计算方差-协方差矩阵
方差 -协方差矩阵

方差 -协方差矩阵方差和协方差是两个核心的统计概念,用于衡量随机变量之间的关系以及其散布情况。
在数据处理中,方差和协方差矩阵被广泛用于探索变量之间的相互作用并且对于许多算法来说也是必要的。
1、方差方差是衡量在一组数据中,变量值的差异性的一种统计量。
如果变量的方差较大,那么数据的散布情况就比较广泛。
在统计数学中,整体数据集合的方差是每个数与其平均数之差的平方的平均数。
由于每个数据点与平均数之差的平方都是非负数,因此方差始终是非负的。
对于总体方差σ²,有以下计算公式:$$ \sigma^2 = \frac{\sum_{i=1}^{n}(x_i - \mu)^2}{n} $$其中,n是样本中变量的数量,μ是变量集合的均值。
当样本为总体时,分母实际上是总体大小N。
这个公式可以用来计算整个数据集的方差。
对于单个随机变量的方差,我们可以使用以下公式:$$ Var(X) = E(X^2) - E(X)^2 $$这个公式的意思是,方差等于X的平方的期望减去X的期望的平方。
简单的说,方差就是每个数据点与这个变量的期望之差的平方的平均数。
如果变量的方差越大,说明数据的散布情况越广泛。
协方差是指两个变量之间的关系。
它用来衡量两个变量之间的共变性。
如果两个变量总是在同一方向变化,那么它们的协方差就是正的;如果它们总是在相反的方向变化,那么它们的协方差就是负的;如果这两个变量相互独立,那么它们的协方差就是0。
协方差的计算公式如下:其中,E表示期望。
协方差是两个变量之间的乘积的期望值减去它们的期望值之积。
值得注意的是,两个变量之间的协方差值与它们的绝对数是相关的。
因此,如果我们试图将协方差用于比较两个变量之间的关系,那么我们需要对它们进行标准化。
协方差矩阵是一个对称矩阵,它记录一个向量中所有变量之间的协方差。
协方差矩阵的对角线元素是每个变量的方差,而非对角线元素是两个变量之间的协方差值。
协方差矩阵可以通过以下公式来计算:其中,E表示期望,(X-E(X))^T表示转置矩阵。
统计学中的协方差矩阵

统计学中的协方差矩阵统计学是研究收集、整理、分析和解释数据的科学领域。
协方差矩阵是统计学中一种重要的工具,用于研究多个变量之间的关系和相关性。
本文将介绍协方差矩阵的定义、性质、计算方法以及在实际应用中的意义。
一、协方差矩阵的定义协方差矩阵是指一个矩阵,其中的元素表示了变量之间的协方差。
假设有n个变量,那么协方差矩阵将是一个n×n的矩阵。
协方差矩阵的第(i,j)个元素表示了第i个变量和第j个变量的协方差。
如果两个变量之间的协方差为正值,表示它们之间存在正相关的关系;如果协方差为负值,表示它们之间存在负相关的关系;如果协方差为零,则表示它们之间不存在线性相关关系。
二、协方差矩阵的性质1. 对称性:协方差矩阵是一个对称矩阵,即第(i,j)个元素等于第(j,i)个元素。
这是因为协方差是一个对称的概念,不依赖于变量的顺序。
2. 非负定性:协方差矩阵是一个非负定矩阵,即对于任意非零的列向量x,有x^TΣx≥0,其中Σ表示协方差矩阵。
这个性质保证了协方差矩阵的主对角线上的元素都是非负的。
三、协方差矩阵的计算方法协方差矩阵的计算涉及到变量之间的协方差。
对于两个变量X和Y,它们的协方差可以用下式表示:Cov(X,Y) = E[(X-μ_X)(Y-μ_Y)],其中μ_X和μ_Y分别表示X和Y的均值。
协方差矩阵的元素由各个变量之间的协方差计算得到。
协方差矩阵Σ的元素可以表示为:Σ_ij = Cov(X_i, X_j),其中X_i和X_j是第i和第j个变量。
根据协方差的计算公式,我们可以通过样本数据的均值和方差来估计协方差矩阵的元素。
四、协方差矩阵在实际应用中的意义协方差矩阵在统计学和金融学等领域中具有广泛的应用价值。
1. 多变量分析:协方差矩阵可以用于多变量分析,帮助研究人员了解多个变量之间的关系和相关性。
通过分析协方差矩阵,可以发现变量之间的线性依赖关系,从而更好地理解数据的结构和特征。
2. 风险管理:在金融学中,协方差矩阵被广泛用于风险管理。
协方差矩阵的概念

协方差矩阵的概念协方差矩阵是概率论和统计学中一个重要的概念,用于描述多维随机变量之间的关联程度。
它是一个对称的矩阵,其中包含了各个随机变量之间的协方差以及它们的方差。
协方差是一种描述两个随机变量之间关系的统计量,它衡量了两个随机变量的变化趋势是否一致。
具体而言,对于随机变量X和Y,它们的协方差定义为E[(X - E[X])(Y - E[Y])],其中E[·]表示期望值操作符。
如果协方差大于0,则表明X和Y 之间存在正相关关系;如果协方差小于0,则表明X和Y之间存在负相关关系;如果协方差等于0,则表明X和Y之间没有线性关系。
对于多个随机变量的情况,我们将它们的协方差组成一个矩阵,即协方差矩阵。
设有n个随机变量X1,X2,...,Xn,它们的协方差矩阵记为Σ,其中Σ(i, j)表示随机变量Xi和Xj之间的协方差。
协方差矩阵是一个对称矩阵,满足以下性质:1. 对角线上的元素是随机变量的方差,即Σ(i, i) = Var(Xi);2. 非对角线上的元素是对应两个随机变量的协方差,即Σ(i, j) = Σ(j, i)。
协方差矩阵的作用主要体现在以下几个方面:1. 描述随机变量之间的关联性:协方差矩阵可以直观地展示多个随机变量之间的相关性。
通过对协方差矩阵进行分析,可以了解随机变量之间的关系强度和方向。
2. 变量选择与降维:通过协方差矩阵,可以判断不同随机变量之间的相关性。
在建模分析中,我们可以通过分析协方差矩阵来选择与目标变量相关性最强的变量,去除冗余的变量,从而实现降低维度的目的。
3. 风险度量:在金融领域,协方差矩阵可用于衡量资产之间的风险关系。
通过计算资产收益率之间的协方差矩阵,可以估计投资组合的风险水平,为资产配置、风险控制提供依据。
4. 生成随机样本:协方差矩阵可用于生成符合特定相关性要求的随机样本。
通过给定均值向量和协方差矩阵,可以使用相关多元正态分布的特性生成具有一定相关性的随机样本。
协方差矩阵的计算

协方差矩阵的计算协方差矩阵是用来衡量多维随机变量之间相互关系的矩阵,其中每一项代表两个不同变量之间的协方差。
它是一个方阵,如果有n个变量,则协方差矩阵的大小就是n×n。
协方差矩阵的计算方式如下:1. 首先,计算每个随机变量的平均值。
设有n个随机变量,对第i个随机变量,它的平均值为x̄i,其计算方式为:x̄i = (x1i + x2i + ... + xki)/k其中xi为第i个随机变量的第j次观测值,k为该随机变量的观测次数。
2. 然后,计算每个随机变量与其他随机变量的协方差。
设第i个随机变量与第j 个随机变量的协方差为cov(xi, xj),其计算方式为:cov(xi, xj) = (∑(xi−x̄i)(xj−x̄j)) / (k−1)其中,xi和xj分别为第i个随机变量和第j个随机变量的第k次观测值,x̄i和x̄j分别为它们的平均值,k为观测次数。
3. 最后,将所有随机变量之间的协方差填充到协方差矩阵中,得到协方差矩阵C:C = [ cov(x1, x1) cov(x1, x2) ... cov(x1, xn)cov(x2, x1) cov(x2, x2) ... cov(x2, xn)... ... ... ...cov(xn, x1) cov(xn, x2) ... cov(xn, xn) ]需要注意的是,协方差矩阵是一个对称矩阵,即cov(xi, xj)=cov(xj, xi),因此矩阵取值时可以只计算其中一半,然后再将它们复制到对称位置上即可。
协方差矩阵的应用非常广泛,在统计分析、机器学习、模式识别等领域都得到了广泛的应用。
例如,在机器学习中,它常被用来计算特征之间的相关性,以便提取出最重要的特征;在模式识别中,它被用来计算类别之间的相似度,以便分类和聚类。
因此,掌握协方差矩阵的计算方法是非常重要的。
协方差矩阵的计算公式例子

协方差矩阵的计算公式例子设有n个观测值的m维随机向量X = (X1, X2, ..., Xm),其中Xi表示第i个变量的取值。
协方差矩阵C是一个m×m的矩阵,其元素Cij表示第i个变量和第j个变量之间的协方差。
协方差的计算公式为:Cij = cov(Xi, Xj) = E[(Xi - E(Xi))(Xj - E(Xj))]其中,cov(Xi, Xj)表示Xi和Xj的协方差,E表示数学期望操作符,E(Xi)表示变量Xi的数学期望。
下面给出一个具体的例子,来说明如何计算协方差矩阵:假设我们有3个样本点的2维随机向量X=[(1,2),(3,5),(4,6)],其中每个样本点有两个变量。
首先,我们需要计算每个变量的均值,即E(Xi),可以通过求和后除以样本点个数来计算。
E(X1)=(1+3+4)/3=8/3≈2.67E(X2)=(2+5+6)/3=13/3≈4.33接下来,我们计算协方差C11,即第一个变量和自己的协方差。
C11 = cov(X1, X1) = E[(X1 - E(X1))(X1 - E(X1))]=[(1-8/3)(1-8/3)+(3-8/3)(3-8/3)+(4-8/3)(4-8/3)]/2=[(-5/3)^2+(-2/3)^2+(-2/3)^2]/2=(25/9+4/9+4/9)/2=33/18≈1.83类似地,我们可以计算其他的协方差:C12 = cov(X1, X2) = E[(X1 - E(X1))(X2 - E(X2))]=[(1-8/3)(2-13/3)+(3-8/3)(5-13/3)+(4-8/3)(6-13/3)]/2=[(-5/3)(-7/3)+(-2/3)(2/3)+(-2/3)(5/3)]/2=(35/9-4/9-10/9)/2=21/18≈1.17C21 = cov(X2, X1) = C12 ≈ 1.17C22 = cov(X2, X2) = E[(X2 - E(X2))(X2 - E(X2))]=[(2-13/3)(2-13/3)+(5-13/3)(5-13/3)+(6-13/3)(6-13/3)]/2=[(1/3)^2+(2/3)^2+(7/3)^2]/2=(1/9+4/9+49/9)/2=54/18≈3综上所述,该样本点的协方差矩阵C为:[1.831.17]C=[1.173.00]注意:协方差矩阵是一个对称矩阵,即Cij = Cji。
方差协方差矩阵

方差协方差矩阵
协方差矩阵是用来描述多维数据变量之间关系的矩阵,它由一系列的方差和协方差组成。
方差是指变量随机变动的幅度,它反映一个变量自身的离散程度;协方差则反映了两个变量的相关性,它的正负号表示变量之间的关系是正相关还是负相关,大小反映两个变量之间的程度变动程度。
协方差矩阵表示多个变量之间相关性的“矩阵”,它把所有变量之间的协方差值放在矩阵的元素里,即矩阵中的元素(ij)表示变量i和变量j之间的协方差。
协方差矩阵是统计分析中重要的工具,使用它可以更好地理解变量之间的关系。
方差矩阵是什么,协方差矩阵计算公式
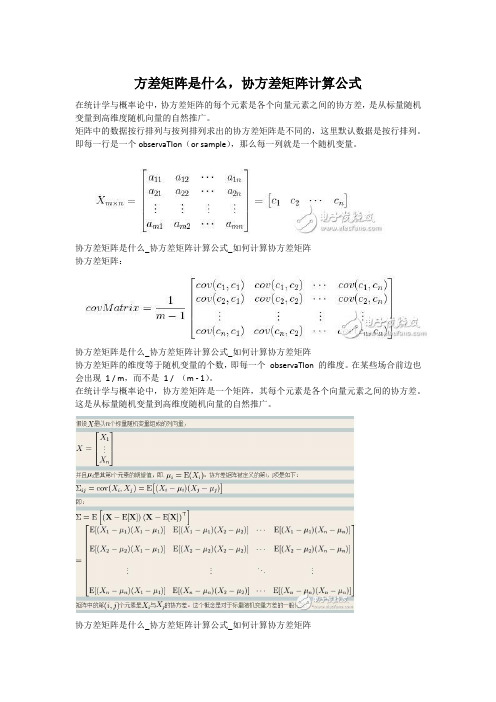
方差矩阵是什么,协方差矩阵计算公式
在统计学与概率论中,协方差矩阵的每个元素是各个向量元素之间的协方差,是从标量随机变量到高维度随机向量的自然推广。
矩阵中的数据按行排列与按列排列求出的协方差矩阵是不同的,这里默认数据是按行排列。
即每一行是一个observaTIon(or sample),那么每一列就是一个随机变量。
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵
协方差矩阵:
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵
协方差矩阵的维度等于随机变量的个数,即每一个observaTIon 的维度。
在某些场合前边也会出现1 / m,而不是1 / (m - 1)。
在统计学与概率论中,协方差矩阵是一个矩阵,其每个元素是各个向量元素之间的协方差。
这是从标量随机变量到高维度随机向量的自然推广。
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵
举个例子,矩阵X 按行排列:
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵1. 求每个维度的平均值
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵2. 将X 的每一列减去平均值
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵其中:
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵3. 计算协方差矩阵
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵注意:
有时候在书上或者网上会看到这样的公式,协方差矩阵Σ:
协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵
这里之所以会是X * X‘ 是因为原始数据集X 是按列排列的,即:。
基本统计量的矩阵表示

基本统计量的矩阵表示基本统计量(如均值、方差、标准差等)可以通过矩阵表示来进行计算和描述。
假设有一个包含n个观测值的数据集,其中每个观测值有p个变量。
1. 均值矩阵(Mean Matrix):均值矩阵是一个1×p的矩阵,其中每个元素表示相应变量的均值。
假设数据集为X,均值矩阵为M,表示为M = [m1, m2, ..., mp],其中mi表示第i个变量的均值。
2. 方差矩阵(Variance Matrix):方差矩阵是一个p×p的矩阵,其中每个元素表示相应变量之间的方差。
假设数据集为X,方差矩阵为V,表示为V = [[v11, v12, ..., v1p], [v21, v22, ..., v2p], ..., [vp1, vp2, ..., vpp]],其中vij表示第i个和第j个变量之间的方差。
3. 协方差矩阵(Covariance Matrix):协方差矩阵是一个p×p的矩阵,其中每个元素表示相应变量之间的协方差。
假设数据集为X,协方差矩阵为C,表示为C = [[c11, c12, ..., c1p], [c21, c22, ..., c2p], ..., [cp1, cp2, ..., cpp]],其中cij表示第i个和第j个变量之间的协方差。
4. 标准差矩阵(Standard Deviation Matrix):标准差矩阵是一个p×p的矩阵,其中每个元素表示相应变量的标准差。
假设数据集为X,标准差矩阵为S,表示为S = [[s1, s2, ..., sp], [s1, s2, ..., sp], ..., [sp, sp, ..., sp]],其中si表示第i个变量的标准差。
这些矩阵表示可以帮助我们更好地理解和分析数据集中变量之间的关系和分布情况。
两个向量的协方差矩阵

两个向量的协方差矩阵协方差矩阵是用来描述两个随机变量之间相关性的矩阵,也常常称为方差-协方差矩阵。
在机器学习和数据分析中,协方差矩阵经常被用来分析数据的结构和相关性,并且用于估计模型参数和做出预测。
本文将重点介绍两个向量的协方差矩阵。
一、定义在概率论和统计学中,给定两个随机向量 $X$ 和 $Y$,协方差矩阵 $\Sigma$ 的定义如下:$$\Sigma_{ij} = Cov(X_i, Y_j) = E[(X_i - E(X_i))(Y_j - E(Y_j))]$$其中 $E(.)$ 表示期望,$Cov(.,.)$ 表示协方差。
协方差是两个变量之间的相关性度量,它衡量的是它们的变化趋势是否相同。
如果协方差为正数,则两个变量的变化趋势是相同的,而如果协方差为负数,则变化趋势是相反的,即一个变量增加时另一个变量会减少。
如果协方差为 0,则两个变量之间没有相关性。
协方差矩阵是一个 $n \times n$ 的矩阵,其中 $n$ 是向量的维度。
例如,如果$X$ 是一个 $n$ 维的向量,则协方差矩阵可以表示为:$$\Sigma =\begin{bmatrix}Cov(X_1, X_1) & Cov(X_1, X_2) & \cdots & Cov(X_1, X_n) \\Cov(X_2, X_1) & Cov(X_2, X_2) & \cdots & Cov(X_2, X_n) \\\vdots & \vdots & \ddots & \vdots \\Cov(X_n, X_1) & Cov(X_n, X_2) & \cdots & Cov(X_n, X_n)\end{bmatrix}$$二、性质协方差矩阵具有以下性质:1. 对称性:$\Sigma$ 是对称矩阵,即 $\Sigma_{ij} = \Sigma_{ji}$。
协方差矩阵具体计算公式

协方差矩阵具体计算公式
协方差矩阵的计算公式是:Cov(x,y)=EXY-EX*EY;
首先,我们需要了解协方差矩阵的重要性,协方差矩阵Cov(xi,xj)的每个元素表示随机变量xi和xj的协方差,对角元素等于向量本身的方差;统计学中最基本的概念是样本的均值、方差和标准差,平均值描述样本集的中点,它告诉我们的信息是有限的,而标准差描述样本集每个样本点与平均值之间的平均距离。
矩阵的协方差矩阵是对称阵,用公式Cov(X, Y) = E[X * Y] - E[X] E[Y] 计算,其中E[X]和E[Y]是列的平局值,E[X*Y]是样本方差,可以用变换成Gramian矩阵减去E[X] E[Y] 后除以n-1,这样Cov(X, Y) = E[X * Y] - E[X] E[Y] 变换为G[X*Y] /(m-1) - (m/m-1)E[X] E[Y].Gramian矩阵就是协方差的和。
如需更多与协方差矩阵相关的知识,可以请教统计学专业人士。
【数学】方差、协方差、协方差矩阵

【数学】⽅差、协⽅差、协⽅差矩阵⽬录设有样本集合a=[a1,a2,⋯,a m]。
【注意,下⽂所述的如向量a=[a1,a2,⋯,a m],并不意味着就是⼀个样本,代表其中有m个特征,⽽是有m个样本,由每个样本的第⼀个特征组成的向量a,具体看下⽂就知道了。
】均值(mean)均值描述的是⼀个样本集合的中间点。
µ=1mm ∑i=1a i标准差(standard deviation)标准差可以⽤来描述单个点到均值的距离的平均值,或者说其描述的就是⼀种分散程度。
【注意:标准差和⽅差中求平均时除以m-1⽽不是m,是因为这样能使我们以较⼩的样本集更好的逼近总体的标准差,即统计上所谓的“⽆偏估计”,若除以m则为有偏】s=1m−1.m∑i=1(a i−µ)2如两个向量[0,5,10]和[4,5,6].两者均值都是5,但是可以看出两者有很⼤的差别,计算得到标准差分别为5和1。
也可以明显看出,后者较前者数据更为集中,所以其标准差也更⼩。
⽅差 (variance):单个向量⽅差⽤来描述数值的分散(离散)程度,也即数据偏离均值的程度。
某个向量的⽅差可以⽤该向量的每个元素减去均值的完全平⽅再求平均来求得。
⽅差仅仅是标准差的平⽅,则有s2=Var(a)=1m−1.m∑i=1(a i−µ)2零均值化(也叫中⼼化)处理是将原数据集减去该数据集的均值,即a=a−µ,这样数据a的均值就是零了。
再说⼀句,零均值化不是简单的将均值令为零,⽽是要减去均值,这样才有零均值,这⾥之所以看到还是a i是因为相减后还令为了a i,即a i=a i−µ,或者说将下⽂中的a i还是要视为a i=a i−µ。
则将向量零均值化处理,可以有Var(a)=1m−1.m∑i=1a2i协⽅差(covariance):两个向量协⽅差可以⽤来表⽰两个向量之间的相关性,如在PCA降维中,我们希望降维后的向量可以保存更多的原始信息,所以尽可能的减少向量之间的相关性,因为相关性越⼤,则就代表着两个变量不是完全独⽴的,也即必然有重复的信息。
协方差矩阵的计算

协方差矩阵的计算1.计算每个随机变量的均值对于给定的数据集,首先需要计算每个随机变量的均值。
即对于每个变量i,计算所有样本的第i个数据的平均值,得到变量i的均值μi。
2.计算每个随机变量与其他随机变量的协方差对于每对变量(i, j),计算协方差cov(i, j)。
协方差可以通过以下公式计算:cov(i, j) = Σ((Xi - μi) * (Xj - μj)) / n其中,Σ表示对所有样本进行求和,n为样本数量,Xi和Xj分别表示第i个和第j个变量的取值。
3.构建协方差矩阵在计算每对变量的协方差之后,将其填充到协方差矩阵中的对应位置。
最终得到一个N×N的协方差矩阵,其中第(i,j)个元素表示第i个随机变量和第j个随机变量的协方差。
需要注意的是,协方差矩阵是对称矩阵,即cov(i, j) = cov(j, i),因此只需要计算和填充半个矩阵就可以了。
例如,对于一个包含3个变量的数据集,协方差矩阵可以表示为:cov(1, 1) cov(1, 2) cov(1, 3cov(2, 1) cov(2, 2) cov(2, 3cov(3, 1) cov(3, 2) cov(3, 3计算协方差矩阵时,还需要注意到协方差的计算结果会受到数据量的影响。
在样本数较小的情况下,协方差的估计可能会存在较大偏差。
这时可以使用无偏估计的方差计算方法来修正协方差的计算结果,公式如下:cov(i, j) = Σ((Xi - μi) * (Xj - μj)) / (n - 1)协方差矩阵在数据分析和模型建立中有广泛的应用。
它可以用于分析随机变量之间的相关性、变量的贡献度、主成分分析等。
协方差矩阵的计算可以帮助我们更好地理解多个变量之间的关系,从而为后续的数据处理和分析提供基础。
2.《数学之美》吴军。
(完整word版)矩阵协方差计算

浅谈协方差矩阵今天看论文的时候又看到了协方差矩阵这个破东西,以前看模式分类的时候就特困扰,没想到现在还是搞不清楚,索性开始查协方差矩阵的资料,恶补之后决定马上记录下来,嘿嘿~本文我将用自认为循序渐进的方式谈谈协方差矩阵.统计学的基本概念学过概率统计的孩子都知道,统计里最基本的概念就是样本的均值,方差,或者再加个标准差。
首先我们给你一个含有n个样本的集合,依次给出这些概念的公式描述,这些高中学过数学的孩子都应该知道吧,一带而过。
均值:标准差:方差:很显然,均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,而标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。
以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1。
8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”.之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”.而方差则仅仅是标准差的平方。
为什么需要协方差?上面几个统计量看似已经描述的差不多了,但我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。
面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子欢迎程度是否存在一些联系啊,嘿嘿~协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:来度量各个维度偏离其均值的程度,标准差可以这么来定义:协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐就越受女孩子欢迎,嘿嘿,那必须的~结果为负值就说明负相关的,越猥琐女孩子越讨厌,可能吗?如果为0,也是就是统计上说的“相互独立”。
计算协方差矩阵

计算协方差矩阵
协方差矩阵是统计学和机器学习中常用的概念,它描述了两个或多个随机变量之间的关系和方差的度量。
计算协方差矩阵是一个重要的任务,因为它可以帮助我们了解数据集中不同变量之间的相关性。
计算协方差矩阵需要使用以下公式:
$$text{Cov}(X,Y)=frac{sum_{i=1}^{n}(x_i-bar{X})(y_i-bar{Y}) }{n-1}$$
其中,$X$和$Y$是两个随机变量,$x_i$和$y_i$是它们的观察值,$bar{X}$和$bar{Y}$是它们的均值,$n$是样本量。
如果有多个随机变量,则可以使用以下矩阵形式的公式来计算协方差矩阵:
$$text{Cov}(X)=frac{1}{n-1}(X-bar{X})^T(X-bar{X})$$ 其中,$X$是一个$ntimes m$的矩阵,$m$是变量的数量,
$bar{X}$是一个$m$维向量,表示每个变量的均值,$(X-bar{X})^T$表示矩阵$X-bar{X}$的转置。
计算协方差矩阵可以使用各种编程语言和工具,如Python的NumPy库、R语言的base和stats包、MATLAB等。
在使用这些工具时,需要注意数据的格式和维度,以确保计算正确的协方差矩阵。
- 1 -。
协方差与协方差矩阵

协⽅差与协⽅差矩阵协⽅差与协⽅差矩阵标签: 协⽅差 协⽅差矩阵 统计引⾔最近在看主成分分析(PCA),其中有⼀步是计算样本各维度的协⽅差矩阵。
以前在看算法介绍时,也经常遇到,现找了些资料复习,总结如下。
协⽅差通常,在提到协⽅差的时候,需要对其进⼀步区分。
(1)随机变量的协⽅差。
跟数学期望、⽅差⼀样,是分布的⼀个总体参数。
(2)样本的协⽅差。
是样本集的⼀个统计量,可作为联合分布总体参数的⼀个估计。
在实际中计算的通常是样本的协⽅差。
随机变量的协⽅差在概率论和统计中,协⽅差是对两个随机变量联合分布线性相关程度的⼀种度量。
两个随机变量越线性相关,协⽅差越⼤,完全线性⽆关,协⽅差为零。
定义如下。
当,是同⼀个随机变量时,与其⾃⾝的协⽅差就是的⽅差,可以说⽅差是协⽅差的⼀个特例。
或由于随机变量的取值范围不同,两个协⽅差不具备可⽐性。
如,,分别是三个随机变量,想要⽐较与的线性相关程度强,还是与的线性相关程度强,通过与⽆法直接⽐较。
定义相关系数为通过的⽅差与的⽅差对协⽅差归⼀化,得到相关系数,的取值范围是。
表⽰完全线性相关,表⽰完全线性负相关,表⽰线性⽆关。
线性⽆关并不代表完全⽆关,更不代表相互独⽴。
样本的协⽅差在实际中,通常我们⼿头会有⼀些样本,样本有多个属性,每个样本可以看成⼀个多维随机变量的样本点,我们需要分析两个维度之间的线性关系。
协⽅差及相关系数是度量随机变量间线性关系的参数,由于不知道具体的分布,只能通过样本来进⾏估计。
设样本对应的多维随机变量为,样本集合为,为样本数量。
与样本⽅差的计算相似,和两个维度样本的协⽅差公式为,其中,,为样本维度这⾥分母为是因为随机变量的数学期望未知,以样本均值代替,⾃由度减⼀。
协⽅差矩阵多维随机变量的协⽅差矩阵对多维随机变量,我们往往需要计算各维度两两之间的协⽅差,这样各协⽅差组成了⼀个的矩阵,称为协⽅差矩阵。
协⽅差矩阵是个对称矩阵,对⾓线上的元素是各维度上随机变量的⽅差。
矩阵的协方差计算公式

矩阵的协方差计算公式矩阵的协方差计算公式是用来计算两个或多个变量之间关系强度的统计指标。
在统计学和金融领域,协方差常用来衡量变量之间的相关性。
矩阵的协方差计算公式可以帮助我们了解变量之间的关系,并为后续分析提供重要的参考。
协方差是描述两个变量之间关系的统计量,它的数值可以为正、负或零。
当协方差为正时,表示两个变量呈正相关关系;当协方差为负时,表示两个变量呈负相关关系;当协方差为零时,表示两个变量之间没有线性关系。
协方差的绝对值越大,表示两个变量之间的关系越强。
那么,矩阵的协方差计算公式是如何得出的呢?我们首先来看一下两个变量的协方差的计算公式:协方差= (∑((X - μx) * (Y - μy))) / n其中,X和Y分别表示两个变量的取值,μx和μy分别表示两个变量的均值,n表示样本个数。
这个公式是用来计算两个变量的协方差的,但是对于多个变量之间的协方差,我们需要使用矩阵的形式来表示。
假设我们有n个变量,那么我们可以将这些变量表示为一个n维向量X = [X1, X2, ..., Xn],其中Xi表示第i个变量的取值。
同样地,我们可以将这些变量的均值表示为一个n维向量μ = [μ1,μ2, ..., μn]。
那么,矩阵的协方差计算公式可以表示为:协方差矩阵= (∑((X - μ) * (X - μ)')) / n其中,(X - μ)表示一个n维列向量,(X - μ)'表示其转置矩阵。
通过这个公式,我们可以计算出n个变量之间的协方差矩阵。
协方差矩阵是一个对称矩阵,对角线上的元素表示各个变量的方差,非对角线上的元素表示不同变量之间的协方差。
对角线上的元素越大,表示该变量的方差越大;非对角线上的元素绝对值越大,表示两个变量之间的关系越强。
矩阵的协方差计算公式在数据分析和建模中具有重要的作用。
通过计算协方差矩阵,我们可以得到变量之间的相关性,从而帮助我们理解数据中的模式和趋势。
协方差矩阵的计算还可以用于特征选择和降维等问题,帮助我们提取出最具代表性的变量。
协方差矩阵与方差的关系

协方差矩阵与方差的关系
协方差矩阵是一个非常重要的概念,它描述了一个多维数据集中不同维度之间的相关性。
而方差则是一个单一变量的离散程度的度量。
在一个多维数据集中,每个变量都有其自己的方差。
协方差矩阵则将所有变量的方差和协方差组合成了一个矩阵。
在这个矩阵中,对角线上的元素是每个变量的方差,而非对角线上的元素表示不同变量之间的协方差。
当所有变量都是相互独立时,协方差矩阵会退化成一个对角矩阵,也就是每个变量的方差都是独立的。
而在变量之间存在相关性时,协方差矩阵的非对角线上的元素会有值,这表示了不同变量之间的相关性。
因此,可以认为方差是协方差矩阵的一种特殊情况,即在所有变量之间都不存在相关性时,协方差矩阵就等同于方差。
在实际应用中,协方差矩阵经常被用于数据分析、机器学习和金融建模等领域。
- 1 -。
协方差矩阵怎么算

协方差矩阵怎么算
协方差矩阵怎么算:
设矩阵A为输入。
A的每一行为一个观测值,每一列代表一个特征(变量)。
计算步骤如下:
1. 计算每一变量的均值(列均值);
2. 中心化──每个元素减去该列的列均值;
3. 转置并相乘。
协方差矩阵Matlab代码如下:
function C = mycov(A)
avg = mean(A);
num = size(A, 1);
normA = A - repmat(avg, num, 1);
C = (normA' * normA) / (num -1);
这和Matlab的cov函数输出一致。
X、Y 是两个随机变量,X、Y 的协方差cov(X, Y) 定义为:
其中:
、
2. 协方差矩阵定义
矩阵中的数据按行排列与按列排列求出的协方差矩阵是不同的,这里
默认数据是按行排列。
即每一行是一个observation(or sample),那么每一列就是一个随机变量。
n个随机变量,m个样本。
协方差矩阵:
协方差矩阵的维度等于随机变量的个数,即每一个observation 的维度。
在某些场合前边也会出现1 / m,而不是1 / (m - 1).。
计算协方差矩阵

计算协方差矩阵
协方差矩阵是指一个随机向量中各个分量之间的协方差构成的矩阵。
求解协方差矩阵的方法有很多种,其中一种常用的方法是利用样本数据来估计真实的协方差矩阵。
具体步骤如下:
1. 收集样本数据,假设我们有n个样本,每个样本有m个特征。
2. 对于每个特征(第i个特征),计算该特征在n个样本中的均值mi。
3. 对于每个特征对(第i个和第j个特征),计算它们在n个样本中的协方差Cov(i,j)。
4. 将所有协方差值填入协方差矩阵的对应位置,得到估计的协方差矩阵。
需要注意的是,当样本数量较少时,估计的协方差矩阵可能会存在偏差。
此时可以使用正则化方法来解决这个问题,比如岭回归、Lasso回归、弹性网络等。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
74
K
-0.0043 -0.0052 0.0181 0.0570 -0.0076 -0.0046
75
BA
0.0857 0.0379 0.0101 -0.0076 0.0896 0.0248
76
IBM
0.0123 -0.0022 -0.0039 -0.0046 0.0248 0.0184
1.7
10.3 我们应该除以M还是M-1?Excel与统计量?
1.6
A
21
收益数据
22
日期
23
3-Jan-94
24
3-Jan-95
25
2-Jan-96
26
2-Jan-97
27
2-Jan-98
28
4-Jan-99
29
3-Jan-00
30
2-Jan-01
31
2-Jan-02
32
2-Jan-03
33
2-Jan-04
34
35
均值
36
标准差
37
方差
38
B
C
D
E
F
G
H
GE 56.44% 18.23% 56.93% 42.87% 47.11% 34.55% 28.15%
50
2-Jan-02
51
2-Jan-03
52
2-Jan-04
53
B
C
D
E
F
G
H
GE 32.78% -5.43% 33.27% 19.21% 23.45% 10.89%
4.49% -19.05% -43.40% -68.45% 12.24%
MSFT -22.89% 11.83% 22.90% 57.73% 16.65% 63.87% -10.18% -68.58% -17.11% -50.85%
lecture
10 FINANCIAL MODELING 金融建模
1.1
第10章 计算方差-协方差矩阵
10.1 引言
要计算有效投资组合,我们就必须计算股票收益数据的方差-协方差矩阵 。本章中,我们将讨论在Excel中怎样实现这个计算。其中最显而易见 的计算为样本方差-协方差矩阵:这是直接由历史收益计算而得的矩阵。 我们介绍几种计算方差-协方差的方法,包括在电子表中用超额收益矩阵 直接计算、VBA实现该方法计算。 即使样本方差-协方差矩阵看起来像一个很明显的选择,但我们将用大量 的文字说明它也许不是方差与协方差最好的估计。样本方差-协方差矩阵 有两个不尽人意的缺陷:一是它常使用不现实的参数,二是它难以用于 预测。这些将主要在10.5和10.6节中讨论。作为样本矩阵的替换,10.9 和10.10节将讨论用于优化方差-协方差矩阵估计的“压缩”方法。 在开始本章之前,你应先阅读第34章数组函数的内容。里面有一些 Excel函数,其参数是向量和矩阵;它们的实施与标准Excel函数略有不 同。本章重点讨论这些数组函数Transpose()和MMult(),还有“自制” 的数组函数的使用。
IBM 21.51% <-- =LN(G5/G4)
6.04% <-- =LN(G6/G5) 27.33% 41.08%
2.63% -2.11% 23.76% 21.76% 4.55% 15.54% 31.80%
23.66% 32.17% 0.1035
21.38% 40.71% 0.1657
18.43% 18.97% 0.0360
4.61% -19.74% -44.78% 35.90%
MSFT -1.50% 33.21% 44.28% 79.12% 38.04% 85.25% 11.20%
-47.19% 4.27%
-29.47% 18.01%
JNJ 6.01% 41.56% 57.71% 22.94% 17.62% 26.62% 3.41% 10.69% 23.11% -5.67% -1.27%
过减去资产各自的平均收益,得到超额收益矩阵(接下来的电子表中的
42-52行)。在55-61行中我们计算样本方差-协方差矩阵。
A
40
超额收益
41
日期
42
3-Jan-94
43
3-Jan-95
44
2-Jan-96
45
2-Jan-97
46
2-Jan-98
47
4-Jan-99
48
3-Jan-00
49
2-Jan-01
2.97 152.93 16.68%
K 20.37 18.47 19.90 29.03 27.59 38.01 34.14 20.93 23.52 28.70 32.00 37.36
0.41 15.44 1.68%
BA 2.34 4.21 4.20 8.09
13.93 20.19 23.47 36.27 48.13 41.39 32.81 48.86
12.64 18.49 43.37 48.51 30.26 31.58 23.52 28.16
JNJ 6.78 7.20
10.91 19.43 24.44 29.15 38.04 39.36 43.80 55.19 52.15 51.49
10.56 336.44 36.70%
10.86 305.82 33.36%
29
3-Jan-00
30
2-Jan-01
31
2-Jan-02
32
2-Jan-03
33
2-Jan-04
34
35
均值
36
标准差
37
方差
IBM
GE 2.36 4.15 4.98 8.80
13.51 21.64 30.57 40.51 42.42 34.82 22.25 31.86
MSFT 2.68 2.64 3.68 5.73
1.5
10.2.1一个稍微更有效率的替代方法 正如你所期望那样,的确存在其他计算方差-协方差矩阵可选方法。这里所 介绍的方法跳过了超额收益的计算,并且直接使用单元格B71:G76中的公 式进行计算。它通过使用数组函数=MMULT(TRANSPOSE(B23:G33B35:G35),B23:G33-B35:G35)/10。通过写入B23:G33-B35我们直 接将每项收益
A
B
C
D
E
F
G
H
6只股票的年度股票价格及收益数据
通用电气公司 (GE), 微软公司 (MSFT), 强生公司 (JNJ), 家乐氏公司 (K), 波音公司 (BA),
1
2
价格数据
3
日期
4
4-Jan-93
5
3-Jan-94
6
3-Jan-95
7
2-Jan-96
8
2-Jan-97
9
2-Jan-98
在前面的计算中我们除以M-1而非M,以此得到无偏的方差和协方差的估 计。不过这个选择看起来几乎没有多大影响。我们引用主流的教科书:“ 对于为什么要用M-1取代M这儿有一段很长的历史。如果你从来没有听说 过,你可以参考任何一本好的统计教材。这里我们主要想提醒你,如果你 在计算一个分布的方差时,这个分布存在已知的先验的均值,而不需要从 历史数据估计的时候,那么M-1应该变回M。(我们同样想说关于在分母 上用M-1替代M上,我们认为对你是已知的,但这却是对你不负责任的— —例如,试图用图例说明去证明一个充满疑问的假设)” Excel本身某程度上在除以M还是M-1这个问题上也有些混乱。在下面的电 子表中我们给出几种计算均值,方差,标准差和协方差的方法。
5.51% 23.86% 0.0570
27.63% 29.93% 0.0896
17.63% <-- =AVERAGE(G23:G33) 13.56% <-- =STDEV(G23:G33) 0.0184 <-- =VAR(G23:G33)
1.4
我们用我们的数字例子来说明计算方差-协方差矩阵的矩阵方法。我们通
K -9.79% 7.46% 37.76% -5.09% 32.04% -10.74% -48.93% 11.67% 19.90% 10.88% 15.49%
BA 58.73% -0.24% 65.55% 54.34% 37.11% 15.05% 43.53% 28.29% -15.09% -23.23% 39.82%
62
63 注意: 将数组函数放进单元格 B56:G61:
64 1. 标记整个区域 B56:G61
65 2. 键入 <-- {=MMULT(TRANSPOSE(B42:G52),B42:G52)/10} 到其中一个单元格.
66 3. 完成输入后, 按 [Ctrl]+[Shift]+[Enter] 作为数组函数输入公式.
K -9.79% 7.46% 37.76% -5.09% 32.04% -10.74% -48.93% 11.67% 19.90% 10.88% 15.49%
BA 58.73% -0.24% 65.55% 54.34% 37.11% 15.05% 43.53% 28.29% -15.09% -23.23% 39.82%
4.61% -19.74% -44.78% 35.90%
MSFT -1.50% 33.21% 44.28% 79.12% 38.04% 85.25% 11.20%
-47.19% 4.27%
-29.47% 18.01%
JNJ 6.01% 41.56% 57.71% 22.94% 17.62% 26.62% 3.41% 10.69% 23.11% -5.67% -1.27%
使用数组函数 {<-- {=MMULT(TRANSPOSE(B42:G52),B42:G52)/10}} 计算样本方差-协方差矩