实验四 内存管理模拟实验
实验4虚拟内存管理实验

实验4虚拟内存管理实验实验4 虚拟内存管理实验一、实验目的1. 掌握虚拟存储器的实现方法2. 掌握各种页面置换算法3. 比较各种页面置换算法的优缺点二、实验内容三、实验结果1. 程序源代码:Main.cpp#include <iostream> #include <string> #include <vector> #include <cstdlib> #include <cstdio> #include </unistd.h> </cstdio> </cstdlib> </vector> </string> </iostream>using namespace std;#define ***** -1const int TOTAL_*****TION(320); const int TOTAL_VP(32);#include \#include \#include \int main() {int i;CMemory a; for(i=4;ii++) {a.FIFO(i); a.LRU(i); // a.NUR(i); // a.OPT(i); cout \}return 0; }Memory.h#ifndef _MEMORY_H// 总共使用页面次数320次// 内存分配的页面数32个#define _MEMORY_Hclass CMemory {public:CMemory(); void initialize(const int nTotal_pf); void FIFO(const int nTotal_pf); void LRU(const int nTotal_pf); 面个数// void NUR(const int nTotal_pf); // void OPT(const int nTotal_pf); private:// 构造函数// 初始化函数// LRU算法,参数表示分配的内存页vector<cpage> _vDiscPages; </cpage>该进程空间内的所有页vector<cpagecontrol> _vMemoryPages; 页向量</cpagecontrol>CPageControl *_pFreepf_head; 于LRU算法CPageControl *_pBusypf_head,*_pBusypf_tail; 指针,用于FIFO算法vector<int> _vMain,_vPage; 产生的指令序列</int>// _vPage表示待处理指令对应的页号int _nDiseffect;// 进程使用的页向量,包含// 为进程分配的物理内存// 空闲物理页头指针,用// 已使用页面头指针,尾// _vMain表示某进程随机// 换入页面次数};CMemory::CMemory():_vDiscPages(TOTAL_VP), // 32 _vMemoryPages(TOTAL_VP), // 32 _vMain(TOTAL_*****TION), // 320 _vPage(TOTAL_*****TION) {int S,i,nRand;// 通过随机数产生一个指令序列(实际上是指令的逻辑地址序列),共320条指令。
内存管理实验报告

内存管理实验报告内存管理实验报告引言内存管理是计算机系统中非常重要的一部分,它负责管理计算机系统的内存资源,为程序的运行提供必要的支持。
本次实验旨在探究不同的内存管理策略对计算机系统性能的影响,以及如何优化内存管理以提高系统效率。
一、实验背景计算机系统中的内存是用于存储程序和数据的关键资源。
在多道程序设计环境下,多个程序需要共享有限的内存资源,因此需要一种有效的内存管理策略来分配和回收内存空间。
本次实验中,我们将研究并比较两种常见的内存管理策略:固定分区和动态分区。
二、实验过程1. 固定分区固定分区是将内存划分为固定大小的若干区域,每个区域可以容纳一个程序。
在实验中,我们将内存划分为三个固定大小的区域,并将三个不同大小的程序加载到内存中进行测试。
通过观察程序的运行情况和内存利用率,我们可以评估固定分区策略的优缺点。
2. 动态分区动态分区是根据程序的大小动态地分配内存空间。
在实验中,我们将使用首次适应算法来实现动态分区。
首次适应算法将按照程序的大小从低地址开始查找可以容纳该程序的空闲分区,并分配给程序使用。
通过观察动态分区策略下的内存利用率和碎片情况,我们可以评估该策略的优劣。
三、实验结果1. 固定分区在固定分区策略下,我们观察到每个程序都能够顺利运行,但是内存利用率较低。
由于每个程序都需要占用一个固定大小的分区,当程序大小与分区大小不匹配时,会出现内存浪费的情况。
此外,固定分区策略也存在无法分配较大程序的问题。
2. 动态分区在动态分区策略下,我们观察到内存利用率较高,碎片情况也较少。
由于动态分区可以根据程序的大小动态分配内存空间,因此可以更加高效地利用内存资源。
然而,动态分区策略也存在着内存分配和回收的开销较大的问题。
四、实验总结通过本次实验,我们对固定分区和动态分区两种内存管理策略进行了比较和评估。
固定分区策略适用于程序大小已知且固定的情况,但会导致内存浪费;而动态分区策略可以更加灵活地分配内存空间,但会增加内存分配和回收的开销。
内存管理实验报告

内存管理实验报告实验名称:内存管理实验目的:掌握内存管理的相关概念和算法加深对内存管理的理解实验原理:内存管理是操作系统中的一个重要模块,负责分配和回收系统的内存资源。
内存管理的目的是高效地利用系统内存,提高系统的性能和稳定性。
实验过程:1.实验环境准备本实验使用C语言编程,要求安装GCC编译器和Linux操作系统。
2.实验内容实验主要包括以下几个部分:a.基本内存管理创建一个进程结构体,并为其分配一定大小的内存空间。
可以通过C语言中的指针操作来模拟内存管理的过程。
b.连续分配内存算法实现两种连续分配内存的算法:首次适应算法和最佳适应算法。
首次适应算法是从低地址开始寻找满足要求的空闲块,最佳适应算法是从所有空闲块中选择最小的满足要求的块。
c.非连续分配内存算法实现分页和分段两种非连续分配内存的算法。
分页是将进程的虚拟地址空间划分为固定大小的页面,然后将页面映射到物理内存中。
分段是将进程的地址空间划分为若干个段,每个段可以是可变大小的。
3.实验结果分析使用实验中的算法和方法,可以实现对系统内存的高效管理。
通过比较不同算法的性能指标,我们可以选择合适的算法来满足系统的需求。
具体而言,连续分配内存算法中,首次适应算法适用于内存中有大量小碎片的情况,可以快速找到满足要求的空闲块。
最佳适应算法适用于内存中碎片较少的情况,可以保证最小的内存浪费。
非连续分配内存算法中,分页算法适用于对内存空间的快速分配和回收,但会带来一定的页表管理开销。
分段算法适用于对进程的地址空间进行分段管理,可以灵活地控制不同段的权限和大小。
实验中还可以通过性能测试和实际应用场景的模拟来评估算法的性能和适用性。
实验总结:本实验主要介绍了内存管理的相关概念和算法,通过编写相应的代码实现了基本内存管理和连续分配、非连续分配内存的算法。
通过实际的实验操作,加深了对内存管理的理解。
在实验过程中,我们发现不同算法适用于不同情况下的内存管理。
连续分配算法可以根据实际情况选择首次适应算法或最佳适应算法。
操作系统实验四存储管理实验(1)

操作系统课程实验年级2012 级专业计算机科学与技术(应用型)姓名学号指导教师日期实验四、存储管理实验一、关键问题1、实验目的理解内存分配和回收原理。
2、实验环境Ubuntu 8.0或者以上,Eclipse集成开发环境3、实验内容3.1 在控制台内观察Linux内存分配情况3.2存储管理模拟实验要求:写一动态分区管理程序,使其内存分配采用最佳适应分配算法。
老师所给的例子为内存分配算法是最先适应分配算法的系统模拟动态分区管理方案,而问题的关键就是如何把最先适应分配算法改为最佳适应分配算法。
二、设计修改思路struct freearea* min1=NULL;//定义了一个符合条件的最小空白块链表首先我们在分配内存函数中需要定义一个记录符合条件的最小空白块的链表结构指针,对当前空闲分区链进行遍历,找到符合条件的最小空白块并记录。
系统为作业分配内存时,根据指针freep查找空闲分区链。
当找到一块可以满足请求中最小的空闲分区时便分配。
当空间被分配后剩余的空间大于规定的碎片,则形成一个较小的空闲分区留在空闲链中。
三、实现修改的关键代码//有两个链:空白块链及作业链.空白块链描述空白块,链首指针freep,初始为一大块空白块.//作业链按从高址到低址的顺序链接,链首指针jobp//为作业jn分配jl大小内存,起始地址为javoid ffallocation(int jl,char jn[10],int* ja){struct mat* jp=NULL;//作业链当前节点struct mat* jp2=NULL;//新的作业节点struct mat* jp1=NULL;//struct freearea* fp=NULL;//当前空白块struct freearea* min1=NULL;//定义了一个符合条件的最小空白块链表int flag=0;int i;*ja=-1;if (totalfree<jl) //剩余空间大小不能满足作业要求return;fp=freep;while (fp!=NULL){if (fp->freesize>jl){ min1=fp;flag=1;break;}fp=fp->next;}if(freep->next!=NULL&&flag==0) {*ja=0;return;}fp=min1->next;while (fp!=NULL){if (fp->freesize>jl&&fp->freesize<min1->freesize)min1=fp;fp=fp->next;//当前空白块大小不满足要求}jobnumber++;totalfree=totalfree-jl;jp2=calloc(1,sizeof(struct mat));//在节点上登记为该作业分配的内存空间// for (i=0;i<10;i++) (jp2->jobname)[i]=' ';i=-1;while(jn[++i])(jp2->jobname)[i]=jn[i];(jp2->jobname)[i]='\0';jp2->joblength=jl;jp2->jobaddress=min1->freeaddress;//登记该作业的起始地址(块的最低地址)*ja=jp2->jobaddress;//将节点jp2插入作业链jobp,按高址到低址的顺序。
实验四 操作系统存储管理实验报告

实验四操作系统存储管理实验报告一、实验目的本次操作系统存储管理实验的主要目的是深入理解操作系统中存储管理的基本原理和方法,通过实际操作和观察,掌握内存分配、回收、地址转换等关键技术,提高对操作系统存储管理机制的认识和应用能力。
二、实验环境操作系统:Windows 10开发工具:Visual Studio 2019三、实验原理1、内存分配方式连续分配:分为单一连续分配和分区式分配(固定分区和动态分区)。
离散分配:分页存储管理、分段存储管理、段页式存储管理。
2、内存回收算法首次适应算法:从内存低地址开始查找,找到第一个满足要求的空闲分区进行分配。
最佳适应算法:选择大小最接近作业需求的空闲分区进行分配。
最坏适应算法:选择最大的空闲分区进行分配。
3、地址转换逻辑地址到物理地址的转换:在分页存储管理中,通过页表实现;在分段存储管理中,通过段表实现。
四、实验内容及步骤1、连续内存分配实验设计一个简单的内存分配程序,模拟固定分区和动态分区两种分配方式。
输入作业的大小和请求分配的分区类型,程序输出分配的结果(成功或失败)以及分配后的内存状态。
2、内存回收实验在上述连续内存分配实验的基础上,添加内存回收功能。
输入要回收的作业号,程序执行回收操作,并输出回收后的内存状态。
3、离散内存分配实验实现分页存储管理的地址转换功能。
输入逻辑地址,程序计算并输出对应的物理地址。
4、存储管理算法比较实验分别使用首次适应算法、最佳适应算法和最坏适应算法进行内存分配和回收操作。
记录不同算法在不同作业序列下的内存利用率和分配时间,比较它们的性能。
五、实验结果与分析1、连续内存分配实验结果固定分区分配方式:在固定分区大小的情况下,对于作业大小小于或等于分区大小的请求能够成功分配,否则分配失败。
内存状态显示清晰,分区的使用和空闲情况一目了然。
动态分区分配方式:能够根据作业的大小动态地分配内存,但容易产生内存碎片。
2、内存回收实验结果成功回收指定作业占用的内存空间,内存状态得到及时更新,空闲分区得到合并,提高了内存的利用率。
内存管理实验
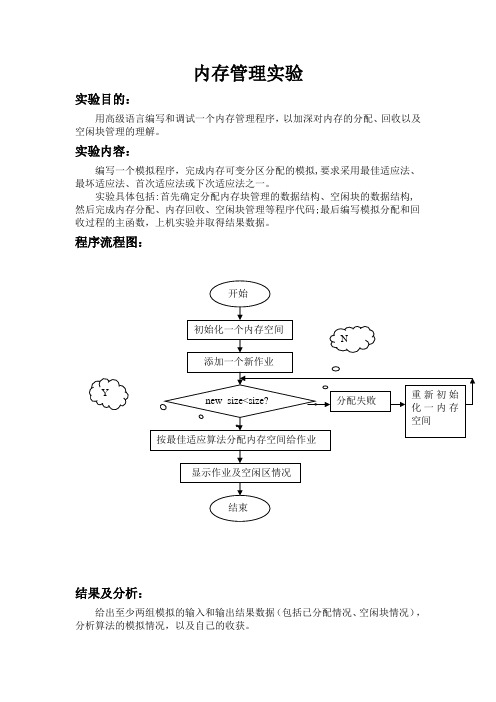
内存管理实验实验目的:用高级语言编写和调试一个内存管理程序,以加深对内存的分配、回收以及空闲块管理的理解。
实验内容:编写一个模拟程序,完成内存可变分区分配的模拟,要求采用最佳适应法、最坏适应法、首次适应法或下次适应法之一。
实验具体包括:首先确定分配内存块管理的数据结构、空闲块的数据结构,然后完成内存分配、内存回收、空闲块管理等程序代码;最后编写模拟分配和回收过程的主函数,上机实验并取得结果数据。
程序流程图:结果及分析:给出至少两组模拟的输入和输出结果数据(包括已分配情况、空闲块情况),分析算法的模拟情况,以及自己的收获。
<一>.第一组数据:输入: 初始化内存空间大小内存首址作业大小作业名称100 1 35 1 输出: ------------已分配表-----------分区号始地址作业名称作业大小状态1 1 1 35 1------------空闲表--------------分区号始地址剩余大小状态2 36 65 0<二>.第二组数据:输入: 作业名称作业大小220输出: -------------已分配表------------分区号始地址作业名称作业大小状态1 1 1 35 12 36 2 20 1--------------空闲表--------------分区号始地址剩余大小状态2 56 45 0源程序:源程序包括两部分:<一>.头文件://-----------------------------------------------------------------// //结构体定义//存储资源表结构(已分区表)typedef struct LNode {int address; //首地址int size; //内存分区大小int state; //状态:0表示空闲,1表示已经装入作业int num; //装入的作业号LNode *Next;}LNode,*mem_list;//-----------------------------------------------------------------////-----------------------------------------------------------------// //函数申明void Init(mem_list &L,int size,int add); //初始化空间段void setfree(mem_list &L);//找出连续的空闲资源,回收空闲空间void AddTask(mem_list &L);//添加作业void Display(mem_list L);//显示作业//-----------------------------------------------------------------////-----------------------------------------------------------------// //函数定义//初始化空间段void Init(mem_list &L,int size,int add) {mem_list p =(mem_list)malloc(sizeof(LNode));p->address = add;p->size = size;p->state = 0;p->num = 0;p->Next = NULL;L->Next = p;}//找出连续的空闲资源,回收空闲空间void setfree(mem_list &L) {mem_list p=L->Next,q = p->Next;while(p && q) {if(p->state == 0 && q->state == 0) {//如果空间连续,则回收p->size += q->size;p->Next = p->Next->Next;delete q;q=p->Next;}else{p = q;q = q->Next;}}printf("回收成功\n");}//添加作业void AddTask(mem_list &L) {int new_size;int new_name;mem_list p = L->Next, best = NULL;printf("请输入作业名称(用数字表示):");scanf("%d",&new_name);printf("请输入作业的大小:");scanf("%d",&new_size);printf("\n\n");if (new_size<=0) {printf("申请失败\n");exit(-1);}while(p) {//查找第一个满足空间分配的节点if(p->state==0 && p->size >= new_size) {best=p;break;}p=p->Next;}if(!p) {printf("对不起,作业%d内存分配不成功\n",new_name);exit(1);}p=L;while(p) {//查找最佳适应节点if(p->state==0 && p->size >= new_size && best->size > p->size) best = p;p = p->Next;}mem_list q =(mem_list)malloc(sizeof(LNode));q->size = best->size - new_size;q->address = best->address + new_size;q->state = 0;q->num=0;best->size = new_size;best->state = 1;best->num = new_name;q->Next = best->Next;best->Next = q;p=L;while(p) {//删除大小为0的结点,当分配空间完时会出现0结点if(p->size == 0) {q->Next = q->Next->Next;delete p;p = q->Next;}else {q = p;p = p->Next;}}}//显示作业void Display(mem_list L) {int count=1;mem_list p = L->Next;printf("----------已分配表----------\n");printf("分区号始地址作业长度状态\n");while(p) {if(p->num) {if(p->state)p->state=1;elsep->state=0;printf("%3d%8d%8d%8d%8d\n",count++,p->address,p->num,p->size,p->s tate);}p = p->Next;}p = L->Next;count = 1;printf("\n\n----------空闲表----------\n");printf("分区号始地址长度状态\n");while(p) {if(!(p->num)) {if(p->state)p->state=1;elsep->state=0;printf("%3d%8d%8d%8d\n\n",++count,p->address,p->size,p->state);}p = p->Next;}}//-----------------------------------------------------------------//<二>.主文件:#include <stdio.h>#include <iostream>#include <stdlib.h>#include <malloc.h>#include "work2.h"void main() {mem_list L=(mem_list)malloc(sizeof(LNode)); //申请节点空间int N,A;char flag;printf("------------------内存管理程序----------------\n");printf(" ********************\n");printf(" * 姓名:阳功力 *\n");printf(" * 学号:052413 *\n");printf(" * 班级: 9452 *\n");printf(" ********************\n\n"); printf("请初始化空间的大小:");scanf("%d",&N);printf("内存首址:");scanf("%d",&A);Init(L,N,A); //初始化大小为N,首址为A的内存空间do {AddTask(L); //添加作业Display(L); //显示作业printf("请选择是否继续添加作业(继续请按'y',否则回收空间结束)...:");scanf("%s",&flag);}while(flag == 'y');setfree(L);}。
操作系统内存管理实验报告

#include <stdio.h>
#include <malloc.h>
t;
int main(void)
{
char *str; /*为字符串申请分配一块内存*/
if ((str = (char *) malloc(10)) == NULL)
根据练习二改编程序如下:
#include <stdio.h>
#include <malloc.h>
#include <string.h>
int main(void)
{
char *str;
/*为字符串申请分配一块内存*/
if ((str = (char *) malloc(20)) == NULL)
{
同组同学学号:
同组同学姓名:
实验日期:交报告日期:
实验(No. 4)题目:编程与调试:内存管理
实验目的及要求:
实验目的:
操作系统的发展使得系统完成了大部分的内存管理工作,对于程序员而言,这些内存管
理的过程是完全透明不可见的。因此,程序员开发时从不关心系统如何为自己分配内存,
而且永远认为系统可以分配给程序所需的内存。在程序开发时,程序员真正需要做的就
printf("String is %s\n Address is %p\n", str, str);
/*重分配刚才申请到的内存空间,申请增大一倍*/
int main(void)
{
char *str;
/*为字符串申请分配一块内存*/
if ((str = (char *) malloc(10)) == NULL)
操作系统实验-内存管理

操作系统实验-内存管理操作系统实验内存管理在计算机系统中,内存管理是操作系统的核心任务之一。
它负责有效地分配和管理计算机内存资源,以满足各种程序和进程的需求。
通过本次操作系统实验,我们对内存管理有了更深入的理解和认识。
内存是计算机用于存储正在运行的程序和数据的地方。
如果没有有效的内存管理机制,计算机系统将无法高效地运行多个程序,甚至可能会出现内存泄漏、内存不足等严重问题。
在实验中,我们首先接触到的是内存分配策略。
常见的内存分配策略包括连续分配和离散分配。
连续分配是将内存空间视为一个连续的地址空间,程序和数据被依次分配到连续的内存区域。
这种方式简单直观,但容易产生内存碎片,降低内存利用率。
离散分配则将内存分成大小相等或不等的块,根据需求进行分配。
其中分页存储管理和分段存储管理是两种常见的离散分配方式。
分页存储管理将内存空间划分为固定大小的页,程序也被分成相同大小的页,通过页表进行映射。
分段存储管理则根据程序的逻辑结构将其分成不同的段,如代码段、数据段等,每个段有不同的访问权限和长度。
接下来,我们研究了内存回收算法。
当程序不再使用分配的内存时,操作系统需要回收这些内存以便再次分配。
常见的内存回收算法有首次适应算法、最佳适应算法和最坏适应算法。
首次适应算法从内存的起始位置开始查找,找到第一个满足需求的空闲区域进行分配;最佳适应算法则选择大小最接近需求的空闲区域进行分配;最坏适应算法选择最大的空闲区域进行分配。
为了更直观地理解内存管理的过程,我们通过编程实现了一些简单的内存管理算法。
在编程过程中,我们深刻体会到了数据结构和算法的重要性。
例如,使用链表或二叉树等数据结构来表示空闲内存区域,可以提高内存分配和回收的效率。
在实验中,我们还遇到了一些实际的问题和挑战。
比如,如何处理内存碎片的问题。
内存碎片是指内存中存在一些无法被有效利用的小空闲区域。
为了解决这个问题,我们采用了内存紧缩技术,将分散的空闲区域合并成较大的连续区域。
操作系统实验之内存管理实验报告

操作系统实验之内存管理实验报告一、实验目的内存管理是操作系统的核心功能之一,本次实验的主要目的是深入理解操作系统中内存管理的基本原理和机制,通过实际编程和模拟操作,掌握内存分配、回收、地址转换等关键技术,提高对操作系统内存管理的认识和实践能力。
二、实验环境本次实验在 Windows 操作系统下进行,使用 Visual Studio 作为编程环境,编程语言为 C++。
三、实验原理1、内存分配算法常见的内存分配算法有首次适应算法、最佳适应算法和最坏适应算法等。
首次适应算法从内存的起始位置开始查找,找到第一个满足需求的空闲分区进行分配;最佳适应算法则选择大小最接近需求的空闲分区;最坏适应算法选择最大的空闲分区进行分配。
2、内存回收算法当进程结束释放内存时,需要将其占用的内存区域回收至空闲分区链表。
回收过程中需要考虑相邻空闲分区的合并,以减少内存碎片。
3、地址转换在虚拟内存环境下,需要通过页表将逻辑地址转换为物理地址,以实现进程对内存的正确访问。
四、实验内容1、实现简单的内存分配和回收功能设计一个内存管理模块,能够根据指定的分配算法为进程分配内存,并在进程结束时回收内存。
通过模拟多个进程的内存请求和释放,观察内存的使用情况和变化。
2、实现地址转换功能构建一个简单的页式存储管理模型,模拟页表的建立和地址转换过程。
给定逻辑地址,能够正确计算出对应的物理地址。
五、实验步骤1、内存分配和回收功能实现定义内存分区的数据结构,包括起始地址、大小、使用状态等信息。
实现首次适应算法、最佳适应算法和最坏适应算法的函数。
创建空闲分区链表,初始化为整个内存空间。
模拟进程的内存请求,调用相应的分配算法进行内存分配,并更新空闲分区链表。
模拟进程结束,回收内存,处理相邻空闲分区的合并。
2、地址转换功能实现定义页表的数据结构,包括页号、页框号等信息。
给定页面大小和逻辑地址,计算页号和页内偏移。
通过页表查找页框号,结合页内偏移计算出物理地址。
内存管理实验报告

操作系统课程设计报告题目:动态分区内存管理班级:计算机1303班学号: 2120131138姓名:徐叶指导教师:代仕芳日期: 2015.11.5一、实验目的及要求本实验要求用高级语言编写模拟内存的动态分区分配和回收算法(不考虑紧凑),以便加深理解并实现首次适应算法(FF)、循环首次适应算法(NF)、最佳适应算法(BF),最坏适应算法(WF)的具体实现。
二、实验内容本实验主要针对操作系统中内存管理相关理论进行实验,要求实验者编写一个程序,该程序管理一块虚拟内存,实现内存分配和回收功能。
1)设计内存分配的数据结构(空闲分区表/空闲分区链),模拟管理64M 的内存块;2)设计内存分配函数;3)设计内存回收函数;4)实现动态分配和回收操作;5)可动态显示每个内存块信息动态分区分配是要根据进程的实际需求,动态地分配内存空间,涉及到分区分配所用的数据结构、分区分配算法和分区的分配回收。
程序主要分为四个模块:(1)首次适应算法(FF)在首次适应算法中,是从已建立好的数组中顺序查找,直至找到第一个大小能满足要求的空闲分区为止,然后再按照作业大小,从该分区中划出一块内存空间分配给请求者,余下的空间令开辟一块新的地址,大小为原来的大小减去作业大小,若查找结束都不能找到一个满足要求的分区,则此次内存分配失败。
(2)循环首次适应算法(NF)该算法是由首次适应算法演变而成,在为进程分配内存空间时,不再是每次都从第一个空间开始查找,而是从上次找到的空闲分区的下一个空闲分区开始查找,直至找到第一个能满足要求的空闲分区,从中划出一块与请求大小相等的内存空间分配给作业,为实现本算法,设置一个全局变量f,来控制循环查找,当f%N==0时,f=0;若查找结束都不能找到一个满足要求的分区,则此次内存分配失败。
(3)最佳适应算法(BF)最坏适应分配算法是每次为作业分配内存时,扫描整个数组,总是把能满足条件的,又是最小的空闲分区分配给作业。
内存模拟管理实验报告

内存模拟管理实验报告引言内存管理是操作系统中重要的一部分,它负责管理计算机的内存资源,合理地分配和回收内存空间。
本实验旨在模拟内存管理过程,通过对内存分配、回收和置换算法的模拟实验,加深对内存管理的理解。
实验目的通过本实验,我们的目标是:1. 掌握内存分配、回收和置换算法的基本原理;2. 理解不同的内存管理算法的特点和适用场景;3. 学会使用模拟软件进行内存管理实验。
系统设计本实验采用基于模拟软件的方式进行,我们使用了一款常用的内存管理模拟软件——MemSim。
该软件可以模拟内存的分配、回收和置换算法,并根据实验结果生成相应的性能报告。
首先,我们在MemSim中设计了一个包含若干作业和内存分区的实验环境。
我们可以设置不同的作业大小和内存分区大小,以及各种不同的内存分配、回收和置换算法。
实验过程首先,我们设计了三种内存分配算法:首次适应算法(First Fit)、最佳适应算法(Best Fit)和最坏适应算法(Worst Fit)。
我们分别选择了一组作业和一组内存分区,并使用这三种算法进行内存分配测试。
我们观察到:- 首次适应算法往往会使碎片数量较少,但存在大量分散的小碎片;- 最佳适应算法分配的内存分区较为紧凑,但会导致外部碎片的增加;- 最坏适应算法可以很好地避免外部碎片的产生,但会导致更多的内部碎片。
接下来,我们针对内存回收算法进行了实验。
我们测试了随时间回收算法(FIFO)和优先级回收算法(Priority)两种算法,并选择了不同的作业和内存分区进行了测试。
我们观察到:- 随时间回收算法在作业的运行时间较长的情况下,表现较好;- 优先级回收算法可以根据作业的优先级来选择回收内存,适合于具有不同优先级的作业。
最后,我们还对内存置换算法进行了实验。
我们测试了最先进入先出算法(FIFO)和最不常使用算法(LFU)。
我们选择了一组较大的内存分区,并模拟了一组较大的作业。
通过实验,我们了解到:- 最先进入先出算法可以很好地保证作业的执行顺序,但会导致较高的缺页率;- 最不常使用算法可以合理地选择置换页面,但会增加算法的复杂度。
实验四-存储器管理

实验四存储器管理1、目的与要求本实验的目的是让学生熟悉存储器管理的方法,加深对所学各种存储器管理方案的了解;要求采用一些常用的存储器分配算法,设计一个存储器管理模拟系统,模拟内存空间的分配和释放。
2、实验内容①设计一个存放空闲块的自由链和一个内存作业分配表,存放内存中已经存在的作业。
②编制一个按照首次适应法分配内存的算法,进行内存分配。
③同时设计内存的回收以及内存清理(如果要分配的作业块大于任何一个空闲块,但小于总的空闲分区,则需要进行内存的清理,空出大块的空闲分区)的算法。
3.实验环境①PC兼容机②Windows、DOS系统、Turbo c 2。
0③C语言4.实验提示一、数据结构1、自由链内存空区采用自由链结构,链首由指针freep指向,链中各空区按地址递增次序排列.初启动时整个用户内存区为一个大空区,每个空区首部设置一个区头(freearea)结构,区头信息包括:Size 空区大小Next 前向指针,指向下一个空区Back 反向指针,指向上一个空区Adderss 本空区首地址2、内存分配表JOBMA T系统设置一个MA T,每个运行的作业都在MAT中占有一个表目,回收分区时清除相应表目,表目信息包括:Name 用户作业名Length 作业区大小Addr 作业区首地址二、算法存储分配算法采用首次适应法,根据指针freep查找自由链,当找到第一块可满足分配请求的空区便分配,当某空区被分配后的剩余空闲空间大于所规定的碎片最小量mini时,则形成一个较小的空区留在自由链中。
回收时,根据MAT将制定分区链入自由链,若该分区有前邻或后邻分区,则将他们拼成一个较大的空区。
当某个分配请求不能被满足,但此时系统中所有碎片总容量满足分配请求的容量时,系统立即进行内存搬家,消除碎片.即将各作业占用区集中下移到用户内存区的下部(高地址部分),形成一片连续的作业区,而在用户内存区的上部形成一块较大的空闲,然后再进行分配。
操作系统实验内存分配

实验四存储器管理一、实验名称:存储器管理二、实验目的在TC、VB、Delphi、C++Builder等语言与开发环境中,模拟操作系统的内存管理;通过程序运行所显示的内存使用的各项指标,加深对内存管理的理解。
三、实验内容实现主存储器空间的分配和回收。
本实验有两个题,学生可选择其中的一题做实验。
第一题:在固定分区管理方式下实现主存分配和回收。
第二题:在可变分区管理方式下采用最先适应算法实现主存分配和实现主存回收。
[提示]:可变分区方式是按作业需要的主存空间大小来分割分区的。
当要装入一个作业时,根据作业需要的主存量查看是否有足够的空闲空间,若有,则按需要量分割一个分区分配给该作业;若无,则作业不能装入。
随着作业的装入、撤离,主存空间被分成许多个分区,有的分区被作业占用,而有的分区是空闲的。
为了说明哪些区是空闲的,可以用来装入新作业,必须要有一张空闲区说明表,格式如下:起址长度状态第一栏14 K 12 K 未分配第二栏32 K 96 K 未分配空表目空表目其中,起址——指出一个空闲区的主存起始地址。
长度——指出从起始地址开始的一个连续空闲的长度。
状态——有两种状态,一种是“未分配”状态,指出对应的由起址指出的某个长度的区域是空闲区;另一种是“空表目”状态,表示表中对应的登记项目是空白(无效),可用来登记新的空闲区(例如,作业撤离后,它所占的区域就成了空闲区,应找一个“空表目”栏登记归还区的起址和长度且修改状态)。
由于分区的个数不定,所以空闲区说明表中应有适量的状态为“空表目”的登记栏目,否则造成表格“溢出”无法登记。
空闲区表的定义为:#define m 10 /*假定系统允许的空闲区表最大为m*/struct{ float address; /*起始地址*/float length; /*长度*/int flag; /*标志,用“0”表示空栏目,用“1”表示未分配*/ }free_table[m]; /*空闲区表*/上述的这张说明表的登记情况是按提示(1)中的例所装入的三个作业占用的主存区域后填写的。
操作系统实验 内存管理

操作系统实验报告计算机学院(院、系)网络工程专业082 班组课学号20 姓名区德智实验日期教师评定实验四内存管理一、实验目的通过实验使学生了解可变式分区管理使用的主要数据结构,分配、回收的主要技术,了解最优分配、最坏分配、最先分配等分配算法。
基本能达到下列具体的目标:1、掌握初步进程在内存中的映像所需要的内存需求。
2、内存的最先分配算法首先实现,再逐步完成最优和最坏的分配算法。
二、实验内容1、在进程管理的基础上实现内存分配。
2、运用java实现整体的布局与分配内存时的动态图画显示。
三、实验步骤1.构建一个Process的对象类,每分配一次内存就实例化一个对象。
这对象包含分配内存的名字,内存大小(byte),绘画的起点像素,绘画的终点像素。
主要代码:public class Process {private String name;private int size;private int beginPx;private int endPx;public int getBeginPx() {return beginPx;}public void setBeginPx(int beginPx) {this.beginPx = beginPx;}public int getEndPx() {return endPx;}public void setEndPx(int endPx) {this.endPx = endPx;}public String getName() {return name;}public void setName(String name) { = name;}public int getSize() {return size;}public void setSize(int size) {this.size = size;}}2.根据用户输入而分配内存的大小,若输入的大小大于目前可分配内存的大小则拒绝分配操作,否则增加一个新进程入链表中,并在已分配表中增加进程的名字,更新剩余内存大小。
操作系统实验报告4

操作系统实验报告4一、实验目的本次操作系统实验的目的在于深入了解和掌握操作系统中进程管理、内存管理、文件系统等核心概念和相关操作,通过实际的实验操作,增强对操作系统原理的理解和应用能力,提高解决实际问题的能力。
二、实验环境本次实验使用的操作系统为 Windows 10,编程语言为 C++,开发工具为 Visual Studio 2019。
三、实验内容与步骤(一)进程管理实验1、进程创建与终止使用 C++语言编写程序,创建多个进程,并在进程中执行不同的任务。
通过进程的标识符(PID)来监控进程的创建和终止过程。
2、进程同步与互斥设计一个生产者消费者问题的程序,使用信号量来实现进程之间的同步与互斥。
观察生产者和消费者进程在不同情况下的执行顺序和结果。
(二)内存管理实验1、内存分配与释放编写程序,使用动态内存分配函数(如`malloc` 和`free`)来分配和释放内存。
观察内存的使用情况和内存泄漏的检测。
2、内存页面置换算法实现几种常见的内存页面置换算法,如先进先出(FIFO)算法、最近最少使用(LRU)算法和最佳置换(OPT)算法。
通过模拟不同的页面访问序列,比较不同算法的性能。
(三)文件系统实验1、文件创建与读写使用 C++语言的文件操作函数,创建一个新文件,并向文件中写入数据。
从文件中读取数据,并进行数据的处理和显示。
2、文件目录操作实现对文件目录的创建、删除、遍历等操作。
观察文件目录结构的变化和文件的组织方式。
四、实验结果与分析(一)进程管理实验结果与分析1、进程创建与终止在实验中,成功创建了多个进程,并通过控制台输出观察到了每个进程的 PID 和执行状态。
可以看到,进程的创建和终止是按照程序的逻辑顺序进行的,操作系统能够有效地管理进程的生命周期。
2、进程同步与互斥在生产者消费者问题的实验中,通过信号量的控制,生产者和消费者进程能够正确地实现同步与互斥。
当缓冲区为空时,消费者进程等待;当缓冲区已满时,生产者进程等待。
操作系统实验(四)实验报告--虚拟内存

操作系统实验(四)实验报告--虚拟内存操作系统实验(四)虚拟内存1、实验题目页面置换算法模拟——OPT、FIFO和LRU算法2、实验目的了解虚拟存储技术的特点,掌握请求页式存储管理的页面置换算法,如最佳(Optimal)置换算法、先进先出(Fisrt In First Out)置换算法和最近最久未使用(Least Recently Used)置换算法3、实验内容1)OPT算法:需要发生页面置换时,算法总是选择在将来最不可能访问的页面进行置换。
2)FIFO算法:算法总是选择在队列中等待时间最长的页面进行置换。
3)LRU算法:如果某一个页面被访问了,它很可能还要被访问;相反,如果它长时间不被访问,那么,在最近未来是不大可能被访问的。
4、程序代码#include<iostream>#include <cstdlib>#include <time.h>#include <cstdio>#define L 30///页面走向长度最大为30using namespace std;int M=4; ///内存块struct P///定义一个结构体{int num,time;}p[30];int Input(int m,P p[L])///打印页面走向状态{m=30;int i,j;j=time(NULL);///取时钟时间srand(j);///以时钟时间x为种子,初始化随机数发生器cout<<"页面走向: ";for(i=0; i<m; i++){p[i].num=rand( )%10;///产生1到10之间的随即数放到数组p中p[i].time=0;cout<<p[i].num<<" ";}cout<<endl;return m;}void print(P *page1)///打印当前的页面{P *page=new P[M];page=page1;for(int i=0; i<M; i++)cout<<page[i].num<<" ";cout<<endl;}int Search(int e,P *page1 )///寻找内存块中与e相同的块号{P *page=new P[M];page=page1;for(int i=0; i<M; i++)if(e==page[i].num)return i; ///返回i值return -1;}int Max(P *page1)///寻找最近最长未使用的页面用于OPT算法{P *page=new P[M];page=page1;int e=page[0].time,i=0;while(i<M) ///找出离现在时间最长的页面{if(e<page[i].time) e=page[i].time;i++;}for( i=0; i<M; i++)if(e==page[i].time)return i; ///找到离现在时间最长的页面返回其块号return -1;}int Count(P *page1,int i,int t,P p[L])///记录当前内存块中页面离下次使用间隔长度用于OPT算法{P *page=new P[M];page=page1;int count=0;for(int j=i; j<L; j++){if(page[t].num==p[j].num )break;///当前页面再次被访问时循环结束else count++;///否则count+1}return count;///返回count的值}int main(){int c=1;int m=0,t=0;float n=0;///缺页次数m=Input(m,p);///调用input函数,返回m值M=4;P *page=new P[M];///dowhile(c==1||c==2||c==3){int i=0;for(i=0; i<M; i++) ///初试化页面基本情况{page[i].num=0;page[i].time=m-1-i;}cout<<"1:FIFO页面置换"<<endl;cout<<"2:LRU页面置换"<<endl;cout<<"3:OPT页面置换"<<endl;cout<<"按其它键结束程序;"<<endl;cin>>c;if(c==1)///FIFO页面置换///FIFO();{n=0;cout<<" FIFO算法页面置换情况如下: "<<endl;cout<<endl;while(i<m){if(Search(p[i].num,page)>=0) ///当前页面在内存中{cout<<p[i].num<<" "; ///输出当前页p[i].numcout<<" "<<endl;i++; ///i加1}else ///当前页不在内存中{if(t==M)t=0;else{n++; ///缺页次数加1page[t].num=p[i].num; ///把当前页面放入内存中cout<<p[i].num<<" ";print(page); ///打印当前页面t++; //下一个内存块i++; ///指向下一个页面}}}cout<<"缺页次数:"<<n<<" 缺页率:"<<n<<"/"<<m<<" ="<<n/m<<endl;}if(c==2)///LRU页面置换,最近最久未使用{n=0;cout<<" LRU算法页面置换情况如下: "<<endl;cout<<endl;while(i<m){int a;t=Search(p[i].num,page);if(t>=0)///如果已在内存块中{page[t].time=0;///把与它相同的内存块的时间置0for(a=0; a<M; a++)if(a!=t)page[a].time++;///其它的时间加1cout<<p[i].num<<" ";cout<<"不缺页"<<endl;}else ///如果不在内存块中{n++; ///缺页次数加1t=Max(page); ///返回最近最久未使用的块号赋值给tpage[t].num=p[i].num; ///进行替换page[t].time=0; ///替换后时间置为0cout<<p[i].num<<" ";print(page);for(a=0; a<M; a++)if(a!=t)page[a].time++; ///其它的时间加1}i++;}cout<<"缺页次数:"<<n<<" 缺页率:"<<n<<"/"<<m<<" = "<<n/m<<endl;}if(c==3)///OPT页面置换{n=0;cout<<" OPT算法置换情况如下:"<<endl;cout<<endl;while(i<m){if(Search(p[i].num,page)>=0)///如果已在内存块中{cout<<p[i].num<<" ";cout<<" "<<endl;i++;}else///如果不在内存块中{int a=0;for(t=0; t<M; t++)if(page[t].num==0)a++;///记录空的内存块数if(a!=0) ///有空内存块{int q=M;for(t=0; t<M; t++)if(page[t].num==0&&q>t)q=t;///把空内存块中块号最小的找出来page[q].num=p[i].num;///把缺页换过来n++; ///缺页次数加一cout<<p[i].num<<" ";print(page);i++;}else{int temp=0,s;for(t=0; t<M; t++) ///寻找内存块中下次使用离现在最久的页面if(temp<Count(page,i,t,p)){temp=Count(page,i,t,p);s=t;}///把找到的块号赋给spage[s].num=p[i].num;n++;cout<<p[i].num<<" ";print(page);i++;}}}cout<<"缺页次数:"<<n<<" 缺页率:"<<n<<"/"<<m<<" = "<<n/m<<endl;}}///while(c==1||c==2||c==3);return 0;}5、心得体会通过该实验,是我对虚拟内存更加了解,对最佳置换算法、先进先出算法、最近最久算法更加了解。
模拟内存管理程序

北京联合大学信息学院实验报告课程名称:计算机操作系统学号:姓名:2014 年 5 月 7 日实验四模拟内存管理程序1、实验目的了解简单的固定大小内存分配方法,掌握分区存储管理技术,了解在分区管理机制下所需的数据结构。
2、实验内容1)、将1024K内存按如下块大小分成十个内存块。
内存块号内存块大小起始地址内存块状态1 512 10 NO2 256 522 NO3 256 778 NO4 128 1034 NO5 128 1162 NO6 128 1290 NO7 32 1418 NO8 32 1450 NO9 16 1482 NO10 16 1498 NO其中,在内存状态中用NO代表该内存块未被分配;用进程名代表该内存块已被分配。
2)、编制模拟内存管理程序,根据调入内存的进程大小分别采用最先适应法和最佳适应法分配内存块。
最佳适应法,如有一个12K的程序被运行时,它应该被分配到内存块号9,若有200K的程序运行时,应将其调入内存块号2。
最先适应法,则是按内存块号的顺序,依次放入各进程名。
有关编程请仔细阅读后面的参考流程。
3、实验要求1)、要求通过键盘输入若干进程名称和程序所占内存空间的大小,把这些进程分配到内存表中,显示内存分配情况。
2)、编制程序可以循环输入,输入某进程结束或某进程添加进来、进程占用存储空间的大小,并显示内存分配情况。
3)、当没有区间存放程序时,应有提示。
4)、所编写的程序,应有退出功能。
5)、每添加、结束一个进程,应有输出显示,输出显示的格式如下:内存块号内存块大小起始地址进程名(内存状态)1 512 10 A12 256 522 NO3 256 778 A24 128 1034 A35 128 1162 NO6 128 1290 NO7 32 1418 NO8 32 1450 NO9 16 1482 NO10 16 1498 NO1.最先适应法从空闲分区表的第一个表目起查找该表,把最先能够满足要求的空闲区分配给作业,这种方法目的在于减少查找时间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验四内存管理模拟实验模拟实现一个简单的固定(可变)分区存储管理系统1.实验目的通过本次课程设计,掌握了如何进行内存的分区管理,强化了对首次适应分配算法和分区回收算法的理解。
2.实验内容(1)建立相关的数据结构,作业控制块、已分配分区及未分配分区(2)实现一个分区分配算法,如最先适应算法、最优或最坏适应分配算法(3)实现一个分区回收算法(4)给定一个作业/进程,选择一个分配或回收算法,实现分区存储的模拟管理图1.流程图3.实验步骤首先,初始化函数initial()将分区表初始化并创建空闲分区列表,空闲区第一块的长度是30,以后的每个块长度比前一个的长度长20。
frees[0].length=30第二块的长度比第一块长20,第三块比第二块长20,以此类推。
frees[i].length=frees[i-1].length+20;下一块空闲区的首地址是上一块空闲区的首地址与上一块空闲区长度的和。
frees[i].front=frees[i-1].front+frees[i-1].length;分配区的首地址和长度都初始化为零occupys[i].front=0;occupys[i].length=0;显示函数show()是显示当前的空闲分区表和当前的已分配表的具体类容,分区的有起始地址、长度以及状态,利用for语句循环输出。
有一定的格式,使得输出比较美观好看。
assign()函数是运用首次适应分配算法进行分区,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。
若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。
这个算法倾向于优先利用内存中低址部分被的空闲分区,从而保留了高址部分的的大空闲区。
着给为以后到达的大作业分配大的内存空间创造了条件。
它的缺点是低地址部分不断被划分,会留下很多难以利用的、很小的空闲分区,而每次查找又都是从低址部分开始,这样无疑会增加查找可用空闲分区的开销。
分配内存,从空闲的分区表中找到所需大小的分区。
设请求的分区的大小为job_length,表中每个空闲分区的大小可表示为free[i].length。
如果frees[i].length>=job_length,即空闲空间I的长度大于等于作业的长度将空闲标志位设置为1,如果不满足这个条件则输出:“对不起,当前没有满足你申请长度的空闲内存,请稍后再试!”。
如果frees[i].length>=job_length空闲区空间I的长度不大于作业长度,I的值加1判断下一个空闲区空间是否大于作业的长度。
把未用的空闲空间的首地址付给已用空间的首地址,已用空间的长度为作业的长度,已用空间数量加1。
如果(frees[i].length>job_length),空间的长度大于作业的长度,frees[i].front+=job_length; 空闲空间的起始首地址=原空闲区间的起始长度加作业长度frees[i].length-=job_length;空闲区间的长度=原空闲区间的长度-作业的长度。
如果空间的长度与作业的长度相等,空闲区向前移一位,空闲区的数量也减一。
这样判断所有情况并相应分配之后,内存空间分配成功。
第二个操作为:撤消相应作业。
在这个操作中,进行了以下步骤:(1)按照系统提示输入将要撤消的作业名;(2)判断该作业是否存在若不存在:输出“没有这个作业名,请重新输入作业名”;若存在:则先分别用flag,start,len保存该作业在分配区表的位置i,内存空间的首地址以及长度。
接着根据回收区的首地址,即该作业的首地址,从空闲区表中找到相应的插入点,将其加入空闲表,此时可能出现以下三种情况之一:1 .回收区只与插入点前一个空闲分区F1相邻接即(frees[i].front+frees[i].length)==start),此时判断其是否与后一个空闲分区F2相邻接,又分两种情况:若相邻接,则将三个分区合并,修改新的空闲分区的首地址和长度。
新的首地址为F1的首地址,长度为三个分区长度之和,相应的代码为:frees[i].length=frees[i].length+frees[i+1].length+len;,并相应的空闲区表。
若不相邻接,即合并后的首应将回收区与插入点的前一分区合并,则不须为回收分区分配新的表项,只须修改其前一分区的大小。
该大小为F1与当前作业大小之和。
frees[i].length+=len;2 .回收分区与插入点前一个空闲分区不邻接但与后一空闲分区F2邻接。
此时应合并当前作业分区与F2分区,合并后的分区首地址为当前作业首地址start,长度为两个分区长度之和。
代码为:frees[i].front=start; frees[i].length+=len;3.回收分区既不与插入点前一空闲分区相邻接,也不与后一空闲分区相邻接。
此时只须将该回收分区插入空闲区表即可。
此时空闲区的数量加1。
将回收区加入空闲区表后还须修改分配区表内容。
具体为:修改分配区表中回收区(第一区)之后的各区指针,使其依次前移一位,即occupys[i]=occupys[i+1];同时已分配分区数量减1,即occupy_quantity--;最后输出内存空间回收完毕!即完成了撤消作业并回收相应空间的操作。
图2.初始化空闲分区列表图3.内存空间分配1图4.内存空间分配2图5.内存回收4.实验总结动态分区分配是根据进程的实际需要,动态地为之分配内存空间。
程序中采用空闲分区表,用于纪录每个空闲分区的情况。
每个空闲分区占一个表目,表目中包括起始地址、长度和状态。
采用已分配表,用于存放请求的作业,每个作业占一个表目,包括起始地址、长度和作业名。
程序调用initial()函数实现对空闲分区的初始化。
将作业装入内存时,运用首次适应分配算法。
程序中调用assign()实现,分配内存时,从表首开始查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲表中。
若不能找到满足要求的空闲区,则此次内存分配失败,返回。
回收内存,即撤销某些作业,调用撤销函数cancel(),根据所撤销作业的首址,从空闲区表中找到相应的插入点,回收内存包括四种情况:(1)回收区与前一空闲分区相邻接,此时将回收区与前一分区合并,并修改前一分区的大小;(2)回收区与后一空闲分区相邻接,此时将回收区与后一分区合并,并修改后一分区的首址和大小;(3)回收区同时与前、后分区相邻接,则将三个分区合并,使用前一分区的首址,大小为三分区大小之和;(4)回收区不与空闲分区相邻,则重新建立一新表项,填写首址和大小,插入表中相应位置。
函数show()用于显示空闲区表和已分配表时,运用for循环,依次显示每个空闲区表和已分配表的信息。
#include<stdlib.h>#include<stdio.h>#include<iostream.h>#include<string.h>#include<iomanip.h>const int MAXJOB=5;//定义表最大记录数typedef struct node{int front;int length;char data[20];}job;//定义job类型的数据类型job frees[MAXJOB];//定义空闲区表int free_quantity;job occupys[MAXJOB];//定义已分配区表int occupy_quantity;//初始化并创建空闲分区表函数int initial(){int i;frees[0].front=0;frees[0].length=30;occupys[0].front=0;occupys[0].length=0;strcpy(frees[0].data,"free");for(i=1;i<MAXJOB;i++){frees[i].front=frees[i-1].front+frees[i-1].length;frees[i].length=frees[i-1].length+20;strcpy(frees[i].data,"free");occupys[i].front=0;occupys[i].length=0;strcpy(occupys[i].data," ");}free_quantity=MAXJOB;occupy_quantity=0;return 1;}//显示函数void show(){int i;printf("----------------------------------------------------------\n");printf("当前空闲分区表如下:\n");printf("起始地址长度状态\n");for(i=0;i<free_quantity;i++){printf("%5d %8d %s\n",frees[i].fro nt,frees[i].length,frees[i].data);}printf("----------------------------------------------------------\n");printf("当前已分配表如下:\n");printf("起始地址长度占用作业名\n");for(i=0;i<occupy_quantity;i++){printf("%5d %6d %s\n",occupys[ i].front,occupys[i].length,occupys[i].data);}printf("----------------------------------------------------------\n");}//首次适应分配算法void assign(){char job_name[20];int job_length;int i,j,flag,t;printf("请输入新申请内存空间的作业名和空间大小:");scanf("%s",job_name);scanf("%d",&job_length);flag=0;for(i=0;i<free_quantity;i++){if(frees[i].length>=job_length) //如果空闲空间I的长度>=作业长度{flag=1; //空闲标志位就置}}if(flag==0){printf("对不起,当前没有能满足你申请长度的空闲内存,请稍候再试!\n");}else{t=0;i=0;while(t==0) //为空闲区间的时候{if(frees[i].length>=job_length){t=1;}i++;//如果空闲空间I的长度不大于作业长度,I加,判断下一个空间}i--;occupys[occupy_quantity].front=frees[i].front;//把未用的空闲空间的首地址付给已用空间的首地址strcpy(occupys[occupy_quantity].data,job_nam e);//已用空间的内容为作业名occupys[occupy_quantity].length=job_length;//已用空间的长度为作业的长度occupy_quantity++; //已用空间数量加if(frees[i].length>job_length) //如果空间的长度大于作业的长度,{frees[i].front+=job_length; //空闲空间的起始首地址=原空闲区间的起始长度加作业长度frees[i].length-=job_length;//空闲区间的长度=原空闲区间的长度-作业的长度}else//如果空间的长度=作业的长度{for(j=i;j<free_quantity-1;j++){frees[j]=frees[j+1];//空闲区间前移一位}free_quantity--;//空闲区间的数量减一}printf("内存空间分配成功!\n");}}//撤消作业void cancel(){char job_name[20];int i,j,flag,p=0;int start;int len;printf("请输入要撤消的作业名:");scanf("%s",job_name);flag=0;for(i=0;i<occupy_quantity;i++){if(!strcmp(occupys[i].data,job_name))//当输入作业名匹配时{flag=i;//把i的值赋给flag;start=occupys[i].front;//把已用空间的首地址赋给startlen=occupys[i].length;//把已用空间的长度赋给len}}if(flag==0){printf("没有这个作业名,请重新输入作业名!\n");}else{ //加入空闲表for(i=0;i<free_quantity;i++){if((frees[i].front+frees[i].length)==start)//上空{if(((i+1)<free_quantity)&&(frees[i+1].front==start+l en))//下空{//第i个空闲区间的长度=第i个空闲区间的长度+第i+1个空闲区间的长度(下空闲区)+lengthfrees[i].length=frees[i].length+frees[i+1].length+len;for(j=i+1;j<free_quantity;j++){frees[j]=frees[j+1];//空闲区间前移一位}free_quantity--;//空闲区的数量渐少了一个p=1;}else{frees[i].length+=len;//(上空下不空)第i个空闲区间的长度=第i个空闲区间的长度+length,空闲区个数不变p=1;}}if(frees[i].front==(start+len))//下空上不空{frees[i].front=start;//起始地址等于待回收地址frees[i].length+=len;//第i个空闲区间的长度=第i个空闲区间的长度+lengthp=1;}}if(p==0) //上下空闲区都不空(直接在空闲区表中找一个空表目,将其内容插入){frees[free_quantity].front=start;frees[free_quantity].length=len;free_quantity++; //空闲区的数量加}//删除分配表中的该作业for(i=flag;i<occupy_quantity;i++){occupys[i]=occupys[i+1];}occupy_quantity--;//已用的区的数量printf("内存空间回收完毕!\n");}}//主函数void main(){int flag=0;int t=1;int chioce=0;printf("|--------------------------------------------------|\n");printf(" |可变分区存储管理模拟系统|\n");printf("|--------------------------------------------------|\n");printf(" |菜单:(0)退出|\n");printf(" | |\n");printf(" |(1)申请空间(2)撤消作业|\n");printf(" | |\n");printf(" |(3)显示空闲表和分配表|\n");printf("|--------------------------------------------------|\n");initial();flag=initial();while(flag==1){printf("^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^\n");printf("请选择:");scanf("%d",&chioce);switch(chioce){case 1:assign(); break;case 2:cancel(); break;case 3:show(); break;case 0:flag=0; break;default:printf("选择错误!");}}// return 0;}。