率,分别 是总体均值、总体方差和总体比率的无偏、有 效和一致的优良估计量;
非参数方法和参数方法

非参数方法和参数方法随着数据科学的快速发展,统计学方法在数据分析中扮演着重要的角色。
在统计学中,非参数方法和参数方法是两种常用的数据分析方法。
本文将详细介绍非参数方法和参数方法的定义、特点和应用。
一、非参数方法非参数方法是指在统计学中,不对总体分布做任何假设的一类方法。
非参数方法通常不依赖于总体的具体分布形式,而是基于样本数据进行推断和分析。
1. 定义非参数方法是一种基于样本数据进行统计推断的方法,不对总体的分布形式做任何假设。
非参数方法的主要特点是不需要对数据进行任何预处理或假设总体分布的形式。
2. 特点非参数方法具有以下特点:(1)无需假设总体分布:非参数方法不依赖于总体分布的假设,因此可以更加灵活地适用于各种类型的数据。
(2)适用范围广:非参数方法适用于各种类型的数据,包括连续型数据、离散型数据和顺序型数据等。
(3)数据要求低:非参数方法对数据的要求相对较低,不需要满足正态分布等假设,适用于小样本和非正态分布的情况。
3. 应用非参数方法在各个领域都有广泛的应用,例如:(1)假设检验:非参数方法可以用于推断两个样本是否来自同一总体分布,常用的非参数假设检验方法有Wilcoxon秩和检验、Mann-Whitney U检验等。
(2)回归分析:非参数回归分析可以用于探索自变量和因变量之间的非线性关系,常用的非参数回归方法有核回归和局部加权回归等。
(3)生存分析:非参数生存分析可以用于估计生存曲线和比较不同组别的生存时间,常用的非参数生存分析方法有Kaplan-Meier方法和Cox比例风险模型等。
二、参数方法参数方法是指在统计学中,对总体分布做出某些假设,并基于这些假设进行推断和分析的方法。
参数方法通常依赖于总体的具体分布形式,通过估计参数来推断总体的特征。
1. 定义参数方法是一种基于总体分布假设的统计推断方法,通过估计参数来推断总体的特征。
参数方法的主要特点是需要对总体分布形式做出假设,并根据样本数据估计参数值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 各类的先验概率P(ωi)
– 各类的条件概率密度函数p(x|ωi)
P(i | x)
p(x | i ) P(i ) p(x | j ) P( j )
j
知识的来源:对问题的一般性认识或一些训练数据 基于样本两步Bayes分类器设计
利用样本集估计p(ωi)和p(x|ωi)
θ N
argmax ln p( x k | θ)
θ k 1
16
• 最大似然估计计算方法
使似然函数梯度为0
θ H (θ) |ˆ θ ln p( xk | θ) |ˆ 0
ML
N
k 1
ML
θ 1
...
s
T
17
一.类概率密度最大似然估计
7
§3-1 参数估计与监督学习(续2)
下图表示对一幅道路图像按路面与非路面分类可用两种不同做法,其中左图 是在图像中路面区与非路面中各找一个窗口,将其中每个象素分别作为这两 类的训练样本集,用这两个样本集在特征空间的分布参数进行设计。 而无监督学习方法则不同,它不预先选择样本类别的样本集,而是将整幅图 的像素都作为待分类样本集,通过它们在特征空间中表现出来的聚类现象, 把不同类别划分开。 图中有监督学习,样本集分布呈现交迭情况,而无监督学习方法由于没有类 别样本指导,无法确定它们的交迭情况,只能按分布的聚类情况进行划分。
N 1 估计值: 1 Xk N k 1
1 N 2 Xk N k 1
Xk
T
结论:①μ的估计即为学习样本的算术平均
②估计的协方差矩阵是矩阵
Xk
平均(nⅹn阵列, nⅹn个值)
Xk
T
的算术
24
二.贝叶斯估计
j
i T
18
1.一般原则:
第i类样本的类条件概率密度: P(Xi|ωi)= P(Xi|ωi,θi) = P(Xi|θi) 原属于i类的学习样本为Xi=(X1 , X2 ,…XN,)T i=1,2,…M 求θi的最大似然估计就是把P(Xi|θi)看成θi的函数,求出使它 最大时的θi值。 ∵学习样本是从总体样本集中独立抽取的 ∴ P ( i | , i ) P ( i | i ) N P( X i | i )
最大似然估计是把待估的参数看作固定的未 知量,而贝叶斯估计则是把待估的参数作为具 有某种先验分布的随机变量,通过对第 i 类学 习样本 Xi 的观察,使概率密度分布 P(Xi|θ) 转 化为后验概率 P(θ|Xi) ,再求贝叶斯估计。 贝叶斯估计和贝叶斯决策完全可以统一 。 E
13
估计量评价标准: 无偏性,有效性,一致性
– 无偏性:E(ˆ )=
– 有效性:方差小即D(ˆ)小,估计更有效
– 一致性:样本数趋于无穷时, ˆ 依概率趋于 :
N
ˆ ) 0 lim P(
则称 ˆ 是θ的一致估计量。
14
最大似然估计计算方法
• Maximum Likelihood (ML)估计 – 估计参数θ是确定而未知的,Bayes估计方法则视θ为 随机变量。 – 样本集可按类别分开,不同类别密度函数的参数, 分别用各类的样本集来训练。 – 概率密度函数形式已知,参数未知,为了描述概率 密度函数p(x|ωi)与参数θ的依赖关系,用p(x|ωi,θ)表 示。 • 独立地按概率密度p(x|θ)抽取样本集 X={X1, X2 ,…, XN},用X 估计未知参数θ
最大似然估计量 为下面方程的解:
利用上式求出 的估值 ,即为 =
i i
ˆ 才使似然函数 有时上式是多解的, 上图有5个解,只有一个解 最大。 20
对对数似然函数求导,求其极大值有时不一定行得通。例如, 随机变量X服从均匀分布,但参数θ1 ,θ2未知,若对其对数似然 函数求导,则方程组中解出的参数θ1和θ2至少有一个为无穷大, 为无意义结果。需用其它方法求解。(见书本二版50页,三版47页)
12
§3-2 参数估计理论
估计量:样本集的某种函数f(X), X={X1, X2 ,…, XN}
参数空间:总体分布未知参数θ所有可能取值组成的
集合(Θ)
点估计的估计量和估计值
ˆ d (x , x ,..., x ) 的估计量(点估计) 1 2 N 是样本集的函数,它对样本集的一次 实现称为估计值
二.监督学习与无监督学习 监督学习:在已知类别样本指导下进行学习和训练,可 以统计出各类训练样本不同的描述量,如其 概率分布,或在特征空间分布的区域等,利 用这些参数进行分类器设计,称为有监督学 习。参数估计和非参数估计都属于监督学习。 无监督学习:不知道样本类别(也就是说没有训练样 本),只知道样本的某些信息,然后利用这 些信息进行估计,如:聚类分析。
基于上述估计值设计判别函数及分类器
面临的问题: 如何利用样本集进行估计 估计量的评价
利用样本集估计错误率
3
基于样本的Bayes分类器
训练 样本集
概率 密度函数
样本分布的 统计特征:
决策规则: 判别函数 决策面方程
• 最一般情况下适用的“最优”分类器:错误率最小,
对分类器设计在理论上有指导意义。
X i X k 1
k
N个学习样本出现概率的乘积,将P(Xi|θi)称作相对于样 本集Xi的参数θ的似然函数。 在N个样本独立抽出条件下,上式取对数可写为:
i log P( X | ) log P( X k | i) i k i k 1 k 1 N N
19
1 N i H ( ) ... log P ( X k | i) 0 k 1 i/θi) P(X p N i i log P ( X | )0 k k 1 1 ......... ......... N i logP ( X k | i) 0 k 1 p
8
§3-1 参数估计与监督学习(续3)
非监督学习与有监督学习方法的区别:
1. 有监督学习方法必须要有训练集与测试样本。在训练集中找规律, 而对测试样本使用这种规律; 而非监督学习没有训练集这一说,只有一组数据,在该组数据集内寻 找规律。 2. 有监督学习方法的目的就是识别事物,识别的结果表现在给待识别 数据加上了标号。因此训练样本集必须由带标号的样本组成。 而非监督学习方法只有要分析的数据集本身,预先没有什么标号。如 果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不以与 某种预先的分类标号对上号为目的。 例如上图的道路图像,有监督学习方法的目的是找到“道路”,而非 监督学习方法则只是将中间一条带状区域区分开来,本质上讲与“道 路”这个标号没有关系。
9
§3-1 参数估计与监督学习(续4)
3. 非监督学习方法寻找数据集中的规律性,这种规律性并 不一定要达到划分数据集的目的,也就是说不一定要 “分类”。这一点比有监督学习方法的用途要广泛。譬 如分析一堆数据的主分量,或分析数据集有什么特点都 可以归于非监督学习方法的范畴。 4. 用非监督学习方法分析数据集的主分量, 与用K-L变换计 算数据集的主分量又有区别。应该说后者从方法上讲不 是一种学习方法。因此用K-L变换找主分量不属于非监督 学习方法。 通过学习逐渐找到规律性是学习方法的特点。在人工神 经元网络中寻找主分量的方法属于非监督学习方法。
21
代入上式得:
X
1 k 1
N
k
0
k
X
1 k 1
N
0
所以
1
( X
k 1
N
k
N ) 0
N
1 N
X
k 1
k
这说明未知均值的最大似然估计正好是训练样本的算 术平均。
22
② ∑, μ均未知 A. 一维情况:n=1对于每个学习样本只有一个特征的简单情 2 况: 1 , 2 1 1
1 1 log P( X k | i ) log( 2 2) X k 1 2 2 2
N
2
2
N 1 i log P( X k | ) ( X k 1) 0 k 1 1 k 1 2
N 1 ( X k 1) i log P( X k | ) [ ]0 2 2 2 2 2 k 1 2 k 1 N
2. 多维正态分布情况
① ∑已知, μ未知,估计μ
P( X i | i ) 服从正态分布
待估参数为 1
i
k 1
N
logP( X k | ) 0
正态分布时
n T 1 1 1 log P( X k | ) log[ 2 | |] X k X k 2 2
• 获取统计分布及其参数很困难,实际问题中并不一
定具备获取准确统计分布的条件。
4
直接确定判别函数
• 基于样本直接确定判别函数方法:
– 针对各种不同的情况,使用不同的准则函数,设计 出满足这些不同准则要求的分类器。
– 这些准则的“最优”并不一定与错误率最小相一致: 次优分类器。 – 实例:正态分布最小错误率贝叶斯分类器在特殊情 况下,是线性判别函数g(x)=wTx(决策面是超平 面),能否基于样本直接确定w ?
第三章 参数估计与非参数估计
• 参数估计与监督学习 • 参数估计理论 • 非参数估计理论
1
x1
g1
分类器 功能结构
x2
. . .
g2