Oracle数据库buffer busy wait等待事件
Oracle 常见的33个等待事件

Oracle 常见的33个等待事件一.等待事件的相关知识:1.1 等待事件主要可以分为两类,即空闲(IDLE)等待事件和非空闲(NON-IDLE)等待事件。
1). 空闲等待事件指ORACLE正等待某种工作,在诊断和优化数据库的时候,不用过多注意这部分事件。
2). 非空闲等待事件专门针对ORACLE的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是在调整数据库的时候需要关注与研究的。
在Oracle 10g中的等待事件有872个,11g中等待事件1116个。
我们可以通过v$event_name 视图来查看等待事件的相关信息。
1.2 查看v$event_name视图的字段结构:SQL> desc v$event_name;名称是否为空? 类型----------------------------------------- -------- --------------- EVENT# NUMBEREVENT_ID NUMBERNAME VARCHAR2(64)PARAMETER1 VARCHAR2(64)PARAMETER2 VARCHAR2(64)PARAMETER3 VARCHAR2(64)WAIT_CLASS_ID NUMBERWAIT_CLASS# NUMBERWAIT_CLASS VARCHAR2(64)1.3 查看等待事件总数:SQL> select count(*) from v$event_name;COUNT(*)----------11161.4 查看等待事件分类情况:/* Formatted on 2010/8/11 16:08:55 (QP5 v5.115.810.9015) */SELECT wait_class#,wait_class_id,wait_class,COUNT(* )AS"count"FROM v$event_nameGROUP BY wait_class#,wait_class_id,wait_classORDER BY wait_class#;WAIT_CLASS# WAIT_CLASS_IDWAIT_CLASS count----------- ------------- -------------------- ----------0 1893977003Other 7171 4217450380Application 172 3290255840Configuration 243 4166625743Administrative 544 3875070507Concurrency 325 3386400367Commit 26 2723168908Idle 947 2000153315Network 358 1740759767 UserI/O 459 4108307767 SystemI/O 3010 2396326234Scheduler 711 3871361733Cluster 5012 644977587Queueing 91.5 相关的几个视图:V$SESSION:代表数据库活动的开始,视为源起。
buffer busy waits处理方式

buffer busy waits处理方式Buffer busy waits can occur when multiple processes or sessions are trying to access the same buffer in the system. This can lead to performance degradation and delays in processing.There are several ways to address buffer busy waits:1. Increase the size of the buffer or cache: By increasing the size of the buffer or cache, you can reduce the likelihood of buffer busy waits occurring. This allows for more data to be stored in memory, reducing the need for frequent disk I/O.2. Optimize SQL queries: Poorly written or inefficient SQL queries can cause buffer busy waits. Optimizing these queries can help to reduce the number of buffer busy waits and improve overall performance.3. Tune database parameters: Adjusting database parameters such as the size of the database buffer cache, the number of database connections, and the number of parallel processes can help to alleviate buffer busy waits. It is important to regularly review and tune these parameters based on system usage and workload.4. Implement resource management tools: Resource management tools such as Oracle Database Resource Manager can be used to allocate system resources more efficiently and prevent buffer busy waits. These tools allow for the prioritization of resource usage and can help to ensure that critical processes receive the necessary resources.5. Monitor and identify bottlenecks: Regularly monitoring the system's performance and identifying any bottlenecks can help to quickly address buffer busy waits. This can be done through the use of performance monitoring tools and by analyzing system logs and diagnostics.6. Consider partitioning tables: If buffer busy waits are mainly occurring on specific tables, partitioning those tables can help distribute the load across multiple buffers and reduce contention. It is important to note that the approach to handling buffer busy waits can vary depending on the specific database system and the underlying workload. It is recommended to consult with a database administrator or performance tuning expert for specific guidance and best practices.。
oracle常见等待事件及处理方法

我们可以通过视图v$session_wait来查看系统当前的等待事件,以及与等待事件相对应的资源的相关信息看书笔记db file scattered read DB ,db file sequential read DB,free buffer waits,log buffer space,log file switch,log file sync我们可以通过视图v$session_wait来查看系统当前的等待事件,以及与等待事件相对应的资源的相关信息,从而可确定出产生瓶颈的类型及其对象。
v$session_wait的p1、p2、p3告诉我们等待事件的具体含义,根据事件不同其内容也不相同,下面就一些常见的等待事件如何处理以及如何定位热点对象和阻塞会话作一些介绍。
<1> db file scattered read DB 文件分散读取(太多索引读,全表扫描-----调整代码,将小表放入内存)这种情况通常显示与全表扫描相关的等待。
当全表扫描被限制在内存时,它们很少会进入连续的缓冲区内,而是分散于整个缓冲存储器中。
如果这个数目很大,就表明该表找不到索引,或者只能找到有限的索引。
尽管在特定条件下执行全表扫描可能比索引扫描更有效,但如果出现这种等待时,最好检查一下这些全表扫描是否必要。
因为全表扫描被置于LRU(Least Recently Used,最近最少适用)列表的冷端(cold end),所以应尽量存储较小的表,以避免一次又一次地重复读取它们。
==================================================该类事件的p1text=file#,p1是file_id,p2是block_id,通过dba_extents即可确定出热点对象(表或索引)select owner,segment_name,segment_typefrom dba_extentswhere file_id = &file_idand &block_id between block_id and block_id + &blocks - 1;==================================================<2> db file sequential read DB 文件顺序读取(表连接顺序不佳-----调整代码,特别是表连接)这一事件通常显示单个块的读取(如索引读取)。
Oracle认证:Freebufferwaits等待事件总结

Oracle认证:Freebufferwaits等待事件总结Oracle认证:Freebufferwaits等待事件总结Free buffer waits1.简述:当数据库要在buffer cache中寻找空闲空间来放置数据,但发现空间不足时,就会产生这个等待;2.详述:a)在用户请求块的DBA上应用HASH函数,获得适当的hash bucket;b)检索bucket对应的chain,确认块头是否存在,若存在就使用;c)若不存在,用户进程在LRU链上按最近最少使用的顺序寻找空闲缓冲区。
若在此过程中发现脏块,则将其移到LRUW列。
找到空闲缓冲区后,就可以从数据文件将块读到该缓冲区上;d)在LRU列上寻找,一般扫描40%的比例,扫完后没有发现空闲缓冲区,就会停止扫描并驱使DBWR将脏块写到磁盘上;e)在等待dbwr写脏块的'过程中,用户进程在等待free buffer waits事件。
3.原因:三部分1.data buffer太小,导致空闲空间不够2.脏块写得慢。
a)内存中的脏数据太多,DBWR无法及时将这些脏数据写到磁盘中以释放空间,也就是可能有批量dml操作。
b)dbwr数太少,db_writer_processes参数是否设得过少,配合os上的ps -ef | grep | grep dbw查看dbwr数量c)缓慢的IO子系统,db file parallel write较多,vd)延迟块清除,即延迟块头事务标记清除。
3.要申请的空间过多a)低效率的SQL语句导致过量的物理读。
4.附录:前台进程扫描lru链表,看有没空闲的空间,一般要扫到预定义的限度才停止扫描,这个限度是LRU链表的百分比,9i中默认40%, 可以通过查询。
select * from x where kvittag = 'kcbfsp';或者查询参数 _db_block_max_scan_pct 也是40. 出现场景:imp,impdp 导数进库也可能出现这个等待。
[AWR报告]logbufferspaces等待事件
![[AWR报告]logbufferspaces等待事件](https://img.taocdn.com/s3/m/05de1ae2f605cc1755270722192e453610665b7d.png)
[AWR报告]logbufferspaces等待事件从今天开始讲解awr报告Top 5 Timed Events部分今天讲log buffer space等待事件log buffer spacelog buffer space 这个等待事件一般来说很少发生,一旦等待比较严重往往说明系统的设置问题如何发生的我们知道Oracle的一些DML操作(insert,update,insert)会产生redo条目,并存储在log buffer中,当发生以下情况时LGWR进程会把log buffer中的信息写入redo log,之后清空log buffer,当redo 条目的产生速度快于LGWR清理的速度就会发生redo log space requests等待事件1. 每三秒钟2. 每一次commit/rollback3. 当其1/3满的时候,这个由_LOG_IO_SIZE参数控制4. 当其达到1M的时候log_bufferlog buffer的大小由参数log_buffer参数决定默认值为512k或者128k*CPU数量,一般来说这个默认值是够用的如果系统DML操作很多且这个等待事件比较严重时可以考虑增加log buffer参数的大小修改该参数需要重启数据库log buffer 过大的问题log buffer过大也会有问题上面说到当log bufffer 1/3满时LGWR进程会清空log buffer 如log buffer为10m,则意味着在没有commit/rollbak的情况下,需要等到3m才会切换,这样会导致LGWR写入redo log缓慢,从而导致log file sync等待所以我们在调优log buffer space时不应该增加其他等待事件,需要取得一个平衡如何调优1.IO性能不好会导致LGWR进程清空log buffer 过慢从而导致log buffer space等待,这时需要将redo log 放在高速的磁盘(SSD)或裸设备上2.减少应用的commit活动,或者使用nologging选项,仅更新表中需要更新的栏位3.物化视图更新使用fast代替complete模式4.查看 log file switch 是否频繁下期预告SQL*Net message from dblink其他专题[安装文档]Oracle 11g RAC安装文档[安装文档]Oracle 9.2.0.8的安装[AWR报告] Instance Efficiency Percentages总结[Python运维]Python监控Oracle数据库总结[Python运维]使用Python监控Oracle索引总结[Python自动化运维] 监控linux/Unix服务器性能及Oracle日志[AWR报告]db file sequential read等待事件[AWR报告]db file scattered read等待事件[AWR报告]log file sync等待事件[AWR报告]log file parallel write等待事件[打造自己的监控系统] Django框架介绍[打造自己的监控系统] 数据库,模块等环境的准备[打造自己的监控系统] 使用Django创建网站[打造自己的监控系统] 使用Django管理数据库表[打造自己的监控系统] 开始我们的第一个网页。
oracle常见等待事件及处理方法

oracle常见等待事件及处理方法Oracle是一种流行的关系型数据库管理系统,它被广泛应用于企业级应用程序中。
在使用Oracle时,我们经常会遇到等待事件,这些事件可能会导致性能下降。
本文将介绍一些常见的Oracle等待事件及其处理方法。
1. DB FILE SEQUENTIAL READDB FILE SEQUENTIAL READ是一种等待事件,它表示Oracle正在等待从磁盘读取数据块。
这种等待事件通常发生在全表扫描或索引扫描期间。
要解决这个问题,可以考虑增加缓存大小或优化查询语句。
2. DB FILE SCATTERED READDB FILE SCATTERED READ是一种等待事件,它表示Oracle正在等待从磁盘读取散布的数据块。
这种等待事件通常发生在使用I/O密集型操作时。
要解决这个问题,可以考虑增加缓存大小或优化查询语句。
3. LOG FILE SYNCLOG FILE SYNC是一种等待事件,它表示Oracle正在等待将日志文件写入磁盘。
这种等待事件通常发生在事务提交时。
要解决这个问题,可以考虑增加日志缓存大小或优化事务提交频率。
4. ENQUEUEENQUEUE是一种等待事件,它表示Oracle正在等待获取锁。
这种等待事件通常发生在并发访问数据库时。
要解决这个问题,可以考虑优化锁定策略或减少并发访问。
5. LATCHLATCH是一种等待事件,它表示Oracle正在等待获取内部数据结构的锁。
这种等待事件通常发生在高并发访问数据库时。
要解决这个问题,可以考虑增加内存大小或优化查询语句。
6. CPU TIMECPU TIME是一种等待事件,它表示Oracle正在等待CPU资源。
这种等待事件通常发生在CPU密集型操作时。
要解决这个问题,可以考虑增加CPU资源或优化查询语句。
总之,Oracle等待事件可能会导致性能下降,但我们可以通过优化查询语句、增加缓存大小、优化锁定策略等方法来解决这些问题。
Oracle常见等待事件说明

Oracle的等待事件是衡量Oracle运行状况的重要依据及指标。
等待事件的概念是在Oracle7.0.1.2中引入的,大致有100个等待事件。
在Oracle 8.0中这个数目增加到了大约150个,在Oracle8i中大约有200个事件,在Oracle9i中大约有360个等待事件。
主要有两种类别的等待事件,即空闲(idle)等待事件和非空闲(non-idle)等待事件。
空闲事件指Oracle正等待某种工作,在诊断和优化数据库的时候,我们不用过多注意这部分事件。
常见的空闲事件有:• dispatcher timer• lock element cleanup• Null event• parallel query dequeue wait• parallel query idle wait - Slaves• pipe get• PL/SQL lock timer• pmon timer- pmon• rdbms ipc message• slave wait• smon timer• SQL*Net break/reset to client• SQL*Net message from client• SQL*Net message to client• SQL*Net more data to client• virtual circuit status• client message非空闲等待事件专门针对Oracle的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是我们在调整数据库的时候应该关注与研究的。
一些常见的非空闲等待事件有:• db file scattered read• db file sequential read• buffer busy waits• free buffer waits• enqueue• latch free• log file parallel write• log file sync1. db file scattered read-DB 文件分散读取这种情况通常显示与全表扫描相关的等待。
Oracle等待事件详解

Oracle等待事件详解个人分类:体系结构篇一.等待事件的相关知识:1.1 等待事件主要可以分为两类:即空闲(IDLE)等待事件和非空闲(NON-I DLE)等待事件。
1). 空闲等待事件指ORAC LE正等待某种工作,在诊断和优化数据库的时候,不用过多注意这部分事件。
2).非空闲等待事件专门针对ORAC LE的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是在调整数据库的时候需要关注与研究的。
在Or acle10g中的等待事件有872个,11g中等待事件1116个。
我们可以通过v$ev ent_n ame 视图来查看等待事件的相关信息。
1.2查看v$e vent_name视图的字段结构:SQ L> de sc v$event_name;名称是否为空?类型----------------------------------------- -----------------------EVE NT# NU MBEREVEN T_ID NUM BERNAME VARC HAR2(64)PARAM ETER1 VARC HAR2(64)PARAM ETER2 VARC HAR2(64)PARAM ETER3 VARC HAR2(64)WAIT_CLASS_ID NUMB ERW AIT_C LASS#NUMBE RWA IT_CL ASS V ARCHA R2(64)1.3 查看等待事件总数:SQL> sel ect c ount(*) fr om v$event_name;C OUNT(*)----------11161.4查看等待事件分类情况:/*Forma ttedon 2010/8/11 16:08:55 (QP5 v5.115.810.9015) */SEL ECT wait_class#, wait_clas s_id,w ait_c lass,C OUNT( * ) AS "count"FRO M v$eve nt_na meGR OUP B Y w ait_c lass#, wai t_cla ss_id, wai t_cla ssOR DER B Y w ait_c lass#;WAI T_CLA SS# W AIT_C LASS_ID WA IT_CL ASS c ount----------- ------------- -------------------- ---------- 0 1893977003 O ther 717 1 4217450380 App licat ion 1723290255840Confi gurat ion 24 3 4166625743 Ad minis trati ve 544 3875070507 Conc urren cy 32 5 3386400367 C ommit2 6 2723168908 Idl e 9472000153315Netwo rk 35 8 1740759767 Us er I/O 459 4108307767 Syst em I/O 30 10 2396326234 S chedu ler 711 3871361733 Clu ster 50 12644977587 Q ueuei ng 91.5相关的几个视图:V$SES SION:代表数据库活动的开始,视为源起。
Oracle数据库日常巡检指令

Oracle 数据库日常巡检指令Oracle数据库的日常巡检内容包括:Oracle数据库基本状况检查;Oracle相关资源的使用情况检查;Oracle数据库性能检查;数据库服务器cpu、mem和I/O 性能检查;数据库服务器安全性及其他事项检查等五大检查项目。
1、数据库基本状况检查(1)、数据库实例状况检查说明:其中“STATUS”表示Oracle当前的实例状态,必须为“OPEN”;“DATABASE_STATUS”表示Oracle当前数据库的状态,必须为“ACTIVE”。
(2)、数据库表空间状态检查说明:输出结果中STATUS应该都为“ONLINE”。
(3)、数据库数据文件检查1 select tablespace_name,status from dba_tablespaces;说明:输出结果中“STATUS”应该都为“AVAILABLE”。
(4)、数据库在线日志检查1 select group#,status,type,member from v$logfile;说明:输出结果应该有3条或3条以上记录,“STATUS”应该为非“INVALID”,非“DELETED”。
“STATUS”的值为空表示正常。
(5)、数据库回滚段检查1 select segment_name,status from dba_rollback_segs;说明:输出结果中所有回滚段的“STATUS”应该为“ONLINE”。
2、数据库相关资源使用情况检查(1)、检查Oracle初始化文件中相关参数值1 select resource_name,max_utilization,initial_allocation, limit_value from v$resource_limit;说明:若字段值【LIMIT_VALU】-【MAX_UTILIZATION】<=5,则表明与RESOURCE_NAME相关的Oracle初始化参数需要调整。
Oracle数据库性能优化与案例分析

Oracle数据库性能优化与案例分析
性能优化探讨
• 原因:为什么? • 慢(响应时间) • 慢(吞吐量)
性能优化探讨
• 目的:为了什么? • 快(响应时间) • 快(吞吐量)
性能优化之案例分析
• 案例之方法论 • 案例之登录访问 • 案例之资源 • 案例之锁
性能优化方法论发展
• 登录输入指标测量 • Logons:= EndSnap. logons cumulative– StartSnap. logons
cumulative。 • Logons Per Second:= Logons / TimeInterval
案例之登录访问
登录输出指标测量:
Logon Response Time:= Network Response Time * 10 + Native TCP Logon :=Network Response Time * 10 + Listener Response Time + Native IPC Logon Time 。
案例之登录访问
• 例:
•
某医院HIS业务系统的账户登录操作异常缓慢,部分情况下
甚至会出现长时间的卡壳情况,业务影响主要发生在每天早上
的上班时刻。
案例之登录访问
优化过程: • 账户登录过程一般涉及到在账户表格以及对应日志表格上的冲
突,比如Buffer busy waits或者TX lock。AWR未体现该特征。 • AWR报告显示connection management call elapsed time时间偏长
成功率:98% 高 失败率:2% 低
失败人数:500*2%=10
oracle 常见等待事件及处理方法

我们可以通过视图v$session_wait来查看系统当前的等待事件,以及与等待事件相对应的资源的相关信息看书笔记db file scattered read DB ,db file sequential read DB,free buffer waits,log buffer space,log file switch,log file sync我们可以通过视图v$session_wait来查看系统当前的等待事件,以及与等待事件相对应的资源的相关信息,从而可确定出产生瓶颈的类型及其对象。
v$session_wait的p1、p2、p3告诉我们等待事件的具体含义,根据事件不同其内容也不相同,下面就一些常见的等待事件如何处理以及如何定位热点对象和阻塞会话作一些介绍。
<1> db file scattered read DB 文件分散读取(太多索引读,全表扫描-----调整代码,将小表放入内存)这种情况通常显示与全表扫描相关的等待。
当全表扫描被限制在内存时,它们很少会进入连续的缓冲区内,而是分散于整个缓冲存储器中。
如果这个数目很大,就表明该表找不到索引,或者只能找到有限的索引。
尽管在特定条件下执行全表扫描可能比索引扫描更有效,但如果出现这种等待时,最好检查一下这些全表扫描是否必要。
因为全表扫描被置于LRU(Least Recently Used,最近最少适用)列表的冷端(cold end),所以应尽量存储较小的表,以避免一次又一次地重复读取它们。
==================================================该类事件的p1text=file#,p1是file_id,p2是block_id,通过dba_extents即可确定出热点对象(表或索引)select owner,segment_name,segment_typefrom dba_extentswhere file_id = &file_idand &block_id between block_id and block_id + &blocks - 1;==================================================<2> db file sequential read DB 文件顺序读取(表连接顺序不佳-----调整代码,特别是表连接) 这一事件通常显示单个块的读取(如索引读取)。
关系型数据库的性能指标

关系型数据库的性能指标一、数据库性能指标数据库性能一般用两个方面的指标来衡量:响应时间和吞吐量。
响应越快,吞吐量越大,数据库性能越好。
1. 操作系统有关的指标:CPU平均利用率、内存平均占用率、硬盘占用率、I/O数量、网络时延2. 数据库有关的指标:I/Owait、Mem平均使用率、cpu平均使用率、在一次I/O操作中所读的最大BLOCKS数、Log的增长情况、数据库的访问速度、数据库能支持的最大用户数、数据库CACHE命中率、不同数据库参数下的性能情况、锁的处理二、Oracle注:以下指标取自Oracle的性能分析工具Statspack所提供的性能分析指标。
1.关于实例效率(Instance Efficiency Percentages)的性能指标(1)缓冲区未等待率(Buffer Nowait %)指在缓冲区中获取Buffer的未等待比率。
该指标的值应接近100%,如果该值较低,则可能要增大buffer cache。
(2)Redo缓冲区未等待率(Redo NoWait %)指在Redo缓冲区获取Buffer的未等待比率。
该指标的值应接近100%,如果该值较低,则有2种可能的情况:1.online redo log没有足够的空间;2.log切换速度较慢。
(3)缓冲区命中率(Buffer Hit %)指数据块在数据缓冲区中的命中率。
(4)内存排序率(In-memory Sort %)指排序操作在内存中进行的比率。
当查询需要排序的时候,数据库会话首先选择在内存中进行排序,当内存大小不足的时候,将使用临时表空间进行磁盘排序,但磁盘排序效率和内存排序效率相差好几个数量级。
(5)共享区命中率(Library Hit%)该指标主要代表sql在共享区的命中率。
(6)软解析的百分比(Soft Parse %)该指标是指Oracle对sql的解析过程中,软解析所占的百分比。
软解析(soft parse)是指当Oracle接到Client提交的Sql后会首先在共享池(Shared Pool)里面去查找是否有之前已经解析好的与刚接到的这一个Sql完全相同的Sql。
GCBufferBusy等待事件

GCBufferBusy等待事件一、原理gc buffer busy acquire/release 往往是 gc current block busy 的衍生产品,当同一实例内的多个进程并发地访问同一个数据块时,首先发起的进程将进入 gc current block busy的等待,而在 buffer waiter list 上的后续进程会陷入gc buffer busy acquire/release 等待(A user on the same instance has started a remote operation on thesame resource and the request has not completed yet or the block was requestedby another node and the block has not been released by the local instance whenthe new local access was made),这里存在一个排队效应,即 gc current block busy是缓慢的,那么在排队的gc buffer busy acquire/release就会更慢:Pin time = (timeto read the block into cache) + (time to modify/process the buffer)Busy time =(average pin time) * (number of interested users waiting ahead of me)不局限于current block (reference AWR Avg global cache current block flush time(ms)), cr block(Avg global cache cr block flush time (ms)) 也存在flush time。
Oracle数据库发生等待事件:enq:TX-rowlockcontention,排查思路
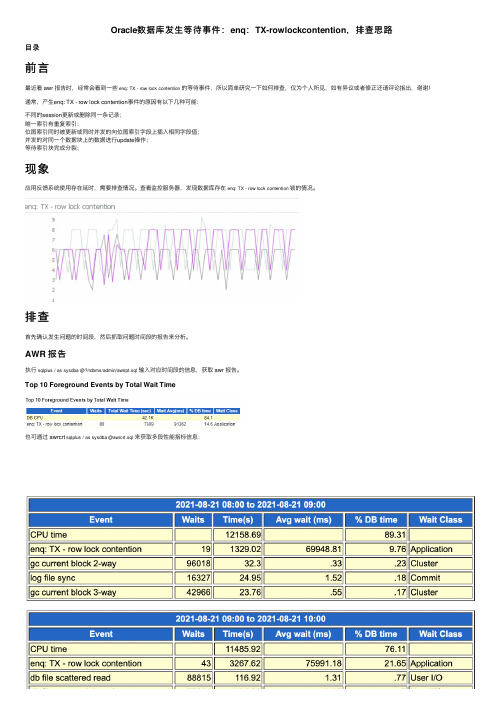
Oracle数据库发⽣等待事件:enq:TX-rowlockcontention,排查思路⽬录前⾔最近看 awr 报告时,经常会看到⼀些enq: TX - row lock contention的等待事件,所以简单研究⼀下如何排查,仅为个⼈所见,如有异议或者修正还请评论指出,谢谢!通常,产⽣enq: TX - row lock contention事件的原因有以下⼏种可能:不同的session更新或删除同⼀条记录;唯⼀索引有重复索引;位图索引同时被更新或同时并发的向位图索引字段上插⼊相同字段值;并发的对同⼀个数据块上的数据进⾏update操作;等待索引块完成分裂;现象应⽤反馈系统使⽤存在延时,需要排查情况。
查看监控服务器,发现数据库存在enq: TX - row lock contention锁的情况。
排查⾸先确认发⽣问题的时间段,然后抓取问题时间段的报告来分析。
AWR 报告执⾏sqlplus / as sysdba @?/rdbms/admin/awrrpt.sql输⼊对应时间段的信息,获取 awr 报告。
Top 10 Foreground Events by Total Wait Time也可通过 awrcrt sqlplus / as sysdba @awrcrt.sql来获取多段性能指标信息:通过观察 awr 报告中段的统计信息章节Segments by Row Lock Waits项,可以发现发⽣锁的对象主要是两张表A和B和A表的索引:与应⽤确认后,发现其中⼀张表A为核⼼业务表,暂时怀疑另⼀张表可能存在问题,这⾥称之为表B,所以A表暂且不考虑。
SQL ordered by Elapsed Time通过 搜索关键字,查出 B 表对应的UPDATE语句,执⾏较为频繁,先记录待查看:sql_id 为:2xb71ufa5wmrh。
ASH 报告抓取对应时间段的 ash 报告,查看是否存在有⽤信息。
buffer busy waits

110 (1014) :
The blocked or waiting session wants to access the current image of the block in either shared (to read) or exclusive (to write) mode, but the blocking session is reading the block into cache.
130 (1013) :
One or more sessions want to access the same block, but it is not in the buffer. One session will perform the I/O operation and post either a db file sequential read or a db file scattered read event, while the waiting sessions will post buffer busy waits with this reason code.
The blocking session is modifying the block, while the blocked session wants the current version of the block in exclusive mode. This happens when two processes want to update the same block.
220 (1016) :
The blocking session is modifying the block, while the blocked session wants to access the block in current mode during buffer lookup.
Oracle数据库缓冲区忙等待的原因解析

众多Oracle有关问题中,其中最重要的一个是缓冲区忙等待(buffer busy wait)事件。
缓冲区忙等待是I/O-bound Oracle系统中最常见的现象,尤其是在Oracle STATSPACK报告的前五个忙等待的读(顺序/分散)系统中,如前5个定时事件:% 总和事件等待时间(s)消逝时间--------------------------- ------------ ----------------------db文件顺序读 2,5987,146 48.54db文件分散读25,5193,246 22.04库缓冲区载入死锁6731,3639.26CPU时间2,1549347.83日志文件平行写 19,1578375.68减轻缓冲区忙等待的主要方式是减少系统中的I/O,这可以通过SQL使用更少的块读(block reads,比如添加索引)的方式得以实现。
即使对于一个比较大的db_cache_size,我们也可以减少缓冲区忙等待的时间。
为了能够查看整个系统的等待事件,我们可以查阅v$system_event性能视图。
这一性能视图提供了等待事件的名称,等待事件与时间的总和,以及每一事件的平均等待时间。
可以通过v$waitstat视图来查询导致等待的缓冲区的类型。
这一视图列出了每一缓冲区类型的等待,COUNT是类所有的等待总和,TIME是这一类所有等待的时间总和,如下所示:select * from v$waitstat;类 COUNTTIME------------------ ---------- ----------datablock19611131870278segment header34535 159082undoheader23363286239undo block 1886 1706当一个session访问缓冲区的块时,就有可能产生缓冲忙等待。
这一缓冲区忙等待的产生可能由以下的原因造成的:块可能被其它的session读到缓冲区,所以session必须等待块的读入结束。
180_ORACLE常见等待事件

Oracle的等待事件是衡量Oracle运行状况的重要依据及指标。
等待事件的概念是在Oracle7.0.1.2中引入的,大致有100个等待事件。
在Oracle 8.0中这个数目增加到了大约150个,在Oracle8i中大约有200个事件,在Oracle9i中大约有360个等待事件。
主要有两种类别的等待事件,即空闲(idle)等待事件和非空闲(non-idle)等待事件。
空闲事件指Oracle正等待某种工作,在诊断和优化数据库的时候,我们不用过多注意这部分事件。
常见的空闲事件有:• disp atcher timer• lock element cleanup• Null event• parallel query dequeue wait• parallel query idle wait - Slaves• pipe get• PL/SQL lock timer• pmon timer- pmon• rdbms ipc message• slave wait• smon timer• SQL*Net break/reset t o client• SQL*Net message from client• SQL*Net message to client• SQL*Net more data to client• virtual circuit status• client message非空闲等待事件专门针对Oracle的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是我们在调整数据库的时候应该关注与研究的。
一些常见的非空闲等待事件有:• db file scatter ed read• db file sequential read• buffer busy waits• free buffer waits• enqueue• latch free• log file parallel write• log file sync查看整个系统的等待事件(rainny):select*from v$system_event twhere t.WAIT_CLASS<>'Idle'order by t.TIME_WAITED desc;1. db file scattered read-DB 文件分散读取这种情况通常显示与全表扫描相关的等待。
关于statspack以及awr使用

关于Statspack,AWR以及ASH使用Statspack部分Statspack是Oracle 8i以后提供的一个非常好的性能监控与诊断工具。
在数据库管理中,Oracle提供的statspack是一个很强大的工具,通过Statspack,可以收集系统信息,诊断数据库故障,也方便第三方技术支持进行远程阅读和建议。
Oracle Statspack 从Oracle8.1.6开始被引入Oracle,并马上成为DBA和Oracle专家用来诊断数据库性能的强有力的工具。
在oracle10g中被awr取代。
通过Statspack我们可以很容易的确定Oracle数据库的瓶颈所在,记录数据库性能状态。
因此了解和使用Statspack对于DBA来说至关重要。
Statspack的脚本位于$ORACLE_HOME/rdbms/admin目录下。
第一部分statspack安装以及卸载Statspack安装安装statspack至少需要100M表空间,如果需要长期监控,这个表空间应该设置的大一些。
Statspack相关数据不要放到system表空间。
在官方文档中明确指出在system表空间中不支持。
Statspack安装脚本位于:Unix:$ORACLE_HOME/rdbms/admin/spcreate.sqlWindow:%ORACLE_HOME%\rdbms\admin\spcreate.sql下面就以window下安装为例子介绍下statspack的安装过程以及出现问题如何处理:首先执行%ORACLE_HOME\rdbms\admin\spcreate.sql然后会提示你输入perfstat用户密码,指定默认表空间以及temporary表空间:下面白色部分已经明确指出system表空间不支持。
检查当前目录下spcusr.lis,spctab.lis和spcpkg.lis这三个文件,这三个文件记录安装过程所有记录,如果有问题可以使用%ORACLE_HOME\rdbms\admin\spdrop.sql删除后再重新安装1. spcusr -> 建用户和授予权限2. spctab -> 建表同义词索引等记录3. spcpkg -> 建包记录在unix下也可以用batch模式安装:SQL> connect / as sysdbaSQL> define default_tablespace='perfstat'SQL> define temporary_tablespace='temp'SQL> define perfstat_password='perfstat'SQL> @?/rdbms/admin/spcreate.sqlSQL> undefine perfstat_passwordstatspack的卸载Statspack卸载脚本位于:Unix:$ORACLE_HOME/rdbms/admin/spdrop.sqlWindow:%ORACLE_HOME%\rdbms\admin\spdrop.sql下面以window下卸载为例子介绍下statspack的卸载:执行%ORACLE_HOME\rdbms\admin\spcreate.sql执行完毕后,它会提示你去检查当前目录下的spdusr.lis和spdtab.lis文件Statspack数据清理(清理全部数据)当存放statspack的表空间快满的时候需要我们去清理表空间,操作如下:Statspack清理脚本位于:Unix:$ORACLE_HOME/rdbms/admin/sptrunc.sqlWindow:%ORACLE_HOME%\rdbms\admin\ sptrunc.sql下面以window下清理为例子介绍下statspack数据清理:执行%ORACLE_HOME\rdbms\admin\ sptrunc.sqlStatspack数据清理(清理指定数据)当存放statspack的表空间快满的时候需要我们去清理表空间,操作如下:Statspack清理脚本位于:Unix:$ORACLE_HOME/rdbms/admin/sppurge.sqlWindow:%ORACLE_HOME%\rdbms\admin\ sppurge.sql下面以window下清理为例子介绍下statspack数据清理:执行%ORACLE_HOME\rdbms\admin\ sppurge.sql下面会列出能清理的相关时间收集的统计信息:下面提示你输入开始和结束时间点,我们上面的是6,7,8,9,这四个数字代表相应时间,我执行这四次操作是连续做的,时间看起来不明显。
ORACLE操作表时”资源正忙,需指定nowait的解锁方法

ORACLE操作表时”资源正忙,需指定nowait"的解锁方法问题:执行drop table table_name 时,提示”资源正忙,需指定nowait"由于TB_PROJECT为设置主键造成只能查询而无法修改和删除的问题导致PL/SQL无响应,从而对此表一直处于锁定状态分析:表示table_name表由某个用户操作时进行了锁定,必须先解锁才能继续进行操作解决:1> 通过此语句查询正在锁定的SESSION_ID:SELECT SESSION_ID FROM V$LOCKED_OBJECT,USER_OBJECTS WHERE V$LOCKED_OBJECT.OBJECT_ID = USER_OBJECTS.OBJECT_ID2> 通过第一步查询到的SESSION_ID查询SERIAL#SELECT SERIAL# FROM V$SESSION WHERE SID='SESSION_ID'(此处为上面查询到的'SESSION_ID)3> 根据1,2步查询到的SESSION_ID和SERIAL#执行ALTER SYSTEM KILL SESSION '48,2476'(48为SESSION_ID的值, 2476为SERIAL#的值)Oracle解锁问题执行truncate table 报错:ORA-00054: 资源正忙,要求指定NOWAIT解决:通过v$session,v$locked_object查看谁锁定了资源select t1.sid, t1.serial#, ername, t1.logon_time from v$session t1 , v$locked_object t2通过alter system kill session 'sid, serial#'把session kill掉alter system kill session '6,8'。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
当会话意图访问缓冲存储器中的数据块,而该数据块正在被其它会话使用时产生buffer busy waits事件。
其它会话可能正在从数据文件向缓冲区存储器度曲同样的数据块,或正在缓冲存储器中对其进行修改。
为了确保读取器会话拥有与获得所有更改或无更改的数据块一致的映像,正在修改该数据块的会话在其标题中标记一个标志,让其他会话知道有一个更改正在进行而等候更改的的完成。
视图v$waitstat不是OWI的组件,但其为没一类缓冲区提供了有用的等待统计。
遭遇buffer busy等待事件最常见的缓冲区类为块、段标题、撤消块、撤消标题。
显示一个查询v$waitstat视图的采样输出:
具体示例如下:
SELECT * FROM V$waitstat WHERE COUNT>0;
CLASS COUNT TIME
------------------ ---------- ----------
data block 4170082 1668098
segment header 116 98
undo header 916 1134
undo block 2087 1681
1、等待参数
buffer wait busy的等待参数描述如下:
P1 在Oracle 8及其以后版本的数据库里,P1显示询问数据块驻留的绝对文件号。
P2 进程需要访问的实际块号。
P3 在Oracle10g以前的版本中,着是表示等待原因的数字。
Oracle在内河代码中在
多个地方用不同的原因码提交。
该原因码取决于版本。
2、等待时间
100厘秒或1秒。
· Oracle会话正在等待钉住一个缓冲区。
必须在读取或修改缓冲区前将它钉住。
在任何
时刻只有一个进程可以钉住一个缓冲区。
·buffer busy waits表明读/读、读/写、写/写争用。
·采取的适当措施取决于P3参数中的原因码。
在SGA中读取或修改缓冲区的会话必须首先获取cache buffers chains锁存器,并且遍历这个缓冲区链,直到他发现必需的缓冲区头。
然后,他必须以共享模式或独占模式获取
一个缓冲区锁或缓冲区头上的pin,这取决于他计划的操作。
一旦缓冲区头被钉住,会话
就释放cache buffers chains锁存器,并在缓冲区自身上执行计划的操作。
如果无法获
取一个pin,会话就在buffer busy waits等待事件上等待。
这种等待时间不会应用于在
会话的私有PGA中执行的读取或写入操作。
3、诊断的原因、诊断和动作
·表示为什么进程无法获得一个缓冲区pin的主要原因码。
·buffer busy waits等待时间需要的块类。
·和buffer busy waits时间相关的SQL语句。
·缓冲区所属的段。
--查找等待块类型
SELECT 'segment Header' CLASS,
a.Segment_Type,
a.Segment_Name,
a.Partition_Name
FROM Dba_Segments a,
V$session_Wait b
WHERE a.Header_File = b.P1
AND a.Header_Block = b.P2
AND b.Event = 'buffer busy waits'
UNION
SELECT 'freelist Groups' CLASS,
a.Segment_Type,
a.Segment_Name,
a.Partition_Name
FROM Dba_Segments a,
V$session_Wait b
WHERE b.P2 BETWEEN a.Header_Block + 1 AND
(a.Header_Block + a.Freelist_Groups)
AND a.Header_File = b.P1
AND a.Freelist_Groups > 1
AND b.Event = 'buffer busy waits'
UNION
SELECT a.Segment_Type || ' Block' CLASS,
a.Segment_Type,
a.Segment_Name,
a.Partition_Name
FROM Dba_Extents a,
V$session_Wait b
WHERE b.P2 BETWEEN a.Block_Id AND a.Block_Id + a.Blocks - 1
AND a.File_Id = b.P1
AND b.Event = 'buffer busy waits'
AND NOT EXISTS (SELECT 1
FROM Dba_Segments
WHERE Header_File = b.P1
AND Header_Block = b.P2);
◆带有原因码130的数据块(类#1)争用
如果buffer busy waits的等待事件主要集中在数据块(类#1)上,并且原因码130,则
表明应用程序运行在同一时刻查询相同数据集的多个会话,采用如下三件事最小化问题:
§减少并发级别或该表在运行现成直接内分区工作的方法。
§优化SQL语句,减少物理读取和逻辑读取的数量。
§增加freeLists和freeList Groups的数量。
◆带有原因码220的数据块(类#1)争用
多个会话同时在相同的对象上DML。
采用如下三件事最小化问题:
减少并发级别或改变划分部分的方法。
减少块中行的数量。
在另一个具有较小块尺寸的表空间中重新构建对象(Oracle 9i或以上版本)。
可以使用较大的PCTFREE重新构建表或索引。
可以使用命令改变表以最小化每个块的最小行数:
ALTER TABLE table_name MINIMIZE RECORDS_PER_BLOCK;
从Oracle 9i开始,可以在另外一个具有较小的块尺寸的表空间中移动或重新构建对象。
虽然这些动作可以最小化buffer busy waits问题,但是他们无疑将增加全表扫描时间
和磁盘空间利用率。
常言道,世上没有免费的午餐。
◆数据段头(类#4)的争用
如果buffer busy waits的等待时间主要集中在数据段头(即表或索引段头,并且不是
插销段头)上,这意味着数据库中的一些表或索引具有高段头活动。
如下解决问题:
增加已经确定对象的进程FreeLists和FreeList Groups的数量。
确保PctFree和PctUsed之间内的间隙不会太小。
确保下一个区尺寸不会太小。
如果不希望混浠FreeLists和FreeList Groups,可以依靠自动段空间管理(Automatic Segment Space Management,ASSM)特性,以分散从插入语句中引入的数据(9i特性)。
◆撤消段都(类#17)的争用
如果buffer busy waits等待时间主要集中在撤消段头上,这表明数据库中的回滚段
过少,或者他们的尺寸太小,从而造成对段头的频繁更新。
如果在Oracle 9i中引入的系统管理撤消,就不需要处理这种问题,因为Oracle将根据需要增加额外的撤消段。
◆撤消块的争用(类#18)
如果buffer busy waits等待时间主要集中在撤消块上,这通常意味着多个并发会话同时查询更新的数据。
当应用程序可以在不同的时间内查询和DML时,这种问题就不会存在。
◆系统级诊断
--文件等待次数
SELECT b.File_Id,
b.File_Name,
a.COUNT
FROM X$kcbfwait a,
Dba_Data_Files b
WHERE a.Indx = b.File_Id-1
AND a.COUNT > 0
ORDER BY a.COUNT;
来源:网络编辑:联动北方技术论坛。