SQLServer排程代码教程
SQLSERVER实用教程所有所有实例及代码

【例2.1】创建一个uname用户定义数据类型, 其基于的系统数据类型是变长为8的字符,不允许空。
Use NorthwindExec sp_addtype uname,'Varchar(8)', 'Not Null '【例2.2】创建一个用户定义的数据类型birthday,其基于的系统数据类型是DateTime,允许空。
Use NorthwindExec sp_addtype birthday,datetime,'Null'【例2.3】创建两个数据类型telephone和fax,为电话及传真号码设置专门的数据类型。
Use SalesExec sp_addtype telephone,'varchar(24) ','Not Null'Exec sp_addtype fax,'varchar(24)','Null'【例2.4】删除用户定义数据类型unameUse NorthwindExec sp_droptype 'uname '【例3.1】使用企业管理器创建一个数据库。
名字为Sales,数据文件名为Sales_Data.Mdf,存储在E:\下,初始大小为2MB,最大为10MB,文件增量以1MB增长,事务日志文件名为Sales_Log.Ldf,存储在在E:\下,初始大小为1MB,最大为5MB,文件增量以1MB增长。
(1)展开服务器,右击“数据库”,在弹出的菜单中选择“新建数据库”命令。
(2)单击数据库属性窗口的“常规”选项卡,在“名称”栏输入销售数据库的名字Sales,结果如图3.3所示。
图3.3 Sales数据库属性窗口(3)单击数据库属性窗口的“数据文件”选项卡,在文件名和位置栏输入文件名及其存放的位置,也可以通过单击“”按钮后进行修改。
本例采用系统默认的数据文件名字Sales_Data,将路径修改为“E:\”,将数据文件的初始大小修改为2MB。
第一章 SQL SERVER编程基础

返回值 返回一系列值的总和 返回一系列值的平均值 其功能是检索表中满足给定条件的记录数
Max(col_name) Min(col_name)
返回一系列值中的最大值 返回一系列值中的最小值
23
注释
注释常用来记录程序名称、 注释常用来记录程序名称、作者名称以及对代码进行重要 修改的日期。 修改的日期。 注释可以用于建立代码文档,或者暂时禁用正在诊断的部 注释可以用于建立代码文档, 语句和批处理。 分 T-SQL 语句和批处理。 注释可以用来描述复杂的计算或用来解释程序设计的方法。 注释可以用来描述复杂的计算或用来解释程序设计的方法。
10
IF...ELSE
IF...ELSE:可以根据指定的条件来执行不同的 : SQL 语句。 语句。 语法: 语法: IF Boolean_expression { sql_statement|statement_block } [ELSE { sql_statement|statement_block } ]
9
BEGIN...END
BEGIN...END:一组要执行的 T-SQL 语句可以包含在 BEGIN...END : 中。 语法: 语法:
BEGIN { statement | statement_block } END
其中, 为语句, 其中,statement 为语句,statement_block 为语 句块。 句块。
USE pubs GO WHILE (SELECT AVG(price) FROM titles) < $30 BEGIN UPDATE titles SET price = price * 2 SELECT MAX(price) FROM titles IF (SELECT MAX(price) FROM titles) > $50 BREAK ELSE CONTINUE END PRINT '价格太高,市场无法承受 价格太高, 价格太高 市场无法承受'
sqlserver代码

sqlserver代码
对于许多软件开发人员来说,SQLServer 是一个非常重要的数据库系统。
在 SQLServer 上编写代码可以帮助开发人员快速地创建、修改和管理数据库。
以下是一些常用的 SQLServer 代码示例:
1. 创建一个数据库:
CREATE DATABASE myDatabase;
2. 创建一个表:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
password VARCHAR(50)
);
3. 插入数据:
INSERT INTO users (id, name, email, password)
'password123');
4. 更新数据:
UPDATE users
SET password = 'newpassword'
WHERE id = 1;
5. 删除数据:
DELETE FROM users
WHERE id = 1;
6. 查询数据:
SELECT * FROM users;
7. 添加索引:
CREATE INDEX idx_name ON users (name);
8. 删除索引:
DROP INDEX idx_name ON users;
以上是一些基本的 SQLServer 代码示例,它们可以帮助开发人员开始使用 SQLServer 来创建和管理数据库。
当然,SQLServer 还有许多其他的功能和语法可以探索,这些示例只是一个入门的起点。
powerdesign sqlserver 排序规则

powerdesign sqlserver 排序规则PowerDesigner的SQL Server排序规则可以通过以下步骤进行设置:1.打开PowerDesigner并连接到您的数据库。
2.在左侧的导航窗格中,展开数据库连接,然后展开“SQL Server”节点。
3.右键单击要设置排序规则的数据库或表,然后选择“Properties”(属性)选项。
4.在“Properties”(属性)窗口中,展开“DDL”选项卡,然后选择“Create”选项。
5.在“Create”选项卡中,找到“ORDER BY”子句,并确保将其设置为所需的排序规则。
6.单击“OK”以保存更改并关闭属性窗口。
7.在PowerDesigner中执行生成脚本或发布脚本以将更改应用到数据库中。
请注意,PowerDesigner的SQL Server排序规则设置可能会因版本而异。
如果您使用的是较旧或较新的版本,请参阅该版本的文档以获取详细的说明和步骤。
当您在使用SQL Server进行排序时,需要注意以下几点:1.字符串排序规则:SQL Server支持不同的字符串排序规则,如区分大小写和不区分大小写、使用不同的字符集等。
在进行排序时,需要根据实际需要选择合适的字符串排序规则。
2.数字排序规则:SQL Server支持不同的数字排序规则,如升序和降序等。
在进行数字排序时,需要注意数据类型的匹配和转换,以确保排序结果准确无误。
3.日期和时间排序规则:SQL Server支持不同的日期和时间排序规则。
在进行日期和时间排序时,需要确保所使用的日期和时间数据类型与排序规则匹配。
在SQL查询中,可以使用ORDER BY子句来指定排序规则。
例如,以下是一个简单的SQL查询示例,按照“LastName”列以升序方式对结果进行排序:sql复制代码SELECT FirstName,LastNameFROM EmployeesORDER BY LastName ASC;在上述示例中,使用了ASC关键字指定升序排序。
sqlserver使用序列的方法

sqlserver使用序列的方法SQL Server是一种关系型数据库管理系统(RDBMS),可以用于存储和管理大量的结构化数据。
在SQL Server中,序列是一种生成唯一数字值的对象。
它可以用于自动生成序列的值,例如订单号、员工ID 等。
接下来,我们将详细介绍如何在SQL Server中使用序列。
1.创建序列在SQL Server中,可以使用CREATE SEQUENCE语句来创建序列。
以下是创建序列的基本语法:CREATE SEQUENCE sequence_name[ AS [ built_in_integer_type | user-defined_integer_type ] ][ START WITH <constant> ][ INCREMENT BY <constant> ][ MINVALUE <constant> | NO MINVALUE ][ MAXVALUE <constant> | NO MAXVALUE ][ CYCLE | NO CYCLE ][ CACHE <constant> | NO CACHE ]其中,sequence_name是序列的名称,built_in_integer_type是SQL Server支持的整数类型,START WITH指定序列的起始值,INCREMENT BY指定序列的增量大小,MINVALUE和MAXVALUE分别指定序列的最小值和最大值,CYCLE表示当达到最大值时是否循环使用值,CACHE表示预先缓存的序列值的数量。
以下是一个创建序列的示例:CREATE SEQUENCE OrderSeqSTART WITH 1INCREMENT BY 1MINVALUE 1NO MAXVALUENO CYCLECACHE 10上述语句将创建一个名为OrderSeq的序列,并设置起始值为1,增量为1,最小值为1,最大值无限制,不循环使用值,同时缓存10个序列值。
sql server调用序列

sql server调用序列SQL Server是一种关系型数据库管理系统,它支持使用SQL语言进行数据管理。
而在SQL Server中,调用序列是一种特殊的对象,它可以用于生成唯一的序列值。
本文将详细介绍如何在SQL Server中调用序列,并探讨其应用场景和优势。
在SQL Server中,调用序列可以通过以下步骤来实现:步骤1:创建序列对象首先,我们需要创建序列对象。
可以使用CREATE SEQUENCE语句来完成此操作。
以下是创建序列对象的示例代码:CREATE SEQUENCE Seq_TestSTART WITH 1INCREMENT BY 1MINVALUE 1MAXVALUE 1000;在上述代码中,我们创建了一个名为Seq_Test的序列对象。
它的起始值为1,步长为1,最小值为1,最大值为1000。
你可以根据实际需求进行相应的设置。
步骤2:调用序列值在创建好序列对象之后,我们可以使用NEXT VALUE FOR语句来调用序列值。
以下是调用序列值的示例代码:SELECT NEXT VALUE FOR Seq_Test;上述代码会返回序列的下一个值,并将其存储在变量或表中,以供后续使用。
你可以根据需要将序列值用于插入、更新或查询操作。
步骤3:释放序列对象在完成对序列的使用后,我们可以使用ALTER SEQUENCE语句来释放序列对象。
以下是释放序列对象的示例代码:ALTER SEQUENCE Seq_Test RESTART;上述代码会将序列对象的当前值重置为起始值。
调用序列在SQL Server中的应用场景非常广泛。
以下是一些常见的应用场景:1. 主键生成:调用序列可以用于生成唯一的主键值,保证数据表中每一行的唯一性。
2. 订单号生成:调用序列可以用于生成唯一的订单号,确保每个订单都有一个唯一的标识。
3. 流水号生成:调用序列可以用于生成唯一的流水号,用于跟踪和记录某项业务的操作流程。
sqlserver修改数据库排序规则的命令

sqlserver修改数据库排序规则的命令SQL Server(微软的关系型数据库管理系统)中可以使用以下命令修改数据库排序规则:1. 修改数据库的默认排序规则:使用ALTER DATABASE 命令可以修改数据库的默认排序规则。
语法如下:ALTER DATABASE database_name COLLATE collation_name;其中`database_name` 是要修改排序规则的数据库的名称,`collation_name` 是要设置的排序规则的名称。
例如,如果要将数据库的默认排序规则修改为`Chinese_PRC_CI_AS`(中文_中国_区分大小写_不区分音调),可以使用以下命令:ALTER DATABASE MyDatabase COLLATE Chinese_PRC_CI_AS;运行此命令后,数据库`MyDatabase`的默认排序规则将被修改为`Chinese_PRC_CI_AS`。
注意:修改数据库的默认排序规则可能会导致已有的数据在排序和比较时发生变化,所以在执行此操作之前要确保了解和考虑可能的影响。
2. 修改表的排序规则:若要修改指定表的排序规则,可以使用ALTER TABLE 命令。
语法如下:ALTER TABLE table_name ALTER COLUMN column_name collation_name;其中`table_name` 是要修改排序规则的表的名称,`column_name` 是要修改排序规则的列的名称,`collation_name` 是要设置的排序规则的名称。
例如,如果要将表`Customers`的列`LastName`的排序规则修改为`Chinese_PRC_CI_AS`,可以使用以下命令:ALTER TABLE Customers ALTER COLUMN LastNameChinese_PRC_CI_AS;运行此命令后,表`Customers`的列`LastName`的排序规则将被修改为`Chinese_PRC_CI_AS`。
sqlserver序号函数

sqlserver序号函数SQL Server序号函数序号函数是SQL Server中对数据行进行排序(按某个给定值排序)的一种方法,它的最终结果是按照某个字段的增序排列,并且可以按照序号的大小从小到大进行排序。
SQL Server中的序号函数和Oracle中的ROW_NUMBER函数类似。
下面就SQL Server序号函数的使用方法做一个简单介绍。
SQL Server序号函数共有三种,分别是ROW_NUMBER、RANK、DENSE_RANK,这三个函数都用于排序,并且可以按某个字段的值进行排序。
ROW_NUMBER函数:ROW_NUMBER函数用于对查询结果进行排序,每行表示一个序号,序号从1开始,每行表示一个序号,序号从1开始,每行数据的序号自动递增。
使用语法:ROW_NUMBER() OVER ( order by 字段1[ASC,DESC],字段2[ASC,DESC]……)RANK函数:RANK函数的结果是从1开始的递增数字,并且当有多行结果相同时,每行的排名都相同,例如第一行排名为1,第二行和第三行排名也为1,第四行排名为2,以此类推。
使用语法:RANK() OVER ( order by 字段1[ASC,DESC],字段2[ASC,DESC]……)DENSE_RANK函数:DENSE_RANK函数的结果于RANK函数相似,但是多行值相同时,它会给出连续的排名。
例如第一行排名为1,第二行和第三行排名也都为1,第四行排名为2,以此类推。
使用语法:DENSE_RANK() OVER (order by 字段1[ASC,DESC],字段2[ASC,DESC]……)实例:假设有表employee,其中有字段name、age、sal(薪水),查询表中每行的age(年龄)字段的序号,要求从小到大排序,则可以使用ROW_NUMBER函数进行排序,具体语句如下:SELECT ROW_NUMBER() OVER (ORDER BY age) AS AgeSequence,name,ageFROM employee以上就是有关SQL Server序号函数的介绍,希望对大家有所帮助。
SQLServer自定义排序

SQLServer⾃定义排序⽅法⼀:⽐如需要对SQL表中的字段NAME进⾏如下的排序:张三(Z)李四(L)王五(W)赵六(Z)按照sql中的默认排序规则,根据字母顺序(a~z)排,结果为:李四王五赵六张三⾃定义排序:order by charindex(NAME,‘张三,李四,王五,赵六’)CHARINDEX函数返回字符或者字符串在另⼀个字符串中的起始位置。
CHARINDEX函数调⽤⽅法如下:CHARINDEX ( expression1 , expression2 [ , start_location ] )Expression1是要到expression2中寻找的字符中,start_location是CHARINDEX函数开始在expression2中找expression1的位置。
CHARINDEX函数返回⼀个整数,返回的整数是要找的字符串在被找的字符串中的位置。
假如CHARINDEX没有找到要找的字符串,那么函数整数“0”。
让我们看看下⾯的函数命令执⾏的结果:CHARINDEX(‘SQL’, ‘Microsoft SQL Server’)这个函数命令将返回在“Microsoft SQL Server”中“SQL”的起始位置,在这个例⼦中,CHARINDEX函数将返回“S”在“Microsoft SQL Server”中的位置11。
接下来,我们看这个CHARINDEX命令:CHARINDEX(‘7.0’, ‘Microsoft SQL Server 2000’)在这个例⼦中,CHARINDEX返回零,因为字符串“7.0” 不能在“Microsoft SQL Server”中被找到。
接下来通过两个例⼦来看看如何使⽤CHARINDEX函数来解决实际的T-SQL问题。
⽅法⼆:针对表table_example的class字段排序,class字段值为:A、B、C、D。
⽤户要求table_example中的数据按照class字段值C、A、D、B的顺序排序。
SqlServervarchar数据中类似于1.1.1.1这种值的排序方法

SqlServervarchar数据中类似于1.1.1.1这种值的排序⽅法select * from 表名
order by Convert(int,left(列名,charindex('.',列名+'.')-1)) asc, 列名asc
charindex('.',列名) 查询第⼀个.(点)在第⼏位
charindex('.',列名+'.') 给没有数据在最后⾯加个.(点)这样可以让第⼀位没有⼩数点的数据也能查出来
left(列名,charindex('.',列名)) 查询⼩数点左⾯值
left(列名,charindex('.',列名+'.')) 在所有值后⾯加个.
left(列名,charindex('.',列名+'.')-1) 查询的值后⾯减少⼀位就是把后⾯的点给去了
Convert(int,left(列名,charindex('.',列名+'.')-1)) 取第⼀个⼩数点前⾯的值转成int类型
Convert(int,left(列名,charindex('.',列名+'.')-1)) asc 取⼩数点前⾯的值转成int类型正排序(但是现在排序有点不准)
Convert(int,left(列名,charindex('.',列名+'.')-1)) asc, 列名asc 所以后⾯再⽤列名asc正排⼀下就完全可以了。
sqlserver排序语句

sqlserver排序语句sqlserver排序语句是sqlserver数据库管理系统中一项重要的数据处理功能,可以对数据库中的记录进行排序处理,实现某个字段或字段的排序过程。
本文主要讨论sqlserver排序语句的构成和使用方法,重点介绍使用sqlserver排序语句实现数据记录排序的方法。
首先要阐述sqlserver排序语句的构成:sqlserver排序语句由order by子句和其他处理语句构成,order by子句决定了记录的排序方式,其他处理语句介绍了数据库中被排序的表或视图。
在sqlserver中,可以使用order by子句按照指定的字段或字段进行排序,同时还可以只指定排序的顺序(升序或降序),order by子句的使用格式如下:order by段1 [asc/desc] [,字段2 [asc/desc] ...] 其中asc表示升序(从小到大),desc表示降序(从大到小)。
要实现sqlserver排序语句,首先要准备数据,将要排序的数据放入数据表或者视图中,然后通过select语句获取这些数据,其语法格式如下:select * from名或视图名接下来就可以使用order by子句进行排序了,其语法格式如下: select * from名或视图名 order by段1 [asc/desc] [,字段2 [asc/desc] ...]例如,要对数据库中的Student表根据字段Grade按升序排序,可以使用如下的sql语句:select * from Student order by Grade asc上述语句可以实现Grade字段的升序排序,从小到大排列,同时如果想要排序的结果以多个字段为基准,也可以使用order by子句来实现。
例如,要根据字段Name和Grade进行混合排序,可以使用如下的sql语句:select * from Student order by Name asc,Grade desc 上述语句可以实现Name字段升序排序,Grade字段降序排序,也可以根据实际情况调整字段排序的顺序。
SQLServer
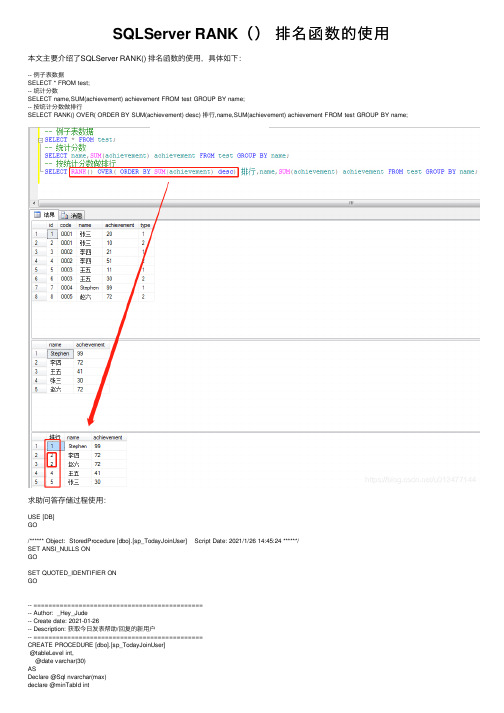
SQLServer RANK()排名函数的使⽤本⽂主要介绍了SQLServer RANK() 排名函数的使⽤,具体如下:-- 例⼦表数据SELECT * FROM test;-- 统计分数SELECT name,SUM(achievement) achievement FROM test GROUP BY name;-- 按统计分数做排⾏SELECT RANK() OVER( ORDER BY SUM(achievement) desc) 排⾏,name,SUM(achievement) achievement FROM test GROUP BY name;求助问答存储过程使⽤:USE [DB]GO/****** Object: StoredProcedure [dbo].[sp_TodayJoinUser] Script Date: 2021/1/26 14:45:24 ******/SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGO-- =============================================-- Author: _Hey_Jude-- Create date: 2021-01-26-- Description: 获取今⽇发表帮助/回复的新⽤户-- =============================================CREATE PROCEDURE [dbo].[sp_TodayJoinUser]@tableLevel int,@date varchar(30)ASDeclare @Sql nvarchar(max)declare @minTabId intdeclare @maxTabId intdeclare @maxf_id intdeclare @helpTableName nvarchar(max)declare @tableCount intBEGIN--最⼩f_id所在表set @minTabId=0set @tableCount=@minTabId--最⼤f_id所在表set @maxf_id=(select MAX(F_ID) from [Table] where F_IsDelete=0)set @maxTabId=@maxf_id/@tablelevelset @helpTableName='SELECT UserID, Max([F_DateTime]) AS dt FROM [Table] GROUP BY UserID'while @tableCount<=@maxTabIdbeginprint @tableCountset @helpTableName += ' UNION SELECT UserID, Max([DateTime]) as dt FROM SubTable'+cast(@tableCount as nvarchar(10))+' GROUP BY UserID 'set @tableCount=@tableCount+1endset @Sql='SELECT [nikename] FROM (SELECT UserID, RANK() OVER(PARTITION BY UserID ORDER BY dt) AS Num,dt FROM ( '+@helpTableName+' ) AS T ) AS NewTLEFT JOIN [UserTable] A WITH(NOLOCK) ON erID = erId WHERE Num = 1 AND dt > '''+@date+''''Exec sp_executesql @SqlENDGOpartition的意思是对数据进⾏分区,sql语句如下SELECT* FROM (SELECTROW_NUMBER() over(partition by [姓名] order by [打卡时间] desc) as rowNum,[姓名],[打卡时间]FROM [dbo].[打卡记录表]) tempWHERE temp.rowNum = 1通过 partition by [姓名] order by [打卡时间] desc,这句就可以做到,让数据按照姓名分组,并且在每组内部按照时间进⾏排序到此这篇关于SQLServer RANK() 排名函数的使⽤的⽂章就介绍到这了,更多相关SQLServer RANK()内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
SQLServer编程入门

SQLServer编程⼊门SQL编程要⽐Java编程、C#编程简单许多,下⾯我们直接讲⼲货21:04:31使⽤变量 局部变量 在T-SQL中,局部变量的名称必须以标记@作为前缀。
T-SQL的局部变量其实和Java中的局部变量的性质是⼀样的,只是声明和调⽤的⽅式有些区别。
声明局部变量: declare @StudentNo int 其中的StudentNo是变量名称,是⾃⼰设定的。
前⾯的declare是声明变量必须要⽤到的,不要改变。
后⾯的int则是数据类型。
变量的赋值: 声明了变量就要使⽤,T-SQL中局部变量赋值有两种⽅法,分别是使⽤set语句或select语句。
语法:set @StudentNo = 1 或者 select @StudentNo = 1set语句和select语句的区别set select同时对多个变量赋值不⽀持⽀持表达式返回多个值时出错将返回的最后⼀个值赋给变量表达式未返回值时变量被赋值为null变量保持原值 全局变量: SQL Server中的所有全局变量都使⽤两个@符号作为前缀。
下⾯列举⼀些常⽤的全局变量↓全局变量变量含义@@error最后⼀个T-SQL错误的错误号@@identity最后⼀次插⼊的标识值@@language当前使⽤的语⾔的名称@@max_connections可以创建的、同时连接的最⼤数⽬@@rowcount受上⼀个sql语句影响的⾏数@@servername本地服务器的名称@@servicename该计算机上的SQL服务的名称@@timeticks当前计算机上每刻度的微秒数@@transcount当前连接打开的事物数@@version SQL Server的版本信息 输出语句: 常⽤的打印输出语句有两种,print语句和select语句,使⽤select语句输出数据是查询语句的特殊应⽤。
语法: print 局部变量或字符串 select 局部变量 as ⾃定义列名 使⽤print打印时可以使⽤“+”拼接字符串或者其他变量。
如何在SQLServer中对行进行动态编号综合教程-电脑资料

如何在SQLServer中对行进行动态编号综合教程-电脑资料如何在SQL中对行进行动态编号,加行号这个问题,在数据库查询中,是经典的问题,。
我把现在的方法整理一下,分享一下技巧吧。
代码基于pubs样板数据库。
在SQL中,一般就这两种方法:1.使用临时表可以使用select into 创建临时表,在第一列,加入Identify(int,1,1)作为行号,这样在产生的临时表中,结果集就有了行号.也是目前效率最高的方法。
这种方法不能用于视图代码:set nocount onselect IDentify(int,1,1) 'RowOrder',au_lname,au_fname into #tmpfrom authorsselect * frm #tmpdrop table #tmp2.使用自连接不用临时表,在SQL语句中,动态的进行排序.这种方法用到的连接是自连接,连接关系一般是大于。
代码:select rank=count(*), a1.au_lname, a1.au_fnamefrom authors a1 innerjoin authors a2 on a1.au_lname + a1.au_fname >= a2.au_lname + a2.au_fnamegroup by a1.au_lname, a1.au_fnameorder by count(*)运行结果:rankau_lnameau_fname1BennetAbraham2Blotchet-HallsReginald3CarsonCheryl4DeFranceMichel5del CastilloInnes6DullAnn7GreeneMorningstar... ... ...缺点:1.使用自联接,所以该方法不适用于处理大量行,电脑资料《如何在SQL Server中对行进行动态编号综合教程》(https://www.)。
sqlserver排序字句

sqlserver排序字句数据检索、查询排序语句代码如下:--执行顺序From Where Selectselect*from(select sal as salary,comm as commission from emp)x where salary<5000--得出Name Work as a Jobselect ename+'Work as a'+job as msg from emp where deptno=10--如果员工工资小于2000返回UnderPaid大于等于4k返回OverPaid之间返回OKselect ename,sal,case when sal<2000 then'UnderPaid'when sal>=4000 then'OverPaid'else'OK'endfrom emp--从表中随机返回N条记录newid()--order by字句中指定数字常量时,是要求根据select列表中相应位置的列排序--order by字句中用函数时,则按函数在没一行计算结果排序select top 5 ename from emp order by newid()--找空值is nullselect*from emp where comm is null--将空值转换为实际值--解释:返回其参数中第一个非空表达式--coalesce联合,合并,结合.英音:[,kəuə'les]美音:[,koə'lɛs]select coalesce(comm,1),empNo from emp--按模式搜索--返回匹配特定子串或模式的行select ename,jobfrom empwhere deptno in(10,20)--按子串排序按照职位字段的最后两个字符排序select ename,job from emp order bysubstring(job,len(job)-2,2)--select top 2 len(job)-2 from emp--select top 2 job from emp--☆☆☆☆☆处理排序空值☆☆☆☆☆[只能是大于0]select ename,sal,commfrom emporder by 1 desc--以降序或升序方式排序非空值,将空值放到最后,可以用case select ename,sal,comm from(select ename,sal,comm,case when comm is null then 0 else 1 end as Afrom emp)xorder by A desc,comm desc。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SQLSERVER排程代码设置排程重庆邮电大学胡伟2013-12-26目录一.设置的步骤 (1)1.定义创建作业 (1)2.定义作业步骤 (1)3.创建调度 (2)4.添加目标服务器 (2)二.调度模板定义 (2)三.调度实例SQL代码 (5)一.设置的步骤1.定义创建作业DECLARE @jobid uniqueidentifierEXEC msdb.dbo.sp_add_job@job_name = N'作业名称', -----这里的作业名称@job_id = @jobid OUTPUT2.定义作业步骤DECLARE @sql nvarchar(400),@dbname sysnameSELECT @dbname=DB_NAME(), --作业步骤在当前数据库中执行 @sql=N'作业步骤内容' --定义的要执行的Transact-SQL语句EXEC msdb.dbo.sp_add_jobstep@job_id = @jobid,@step_name = N'作业步骤名称',@subsystem = 'TSQL', --步骤的类型,一般为TSQL @database_name=@dbname,@command = @sql3.创建调度使用后面专门定义的几种作业调度模板EXEC msdb..sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type=4, --每天@freq_interval=1, --指定每多少天发生一次,这里是1天.@freq_subday_type=0x8, --重复方式,0x1=在指定的时间,0x4=多少分钟,0x8=多少小时执行一次@freq_subday_interval=1, --重复周期数,这里每小时执行一次@active_start_date = NULL, --作业执行的开始日期,为NULL时表示当前日期,格式为YYYYMMDD@active_end_date = 99991231, --作业执行的停止日期,默认为99991231,格式为YYYYMMDD@active_start_time = 000000, --作业执行的开始时间,格式为HHMMSS @active_end_time = 235959 --作业执行的停止时间,格式为HHMMSS4.添加目标服务器DECLARE @servername sysnameSET @servername=CONVERT(nvarchar(128),SERVERPROPERTY(N'ServerName')) EXEC msdb.dbo.sp_add_jobserver@job_id = @jobid, @server_name = @servername --使用当前SQL实例注意:如果此排程直接在对应的数据库使用将ServerName 改为local 即可二.调度模板定义1.日调度EXEC msdb..sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type=4, --每天@freq_interval=1, --指定每多少天发生一次,这里是1天.@freq_subday_type=0x8, --重复方式,0x1=在指定的时间,0x4=多少分钟,0x8=多少小时执行一次@freq_subday_interval=1, --重复周期数,这里每小时执行一次@active_start_date = NULL, --作业执行的开始日期,为NULL时表示当前日期,格式为YYYYMMDD@active_end_date = 99991231, --作业执行的停止日期,默认为99991231,格式为YYYYMMDD@active_start_time = 00000, --作业执行的开始时间,格式为HHMMSS @active_end_time = 235959 --作业执行的停止时间,格式为HHMMSS --*/2.周调度EXEC msdb.dbo.sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type = 8, --每周@freq_recurrence_factor = 1, --每多少周执行一次,这里是每周@freq_interval = 62, --在星期几执行,由POWER(2,N)表示,N的值为0~6,代表星期日~星期六,如果指定两个,则将值相加,例如,值为65表示在星期天和星期日执行(POWER(2,0)+POWER(2,6))@freq_subday_type = 0x8, --重复方式,0x1=在指定的时间,0x4=多少分钟,0x8=多少小时执行一次@freq_subday_interval = 1, --重复周期数,这里每小时执行一次@active_start_date = NULL, --作业执行的开始日期,为NULL时表示当前日期,格式为YYYYMMDD@active_end_date = 99991231, --作业执行的停止日期,默认为99991231,格式为YYYYMMDD@active_start_time = 00000, --作业执行的开始时间,格式为HHMMSS @active_end_time = 235959 --作业执行的停止时间,格式为HHMMSS --*/3.月调度1(每X个月的每月几号)EXEC msdb.dbo.sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type = 16, --每月@freq_recurrence_factor = 2, --每多少月执行一次,这里是每2个月@freq_interval = 2, --在执行月的第几天执行,这里是第2天@freq_subday_type = 0x8, --重复方式,0x1=在指定的时间,0x4=多少分钟,0x8=多少小时执行一次@freq_subday_interval = 1, --重复周期数,这里每小时执行一次@active_start_date = NULL, --作业执行的开始日期,为NULL时表示当前日期,格式为YYYYMMDD@active_end_date = 99991231, --作业执行的停止日期,默认为99991231,格式为YYYYMMDD@active_start_time = 00000, --作业执行的开始时间,格式为HHMMSS @active_end_time = 235959 --作业执行的停止时间,格式为HHMMSS --*/4.月调度2(每X个月的相对时间)EXEC msdb.dbo.sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type = 32, --每月@freq_recurrence_factor = 2, --每多少月执行一次,这里是每2个月@freq_interval = 9, --在当月的那个时间执行,1~7=星期日至星期六,8=日 ,9=工作日,10=周末@freq_relative_interval = 1, --在第几个相对时间执行,允许的值为1,2,4,8代表第1~4个相对时间,16表示最后一个相对时间@freq_subday_type = 0x8, --重复方式,0x1=在指定的时间,0x4=多少分钟,0x8=多少小时执行一次@freq_subday_interval = 1, --重复周期数,这里每小时执行一次@active_start_date = NULL, --作业执行的开始日期,为NULL时表示当前日期,格式为YYYYMMDD@active_end_date = 99991231, --作业执行的停止日期,默认为99991231,格式为YYYYMMDD@active_start_time = 00000, --作业执行的开始时间,格式为HHMMSS @active_end_time = 235959 --作业执行的停止时间,格式为HHMMSS--*/5.在特定时候执行的作业调度EXEC msdb.dbo.sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type = 64 --64=在SQLServerAgent 服务启动时运行,128=计算机空闲时运行--*/6.只执行一次的作业调度EXEC msdb..sp_add_jobschedule@job_id = @jobid,@name = N'调度名称',@freq_type=1, --仅执行一次@active_start_date = NULL, --作业执行的开始日期,为NULL时表示当前日期,格式为YYYYMMDD@active_start_time = 00000 --作业执行的开始时间,格式为HHMMSS --*/三.调度实例SQL代码DECLARE @jobid uniqueidentifier -------创建作业EXEC msdb.dbo.sp_add_job@job_name = N'DbMonitoringTools_Table_SUM', ----这是排程的名称@job_id = @jobid OUTPUTDECLARE @sql nvarchar(400), ----------定义作业步骤@dbname sysnameSELECT @dbname=N'DbMonitoringTools', ---这是排程对应的数据库名@sql=N'exec rptTable_Recod_Sum' ----执行rptTable_Recod_Sum存储过程EXEC msdb.dbo.sp_add_jobstep@job_id = @jobid,@step_name = N'aa', ---------步骤名称自己取名@subsystem = 'TSQL',@database_name=@dbname,@command = @sqlEXEC msdb..sp_add_jobschedule -----------调度模板@job_id = @jobid,@name = N'aa', ----排程名称(其实是排程参数设置)@freq_type=4,@freq_interval=1, -------执行次数1次@freq_subday_type=0x8, -------排程的间隔0x8,代表小时@freq_subday_interval=24, -------24小时@active_start_date = NULL,@active_end_date = 99991231,@active_start_time = 000000, -----代表排程执行的开始时间@active_end_time = 010000-----代表排程执行的终止时间DECLARE @servername sysname -------设置执行排程的服务器名SET @servername = N'(local)' ------- local默认为排程所在的服务器EXEC msdb.dbo.sp_add_jobserver@job_id = @jobid,@server_name = @servername。