Protobuf编码详解
protobuf 编码原理

Protobuf编码原理1. 简介protobuf(Protocol Buffers)是一种用于结构化数据序列化的语言无关、平台无关、可扩展的机制。
它由Google开发,广泛应用于分布式系统中的数据通信和持久化存储。
protobuf定义了一种简洁的数据描述语言,通过这种语言可以定义数据结构的模式,然后使用编译器生成对应的代码,以便在不同的平台和语言间进行数据交换。
protobuf支持多种编程语言,如C++、Java、Python等。
protobuf的编码原理主要涉及到数据结构的定义、编码规则和编解码过程。
下面将详细介绍这些内容。
2. 数据结构定义在protobuf中,数据结构的定义通过.proto文件完成,这是一种文本文件,用于描述消息类型和字段。
一个.proto文件通常包含一个或多个message类型的定义。
每个message类型可以包含多个字段,每个字段都有一个唯一的标识号和一个类型。
标识号用于在编码和解码过程中标识字段,类型用于指定字段的数据类型。
protobuf支持的数据类型包括基本类型(如int、float、bool等)、字符串、嵌套message、枚举等。
下面是一个简单的.proto文件示例:syntax = "proto3";message Person {string name = 1;int32 age = 2;repeated string hobbies = 3;}在上述示例中,定义了一个名为Person的message类型,它包含三个字段:name、age和hobbies。
name字段的类型是字符串,age字段的类型是32位整数,hobbies字段的类型是字符串数组。
3. 编码规则protobuf使用一种紧凑、高效的编码规则将数据序列化为二进制格式。
这种编码规则被称为Varint编码和Length-Delimited编码。
3.1 Varint编码Varint编码用于对整数进行编码,它将一个整数按照变长编码的方式写入到字节流中。
protobuf 整数编码

在Protocol Buffers(protobuf)中,整数编码使用了一种称为Varint的紧凑编码方式。
Varint 是一种可变长度的编码方式,可以有效地表示不同大小的整数值。
Varint编码的规则如下:
1. 对于正整数,Varint编码将整数的二进制表示按照小端(little-endian)顺序拆分成7位一组的片段,每个片段的最高位用于表示是否为最后一个片段,其余7位用于存储整数值。
2. 对于负整数,Varint编码先将整数取反,然后按照正整数的编码规则进行编码,最后在编码结果前加上0x80标识为负数。
以下是一些示例:
- 对于整数300,二进制表示为100101100,Varint编码为10101100 00000010。
- 对于整数-300,先取反得到11111111111111111111111111111011011,然后按照正整数的编码规则得到10101100 00000010,最后在编码结果前加上0x80得到10000001 01011000 00000010。
在使用Protocol Buffers时,整数类型(如int32、int64、uint32、uint64等)会使用Varint 编码来进行序列化和反序列化。
这种编码方式可以有效地减小数据的存储和传输开销,特别适合于对数据大小敏感的场景。
protobuf float编码

Protobuf Float编码1. 介绍Protocol Buffers(简称为ProtoBuf)是一种用于序列化结构化数据的二进制格式,由Google开发并用于内部数据传输。
它的主要优势是它可以提供高效的数据交换格式,使得数据在不同平台之间的传输和存储变得更加简单高效。
在ProtoBuf中,数据的编码和解码是通过定义消息格式来完成的,而其中一个常用的数据类型是浮点数(Float)。
本文将深入讨论ProtoBuf中浮点数的编码方式,主要包括: 1. 浮点数的二进制表示 2. ProtoBuf中的浮点数编码规则 3. 浮点数编码的优势和限制 4. 示例和实践建议2. 浮点数的二进制表示在计算机中,浮点数(float)是一种用于表示实数的数据类型。
它的内部二进制表示方式采用了科学计数法,包括三个主要组成部分:符号位、指数位和尾数位。
具体地,一个浮点数可以表示为 (-1)^S * M * 2^E,其中S表示符号位(0为正,1为负),M表示尾数位,E表示指数位。
以32位浮点数为例,它将其中1位用于符号位,8位用于指数位,23位用于尾数位。
而64位浮点数则分别使用1位、11位和52位表示这三个部分。
这种二进制表示方式使得浮点数能够精确地表示绝大多数实数,并提供了较高的计算精度。
3. ProtoBuf中的浮点数编码规则ProtoBuf在编码浮点数时采用了一种可变长度编码方式,称为”Varint”编码。
Varint编码将整数表示为一系列字节,每个字节的前7位用于存储数据,最高位用于标记是否还有后续字节。
对于32位浮点数,ProtoBuf使用四个字节进行编码。
具体的编码规则如下: 1.如果数值在-128到127之间,则使用一个字节进行编码,最高位为0。
2. 如果数值在-32768到32767之间,则使用两个字节进行编码,最高位为10。
3. 如果数值在-8388608到8388607之间,则使用三个字节进行编码,最高位为110。
protobuf float编码

protobuf float编码protobuf是一种高效的数据序列化协议,具有良好的可扩展性和跨平台性。
在protobuf中,float类型的数据被编码为32位的二进制数据。
在这篇文章中,我们将详细介绍protobuf中float类型数据的编码方式。
在protobuf中,float类型的数据使用IEEE 754标准进行编码。
具体来说,float类型的数据被表示为一个32位的二进制数据,其中符号位占据第一位,指数位占据接下来的8位,尾数位占据接下来的23位。
符号位用于表示数据的正负,0表示正数,1表示负数。
指数位用于表示数据的指数部分,采用阶码偏移编码方法,其中指数部分的值为实际指数值减去127,这样可以将指数部分的范围从-127到128转换为了0到255。
尾数位用于表示数据的小数部分,采用基数为2的表示方法。
具体来说,对于一个float类型的数据,我们可以按照以下步骤进行编码:1. 将数据转换为32位的二进制数据,其中符号位占据第一位,指数位占据接下来的8位,尾数位占据接下来的23位。
2. 如果数据为正数,则符号位为0;如果数据为负数,则符号位为1,并将数据取反。
3. 计算数据的指数部分,具体方法为将实际指数值加上127,然后将结果转换为8位的二进制数据。
4. 将指数部分和尾数部分合并为一个32位的二进制数据。
5. 最终得到的32位二进制数据即为float类型数据在protobuf 中的编码结果。
通过以上步骤,我们可以将任意一个float类型的数据表示为protobuf中的二进制数据,从而实现数据序列化和传输。
同时,由于protobuf采用了IEEE 754标准对float类型数据进行编码,所以可以保证数据的精度和稳定性。
protobuf二进制解析

protobuf二进制解析
protobuf是一种轻量级的数据交换格式,采用二进制编码,具有高效性和跨语言支持等优势。
在使用protobuf进行数据交互时,需要对其进行二进制解析。
protobuf的二进制编码格式由tag和value两部分组成。
tag 表示该字段在消息中的编号和类型,value则表示该字段的值。
在解析时,需要根据tag来确定该字段的类型和编号,再根据value 来读取该字段的值。
protobuf提供了多种语言的解析库,如C++、Java、Python 等。
这些库可以自动生成相应语言的解析代码,简化了解析过程。
对于没有对应解析库的语言,也可以手动解析二进制数据。
在进行protobuf二进制解析时,需要注意以下几点:
1. 解析时需要按照protobuf定义的消息格式进行解析,否则会出现解析错误。
2. 解析时需要注意字节序问题,在不同平台上可能存在不同的字节序,需要进行转换。
3. 解析时需要注意数据类型的匹配,如将字符串类型解析为整型会出现解析错误。
4. 解析时需要注意精度问题,如将浮点型转换为整型会出现精度丢失。
总之,对于需要进行二进制数据交换的应用场景,protobuf是一个不错的选择。
通过了解protobuf的二进制编码格式和解析方
式,可以更好地使用protobuf进行数据交换。
protobuf编码实现解析(java)
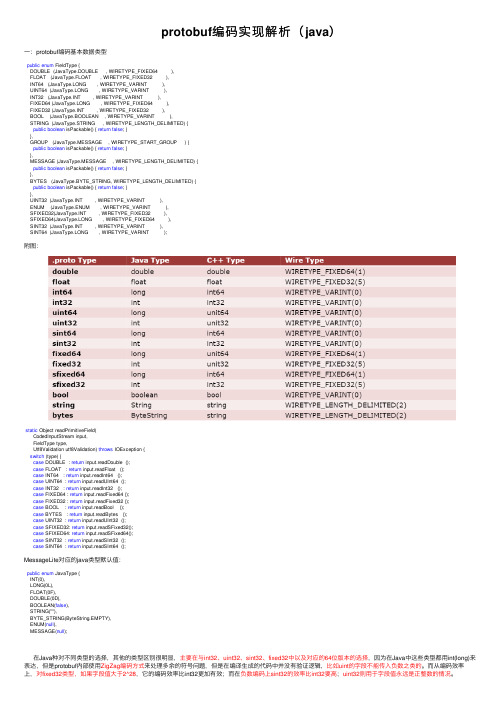
protobuf编码实现解析(java)⼀:protobuf编码基本数据类型public enum FieldType {DOUBLE (JavaType.DOUBLE , WIRETYPE_FIXED64 ),FLOAT (JavaType.FLOAT , WIRETYPE_FIXED32 ),INT64 (JavaType.LONG , WIRETYPE_VARINT ),UINT64 (JavaType.LONG , WIRETYPE_VARINT ),INT32 (JavaType.INT , WIRETYPE_VARINT ),FIXED64 (JavaType.LONG , WIRETYPE_FIXED64 ),FIXED32 (JavaType.INT , WIRETYPE_FIXED32 ),BOOL (JavaType.BOOLEAN , WIRETYPE_VARINT ),STRING (JavaType.STRING , WIRETYPE_LENGTH_DELIMITED) {public boolean isPackable() { return false; }},GROUP (JavaType.MESSAGE , WIRETYPE_START_GROUP ) {public boolean isPackable() { return false; }},MESSAGE (JavaType.MESSAGE , WIRETYPE_LENGTH_DELIMITED) {public boolean isPackable() { return false; }},BYTES (JavaType.BYTE_STRING, WIRETYPE_LENGTH_DELIMITED) {public boolean isPackable() { return false; }},UINT32 (JavaType.INT , WIRETYPE_VARINT ),ENUM (JavaType.ENUM , WIRETYPE_VARINT ),SFIXED32(JavaType.INT , WIRETYPE_FIXED32 ),SFIXED64(JavaType.LONG , WIRETYPE_FIXED64 ),SINT32 (JavaType.INT , WIRETYPE_VARINT ),SINT64 (JavaType.LONG , WIRETYPE_VARINT );附图:static Object readPrimitiveField(CodedInputStream input,FieldType type,Utf8Validation utf8Validation) throws IOException {switch (type) {case DOUBLE : return input.readDouble ();case FLOAT : return input.readFloat ();case INT64 : return input.readInt64 ();case UINT64 : return input.readUInt64 ();case INT32 : return input.readInt32 ();case FIXED64 : return input.readFixed64 ();case FIXED32 : return input.readFixed32 ();case BOOL : return input.readBool ();case BYTES : return input.readBytes ();case UINT32 : return input.readUInt32 ();case SFIXED32: return input.readSFixed32();case SFIXED64: return input.readSFixed64();case SINT32 : return input.readSInt32 ();case SINT64 : return input.readSInt64 ();MessageLite对应的java类型默认值:public enum JavaType {INT(0),LONG(0L),FLOAT(0F),DOUBLE(0D),BOOLEAN(false),STRING(""),BYTE_STRING(ByteString.EMPTY),ENUM(null),MESSAGE(null);在Java种对不同类型的选择,其他的类型区别很明显,主要在与int32、uint32、sint32、fixed32中以及对应的64位版本的选择,因为在Java中这些类型都⽤int(long)来表达,但是protobuf内部使⽤ZigZag编码⽅式来处理多余的符号问题,但是在编译⽣成的代码中并没有验证逻辑,⽐如uint的字段不能传⼊负数之类的。
protobuf编码
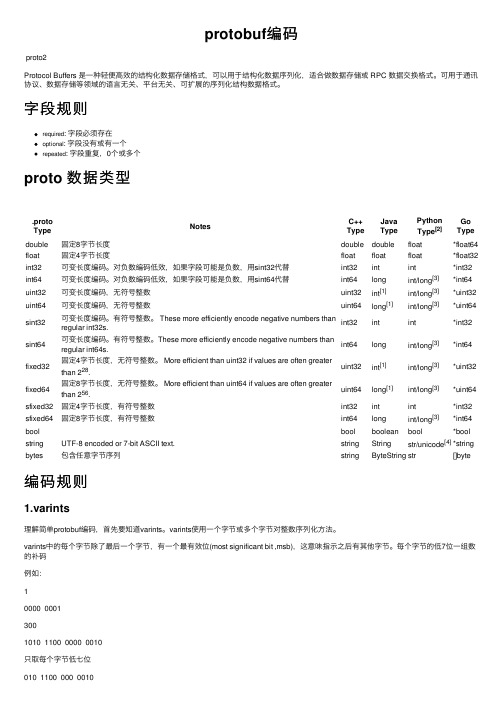
protobuf编码proto2Protocol Buffers 是⼀种轻便⾼效的结构化数据存储格式,可以⽤于结构化数据序列化,适合做数据存储或 RPC 数据交换格式。
可⽤于通讯协议、数据存储等领域的语⾔⽆关、平台⽆关、可扩展的序列化结构数据格式。
字段规则required: 字段必须存在optional: 字段没有或有⼀个repeated: 字段重复,0个或多个proto 数据类型.protoType Notes C++TypeJavaTypePythonType[2]GoTypedouble固定8字节长度double double float*float64 float固定4字节长度float float float*float32 int32可变长度编码。
对负数编码低效,如果字段可能是负数,⽤sint32代替int32int int*int32 int64可变长度编码。
对负数编码低效,如果字段可能是负数,⽤sint64代替int64long int/long[3]*int64 uint32可变长度编码,⽆符号整数uint32int[1]int/long[3]*uint32 uint64可变长度编码,⽆符号整数uint64long[1]int/long[3]*uint64sint32可变长度编码。
有符号整数。
These more efficiently encode negative numbers thanregular int32s.int32int int*int32sint64可变长度编码。
有符号整数。
These more efficiently encode negative numbers thanregular int64s.int64long int/long[3]*int64fixed32固定4字节长度,⽆符号整数。
More efficient than uint32 if values are often greaterthan 228.uint32int[1]int/long[3]*uint32fixed64固定8字节长度,⽆符号整数。
Protobuf编码

Protobuf编码Varint编码规则:在⼀个字节的8位⾥⽤低7位存储数字的⼆进制补码,第⼀位为标识位(most significant bit--msb)⽤来表⽰下⼀个字节是否还有意义,是否要继续读取下⼀个字节。
⼆进制补码的低位排在编码序列的前头(逆序是以7位⼀组逆序)。
这个办法是为了少存0节省空间,同时也是为了⽅便移位运算。
举个例⼦:int a = 1;数字1的⼆进制补码表⽰为:00000000000000000000000000000001使⽤varints编码后为:1.以7位1组为单位逆序:000000100000000000000000000000002.第⼀位⾼位判断是否需要拼接下⼀个字节来表⽰数字1,这⾥不需要,所以只需⼀组最⾼位补0000000010000000000000000000000003.故数字1的vriant编码:00000001⼗六进制表⽰为:0x01举个复杂的例⼦:int a = 251;数字251的⼆进制补码表⽰为:00000000000000000000000011111011使⽤varint编码:1.以7位1组单位逆序:111101100000010000000000000000002.7位1组,第⼀位⾼位为msb表⽰是否需要下⼀个字节,这⾥第⼀个字节需要下⼀个字节,故第⼀个字节补⾼位为1。
第⼆个字节不需要第三个字节了,故第⼆个字节补⾼位为0 1111101100000001000000000000000000故数字251的varint编码为:1111101100000001⼗六进制表⽰为:0xFB01由此可见Varint编码⽅式通过逆序存储补码以及牺牲每⼀个字节的最⾼位⽤来表⽰是否需要读取下⼀个字节,可以将4字节的整数类型压缩⾄2个字节存储。
但是因为4个字节中每个字节都少了⼀个bit位,因此采⽤Varint编码4个字节能表⽰的最⼤数字就是228-1了⽽不再是232-1。
Protobuf3编解码

Protobuf3编解码我们已经基本能够使⽤Protocol Buffers⽣成代码,编码,解析,输出及读⼊序列化数据。
该篇主要讲述PB message的底层⼆进制格式。
不了解该部分内容,并不影响我们在项⽬中使⽤Protocol Buffers,但是了解⼀下PB格式是如何做到smaller这⼀层,确实是很有必要的。
Protobuf 序列化后所⽣成的⼆进制消息⾮常紧凑,这得益于 Protobuf 采⽤的⾮常巧妙的 Encoding ⽅法。
1.什么是 Varint(1).Varint 是⼀种紧凑的表⽰数字的⽅法,它⽤⼀个或多个字节来表⽰⼀个数字,值越⼩的数字使⽤越少的字节数。
这能减少⽤来表⽰数字的字节数。
⽐如对于 int32 类型的数字,⼀般需要 4 个 byte 来表⽰。
但是采⽤ Varint,对于很⼩的 int32 类型的数字,则可以⽤ 1 个 byte 来表⽰。
当然凡事都有好的也有不好的⼀⾯,采⽤ Varint 表⽰法,⼤的数字则需要 5 个 byte 来表⽰。
(2).Varint 中的每个 byte 的最⾼位 bit 有特殊的含义,如果该位为 1,表⽰后续的 byte 也是该数字的⼀部分,如果该位为 0,则结束。
其他的7 个 bit 都⽤来表⽰数字。
因此⼩于 128 的数字都可以⽤⼀个 byte 表⽰。
⼤于 128 的数字,⽐如 300,会⽤两个字节来表⽰:1010 1100 0000 0010下图演⽰了 Protocol Buffer 如何解析两个 bytes。
注意到最终计算前将两个 byte 的位置相互交换过⼀次,这是因为 Google Protocol Buffer 字节序采⽤ little-endian 的⽅式。
Varint 编码图 6. Varint 编码消息经过序列化后会成为⼀个⼆进制数据流,该流中的数据为⼀系列的 Key-Value 对。
如下图所⽰:Message Buffer图 7. Message Buffer采⽤这种 Key-Pair 结构⽆需使⽤分隔符来分割不同的 Field。
ProtoBuf编解码

ProtoBuf编解码简介:Protobuf是Protocol Buffers的简称,它是Google公司开发的⼀种数据描述语⾔,并于2008年对外开源。
Protobuf刚开源时的定位类似于XML、JSON等数据描述语⾔,通过附带⼯具⽣成代码并实现将结构化数据序列化的功能。
但更关注的是Protobuf作为接⼝规范的描述语⾔,可以作为设计安全的跨语⾔PRC接⼝的基础⼯具为什么选择Protobuf⼀般⽽⾔需要⼀种编解码⼯具会参考:编解码效率⾼压缩⽐多语⾔⽀持其中压缩与效率 最被关注的点:安装编译器protobuf的编译器叫: protoc(protobuf compiler), 需要到这⾥下载编译器:这个压缩包⾥⾯有:include, 头⽂件或者库⽂件bin, protoc编译器readme.txt, ⼀定要看,按照这个来进⾏安装安装编译器⼆进制linux/unix系统直接:mv bin/protoc usr/binwindows系统:注意: Windows 上的 git-bash 上默认的 /usr/bin ⽬录在:C:\Program Files\Git\usr\bin\因此⾸先将bin下的 protoc 编译器放到C:\Program Files\Git\usr\bin\安装编译器库include 库⽂件需要放到: /usr/local/include/,如果没有include,⼿动创建即可linux/unix系统直接:mv include/google /usr/local/includewindows系统:C:\Program Files\Git\usr\local\include验证安装C:\Users\snow>protoc --versionlibprotoc 3.19.1使⽤流程⾸先需要定义数据,通过编译器,来⽣成不同语⾔的代码创建hello.proto⽂件,其中包装HelloService服务中⽤到的字符串类型syntax = "proto3";package hello;option go_package = "/ProtoDemo/pb";message String {string value = 1 ;}syntax:表⽰采⽤proto3的语法。
Protobuf编码详解

prtotocol buffer是google于2008年开源的一款非常优秀的序列化反序列化工具,它最突出的特点是轻便简介,而且有很多语言的接口(官方的支持C++,Java,Python,C,以及第三方的Erlang, Perl等)。
本文从protobuf如何将特定结构体序列化为二进制流的角度,看看为什么Protobuf如此之快。
一,示例从例子入手是学习一门新工具的最佳方法。
下面我们通过一个简单的例子看看我们如何用protobuf 的C++接口序列化反序列化一个结构体。
1,编辑您将要序列化的结构体描述文件Hello.proto每个结构体必须用message来描述,其中的每个字段的修饰符有required, repeated和optional 三种,required表示该字段是必须的,repeated表示该字段可以重复出现,它描述的字段可以看做C语言中的数组,optional表示该字段可有可无。
同时,必须人为地为每个字段赋予一个标号field_number,如上图中的1,2,3,4所示。
更详细的proto文件的编写规则见这里。
2,用protoc工具“编译”Hello.protoprotoc工具使用的一般格式是:protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto其中SRC_DIR是proto文件所在的目录,DST_DIR是编译proto文件后生成的结构体处理文件的目录之后会生成对结构体Hello.proto中描述的各字段做序列化反序列化的类3, 编写序列化进程我们用set方法为结构体中的每个成员赋值,然后调用SerializeToOstream将结构体序列化到文件log中。
并编译它:4,编写反序列化进程用ParseFromIstream将文件中的内容序列化到类Hello的对象msg中。
并编译它:,5,做序列化和反序列化操作上面只是一个简单的例子,并没有对protobuf的性能做测试,protobuf的性能测试详见这里。
go语言测试Protobuf编码解码过程(附测试代码)

go语⾔测试Protobuf编码解码过程(附测试代码)简介Google Protocol Buffer( 简称 Protobuf)是Google公司内部的混合语⾔数据标准,他们主要⽤于RPC系统和持续数据存储系统。
Protobuf应⽤场景Protocol Buffers 是⼀种轻便⾼效的结构化数据存储格式,可以⽤于结构化数据串⾏化,或者说序列化。
它很适合做数据存储或RPC数据交换格式。
可⽤于通讯协议、数据存储等领域的语⾔⽆关、平台⽆关、可扩展的序列化结构数据格式。
简单来说,Protobuf的功能类似于XML,即负责把某种数据结构的信息,以某种格式保存起来。
主要⽤于数据存储、传输协议等使⽤场景。
为什么已经有了XLM,JSON等已经很普遍的数据传输⽅式,还要设计出Protobuf这样⼀种新的数据协议呢?Protobuf 优点性能好/效率⾼时间维度:采⽤XML格式对数据进⾏序列化时,时间消耗上性能尚可;对于使⽤XML格式对数据进⾏反序列化时的时间花费上,耗时长,性能差。
空间维度:XML格式为了保持较好的可读性,引⼊了⼀些冗余的⽂本信息。
所以在使⽤XML格式进⾏存储数据时,也会消耗空间。
整体⽽⾔,Protobuf以⾼效的⼆进制⽅式存储,⽐XML⼩3到10倍,快20到100倍。
代码⽣成机制代码⽣成机制的含义在Go语⾔中,可以通过定义结构体封装描述⼀个对象,并构造⼀个新的结构体对象。
⽐如定义Person结构体,并存放于Person.go⽂件:1 type Person struct{2 Name string3 Age int4 Sex int5 }在分布式系统中,因为程序代码时分开部署,⽐如分别为A、B。
A系统在调⽤B系统时,⽆法直接采⽤代码的⽅式进⾏调⽤,因为A系统中不存在B系统中的代码。
因此,A系统只负责将调⽤和通信的数据以⼆进制代码⽣成机制的优点⾸先,代码⽣成机制能够极⼤解放开发者编写数据协议解析过程的时间,提⾼⼯作效率;其次,易于开发者维护和迭代,当需求发⽣变更时,开发者只需要修改对应的数据传输⽂件内容即可完成所有的修改。
protobuf 编码规则

protobuf 编码规则Protobuf(Protocol Buffers)是一种高效的二进制序列化格式,由Google开发。
它主要用于网络通信、数据存储等场景,具有高效、易用、跨平台等特点。
Protobuf的编码规则如下:1. 消息结构:Protobuf消息的二进制数据是由一系列的键值对依次排列构成。
每个键值对包括Tag信息和Data信息两部分。
Tag信息用来标识每一个字段,包括wire-type和field-number;Data信息用来存储字段值编码后的二进制序列。
2. Tag生成规则:Tag用一个字节表示,其中低3个字节标识wire-type,生成规则如下:Tag=field-number<<3wire-type。
3. 编码方式:Protobuf采用可变长的编码方式,包括Varint、Fixed32、Fixed64等。
其中,Varint是一种可变长的整数编码方式,它采用一种类似于前缀编码的方式,将正整数编码为变长的字节序列。
4. 字段编号:字段的编号采用field-number标识,它是一个非负整数。
在定义消息类型时,需要为每个字段指定一个唯一的field-number。
5. 字段类型:字段的类型由protobuf的数据类型定义,包括int32、int64、uint32、uint64、sint32、sint64、fixed32、fixed64、sfixed32、sfixed64、float、double、bool等。
总的来说,Protobuf的编码规则主要包括消息结构、Tag生成规则、编码方式、字段编号和字段类型等几个方面。
这些规则使得Protobuf具有高效、紧凑和灵活的特点,能够满足各种不同的应用场景需求。
go语言的protobuf的解析代码

go语言的protobuf的解析代码Go语言是一种开源的编程语言,它拥有简洁、高效和并发性强的特点。
在Go语言中,我们可以使用protobuf(Protocol Buffers)来进行数据的序列化和反序列化操作。
protobuf是一种轻量级的数据交换格式,它可以将结构化数据转化为二进制格式,从而实现高效的数据传输和存储。
在Go语言中使用protobuf,我们首先需要定义一个.proto文件来描述数据的结构和类型。
这个.proto文件类似于一种数据模板,通过定义消息的字段和类型,我们可以确保数据在不同系统之间的兼容性。
在.proto文件中,我们可以使用一些特定的语法来定义消息的字段和类型,比如int、string、bool等基本类型,以及message类型来定义复杂的数据结构。
定义好.proto文件后,我们需要使用protobuf的编译器将.proto 文件编译成对应的Go语言代码。
这些生成的代码包含了消息的结构体和相关的方法,可以帮助我们进行数据的序列化和反序列化操作。
在Go语言中解析protobuf数据非常简单,我们只需要导入相关的包,并使用protobuf提供的函数和方法即可。
首先,我们需要创建一个空的消息结构体实例,然后使用protobuf提供的Unmarshal函数将二进制数据解析到消息结构体中。
解析完成后,我们可以通过访问消息结构体的字段来获取相应的数据。
除了解析数据,我们还可以使用protobuf将数据序列化为二进制格式。
在Go语言中,我们可以使用protobuf提供的Marshal函数将消息结构体序列化为二进制数据。
序列化后的数据可以方便地进行传输和存储。
总结一下,Go语言的protobuf解析代码非常简洁和高效。
通过定义.proto文件和使用protobuf提供的函数和方法,我们可以轻松地进行数据的序列化和反序列化操作。
这种灵活和高效的数据交换方式使得Go语言在分布式系统和网络通信中得到广泛应用。
protobuf二进制解析

protobuf二进制解析Protobuf二进制解析——优化数据传输和存储的利器在现代软件开发中,数据的传输和存储是一个非常重要的环节。
在网络通信中,数据的传输速度直接影响着系统的响应速度和用户体验;在数据存储中,数据的大小和读写效率关系着磁盘空间和系统性能。
为了解决这些问题,Google开发了一种高效的序列化框架——Protocol Buffers(简称Protobuf),它通过二进制的方式序列化和反序列化数据,优化了数据的传输和存储效率。
1. Protobuf简介Protocol Buffers是一种轻便高效的数据交换格式,使用二进制编码来压缩数据,相比于XML和JSON等文本格式,Protobuf具有更小的体积和更高的解析速度。
Protobuf使用.proto文件定义数据结构,通过编译器生成对应的代码,开发者可以使用生成的代码来序列化和反序列化数据。
2. Protobuf的优势2.1 高效的数据传输由于Protobuf使用二进制编码,相比于文本格式,它可以将数据压缩到更小的体积,减少了网络传输的数据量。
在网络通信中,数据量的减小意味着传输速度的提升,从而提高了系统的响应速度和用户体验。
2.2 快速的数据解析Protobuf的二进制编码可以被快速解析,相比于文本格式,它不需要进行解析器的初始化和语法分析,可以直接通过二进制位运算来解析数据,大大提高了解析的速度。
2.3 灵活的数据结构Protobuf的.proto文件可以定义复杂的数据结构,支持嵌套、枚举、可选字段和重复字段等特性,开发者可以根据实际需求来定义数据结构。
同时,Protobuf还支持数据版本的兼容性,可以向后兼容和向前兼容,方便系统的升级和扩展。
3. Protobuf的应用场景3.1 网络通信在分布式系统中,各个节点之间需要进行大量的数据交互,使用Protobuf可以大幅减少数据的传输量,提高网络通信的效率。
特别是在移动端的开发中,网络传输是一个非常重要的环节,Protobuf 的高效传输可以节省用户流量,提高应用的响应速度。
go语言的protobuf的解析代码

go语言的protobuf的解析代码
Go语言的protobuf解析代码是用于解析和处理protobuf格式的数据。
protobuf是一种轻量级的数据交换格式,它可以将结构化数据序列化为二进制格式,以便于存储和传输。
在Go语言中使用protobuf解析数据需要先定义数据的结构,然后使用protobuf的编译器将结构体定义文件(.proto)编译成Go语言可识别的代码文件,这样就可以在Go代码中使用这些生成的代码来进行数据的解析和处理。
我们需要在Go代码中引入protobuf的相关包,然后导入生成的代码文件。
接下来,我们可以使用protobuf提供的函数来解析数据。
对于一个protobuf格式的数据,我们可以通过调用解析函数来将其解析为Go语言中的结构体对象。
解析函数会根据结构体的定义和数据的格式,将数据的字段值赋给结构体对应的字段。
在解析过程中,我们可以根据需求对数据进行验证和处理。
例如,可以检查字段值是否符合预期的范围,或者根据字段值的不同进行不同的处理逻辑。
当数据解析完成后,我们就可以使用Go语言的代码来操作和处理这些数据了。
这样可以更方便地对数据进行操作,而不需要手动解析和处理二进制数据。
protobuf的解析代码可以帮助我们更高效地处理结构化数据,尤其是在网络传输和存储方面。
通过使用protobuf,我们可以减少数据的大小和传输时间,并且可以更好地控制数据的格式和结构。
Go语言的protobuf解析代码可以帮助我们更方便地解析和处理protobuf格式的数据。
通过使用protobuf,我们可以更高效地处理结构化数据,提高代码的可读性和可维护性。
protobuf proto3 默认编码格式

Protobuf Proto3 默认编码格式1. 介绍Protocol Buffers(简称 Protobuf)是一种轻量级的数据交换格式,由 Google 开发并在 2008 年开源。
Protobuf 使用简单、高效、灵活,支持多种编程语言,被广泛应用于分布式系统中的数据通信和持久化存储。
Proto3 是 Protocol Buffers 的第三个版本,于 2016 年发布。
与前两个版本相比,Proto3 有一些重要的改进,包括更简洁的语法和默认编码格式。
本文将详细探讨 Proto3 默认编码格式,包括其特点、使用方法以及与其他版本的比较。
2. Proto3 默认编码格式的特点Proto3 默认使用的编码格式是 Base 128 Varints。
这是一种变长编码格式,可以有效地压缩整数类型的数据。
Proto3 默认编码格式的特点如下: - 简洁:Base 128 Varints 编码格式使用变长字节序,可以根据数值大小动态选择所需的字节数。
相比于固定字节长度的编码格式,它可以节省存储空间。
- 高效:Base 128 Varints 编码格式适用于表示小整数,尤其是相对较小的正整数。
对于较大的整数,Proto3 会使用固定字节长度的编码格式,以兼顾性能和存储空间的平衡。
- 兼容性:Proto3 默认编码格式与前两个版本的 Protocol Buffers 兼容。
这意味着可以在 Proto3 中使用旧版本的数据,而且可以使用 Proto3 生成的代码读取旧版本的数据。
3. 使用 Proto3 默认编码格式在使用 Proto3 默认编码格式之前,我们需要先定义消息的结构。
以下是一个示例的 Proto3 消息定义:syntax = "proto3";message Person {string name = 1;int32 age = 2;repeated string hobbies = 3;}在这个示例中,我们定义了一个名为 Person 的消息类型,包含了 name、age 和hobbies 三个字段。
protobuf tag编码

protobuf tag编码
ProtocolBuffers(protobuf)是一种用于序列化结构化数据的数据交换格式。
在protobuf消息中,每个字段都有一个唯一的标识符(tag)。
tag是一个整数,用于标识消息中的字段,以便在序列化和反序列化时可识别字段。
tag必须是正整数,范围从1到2^29-1,且不能重复。
在protobuf消息的二进制编码中,tag是一个变长整数,占用1到5个字节。
编码格式如下:
1.标识字段的类型和编号,以及是否为结尾标识;
2.将类型和编号编码为一个整数,使用Varint编码;
3.将上述整数左移3位,然后与字段类型的值按位或,得到一个新的整数;
4.重复步骤2和3,直到所有字段的tag都编码完毕。
在解析protobuf消息时,通过读取tag的值,可以确定当前读取的数据类型和字段编号,从而正确地解析消息。
因此,在定义protobuf消息时,tag的选择非常重要,必须考虑到消息的可扩展性和兼容性。
总之,tag编码是protobuf消息编码中的一个重要部分,可以确保消息的可识别性和可扩展性。
在定义和使用protobuf消息时,必须认真考虑tag的选择和编码方式,以确保消息的正确性和可维护性。
- 1 -。
protobuf 压缩原理

protobuf 压缩原理
Protobuf(Protocol Buffers)是一种轻量级的数据序列化协议,用于结构化数据的存储和传输。
它的压缩原理主要包括以下几个方面:
1. 压缩编码:Protobuf使用一种称为Varint的压缩编码方式来
表示整数类型的字段。
Varint编码将一个整数按照一定规则拆
分成多个字节,使用最高位的一个比特来表示是否还有后续字节,以此来节省存储空间。
对于小的整数,只需要使用一个字节,而对于较大的整数,需要使用多个字节。
2. 字段标识:每个字段在序列化时都会被赋予一个唯一的标识,用于区分不同的字段。
这个标识是一个由字段的索引和类型组合成的32位整数。
在压缩时,Protobuf会使用Varint编码将
字段标识存储起来,以便在解析时能够准确地找到对应的字段。
3. 省略默认值:在序列化时,Protobuf会检查每个字段的值是
否与其默认值相同。
如果是,默认值将被省略,只有非默认值才会被编码。
这样可以节省空间,特别是对于一些重复出现的字段。
4. 内存布局:在内存中,Protobuf会使用连续的二进制数据来
存储序列化后的消息。
相比于JSON或XML等文本格式,这
种紧凑的二进制布局可以更高效地使用空间。
总的来说,Protobuf通过压缩编码、字段标识、省略默认值和
紧凑的内存布局等方式来实现数据的压缩和节省存储空间。
这使得Protobuf在网络传输和存储领域具有很高的性能和效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
prtotocol buffer是google于2008年开源的一款非常优秀的序列化反序列化工具,它最突出的特点是轻便简介,而且有很多语言的接口(官方的支持C++,Java,Python,C,以及第三方的Erlang, Perl等)。
本文从protobuf如何将特定结构体序列化为二进制流的角度,看看为什么Protobuf如此之快。
一,示例从例子入手是学习一门新工具的最佳方法。
下面我们通过一个简单的例子看看我们如何用protobuf 的C++接口序列化反序列化一个结构体。
1,编辑您将要序列化的结构体描述文件Hello.proto每个结构体必须用message来描述,其中的每个字段的修饰符有required, repeated和optional 三种,required表示该字段是必须的,repeated表示该字段可以重复出现,它描述的字段可以看做C语言中的数组,optional表示该字段可有可无。
同时,必须人为地为每个字段赋予一个标号field_number,如上图中的1,2,3,4所示。
更详细的proto文件的编写规则见这里。
2,用protoc工具“编译”Hello.protoprotoc工具使用的一般格式是:protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto其中SRC_DIR是proto文件所在的目录,DST_DIR是编译proto文件后生成的结构体处理文件的目录之后会生成对结构体Hello.proto中描述的各字段做序列化反序列化的类3, 编写序列化进程我们用set方法为结构体中的每个成员赋值,然后调用SerializeToOstream将结构体序列化到文件log中。
并编译它:4,编写反序列化进程用ParseFromIstream将文件中的内容序列化到类Hello的对象msg中。
并编译它:,5,做序列化和反序列化操作上面只是一个简单的例子,并没有对protobuf的性能做测试,protobuf的性能测试详见这里。
二,protocol buffer的数据类型从第一节中的例子可以看出,用Protocol buffer时需要用户自定义自己的结构体,而且结构体中的定义规则要符合google制定的规则。
结构体中每个字段都需要一个数据类型,protocol buffer支持的数据类型在源代码wire_format_lite.h中定义:其中:VARINT类数据表示要用variant编码对所传入的数据做压缩存储,variant编码细节见下一节。
FIXED32和FIXED64类数据不对用户传入的数据做variant压缩存储,只存储原始数据。
LENGTH_DELIMITED类数据主要针对string类型、repeated类型和嵌套类型,对这些类型编码时需要存储他们的长度信息。
START_GROUP是一个组(该组可以是嵌套类型,也可以是repeated类型)的开始标志。
END_GROUP是一个组(该组可以是嵌套类型,也可以是repeated类型)的结束标志。
每类数据包含的具体数据类型如下表所示:WireType 表示类型VARINT int32,int64,uint32,uint64,sint32,sint64,bool, enumFIXED64 fixed64,sfixed64,doubleLENGTH_DELIMITED string,bytes,embedded messages, packed repeadted fieldSTART_GROUP group的开始标志END_GROUP group的结束标志FIXED32 fixed32,sfixed32,float三,protocol buffer的编码一言以蔽之,ProtocolBuffer的编码是尽其所能地将字段的元信息和字段的值压缩存储,并且字段的元信息中含有对这个字段描述的所有信息。
整个结构体序列化后抽象地看起来像下图这样:可以看到,整个消息是以二进制流的方式存储,在这个二进制流中,逐个字段以定义的顺序紧紧相邻。
每个字段中由元信息tag和字段的值value组成。
其中tag是这样编码的:1)field_number << 3 | wire_type2)对上面得到的无符号类型整数做variant编码其中field_number第一节中提到的每个字段的标号,wire_type是第二节中提到的该字段的数据类型。
1,variant编码variant是一种紧凑型数字编码,将元数据跟数字保存在一起,如下图所示是数字131415的variant 编码:其中第一个字节的高位msb(Most Significant Bit )为1表示下一个字节还有有效数据,msb为0表示该字节中的后7为是最后一组有效数字。
踢掉最高位后的有效位组成真正的数字。
从上面可以看出,variant编码存储比较小的整数时很节省空间,小于等于127的数字可以用一个字节存储。
但缺点是对于大于268,435,455(0xfffffff)的整数需要5个字节来存储。
但是一般情况下(尤其在tag编码中)不会存储这么大的整数。
对一个整数的variant编码的代码位于./src/google/protobuf/io/coded_:WriteVarint32FallbackToArrayInline()函数中,摘录如下;inline uint8* CodedOutputStream::WriteVarint32FallbackToArrayInline( uint32 value, uint8* target) {整个结构体的序列化过程如下:a, 调用Hello类的ByteSize()计算出序列化后的长度,分配该长度的空间,以备以后将每个字段填充到该空间中,示例中的长度计算公式是:1+Int32Size()+1+4+1+StringSize()b, 调用Hello类的SerializeWithCachedSizes()对每个元素序列化下面是对每一类元素的序列化编码详解2 int32/int64/uint32/uint64类型的编码a,计算长度 1 + Int32Size(值);b,调用WireFormatLite::WriteInt32(…)将该字段的元信息和字段值写入到新空间中:例如用户为int32传入值123,则该字段的存储如下:第一个字节variant(1<<3|0) 第二个字节variant(123)3,String类型的编码a, 计算长度 1 + variant(stringLength)+stringLengthb, 调用WireFormatLite::WriteString(…)将该字段的元信息、长度和值写入到新空间中例如用户为string传入值“hello”,则该字段的存储如下:第一个字节variant(2<<3|2) ,第二个字节variant(5) ,剩余的字节“hello”4,float类型的编码a, 计算长度1+4b,调用WireFormatLite::WriteFloat(…)将该字段的元信息和值写入到新空间中其中写float内存拷贝的代码非常精炼:+ View Code5, 嵌套结构体编码a, 1 + variant32(embedded长度)+embedded的长度b,调用WireFormatLite::WriteMessageMaybeToArray(…)将该字段的元信息、长度和值写入到新空间中6,repeated类型字段编码a,计算长度1*repeated个数+ variant32(repeated长度)+repeated长度b,调用WireFormatLite::WriteMessageMaybeToArray(…)将下图所示编码的值写入到新空间中7,sint32, sint64类型字段编码从int32编码中可以看出,当int32传入-1时所耗的空间很大,所以结构体定义中引入了sint32和sint64类型的数据,这种数据采用一种叫zigzag的编码方式,使绝对值比较小的整数也占用比较小的字节。
zigzag编码的映射关系图如下它将原始类型为int32的数用uint32的数表示,当一个数的绝对值比较小时,将其用uint32表示,再采用variant编码存储就会比较节省空间。
对一个整数的zigzag编码也很巧妙:+ View Code四总结从上面的编码可以看出, protocol buffer压榨每一个没有真正用到的字节,使之序列化后的字节尽量少,清晰的数据编码和诸多的位操作使之变得很轻便简洁高效。
同时它提供了很多编程语言的接口,可以广泛应用于RPC系统中。
但是,由于它将元信息编码到二进制位中,使得序列化后的数据可读性非常差(其实是没有可读性^.^)。
五参考文献https:///protocol-buffers/ protobuf官方首页https:///protocol-buffers/docs/encoding 详细讲述了protobuf的编码细节(有些地方比本文还详细)/p/thrift-protobuf-compare/wiki/Benchmarking protobuf性能/p/protobuf/wiki/ThirdPartyAddOns提供了其他众多语言实现的protocol buffer,但是安全性和效率不能保证/colorful/archive/2012/05/05/173761.html提供了安装protobuf 的方法,并给出了一个小例子。