Oracle 常见的33个等待事件
Oracle等待视图v$session_wait

db file scattered read 2 0 2
V$SESSION_EVENT
本视图记录了每个session的每一项等待事件。由上文所知V$SESSION_WAIT显示了session的当前等待事件,而V$SESSION_EVENT则记录了session自启动起所有的事件。
V$SESSION_EVENT中的常用列
SID:session标识
FROM v$session_wait GROUP BY event ORDER B Curr Tot
--------------------------------------------- ---- ----- -----
值=0:session正在等待当前的事件。
值=-1:最后一次等待时间小于1个统计单位,当前未在等待状态。
值=-2:时间统计状态未置为可用,当前未在等待状态。
3.Wait_time和Second_in_wait字段值与state相关:
如果state值为Waiting,那么wait_time值无用。Second_in_wait值是实际的等待时间(单位:秒)。
210 Session想读入SCUR或XCUR中的块,如果块交换或者session处于非连续的TX模式,所以等待可能需要很长的时间。
220 在缓冲区查询一个块的当前版本,但有人以不合法的模式使用这一块,所以我们只能等待。
230 以CR/CRX方式获得一个块,但块中的更改开始并且没有结束。
231 CR/CRX扫描找到当前块,但块中的更改开始并且没有结束。
EVENT:session等待的事件
TOTAL_WAITS:此session当前事件的总等待数
oracle ash报告解读

oracle ash报告解读Oracle ASH(Active Session History)报告是对数据库实例中活动会话(active sessions)的记录和统计。
通过ASH报告,可以了解数据库中的各种活动情况,包括等待事件(wait event)、SQL语句运行情况、并发情况等,对于性能问题的分析和排查非常有帮助。
ASH报告提供了以下关键信息:1. 等待事件:记录了数据库中所有活动会话正在等待的事件,包括等待的类型、等待的时间等。
对于性能问题的排查,这是非常重要的一个指标,可以快速定位到导致性能问题的等待事件。
2. SQL语句信息:记录了数据库中活动会话正在执行的SQL 语句的相关信息,包括SQL语句的执行计划、IO信息、CPU 使用情况等。
通过这些信息,可以找到执行时间最长的SQL 语句,从而针对性地进行性能优化。
3. 系统资源使用情况:记录了数据库实例中各种系统资源的使用情况,包括CPU使用情况、内存使用情况、IO情况等。
通过这些信息,可以了解到系统资源的状况,以及是否存在资源瓶颈。
4. 并发情况:记录了数据库实例中并发活动的情况,包括并发会话的数量、并发活动的时间分布等。
通过这些信息,可以了解到系统的并发负载情况,以及是否存在过度并发导致的性能问题。
解读ASH报告时,需要关注以下几个方面:1. 查找等待事件:根据ASH报告中记录的等待事件信息,可以找到导致性能问题的等待事件,通常这些等待事件的时间占比较高,需要针对这些等待事件进行排查和优化。
2. 分析SQL语句:根据ASH报告中记录的SQL语句信息,可以找到执行时间最长的SQL语句,并分析其执行计划、IO 信息、CPU使用情况等,以找出优化的方向。
3. 关注系统资源使用情况:ASH报告中记录了系统资源的使用情况,可以了解到系统是否存在资源瓶颈,以及是否需要进行资源调优。
4. 观察并发情况:通过ASH报告中记录的并发活动情况,可以了解到系统的并发负载情况,如果并发负载过高可能会导致性能问题,需要进行相应的优化措施。
oracle常见等待事件及处理方法

我们可以通过视图v$session_wait来查看系统当前的等待事件,以及与等待事件相对应的资源的相关信息看书笔记db file scattered read DB ,db file sequential read DB,free buffer waits,log buffer space,log file switch,log file sync我们可以通过视图v$session_wait来查看系统当前的等待事件,以及与等待事件相对应的资源的相关信息,从而可确定出产生瓶颈的类型及其对象。
v$session_wait的p1、p2、p3告诉我们等待事件的具体含义,根据事件不同其内容也不相同,下面就一些常见的等待事件如何处理以及如何定位热点对象和阻塞会话作一些介绍。
<1> db file scattered read DB 文件分散读取(太多索引读,全表扫描-----调整代码,将小表放入内存)这种情况通常显示与全表扫描相关的等待。
当全表扫描被限制在内存时,它们很少会进入连续的缓冲区内,而是分散于整个缓冲存储器中。
如果这个数目很大,就表明该表找不到索引,或者只能找到有限的索引。
尽管在特定条件下执行全表扫描可能比索引扫描更有效,但如果出现这种等待时,最好检查一下这些全表扫描是否必要。
因为全表扫描被置于LRU(Least Recently Used,最近最少适用)列表的冷端(cold end),所以应尽量存储较小的表,以避免一次又一次地重复读取它们。
==================================================该类事件的p1text=file#,p1是file_id,p2是block_id,通过dba_extents即可确定出热点对象(表或索引)select owner,segment_name,segment_typefrom dba_extentswhere file_id = &file_idand &block_id between block_id and block_id + &blocks - 1;==================================================<2> db file sequential read DB 文件顺序读取(表连接顺序不佳-----调整代码,特别是表连接)这一事件通常显示单个块的读取(如索引读取)。
Oracle错误代码案例总结及解决方案

常见错误:ORA-00001:违反唯一约束条件(主键错误)ORA—00028:无法连接数据库进程ORA—00900:无效sql语句ORA—00904:字段名写错或是建表时最后一个字段有逗号ORA-00907:缺少右括号ORA—00911:无效字符ORA—00917:缺少逗号ORA-00918:未明确定义列ORA-00922:丢失或无效的选项(表名等可能有空格)ORA—00923:未找到FROM关键字ORA—00926:缺少valueORA—00933: SQL命令未正确结束ORA—00936:缺少表达式ORA—00937:不是单组分组函数ORA—00942:表或视图不存在ORA-00947:没有足够的值(一般是插入语句出现的错,插入值的数量与字段不符)ORA-00979:不是group by的表达式ORA—01009:缺少法定参数(eg:sql做参数时,且sql语句为空时,报错)ORA-01098:数据库无法关闭及启动ORA—01400:无法将null值插入ORA—01401:插入的值对于列过大ORA-01476:sql中存在除数为零ORA—01579: 恢复过程中出现写错误ORA—01580: 创建控制备份文件时出错ORA-01581: 尝试使用已分配的回退段() 新区()ORA-01582:无法打开要备份的控制文件ORA—01583: 无法获得要备份的控制文件的块大小ORA-01584:无法获得要备份的控制文件的文件大小ORA-01585: 标识备份文件时出错ORA-01586: 无法打开要备份的目标文件ORA-01587: 复制控制文件的备份文件时出错ORA-01588:要打开数据库则必须使用RESETLOGS 选项ORA-01589: 要打开数据库则必须使用RESETLOGS 或NORESETLOGS 选项ORA-01590:段可用列表数()超出最大数ORA—01591:锁定已被有问题的分配事务处理挂起ORA—01592:将第7 版回退段() 转换为Oracle 8 版格式时出错ORA—01593: 回退段最佳大小(blks) 小于计算的初始大小( blks)ORA—01594: 尝试放回已释放的回退段()区()ORA-01595:释放区() 回退段()时出错ORA—01596: 无法在参数中指定系统ORA-01597:无法改变联机或脱机系统回退段ORA-01598: 回退段''未联机ORA-01599: 无法获得回退段(), 高速缓存空间已满ORA—01600: 至多只有一个””在子句""()中ORA-01601: 子句””()中的存储桶大小非法ORA-01603:子句"”()中的分组大小非法ORA—01604: 子句”"()中的编号范围非法ORA—01605: 子句”"()中缺少编号ORA—01606: gc_files_to_locks 不同于另一已安装例程的参数ORA-01608:无法将回退段’'联机,其状态为()ORA-01609:日志是线程的当前日志—无法删除成员ORA—01610: 使用BACKUP CONTROLFILE 选项的恢复必须已完成ORA-01611: 线程编号无效- 必须介于1 和之间ORA-01612: 线程已经启用ORA—01613:线程只有日志- 要求至少启用2 个日志ORA-01614:线程正忙- 无法启用ORA—01615: 线程已安装—无法禁用ORA-01616: 线程已打开—无法禁用ORA-01617: 无法安装: 不是有效的线程编号ORA-01618: 线程未启用- 无法安装ORA—01619:线程已由另一例程安装ORA-01620: 没有可用于安装的公用线程ORA-01621:数据库打开时无法重命名当前日志的成员ORA—01622: 必须指定线程编号- 没有特定默认值ORA-01623: 日志是线程的当前日志- 无法删除ORA—01624: 线程的紧急恢复需要日志ORA-01625:回退段'’不属于此例程ORA—01626:回退段号''无法处理更多事务处理ORA—01627: 回退段号''未联机ORA—01628: 已达到max # extents ()(回退段)ORA-01629: 已达到max #extents (),此时正在保存表空间的撤消ORA—01630: 表空间中的temp 段达到max #extents()ORA-01631:表。
Oracle常见死锁发生的原因以及解决方法

Oracle常见死锁发生的原因以及解决方法死锁是指在并发程序中,两个或多个进程因为争夺系统资源而陷入无限等待的状态,从而无法继续执行下去。
在Oracle数据库中,死锁是一个非常常见的问题,它会导致系统性能下降,甚至造成系统崩溃。
本文将详细介绍Oracle常见死锁发生的原因以及解决方法。
一、死锁发生的原因1.竞争资源:当多个进程同时请求相同的资源时,可能会导致死锁的发生。
例如,如果两个进程同时请求一个表的写锁,那么它们就会陷入死锁状态。
2.锁的顺序:当多个进程按照不同的顺序请求锁时,可能会导致死锁的发生。
例如,如果进程A先请求资源X,再请求资源Y,而进程B先请求资源Y,再请求资源X,那么它们就会陷入死锁状态。
3.锁的持有时间:当一个进程持有一个锁,并且在等待其他资源时继续保持该锁,可能会导致死锁的发生。
例如,如果进程A持有资源X的锁,并且在等待资源Y时继续保持该锁,而进程B持有资源Y的锁,并且在等待资源X时继续保持该锁,那么它们就会陷入死锁状态。
二、死锁的解决方法1. 死锁检测和解除:Oracle数据库提供了死锁检测和解除的机制。
当一个进程请求一个资源时,数据库会检查是否存在死锁。
如果存在死锁,数据库会选择一个进程进行回滚,解除死锁状态,并且通知其他进程重新尝试获取资源。
2.超时设置:为了避免死锁的发生,可以设置超时时间。
当一个进程请求一个资源时,如果在指定的超时时间内无法获取资源,那么就放弃该请求,并且释放已经持有的资源。
这样可以防止死锁的发生,但是会增加系统的开销。
3.锁的顺序:为了避免死锁的发生,可以规定所有进程按照相同的顺序请求锁。
例如,可以规定所有进程按照资源的名称进行排序,然后按照顺序请求锁。
这样可以避免死锁的发生,但是可能会影响系统的性能。
4.锁的粒度:为了避免死锁的发生,可以尽量减小锁的粒度。
例如,可以将一个大的锁分解成多个小的锁,这样可以减少锁的冲突,降低死锁的概率。
但是需要注意的是,锁的粒度过小可能会导致系统的性能下降。
oracle常见等待事件及处理方法

oracle常见等待事件及处理方法Oracle是一种流行的关系型数据库管理系统,它被广泛应用于企业级应用程序中。
在使用Oracle时,我们经常会遇到等待事件,这些事件可能会导致性能下降。
本文将介绍一些常见的Oracle等待事件及其处理方法。
1. DB FILE SEQUENTIAL READDB FILE SEQUENTIAL READ是一种等待事件,它表示Oracle正在等待从磁盘读取数据块。
这种等待事件通常发生在全表扫描或索引扫描期间。
要解决这个问题,可以考虑增加缓存大小或优化查询语句。
2. DB FILE SCATTERED READDB FILE SCATTERED READ是一种等待事件,它表示Oracle正在等待从磁盘读取散布的数据块。
这种等待事件通常发生在使用I/O密集型操作时。
要解决这个问题,可以考虑增加缓存大小或优化查询语句。
3. LOG FILE SYNCLOG FILE SYNC是一种等待事件,它表示Oracle正在等待将日志文件写入磁盘。
这种等待事件通常发生在事务提交时。
要解决这个问题,可以考虑增加日志缓存大小或优化事务提交频率。
4. ENQUEUEENQUEUE是一种等待事件,它表示Oracle正在等待获取锁。
这种等待事件通常发生在并发访问数据库时。
要解决这个问题,可以考虑优化锁定策略或减少并发访问。
5. LATCHLATCH是一种等待事件,它表示Oracle正在等待获取内部数据结构的锁。
这种等待事件通常发生在高并发访问数据库时。
要解决这个问题,可以考虑增加内存大小或优化查询语句。
6. CPU TIMECPU TIME是一种等待事件,它表示Oracle正在等待CPU资源。
这种等待事件通常发生在CPU密集型操作时。
要解决这个问题,可以考虑增加CPU资源或优化查询语句。
总之,Oracle等待事件可能会导致性能下降,但我们可以通过优化查询语句、增加缓存大小、优化锁定策略等方法来解决这些问题。
Oracle错误一览表2

ORA-02201: 此处不允许序列(号)ORA-02202: 此群集中不允许添加其它表ORA-02203: 不允许的INITIAL 存储选项ORA-02204: 不允许ALTER, INDEX 和EXECUTE 用于视图ORA-02205: 只有SELECT 和ALTER 权限对序列有效ORA-02206: 重复的INITRANG 选项说明ORA-02207: 无效的INITRANS 选项值ORA-02208: 重复的MAXTRANS 选项说明ORA-02209: 无效的MAXTRANS 选项值ORA-02210: 未指定ALTER TABLE 的选项ORA-02211: 无效的PCTFREE 或PCTUSED 值ORA-02212: 重复的PCTFREE 选项说明ORA-02213: 重复的PCTUSED 选项说明ORA-02214: 重复的BACKUP 选项说明ORA-02215: 重复的表空间名子句ORA-02216: 需要表空间名ORA-02217: 重复的存储选项说明ORA-02218: 无效的INITIAL 存储选项值ORA-02219: 无效的NEXT 存储选项值ORA-02220: 无效的MINEXTENTS 存储选项值ORA-02221: 无效的MAXEXTENTS 存储选项值ORA-02222: 无效的PCTINCREASE 存储选项值ORA-02223: 无效的OPTIMAL 存储选项值ORA-02224: EXECUTE 权限对于表不允许ORA-02225: 只有EXECUTE 和DEBUG 权限对过程有效ORA-02226: 无效的MAXEXTENTS 值(最大允许为: )ORA-02227: 无效的群集名ORA-02228: 重复的SIZE 说明ORA-02229: 无效的SIZE 选项值ORA-02230: 无效的ALTER CLUSTER 选项ORA-02231: 缺少或无效的ALTER DATABASE 选项ORA-02232: 无效的MOUNT 模式ORA-02233: 无效的CLOSE 模式ORA-02234: 已经记录对此表的更改ORA-02235: 此表已将更改记录在另一表中ORA-02236: 无效的文件名ORA-02237: 无效的文件大小ORA-02238: 文件名列表具有不同的文件数ORA-02239: 存在引用此序列的对象ORA-02240: 无效的OBJNO 或TABNO 值ORA-02241: 必须是EXTENTS (FILE <n> BLOCK <n> SIZE <n>,...) 格式ORA-02242: 未指定ALTER INDEX 的选项ORA-02243: ALTER INDEX 或ALTER MATERIALIZED VIEW 选项无效ORA-02244: 无效的ALTER ROLLBACK SEGMENT 选项ORA-02245: 无效的ROLLBACK SEGMENT 名ORA-02246: 缺少EVENTS 文本ORA-02247: 未指定ALTER SESSION 的选项ORA-02248: 无效的ALTER SESSION 选项ORA-02249: 缺少或无效的MAXLOGMEMBERS 值ORA-02250: 缺少或无效的约束条件名ORA-02251: 此处不允许子查询ORA-02252: 检查未正确结束的约束条件ORA-02253: 此处不允许约束条件说明ORA-02254: 此处不允许DEFAULT <表达式>ORA-02255: obsolete 7.1.5ORA-02256: 要引用的列数必须与已引用道感数匹配ORA-02257: 超出最大列数ORA-02258: 重复或冲突的NULL 和(或)NOT NULL 说明ORA-02259: 重复的UNIQUE/PRIMARY KEY 说明ORA-02260: 表只能具有一个主键ORA-02261: 表中已存在这样的唯一关键字或主键ORA-02262: 对列默认值表达式进行类型检查时, 出现ORA- ORA-02263: 需要指定此列的数据类型ORA-02264: 名称已被一现有约束条件占用ORA-02265: 无法推导引用列的数据类型ORA-02266: 表中的唯一/主键被启用的外部关键字引用ORA-02267: 列类型与引用的列类型不兼容ORA-02268: 引用的表不具有主键ORA-02269: 关键字列不能是LONG 数据类型ORA-02270: 此列列表的唯一或主键不匹配ORA-02271: 表没有这样的约束条件ORA-02272: 约束条件列不能是LONG 数据类型ORA-02273: 此唯一/主键已被某些外部关键字引用ORA-02274: 重复的引用约束条件说明ORA-02275: 此表中已经存在这样的引用约束条件ORA-02276: 默认值类型与列类型不兼容ORA-02277: 无效的序列名ORA-02278: 重复或冲突的ORDER/NOORDER 说明ORA-02279: 重复或冲突的ORDER/NOORDER 说明ORA-02280: 重复或冲突的ORDER/NOORDER 说明ORA-02281: 重复或冲突的ORDER/NOORDER 说明ORA-02282: 重复或冲突的ORDER/NOORDER 说明ORA-02283: 无法改变起始序号ORA-02284: 重复的INCREMENT BY 说明ORA-02285: 重复的START WITH 说明ORA-02286: 未指定ALTER SEQUENCE 的选项ORA-02287: 此处不允许序号ORA-02288: 无效的OPEN 模式ORA-02289: 序列(号)不存在ORA-02290: 违反检查约束条件(.)ORA-02291: 违反完整约束条件(.) - 未找到父项关键字ORA-02292: 违反完整约束条件(.) - 已找到子记录日志ORA-02293: 无法验证(.) - 违反检查约束条件ORA-02294: 无法启用(.) - 约束条件在验证过程中更改ORA-02295: 找到约束条件的多个启用/禁用子句ORA-02296: 无法启用(.) - 找到空值ORA-02297: 无法禁用约束条件(.) - 存在依赖关系ORA-02298: 无法验证(.) - 未找到父项关键字ORA-02299: 无法验证(.) - 未找到重复关键字ORA-02300: 无效的OIDGENERATORS 值ORA-02301: OIDGENERATORS 的最大数为255ORA-02302: 无效或缺少类型名ORA-02303: 无法使用类型或表的相关性来删除或取代一个类型ORA-02304: 无效的对象标识文字ORA-02305: 只有EXECUTE, DEBUG 和UNDER权限对类型有效ORA-02306: 无法创建已具有有效相关性的类型ORA-02307: 无法使用REPLACE 选项改变无效类型ORA-02308: 无效的对象类型列选项ORA-02309: 违反原子NULLORA-02310: 超出表中允许的最大列数ORA-02311: 无法使用COMPILE 选项改变具有类型或表相关性的有效类型ORA-02313: 对象类型包含不可查询的类型属性ORA-02315: 默认构造符的参数个数错误ORA-02320: 无法创建嵌套表列的存储表ORA-02322: 无法访问嵌套表列的访问表ORA-02324: THE 子查询的SELECT 列表中存在多列ORA-02327: 无法以数据类型的表达式创建索引ORA-02329: 数据类型的列不能是唯一关键字或主键ORA-02330: 不允许的数据类型说明ORA-02331: 无法创建数据类型为的列的约束条件ORA-02332: 无法对此列的属性创建索引ORA-02333: 无法对此列的属性创建约束条件ORA-02334: 无法推断列类型ORA-02335: 无效的群集列数据类型ORA-02336: 无法访问列属性ORA-02337: 不是对象类型列ORA-02338: 缺少或无效的列约束条件说明ORA-02339: 无效的列说明ORA-02340: 无效的列说明ORA-02342: 取代类型具有编译错误ORA-02344: 无法撤消执行具有表相关性的类型ORA-02345: 无法创建具有基于CURSOR 运算符的列的视图ORA-02347: 无法授权给对象表列ORA-02348: 无法创建具有嵌入LOB 的VARRAY 列ORA-02349: 无效的用户自定义类型- 类型不完整ORA-02351: 记录: 被拒绝- 表, 列上出错ORA-02352: 直接路径连接必须在同类间进行ORA-02353: 多字节字符错误ORA-02354: 字段中出现转换初始化错误ORA-02355: CONSTANT 字段中出现转换错误ORA-02356: 数据库空间耗尽。
详解log file sync等待事件

数据库中的log file sync等待事件指的是,当user session 提交(commit)时,user session会通知LGWR进程将redo buffer中的信息写入到redo log file,当LGWR进程完成写操作后,LGWR进程再post(通知)user session 写操作已经完成,user session 接收到LGWR的通知后提交操作才完成。
因此user session 在没有收到LGWR post(通知)之前一致处于等待状态,具体的等待事件为log file sync。
根据实践经验,引起log file sync等待事件的原因有以下几种:⏹事务过度的提交,即应用程序过度commit或者rollback。
⏹存储I/O资源紧张,导致lgwr进程写速度缓慢。
⏹CPU资源紧张,lgwr进程获得不了响应的CPU时间片。
⏹RAC节点之间SCN同步。
⏹RAC节点之间CR块传递。
⏹控制文件争用。
不同的原因,其解决方法会不同,当多种原因混合在一起时,则需要进行综合考虑。
事务过度提交事务过度提交是引起log file sync等待事件的主要原因之一。
前面提到,默认情况下,当事务提交时,LGWR进程会将事务相关的日志条目立即写至redolog中,直到日志写成功之后才显示提交成功。
所以事务提交越频繁,触发LGWR进程写操作越频繁,引起log file sync等待时间的可能性越大。
所以当由于事务过度提交引起log file sync等待事件时,最好的解决方法是修改应用,将小事务变成大事务。
可在很多情况下,修改应用不是很简单的事情,需要应用厂商配合。
当应用厂商配合程度不足时,我们就需要在DB端想办法了。
所幸的是从Oracle 10g开始,Oracle推出了新的数据库参数commit_write用于控制LGWR进程写日志操作,其默认值为空,表示wait和immediate。
也可以将其在线修改(即参数值修改后不需要重启数据库就能生效)成nowait和batch,表示事务提交时,LGWR进程并不马上将事务相关条目写至日志文件中,而是异步模式将相关条目批量(batch)写至日志文件中。
oracle遇到的问题及答案

oracle遇到的问题及答案问题⼀:Oracle 11G⽤EXP时,空表不能导出解决⽅法第⼀查询空表到底有多少张,也就是查询为分配分配segment的表有多少张SQL> select table_name from user_tables where NUM_ROWS=0;TABLE_NAME------------------------------DATA_BACKUPEQUIPMENTFEEDBACK_ACCESSORIESSPECIALPICTASK_THIRDTASK_THIRDBATCHTASK_THIRD_DATATASK_THIRD_FEEDBACKTESTDATA_THIRDTHIRD_ACCESSORIES已选择10⾏。
第⼆查询在当前⽤户下有总的有多少张表SQL> select count(*) FROM USER_TABLES;COUNT(*)----------32第三导出当前⽤户下的数据C:\Users\Administrator>exp lcpt/lcpt file=E:\0702bj\lcpt.dmp wner=lcpt log=E 702bj\lcpt.logExport: Release 11.2.0.1.0 - Production on 星期⼀ 7⽉ 2 10:42:07 2012 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. 连接到: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Productio With the Partitioning, OLAP, Data Mining and Real Application Testing options 已导出 ZHS16GBK 字符集和 AL16UTF16 NCHAR 字符集即将导出指定的⽤户.... 正在导出 pre-schema 过程对象和操作. 正在导出⽤户 LCPT 的外部函数库名. 导出 PUBLIC 类型同义词. 正在导出专⽤类型同义词. 正在导出⽤户 LCPT 的对象类型定义即将导出 LCPT 的对象.... 正在导出数据库链接. 正在导出序号. 正在导出簇定义. 即将导出 LCPT 的表通过常规路径.... . 正在导出表 ACCESSORIES导出了 18 ⾏. . 正在导出表 AUTH导出了 240 ⾏. . 正在导出表 DATA_TEMP导出了 1 ⾏. . 正在导出表 FEEDBACK导出了 1 ⾏. . 正在导出表 FUNCTION导出了 112 ⾏. . 正在导出表 LIMIT导出了 1 ⾏. . 正在导出表MODULE导出了 37 ⾏. . 正在导出表 READ_ACCESSORIES导出了 2 ⾏. . 正在导出表 REGIONINFO导出了 19 ⾏. . 正在导出表 REPORT_EVENT导出了 8 ⾏. . 正在导出表 ROLE导出了 5 ⾏. . 正在导出表 ROLEAUTH导出了 606 ⾏. . 正在导出表STAFFLOG导出了 512 ⾏. . 正在导出表 STAFFROLE导出了 56 ⾏. . 正在导出表 STAFFS导出了 7 ⾏. . 正在导出表TASKINFO导出了 51 ⾏. . 正在导出表 TASK_FILIALE导出了 2 ⾏. . 正在导出表 TASK_FILIALE_FEEDBACK导出了 2 ⾏. . 正在导出表 TASK_SWARAJ_READ导出了 49 ⾏. . 正在导出表 TESTDATA导出了 407 ⾏. . 正在导出表 THIRDFACTURER导出了 3 ⾏. . 正在导出表 USESSION导出了 1 ⾏. 正在导出同义词. 正在导出视图. 正在导出存储过程. 正在导出运算符. 正在导出引⽤完整性约束条件. 正在导出触发器. 正在导出索引类型. 正在导出位图, 功能性索引和可扩展索引. 正在导出后期表活动. 正在导出实体化视图. 正在导出快照⽇志. 正在导出作业队列. 正在导出刷新组和⼦组. 正在导出维. 正在导出 post-schema 过程对象和操作. 正在导出统计信息成功终⽌导出, 没有出现警告。
oracle常见等待事件及处理方法

enqueue 是一种保护共享资源的锁定机制。该锁定机制保护共享资源,如记录中的数据,以避免两个人在同一时间更新同一数据。enqueue 包括一个排队机制,即FIFO(先进先出)排队机制。注意:Oracle 的latch 机制不是FIFO。Enqueue 等待通常指的是ST enqueue、HW enqueue、TX4 enqueue 和TM enqueue。
<2> db file sequential read DB 文件顺序读取 (表连接顺序不佳-----调整代码,特别是表连接)
这一事件通常显示单个块的读取(如索引读取)。这种等待的数目很多时,可能显示表的连接顺序不佳,或者不加选择地进行索引。对于大量事务处理、调整良好的系统,这一数值大多是很正常的,但在某些情况下,它可能暗示着系统中存在问题。你应当将这一等待统计量与Statspack 报告中的已知问题(如效率较低的SQL)联系起来。检查索引扫描,以保证每个扫描都是必要的,并检查多表连接的连接顺序。DB_CACHE_SIZE 也是这些等待出现频率的决定因素。有问题的散列区域(Hash-area)连接应当出现在PGA 内存中,但它们也会消耗大量内存,从而在顺序读取时导致大量等待。它们也可能以直接路径读/写等待的形式出现。
<7> log buffer space 日志缓冲空间 (写REDO慢-----增大log_buffer,redo log file放到快速磁盘上)
当日志缓冲(log buffer)写入重做日志(redo log)的速度比LGWR 的写入速度慢,或者是当日志转换(log switch)太慢时,就会发生这种等待。为解决这个问题,可以增大日志文件的大小,或者增加日志缓冲器的大小,或者使用写入速度更快的磁盘。甚至可以考虑使用固态磁盘,因为它们的速度很高。
library cache lock 等待原理

library cache lock 等待原理
在数据库系统中,Library Cache Lock是一种用于控制LibraryCache并发访问的锁。
它通过在对象句柄上获取锁,来防止多个客户端同时访问同一个对象,或者长时间地保持对某个对象的依赖。
此外,在用户试图在LibraryCache中查找定位对象时,也需要获取LibraryCache Lock。
对于LibraryCache Lock,有三种模式分别是null、share、exclusive,对于该锁的获得等待时间为3秒,其中1秒用于pmon进程。
如果超过3秒,就会产生等待。
LibraryCache Lock等待事件是Oracle数据库中较为常见的等待事件之一。
可能的原因包括登录密码错误尝试过多、热表收集统计信息和SQL解析失败等。
oracle监控指标

Oracle监控指标1. 简介Oracle是一种关系型数据库管理系统,被广泛应用于企业级应用程序中。
在使用Oracle数据库时,监控数据库的性能和运行状态是非常重要的。
通过监控指标,可以及时发现并解决潜在的问题,确保数据库的稳定性和可靠性。
本文将介绍Oracle数据库中常见的监控指标,包括性能指标、存储指标、会话指标、等待事件指标等。
通过对这些指标的监控和分析,可以全面了解数据库的运行状况,并采取相应的措施进行优化和调整。
2. 性能指标性能是数据库系统最重要的衡量标准之一。
下面是一些常见的Oracle性能指标:CPU利用率CPU利用率是衡量数据库服务器CPU资源使用情况的重要指标。
可以通过查询V$SYSSTAT视图中与CPU相关的统计信息来获取CPU利用率信息。
内存利用率内存利用率反映了数据库服务器内存资源使用情况。
可以通过查询V$SGASTAT视图中与内存相关的统计信息来获取内存利用率信息。
IO吞吐量IO吞吐量是衡量磁盘I/O操作效率的重要指标。
可以通过查询V$SYSSTAT视图中与I/O相关的统计信息来获取IO吞吐量信息。
响应时间响应时间是衡量数据库系统性能的关键指标之一。
可以通过查询V$SYS_TIME_MODEL视图中的统计信息来获取响应时间信息。
3. 存储指标存储是数据库系统中最重要的资源之一,对存储进行有效管理和监控是确保数据库性能稳定的关键。
下面是一些常见的Oracle存储指标:表空间使用率表空间使用率是衡量数据库存储资源利用情况的重要指标。
可以通过查询DBA_TABLESPACE_USAGE_METRICS视图来获取表空间使用率信息。
数据文件使用率数据文件使用率反映了数据库中数据文件的利用情况。
可以通过查询DBA_DATA_FILES视图来获取数据文件使用率信息。
日志文件使用率日志文件使用率是衡量数据库日志文件利用情况的重要指标。
可以通过查询V$LOG视图来获取日志文件使用率信息。
OracleLatchfree等待事件

Latch free等待事件原文:oracle wait interface—a practical guide to performance diagnostics & tuning Richmond sheeKirtikumar deshpandeK gopalakrishnanMcgraw-hill/osborne2100 powell street, 10th floorEmeryville, california 94608U.s.a.Chapter 6: interpreting locks-related wait events - latch free文档修订历史:本文只是对原文的一个大概的翻译,建议最好还是阅读原文。
如果你发现有任何问题,欢迎反馈****************Latch free等待事件的三个参数:p1-latch的地址;p2-latch编号;p3-请求次数。
从oracle10g起,latch free不再包含所有的latch等待,有些latch等待可能表现为单独的等待事件,这个后面有提到一些这样的等待事件,一般情况下我们还是统称为latch free等待事件。
在处理latch free等待事件时,需要注意以下几点:⏹Latch只是用来保护sga中的内存结构。
对数据库中的对象的保护,使用的lock而不是latch。
Oracle sga中有许多latch,用来保护sga中各种内存结构不会因为并发访问而损坏。
⏹等待latch的是oracle会话。
不同的latch类型会导致会话采取不同的策略。
⏹在oracle9i(包括9i)之前,latch free等待事件包括了所有的latch等待,但从oracle10g起,latch被分成不同的种类,并且某些latch表现为独立的等待事件。
什么是latchLatch是一种锁机制。
你应该已经熟悉latch的概念和用法,虽然可能你自己并没有意识到。
[ORACLE]oraclesql执行过程发生的等待事件
![[ORACLE]oraclesql执行过程发生的等待事件](https://img.taocdn.com/s3/m/e2cd8627a22d7375a417866fb84ae45c3b35c2ac.png)
[ORACLE]oraclesql执⾏过程发⽣的等待事件1.Parse 阶段常见的等待事件:Library cache pin这个等待事件和library cache lock ⼀样是发⽣在共享池中并发操作引起的事件。
通常来讲,如果Oracle 要对⼀些PL/SQL 或者视图这样的对象做重新编译,需要将这些对象pin到共享池中。
如果此时这个对象被其他的⽤户特有,就会产⽣⼀个library cache pin的等待。
这个等待事件也包含四个参数:Handle address: 被加载的对象的地址。
Lock address:锁的地址。
Mode:被加载对象的数据⽚段。
Namespace:被加载对象在v$db_object_cache 视图中namespace名称。
Library cache pin这个等待事件和library cache lock ⼀样是发⽣在共享池中并发操作引起的事件。
通常来讲,如果Oracle 要对⼀些PL/SQL 或者视图这样的对象做重新编译,需要将这些对象pin到共享池中。
如果此时这个对象被其他的⽤户特有,就会产⽣⼀个library cache pin的等待。
这个等待事件也包含四个参数:Handle address: 被加载的对象的地址。
Lock address:锁的地址。
Mode:被加载对象的数据⽚段。
Namespace:被加载对象在v$db_object_cache 视图中namespace名称latch:shared poolpin S wait on Xibrary cache: mutex X/cursor: pin S2.Execute阶段常见的等待事件:db file sequential read这个等待事件在实际⽣产库也很常见,当Oracle 需要每次I/O只读取单个数据块这样的操作时,会产⽣这个等待事件。
最常见的情况有索引的访问(除IFFS外的⽅式),回滚操作,以ROWID的⽅式访问表中的数据,重建控制⽂件,对⽂件头做DUMP等。
Oracle数据库发生等待事件:enq:TX-rowlockcontention,排查思路
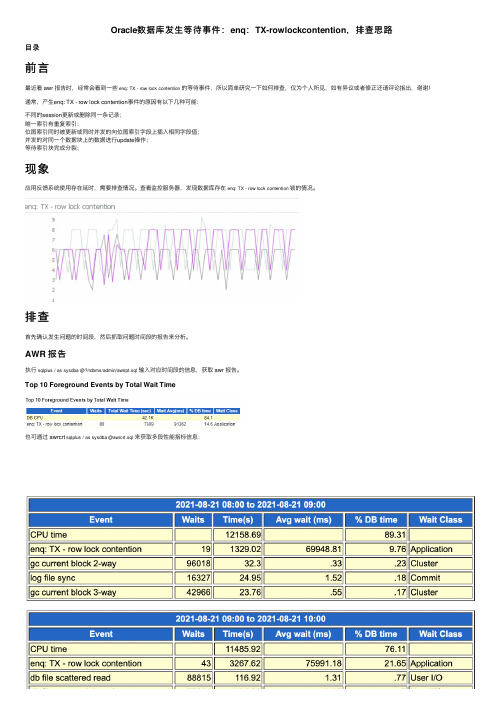
Oracle数据库发⽣等待事件:enq:TX-rowlockcontention,排查思路⽬录前⾔最近看 awr 报告时,经常会看到⼀些enq: TX - row lock contention的等待事件,所以简单研究⼀下如何排查,仅为个⼈所见,如有异议或者修正还请评论指出,谢谢!通常,产⽣enq: TX - row lock contention事件的原因有以下⼏种可能:不同的session更新或删除同⼀条记录;唯⼀索引有重复索引;位图索引同时被更新或同时并发的向位图索引字段上插⼊相同字段值;并发的对同⼀个数据块上的数据进⾏update操作;等待索引块完成分裂;现象应⽤反馈系统使⽤存在延时,需要排查情况。
查看监控服务器,发现数据库存在enq: TX - row lock contention锁的情况。
排查⾸先确认发⽣问题的时间段,然后抓取问题时间段的报告来分析。
AWR 报告执⾏sqlplus / as sysdba @?/rdbms/admin/awrrpt.sql输⼊对应时间段的信息,获取 awr 报告。
Top 10 Foreground Events by Total Wait Time也可通过 awrcrt sqlplus / as sysdba @awrcrt.sql来获取多段性能指标信息:通过观察 awr 报告中段的统计信息章节Segments by Row Lock Waits项,可以发现发⽣锁的对象主要是两张表A和B和A表的索引:与应⽤确认后,发现其中⼀张表A为核⼼业务表,暂时怀疑另⼀张表可能存在问题,这⾥称之为表B,所以A表暂且不考虑。
SQL ordered by Elapsed Time通过 搜索关键字,查出 B 表对应的UPDATE语句,执⾏较为频繁,先记录待查看:sql_id 为:2xb71ufa5wmrh。
ASH 报告抓取对应时间段的 ash 报告,查看是否存在有⽤信息。
dbfilesequentialread事件的优化(一)

dbfilesequentialread事件的优化(⼀)db file sequential read 事件的优化(⼀)db file sequential read等待事件有3个参数:file#,first block#,和block数量。
在10g中,这等待事件受到⽤户I/O等待级别的影响。
当处理db file sequential read等待事件的时候,牢记以下关键想法。
l Oracle进程需要⼀个当前不在SGA中的块,等待数据库块从磁盘读⼊到SGA中l 要看的两个重要的数字是单独会话的TIME_WAITED和AVERAGE_WAIT。
l 重要db file sequential read等待时间最可能是⼀个应⽤问题。
db file sequential read等待时间是由于执⾏对索引,回滚(undo)段,和表(当借助rowid来访问),控制⽂件和数据⽂件头的单块读操作SQL语句(⽤户和递归)引起的。
对于这些对象的物理I/O请求是很正常的,因此db file sequential read等待的存在不是⼀定意味库或应⽤出错了。
如果会话在这事件上花了好长事件,它可能也不是⼀个糟糕的事情。
相反,如果会话花了⼤量时间在equeue或latch free上,那么⼀定是有问题。
这⼉单块读变的复杂了。
==========⽬的:从得到各个session中db file sequential read等待事件的总的等待时间,和等待时间所占总的等待时间(各种等待事件的总和时间)的⽐例中分析哪⼀个sid更⾼,更重要。
==========select a.sid,a.event,a.time_waited,a.time_waited / c.sum_time_waited * 100 pct_wait_time,round((sysdate - b.logon_time) * 24) hours_connectedfrom v$session_event a, v$session b,(select sid, sum(time_waited) sum_time_waitedfrom v$session_eventwhere event not in ('Null event','client message','KXFX: Execution Message Dequeue - Slave','PX Deq: Execution Msg','KXFQ: kxfqdeq - normal deqeue','PX Deq: Table Q Normal','Wait for credit - send blocked','PX Deq Credit: send blkd','Wait for credit - need buffer to send','PX Deq Credit: need buffer','Wait for credit - free buffer','PX Deq Credit: free buffer','parallel query dequeue wait','PX Deque wait','Parallel Query Idle Wait - Slaves','PX Idle Wait','pipe get','rdbms ipc message','rdbms ipc reply','pmon timer','smon timer','PL/SQL lock timer','SQL*Net message from client','WMON goes to sleep')having sum(time_waited) > 0 group by sid) cwhere a.sid = b.sidand a.sid = c.sidand a.time_waited > 0and a.event = 'db file sequential read'order by hours_connected desc, pct_wait_time;SID EVENT TIME_WAITED PCT_WAIT_TIME HOURS_CONNECTED---- ----------------------- ----------- ------------- ---------------186 db file sequential read 64446 77.0267848 105284 db file sequential read 1458405 90.992838 105194 db file sequential read 1458708 91.0204316 105322 db file sequential read 1462557 91.1577045 105139 db file sequential read 211325 52.6281055 11256 db file sequential read 247236 58.0469755 11192 db file sequential read 243113 88.0193625 2你能做两件事来最⼩化db file sequential read事件:l 通过降低physical和logical read来优化导致⼤多数wait的SQL语句l 降低平均等待时间此外,当前正运⾏的SQL语句可能或不可能是导致wait的。
oracle数据库latch free问题分析

Latch free问题分析
1、现象
Latch wait是非常常见的一种等待事件,latch是闩锁,一种轻量级的锁机制,用于保护共享内存,也可以说是内存上的锁,它被快速的获取和释放,防止内存结构被并发访问
2、问题分析
10g 以前所有v$session_wait看到的闩锁等待都叫latch free,并不能直接的区分,除非用10046事件跟踪,statpack,或tkprof方式分析,10g之后有了明显的提示比如latch: shared pool但大部分仍然笼统的叫latch free
2.1)使用Tkrof分析:
首先判断哪个阶段出现的问题,以下可以看到parse出现了大量的时间消耗
然后对单独对这个阶段生成tkprof进行详细分析
2.2)Awr或statspack方式分析。
关于statspack以及awr使用

关于Statspack,AWR以及ASH使用Statspack部分Statspack是Oracle 8i以后提供的一个非常好的性能监控与诊断工具。
在数据库管理中,Oracle提供的statspack是一个很强大的工具,通过Statspack,可以收集系统信息,诊断数据库故障,也方便第三方技术支持进行远程阅读和建议。
Oracle Statspack 从Oracle8.1.6开始被引入Oracle,并马上成为DBA和Oracle专家用来诊断数据库性能的强有力的工具。
在oracle10g中被awr取代。
通过Statspack我们可以很容易的确定Oracle数据库的瓶颈所在,记录数据库性能状态。
因此了解和使用Statspack对于DBA来说至关重要。
Statspack的脚本位于$ORACLE_HOME/rdbms/admin目录下。
第一部分statspack安装以及卸载Statspack安装安装statspack至少需要100M表空间,如果需要长期监控,这个表空间应该设置的大一些。
Statspack相关数据不要放到system表空间。
在官方文档中明确指出在system表空间中不支持。
Statspack安装脚本位于:Unix:$ORACLE_HOME/rdbms/admin/spcreate.sqlWindow:%ORACLE_HOME%\rdbms\admin\spcreate.sql下面就以window下安装为例子介绍下statspack的安装过程以及出现问题如何处理:首先执行%ORACLE_HOME\rdbms\admin\spcreate.sql然后会提示你输入perfstat用户密码,指定默认表空间以及temporary表空间:下面白色部分已经明确指出system表空间不支持。
检查当前目录下spcusr.lis,spctab.lis和spcpkg.lis这三个文件,这三个文件记录安装过程所有记录,如果有问题可以使用%ORACLE_HOME\rdbms\admin\spdrop.sql删除后再重新安装1. spcusr -> 建用户和授予权限2. spctab -> 建表同义词索引等记录3. spcpkg -> 建包记录在unix下也可以用batch模式安装:SQL> connect / as sysdbaSQL> define default_tablespace='perfstat'SQL> define temporary_tablespace='temp'SQL> define perfstat_password='perfstat'SQL> @?/rdbms/admin/spcreate.sqlSQL> undefine perfstat_passwordstatspack的卸载Statspack卸载脚本位于:Unix:$ORACLE_HOME/rdbms/admin/spdrop.sqlWindow:%ORACLE_HOME%\rdbms\admin\spdrop.sql下面以window下卸载为例子介绍下statspack的卸载:执行%ORACLE_HOME\rdbms\admin\spcreate.sql执行完毕后,它会提示你去检查当前目录下的spdusr.lis和spdtab.lis文件Statspack数据清理(清理全部数据)当存放statspack的表空间快满的时候需要我们去清理表空间,操作如下:Statspack清理脚本位于:Unix:$ORACLE_HOME/rdbms/admin/sptrunc.sqlWindow:%ORACLE_HOME%\rdbms\admin\ sptrunc.sql下面以window下清理为例子介绍下statspack数据清理:执行%ORACLE_HOME\rdbms\admin\ sptrunc.sqlStatspack数据清理(清理指定数据)当存放statspack的表空间快满的时候需要我们去清理表空间,操作如下:Statspack清理脚本位于:Unix:$ORACLE_HOME/rdbms/admin/sppurge.sqlWindow:%ORACLE_HOME%\rdbms\admin\ sppurge.sql下面以window下清理为例子介绍下statspack数据清理:执行%ORACLE_HOME\rdbms\admin\ sppurge.sql下面会列出能清理的相关时间收集的统计信息:下面提示你输入开始和结束时间点,我们上面的是6,7,8,9,这四个数字代表相应时间,我执行这四次操作是连续做的,时间看起来不明显。
性能优化:调整IO相关的等待

性能优化:调整IO相关的等待编辑手记:对Oracle数据库进行调整优化,基本上最终都可以归结到I/O调整上,因此,了解如何来优化Oracle数据库的I/O对于一个DBA来说就显得至关重要。
今天挑选此文与大家共勉。
I/O相关竞争等待简介当Oracle数据库出现I/O相关的竞争等待的时候,一般来说都会引起Oracle数据库的性能低下,发现数据库存在I/O相关的竞争等待一般可以通过以下的三种方法来查看Oracle数据库是否存在I/O相关的竞争等待:(1)Statpack报告中在"Top 5 WaitEvents"部分中主要都是I/O相关的等待事件。
(2)数据库的等待事件的SQL语句跟踪中主要都是I/O相关的等待事件的限制。
(3)操作系统工具显示存储数据库文件的存储磁盘有非常高的利用率。
数据库如果发现存在I/O竞争,那我们就必须要通过各种方法来调整优化Oracle数据库。
在调优数据库的过程中,其中一个重要的步骤就是对响应时间的分析,看看数据库消耗的时间究竟是消耗在具体什么上面了。
对于Oracle数据库来说,响应时间的分析可以用下面公式来计算:Response Time = Service Time + WaitTimeService Time是指'CPU used by this session'的统计时间。
Wait Time是指所有消耗在等待事件上的总的时间。
因为等待事件有很多,因此我们还需要去判定哪些是真的很重要的等待事件,很多调优工具比如说statpack都是列出最重要的等待事件,statpack工具的报告中的重要的等待事件都是包含在一个叫Top 5 Wait Events的部分中。
在某些情况下, Service Time会比WaitTime显得更加重要(例如CPU使用率),此时等待事件产生的影响就显得不是那么重要了,重点调整的目标应该放在Service Time上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Oracle 常见的33个等待事件一.等待事件的相关知识:1.1 等待事件主要可以分为两类,即空闲(IDLE)等待事件和非空闲(NON-IDLE)等待事件。
1). 空闲等待事件指ORACLE正等待某种工作,在诊断和优化数据库的时候,不用过多注意这部分事件。
2). 非空闲等待事件专门针对ORACLE的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是在调整数据库的时候需要关注与研究的。
在Oracle 10g中的等待事件有872个,11g中等待事件1116个。
我们可以通过v$event_name 视图来查看等待事件的相关信息。
1.2 查看v$event_name视图的字段结构:SQL> desc v$event_name;名称是否为空? 类型----------------------------------------- -------- --------------- EVENT# NUMBEREVENT_ID NUMBERNAME VARCHAR2(64)PARAMETER1 VARCHAR2(64)PARAMETER2 VARCHAR2(64)PARAMETER3 VARCHAR2(64)WAIT_CLASS_ID NUMBERWAIT_CLASS# NUMBERWAIT_CLASS VARCHAR2(64)1.3 查看等待事件总数:SQL> select count(*) from v$event_name;COUNT(*)----------11161.4 查看等待事件分类情况:/* Formatted on 2010/8/11 16:08:55 (QP5 v5.115.810.9015) */SELECT wait_class#,wait_class_id,wait_class,COUNT(* )AS"count"FROM v$event_nameGROUP BY wait_class#,wait_class_id,wait_classORDER BY wait_class#;WAIT_CLASS# WAIT_CLASS_IDWAIT_CLASS count----------- ------------- -------------------- ----------0 1893977003Other 7171 4217450380Application 172 3290255840Configuration 243 4166625743Administrative 544 3875070507Concurrency 325 3386400367Commit 26 2723168908Idle 947 2000153315Network 358 1740759767 UserI/O 459 4108307767 SystemI/O 3010 2396326234Scheduler 711 3871361733Cluster 5012 644977587Queueing 91.5 相关的几个视图:V$SESSION:代表数据库活动的开始,视为源起。
V$SESSION_WAIT:视图用以实时记录活动SESSION的等待情况,是当前信息。
V$SESSION_WAIT_HISTORY:是对V$SESSION_WAIT的简单增强,记录活动SESSION的最近10次等待。
V$SQLTEXT:当数据库出现瓶颈时,通常可以从V$SESSION_WAIT找到那些正在等待资源的SESSION,通过SESSION的SID,联合V$SESSION和V$SQLTEXT视图就可以捕获这些SESSION正在执行的SQL语句。
V$ACTIVE_SESSION_HISTORY: 是ASH的核心,用以记录活动SESSION的历史等待信息,每秒采样一次,这部分内容记录在内存中,期望值是记录一个小时的内容。
WRH#_ACTIVE_SESSION_HISTORY: 是V$ACTIVE_SESSION_HISTORY在AWR的存储地。
V$ACTIVE_SESSION_HISTORY: 中的信息会被定期(每小时一次)的刷新到负载库中,并缺省保留一个星期用于分析。
DBA_HIST_ACTIVE_SESS_HISTORY: 视图是WRH#_ACTIVE_SESSION_HISTORY视图和其他几个视图的联合展现,通常通过这个视图进行历史数据的访问。
V$SYSTEM_EVENT由于V$SESSION记录的是动态信息,和SESSION的生命周期相关,而并不记录历史信息,所以ORACLE提供视图V$SYSTEM_EVENT来记录数据库自启动以来所有等待事件的汇总信息。
通过这个视图,用户可以迅速获得数据库运行的总体概况。
二.33个常见的等待事件1.Buffer busy waits从本质上讲,这个等待事件的产生仅说明了一个会话在等待一个Buffer(数据块),但是导致这个现象的原因却有很多种。
常见的两种是:当一个会话视图修改一个数据块,但这个数据块正在被另一个会话修改时。
当一个会话需要读取一个数据块,但这个数据块正在被另一个会话读取到内存中时。
Oracle 操作的最小单位是块(Block),即使你要修改一条记录,也需要对这条记录所在的这个数据块做操作。
当你对这个数据块做修改时,其他的会话将被阻止对这个数据块上的数据做修改(即使其他用户修改的不是当前用户修改的数据),但是可以以一致性的方式读取这个数据块(from undo)。
当前的用户修改完这个数据块后,将会立即释放掉加在这个数据块上的排他锁,这样另一个会话就可以继续修改它。
修改操作是一个非常短暂的时间,这种加锁的机制我们叫Latch。
当一个会话修改一个数据块时,是按照以下步骤来完成的:以排他的方式获得这个数据块(Latch)修改这个数据块。
释放Latch。
Buffer busy waits等待事件常见于数据库中存在的热快的时候,当多个用户频繁地读取或者修改同样的数据块时,这个等待事件就会产生。
如果等待的时间很长,我们在AWR或者statspack 报告中就可以看到。
这个等待事件有三个参数。
查看有几个参数我们可以用以下SQL:SQL> select name, parameter1, parameter2, parameter3 from v$event_name where name='buffer busy waits';NAME PARAMETER1 PARAMETER2 PARAMETER3-------------------- ---------- ---------- ---------- buffer busy waits file# block# class#在下面的示例中,查询的方法和这个一样,所以其他事件对参数的查询将不做过多的说明。
File#: 等待访问数据块所在的文件id号。
Blocks:等待访问的数据块号。
ID:在10g之前,这个值表示一个等待时间的原因,10g之后则表示等待事件的类别。
2.Buffer latch内存中数据块的存放位置是记录在一个hash列表(cache buffer chains)当中的。
当一个会话需要访问某个数据块时,它首先要搜索这个hash 列表,从列表中获得数据块的地址,然后通过这个地址去访问需要的数据块,这个列表Oracle会使用一个latch来保护它的完整性。
当一个会话需要访问这个列表时,需要获取一个Latch,只有这样,才能保证这个列表在这个会话的浏览当中不会发生变化。
产生buffer latch的等待事件的主要原因是:Buffer chains太长,导致会话搜索这个列表花费的时间太长,使其他的会话处于等待状态。
同样的数据块被频繁访问,就是我们通常说的热快问题。
产生buffer chains太长,我们可以使用多个buffer pool的方式来创建更多的buffer chains,或者使用参数DB_BLOCK_LRU_LATCHES来增加latch的数量,以便于更多的会话可以获得latch,这两种方法可以同时使用。
这个等待事件有两个参数:Latch addr:会话申请的latch在SGA中的虚拟地址,通过以下的SQL语句可以根据这个地址找到它对应的Latch名称:select* from v$latch a,v$latchname b where addr=latchaddr and tch#=tch#;-- 这里的latch addr 是你从等待事件中看到的值chain#:buffer chains hash 列表中的索引值,当这个参数的值等于s 0xfffffff时,说明当前的会话正在等待一个LRU latch。
3.Control file parallel write当数据库中有多个控制文件的拷贝时,Oracle 需要保证信息同步地写到各个控制文件当中,这是一个并行的物理操作过程,因为称为控制文件并行写,当发生这样的操作时,就会产生control file parallel write等待事件。
控制文件频繁写入的原因很多,比如:日志切换太过频繁,导致控制文件信息相应地需要频繁更新。
系统I/O 出现瓶颈,导致所有I/O出现等待。
当系统出现日志切换过于频繁的情形时,可以考虑适当地增大日志文件的大小来降低日志切换频率。
当系统出现大量的control file parallel write 等待事件时,可以通过比如降低控制文件的拷贝数量,将控制文件的拷贝存放在不同的物理磁盘上的方式来缓解I/O 争用。
这个等待事件包含三个参数:Files:Oracle 要写入的控制文件个数。
Blocks:写入控制文件的数据块数目。
Requests:写入控制请求的I/O 次数。
4.Control file sequential read当数据库需要读取控制文件上的信息时,会出现这个等待事件,因为控制文件的信息是顺序写的,所以读取的时候也是顺序的,因此称为控制文件顺序读,它经常发生在以下情况:备份控制文件RAC 环境下不同实例之间控制文件的信息共享读取控制文件的文件头信息读取控制文件其他信息这个等待事件有三个参数:File#:要读取信息的控制文件的文件号。
Block#:读取控制文件信息的起始数据块号。
Blocks:需要读取的控制文件数据块数目。
5.Db file parallel read这是一个很容易引起误导的等待事件,实际上这个等待事件和并行操作(比如并行查询,并行DML)没有关系。
这个事件发生在数据库恢复的时候,当有一些数据块需要恢复的时候,Oracle会以并行的方式把他们从数据文件中读入到内存中进行恢复操作。