2.2 单层感知器模型与学习算法
单层感知器算法及其训练过程探究

单层感知器算法及其训练过程探究随着人工智能和机器学习技术的发展,单层感知器算法因为其简单和易于理解的特点成为了很多人学习和掌握机器学习初步知识的入门之路。
本文将介绍单层感知器算法及其训练过程探究。
一、单层感知器算法单层感知器是一种线性分类模型,也是神经网络的一种。
它通过一些列数值计算和激活函数的运用,将输入的向量映射到某个输出的标签值,用于相应的分类任务中。
单层感知器算法的基本流程是:输入向量 x 经过线性函数运算 h(x) = w*x+b 之后,再经过激活函数 g(h(x)) ,得到分类的输出 y。
其中,w 是权重,b 是偏差量。
在训练过程中,单层感知器通过反向传播算法对权重和偏差量进行不断调整,从而不断提高分类准确率。
二、单层感知器的训练过程单层感知器的训练过程可以分为以下几步:1. 准备数据准备数据是机器学习的第一步,也是单层感知器训练的必要条件。
通常,我们需要用一些已经标记好标签的数据集,输入向量 x 和对应的标签 y,作为算法的训练数据集。
2. 初始化权重和偏差量在开始训练之前,需要初始化权重 w 和偏差量 b。
通常,我们可以使用随机的小数值来初始化它们。
3. 计算误差并更新参数单层感知器的权重和偏差量通过随机初始化后,就可以开始输入训练集数据,并对其进行分类。
如果分类结果与真实标签不一致,则需要通过误差计算来调整权重和偏差。
通常,我们可以使用代价函数作为误差计算的准则,常见的代价函数有均方误差MSE 和交叉熵 CE. 通过代价函数计算出误差值,再通过反向传播算法对权重和偏差量进行更新,不断调整,直到误差值最小化。
4. 不断迭代在更新了权重和偏差量之后,需要再次用训练集测试,并根据误差值调整权重和偏差,直到误差值达到预设精度或者达到最大迭代次数停止。
三、总结单层感知器算法作为神经网络中的一种基本算法,其训练过程简单,易于理解,对于初学者来说是一种入门机器学习和神经网络的良好途径。
总之,单层感知器是机器学习和深度学习的起点,学习它可以让我们更好地理解更复杂的神经网络和机器学习算法,为未来更高级的研究打下坚实的基础。
感知器神经网络

感知器神经网络感知器是一种前馈人工神经网络,是人工神经网络中的一种典型结构。
感知器具有分层结构,信息从输入层进入网络,逐层向前传递至输出层。
根据感知器神经元变换函数、隐层数以及权值调整规则的不同,可以形成具有各种功能特点的人工神经网络。
本节将介绍单层感知器和多层感知器的工作原理。
5.3.1单层感知器1958年,美国心理学家Frank Rosenblatt 提出一种具有单层计算单元的神经网络,称为Perceptron ,即感知器。
感知器是模拟人的视觉接受环境信息,并由神经冲动进行信息传递的层次型神经网络。
感知器研究中首次提出了自组织、自学习的思想,而且对所能解决的问题存在着收敛算法,并能从数学上严格证明,因而对神经网络研究起了重要推动作用。
单层感知器的结构与功能都非常简单,以至于在解决实际问题时很少采用,但由于它在神经网络研究中具有重要意义,是研究其它网络的基础,而且较易学习和理解,适合于作为学习神经网络的起点。
1.感知器模型单层感知器是指只有一层处理单元的感知器,如果包括输入层在内,应为两层,如图5-14所示。
图中输入层也称为感知层,有n 个神经元节点,这些节点只负责引入外部信息,自身无信息处理能力,每个节点接收一个输入信号,n 个输入信号构成输入列向量X 。
输出层也称为处理层,有m 个神经元节点,每个节点均具有信息处理能力,m 个节点向外部输出处理信息,构成输出列向量O 。
两层之间的连接权值用权值列向量Wj 表示,m 个权向量构成单层感知器的权值矩阵W 。
3个列向量分别表示为:()()()121212,,,,,,,,,,,,,,,,1,2,,T i n Ti n Tj j j ij nj X x x x x O o o o o W w w w w j m====图5-14单层感知器对于处理层中任一节点,由第二节介绍的神经元数学模型知,其净输入j net '为来自输入层各节点的输入加权和∑==ni i ij j x w net 1'(5-26)输出o j 为节点净输入与阈值之差的函数,离散型单计算层感知器的转移函数一般采用符号函数。
感知器算法

y = f (∑ wi xi − θ )
i =1
d
而且f为一阶跃函数, 而且 为一阶跃函数,即: 为一阶跃函数
d 1, ∑ wi xi − θ ≥ 0 i =1 y = f ( x) = = sgn( w0T x − θ ) d −1, w x − θ < 0 ∑ i i i =1
四、感知器训练算法在多类问题中的应用 就第二章中的第三种情况为例说明) (就第二章中的第三种情况为例说明) 判决规则:对于c种类型 存在k个判决函 种类型, 判决规则:对于 种类型,存在 个判决函 数 d j ( x)( j = 1, 2,⋯, k ) ,若 di ( x) > d j ( x)( j = 1, 2,⋯ , k , j ≠ i) , x ∈ ωi 则判: 则判: 假设k=c, 多类问题的感知器算法的步骤如下: 多类问题的感知器算法的步骤如下: 假设 (1) 赋给初值: 赋给初值: 赋初值,选择正常数c, 给 Wi 赋初值,选择正常数 把训练样本 变成增广型, 变成增广型,k=0; x (2) 输入训练样本 xk,k ∈{x1 , x2 ,⋯, xn },假定 x ∈ ωi ;
训练样本
x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4 x1 x2 x3 x4 1011 0111 1101 0101 1011 0111 1101 0101 1011 0111 1101 0101 1011 0111 1101 0101
W(K)Tx
+ + + 0 0 + 0 + + + -
(3) 计算 个判决函数值: 计算c个判决函数值 个判决函数值:
di ( xk ) = [Wi (k )]T xk , i = 1, 2,⋯ , c
感知模型算法

感知模型算法感知模型算法是机器学习领域中一种常用的算法,它主要用于模拟和复制人类的感知过程,从而实现对输入数据的理解和分析。
在这篇文章中,我将介绍感知模型算法的原理、应用和优缺点。
感知模型算法是一种二分类模型,它通过学习输入数据的特征和标签之间的关系,来预测新数据的标签。
算法的核心思想是将输入数据映射到一个多维空间中,并在该空间中寻找一个超平面,将不同类别的数据点完全分开。
在这个过程中,感知模型通过迭代计算权重和偏置,不断调整超平面的位置,使得误分类点的数量最小化。
感知模型算法的应用非常广泛,特别是在图像识别、自然语言处理和推荐系统等领域。
在图像识别中,感知模型可以识别不同类别的物体或图像,从而实现自动化的图像分类和标注。
在自然语言处理中,感知模型可以识别文本中的情感、主题或实体,从而为用户提供更加个性化和精准的服务。
在推荐系统中,感知模型可以根据用户的历史行为和偏好,预测用户可能喜欢的物品或内容。
然而,感知模型算法也有一些局限性。
首先,感知模型只能处理线性可分的数据集,对于非线性可分的数据集效果不佳。
其次,感知模型对数据的初始权重和偏置值非常敏感,可能会陷入局部最优解。
此外,感知模型算法对于噪声数据非常敏感,可能会导致误分类。
为了克服感知模型算法的局限性,研究者们提出了许多改进和扩展的算法。
比如,多层感知机(Multilayer Perceptron,简称MLP)通过引入隐藏层和非线性激活函数,可以处理复杂的非线性问题。
支持向量机(Support Vector Machine,简称SVM)通过引入核函数,可以处理非线性可分的数据集。
卷积神经网络(Convolutional Neural Network,简称CNN)通过引入卷积操作和池化操作,可以处理图像和语音等具有空间结构的数据。
总结来说,感知模型算法是机器学习领域中一种重要的算法,它可以模拟和复制人类的感知过程,实现对输入数据的理解和分析。
单层感知器实现逻辑‘与’功能

单层感知器实现逻辑‘与’功能1.感知器实现逻辑‘与’功能的学习算法单层感知器,即只有一层处理单元的感知器。
感知器结构如下图所示:图1:感知器结构表1:与运算的真值表x 1 x 2 y 0 0 0 0 1 0 1 0 0 111分界线的方程(w 1x 1+w 2x 2-T=0)可以为: 0.5x 1+0.5x 2-0.75=0输入为k x 1、k x 2,输出为yk 。
当k x 1和k x 2均为1时,yk 为1,否则yk 为0。
设阈值θ=0.05,训练速率系数η=0.02,初始设置加权为058.0)0(1=w ,065.0)0(2=w 。
由于只有一个输出,得加权修正公式为:k k i i x n w n w ηδ+=+)()1(k k k y T -=δ第一步:w(0)=(0.058, 0.065),加入x1=(0, 0),05.01221111-=-+=θxwxws,则y1=0。
由于T1=0,δ1= T1- y1=0,故w(1)=(0.058, 0.065)第二步:加入x2=(0, 1),015.02222112=-+=θxwxws,则y2=1。
由于T 2=0,则δ2= T2- y2=-1,故w(2)=w(1)+0.02(-1)x2=(0.058, 0.045)第三步:加入x3=(1, 0),008.03223113=-+=θxwxws,则y3=1。
由于T 3=0,则δ3= T3- y3=-1,故w(3)=w(2)+0.02(-1)x3=(0.038, 0.045)第四步:加入x4=(1, 1),033.04224114=-+=θxwxws,则y4=1。
由于T 4=1,则δ4= T4- y4=0,故w(4)=w(3)=(0.038, 0.045)第五步:加入x1=(0, 0),S1=-0.05,则y1=0。
由于T1=0,δ1=0,故w(5)=(0.038,0.045)第六步:加入x2=(0, 1),S2=-0.005,则y2=0。
感知器学习算法 PPT课件

感知器结构
3.1.3感知器的局限性
问题:能否用感知器实现“异或”功能?
前
“异或”的真值表
馈 神
x1
x2
y
经 网
000
络
单
011
层
感 知
101
器
110
x1
O
O
x2
--
北京工商大学信息工程学院
19
3.1.4感知器的学习
关键问题就是求
WTj X 0
北京工商大学信息工程学院
单
层
感 知
则由方程
wijx1+w2jx2-Tj=0
(3.3)
器 确定了二维平面上的一条分界线。
--
北京工商大学信息工程学院
5
(1)输入是二维
wij x1+w2j x2 – Tj = 0
wij x1 = Tj - w2j x2 x1 = (Tj -w2j x2) / wij
= - ( w2j/ wij ) x2 +Tj / wij = a x2 +c
络
n
单 层
输出:
o j sgn(net j T j ) sgn(
wij
xi
)
s
gn(W
T j
X
)
感
知
i 0
器
(3.2)
--
北京工商大学信息工程学院
4
3.1.2感知器的功能
(1)设输入向量X=(x1 ,x2)T
x1
oj
前 馈
x2
-1
神 经 网 络
输出:o
j
单层感知器

i
y
f
... ...
xN
N
输入 x(n) 1, x1(n), x2(n),L , xN (n)T
权值 ω(n) b(n),1(n),2(n),L ,N (n)T
N
v(n) i xi ωT (n)x(n) i0
2.单层感知器的学习算法
(1)定义变量和参数。X为输入,y为实际输出,d为 期望输出,b为偏置,w为权值。
➢ 粗准焦螺旋 和细准焦螺旋的类比。——自适应 学习率。
3.感知器的局限性
单层感知器无法解决线性不可分问题, 只能做近似分类。 感知器的激活函数使用阈值函数,输出值只有 两种取值,限制了在分类种类上的扩展 。 如果输入样本存在奇异样本,网络需要花费很 长的时间。 感知器的学习算法只对单层有效 。
4.单层感知器相关函数详解
>> T=[0,0,0,0,0,1,1,1,1,1] % 训练输出,负数输出0,非负数输出1
>> net=train(net,P,T);
>> newP=-10:.2:10;
% 测试输入
>> newT=sim(net,newP);
>> plot(newP,newT,'LineWidth',3);
>> title('判断数字符号的感知器');
3, 0 x1
l2类 4, 1
向量 ω 2, 3
二维空间中的超平面是一条
直线。在直线下方的点,输
出-1;在直线上方的点,输
出1。分类面:
1x1 2 x2 b 0
2.单层感知器的学习算法
在实际应用中 ,通常采用纠错学习规则的学习算法。
感知器模型及其学习算法

感知器模型及其学习算法1感知器模型感知器模型是美国学者罗森勃拉特(rosenblatt)为研究大脑的存储、学习和认知过程而提出的一类具有自学习能力的神经网络模型,它把神经网络的研究从纯理论探讨引向了从工程上的实现。
rosenblatt明确提出的感知器模型就是一个只有单层排序单元的前向神经网络,称作单层感知器。
2单层感知器模型的自学算法算法思想:首先把连接权和阈值初始化为较小的非零随机数,然后把有n个连接权值的输入送入网络,经加权运算处理,得到的输出如果与所期望的输出有较大的差别,就对连接权值参数按照某种算法进行自动调整,经过多次反复,直到所得到的输出与所期望的输出间的差别满足要求为止。
?为简单起见,仅考虑只有一个输出的简单情况。
设xi(t)是时刻t感知器的输入(i=1,2,......,n),ωi(t)是相应的连接权值,y(t)是实际的输出,d(t)是所期望的输出,且感知器的输出或者为1,或者为0。
3线性不可分问题单层感知器无法抒发的问题被称作线性不容分后问题。
1969年,明斯基证明了“异或”问题就是线性不容分后问题:“异或”(xor)运算的定义如下:由于单层感知器的输出为y(x1,x2)=f(ω1×x1+ω2×x2-θ)所以,用感知器实现简单逻辑运算的情况如下:(1)“与”运算(x1∧x2)令ω1=ω2=1,θ=2,则y=f(1×x1+1×x2-2)显然,当x1和x2均为1时,y的值1;而当x1和x2有一个为0时,y的值就为0。
(2)“或”运算(x1∨x2)令ω1=ω2=1,θ=0.5y=f(1×x1+1×x2-0.5)显然,只要x1和x2中有一个为1,则y的值就为1;只有当x1和x2都为0时,y的值才为0。
(3)“非”运算(~x1)令ω1=-1,ω2=o,θ=-0.5,则y=f((-1)×x1+1×x2+0.5))显然,无论x2为何值,x1为1时,y的值都为0;x1为o时,y的值为1。
人工神经元模型及学习方法

• τij—— 输入输出间的突触时延; 输入输出间的突触时延; • Tj —— 神经元 的阈值; 神经元j的阈值 的阈值; • wij—— 神经元 到 j 的突触连接系数或称 神经元i到 权重值; 权重值; • f ( ) —神经元转移函数。 神经元转移函数。 神经元转移函数
o j (t + 1) = f {[
满足y=x1.x2逻辑与关系。 。
逻辑或: 二个兴奋性输入) 令T=1,I=0,E=x1+x2(二个兴奋性输入) , , 当x1=1, x2=1, E=1+1=2, 当x1=1, x2=0, E=1+0=1, 当x1=0, x2=1, E=0+1=1, 当x1=0, x2=0, E=0+0=0, 满足y=x1+x2逻辑或关系 触发 y=1 触发 y=1 触发 y=1 不触发 y=0
x1 0 0 1 1
x2 0 1 0 1
y 0 0 0 1
感知器结构
x1 x2
○ ○
0.5 0.5
○
0.75 -1
y
wix1+w2x2 -T=0 0.5x1+0.5x2-0.75=0
感知器的学习算法
感知器学习规则的训练步骤:
(1) 对各权值w0j(0),w1j(0),┄,wnj(0),j=1, 2,┄,m (m为计算层的节点数)赋予较小的非零随机数; (2) 输入样本对{Xp,dp},其中Xp=(-1,x1p,x2p,┄,xnp), dp为期望的输出向量(教师信号),上标p代表 样本对的模式序号,设样本集中的样本总数为P, 则p=1,2,┄,P;
(4)概率型转移函数 概率型转移函数
P(1) =
1 1+e
− x/T
神经网络感知器

--
神 经 网 络
输出:o j
1 1
w1 j x1 w2 j x2 Tj 0 w1 j x1 w2 j x2 Tj 0
单
层 感 知
则由方程
w1jx1+w2jx2-Tj=0
(3.3)
器 确定了二维平面上的一条分界线。
4
(1)输入是二维
w1j x1+w2j x2 – Tj = 0
w1j x1 = Tj - w2j x2 x1 = (Tj -w2j x2) / w1j
>>z = 10*sin(pi/3)* ... >>sin(pi/3);
46
2 MATLAB基本运算
MATLAB的查询命令 ➢键入help inv即可得知有关inv命令的用法
向量与矩阵的表示及运算 ➢向量的表示方法与运算 >>x = [1 3 5 2]; %表示一个行向量 >>y = 2*x+1 y= 3 7 11 5
30
3.1.4感知器的学习算法
解:第一步 输入X1,得
WT(0)X1=(0.5,1,-1,0)(-1,1,-2,0)T=2.5
前
馈 神
o1(0)=sgn(2.5)=1
经
网
--
络 单
W(1)= W(0)+η[d1- o1(0)] X1
层 感
=(0.5,1,-1,0)T+0.1(-1-1)(-1,1,-2,0)T
馈 神 经 网 络
隐
无隐层
层
数
的
感
—
多
知
单隐层
层
器
感
的
知
分
器
类
ann2 神经网络 第二章 感知器

自适应线性元件
• 神经元i的输入信号向量: T X i [ x0i , x1i , xmi ] , X i 常取 1
T W [ w , w , w ] • 突触权值向量: i 0i 1i mi
• w0i常接有单位输入,用以控制阈值电平。 • 模拟输出: y i X iT W W T X • 二值输出:
2014/4/13
史忠植
神经网路
8
单层感知器的学习算法
• 第二步:初始化,赋给 Wj(0) 各一个较小的随机非零 值, n = 0; • 第三步:对于一组输入样本X(n)= [1, x1(n), x2(n), …, xm(n)],指定它的期望输出(亦称之为导师信号)。 if X l1,d 1 if X l 2,d 1 • 第四步:计算实际输出:
2014/4/13
史忠植
神经网路
10
对于线性可分的两类模式,单层感知器的学习算 法是收敛的。
判决边界
类 l1 类 l1
类l2
类l2
2014/4/13
史忠植
神经网路
11
x1
0 0 1 1
x2
0 1 0 1
“与”
x1 x2 Y=w1· x1+w2· x2- b=0
0 0 0 1 Y=w1· 0+w2· 0-b<0 Y=w1· 0+w2· 1-b<0 Y=w1· 1+w2· 0-b<0 Y=w1· 1+w2· 1 - b ≥0
E (W ) e(n) e( n ) W W
31
E (W ) X ( n ) e( n ) W
为使误差尽快减小,令权值沿着误差函数负梯度方向 改变,即: E (W )
感知器算法原理

感知器算法原理感知器算法是一种二分类的分类算法,基于线性模型的思想。
其原理是通过输入的特征向量和权重向量的线性组合,经过阈值函数进行判别,实现对样本的分类。
具体来说,感知器算法的输入为一个包含n个特征的特征向量x=(x₁, x₂, ..., xn),以及对应的权重向量w=(w₁, w₂, ..., wn),其中wi表示特征xi对应的权重。
感知器算法的目标是找到一个超平面,将正负样本正确地分离开来。
如果超平面上方的点被判为正样本,超平面下方的点被判为负样本,则称超平面为正类超平面;反之,则称超平面为负类超平面。
感知器算法的具体步骤如下:1. 初始化权重向量w和阈值b。
2. 对于每个样本(xᵢ, yᵢ),其中xᵢ为特征向量,yᵢ为样本的真实标签。
3. 计算样本的预测输出值y_pred=sign(w·x + b),其中·表示向量内积操作,sign为符号函数,将预测值转化为+1或-1。
4. 如果预测输出值与真实标签不一致(y_pred ≠ yᵢ),则更新权重向量w和阈值b:- w:=w + η(yᵢ - y_pred)xᵢ- b:=b + η(yᵢ - y_pred),其中η为学习率,用于控制权重的更新速度。
5. 重复步骤3和4,直到所有样本都被正确分类,或达到预定的迭代次数。
感知器算法的核心思想是不断地通过训练样本来优化权重向量和阈值,使得模型能够将正负样本准确地分开。
然而,感知器算法只对线性可分的问题有效,即存在一个超平面能够完全分开正负样本。
对于线性不可分问题,感知器算法无法收敛。
因此,通常需要通过特征工程或使用其他复杂的分类算法来解决线性不可分的情况。
神经网络
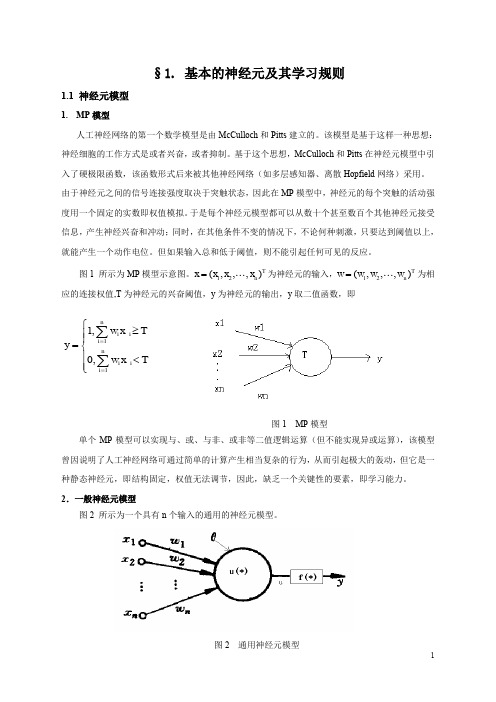
, xn , 1)T , wn , )T
当前权值: w(t ) ( w1 , w2 , 期望输出: d (d1 , d2 ,
, d n )T
权值调节公式: w(t 1) w(t ) w(t ) ,其中 为学习率,一般取较小的值,权值调整量
w(t ) 一般与 x,d 及当前权值 w(t)有关。
1 1 (d y )2 [d f (u )]2 2 2
4
神经元权值调节 学习规则的目的是:通过训练权值 w,使得对于训练样本对(x,d) ,神经元 的输出误差 E
1 1 (d y )2 [d f (u )]2 达最小,误差 E 是权向量 w 的函数,欲使误差 E 最小, 2 2
T
, 指定它的期望输出 d,if
d=1 , if X
2
d=-1
T
第四步,计算实际输出 y(n) sgn( w (n) x(n)) 第五步,调整权值向量 w(t 1) w(t ) (d (n) y(n)) x(n) 第六步,若 e(n) d (n) y(n) ,或 w(n 1) w(n) ,算法结束,否则,n=n+1,转到 第二步。
6
单输出两层感知器。
x1 x2
. . .
w1j w2j wnj b(n)
图 4 两层感知器模型
u(*)
uj
f(u)
yj
xn
学习算法如下: 第一步,设置变量和参量
x(n) 1, x1 (n), x2 (n),
, xm (n) 为输入向量,或训练样本。
T
w(n) b(n), w1 (n), w2 (n),
T T i 1,2, , p
实验一 单层感知器

1
1.5
2 Epoch
2.5
3
-0.5
0
0.5 Inputx
1
1.5
2
误差的收敛曲线 (4) 保存文件 通过菜单选择 File Save,或者点击左上角 (5) 运行及调试程序 点击上方 ,或者使用快捷键 F5。
样本分布及分界线示意
,或者使用快捷键 Ctrl+S
针对提示的错误的位置修改程序,直到正确运行。 *注意检查变量矩阵的字母大小写,矩阵叉乘是否需要转置。 (6) 存储图像 在图上通过菜单选择 File Save,或者使用快捷键 Ctrl+S 再 EditCopy Figure,将图粘贴到 word 上作为实验报告的依据。 (7) 设置阈值 T=0.1,改变学习率观察收敛曲线的收敛情况,对每个不同的学习率,分 别运行程序 10 次,将所用迭代次数的平均值填入下表: 学习率η 迭代次数 *提示:可以利用 for 循环直接接到该表结果 (8) 设置学习率η=0.1,改变学习率观察收敛曲线的收敛情况,对每个不同的阈值 T, 分别运行程序 10 次,将所用迭代次数的平均值填入下表: 阈值 T 迭代次数 (9) 设置学习率η=0.1, 设置阈值 T=0.1,运行程序 10 次,记录下迭代次数平均值,再将 变换函数改为单极点 Sigmoid 函数,再运行程序 10 次,记录下迭代次数平均值。 变换函数 迭代次数 单极点二值函数 单极点 Sigmoid 函数 0.01 0.05 0.1 0.5 1 2 10 0.01 0.05 0.1 0.5 1 2 10
8
单层感知器模型
o j sgn(net ' j T j ) sgn( wij xi ) sgn(W jT X )
感知器算法原理及应用

感知器算法原理及应用随着人工智能应用领域不断扩大,越来越多的算法被使用。
其中,感知器算法是一种经典的机器学习算法,广泛应用于图像、语音、自然语言处理等领域。
本文将介绍感知器算法的原理和应用。
一、感知器算法原理感知器算法是一种以 Rosenblatt 为代表的机器学习算法,最初用于二元分类。
它的基本工作原理是通过对输入数据进行加权和,并与一个阈值进行比较,来决定输出结果。
另外,感知器算法是一种基于梯度下降优化的算法,通过不断调整权值和阈值,以使分类的效果更好。
1.1 基本模型感知器模型通常用于二元分类任务,如将一个输入数据分为两类。
模型的输入是一个特征向量 x 和一个阈值θ,这两者加权后的结果通过一个激活函数 f(x) 来得到输出 y。
感知器模型可以表示为:其中,w 是权重向量,f(x) 是激活函数,可以是阶跃函数、线性函数或者 sigmoid 函数等等。
1.2 误差更新感知器算法的关键是误差更新问题。
在二元分类任务中,我们将预测值 y 限制在 0 和 1 之间。
对于一个正确的预测 y_hat 和一个错误的预测 y,我们定义误差为:error = y_hat - y误差可以用于更新权重向量 w 和阈值θ。
为了最小化误差,我们需要在每一轮训练中更新权重和阈值,以使误差最小化。
通俗的说,就是调整权重和阈值来训练模型。
在 Rosenblatt 的感知器算法中,权重和阈值的调整如下:w = w + α(error)x其中,α 是学习率,它控制着权重和阈值的更新速率,可以视作一种步长。
它的取值通常是一个较小的正数,如 0.01。
1.3 二元分类感知器算法最初用于二元分类任务,如将输入数据分为正类和负类。
实际运用中,只有两种不同的输出可能,1 和 -1,用 y ∈{-1, 1} 来表示分类结果。
分类器的训练过程可以是迭代的,每一次迭代会调整权重和偏差,以使分类效果更好。
二、感知器算法应用感知器算法是一种简单而有效的机器学习算法,可以广泛应用于图像、语音、自然语言处理等领域,以下是几个典型的应用场景。
一.单层感知器

⼀.单层感知器单层感知器属于单层前向⽹络,即除输⼊层和输出层之外,只拥有⼀层神经元节点。
特点:输⼊数据从输⼊层经过隐藏层向输出层逐层传播,相邻两层的神经元之间相互连接,同⼀层的神经元之间没有连接。
感知器(perception)是由美国学者F.Rosenblatt提出的。
与最早提出的MP模型不同,神经元突触权值可变,因此可以通过⼀定规则进⾏学习。
可以快速、可靠地解决线性可分的问题。
1.单层感知器的结构 单层感知器由⼀个线性组合器和⼀个⼆值阈值元件组成。
输⼊向量的各个分量先与权值相乘,然后在线性组合器中进⾏叠加,得到⼀个标量结果,其输出是线性组合结果经过⼀个⼆值阈值函数。
⼆值阈值元件通常是⼀个上升函数,典型功能是⾮负数映射为1,负数映射为0或负⼀。
输⼊是⼀个N维向量 x=[x1,x2,...,xn],其中每⼀个分量对应⼀个权值wi,隐含层输出叠加为⼀个标量值:随后在⼆值阈值元件中对得到的v值进⾏判断,产⽣⼆值输出:可以将数据分为两类。
实际应⽤中,还加⼊偏置,值恒为1,权值为b。
这时,y输出为:把偏置值当作特殊权值: 单层感知器结构图: 单层感知器进⾏模式识别的超平⾯由下式决定:当维数N=2时,输⼊向量可以表⽰为平⾯直⾓坐标系中的⼀个点。
此时分类超平⾯是⼀条直线:这样就可以将点沿直线划分成两类。
2.单层感知器的学习算法(1)定义变量和参数,这⾥的n是迭代次数。
N是N维输⼊,将其中的偏置也作为输⼊,不过其值恒为1,。
x(n)=N+1维输⼊向量=[+1,x1(n),x2(n),...,xN(n)]T w(n)=N+1维权值向量=[b(n),w1(n),w2(n),...,wN(n)]T b(n)=偏置 y(n)=实际输出 d(n)=期望输出 η(n)=学习率参数,是⼀个⽐1⼩的正常数所以线性组合器的输出为:v(n)=w T(n)x(n)(2)初始化。
n=0,将权值向量w设置为随机值或全零值。
(3)激活。
人工神经网络与神经网络优化算法

其中P为样本数,t j, p 为第p个样本的第j个输
出分量。
感知器网络
1、感知器模型 2、学习训练算法 3、学习算法的收敛性 4.例题
感知器神经元模型
感知器模型如图Fig2.2.1 I/O关系
n
y wipi bi
i 1
y {10
y0 y0
图2.2.1
单层感知器模型如图2.2.2
定义加权系数
10.1 人工神经网络与神经网络优化算法
③第 l 1层第 i个单元到第个单元的权值表为
; l1,l ij
④第 l 层(l >0)第 j 个(j >0)神经元的
输入定义为 , 输出定义 Nl1
x
l j
y l 1,l ij
l 1 i
为
yLeabharlann l jf (xlj )
, 其中 i0 f (•)为隐单元激励函数,
人工神经网络与神经网络优化算法
自20世纪80年代中期以来, 世界上许多国 家掀起了神经网络的研究热潮, 可以说神 经网络已成为国际上的一个研究热点。
1.构成
生物神经网
枝蔓(Dendrite)
胞体(Soma)
轴突(Axon) 胞体(Soma)
2.工作过程
突触(Synapse)
生物神经网
3.六个基本特征: 1)神经元及其联接; 2)神经元之间的联接强度决定信号传递的强
函数的饱和值为0和1。
4.S形函数
o
a+b
c=a+b/2
(0,c)
net
a
2.2.3 M-P模型
McCulloch—Pitts(M—P)模型, 也称为处理单元(PE)
x1 w1
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2014-3-15
2.2.2单层感知器的学习算法
单层感知器学习算法思想
基于迭代的思想,通常是采用误差校正学习规则的 学习算法。 可以将偏置作为神经元权值向量的第一个分量加到 权值向量中,也可以设其值为0 输入向量和权值向量可分别写成如下的形式:
X n 1, x1 n , x2 n , ,xm n
d ( n )为期望输出, 为学习 f()为激活函数, y ( n )为网络实际输出,
给权值向量 W (1) 的各个分量赋一个较小的随机非零值,置 n 1
1 2 m
第三步,输入一组样本 X n 1, x n , x n ,,x n ,并给出 它的期望输出 d (n )。 y ( n ) f w ( n ) x ( n ) 第四步,计算实际输出: 第五步,求出期望输出和实际输出求出差 e d (n) y (n)
2014-3-15
2.2.3 单层感知器的MATLAB实现
使用MATLAB实现神经网络的步骤如下: 第一步 根据应用创建一个神经网络; 第二步 设定神经网络的训练参数,利 用给定样本对创建的神经网络进行训练; 第三步 输入测试数据,测试训练好的 神经网络的性能。 例2-1:见《神经网络实用教程》第22页
2.2.2单层感知器的学习算法
学习算法实例: 构建一个神经元,它能够实现逻辑与操作
逻辑“与”真值表
x1 0 0 1 1
x2 0 1 0 1
d 0 0 0 1
2014-3-15
2.2.2单层感知器的学习算法
确定权值和阈值
w 1=
w2= b=
2014-3-15
2.2.2单层感知器的学习算法
设阈值为0.6,初始权值均为0.1,学习 率为0.6,误差值要求为0,神经元的激活 函数为硬限幅函数,求权值w1与w2
2014-3-15
2.2.3 单层感知器的MATLAB实现
mae() 功能 平均绝对误差性能函数 格式 perf=mae(E,w,pp) 说明 perf表示平均绝对误差和, E 为误差矩阵或向量(网络的目标向量与 输出向量之差), w为所有权值和偏值 向量(可忽略), pp为性能参数(可忽 略)。
迭代次数 变量 样本标号
(3)
2 1
输入或权值标号
2014-3-15
2014-3-15
对于样本1,输出神经元的输入为: 输出神经元的输出为:
0 w10 (0) x1 (1) w2 (0) x2 (1) 0.1 0 0.1 0 0
y1 (1) sgn{[W T 0 (0) X (1)] b}
i 1
2014-3-15
wi xi b 0
m
2.2.1单层感知器
单层感知器工作原理
对于只有两个输入的判别边界是直线(如下式 所示),选择合适的学习算法可训练出满意的w1 和w2 , 当它用于两类模式的分类时,相当于在高维样本空 间中,用一个超平面将两类样本分开。
w1x1 w2 x2 b 0
1 1 w1 (3) x1 (4) w2 (3) x2 (4) 0.1 1 0.1 1 0.2
2014-3-15
2.2.2单层感知器的学习算法
输出神经元的输出为:
y (4) sgn{[W (3) X (4)] b}
1 T1
sgn{w (3) x1 (4) w (3) x2 (4) 0.6}
2.2.3 单层感知器的MATLAB实现
MATLAB中单层感知器常用工具函数名称 和基本功能
函数名 newp() hardlim() learnp() train() 生成一个感知器 硬限幅激活函数 感知器的学习函数 神经网络训练函数 功 能
sim()
mae() plotpv()
神经网络仿真函数
m i 0 i i
根据误差判断目前输出是否满足条件,一般为对所有样本误差为零或者均 小于预设的值,则算法结束,否则将值增加1,并用下式调整权值: 然后转到第三步,进入下一轮计算过程
2014-3-15
w n 1 w n d n y n x n
0 sgn{w10 (0) x1 (1) w2 (0) x2 (1) 0.6}
0
2014-3-15
2.2.2单层感知器的学习算法
权值调整
1 w1 (1) w10 (0) (d (1) y1 (1)) x1 0.1 1 w2 (1) 0.1
样本2与3同样本1,因输出为0省略 对于样本4,输出神经元的输入为:
2014-3-15
2.2.3 单层感知器的MATLAB实现
train() 功能 神经网络训练函数 格式
[net,tr,Y,E,Pf,Af] = train(NET,P,T,Pi,Ai,VV,TV)
说明 net为训练后的网络;tr为训练记录;Y为网络输 出矢量;E为误差矢量;Pf为训练终止时的输入延迟状 态;Af为训练终止时的层延迟状态;NET为训练前的网 络;P为网络的输入向量矩阵;T表示网络的目标矩阵, 缺省值为0;Pi表示初始输入延时,缺省值为0;Ai表示 初始的层延时,缺省值为0; VV为验证矢量(可省略); TV为测试矢量(可省略)。网络训练函数是一种通用的 学习函数,训练函数重复地把一组输入向量应用到一个 网络上,每次都更新网络,直到达到了某种准则,停止 准则可能是达到最大的学习步数、最小的误差梯度或误 差目标等。
2014-3-15
2.2.2单层感知器的学习算法
w (3) x1 (4) w (3) x2 (4) 0.7 1 0.7 1 1.4
2 1 2 2
y 2 (4) sgn{[W T 2 (3) X (4)] b}
2 sgn{w12 (3) x1 (4) w2 (3) x2 (4) 0.6}
1 1 1 2
0
权值调整:
1 1 w1 (4) w1 (3) (d (4) y1 (4)) x1 0.1 0.6 1 1 0.7 1 w2 (4) 0.7
2014-3-15
2.2.2单层感知器的学习算法
此时完成一次循环过程,由于误差没有 达到0,返回第2步继续循环,在第二次循 环中,前三个样本输入时因误差均为0, 所以没有对权值进行调整,各权值仍保持 第一次循环的最后值,第四个样本输入时 各参数值如下:
2.2感知器神经网络模型 与学习算法
智能中国网提供学习支持
2.2.1单层感知器
概述
由美国学者Rosenblatt在1957年首次提出 学习算法是Rosenblatt在1958年提出的 包含一个突触权值可调的神经元 属于前向神经网络类型 只能区分线性可分的模式 IEEE设立以其名字命名的奖项
1
w12 (4) w12 (3) ( d (4) y1(4)) x1 0.7 0.6 0 1 0.7
2 w2 (4) 0.7
2014-3-15
2.2.2单层感知器的学习算法
计算误差时,对所有的样本, 网络的输出误差均为0,达到 预定的要求,训练结束
2014-3-15
说明 Y为网络的输出;Pf表示最终的输入延时状态; Af表示最终的层延时状态;E为实际输出与目标矢量之间 的误差;perf为网络的性能值;NET为要测试的网络对象; P为网络的输入向量矩阵;Pi为初始的输入延时状态(可 省略);Ai为初始的层延时状态(可省略);T为目标矢 量(可省略)。式(1)、(2)用于没有输入的网络,其中Q 为批处理数据的个数,TS为网络仿真的时间步数。
2014-3-15
2.2.3 单层感知器的MATLAB实现
plotpc()
功能 在存在的图上绘制出感知器的分类线函数 格式 (1) plotpc(W,B) (2) plotpc(W,B,H) 说明 硬特性神经元可将输入空间用一条直线(如果 神经元有两个输入),或用一个平面(如果神经元有三 个输入),或用一个超平面(如果神经元有三个以上输 入)分成两个区域。plotpc(W,B)对含权矩阵w和偏置 矢量b的硬特性神经元的两个或三个输入画一个分类 线。这一函数返回分类线的句柄以便以后调回的句柄。 它在画新分类线之前,删除旧线。
2014-3-15
2.2.3 单层感知器的MATLAB实现
sim()
功能 对网络进行仿真 格式
(1) [Y,Pf,Af,E,perf] = sim(NET,P,Pi,Ai,T) (2) [Y,Pf,Af,E,perf] = sim(NET,{Q TS},Pi,Ai,T) (3) [Y,Pf,Af,E,perf] = sim(NET,Q,Pi,Ai,T)
2014-3-15
2.2.3 单层感知器的MATLAB实现
P= [-0.4 -0.5 0.6; 0.9 0 0.1]; %给定训练样本数据 T= [1 1 0]; %给定样本数据所对应的类别,用1和0来表示两种类别 %创建一个有两个输入、样本数据的取值范围都在[-1,1]之间,并且 %网络只有一个神经元的感知器神经网络 net=newp([-1 1;-1 1],1); net.trainParam.epochs = 20; %设置网络的最大训练次数为20次 net=train(net,P,T); %使用训练函数对创建的网络进行训练 Y=sim(net,P) %对训练后的网络进行仿真 E1=mae(Y-T) %计算网络的平均绝对误差,表示网络错误分类 Q=[0.6 0.9 -0.1; -0.1 -0.5 0.5]; %检测训练好的神经网络的性能 Y1=sim(net,Q) %对网络进行仿真,仿真输出即为分类的结果 figure; %创建一个新的绘图窗口 plotpv(Q,Y1); %在坐标图中绘制测试数据 plotpc(net.iw{1},net.b{1}) %在坐标图中绘制分类线